Bush hid the facts что будет
Проверено на лицензионной Win-XP SP2
Часть «пасхальных яиц» из 98-х работает и в XP (скринсейверы)
Как выиграть в «Косынку»
Тупо нажмите Alt+Shift+2
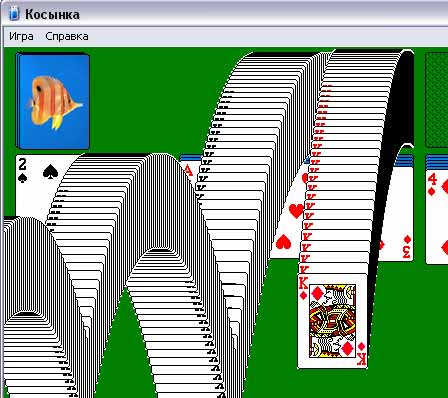
(Alt лучше слева, двойку лучше не на цифровой клавиатуре, а над буквами)
Очков от этого, само собой, все равно будет ноль.
Что прячет Джордж Буш?
Внимание, работает только в XP!
1. Откройте Блокнот (Notepad).
2. Напишите в новом файле:
Bush hid the facts
3. Сохраните файл как bush.txt
4. Закройте Блокнот.
5. Теперь откройте bush.txt из того места, где сохранили.
Вместо сохраненного текста увидите символы-квадратики:
Промежность под фильтром?
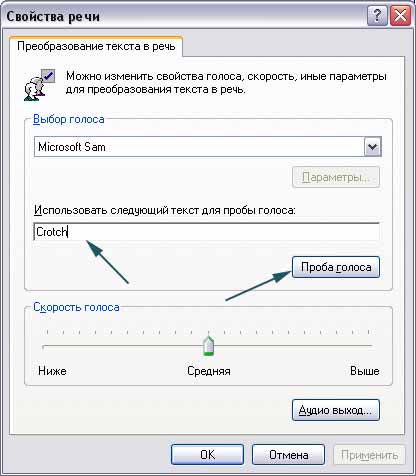
1. ОткройтеПанель управления -> Речь
2. Наберите для пробы:
Crotch
В пробе услышите «Crow’s nest» — «Воронье гнездо».
Информация в этом блоке размещается на правах рекламы:
Последние обновленные разделы сайта:
08.01 АНЕКДОТЫ : про кино — 222 стр., про Новый год — 74 стр., про интернет и компьютер — 325 стр., про рекламу — 197 стр.
31.12 КИНОЛЯПЫ : Джинн. Убийца. Оппенгеймер. Барби. Мать. Удача. Форсаж-10. Трансформеры-7: Восхождение Звероботов. Индиана Джонс и Колесо судьбы. Большой прыжок. Лютер: Павшее солнце. Крушение. Меню. Треугольник печали. Топ Ган: Мэверик. Не беспокойся, дорогая. На западном фронте без перемен.
30.12 РЕЦЕНЗИИ : Елки-10. Крик. Ночь перед Рождеством. Гномы. Новогодний беспредел. Кентервильское привидение. Дворец. Убийца. Одержимые злом. Пила-10. Кошки-мышки. Миссия невыполнима: Смертельная расплата, часть.1. Исчезнувшая в звездах.
22.12 КИНОСТАТЬИ : История «Реальной любви»: новогоднему ромкому 20 лет. В центре зоны интересов: European Film Awards 2023. 10 главных российских кинопремьер ближайшего будущего. Человек, открывший дверь в Нарнию: 125 лет со дня рождения К.С.Льюиса. Вижу тебя насквозь!
01.12 ХОЛКИ-МОРКИ : 194 страница.




ГЛАВНАЯ : Знаменательные даты, факты из мира науки и искусства обновляются на сайте ежедневно. Также на главной есть новости, не всегда попадающие в архивы и не связанные с остальными разделами.
Самые популярные разделы форума:
Новинки кино : Краткие обзоры новинок кинопроката и документальных фильмов.
Флудильня : разные темы, от «Придумайте название» до приколов типа «Скрипка-Лиса»
События в мире : новости из разных источников, иногда просто приколы и маразмы.
Кинояпы в зарубежных фильмах : Обсуждение статей соответствующей рубрики, предложения.
Буш скрыл факты — Bush hid the facts
Буш скрыл факты — общее название для ошибки, присутствующей в некоторых версиях Microsoft Windows, из-за которой текст, закодированный в ASCII, интерпретируется так, как если бы он был UTF-16LE, в результате искаженный текст. Когда строка «Буш скрыл факты» без новой строки или кавычек была помещена в новый документ Блокнот и сохранена, закрыта и снова открыта, бессмысленная последовательность китайских иероглифов «畂 桳 栠 摩 琠 敨 映 捡 獴 «будет
Хотя «Буш скрыл факты» — это предложение, наиболее часто представляемое в Интернете для того, чтобы вызвать ошибку, ошибка может быть вызвана множеством строк с буквами и пробелами в тех же позициях, например «чххх чхх чхх чхххх». Другие последовательности также вызывают ошибку, включая даже текст «a».
Ошибка возникает, когда строка передается в Win32 определение кодировки функция IsTextUnicode . IsTextUnicode видит, что байты соответствуют кодировке UTF-16LE допустимых (если бессмысленные) китайские символы Unicode, делает вывод о том, что текст действителен UTF-16LE китайский и возвращает true , а затем приложение неправильно интерпретирует текст как UTF-16LE.
Ошибка существовала с тех пор, как IsTextUnicode был введен с Windows NT 3.5 в 1994 году, но не был обнаружен до начала 2004 года. Многие текстовые редакторы и инструменты демонстрируют такое поведение в Windows, потому что они используют IsTextUnicode для определения кодировки текстовых файлов. Начиная с Windows Vista, Блокнот был изменен для использования другого алгоритма обнаружения, который не обнаруживает ошибки, но IsTextUnicode остается неизменным в операционной системе, поэтому любые другие инструменты, использующие
Обходные пути
Для этой ошибки существует несколько обходных путей:
- Редактирование текста, чтобы он не был шаблоном, который запускает эту ошибку, позволит избежать ее. Например, добавление новой строки в первые 20 символов будет работать.
- Если файл сохранен как «UTF-8 », а не «ANSI», текст загружается правильно, потому что Блокнот добавляет перед ним знак порядка байтов UTF-8 , который является шаблоном, который не вызывает ошибку. UTF-8 без отметки порядка байтов все равно вызовет ошибку, поскольку эта последовательность в UTF-8 представлена идентично ASCII.
- Ошибки также можно избежать, сохранив как «Unicode», который в Microsoft Windows означает UTF-16LE. При загрузке этого текста IsTextUnicode должен (и возвращается) возвращать истину, а текст правильный.
- Чтобы получить исходный текст с помощью Блокнота, откройте диалоговое окно «Открыть файл», выберите файл, выберите «ANSI» или «UTF-8» в списке «Кодировка» и нажмите «Открыть». В Windows 2000 в Блокноте отсутствует список «Кодировка». этого тоже не хватает. WordPad, похоже, загружает текст правильно без выбора кодировки, поскольку он использует собственное определение кодировки.
Ссылки
Внешние ссылки
- Проблема кодировки файла Блокнота, redux — Раймонд Чен
- IsTextUnicode — Библиотека MSDN
Bush hid the facts что будет
29.02.2012 21:08 | Автор: Автор |  |
|  |
| 
Создание пасхальных яиц не обошло стороной и разработчиков Windows. Стоит заметить, что подобные советы вряд ли помогут в работе в виду своей, собственно говоря, бесполезности. Но ведь при создании этих программок никто и не претендовал на серьезность!
Итак, что же может предложить старый добрый Windows?
Если имеется выход в интернет, стоит открыть «Пуск», выбрать строку «Выполнить», в открывшемся окне набрать фразу telnet towel.blinkenlights.nl. В результате можно увидеть один из вариантов Star Wars 4 =). Если же набрать notepad /.setup, то откроется программа «Блокнот», в которой, увы, не получится поработать, так как она тут же зависнет.
Если захочется вновь созданные папки назвать CON, AUX, NUL, PRN, то все попытки окажутся тщетными. Все дело в том, что в Windows эти имена зарезервированы для собственных нужд.
Открыв папку WINDOWS, несложно найти пустой файл 0.txt и файл clock.avi. Именно они, «забытые» намеренно, и являются пасхалками.
Набрав в Блокноте фразу «Bush hid the facts» (кавычки ставить не надо), нужно сохранить файл (имя выбирается произвольное). При открытии этого документа вместо текста на экране появятся иероглифы.
Стоит опробовать еще одну хитрость. Для этого в папке WINDOWS необходимо найти файл system.ini. Затем в пункте [386enh] трансформировать параметры messagetextcolor и messagebackcolor путем добавления какой-либо цифры, например messagebackcolor=1 и messagetextcolor=2. Может случиться, что таких параметров не окажется вообще, тогда нужно их создать самостоятельно. Выполнение этих действий приведет к тому, что так называемый экран смерти поменяет свой цвет с синего на зеленый.
Очень интересен и один музыкальный эффект, предлагаемый Windows XP. Если открыть последовательно С?Windows?system32?oobe?images?title.wma, то в течение 5 минут 24 секунд можно наслаждаться очень красивой музыкой.
Получить десятикратный зум в Paint’е тоже несложно. Открыв изображение и кликнув на лупе, нужно всего лишь подвести курсор точно на линию под указателем восьмикратного увеличения и щелкнуть по левой кнопке мышки.
Конечно же, не остались без внимания и игры.
Для «Сапера» есть возможность остановить время игры. Для этого необходимо после запуска, когда таймер начнет отсчитывать секунды, воспользоваться сочетанием клавиш WinKey+D. Игра автоматически свернется. Велика вероятность, что таймер остановился. Это можно проверить, если нажать на нижней панели на ярлычок игры. Можно помочь себе и в поисках мин, выполнив ряд действий. Для начала нужно сделать рабочий стол видимым, то есть свернуть все ранее открытые окна программ. Через «Пуск» запустить игру, набрать «xyzzy» и на секунду нажать Shift. Встав на игровое поле, нужно двигать курсор по квадратам. Если мины в данном месте нет, то на рабочем столе слева в верхнем углу появится маленькая белая точка. Когда в клетке есть мина, эта точка гаснет.

Если во время игры в Солитер возникают проблемы, то можно воспользоваться сочетанием клавиш Ctrl + Shift + F10. Их одновременное нажатие приведет к появлению диалогового окна, в котором необходимо выбрать команду «Отменить» и переложить любую карту. Удивительно, но пасьянс разложится сам собой, причем мгновенно.
Pinball – игра увлекательная. Один минус – слишком мало шариков дается для игры. Этот недостаток можно поправить, набрав 1ball. Можно также добиться повышения в звании или добиться на время увеличения шарика, если набрать rmax или gmax соответственно. Все действия производятся в тот момент, когда шар находится в стартовом створе.
Newer news items:
- 28/03/2012 07:40 — Outlook Express, версия 2003 года
- 25/03/2012 19:40 — Почтовые клиенты: Outlook Express 6.0
- 18/03/2012 15:23 — Почтовые клиенты – что лучше?
- 18/03/2012 10:15 — Интересные программы для компьютера
- 12/03/2012 19:23 — «Разгоняем» компьютер
Older news items:
- 29/02/2012 21:06 — Пасхальные яйца в компьютерных программах
- 26/02/2012 07:44 — Новые утилиты для разработчиков
- 24/02/2012 07:34 — Секреты Автокад
- 13/02/2012 09:52 — Skype на экране телевизора
- 11/01/2012 11:04 — Графические программы для смартфонов
Bush hid the facts что будет
Somebody immediately saying it’s an encoding error accompanied by several people «troubleshooting» by copy and pasting the resulting text to other programs, and ending off with someone three years later posting in all caps asking for help with a completely unrelated problem.
«As of Windows Vista, Notepad has been modified to use a different detection algorithm that does not exhibit the bug, but IsTextUnicode remains unchanged in the operating system, so any other tools that use the function are still affected.»
I find this line astonishing. I was hoping there would be more to this story than «we fixed Notepad and left OS function broken» but after following the reference it seems they just didn’t think it worth fixing.
The alternative is ‘my application could open this string just fine, and now it can’t anymore’. You can’t do heuristics without allowing mistakes and on the Windows platform backwards compatibility is considered very important.
I appreciate the responsibility for maintaining backward compatibility, but I got a different vibe from that blog post.
or they took the linus approach of «don’t break user space» and force every one else to fix their code because they fixed their code.
I’m glad UTF16 is (albeit slowly) going the way of the dodo by becoming just an internal representation for a few older toolkits and programming languages. It was incredibly nonsensical how inconvenient it was compared to UTF8. At least in UTF8 you can’t do the extremely wrong assumption that 1 (w)char == 1 character, or rather, you can do that but it will explode on your hands way sooner than with UTF16.
Even though, I must say that the fact that now Windows puts a useless BOM at the beginning of every file is very annoying.
UTF16 was an extension of the original «obvious» Unicode encoding, back when Unicode started and was defined as fitting the world’s languages into a 16-bit spec (what is now the Basic Multilingual Plane). UTF16 allowed (most) older UCS2 documents to be upgraded for free to UTF16, much the way that ASCII documents are also valid UTF8.
Some of the weirdness in the Unicode spec even comes from the need for backwards compatibility. 17 planes and 1,114,078 total usable codepoints. these numbers would not have been arrived if the system had the foresight that 16-bit wasn’t enough in the first place. They were derived from reassigning private use area codepoints into surrogate pairs for UTF16. Unicode would probably have rather (maybe should have) started out as a 32-bit spec and avoided this mess from the get-go.
You know I’d love to read a book about the Unicode standardization process. Unicode and the “16-bits is enough for all modern scripts” business must be one of the biggest failures of requirements analysis in computing history. And the fact that at the same time they were upsetting so many of their partners with Asian unification to me means there must have been a real issue with personalities and project responsibilities.
Well, probably not 32 exactly. They had a 31 bit spec at the time but decided they could simplify to 16 bits. Also UTF-8 is naturally optimized for 31 bits.
> just an internal representation for a few older toolkits and programming languages
Maybe «older» but very much current, Qt’s QString type internally uses UTF-16. https://doc.qt.io/qt-5/qstring.html
Yeah, because Qt started in the early 90s, when UCS2 hadn’t still fiascoed and it was being adopted in droves as the «newer» solution to all encoding issues — you simply swapped `char` for `wchar_t`, made a `w` version of every C and C++ IO function and that’s it, right?
Sadly, it wasn’t it. 16 bits weren’t enough, and stuff like the fact a Unicode rune ≠ printed character (i.e. [è] can either be a single codepoints, or a combination of a [`] modifier and the latin letter [e]) meant there was basically no point in using 16/32 bit chars in the first place. When people really understood this it was almost the ’00s, and stuff like Python, Windows, macOS (due to NextStep), Java, .NET, Qt were stuck. It’s impossible to go back to plain `char` without annihilating backward compatibility, so everyone kept using it internally.
Fun fact, some of those languages and frameworks I mentioned never bothered switching completely to UTF-16 — for instance, Python now uses a weird mixture of ASCII and UCS2 internally.
> for instance, Python now uses a weird mixture of ASCII and UCS2 internally.
Really? Last I heard (PEP 393), the rule was: «8 bits if all codepoints are less than 256 (i.e. Latin-1); 16 bits if all codepoints are less than 2^16 (i.e. BMP); otherwise 32 bits». This means that text with all Latin-1 characters (which are approximately the first 256 codepoints of Unicode) will be stored internally as, well, Latin-1. This implies that ASCII strings are stored as ASCII.
Yep, that’s what I meant. They either use ASCII, UCS2 or UCS4 depending on the type of string. Doesn’t make a lot of sense to me, but I guess they couldn’t just throw 16 bit chars away.
I’m not 100% sure on this, but I don’t backwards-compatibility mattered in this decision. They wanted memory-efficient and O(1)-indexable strings.
And both Java and Javascript, an thus any language derived from from them. I’d go as far as saying that a majority of the code being written today uses UTF-16.
With these languages not even providing alternative API’s that are easy to use means it’ll be some time before we don’t have to suffer this.
I’ve seen a trend from those languages and APIs of hiding UTF-16 away. They have to interoperate with everything else using just UTF8, while the rest of the world doesn’t give a half damn about UTF-16 (the fact you have to also take endianess into account I think was one of the biggest crippling blows 16 bit encoding had ever received)
> just an internal representation for a few older toolkits and programming languages.
One quite significant programming language being JavaScript — I know we have TextEncoder and TextDecoder now, and for the typical ways strings are used in JS this is a complete non-issue. But any context in which one would want to iterate over individual characters in strings in JavaScript there’s a chance one might end up having to deal with UTF16 quirks.
Iterating over characters is not that much more useful than iterating over code units, actually (the only sensible use cases I can think of right now are things you should never really have to worry about implementing at the application level, such as sorting or comparing strings). For many useful use cases you basically need grapheme clusters, which is a lot closer to what humans think of as a character. And once you’re at that point it’s much less relevant whether the code units are 8 or 16 bits wide.
Right, I forgot about both codePointAt and charCodeAt existing (the former being useful for what you are talking about, the latter what people used to have to deal with before ES2015).
This exactly. One of the biggest reasons why UTF-32 doesn’t make sense IMHO is not only its general overhead but the fact it reiterates on the broken concept of `char` == «glyph». That is never correct on Unicode, no matter the byte size, because so many characters can be spread over multiple codepoints. Iterating over codepoints is the only thing UTF-32 simplifies and it is honestly kinda pointless. That’s why it took a while for Rust to implement the `Chars` iterator.
Does anybody know what the Chinese characters say? I put them into Google Translate and got: «Kang 栠 栠 栠 栠 敨 ying picking mongoose». I’m guessing its gibberish, but sometimes you can’t trust machine translation.
I remember this one! I found it so fascinating and ended up spending a lot of time making up funny sentences which triggered the bug.
The wiki article does not say whether phrasing of the example as «Bush Hid the Facts» instead of using some other text, is related to the presidency of George W. Bush. It seems to be, or is it entirely unrelated?
IIRC it was related to 9/11 conspiracy theories. At the time, a lot of conspiracy garbage was forwarded through chain e-mail. This is one of two examples that I personally remember getting forwarded from a particular aunt (the «Bush Hid the Facts» text disappearing being «proof» for the whole inside job theory it presumably alludes to). The sort of stuff that aunt would nowadays share on that Face Website.
The other that I remember her sending me was along the lines of «OMG if you enter that planes flight number into MS Word 97 and set the font to Windings you get a picture of a plane, two buildings, a skull and a Star of David!!1!eleven».
On a side note: If you entered the right combination of text into Excel 97, you could fly a plane over a fractal landscape 😉
The kind of «logic» at work here is still used nowadays (e.g. the Sandy Hook school shooting conspiracy theory, with followers pointing towards the name appearing in a movie at the time). It still eludes me what the logic behind this is supposed to be. So if you plan a massive government conspiracy, you make sure to plant very precise, hidden clues all over the place in movies, TV shows, random office software and similar things years in advance, because. um. why exactly?
Indeed. These were very big in middle school computer labs circa 2005.
I wonder if anyone with more historical perspective knows of any older examples of these blatantly false theories from other eras or if this type of conspiracy theory is unique to the digital age?