Полное руководство по линейной регрессии в Python
Линейная регрессия — это метод, который мы можем использовать для понимания взаимосвязи между одной или несколькими предикторными переменными и переменной отклика.
В этом руководстве объясняется, как выполнить линейную регрессию в Python.
Пример: линейная регрессия в Python
Предположим, мы хотим знать, влияет ли количество часов, потраченных на учебу, и количество сданных подготовительных экзаменов на оценку, которую студент получает на определенном экзамене.
Чтобы изучить эту связь, мы можем выполнить следующие шаги в Python, чтобы провести множественную линейную регрессию.
Шаг 1: Введите данные.
Во-первых, мы создадим DataFrame pandas для хранения нашего набора данных:
import pandas as pd #create data df = pd.DataFrame() #view data df hours exams score 0 1 1 76 1 2 3 78 2 2 3 85 3 4 5 88 4 2 2 72 5 1 2 69 6 5 1 94 7 4 1 94 8 2 0 88 9 4 3 92 10 4 4 90 11 3 3 75 12 6 2 96 13 5 4 90 14 3 4 82 15 4 4 85 16 6 5 99 17 2 1 83 18 1 0 62 19 2 1 76 Шаг 2: Выполните линейную регрессию.
Далее мы будем использовать функцию OLS() из библиотеки statsmodels для выполнения обычной регрессии методом наименьших квадратов, используя «часы» и «экзамены» в качестве переменных-предикторов и «оценку» в качестве переменной ответа:
import statsmodels.api as sm #define response variable y = df['score'] #define predictor variables x = df[['hours', 'exams']] #add constant to predictor variables x = sm.add_constant(x) #fit linear regression model model = sm.OLS(y, x).fit() #view model summary print(model.summary()) OLS Regression Results ============================================================================== Dep. Variable: score R-squared: 0.734 Model: OLS Adj. R-squared: 0.703 Method: Least Squares F-statistic: 23.46 Date: Fri, 24 Jul 2020 Prob (F-statistic): 1.29e-05 Time: 13:20:31 Log-Likelihood: -60.354 No. Observations: 20 AIC: 126.7 Df Residuals: 17 BIC: 129.7 Df Model: 2 Covariance Type: nonrobust ============================================================================== coef std err t P>|t| [0.025 0.975] ------------------------------------------------------------------------------ const 67.6735 2.816 24.033 0.000 61.733 73.614 hours 5.5557 0.899 6.179 0.000 3.659 7.453 exams -0.6017 0.914 -0.658 0.519 -2.531 1.327 ============================================================================== Omnibus: 0.341 Durbin-Watson: 1.506 Prob(Omnibus): 0.843 Jarque-Bera (JB): 0.196 Skew: -0.216 Prob(JB): 0.907 Kurtosis: 2.782 Cond. No. 10.8 ============================================================================== Шаг 3: Интерпретируйте результаты.
Вот как интерпретировать наиболее релевантные числа в выводе:
R-квадрат: 0,734.Это известно как коэффициент детерминации. Это доля дисперсии переменной отклика, которая может быть объяснена переменными-предикторами. В этом примере 73,4% вариаций в экзаменационных баллах можно объяснить количеством часов обучения и количеством сданных подготовительных экзаменов.
F-статистика: 23,46.Это общая F-статистика для регрессионной модели.
Вероятность (F-статистика): 1,29e-05. Это p-значение, связанное с общей F-статистикой. Он говорит нам, является ли регрессионная модель в целом статистически значимой. Другими словами, он говорит нам, имеют ли объединенные две предикторные переменные статистически значимую связь с переменной отклика. В этом случае p-значение меньше 0,05, что указывает на то, что переменные-предикторы «учебные часы» и «пройденные подготовительные экзамены» в совокупности имеют статистически значимую связь с экзаменационным баллом.
coef: коэффициенты для каждой переменной-предиктора говорят нам о среднем ожидаемом изменении переменной отклика, предполагая, что другая переменная-предиктор остается постоянной. Например, ожидается, что за каждый дополнительный час, потраченный на учебу, средний экзаменационный балл увеличится на 5,56 при условии, что количество сданных подготовительных экзаменов останется неизменным.
Вот еще один способ подумать об этом: если учащийся A и учащийся B сдают одинаковое количество подготовительных экзаменов, но учащийся A учится на один час больше, то ожидается, что учащийся A наберет на 5,56 балла больше, чем учащийся B.
Мы интерпретируем коэффициент для перехвата как означающий, что ожидаемая оценка экзамена для студента, который учится ноль часов и сдает нулевые подготовительные экзамены, составляет 67,67 .
Р>|т|. Отдельные p-значения говорят нам, является ли каждая предикторная переменная статистически значимой. Мы видим, что «часы» статистически значимы (p = 0,00), а «экзамены»(p = 0,52) не является статистически значимым при α = 0,05. Поскольку «экзамены» не являются статистически значимыми, мы можем решить исключить их из модели.
Расчетное уравнение регрессии: мы можем использовать коэффициенты из выходных данных модели, чтобы создать следующее расчетное уравнение регрессии:
экзаменационный балл = 67,67 + 5,56*(часы) – 0,60*(подготовительные экзамены)
Мы можем использовать это оценочное уравнение регрессии, чтобы рассчитать ожидаемый балл экзамена для учащегося на основе количества часов, которые он изучает, и количества подготовительных экзаменов, которые он сдает. Например, студент, который занимается три часа и сдает один подготовительный экзамен, должен получить 83,75 балла:
Имейте в виду, что, поскольку пройденные подготовительные экзамены не были статистически значимыми (p = 0,52), мы можем решить удалить их, поскольку они не улучшают общую модель. В этом случае мы могли бы выполнить простую линейную регрессию, используя только изученные часы в качестве переменной-предиктора.
Шаг 4: Проверьте предположения модели.
После выполнения линейной регрессии есть несколько предположений, которые вы можете проверить, чтобы убедиться, что результаты регрессионной модели надежны. Эти предположения включают:
Предположение № 1: существует линейная связь между переменными-предикторами и переменной-откликом.
- Проверьте это предположение, сгенерировавграфик остатков , который отображает подогнанные значения в сравнении с остаточными значениями для регрессионной модели.
Допущение № 2: Независимость остатков.
- Проверьте это предположение, выполнив тест Дарбина-Ватсона .
Допущение № 3: гомоскедастичность остатков.
- Проверьте это предположение, выполнив тест Бреуша-Пагана .
Допущение № 4: Нормальность остатков.
- Проверьте это предположение визуально, используя график QQ .
- Проверьте это предположение с помощью формальных тестов, таких как тест Харка-Бера или тестАндерсона-Дарлинга .
Предположение № 5: Убедитесь, что мультиколлинеарность не существует среди переменных-предикторов.
- Проверьте это предположение, рассчитав значение VIF каждой переменной-предиктора.
Если эти предположения выполняются, вы можете быть уверены, что результаты вашей модели множественной линейной регрессии надежны.
Вы можете найти полный код Python, использованный в этом руководстве , здесь .
Как вывести коэффициенты линейной регрессии python

Комментарии
Популярные По порядку
Не удалось загрузить комментарии.
ЛУЧШИЕ СТАТЬИ ПО ТЕМЕ
ООП на Python: концепции, принципы и примеры реализации
Программирование на Python допускает различные методологии, но в его основе лежит объектный подход, поэтому работать в стиле ООП на Python очень просто.
Пишем свою нейросеть: пошаговое руководство
Отличный гайд про нейросеть от теории к практике. Вы узнаете из каких элементов состоит ИНС, как она работает и как ее создать самому.
Программирование на Python: от новичка до профессионала
Пошаговая инструкция для всех, кто хочет изучить программирование на Python (или программирование вообще), но не знает, куда сделать первый шаг.
Решаем задачу численного прогнозирования с помощью линейной регрессии на Python
Задача регрессии возникает, когда требуется предсказать цену, температура, пульс, время, давление или другое численный показатель. Это пример контролируемого (supervised) машинного обучения, когда на основе истории предыдущих данных мы получаем предсказание. В этой статье обсудим, как можно спрогнозировать будущее, решая задачу линейной регрессии на Python.
Постановка задачи и исходный датасет
Продолжим работу с датасетом нью-йоркских апартаментов (отелей), доступных для проживания на некоторое время. Для дальнейшего анализа возьмем район Бруклин:
import pandas as pd data = pd.read_csv('../AB_NYC_2019.csv') data = data[data['neighbourhood_group'] == 'Brooklyn']
На этом наборе данных будем прогнозировать цены, по которым можно арендовать отдельные аппартаменты.
Линейная регрессия с одной независимой переменной
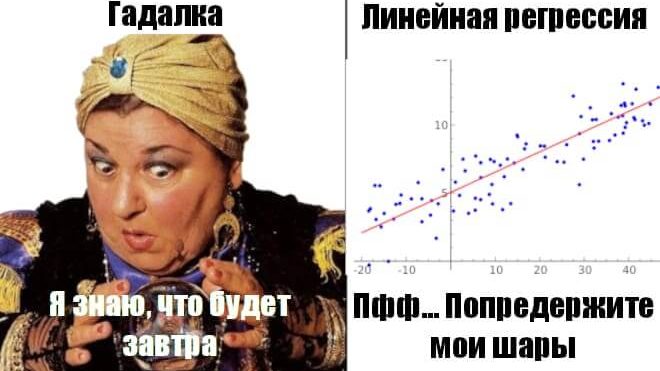
Графически линейная регрессия с одной независимой выглядит как прямая. Она решает задачу регрессии нахождением прямой, которая наилучшим образом соответствует точкам наблюдений. Следующий рисунок иллюстрирует вышесказанное:
Модель линейной регрессии может быть задана следующим образом:
Следовательно, для решения задачи регрессии требуется найти коэффициенты (коэффициент наклона) и (точка пересечения линии с осью ординат). Не вдаваясь в подробности, их можно выразить так:
![\[ a=\frac<\sum(x-\bar<x></p>
<p>)(y-\bar)><\sum(x-\bar<x>)^2> \]» width=»164″ height=»43″ /></p>
<p><img decoding=](https://python-school.ru/wp-content/ql-cache/quicklatex.com-ce7eea517462090da3e4aa2d9f5be9f5_l3.png)
Как можно заметить, линейная регрессия с одной независимой переменной показывает неудачные результаты, так как является практически параллельной оси абсцисс. Поэтому предсказание будет одним и тем же, примерно равным 4.6. При переводе обратно в нормальный масштаб равняется $100.
Линейная регрессия в библиотеках statsmodel и seaborn
Чтобы получить линейную регрессию, Data Scientist, который работает с Python, может воспользоваться готовыми библиотеками, а не писать собственное решение. Например, отлично подойдет библиотека Statsmodel, о которой мы уже говорили здесь. Она позволит получить линейную регрессию очень быстро:
import statsmodels.formula.api as smf model = smf.ols('price ~ number_of_reviews', data=data) res = model.fit() res.summary()
Метод summary выдает резюме после вычислений линейной регрессии по методу наименьших квадратов. Но нас интересуют коэффициенты и , которые в данном случае равны:

Как видим, intercept — это , number_of reviews , — это , что соответствуют прошлым вычислениям.
Помимо Statsmodel, можно воспользоваться библиотекой Seaborn, которая также часто применяется в задачах Machine Learning и других методах Data Science. Она имеет функцию regplot , которая сразу построит соответствующую прямую:
import seaborn as sns sns.regplot(x, y)
Линейная регрессия с несколькими переменными в Scikit-learn
В действительности ML-модели редко обучаются только на одном признаке, что подтверждают построенные графики. Поэтому уравнение для линейной регрессии можно обобщить до переменных (признаков):
![\[ y = ax_1 + ax_2 \dots + \dots + ax_n \]](https://python-school.ru/wp-content/ql-cache/quicklatex.com-a76fa97ac86f43f49f95dac412a3cbb6_l3.png)
где задача сводится к нахождению коэффициентов. Не вдаваясь в подробности их нахождения, отметим, что Python-библиотека Scikit-learn предоставляет для этого уже готовый интерфейс.
Рассмотрим пример в Python. Выберем в качестве независимых переменных признаки: number_of_reviews , reviews_per_month , calculated_host_listings_count . Атрибут reviews_per_month имеет Nan-значения, поэтому в дальнейшем заполним их нулями. К тому же, мы отфильтровали те данные, которые имеют нулевую цену:
d = data[data.price > 0] d['reviews_per_month'].fillna(0, inplace=True) x = d.loc[:, ('reviews_per_month', 'calculated_host_listings_count', 'number_of_reviews')] y = d.loc[:, 'price']
Здесь используется метод loc , который, согласно документации, быстрее и производительнее явного вызова столбцов [1]. Нам также требуется разбить полученные данные на тренировочную и тестовую выборки, чтобы на одних данных обучить модель, а на других – проверить ее корректность. В Scikit-learn имеется функция train_test_split , возвращающая две пары массивов — тренировочного и тестового:
from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
Данная функция принимает в качестве аргумента также test_size , который определяет долю, отведенную на тестовую выборку.
Теперь к самому главному — обучению модели линейной регрессии. В Scikit-learn есть класс LinearRegression , который выполнит за нас работу в Python:
from sklearn.linear_model import LinearRegression model = LinearRegression().fit(x_train, y_train)
В метод fit мы посылаем те данные, на которых ML-модель обучается. Попробуем получить предсказания на основе тестовой выборки:
y_pred = model.predict(x_test)
А как узнать, что такая модель лучшая из всех доступных? Нужно воспользоваться метриками качества.
Метрики качества для оценки работоспособности модели
Чтобы оценить работоспособность модели, применяют специальные метрики. Для задачи регрессии применяют среднеквадратическую (MSE) и абсолютную ошибки (MAE). Среднеквадратическая ошибка находится как:
![\[ MSE = \frac<1>\sum(y-y_)^2 \]» width=»201″ height=»36″ /></p>
<p>Абсолютная опускает возведение в квадрат:</p>
<p><img decoding=](https://python-school.ru/wp-content/ql-cache/quicklatex.com-da5ba05efb6b7b54d19b0c69bf78689c_l3.png)
По оси X у нас есть LSTAT, а по оси Y — TARGET. Просто взглянув на это, можно увидеть отрицательную взаимосвязь: когда LSTAT растет, TARGET падает.
Функция оценки/стоимости
Как мы можем решить проблему предсказания TARGET на основе LSTAT? Хорошая отправная точка для размышлений: допустим, мы разрабатываем множество моделей для прогнозирования целевого показателя, как нам выбрать лучшую из них? Как только мы найдем подходящее для сравнения значение, наша задача — минимизировать/максимизировать его.
Это чрезвычайно полезно, если вы можете свести проблему к единственной оценочной метрике. Тогда это очень упрощает цикл разработки модели. Однако в реальном мире прийти к такому упрощению может быть непросто. Иногда не совсем понятно, что вы хотите, чтобы ваша модель максимизировала/минимизировала. Но это проблема для другой статьи.
Поэтому для нашей задачи предлагаю использовать среднюю квадратическую ошибку (mean squared error) в качестве оценочной метрики. Для лучшего понимания смысла MSE, давайте определимся с терминологией:

Таким образом, MSE:

По сути, для каждой точки мы вычитаем предсказанное нами значение из фактического. Затем, поскольку нас не волнует направление ошибки, мы возводим разницу в квадрат. Наконец, мы вычисляем среднее всех этих значений. Таким образом, мы хотим, чтобы среднее расстояние между предсказанными и фактическими показателями было минимальным.
Вам может быть интересно, почему мы возводили разницу в квадрат вместо того, чтобы брать абсолютное значение. Оказывается, что для некоторых из представленных ниже математических операций возведение в квадрат работает лучше. Кроме того, это метод максимального правдоподобия. Тем не менее, такой подход приводит к тому, что крупные ошибки имеют более сильное влияние на среднее значение, поскольку мы возводим в квадрат каждое отклонение.
Наша модель
Теперь, когда у нас есть функция оценки, как найти способ ее минимизировать? В этом посте мы рассмотрим модель линейной регрессии. Она выглядит следующим образом:

Где j — количество имеющихся у нас предсказателей (независимых переменных), значения бета — это наши коэффициенты. А бета 0 является смещением (intercept). По сути, данная модель представляет собой линейную комбинацию наших предсказателей с intercept.
Теперь, когда у нас есть модель и функция оценки, наша задача состоит в том, чтобы найти бета-значения, которые минимизируют MSE для наших данных. Для линейной регрессии на самом деле существует решение в замкнутой форме, называемое нормальным уравнением. Однако в этом посте мы собираемся использовать другую технику — градиентный спуск.
Градиентный спуск
Градиентный спуск — это метод, который мы позаимствовали из оптимизации. Очень простой, но мощный алгоритм, который можно использовать для поиска минимума функции.
- Выберите случайное начальное значение.
- Делайте шаги, пропорциональные отрицательному градиенту в текущей точке.
- Повторяйте, пока не достигните предела.
Этот метод найдет глобальный минимум, если функция выпуклая. В противном случае мы можем быть уверены только в том, что достигнем локальный минимум.
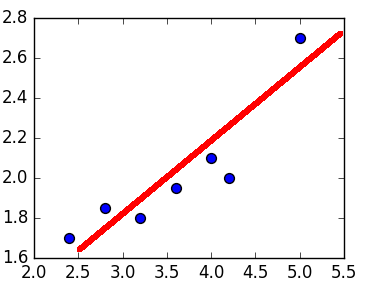
Первый вопрос, на который нам нужно ответить: является ли наша функция оценки выпуклой? Давайте посмотрим:
mses = [] lstat_coef = range(-20, 23) for coef in lstat_coef: pred_values = np.array([coef * lstat for lstat in boston_df.LSTAT.values]) mses.append(np.sum((target - pred_values)**2)) plt.plot(lstat_coef, mses);
Для построения графика выше мы взяли диапазон значений коэффициентов для LSTAT, и для каждого из них рассчитали MSE на основе наших данных. Если мы затем отобразим полученные значения, мы получим приведенную выше кривую — выглядит довольно выпуклой! И оказывается, что наша функция MSE с нашей моделью линейной регрессии всегда будет выпуклой! Это означает: мы можем использовать градиентный спуск, чтобы найти оптимальные коэффициенты для нашей модели!
Одна из причин того, что градиентный спуск более распространен, чем нормальное уравнение для машинного обучения, заключается в том, что он намного лучше масштабируется по мере увеличения количества показателей. Это также стандартный метод оптимизации, который используется повсюду в машинном обучении. Поэтому понимание того, как он работает, чрезвычайно важно.
Градиенты
Если вы снова посмотрите на наш псевдокод для градиентного спуска, вы увидите, что на самом деле все, что нам нужно сделать, это вычислить градиенты. Итак, что такое градиенты? Это просто частные производные по коэффициентам. Для каждого имеющегося коэффициента нам нужно будет вычислить производную MSE по этому коэффициенту. Давайте начнем!
Для начала запишем выражение для MSE, подставив функцию оценки со смещением и единственной переменной LSTAT:
Теперь, взяв производную по бета 0, мы получим (умноженное на -1):
Теперь давайте запустим наш алгоритм градиентного спуска и убедимся, что MSE действительно уменьшается:
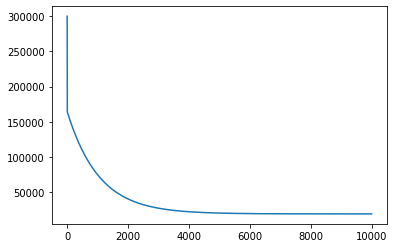
beta_0 = 0 beta_1 = 0 learning_rate = 0.001 lstat_values = boston_df.LSTAT.values n = len(lstat_values) all_mse = [] for _ in range(10000): predicted = beta_0 + beta_1 * lstat_values residuals = target - predicted all_mse.append(np.sum(residuals**2)) beta_0 = beta_0 - learning_rate * ((2/n) * np.sum(residuals) * -1) beta_1 = beta_1 - learning_rate * ((2/n) * residuals.dot(lstat_values) * -1) plt.plot(range(len(all_mse)), all_mse);
Первый график, представленный выше, показывает значение MSE, когда мы запускаем градиентный спуск. Как и следовало ожидать, MSE уменьшается со временем по мере выполнения алгоритма. Это означает, что мы постоянно приближаемся к оптимальному решению.
На графике видно, что мы вполне могли завершить работу раньше. MSE переходит в прямую (почти не изменяется) примерно после 4000 итераций.
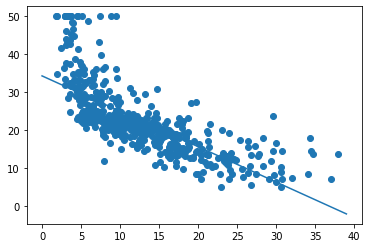
print(f"Beta 0: ") print(f"Beta 1: ") plt.scatter(boston_df['LSTAT'], target) x = range(0, 40) plt.plot(x, [beta_0 + beta_1 * l for l in x]);
Итак, запуск градиентного спуска показал, что оптимальное смещение составляет 34.55, а оптимальный наклон равен -0,95. На приведенном выше графике эта линия показана поверх наших данных, она выглядит как аппроксимирующая прямая.
Скорость обучения
Один параметр, который нам еще предстоит обсудить, — это скорость обучения. Эта скорость — гиперпараметр, используемый для определения того, насколько большие шаги мы делаем от направления градиента. Как узнать, какое значение выбрать? Как правило, можно попробовать множество вариантов. Вот некоторые из них, которые были предложены Andrew Ng: .001, .003, .01, .03, .1, .3, 1, 3.
Выбор слишком малого значения приводит к более медленной сходимости. Выбор слишком большого значения может привести к перешагиванию через минимум и расхождению.
Существуют также другие оптимизаторы градиентного спуска, которые более сложны и адаптируют скорость обучения за вас. Это также то, что вы можете делать самостоятельно, постепенно снижая скорость обучения.
Когда прекратить итерацию?
В моем коде я просто выполняю наш цикл 10000 раз. Почему 10000? Никакой реальной причины, кроме моей уверенности в том, что этого достаточно, чтобы достичь минимума. Такой подход точно нельзя назвать лучшей практикой. Вот несколько более разумных идей:
- Следите за оценкой после каждого цикла, и когда ее очередное изменение меньше некоторого граничного значения — скажем, 0.001 — останавливайтесь.
- Используйте проверочный датасет (validation set) и отслеживайте число ошибок, например, с помощью MSE. Когда метрика перестанет уменьшаться, остановитесь.
Нормализация данных
При работе с градиентным спуском вы хотите, чтобы все ваши данные были нормализованы. Вычтите среднее значение и разделите на стандартное отклонение для всех ваших тренировочных показателей. Обычно это ускоряет обучение и снижает вероятность застревания в локальном оптимуме, если функция оценки не является выпуклой.
Другие виды градиентного спуска
Показанный здесь градиентный спуск представляет собой классическую форму, что означает: каждое обновление коэффициента использует все данные для вычисления градиентов. Существует также стохастический градиентный спуск. Ему необходима только 1 строка данных (1 наблюдение) для пересчета коэффициентов в каждом цикле.
Такой способ намного лучше масштабируется, так как нужно обработать только одну строку данных за раз перед обновлением. Также он является более неопределенным, поскольку вы пытаетесь перемещаться с использованием градиента, рассчитанного на основе единственного наблюдения.
Другой тип градиентного спуска — это мини-пакетный градиентный спуск. Эта форма представляет собой компромисс между двумя, где вы выбираете размер пакета. Скажем, 32 (или, что еще лучше, пакетный график, который начинается с небольших пакетов и увеличивается с увеличением количества эпох), и каждая итерация вашего градиентного спуска использует 32 случайные строки данных для вычисления градиента (алгоритм воспользуется всеми строками перед повторной выборкой раннее обработанных). В результате мы получаем некоторую масштабируемость, но и некоторую неопределенность.
Такое случайное поведение оказывается полезным для функций оценки, которые не являются выпуклыми (глубокое обучение), поскольку оно может помочь модели избежать локального минимума. Это наиболее распространенный метод для невыпуклых функций оценки.
Допущения нашей модели
Всякий раз, когда вы имеете дело с моделью, хорошо знать, какие допущения она делает. Университет Дьюка написал об этом целую статью:
Реализация линейной регрессии в Scikit-Learn
Теперь, когда мы немного разбираемся в теории и реализации, давайте обратимся к библиотеке scikit-learn, чтобы на самом деле использовать линейную регрессию на наших данных. Написание моделей с нуля довольно полезно для обучения, но на практике вам, как правило, гораздо лучше использовать проверенную и широко используемую библиотеку.
Для начала нужно нормализовать данные:
from sklearn.linear_model import SGDRegressor from sklearn.metrics import mean_squared_error from sklearn.preprocessing import StandardScaler scaler = StandardScaler() scaler.fit(boston_df) scaled_df = scaler.transform(boston_df)У Scikit-learn довольно удобный API. Он предоставляет множество моделей, и все они имеют функции fit и predict . Вы можете вызвать fit с вашими X и y данными для обучения модели, а затем использовать predict для получения предсказанных значений на основе новых данных. Scikit-learn также предоставляет множество метрик, которые вы можете использовать для оценки, такие как MSE. Здесь я вычисляю среднеквадратическую ошибку (RMSE). Так мы можем использовать шкалу нашего целевого показателя, что, легче для понимания.
SGDRegressor выполняет линейную регрессию с использованием градиентного спуска и принимает следующие аргументы: tol (сообщает модели, когда следует прекратить итерацию) и eta0 (начальная скорость обучения).
linear_regression_model = SGDRegressor(tol=.0001, eta0=.01) linear_regression_model.fit(scaled_df, target) predictions = linear_regression_model.predict(scaled_df) mse = mean_squared_error(target, predictions) print("RMSE: <>".format(np.sqrt(mse)))RMSE в итоге составила 4.68… для нашей обучающей выборки с использованием scikit-learn.
Полиномиальные переменные
Рассматривая построенный выше график стоимости от LSTAT, вы могли заметить, что между данными показателями существует полиномиальная связь. Линейная регрессия хорошо подходит в случае линейной зависимости, но, если вы добавите полиномиальные показатели, такие как LSTAT, вы сможете установить более сложные отношения. SKLearn упрощает данный процесс:
from sklearn.preprocessing import PolynomialFeatures poly = PolynomialFeatures(2, include_bias=False) poly_df = poly.fit_transform(boston_df) scaled_poly_df = scaler.fit_transform(poly_df) print(f"shape: ") linear_regression_model.fit(scaled_poly_df, target) predictions = linear_regression_model.predict(scaled_poly_df) mse = mean_squared_error(target, predictions) print("RMSE: <>".format(np.sqrt(mse)))shape: (506, 104) RMSE: 3.243477309312183Функция PolynomialFeatures сгенерировала новую матрицу показателей, состоящую из всех их полиномиальных комбинаций со степенью меньше или равной указанной (в нашем примере 2). Затем мы нормализовали эти данные и скормили их нашей модели. Так мы получили улучшенную тренировочную RMSE, равную 3.24. Однако обратите внимание, что эти результаты, представленные в иллюстративных целях, используют только тренировочную выборку.
Категориальные переменные
Линейная регрессия — одна из моделей, с которой нужно быть осторожным, когда у вас есть качественные данные. Если у вас переменные со значениями 1, 2 и 3, которые на самом деле означают «Мужской», «Женский», «Нет ответа», не передавайте их модели таким образом, даже если они являются числами.
Если бы вы это сделали, модель присвоила бы такому показателю коэффициент — возможно, 0.1. Это будет означать, что принадлежность к женскому полу увеличивает предсказанное значение на 0.1. А отсутствие ответа — на 0.2. Но, возможно, метка «Женский» должна повысить результат на 1.2, а «Нет ответа» — всего на 0.001. Чтобы решить данную проблему, вы должны преобразовать такие значения в фиктивные переменные, чтобы каждая категория имела свой собственный вес. Вы можете узнать, как это сделать с помощью scikit-learn, здесь.
Интерпретация вашей модели
Линейная регрессия — это отличная статистическая модель, которая существует уже давно. Есть много статистических методов, которые можно использовать для ее оценки и интерпретации. Мы не будем рассматривать их все и на самом деле сосредоточимся на очень простых подходах, которые, возможно, более распространены в машинном обучении, чем в статистике.
Во-первых, давайте посмотрим на коэффициенты, которым научилась наша модель (по всем показателям):
linear_regression_model.fit(scaled_df, target) sorted(list(zip(boston_df.columns, linear_regression_model.coef_)), key=lambda x: abs(x[1]))[('AGE', -0.09572161737815363), ('INDUS', -0.21745291834072922), ('CHAS', 0.7410105153873195), ('B', 0.8435653632801421), ('CRIM', -0.850480180062872), ('ZN', 0.9500420835249525), ('TAX', -1.1871976153182786), ('RAD', 1.7832553590229068), ('NOX', -1.8352515775847786), ('PTRATIO', -2.0059298125382456), ('RM', 2.8526547965775757), ('DIS', -2.9865347158079887), ('LSTAT', -3.724642983604627)]Что они означают? Каждый коэффициент представляет собой среднее изменение цены на жилье при изменении соответствующего показателя на единицу с условием, что все остальные показатели остаются неизменными. Например, если значения других показателей не затрагиваются, то увеличение LSTAT на единицу снижает наш целевой показатель (цену на жилье) на 3.72, а увеличение RM увеличивает его на 2.85.
Таким образом, если вы хотите повысить стоимость дома, то может быть стоит начать с увеличения RM и уменьшения LSTAT. Я говорю «может быть», потому что линейная регрессия рассматривает корреляции. Судя по нашим данным, такая взаимосвязь имеет место быть, что само по себе не означает обязательное наличие причинно-следственной связи между показателями.
Доверительные интервалы
Часто в машинном обучении очень полезно иметь доверительный интервал вокруг ваших оценок. Есть разные способы сделать это, но одним довольно общим методом является использование bootstrap .
Bootstrap — это случайная выборка на основе наших данных, и эта выборка того же размера, что и исходные данные. Так мы можем создать несколько представлений одних и тех же данных. Давайте создадим 1000 bootstrap-семплов наших данных.
from sklearn.utils import resample n_bootstraps = 1000 bootstrap_X = [] bootstrap_y = [] for _ in range(n_bootstraps): sample_X, sample_y = resample(scaled_df, target) bootstrap_X.append(sample_X) bootstrap_y.append(sample_y)Затем мы обучим модель на каждом из полученных датасетов и получим следующие коэффициенты:
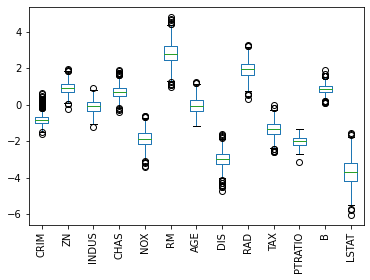
linear_regression_model = SGDRegressor(tol=.0001, eta0=.01) coeffs = [] for i, data in enumerate(bootstrap_X): linear_regression_model.fit(data, bootstrap_y[i]) coeffs.append(linear_regression_model.coef_) coef_df = pd.DataFrame(coeffs, columns=boston_df.columns) coef_df.plot(kind='box') plt.xticks(rotation=90);
На представленной диаграмме размаха показан диапазон значений коэффициентов, которые мы получили для каждого показателя для всех моделей, которые мы обучили. AGE — особенно интересен, потому что значения коэффициентов были как положительными, так и отрицательными, что является хорошим признаком того, что, вероятно, нет никакой связи между возрастом и стоимостью.
Кроме того, мы можем увидеть, что LSTAT имеет большой разброс в значениях коэффициентов, в то время как PTRATIO имеет относительно небольшую дисперсию, что повышает доверие к нашей оценке этого коэффициента.
Мы даже можем немного углубиться в полученные коэффициенты для LSTAT:
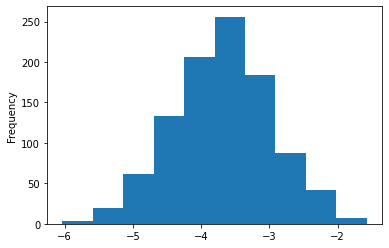
print(coef_df['LSTAT'].describe()) coef_df['LSTAT'].plot(kind='hist');count 1000.000000 mean -3.686064 std 0.713812 min -6.032298 25% -4.166195 50% -3.671628 75% -3.202391 max -1.574986 Name: LSTAT, dtype: float64
Теперь мы можем с большой уверенностью сказать, что фактический коэффициент LSTAT отрицателен и почти наверняка находится между -2 и -5.5.
Разделение на обучающий/тестовый датасеты и кросс-валидация
До этого момента мы тренировались на всех имеющихся данных. Это может иметь смысл, потому что мы хотим максимизировать их полезность, используя как можно больше данных для обучения. С другой стороны, из-за такого подхода нам становится труднее оценивать, насколько хорошо работает наша модель. Причина этого в том, что, если мы продолжим рассчитывать MSE, используя тренировочные данные, мы можем обнаружить, что при применении модели на незнакомых ей данных, она работает довольно плохо.
Эта идея называется переобучением (overfitting). По сути, такая модель работает намного лучше с обучающими данными, чем с новыми. Она была чрезмерно натренирована на обнаружение уникальных характеристик обучающего множества, которые не являются общими закономерностями, присущими генеральной совокупности.
Другая сторона проблемы называется bias. Модель имеет высокий bias, когда она плохо обучена. В этом случае MSE будет высокой как для тренировочных данных, так и для данных, не показанных во время обучения.
В ML всегда существует компромисс между смещением (bias) и дисперсией (overfitting). По мере того, как ваши модели становятся более сложными, возрастает риск переобучения на тренировочных данных.
Теперь, когда мы знаем о проблемах с вычислением MSE, используя только обучающее множество, что мы можем сделать, чтобы лучше судить о способности модели к обобщению? А также диагностировать overfitting и bias? Типичным решением является разделение наших данных на две части: обучающий и тестовый датасеты.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(scaled_df, target, test_size=0.33, random_state=42)Теперь, когда у нас есть два отдельных набора данных, мы можем тренировать модель на обучающем множестве и вычислять метрики, используя оба датасета (лучше всего использовать ваши тестовые данные после настройки модели):
linear_regression_model = SGDRegressor(tol=.0001, eta0=.01) linear_regression_model.fit(X_train, y_train) train_predictions = linear_regression_model.predict(X_train) test_predictions = linear_regression_model.predict(X_test) train_mse = mean_squared_error(y_train, train_predictions) test_mse = mean_squared_error(y_test, test_predictions) print("Train MSE: <>".format(train_mse)) print("Test MSE: <>".format(test_mse))Train MSE: 23.068773005090424 Test MSE: 21.243935754712375Отлично! Теперь у нас есть MSE как для тренировочных данных, так и для данных тестирования. И оба значения довольно близки, что говорит об отсутствии проблемы с переобучением. Но достаточно ли они низкие? Большие значения предполагают наличие высокого bias.
Один из способов разобраться в этом — построить график обучения. Кривая обучения отображает нашу функцию ошибок (MSE) с различными объемами данных, используемых для тренировки. Вот наш график:
# Источник: http://scikit-learn.org/0.15/auto_examples/plot_learning_curve.html def plot_learning_curve(estimator, title, X, y, ylim=None, cv=None, n_jobs=1, train_sizes=np.linspace(.1, 1.0, 5)): plt.figure() plt.title(title) if ylim is not None: plt.ylim(*ylim) plt.xlabel("Train примеры") plt.ylabel("Оценка") train_sizes, train_scores, test_scores = learning_curve( estimator, X, y, cv=cv, n_jobs=n_jobs, train_sizes=train_sizes, scoring=make_scorer(mean_squared_error)) train_scores_mean = np.mean(train_scores, axis=1) train_scores_std = np.std(train_scores, axis=1) test_scores_mean = np.mean(test_scores, axis=1) test_scores_std = np.std(test_scores, axis=1) plt.grid() plt.fill_between(train_sizes, train_scores_mean - train_scores_std, train_scores_mean + train_scores_std, alpha=0.1, color="r") plt.fill_between(train_sizes, test_scores_mean - test_scores_std, test_scores_mean + test_scores_std, alpha=0.1, color="g") plt.plot(train_sizes, train_scores_mean, 'o-', color="r", label="Train score") plt.plot(train_sizes, test_scores_mean, 'o-', color="g", label="C-V score") plt.legend(loc="best") return plt plot_learning_curve(linear_regression_model, "Кривая обучения", X_train, y_train, cv=5);
Вы можете видеть, что с менее чем 50 обучающими примерами тренировочная MSE неплохая, а кросс-валидация оставляет желать лучшего — довольно плохая (мы еще не говорили о кросс-валидации, так что пока думайте об этом как о тестировании). Если бы у нас было только такое количество данных, это выглядело бы как явная проблема высокой дисперсии (переобучения).
По мере увеличения наших данных мы начинаем улучшать оба результата, и они становятся очень похожими, что говорит о том, что у нас нет проблемы переобучения. Как правило, при высокой дисперсии на этом графике две линии будут находится довольно далеко друг от друга, и кажется, что, если мы продолжим добавлять больше данных, они могут сойтись.
Этот график больше похож на проблему с большим смещением (bias), поскольку две наши кривые очень близки и сглаживаются. Однако трудно сказать наверняка, потому что, возможно, мы только что достигли наилучшего возможного MSE. В таком случае это не будет проблемой высокого смещения. Такой результат был бы ей только в том случае, если бы наши кривые выровнялись при значении MSE выше оптимального. В реальной жизни вы не знаете, какова оптимальная MSE, поэтому вам нужно немного поразмышлять, считаете ли вы, что уменьшение bias улучшит ваш результат — но лучше просто попробуйте!
Устранение проблем высоких bias/variance
Итак, теперь, когда вы диагностировали проблему смещения или дисперсии, как ее исправить?
Для высокой дисперсии:
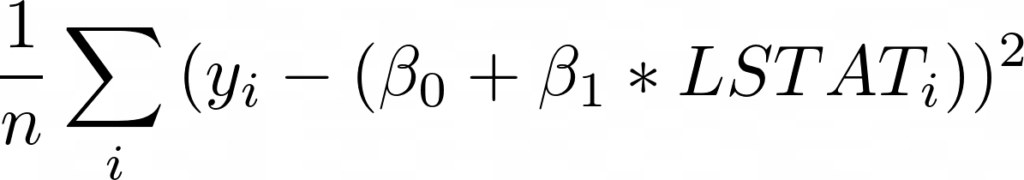

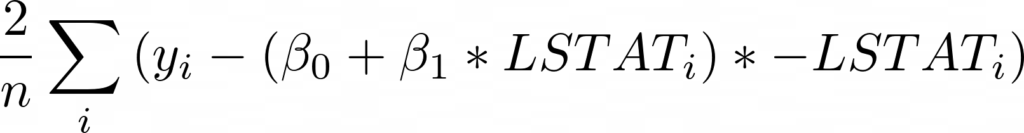

- Получите больше данных для обучения
- Попробуйте меньший набор показателей
- Используйте менее сложную модель
- Добавьте регуляризацию
Для высокого смещения:
- Попробуйте увеличить число показателей
- Перейдите на более сложную модель
Кросс-валидация и настройка гиперпараметров
Ранее мы упоминали этот термин: кросс-валидация. Давайте поговорим об этом сейчас. На данный момент мы узнали, что неплохо разделить данные на наборы для обучения и тестирования, чтобы лучше понять, насколько хорошо работает модель. Это замечательно, но представьте, что мы хотим протестировать несколько разных моделей или протестировать разные параметры нашей модели — например, другую скорость обучения или толерантность. Как бы нам решить, какая модель или какой параметр лучше? Будем ли мы обучать все на тренировочных данных и тестировать все на наших тестовых данных?
Надеюсь, вы понимаете, что это не имеет смысла, потому что тогда мы, по сути, оказались бы в том же месте, что и раньше, без возможности проверить, насколько хорошо мы справляемся с ранее неизвестными данными. Итак, мы хотим сохранить датасет для тестирования незапятнанным в том смысле, что в идеальном мире мы бы запускали наши тесты на нем только после того, как провели все необходимые эксперименты и были уверены в том, что нашли самую лучшую модель.
Похоже, нам нужен третий набор данных – датасет для валидации. По сути, мы можем разбить наши обучающие данные на две части: обучающий и проверочный датасеты. Все модели будут обучены на тренировочном множестве, а затем протестированы на нашем проверочном наборе. Затем мы выберем модель, которая лучше всего справляется с проверкой, и посмотрим, насколько удачно она пройдет тестирование. Результаты тестирования покажут, как хорошо наша модель будет работать с незнакомыми данными, и на этом мы завершим процесс разработки.
Примечание: в статье предполагается, что используемые тестовые и проверочные датасеты представляют собой репрезентативные выборки из нашей совокупности. Например, если средняя цена дома в вашем проверочном множестве составляет 1 миллион, а для генеральной совокупности соответствующее значение равно 300 тысячам, у вас плохая выборка. Часто мы случайным образом делим имеющиеся данные на три выборки, но всегда полезно подтвердить, что эти наборы являются репрезентативными. В противном случае вы обнаружите, что ваша модель, которая хорошо зарекомендовала себя при проверке и тестировании, плохо работает на реальных данных.
На практике вместо создания единого множества для проверки мы часто используем k-блочную кросс-валидацию.
Это означает, что мы выбираем значение k, скажем 3. Затем мы берем наши обучающие данные и делим их на 3 части. Мы случайным образом выбираем 2 блока для тренировки, а затем используем оставшийся для тестирования. Повторяем этот процесс еще 2 раза, так чтобы все наблюдения были использованы как для обучения, так и для проверки, и каждое из них применялось для валидации только один раз. После этого усредняем все три оценки (в нашем случае MSE), чтобы получить общую оценку для конкретной модели. Затем мы можем повторить этот процесс для других моделей, чтобы найти лучшую.
Вот видео, которое более наглядно описывает этот подход (с русскими субтитрами): https://www.youtube.com/watch?v=TIgfjmp-4BA
Этот процесс довольно просто реализуется с помощью sklearn:
from sklearn.model_selection import RandomizedSearchCV param_dist = linear_regression_model = SGDRegressor(tol=.0001) n_iter_search = 8 random_search = RandomizedSearchCV(linear_regression_model, param_distributions=param_dist, n_iter=n_iter_search, cv=3, scoring='neg_mean_squared_error') random_search.fit(X_train, y_train) print("Лучшие параметры: <>".format(random_search.best_params_)) print("Лучшая оценка MSE: <>".format(random_search.best_score_))Лучшие параметры: Лучшая оценка MSE: -25.64219216972172Здесь мы фактически использовали рандомизированный поиск ( RandomizedSearchCV ), который обычно лучше, чем поиск по всем возможным значениям. Часто вы хотите попробовать много разных параметров для множества различных регуляторов, и сеточный поиск (перебор всех возможных комбинаций) вам не подходит.
Обычно вы хотите использовать рандомизированный поиск (случайный выбор комбинаций), как мы сделали выше. Хотя, поскольку у нас было только небольшое количество значений, мы заставили его работать как сеточный поиск, установив n_iter_search равным числу вариантов, которые мы хотели попробовать.
Мы также установили cv=3 , чтобы иметь 3 блока и использовали отрицательную MSE, потому что функции CV в scikit-learn пытаются максимизировать значение.
Вы можете узнать больше о случайном и «сеточном» вариантах поиска здесь: https://scikit-learn.org/stable/modules/grid_search.html.
Кроме того, в scikit-learn есть много других CV функций, которые полезны, особенно если вы хотите протестировать разные модели с одинаковыми блоками. Вот некоторая документация: https://scikit-learn.org/stable/modules/cross_validation.html.
Регуляризация
В качестве средства борьбы с высокой дисперсией я упомянул регуляризацию. Вы можете думать о ней как о методе, который используется для наказания модели за обучение сложным взаимосвязям. Для линейной регрессии она принимает форму трех популярных подходов. Все эти методы сосредоточены на идее ограничения того, насколько большими могут быть коэффициенты наших показателей.
Идея состоит в том, что если мы переоцениваем влияние предсказателя (большое значение коэффициента), то, вероятно, мы переобучаемся. Примечание: у нас все еще могут быть просто большие коэффициенты. Регуляризация говорит о том, что уменьшение MSE должно оправдывать увеличение значений коэффициентов.
- Регуляризация L1 (Lasso): вы добавляете сумму абсолютных значений коэффициентов к функции оценки. Этот метод может принудительно обнулить коэффициенты, что затем может быть средством выбора показателей.
- Регуляризация L2 (Ridge): вы добавляете сумму квадратов значений коэффициентов к функции оценки.
- Эластичная сетка: вы добавляете обе и выбираете, как их утяжелить.
Каждый из этих методов принимает весовой множитель, который говорит вам, насколько сильное влияние регуляризация будет иметь на функцию оценки. В scikit-learn такой параметр называется альфа. Альфа равный 0 не добавит штрафа, в то время как высокое его значение будет сильно наказывать модель за наличие больших коэффициентов. Вы можете использовать кросс-валидацию, чтобы найти хорошее значение для альфа.
Sklearn упрощает это:
from sklearn.linear_model import ElasticNetCV clf = ElasticNetCV(l1_ratio=[.1, .5, .7, .9, .95, .99, 1], alphas=[.1, 1, 10]) clf.fit(X_train, y_train) train_predictions = clf.predict(X_train) test_predictions = clf.predict(X_test) print("Train MSE: <>".format(mean_squared_error(y_train, train_predictions))) print("Test MSE: <>".format(mean_squared_error(y_test, test_predictions)))Train MSE: 23.58766002758097 Test MSE: 21.54591803491954Здесь мы использовали функцию ElasticNetCV , которая имеет встроенную кросс-валидацию, чтобы выбрать лучшее значение для альфы. l1_ratio — это вес, который придается регуляризации L1. Оставшийся вес применяется к L2.
Итог
Если вы зашли так далеко, поздравляю! Это была тонна информации, но я обещаю, что, если вы потратите время на ее усвоение, у вас будет очень твердое понимание линейной регрессии и многих вещей, которые она может делать!
Кроме того, здесь вы можете найти весь код статьи.