Анализ трудоёмкости алгоритмов
Целью анализа трудоёмкости алгоритмов является нахождение оптимального алгоритма для решения задачи.
В качестве критерия оптимальности алгоритма выбирается трудоемкость алгоритма, понимаемая как количество элементарных операций, которые надо выполнить для решения задачи с помощью данного алгоритма.
Функцией трудоемкости называется отношение, связывающие входные данные алгоритма с количеством элементарных операций.
Одним из упрощенных видов анализа, является асимптотический анализ алгоритмов.
Целью асимптотического анализа является сравнение затрат времени и других ресурсов при использовании различных алгоритмов, предназначенных для решения одной и той же задачи, при больших объемах входных данных.
Используемая в асимптотическом анализе оценка функции трудоёмкости, называемая сложностью алгоритма, позволяет определить, как быстро растет трудоёмкость алгоритма с увеличением объема данных.
Для описания скорости роста функций используется асимптотическая оценка O.
Она представляет собой верхнюю асимптотическую оценку трудоемкости алгоритма и позволяет определить, как быстро растет трудоемкость алгоритма с увеличением объема данных.
Определение. T(n) = O(f(n)), если существуют константы c > 0, n0 > 0 такие, что выполняется неравенство: 0 T(n) cf(n) для любого n >= n0
Здесь n — величина объёма данных.
Иначе говоря, запись T(n) = O(f(n)) означает, что T(n) принадлежит классу функций, которые растут не быстрее, чем функция f(n) с точностью до постоянного множителя.
Когда используют обозначение O(), имеют в виду не точное время исполнения, а только его предел сверху, причем с точностью до постоянного множителя.
Напр., если говорят, что алгоритму требуется время порядка O(n 2 ), то имеют в виду, что время выполнения задачи растет не быстрее, чем квадрат количества элементов.
Пример. Функция T(n) = 3n 3 +2n 2 имеет степень роста O(n 3 ), т.е. время выполнения задачи растет не быстрее, чем куб количества исходных данных. Если c = 5, n0 = 0, то 3n 3 +2n 2 n 3
При оценке трудоемкости используют правило сумм: в общем случае трудоемкость выполнения программных фрагментов имеет порядок фрагмента с наибольшим временем выполнения.
Пример. Пусть есть три фрагмента с временами выполнения O(n 3 ), O(n 2 ), O(nlogn). Тогда время выполнения первых двух фрагментов – это максимум из первых двух оценок — O(n 3 ). Затем сравнивается результат и третья оценка.
Для всех трех — O(n 3 ).
При оценке трудоемкости используется также правило произведений: если T1(n) и T2(n) имеют степени роста O(f(n)) и O(g(n)) соответственно, то произведение T1(n)T2(n) имеет степень роста O(f(n))O(g(n)).
Например, O(n 2 / 2) эквивалентно O(n 2 ).
Скорость роста некоторых функций:
n log n n*log n n 2
256 8 2048 65536
4096 12 49152 16777216
65536 16 1048565 4294967296
1048476 20 20969520 1099301922576
16775616 24 402614784 281421292179456
Из таблицы видно, что для задач с небольшим значением n метод решения задачи не влияет на скорость, но по мере роста n время, нужное для получения решения, становится большим (10 7 секунд равно 3,8 месяца, 10 8 секунд – 3,1 года).
Оценка Ώ задает нижнюю асимптотическую оценку роста функции T(n) и определяет класс функций, которые растут не медленнее, чем f(n) с точностью до постоянного множителя.
Определение. T(n) = Ώ(f(n)), если существуют константы c > 0, n0 > 0 такие, что выполняется неравенство: T(n) >= cf(n) >= 0 для любого n >= n0.
Например, запись T(n) = Ώ(nlog(n)) обозначает класс функций, которые растут не медленнее, чем f(n) = nlog(n).
(В этот класс попадают все полиномы со степенью, большей единицы, равно как и все степенные функции с основанием большим единицы).
Для задания одновременно верхней и нижней оценки роста функции T(n) используется оценка Ө (“тэта большое”).
Определение. T(n) = Ө(f(n)), если при f > 0 и n > 0 существуют константы c1, c2, n0 такие, что выполняется неравенство: c1f(n) T(n) c2f(n) для любого n >= n0.
Функция f(n) является асимптотически точной оценкой функции T(n), т.к. по определению функция T(n) не отличается от функции f(n) с точностью до постоянного множителя.
Например, для метода пирамидальной сортировки оценка трудоёмкости составляет T(n) = Ө(nlog(n)), то есть f(n) = nlogn.
Равенство T(n) = Ө(f(n)) выполняется тогда и только тогда, когда T(n) = O(f(n)) и T(n) = Ώ (f(n)).
Важно понимать, что Ө(f(n)) представляет собой не функцию, а множество функций, описывающих рост T(n) с точностью до постоянного множителя.
Асимптотические оценки можно представить в порядке увеличения скорости их роста:
Научный форум dxdy
Как определить трудоемкость составленного алгоритма?
| На страницу 1 , 2 След. |
Как определить трудоемкость составленного алгоритма?
18.06.2007, 11:21
Помогите, кто знает, как определить трудоемкость составленных алгоритмов?! Необходимо для сравнения, кто оптимальнее..
18.06.2007, 14:17
| Заблокирован |
Если грубо — надо посчитать вложенные циклы. По сути трудоёмкость — это оценка функции роста количества итераций при линейном приращении объема данных.

Например, если при увеличении размера входного массива в 2 раза количество итераций алгоритма по его обработке возрастёт в 4 раза, то это — квадратичная зависимость .
Можно эту функцию получить и экспериментально — нужно просто замерить время работы алгоритма на различных объёмах входных данных и построить график.
Может оказаться, что алгоритм с большей трудоёмкостью будет более эффективен на небольших объемах данных, поскольку коэффициенты при её расчёте обычно опускаются и считается предельная оценка при 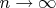 . Например, алгоритм
. Например, алгоритм  будет явно эффективнее на небольших объемах, чем
будет явно эффективнее на небольших объемах, чем  . Поэтому Вам, возможно, будет интереснее замерить реальную производительность и получить графическую зависимость экспериментально.
. Поэтому Вам, возможно, будет интереснее замерить реальную производительность и получить графическую зависимость экспериментально.
18.06.2007, 19:18
| Заслуженный участник |
Вас интересует трудоемкость (т.е. сколько усилий должен затратить программист на разработку алгоритма) или сложность (как долго комп будет щелкать, пока выдаст ответ)? На эти вопросы ответы разные… и занимаются ими разные дисциплины.
21.06.2007, 13:43
незваный гость писал(а):
👿
Вас интересует трудоемкость (т.е. сколько усилий должен затратить программист на разработку алгоритма) или сложность (как долго комп будет щелкать, пока выдаст ответ)? На эти вопросы ответы разные… и занимаются ими разные дисциплины.
По сути мне только лишь надо показать сложность.. т.е. какой алгоритм меньше занимает памяти, да и вообще быстрее работает. на пальцах то объяснить не сложно, но вот документально подтвердить..
Поискав по интернету.. много чего нашла, но, честно, доскональный анализ мне не нужен..
просто надо быстро и явно показать разницу.
Добавлено спустя 5 минут 7 секунд:
AlexDem писал(а):
Может оказаться, что алгоритм с большей трудоёмкостью будет более эффективен на небольших объемах данных, поскольку коэффициенты при её расчёте обычно опускаются и считается предельная оценка при . Например, алгоритм будет явно эффективнее на небольших объемах, чем .
Вот как раз так и у меня приведен пример маленькой размерности, но разработан он для больших.. и в этой сути мне и необходимо сравнение..
21.06.2007, 14:10
| Заблокирован |
незваный гость писал(а):
Вас интересует трудоемкость (т.е. сколько усилий должен затратить программист на разработку алгоритма) или сложность (как долго комп будет щелкать, пока выдаст ответ)?
Вопрос терминологии. По-моему, трудоёмкость алгоритма — то же, что и вычислительная сложность. А первое — трудоёмкость разработки, т.е. как долго программист будет щёлкать, пока выдаст программу
Fides писал(а):
Вот как раз так и у меня приведен пример маленькой размерности, но разработан он для больших.. и в этой сути мне и необходимо сравнение..
Ну и. В чём загвоздка? Если алгоритм сложный, то может проще его реализовать, а трудоёмкость измерить?

Вот у этого трудоёмкость — :
void fun(int array[], int size) {
int i;
Вот у этого трудоёмкость — :
void fun(int array[], int size) {
int i, j;
Трудоёмкость второго выше, поскольку на каждый элемент массива выволняется перебор элементов этого же массива во вложенном цикле. Поэтому во втором случае на каждую из 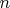 итераций охватывающего цикла приходится итераций вложенного цикла. Итого
итераций охватывающего цикла приходится итераций вложенного цикла. Итого  . Для оценки трудоёмкости достаточно взять кусок алгоритма с наибольшей вложенностью циклов.
. Для оценки трудоёмкости достаточно взять кусок алгоритма с наибольшей вложенностью циклов.

На простых алгоритмах всё просто, но даже посчитать трудоёмкость быстрой сортировки уже будет сложнее.
21.06.2007, 22:30
| Заслуженный участник |
AlexDem писал(а):
Вопрос терминологии.
И правильного ее использования. Трудоемкость (как сложность) я нигде не встречал. (Мы можем, кстати, называть производную — наклоном.)
AlexDem писал(а):
На простых алгоритмах всё просто, но даже посчитать трудоёмкость быстрой сортировки уже будет сложнее.
Не очень удивительно. Поскольку хорошо известно, что для быстрой сортировки 
Краснеть обычно приходится не когда не знаешь, а когда не хочешь узнать. Никто со знанием интеграла (и алгорифма быстрой сортировки) еще не родился…
22.06.2007, 03:37
незваный гость писал(а):
👿
Краснеть обычно приходится не когда не знаешь, а когда не хочешь узнать. Никто со знанием интеграла (и алгорифма быстрой сортировки) еще не родился…
ну.. я считаю, что для магистра прикладной математики и кибернетики — это стыдно!!
25.06.2007, 09:41
| Заблокирован |
незваный гость писал(а):
AlexDem писал(а):
Вопрос терминологии.
И правильного ее использования. Трудоемкость (как сложность) я нигде не встречал. (Мы можем, кстати, называть производную — наклоном.)
Термин «трудоёмкость алгоритма» существует и был употреблён вполне корректно. В этом легко можно убедиться, поискав словосочетание в поисковике. Вот, например, по одной из первых ссылок:
Цитата:
Трудоемкость алгоритма .
то же что Временная сложность .
Временная сложность
Time complexity
основной параметр, характеризующий алгоритм; определяется как число шагов, выполняемых алгоритмом в худшем случае, обычно рассматривается как функция размера задачи, представленной входными данными. Обычно под размером теоретико-графовой задачи понимается число вершин графа , число дуг 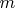 или пара
или пара  . Под шагом алгоритма понимается выполнение одной из команд некоторой гипотетической машины. Поскольку при таком определении шага сложность алгоритма зависит от конкретного вида машинных команд, во внимание принимается асимптотическая сложность, т.е. асимптотическая скорость увеличения числа шагов алгоритма, когда размерность задачи неограниченно растет. Ясно, что при двух произвольных «разумных» способах перевода алгоритма в последовательность машинных команд соответствующие сложности различаются не более чем на мультипликативную константу, а их скорость роста одинакова.
. Под шагом алгоритма понимается выполнение одной из команд некоторой гипотетической машины. Поскольку при таком определении шага сложность алгоритма зависит от конкретного вида машинных команд, во внимание принимается асимптотическая сложность, т.е. асимптотическая скорость увеличения числа шагов алгоритма, когда размерность задачи неограниченно растет. Ясно, что при двух произвольных «разумных» способах перевода алгоритма в последовательность машинных команд соответствующие сложности различаются не более чем на мультипликативную константу, а их скорость роста одинакова.
Другое название — Вычислительная сложность . См. также Сложность РАМ .
Литература: Ахо-Хопкрофт-Ульман, Евстигнеев-Касьянов/94, Липский.
незваный гость писал(а):
AlexDem писал(а):
На простых алгоритмах всё просто, но даже посчитать трудоёмкость быстрой сортировки уже будет сложнее.
Не очень удивительно. Поскольку хорошо известно, что для быстрой сортировки
Не думаю, что «в среднем» здесь корректное выражение, поскольку я не могу представить себе набор данных, на котором стандартный алгоритм быстрой сортировки работал бы эффективнее, чем — для этого нужно разделить отрезок ровнее, чем пополам. Это, скорее, наилучшая оценка, к которой алгоритм устойчиво стремится.
Сложность получается в том случае, если средний по счёту элемент диапазона на каждом шаге рекурсии будет оказываться близким к минимальному или максимальному значению диапазона. Вероятность этого на каждом шаге равна  — малый интервал, принимаемый нами за неэффективное деление. На последовательности шагов эта вероятность будет равна
— малый интервал, принимаемый нами за неэффективное деление. На последовательности шагов эта вероятность будет равна  видим, что интервал
видим, что интервал  обязан быть конечным, иначе диапазон будет делиться на два бесконечных, то есть — пополам. Следовательно
обязан быть конечным, иначе диапазон будет делиться на два бесконечных, то есть — пополам. Следовательно  .
.
Но и на конечных можно избежать любой вероятности появления , добавив предварительную логику поиска среднего элемента. Например, цикл поиска более-менее оптимального значения. Его сложность на каждом шаге будет не выше , и даже если он будет вызываться на каждом шаге рекурсии, по совокупности — не выше  . Тогда общая сложность будет
. Тогда общая сложность будет  с гарантией того, что трудоёмкость не будет продемонстрирована никогда. В пределе ничуть не хуже, чем .
с гарантией того, что трудоёмкость не будет продемонстрирована никогда. В пределе ничуть не хуже, чем .
Сетевой метод оценки трудоемкости алгоритмов
Количество вычислений, производимых при расчетах трудоемкости алгоритмов, можно значительно сократить, если использовать сетевой подход к анализу трудоемкости алгоритмов. Он позволяет получать среднюю, минимальную и максимальную трудоемкость.
Суть сетевого подхода состоит в выделении путей на графе алгоритма, соответствующих минимальной, средней и максимальной трудоемкости последовательности операторов. Эти пути могут быть выделены только на графах, не содержащих циклов. По этой причине методика сетевого подхода начинается с анализа трудоемкости алгоритмов, не содержащих циклы. Затем рассматривается прием исключения циклов из графа алгоритма путем замены их операторами с эквивалентной трудоемкостью. Этот прием позволяет распространить сетевой подход на любые алгоритмы, в том числе содержащие любое количество циклов.
Оценка средней трудоемкости алгоритмов
Алгоритм будем представлять в виде графа, состоящего из К операторных вершин и имеющего единственную конечную вершину с номером К=К+1; дуги графа отмечены вероятностями переходов Pij. Каждой вершине графа поставлено в соответствие среднее значение трудоемкости ki или lj. Задача оценки трудоемкости алгоритма сводится к определению среднего числа n1,n2,…,nk обращений к операторам за один прогон алгоритма.
Для применения сетевого подхода к оценке трудоемкости алгоритма, не содержащего циклы, вершины графа алгоритма должны быть пронумерованы в порядке их следования, т.е. так, чтобы любая вершина имела номер, больший любого номера предшествующих ей вершин. Нумерация проводится следующим образом. Начальной вершине присваивается номер 0. Очередной номер i=1,2,… присваивается вершине, в которую входят дуги от уже пронумерованных вершин с номерами, меньшими i. При этом любым двум вершинам должны соответствовать разные номера. Такой порядок нумерации является результативным для любого графа без циклов. Причем конечная вершина графа будет иметь максимальный номер К. Пример корректной нумерации вершин графа (*):
Поскольку граф не содержит циклов, то при прогоне алгоритма вершина 1 будет выполнена точно один раз, то есть n1 = 1. Среднее число попаданий вычислительного процесса в вершину определяется выражением:

где Рji — вероятность перехода из вершины j в вершину i.
При установленном порядке нумерации вершин на момент вычисления ni значения n1, n2. ni-1 уже определены. Поэтому вычисление значения ni сводится к суммированию произведений, причем поскольку Pij = 0 для всех j0, то суммирование следует проводить только для j
Определим среднее число обращений n1, n2. nk к операторам алгоритма изображенного графа (предыдущий рисунок)

Рассмотрим случай алгоритма, содержащего циклы:

Непосредственное применение описанной методики к таким алгоритмам невозможно и для вычисления значений n1, n2. nk необходимо исключить циклы, заменяя их операторами с эквивалентной трудоемкостью.

Для упрощения описания метода примем, что алгоритм состоит из однотипных операторов, например, только основных операторов. Разделим циклы по рангам. К рангу 1 относятся циклы, которые не содержат внутри себя ни одного цикла, к рангу 2 — циклы, внутри которых есть циклы не выше ранга 1 и так далее. Например, рассматриваемый алгоритм содержит два цикла С1 и С2 ранга 1 и один цикл С2 ранга 2. Совокупность операторов, входящих в цикл, и связывающих их дуг, за исключением дуги, замыкающей цикл, называют телом цикла. Тело цикла ранга 1 является графом без циклов. Применяя к этому графу ранее рассмотренную методику, можно определить значения ni для каждого из операторов, принадлежащих телу цикла, и, следовательно, трудоемкость тела С-го цикла.
Здесь суммирование проводится по всем вершинам Vj, содержащимся в цикле С.
Пусть известно среднее число повторений цикла nc, равное числу выполнений тела цикла при одном прогоне алгоритма. Если вероятность перехода по дуге, замыкающей цикл, равна Pkl, то nC=

В этом случае средняя трудоемкость цикла равна:

и цикл С можно заменить оператором с трудоемкостью kC.
Применяя указанную процедуру замены циклов операторами ко всем циклам ранга 1, затем к циклам ранга 2 и так далее, в конце концов придем к графу без циклов, трудоемкость которого находится уже рассмотренным способом.
Определим трудоемкость, заданную приведенным выше графом.
Положим, что трудоемкость всех операторов одинакова и равна 1. Среднее число повторений циклов С1, С2 и С3 определяется из вероятностей переходов, указанных на графе, следующими значениями:


Выделим тела циклов С1 и С2 первого ранга:
Применяя к этим графам рассмотренную ранее методику, определяем среднюю трудоемкость kC1 и kC2 выполнения тел этих циклов:


Определяем трудоемкость тел этих циклов:


Средняя трудоемкость циклов С1 иС2 вычисляется умножением полученных значений на среднее число повторений этих циклов:
Заменяя в исходном графе циклы С1 и С2 операторами С1 и С2 с трудоемкостью kC1 и kC2, получим граф:

Тело цикла С3 имеет вид:

Определим трудоемкость тела цикла С3:


С учетом числа nC3 повторений цикла трудоемкость цикла составит:
Заменив цикл С3 оператором С3 с трудоемкостью kC3, получим граф:

Трудоемкость всего алгоритма, представляемого этим графом, равна:
Оценка минимальной и максимальной трудоемкости алгоритма.
Минимально возможное и максимально возможное значение трудоемкости на момент окончания выполнения оператора Vi обозначим соответственно через Ai и Bi. Имеем A0=0, B0=0. Тогда для остальных вершин с номерами i=1,2. k:


где (j, i) — дуга, выходящая из вершины j и входящая в вершину i;
D — множество дуг графа программы.
Минимальное min (Aj) и максимальное max (Bj) значения определяются по отношению ко всем вершинам j из которых выходят дуги, входящие в вершину i.
Значения kimin и kimax характеризуют минимальную и максимальную трудоемкость оператора Vi.
Для конечной вершины К графа вычисляются значения


характеризующие минимальную и максимальную трудоемкость алгоритма.
Определим минимальную и максимальную трудоемкость алгоритма, не содержащего циклов (*).
Примем, что трудоемкость каждого оператора постоянна и равна 1.
Последовательно применяя , получим:


Таким образом минимальная трудоемкость алгоритма Ak = 5, а максимальная Bk = 7 операций.
Минимальная и максимальная трудоемкость алгоритмов, содержащих циклы, находятся по аналогии с методом определения средней трудоемкости алгоритмов с циклами. При этом выделяются циклы первого ранга. Находятся минимальная А и максимальная В трудоемкость тела цикла. Минимальная и максимальная трудоемкость цикла определяется значениями и , где nmin и nmax — минимальное и максимальное число повторений цикла. Затем цикл заменяется оператором с трудоемкостью kmin= и kmax = и вновь применяется процедура исключения циклов. Процесс повторяется до тех пор, пока граф алгоритма не будет преобразован к форме без циклов. Сетевые модели вычислительных систем.
Представление ВС в виде стохастической сети.

ВС можно рассматривать как совокупность устройств, процессы функционирования которых являются процессами массового обслуживания и для их описания используют модели теории массового обслуживания. Основными моделями, используемыми в теории массового обслуживания, являются одно — и многоканальные системы массового обслуживания (СМО). В одноканальной СМО обслуживание заявок организуется следующим образом.
На вход СМО поступают заявки с интенсивностью . Так как СМО содержит один канал (прибор), то в каждый момент времени может обслуживаться только одна заявка. Среднее время обслуживания заявки равно V. Другие заявки, поступающие в систему, когда канал был занят обслуживанием, образуют очередь О. Из этой очереди по окончании обслуживания заявки выбирается следующая заявка и так далее. Если канал свободен и в очереди нет заявок, то канал простаивает. Вновь прибывшая заявка сразу занимает простаивающий канал, если в очереди нет других заявок.

Многоканальная СМО содержит К однотипных каналов, среднее время обслуживания заявок V в которых непременно одинаково.
В системе одновременно может обслуживаться до К заявок. Заявки, застающие все каналы занятыми ожидают освобождение каналов в очереди О. Характерная особенность рассматриваемой СМО — полная доступность каналов, при которой любая заявка может быть обслужена любым свободным каналом. Если налагаются ограничения на условия выбора каналов для обслуживания входных заявок, то многоканальная система разбивается на ряд независимых одно — и многоканальных систем. Например, если в системе (*) заявки с вероятностью Р1 поступают на обслуживание в первые (к-1) полнодоступные каналы и с вероятностью Р2 = 1 — Р1 в к-й канал, то исходная система разбивается на две независимые системы, первой из которых является (к-1) — канальная система, а второй — одноканальная система, с интенсивностями входящих потоков заявок Р1 и Р2 соответственно.
Обычно ВС состоит из нескольких подсистем, каждая из которых представляется одно — или многоканальной СМО. К таким подсистемам относятся процессор с оперативной памятью, селекторные (СК) и мультиплексные каналы (МК) с подключенными к ним устройствами ввода-вывода.
Модель процессора с оперативной памятью.

Подсистема «процессор — оперативная память » рассматривается как однокритериальная СМО. Обслуживающим каналом (прибором) в этой системе является процессов Пр. При работе ВС в мультипрограммном режиме в оперативной памяти размещено несколько программ П1, П2. ПМ.
Одни программы находятся в состоянии готовности к выполнению, другие в состоянии ожидания некоторых событий, например завершения операции ввода-вывода.
Совокупности готовых к выполнению программ соответствует очередь О заявок в СМО. Программа из очереди, получившая доступ к процессору Пр, переходит в состояние счета. Среднее время непрерываемого счета программы определяет среднюю продолжительность V процесса обслуживания заявки в СМО. Процесс счета, то есть обслуживание программы процессором, прекращается в момент, когда программа обращается к системе ввода-вывода, то есть к устройству ввода-вывода или к ВЗУ. При этом считается, что программа на счет обслужена и покидает систему «процессор — оперативная память». Обслуживание этой заявки, то есть этой программы, будет продолжено другим устройством ВС. Интенсивность поступления заявок в СМО определяется суммарной интенсивностью пополнения списка готовых к выполнению программ, как за счет поступления новых программ, так и за счет программ, для которых завершен ввод-вывод. Непременное условие готовности программы — наличие ее в оперативной памяти.
СЛОЖНОСТЬ АЛГОРИТМОВ
Трудоемкость алгоритма — это количество операций, которые необходимо выполнить в процессе решения поставленной задачи с помощью этого алгоритма. Практические оценки трудоемкости вычислительных алгоритмов, как правило, осуществляются раздельно для разных операций с группированием только однородных действий, таких как сложение и вычитание. Операции умножения и деления существенно различаются по длительности, поэтому оцениваются раздельно. В алгоритмах сортировки следует раздельно учитывать количества операций сравнения и перестановок. В алгоритмах поиска достаточно оценить только количество операций сравнения.
Трудоемкость алгоритма может зависеть от следующих свойств исходных данных:
- 1) объем данных (длина входа);
- 2) конкретика значений данных;
- 3) порядок поступления данных с конкретными значениями.
Объем исходных данных решающим образом влияет на трудоемкость практически всех алгоритмов, но и конкретика данных весьма существенна.
Например, количество операций при вычислении значения полинома существенно зависит от количества нулевых коэффициентов, а при сортировке массива — от исходного порядка следования элементов (при благоприятном раскладе — перестановки данных могут не потребоваться вовсе).
Зависимость количества выполняемых операций от длины входа л называется функцией трудоемкости /(л). Зависимость трудоемкости от конкретики значений и порядка поступления данных обусловливает изменчивость количества выполняемых операций при фиксированном л, и функция трудоемкости /(л) становится случайной функцией. Поэтому можно вести речь о минимальном /mjn (л), максимальном /тах (л) и среднем количестве /(л) операций, выполняемых исполнителем алгоритма при конкретной длине входа.
Часто анализ алгоритмов осуществляется упрощенно — их трудоемкость оценивается при больших объемах входных данных, т.е. при л —> Такой анализ называется асимптотическим.