Как в PostgreSQL добавить строку, если такой еще нет

Пытаюсь запустить в PostgreSQL такой код и получаю ошибку:
Отслеживать
задан 6 фев 2023 в 8:58
43 7 7 бронзовых знаков
Запрос либо возвращает набор записей, либо нет. А возвращать или нет по какому-то условию — так не бывает в принципе. Соответственно вопрос — какие записи должны быть возвращены, если имя в таблицу добавилось. PS. Показанная конструкция может быть в коде хранимой процедуры, а не сама по себе. PPS. «просто вернуть все имена» у меня как-то не совмещается с WHERE name = ‘John’ .. PPPS. А почему проверяется ‘John’, а вставляется ‘Jack’?
6 фев 2023 в 9:10
С John и Jack перепутал, когда менял данные, сейчас поменяю. Мне нужно добавить запись, если ее еще не существует, возвращать что-либо нужды нет, разумеется, если без этого можно обойтись. В одном вопросе данную конструкцию обсуждали для oracle, соответственно, думал, что она рабочая, но синтаксис не подходит для postgre.
6 фев 2023 в 9:23
Ну тогда тупо INSERT .. ON CONFLICT DO NOTHING.
6 фев 2023 в 9:27
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Для начала надо добавить уникальный ключ для поля name
Чтобы PostgrSQL сам проверял наличие поля с таким значением и не позволял вставлять запись если запись уже есть.
В этом случае можно делать просто
INSERT INTO names ('John'); и обрабатывать ошибки при данном запросе.
Если ошибки обрабатывать не хочется или, вдруг, нет такой возможности, то можно изменить запрос
INSERT INTO names ('John') ON CONFLICT DO NOTHING; Т.е. точно так же вставляется запись, но если она уже есть в таблице и возникает ошибка, то на эту ошибку сервер ничего не делает и продолжает работу дальше.
В качестве бонуса можно в случае конфликта например изменять какие-то другие поля в данной строке, которая уже есть в таблице
INSERT INTO names ('John') ON CONFLICT DO UPDATE ; Операции с данными
Для добавления данных применяется команда INSERT , которая имеет следующий формальный синтаксис:
INSERT INTO имя_таблицы (столбец1, столбец2, . столбецN) VALUES (значение1, значение2, . значениеN)
После INSERT INTO идет имя таблицы, затем в скобках указываются все столбцы через запятую, в которые надо добавлять данные. И в конце после слова VALUES в скобках перечисляются добавляемые значения.
Допустим, у нас в базе данных есть следующая таблица:
CREATE TABLE Products ( Id SERIAL PRIMARY KEY, ProductName VARCHAR(30) NOT NULL, Manufacturer VARCHAR(20) NOT NULL, ProductCount INTEGER DEFAULT 0, Price NUMERIC );
Добавим в нее одну строку с помощью команды INSERT:
INSERT INTO Products VALUES (1, 'Galaxy S9', 'Samsung', 4, 63000)
После удачного выполнения в pgAdmin в поле сообщений должно появиться сообщение «INSERT 0 1»:
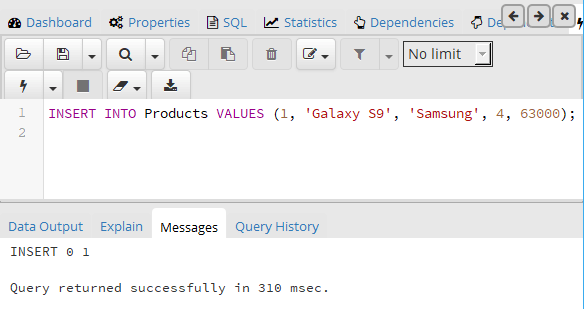
Стоит учитывать, что значения для столбцов в скобках после ключевого слова VALUES передаются по порядку их объявления. Например, в выражении CREATE TABLE выше можно увидеть, что первым столбцом идет Id, поэтому этому столбцу передаетсячисло 1. Второй столбец называется ProductName, поэтому второе значение — строка «Galaxy S9» будет передано именно этому столбцу и так далее. То есть значения передаются столбцам следующим образом:
- Id: 1
- ProductName: ‘Galaxy S9’
- Manufacturer: ‘Samsung’
- ProductCount: 4
- Price: 63000
Также при вводе значений можно указать непосредственные столбцы, в которые будут добавляться значения:
INSERT INTO Products (ProductName, Price, Manufacturer) VALUES ('iPhone X', 71000, 'Apple');
Здесь значение указывается только для трех столбцов. Причем теперь значения передаются в порядке следования столбцов:
- ProductName: ‘iPhone X’
- Manufacturer: ‘Apple’
- Price: 71000
Для столбца Id значение будет генерироваться автоматически базой данных, так как он представляет тип Serial. То есть к значению из последней строки будет добавляться единица.
Для остальных столбцов будет добавляться значение по умолчанию, если задан атрибут DEFAULT (например, для столбца ProductCount), значение NULL. При этом неуказанные столбцы (за исключением тех, которые имеют тип Serial) должны допускать значение NULL или иметь атрибут DEFAULT.
Если конкретные столбцы не указываются, как в первом примере, тогда мы должны передать значения для всех столбцов в таблице.
Также мы можем добавить сразу несколько строк:
INSERT INTO Products (ProductName, Manufacturer, ProductCount, Price) VALUES ('iPhone 6', 'Apple', 3, 36000), ('Galaxy S8', 'Samsung', 2, 46000), ('Galaxy S8 Plus', 'Samsung', 1, 56000)
В данном случае в таблицу будут добавлены три строки.
Возвращение значений
Если мы добавляем значения только для части столбцов, то мы можем не знать, какие значения будут у других столбцов. Например, какое значени получит столбец Id у товара. С помощью оператора RETURNING мы можем получить это значение:
INSERT INTO Products (ProductName, Manufacturer, ProductCount, Price) VALUES('Desire 12', 'HTC', 8, 21000) RETURNING id;
Как добавить строку в постгрес через pgadmin
Сразу после создания таблицы она не содержит никаких данных. Поэтому, чтобы она была полезна, в неё прежде всего нужно добавить данные. По сути данные добавляются в таблицу по одной строке. И хотя вы конечно можете добавить в таблицу несколько строк, добавить в неё меньше, чем строку, невозможно. Даже если вы указываете значения только некоторых столбцов, создаётся полная строка.
Чтобы создать строку, вы будете использовать команду INSERT . В этой команде необходимо указать имя таблицы и значения столбцов. Например, рассмотрим таблицу товаров из Главы 5:
CREATE TABLE products ( product_no integer, name text, price numeric );
Добавить в неё строку можно было бы так:
INSERT INTO products VALUES (1, 'Cheese', 9.99);
Значения данных перечисляются в порядке столбцов в таблице и разделяются запятыми. Обычно в качестве значений указываются константы, но это могут быть и скалярные выражения.
Показанная выше запись имеет один недостаток — вам необходимо знать порядок столбцов в таблице. Чтобы избежать этого, можно перечислить столбцы явно. Например, следующие две команды дадут тот же результат, что и показанная выше:
INSERT INTO products (product_no, name, price) VALUES (1, 'Cheese', 9.99); INSERT INTO products (name, price, product_no) VALUES ('Cheese', 9.99, 1);
Многие считают, что лучше всегда явно указывать имена столбцов.
Если значения определяются не для всех столбцов, лишние столбцы можно опустить. В таком случае эти столбцы получат значения по умолчанию. Например:
INSERT INTO products (product_no, name) VALUES (1, 'Cheese'); INSERT INTO products VALUES (1, 'Cheese');
Вторая форма является расширением PostgreSQL . Она заполняет столбцы слева по числу переданных значений, а все остальные столбцы принимают значения по умолчанию.
Для ясности можно также явно указать значения по умолчанию для отдельных столбцов или всей строки:
INSERT INTO products (product_no, name, price) VALUES (1, 'Cheese', DEFAULT); INSERT INTO products DEFAULT VALUES;
Одна команда может вставить сразу несколько строк:
INSERT INTO products (product_no, name, price) VALUES (1, 'Cheese', 9.99), (2, 'Bread', 1.99), (3, 'Milk', 2.99);
Также возможно вставить результат запроса (который может не содержать строк либо содержать одну или несколько):
INSERT INTO products (product_no, name, price) SELECT product_no, name, price FROM new_products WHERE release_date = 'today';
Это позволяет использовать все возможности механизма запросов SQL (см. Главу 7) для вычисления вставляемых строк.
Подсказка
Когда нужно добавить сразу множество строк, возможно будет лучше использовать команду COPY . Она не такая гибкая, как INSERT , но гораздо эффективнее. Дополнительно об ускорении массовой загрузки данных можно узнать в Разделе 14.4.
| Пред. | Наверх | След. |
| Глава 6. Модификация данных | Начало | 6.2. Изменение данных |
Как добавить строку в постгрес через pgadmin
Как правило, работа с базой данных осуществляется с помощью специального языка запросов — SQL. Рассмотрим, как выполнять простейшие SQL-запросы к базе данных в pgAdmin.
К примеру, возьмем базу данных test1, которая была создана в прошлой теме (или создадим новую) и добавим в нее таблицу и некоторые начальные данные. Для этого нажмем в правой части окна pgAdmin на базу данных правой кнопкой мыши и в появившемся контекстном меню выберем пункт Query Tool :
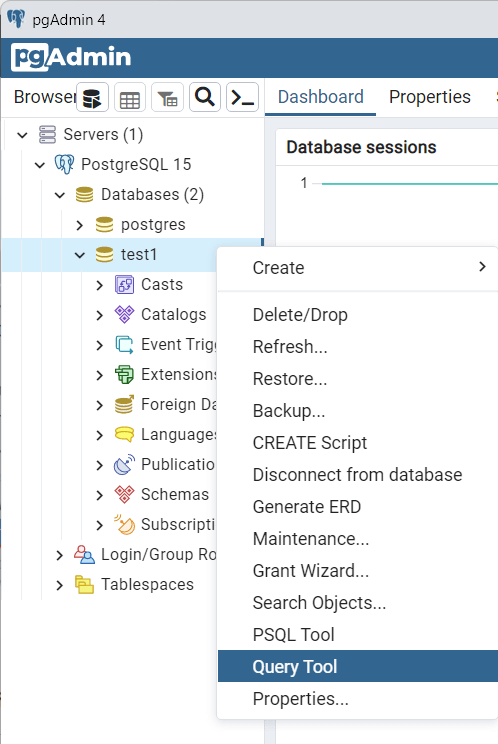
После этого в центральной части программы откроется поле для ввода кода SQL. Введем следующий набор выражений:
CREATE TABLE users ( Id SERIAL PRIMARY KEY, Name CHARACTER VARYING(30), Age INTEGER ); INSERT INTO users (Name, Age) VALUES ('Tom', 33);
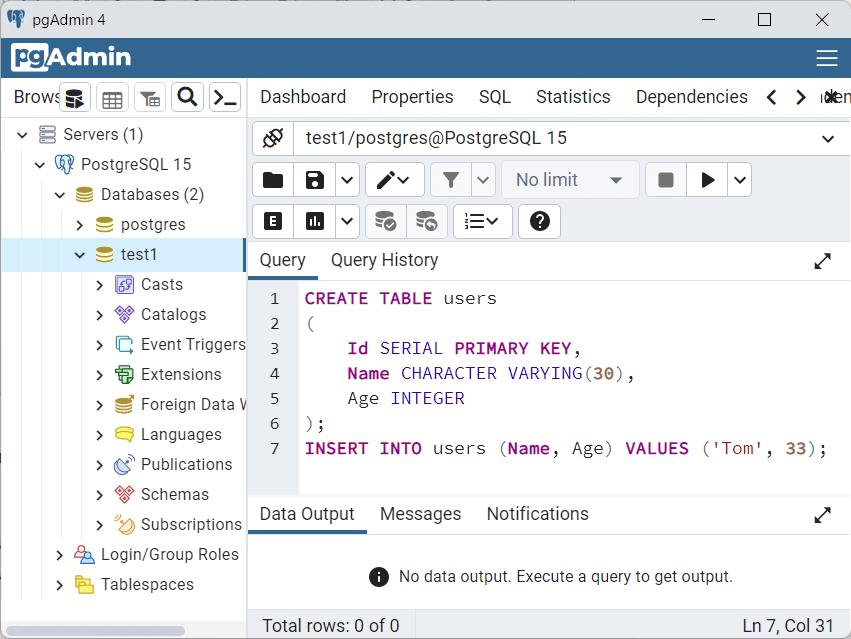
Фактически весь код разбивается на две части. Первая часть — инструкция CREATE TABLE , которая создает таблицу users с тремя столбцами Id, Name и Age. И вторая часть — инструкция INSERT , которая добавляет в таблицу одну строку.
Чтобы выполнить данные инструкции, нажмем над кодом в панели инструментов на стрелочку. И после этого в выбранную базу данных (test1) будет добавлена таблица users, в которую будет добавлена одна строка.
Впоследствии подобным образом будет выполняться любой другой код SQL к базе данных. Также выбирается нужная база данных, выбирается параметр Query Tool, и далее в поле ввода вводится код SQL, который затем выполняется.
Следует отметить, что для каждой таблицы определяется схема. По умолчанию это схема «public». Поэтому чтобы найти таблицу, нам надо обратиться к узлу базы данных, раскрыть его, далее выбрать подузел Schemas , в нем подузел public (название схема), и далее в нем подузел Tables , который представляет все таблицы, ассоциированные со схемой public:
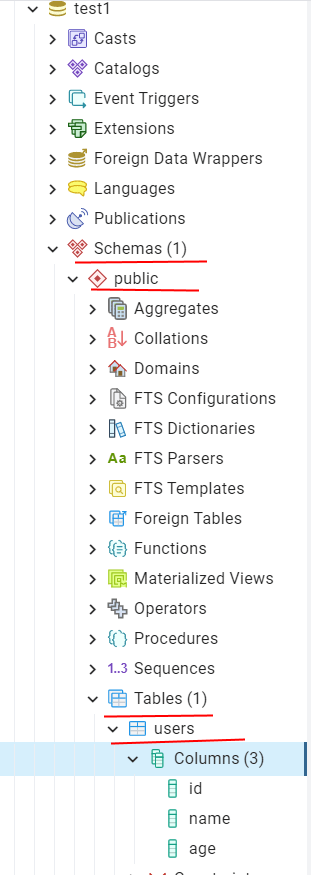
Теперь получим данные из таблицы, которые были добавлены при ее создании. Для этого выполним следующий код:
SELECT * FROM users
И внизу программы в поле Data Output мы увидим в табличном представлении те данные, которые ранее были добавлены.