Извлечение субтитров
1. Нажмите на поле выбора субтитров рядом с видеофайлом, из которого хотите извлечь субтитры.
Убедитесь, что для конвертации выбран видеоформат.
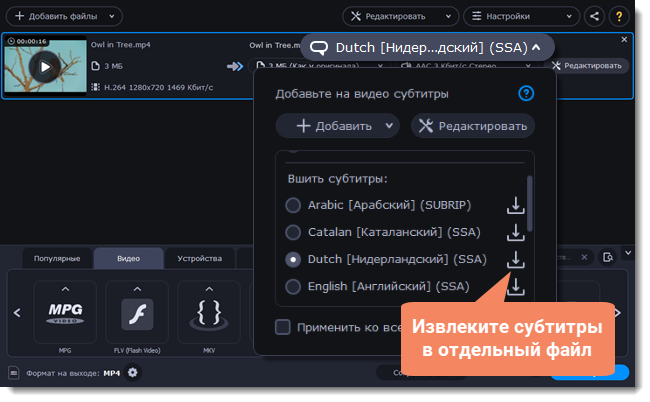
2. В появившемся окне нажмите на кнопку Сохранить субтитры в отдельный файл.
Теперь файл с извлеченными субтитрами будет по умолчанию сохранен в папке Movavi Library .
Файл в папке откроется автоматически по окончании процесса извлечения.
Хитрые субтитры
Я начал смотреть фильмы на английском языке с английскими же субтитрами. И немедленно столкнулся с проблемой. Если народ на экране начинает активно тараторить, то субтитры слишком быстро исчезают с экрана. Я за ними не успеваю. Приходится не только всё время останавливать просмотр, но и постоянно отматывать фильм на несколько секунд назад. А иногда и вперёд. Когда говорят длинными фразами, фразы на экран целиком не влезают, смысл сказанного начинает теряться, хочется видеть фразу целиков, в том числе и то, что ещё не сказано.
Т.е. на экране что-то вот такое:

А хочется, чтобы было вот так:

Уговорить подвернувшиеся под руку видеоплееры показывать субтитры так, как мне того хочется, я не сумел. Но вспомнил, что обычно субтитры — это всего лишь небольшие текстовые файлы. И, значит, их можно слегка преобразовать и получить на экране ровно то, что хочется.
Алгоритм прост. Текущая фраза (текущий субтитр) выводится зелёным. Над ним — три предыдущих субтитра. Под ним — один следующий.
Как получить субтитры в «моём» формате? Всё очень просто. Находите файл с субтитрами с расширением .srt, запихиваете его в форму вверху страницы и жмёте кнопочку «Конвертировать».
Разница в отображении субтитров (другой размер шрифта, выравнивание по левому краю, отображение не на прозрачном, а на чёрном фоне) — это не моя работа с субтитрами, это настройки видеоплеера (плеер, который вы видите на скриншотах — это MPC-HC).
ЧАВО
— Что делать, если у меня субтитры не в формате .srt, а в каком-то другом формате?
— Сконвертировать их в .srt. Существуют всевозможные онлайн-конвертеры. Например, вот этот.
— Что делать, если у меня видеофайл с расширением .mkv и субтитры «зашиты» внутри этого файла?
— Извлечь субтитры из .mkv можно, но придётся немного повозиться. Скачайте MKVToolNix (я скачивал portable-версию). Скачайте MKVExtractGUI-2 и распакуйте в ту же папку. Запустите MKVExtractGUI2.exe, откройте с его помощью видеофайл, найдите нужную дорожку с субтитрами (subtitles), нажмите Extract.
— Зачем выводить субтитры на чёрном фоне?
— Это для ABBYY Lingvo x6. Можно подвести курсор мышки к слову из субтитров — и немедленно получить перевод. Очень удобно, не надо вводить слово в словарь (вроде бы работает не во всех видеоплеерах, но с MPC-HC проблем нет). Если же субтитры выводить на прозрачном фоне, то Lingvo не справляется с распознаванием слов.
Замечания, дополнения, сообщения об ошибках и плюшки с благодарностью принимаются.
Георгий Киселёв
Извлечение субтитров из видеофайла MKV
В предыдущих статьях мы рассказывали, как объединить несколько субтитров для их одновременного отображения на экране вместе с фильмом. Обычно фильмы в формате AVI поставляются с субтитрами в отдельных файлах в формате SRT. В случае же фильмов в формате MKV субтитры могут содержаться в самом файле и чтобы выполнить объединение, их нужно предварительно извлечь.
Отметим, что прибегать к этому следует в том случае, если у Вас нет возможности воспользоваться плеерами, поддерживающими одновременное воспроизведение нескольких субтитров непосредственно из файла видео.
Для извлечения субтитров из MKV-файла воспользуемся популярным бесплатным набором инструментов для работы с форматом мультимедийного контейнера MKV – MKVToolNix и графической оболочкой для него – gMKVExtractGUI.
Вы можете скачать как инсталлятор, так и портативную версию MKVToolNix, не требующую установки. Для примера в данной статье мы будем использовать портативную версию.
Подготовка к извлечению субтитров
Распакуйте скачанный архив с программой MKVToolNix в любое удобное место на компьютере. Распакуйте файлы из архива gMKVExtractGUI в папку с программой MKVToolNix.
Извлечение субтитров
Запустите файл «gMKVExtractGUI.exe», в поле «Input Files» окна программы добавьте файл видео в формате MKV, из которого нужно извлечь субтитры.
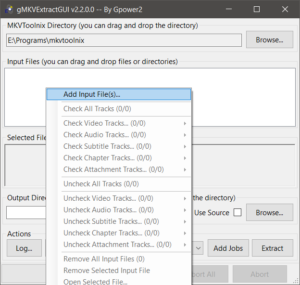
Программа просканирует видеофайл и в том же поле выведет список содержащихся в нем дорожек. Субтитры в списке будут помечены словом «subtitles». Также будут отображены языки дорожки («rus», «eng» и т.д.). Отметьте галочками те дорожки субтитров, которые хотите извлечь.
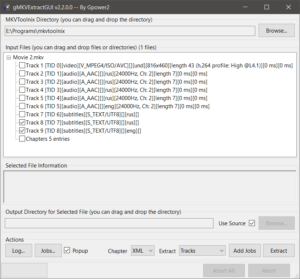
Укажите место сохранения извлеченных файлов в поле «Output Directory for Selected File». Если поставить галочку «Use Source», извлеченные файлы будут записаны в ту же папку, где расположен исходный видеофайл.
Убедитесь, что в поле извлечения данных «Extract» указано значение «Tracks» (Дорожки). Нажмите на кнопку «Extract», чтобы запустить процесс извлечения.
После завершения процесса Вы должны увидеть извлеченные файлы субтитров в папке назначения.

Как видите, таким способом можно извлечь любые дорожки из видеофайла в формате MKV. Теперь Вы можете воспользоваться одним из сервисов, позволяющих получить двойные субтитры для воспроизведения вместе с фильмом практически на любом современном медиапроигрывателе.
Оцените статью: /rating_on.png) 5,00 из 5 (голосов: 14)
5,00 из 5 (голосов: 14)
Автоматизация выгрузки субтитров из *.mkv файлов
Пару месяцев назад у меня появился телевизор со SmartTV от Samsung. Девайс быстро подружился с медиацентром (роль которого исполняет Plex Media Server) с помощью нативного приложения, однако почти сразу же обнаружился весьма неприятный недостаток — отсутствие поддержки вшитых субтитров в *.mkv. Перспектива ручками извлекать субтитры из каждого файла меня отнюдь не радовала, и, поскольку торрент-клиент крутится на той же машине, что и медиасервер, было принято решение автоматизировать процесс обработки скачанных фильмов.
Под катом — рассказ о том, как при помощи 30 строчек кода на js пары шелл-скриптов и плагина для Deluge привести *mkv-файлы в удобоваримый для телевизора вид.
Исходные данные
Итак, у нас есть: headless-машина с Ubuntu Server 12.04LTS, Deluge 1.3.5 и Plex Media Server 0.9.7.28 с веб-интерфейсом. Для начала составим мини-ТЗ.
- обработка данных о свежескачанном торренте и вычленение списка *.mkv-файлов;
- извлечение субтитров;
- обновление медиатеки Plex’a.
- иметь возможность извлекать субтитры только для определенных языков;
- иметь возможность вручную скормить скрипту произвольный файл.
Хук для deluge
В базовой установке Deluge присутствует плагин Execute, позволяющий выполнить произвольный скрипт при добавлении торрента и/или завершении его загрузки (документацию и примеры можно посмотреть здесь). Нас же интересует лишь точный формат передаваемых аргументов, описания которого в манах нет, но пример которого можно легко получить с помощью тестового скрипта:
#!/bin/bash echo -e "$1\n$2\n$3" >> /specshare/sample.txt Сохраним скрипт в какой-нибудь общедоступной директории (я использовал для этого кастомную директорию /specshare) под именем testhook.sh и дадим нужные права на исполнение с помощью
sudo chmod +x testhook.sh 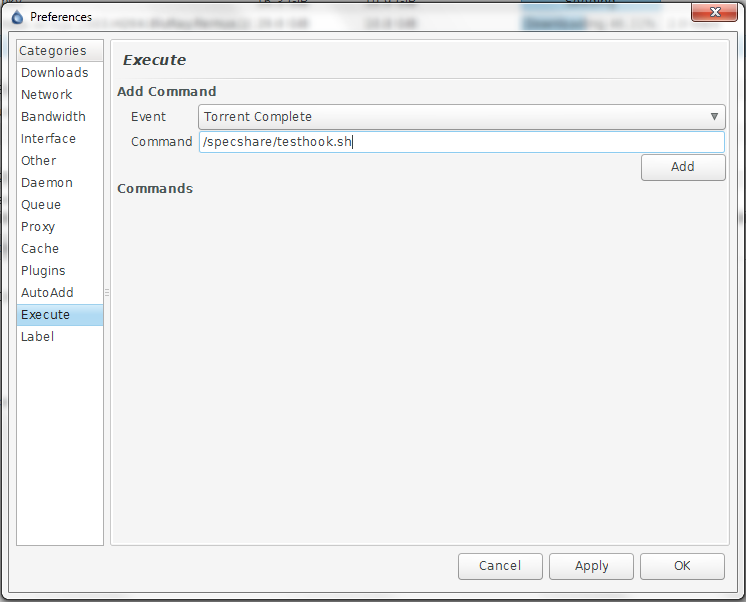
Далее необходимо подключить скрипт. Для удаленного доступа к Deluge я использую GTK-клиент, в котором последовательность действий такова:
- открываем в нем Edit-Preferences-Plugins и ставим галочку напротив Execute, после чего на панели Categories появится соответствующий пункт;
- в разделе Execute, в комбо-боксе Event ставим Torrent Complete, в поле Command указываем путь к скрипту:
- жмем Add, OK, после чего перезапускаем демона:
sudo service deluged restart Последний шаг необходим, иначе скрипт попросту не будет вызываться, при этом корректно отображаясь в настройках. Теперь ставим на закачку небольшой торрент и получаем в файле sample.txt что-то вроде:
1759d534dbe371565632ec0cccbb1579d344c5ca
Totally.Legal.Open.Source.Software.iso
/store/distribs
Первый параметр — универсальный идентификатор торрента, позволяющий запросить по нему у демона дополнительную информацию. Второй — имя торрента; как правило, это либо имя файла, либо имя директории (если файлов в раздаче несколько). Третий — имя родительской папки для торрента.
Теперь, когда мы знаем, как выглядят входные параметры, создадим два файла в той же директории, где лежал testhook.sh: extractor.sh и deluge-movie-callback.sh. Первый скрипт будет отвечать за непосредственное извлечение субтитров, и к нему мы вернемся чуть позже, а во второй файл введем следующее:
#!/bin/bash torrentname=$2; torrentpath=$(readlink -f "$3"); fullpath="$torrentpath/$torrentname"; echo "=========================== $(date +"%D %T"): $1 $2 $3" >> /specshare/log.txt; echo "$(date +"%D %T"): $fullpath" >> /specshare/log.txt; if [[ "$fullpath" != /store/films/* ]]; then echo "$(date +"%D %T"): Invalid path" >> /specshare/log.txt; exit 0; fi; echo "$(date +"%D %T"): path ok" >> /specshare/log.txt; mkvlist=$(find "$fullpath" -type f | grep .mkv); while read -r fname; do /specshare/extractor.sh "$fname" "eng,rus,unk"; done Ничего особо сложного здесь не происходит — мы склеиваем полное имя файла из аргументов $3 и $2, разрешаем симлинки (ежели таковые найдутся), валидируем путь (фильмы и только они скачиваются в директорию /store/films, для остальных видеофайлов мне не нужны субтитры) и для полученного пути запрашиваем все вложенные mkv-файлы. После этого для каждого .mkv запускаем extractor.sh, передавая в качестве параметра путь и список кодов ISO 639-1 для необходимых языков. «unk» — это наше собственное обозначение для отсутствующего языка, на случай, если для каких-то потоков с субтитрами он не указан. Выполнение скрипта логгируется.
Небольшое замечание о логах
Писать логи куда попало, в общем-то, нехорошо, но мы пожертвуем правильностью в угоду удобству доступа и простоте (в моем случае /specshare расшарена через самбу и с минимумом телодвижений доступна на виндовом десктопе).
Извлечение субтитров
Для извлечения дорожек с субтитрами воспользуемся пакетом mkvtoolnix. Установка проста:
sudo apt-get install mkvtoolnix Нас интересует две утилиты: mkvmerge и mkvextract. Первая позволяет получить список потоков в контейнере:
mkvmerge -I
Формальной, для этой цели предназначена утилита mkvinfo из того же пакета, однако вывод mkvmerge лаконичней и гораздо лучше поддается парсингу. На выходе мы получим примерно такой список:
Track ID 1: video (V_MPEG4/ISO/AVC) [language:eng track_name:The\sMatrix\s1999\s1080p\sBluRay\sDD5.1\sx264-CtrlHD display_dimensions:1280x532 default_track:0 forced_track:0 packetizer:mpeg4_p10_video default_duration:41708332]
Track ID 2: audio (A_AC3) [language:rus track_name:DUB-Blu-ray default_track:1 forced_track:0 default_duration:32000000 audio_sampling_frequency:48000 audio_channels:6]Track ID 9: audio (A_DTS) [language:eng track_name:Original default_track:0 forced_track:0 default_duration:10666666 audio_sampling_frequency:48000 audio_channels:6]
Track ID 10: subtitles (S_TEXT/UTF8) [language:rus track_name:Sub default_track:0 forced_track:0]
Track ID 11: subtitles (S_TEXT/UTF8) [language:rus track_name:Sub-(по\s\2правильному\2\sпереводу\sГоблина) default_track:0 forced_track:0]
Track ID 12: subtitles (S_TEXT/UTF8) [language:eng track_name:Sub default_track:0 forced_track:0]
Track ID 13: subtitles (S_TEXT/UTF8) [language:eng track_name:Sub-SDH default_track:0 forced_track:0]
Нас интересуют потоки с типом subtitles и кодеком S_TEXT/UTF8, для которых нам нужен TrackID и код языка. Помимо S_TEXT/UTF8 мне встречались субтитры с кодировкой S_HDMV/PGS, но это птица редкая, требует она конвертации в srt, и поэтому субтитры такого типа мы рассматривать не будем. Заинтересовавшимся предлагают обратить внимание на утилиту BDSup2Sub.
Для непосредственного извлечения потока используем:
mkvextract tracks :
Первые два параметра (TrackID и имя файла-контейнера) довольно очевидны, а вот с третьим — именем для файла с субтитрами — все немного сложнее. Здесь необходимо ненадолго прерваться и ознакомиться с правилами именования внешних субтитров в Plex.
Согласно приведенной спецификации, имя субтитров должно иметь формат
..srt,
где должно совпадать с именем основного медиафайла. Подвох в том, что такая схема именования запрещает иметь несколько внешних субтитров для одного языка. К счастью, есть небольшая лазейка - если не соответствует ни одному языку, то субтитры все равно будут импортированы с пометкой, что язык неизвестен (и таких субтитров может быть сколько угодно). Мы поступим следующим образом: будем пытаться извлечь субтитры в соответствии с правилами наименования, а если такой файл уже существует - просто припишем к число. Не слишком удобно, однако лучше, чем ничего.
Откроем файл extractor.sh и напишем там следующее:
#!/bin/bash if [[ "$1" != *.mkv ]]; then exit 0; fi; FORMAT_FULL=".*ID[[:space:]]([[:digit:]]+):[[:space:]]([[:alpha:]]+)[[:space:]]\((.*)\).*language:([[:alpha:]]+)"; FORMAT_SHORT=".*ID[[:space:]]([[:digit:]]+):[[:space:]]([[:alpha:]]+)[[:space:]]\((.*)\)"; baseName=$; requiredLangs=$(echo "$2" | tr "," "\n"); echo "$(date +"%D %T"): $baseName" >> /specshare/log.txt; counter=0; tracks=$(mkvmerge -I "$1"); while read -r track; do echo -e "$(date +"%D %T"): $track" >> /specshare/log.txt; if [[ $track =~ $FORMAT_FULL ]]; then tType=$; lang=$; codec=$; else if [[ $track =~ $FORMAT_SHORT ]]; then tType=$; codec=$; lang="unk"; else fi fi; langMatch=false; idMatch=false; typeMatch=false; codecMatch=false; shouldExtract=false; for reqLang in $requiredLangs; do [ "$reqLang" == "$lang" ] && langMatch=true; done [ "$tType" == "subtitles" ] && typeMatch=true; [ "$codec" == "S_TEXT/UTF8" ] && codecMatch=true; [ $id -ne -1 ] && idMatch=true; $langMatch && $idMatch && $typeMatch && $codecMatch && shouldExtract=true; if $shouldExtract ; then subName="$baseName.$lang.srt" if [ -f "$subName" -o "$lang" == "unk" ]; then subName="$baseName.$lang$counter.srt"; (( counter++ )); fi mkvextract tracks "$1" $id:"$subName"; fi done Алгоритм прост: мы запрашиваем список потоков, каждый из них разбираем регуляркой и, при выполнении условий для типа/кодека/языка, извлекаем файл. К сожалению, мне не удалось заставить работать квантификаторы для capturing groups в POSIX-версии регекспов, поэтому ситуация, когда язык для субтитров отсутствует, обрабатывается отдельной версией регулярного выражения. Буду рад советам на тему того, как это поправить.
Итак, у нас есть видеофайл и пачка распакованных субтитров. Пора переходить к завершающей стадии - импорту всего этого в Plex.
Обновлением медиатеки
Консольный метод
- возможны проблемы с использованием подключаемых библиотек;
- сканирование необходимо запускать из-под того же пользователя, из-под которого работает сам PMS;
Метод с GET-запросом
Веб-панель PMS, помимо предоставления UI для управления медиатекой, позволяет использовать GET-запросы к определенным URL для запуска сканирования. Для этого URL должен иметь следующий вид:
http://:32400/library/sections//refresh 
где sectionId - номер соответствующей секции медиатеки в базе PMS. Чтобы его узнать, достаточно зайти в нужный раздел в веб-интерфейсе и посмотреть на содержимое адресной строки
В моем случае номер секции для фильмов - 3.
Теперь, когда мы знаем адрес, откроем снова deluge-movie-callback.sh и добавим в конец что-то вроде
wget -qO - http://192.168.13.1:32400/library/sections/3/refresh >> /dev/null ; Можно добавить к URL параметры ?deep=1 или ?force=1 для более тщательного сканирования.
У нас готовы оба скрипта, осталось дать им права на запуск и добавить deluge-movie-callback.sh в настройки Execute. Этот процесс уже рассматривался, так что я не буду заострять на нем внимание.
- Перед вводом в эксплуатацию тщательно протестируйте скрипты на нескольких небольших раздачах. Эмоции, которые испытываешь, проснувшись утром и обнаружив, что немного опечатался в условии и весь жесткий диск забит извлеченными видео- и аудиодорожками, не передать цензурными словами.
- Извлечение субтитров - процедура тяжелая и ресурсоемкая, и весьма ощутимо сказывается на производительность всей системы. Хорошо подумайте, прежде чем извлекать из файлов всю начинку.
- Если в Deluge настроено автоматическое перемещение файлов после окончания загрузки, то вызов скрипта будет осуществляться после перемещения, и в параметрах будет новый путь. Это также верно при использовании плагина Label.
- Я не стал уделять много внимания вопросу прав на скрипты, ограничившись правами на запуск, но на практике необходимо убедиться, что пользователь, из под которого запущен демон deluged, имеет необходимые права на доступ к соответствующим файлам. Проще всего это проверить, переключившись c помощью sudo su - и попытавшись провести тест из консоли.