r studio импорт csv
Подскажите, как импортировать несколько csv в R за раз? нашла такой код, но на выходе получаю все данные в одном столбце, не могу понять, как их разделить по точке с запятой.
im = list.files(pattern = "*.csv") my_data = lapply(im, read_csv) df Отслеживать
задан 11 мар 2022 в 11:19
19 7 7 бронзовых знаков
CSV - это "Comma-Separated Values", т.е. "Значения, Разделённые Запятой". Если в качестве разделителя используется точка с запятой - это не CSV. Для импорта SSV (Semicolon-Separated Values) используется read_csv2 . Либо lapply(im, read.csv, sep=";") .
11 мар 2022 в 11:43
спасибо, получила, что хотела
11 мар 2022 в 11:43
0
Сортировка: Сброс на вариант по умолчанию
Знаете кого-то, кто может ответить? Поделитесь ссылкой на этот вопрос по почте, через Твиттер или Facebook.
-
Важное на Мете
Похожие
Подписаться на ленту
Лента вопроса
Для подписки на ленту скопируйте и вставьте эту ссылку в вашу программу для чтения RSS.
Дизайн сайта / логотип © 2024 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2024.1.3.2953
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Как импортировать файлы CSV в R (шаг за шагом)
Предположим, у меня есть файл CSV с именем data.csv, сохраненный в следующем месте:
C:\Пользователи\Боб\Рабочий стол\data.csv
И предположим, что файл CSV содержит следующие данные:
team, points, assists 'A', 78, 12 'B', 85, 20 'C', 93, 23 'D', 90, 8 'E', 91, 14 Существует три распространенных способа импорта этого CSV-файла в R:
1. Используйте read.csv из базы R (самый медленный метод, но отлично работает для небольших наборов данных)
data1 2. Используйте read_csv из пакета readr (в 2-3 раза быстрее, чем read.csv)
library (readr) data2 3. Используйте fread из пакета data.table (в 2-3 раза быстрее, чем read_csv)
library (data.table) data3 В этом руководстве показан пример использования каждого из этих методов для импорта CSV-файла в R.
Способ 1: использование read.csv
Если ваш CSV-файл достаточно мал, вы можете просто использовать функцию read.csv из Base R, чтобы импортировать его.
При использовании этого метода обязательно укажите stringsAsFactors=FALSE , чтобы R не преобразовывал символьные или категориальные переменные в факторы.
В следующем коде показано, как использовать read.csv для импорта этого CSV-файла в R:
#import data data1 Способ 2: использование read_csv
Если вы работаете с большими файлами, вы можете использовать функцию read_csv из пакета readr:
library (readr) #import data data2 Способ 3: Использование фрида
Если ваш CSV очень большой, самый быстрый способ импортировать его в R — использовать функцию fread из пакета data.table:
library (data.table) #import data data3 Обратите внимание, что в каждом примере мы использовали двойную обратную косую черту (\) в пути к файлу, чтобы избежать следующей распространенной ошибки:
Error: '\U' used without hex digits in character string starting ""C:\U" Дополнительные ресурсы
В следующих руководствах объясняется, как импортировать другие типы файлов в R:
16) Импорт данных в R
Данные могут существовать в разных форматах. Для каждого формата R имеет определенную функцию и аргумент. В этом руководстве объясняется, как импортировать данные в R.
В этом уроке вы узнаете
- Читать CSV
- Чтение файлов Excel
- readxl_example ()
- read_excel ()
- excel_sheets ()
- Импорт данных из другого статистического программного обеспечения
- Читать сас
- Читать STATA
- Читать SPSS
- Лучшие практики для импорта данных
Читать CSV
Одним из наиболее распространенных хранилищ данных являются форматы файлов .csv (значения, разделенные запятыми). R загружает массив библиотек во время запуска, включая пакет utils. Этот пакет удобен для открытия CSV-файлов в сочетании с функцией reading.csv (). Вот синтаксис для read.csv
read.csv(file, header = TRUE, sep = ",")
Аргумент :
- file : PATH, где хранится файл
- header : подтвердите, имеет ли файл заголовок или нет, по умолчанию заголовок установлен в TRUE
- sep : символ, используемый для разделения переменной. По умолчанию `,`.
Мы будем читать данные файла с именем mtcats. CSV-файл хранится в Интернете. Если ваш файл .csv хранится локально, вы можете заменить PATH внутри фрагмента кода. Не забудьте обернуть его внутри ». PATH должен быть строковым значением.
Для пользователя Mac путь к папке загрузки:
"/Users/USERNAME/Downloads/FILENAME.csv"
Для пользователей Windows:
"C:\Users\USERNAME\Downloads\FILENAME.csv"
Обратите внимание, что мы всегда должны указывать расширение имени файла.
PATHВывод:
## [1] 12class(df$X)Вывод:
## [1] "factor"R по умолчанию возвращает значения символов как фактор. Мы можем отключить этот параметр, добавив stringsAsFactors = FALSE.
PATHВывод:
## [1] "character"Класс для переменной X теперь является символом.
Чтение файлов Excel
Файлы Excel очень популярны среди аналитиков данных. Таблицы просты в работе и гибки. R оснащен библиотекой readxl для импорта электронных таблиц Excel.
Используйте этот код
require(readxl)чтобы проверить, установлен ли readxl на вашем компьютере. Если вы устанавливаете r с помощью r-conda-essential, библиотека уже установлена. Вы должны увидеть в окне команд:
Вывод:
Loading required package: readxl.Если пакет не выходит, вы можете установить его с библиотекой conda или в терминале, используйте conda install -c mittner r-readxl.
Используйте следующую команду, чтобы загрузить библиотеку для импорта файлов Excel.
library(readxl)readxl_example ()
Мы используем примеры, включенные в пакет readxl во время этого урока.
readxl_example()чтобы увидеть все доступные таблицы в библиотеке.
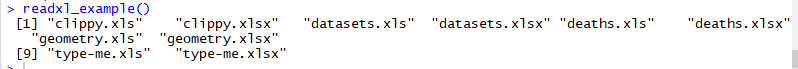
Чтобы проверить расположение таблицы с именем clippy.xls, просто используйте
readxl_example("geometry.xls")

Если вы устанавливаете R с помощью conda, электронные таблицы находятся в Anaconda3 / lib / R / library / readxl / extdata / filename.xls
read_excel ()
Функция read_excel () отлично подходит для открытия расширений xls и xlsx.
read_excel(PATH, sheet = NULL, range= NULL, col_names = TRUE) arguments: -PATH: Path where the excel is located -sheet: Select the sheet to import. By default, all -range: Select the range to import. By default, all non-null cells -col_names: Select the columns to import. By default, all non-null columnsМы можем импортировать электронные таблицы из библиотеки readxl и посчитать количество столбцов на первом листе.
# Store the path of `datasets.xlsx` exampleВывод:
excel_sheets ()
Файл datasets.xlsx состоит из 4 листов. Мы можем узнать, какие листы доступны в книге, используя функцию excel_sheets ()
example excel_sheets(example)Вывод:
[1] "iris" "mtcars" "chickwts" "quakes"Если рабочий лист включает в себя много листов, легко выбрать конкретный лист, используя аргументы листа. Мы можем указать название листа или индекс листа. Мы можем проверить, возвращает ли обе функции один и тот же вывод с помощью метода unique ().
exampleВывод:
## [1] TRUEМы можем контролировать, какие ячейки читать 2 способами
- Используйте аргумент n_max для возврата n строк
- Используйте аргумент диапазона в сочетании с cell_rows или cell_cols
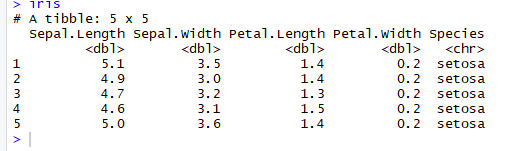
Например, мы устанавливаем n_max равным 5, чтобы импортировать первые пять строк.
# Read the first five row: with header iris <-read_excel(example, n_max =5, col_names =TRUE)
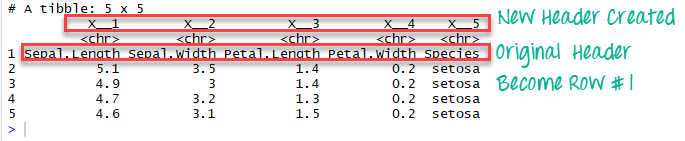
Если мы изменим col_names на FALSE, R автоматически создаст заголовки.
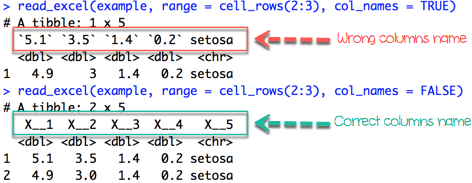
# Read the first five row: without header iris_no_header <-read_excel(example, n_max =5, col_names =FALSE)В фрейме данных iris_no_header R создал пять новых переменных с именами X__1, X__2, X__3, X__4 и X__5
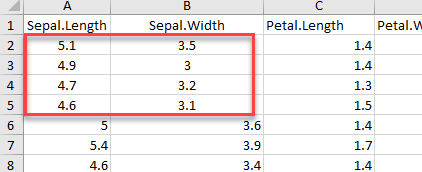
Мы также можем использовать диапазон аргументов для выбора строк и столбцов в электронной таблице. В приведенном ниже коде мы используем стиль Excel, чтобы выбрать диапазон от A1 до B5.
# Read rows A1 to B5 example_1 <-read_excel(example, range = "A1:B5", col_names =TRUE) dim(example_1)Вывод:
## [1] 4 2Мы видим, что example_1 возвращает 4 строки с 2 столбцами. У набора данных есть заголовок, поэтому размер равен 4×2.
Во втором примере мы используем функцию cell_rows (), которая управляет диапазоном возвращаемых строк. Если мы хотим импортировать строки с 1 по 5, мы можем установить cell_rows (1: 5). Обратите внимание, что cell_rows (1: 5) возвращает тот же вывод, что и cell_rows (5: 1).
# Read rows 1 to 5 example_2 <-read_excel(example, range =cell_rows(1:5),col_names =TRUE) dim(example_2)Вывод:
## [1] 4 5Однако example_2 представляет собой матрицу 4×5. Набор данных iris имеет 5 столбцов с заголовком. Мы возвращаем первые четыре строки с заголовком всех столбцов
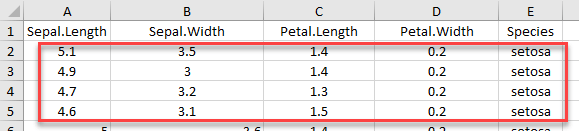
Если мы хотим импортировать строки, которые не начинаются с первой строки, мы должны включить col_names = FALSE. Если мы используем range = cell_rows (2: 5), становится очевидно, что наш фрейм данных больше не имеет заголовка.
iris_row_with_header <-read_excel(example, range =cell_rows(2:3), col_names=TRUE) iris_row_no_header <-read_excel(example, range =cell_rows(2:3),col_names =FALSE)
We can select the columns with the letter, like in Excel. # Select columns A and B col <-read_excel(example, range =cell_cols("A:B")) dim(col)Вывод:
## [1] 150 2Примечание: range = cell_cols (“A: B”), возвращает выходные данные всех ячеек с ненулевым значением. Набор данных содержит 150 строк, поэтому read_excel () возвращает строки до 150. Это проверяется с помощью функции dim ().
read_excel () возвращает NA, когда в ячейке появляется символ без числового значения. Мы можем посчитать количество пропущенных значений с помощью комбинации двух функций
iris_na <-read_excel(example, na ="setosa") sum(is.na(iris_na))Вывод:
## [1] 50У нас пропущено 50 значений, которые являются строками, принадлежащими видам сетоз.
Импорт данных из другого статистического программного обеспечения
Мы будем импортировать различные файлы формата с пакетом небес. Этот пакет поддерживает программное обеспечение SAS, STATA и SPSS. Мы можем использовать следующую функцию для открытия различных типов наборов данных в соответствии с расширением файла:
- SAS: read_sas ()
- STATA: read_dta () (или read_stata (), которые идентичны)
- SPSS: read_sav () или read_por (). Нам нужно проверить расширение
В этой функции требуется только один аргумент. Нам нужно знать ПУТЬ, где хранится файл. Вот и все, мы готовы открыть все файлы из SAS, STATA и SPSS. Эти три функции также принимают URL.
library(haven)
В гавань входит conda r-essential, в противном случае перейдите по ссылке или в терминале. conda установите -c conda-forge r-haven
Читать сас
Для нашего примера мы собираемся использовать набор входных данных из IDRE.
PATH_sasВывод:
## # A tibble: 6 x 4 ## ADMIT GRE GPA RANK ## ## 1 0 380 3.61 3 ## 2 1 660 3.67 3 ## 3 1 800 4.00 1 ## 4 1 640 3.19 4 ## 5 0 520 2.93 4 ## 6 1 760 3.00 2Читать STATA
Для файлов данных STATA вы можете использовать read_dta (). Мы используем точно такой же набор данных, но храним его в файле .dta.
PATH_stataВывод:
## # A tibble: 6 x 4 ## admit gre gpa rank ## ## 1 0 380 3.61 3 ## 2 1 660 3.67 3 ## 3 1 800 4.00 1 ## 4 1 640 3.19 4 ## 5 0 520 2.93 4 ## 6 1 760 3.00 2Читать SPSS
Мы используем функцию read_sav (), чтобы открыть файл SPSS. Расширение файла “.sav”
PATH_spssВывод:
## # A tibble: 6 x 4 ## admit gre gpa rank ## ## 1 0 380 3.61 3 ## 2 1 660 3.67 3 ## 3 1 800 4.00 1 ## 4 1 640 3.19 4 ## 5 0 520 2.93 4 ## 6 1 760 3.00 2Лучшие практики для импорта данных
Когда мы хотим импортировать данные в R, полезно реализовать следующий контрольный список. Это позволит легко импортировать данные в R:
- Типичным форматом электронной таблицы является использование первых строк в качестве заголовка (обычно это имя переменной).
- Избегайте именовать набор данных с пробелами; это может привести к интерпретации как отдельной переменной. В качестве альтернативы, предпочтите использовать «_» или «-».
- Короткие имена являются предпочтительными
- Не включайте символ в имя: то есть: exchange_rate _ $ _ € не правильно. Предпочитаю называть это: exchange_rate_dollar_euro
- В противном случае используйте NA для пропущенных значений; нам нужно очистить формат позже.
Резюме
В следующей таблице приведены функции, которые необходимо использовать для импорта файлов различных типов в R. В первом столбце указана библиотека, связанная с этой функцией. Последний столбец ссылается на аргумент по умолчанию.
Импортирование данных в R

В предыдущих сообщениях было рассмотрено как, работая непосредственно в системе R, можно создать небольшие по объему объекты для хранения данных (векторы, матрицы, списки, таблицы данных). Однако возможности системы R по вводу и редактированию данных умышленно ограничены ее создателями, которые предполагали, что для этого будут использоваться другие средства (например, программа Microsoft Excel). Поэтому подлежащие анализу объемные таблицы данных обычно подготавливаются при помощи сторонних приложений, и только потом загружаются в рабочую среду R из внешних файлов. Хотя предпочтение при этом отдается текстовым файлам, с сайта CRAN можно скачать специальную библиотеку foreign , функции которой позволяют импортировать таблицы, сохраненные во множестве других распространенных форматов (Excel, SPSS, SAS, STATA, Acces, Matlab, SQL, Oracle, и т.п.; см. также руководство R Data Import/Export).
Импортирование данных в систему R часто вызывает проблемы у тех, кто только начинает работать с этой программой. Но ничего сложного в этом нет. Ниже будут подробно рассмотрены наиболее распространенные способы импорта таблиц данных в рабочую среду R, однако сначала ознакомимся с правилами подготовки загружаемых файлов:
- В импортируемой таблице с данными не должно быть пустых ячеек. Если некоторые значения по тем или иным причинам отсутствуют, вместо них следует ввести NA .
- Импортируемую таблицу с данными рекомендуется преобразовать в простой текстовый файл с одним из допустимых расширений. На практике обычно используются файлы с расширением .txt , в которых значения переменных разделены знаками табуляции (tab-delimited files), а также файлы с расширением .csv (comma separated values), в которых значения переменных разделены запятыми.
- В качестве первой строки в импортируемой таблице рекомендуется ввести заголовки столбцов-переменных. Такая строка – удобный, но не обязательный элемент загружаемого файла. Если она отсутствует, то об этом необходимо сообщить в описании команды, которая будет управлять загрузкой файла (например, read.table() – см. ниже). Все последующие строки файла в качестве первого элемента содержат заголовки строк (если таковые предусмотрены), после которых следуют значения каждой из имеющихся в таблице переменных. В именах столбцов таблицы не допускается наличие пробелов. Кроме того, имена столбцов (так же как и имена строк) не должны начинаться с точки или чисел. Во избежание связанных с кодировкой проблем все текстовые величины в импортируемых файлах рекомендуется создавать с использованием букв латинского алфавита.
- Подлежащий импортированию файл рекомендуется поместить в т.н. рабочую папку программы, т.е. папку, в которой R по умолчанию будет "пытаться" найти этот файл. Чтобы выяснить путь к рабочей папке R на своем компьютере используйте команду getwd() (getworking directory – узнать рабочую директорию); например:
getwd() [1] "C:/Temp/"
Изменить рабочую директорию можно при помощи команды setwd() (set working directory – создать рабочую директорию):
setwd("C:/My Documents") # при выполнении приведенной команды внешне ничего не произойдет, # однако последующее применение команды getwd() покажет, # что путь к рабочей папке изменился: getwd() [1] "C:/My Documents/"
Ниже приведен фрагмент типичной таблицы данных, которая может быть успешно загружена для анализа в среду R. Используйте этот фрагмент в качестве образца при оформлении своих таблиц с данными.