Чтение и сохранение в файл списков и словарей в Python
Строки могут быть легко записаны и считаны из файла. Числа требуют немного больше усилий, так как метод file.read() возвращает только строки, которые должны быть переданы функции int() , которая принимает строку типа ‘123’ и возвращает ее числовое значение 123 . Когда вы хотите сохранить более сложные типы данных, такие как вложенные списки и словари, разбор и сериализация вручную усложняются.
Вместо того, чтобы пользователи постоянно писали и отлаживали код для сохранения сложных типов данных в файлы, Python позволяет использовать популярный формат обмена данными, называемый JSON (JavaScript Object Notation). Стандартный модуль, называемый json , может принимать иерархии данных Python и преобразовывать их в строковые представления. Этот процесс называется сериализацией. Восстановление данных из строкового представления называется десериализацией. Между сериализацией и десериализацией строка, представляющая объект, может быть сохранена в файле или отправлена по сетевому соединению на какой-либо удаленный компьютер.
Если у вас есть объект x , вы можете просмотреть его строковое представление JSON с помощью простой строки кода:
>>> import json >>> json.dumps([1, 'simple', 'list']) # '[1, "simple", "list"]'
Другой метод этого модуля json.dump() просто сериализует объект в текстовый файл. Итак, если объект fp текстового файла открыт для записи, мы можем сделать следующее:
json.dump(x, fp)
Чтобы снова декодировать объект, если fp это объект текстового файла, который был открыт для чтения:
x = json.load(fp)
Этот простой метод сериализации может обрабатывать списки и словари, но сериализация произвольных экземпляров классов в JSON требует дополнительных усилий.
Дополнительно смотрите встроенный модуль pickle . В отличие от JSON , pickle — это протокол, который позволяет сериализовать произвольно сложные объекты Python.
Протокол pickle специфичен для Python и не может использоваться для связи с приложениями, написанными на других языках. Он также по умолчанию небезопасен! Десериализация данных pickle , поступающих из ненадежного источника, может выполнить произвольный код, если данные были созданы опытным злоумышленником.
- ОБЗОРНАЯ СТРАНИЦА РАЗДЕЛА
- Составление пути к файлу в Unix и Windows
- Открытие/закрытие файла для чтения/записи
- Типы обрабатываемых данных и файлов
- Способы чтения открытого файла
- Способы записи в открытый файл
- Одновременное чтение из одного и запись в другой файл
- Добавление данных в открытый файл
- Управление указателем чтения/записи в файле
- Создание менеджера для обработки файла
- Сохранение словарей в формат JSON
- Встроенные модули для работы с разными форматами
Как преобразовать словарь в текстовый файл в python?
Есть скачанный словарь dictionary.pkl. Нужно записать данные из словаря в txt файл. То есть каждая пара ключа и значения должны записаться в отдельной строке и разделяться через запятую.
Это часть словаря.
‘Sundar Ande’: 6400,
‘Mozhe Atkinson’: 2800,>
На выходе должно получиться:
Ellen Abel,11000
Sundar Ande,6400
Mozhe Atkinson,2800
- Вопрос задан более трёх лет назад
- 7084 просмотра
1 комментарий
Простой 1 комментарий
Изменение данных в словаре — Python: Cловари и множества
Словарь в Python — изменяемый или мутабельный. Но для добавления новой пары «ключ-значение» не нужны отдельные методы, вроде спискового метода .append — достаточно обычного присваивания:
d = <> # пустой словарь d["a"] = 100 print(d) # => d["b"] = 200 d["a"] = 0 print(d) # => Здесь вы можете увидеть, что присваивание значения новому ключу выглядит точно так же, как и присваивание существующему. Именно эту тему мы изучим подробнее в этом уроке
Метод pop
Удаление элементов из словаря можно сделать с помощью метода pop — в этом словарь уже больше похож на список. Только вместо индекса используется ключ:
d = 'a': 1, 'b': 2> d.pop('a') # 1 d # d.pop('BANG') # KeyError: 'BANG' Этот пример показывает, что будет, если попытаться извлечь значение по несуществующему ключу — мы получим исключение.
Однако метод pop можно вызывать с указанием значения по умолчанию. В этом случае при отсутствии ключа в словаре будет возвращено это самое значение, а исключение возбуждено не будет:
d = 'a': 1, 'b': 2> d.pop('BANG', None) d.pop('BANG', 42) # 42 Аналогом спискового pop без аргументов для словаря служит метод popitem . Этот метод извлекает ключ и значение в виде кортежа, а если словарь уже пуст, то возбуждает исключение:
d = 'a': 1> d.popitem() # ('a', 1) d.popitem() # KeyError: 'popitem(): dictionary is empty' В пайтоне, начиная с версии 3.7, гарантирован порядок LIFO — Last In First Out. Это значит, что пары будут извлекаться в порядке обратном добавлению, то есть последняя добавленная пара, будет извлечена первой. При этом мы можем быть уверены в том, что:
- Все пары будут извлечены
- Каждая пара будет извлечена строго один раз
Дополнение одного словаря другим
У списка есть метод extend , который расширяет один список другим. У словаря есть похожий по смыслу метод update . Но при вызове update ассоциированный объект словаря не просто получает пары «ключ-значение» из нового словаря. Происходит именно обновление данных — поэтому метод и называется update . Работает это так:
- Новые ключи дописываются в словарь
- Если какие-то ключи уже существовали до этого, то связанные с ними значения, будут заменены новыми
Так это выглядит в коде:
cart = 'apples': 2, 'oranges': 1> addon = 'oranges': 5, 'lemons': 3> cart.update(addon) cart # В коде выше мы добавили лимоны и обновили количество апельсинов.
Копирование словаря
В случае списков мы можем сложить два списка двумя способами:
- Просто сложить два списка и получить новый
- Сделать копию одного списка и дополнить ее данными из второго
Но словари нельзя складывать, да и срезы словари тоже не поддерживают. Зато у словаря есть метод copy . Он работает как копирование списка с помощью среза [:] — при вызове он возвращает поверхностную копию из словаря. Так же ее называют «неглубокой копией» или shallow copy.
Поверхностная копия воспроизводит только структуру словаря: не копирует значения, а только создает на них новые ссылки. Тем не менее поверхностная копия — это новый словарь, который может изменять свой состав, не влияя на оригинал:
d = 'a': 1, 'b': [42]> c = d.copy() c.update('a': 10, '1k': 1024>) c # c['b'].append(None) c # d # Словарь c получил собственную структуру, при этом его обновление не затронуло оригинальный словарь d . Однако изменение объекта списка по ссылке затронуло и оригинал, потому что при копировании словаря ссылка на список тоже скопировалась.
Очистка словаря
Списки можно очистить с помощью присваивания срезу l[:] = [] . В случае словаря вместо присваивания срезу используется метод clear .
Метод clear() удаляет все элементы из текущего словаря:
d = 'a': 1> Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Наши выпускники работают в компаниях:
Как читать и записывать файлы CSV в Python
Давайте запишем следующие данные в наш файл CSV. Он содержит информацию о трех разных штатах США в виде списка, отдельные элементы которого представляют собой словарь.
state_info = [ < "Name": "Colorado", "Largest City": "Denver", "Capital City": "Denver", "Population": "5773714" >, < "Name": "Connecticut", "Largest City": "Hartford", "Capital City": "Bridgeport", "Population": "3605944" >, < "Name": "Delaware", "Largest City": "Dover", "Capital City": "Wilmington", "Population": "989948" >]Код показан ниже.
import csv fields = ['Name', 'Capital City', 'Largest City', 'Population']; with open('state-data.csv', 'a', newline='') as state_file: writer = csv.DictWriter(state_file, fields) writer.writerows(state_info)Сначала мы определяем имена полей в виде списка и сохраняем их в переменных полей ( fields ). Это позволяет объекту записи ( writer ) знать, каким будет заголовок каждого столбца в файле CSV. Метод writerows() сразу записывает все строки, которые мы ему передаем, в CSV-файл. Единственное условие для writerows() состоит в том, что строки, которые мы хотим записать, являются итерируемыми.
Каждая отдельная строка сама по себе также должна быть итерируемой строкой или числом, если мы используем функцию writer() , как мы делали в предыдущем примере. В противном случае каждая строка должна быть словарем, который сопоставляет имена полей ( fieldnames )со строками или числами, чтобы класс DictWriter мог ее обработать.
Теперь попробуем записать в наш CSV-файл следующие данные:
state_info = [ < "Name": "Florida", "Capital City": "Tallahassee" >, < "Name": "Georgia", "Area": "153910", "Largest City": "Atlanta", "Population": "10711908", "Capital City": "Atlanta", >]В приведенных выше данных есть два примечательных момента. Во-первых, в нашем штате Флорида отсутствует некоторая информация. Во-вторых, у штата Джорджия есть дополнительная информация, основанная на том, что мы храним в таблице. В-третьих, ключи для штата Джорджия расположены не в том порядке, в котором мы определили поля для нашего CSV-файла.
Как мы можем обрабатывать такие нестандартные данные? Класс DictWriter предлагает решение. Для отсутствующих ключей мы можем просто указать значение по умолчанию, используя параметр restval . По умолчанию это пустая строка. Однако вы также можете указать пользовательское значение, например Неизвестно (Unknown). Для дополнительных ключей вы можете использовать параметр extrasaction , чтобы указать DictWriter игнорировать эти ключи. Этот параметр по умолчанию вызовет ошибку ValueError .
Вот как писать во все строки сразу.
import csv fields = ['Name', 'Capital City', 'Largest City', 'Population'] with open('state-data.csv', 'a', newline='') as state_file: writer = csv.DictWriter(state_file, fields, restval='Unknown', extrasaction='ignore') writer.writerows(state_info)Наш CSV-файл после всех операций записи будет выглядеть так:
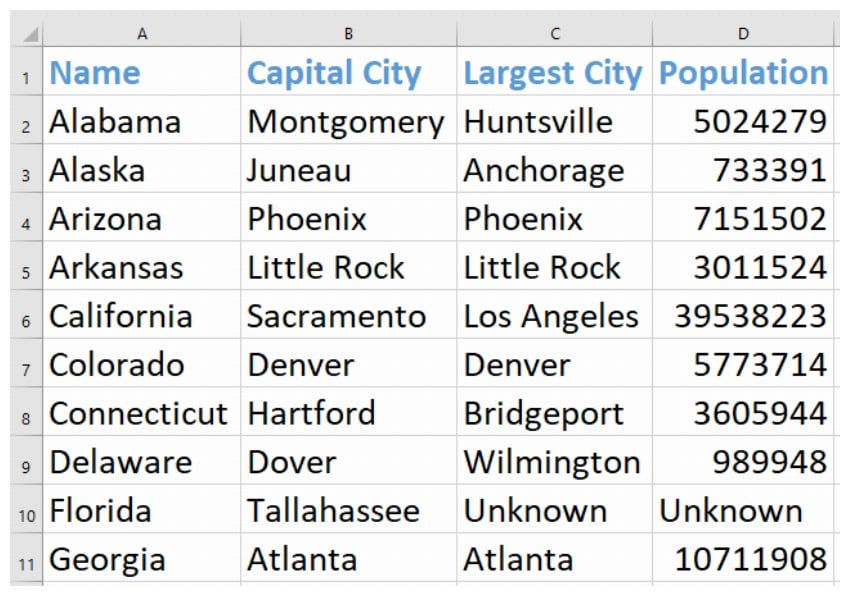
Вывод
В этом руководстве рассмотрена большая часть того, что требуется для успешного чтения и записи в CSV-файл с использованием различных функций и классов, предоставляемых Python. Файлы CSV широко используются в программных приложениях, потому что их легко читать и ими легко управлять, а их небольшой размер делает их относительно быстрыми для обработки и передачи.