Установка Jupyter Notebook на компьютере и ее подключение к Apache Spark в HDInsight
Из этой статьи вы узнаете, как установить Jupyter Notebook с пользовательскими ядрами PySpark (для Python) и Apache Spark (для Scala) с помощью магических команд Spark, а затем подключить эту записную книжку к кластеру HDInsight.
Для установки Jupyter и подключения к Apache Spark в HDInsight необходимо выполнить четыре основных шага.
- Настроить кластер Spark.
- Установить Jupyter Notebook.
- Установите ядра PySpark и Spark с помощью волшебной команды Spark.
- Настройте волшебную команду Spark для доступа к кластеру Spark в HDInsight.
Дополнительные сведения о пользовательских ядрах и магических командах Spark см. в разделе Ядра, доступные для Jupyter Notebook с кластерами Apache Spark Linux в HDInsight.
Предварительные требования
- Кластер Apache Spark в HDInsight. Инструкции см. в статье Начало работы. Создание кластера Apache Spark в HDInsight на платформе Linux и выполнение интерактивных запросов с помощью SQL Spark. Локальная записная книжка подключается к кластеру HDInsight.
- Опыт работы с записными книжками Jupyter с Spark в HDInsight.
Установка Jupyter Notebook на компьютер
Перед установкой Jupyter Notebook необходимо установить Python. Дистрибутив Anaconda установит как Python, так и Jupyter Notebook.
Скачайте установщик Anaconda для своей платформы и запустите программу установки. В мастере установки укажите параметр для добавления Anaconda в переменную PATH. См. также Установка Jupyter с помощью Anaconda.
Установка магических команд Spark
- Введите команду pip install sparkmagic==0.13.1 , чтобы установить магические команды Spark для кластеров HDInsight версии 3.6 и 4.0. См. также документацию по sparkmagic.
- Убедитесь, что мини-приложение ipywidgets установлено правильно. Для этого выполните следующую команду:
jupyter nbextension enable --py --sys-prefix widgetsnbextension Установка ядер PySpark и Spark
- Определите место установки sparkmagic с помощью следующей команды:
pip show sparkmagic | Ядро | Get-Help |
|---|---|
| Spark | jupyter-kernelspec install sparkmagic/kernels/sparkkernel |
| SparkR | jupyter-kernelspec install sparkmagic/kernels/sparkrkernel |
| PySpark | jupyter-kernelspec install sparkmagic/kernels/pysparkkernel |
| PySpark3 | jupyter-kernelspec install sparkmagic/kernels/pyspark3kernel |
jupyter serverextension enable --py sparkmagic Настройка волшебной команды Spark для подключения к кластеру HDInsight Spark
В этом разделе вы настроите подключение магической команды Spark, установленной ранее, к кластеру Apache Spark.
-
Запустите оболочку Python с помощью следующей команды:
python import os path = os.path.expanduser('~') + "\\.sparkmagic" os.makedirs(path) print(path) exit() < "kernel_python_credentials" : < "username": "", "base64_password": "", "url": "https://.azurehdinsight.net/livy" >, "kernel_scala_credentials" : < "username": "", "base64_password": "", "url": "https://.azurehdinsight.net/livy" >, "custom_headers" : < "X-Requested-By": "livy" >, "heartbeat_refresh_seconds": 5, "livy_server_heartbeat_timeout_seconds": 60, "heartbeat_retry_seconds": 1 > | Значение шаблона | Новое значение |
|---|---|
| Имя для входа в кластер, значение по умолчанию — admin . | |
| Имя кластера | |
| Фактический пароль в кодировке Base64. Сгенерировать пароль в кодировке base64 можно здесь: https://www.url-encode-decode.com/base64-encode-decode/. | |
| «livy_server_heartbeat_timeout_seconds»: 60 | При использовании sparkmagic 0.12.7 (кластеры версии 3.5 и 3.6) не заменяйте. При использовании sparkmagic 0.2.3 (кластеры версии 3.4) замените на «should_heartbeat»: true . |
Полный пример файла можно просмотреть в образце config.json.
Совет Сигналы пульса отправляются, чтобы предотвратить утечку сеансов. При переходе в спящий режим или завершении работы компьютера пульс не отправляется, что приводит к очистке сеанса. Если вы хотите отключить такое поведение для кластеров версии 3.4, то можете настроить для параметра Livy livy.server.interactive.heartbeat.timeout значение 0 с помощью пользовательского интерфейса Ambari. Если для кластеров версии 3.5 не настроить соответствующую конфигурацию, приведенную выше, то сеанс не будет удален.
jupyter notebook 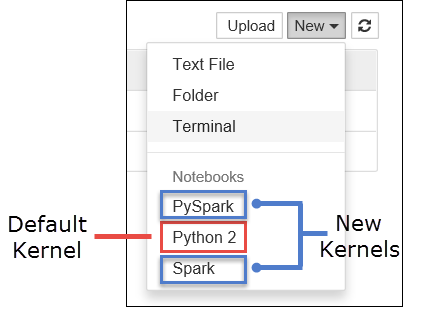
Убедитесь, что вы можете использовать магическую команду Spark, доступную вместе с ядрами. Выполните следующие шаги. а. Создайте новую записную книжку. В правом верхнем углу щелкните Создать. Должны отобразиться ядро по умолчанию Python 2 или Python 3 и установленные ядра. Фактические значения могут отличаться в зависимости от выбранных вариантов установки. Выберите PySpark.
Важно! Щелкнув Создать, проверьте оболочку на наличие ошибок. Если отображается сообщение об ошибке TypeError: __init__() got an unexpected keyword argument ‘io_loop’ , возможно, возникла известная проблема с определенными версиями Tornado. Если это так, завершите работу ядра, а затем перейдите на использование более ранней версии установки Tornado с помощью следующей команды: pip install tornado==4.5.3 .
b. Запустите следующий фрагмент кода.
%%sql SELECT * FROM hivesampletable LIMIT 5 Зачем устанавливать Jupyter на моем компьютере?
Причины, по которым требуется установить на компьютер Jupyter и подключить к кластеру Apache Spark в HDInsight.
- Предоставляет возможность создавать записные книжки локально, тестировать приложение в работающем кластере, а затем отправлять записные книжки в кластер. Для отправки записных книжек в кластер можно отправить их с помощью Jupyter Notebook, которая запущена на кластере, или сохранить их в папке /HdiNotebooks в учетной записи хранения, связанной с кластером. Дополнительные сведения о хранении записных книжек в кластере см. в разделе Где хранятся записные книжки Jupyter.
- С помощью локально доступных записных книжек вы сможете подключиться к различным кластерам Spark в зависимости от потребностей вашего приложения.
- Можно использовать GitHub для реализации системы управления версиями, чтобы контролировать версии записных книжек. Вы также можете создать среду совместной работы, в которой несколько пользователей будут работать с одной записной книжкой.
- Вы можете работать с записными книжками локально даже без кластера. Кластер нужен только для тестирования записных книжек, но не обязателен для ручного управления записными книжками или средой разработки.
- Возможно, вам будет проще настроить локальную среду разработки, чем настраивать установку Jupyter в кластере. Вы можете спокойно пользоваться любым программным обеспечением, установленным локально, не настраивая удаленные кластеры.
Если Jupyter установлен на локальном компьютере, несколько пользователей могут одновременно запустить одну и ту же записную книжку в одном кластере Spark. В такой ситуации создаются несколько сеансов Livy. Если вы столкнетесь с проблемами и начнете их отладку, вам будет сложно определить, какой сеанс Livy какому пользователю принадлежит.
Дальнейшие действия
- Обзор: Spark в Azure HDInsight
- Ядра для Jupyter Notebook в Apache Spark
- Использование внешних пакетов с Jupyter Notebook в Apache Spark
Как запустить Jupyter Notebook с GitHub
Jupyter Notebooks становятся стандартом де факто для программирования в области ИИ, машинного обучения и Data Science. Они также очень эффективны в обучении, используя принцип литературного программирования для сочетания в одном документе программного кода и его описания. В этой статье я опишу несколько способов запуска Jupyter Notebooks, как локально на вашем компьютере, так и в облаке.
Ранее, в статье про Azure Notebooks, я описывал как можно удобно запускать код онлайн и делиться кодом с помощью этого инструмента. К сожалению, этот сервис превратился в более профессиональное решение, но необходимость запускать Jupyter Notebooks осталась. Рассмотрим, как же можно запустить Jupyter Notebook.
Просто посмотреть
Если вы просто хотите посмотреть на код в ноутбуке, не запуская его — это очень просто! Если код расположен в репозитории GitHub — просто откройте файл .ipynb , и его содержимое будет показано прямо в браузере.
Можно также использовать nbviewer для просмотра ноутбуков. Для этого нужно будет ввести онлайн имя/репозиторий на GitHub, либо любую URL, доступную через интернет. Вот пример того, как выглядит репозиторий GitHub при открытии в nbviewer.
Ещё одной хорошей опцией будет использовать Visual Studio Code, в которой возможность просмотра ноутбуков встроена “из коробки”. Если Visual Studio Code не установлена — можно использовать онлайн-версию vscode.dev, или github.dev.
GitHub.dev — это отличный способ открыть любой репозиторий в режиме Visual Studio Code для простого редактирования файлов. Для этого достаточно в адресе репозитория заменить github.com на github.dev . Заодно становится доступным просмотр ноутбуков.
Запуск локально или в облаке
В большинстве случае вам захочется не только посмотреть, но и запустить Jupyter notebooks, изменить код и посмотреть, как он работает. В этом случае — читайте дальше!
- Установить всё необходимое окружение у себя на компьютере
- Использовать облачные сервисы
В первом случае у вас есть полный контроль над окружением, файлами и вычислительными ресурсами, но придётся потратить некоторое время на установку. Во втором случае, вы будете использовать чьи-то вычислительные ресурсы, и скорее всего количество бесплатных ресурсов, доступных вам, будет ограничено. Зато не потребуется установка ПО, и вы сможете начать работать за считанные минуты.
Локальная установка
Если вы работаете в области ИИ, машинного обучения или Data Science, у вас уже скорее всего установлена среда Python. Иметь Python на своём компьютере — это в любом случае хорошая идея, поскольку велика вероятность, что она вам рано или поздно понадобится.
Проще всего установить Python с помощью дистрибутива Miniconda. Хотя большинство обычно рекомендует ставить Anaconda, которая включает в себя большое количество библиотек, я всегда рекомендую начинать с “голой” установки Python, а все библиотеки устанавливать по мере необходимости. У Miniconda размер первоначального установщика всего 50 Mb, в противовес почти 500 Mb у Anaconda.
Установив Miniconda, будет необходимо установить Jupyter:
conda install -c conda-forge notebook pip install notebook После установки, перейдите в папку с вашими ноутбуками, и запустите Jupyter:
jupyter notebook Откроется окно браузера, и можно начинать работать!
В некоторых репозиториях GitHub есть файл requirements.txt , содержащий сведения о необходимых для работы проекта библиотеках. В этом случае рекомендуется перед запуском ноутбука установить эти библиотеки командой
pip install -r requirements.txt Возможно, вместо классического Jupyter, вы захотите установить JupyterLab, его более продвинутую версию.
pip install juputerlab jupyter-lab 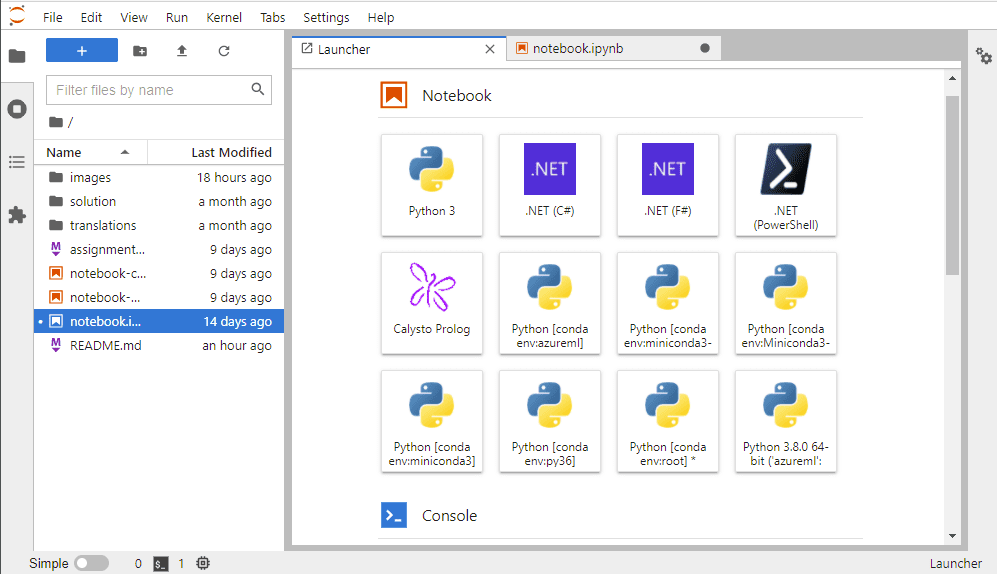
JupyterLab больше напоминает полноценную среду разработки, позволяя вам, помимо ноутбуков, редактировать скрипты Python, текстовые файлы и многое другое.
Поддержка языков .NET
Jupyter поддерживает много различных языков программирования в дополнение к Python. Если вы хотите использовать C# или F#, вы можете установить .NET Interactive. Установка поддержки .NET для Jupyter описана здесь
Используем Visual Studio Code
Редактировать и исполнять ноутбуки в браузере — не лучшая идея. Намного больше возможностей доступно при использовании Visual Studio Code, в которой есть отличная поддержка Jupyter Notebooks, с возможностью просмотра значений переменных, отладки и т.д. Для выполнения ноутбуков, вам нужно будет установить расширение Python (или расширение .NET, для C#/F#). Вам также понадобится установленное на вашем компьютере Python-окружение, описанное в предыдущем разделе.
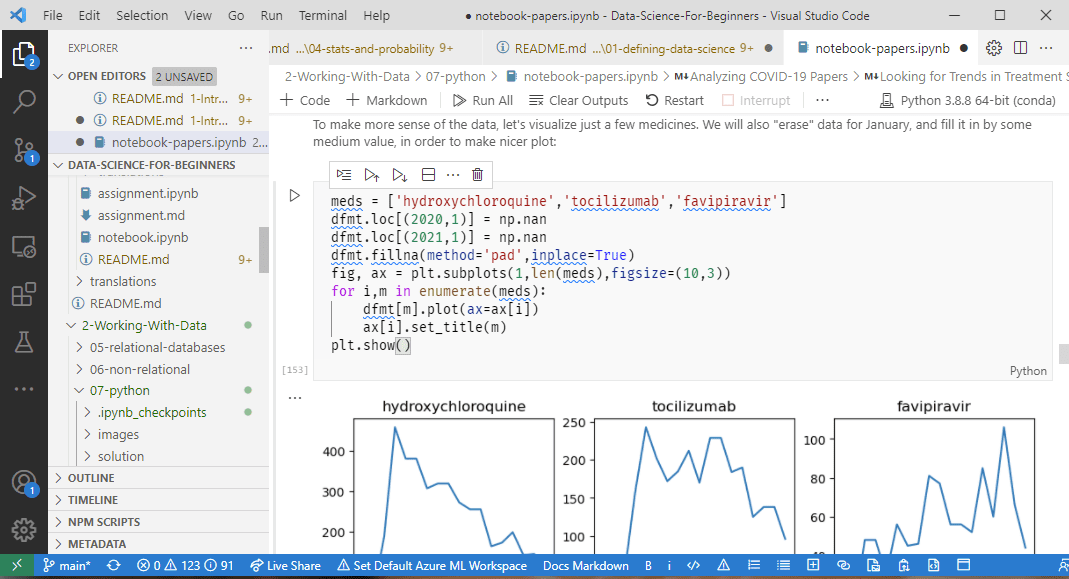
Вот ещё немного документации по использованию Jupyter в VS Code.
Установка Python на ваш компьютер — хорошее решение в долгосрочной перспективе, но если вы хотите запустить ноутбук по-быстрому — имеет смысл использовать облачное окружение. Вам не придётся ничего устанавливать на свой компьютер, и вы сможете наслаждаться работой уже через несколько минут. Иногда имеет смысл использовать облачные окружения даже тогда, когда у вас есть Python — например, чтобы избежать конфликта библиотек и запустить ноутбук в “чистом” окружении.
MyBinder
MyBinder.org позволяет вам создать виртуализированное (точнее, контейнеризованное) окружение Jupyter из любого GitHub-репозитория. Вы просто вводите GitHub URL, а Binder создаст контейнер и запустит среду Jupyter. Многие репозитории с ноутбуками даже содержат кнопку Launch Binder, позволяющую вам открыть проект в Binder автоматически.
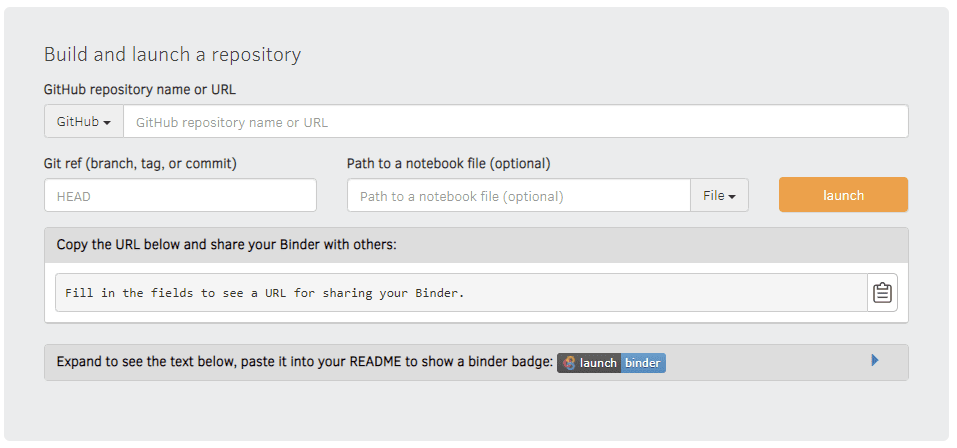
Binder попытается создать окружение, наилучшим образом подходящее для вашего проекта. Например, если в репозитории есть файл requirements.txt с описанием необходимых библиотек, они будут автоматически установлены. Более тонко можно настраивать конфигурацию с помощью файлов в директории binder — вплоть до описания Docker-контейнера, который необходимо собрать для запуска.
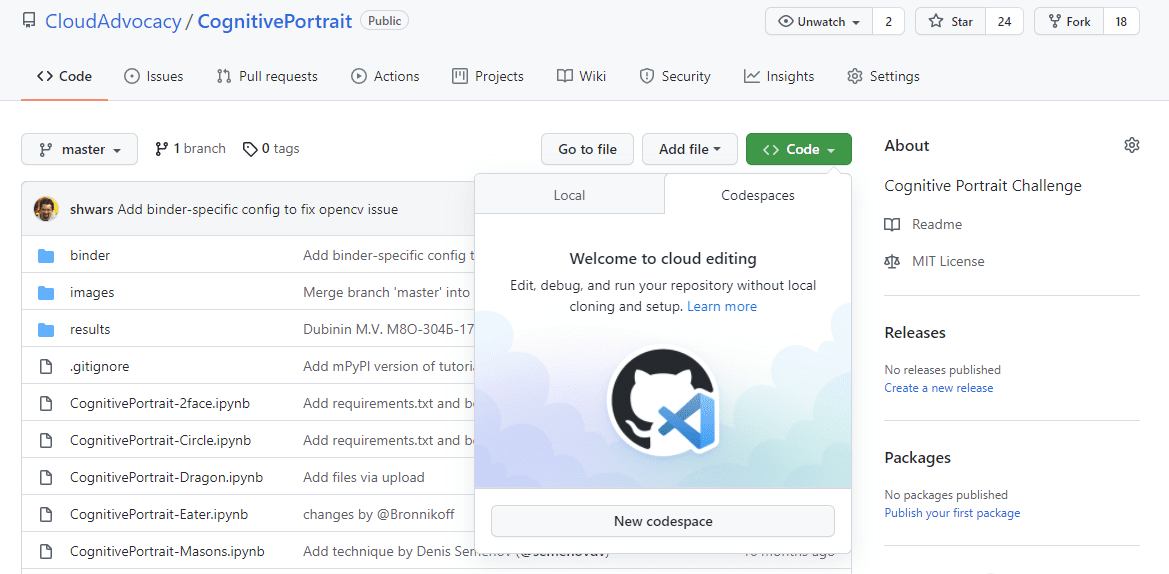
GitHub Codespaces
GitHub Codespaces — это новая встроенная в GitHub возможность открывать любой репозиторий в виртуализированном облачном окружении, доступном через среду VS Code в браузере или настольной версии. В настоящий момент Codespaces функционируют в режиме бета-тестирования, предоставляя индивидуальным пользователям некоторый объем бесплатных вычислительных ресурсов.
Datalore, CoCalc и др.
- JetBrains Datalore предоставляет некоторый объем бесплатных вычислительных ресурсов (в настоящий момент — 120 часов в месяц), а также некоторое количество GPU. Вам придётся предварительно загрузить ваши ноутбуки в рабочую область Datalore.
- CoCalc — это полноценное окружение для специалистов по Data Science, поддерживающее несколько популярных языков, таких как R, Julia и Sage, систему символьной компьютерной алгебры. Вы также можете запускать ограниченный набор GUI-приложений Linux и редактировать тексты в LaTeX. Я ранее писал про CoCalc в моей заметке про использование систем символьной алгебры для школьников.
- Про Google Colab вы скорее всего и так уже знаете, поэтому я не буду здесь его подробно описывать.
Заключение
- Установить Python-окружение на ваш компьютер, и использоват интерфейс Jupyter/JupyterLab в браузере, или Visual Studio Code
- Запустить в облачной среде онлайн, используя Binder, или одну из описанных выше опций.
У обоих подходов есть свои позитивные и негативные стороны, и я надеюсь, что после прочтения этой заметки вы сможете легко выбрать для себя оптимальный способ запуска Jupyter Notebooks.
Dmitri Soshnikov 2021-09-08 EDUCATION
jupyter notebooks
Как запустить Jupyter Notebook в браузере без бэкенда
К старту нашего флагманского курса по Data Science представляем перевод обзора JupyterLite прямо из блога его разработчиков. JupyterLite — это перезагрузка множества попыток создать полный статический выполняемый в браузере дистрибутив Jupyter, чтобы не было необходимости запускать сервер Jupyter.
Цель проекта — дать лёгкую вычислительную среду в браузере, доступную по одному клику спустя несколько секунд, без установки чего-либо на устройство конечного пользователя. При работе с дистрибутивами в браузере не нужно предоставлять среду выполнения на бэкенде. Приложение в основном представляет собой набор статических файлов, поэтому проще масштабируется и его легче развёртывать.
Полноценный дистрибутив JupyterLab в браузере
JupyterLite разработан с нуля, он повторно использует множество плагинов и компонентов JupyterLab как есть. В дополнение к JupyterLab JupyterLite по умолчанию работает с интерфейсом RetroLab:
Благодаря повторному использованию компонентов JupyterLab JupyterLite получает преимущества многих улучшений: новых функций, исправлений специальных возможностей и улучшений обслуживания. В JupyterLite также можно включить совместную работу в реальном времени из JupyterLab 3.1.
Pyolite — поддерживаемое Pyodide ядро Python
Pyodide — это скомпилированный в WebAssembly интерпретатор CPython 3.8, позволяющий запускать Python в браузере, а также скомпилированных научных пакетов Python.
Из индекса пакетов PyPI Pyodide может установить любой пакет wheel, он содержит комплексный интерфейс внешних функций, предоставляющий экосистему пакетов Python для JavaScript и пользовательский интерфейс браузера для Python, в том числе DOM.

С версии 0.17 за последние несколько лет Pyodide получил множество улучшений: меньший размер двоичных файлов, поддержку asyncio и улучшение трансляции типов между Python и JavaScript.
JupyterLite по умолчанию поставляется с Pyolite — ядром Python, которое поддерживается Pyodide. Это ядро работает в веб-воркере, а значит при выполнении интенсивных вычислений не блокирует основной поток пользовательского интерфейса.
IPython в браузере
Pyolite теперь работает на IPython, что открывает доступ к его магическим командам, завершению кода, расширенному отображению, интерактивным виджетам и многим другим функциям.
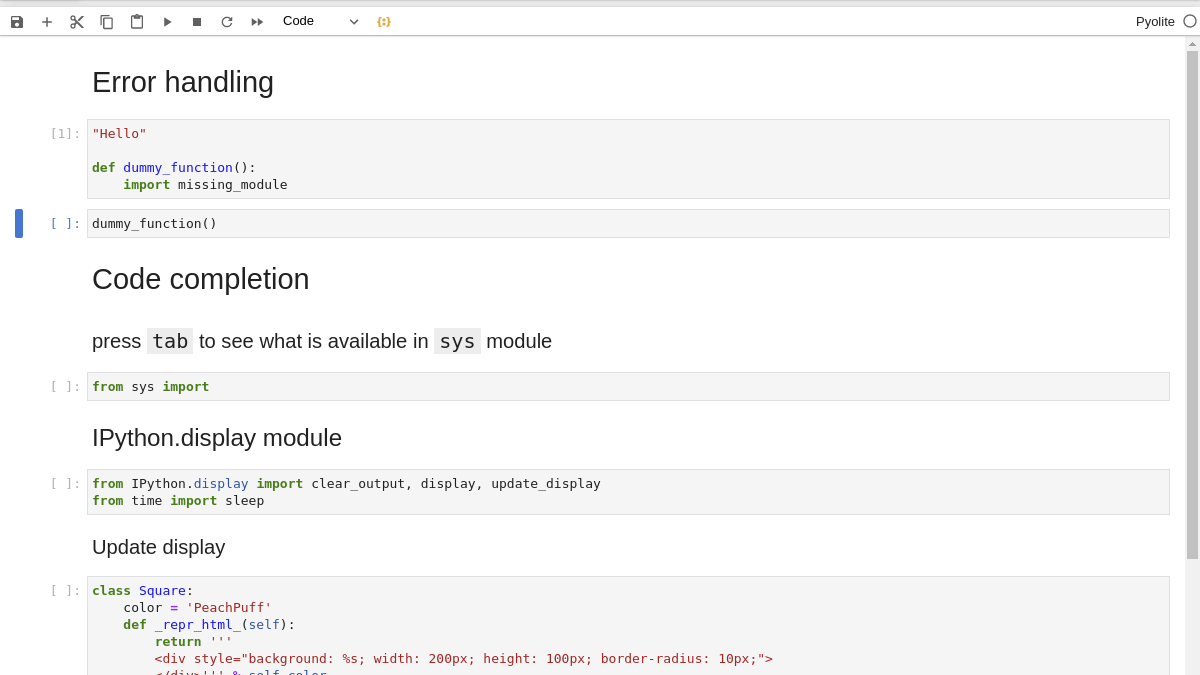
Интерактивная визуализация
В JupyterLite также поддерживаются многие библиотеки визуализации, такие как Altair и Plotly, что позволяет быстро и удобно создавать рисунки и графики:
Поддержка виджетов Jupyter
В основе виджетов Jupyter лежит спецификация кастомных сообщений протокола Jupyter между ядром и интерфейсом. Мартин Рену добавил поддержку Comms в ядре Pyolite, что позволило многим существующим основным и сторонним виджетам, например bqplot, ipyleaflet и ipycanvas, работать из коробки.
Больше, чем просто Python
JupyterLite работает со множеством ядер. Дистрибутив по умолчанию содержит ядра JavaScript и p5:

Эти ядра выполняются в IFrame как изолированные окружения. С помощью протокола отображения Jupyter можно легко отображать кастомные анимации:
JupyterLite гибко настраивается
Как и многие инструменты Jupyter, JupyterLite легко настраивается. С версии 3.0 поддерживается новая встроенная система расширения JupyterLab, а существующие расширения JupyterLab легко повторно использовать в JupyterLab.
Серверная часть JupyterLite в браузере также использует плагины. Сервер — это регистрирующее несколько плагинов приложение Lumino без оболочки, где регистрируются, например, менеджер содержимого или служба сеансов.
Такой подход делает замену одного плагина на другой очень удобной для разработчиков или администраторов сайта.
Пример: замена менеджера содержимого по умолчанию, который хранит блокноты и файлы в LocalStorage, на менеджера, сохраняющего содержимое в AWS S3.
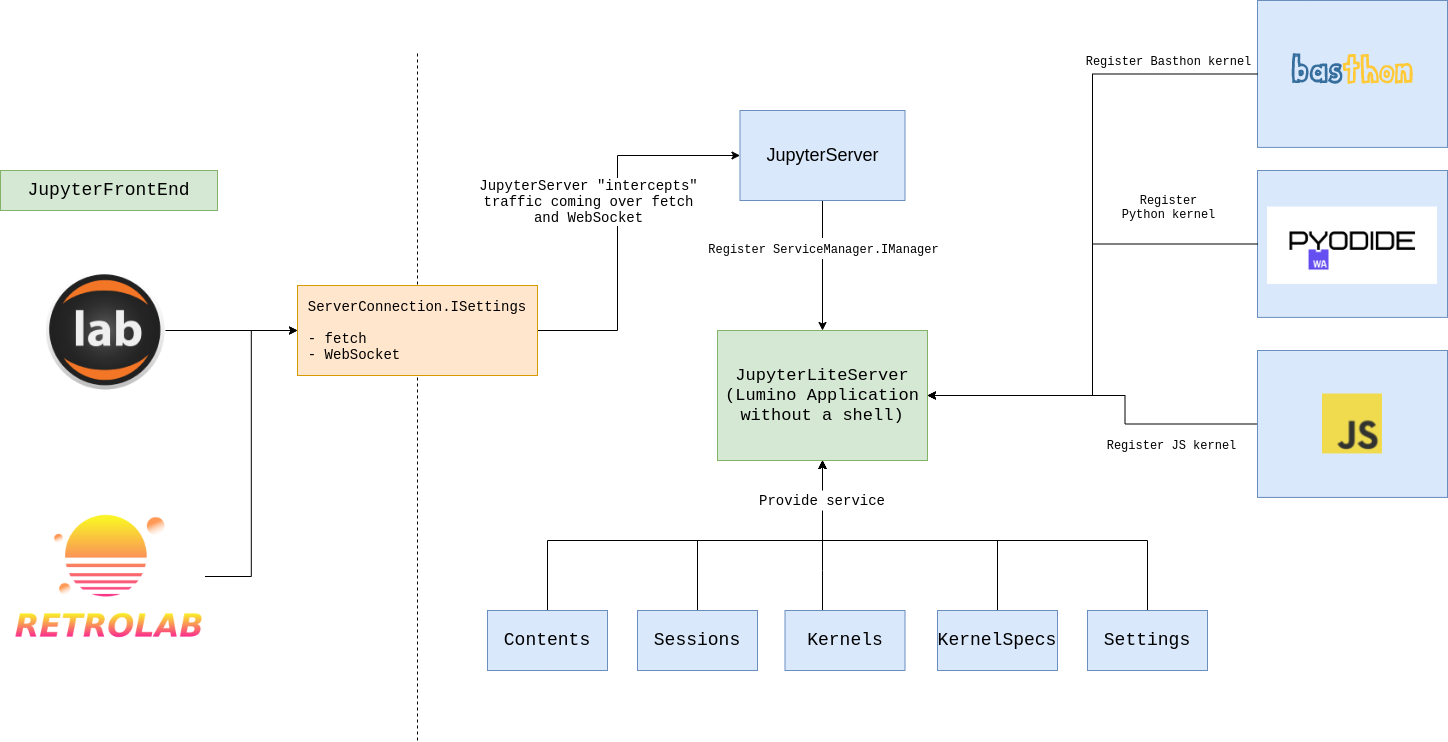
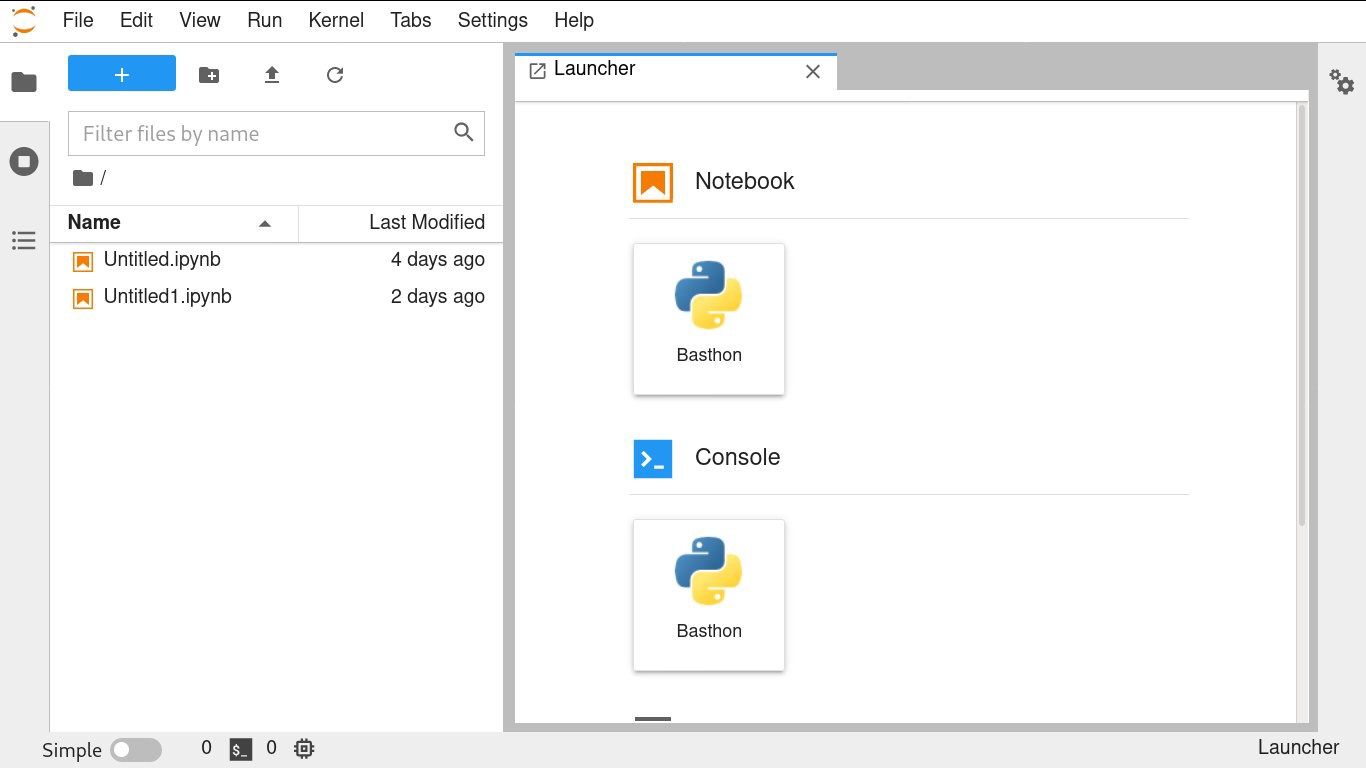
Модульность и гибкость JupyterLite позволяют легко добавлять ядра. Ядро Basthon, прототип для запуска которого разрабатывается в этом репозитории, использует несколько иную модель выполнения, чем Pyolite: оно запускается в основном потоке пользовательского интерфейса, поэтому пользователи могут напрямую управлять DOM главного окна из Python.
Pyolite, в свою очередь, запускается в веб-воркере как фоновый поток. Оба подхода имеют свои плюсы и минусы, а система плагинов JupyterLite позволяет авторам расширений полностью контролировать свои ядра.
Развёртывание
JupyterLite легко разворачивается как статический веб-сайт. Никакой сложной настройки, никаких проблем с масштабируемостью. Только простой, обычный HTTP-сервер статических файлов.
Поэтому появляются варианты: Nginx, Binder, GitHub Pages или страницы GitLab, Vercel, Netlify и многие другие. Можно развернуть JupyterLite в ReadTheDocs, где размещён и постоянно обновляется демонстрационный сайт JupyterLite.
Многие сценарии развёртывания уже задокументированы здесь, также есть демонстрационный шаблон, позволяющий легко развернуть настраиваемый веб-сайт JupyterLite на страницах GitHub одним кликом.
Благодаря работе Николаса Боллвега в JupyterLite для удобства развёртывания появился инструмент командной строки jupyterlite. Одна из задач JupyterLite — позволить любому пользователю собрать собственный дистрибутив с необходимым ему набором плагинов и расширений. Сегодня для этого нужно работать с jupyterlite, но можно представить экспорт удобнее:
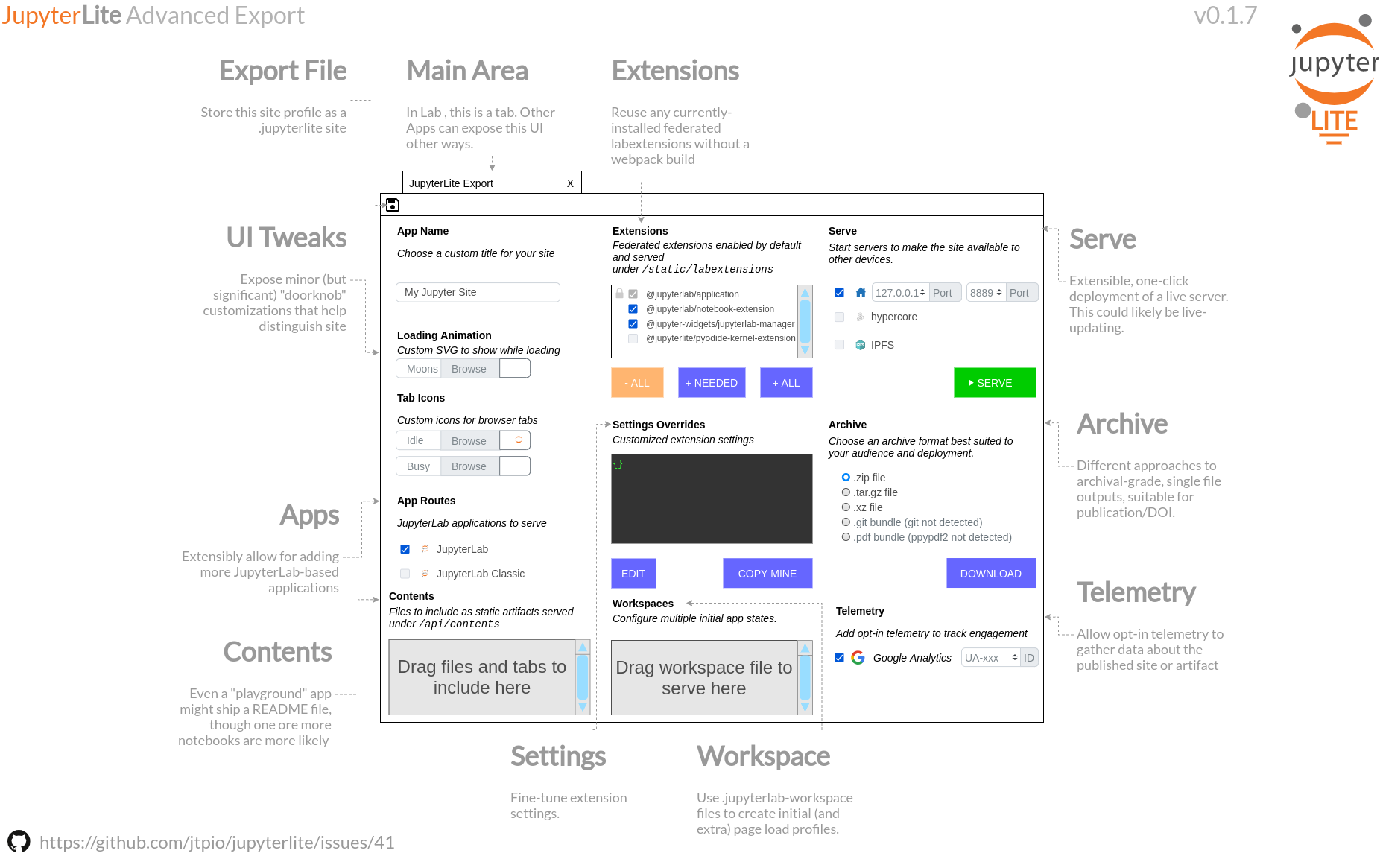
Широкий спектр вариантов
Благодаря простоте развёртывания и низкому порогу входа JupyterLite отлично подходит для широкого спектра задач. В образовательном пространстве он упрощает доступ к учебным материалам и вычислительным средам. Преподаватели и студенты могут сосредоточиться на содержании своих занятий, не беспокоясь о развёртывании и мониторинге серверов.
С помощью JupyterLite мы также надеемся привлечь новую волну пользователей Jupyter и сделать всю экосистему ещё доступнее для новичков и более широкого сообщества. В случае небольших проектов это может даже снизить нагрузку на mybinder.org посредством развёрнутой на CDN версии JupyterLite — binderlite.
Как быстро попробовать JupyterLite
JupyterLite можно протестировать по этой ссылке.
Локальный запуск
Во-первых, установите пакет CLI:
pip install --pre jupyterliteЗатем создайте веб-сайт JupyterLite и разместите его на локальном сервере:
jupyter lite init jupyter lite build jupyter lite serveДокументация приложения jupyterlite находится здесь.
А поработать с JupyterLab или JupyterLite на практике вы сможете на наших курсах по Data Science, а на курсе «Machine Learning и Deep Learning» используется оборудование нашего партнёра и лидера в области вычислений для искусственного интеллекта — компании NVIDIA. Кроме того, здесь вы можете узнать, как начать карьеру или прокачаться, например, в Fullstack-разработке на Python:

Data Science и Machine Learning
- Профессия Data Scientist
- Профессия Data Analyst
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс по Data Engineering
- Курс «Machine Learning и Deep Learning»
- Курс по Machine Learning
Python, веб-разработка
- Профессия Fullstack-разработчик на Python
- Курс «Python для веб-разработки»
- Профессия Frontend-разработчик
- Профессия Веб-разработчик
Мобильная разработка
- Профессия iOS-разработчик
- Профессия Android-разработчик
Java и C#
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия C#-разработчик
- Профессия Разработчик игр на Unity
От основ — в глубину
- Курс «Алгоритмы и структуры данных»
- Профессия C++ разработчик
- Профессия Этичный хакер
А также:
NeilAlishev / Instruction.md
Это очень частая проблема, которая появляется на некоторых ОС. Дело в том, что среда разработки запустилась, но браузер не открылся автоматически.
Как решить эту проблему?
В первую очередь, попробуйте запустить Anaconda Navigator с правами администратора (правой кнопкой мыши нажать на иконку Anaconda Navigator, во всплывающем меню выбрать «Запуск от имени администратора»). Теперь, запустите Jupyter Notebook.
Если все равно не открывается окно браузера, выполните инструкции описанные далее.
- Запустите программу, которая называется CMD.exe Prompt (может также называться Anaconda Prompt), нажав на Launch. Эта программа находится тут же, в Anaconda Navigator, рядом с программой Jupyter Notebook. После нажатия на Launch, должна открыться командная строка. Если этой программы нет в Anaconda Navigator, можно найти программу «Anaconda Prompt» на компьютере с помощью обычного поиска по программам.
- В этой командной строке мы должны выполнить команду jupyter notebook list (если команда не сработала, попробуйте сначала выполнить команду jupyter notebook list -V , а потом уже команду jupyter notebook list )
- Вышеупомянутая команда показывает тот адрес, по которому мы сможем получить доступ к нашей среде разработки. Адрес имеет вид: http://localhost:8888/?token=СЛУЧАЙНАЯ_ПОСЛЕДОВАТЕЛЬНОСТЬ_БУКВ_И_ЦИФР
Вам необходимо скопировать этот адрес, вставить его в адресную строку вашего браузера и перейти на эту страницу. После этого откроется среда разработки Jupyter Notebook. Можно работать.
Чтобы скопировать адрес из командной строки Windows, необходимо кликнуть правой кнопкой мыши в любом месте командной строки. В выпадающем меню надо выбрать пункт «пометить». После этого, можно будет выделить курсором интересующий нас адрес. После того, как адрес будет выделен, надо нажать на клавишу Enter на вашей клавиатуре. Готово — адрес скопирован в буфер обмена. Можно его вставлять в адресную строку браузера.
ОС Linux или Mac OS: Надо просто открыть терминал и там написать jupyter notebook Полученный адрес надо скопировать в адресную строку браузера.
P.S. Если Jupyter Notebook так и не запустился, можно использовать среду разработки PyCharm. Эта среда разработки ничуть не хуже, чем Jupyter Notebook, и тоже отлично нам подойдет.