Как использовать обученную модель нейронной сети?
Добрый день! Не могу понять, как использовать уже обученную модель нейронной сети. Программирую на питоне, использую библиотеку keras. Анализирую временные ряды. Нейронная сеть обучена, модель сохранена. Как описано в документации keras, надо вызвать метод model_name.predict(). Хорошо. Делаю так: model.predict(dataset), где dataset — это значения за последние 90 дней. А мне надо получить прогноз вперед на, скажем, 10 дней. Но прогноз делается только для указанного набора данных на 90 дней! То есть можно только сравнить исходные данные и прогнозные. Практического толка никакого. Так как же делать прогноз наперед?
Отслеживать
задан 24 янв 2018 в 11:14
107 11 11 бронзовых знаков
Вам надо скормить модели входные данные за следующие 10 дней. Данные должны быть в нужном формате (такой же как у вашего dataset )
24 янв 2018 в 12:26
MaxU, вы меня не поняли. Стоит задача именно предсказать значения на 10 дней вперед. Сегодня 24 января, мне нужен прогноз по 3 февраля. А метод predict( ), в том то и проблема, можно использовать только при наличии входных данных. Вот как сделать так, чтобы я передал в обученную модель сети данные за последние 90 дней, включая сегодняшний, а она мне предсказала значения на 10 дней с завтрашнего дня?
24 янв 2018 в 14:37
Как выглядит ваш dataset ? Из чего он состоит?
24 янв 2018 в 15:35
по-моему данные за прошедшие 90 дней нужны были только для обучения модели. Для предсказания они не нужны..
24 янв 2018 в 17:49
MaxU, в любом случае спасибо ) Я вчера наткнулся на пример кода, который вроде реализует то, что я хочу. Посмотрим, что он выдает, а там видно будет ))
Предобученные модели

С помощью deep learning можно решить многие задачи computer vision — обнаружения и классификации объектов, распознавания лиц, генерации изображений, сегментации.
Обучение модели может занимать от считанных минут до нескольких месяцев (в зависимости от набора данных и конкретной задачи). Из-за значительных вычислительных затрат еще несколько лет назад этим занимались исследовательские университеты и крупные технологические компании. Сейчас нам помогает трансферное обучение.
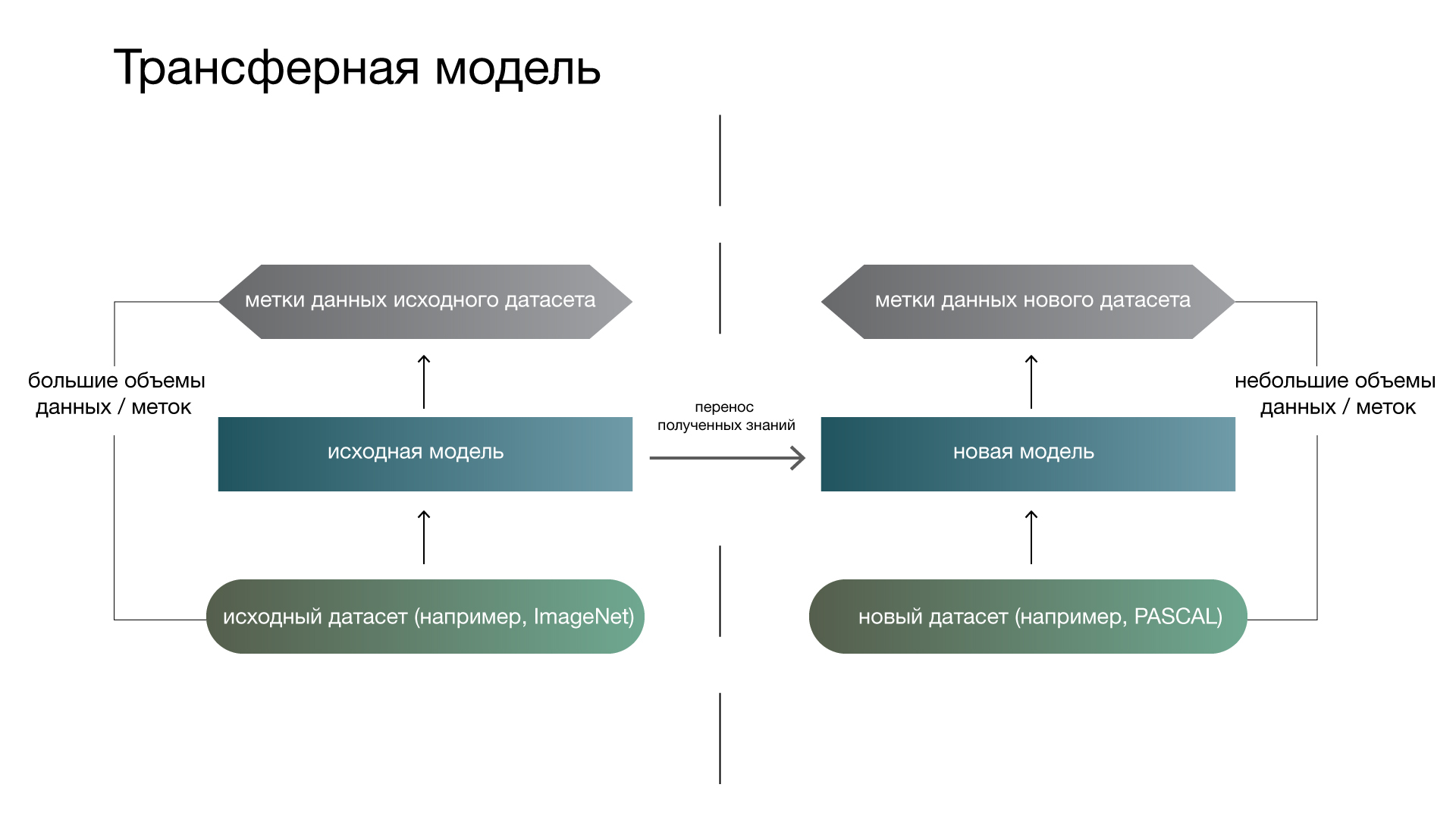
Трансферное обучение
Трансферное обучение — подраздел ML. Его цель — применение знаний, полученных благодаря решению одной задачи, к другой, но схожей задаче. Это популярный метод компьютерного зрения — он позволяет получить точные модели, экономя время и деньги. При переносе обучения мы начинаем с признаков, усвоенных при решении другой задачи, вместо того чтобы тренировать модели с нуля.
Еще в 2016 году Эндрю Ын спрогнозировал рост популярности метода: «Трансферное обучение будет следующим двигателем коммерческого успеха ML после обучения с учителем».
Предобученные модели: что это и где их искать
Трансферное обучение предполагает использование предобученных моделей (созданных и натренированных на большом наборе общедоступных данных). Чаще всего их разрабатывают крупные технологические компании или ведущие исследователи в области компьютерного зрения. Эти модели обучаются на внушительных объемах данных (например, ImageNet — ~14 млн изображений, Google Landmarks Dataset v2 — ~5 млн изображений).
Выбор предобученной модели зависит от задачи. YOLOv2 используется для обнаружения и классификации объектов, OpenFace — для распознавания лиц, ResNet — для классификации изображений.
Для успешного трансферного обучения нужна модель, натренированная на наборе данных, схожем с целевым. Так, модель, обученная на изображениях лиц, не лучшим образом обобщается для задачи распознавания текста. Поэтому популярны модели, обученные на больших и разнообразных наборах данных (выученные признаки встречаются в других наборах с высокой вероятностью).
Фреймворки машинного обучения — один из источников натренированных моделей. Наборы предобученных моделей предоставляют Tensorflow, PyTorch, Keras, Caffe2. Например:
- Tensorflow Model Garden — репозиторий с множеством реализаций SOTA-моделей на основе TensorFlow.
- Модели Torchvision включают основные архитектуры для задачи классификации изображений (AlexNet, VGG, ResNet и другие).
- Keras applications предоставляет коллекцию популярных моделей для задачи классификации, которые легко подгрузить с помощью оболочки Keras.
- Caffe и Caffe2 также предоставляют набор готовых предобученных моделей.
курсы по теме:
Data Science with Python
Памятка по TensorFlow: привет глубокому обучению!
Вы хотите освоить глубокое обучение с помощью TensorFlow? Независимо от того, являетесь ли вы новичком или опытным специалистом по данным, наша исчерпывающая шпаргалка по TensorFlow поможет вам. С помощью этой памятки вы сможете изучить основы TensorFlow, узнать о его возможностях и вывести свои навыки глубокого обучения на новый уровень.
Почему Tensorflow?
Исследования показали, что TensorFlow — эффективная и масштабируемая платформа для задач глубокого обучения. Исследование, проведённое сотрудниками Google, показало, что TensorFlow превзошёл другие популярные фреймворки глубокого обучения, достигнув более высокой производительности и более быстрого обучения в крупномасштабных нейронных сетях.
Другой эксперимент, проведённый исследователями из Массачусетского технологического института и Калифорнийского университета в Беркли, показал, что TensorFlow — это универсальный инструмент для разработки и развёртывания моделей глубокого обучения в самых разных приложениях.
Шпаргалка по Tensorflow
Эта шпаргалка специально разработана для тех, кто работает с Python и Data Science, что делает её ценным инструментом для всех, кто хочет погрузиться в мир глубокого обучения.
Итак, если вы готовы упростить своё путешествие по глубокому обучению, давайте подробнее рассмотрим, что может предложить эта шпаргалка.
Приготовьтесь сказать привет глубокому обучению с TensorFlow!
Импорт TensorFlow и проверка версии
Прежде чем приступить к работе с TensorFlow, вам необходимо импортировать библиотеку и убедиться, что у вас установлена правильная версия. Этот процесс включает в себя использование оператора import и атрибута __version__.
# Importing TensorFlow and checking the version import tensorflow as tf print(‘TensorFlow version:’, tf.__version__)
В этом коде мы импортируем TensorFlow с помощью оператора import и проверяем версию, благодаря атрибуту __version__.
Построение последовательной модели в TensorFlow
В TensorFlow вы можете построить последовательную модель, создав экземпляр объекта Sequential и добавив к нему слои с помощью метода add(). Этот процесс включает в себя определение архитектуры модели, в том числе входные и выходные формы, функции активации и количество единиц в каждом слое.
# Building a sequential model model = tf.keras.Sequential([ tf.keras.layers.Dense(64, activation=’relu’, input_shape=(784,)), tf.keras.layers.Dense(10, activation=’softmax’) ])
В этом коде мы создаём последовательную модель с двумя плотными слоями, используя объект Sequential и класс слоя Dense. Мы определяем входную форму первого слоя как кортеж (784,), который соответствует плоской форме набора данных MNIST. Также мы указываем функцию активации для каждого слоя ( relu для первого слоя и softmax для выходного слоя), а также количество единиц в каждом слое ( 64 для первого слоя и 10 для выходного слоя).
Компиляция модели в TensorFlow
После построения модели в TensorFlow перед обучением её необходимо скомпилировать. Этот процесс включает в себя указание функции потерь, оптимизатора и метрики оценки для модели с использованием метода compile().
# Compiling the model model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
В этом коде мы компилируем последовательную модель с помощью метода compile() и указываем функцию потерь categorical_crossentropy, оптимизатор adam и метрику accuracy для оценки во время обучения.
Обучение модели в TensorFlow
Чтобы обучить модель в TensorFlow, вам нужно вызвать метод fit() на скомпилированной модели и передать данные обучения и проверки, а также размер пакета и количество эпох.
# Training the model model.fit(X_train, y_train, batch_size=32, epochs=10, validation_data=(X_val, y_val))
В этом коде мы обучаем скомпилированную модель с помощью метода fit() и передаём обучающие данные ( X_train и y_train), размер партии ( 32), количество эпох ( 10) и данные проверки ( X_val и y_val). Модель будет обучаться в течение 10 эпох с размером пакета 32 и проверять данные проверки после каждой эпохи.
Оценка модели в TensorFlow
После того, как вы обучили модель в TensorFlow, вы можете оценить её производительность на тестовом наборе с помощью метода evaluate(). Этот процесс включает в себя передачу тестовых данных в качестве аргументов и вычисление метрики потерь и оценки в тестовом наборе.
# Evaluating the model loss, accuracy = model.evaluate(X_test, y_test) print(‘Test Loss:’, loss) print(‘Test Accuracy:’, accuracy)
В этом коде мы оцениваем обученную модель с помощью метода evaluate() и передаём тестовые данные ( X_test и y_test). Затем мы вычисляем метрики потерь и точности в тестовом наборе и выводим их.
Сохранение и загрузка модели в TensorFlow
В TensorFlow вы можете сохранить обученную модель на диск с помощью метода save()и загрузить её обратно в память с помощью функции load_model(). Это позволяет повторно использовать обученную модель в будущих сеансах без необходимости переобучения её с нуля.
# Saving the model to disk model.save(‘my_model.h5’) # Loading the model from disk new_model = tf.keras.models.load_model(‘my_model.h5’)
В этом коде мы сохраняем обученную модель на диск с помощью метода save()и загружаем её обратно в память с помощью функции load_model(). Мы сохраняем модель как файл HDF5 с именем my_model.h5 и загружаем её обратно в новую переменную с именем new_model.
Использование обратных вызовов в TensorFlow
В TensorFlow вы можете использовать обратные вызовы для настройки поведения процесса обучения. Обратные вызовы — это функции, которые выполняются во время обучения в определённых точках, таких как начало или конец эпохи. Их можно использовать для таких задач, как сохранение модели, ранняя остановка или снижение скорости обучения.
# Defining a callback function callback = tf.keras.callbacks.EarlyStopping(monitor=’val_loss’, patience=3) # Training the model with the callback function model.fit(X_train, y_train, batch_size=32, epochs=10, validation_data=(X_val, y_val), callbacks=[callback])
Объяснение: В этом коде мы определяем функцию обратного вызова, которая выполняет досрочную остановку, если потеря проверки не улучшится после трёх эпох. Мы создаём экземпляр обратного вызова EarlyStopping и передаём его методу fit() в виде списка обратных вызовов. Модель будет обучаться в течение 10 эпох и остановится раньше, если потеря проверки не улучшится после трёх эпох.
Использование регуляризации в TensorFlow
В TensorFlow вы можете использовать методы регуляризации, такие как L1, L2 и отсев, чтобы предотвратить переобучение в ваших моделях. Регуляризация включает в себя добавление штрафов к функции потерь, которые препятствуют использованию больших весов или активаций в модели.
# Adding L2 regularization to a dense layer model.add(tf.keras.layers.Dense(64, activation=’relu’, kernel_regularizer=tf.keras.regularizers.l2(0.01)))
В этом коде мы добавляем регуляризацию L2 к плотному слою модели, передавая аргумент kernel_regularizer конструктору слоя Dense. Указываем силу регуляризации использования 0.01 функции l2() из модуля tf.keras.regularizers.
Использование свёрточных слоев в TensorFlow
В TensorFlow вы можете использовать свёрточные слои для извлечения признаков из изображений и других многомерных данных. Свёрточные слои состоят из фильтров, которые скользят по входным данным и создают карту объектов.
# Adding a 2D convolutional layer model.add(tf.keras.layers.Conv2D(32, (3, 3), activation=’relu’, input_shape=(28, 28, 1))) # Adding a 2D max pooling layer model.add(tf.keras.layers.MaxPooling2D((2, 2)))
В этом коде мы добавляем к модели двухмерный свёрточный слой, используя класс Conv2D слоя. Мы указываем фильтры размера (3, 3), активации relu и входной формы (28, 28, 1)(соответствующей набору данных MNIST). Затем мы добавляем слой пула 2D max, используя класс слоя MaxPooling2D с размером пула (2, 2).
Использование повторяющихся слоёв в TensorFlow
В TensorFlow вы можете использовать повторяющиеся слои для моделирования последовательных данных, таких как временные ряды или естественный язык. Рекуррентные слои состоят из рекуррентных блоков, которые обрабатывают каждый элемент в последовательности и создают выходное и скрытое состояние, которые передаются следующему блоку.
# Adding a simple RNN layer model.add(tf.keras.layers.SimpleRNN(64, activation=’relu’, input_shape=(None, 1))) # Adding a LSTM layer model.add(tf.keras.layers.LSTM(64, activation=’relu’))
В этом коде мы добавляем в модель слой простой рекуррентной нейронной сети (RNN), используя класс слоя SimpleRNN . Мы указываем 64 повторяющиеся единицы, активацию relu и входную форму (None, 1)(где None представляет любую длину последовательности). Затем мы добавляем слой долговременной кратковременной памяти (LSTM), используя класс словя LSTM с теми же параметрами.
Использование трансферного обучения в TensorFlow
Трансферное обучение — это метод, в котором предварительно обученная модель используется в качестве отправной точки для новой задачи. В TensorFlow вы можете использовать предварительно обученные модели из таких источников, как TensorFlow Hub или модуль приложений Keras, для выполнения трансферного обучения.
# Loading a pre-trained model base_model = tf.keras.applications.MobileNetV2(input_shape=(224, 224, 3), include_top=False, weights=’imagenet’) # Freezing the pre-trained layers for layer in base_model.layers: layer.trainable = False # Adding new output layers for a new task x = tf.keras.layers.GlobalAveragePooling2D()(base_model.output) x = tf.keras.layers.Dense(128, activation=’relu’)(x) predictions = tf.keras.layers.Dense(10, activation=’softmax’)(x) # Creating a new model model = tf.keras.models.Model(inputs=base_model.input, outputs=predictions)
В этом коде мы загружаем предварительно обученную модель MobileNetV2 из модуля Keras Applications с входной формой (224, 224, 3)верхнего уровня классификации и без него.
Затем мы заморозим предварительно обученные слои, установив для их атрибута trainable значение False.
Мы добавляем новые выходные слои для новой задачи, применяя глобальное усреднение к выходным данным базовой модели, добавляя плотный слой с 128 единицами и активацией relu и добавляя плотный слой с 10 единицами и активацией softmax. Наконец, мы создаём новую модель, которая принимает входные данные базовой модели и выводит новые прогнозы.
Использование пользовательских функций потерь в TensorFlow
В TensorFlow вы можете определить собственные функции потерь для своих моделей с помощью модуля tf.keras.losses. Это позволяет вам создавать функции потерь, адаптированные к вашей конкретной проблеме, которые могут включать дополнительные условия или штрафы.
# Defining a custom loss function def custom_loss(y_true, y_pred): squared_difference = tf.square(y_true — y_pred) return tf.reduce_mean(squared_difference, axis=-1) # Compiling the model with the custom loss function model.compile(optimizer=’adam’, loss=custom_loss)
В этом коде мы определяем пользовательскую функцию потерь custom_loss, которая вычисляет среднеквадратичную ошибку между истинным и прогнозируемым значениями. Мы используем операции TensorFlow для вычисления квадрата разницы и уменьшения среднего по последней оси. Затем мы компилируем модель с оптимизатором adam и пользовательской функцией потерь.
Использование пользовательских метрик в TensorFlow
В TensorFlow вы можете определить пользовательские метрики для оценки производительности ваших моделей во время обучения и тестирования. Пользовательские показатели могут быть определены с помощью модуля tf.keras.metrics и могут включать дополнительные условия или штрафы.
# Defining a custom metric function def custom_metric(y_true, y_pred): absolute_difference = tf.abs(y_true — y_pred) return tf.reduce_mean(absolute_difference, axis=-1) # Compiling the model with the custom metric model.compile(optimizer=’adam’, loss=’sparse_categorical_crossentropy’, metrics=[custom_metric])
В этом коде мы определяем пользовательскую метрику custom_metric, которая вычисляет среднюю абсолютную ошибку между истинным и прогнозируемым значениями. Мы используем операции TensorFlow для вычисления абсолютной разницы и уменьшения среднего по последней оси. Затем мы компилируем модель с оптимизатором adam, разреженной категориальной функцией кросс-энтропийных потерь и пользовательской метрикой.
Использование функционального API в TensorFlow
Функциональный API Keras позволяет создавать сложные модели с несколькими входами и выходами, общими слоями и нелинейными связями между слоями.
# Defining the inputs input_1 = tf.keras.layers.Input(shape=(28, 28, 1)) input_2 = tf.keras.layers.Input(shape=(10,)) # Adding some layers to the first input x = tf.keras.layers.Conv2D(32, (3, 3), activation=’relu’)(input_1) x = tf.keras.layers.MaxPooling2D((2, 2))(x) x = tf.keras.layers.Flatten()(x) # Merging the inputs with a shared layer merged = tf.keras.layers.concatenate([x, input_2]) # Adding some more layers y = tf.keras.layers.Dense(64, activation=’relu’)(merged) output = tf.keras.layers.Dense(10, activation=’softmax’)(y) # Creating the model model = tf.keras.models.Model(inputs=[input_1, input_2], outputs=output)
В этом коде мы определяем два входа для модели: input_1 для данных изображения и input_2 для дополнительных функций.
Мы добавляем несколько слоёв к первому входу для обработки данных изображения, включая слой свёртки 2D, слой максимального объединения и слой сглаживания.
Затем мы объединяем выходные данные этих слоёв со вторым входом, используя конкатенированный слой.
Мы добавляем ещё несколько слоёв к объединённому выводу, в том числе плотный слой с 64 единицами и активацией relu и плотный выходной слой с 10 единицами и активацией softmax. Наконец, мы создаём модель с классом Model, используя входные и выходные данные.
Использование обратных вызовов в TensorFlow
В TensorFlow вы можете использовать обратные вызовы для настройки поведения ваших моделей во время обучения. Обратные вызовы — это функции, которые вызываются в определённые моменты во время обучения, например, в конце каждой эпохи, и могут выполнять такие задачи, как сохранение модели, ранняя остановка или изменение скорости обучения.
# Defining a callback for early stopping early_stopping_callback = tf.keras.callbacks.EarlyStopping(monitor=’val_loss’, patience=3) # Fitting the model with callbacks history = model.fit(x_train, y_train, epochs=10, validation_data=(x_val, y_val), callbacks=[early_stopping_callback])
В этом коде мы определяем обратный вызов, вызываемый early_stopping_callback с использованием класса EarlyStopping из модуля tf.keras.callbacks. Этот обратный вызов будет отслеживать потерю проверки и останавливать обучение, если оно не улучшается в течение 3 последовательных эпох. Затем мы подгоняем модель к обучающим данным для 10 эпох с включёнными проверочными данными и обратным вызовом. Переменная history будет содержать информацию о производительности обучения и проверки с течением времени.
Заключение
В этой статье мы рассмотрели возможности и универсальность TensorFlow, популярной платформы с открытым исходным кодом для глубокого обучения.
Мы рассмотрели ряд тем, включая основы TensorFlow, создание и обучение глубоких нейронных сетей и применение этих методов в реальных приложениях.
С TensorFlow вы можете упростить процесс глубокого обучения и вывести свои навыки на новый уровень.
Используя TensorFlow, вы можете исследовать возможности глубокого обучения и получать новые знания из ваших данных.
Так зачем ждать? Начните изучать мощь TensorFlow сегодня и раскройте потенциал своих данных!
Учебник по Python. Обучение и сохранение модели Python с помощью T-SQL
В четвертой части этой серии руководств вы узнаете, как обучить модель машинного обучения с помощью пакетов Python scikit-learn и revoscalepy. Эти библиотеки Python устанавливаются в составе машинного обучения SQL Server.
Вы загрузите модули и вызовете необходимые функции для создания и обучения модели с помощью хранимой процедуры SQL Server. Для модели требуются функции данных, разработанные в предыдущих частях этой серии руководств. Наконец, вы сохраните обученную модель в таблице SQL Server.
Работая с этой статьей, вы узнаете о следующем.
- Создание и обучение модели с помощью хранимой процедуры SQL
- Сохранение обученной модели в таблице SQL
В первой части были установлены необходимые компоненты и восстановлена демонстрационная база данных.
Во второй части вы изучили образец данных и создали несколько графиков.
В третьей части вы узнали, как создавать функции из необработанных данных с помощью функции Transact-SQL. Затем вы вызвали эту функцию из хранимой процедуры, чтобы создать таблицу, содержащую значения характеристик.
Из пятой части вы узнаете, как ввести в эксплуатацию модели, которые были обучены и сохранены в соответствии с инструкциями в четвертой части.
Разделение примера данных на обучающий и проверочный наборы
- Создайте хранимую процедуру с именем PyTrainTestSplit, чтобы разделить данные в таблице nyctaxi_sample на две части: nyctaxi_sample_training и nyctaxi_sample_testing. Чтобы создать ее, выполните следующий код:
DROP PROCEDURE IF EXISTS PyTrainTestSplit; GO CREATE PROCEDURE [dbo].[PyTrainTestSplit] (@pct int) AS DROP TABLE IF EXISTS dbo.nyctaxi_sample_training SELECT * into nyctaxi_sample_training FROM nyctaxi_sample WHERE (ABS(CAST(BINARY_CHECKSUM(medallion,hack_license) as int)) % 100) < @pct DROP TABLE IF EXISTS dbo.nyctaxi_sample_testing SELECT * into nyctaxi_sample_testing FROM nyctaxi_sample WHERE (ABS(CAST(BINARY_CHECKSUM(medallion,hack_license) as int)) % 100) >@pct GO EXEC PyTrainTestSplit 60 GO Создание модели логистической регрессии
После подготовки данных их можно использовать для обучения модели. Для этого вызывается хранимая процедура, которая выполняет некоторый код Python, принимая таблицу обучающих данных в качестве входных данных. В этом руководстве вы создадите две модели. Обе модели будут использовать двоичную классификацию.
- Хранимая процедура PyTrainScikit создает модель прогнозирования чаевых с помощью пакета scikit-learn.
- Хранимая процедура TrainTipPredictionModelRxPy создает модель прогнозирования чаевых с помощью пакета revoscalepy.
Эта хранимая процедура использует указанные входные данные для создания и обучения модели логистической регрессии. Весь код Python упаковывается в системную хранимую процедуру sp_execute_external_script .
Чтобы упростить повторное обучение модели на основе новых данных, можно поместить вызов sp_execute_external_script в другую хранимую процедуру и передать ей новые обучающие данные в качестве параметра. В этом разделе описаны этапы этого действия.
PyTrainScikit
- В среде Среда Management Studio откройте новое окно Запрос и выполните приведенную ниже инструкцию, чтобы создать хранимую процедуру PyTrainScikit. Поскольку хранимая процедура уже включает в себя определение входных данных, указывать входной запрос не требуется.
DROP PROCEDURE IF EXISTS PyTrainScikit; GO CREATE PROCEDURE [dbo].[PyTrainScikit] (@trained_model varbinary(max) OUTPUT) AS BEGIN EXEC sp_execute_external_script @language = N'Python', @script = N' import numpy import pickle from sklearn.linear_model import LogisticRegression ##Create SciKit-Learn logistic regression model X = InputDataSet[["passenger_count", "trip_distance", "trip_time_in_secs", "direct_distance"]] y = numpy.ravel(InputDataSet[["tipped"]]) SKLalgo = LogisticRegression() logitObj = SKLalgo.fit(X, y) ##Serialize model trained_model = pickle.dumps(logitObj) ', @input_data_1 = N' select tipped, fare_amount, passenger_count, trip_time_in_secs, trip_distance, dbo.fnCalculateDistance(pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude) as direct_distance from nyctaxi_sample_training ', @input_data_1_name = N'InputDataSet', @params = N'@trained_model varbinary(max) OUTPUT', @trained_model = @trained_model OUTPUT; ; END; GO DECLARE @model VARBINARY(MAX); EXEC PyTrainScikit @model OUTPUT; INSERT INTO nyc_taxi_models (name, model) VALUES('SciKit_model', @model); Обработка данных и компоновка модели может занять несколько минут. Сообщения, которые должны передаваться в поток stdout Python, отображаются в окне Сообщения среды Среда Management Studio. Пример:
STDOUT message(s) from external script: C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES\lib\site-packages\revoscalepy SciKit_model 0x800363736B6C6561726E2E6C696E6561. TrainTipPredictionModelRxPy
Эта хранимая процедура использует пакет Python revoscalepy. Он содержит объекты, преобразования и алгоритмы, аналогичные тем, которые содержатся в пакете RevoScaleR для языка R.
С помощью revoscalepy можно создавать удаленные контексты вычислений, перемещать данные между контекстами вычислений, преобразовывать данные и обучать прогнозные модели с помощью популярных алгоритмов, таких как логистическая и линейная регрессия, деревья принятия решений и др. Дополнительные сведения см. в статьях Модуль revoscalepy в SQL Server и Справочник по функции revoscalepy.
-
В среде Среда Management Studio откройте новое окно Запрос и выполните приведенную ниже инструкцию, чтобы создать хранимую процедуру TrainTipPredictionModelRxPy. Поскольку хранимая процедура уже включает в себя определение входных данных, указывать входной запрос не требуется.
DROP PROCEDURE IF EXISTS TrainTipPredictionModelRxPy; GO CREATE PROCEDURE [dbo].[TrainTipPredictionModelRxPy] (@trained_model varbinary(max) OUTPUT) AS BEGIN EXEC sp_execute_external_script @language = N'Python', @script = N' import numpy import pickle from revoscalepy.functions.RxLogit import rx_logit ## Create a logistic regression model using rx_logit function from revoscalepy package logitObj = rx_logit("tipped ~ passenger_count + trip_distance + trip_time_in_secs + direct_distance", data = InputDataSet); ## Serialize model trained_model = pickle.dumps(logitObj) ', @input_data_1 = N' select tipped, fare_amount, passenger_count, trip_time_in_secs, trip_distance, dbo.fnCalculateDistance(pickup_latitude, pickup_longitude, dropoff_latitude, dropoff_longitude) as direct_distance from nyctaxi_sample_training ', @input_data_1_name = N'InputDataSet', @params = N'@trained_model varbinary(max) OUTPUT', @trained_model = @trained_model OUTPUT; ; END; GO - Запрос SELECT применяет пользовательскую скалярную функцию fnCalculateDistance для вычисления прямого расстояния между местами посадки и высадки. Результаты выполнения запроса сохраняются во входной переменной Python по умолчанию InputDataset .
- Двоичная переменная tipped применяется в качестве столбца меток (результатов) и формируется модель с использованием следующих столбцов признаков: passenger_count, trip_distance, trip_time_in_secsи direct_distance.
- Обученная модель сериализуется и сохраняется в переменной Python logitObj . С помощью ключевого слова OUTPUT T-SQL можно добавить переменную в качестве выходных данных хранимой процедуры. На следующем шаге эта переменная используется для вставки двоичного кода модели в таблицу базы данных nyc_taxi_models. Этот механизм упрощает хранение и повторное использование моделей.
DECLARE @model VARBINARY(MAX); EXEC TrainTipPredictionModelRxPy @model OUTPUT; INSERT INTO nyc_taxi_models (name, model) VALUES('revoscalepy_model', @model); Обработка данных и компоновка модели может занять некоторое время. Сообщения, которые должны передаваться в поток stdout Python, отображаются в окне Сообщения среды Среда Management Studio. Пример:
STDOUT message(s) from external script: C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES\lib\site-packages\revoscalepy revoscalepy_model 0x8003637265766F7363616c. В следующей части этого учебника обученная модель будет использоваться для создания прогнозов.
Дальнейшие шаги
Работая с этой статьей, вы выполните следующие задачи:
- Создание и обучение модели с помощью хранимой процедуры SQL
- Обученная модель сохранена в таблице SQL