Техники повторного использования кода и разбиения сложных объектов на составные
В этой статье я опишу различные техники повторного использования кода и разбиения сложных объектов на части, с которыми я столкнулся. Постараюсь объяснить, почему классическое наследование, а также некоторые другие популярные подходы не работают в сложных случаях, и какие есть альтернативы.
Возможно многих удивит, что в основе большинства подходов повторного использования кода и создания составных объектов лежат стандартные структуры данных – массив, список, словарь, дерево, граф.
Т.к. в последние годы я пишу на JavaScript и React, то они будут использоваться в некоторых примерах. Да и в целом, периодически я буду упоминать React и другие веб-технологии. Тем не менее, думаю, что значительная часть статьи должна быть понятна и полезна разработчикам из других стеков.
Для некоторых подходов я добавил схемы, чтобы показать, как организованы составляющие сложных объектов. Будет часто упоминаться агрегация (агрегирование/делегирование/включение) и композиция.
Чтобы разделить логику одного сложного объекта на составные части, существуют несколько механизмов:
- Разделение функционала на классы/объекты и смешивание их полей, методов в одном объекте.
- Вынесение части функционала в обертки и помещение в них основного объекта, либо вкладывание объектов один в другой с организацией списка вложенных объектов.
- Вынесение части функционала в отдельные объекты/функции и помещение их в основной объект.
- Разделение функционала объекта на независимые части и использование какого-то внешнего механизма для организации нужного поведения с использованием этих частей.
В статье же я разделил техники/паттерны в зависимости от получаемой структуры данных, используемой для хранения составляющих сложного объекта.
Объединение (смешивание) функционала нескольких объектов в одном
Смешивание и примеси (миксины)
Самый простой, но ненадежный способ повторного использования кода – объединить один объект с другим(и). Подходит лишь для простых случаев, т.к. высока вероятность ошибки из-за замещения одних полей другими с такими же именами. К тому же, так объект разрастается и может превратиться в антипаттерн God Object.
Существует паттерн примесь (mixin/миксина), в основе которого лежит смешивание.
Примесь – это объект, поля и методы которого смешиваются с полями и методами других объектов, расширяя функциональность объекта, но который не используется сам по себе.
Можно добавить несколько миксин к одному объекту/классу. Тогда это схоже с множественным наследованием.
Классическое наследование
Здесь описывается классическое наследование, а не то, как наследование классов устроено в JS.
Подразумеваю, что читатель уже знаком с понятиями «наследование» и «множественное наследование». В отличие от простого смешивания, в классическом наследовании есть ряд строгих правил и механизмов, которые позволяет избежать множество проблем. В основе классического наследования лежит все то же смешивание — члены нескольких объектов объединяются в один объект.
При наследовании происходит копирование членов родительского класса в класс-наследник. При создании экземпляра класса тоже происходит копирования членов класса. Я не исследовал детали этих механизмов, к тому же они явно отличаются в различных языках. Подробнее с этой темой можно ознакомиться в 4-ой главе книги «Вы не знаете JS: this и Прототипы Объектов».
Когда можно использовать наследование, а когда не стоит?
Наследования не стоит использовать в качестве основной техники для повторного использования кода для сложных объектов. Его можно использовать совместно с композицией для наследования отдельных частей сложного объекта, но не для самого сложного объекта. Например, для React компонентов наследование плохо, а для частей (вроде объектных аналогов custom hooks) из которых мог быть состоять компонент-класс, наследования вполне можно использовать. Но даже так, в первую очередь стоит рассматривать разбиение на большее число составляющих или применения других техник, вместо наследования.
При возможности появления сложной иерархии наследование (более 2-х уровней, где первый уровень иерархии – родитель, а второй уровень — наследники) тоже не следует использовать наследование.
Множественное наследование и интерфейсы
При использовании множественного наследования получаются довольно запутанные иерархии классов. Поэтому во многих языках отказались от множественного наследования реализации. Но множественное наследование по-прежнему применяют при наследовании абстракций в виде интерфейсов.
Интерфейсы есть, например, в Typescript. Реализация нескольких интерфейсов в одном классе отчасти похоже на наследование, но с их использованием «наследуется» только описание свойств и сигнатура методов интерфейса. Наследование реализации не происходит.
Интерфейсы следует понимать не как наследование, а как контракт, указывающий, что данный класс реализует такой-то интерфейс. Плохо, когда один класс реализует слишком много интерфейсов. Это означает, что-либо интерфейсы слишком сильно разбиты на части, либо у объекта слишком большая ответственность.
Композиция/агрегация с использованием списка
Прототипное наследование
При прототипном наследовании уже не происходит смешивания родительского объекта и его наследника. Вместо этого наследник ссылается на родительский объект (прототип).
При отсутствии свойства (поле, метод и т.д.) в объекте, происходит поиск этого свойства в цепочке прототипов. То есть часть функционала делегируется вложенному объекту, который тоже может делегировать функционал вложенному объекту внутри себя. И так далее по цепочке. Прототип на любом уровне цепочки может быть только один.
Стоит отметить, что в JavaScript операции записи/удаления работают непосредственно с объектом. Они не используют прототип (если это обычное свойство, а не сеттер). Если в объекте нет свойства для записи, то создается новое. Подробнее об этом.
Цепочка прототипов организована как стек (Last-In-First-Out или LIFO). Какой объект добавлен в цепочку последним (если считать от итогового объекта-контейнера), к тому обращение будет первым.
Также существует вариант, когда при создании нового объекта с прототипом, создается копия прототипа. В таком случае используется больше памяти (хотя это проблема разрешаема), но зато это позволяет избежать ошибок в других объектах из-за изменения прототипа конкретного объекта.
Паттерн Декоратор и аналоги
Декоратор (wrapper/обертка) позволяет динамически добавлять объекту новую функциональность, помещая его в объект-обертку. Обычно объект оборачивается одним декоратором, но иногда используется несколько декораторов и получается своего рода цепочка декораторов.
Цепочка декораторов устроена как стек (LIFO). Какой объект добавлен в цепочку последним (если считать от итогового объекта-контейнера), к тому обращение будет первым.
Цепочка декораторов похожа на цепочку прототипов, но с другими правилами работы с цепочкой. Оборачиваемый объект и декоратор должны иметь общий интерфейс.
На схеме ниже пример использования нескольких декораторов на одном объекте:

Как в случае с прототипами, зачастую можно подменять декораторы во время выполнения. Декоратор оборачивает только один объект. Если оборачивается несколько объектов, то это уже что-то другое.
HOF (higher order function) и HOC (Higher-Order Component) — паттерны с похожей идей. Они оборачивают функцию/компонент другой функцией/компонентом для расширения функционала.
HOF — функция, принимающая в качестве аргументов другие функции или возвращающая другую функцию в качестве результата. Примером HOF в JS является функция bind, которая, не меняя переданную функцию, возвращает новую функцию с привязанным к ней с помощью замыкания значением. Другим примером HOF является карринг.
HOC — чистая функция, которая возвращает другой компонент (а он уже содержит в себе произвольную логику), который внутри себя «рендерит» переданный компонент. При этом сам переданный компонент не меняется, но в него могут быть переданы props.
Также стоит упомянуть композицию функций. Это тоже своего рода обертка. С помощью этой техники создаются цепочки вложенных функций:
const funcA = сompose(funcB, funcC, funcD);или же менее читабельный вариант:
const funcA = ()=> < funcB( funcC( funcD() ) ) ; >;То же самое можно получить такой записью:
function funcA() < function funcB() < function funcC() < function funcD() >> > Недостатком последнего варианта является жесткая структура функций. Нельзя поменять их очередность или заменить одну из функций без создания новой аналогичной цепочки или ее части. funcC нельзя использовать без funcD, а funcB без funcC и без funcD. В первых же двух примерах – можно. Там функции независимы друг от друга.
Итого
Прототипное наследование и использование декораторов гибче, чем подходы со смешиванием.
Часто говорят: «предпочитайте композицию наследованию». Стоит учесть, что существует множество вариантов композиции с различной эффективностью в той или иной ситуации. Только от простой замены наследования на композицию, вряд ли получиться решить проблемы без появления новых проблем. Нужно еще выбрать подходящую замену.
Когда по аналогии с иерархией наследования используется несколько уровней вложения одних объектов в другие, получается иерархия вложенных объектов. Почти то же самое, что и наследование, только с возможностью подменять объекты в иерархии. Конечно, в случае декораторов этого обычно избегают и вместо иерархии получается цепочка. В цепочке декораторов выходит так, что каждый следующий используемый декоратор помимо своих членов классов должен реализовать члены всех остальных объектов в цепочке. В итоге, по аналогии с наследованием, снова получается раздутый объект с множеством полей и методов. На схеме выше был пример такого объекта — DecoratorC.
Зачастую при использовании нескольких декораторов на одном объекте не добавляют новые поля и методы, а лишь подменяют реализацию уже существующих членов объекта. Остается другой недостаток – из-за большой вложенности довольно сложно разобраться, что же делает итоговый составной объект, т.к. для этого надо пройтись по цепочке вложенных объектов.
Как видите, по-прежнему остаются довольно серьезные проблемы. Но, есть другие решения, о которых рассказано в следующих главах.
Композиция/агрегация с использованием одноуровневых структур данных (ссылка, массив ссылок, словарь)
Под одноуровневой структурой данных я подразумеваю структуру, элементы которой не ссылаются на другие элементы.
Паттерн стратегия
Паттерны декоратор и стратегия служат для одной цели – с помощью делегирования расширить функциональность объекта. Но делают они это по разному. Хорошо описана эта разница по ссылке: «Стратегия меняет поведение объекта «изнутри», а Декоратор изменяет его «снаружи».»
Паттерн Cтратегия описывает разные способы произвести одно и то же действие, позволяя динамически заменять эти способы в основном объекте (контексте).
На схеме ниже пара примеров связи стратегий с основным объектом.

К похожим способам (использование ссылки) расширения функционала объекта и повторного использования кода можно отнести события в HTML элементах и директивы в Angular и Vue.
// html // vueEntity Component (EC)
Я не знаю, как называется данный паттерн. В книге Game Programming Patterns он называется просто «Компонент», а по ссылке его называют системой компонентов/сущностей. В статье же я буду называть его Entity Component (EС), чтобы не путать с подходом, который будет описан в следующей главе.

Сначала пройдемся по определением:
- Entity (сущность) – объект-контейнер, состоящий из компонентов c данными и логикой. В React и Vue аналогом Entity является компонент. В Entity не пишут пользовательскую логику. Для пользовательской логики используются компоненты. Компоненты могут храниться в динамическом массиве или словаре.
- Component – объект со своими данными и логикой, который можно добавлять в любую Entity. В React компонентах похожим аналогом являются custom hooks. И описываемые здесь компоненты и пользовательские хуки в React служат для одной цели – расширять функционал объекта, частью которого они являются.
Обычно Entity может содержать вложенные entities, тем самым образуя дерево entities. Не думаю, что это является неотъемлемой его частью, а скорее является смешиванием нескольких подходов.
Данный паттерн похож на паттерн стратегия. Если в объекте использовать динамический массив со стратегиями, организовать их добавление, удаление и получение определенной стратегии, то это будет похоже на Entity Component. Есть еще одно серьезное отличие — контейнер не реализует интерфейс компонентов или методы для обращения к методам компонентов. Контейнер только предоставляет доступ к компонентам и хранит их. Получается составной объект, который довольно своеобразно делегирует весь свой функционал вложенным объектом, на которые он ссылается. Тем самым EC избавляет от необходимости использования сложных иерархий объектов.
Плюсы EC
- Низкий порог вхождения, т.к. в основе используется простая одноуровневая структура данных.
- легко добавлять новую функциональность и использовать код повторно.
- можно изменять составной объект (Entity) в процессе выполнения, добавляя или удаляя его составляющие (компоненты)
Минусы
- для простых проектов является ненужным усложнением из-за разбиение объекта на контейнер и компоненты
В одной из своих следующих статей я опишу применение этого подхода для React компонентов. Тем самым я покажу, как избавиться от первых двух недостатков компонентов на классах, описанных в документации React-а:
Трудно повторно использовать логику состояний между компонентами.
Сложные компоненты становятся трудными для понимания.
Этот подход используется с самого начала выхода движка Unity3D для расширения функционала элементов (объектов) дерева сцены, включая UI элементы, где вы можете получше ознакомится с данным подходом. Но в таком случае придётся потратить не мало времени на изучение движка.
Итого
Паттерн стратегия сам по себе не очень мощный, но если развить его идею, можно получить довольно эффективные техники. К такой можно отнести Entity Component.
В случае использования EC может появиться новая проблема – при большом количестве компонентов, связанных между собой в одном объекте, становиться сложно разобраться в его работе. Выходом может стать некий компонент, который контролирует взаимодействия между компонентами в одной Entity или в группе вложенных Entities. Такой подход известен как паттерн Посредник (Mediator).
Но даже “посредника“ будет недостаточно для более сложных случаев. К тому же он не является универсальным. Для каждой Entity с множеством связанных компонентов придёться реализовывать новый тип “посредника”. Есть и другой выход. EC можно комбинировать с другими подходами на основе графов и деревьев, которые будут описаны позже.
Композиция/агрегация с вынесением логики вне объекта и его составляющих
Entity Component System (ECS)
Я не работал с этим подходом, но опишу то, как я его понял.
В ECS объект разбивается на 3 типа составляющих: сущность, компонент (один или несколько), система (общая для произвольного числа объектов). Этот подход похож на EC, но объект разбивается уже на 3 типа составляющих, а компонент содержит только данные.
Определения:
- Entity – его основное назначение, это идентифицировать объект в системе. Зачастую Entity является просто числовым идентификатором, с которым сопоставляется список связанных с ним компонентов. В других вариациях Entity также может брать на себя роль контейнера для компонентов. Как и в EC подходе, в Entity нельзя писать пользовательский код, только добавлять компоненты.
- Component — объект с определенными данными для Entity. Не содержит логики.
- System — в каждой системе описывается логика. Каждая система перебирает список компонентов определенных типов или компоненты определенных entities и выполняет логику с использованием данных в компонентах. Может извлекать компоненты из entities. Результатом выполнения системы будет обновление данных в компонентах. В некоторых случаях системы могут быть обычными функциями, получающими на вход нужные данные.
Также может быть некий объект-менеджер (или несколько менеджеров), который хранит все системы и объекты, а также периодически запускает все системы. Здесь уже реализация произвольная.
Пример простой ECS: Допустим есть несколько объектов, у которых есть идентификаторы. Несколько из этих объектов ссылаются на компоненты Position, в которых хранятся текущие координаты x, y, и на компонент Speed, который содержит текущую скорость. Есть система Movement, которая перебирает объекты, извлекает из них компоненты Position и Speed, вычисляет новую позицию и сохраняет новые значения x, y в компонент Position.
Как я уже говорил, реализации ECS могут отличаться. Например:
b) компоненты содержится в массивах/словарях. Entity является просто идентификатором, по которому определяется компонент, связанный с сущностью. Раз, два и три.
На схеме изображен первый вариант, когда entity ссылается на свои компоненты.

Плюсы ECS
- Слабое сцепление составляющих объекта, поэтому легко добавлять новую функциональность комбинирую по-разному составляющие.
- Проще тестировать, т.к. нужно тестировать только системы. Компоненты и сущности тестировать не нужно.
- Легко выполнять многопоточно.
- Более эффективное использование памяти, кэша и, следовательно, большая производительность.
- Легко реализовать сохранение всего приложения, т.к. данные отделены от функционала.
Минусы ECS
- Высокая сложность, не стандартный подход.
- для простых проектов является ненужным усложнением.
Так как я занимаюсь фронтенд разработкой, а она по большей части относится к разработки UI, то упомяну, что ECS используется в игре World of Tanks Blitz для разработки UI.
Итого
ECS является хорошей альтернативой созданию сложных иерархий наследования. В ECS можно создать иерархии наследования для компонентов или систем, но вряд ли от этого почувствуется выгода. Скорее, быстро почувствуются проблемы от таких попыток.
Как и в аналогичном случае с EС, системы в данном подходе можно комбинировать с подходами на основе графов и деревьев. В таком случае логика по-прежнему будет реализована в системах, а хранение данных в компонентах. Но, я не знаю, эффективно ли совмещение этих подходов на практике. В первую очередь нужно стремиться реализовывать системы попроще, а уже потом рассматривать комбинацию с другими подходами.
Композиция/агрегация с использованием графов
К данному способу повторного использования кода я отнес паттерн «машина состояний» (State machine/Finite state machine/конечный автомат).
Аналогом машины состояний простой является switch:
switсh (condition)
Недостатком является то, что он может сильно разрастить, а также у разработчика может не быть возможности добавить новые состояния в систему.
Для сложных случаев каждое состояние с логикой можно вынести в отдельный объект и переключаться между ними.
В более сложных случаях можно разделить на большее число составляющих: состояние, действие, переход, условие перехода, событие.
Также существуют иерархические машины состояний, где состояние может содержать вложенный граф состояний.
Я уже описывал паттерн “Машина состояний” и его составляющие, и вкратце писал о иерархической машине состояний в статье «Приемы при проектировании архитектуры игр» в главе «машина состояний».
Преимущества использования машины состояний:
Хорошо описано по этой ссылке.
Добавлю, что становится легче предусмотреть, обработать и протестировать все возможные случаи работы контекста (подсистемы), т.к. видны все его состояния и переходы. Особенно, если состояния являются просто объектами с данными и отделены от остальной логики и отображения.
Где при разработке UI можно использовать машину состояний?
Например, для логики сложной формы, у которой поведение и набор полей немного отличается в зависимости от роли пользователя и других параметров. Каждый объект-состояние может описывать состояние всех компонентов формы (активный, видимый, фиксированный текст элемента в таком-то состоянии и т.д.), отображение которых может отличаться в зависимости от роли пользователя и других параметров. Компоненты формы получают часть объекта-состояния, которая им нужна для своего отображения.
Другие примеры использования в UI:
state-machines-in-user-interfaces
xstate (библиотека для JS, которую можно использовать c React, Vue, Svelte)
react-automata (библиотека для React)
Машины состояний и разработка веб-приложений
Подходит ли State machine в качестве основного механизма повторного использования кода и разбиения сложных объектов на составные части?
Иногда он так и используется. Но, он мне кажется сложноватым и не всегда подходящим для использования в качестве основного. Зато он точно хорош в качестве дополнительного, когда нужно организовать взаимодействия между несколькими объектами или частями составного объекта.
Стоит учитывать, что граф может получиться слишком сложным. Если у вас обычный код получается запутанным, то и граф скорее всего получится запутанным. В сложном графе нужно стремиться уменьшать количество связей, группировать состояния.
Композиция/агрегация с использованием деревьев
Паттерн composite и другие древовидные структуры
Деревья часто встречается в разработке. Например, объекты в JavaScript могут содержать вложенные объекты, а те также могут содержать другие вложенные объекты, тем самым образую дерево. XML, JSON, HTML, DOM-дерево, паттерн Комповщик (Composite) – все это примеры древовидной композиции.
Дерево является графом, в котором между любыми 2-мя его узлами может быть только один путь. Благодаря этому, в нем гораздо проще разобраться, чем в графе получаемом с помощью машины состояний.
Behaviour tree
Интересным вариантом композиции является Behaviour tree (дерево поведения). Это организация логики программы (обычно AI) или ее частей в виде дерева.
В дереве поведения в качестве узлов выступают управляющие блоки — условие, цикл, последовательность действий, параллельное выполнение действий и блоки действий. В теории, могут быть реализованы и другие управляющие блоки, вроде switch case, асинхронного блока и других аналогов управляющих конструкций языка, но я не встречал подобного. Код действий для деревьев поведения пишет разработчик. Обычно решения для деревьев поведений содержат визуальный редактор для их создания и отладки.
Я уже описывал деревья поведений в прошлом в этой статье.
Более наглядный пример схемы готового дерева из плагина banana-tree

Дерево поведения можно рассматривать как аналог обычной функции с вложенными функциями. Я думаю, понятно, что схему выше можно перевести в функцию с вложенными функциями, условиями и циклами.
Если в функции написать слишком много кода или же в ней будет слишком много вложенных условий, то она будет нечитабельна и с ней будет тяжело работать. Аналогично и с деревьями поведения. Их следует делать как можно проще и с меньшей вложенностью блоков с циклами и условиями.
Деревья поведения позволяют создавать сложную логику с помощью комбинации более простых действий. Сложная логика тоже может быть оформлена в виде узла дерева (в виде действия или поддерева). Также деревья поведения предоставляют единый механизм для разработки в таком стиле. Этот подход мотивирует выносить функционал в отдельные настраиваемые объекты, зачастую предоставляет наглядное средство для отладки, упорядочивает и уменьшает связи между объектами, позволяет избежать жесткой зависимости составляющих.
Для простых случаев, как обычно, этот подход будет ненужным усложнением.
Смешанные подходы
Для более эффективной организации кода можно комбинировать некоторые подходы. Например, в качестве узлов машины состояний можно использовать деревья поведения.
Довольно многое можно отнести к смешанным подходам. Entity Component в Unity3D реализован так, что позволяет хранить не только компоненты, но и вложенные сущности. А для пользовательских компонентов можно использовать наследование в простых случаях, либо объединить компоненты с более продвинутыми техниками (паттерн mediator, машина состояний, дерево поведения и другие).
Примером смешивания подходов является анимационная система Mecanim в Unity3D, которая использует иерархическую машину состояний с деревьями смешивания (blend tree) для анимаций. Это относится не совсем к коду, но является хорошим примером комбинации подходов.
К смешанным подходам я отнес React компоненты с хуками, т.к. там довольно специфичный случай. С точки зрения разработчика, для повторного использования кода в компоненте используется дерево функций (хуков). С точки зрения организации данных в компоненте – компонент хранит список с данными для хуков. К тому же связь между хуками и компонентом устанавливается во время выполнения. Т.к. я разрабатываю на React, то решил включить частичное описание внутреннего устройство компонента с хуками в статью.
React hooks
Эта часть статьи для разработчиков, знакомых c React. Остальным многое в ней будет не понятно.
Особенность функциональных компонентов в React-е в том, что разработчик не указывает сам связь между компонентом и его хуками. Отсюда возникает вопрос, как React определяет к какому компоненту применить такой-то хук?
Как я понял, хуки при вызове добавляют к текущему обрабатываемому компоненту (точнее к fiber-ноде) свое состояние – объект, в котором могут быть указаны переданные сallback-и (в случае useEffect, useCallback), массив зависимостей, значения (в случае useState) и прочие данные (в случае useMemo, useRef, …).
А вызываются хуки при обходе дерева компонентов, т.е. когда вызывается функция-компонент. React-у известно, какой компонент он обходит в данный момент, поэтому при вызове функции-хука в компоненте, состояние хука добавляется (или обновляется при повторных вызовах) в очередь состояний хуков fiber-ноды. Fiber-нода – это внутреннее представление компонента.
Стоит отметить, что дерево fiber элементов не совсем соответствует структуре дерева компонентов. У Fiber-ноды только одна дочерняя нода, на которую указывает ссылка child. Вместо ссылки на вторую ноду, первая нода ссылается на вторую (соседнюю) с помощью ссылки sibling. К тому же, все дочерние ноды ссылаются на родительскую ноду с помощью ссылки return.
Также для оптимизации вызова эффектов (обновление DOM, другие сайд-эффекты) в fiber-нодах используются 2 ссылки (firstEffect, nextEffect), указывающие на первую fiber-ноду с эффектом и следующую ноду, у которой есть эффект. Таким образом, получается список нод с эффектами. Ноды без эффектов в нем отсутствуют. Подробнее об этом можно почитать по ссылкам в конце главы.
Вернемся к хукам. Структура сложного функционального компонента с несколькими вложенными custom hooks для разработчика выглядит как дерево функций. Но React хранит в памяти хуки компонента не как дерево, а как очередь. На схеме ниже изображен компонент с вложенными хукам, а под ним fiber-нода с очередью состояний этих же хуков.

На схеме в fiber-ноде отображены также поля, которые участвует в создании различных структур для оптимизации рендеринга. Они не будут рассмотрены в рамках статьи.
Чтобы просмотреть содержимое fiber-ноды, достаточно воспользоваться console.log и вставить туда JSX код, который возвращает компонент:
function MyComponent() < const jsxContent = (); console.log(jsxContent); return jsxContent; >Корневую fiber-ноду можно просмотреть следующим образом:
const rootElement = document.getElementById('root'); ReactDOM.render(, rootElement); console.log(rootElement._reactRootContainer._internalRoot);Пример компонента с хуками и отображение его fiber-ноды
import < useState, useContext, useEffect,useMemo, useCallback, useRef, createContext >from 'react'; import ReactDOM from 'react-dom'; const ContextExample = createContext(''); function ChildComponent() < useState('childComponentValue'); return ; > function useMyHook() < return useState('valueB'); >function ParentComponent() < const [valueA, setValueA] = useState('valueA'); useEffect(function myEffect() <>, [valueA]); useMemo(() => 'memoized ' + valueA, [valueA]); useCallback(function myCallback() <>, [valueA]); useRef('refValue'); useContext(ContextExample); useMyHook(); const jsxContent = ( ); console.log('component under the hood: ', jsxContent); return jsxContent; > const rootElement = document.getElementById('root'); ReactDOM.render( > , rootElement, );
Также есть интересная наработка: react-fiber-traverse
С более подробным описанием работы внутренних механизмов React на русском языке можно ознакомиться по ссылкам:
- Как Fiber в React использует связанный список для обхода дерева компонентов
- Fiber изнутри: подробный обзор нового алгоритма согласования в React
- Как происходит обновление свойств и состояния в React — подробное объяснение
- За кулисами системы React hooks
- Видео: Под капотом React hooks
У подхода с хуками на данный момент есть недостаток — фиксированное дерево функций (хуков) в компонентах. При стандартном использовании хуков, нельзя изменить логику уже написанного компонента или хуков, состоящих из других хуков. К тому же это мешает тестированию хуков по отдельности. В какой-то степени можно улучшить ситуацию композицией (compose) хуков. Например, существует такое решение. Или можно сделать, чтобы хуки задавались через props, по аналогии с директивами в Angular и Vue. Пример. Возможно существуют еще какие-нибудь решения.
Линейность кода и составляющих сложного объекта
Известно, что множество вложенные условий, callback-ов затрудняют читаемость кода:
Замена вложенных условных операторов граничным оператором
Качество кода (в статье упоминается линейный код)
Как писать чистый код (в статье упоминается линейность кода).
Я думаю, что наследование, большие цепочки и иерархии вложенных объектов могут привести к аналогичной ситуации, но для составляющих сложного объекта. Даже если объект расположен линейно в коде, внутри он может быть устроен так, что необходимо пройтись по множеству родительских классов или вложенных объектов, чтобы разобраться в его функционале. Я уже писал ранее про деревья поведения, что в них следует избегать большой вложенности. Так и в других случаях.
- Веб-разработка
- JavaScript
- Проектирование и рефакторинг
- ООП
- ReactJS
Механизмы повторного использования
Большинству проектировщиков известны концепции объектов, интерфейсов, классов и наследования. Трудность в том, чтобы применить эти знания для построения гибких, повторно используемых программ. С помощью паттернов проектирования вы сможете сделать это проще.
Наследование и композиция
Два наиболее распространенных приема повторного использования функциональности в объектно-ориентированных системах – это наследование класса и композиция объектов. Как мы уже объясняли, наследование класса позволяет определить реализацию одного класса в терминах другого. Повторное использование за счет порождения подкласса называют еще прозрачным ящиком (white-box reuse). Такой термин подчеркивает, что внутреннее устройство родительских классов видимо подклассам.
Композиция объектов – это альтернатива наследованию класса. В этом случае новую, более сложную функциональность мы получаем путем объединения или композиции объектов. Для композиции требуется, чтобы объединяемые объекты имели четко определенные интерфейсы. Такой способ повторного использования называют черным ящиком (black-box reuse), поскольку детали внутреннего устройства объектов остаются скрытыми.
И у наследования, и у композиции есть достоинства и недостатки. Наследование класса определяется статически на этапе компиляции, его проще использовать, поскольку оно напрямую поддержано языком программирования. В случае наследования классов упрощается также задача модификации существующей реализации. Если подкласс замещает лишь некоторые операции, то могут оказаться затронутыми и остальные унаследованные операции, поскольку не исключено, что они вызывают замещенные.
Но у наследования класса есть и минусы. Во-первых, нельзя изменить унаследованную от родителя реализацию во время выполнения программы, поскольку само наследование фиксировано на этапе компиляции. Во-вторых, родительский класс нередко хотя бы частично определяет физическое представление своих подклассов. Поскольку подклассу доступны детали реализации родительского класса, то часто говорят, что наследование нарушает инкапсуляцию [Sny86]. Реализации подкласса и родительского класса настолько тесно связаны, что любые изменения последней требуют изменять и реализацию подкласса.
Зависимость от реализации может повлечь за собой проблемы при попытке повторного использования подкласса. Если хотя бы один аспект унаследованной реализации непригоден для новой предметной области, то приходится переписывать родительский класс или заменять его чем-то более подходящим. Такая зависимость ограничивает гибкость и возможности повторного использования. С проблемой можно справиться, если наследовать только абстрактным классам, поскольку в них обычно совсем нет реализации или она минимальна.
Композиция объектов определяется динамически во время выполнения за счет того, что объекты получают ссылки на другие объекты. Композицию можно применить, если объекты соблюдают интерфейсы друг друга. Для этого, в свою очередь, требуется тщательно проектировать интерфейсы, так чтобы один объект можно было использовать вместе с широким спектром других. Но и выигрыш велик. Поскольку доступ к объектам осуществляется только через их интерфейсы, мы не нарушаем инкапсуляцию. Во время выполнения программы любой объект можно заменить другим, лишь бы он имел тот же тип. Более того, поскольку при реализации объекта кодируются прежде всего его интерфейсы, то зависимость от реализации резко снижается.
Композиция объектов влияет на дизайн системы и еще в одном аспекте. Отдавая предпочтение композиции объектов, а не наследованию классов, вы инкапсулируете каждый класс и даете ему возможность выполнять только свою задачу. Классы и их иерархии остаются небольшими, и вероятность их разрастания до неуправляемых размеров невелика. С другой стороны, дизайн, основанный на композиции, будет содержать больше объектов (хотя число классов, возможно, уменьшится), и поведение системы начнет зависеть от их взаимодействия, тогда как при другом подходе оно было бы определено в одном классе.
Это подводит нас ко второму правилу объектно-ориентированного проектирования: предпочитайте композицию наследованию класса.
В идеале, чтобы добиться повторного использования, вообще не следовало бы создавать новые компоненты. Хорошо бы, чтобы можно было получить всю нужную функциональность, просто собирая вместе уже существующие компоненты. На практике, однако, так получается редко, поскольку набор имеющихся компонентов все же недостаточно широк. Повторное использование за счет наследования упрощает создание новых компонентов, которые можно было бы применять со старыми. Поэтому наследование и композиция часто используются вместе.
Тем не менее наш опыт показывает, что проектировщики злоупотребляют наследованием. Нередко дизайн мог бы стать лучше и проще, если бы автор больше полагался на композицию объектов.
Делегирование
С помощью делегирования композицию можно сделать столь же мощным инструментом повторного использования, сколь и наследование [Lie86, JZ91]. При делегировании в процесс обработки запроса вовлечено два объекта: получатель поручает выполнение операций другому объекту – уполномоченному. Примерно так же подкласс делегирует ответственность своему родительскому классу. Но унаследованная операция всегда может обратиться к объекту-получателю через переменную-член (в C++) или переменную self (в Smalltalk). Чтобы достичь того же эффекта для делегирования, получатель передает указатель на самого себя соответствующему объекту, дабы при выполнении делегированной операции последний мог обратиться к непосредственному адресату запроса.
Например, вместо того чтобы делать класс Window (окно) подклассом класса Rectangle (прямоугольник) – ведь окно является прямоугольником, – мы можем воспользоваться внутри Window поведением класса Rectangle, поместив в класс Window переменную экземпляра типа Rectangle и делегируя ей операции, специфичные для прямоугольников. Другими словами, окно не является прямоугольником, а содержит его. Теперь класс Window может явно перенаправлять запросы своему члену Rectangle, а не наследовать его операции.
На диаграмме ниже изображен класс Window, который делегирует операцию Area() над своей внутренней областью переменной экземпляра Rectangle.
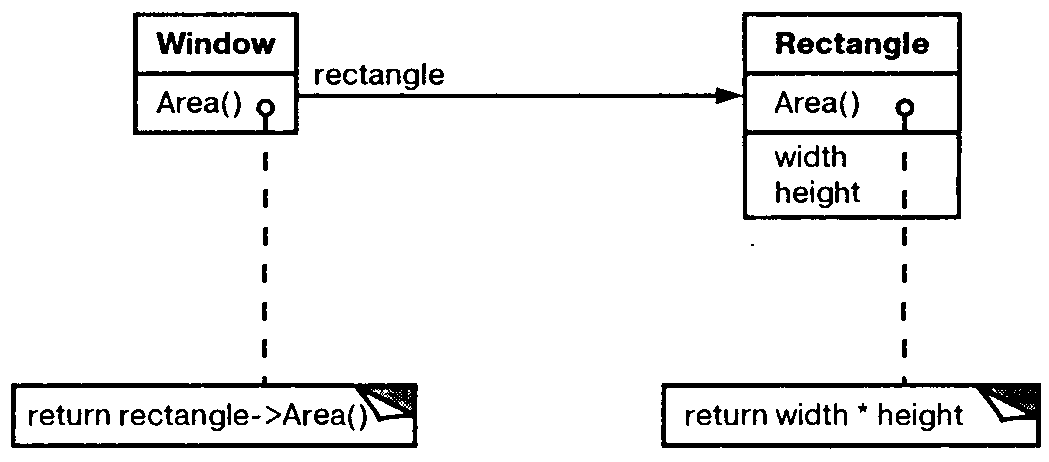
Сплошная линия со стрелкой обозначает, что класс содержит ссылку на экземпляр другого класса. Эта ссылка может иметь необязательное имя, в данном случае прямоугольник.
Главное достоинство делегирования в том, что оно упрощает композицию поведений во время выполнения. При этом способ комбинирования поведений можно изменять. Внутреннюю область окна разрешается сделать круговой во время выполнения, просто подставив вместо экземпляра класса Rectangle экземпляр класса Circle; предполагается, конечно, что оба эти класса имеют одинаковый тип.
У делегирования есть и недостаток, свойственный и другим подходам, применяемым для повышения гибкости за счет композиции объектов. Заключается он в том, что динамическую, в высокой степени параметризованную программу труднее понять, нежели статическую. Есть, конечно, и некоторая потеря машинной производительности, но неэффективность работы проектировщика гораздо более существенна. Делегирование можно считать хорошим выбором только тогда, когда оно позволяет достичь упрощения, а не усложнения дизайна. Нелегко сформулировать правила, ясно говорящие, когда следует пользоваться делегированием, поскольку эффективность его зависит от контекста и вашего личного опыта. Лучше всего делегирование работает при использовании в составе привычных идиом, то есть в стандартных паттернах.
Делегирование используется в нескольких паттернах проектирования: состояние, стратегия, посетитель. В первом получатель делегирует запрос объекту, представляющему его текущее состояние. В паттерне стратегия обработка запроса делегируется объекту, который представляет стратегию его исполнения. У объекта может быть только одно состояние, но много стратегий для исполнения различных запросов. Назначение обоих паттернов – изменить поведение объекта за счет замены объектов, которым делегируются запросы. В паттерне посетитель операция, которая должна быть выполнена над каждым элементом составного объекта, всегда делегируется посетителю.
В других паттернах делегирование используется не так интенсивно. Паттерн посредник вводит объект, осуществляющий посредничество при взаимодействии других объектов. Иногда объект-посредник реализует операции, переадресуя их другим объектам; в других случаях он передает ссылку на самого себя, используя тем самым делегирование как таковое. Паттерн цепочка обязанностей обрабатывает запросы, перенаправляя их от одного объекта другому по цепочке. Иногда вместе с запросом передается ссылка на исходный объект, получивший запрос, и в этом случае мы снова сталкиваемся с делегированием. Паттерн мост отделяет абстракцию от ее реализации. Если между абстракцией и конкретной реализацией имеется существенное сходство, то абстракция может просто делегировать операции своей реализации.
Делегирование показывает, что наследование как механизм повторного использования всегда можно заменить композицией.
Наследование и параметризованные типы
Еще один (хотя и не в точности объектно-ориентированный) метод повторного использования имеющейся функциональности – это применение параметризованных типов, известных также как обобщенные типы (Ada, Eiffel) или шаблоны (C++). Данная техника позволяет определить тип, не задавая типы, которые он использует. Неспецифицированные типы передаются в виде параметров в точке использования. Например, класс List (список) можно параметризовать типом помещаемых в список элементов. Чтобы объявить список целых чисел, вы передаете тип integer в качестве параметра параметризованному типу List. Если же надо объявить список строк, то в качестве параметра передается тип String. Для каждого типа элементов компилятор языка создаст отдельный вариант шаблона класса List.
Параметризованные типы дают в наше распоряжение третий (после наследования класса и композиции объектов) способ комбинировать поведение в объектно-ориентированных системах. Многие задачи можно решить с помощью любого из этих трех методов. Чтобы параметризовать процедуру сортировки операцией сравнения элементов, мы могли бы сделать сравнение:
- операцией, реализуемой подклассами (применение паттерна шаблонный метод);
- функцией объекта, передаваемого процедуре сортировки (стратегия);
- аргументом шаблона в C++ или обобщенного типа в Ada, который задает имя функции, вызываемой для сравнения элементов.
Но между тремя данными подходами есть важные различия. Композиция объектов позволяет изменять поведение во время выполнения, но для этого требуются косвенные вызовы, что снижает эффективность. Наследование разрешает предоставить реализацию по умолчанию, которую можно замещать в подклассах. С помощью параметризованных типов допустимо изменять типы, используемые классом. Но ни наследование, ни параметризованные типы не подлежат модификации во время выполнения. Выбор того или иного подхода зависит от проекта и ограничений на реализацию.
Ни в одном из паттернов, описанных в этой книге, параметризованные типы не используются, хотя изредка мы прибегаем к ним для реализации паттернов в C++. В языке вроде Smalltalk, где нет проверки типов во время компиляции, параметризованные типы не нужны вовсе.
Композиция или наследование: как выбрать?
… не было ни композиции, ни наследования, только код.
И был код неповоротливым, повторяющимся, нераздельным, несчастным, избыточным и измученным.
Основным инструментом для повторного использования кода была копипаста. Процедуры и функции были редкостью, подозрительными новомодными штучками. Вызов процедур был дорогим удовольствием. Части кода, отделенные от основной логики, вызывали недоумение!
Мрачные были времена.
Но вот лучик ООП воссиял над миром… Правда, несколько десятилетий 1 никто этого не замечал. Покуда не появился графический интерфейс 2 , которому, как выяснилось, очень-очень не хватало ООП. Когда нажимаешь на кнопку в окне, что может быть проще, чем отправить кнопке (или ее представителю) сообщение «Нажатие» 3 и получить результат?
И вот тут ООП взлетел. Было написано множество 4 книг, расплодились бесчисленные 5 статьи. Так что сегодня-то каждый может в объектно-ориентированное программирование, так?
Увы, код (и интернет) говорит, что не так
Самые жаркие споры и наибольшее непонимание, похоже, вызывает выбор между композицией и наследованием, зачастую выраженный мантрой «предпочитайте композицию наследованию». Вот об этом и поговорим.
Когда мантры вредят
В житейском плане «предпочитать композицию наследованию» в целом нормально, хоть я и не любитель мантр. Несмотря на то, что они зачастую и несут зерно истины, слишком легко поддаться соблазну и бездумно следовать лозунгу, не понимая, что за ним скрывается. А это всегда выходит боком.
Желтушные статьи с заголовками вроде «Наследование — зло» 6 тоже не по мне, особенно если автор пытается обосновать свои набросы, сначала неправильно применяя наследование, а потом делая вывод, что оно во всем виновато. Ну типа «молотки — отстой, потому что ими нельзя завинтить шуруп.»
Определения
Далее в статье я буду понимать под ООП «классический» объектный язык, который поддерживает классы со свойствами, методами и простое (одиночное) наследование. Никаких вам интерфейсов, примесей, аспектов, множественного наследования, делегатов, замыканий, лямбд, — ничего, кроме самых простых вещей:
- Класс: именованная сущность из предметной области, возможно, имеющая предка (суперкласс), определенная как набор полей и методов.
- Поле: именованное свойство с определенным типом, которое может, в частности, ссылаться на другой объект (см. композиция).
- Метод: именованная функция или процедура, с параметрами или без них, реализующая какое-то поведение класса.
- Наследование: класс может унаследовать — использовать по умолчанию — поля и методы своего предка. Наследование транзитивно: класс может наследоваться от другого класса, который наследуется от третьего, и так далее вплоть до базового класса (обычно — Object ), возможно, неявного. Наследник может переопределить какие-то методы и поля чтобы изменить поведение по умолчанию.
- Композиция: если поле у нас имеет тип Класс, оно может содержать ссылку на другой объект этого класса, создавая таким образом связь между двумя объектами. Не влезая в дебри различий между простой ассоциацией, агрегированием и композицией, давайте «на пальцах» определим: композиция — это когда один объект предоставляет другому свою функциональность частично или полностью.
- Инкапсуляция: мы обращаемся с объектами как с единой сущностью, а не как с набором отдельных полей и методов, тем самым скрываем и защищаем реализацию класса. Если клиентский код не знает ничего, кроме публичного интерфейса, он не может зависеть от деталей реализации.
Наследование фундаментально
Наследование — это фундаментальное понятие ООП. В языке программирования могут быть объекты и сообщения, но без наследования он не будет объектно-ориентированным (только основанным на объектах, но все еще полиморфным).
… как и композиция
Композиция это тоже фундаментальное свойство, причем любого языка. Даже если язык не поддерживает композицию (что редкость в наши дни), люди все равно будут мыслить категориями частей и компонентов. Без композиции было бы невозможно решить сложные задачи по частям.
(Инкапсуляция тоже вещь фундаментальная, но сейчас речь не о ней)
Так от чего весь сыр-бор?
Ну хорошо, и композиция, и наследование фундаментальны, в чем дело-то?
А дело в том, что можно подумать, что одно всегда может заменить другое, или что первое лучше или хуже второго. Разработка ПО — это всегда выбор разумного баланса, компромисс.
С композицией все более-менее просто, мы с ней постоянно сталкиваемся в жизни: у стула есть ножки, стена состоит из кирпичей и цемента и тому подобное. А вот наследование, несмотря на свое простое определение, может все усложнить и запутать, если хорошенько не поразмыслить над тем, как его применять. Наследование это весьма абстрактная штука, о нем можно рассуждать, но так просто его не потрогаешь. Мы, конечно, можем сымитировать наследование, используя композицию, но это, как правило, слишком много возни. Для чего нужна композиция — очевидно: из частей собрать целое. А вот с наследованием сложнее, потому что оно сразу о двух вещах: о смысле и о механике.
Наследование смысловое
Как в биологии классификация таксонов организует их в иерархии, так наследование отражает иерархию понятий из предметной области. Упорядочивает их от общего к частному, собирает родственные идеи в ветви иерархического древа. Смысл (семантика) класса по большей части выражен в его интерфейсе — наборе сообщений, которые класс способен понять, но также определяется и теми сообщениями, которыми класс отвечает. Унаследовался от предка — будь добр не только понять все сообщения, которые мог понять предок, но также и уметь ответить как он (сохранить поведение предка — прим. пер.) И поэтому наследование связывает наследника с предком гораздо сильнее, чем если бы мы взяли просто экземпляр предка как компонент. Обратите внимание, даже если класс делает что-то совсем простое, почти не имеет логики, его имя несет существенную смысловую нагрузку, разработчик делает из него важные выводы о предметной области.
Наследование механическое
Говоря о наследовании в механическом плане, мы имеем в виду, что наследование берет данные (поля) и поведение (методы) базового класса и позволяет использовать их повторно или же дополнить в наследниках. С точки зрения механики, если потомок унаследует реализацию (код) предка, то неизбежно получит и его интерфейс.
Я уверен, что в недопонимании виновата именно эта двойственная природа наследования 7 в большинстве ОО-языков. Многие считают, что наследование — это чтобы повторно использовать код, хотя оно не только для этого. Если придавать повторному использованию чрезмерное значение — жди беды в архитектуре. Вот пара примеров.
Как не надо наследовать. Пример 1
class Stack extends ArrayList < public void push(Object value) < … >public Object pop() < … >>Казалось бы, класс Stack , все хорошо. Но посмотрите внимательно на его интерфейс. Что должно быть в классе с именем Stack? Методы push() и pop() , что же еще. А у нас? У нас есть get() , set() , add() , remove() , clear() и еще куча барахла, доставшегося от ArrayList , которое стеку ну вообще не нужно.
Можно было бы переопределить все нежелательные методы, а некоторые (например, clear() ) даже и адаптировать под наши нужды, но не многовато ли работы из-за одной ошибки в дизайне? На самом деле трех: одной смысловой, одной механической и одной комбинированной:
- Утверждение «Stack это ArrayList» ложно. Stack не является подтипом ArrayList . Задача стека — обеспечить выполнение правила LIFO (последним пришел, первым ушел), которое легко удовлетворяется интерфейсом push/pop, но никак не соблюдается интерфейсом ArrayList .
- Механически наследование от ArrayList нарушает инкапсуляцию. Клиентскому коду не должно быть известно, что мы решили использовать ArrayList для хранения элементов стека.
- Ну и наконец, реализуя стек через ArrayList мы смешиваем две разные предметные области: ArrayList — это коллекция с произвольным доступом, а стек — это понятие из мира очередей, со строго ограниченным (а не произвольным) 8 доступом.
Последний пункт — незначительная на первый взгляд, но важная вещь. Посмотрим на нее пристальнее.
Как не надо наследовать. Пример 2
Частая ошибка при наследовании — это создать модель из предметной области, унаследовав ее от готовой реализации. Вот, скажем, нам надо выделить некоторых наших клиентов (класс Customer ) в определенное подмножество. Легко! Наследуемся от ArrayList , называем это CustomerGroup и понеслась.
Не тут-то было. Поступив так мы опять спутаем две предметные области. Старайтесь избегать этого:
- ArrayList это уже наследник списка, утилиты типа «коллекция», готовой реализации.
- CustomerGroup это совсем другая штука — класс из предметной области (домена).
- Классы из предметной области должны использовать реализации, а не наследовать их.
Слой предметной области не должен знать, как у нас там все внутри сделано. Рассуждая о том, что делает наша программа, мы оперируем понятиями из предметной области, и мы не хотим отвлекаться на нюансы внутреннего устройства. Если видеть в наследовании только инструмент повторного использования кода, мы раз за разом будем попадаться в эту ловушку.
Дело не в одиночном наследовании
Одиночное наследование пока остается самой популярной моделью ООП. Оно неизбежно влечет наследование реализации, которое приводит к сильному зацеплению (coupling — прим. пер.) между классами. Может показаться, что беда в том, что ветка наследования у нас только одна на обе потребности: и смысловую и механическую. Если использовали для одного, то для другого уже нельзя. А раз так, может быть множественное наследование все исправит?
Нет. Отношение наследования не должно пересекать границы между предметными областями: инструментальной (структуры данных, алгоритмы, сети) и прикладной (бизнес-логика). Если CustomerGroup будет наследовать ArrayList и одновременно, скажем, DemographicSegment, то две предметные области переплетутся между собой, а «видовая принадлежность» объектов станет неочевидна.
Предпочтительно (по крайней мере, с моей точки зрения) делать так. Наследуемся от имеющихся в языке инструментальных классов по минимуму, ровно настолько, чтобы реализовать «механическую» часть вашей логики. Потом соединяем получившиеся части композицией, но не наследованием. Иными словами:
От инструментов можно наследовать только другие инструменты.
Это очень частая ошибка новичков. Что не удивительно, ведь так просто взять и унаследовать. Редко где встретишь обсуждения, почему именно это неправильно. Еще раз: бизнес-сущности должны пользоваться инструментами, а не быть ими. Мухи (инструменты) — отдельно, котлеты (бизнес-модели) — отдельно.
Так когда же нужно наследование?
Наследуемся как надо
Чаще всего — и при этом с наибольшей отдачей — наследование применяют для описания объектов, незначительно отличающихся друг от друга (в оригинале используется термин «differential programming» — прим. пер.) Например, нам нужна особенная кнопка с небольшими дополнениями. Нормально, наследуемся от существующего класса Кнопка. Потому что наш новый класс, это все еще кнопка, а мы полностью наследуем API класса Кнопка, его поведение и реализацию. Новая функциональность только добавляется к существующему. А вот если в наследнике часть функциональности убирается, это повод задуматься, а нужно ли наследование.
Наследование полезнее всего для группировки сходных сущностей и понятий, определения семейств классов, и вообще для организации терминов и понятий, описывающих предметную область. Зачастую, когда значительная часть предметной логики уже реализована, исходно выбранные иерархии наследования перестают работать. Если всё к тому идет, не бойтесь разобрать и заново сложить эти иерархии 9 так, чтобы они лучше соответствовали и работали друг с другом.
Композиция или наследование: что выбрать?
В ситуации, когда вроде бы подходит и то и другое, взгляните на дизайн в двух плоскостях:
- Структура и механическое исполнение бизнес-объектов.
- Что они обозначают по смыслу и как взаимодействуют.
Пока наследование остается внутри одной плоскости, все нормально. Но если иерархия проходит через две плоскости сразу, это плохой симптом.
Например, у вас есть один объект внутри другого. Внутренний объект реализует значительную часть поведения внешнего. У внешнего объекта куча прокси-методов, которые тупо пробрасывают параметры во внутренний объект и возвращают от него результат. В этом случае посмотрите, а не стоит ли унаследоваться от внутреннего объекта, хотя бы частично.
Разумеется, никакие инструкции не заменят голову на плечах. Когда строишь объектную модель, вообще полезно думать. Но если вам хочется конкретных правил, то пожалуйста.
- Оба класса из одной предметной области
- Наследник является корректным подтипом (в терминах LSP — прим. пер.) предка
- Код предка необходим либо хорошо подходит для наследника
- Наследник в основном добавляет логику
Иногда все эти условия выполняются одновременно:
- в случае моделирования высокоуровневой логики из предметной области
- при разработке библиотек и расширений для них
- при дифференциальном программировании (автор снова использует термин «differential programming», очевидно, понимая под ним нечто, отличное от DDP — прим. пер.)
Если это не ваш случай, то и наследование вам, скорее всего, будет нужно не часто. Но не потому, что надо «предпочитать» композицию наследованию, и не потому что она «лучше». Выбирайте то, что подходит наилучшим образом для конкретно вашей задачи.
Надеюсь, эти правила помогут вам понять разницу между двумя подходами.
Послесловие
Отдельная благодарность сотрудникам ThoughtWorks за их ценный вклад и замечания: Питу Хогсону, Тиму Брауну, Скотту Робинсону, Мартину Фаулеру, Минди Ор, Шону Ньюхэму, Сэму Гибсону и Махендре Кария.
1
Первый официальный ОО-язык, SIMULA 67, появился в 1967 году.
2
Системные и прикладные программисты приняли на вооружение C++ в середине 1980-х, но перед тем, как ООП стал общепринятым, прошел еще десяток лет.
3
Я намеренно упрощаю, не говорю про паб/саб, делегатов и тому подобное, чтобы не раздувать статью.
4
На момент написание этого текста Амазон предлагает 24777 книг по ООП.
5
Поиск в гугле по фразе «объектно-ориентированное программирование» дает 8 млн результатов.
6
Поиск в гугле выдает 37600 результатов по запросу «наследование это зло».
7
Смысл (интерфейс) и механику (исполнение) можно разделить за счет усложнения языка. См. пример из спецификации языка D.
8
С грустью замечу, что в Java Stack унаследован от Vector .
9
Проектирование для повторного использования через наследования выходит за рамки темы статьи. Просто имейте в виду, что ваш дизайн должен удовлетворить потребности и тех, кто пользуется базовым классом, и тех, кому нужен наследник.
Переводчик выражает благодарность ООП-чату в Telegram, без которого этот текст не смог бы появиться.
- Программирование
- Анализ и проектирование систем
- Совершенный код
- Проектирование и рефакторинг
- ООП
6: Повторное использование классов.
Одной из наиболее притягательных возможностей языка Java является возможность повторного использования кода. Но что действительно «революционно», так это наличие возможности выполнять не только простое копирование и изменение этого кода.
Такой подход использован в процедурных языках программирования, наподобие C, но он работает не очень хорошо. Как и все в Java, решение с повторным использованием кода вертится вокруг классов. Вы повторно используете код, создавая новый класс, но вместо того, что бы создавать его с нуля Вы используете уже существующие классы, которые кто-то уже создал и отладил.
Уловка в том, что бы использовать классы без копания в их исходном коде. В этой главе вы увидите два способа достижения этого. Первый — почти прямой: Вы просто создаете объекты ваших уже существующих классов внутри нового класса. Это называется «композиция» , потому, что новый класс создается из объектов уже существующих классов. Вы просто повторно используете функциональность кода, но не его самого.
Второй подход более искусный. Суть его в том, что создается новый класс с типом существующего класса. Вы буквально берете оболочку (интерфейс) существующего класса и добавляете свой код к нему без модификации существующего класса. Этот магический акт называется «наследование» , и компилятор языка при этом выполняет большую часть работы. Наследование является одним из краеугольных камней объектно-ориентированного программирования и имеет более широкий смысл, который будет раскрыт в главе 7.
Это исключительно, но синтаксис и поведение идентичны для обоих способов, для композиции и наследования (обусловлено тем, что оба пути создают новые типы из существующих типов). В этой главе Вы узнаете об обоих этих механизмах повторного использования.
Синтаксис композиции
До сих пор, композиция достаточно часто использовалась, Вы просто помещали ссылку на объект внутрь нового класса. Для примера, представьте себе, что Вы хотите получить объект, который хранит различные объекты типа String, пару примитивных типов и объект другого класса. Для не примитивных объектов Вы помещаете ссылки внутри вашего класса, но примитивные типы Вы определяете напрямую:
//: c06:SprinklerSystem.java // Композиция для повторного использования кода. class WaterSource < private String s; WaterSource() < System.out.println("WaterSource()"); s = new String("Constructed"); > public String toString() < return s; > > public class SprinklerSystem < private String valve1, valve2, valve3, valve4; WaterSource source; int i; float f; void print() < System.out.println("valve1 valve2 valve3 valve4 i f source #0000ff" size="+1">static void main(String[] args) < SprinklerSystem x = new SprinklerSystem(); x.print(); > > ///:~
Один из методов определенных в WaterSource особенный — toString( ). Вы узнаете позже, что все не примитивные объекты имеют метод toString( ) и он вызывается в особых ситуациях, когда компилятор хочет получить String, но эти объекты не являются таковыми. Так в выражении:
System.out.println("source source = ") к WaterSource. И при этом для компилятора нет никакой разницы, поскольку Вы можете только добавить строку (String) к другой строке (String), при этом он "скажет": "Я преобразую source в String вызвав метод toString( )!" После выполнения этой операции компилятор объединит эти две строки и передаст результат в виде опять же строки в System.out.println( ). В любое время, когда вы захотите получить доступ к такой линии поведения с классом, Вам нужно только написать в нем метод toString( ) . На первый взгляд, вы можете позволить Java принять на себя заботу об безопасности, потому, что компилятор автоматически создаст объекты для каждой ссылки, как в предыдущем коде. Например, вызов конструктора по умолчанию для WaterSource при инициализации source. Вывод печатаемых данных на самом же деле такой:
valve1 = null valve2 = null valve3 = null valve4 = null i = 0 f = 0.0 source = null
Примитивные типы-поля класса автоматически инициализируются в нулевое значение, как и было описано в главе 2. Но ссылки на объекты инициализируются в null и если Вы попытаетесь вызвать любой из этих методов, то Вы получите исключение. В действительности достаточно хорошо (и удобно) то, что Вы можете распечатать их без обработки исключения.
Этот пример дает понять, что компилятор только просто создает объект по умолчанию для каждой ссылки, потому, что в противном случае система может в отдельных случаях подвергнуться перегрузке. Если же Вы желаете инициализировать полностью эти ссылки, Вы можете сделать это такими способами:
- В месте, где объект был определен. Это означает, что они будут всегда проинициализированы до того, как будет вызван конструктор.
- В конструкторе класса.
- Прямо перед тем моментом, как Вам действительно понадобится использовать этот объект. Этот способ часто называют "ленивой инициализацией".
При этом может быть уменьшена перегрузка системы в ситуациях, когда объектам нет необходимости быть созданным все время работы программы.
Все три подхода представлены ниже:
//: c06:Bath.java // Инициализация конструктора с композицией. class Soap < private String s; Soap() < System.out.println("Soap()"); s = new String("Constructed"); > public String toString() < return s; > > public class Bath < private String // Инициализация в точке определения: s1 = new String("Happy"), s2 = "Happy", s3, s4; Soap castille; int i; float toy; Bath() < System.out.println("Inside Bath()"); s3 = new String("Joy"); i = 47; toy = 3.14f; castille = new Soap(); > void print() < // Отложенная (ленивая) инициализация: if(s4 == null) s4 = new String("Joy"); System.out.println("s1 s2 s3 s4 i toy castille #0000ff" size="+1">static void main(String[] args) < Bath b = new Bath(); b.print(); > > ///:~
Заметьте, что в конструкторе Bath оператор выполняется до того, как произойдет инициализация. Если вы не проинициализируете объект в точке определения, то нет никакой гарантии, что Вы выполните инициализацию до того, как вы пошлете сообщение объекту и неизбежно получите исключение.
Ниже приведен вывод программы:
Inside Bath() Soap() s1 = Happy s2 = Happy s3 = Joy s4 = Joy i = 47 toy = 3.14 castille = Constructed
Когда вызывается print( ) он заполняется из s4 потому, что все поля были правильно инициализированы до того времени, когда они были использованы.
Синтаксис наследования
Наследование является неотъемлемой частью Java, впрочем, как и других ОО языков программирования. Это очевидно - Вы всегда осуществляете операцию наследования, когда создаете класс, даже если ваш класс не является наследником какого либо другого, потому, что Вы неявно наследуете стандартный корневой класс Java Object.
Синтаксис наследования похож на композицию, но процедура выполнения заметно отличается. Когда Вы наследуете, Вы "говорите": "Этот класс такой же, как тот старый класс!" Вы излагаете эту фразу в коде давая классу имя, как обычно, но до того, как начнете работать с телом класса, добавляете ключевое слово extends следующее до имени базового класса. Когда вы сделаете это, вы автоматически получите все поля данных и методы базового класса. Вот пример:
//: c06:Detergent.java // Свойства и синтаксис наследования. class Cleanser < private String s = new String("Cleanser"); public void append(String a) < s += a; >public void dilute() < append(" dilute()"); > public void apply() < append(" apply()"); > public void scrub() < append(" scrub()"); > public void print() < System.out.println(s); >public static void main(String[] args) < Cleanser x = new Cleanser(); x.dilute(); x.apply(); x.scrub(); x.print(); > > public class Detergent extends Cleanser < // Изменяем метод: public void scrub() < append(" Detergent.scrub()"); super.scrub(); // Вызываем метод базового класса > // Все методы наследования: public void foam() < append(" foam()"); > // Проверяем новый класс: public static void main(String[] args) < Detergent x = new Detergent(); x.dilute(); x.apply(); x.scrub(); x.foam(); x.print(); System.out.println("Testing base class:"); Cleanser.main(args); > > ///:~
Этот пример показывает несколько возможностей. Сперва в методе Cleanser append( ) , String-и конкатенируются с s при помощи оператора "+=", это один из операторов (с плюсом впереди), который перегружается Java для работы с типом String.
Во-вторых, оба Cleanser и Detergent содержат метод main( ). Вы можете создать main( ) для каждого из ваших классов и часто рекомендуется писать такой код для тестирования каждого из классов. Если же у Вас имеется множество классов в программе, то выполнится только метод main( ) того класса, который был вызван из командной стоки. Так что в этом случае, когда вы вызовите java Detergent, будет вызван метод Detergent.main( ) . Но так же вы можете вызвать java Cleanser для выполнения Cleanser.main( ), несмотря даже на то, что класс Cleanser не public . Эта техника помещения метода main( ) в каждый класс позволяет легко проверять каждый из классов программы по отдельности. И Вам нет необходимости удалять main( ) когда вы закончили проверки, Вы можете оставить его для будущих проверок.
Здесь Вы можете видеть, что Detergent.main( ) явно вызывает Cleanser.main( ) , передавая ему те же самые аргументы из командной строки(тем не менее, Вы могли были передать ему любой , массив элементов типа String).
Важно то, что все методы в Cleanser - public. Помните, если Вы оставите любой из спецификаторов доступа в состоянии по умолчанию, т.е. он будет friendly, то доступ к нему могут получить только члены этого же пакета. Поэтому в этом пакете все могут использовать эти методы, если у них нет спецификатора доступа. Detergent с эти проблем не имеет, к примеру. Но в любом случае, если класс из другого пакета попытается наследовать Cleanser он получит доступ только к членам со спецификатором public. Так что если Вы планируете использовать наследование, то в качестве главного правила делайте все поля private и все методы public. (protected так же могут получить доступ к наследуемым классам, но Вы узнаете об этом позже.) Естественно в частных случаях Вы должны делать поправки на эти самые частные случаи, но все равно это полезная линия поведения.
Замете, что Cleanser имеет набор методов из родительского интерфейса: append( ), dilute( ), apply( ), scrub( ), и print( ). Из-за того, что Detergent произошел от Ceanser (при помощи ключевого слова extends ) он автоматически получил все те методы, что есть в его интерфейсе, даже не смотря на то, что вы не видите их определенных в Detergent. Вы можете подумать о наследовании, а уже только затем о повторном использовании интерфейса.
Как видно в scrub( ) , возможно создать метод, который определяется в базовом классе, а затем уже его модифицировать. В таком случае, Вы можете захотеть вызвать метод внутри базового класса этот новый модифицированный метод. Но внутри scrub( ) вы не можете просто вызвать scrub( ), поскольку эта операция вызовет рекурсивный вызов, а это не то, что Вы хотите. Для разрешения этой проблемы в Java используется ключевое слово super , которое ссылается на superclass, который в свою очередь является классом, от которого произошел текущий класс. Поэтому выражение super.scrub( ) вызывает метод базового класса scrub( ).
При наследовании вы не ограничены в использовании методов базового класса. Вы можете так же добавлять новые методы в новый класс. Это сделать очень просто, нужно просто определить их. Метод foam( ) тому демонстрация.
В Detergent.main( ) вы можете увидеть, что у объекта Detergent Вы можете вызвать все методы, которые доступны в Cleanser так же, как и в Detergent (в том числе и foam( )).
Инициализация базового класса
До этого у нас было запутано два класса - базовый и произошедший от него вместо просто одного, это может привести в небольшое замешательство при попытке представить результирующий объект произведенный произошедшим (дочерним) классом. С наружи он выглядит, как новый класс имеющий тот же интерфейс, что и базовый класс и может иметь те же самые методы и поля. Но наследование не просто копирует интерфейс базового класса. Когда Вы создаете объект произошедшего (дочернего) класса он содержит еще и подобъект базового класса. Этот подобъект точно такой же, как если бы вы создали объект базового класса самостоятельно.
Естественно, что необходимо правильно и корректно проинициализировать этот подобъект и здесь есть только один гарантированный путь: осуществить инициализацию в конструкторе, путем вызова конструктора базового класса, который имеет все необходимые сведения и привилегии для осуществления инициализации самого базового класса. Java автоматически вставляет вызов базового класса в конструктор произошедшего (наследуемого) от этого класса. Следующий пример демонстрирует эту работу с трети уровнем наследования:
//: c06:Cartoon.java // Конструктор вызывается на стадии инициализации. class Art < Art() < System.out.println("Art constructor"); > > class Drawing extends Art < Drawing() < System.out.println("Drawing constructor"); > > public class Cartoon extends Drawing < Cartoon() < System.out.println("Cartoon constructor"); > public static void main(String[] args) < Cartoon x = new Cartoon(); > > ///:~
Вывод этой программы показывает автоматические вызовы:
Art constructor Drawing constructor Cartoon constructor
Как Вы можете видеть конструктор базового класса проинициализировал его до того, как к нему смог получить доступ произошедший от него класс.
Даже, если Вы не создаете конструктор для Cartoon( ), компилятор синтезирует конструктор по умолчанию для вызова конструктора базового класса.
Конструктор с аргументами
Предыдущий пример имеет конструктор по умолчанию ; и при этом он не имеет каких либо аргументов. Для компилятора такой вызов прост, нет ненужных вопросов по поводу аргументов, которые нужно передать. Если Ваш класс не имеет аргументов по умолчанию или если Вы хотите вызвать конструктор базового класса, который имеет аргументы, Вы должны просто использовать ключевое слово super и передать ему список аргументов:
//: c06:Chess.java // Наследование, конструкторы и аргументы. class Game < Game(int i) < System.out.println("Game constructor"); > > class BoardGame extends Game < BoardGame(int i) < super(i); System.out.println("BoardGame constructor"); > > public class Chess extends BoardGame < Chess() < super(11); System.out.println("Chess constructor"); > public static void main(String[] args) < Chess x = new Chess(); > > ///:~
Если же Вы не вызовите конструктор базового класса в BoardGame( ), тогда компилятор выдаст сообщение, что он не может найти конструктор для Game( ). В дополнение к вышесказанному - вызов конструктора базового класса должен быть осуществлен в первую очередь в конструкторе класса наследника. (Компилятор сообщит Вам об этом, если Вы сделали что-то не так.)
Обработка исключений конструктора
Как только что было замечено, компилятор предлагает Вам поместить конструктор базового класса в конструктор класса наследника. Это означает, что ничего другого не может произойти до его вызова. Как Вы увидите в главе 10, при этом нужно так же позаботится об обработке исключения пришедшего из конструктора базового класса.
Объединение композиции и наследования
Совместное использование композиции и наследования часто и широко используется при программировании. Следующий пример показывает создание более комплексного класса использующего оба метода и композицию, и наследование с необходимыми инициализациями конструкторов :
//: c06:PlaceSetting.java // Объединение композиции и наследования. class Plate < Plate(int i) < System.out.println("Plate constructor"); > > class DinnerPlate extends Plate < DinnerPlate(int i) < super(i); System.out.println( "DinnerPlate constructor"); > > class Utensil < Utensil(int i) < System.out.println("Utensil constructor"); > > class Spoon extends Utensil < Spoon(int i) < super(i); System.out.println("Spoon constructor"); > > class Fork extends Utensil < Fork(int i) < super(i); System.out.println("Fork constructor"); > > class Knife extends Utensil < Knife(int i) < super(i); System.out.println("Knife constructor"); > > // Нормальный путь, сделать что-то: class Custom < Custom(int i) < System.out.println("Custom constructor"); > > public class PlaceSetting extends Custom < Spoon sp; Fork frk; Knife kn; DinnerPlate pl; PlaceSetting(int i) < super(i + 1); sp = new Spoon(i + 2); frk = new Fork(i + 3); kn = new Knife(i + 4); pl = new DinnerPlate(i + 5); System.out.println( "PlaceSetting constructor"); > public static void main(String[] args) < PlaceSetting x = new PlaceSetting(9); > > ///:~
В то время, как компилятор требует от Вас инициализировать базовые классы и требует, что бы Вы делали это в начале конструктора, он не убеждается, в том, что Вы инициализировали остальные объекты, так что Вам придется быть осторожным.
Гарантия правильной очистки.
Java не поддерживает концепцию C++ связанную с деструктором , специальным методом, который автоматически вызывается при уничтожении объекта. Причина этого в том, что в Java нужно просто забыть об объекте, позволяя тем самым освободить сборщику мусора память, если это необходимо .
Зачастую этот подход отлично работает, но иногда ваш класс может осуществлять некоторые действия во время его цикла жизни и требуется его очистить грамотно. Как уже упоминалось в главе 4, Вы не можете знать когда будет вызван сборщик мусора, и будет ли он вообще вызван. Так что, если Вы хотите очистить нечто в вашем классе, то Вам необходимо просто написать специальный метод выполняющий эту работу, и убедиться, что другой (возможный) программист знает, что он должен взывать этот метод. Эта проблема описана в главе 10 (" Обработка ошибок с помощью исключений"), Вы должны обработать исключение поместив некий очищающий код в блок finally.
Давайте рассмотрим пример вспомогательной компьютерной системы дизайна, которая рисует картинку на экране:
//: c06:CADSystem.java // Обеспечение правильной очистки. import java.util.*; class Shape < Shape(int i) < System.out.println("Shape constructor"); > void cleanup() < System.out.println("Shape cleanup"); > > class Circle extends Shape < Circle(int i) < super(i); System.out.println("Drawing a Circle"); > void cleanup() < System.out.println("Erasing a Circle"); super.cleanup(); > > class Triangle extends Shape < Triangle(int i) < super(i); System.out.println("Drawing a Triangle"); > void cleanup() < System.out.println("Erasing a Triangle"); super.cleanup(); > > class Line extends Shape < private int start, end; Line(int start, int end) < super(start); this.start = start; this.end = end; System.out.println("Drawing a Line: " + start + ", " + end); > void cleanup() < System.out.println("Erasing a Line: " + start + ", " + end); super.cleanup(); > > public class CADSystem extends Shape < private Circle c; private Triangle t; private Line[] lines = new Line[10]; CADSystem(int i) < super(i + 1); for(int j = 0; j < 10; j++) lines[j] = new Line(j, j*j); c = new Circle(1); t = new Triangle(1); System.out.println("Combined constructor"); > void cleanup() < System.out.println("CADSystem.cleanup()"); // Порядок очистки // обратен порядку инициализации t.cleanup(); c.cleanup(); for(int i = lines.length - 1; i >= 0; i--) lines[i].cleanup(); super.cleanup(); > public static void main(String[] args) < CADSystem x = new CADSystem(47); try < // Код и исключения обрабатываются. > finally < x.cleanup(); >> > ///:~
Все в этой системе является разновидностями шейпа (Shape) (который в свою очередь является разновидностью объекта(Object) в силу того, что он косвенным образом наследует корневой класс). Каждый класс переопределяет метод шейпа cleanup( ) в дополнении к этому еще и вызывает метод базового класса через использование super. Специфичные классы Shape, такие, как Circle, Triangle и Line все имеют конструкторы, которые рисуют, хотя любой метод, вызванный во время работы, должен быть доступным для чего либо нуждающегося в очистке. Каждый класс имеет свой собственный метод cleanup( ) для восстановления не использующих память вещей существовавших до создания объекта.
В методе main( ), Вы можете видеть два ключевых слова, которые для Вас новы, и не будут официально представлены до главы 10: try и finally. Ключевое слово try сигнализирует о начале блока (отделенного фигурными скобками), который является охраняемой областью, что означает, что он предоставляет специальную обработку при возникновении исключений. Одной из специальных обработок является порция кода заключенная в блок finally следующий за охраняемой областью и который всегда выполняется, вне зависимости от завершения блока try . (С обработкой исключений имеется возможность покинуть блок try бесчисленным количеством способов.) Здесь, finally означает:"Всегда вызывать cleanup( ) для x, без разницы, что случилось". Эти ключевые слова будут основательно разъяснены в главе 10.
Заметьте, что в Вашем методе очистки Вы должны так же быть внимательны в вызове очередности для базового класса и для вашего класса, в зависимости от отношений с подобъектом. В основном, Вы должны следовать тем же путем, как и в C++ в деструткорах: Сначала осуществляется очистка вашего класса в обратной последовательности создания. (В основном требуется, чтобы элементы базового класса были все еще доступны.) Затем вызвать метод очистки базового класса, как показано в примере.
Вообще может быть множество случаев, в которых очистка это не проблема, Вы просто позволяете сборщику мусора выполнить свою работу. Но, когда Вы должны очистку сделать самостоятельно, следует быть внимательным, усердным и осторожным.
Порядок сборки мусора
Здесь не так уж и много уверенности, когда придет время сбора мусора . Сборщик мусора может быть так и ни разу не вызван. Если же он вызван, то он может освободить ресурсы от ненужных объектов, в каком ему заблагорассудится порядке. Поэтому лучше не рассчитывать полностью на сборщик мусора с полной очисткой памяти. Если вы хотите очистить для себя достаточно ресурсов - напишите свой собственной метод по очистке и не полагайтесь только на finalize( ). (Как уже упоминалось в главе 4, в Java можно принудительно вызвать все завершители.)
Скрытие имен
Только программисты C++ могут быть "обрадованы" скрытием имен, из-за того, что они работают по другому в этом языке (Java). Если базовый класс в Java имеет метод, который многократно перегружался, то при переопределении имени этого метода в классе потомке не будут скрыты методы в базовом классе. Поэтому перегрузка работает, не обращая,внимание на место определения метода, на этом уровне или в базовом классе:
//: c06:Hide.java // Перегрузка имени базового класса в дочернем, не скрывает метод базового класса. class Homer < char doh(char c) < System.out.println("doh(char)"); return 'd'; > float doh(float f) < System.out.println("doh(float)"); return 1.0f; > > class Milhouse <> class Bart extends Homer < void doh(Milhouse m) <> > class Hide < public static void main(String[] args) < Bart b = new Bart(); b.doh(1); // doh(float) использован b.doh('x'); b.doh(1.0f); b.doh(new Milhouse()); > > ///:~
Как Вы увидите в следующей главе, такой подход далек от наиболее частого использования при переопределении методов. Нужно использовать метод с тем же именем используя практически ту же сигнатуру и возвращая тот же тип в базовом классе. Если сделать по другому, то это уже не сработает (поэтому то C++ и запрещает такой прием, что бы ограничить программиста в создании новой возможной ошибки).
Выборочная композиция против наследования
Оба метода, композиция и наследование, позволяют Вам поместить подобъект внутрь вашего нового класса. Вы можете быть изумлены различием между ними двумя и при этом метаться при выборе одного способа перед другим.
Композиция в основном используется когда Вам нужно использовать возможности существующего класса, но не использовать его интерфейс. Это значит, что Вы внедряете объект, так, что вы можете использовать его для получения доступа к функциональности внедряемного объекта в вашем новом классе, но пользователь вашего нового класса видит интерфейс вашего нового класса раньше, чем интерфейс внедряемого объекта. Что бы добиться такого эффекта, Вы должны включать private объекты существующих классов внутрь вашего нового класса.
Иногда требуется разрешить пользователю класса получить доступ к вашему новому классу напрямую; что бы сделать это, нужно сделать объекты public. Эти объекты используют реализацию скрытия самих себя, так что такой подход достаточно безопасен. Если пользователь знает, что Вы собрали этот класс из различных частей, то интерфейс этого класса будет для него более легок в понимании. Объект car хороший пример, иллюстрирующий данную технологию:
//: c06:Car.java // Композиция с public объектами. class Engine < public void start() <> public void rev() <> public void stop() <> > class Wheel < public void inflate(int psi) <> > class Window < public void rollup() <> public void rolldown() <> > class Door < public Window window = new Window(); public void open() <> public void close() <> > public class Car < public Engine engine = new Engine(); public Wheel[] wheel = new Wheel[4]; public Door left = new Door(), right = new Door(); // 2-door public Car() < for(int i = 0; i < 4; i++) wheel[i] = new Wheel(); > public static void main(String[] args) < Car car = new Car(); car.left.window.rollup(); car.wheel[0].inflate(72); > > ///:~
В силу того, что состав класса car является частью анализа проблемы (а не просто часть основного приема программирования), создание членов классов public поможет программисту понять, как использовать класс и требует меньше кода и меньшей запутанности для создания класса. Но все равно, помните, что этот прием только для специальных случаев, и в основном вы должны делать поля private.
При наследовании, Вы берете существующий класс и создаете специальную его версию. В основном это означает, что Вы берете главный, целевой класс и приспосабливаете его для частных нужд. Немного поразмыслив, Вы увидите, что нет разницы при создании класса car используя объект vehicle - car не содержит vehicle, он и есть vehicle. Отсюда связь он и есть используется в наследовании, а содержит при композиции.
protected
Итак вы только что получили представление о наследовании и теперь пришло время раскрыть смысл ключевого слова protected . В идеальном мире, private объекты всегда являются действительно private, но в реальных проектах, где вы пытаетесь во многих местах скрыть от внешнего мира нечто, Вам часто нужна возможность получить к нему доступ из классов наследников. Ключевое слово protected поэтому не такая уж и ненужная назойливость или догма. Оно объявляет "Этот объект частный (private), если к нему пытается подобраться пользователь, но он доступен для всех остальных находящихся в том же самом пакете(package)". То есть , protected в Java автоматически означает friendly.
Наилучшим решением при этом оставить данным модификатор private, но с другой стороны для доступа к ним оставить protected методы:
//: c06:Orc.java // Ключевое слово protected. import java.util.*; class Villain < private int i; protected int read() < return i; > protected void set(int ii) < i = ii; >public Villain(int ii) < i = ii; >public int value(int m) < return m*i; > > public class Orc extends Villain < private int j; public Orc(int jj) < super(jj); j = jj; > public void change(int x) < set(x); >> ///:~
Вы можете видеть, что change( ) имеет доступ к set( ) потому, что он protected.
Инкрементная разработка
Одним из преимуществ наследования является поддержка инкрементной разработки , при помощи которой Вы можете создавать новый код, без внесения возможных ошибок в уже существующий. При этом новые ошибки так же остаются внутри нового кода. Наследуя из существующего, функционального класса и добавляя методы и поля данных, а так же переопределяя существующие методы, Вы оставляете в первозданном виде уже существующий код, тем самым кто-то сможет воспользоваться им нетронутым и без новых ошибок. Если же вдруг случится ошибка, Вы будете знать, что она в вашем коде, и при этом ее найти будет проще и быстрее, чем если бы Вы модифицировали уже существующий и отлаженный код.
То, как чисто разделяются классы может показаться удивительно. Вам не нужен исходный код, поскольку вы можете использовать технологию повторного использования исходного кода. Самое большое, что вам нужно сделать, это импортировать пакет. И это справедливо и для наследования и для композиции.
Важно понимать, что инкрементальная разработка программы всего лишь процесс, похожий на обучение человека. Вы можете анализировать вашу будущую программу сколько угодно, но все равно останутся вопросы которые возникнут только в процессе разработки проекта. Ваш проект будет более удачлив и более гибким, если Вы будете растить его как органическую структуру, как эволюционирующее создание, по сравнению, если бы Вы начали создавать его как единообразной квадратно-стеклянный небоскреб, пытаясь учесть в нем все нюансы.
Несмотря на то, что наследование для экспериментов может быть просто превосходной техникой, однако после некоторой точки стабилизации Вам необходимо окинуть взором вашу иерархию классов и привести ее в разумные размеры. Помните, что наследование определяет связь - Этот новый класс такого же типа, как и тот старый. Ваша программа не должен разбрасываться битами вокруг, а вместо этого создавать и манипулировать объектами многих типов для выражения модели в терминах проблемной области .
Приведение к базовому типу
Наиболее важный аспект наследования заключается вовсе не в снабжении нового класса новыми методами. А заключается он в отношении между новым классом и базовым классом. Данное отношение можно определить так "Новый класс имеет тип существующего класса."
Это описание, не просто причудливая форма раскрытия сущности наследования, такая форма поддерживается напрямую языком Java. В примере, рассматриваемый базовый класс называется Instrument и представляет музыкальные инструменты, а дочерний класс называется Wind (духовые инструменты). Поскольку наследование подразумевает, что все методы в базовом классе так же доступны и в дочернем классе, то любое сообщение, которое может быть послано базовому классу, так же доступно и в дочернем. Если класс Instrument имеет метод play( ), то и Wind так же может его использовать. Это означает, что мы можем точно так же сказать, что объект Wind так же и типа Instrument. Следующий пример показывает, как компилятор поддерживает это высказывание:
//: c06:Wind.java // Наследование и приведение к базовому типу. import java.util.*; class Instrument < public void play() <> static void tune(Instrument i) < // . i.play(); > > // Объект Wind так же Instrument // потому что они имеют общий интерфейс: class Wind extends Instrument < public static void main(String[] args) < Wind flute = new Wind(); Instrument.tune(flute); // Upcasting > > ///:~
Что действительно интересно в этом примере, так это то, что метод tune( ) поддерживает ссылку на Instrument. Однако, в Wind.main( ) метод tune( ) вызывается с передачей ссылки на Wind. Из этого следует, что Java специфична с проверкой типов, это выглядит достаточно странно, если метод принимающий в качестве параметра один тип, вдруг спокойно принимает другой, но так пока вы не поймете, что объект Wind так же является и объектом типа Instrument, и в нем нет метода tune( ) который можно было бы вызвать для Instrument. Внутри tune( ), код работает с типами Instrument и с чем угодно от него произошедшим, а факт конвертации ссылки на Wind в ссылку на Instrument называется приведением к базовому типу (upcasting).
Почему "приведение к базовому типу"?
Причина этого термина кроется в недрах истории, и основана она диаграмме наследования классов имеющую традиционное начертание: сверху страницы корень, растущий вниз. Естественно, Вы можете нарисовать свою собственную диаграмму, каким угодно образом. Диаграмма наследования для Wind.java:
Преобразование (casting) дочернего к базовому происходит при движении вверх (up) по диаграмме наследования, так что получается - upcasting (приведение к базовому типу). Приведение к базовому типу всегда безопасно, поскольку Вы переходите от более общего типа, к более конкретному. Так что дочерний класс является супермножеством базового класса. Он может содержать больше методов, чем базовый класс, но он должен содержать минимум все те методы, что есть в базовом классе. Только одна вещь может случится при приведении к базовому типу, это, что могут потеряться некоторые методы. Вот по этому то компилятор и позволяет осуществлять приведение к базовому типу без каких либо ограничений на приведение типов или специальных замечаний.
Вы так же можете осуществить обратную приведению к базовому типу операцию, называемую приведение базового типа к дочернему (downcasting), но при этом возникает небольшая дилемма, которая разъяснена в главе 12.
И снова композиция против наследования
В объектно-ориентированном программировании наиболее используемый способ заключается в создании и использовании кода с хранением и кода и данных в одном пакете-классе. Вы так же используете существующие классы для создания новых классов при помощи композиции. Менее часто используется наследование. Однако, наследование более выразительно при изучении ООП, но это вовсе не значит, что его нужно использовать, где только возможно. Тем не менее, Вы должны использовать наследование, там, где его использование полезно. Один из понятных путей для определения, что Вы должны использовать, наследование или композицию заключается в выяснении нужно ли будет вам приводить что-то к базовому типу или нет. Если вам необходимо приведение к базовому типу, то наследование просто необходимо, но если же Вы не нуждаетесь в этом, то стоит присмотреться, а так ли уж необходимо здесь наследование. Следующая глава (полиморфизм) предоставляет одну из наиболее непреодолимых причин для приведения к базовому типу, но если Вы вспомните вопрос "Нужно ли мне приведение к базовому типу?", то Вы получите хороший способ для решения при выборе между композицией или наследованием.
Ключевое слово final
В Java ключевое слово final имеет слегка разные значения в зависимости от контекста, но в основном, оно определяется так "Это не может быть изменено". Вы можете хотеть запретить изменения по двум причинам: дизайн или эффективность. Поскольку эти две причины слегка различаются, то существует возможность неправильного употребления ключевого слова final.
В следующих секциях обсуждается применение final тремя способами: для данных, для методов и для классов.
Данные final
Многие языки программирования имеют пути сообщить компилятору, что данный кусочек данных является неизменным, константой. Константа наиболее удобна для применения в следующих двух случаях:
- Она должна быть константой во время компиляции и не может быть изменена никогда.
- Она может быть инициализирована во время инициализации и не должна быть изменена после.
В случае константы во время компиляции компилятор свертывает константу до значения в любых вычислениях, где она используется; при этом, нагрузка при вычислениях во время работы программы может быть значительно снижена. В Java константы такого рода должны быть примитивного типа и объявлены с использованием final. Значение должно быть определено во время определения переменной, как и любой константы.
Поля имеющие модификаторы static и final вообще являются ячейкой для хранения и не могут быть изменены.
При использовании final с объектами, а не с примитивными типами получается несколько не тот эффект. С примитивами, final создает константу значения, а с объектами - ссылку, final создает ссылку - константу. Как только ссылка инициализируется на какой-то объект, она уже не может быть в последствии перенаправлена на другой объект. Однако сам объект может быть модифицирован; Java не предоставляет способа создать объект - константу. (Однако, Вы можете написать свой собственный класс с эффектом константы.) Эти же ограничения накладываются и на массивы, поскольку они тоже объекты.
Ниже представлен пример, демонстрирующий использование полей с модификатором final:
//: c06:FinalData.java // Эффект полей final. class Value < int i = 1; > public class FinalData < // Может быть константой во время компиляции final int i1 = 9; static final int VAL_TWO = 99; // Обычная public константы: public static final int VAL_THREE = 39; // Не может быть константой во время компиляции: final int i4 = (int)(Math.random()*20); static final int i5 = (int)(Math.random()*20); Value v1 = new Value(); final Value v2 = new Value(); static final Value v3 = new Value(); // Массивы: final int[] a = < 1, 2, 3, 4, 5, 6 >; public void print(String id) < System.out.println( id + ": " + "i4 , i5 #0000ff" size="+1">static void main(String[] args) < FinalData fd1 = new FinalData(); //! fd1.i1++; // Ошибка: значение не может быть изменено fd1.v2.i++; // Объект не константа! fd1.v1 = new Value(); // OK -- не final for(int i = 0; i < fd1.a.length; i++) fd1.a[i]++; // Объект не константа! //! fd1.v2 = new Value(); // Ошибка: Нельзя //! fd1.v3 = new Value(); // изменить ссылку //! fd1.a = new int[3]; fd1.print("fd1"); System.out.println("Creating new FinalData"); FinalData fd2 = new FinalData(); fd1.print("fd1"); fd2.print("fd2"); > > ///:~
Поскольку i1 и VAL_TWO являются final примитивами со значениями во время компиляции, то они могут быть использованы в обоих случаях, как константы времени компиляции и не имеют при этом отличий. VAL_THREE определена более типичным путем и Вы можете видеть, как определяются константы: public так, что она может быть использована вне пакета, static т.е. может существовать только одна и final объявляет, что она и есть константа. Заметьте, что примитивы final static с начальными неизменяемыми значениями (константы времени компилирования) называются большими буквами и слова разделены подчеркиванием (такие наименование похожи на константы в C.) Так же заметьте, что i5 не может быть известна во время компиляции, поэтому она названа маленькими буквами.
Просто, если, что-то определено, как final это еще не значит, что его значение известно на стадии компиляции. Это утверждение демонстрируется инициализацией i4 и i5 во время выполнения с использованием случайно генерируемых чисел. Та порция примера так же показывает различие между созданием final с модификатором static и без него. Это различие заметно, только во время инициализации во время выполнения, это происходит из-за того, что значения времени компиляции обращаются в те же самые самим компилятором. (И по видимому, существенно оптимизированными.) Это различие показано в выводе программы после одного запуска:
fd1: i4 = 15, i5 = 9 Creating new FinalData fd1: i4 = 15, i5 = 9 fd2: i4 = 10, i5 = 9
Заметьте, что значения i4 для fd1 и для fd2 уникальны, но значение для i5 не изменилось после создания второго объекта FinalData. Такое произошло потому, что i5 static и инициализировалась только один раз при загрузке, а не каждый раз, когда создавался новый объект.
Переменные v1 и v4 демонстрируют значение final ссылки. Как Вы можете видеть в методе main( ), только потому, что v2 является final вовсе не означает, что Вы не можете изменить ее значение. Хотя, Вы не можете перенаправить v2 на новый объект, и это потому, что она final. Вот такой смысл вкладывается в понятие final ссылок. Вы так же можете увидеть точно такое же действие на примере массивов, поскольку они являются так же разновидностью ссылок. (Я например не знаю способа, как сделать ссылки массивов самих на себя final.) Таким образом, создание ссылок с типом final менее удобна в использовании, чем создание примитивов с модификатором final.
Пустые final
Java позволяет создавать пустые (чистые) final объекты (blank final), это такие поля данных, которые были объявлены как final но при этом не были инициализированы значением. Во всех случаях, пустая final переменная должна быть инициализирована до ее использования и компилятор обеспечивает это условие. Тем не менее, пустые final поля предоставляют большую гибкость при использовании модификатора final, к примеру, final поле внутри класса может быть разным для каждой копии объекта. Вот пример:
//: c06:BlankFinal.java // "Пустые" final данные. class Poppet < >class BlankFinal < final int i = 0; // инициализируем final final int j; // пустой final final Poppet p; // Ссылка на пустой final // Пустой final ДОЛЖЕН быть инициализирован // в конструкторе: BlankFinal() < j = 1; // инициализируем чистую final p = new Poppet(); > BlankFinal(int x) < j = x; // Инициализируем чистую final p = new Poppet(); > public static void main(String[] args) < BlankFinal bf = new BlankFinal(); > > ///:~
Вы принудительно должны осуществить соединение переменной final со значением при ее определении или в конструкторе. При этом гарантировано не будет доступа к переменной, до ее инициализации.
Аргументы final
Java позволяет Вам так же создавать и аргументы final определением их таким образом прямо в списке аргументов. Это означает, что внутри метода Вы не сможете изменить этот аргумент или его ссылку:
//: c06:FinalArguments.java // Использование "final" с аргументами методов. class Gizmo < public void spin() <> > public class FinalArguments < void with(final Gizmo g) < //! g = new Gizmo(); // Неверно -- g - final > void without(Gizmo g) < g = new Gizmo(); // OK -- g не final g.spin(); > // void f(final int i) < i++; >// Не может измениться // Вы можете только читать примитив: int g(final int i) < return i + 1; > public static void main(String[] args) < FinalArguments bf = new FinalArguments(); bf.without(null); bf.with(null); > > ///:~
Заметьте, что Вы все еще можете соединить null ссылку с final аргументом, без реакции со стороны компилера, таким же образом, как и с не final аргументами.
Методы f( ) и g( ) показывают, что случается, когда примитивный аргумент - final: Вы можете прочитать его, но не можете изменить его.
Final методы
Существует две причины для final методов. Первая - закрытие методов, от возможной модификации при наследовании класса. Такой подход применяется если Вы хотите быть уверенны, что этот метод не будет переопределен в дочерних классах и поведение класса не изменится.
Вторая причина - final методы более эффективны. Если Вы делаете метод с модификатором final, Вы тем самым разрешаете компилятору все вызовы этого метода превратить во внутренние (inline) вызовы. Когда компилятор видит final метод он может(на свое усмотрение) пропустить нормальный метод добавления кода, т.е. обычного исполнения метода (поместить аргументы в стек, перепрыгнуть на код метода и выполнить его, перепрыгнуть обратно на стек аргументов и очистить их, разобраться с возвращаемым значением) и заменить вызов метода на копию актуального кода из тела метода. При этом снижается загрузка машины при выполнении вызова метода. Естественно, если ваш метод велик, тогда ваш код распухнет и вероятно Вы не увидите никаких преимуществ по производительности от использования прямых вызовов, поскольку все повышения производительности при вызове будут съедены временем выполнения кода внутри самого метода. Поэтому Java компилятор способен определять такие ситуации и решать, когда осуществлять компиляцию final метода во внутренние вызовы. Но, все таки не следует слишком уж доверять компилятору и создавать final методы, только, если они действительно небольшие и Вы действительно хотите запретить их изменение при наследовании.
final и private
Любой private метод косвенным образом final. Поскольку Вы не можете получить доступ к private методу, Вы не можете переопределить его (даже если компилятор не выдаст сообщения об ошибке при переопределении, Вы все равно не сможете переопределить его, Вы просто создадите новый метод). Вы можете добавить спецификатор final к private методу, но это не добавит ему никаких дополнительных возможностей.
Эта особенность может создать неудобство, поскольку если Вы попытаетесь перекрыть private метод (который косвенно и final) то оно будет работать:
//: c06:FinalOverridingIllusion.java // Это только выглядит так, как буд-то вы перекрыли // private или private final метод. class WithFinals < // Идентично "private": private final void f() < System.out.println("WithFinals.f()"); > // Так же автоматически "final": private void g() < System.out.println("WithFinals.g()"); > > class OverridingPrivate extends WithFinals < private final void f() < System.out.println("OverridingPrivate.f()"); > private void g() < System.out.println("OverridingPrivate.g()"); > > class OverridingPrivate2 extends OverridingPrivate < public final void f() < System.out.println("OverridingPrivate2.f()"); > public void g() < System.out.println("OverridingPrivate2.g()"); > > public class FinalOverridingIllusion < public static void main(String[] args) < OverridingPrivate2 op2 = new OverridingPrivate2(); op2.f(); op2.g(); // Вы можете привести к базовому типу: OverridingPrivate op = op2; // Но Вы не можете вызвать методы: //! op.f(); //! op.g(); // Так же здесь: WithFinals wf = op2; //! wf.f(); //! wf.g(); > > ///:~
"Переопределение" может быть использовано только если это что-то является частью интерфейса базового класса. То есть, Вы должны быть способны привести метод к базовому типу объекта и вызвать тот же самый метод (как это делается будет объяснено в следующей главе). Если же метод private, то он не является частью интерфейса базового класса. Он это просто немного кода скрытого внутри класса, и просто так случилось, что он имеет то же имя, но если уж Вы создаете метод с модификатором public, protected или friendly в дочернем классе, то здесь нет связи с методом из базового класса. Поэтому private метод недоступный и эффективный способ скрыть какой-либо код, и при этом он не влияет на организацию кода в котором он был объявлен.
Final классы
Когда Вы объявляете целый класс final (путем добавления в его определение ключевого слова final), Вы тем самым заявляете, что не хотите наследовать от этого класса или что бы кто-то другой мог наследовать от него. Другими словами, по некоторым причинам в вашем классе не должны делаться какие-либо изменения, или по причинам безопасности не могут быть созданы подклассы. В другом же случае, причиной сделать класс final может послужить эффективность выполнения кода класса, но здесь нужно быть уверенным, что все, что внутри класса уже оптимизировано как можно более максимально.
//: c06:Jurassic.java // Создание целого final класса. class SmallBrain <> final class Dinosaur < int i = 7; int j = 1; SmallBrain x = new SmallBrain(); void f() <> > //! класс Further расширяет Dinosaur <> // Ошибка: Нельзя расширить класс 'Dinosaur' public class Jurassic < public static void main(String[] args) < Dinosaur n = new Dinosaur(); n.f(); n.i = 40; n.j++; > > ///:~
Заметьте, что поля данных могут быть final, а могут и не быть, по вашему выбору. Те же самые правила применимы и к final членам класса вне зависимости определен ли сам класс, как final. Определение класса, как final просто предотвращает дальнейшее от него наследование. Несмотря на это, поскольку он предотвращает наследование всех методов в классе final, то они безоговорочно тоже становятся final, поскольку нет способа для их переопределения. Так что компилятор имеет тоже полезное действие, как если бы Вы определили каждый из методов как final.
Вы можете добавить спецификатор final к методу в final классе, но это уже ничего означать не будет.
Предостережение о Final
Может показаться, что создание final метода во время разработки класса хорошая идея. Вы можете чувствовать, что эффективность и важность его высоки и никто не должен перекрыть этот метод. Иногда это действительно так.
Но будьте осторожны в своих предположениях. Обычно трудно предположить, как именно будет в дальнейшем этот класс использоваться, особенно в качестве основного-целевого класса. Если Вы определили метод как final Вы можете предотвратить повторное его использование через наследование в других проектах, других программистов и просто потому, что Вы не можете себе представить, каким образом они будут это делать.
Хорошим примером для этого может послужить стандартная библиотека Java. В частности, Java 1.0/1.1 класс Vector был часто использован и мог бы быть еще больше удобным в применении, если бы в иерархии все его методы, не бы ли бы сделаны final. Его изменение бы легко сделать через наследование и переопределение методов, но разработчики сочли это не подходящим. И здесь зарыта ирония двух причин. Первая, Stack наследуется от Vector, отсюда Stack является Vector, что с точки зрения логики не совсем правда. Вторая, многие из наиболее важных методов класса Vector, такие как addElement( ) и elementAt( ) являются синхронизированными (synchronized). Как Вы увидите в главе 14, при этом система подвергается значительным перегрузкам, которые возможно могут свести на нет все возможности предоставляемые final. Такая неувязочка подтверждает легенду о том, что программисты плохо себе представляют, в каком именно месте должна быть произведена оптимизация. Это просто плохой и неуклюжий дизайн воплощенный в двух стандартных библиотеках, которыми мы все должны пользоваться. (Хорошо, то, что в Java 2 контейнерная библиотека заменила Vector на ArrayList, который ведет себя более прилично. Плохо то, что осталось множество программного обеспечения уже написанного с использованием старой контейнерной библиотеки.)
Так же следует заметить, что другая не менее интересная библиотека Hashtable, не имеет ни одного метода с модификатором final. Как уже упоминалось в этой книге - различные классы написаны различными людьми и из-за этого встречаются такие похожие и не похожие библиотеки. А вот это уже не должно волновать потребителей классов. Если такие вещи противоречивы, то это лишь добавляет работы пользователям. Еще одна победная песнь грамотному дизайну и созданию кода. (Заметьте, что в Java 2 контейнерная библиотека заменила Hashtable на HashMap.)
Инициализация и загрузка классов
В большинстве традиционных языках программирования, программы загружаются как единая часть при запуске. После этого следует стадия инициализации, и после нее программа начинает работать. Процесс инициализации в этих языках должен с осторожностью контролироваться, потому, что последовательность инициализации static "объектов" может вызвать проблемы. C++, к примеру, имеет проблемы, если один из static "объектов" ожидает другой static "объект", но до того, как второй был проинициализирован.
Java же не имеет такой проблемы, поскольку в ней используется отличный подход по загрузке файлов. Поскольку в Java все является объектами, то многие виды деятельности более просты в исполнении, и загрузка входит в их число. Как Вы узнаете в следующей главе, скомпилированный код для каждого класса существует в своем собственном отдельном файле. Эти файлы не загружаются, до того момента, как понадобится код хранящийся в них. Обычно, Вы можете сказать: "Код классов загружается при первой попытке их использования." Но загрузка так же осуществляется часто до того, как первый класс был загружен и проинициализирован полностью, и загрузка других классов случается, когда осуществляется доступ к static полям или static методам.
Точка первого использования другого класса находится там же, где и инициализация static объекта. Все static объекты и весь static блок кода будет инициализирован в текстовом порядке (это значит, что они будут инициализироваться в том порядке, в каком Вы их написали в определении класса) при загрузке. Static объекты, естественно инициализируются только один раз.
Инициализация с наследованием
Полезно взглянуть на процесс инициализации целиком, включая наследование, что бы получить полную картину того, что же происходит на самом деле. Рассмотрим следующий код:
//: c06:Beetle.java // Полный процесс инициализации. class Insect < int i = 9; int j; Insect() < prt("i , j #0000ff" size="+1">int x1 = prt("static Insect.x1 initialized"); static int prt(String s) < System.out.println(s); return 47; > > public class Beetle extends Insect < int k = prt("Beetle.k initialized"); Beetle() < prt("k j #0000ff" size="+1">int x2 = prt("static Beetle.x2 initialized"); public static void main(String[] args) < prt("Beetle constructor"); Beetle b = new Beetle(); > > ///:~
Вот вывод программы:
static Insect.x1 initialized static Beetle.x2 initialized Beetle constructor i = 9, j = 0 Beetle.k initialized k = 47 j = 39
Первая вещь, которая происходит, когда Вы запускаете Java и Beetle это то, что Вы пытаетесь получить доступ к Beetle.main( ) (к static методу), так, что загрузчик пытается найти и открыть скомпилированный код к классу Beetle (он нашел его в файле Beetle.class). В процессе его загрузки компилятор обнаруживает, что этот класс имеет базовый класс (об этом ему сообщает ключевое слово extends), оный он и загружает в последствии. Случилось ли это или нет, Вы собираетесь создать объект базового класса. (Попробуйте закомментировать создание объекта, для того, что бы сделать это самостоятельно.)
Если базовый класс имеет так же базовый класс, то этот второй базовый класс будет загружен и так далее. Дальше, производится инициализация static элементов в корневом классе (в нашем случае в классе Insect), а только затем в дочернем и так далее. И это важно, поскольку static элементы дочернего класса могут быть зависимы от членов базового класса, которые могут не быть проинициализированы корректно к этому времени.
Теперь все нужные классы уже загружены, так что наш объект может быть создан. Сперва, все примитивные элементы нашего объекта устанавливаются в их значения по умолчанию, а ссылки на объекты устанавливаются в null, в "железе" просто устанавливаются ячейки памяти в двоичный ноль. После этого вызывается конструктор базового класса. При этом вызов осуществляется автоматически, но Вы можете так же выбрать какой-то конкретный конструктор базового класса (первый оператор в конструкторе Beetle( )) используя super. Создание базового класса происходит по тем же правилам и в том же порядке, что и создание дочернего класса. После того, как отработает конструктор базового класса все представления переменных уже будут проинициализированы в текстовом порядке.
Резюме
Оба метода, и наследование и композиция позволяют Вам создать новый тип из уже существующего. Обычно, Вы используете композицию для повторного использования существующих типов как части имплементации нового типа, а наследование когда Вам необходимо повторно использовать интерфейс. В силу того, что дочерний класс имеет интерфейс базового класса, он может быть приведен к базовому типу, что весьма важно для полиморфизма, что собственно Вы и увидите в следующей главе.
Относитесь с осторожностью к наследованию в объектно-ориентированном программировании, когда Вы начинаете разработку нового проекта используйте лучше композицию, а после того, как ваш код будет доведен до совершенства измените композицию на наследование если это конечно необходимо. Композиция имеет тенденцию к большей гибкости. Вы так же можете изменять поведение объектов с композицией во время исполнения.
Повторное использование композиции и наследования оказывает огромную помощь для быстрой разработки проектов, Вы обычно хотите изменить иерархию ваших классов, до того, как другие программисты станут работать с вашим проектом и с вашими классами. Вашим преимуществом при этом будет наследование, где каждый класс не большой по размеру (но и не слишком маленький, что бы не потерять функциональность) и выполняет узкую задачу.
Упражнения
Решения этих упражнений могут быть найдены в электронном документе The Thinking in Java Annotated Solution Guide, доступном с www.BruceEckel.com.
- Создайте два класса, A и B, с конструкторами по умолчанию (пустой список аргументов), которые объявляют сами себя. Наследуйте новый класс C от A, и создайте объект класса B внутри C. Не создавайте конструктор для C. Создайте объект класса C и наблюдайте за результатами.
- Модифицируйте упражнение 1 так, что A и B получат конструкторы с аргументами взамен конструкторов по умолчанию. Напишите конструктор для C и осуществите инициализацию с конструктором C.
- Создайте простой класс. Внутри второго класса создайте объект первого класса. Используйте ленивую инициализацию для создания экземпляра этого объекта.
- Наследуйте новый класс от класса Detergent. Переопределите scrub( ) и добавьте новый метод называемый sterilize( ).
- Возьмите файл Cartoon.java и закомментируйте конструктор для класса Cartoon. Объясните, что случилось.
- Возьмите файл Chess.java и закомментируйте конструктор для класса Chess. Объясните, что произошло.
- Докажите, что конструктор по умолчанию создается компилятором.
- Докажите, что конструктор базового класса вызывается всегда и он вызывается до вызова конструктора дочернего класса.
- Создайте базовый класс с конструктором не по умолчанию и наследуйте от него класс с конструктором по умолчанию и не по умолчанию. В конструкторах дочернего класса вызовите конструктор базового класса.
- Создайте класс Root, который содержит экземпляр каждого из классов (которые Вы так же должны создать) Component1, Component2, и Component3. Наследуйте класс Stem от Root который будет так же содержать экземпляры каждого компонента. Каждый класс должен содержать конструктор по умолчанию, который печатает сообщение о этом классе.
- Измените, упражнение 10, так, что бы каждый класс имел только конструкторы не по умолчанию.
- 12. Добавьте в существующую иерархию методы cleanup( ) во все классы в упражнении 11.
- Создайте класс с методом, который перегружен три раза. Наследуйте новый класс, добавьте новую перегрузку метода и посмотрите на то, что все четыре метода доступны в дочернем классе.
- В Car.java добавьте метод service( ) в Engine и вызовите этот метод в main( ).
- Создайте класс внутри пакета. Ваш класс должен иметь один метод с модификатором protected. Снаружи пакета попытайтесь вызвать метод и затем объясните результаты. После этого наследуйте новый класс и вызовите этот метод уже из него.
- Создайте класс Amphibian. От него наследуйте класс Frog. Поместите соответствующие методы в базовый класс. В main( ), создайте Frog и приведите его к базовому типу Amphibian и покажите то, что все методы работают.
- Измените, упражнение 16 так, что бы Frog переопределял определения методов из базового класса (предоставьте новые определения, используя те же самые обозначения методов). Заметьте, что случилось в main( ).
- Создайте новый класс с полем static final и полем final, а затем покажите разницу между ними.
- Создайте класс с пустой final ссылкой на объект. Осуществите ее инициализацию внутри метода (не конструктора) сразу после того, как вы его определили. Покажите то, что final должна быть инициализирована до использования и после этого ее нельзя изменить.
- Создайте класс, содержащий final метод. Наследуйте от этого класса и попытайтесь переопределить этот метод.
- Создайте класс с модификатором final и попытайтесь наследовать от него.
- Докажите, что загрузка класса имеет место быть только один раз. Докажите, что загрузка может быть вызвана созданием первого экземпляра этого класса или доступом к static элементу.
- В Beetle.java, наследуйте специфический тип beetle от класса Beetle, следуйте тому же самому формату, как в существующих классах. Проследите и объясните вывод.