Описательная статистика в EXCEL
Задача описательной статистики (descriptive statistics) заключается в том, чтобы с использованием математических инструментов свести сотни значений выборки к нескольким итоговым показателям, которые дают представление о выборке .В качестве таких статистических показателей используются: среднее , медиана , мода , дисперсия, стандартное отклонение и др.
Опишем набор числовых данных с помощью определенных показателей. Для чего нужны эти показатели? Эти показатели позволят сделать определенные статистические выводы о распределении , из которого была взята выборка . Например, если у нас есть выборка значений толщины трубы, которая изготавливается на определенном оборудовании, то на основании анализа этой выборки мы сможем сделать, с некой определенной вероятностью, заключение о состоянии процесса изготовления.
Надстройка Пакет анализа
Для вычисления статистических показателей одномерных выборок , используем надстройку Пакет анализа . Затем, все показатели рассчитанные надстройкой, вычислим с помощью встроенных функций MS EXCEL.
СОВЕТ : Подробнее о других инструментах надстройки Пакет анализа и ее подключении – читайте в статье Надстройка Пакет анализа MS EXCEL .
Выборку разместим на листе Пример в файле примера в диапазоне А6:А55 (50 значений).
Примечание : Для удобства написания формул для диапазона А6:А55 создан Именованный диапазон Выборка.
В диалоговом окне Анализ данных выберите инструмент Описательная статистика .

После нажатия кнопки ОК будет выведено другое диалоговое окно,
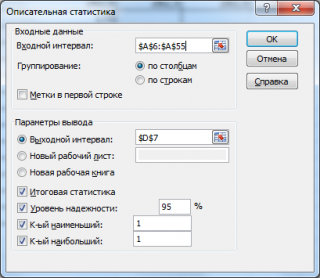
в котором нужно указать:
- входной интервал (Input Range) – это диапазон ячеек, в котором содержится массив данных. Если в указанный диапазон входит текстовый заголовок набора данных, то нужно поставить галочку в поле Метки в первой строке (Labelsinfirstrow). В этом случае заголовок будет выведен в Выходном интервале. Пустые ячейки будут проигнорированы, поэтому нулевые значения необходимо обязательно указывать в ячейках, а не оставлять их пустыми;
- выходной интервал (Output Range). Здесь укажите адрес верхней левой ячейки диапазона, в который будут выведены статистические показатели;
- Итоговая статистика (SummaryStatistics) . Поставьте галочку напротив этого поля – будут выведены основные показатели выборки: среднее, медиана, мода, стандартное отклонение и др.;
- Также можно поставить галочки напротив полей Уровень надежности (ConfidenceLevelforMean) , К-й наименьший (Kth Largest) и К-й наибольший (Kth Smallest).
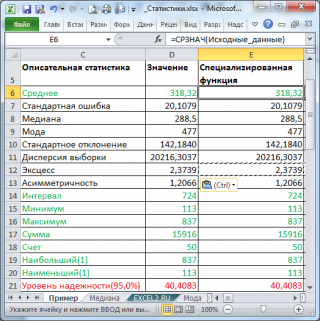
В результате будут выведены следующие статистические показатели:
Все показатели выведены в виде значений, а не формул. Если массив данных изменился, то необходимо перезапустить расчет.
Если во входном интервале указать ссылку на несколько столбцов данных, то будет рассчитано соответствующее количество наборов показателей. Такой подход позволяет сравнить несколько наборов данных. При сравнении нескольких наборов данных используйте заголовки (включите их во Входной интервал и установите галочку в поле Метки в первой строке ). Если наборы данных разной длины, то это не проблема — пустые ячейки будут проигнорированы.
Зеленым цветом на картинке выше и в файле примера выделены показатели, которые не требуют особого пояснения. Для большинства из них имеется специализированная функция:
- Интервал (Range) — разница между максимальным и минимальным значениями;
- Минимум (Minimum) – минимальное значение в диапазоне ячеек, указанном во Входном интервале (см. статью про функцию МИН() );
- Максимум (Maximum)– максимальное значение (см. статью про функцию МАКС() );
- Сумма (Sum) – сумма всех значений (см. статью про функцию СУММ() );
- Счет (Count) – количество значений во Входном интервале (пустые ячейки игнорируются, см. статью про функцию СЧЁТ() );
- Наибольший (Kth Largest) – выводится К-й наибольший. Например, 1-й наибольший – это максимальное значение (см. статью про функцию НАИБОЛЬШИЙ() );
- Наименьший (Kth Smallest) – выводится К-й наименьший. Например, 1-й наименьший – это минимальное значение (см. статью про функцию НАИМЕНЬШИЙ() ).
Ниже даны подробные описания остальных показателей.
Среднее выборки
Среднее (mean, average) или выборочное среднее или среднее выборки (sample average) представляет собой арифметическое среднее всех значений массива. В MS EXCEL для вычисления среднего выборки используется функция СРЗНАЧ() . Выборочное среднее является «хорошей» (несмещенной и эффективной) оценкой математического ожидания случайной величины (подробнее см. статью Среднее и Математическое ожидание в MS EXCEL ).
Медиана выборки
Медиана (Median) – это число, которое является серединой множества чисел (в данном случае выборки): половина чисел множества больше, чем медиана , а половина чисел меньше, чем медиана . Для определения медианы необходимо сначала отсортировать множество чисел . Например, медианой для чисел 2, 3, 3, 4 , 5, 7, 10 будет 4.
Если множество содержит четное количество чисел, то вычисляется среднее для двух чисел, находящихся в середине множества. Например, медианой для чисел 2, 3, 3 , 5 , 7, 10 будет 4, т.к. (3+5)/2.
Если имеется длинный хвост распределения, то Медиана лучше, чем среднее значение , отражает «типичное» или «центральное» значение. Например, рассмотрим несправедливое распределение зарплат в компании, в которой руководство получает существенно больше, чем основная масса сотрудников.
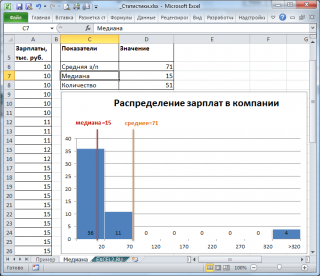
Очевидно, что средняя зарплата (71 тыс. руб.) не отражает тот факт, что 86% сотрудников получает не более 30 тыс. руб. (т.е. 86% сотрудников получает зарплату в более, чем в 2 раза меньше средней!). В то же время медиана (15 тыс. руб.) показывает, что как минимум у 50% сотрудников зарплата меньше или равна 15 тыс. руб.
Для определения медианы в MS EXCEL существует одноименная функция МЕДИАНА() , английский вариант — MEDIAN().
Медиану также можно вычислить с помощью формул
Подробнее о медиане см. специальную статью Медиана в MS EXCEL .
СОВЕТ : Подробнее про квартили см. статью, про перцентили (процентили) см. статью.
Мода выборки
Мода (Mode) – это наиболее часто встречающееся (повторяющееся) значение в выборке . Например, в массиве (1; 1; 2 ; 2 ; 2 ; 3; 4; 5) число 2 встречается чаще всего – 3 раза. Значит, число 2 – это мода . Для вычисления моды используется функция МОДА() , английский вариант MODE().
Примечание : Если в массиве нет повторяющихся значений, то функция вернет значение ошибки #Н/Д. Это свойство использовано в статье Есть ли повторы в списке?
Начиная с MS EXCEL 2010 вместо функции МОДА() рекомендуется использовать функцию МОДА.ОДН() , которая является ее полным аналогом. Кроме того, в MS EXCEL 2010 появилась новая функция МОДА.НСК() , которая возвращает несколько наиболее часто повторяющихся значений (если количество их повторов совпадает). НСК – это сокращение от слова НеСКолько.
Например, в массиве (1; 1; 2 ; 2 ; 2 ; 3; 4 ; 4 ; 4 ; 5) числа 2 и 4 встречаются наиболее часто – по 3 раза. Значит, оба числа являются модами . Функции МОДА.ОДН() и МОДА() вернут значение 2, т.к. 2 встречается первым, среди наиболее повторяющихся значений (см. файл примера , лист Мода ).
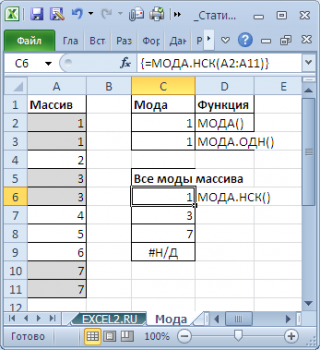
Чтобы исправить эту несправедливость и была введена функция МОДА.НСК() , которая выводит все моды . Для этого ее нужно ввести как формулу массива .
Как видно из картинки выше, функция МОДА.НСК() вернула все три моды из массива чисел в диапазоне A2:A11 : 1; 3 и 7. Для этого, выделите диапазон C6:C9 , в Строку формул введите формулу =МОДА.НСК(A2:A11) и нажмите CTRL+SHIFT+ENTER . Диапазон C 6: C 9 охватывает 4 ячейки, т.е. количество выделяемых ячеек должно быть больше или равно количеству мод . Если ячеек больше чем м о д, то избыточные ячейки будут заполнены значениями ошибки #Н/Д. Если мода только одна, то все выделенные ячейки будут заполнены значением этой моды .
Теперь вспомним, что мы определили моду для выборки, т.е. для конечного множества значений, взятых из генеральной совокупности . Для непрерывных случайных величин вполне может оказаться, что выборка состоит из массива на подобие этого (0,935; 1,211; 2,430; 3,668; 3,874; …), в котором может не оказаться повторов и функция МОДА() вернет ошибку.
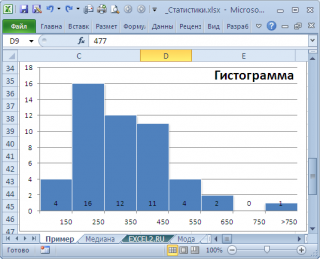
Даже в нашем массиве с модой , которая была определена с помощью надстройки Пакет анализа , творится, что-то не то. Действительно, модой нашего массива значений является число 477, т.к. оно встречается 2 раза, остальные значения не повторяются. Но, если мы посмотрим на гистограмму распределения , построенную для нашего массива, то увидим, что 477 не принадлежит интервалу наиболее часто встречающихся значений (от 150 до 250).
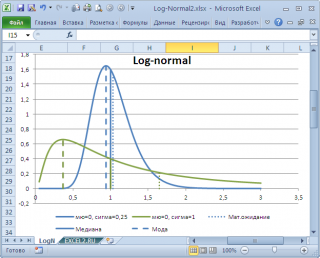
Проблема в том, что мы определили моду как наиболее часто встречающееся значение, а не как наиболее вероятное. Поэтому, моду в учебниках статистики часто определяют не для выборки (массива), а для функции распределения. Например, для логнормального распределения мода (наиболее вероятное значение непрерывной случайной величины х), вычисляется как exp ( m — s 2 ) , где m и s параметры этого распределения.
Понятно, что для нашего массива число 477, хотя и является наиболее часто повторяющимся значением, но все же является плохой оценкой для моды распределения, из которого взята выборка (наиболее вероятного значения или для которого плотность вероятности распределения максимальна).
Для того, чтобы получить оценку моды распределения, из генеральной совокупности которого взята выборка , можно, например, построить гистограмму . Оценкой для моды может служить интервал наиболее часто встречающихся значений (самого высокого столбца). Как было сказано выше, в нашем случае это интервал от 150 до 250.
Вывод : Значение моды для выборки , рассчитанное с помощью функции МОДА() , может ввести в заблуждение, особенно для небольших выборок. Эта функция эффективна, когда случайная величина может принимать лишь несколько дискретных значений, а размер выборки существенно превышает количество этих значений.
Например, в рассмотренном примере о распределении заработных плат (см. раздел статьи выше, о Медиане), модой является число 15 (17 значений из 51, т.е. 33%). В этом случае функция МОДА() дает хорошую оценку «наиболее вероятного» значения зарплаты.
Примечание : Строго говоря, в примере с зарплатой мы имеем дело скорее с генеральной совокупностью , чем с выборкой . Т.к. других зарплат в компании просто нет.
О вычислении моды для распределения непрерывной случайной величины читайте статью Мода в MS EXCEL .
Мода и среднее значение
Не смотря на то, что мода – это наиболее вероятное значение случайной величины (вероятность выбрать это значение из Генеральной совокупности максимальна), не следует ожидать, что среднее значение обязательно будет близко к моде .
Примечание : Мода и среднее симметричных распределений совпадает (имеется ввиду симметричность плотности распределения ).
Представим, что мы бросаем некий «неправильный» кубик, у которого на гранях имеются значения (1; 2; 3; 4; 6; 6), т.е. значения 5 нет, а есть вторая 6. Модой является 6, а среднее значение – 3,6666.
Другой пример. Для Логнормального распределения LnN(0;1) мода равна =EXP(m-s2)= EXP(0-1*1)=0,368, а среднее значение 1,649.
Дисперсия выборки
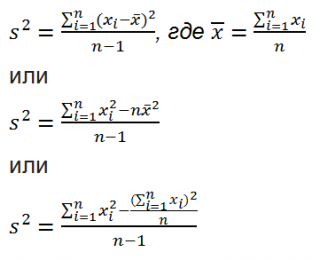
Дисперсия выборки или выборочная дисперсия ( sample variance ) характеризует разброс значений в массиве, отклонение от среднего .
Из формулы №1 видно, что дисперсия выборки это сумма квадратов отклонений каждого значения в массиве от среднего , деленная на размер выборки минус 1.
В MS EXCEL 2007 и более ранних версиях для вычисления дисперсии выборки используется функция ДИСП() . С версии MS EXCEL 2010 рекомендуется использовать ее аналог — функцию ДИСП.В() .
Дисперсию можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера ): =КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1) =(СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/ (СЧЁТ(Выборка)-1) – обычная формула =СУММ((Выборка -СРЗНАЧ(Выборка))^2)/ (СЧЁТ(Выборка)-1) – формула массива
Дисперсия выборки равна 0, только в том случае, если все значения равны между собой и, соответственно, равны среднему значению .
Чем больше величина дисперсии , тем больше разброс значений в массиве относительно среднего .
Размерность дисперсии соответствует квадрату единицы измерения исходных значений. Например, если значения в выборке представляют собой измерения веса детали (в кг), то размерность дисперсии будет кг 2 . Это бывает сложно интерпретировать, поэтому для характеристики разброса значений чаще используют величину равную квадратному корню из дисперсии – стандартное отклонение .
Стандартное отклонение выборки
Стандартное отклонение выборки (Standard Deviation), как и дисперсия , — это мера того, насколько широко разбросаны значения в выборке относительно их среднего .
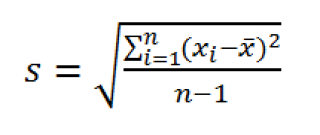
По определению, стандартное отклонение равно квадратному корню из дисперсии :
Стандартное отклонение не учитывает величину значений в выборке , а только степень рассеивания значений вокруг их среднего . Чтобы проиллюстрировать это приведем пример.
Вычислим стандартное отклонение для 2-х выборок : (1; 5; 9) и (1001; 1005; 1009). В обоих случаях, s=4. Очевидно, что отношение величины стандартного отклонения к значениям массива у выборок существенно отличается.
В MS EXCEL 2007 и более ранних версиях для вычисления Стандартного отклонения выборки используется функция СТАНДОТКЛОН() . С версии MS EXCEL 2010 рекомендуется использовать ее аналог СТАНДОТКЛОН.В() .
Стандартное отклонение можно также вычислить непосредственно по нижеуказанным формулам (см. файл примера ): =КОРЕНЬ(КВАДРОТКЛ(Выборка)/(СЧЁТ(Выборка)-1)) =КОРЕНЬ((СУММКВ(Выборка)-СЧЁТ(Выборка)*СРЗНАЧ(Выборка)^2)/(СЧЁТ(Выборка)-1))
Стандартная ошибка
В Пакете анализа под термином стандартная ошибка имеется ввиду Стандартная ошибка среднего (Standard Error of the Mean, SEM). Стандартная ошибка среднего — это оценка стандартного отклонения распределения выборочного среднего .
Примечание : Чтобы разобраться с понятием Стандартная ошибка среднего необходимо прочитать о выборочном распределении (см. статью Статистики, их выборочные распределения и точечные оценки параметров распределений в MS EXCEL ) и статью про Центральную предельную теорему .
Стандартное отклонение распределения выборочного среднего вычисляется по формуле σ/√n, где n — объём выборки, σ — стандартное отклонение исходного распределения, из которого взята выборка . Т.к. обычно стандартное отклонение исходного распределения неизвестно, то в расчетах вместо σ используют ее оценку s — стандартное отклонение выборки . А соответствующая величина s/√n имеет специальное название — Стандартная ошибка среднего. Именно эта величина вычисляется в Пакете анализа.
В MS EXCEL стандартную ошибку среднего можно также вычислить по формуле =СТАНДОТКЛОН.В(Выборка)/ КОРЕНЬ(СЧЁТ(Выборка))
Асимметричность
Асимметричность или коэффициент асимметрии (skewness) характеризует степень несимметричности распределения ( плотности распределения ) относительно его среднего .

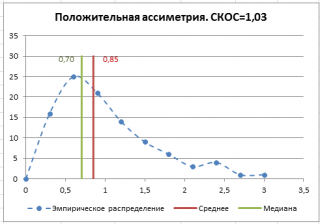
Положительное значение коэффициента асимметрии указывает, что размер правого «хвоста» распределения больше, чем левого (относительно среднего). Отрицательная асимметрия, наоборот, указывает на то, что левый хвост распределения больше правого. Коэффициент асимметрии идеально симметричного распределения или выборки равно 0.
Примечание : Асимметрия выборки может отличаться расчетного значения асимметрии теоретического распределения. Например, Нормальное распределение является симметричным распределением ( плотность его распределения симметрична относительно среднего ) и, поэтому имеет асимметрию равную 0. Понятно, что при этом значения в выборке из соответствующей генеральной совокупности не обязательно должны располагаться совершенно симметрично относительно среднего . Поэтому, асимметрия выборки , являющейся оценкой асимметрии распределения , может отличаться от 0.
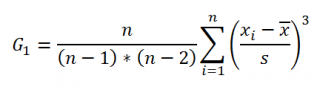
Функция СКОС() , английский вариант SKEW(), возвращает коэффициент асимметрии выборки , являющейся оценкой асимметрии соответствующего распределения, и определяется следующим образом:
где n – размер выборки , s – стандартное отклонение выборки .
В файле примера на листе СКОС приведен расчет коэффициента асимметрии на примере случайной выборки из распределения Вейбулла , которое имеет значительную положительную асимметрию при параметрах распределения W(1,5; 1).
Эксцесс выборки
Эксцесс показывает относительный вес «хвостов» распределения относительно его центральной части.
Для того чтобы определить, что относится к хвостам распределения, а что к его центральной части, можно использовать границы μ +/- σ .
Примечание : Не смотря на старания профессиональных статистиков, в литературе еще попадается определение Эксцесса как меры «остроконечности» (peakedness) или сглаженности распределения. Но, на самом деле, значение Эксцесса ничего не говорит о форме пика распределения.
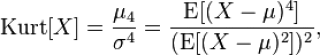
Согласно определения, Эксцесс равен четвертому стандартизированному моменту:
Для нормального распределения четвертый момент равен 3*σ 4 , следовательно, Эксцесс равен 3. Многие компьютерные программы используют для расчетов не сам Эксцесс , а так называемый Kurtosis excess, который меньше на 3. Т.е. для нормального распределения Kurtosis excess равен 0. Необходимо быть внимательным, т.к. часто не очевидно, какая формула лежит в основе расчетов.
Примечание : Еще большую путаницу вносит перевод этих терминов на русский язык. Термин Kurtosis происходит от греческого слова «изогнутый», «имеющий арку». Так сложилось, что на русский язык оба термина Kurtosis и Kurtosis excess переводятся как Эксцесс (от англ. excess — «излишек»). Например, функция MS EXCEL ЭКСЦЕСС() на самом деле вычисляет Kurtosis excess.
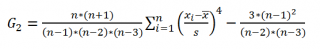
Функция ЭКСЦЕСС() , английский вариант KURT(), вычисляет на основе значений выборки несмещенную оценку эксцесса распределения случайной величины и определяется следующим образом:
Как видно из формулы MS EXCEL использует именно Kurtosis excess, т.е. для выборки из нормального распределения формула вернет близкое к 0 значение.
Если задано менее четырех точек данных, то функция ЭКСЦЕСС() возвращает значение ошибки #ДЕЛ/0!
Вернемся к распределениям случайной величины . Эксцесс (Kurtosis excess) для нормального распределения всегда равен 0, т.е. не зависит от параметров распределения μ и σ. Для большинства других распределений Эксцесс зависит от параметров распределения: см., например, распределение Вейбулла или распределение Пуассона , для котрого Эксцесс = 1/λ.
Уровень надежности
Уровень надежности — означает вероятность того, что доверительный интервал содержит истинное значение оцениваемого параметра распределения.
Вместо термина Уровень надежности часто используется термин Уровень доверия . Про Уровень надежности (Confidence Level for Mean) читайте статью Уровень значимости и уровень надежности в MS EXCEL .
Задав значение Уровня надежности в окне надстройки Пакет анализа , MS EXCEL вычислит половину ширины доверительного интервала для оценки среднего (дисперсия неизвестна) .
Тот же результат можно получить по формуле (см. файл примера ): =ДОВЕРИТ.СТЬЮДЕНТ(1-0,95;s;n) s — стандартное отклонение выборки , n – объем выборки .
Функция ДОВЕРИТ
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще. Меньше
В этой статье описаны синтаксис формулы и использование в Microsoft Excel.
Описание
Возвращает доверительный интервал для среднего генеральной совокупности с нормальным распределением.
Доверительный интервал — это диапазон значений. Выборка «x» находится в центре этого диапазона, а диапазон — x ± ДОВЕРИТ. Например, если x — это пример времени доставки продуктов, заказаных по почте, то x ± ДОВЕРИТ — это диапазон средств численности населения. Для любого средней численности населения (μ0) в этом диапазоне вероятность получения выборки от μ0 больше, чем x, больше, чем альфа; для любого средней численности населения (μ0, не в этом диапазоне), вероятность получения выборки от μ0 больше, чем x, меньше, чем альфа. Другими словами, предположим, что для построения двунамерного теста на уровне значимости альфа гипотезы о том, что это μ0, используются значения x, standard_dev и размер. Тогда мы не отклонить эту гипотезу, если μ0 находится через доверительный интервал, и отклонить эту гипотезу, если μ0 не находится в доверительный интервал. Доверительный интервал не позволяет нам сделать вывод о том, что вероятность 1 — альфа, что следующий пакет займет время доставки через доверительный интервал.
Важно: Эта функция была заменена одной или несколькими новыми функциями, которые обеспечивают более высокую точность и имеют имена, лучше отражающие их назначение. Хотя эта функция все еще используется для обеспечения обратной совместимости, она может стать недоступной в последующих версиях Excel, поэтому мы рекомендуем использовать новые функции.
Чтобы узнать больше о новых функциях, см. в разделах Функция ДОВЕРИТ.НОРМ и Функция ДОВЕРИТ.СТЬЮДЕНТ.
Синтаксис
Аргументы функции ДОВЕРИТ описаны ниже.
- Альфа — обязательный аргумент. Уровень значимости, используемый для вычисления доверительного уровня. Доверительный уровень равен 100*(1 — альфа) процентам или, иными словами, значение аргумента «альфа», равное 0,05, означает 95-процентный доверительный уровень.
- Стандартное_откл — обязательный аргумент. Стандартное отклонение генеральной совокупности для диапазона данных, предполагается известным.
- Размер — обязательный аргумент. Размер выборки.
Замечания
- Если какой-либо из аргументов не является числом, возвращается #VALUE! значение ошибки #ЗНАЧ!.
- Если альфа ≤ 0 или ≥ 1, доверит возвращает #NUM! значение ошибки #ЗНАЧ!.
- Если Standard_dev ≤ 0, возвращается #NUM! значение ошибки #ЗНАЧ!.
- Если значение аргумента «размер» не является целым числом, оно усекается.
- Если размер < 1, доверит возвращает #NUM! значение ошибки #ЗНАЧ!.
- Если предположить, что альфа = 0,05, то нужно вычислить область под стандартной нормальной кривой, которая равна (1 — альфа), или 95 процентам. Это значение равно ± 1,96. Следовательно, доверительный интервал определяется по формуле:
Пример
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Уровень значимости и уровень надежности в EXCEL
СОВЕТ : Для понимания терминов Уровень значимости и Уровень надежности потребуется знание следующих понятий:
- выборочное распределение среднего ;
- стандартное отклонение ;
- проверка гипотез ;
- нормальное распределение .
Уровень значимости статистического теста – это вероятность отклонить нулевую гипотезу , когда на самом деле она верна. Другими словами, это допустимая для данной задачи вероятность ошибки первого рода (type I error).
Уровень значимости обычно обозначают греческой буквой α ( альфа ). Чаще всего для уровня значимости используют значения 0,001; 0,01; 0,05; 0,10.
Например, при построении доверительного интервала для оценки среднего значения распределения , его ширину рассчитывают таким образом, чтобы вероятность события « выборочное среднее (Х ср ) находится за пределами доверительного интервала » было равно уровню значимости . Реализация этого события считается маловероятным (практически невозможным) и служит основанием для отклонения нулевой гипотезы о равенстве среднего заданному значению .
Ошибка первого рода часто называется риском производителя. Это осознанный риск, на который идет производитель продукции, т.к. он определяет вероятность того, что годная продукция может быть забракована, хотя на самом деле она таковой не является. Величина ошибки первого рода задается перед проверкой гипотезы , таким образом, она контролируется исследователем напрямую и может быть задана в соответствии с условиями решаемой задачи.
Чрезмерное уменьшение уровня значимости α (т.е. вероятности ошибки первого рода ) может привести к увеличению вероятности ошибки второго рода , то есть вероятности принять нулевую гипотезу , когда на самом деле она не верна. Подробнее об ошибке второго рода см. статью Ошибка второго рода и Кривая оперативной характеристики .
Уровень значимости обычно указывается в аргументах обратных функций MS EXCEL для вычисления квантилей соответствующего распределения: НОРМ.СТ.ОБР() , ХИ2.ОБР() , СТЬЮДЕНТ.ОБР() и др. Примеры использования этих функций приведены в статьях про проверку гипотез и про построение доверительных интервалов .
Уровень надежности
Уровень доверия (этот термин более распространен в отечественной литературе, чем Уровень надежности ) — означает вероятность того, что доверительный интервал содержит истинное значение оцениваемого параметра распределения.
Уровень доверия равен 1-α, где α – уровень значимости .
Термин Уровень надежности имеет синонимы: уровень доверия, коэффициент доверия, доверительный уровень и доверительная вероятность (англ. Confidence Level , Confidence Coefficient ).
В математической статистике обычно используют значения уровня доверия 90%; 95%; 99%, реже 99,9% и т.д.
Например, Уровень доверия 95% означает, что событие, вероятность которого 1-0,95=5% исследователь считать маловероятным или невозможным. Разумеется, выбор уровня доверия полностью зависит от исследователя. Так, степень доверия авиапассажира к надежности самолета, несомненно, должна быть выше степени доверия покупателя к надежности электрической лампочки.
Примечание : Стоит отметить, что математически не корректно говорить, что Уровень доверия является вероятностью, того что оцениваемый параметр распределения принадлежит доверительному интервалу , вычисленному на основе выборки . Поскольку, считается, что в математической статистике отсутствуют априорные сведения о параметре распределения. Математически правильно говорить, что доверительный интервал , с вероятностью равной Уровню доверия, накроет истинное значение оцениваемого параметра распределения.
Уровень надежности в MS EXCEL
В MS EXCEL Уровень надежности упоминается в надстройке Пакет анализа . После вызова надстройки, в диалоговом окне необходимо выбрать инструмент Описательная статистика .
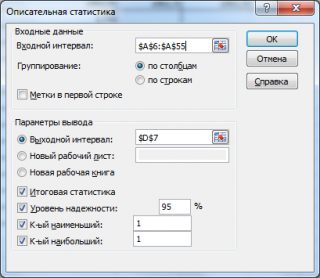
После нажатия кнопки ОК будет выведено другое диалоговое окно.
В этом окне задается Уровень надежности, т.е.значениевероятности в процентах. После нажатия кнопки ОК в выходном интервале выводится значение равное половине ширины доверительного интервала . Этот доверительный интервал используется для оценки среднего значения распределения, когда дисперсия не известна (подробнее см. статью про доверительный интервал ).
Необходимо учитывать, что данный доверительный интервал рассчитывается при условии, что выборка берется из нормального распределения . Но, на практике обычно принимается, что при достаточно большой выборке (n>30), доверительный интервал будет построен приблизительно правильно и для распределения, не являющегося нормальным (если при этом это распределение не будет иметь сильной асимметрии ).
Примечание : Понять, что в диалоговом окне речь идет именно об оценке среднего значения распределения , достаточно сложно. Хотя в английской версии диалогового окна это указано прямо: Confidence Level for Mean .
Если Уровень надежности задан 95%, то надстройка Пакет анализа использует следующую формулу (выводится не сама формула, а лишь ее результат):
или эквивалентную ей
где =СТАНДОТКЛОН.В(Выборка)/КОРЕНЬ(СЧЁТ(Выборка)) – является стандартной ошибкой среднего (формулы приведены в файле примера ).
=ДОВЕРИТ.СТЬЮДЕНТ(1-0,95; СТАНДОТКЛОН.В(Выборка); СЧЁТ(Выборка))
Функция ЛИНЕЙН
Excel для Microsoft 365 Excel для Microsoft 365 для Mac Excel для Интернета Excel 2021 Excel 2021 для Mac Excel 2019 Excel 2019 для Mac Excel 2016 Excel 2016 для Mac Excel 2013 Excel 2010 Excel 2007 Excel для Mac 2011 Excel Starter 2010 Еще. Меньше
В этой статье описаны синтаксис формулы и использование функции LINEST в Microsoft Excel. Ссылки на дополнительные сведения о диаграммах и выполнении регрессионного анализа можно найти в разделе См. также.
Описание
Функция ЛИНЕЙН рассчитывает статистику для ряда с применением метода наименьших квадратов, чтобы вычислить прямую линию, которая наилучшим образом аппроксимирует имеющиеся данные и затем возвращает массив, который описывает полученную прямую. Функцию ЛИНЕЙН также можно объединять с другими функциями для вычисления других видов моделей, являющихся линейными по неизвестным параметрам, включая полиномиальные, логарифмические, экспоненциальные и степенные ряды. Поскольку возвращается массив значений, функция должна задаваться в виде формулы массива. Инструкции приведены в данной статье после примеров.
Уравнение для прямой линии имеет следующий вид:
y = m1x1 + m2x2 +. + b
если существует несколько диапазонов значений x, где зависимые значения y — функции независимых значений x. Значения m — коэффициенты, соответствующие каждому значению x, а b — постоянная. Обратите внимание, что y, x и m могут быть векторами. Функция ЛИНЕЙН возвращает массив . Функция ЛИНЕЙН может также возвращать дополнительную регрессионную статистику.
Синтаксис
ЛИНЕЙН(известные_значения_y; [известные_значения_x]; [конст]; [статистика])
Аргументы функции ЛИНЕЙН описаны ниже.
Синтаксис
- Известные_значения_y. Обязательный аргумент. Множество значений y, которые уже известны для соотношения y = mx + b.
- Если массив известные_значения_y имеет один столбец, то каждый столбец массива известные_значения_x интерпретируется как отдельная переменная.
- Если массив известные_значения_y имеет одну строку, то каждая строка массива известные_значения_x интерпретируется как отдельная переменная.
- Массив известные_значения_x может содержать одно или несколько множеств переменных. Если используется только одна переменная, то массивы известные_значения_y и известные_значения_x могут иметь любую форму — при условии, что они имеют одинаковую размерность. Если используется более одной переменной, то известные_значения_y должны быть вектором (т. е. интервалом высотой в одну строку или шириной в один столбец).
- Если массив известные_значения_x опущен, то предполагается, что это массив , имеющий такой же размер, что и массив известные_значения_y.
- Если аргумент конст имеет значение ИСТИНА или опущен, то константа b вычисляется обычным образом.
- Если аргумент конст имеет значение ЛОЖЬ, то значение b полагается равным 0 и значения m подбираются таким образом, чтобы выполнялось соотношение y = mx.
- Если статистика имеет true, то LINEST возвращает дополнительную регрессию; в результате возвращается массив .
- Если аргумент статистика имеет значение ЛОЖЬ или опущен, функция ЛИНЕЙН возвращает только коэффициенты m и постоянную b. Дополнительная регрессионная статистика.
Стандартные значения ошибок для коэффициентов m1,m2. mn.
Стандартное значение ошибки для постоянной b (seb = #Н/Д, если аргумент конст имеет значение ЛОЖЬ).
Коэффициент определения. Сравнивает предполагаемые и фактические значения y и диапазоны значений от 0 до 1. Если значение 1, то в выборке будет отличная корреляция— разница между предполагаемым значением y и фактическим значением y не существует. С другой стороны, если коэффициент определения — 0, уравнение регрессии не помогает предсказать значение y. Сведения о том, как вычисляется 2, см. в разделе «Замечания» далее в этой теме.
Стандартная ошибка для оценки y.
F-статистика или F-наблюдаемое значение. F-статистика используется для определения того, является ли случайной наблюдаемая взаимосвязь между зависимой и независимой переменными.
Степени свободы. Степени свободы используются для нахождения F-критических значений в статистической таблице. Для определения уровня надежности модели необходимо сравнить значения в таблице с F-статистикой, возвращаемой функцией ЛИНЕЙН. Дополнительные сведения о вычислении величины df см. ниже в разделе «Замечания». Далее в примере 4 показано использование величин F и df.
Регрессионная сумма квадратов.
Остаточная сумма квадратов. Дополнительные сведения о расчете величин ssreg и ssresid см. в подразделе «Замечания» в конце данного раздела.
На приведенном ниже рисунке показано, в каком порядке возвращается дополнительная регрессионная статистика.
Замечания
- Любую прямую можно описать ее наклоном и пересечением с осью y: Наклон (m):
Чтобы найти наклон линии, обычно записанной как m, возьмите две точки на строке (x1;y1) и (x2;y2); наклон равен (y2 — y1)/(x2 — x1). Y-перехват (b):
Y-пересечение строки, обычно записанное как b, — это значение y в точке, в которой линия пересекает ось y. Уравнение прямой имеет вид y = mx + b. Если известны значения m и b, то можно вычислить любую точку на прямой, подставляя значения y или x в уравнение. Можно также воспользоваться функцией ТЕНДЕНЦИЯ. - Если имеется только одна независимая переменная x, можно получить наклон и y-пересечение непосредственно, воспользовавшись следующими формулами: Наклон:
=ИНДЕКС( LINEST(known_y,known_x’s);1) Y-перехват:
=ИНДЕКС( LINEST(known_y,known_x),2) - Точность аппроксимации с помощью прямой, вычисленной функцией ЛИНЕЙН, зависит от степени разброса данных. Чем ближе данные к прямой, тем более точной является модель ЛИНЕЙН. Функция ЛИНЕЙН использует для определения наилучшей аппроксимации данных метод наименьших квадратов. Когда имеется только одна независимая переменная x, значения m и b вычисляются по следующим формулам: где x и y — выборочные средние значения, например x = СРЗНАЧ(известные_значения_x), а y = СРЗНАЧ(известные_значения_y).
- Функции ЛИННЕСТРОЙ и ЛОГЪЕСТ могут вычислять наилучшие прямые или экспоненциальное кривой, которые подходят для ваших данных. Однако необходимо решить, какой из двух результатов лучше всего подходит для ваших данных. Вы можетевычислить known_y(known_x) для прямой линии или РОСТ(known_y, known_x в) для экспоненциальной кривой. Эти функции без аргумента new_x возвращают массив значений y, спрогнозируемых вдоль этой линии или кривой в фактических точках данных. Затем можно сравнить спрогнозируемые значения с фактическими значениями. Для наглядного сравнения можно отобразить оба этих диаграммы.
- Проводя регрессионный анализ, Microsoft Excel вычисляет для каждой точки квадрат разности между прогнозируемым значением y и фактическим значением y. Сумма этих квадратов разностей называется остаточной суммой квадратов (ssresid). Затем Microsoft Excel подсчитывает общую сумму квадратов (sstotal). Если конст = ИСТИНА или значение этого аргумента не указано, общая сумма квадратов будет равна сумме квадратов разностей действительных значений y и средних значений y. При конст = ЛОЖЬ общая сумма квадратов будет равна сумме квадратов действительных значений y (без вычитания среднего значения y из частного значения y). После этого регрессионную сумму квадратов можно вычислить следующим образом: ssreg = sstotal — ssresid. Чем меньше остаточная сумма квадратов по сравнению с общей суммой квадратов, тем больше значение коэффициента определения r 2 — индикатор того, насколько хорошо уравнение, выданное в результате регрессионного анализа, объясняет связь между переменными. Значение r 2 равно ssreg/sstotal.
- В некоторых случаях один или несколько столбцов X (предполагается, что значения Y и X — в столбцах) могут не иметь дополнительного прогнозируемого значения при наличии других столбцов X. Другими словами, удаление одного или более столбцов X может привести к одинаковой точности предсказания значений Y. В этом случае эти избыточные столбцы X следует не использовать в модели регрессии. Этот вариант называется «коллинеарность», так как любой избыточный X-столбец может быть выражен как сумма многих не избыточных X-столбцов. Функция ЛИНЕЙН проверяет коллинеарность и удаляет все избыточные X-столбцы из модели регрессии при их идентификации. Удалены столбцы X распознаются в результатах LINEST как имеющие коэффициенты 0 в дополнение к значениям 0 se. Если один или несколько столбцов будут удалены как избыточные, это влияет на df, поскольку df зависит от числа X столбцов, фактически используемых для прогнозирования. Подробные сведения о вычислении df см. в примере 4. Если значение df изменилось из-за удаления избыточных X-столбцов, это также влияет на значения Sey и F. Коллинеарность должна быть относительно редкой на практике. Однако чаще всего возникают ситуации, когда некоторые столбцы X содержат только значения 0 и 1 в качестве индикаторов того, является ли тема в эксперименте участником определенной группы или не является ее участником. Если конст = ИСТИНА или опущен, функция LYST фактически вставляет дополнительный столбец X из всех 1 значений для моделирования перехвата. Если у вас есть столбец с значением 1 для каждой темы, если мальчик, или 0, а также столбец с 1 для каждой темы, если она является женщиной, или 0, последний столбец является избыточным, так как записи в нем могут быть получены из вычитания записи в столбце «самец» из записи в дополнительном столбце всех 1 значений, добавленных функцией LINEST.
- Вычисление значения df для случаев, когда столбцы X удаляются из модели вследствие коллинеарности происходит следующим образом: если существует k столбцов известных_значений_x и значение конст = ИСТИНА или не указано, то df = n – k – 1. Если конст = ЛОЖЬ, то df = n — k. В обоих случаях удаление столбцов X вследствие коллинеарности увеличивает значение df на 1.
- При вводе константы массива (например, в качестве аргумента известные_значения_x) следует использовать точку с запятой для разделения значений в одной строке и двоеточие для разделения строк. Знаки-разделители могут быть другими в зависимости от региональных параметров.
- Следует отметить, что значения y, предсказанные с помощью уравнения регрессии, возможно, не будут правильными, если они располагаются вне интервала значений y, которые использовались для определения уравнения.
- Основной алгоритм, используемый в функции ЛИНЕЙН, отличается от основного алгоритма функций НАКЛОН и ОТРЕЗОК. Разница между алгоритмами может привести к различным результатам при неопределенных и коллинеарных данных. Например, если точки данных аргумента известные_значения_y равны 0, а точки данных аргумента известные_значения_x равны 1, то:
- Функция ЛИНЕЙН возвращает значение, равное 0. Алгоритм функции ЛИНЕЙН используется для возвращения подходящих значений для коллинеарных данных, и в данном случае может быть найден по меньшей мере один ответ.
- Наклон и ОТОКП возвращают #DIV/0! ошибка «#ЗНАЧ!». Алгоритм функций НАКЛОН и ОТОКП предназначен для поиска только одного ответа, и в этом случае может быть несколько ответов.
Примеры
Пример 1. Наклон и Y-пересечение
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Известные значения y
Известные значения x
Результат (наклон)
Результат (y-пересечение)
Формула (формула массива в ячейках A7:B7)
Пример 2. Простая линейная регрессия
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Вычисляет предполагаемый объем продаж в девятом месяце на основе данных о продажах за период с первого по шестой месяцы.
Пример 3. Множественная линейная регрессия
Скопируйте образец данных из следующей таблицы и вставьте их в ячейку A1 нового листа Excel. Чтобы отобразить результаты формул, выделите их и нажмите клавишу F2, а затем — клавишу ВВОД. При необходимости измените ширину столбцов, чтобы видеть все данные.
Общая площадь (x1)
Количество офисов (x2)
Количество входов (x3)
Время эксплуатации (x4)
Оценочная цена (y)
Формула (формула динамического массива, введенная в A19)
=ЛИНЕЙН(E2:E12; A2:D12; ИСТИНА; ИСТИНА)
Пример 4. Использование статистики F и r 2
В предыдущем примере коэффициент определения (r 2) составляет 0,99675 (см. ячейку A17 в результатах для ЛИТН), что указывает на крепкая связь между независимыми переменными и ценой продажи. F-статистику можно использовать для определения случайности этих результатов с таким высоким значением r2.
Предположим, что на самом деле взаимосвязи между переменными не существует, просто статистический анализ вывел сильную взаимозависимость по взятой равномерной выборке 11 зданий. Величина «Альфа» используется для обозначения вероятности ошибочного вывода о существовании сильная взаимозависимости.
Значения F и df в результатах функции LINEST можно использовать для оценки вероятности возникновения более высокого F-значения. F можно сравнивать с критическими значениями в опубликованных F-таблицах или с помощью функции FРАСП в Excel для вычисления вероятности случайного возникновения большего F-значения. Соответствующее F-распределение имеет v1 и v2 степени свободы. Если n — количество точек данных и конст = ИСТИНА или опущен, то v1 = n – df – 1 и v2 = df. (Если конст = ЛОЖЬ, то v1 = n – df и v2 = df.) Функция FIST с синтаксисом FDIST(F;v1;v2) возвращает вероятность возникновения более высокого F-значения, случайного. В этом примере df = 6 (ячейка B18) и F = 459,753674 (ячейка A18).
Предположим, что альфа имеет значение 0,05, v1 = 11 – 6 – 1 = 4, а v2 = 6, критический уровень F составляет 4,53. Поскольку F = 459,753674 значительно больше 4,53, вероятность того, что F-значение этого высокой случайности превышает 4,53, крайне маловероятно. (Если значение «Альфа» = 0,05, гипотеза о том, что между known_y и known_x нет связи, отклоняется при превышении F критического уровня (4,53).) Функцию FDIST в Excel можно использовать для получения вероятности случайного возникновения F-значения. Например, FIST(459,753674, 4, 6) = 1,37E-7, очень небольшая вероятность. Можно сделать вывод о том, что формула регрессии полезна для предсказания оценочного значения офисных зданий в этой области, найдя критический уровень F в таблице или с помощью функции FDIST. Помните, что крайне важно использовать правильные значения 1 и 2, вычисленные в предыдущем абзаце.
Пример 5. Вычисление t-статистики
Другой тест позволяет определить, подходит ли каждый коэффициент наклона для оценки стоимости здания под офис в примере 3. Например, чтобы проверить, имеет ли срок эксплуатации здания статистическую значимость, разделим -234,24 (коэффициент наклона для срока эксплуатации здания) на 13,268 (оценка стандартной ошибки для коэффициента времени эксплуатации из ячейки A15). Ниже приводится наблюдаемое t-значение:
t = m4 ÷ se4 = –234,24 ÷ 13,268 = –17,7
Если абсолютное значение t достаточно велико, можно сделать вывод, что коэффициент наклона можно использовать для оценки стоимости здания под офис в примере 3. В таблице ниже приведены абсолютные значения четырех наблюдаемых t-значений.
Если обратиться к справочнику по математической статистике, то окажется, что t-критическое двустороннее с 6 степенями свободы равно 2,447 при Альфа = 0,05. Критическое значение также можно также найти с помощью функции Microsoft Excel СТЬЮДРАСПОБР. СТЬЮДРАСПОБР(0,05; 6) = 2,447. Поскольку абсолютная величина t, равная 17,7, больше, чем 2,447, срок эксплуатации — это важная переменная для оценки стоимости здания под офис. Аналогичным образом можно протестировать все другие переменные на статистическую значимость. Ниже приводятся наблюдаемые t-значения для каждой из независимых переменных.
t-наблюдаемое значение