Частота встречаемости символа в строке
Определить, как часто встречается определенный символ в строке.
- s – строка;
- c – символ;
- count – количество найденных символов в строке;
- freq – частота встречаемости, определяемая по формуле (n / len) * 100 .
Алгоритм решения задачи:
- Получить строку и символ.
- Определить длину строки.
- Перебрать каждый символ в строке:
- если очередной символ строки совпадает с заданным символом, то увеличить счетчик символов count на единицу.
Программа на языке Паскаль:
var s: string; c: char; count, i: byte; freq: real; begin write('String: '); readln(s); write('Char: '); readln(c); count := 0; for i:=1 to length(s) do if s[i] = c then count := count + 1; freq := (count / length(s)) * 100; writeln('Frequency: ', freq:5:2, '%'); end.String: hello world Char: l Frequency: 27.27%Частотный анализ текста. Пример написания калькулятора
Немного о частотном анализе текста и рассказ о создании калькулятора.
В общем, есть такая тема — частотный анализ текста. Утверждается, что для данного языка частота встречаемости отдельных букв в осмысленном тексте есть устойчивая величина. Устойчивыми также являются комбинации двух, трех (биграммы, триграммы) и четырех букв.
Этот факт, в частности, использовался в криптографии для вскрытия шифров.Я в криптографии не очень, и единственное, что приходит на ум, это вскрытие шифра прямой замены. Надо сказать, наиболее примитивного шифра, когда символы исходного алфавита, используемого в сообщении, преобразуются в другие символы по определенному правилу. Такие шифры, кстати сказать, можно было вскрывать и без применения статистического анализа (где для уменьшения погрешности, очевидно, требуется наличие довольно больших кусков текста), а просто догадываясь о некоторых словах — см. рассказ «Пляшущие человечки».
Вот тут, впрочем, интересная статья про историю криптографии.
На самом деле частота встречаемости букв также зависит от типа текста. Калькулятор ниже рассчитывает частоты букв для введенного пользователем текста и выводит для сравнения теоретические частоты букв для художественного русского текста. В качестве значения по умолчанию взят научный текст (начало определения дифференциального уравнения из Википедии), и сразу видно, как, например, различается частота встречаемости буквы Ф в художественном и научном текстах.
Частоты букв для художественного текста я взял отсюда, ну а по указанному адресу утверждают, что взяли их из книги «Яглом А. М., Яглом И. М., Вероятость и информация, М.: Наука, 1973».
Этот калькулятор был создан как пример, для того чтобы продолжить рассказ о том, как создавать калькуляторы на этом сайте, начатый здесь — Площадь четырехугольника. Пример написания калькулятора. В данном случае на примере этого калькулятора я расскажу о том, как писать калькуляторы, выводящие таблицы и строящие графики. Как обычно, все что нужно от автора — некоторое знание Javascript, ну или вообще любого алгоритмического языка программирования. Интересующиеся смотрят текст после самого калькулятора.
Python. Частота появления слов и букв независимо от их регистра в тексте который находиться в файле
Нужно написать программу, которая будет анализировать частоту с которой в тексте(в файле) будут встречаться отдельные буквы или слова независимо от их регистра и выводить в консоль потом записывать в новый файл. Для начала:
with open(filename, encoding="utf8") as file: text = file.read() text = text.replace("\n", " ") text = text.replace(",", "").replace(".", "").replace(":", "").replace(";", "").replace("?", "").replace("!", "") text = text.lower() words = text.split()Таким образом получаем текст из файла и убираем всё лишние из текста, а дальше как правильно сделать не понимаю.
Отслеживать
7,797 13 13 золотых знаков 25 25 серебряных знаков 55 55 бронзовых знаков
задан 24 окт 2022 в 22:10
Василий Котеков Василий Котеков
27 6 6 бронзовых знаков2 ответа 2
Сортировка: Сброс на вариант по умолчанию
Для слов
from collections import Counter import re words = re.findall(r'\w+', text.lower()) cnt = Counter(words).most_common(10) # для примера 10 самых популярных with open("new.txt", "w") as file: file.write(cnt)Для букв
Тоже самое, но для паттерна для модуля re использовать отдельные буквы. В зависимоти от того насколько большой текст, возможно, стоит отказаться для подсчета букв от данного модуля и использовать конструкцию
str.count("a")И использовать перебор по всем буквам алфавита
from string import ascii_lowercase as letters cnt = Counter() for letter in letters: cnt[letter] = text.lower().count(letter)Запись организовать как указано выше
и так далее, для чисел, для знаков и прочее
Чтобы удалить все знаки препинания, тоже можно воспользоваться модулем re
import re text = re.sub(r'[^\w\s]', '', text)Теперь если все объеденить
import re import json from collections import Counter from string import ascii_lowercase as letters # чтение def read_file(path): result = None with open(path, encoding="utf8") as file: text = file.read().lower() result = re.sub(r'[^\w\s]', '', text) # это излишнее можно удалить, только для примера использую return result def find_words(text): words = re.findall(r'\w+', text) cnt = Counter(words) return dict(cnt) def find_letters(text): cnt = Counter() for letter in letters: cnt[letter] = text.count(letter) return dict(cnt) # запись def write_file(all_entities, path): with open(path, "w") as file: json.dump(all_entities, file, indent = 4) # Основная логика file = read_file("test_data.txt") words = find_words(file) letters = find_letters(file) common_dict = write_file(common_dict, "new_file.txt")Пример результирующего файла на тексте рыбе
< "words": < "but": 4, "i": 2, "must": 1, "explain": 1, "to": 7, "you": 2, "how": 2, "all": 1, "this": 1, "mistaken": 1, "idea": 1, "of": 7, "denouncing": 1, "pleasure": 7, "and": 4, "praising": 1, "pain": 5, "was": 1, "born": 1, "will": 1, "give": 1, "a": 5, "complete": 1, "account": 1, "the": 5, "system": 1, "expound": 1, "actual": 1, "teachings": 1, "great": 2, "explorer": 1, "truth": 1, "masterbuilder": 1, "human": 1, "happiness": 1, "no": 3, "one": 2, "rejects": 1, "dislikes": 1, "or": 4, "avoids": 2, "itself": 2, "because": 4, "it": 3, "is": 3, "those": 1, "who": 5, "do": 1, "not": 1, "know": 1, "pursue": 1, "rationally": 1, "encounter": 1, "consequences": 2, "that": 3, "are": 1, "extremely": 1, "painful": 1, "nor": 1, "again": 1, "there": 1, "anyone": 1, "loves": 1, "pursues": 1, "desires": 1, "obtain": 2, "occasionally": 1, "circumstances": 1, "occur": 1, "in": 1, "which": 2, "toil": 1, "can": 1, "procure": 1, "him": 1, "some": 2, "take": 1, "trivial": 1, "example": 1, "us": 1, "ever": 1, "undertakes": 1, "laborious": 1, "physical": 1, "exercise": 1, "except": 1, "advantage": 1, "from": 1, "has": 2, "any": 1, "right": 1, "find": 1, "fault": 1, "with": 1, "man": 1, "chooses": 1, "enjoy": 1, "annoying": 1, "produces": 1, "resultant": 1 >, "letters": < "a": 74, "b": 13, "c": 32, "d": 17, "e": 93, "f": 13, "g": 10, "h": 33, "i": 53, "j": 2, "k": 5, "l": 33, "m": 14, "n": 56, "o": 68, "p": 27, "q": 2, "r": 43, "s": 59, "t": 61, "u": 42, "v": 7, "w": 13, "x": 7, "y": 11, "z": 0 >>Научный форум dxdy
Дано текстовое сообщение,найти частоту символов,энтропию.
Дано текстовое сообщение,найти частоту символов,энтропию.
17.10.2017, 11:58Последний раз редактировалось seven-red 17.10.2017, 12:02, всего редактировалось 1 раз.
Добрый день дана следующая задача c которой хочется разобраться
Дано слово «Раскраска». Подсчитать частоты встречаемости символов и найти:
— количество информации в сообщении;
— энтропию с помощью полученных частот;
— абсолютную избыточность кодирования;
— теоретическую максимальную степень сжатия сообщения;Я нашёл частоту встречаемости символов таким образом. Для начала выписал сколько раз встречается каждый символ и применял следующую формулу

А=3 раза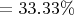
С=2 раза
К=2 разаФормулы нахождения количества информации и энтропии(как и все дальнейшие формулы) были взяты из методички
1)Количество информации
2)Энтропия
4)теоретическую максимальную степень сжатия сообщения и
и  используются следующие формулы
используются следующие формулы —
—  логарифм числа символов в алфавите сообщений
логарифм числа символов в алфавите сообщенийОпять же как я понял
 это энтропия полученная с помощью частот,а вот что означает
это энтропия полученная с помощью частот,а вот что означает 
И по поводу здесь получается нахождения логарифма количества символов в строке?