Пример нейронных сетей на C++
Вот уже который день пытаюсь найти в гугле нормальный полный пример реализации простой нейронной сети на c++, непонимаю почему за столько лет популярности данной темы, в сети до сих пор не появилась тонна информации по данной теме. Помогите пожалуйста. PS Единственное что есть https://habr.com/ru/post/440162/ где почему-то реалзацию автора раскритиковали с ног до головы, может он что-то неправильно сделал? Еще есть вопрос по его коду, который мне вообще не понятен, насколько я понимаю, нейронная сеть состоит из нейронов, которые состоят в слоях и которые связанные между собой, сам нейрон содержит- является значением(весом) float Что делает данный автор:
void setIO(int inputs, int outputs) < //--- initialization values and allocating memory in=inputs; out=outputs; errors = (float*) malloc((out)*sizeof(float)); hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float*)); for(int inp =0; inp < in+1; inp++) < matrix[inp] = (float*) malloc(out*sizeof(float)); >for(int inp =0; inp < in+1; inp++) < for(int outp =0; outp < out; outp++) < matrix[inp][outp] = randWeight; >> > Он создает слой, который состоит из inputs-количества нейронов, которые имеют не одно значение, а целых outputs, почему так? и зачем отдельно еще делать
errors = (float*) malloc((out)*sizeof(float)); hidden = (float*) malloc((out)*sizeof(float)); Отслеживать
2,261 1 1 золотой знак 8 8 серебряных знаков 11 11 бронзовых знаков
задан 16 июл 2020 в 12:54
1 1 1 бронзовый знак
16 июл 2020 в 13:00
«может он что-то неправильно сделал» — да почти все неправильно сделал
16 июл 2020 в 13:01
Кстати, его раскритиковал участник русского стековерфлова @gbg, так что тут будет то же самое 🙂
16 июл 2020 в 13:01
Сам нейрон не является весом:) он является контрольной точкой, «сумматором»
16 июл 2020 в 13:29
Тоесть нейрон не имеет веса, он хранит в себе веса всех входящих в него нейронов, я правильно понял?
16 июл 2020 в 15:52
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
//Had a lot of trouble with shuffle #include #include #include #include #include #define PI 3.141592653589793238463 #define N #define epsilon 0.1 #define epoch 2000 using namespace std; // Just for GNU Plot issues extern "C" FILE *popen(const char *command, const char *mode); // Defining activation functions //double sigmoid(double x) < return 1.0f / (1.0f + exp(-x)); >//double dsigmoid(double x) < return x * (1.0f - x); >double tanh(double x) < return (exp(x)-exp(-x))/(exp(x)+exp(-x)) ;>double dtanh(double x) double lin(double x) < return x;>double dlin(double x) < return 1.0f;>double init_weight() < return (2*rand()/RAND_MAX -1); >double MAXX = -9999999999999999; //maximum value of input example // Network Configuration static const int numInputs = 1; static const int numHiddenNodes = 7; static const int numOutputs = 1; // Learning Rate const double lr = 0.05f; double hiddenLayer[numHiddenNodes]; double outputLayer[numOutputs]; double hiddenLayerBias[numHiddenNodes]; double outputLayerBias[numOutputs]; double hiddenWeights[numInputs][numHiddenNodes]; double outputWeights[numHiddenNodes][numOutputs]; static const int numTrainingSets = 50; double training_inputs[numTrainingSets][numInputs]; double training_outputs[numTrainingSets][numOutputs]; // Shuffling the data with each epoch void shuffle(int *array, size_t n) < if (n >1) //If no. of training examples > 1 < size_t i; for (i = 0; i < n - 1; i++) < size_t j = i + rand() / (RAND_MAX / (n - i) + 1); int t = array[j]; array[j] = array[i]; array[i] = t; >> > // Forward Propagation. Only used after training is done. void predict(double test_sample[]) < for (int j=0; jhiddenLayer[j] = tanh(activation); > for (int j=0; j outputLayer[j] = lin(activation); > //std::cout int main(int argc, const char * argv[]) < ///TRAINING DATA GENERATION for (int i = 0; i < numTrainingSets; i++) < double p = (2*PI*(double)i/numTrainingSets); training_inputs[i][0] = (p); training_outputs[i][0] = sin(p); ///FINDING NORMALIZING FACTOR for(int m=0; m///NORMALIZING for (int i = 0; i < numTrainingSets; i++) < for(int m=0; m///WEIGHT & BIAS INITIALIZATION for (int i=0; i > for (int i=0; i > for (int i=0; i ///FOR INDEX SHUFFLING int trainingSetOrder[numTrainingSets]; for(int j=0; j performance, epo; ///STORE MSE, EPOCH for (int n=0; n < epoch; n++) < double MSE = 0; shuffle(trainingSetOrder,numTrainingSets); std::couthiddenLayer[j] = tanh(activation); > for (int j=0; j outputLayer[j] = lin(activation); > //std::cout /// For W double deltaHidden[numHiddenNodes]; for (int j=0; j deltaHidden[j] = errorHidden*dtanh(hiddenLayer[j]); > ///Updation /// For V and b for (int j=0; j > /// For W and c for (int j=0; j > > //Averaging the MSE MSE /= 1.0f*numTrainingSets; //cout // Print weights std::cout std::cout std::cout std::cout std::cout std::cout std::cout x; vector y1, y2; //double test_input[1000][numInputs]; int numTestSets = numTrainingSets; for (float i = 0; i < numTestSets; i=i+0.25) < double p = (2*PI*(double)i/numTestSets); x.push_back(p); y1.push_back(sin(p)); double test_input[1]; test_input[0] = p/MAXX; predict(test_input); y2.push_back(outputLayer[0]*MAXX); >FILE * gp = popen("gnuplot", "w"); fprintf(gp, "set terminal wxt size 600,400 \n"); fprintf(gp, "set grid \n"); fprintf(gp, "set title '%s' \n", "f(x) = x sin (x)"); fprintf(gp, "set style line 1 lt 3 pt 7 ps 0.1 lc rgb 'green' lw 1 \n"); fprintf(gp, "set style line 2 lt 3 pt 7 ps 0.1 lc rgb 'red' lw 1 \n"); fprintf(gp, "plot '-' w p ls 1, '-' w p ls 2 \n"); ///Exact f(x) = sin(x) -> Green Graph for (int k = 0; k < x.size(); k++) < fprintf(gp, "%f %f \n", x[k], y1[k]); >fprintf(gp, "e\n"); ///Neural Network Approximate f(x) = xsin(x) -> Red Graph for (int k = 0; k < x.size(); k++) < fprintf(gp, "%f %f \n", x[k], y2[k]); >fprintf(gp, "e\n"); fflush(gp); ///FILE POINTER FOR SECOND PLOT (PERFORMANCE GRAPH) FILE * gp1 = popen("gnuplot", "w"); fprintf(gp1, "set terminal wxt size 600,400 \n"); fprintf(gp1, "set grid \n"); fprintf(gp1, "set title '%s' \n", "Performance"); fprintf(gp1, "set style line 1 lt 3 pt 7 ps 0.1 lc rgb 'green' lw 1 \n"); fprintf(gp1, "set style line 2 lt 3 pt 7 ps 0.1 lc rgb 'red' lw 1 \n"); fprintf(gp1, "plot '-' w p ls 1 \n"); for (int k = 0; k < epo.size(); k++) < fprintf(gp1, "%f %f \n", epo[k], performance[k]); >fprintf(gp1, "e\n"); fflush(gp1); system("pause"); //_pclose(gp); return 0; > Отслеживать
ответ дан 16 июл 2020 в 19:29
user398400 user398400
51 1 1 бронзовый знак
-
Важное на Мете
Похожие
Подписаться на ленту
Лента вопроса
Для подписки на ленту скопируйте и вставьте эту ссылку в вашу программу для чтения RSS.
Дизайн сайта / логотип © 2024 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2024.1.3.2953
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.
Простенькая нейронная сеть на C++
Искусственные нейронные сети — всего лишь математическая модель, которая работает по принципу, похожему на работу реальной нейронной сети нашего мозга. Однако, в искусственной нейронной сети, нейроны — абстракция и на самом деле мы имитируем не их, а только их поведение.
У каждой нейронной сети есть слои, в нашем случае три слоя: входной (input layer), скрытый (hidden layer) и выходной (output layer). Как понятно из названия, на первый слой подаются некоторые данные, выходной отдаёт обработанные. Но что же делает скрытый слой и почему он так называется? Дело в том, что этот слой недоступен пользователю, но очень важен, потому что без него наша сеть будет глупой. Каждый слой имеет по несколько нейронов (а может и довольно много, к примеру, нейросеть, обрабатываются изображения, обязана иметь очень много входных нейронов, та же картинка 1920×1080 содержит 2,073,600 пикселей), связанных с нейронами следующего слоя. По этим связам «передаётся» сигнал, при том эти связи ещё и имеют некоторый коэффициент. Рассмотрим поближе:
Каждый входной нейрон связан с нейроном h₁, я отметил эти связи специально красным. На вход этого нейрона идут сигналы со всего предудущего слоя, так же и со вторым. В итоге этот нейрон обрабатывает полученные данные, прогоняет через функцию активации и выдаёт. Но как он их обрабатывает?
Суть в том, что каждая связь имеет некоторый коэффициент, называемый «весом» (weight), он, грубо говоря, определяет важность такого-то нейрона и именно он подбирается при обучении. При том этот коэффициент принадлежит каждому из связей, как показано ниже:
Выглядит непонятно? Да, тут скорее моя вина, но сейчас разъясню: первое число — номер данного нейрона, второе — нейрон, к которому идёт. А в случае связей между скрытым и выходным, думаю, понятно. Итак, как же мы обрабатываем сигналы? Сигналы со всех нейронов перемножаются на собственные веса и складываются. Пример:
Надеюсь, что понятно, хотя позже я покажу, как ещё проще это делать. В нашем примере мы берём сигнал с первого входного нейрона, умножаем на его вес к первому скрытому нейрону, складываем с произведением сигнала со второго входного нейрона и его веса к первому скрытому нейрону и то же самое с третьим.
Но в таком виде это лишь вход на скрытый нейрон, а как же получить выход? Дело в том, что настоящие нейроны должны «возбудиться» от сигнала, потому нам потребуется функция активации и мы будем использовать самую популярную из них — сигмоиду, так выглядит её график:
А так она сама (формула прямиком из википедии):
Считать мы, конечно же, вручную не будем, этого достаточно в других статьях, но вот чего я не нашёл там, так это матриц. Я рассчитываю, что вы понимаете, что такое матрица, но насчёт произведения матриц советую почитать эту статью, после чего можем продолжить.
На этом моменте я буду приводить примеры кода на C++, используя библиотеку boost, код на гитхабе
Подключаем заголовные файлы матриц, векторов и их вывода:
#include #include #include
Затем для удобства мы воспользуемся директивой using:
using boost::numeric::ublas::matrix; using boost::numeric::ublas::vector; using boost::numeric::ublas::prod;
boost::numeric::ublas::prod — умножение матриц.
Это матрица весов входных нейронов к нейронам скрытого слоя. Каждая строка ведёт к каждому нейрону скрытого слоя от конкретного нейрона входного слоя. Теперь вектор входных сигналов:
А теперь, если вы читали про умножение матриц, вам будет понятно, если же нет, то ничего страшного, ведь благодаря библиотеке boost это делает всего с одной функцией.
Что здесь примечательного, кроме неаккуратных скобочек? Это же вектор входных сигналов на скрытый слой. Заинтересовало? Тогда уж точно надо прочесть про умножение матриц и понять, почему получился такой результат. Теперь, пожалуй, перейдём к коду.
matrix weights_itoh(2, 3, 0); vector inputs(3, 0);
Матрица весов от входных нейронов к скрытым. Что не так с размерностью? Ну, дело в том, что матрицы считают по столбцам и строкам, а не наоборот. В нашей матрице 2 столбца и 3 строки и заполняем её нулями (для эстетики). Вектор же имеет три компоненты и тоже заполняется нулями.
Далее в моём коде можно увидеть, что я использую функцию fill для заполнения рандомными значениями, она не так важна здесь, потому просто гляньте её до ужаса банальную реализацию и поймёте, что к чему. Там же есть функция, которая принимает вектор и все его компоненты прогоняет через сигмоиду.
Сразу же за этим я создаю матрицу весов скрытого слоя к выходному и инициализирую вектор сигналов:
matrix weights_htoo(1, 2, 0); vector outputs_hidden = sigmoid(prod(weights_itoh, inputs));
Как видите, вектор, получившийся в результате умножения матрицы весов и входных сигналов мы прогоняем через функцию активации и это уже в последствии используем. Заполняем последнюю матрицу весов случайными значениями и считаем вектор выходных сигналов (так, как у нас один выходной нейрон, но считается для вектора, то вектор будет содержать лишь одно значение).
vector output = sigmoid(prod(weights_htoo, outputs_hidden));
Можем его вывести через std::cout, потому что мы подключили заголовочный файл вывода матриц и векторов.
И что, всё? Ну да, я здесь не обучаю её, потому что статья и так получилось массивной (по моим ощущениям, ведь писал целый день) и у меня ещё мало материала, потому оставлю ниже ссылки на полезные ресурсы для новичков.
Тарик Рашид — «Создаём нейронную сеть» (правда, книга про питон)
- https://habr.com/ru/post/312450/
- https://habr.com/ru/post/313216/
- https://habr.com/ru/post/425717/
Пример простой нейросети на С/C++
Решил поделиться простым и ёмким на мой взгляд решением нейронной сети на С++.
Почему эта информация должна быть интересна?
Ответ: я старался в минимальном наборе запрограммировать работу многослойного перцептрона, да так, чтобы его можно было настраивать как душе угодно всего в нескольких строчках кода, а реализация основных алгоритмов работы на «С» позволит с лёгкостью переносить на «С» ориентированные языки(в прочем и на любые другие) без использования сторонних библиотек!
Прошу взглянуть на то, что из этого вышло
Про предназначение нейронных сетей я вам рассказывать не буду, надеюсь вас не забанили в google и вы сможете найти интересующую вас информацию(назначение, возможности, области применения и так далее).
Исходный код вы найдёте в конце статьи, а пока по порядку.
Начнём разбор
1) Архитектура и технические подробности
— многослойный перцептрон с возможностью конфигурации любого количества слоев с заданной шириной. Ниже представлен
пример конфигурации
myNeuero.cpp
inputNeurons = 100; //ширина входного слоя outputNeurons =2; //ширина выходного слоя nlCount = 4; //количество слоёв ( по факту их 3, указываемое число намеренно увеличено на 1 list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); inputs = (float*) malloc((inputNeurons)*sizeof(float)); targets = (float*) malloc((outputNeurons)*sizeof(float)); list[0].setIO(100,20); //установка ширины INPUTS/OUTPUTS для каждого слоя list[1].setIO(20,6); // -//- list[2].setIO(6,3); // -//- list[3].setIO(3,2); // -//- выходной слой
Обратите внимание, что установка ширины входа и выхода для каждого слоя выполняется по определённому правилу — вход текущего слоя = выходу предыдущего. Исключением является входной слой.
Таким образом, вы имеете возможность настраивать любую конфигурацию вручную или по заданному правилу перед компиляцией или после компиляции считывать данные из source файлов.
— реализация механизма обратного распространения ошибки с возможностью задания скорости обучения
#define learnRate 0.1
— установка начальных весов
#define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5))
Примечание: если слоёв больше трёх (nlCount > 4), то pow(out,-0.5) необходимо увеличивать, чтобы при прямом прохождении сигнала его энергия не сводилась к 0. Пример pow(out,-0.2)
— основа кода на С. Основные алгоритмы и хранение весовых коэффициентов реализовано в виде структуры на языке С, всё остальное является оболочкой вызывающей функции данной структуры, она же является отображением любого из слоёв взятом в отдельности
Структура слоя
struct nnLay < int in; int out; float** matrix; float* hidden; float* errors; int getInCount()int getOutCount() float **getMatrix() void updMatrix(float *enteredVal) < for(int ou =0; ou < out; ou++) < for(int hid =0; hid < in; hid++) < matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]); >matrix[in][ou] += (learnRate * errors[ou]); > >; void setIO(int inputs, int outputs) < in=inputs; out=outputs; hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float)); for(int inp =0; inp < in+1; inp++) < matrix[inp] = (float*) malloc(out*sizeof(float)); >for(int inp =0; inp < in+1; inp++) < for(int outp =0; outp < out; outp++) < matrix[inp][outp] = randWeight; >> > void makeHidden(float *inputs) < for(int hid =0; hid < out; hid++) < float tmpS = 0.0; for(int inp =0; inp < in; inp++) < tmpS += inputs[inp] * matrix[inp][hid]; >tmpS += matrix[in][hid]; hidden[hid] = sigmoida(tmpS); > >; float* getHidden() < return hidden; >; void calcOutError(float *targets) < errors = (float*) malloc((out)*sizeof(float)); for(int ou =0; ou < out; ou++) < errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]); >>; void calcHidError(float *targets,float **outWeights,int inS, int outS) < errors = (float*) malloc((inS)*sizeof(float)); for(int hid =0; hid < inS; hid++) < errors[hid] = 0.0; for(int ou =0; ou < outS; ou++) < errors[hid] += targets[ou] * outWeights[hid][ou]; >errors[hid] *= sigmoidasDerivate(hidden[hid]); > >; float* getErrors() < return errors; >; float sigmoida(float val) < return (1.0 / (1.0 + exp(-val))); >float sigmoidasDerivate(float val) < return (val * (1.0 - val)); >; >;
2) Применение
Тестирование проекта с набором mnist произошло удачно, удалось добиться условной вероятности распознавания рукописного текста 0,9795 (nlCount = 4, learnRate = 0.03 и несколько эпох). Основная цель теста была в проверке работоспособности нейронной сети, с чем она справилась.
Ниже мы рассмотрим работу на «условной задаче».
Исходные данные:
-2 случайных входных вектора размером в 100 значений
-нейросеть со случайной генерацией весов
-2 заданные цели
Код в функции main()
< //. ________ ДЛЯ ВЫВОДА ВМЕСТО qDebug() можете использовать std::cout или std::cerr myNeuro *bb = new myNeuro(); //----------------------------------INPUTS----GENERATOR------------- /! создаём 2 случайнозаполненных входных вектора qsrand((QTime::currentTime().second())); float *abc = new float[100]; for(int i=0; i<100;i++) < abc[i] =(qrand()%98)*0.01+0.01; >float *cba = new float[100]; for(int i=0; i <100;i++) < cba[i] =(qrand()%98)*0.01+0.01; >//---------------------------------TARGETS----GENERATOR------------- // создаем 2 цели обучения float *tar1 = new float[2]; tar1[0] =0.01; tar1[1] =0.99; float *tar2 = new float[2]; tar2[0] =0.99; tar2[1] =0.01; //--------------------------------NN---------WORKING--------------- // первичный опрос сети bb->query(abc); qDebug()query(cba); // обучение int i=0; while(i<100000) < bb->train(abc,tar1); bb->train(cba,tar2); i++; > //просмотр результатов обучения (опрос сети второй раз) qDebug()query(abc); qDebug()query(cba); >Результат работы нейронной сети
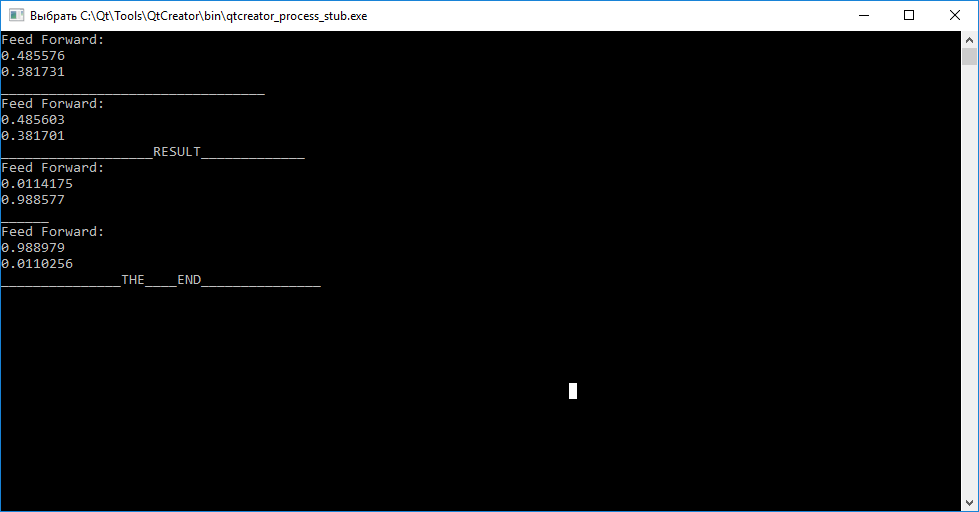
Итоги
Как вы видите, вызов функции query(inputs) до обучения для каждого из векторов не даёт нам судить об их отличиях. Далее, вызывая функцию train(input, target), для обучения с целью расстановки весовых коэффициентов так, чтобы нейросеть в последующем могла различать входные вектора.
После завершения обучения наблюдаем, что попытка сопоставить вектору «abc» — «tar1», а «cba» — «tar2» удалась.
Вам предоставляется возможность используя исходные коды самостоятельно протестировать работоспособность и поэкспериментировать с конфигурацией!
P.S.: данный код писался из QtCreator, надеюсь «заменить вывод» вам не составит труда, оставляйте свои замечания и комментарии.
P.P.S.: если кому интересен детальный разбор работы struct nnLay<> пишите, будет новый пост.
P.P.P.S.: надеюсь кому нибудь пригодится «С» ориентированный код для переноса на другие инструменты.
Исходники
#include #include #include #include "myneuro.h" int main(int argc, char *argv[]) < QCoreApplication a(argc, argv); myNeuro *bb = new myNeuro(); //----------------------------------INPUTS----GENERATOR------------- qsrand((QTime::currentTime().second())); float *abc = new float[100]; for(int i=0; i<100;i++) < abc[i] =(qrand()%98)*0.01+0.01; >float *cba = new float[100]; for(int i=0; i <100;i++) < cba[i] =(qrand()%98)*0.01+0.01; >//---------------------------------TARGETS----GENERATOR------------- float *tar1 = new float[2]; tar1[0] =0.01; tar1[1] =0.99; float *tar2 = new float[2]; tar2[0] =0.99; tar2[1] =0.01; //--------------------------------NN---------WORKING--------------- bb->query(abc); qDebug()query(cba); int i=0; while(i<100000) < bb->train(abc,tar1); bb->train(cba,tar2); i++; > qDebug()query(abc); qDebug()query(cba); qDebug()
#include "myneuro.h" #include myNeuro::myNeuro() < //--------многослойный inputNeurons = 100; outputNeurons =2; nlCount = 4; list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); inputs = (float*) malloc((inputNeurons)*sizeof(float)); targets = (float*) malloc((outputNeurons)*sizeof(float)); list[0].setIO(100,20); list[1].setIO(20,6); list[2].setIO(6,3); list[3].setIO(3,2); //--------однослойный--------- // inputNeurons = 100; // outputNeurons =2; // nlCount = 2; // list = (nnLay*) malloc((nlCount)*sizeof(nnLay)); // inputs = (float*) malloc((inputNeurons)*sizeof(float)); // targets = (float*) malloc((outputNeurons)*sizeof(float)); // list[0].setIO(100,10); // list[1].setIO(10,2); >void myNeuro::feedForwarding(bool ok) < list[0].makeHidden(inputs); for (int i =1; ireturn; > else < // printArray(list[3].getErrors(),list[3].getOutCount()); backPropagate(); >> void myNeuro::backPropagate() < //-------------------------------ERRORS-----CALC--------- list[nlCount-1].calcOutError(targets); for (int i =nlCount-2; i>=0; i--) list[i].calcHidError(list[i+1].getErrors(),list[i+1].getMatrix(), list[i+1].getInCount(),list[i+1].getOutCount()); //-------------------------------UPD-----WEIGHT--------- for (int i =nlCount-1; i>0; i--) list[i].updMatrix(list[i-1].getHidden()); list[0].updMatrix(inputs); > void myNeuro::train(float *in, float *targ) < inputs = in; targets = targ; feedForwarding(true); >void myNeuro::query(float *in) < inputs=in; feedForwarding(false); >void myNeuro::printArray(float *arr, int s) < qDebug()>#ifndef MYNEURO_H #define MYNEURO_H #include #include #include #include #define learnRate 0.1 #define randWeight (( ((float)qrand() / (float)RAND_MAX) - 0.5)* pow(out,-0.5)) class myNeuro < public: myNeuro(); struct nnLay< int in; int out; float** matrix; float* hidden; float* errors; int getInCount()int getOutCount() float **getMatrix() void updMatrix(float *enteredVal) < for(int ou =0; ou < out; ou++) < for(int hid =0; hid < in; hid++) < matrix[hid][ou] += (learnRate * errors[ou] * enteredVal[hid]); >matrix[in][ou] += (learnRate * errors[ou]); > >; void setIO(int inputs, int outputs) < in=inputs; out=outputs; hidden = (float*) malloc((out)*sizeof(float)); matrix = (float**) malloc((in+1)*sizeof(float)); for(int inp =0; inp < in+1; inp++) < matrix[inp] = (float*) malloc(out*sizeof(float)); >for(int inp =0; inp < in+1; inp++) < for(int outp =0; outp < out; outp++) < matrix[inp][outp] = randWeight; >> > void makeHidden(float *inputs) < for(int hid =0; hid < out; hid++) < float tmpS = 0.0; for(int inp =0; inp < in; inp++) < tmpS += inputs[inp] * matrix[inp][hid]; >tmpS += matrix[in][hid]; hidden[hid] = sigmoida(tmpS); > >; float* getHidden() < return hidden; >; void calcOutError(float *targets) < errors = (float*) malloc((out)*sizeof(float)); for(int ou =0; ou < out; ou++) < errors[ou] = (targets[ou] - hidden[ou]) * sigmoidasDerivate(hidden[ou]); >>; void calcHidError(float *targets,float **outWeights,int inS, int outS) < errors = (float*) malloc((inS)*sizeof(float)); for(int hid =0; hid < inS; hid++) < errors[hid] = 0.0; for(int ou =0; ou < outS; ou++) < errors[hid] += targets[ou] * outWeights[hid][ou]; >errors[hid] *= sigmoidasDerivate(hidden[hid]); > >; float* getErrors() < return errors; >; float sigmoida(float val) < return (1.0 / (1.0 + exp(-val))); >float sigmoidasDerivate(float val) < return (val * (1.0 - val)); >; >; void feedForwarding(bool ok); void backPropagate(); void train(float *in, float *targ); void query(float *in); void printArray(float *arr,int s); private: struct nnLay *list; int inputNeurons; int outputNeurons; int nlCount; float *inputs; float *targets; >; #endif // MYNEURO_HИстинная реализация нейросети с нуля на языке программирования C#

Здравствуй, Хабр! Данная статья предназначена для тех, кто приблизительно шарит в математических принципах работы нейронных сетей и в их сути вообще, поэтому советую ознакомиться с этим перед прочтением. Хоть как-то понять, что происходит можно сначала здесь, потом тут.
Недавно мне пришлось сделать нейросеть для распознавания рукописных цифр(сегодня будет не совсем её код) в рамках школьного проекта, и, естественно, я начал разбираться в этой теме. Посмотрев приблизительно достаточно об этом в интернете, я понял чуть более, чем ничего. Но неожиданно(как это обычно бывает) получилось наткнуться на книгу Саймона Хайкина(не знаю почему раньше не загуглил). И тогда началось потное вкуривание матчасти нейросетей, состоящее из одного матана.
На самом деле, несмотря на обилие математики, она не такая уж и запредельно сложная. Понять сатанистские каракули и письмена этого пособия сможет среднестатистический 11-классник товарищ-физмат или 1~2-курсник технарьского учебного заведения. Помимо этого, пусть книга достаточно объёмная и трудная для восприятия, но вещи, написанные в ней, реально объясняют, что «твориться у тачки под капотом». Как вы поняли я крайне рекомендую(ни в коем случае не рекламирую) «Нейронные сети. Полный курс» Саймона Хайкина к прочтению в том случае, если вам придётся столкнуться с применением/написанием/разработкой нейросетей и прочего подобного stuff’а. Хотя в ней нет материала про новомодные свёрточные сети, никто не мешает загуглить лекции от какого-нибудь харизматичного работника Yandex/Mail.ru/etc. никто не мешает.
Конечно, осознав устройство сеток, я не мог просто остановиться, так как впереди предстояло написание кода. В связи со своим параллельным занятием, заключающемся в создани игр на Unity, языком реализации оказался весьма популярный шарп 7 версии(ибо она последняя актуальная на момент написания статьи). Именно в этот момент, оказавшись на просторах интернета, я понял, что число внятных туториалов по написанию нейросетей с нуля(без ваших фреймворков) на шарпе бесконечно мало. Ладно. Я мог использовать, всякие Theano и Tensor Flow, НО под капотом моей смерть-машины в моём ноутбуке стоит «красная» видеокарта без особой поддержки API, через которые обращаются к мощи GPU(ведь именно их и используют Theano/Tensor Flow/etc.).
Помогите разобраться в вопросе:
Моя видеокарта называется ATI Radeon HD Mobility 4570. И если кто знает, как обратиться к её мощностям для параллелизации нейросетевых вычислений, пожалуйста, напишите в комментарии. Тогда вы поможете мне, и возможно у этой статьи появится продолжение. Не осуждается предложение других ЯП.
Просто, как я понял, она настолько старая, что вообще ничего не поддерживает. Может быть я не прав.
То, что я увидел(третье вообще какая-то эзотерика с некрасивым кодом), несомненно может повергнуть в шок и вас, так как выдаваемое за нейросети связано с ними так же, как и тексты Lil Pump со смыслом. Вскоре я понял, что могу рассчитывать только на себя, и решил написать данную статью, чтобы всякие юзеры не вводили других в заблуждение.
Здесь я не буду рассматривать код сети для распознования цифр(как упоминалось ранее), ибо я оставил его на флэшке, удалив с ноута, а искать сей носитель информации мне лень, и в связи с этим я помогу вам сконструировать многослойный полносвязный персептрон для решения задачи XOR и XAND(XNOR, хз как ещё).
Прежде чем начать программировать это, можно нужно нарисовать на бумаге, дабы облегчить представление структуры и работы нейронки. Моё воображение вылилось в следующую картинку. И да, кстати, это консольное приложение в Visual Studio 2017, с .NET Framework версии 4.7.
Краткая инфа по сетке(для тех, кому это хоть о чём-то говорит)
Многослойный полносвязный персептрон.
Один скрытый слой.
4 нейрона в скрытом слое(на этом количестве персептрон сошёлся).
Алгоритм обучения — backpropagation.
Критерий останова — преодоление порогового значения среднеквадратичной ошибки по эпохе.(0.001)
Скорость обучения — 0.1.
Функция активации — логистическая сигмоидальная.

Потом надо осознать, что нам нужно куда-то записывать веса, проводить вычисления, немного дебажить, ну и кортежи поиспользовать. Соответственно, using’и у нас такие.
В папке release||debug этого прожекта располагаются файлы(на каждый слой по одному) по имени типа (fieldname)_memory.xml сами знаете для чего. Они создаются заранее с учётом общего количества весов каждого слоя. Знаю, что XML — это не лучший выбор для парсинга, просто времени было немного на это дело.
using System.Xml; using static System.Math; using static System.Console;Также вычислительные нейроны у нас двух типов: скрытые и выходные. А веса могут считываться или записываться в память. Реализуем сию концепцию двумя перечислениями.
enum MemoryMode < GET, SET >enum NeuronType
Всё остальное будет происходить внутри пространства имён, которое я назову просто: Neural Network.
namespace NeuralNetwork < //всё, что будет описано ниже, располагается здесь >Прежде всего, важно понимать, почему нейроны входного слоя я изобразил квадратами. Ответ прост. Они ничего не вычисляют, а лишь улавливают информацию из внешнего мира, то есть получают сигнал, который будет пропущен через сеть. Вследствие этого, входной слой имеет мало общего с остальными слоями. Вот почему стоит вопрос: делать для него отдельный класс или нет? На самом деле, при обработке изображений, видео, звука стоит его сделать, лишь для размещения логики по преобразованию и нормализации этих данных к виду, подаваемому на вход сети. Вот почему я всё-таки напишу класс InputLayer. В нём находиться обучающая выборка организованная необычной структурой. Первый массив в кортеже — это сигналы-комбинации 1 и 0, а второй массив — это пара результатов этих сигналов после проведения операций XOR и XAND(сначала XOR, потом XAND).
class InputLayer < private (double[], double[])[] _trainset = new(double[], double[])[]//да-да, массив кортежей из 2 массивов < (new double[]< 0, 0 >, new double[]< 0, 1 >), (new double[]< 0, 1 >, new double[]< 1, 0 >), (new double[]< 1, 0 >, new double[]< 1, 0 >), (new double[]< 1, 1 >, new double[]< 0, 1 >) >; //инкапсуляция едрид-мадрид public (double[], double[])[] Trainset < get =>_trainset; >//такие няшные свойства нынче в C# 7 >Теперь реализуем самое важное, то без чего ни одна нейронная сеть не станет терминатором, а именно — нейрон. Я не буду использовать смещения, потому что просто не хочу. Нейрон будет напоминать модель МакКаллока-Питтса, но иметь другую функцию активации(не пороговую), методы для вычисления градиентов и производных, свой тип и совмещенные линейные и нелинейные преобразователи. Естественно без конструктора уже не обойтись.
class Neuron < public Neuron(double[] inputs, double[] weights, NeuronType type) < _type = type; _weights = weights; _inputs = inputs; >private NeuronType _type; private double[] _weights; private double[] _inputs; public double[] Weights < get =>_weights; set => _weights = value; > public double[] Inputs < get =>_inputs; set => _inputs = value; > public double Output < get =>Activator(_inputs, _weights); > private double Activator(double[] i, double[] w)//преобразования < double sum = 0; for (int l = 0; l < i.Length; ++l) sum += i[l] * w[l];//линейные return Pow(1 + Exp(-sum), -1);//нелинейные >public double Derivativator(double outsignal) => outsignal * (1 - outsignal);//формула производной для текущей функции активации уже выведена в ранее упомянутой книге public double Gradientor(double error, double dif, double g_sum) => (_type == NeuronType.Output) ? error * dif : g_sum * dif;//g_sum - это сумма градиентов следующего слоя >Ладно у нас есть нейроны, но их необходимо объединить в слои для вычислений. Возвращаясь к моей схеме выше, хочу объяснить наличие чёрного пунктира. Он разделяет слои так, чтобы показать, что они содержат. То есть один вычислительный слой содержит нейроны и веса для связи с нейронами предыдущего слоя. Нейроны объединяются массивом, а не списком, так как это менее ресурсоёмко. Веса организованы матрицей(двумерным массивом) размера(нетрудно догадаться) [число нейронов текущего слоя X число нейронов предыдущего слоя]. Естественно, слой инициализирует нейроны, иначе словим null reference. При этом эти слои очень похожи друг на друга, но имеют различия в логике, поэтому скрытые и выходной слои должны быть реализованы наследниками одного базового класса, который кстати оказывается абстрактным.
abstract class Layer//модификаторы protected стоят для внутрииерархического использования членов класса > protected int numofneurons;//число нейронов текущего слоя protected int numofprevneurons;//число нейронов предыдущего слоя protected const double learningrate = 0.1d;//скорость обучения Neuron[] _neurons; public Neuron[] Neurons < get =>_neurons; set => _neurons = value; > public double[] Data//я подал null на входы нейронов, так как //а только после вычисления выходов предыдущего слоя > public double[,] WeightInitialize(MemoryMode mm, string type) < double[,] _weights = new double[numofneurons, numofprevneurons]; WriteLine($"weights are being initialized. "); XmlDocument memory_doc = new XmlDocument(); memory_doc.Load($"_memory.xml"); XmlElement memory_el = memory_doc.DocumentElement; switch (mm) < case MemoryMode.GET: for (int l = 0; l < _weights.GetLength(0); ++l) for (int k = 0; k < _weights.GetLength(1); ++k) _weights[l, k] = double.Parse(memory_el.ChildNodes.Item(k + _weights.GetLength(1) * l).InnerText.Replace(',', '.'), System.Globalization.CultureInfo.InvariantCulture);//parsing stuff break; case MemoryMode.SET: for (int l = 0; l < Neurons.Length; ++l) for (int k = 0; k < numofprevneurons; ++k) memory_el.ChildNodes.Item(k + numofprevneurons * l).InnerText = Neurons[l].Weights[k].ToString(); break; >memory_doc.Save($"_memory.xml"); WriteLine($" weights have been initialized. "); return _weights; > abstract public void Recognize(Network net, Layer nextLayer);//для прямых проходов abstract public double[] BackwardPass(double[] stuff);//и обратных >Соль абстрактных классов
Класс Layer — это абстрактный класс, поэтому нельзя создавать его экземпляры. Это значит, что наше желание сохранить свойства «слоя» выполняется путём наследования родительского конструктора через ключевое слово base и пустой конструктор наследника в одну строчку(ибо вся логика конструктора определена в базовом классе, и её не надо переписывать).
Теперь непосредственно классы-наследники: Hidden и Output. Сразу два класса в цельном куске кода.
class HiddenLayer : Layer < public HiddenLayer(int non, int nopn, NeuronType nt, string type) : base(non, nopn, nt, type)<>public override void Recognize(Network net, Layer nextLayer) < double[] hidden_out = new double[Neurons.Length]; for (int i = 0; i < Neurons.Length; ++i) hidden_out[i] = Neurons[i].Output; nextLayer.Data = hidden_out; >public override double[] BackwardPass(double[] gr_sums) < double[] gr_sum = null; //сюда можно всунуть вычисление градиентных сумм для других скрытых слоёв //но градиенты будут вычисляться по-другому, то есть //через градиентные суммы следующего слоя и производные for (int i = 0; i < numofneurons; ++i) for (int n = 0; n < numofprevneurons; ++n) Neurons[i].Weights[n] += learningrate * Neurons[i].Inputs[n] * Neurons[i].Gradientor(0, Neurons[i].Derivativator(Neurons[i].Output), gr_sums[i]);//коррекция весов return gr_sum; >> class OutputLayer : Layer < public OutputLayer(int non, int nopn, NeuronType nt, string type) : base(non, nopn, nt, type)<>public override void Recognize(Network net, Layer nextLayer) < for (int i = 0; i < Neurons.Length; ++i) net.fact[i] = Neurons[i].Output; >public override double[] BackwardPass(double[] errors) < double[] gr_sum = new double[numofprevneurons]; for (int j = 0; j < gr_sum.Length; ++j)//вычисление градиентных сумм выходного слоя < double sum = 0; for (int k = 0; k < Neurons.Length; ++k) sum += Neurons[k].Weights[j] * Neurons[k].Gradientor(errors[k], Neurons[k].Derivativator(Neurons[k].Output), 0);//через ошибку и производную gr_sum[j] = sum; >for (int i = 0; i < numofneurons; ++i) for (int n = 0; n < numofprevneurons; ++n) Neurons[i].Weights[n] += learningrate * Neurons[i].Inputs[n] * Neurons[i].Gradientor(errors[i], Neurons[i].Derivativator(Neurons[i].Output), 0);//коррекция весов return gr_sum; >>В принципе, всё самое важное я описал в комментариях. У нас есть все компоненты: обучающие и тестовые данные, вычислительные элементы, их «конгламераты». Теперь настало время всё связать обучением. Алгоритм обучения — backpropagation, следовательно критерий останова выбираю я, и выбор мой — есть преодоление порогового значения среднеквадратичной ошибки по эпохе, которое я выбрал равным 0.001. Для поставленной цели я написал класс Network, описывающий состояние сети, которое принимается в качестве параметра многих методов, как вы могли заметить.
class Network < //все слои сети InputLayer input_layer = new InputLayer(); public HiddenLayer hidden_layer = new HiddenLayer(4, 2, NeuronType.Hidden, nameof(hidden_layer)); public OutputLayer output_layer = new OutputLayer(2, 4, NeuronType.Output, nameof(output_layer)); //массив для хранения выхода сети public double[] fact = new double[2];//не ругайте за 2 пожалуйста //ошибка одной итерации обучения double GetMSE(double[] errors) < double sum = 0; for (int i = 0; i < errors.Length; ++i) sum += Pow(errors[i], 2); return 0.5d * sum; >//ошибка эпохи double GetCost(double[] mses) < double sum = 0; for (int i = 0; i < mses.Length; ++i) sum += mses[i]; return (sum / mses.Length); >//непосредственно обучение static void Train(Network net)//backpropagation method < const double threshold = 0.001d;//порог ошибки double[] temp_mses = new double[4];//массив для хранения ошибок итераций double temp_cost = 0;//текущее значение ошибки по эпохе do < for (int i = 0; i < net.input_layer.Trainset.Length; ++i) < //прямой проход net.hidden_layer.Data = net.input_layer.Trainset[i].Item1; net.hidden_layer.Recognize(null, net.output_layer); net.output_layer.Recognize(net, null); //вычисление ошибки по итерации double[] errors = new double[net.input_layer.Trainset[i].Item2.Length]; for (int x = 0; x < errors.Length; ++x) errors[x] = net.input_layer.Trainset[i].Item2[x] - net.fact[x]; temp_mses[i] = net.GetMSE(errors); //обратный проход и коррекция весов double[] temp_gsums = net.output_layer.BackwardPass(errors); net.hidden_layer.BackwardPass(temp_gsums); >temp_cost = net.GetCost(temp_mses);//вычисление ошибки по эпохе //debugging WriteLine($""); > while (temp_cost > threshold); //загрузка скорректированных весов в "память" net.hidden_layer.WeightInitialize(MemoryMode.SET, nameof(hidden_layer)); net.output_layer.WeightInitialize(MemoryMode.SET, nameof(output_layer)); > //тестирование сети static void Test(Network net) < for (int i = 0; i < net.input_layer.Trainset.Length; ++i) < net.hidden_layer.Data = net.input_layer.Trainset[i].Item1; net.hidden_layer.Recognize(null, net.output_layer); net.output_layer.Recognize(net, null); for (int j = 0; j < net.fact.Length; ++j) WriteLine($""); WriteLine(); > > //запуск сети static void Main(string[] args) < Network net = new Network(); Train(net); Test(net); ReadKey();//чтоб консоль не закрывалась :) >>
Результат обучения.
Итого, путём насилования мозга несложных манипуляций, мы получили основу работающей нейронной сети. Для того, чтобы заставить её делать что-либо другое, достаточно поменять класс InputLayer и подобрать параметры сети для новой задачи.
За сим всё, буду рад ответить на вопросы в комментариях, а пока извольте, новые дела ждут.
P.S.: Для желающих потыкать в код клацать.
UPD1(22.10.2020): господи как давно это было, надеюсь больше не буду писать такие статьи. Скорее всего в то время хотел поделиться с сообществом таким кодом, но так в ML никто не пишет)
Ещё я веду telegram канал StepOne, где оставляю небольшие заметки про разработку и мир IT.