Распознавание образов в Python. Часть I — введение
Далее распакуйте архив и переместите директорию «images» туда, где вы будете создавать ваш код. Таким образом, у нас теперь есть некоторое количество тестовых изображений, которые мы и будем использовать. Также у нас отдельно есть изображения цифр в папке «numbers» .
Теперь нам необходим язык Python. Хотя данная серия статей создавалась на Python 2.7, все это также можно повторить без каких-либо проблем и на Python 3.
Далее нам потребуются библиотеки Matplotlib , NumPy и PIL (или иначе Pillow ). Простейший способ их установки — через пакетный менеджер pip .
После установки Python перейдите в командную строку, cmd.exe для Windows или bash для Linux, и наберите в ней:
pip install numpy pip install matplotlib
Если есть какие-то проблемы, можно, например, почитать пособие по этому пакетному менеджеру.
Теперь, все установив, мы готовы переходить к следующей части.
Распознавание объектов на фото и видео
![]()
Нейросети умеют распознавать образы на фото. Например, если отдать модели на вход фотографии разных людей, она сможет найти соответствия фотографиям в базе, если обучить модель распознавать мебель, то она отличит стол от шкафа.
У Сбера есть собственная система распознавания Layer, которая умеет работать с изображениями и видео. Платформа может распознать, например, какая одежда на человеке, и найти похожую в каталоге партнёров. Посмотрим, как это работает и какие возможности даёт программа.
Видеозвонки в SberJazz
Общайтесь с друзьями и близкими везде, где есть Интернет
Попробовать сейчас
Как работает технология распознавания образов
Нейросети, которые работают с распознаванием образов с картинки, сравнивают данные с базой изображений и ищут соответствия. Работа сервиса распознавания объектов базируется на уникальном алгоритме на основе технологий AI и Computer Vision.
Обнаружение объектов
Перед тем как что-то распознать, это что-то нужно найти на изображении или видео. Для этого используется нейросеть-детектор. Представьте себе сцену из фильма: кроме героев, на экране показаны предметы мебели, здания. Чтобы понять, что конкретно мы видим на изображении, нужен детектор, который разбивает общую картину на отдельные образы.
После того как все объекты найдены через графический распознаватель, этим предметам присваивается какой-то класс. Например, модель может различить одежду, мебель на видео — это разные классы объектов.

Дальше нейросети будут искать в своей базе похожие объекты в зависимости от класса. Определить, какой актёр перед нами или что за предмет мебели в кадре, — задачи для разных нейросетей. В рамках Layer используется также база партнерских товаров, по которой система ищет похожие на распознанные на видео, чтобы обогатить стоп-кадр торговым предложением.
При этом программ-детекторов может быть несколько, каждая берёт на себя какую-то конкретную задачу по поиску образов. В конечном счёте цель — получить как можно больше распознанных объектов с правильно определённым типом.
Отслеживание между кадрами
Здесь мы говорим только про видео, когда система должна находить объекты на меняющихся кадрах. Отслеживание нужно, чтобы не приходилось распознавать объект снова и снова: это экономит много ресурсов программы по распознаванию. Решение позволяет «помнить», что перед нами всё ещё тот же самый предмет.
Для отслеживания уже обнаруженного графического элемента используются специальные нейронные сети, которые присваивают объекту идентификатор и «следят» за ним между кадрами.
Распознавание объекта
После того как программа нашла объект и начала отслеживание, информация о нём передаётся в нейросеть-энкодер, которая распознаёт изображение и ищет в базе аналоги. Так, в рамках Layer возможно распознавание одежды того же цвета и фасона по товарам от партнеров.
Важно упомянуть, что сеть, которая находит похожие образы в базе, работает не с самими изображениями, а с их эмбеддингами. Эмбеддинг — это картинка, преобразованная в ряд чисел по определённому правилу. Сравнивая эти ряды чисел между собой, модель понимает степень похожести изображений — распознаваемого и из базы. Поэтому платье героини сначала превращается в числовой код, и только потом отдаётся в базу данных для поиска аналогичных платьев.
Возможности применения сервиса для бизнеса
Сбер развил идею определения графических объектов, чтобы её можно было использовать в медиапространстве. Так появился сервис Layer, которые позволяет обогащать контент дополнительными данными.
Основная идея в том, чтобы из любого видео — неважно, фильм это, сериал или клип — можно было «вытащить» предметы, которые участвуют в съёмках. Впечатляет? Это уже работает в некоторых видеосервисах. Но обо всех возможностях по порядку.
Layer для e-commerce
Технология Layer будет полезна в e-commerce — для построения рекомендаций к товарам на сайте на основе подбора визуально похожих предложений. С помощью AI система проанализирует каталог и подберёт для пользователя релевантные рекомендации.
Кроме рекомендаций, система может быть использована при модерации изображений — чтобы определить, относится ли заданное изображение к определённому классу.
Если вы продавец, то можете стать партнёром системы, чтобы предлагать свои товары в рамках поиска похожих предложений — это дополнительный способ монетизации. Дальше расскажем, какие товары можно предложить.
Layer для поиска вещи на видео
Первая возможность, которую даёт приложение для распознавания графических объектов, — это поиск вещей. Вот несколько идей, что именно можно находить:
- Одежда на актёрах. Если понравилась юбка или рубашка на актёре, можно нажать на паузу и посмотреть, что это за вещь и где её можно купить. Нейронная сеть найдёт максимально похожие образцы из магазинов партнёров.
- Мебель. Предметы интерьера тоже могут быть товаром, который захочет купить зритель. С помощью программы анализа изображений получится найти такой же диван (ну или очень похожий).
- Аксессуары и декор. Постер, картина, какой-то домашний декор тоже могут быть распознаны, чтобы найти похожее.
Важно понимать, что распознавание ограничивается базой исходных образцов. В частности, в приложение от Сбера включён перечень товаров от компаний-партнёров, на сайте которых можно купить понравившиеся вещи.
В связи с ограниченностью исходной базы, скорее всего, будут найдены не те же товары, но максимально похожие по цвету, форме и другим признакам. Кроме одежды и мебели, Layer от Сбера может распознавать и искать похожую еду. Как насчёт того, чтобы заказать блюдо, которое ест героиня любимого сериала?
В дальнейшем планируется расширять перечень категорий товаров, которые могут распознаваться. Для этого нужно обучать нейронную сеть на новых исходных изображениях, создавать новый класс объектов для определения приложением.
Создаём свою модель распознавания лиц на Python
У нас уже есть большой цикл про компьютерное зрение и распознавание лиц. В этом цикле мы научились видеть лицо человека, определять примерный возраст и пол, работать с веб-камерой и с файлами. Если не читали, можно начать сейчас:
- Как работает распознавание лиц;
- Находим лица в картинке с веб-камеры;
- Учим нейросеть определять пол и возраст по картинке с камеры;
- Учим нейросеть распознавать возраст по фотографии.
Пока что наш алгоритм не умеет различать разных людей в кадре. Максимум — сказать, что это «мужчина, столько-то лет», а кто конкретно — нет.
Чтобы нейронка научилась узнавать вас по лицу, нужно создать собственную модель распознавания лиц и скормить её нейросети. Тогда она сможет определять и подписывать имя человека в кадре. Сегодня мы сделаем первую часть — соберём датасет и обучим на нём нашу нейросеть. А во второй части прикрутим новую модель к алгоритмам распознавания.
Коротко про распознавание лиц и компьютерное зрение
- Для распознавания лица компьютер должен получить изображение — через камеру или готовый файл.
- Компьютер использует особый алгоритм, который разбивает изображение на прямоугольники.
- С помощью этих прямоугольников алгоритм пытается найти на картинке знакомые переходы между светлыми и тёмными областями.
- Если в одном месте программа находит много таких совпадений, то, скорее всего, это лицо человека.
- Чтобы программистам каждый раз не писать свой код распознавания с нуля, сделали библиотеку компьютерного зрения — cv2. Если в неё загрузить заранее подготовленные параметры лиц, она сможет распознавать их намного точнее.
- С помощью этой библиотеки можно находить на картинке не только лица, но и другие предметы — для этого нужно использовать дополнительные библиотеки либо обучать систему самому.
- Чтобы нейросеть могла понять, кто именно перед ней, её тоже нужно этому обучить отдельно.
Что нужно для обучения нейросети
Чтобы научить нейросеть узнавать конкретных людей в кадре, нужно:
- Собрать датасет.
- Обучить нейросеть на этом датасете и выгрузить результат обучения в отдельный файл.
Датасет в нашем случае — это набор фотографий. Фото должны быть подобраны так, чтобы лицо было в разных ракурсах или с разным освещением. Чем больше фото, тем точнее обучение. Идеально, если по имени файла сразу будет понятно, какие фото к какому человеку относятся.
Когда датасет будет собран, мы отдадим его нейросети — она распознает все лица и построит их модель, которую можно сохранить в отдельном файле. Если этот файл потом отдать другой нейросети, она сможет понять, кто именно находится перед ней в кадре.
Подготовка
В папке, где будет лежать скрипт, нужно создать две папки:
В первой папке будут лежать фотографии, на которых будет учиться нейросеть, а во второй будут результаты этого обучения.
Ещё нужно скачать файл haarcascade_frontalface_default.xml и положить его туда же, где и скрипт. Это модель распознавания лиц по примитивам Хаара.
Собираем датасет
В коммерческих проектах датасет собирают долго и из разных источников, а потом вручную проверяют каждое фото, подходит оно или нет. Чтобы не тратить на это время, используем такой лайфхак: мы сгенерируем датасет из кадров с камеры. Для этого мы запустим захват видео и каждые 100 миллисекунд будем брать новый кадр и запоминать лицо оттуда.
Точно так же работает разблокировка по лицу с помощью камеры в Андроиде: телефон просит покрутить головой перед камерой, а сам в это время делает много снимков, а потом тренирует модель распознавания.
Сначала подключим все нужные библиотеки:
# подключаем библиотеку машинного зрения
import cv2
# библиотека для вызова системных функций
import os
Сразу подключим модель с примитивами Хаара к нейросети — это тот самый файл, который скачивали отдельно.
Чтобы нейросеть в процессе обучения знала, кому принадлежат эти фотографии, добавим параметр id. Это будет внутренний номер пользователя, который мы потом превратим в настоящее имя:
# получаем путь к этому скрипту path = os.path.dirname(os.path.abspath(__file__)) # указываем, что мы будем искать лица по примитивам Хаара detector = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml") # счётчик изображений i=0 # расстояния от распознанного лица до рамки offset=50 # запрашиваем номер пользователя name=input('Введите номер пользователя: ') # получаем доступ к камере video=cv2.VideoCapture(0)Последнее, что осталось, — сделать цикл, который соберёт как минимум 30 фотографий, найдёт на них лица и запишет их файл с нужными именами. Так как примитивы Хаара — это чёрно-белые прямоугольники, для простоты и ускорения работы мы тоже будем переводить кадры в ч/б. Чтобы потом в процессе тренировки нейросети было проще, мы будем сохранять не кадр с камеры целиком, а только лицо:
# запускаем цикл while True: # берём видеопоток ret, im =video.read() # переводим всё в ч/б для простоты gray=cv2.cvtColor(im,cv2.COLOR_BGR2GRAY) # настраиваем параметры распознавания и получаем лицо с камеры faces=detector.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5, minSize=(100, 100)) # обрабатываем лица for(x,y,w,h) in faces: # увеличиваем счётчик кадров i=i+1 # записываем файл на диск cv2.imwrite("dataSet/face-"+name +'.'+ str(i) + ".jpg", gray[y-offset:y+h+offset,x-offset:x+w+offset]) # формируем размеры окна для вывода лица cv2.rectangle(im,(x-50,y-50),(x+w+50,y+h+50),(225,0,0),2) # показываем очередной кадр, который мы запомнили cv2.imshow('im',im[y-offset:y+h+offset,x-offset:x+w+offset]) # делаем паузу cv2.waitKey(100) # если у нас хватает кадров if i>30: # освобождаем камеру video.release() # удалаяем все созданные окна cv2.destroyAllWindows() # останавливаем цикл breakСохраняем скрипт как face_gen.py — потому что для тренировки нам понадобится отдельный код. После запуска в терминале нужно будет ввести номер пользователя — им может быть любое число. Во время работы скрипт покажет нам 30 кадров, которые он сделал, а в папке dataSet появятся новые файлы — это значит, что мы всё сделали правильно:
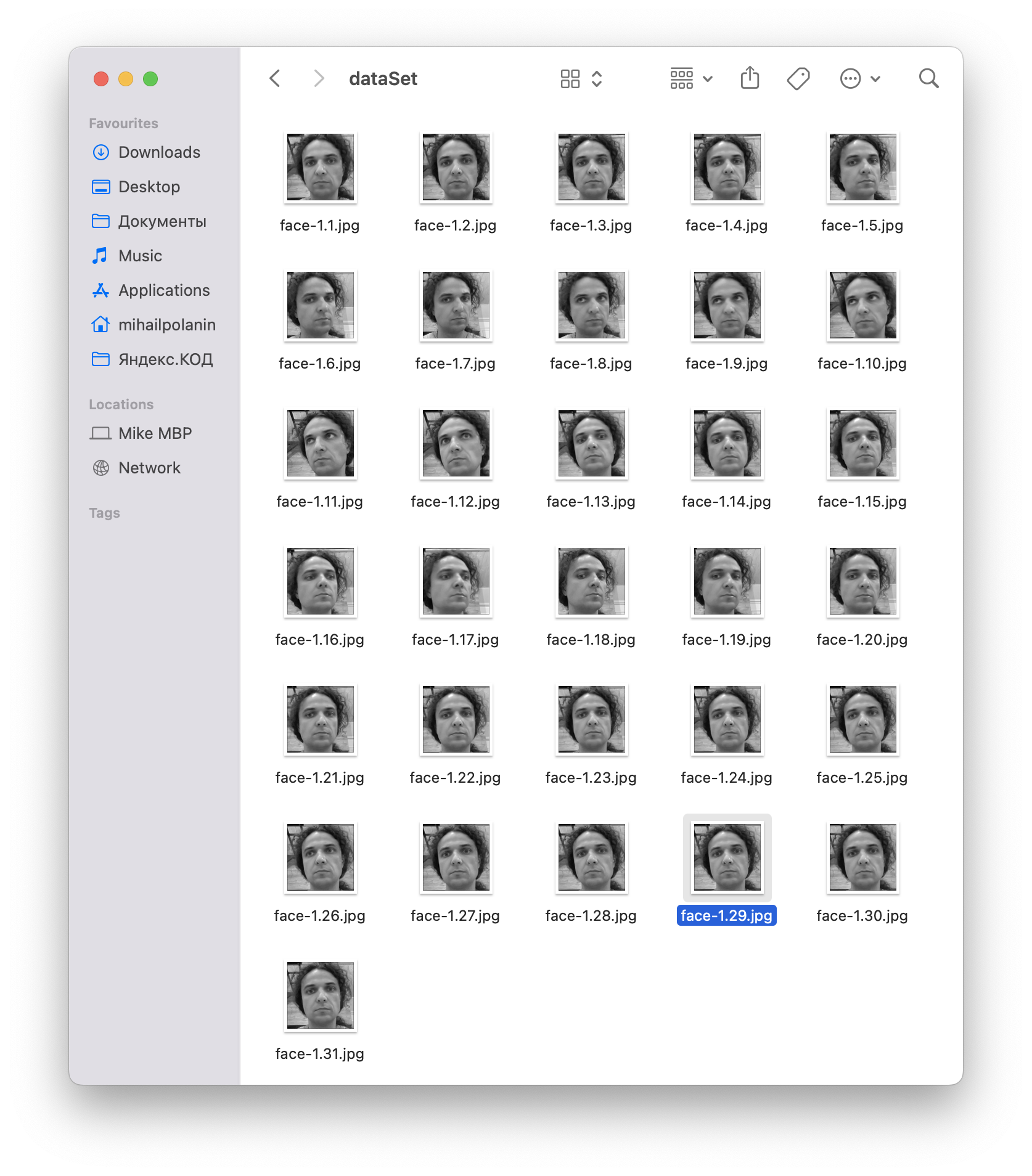
Обучаем нейросеть
Создаём новый файл face_train.py — он будет отвечать за обучение на собранном датасете. Так как мы сами придумывали формат имени файла, то это сильно упростит нам задачу: цифра, которая стоит после дефиса и до первой точки, и будет id пользователя:
face-1.29.jpg ← здесь после дефиса и до первой точки стоит число 1, значит эта фотография относится к пользователю с >
Начало скрипта будет похоже на предыдущее, добавятся только две библиотеки — для обучения нейросети и для работы с изображениями:
# подключаем библиотеку компьютерного зрения import cv2 # библиотека для вызова системных функций import os # для обучения нейросетей import numpy as np # встроенная библиотека для работы с изображениями from PIL import Image # получаем путь к этому скрипту path = os.path.dirname(os.path.abspath(__file__)) # создаём новый распознаватель лиц recognizer = cv2.face.LBPHFaceRecognizer_create() # указываем, что мы будем искать лица по примитивам Хаара faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml") # путь к датасету с фотографиями пользователей dataPath = path+r'/dataSet'Теперь самое интересное — собираем картинки и id пользователя из датасета. Для простоты id будем называть подписью — если у нас не будет сведений о том, что за человек на фотографиях, будем просто выводить номер пользователя как подпись.
Логика будет такая:
- Открываем папку с картинками.
- По очереди читаем каждую картинку и переводим её в специальный формат, с которым умеет работать библиотека numpy.
- Получаем id пользователя из имени файла — просто убираем всё до дефиса и после первой точки.
- Определяем лицо на картинке — это будет просто, потому что на картинках и так будут только лица.
- Добавляем лица в список лиц.
- Добавляем id пользователя в список пользователей
- Чтобы было видно, что скрипт работает, на долю секунды будем выводить на экран текущую картинку.
- На выходе получим список с лицами и идентификаторами пользователей, к которым они относятся.
Запишем это в виде кода на Python:
# получаем картинки и подписи из датасета def get_images_and_labels(datapath): # получаем путь к картинкам image_paths = [os.path.join(datapath, f) for f in os.listdir(datapath)] # списки картинок и подписей на старте пустые images = [] labels = [] # перебираем все картинки в датасете for image_path in image_paths: # читаем картинку и сразу переводим в ч/б image_pil = Image.open(image_path).convert('L') # переводим картинку в numpy-массив image = np.array(image_pil, 'uint8') # получаем id пользователя из имени файла nbr = int(os.path.split(image_path)[1].split(".")[0].replace("face-", "")) # определяем лицо на картинке faces = faceCascade.detectMultiScale(image) # если лицо найдено for (x, y, w, h) in faces: # добавляем его к списку картинок images.append(image[y: y + h, x: x + w]) # добавляем id пользователя в список подписей labels.append(nbr) # выводим текущую картинку на экран cv2.imshow("Adding faces to traning set. ", image[y: y + h, x: x + w]) # делаем паузу cv2.waitKey(100) # возвращаем список картинок и подписей return images, labelsНаконец, обучаем и сохраняем модель, чтобы её можно было использовать в других проектах. При этом нейросети неважно, сколько пользователей и фотографий будет в датасете — один или тысяча. Она запомнит их все, сопоставит одно с другим и запомнит, как выглядит пользователь под каждым номером. Результат такой обработки сохраним в yml-файле — это один из стандартных форматов для таких моделей:
# получаем список картинок и подписей
images, labels = get_images_and_labels(dataPath)
# обучаем модель распознавания на наших картинках и учим сопоставлять её лица и подписи к ним
recognizer.train(images, np.array(labels))
# сохраняем модель
recognizer.save(path+r’/trainer/trainer.yml’)
# удаляем из памяти все созданные окнаы
cv2.destroyAllWindows()
Если после запуска скрипта в папке trainer появился файл trainer.yml — поздравляем, вы только что обучили нейросеть распознавать лицо человека!
face_gen.py
# подключаем библиотеку машинного зрения import cv2 # библиотека для вызова системных функций import os # получаем путь к этому скрипту path = os.path.dirname(os.path.abspath(__file__)) # указываем, что мы будем искать лица по примитивам Хаара detector = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml") # счётчик изображений i=0 # расстояния от распознанного лица до рамки offset=50 # запрашиваем номер пользователя name=input('Введите номер пользователя: ') # получаем доступ к камере video=cv2.VideoCapture(0) # запускаем цикл while True: # берём видеопоток ret, im =video.read() # переводим всё в ч/б для простоты gray=cv2.cvtColor(im,cv2.COLOR_BGR2GRAY) # настраиваем параметры распознавания и получаем лицо с камеры faces=detector.detectMultiScale(gray, scaleFactor=1.2, minNeighbors=5, minSize=(100, 100)) # обрабатываем лица for(x,y,w,h) in faces: # увеличиваем счётчик кадров i=i+1 # записываем файл на диск cv2.imwrite("dataSet/face-"+name +'.'+ str(i) + ".jpg", gray[y-offset:y+h+offset,x-offset:x+w+offset]) # формируем размеры окна для вывода лица cv2.rectangle(im,(x-50,y-50),(x+w+50,y+h+50),(225,0,0),2) # показываем очередной кадр, который мы запомнили cv2.imshow('im',im[y-offset:y+h+offset,x-offset:x+w+offset]) # делаем паузу cv2.waitKey(100) # если у нас хватает кадров if i>30: # освобождаем камеру video.release() # удаляем все созданные окна cv2.destroyAllWindows() # останавливаем цикл breakface_train.py
# подключаем библиотеку компьютерного зрения import cv2 # библиотека для вызова системных функций import os # для обучения нейросетей import numpy as np # встроенная библиотека для работы с изображениями from PIL import Image # получаем путь к этому скрипту path = os.path.dirname(os.path.abspath(__file__)) # создаём новый распознаватель лиц recognizer = cv2.face.LBPHFaceRecognizer_create() # указываем, что мы будем искать лица по примитивам Хаара faceCascade = cv2.CascadeClassifier(cv2.data.haarcascades + "haarcascade_frontalface_default.xml") # путь к датасету с фотографиями пользователей dataPath = path+r'/dataSet' # получаем картинки и подписи из датасета def get_images_and_labels(datapath): # получаем путь к картинкам image_paths = [os.path.join(datapath, f) for f in os.listdir(datapath)] # списки картинок и подписей на старте пустые images = [] labels = [] # перебираем все картинки в датасете for image_path in image_paths: # читаем картинку и сразу переводим в ч/б image_pil = Image.open(image_path).convert('L') # переводим картинку в numpy-массив image = np.array(image_pil, 'uint8') # получаем id пользователя из имени файла nbr = int(os.path.split(image_path)[1].split(".")[0].replace("face-", "")) # определяем лицо на картинке faces = faceCascade.detectMultiScale(image) # если лицо найдено for (x, y, w, h) in faces: # добавляем его к списку картинок images.append(image[y: y + h, x: x + w]) # добавляем id пользователя в список подписей labels.append(nbr) # выводим текущую картинку на экран cv2.imshow("Adding faces to traning set. ", image[y: y + h, x: x + w]) # делаем паузу cv2.waitKey(100) # возвращаем список картинок и подписей return images, labels # получаем список картинок и подписей images, labels = get_images_and_labels(dataPath) # обучаем модель распознавания на наших картинках и учим сопоставлять её лица и подписи к ним recognizer.train(images, np.array(labels)) # сохраняем модель recognizer.save(path+r'/trainer/trainer.yml') # удаляем из памяти все созданные окнаы cv2.destroyAllWindows()Что дальше
Теперь у нас всё готово для того, чтобы мы добавили новую модель в скрипт распознавания лиц. Сделаем это в следующий раз и посмотрим, как нейросеть справляется с этой задачей.
Любите данные? Посмотрите вот это
Возможно, у вас получится построить карьеру в мире дата-сайенса. Это новое направление, в котором очень нужны люди. Изучите эту сферу и начните карьеру в ИТ: старт — бесплатно, а после обучения — помощь с трудоустройством.



Получите ИТ-профессию
В «Яндекс Практикуме» можно стать разработчиком, тестировщиком, аналитиком и менеджером цифровых продуктов. Первая часть обучения всегда бесплатная, чтобы попробовать и найти то, что вам по душе. Дальше — программы трудоустройства.
Создание приложения для распознавания текста с изображений и аудиофайлов
Запись текста с фотографии листа или из аудиозаписи в текстовый файл, доступный для редактирования – довольно часто встречающаяся задача при работе в офисах или учёбы. Для распознавания текстов и аудио в платных сервисах и программах сегодня используются такие подходы, как машинное зрение и распознавание речи с использованием глубоких нейронных сетей.
Детектирование (обнаружение) и классификация символов на изображении осуществляется с использованием различных архитектур свёрточных нейронных сетей [1]. Обработка естественного языка основана на использовании глубоких рекуррентных нейронных сетей, состоящих из ячеек долгой краткосрочной памяти LSTM [2]. При создании соответствующих приложений для работы с текстами, этап реализации нейронных сетей можно пропустить, используя соответствующие свободно распространяемые библиотеки.
В данной статье я хочу поделиться реализацией приложения, позволяющего пользователю преобразовать и сохранить текстовую информацию из изображения листа или аудио-файла.
Архитектура приложения и используемый стек технологий
Архитектура разрабатываемого приложения приведена на рисунке 1.
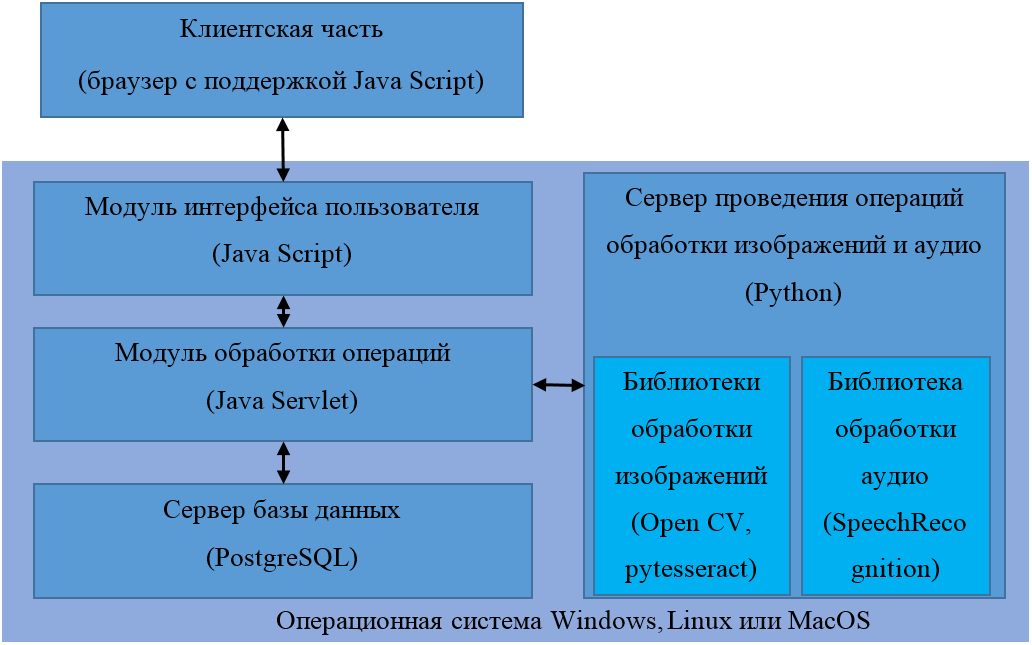
Архитектура на рисунке 1 реализована как клиент-сервер, в парадигме MVC (Model-View-Controller). Все данные разделяются на компоненты трёх видов: модель, представление и контроллер. Такая архитектура позволяет добиться расширяемости, за счёт независимости изменений каждого компонента.
Модуль интерфейса пользователя предназначен для формирования элементов пользовательского интерфейса и вызовов операций обработки данных. Код модуля размещается на сервере и выполняется в браузере пользователя. Пользователь работает с приложением с использованием браузера с поддержкой Java Script, для тестирования клиентской части использовался Google Chrome. В функции для клиентов входят: отображение информации, загрузка на сервер документов, получение результатов с сервера.
Серверные компоненты системы могут функционировать под управлением любого типа операционной системы, разработка и тестирование велась на Windows.
Модуль обработки операций реализует бизнес-логику программной системы. Он обрабатывает запросы пользователей, вызывает операции сервера проведения расчётов и сервера базы данных. Для реализации модуля была выбрана технология Java Servlet.
Для хранения и функционирования модуля обработки операций и модуля интерфейса пользователя был выбран веб сервер Apache Tomcat, обладающий высокой производительностью, гибким функционалом. Кроме того, Apache Tomcat не требует затрат на лицензирование. Взаимодействие между клиентской и серверной частями программной системы осуществляется по протоколу http (браузер на ПК).
Сервер проведения операций обработки изображений и аудио отвечает за задачи, связанные собственно с извлечением текстов из изображений и аудио-записей и их сохранения в текстовый файлы (использованы файлы *.docx). Указанный сервер реализован на языке Python с использованием библиотеки обработки изображений OpenCV и фреймворка TensorFlow.
Для хранения информации программной системы была выбрана система управления базами данных (СУБД) PostgreSQL. Плюсами выбранной СУБД являются отсутствие платы за лицензионное использование и кроссплатформенностью.
После разработки архитектуры были определены интегрированные среды разработки (IDE) компонент сервера и клиентской части. Для сервера проведения расчётов на Python используется PyCharm, для остальных компонент серверной и клиентской части системы — IntelliJ IDEA; обе IDE разработана компанией JetBrains, похожи по функционалу и интерфейсу, являются кроссплатформенными.
Исходный код приложения находится в репозитории, далее раскрою подробнее реализацию основных компонент приложения.
Разработка сервера обработки текстовых и аудио файлов
Для выполнения задачи распознавания текста с изображения используется технология OCR — обнаружение текстового содержимого на изображениях и перевод изображений в закодированный текст, который компьютер может легко понять. Изображение, содержащее текст, сканируется и анализируется, чтобы идентифицировать символы в нем. После идентификации символ преобразуется в машинно‑кодированный текст.
Для целей OCR использовался пакет PyTesseract, являющейся оболочной для Google Tesseract‑OCR Engine. Tesseract использует нейронные сети и двухступенчатый подход к распознаванию. В первый проход происходит распознавание символов. На втором этапе производится заполнение любых символов, которые имеют низкое значение вероятности правильного определения класса, символами, наиболее подходящими по контексту. Этапы выполняются на базе рекуррентной нейронной сети LSTM, наиболее подходящей для обработки естественного языка.
При работе с документом в формате PDF сначала документ извлекается из массива байт, сохраняется как временный файл и читается в память с использованием библиотеки fitz. Статический метод для этой операции приведён ниже.
import fitz @staticmethod def __getPDF(dictOfProject, parameters): for imageFromList in dictOfProject['InputDocument']: byteImage = bytes.fromhex(imageFromList) fileName = str(parameters.imagesFolder.joinpath('example.pdf').resolve()) file = open(fileName, 'wb') file.write(byteImage) file.close() pdfDocument = fitz.open(fileName) return pdfDocumentЗатем документ постранично сохраняется в изображения в формате PNG, и с использованием библиотеки pytesseract извлекается текст из каждого изображения, сохраняясь в текстовый файл, созданный с использованием библиотеки docx.
Код методов для выполнения OCR:
import os import docx import cv2 @staticmethod def __recognitionText(pdfDocument, parameters): mydoc = docx.Document() for current_page in range(len(pdfDocument)): for image in pdfDocument.get_page_images(current_page): xref = image[0] fileName = str(parameters.imagesFolder.joinpath("page%s-%s.png" % (current_page, xref)).resolve()) # читать изображение с помощью OpenCV ConvertPdfToTextCalculator.__takeImage(parameters.pytesseract, mydoc,fileName) pdfDocument.close() return mydoc @staticmethod def __takeImage(pytesseract, mydoc,fileName): image = cv2.imread(fileName) # получаем строку pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe' string = pytesseract.image_to_string(image, lang='rus') # добавляем в документ mydoc.add_paragraph(string)Для обработки аудио была использована библиотека Speech Recognition (в коде обозначена как sr), основанная на использовании скрытой марковской модели [3] и представляющая собой инструмент для передачи речевых API (мной был использован Google Speech). Для работы со звуком как с объектом и разбивки его на отрезки по параметру тишины использован высокоуровневый интерфейс pydub, а именно класс AudioSegment и метод split_on_silence.
Метод создания объекта класса AudioSegment:
@staticmethod def __getWav(dictOfProject, parameters): for imageFromList in dictOfProject['InputDocument']: byteFile = bytes.fromhex(imageFromList) fileName = str(parameters.imagesFolder.joinpath('example.wav').resolve()) file = open(fileName, 'wb') file.write(byteFile) file.close() sound = parameters.AudioSegment.from_wav(fileName) return soundМетод разбивки объекта на звуки, разделённые тишиной:
@staticmethod def __getSounds(soundDocument, parameters): chunks = parameters.split_on_silence(soundDocument, min_silence_len=500, silence_thresh=soundDocument.dBFS - 15, keep_silence=500, ) return chunksМетод расшифровки и записи текстового файла:
def __recognitionSound(chunks, parameters): mydoc = docx.Document() r = parameters.sr.Recognizer() for i, audio_chunk in enumerate(chunks, start=1): chunk_filename = os.path.join(parameters.imagesFolder, f"chunk.wav") audio_chunk.export(chunk_filename, format="wav") start_time = datetime.now() print(datetime.now() - start_time) with parameters.sr.AudioFile(chunk_filename) as source: audio_listened = r.record(source) try: text = r.recognize_google(audio_listened, language=parameters.language) except parameters.sr.UnknownValueError as e: print("Error:", str(e)) else: text = f". " print(" -- :", text) mydoc.add_paragraph(text) print("Время выполнения: ") print(datetime.now() - start_time) return mydocФайлы *.pdf или *.wav поступают на сервер от клиента через модуль обработки операций, в виде массива байт. Для передачи данных на сервере использована технология сокетов. Для хранения настроек сервера и обработки входящих запросов был создан отдельный класс NetworkServer.
Основной файл запуска cvserver.py выглядит следующим образом:
import keyboard from core.clientServer.networkServer import NetworkServer if __name__ == '__main__': server = NetworkServer() port = 10000 server.init(port) server.start() print("Система запущена!") print("Для выхода введите q") keyboard.wait("q") server.stop() server.done() print("Работа завершена")Код класса NetworkServer:
import socket from threading import Thread from core.clientsManager import ClientsManager from core.clientServer.clientHandler import ClientHandler from core.requests.requestFactory import RequestFactory class NetworkServer(object): def __init__(self): self._socket = None self._continueWork = False self._thread = None self._clientsManager = ClientsManager() self._requestFactory = RequestFactory() def init(self, portNumber): self._socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) self._socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) self._socket.settimeout(0.1) self._socket.bind(("127.0.0.1", portNumber)) self._socket.listen(0) def done(self): self.stop() if not (self._socket is None): self._socket.close() self._socket = None def start(self): if not (self._thread is None): self.stop() self._continueWork = True self._thread = Thread(target=self.__work) self._thread.start() def stop(self): if self._thread is None: return self._continueWork = False self._thread.join() self._thread = None def __work(self): while self._continueWork: try: clientSocket, clientAddress = self._socket.accept() client = ClientHandler(self, clientSocket) self.getClientsManager().Add(client) client.run() except socket.timeout: pass except Exception as e: print("Exception occur: " + e.__str__()) raise def getClientsManager(self): return self._clientsManager def getRequestFactory(self): return self._requestFactoryСервер может работать с несколькими потоками за счёт использования класса Thread(). Для выстраивания очередей используется вспомогательный класс ClientsManager.
from threading import Lock class ClientsManager(object): def __init__(self): self._clientsLock = Lock() self._clients = [] def Add(self, client): self._clientsLock.acquire() if not (client in self._clients): self._clients.append(client) self._clientsLock.release() def Remove(self, client): self._clientsLock.acquire() if client in self._clients: self._clients.remove(client) self._clientsLock.release()Для работы с входящими запросами и отсылкой ответов используется класс ClientHandler.
from threading import Thread from core.requests.requestResponseBuilder import RequestResponseBuilder class ClientHandler(object): RECEIVE_TIMEOUT = 30 def __init__(self, parent, clientSocket): self._parent = parent self._socket = clientSocket self._thread = None def run(self): self._thread = Thread(target=self.__work) self._thread.start() def __work(self): self._socket.settimeout(self.RECEIVE_TIMEOUT) requestCode, requestBody = RequestResponseBuilder.readRequest(self._socket) responseBody = self._parent.getRequestFactory().handle(requestCode, requestBody) RequestResponseBuilder.writeResponse(self._socket, responseBody) self._socket.close() self._parent.getClientsManager().Remove(self)Вспомогательный класс RequestFactory выполняет адресацию запросов к классам-обработчикам (RecognitionTextHandler и RecognitionSpeechHandler), в зависимости от кода запроса.
from typing import Optional from core.requests.recognitionTextHandler import RecognitionTextHandler from core.requests.recognitionSpeechHandler import RecognitionSpeechHandler from core.requests.requestCodes import RequestCodes class RequestFactory(object): def __init__(self) -> None: self._handlers = < RequestCodes.RecognitionText: RecognitionTextHandler(), RequestCodes.RecognitionSpeech: RecognitionSpeechHandler() >def handle(self, requestCode: int, requestBody: bytearray) -> Optional[bytes]: if requestCode in self._handlers: response = self._handlers[requestCode].handle(requestBody) else: response = None return responseВ класс RequestResponseBuilder вынесены статические методы работы для «упаковки» и «распаковки» запросов и ответов в массивы байт.
Используемые в RequestFactory классы-обработчики запросов по сути нужны для передачи распакованного запроса и инструментов для обработки в классы-калькуляторы для выполнения собственно обработки изображений и аудио, статические методы из которых приведены в начале раздела.
Код класса – обработчика для распознавания текста:
import json from typing import Optional import pytesseract from core.calculators.convertPdfToTextCalculator import ConvertPdfToTextCalculator from core.optParameters import OptParameters from core.commonUtils import CommonUtils class RecognitionTextHandler(object): def __init__(self): self.pytesseract = pytesseract self.pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe' def handle(self, packedParameters: bytearray) -> Optional[bytes]: if packedParameters is None or len(packedParameters) == 0: return None parametersStr = packedParameters.decode("utf8") parameters = json.loads(parametersStr) optParameters = OptParameters() optParameters.pytesseract = self.pytesseract optParameters.imagesFolder = CommonUtils.getSolutionFolder().joinpath("CVServer").joinpath("main").joinpath("data") result = ConvertPdfToTextCalculator.calculate(parameters, optParameters) try: response = json.dumps(result).encode("utf8") except: print('Error') return responseКод класса – обработчика для распознавания речи:
import json from typing import Optional import speech_recognition as sr from core.calculators.convertWavToTextCalculator import ConvertWavToTextCalculator from core.optParameters import OptParameters from core.commonUtils import CommonUtils from pydub import AudioSegment from pydub.silence import split_on_silence class RecognitionSpeechHandler(object): def __init__(self): self.sr = sr self.AudioSegment = AudioSegment self.split_on_silence = split_on_silence def handle(self, packedParameters: bytearray) -> Optional[bytes]: if packedParameters is None or len(packedParameters) == 0: return None parametersStr = packedParameters.decode("utf8") parameters = json.loads(parametersStr) optParameters = OptParameters() optParameters.AudioSegment = self.AudioSegment optParameters.split_on_silence = self.split_on_silence optParameters.sr = self.sr optParameters.imagesFolder = CommonUtils.getSolutionFolder().joinpath("CVServer").joinpath("main").joinpath("data").joinpath("sound") result = ConvertWavToTextCalculator.calculate(parameters, optParameters) try: response = json.dumps(result).encode("utf8") except: print('Error') return responseОтвет передается в виде словаря со структурой , где itemhex – байтовое представление файла с результатами распознавания, к которому применена функция hex().
Опишем структуру базы данных и остальные модули приложения.
Разработка базы данных
Используемая в ходе работы информация храниться в реляционной базе данных. На рисунке 2 приведена ER диаграмма (сущность-связь) спроектированной для системы базы данных.
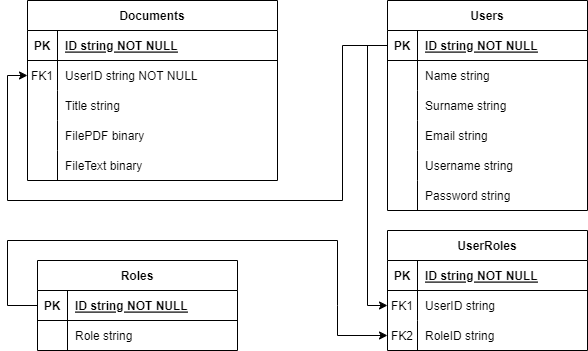
Модель данных, приведённая на рисунке 2, содержит 4 сущности – таблицы базы данных системы. Каждый экземпляр каждой сущности имеет идентификатор ID, представляющий собой уникальную строку символов, задаваемую с использованием текстового представления стандарта UUID.
Структура базы данных имеет две группы сущностей: 1) отвечающих за авторизацию и права пользователей; 2) отвечающих за хранение информации по распознаваемым файлам.
Опишем сущности первой группы, отвечающие за параметры безопасности и разграничение уровней доступа в системе. Сущность Users содержит информацию по личным данным пользователя: Name (имя), Surname (фамилия), Email (адрес почты), Username (логин), Password (пароль).
Сущность Roles содержит информацию о ролях, имеет поле Role, принимающие два значения: user и admin.
Связь между Users и Roles осуществляется с использованием таблицы UserRoles, в которой хранятся идентификаторы UserID и RoleID.
Вторая группа включает только лишь одну сущность Documents, содержащую поля UserID (идентификатор для связи с Users), название распознаваемого файла Title и его содержимого FilePDF и результата его расшифровки в текст FileTXT. FilePDF — это документ *.pdf или *.wav в виде массива байт, FileTXT — документ *.docx в виде массива байт.
Для создания тестового варианта базы данных использовался код на Python с использованием SQLAlchemy, позволяющий создать структуру и тестовое наполнения базы данных PostgreSQL. Код для генерации теста находится в папке Tools/ DBGenerate проекта
на Github.
Разработка остальных модулей
Структура клиентской и серверной частей, за исключением сервера проведения операций обработки изображений и аудио, приведена на рисунке 3.
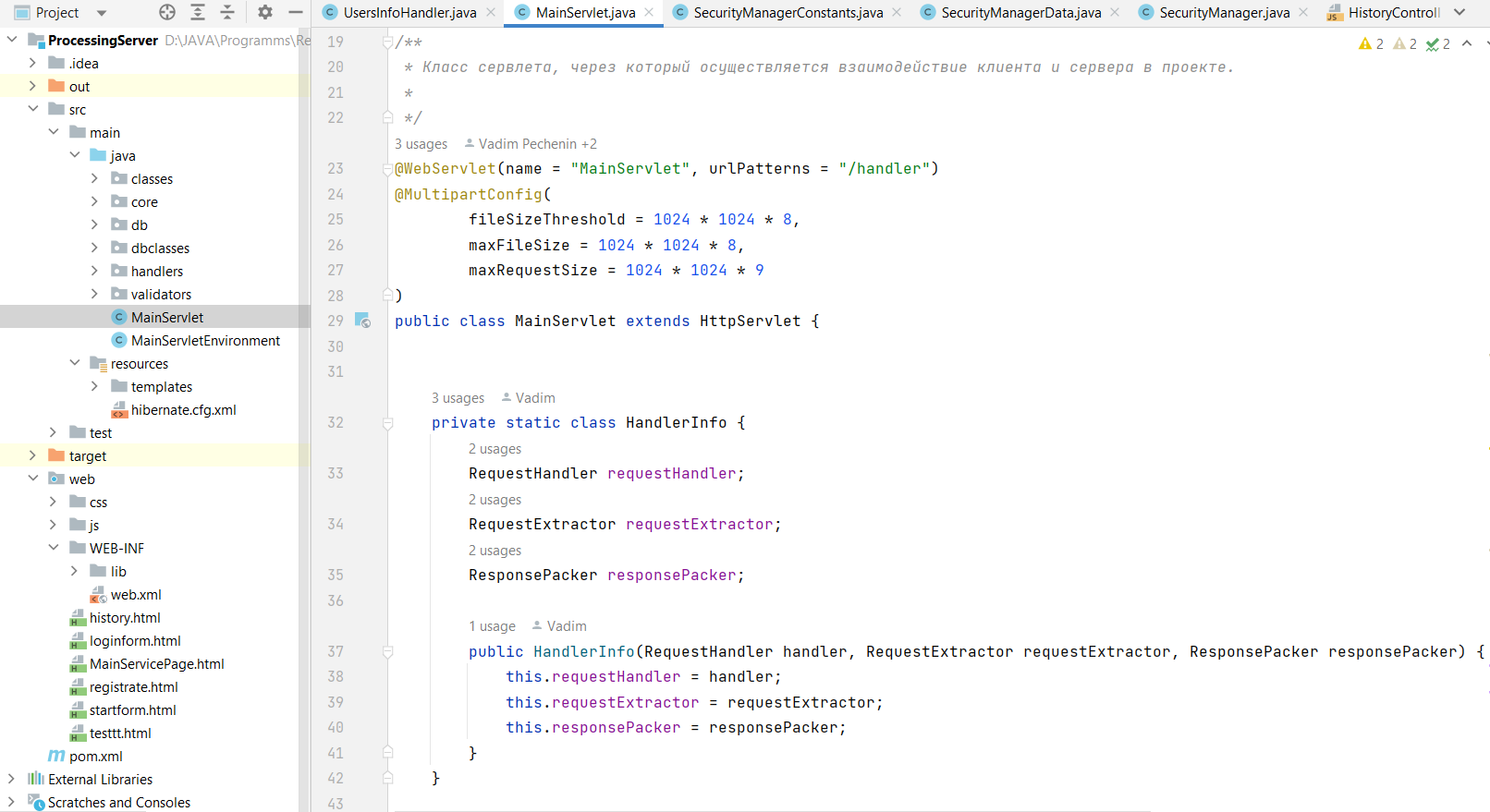
Ядром модуля обработки операций является класс MainServlet, наследующий абстрактный класс HttpServlet. Он содержит экземпляры внутреннего класса HandlerInfo в виде структуры «словарь» handlers, хранящий все обработчики запросов и способ их распаковки, а также способ упаковки ответов клиенту. Код класса MainServlet:
import classes.RequestCode; import core.interaction.*; import handlers.DocumentsHandler; import handlers.SessionHandler; import handlers.UsersInfoHandler; import jakarta.servlet.ServletConfig; import jakarta.servlet.ServletException; import jakarta.servlet.annotation.MultipartConfig; import jakarta.servlet.annotation.WebServlet; import jakarta.servlet.http.HttpServlet; import jakarta.servlet.http.HttpServletRequest; import jakarta.servlet.http.HttpServletResponse; import java.io.IOException; import java.util.HashMap; import java.util.Map; /** * Класс сервлета, через который осуществляется взаимодействие клиента и сервера в проекте. * */ @WebServlet(name = "MainServlet", urlPatterns = "/handler") @MultipartConfig( fileSizeThreshold = 1024 * 1024 * 8, maxFileSize = 1024 * 1024 * 8, maxRequestSize = 1024 * 1024 * 9 ) public class MainServlet extends HttpServlet < private static class HandlerInfo < RequestHandler requestHandler; RequestExtractor requestExtractor; ResponsePacker responsePacker; public HandlerInfo(RequestHandler handler, RequestExtractor requestExtractor, ResponsePacker responsePacker) < this.requestHandler = handler; this.requestExtractor = requestExtractor; this.responsePacker = responsePacker; >> private volatile Boolean isInitialized; private final Object isInitializedLock = new Object(); private final Map handlers; private MainServletEnvironment environment; public MainServlet() < handlers = new HashMap<>(); > @Override public void init(ServletConfig config) throws ServletException < super.init(config); //Запуск сессии if(isInitialized == null) < synchronized(isInitializedLock) < if(isInitialized == null) < isInitialized = initializeImpl(); >> > log("Method init =)"); > @Override protected void service(HttpServletRequest httpServletRequest, HttpServletResponse httpServletResponse) throws ServletException, IOException, IOException < String command = null; try < if (isInitialized) < command = httpServletRequest.getParameter("cmd"); HandlerInfo handlerInfo = handlers.get(command); if (handlerInfo != null) < Request request = handlerInfo.requestExtractor.extract(httpServletRequest); InnerResponseRecipient responseRecipient = new InnerResponseRecipient(); handlerInfo.requestHandler.executeRequest(responseRecipient, request); handlerInfo.responsePacker.pack(request, responseRecipient.response, httpServletRequest, httpServletResponse); >else < handleError(httpServletResponse, "templates/CommandNotSupported.html"); >> else < handleError(httpServletResponse, "templates/InitializationFailed.html"); >> catch (Exception e) < System.out.printf("Команда не поддерживается, код %s", command); handleError(httpServletResponse, "templates/ExceptionOccur.html"); e.printStackTrace(); >log("Method service =)"); > private void handleError(HttpServletResponse httpServletResponse, String errorTemplate) throws IOException < String pageText = environment.resourceManager.getResource(errorTemplate); HttpServletResponseBuilder.onStringResponse(httpServletResponse, HttpServletResponse.SC_BAD_REQUEST, HttpServletResponseBuilder.HTMLContentType, pageText); >@Override public void destroy() < super.destroy(); log("Method desctoy =)"); >private boolean initializeImpl() < boolean result; try < environment = MainServletEnvironment.create(); result = environment != null; if (result) < RequestHandler sessionHandler = new SessionHandler(environment.sessionManager, environment.securityManager); register(RequestCode.SESSION_OPEN, sessionHandler, environment.editContentRequestExtractor, environment.sessionOpenResponsePacker); register(RequestCode.SESSION_CLOSE, sessionHandler, environment.baseRequestExtractor, environment.sessionCloseResponsePacker); RequestHandler usersInfoHandler = new UsersInfoHandler(environment.sessionManager, environment.securityManager, environment.documentManager); register(RequestCode.USERS_INFO, usersInfoHandler, environment.editContentRequestExtractor, environment.objectResponsePacker); register(RequestCode.CURRENT_USER_INFO, usersInfoHandler, environment.baseRequestExtractor, environment.objectResponsePacker); register(RequestCode.REGISTRATION_USER_INFO, usersInfoHandler, environment.entityWithViolationsRequestExtractor, environment.sessionOpenResponsePacker); register(RequestCode.GET_DOCUMENTS_HISTORY, usersInfoHandler, environment.baseRequestExtractor, environment.objectResponsePacker); register(RequestCode.GET_DOCUMENT_BY_ID, usersInfoHandler, environment.editContentRequestExtractor, environment.objectResponsePacker); RequestHandler documentsHandler = new DocumentsHandler(environment.sessionManager, environment.documentManager); register(RequestCode.RECOGNIZE_DOCUMENT, documentsHandler, environment.requestWithAttachmentsExtractor, environment.objectResponsePacker); register(RequestCode.RECOGNIZE_AUDIO_DOCUMENT, documentsHandler, environment.requestWithAttachmentsExtractor, environment.objectResponsePacker); register(RequestCode.SAVE_DOCUMENT, documentsHandler, environment.requestWithAttachmentsExtractor, environment.baseResponsePacker); >> catch (Exception e) < e.printStackTrace(); result = false; >return result; > private void register(RequestCode code, RequestHandler handler, RequestExtractor requestExtractor, ResponsePacker responsePacker) < handlers.put(code.toString(), new HandlerInfo(handler, requestExtractor, responsePacker)); >>Кроме того, MainServlet содержит экземпляр класса MainServlet Environment, содержащий экземпляры классов‑менеджеров для работы с базой данных, экземпляры классов для работы с запросами‑ответами и для работы с базой данных. MainServlet имеет следующие методы: initialize() — инициализирует единственный раз запуск метода initializeImpl(); initializeImpl() — запускает метод create() класса MainServlet Environment, и заполняет словарь handlers посредством метода register(); метод service() принимает запросы и отправляет ответы; метод handleError() нужен для обработки ошибок, когда приходит запрос, отсутствующий в словаре handlers.Код класса WebHandlerEnvironment:
import core.ResourceManager; import core.SessionManager; import core.documentManager.DocumentManager; import core.interaction.RequestExtractor; import core.interaction.ResponsePacker; import core.interaction.requestExtractors.BaseRequestExtractor; import core.interaction.requestExtractors.EditContentRequestExtractor; import core.interaction.requestExtractors.RequestWithAttachmentsExtractor; import core.interaction.requestExtractors.entityRequestExtractor.EntityRequestExtractor; import core.interaction.requestExtractors.entityRequestExtractor.EntityWithViolationsRequestExtractor; import core.interaction.responsePackers.BaseResponsePacker; import core.interaction.responsePackers.ObjectResponsePacker; import core.interaction.responsePackers.SessionCloseResponsePacker; import core.interaction.responsePackers.SessionOpenResponsePacker; import db.HibernateSessionFactory; import org.hibernate.SessionFactory; import core.securityManager.SecurityManager; public class MainServletEnvironment < final public SessionFactory hibernateSessionFactory; final public SessionManager sessionManager; final public SecurityManager securityManager; final public DocumentManager documentManager; final public ResourceManager resourceManager; final public RequestExtractor baseRequestExtractor; final public RequestExtractor editContentRequestExtractor; final public RequestWithAttachmentsExtractor requestWithAttachmentsExtractor; final public EntityRequestExtractor entityRequestExtractor; final public EntityWithViolationsRequestExtractor entityWithViolationsRequestExtractor; final public ResponsePacker sessionOpenResponsePacker; final public ResponsePacker sessionCloseResponsePacker; final public BaseResponsePacker baseResponsePacker; final public ObjectResponsePacker objectResponsePacker; private MainServletEnvironment(SessionFactory hibernateSessionFactory, SessionManager sessionManager, SecurityManager securityManager,DocumentManager documentManager) < this.hibernateSessionFactory = hibernateSessionFactory; this.sessionManager = sessionManager; this.securityManager = securityManager; this.resourceManager = new ResourceManager(); this.documentManager = documentManager; this.baseRequestExtractor = new BaseRequestExtractor(); this.editContentRequestExtractor = new EditContentRequestExtractor(); this.entityRequestExtractor = new EntityRequestExtractor(); this.entityWithViolationsRequestExtractor = new EntityWithViolationsRequestExtractor(); this.requestWithAttachmentsExtractor = new RequestWithAttachmentsExtractor(); this.baseResponsePacker = new BaseResponsePacker(); this.objectResponsePacker = new ObjectResponsePacker(resourceManager); this.sessionCloseResponsePacker = new SessionCloseResponsePacker(resourceManager); this.sessionOpenResponsePacker = new SessionOpenResponsePacker(resourceManager); >public static MainServletEnvironment create() < boolean result; SessionFactory hibernateSessionFactory = null; SessionManager sessionManager = null; SecurityManager securityManager = null; DocumentManager documentManager = null; try < hibernateSessionFactory = HibernateSessionFactory.getSessionFactory(); sessionManager = new SessionManager(); securityManager = new SecurityManager(hibernateSessionFactory, sessionManager); documentManager = new DocumentManager(hibernateSessionFactory, sessionManager); result = securityManager.init(); >catch (Exception e) < e.printStackTrace(); result = false; >return result ? new MainServletEnvironment(hibernateSessionFactory, sessionManager, securityManager, documentManager): null; > >В качестве контейнера сервлетов используется Apache Tomcat. Обработка каждого запроса выделено в отдельные классы в пакете handlers, которые связываются с классами сервисов в пакете core. Работа с базой данных осуществляется с использованием классов пакетов dbclasses и db, где хранятся классы сущностей и сервисы работы с ними соответственно.
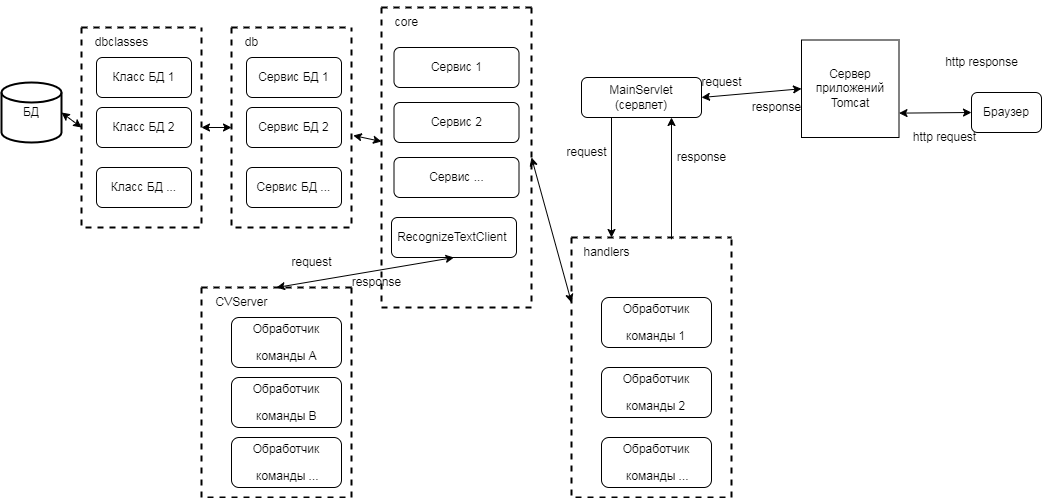
Запросы от клиента к серверу проведения операций обработки изображений и аудио (CVServer на диаграмме рисунка 4) производятся через класс RecognizeTextClient пакета core. Запросы клиента и ответы сервера производятся по протоколу http. Код класса RecognizeTextClient:
import classes.RecognitionDocument; import core.recognitionClient.handlers.TextRecognitionHandler; import java.io.IOException; import java.io.InputStream; import java.io.OutputStream; import java.net.Socket; import java.nio.charset.StandardCharsets; import java.util.List; import java.util.Objects; /** * Класс для отправки на сервер распознавания запроса на распознавания текста с pdf документа */ public class RecognizeTextClient < private static final String SERVER_IP = "127.0.0.1"; private static final int SERVER_PORT = 10000; private static final int RequestCodeLength = 3; private static final int RequestBodyLength = 8; private static final int ResponseHeaderLength = 10; private final String requestHeaderMask; private final TextRecognitionHandler textRecognitionHandler; private Socket clientSocket; private InputStream in; private OutputStream out; public RecognizeTextClient()< requestHeaderMask = String.format("%%0%dd%%0%dd", RequestCodeLength, RequestBodyLength); textRecognitionHandler = new TextRecognitionHandler(); >private boolean connect() < try < clientSocket = new Socket(SERVER_IP, SERVER_PORT); in = clientSocket.getInputStream(); out = clientSocket.getOutputStream(); >catch (IOException ignored) < clientSocket = null; >return clientSocket != null; > private void disconnect() < if(clientSocket != null) < try< in.close(); out.close(); clientSocket.close(); >catch (IOException ignored) < >> clientSocket = null; > private String writeRequestReadResponse(int requestCode, String request) throws IOException < byte[] requestBody = request.getBytes(StandardCharsets.UTF_8); String requestHeaderStr = String.format(requestHeaderMask, requestCode, requestBody.length); byte[] requestHeader = requestHeaderStr.getBytes(StandardCharsets.UTF_8); byte[] responseHeader = new byte[ResponseHeaderLength]; byte[] responseBody; String response; out.write(requestHeader); out.write(requestBody); out.flush(); readNBytes(responseHeader, ResponseHeaderLength); String responseHeaderStr = new String(responseHeader, StandardCharsets.UTF_8); int responseBodyLength = Integer.parseInt(responseHeaderStr); if(responseBodyLength != 0 ) < responseBody = new byte[responseBodyLength]; readNBytes(responseBody, responseBodyLength); response = new String(responseBody, StandardCharsets.UTF_8); >else < response = ""; >return response; > private void readNBytes(byte[] b, int len) throws IOException < Objects.requireNonNull(b); if (len < 0 || len >b.length) throw new IndexOutOfBoundsException(); int n = 0; while (n < len) < int count = in.read(b, n, len - n); if (count < 0) break; n += count; >> private String executeOperation(int operationCode, String operationParameters) < String response = null; if(connect()) < try< response = writeRequestReadResponse(operationCode, operationParameters); >catch (IOException ignored) < >> disconnect(); return response; > public boolean recognitionText(List inputDocument, RecognitionDocument calculateResult) < String parameters = textRecognitionHandler.getRequestParameters(inputDocument); String response = executeOperation(CalculateServerRequestCode.RECOGNIZE_TEXT, parameters); if(!textRecognitionHandler.parseResponse(response)) return false; calculateResult.setValue(textRecognitionHandler.getInfos()); return textRecognitionHandler.getResult(); >public boolean recognitionAudio(List inputDocument, RecognitionDocument calculateResult) < String parameters = textRecognitionHandler.getRequestParameters(inputDocument); String response = executeOperation(CalculateServerRequestCode.RECOGNIZE_AUDIO, parameters); if(!textRecognitionHandler.parseResponse(response)) return false; calculateResult.setValue(textRecognitionHandler.getInfos()); return textRecognitionHandler.getResult(); >> В пакете validators хранятся классы для проверки правильности заполнения полей формы при регистрации.
Для работы с базой данных, как отмечалось ранее, используется библиотека Hibernate. Ниже приведён код класса для инициализации SessionFactory (используется для получения объектов, необходимых для операции с базой данных). Код класса HibernateSessionFactory:
package db; import dbclasses.*; import org.hibernate.SessionFactory; import org.hibernate.boot.registry.StandardServiceRegistryBuilder; import org.hibernate.cfg.Configuration; /** * Класс для создания SessionFactory. */ public class HibernateSessionFactory < private static volatile SessionFactory sessionFactory; //настройки и работа с сессиями (фабрика сессий) private static final Object sessionFactoryLock = new Object(); public static SessionFactory getSessionFactory() < if (sessionFactory == null) < synchronized(sessionFactoryLock) < if (sessionFactory == null) < try < Configuration configuration = new Configuration().configure(); configuration.addAnnotatedClass(User.class); configuration.addAnnotatedClass(Role.class); configuration.addAnnotatedClass(UserRole.class); configuration.addAnnotatedClass(Document.class); StandardServiceRegistryBuilder builder = new StandardServiceRegistryBuilder().applySettings(configuration.getProperties()); sessionFactory = configuration.buildSessionFactory(builder.build()); >catch (Exception e) < System.out.println("Исключение!" + e); >> > > return sessionFactory; > >В приведённом выше классе HibernateSessionFactory находятся все классы-сущности для таблиц базы данных. Приведем цепочку классов для работы с сущностью Document. Класс-обработчик, используемый в MainServlet (рисунок 4), носит название DocumentsHandler:
package handlers; import classes.*; import core.SessionManager; import core.documentManager.DocumentManager; import core.interaction.Request; import core.interaction.RequestHandlerContainer; import core.interaction.Response; import core.interaction.ResponseRecipient; import core.interaction.requests.RequestWithAttachments; import core.interaction.responses.ObjectResponse; import core.recognitionClient.RecognizeTextClient; import dbclasses.Document; import java.nio.charset.StandardCharsets; import java.time.Clock; import java.util.List; import java.util.Objects; public class DocumentsHandler extends RequestHandlerContainer < private final SessionManager sessionManager; private final DocumentManager documentManager; public DocumentsHandler(SessionManager sessionManager, DocumentManager documentManager) < super(); this.sessionManager = sessionManager; this.documentManager = documentManager; register(RequestCode.RECOGNIZE_DOCUMENT.toString(), this::DocumentRecognize); register(RequestCode.RECOGNIZE_AUDIO_DOCUMENT.toString(), this::AudioDocumentRecognize); register(RequestCode.SAVE_DOCUMENT.toString(), this::DocumentSave); >private boolean DocumentRecognize(ResponseRecipient responseRecipient, Request requestBase) < RequestWithAttachments request = (RequestWithAttachments) requestBase; boolean result; Session session = sessionManager.getSession(request.sessionID); session.lastActivityTime = Clock.systemDefaultZone().instant(); RecognizeTextClient recognizeTextClient = new RecognizeTextClient(); RecognitionDocument calculateResult = new RecognitionDocument(); result = recognizeTextClient.recognitionText(request.attachments, calculateResult); Response response = new ObjectResponse(request.code, request.sessionID, result, calculateResult); if (responseRecipient != null) < responseRecipient.ReceiveResponse(response); >return result; > private boolean AudioDocumentRecognize(ResponseRecipient responseRecipient, Request requestBase) < RequestWithAttachments request = (RequestWithAttachments) requestBase; boolean result; Session session = sessionManager.getSession(request.sessionID); session.lastActivityTime = Clock.systemDefaultZone().instant(); RecognizeTextClient recognizeTextClient = new RecognizeTextClient(); RecognitionDocument calculateResult = new RecognitionDocument(); result = recognizeTextClient.recognitionAudio(request.attachments, calculateResult); Response response = new ObjectResponse(request.code, request.sessionID, result, calculateResult); if (responseRecipient != null) < responseRecipient.ReceiveResponse(response); >return result; > private boolean DocumentSave(ResponseRecipient responseRecipient, Request requestBase) < RequestWithAttachments request = (RequestWithAttachments) requestBase; boolean result = false; Session session = sessionManager.getSession(request.sessionID); session.lastActivityTime = Clock.systemDefaultZone().instant(); byte[] filepdf = request.attachments.get(0); byte[] filetext = request.attachments.get(1); String titleOfDocument = new String(request.attachments.get(2), StandardCharsets.UTF_8); String[] userIDs = new String[] ; Document document = new Document(); if(session != null) < for (String userID : userIDs) < if (Objects.equals(userID, session.currentUserID)) < document.setUserID(userID); document.setTitle(titleOfDocument); document.setFilepdf(filepdf); document.setFiletext(filetext); result = saveDocument(document, result); >> > Response response = new Response(request.code, request.sessionID, result); if (responseRecipient != null) < responseRecipient.ReceiveResponse(response); >return result; > private boolean saveDocument(Document entity, boolean result) < if (entity!=null)< try< documentManager.save(entity); result = true; >catch(Exception e) < e.printStackTrace(); result = false; >> return result; > private boolean DocumentInfoID(ResponseRecipient responseRecipient, Request request, String sessionID, String[] userIDs, String ID) < boolean result; Listdocuments = documentManager.getDocumentByID(sessionID, userIDs, ID); DocumentsInfo view = new DocumentsInfo(documents); result = documents.size() != 0; ObjectResponse response = new ObjectResponse(request.code, request.sessionID, result, view); if (responseRecipient != null) < responseRecipient.ReceiveResponse(response); >return true; > >Класс-обработчик содержит методы для работы с поступающими запросами (RECOGNIZE_DOCUMENT, RECOGNIZE_AUDIO_DOCUMENT, SAVE_DOCUMENT), использует для операций класс RecognizeTextClient для выполнения детектирования текста и DocumentManager для операций с базой данных, находящийся в пакете core (рисунок 4):
package core.documentManager; import classes.Session; import core.CommonUtils; import core.SessionManager; import db.DocumentManagerService; import dbclasses.Document; import java.util.*; /** * Менеджер для работы с сущностью Document */ public class DocumentManager < private final DocumentManagerService service; private final SessionManager sessionManager; private final DocumentManagerData data; public DocumentManager(org.hibernate.SessionFactory hibernateSessionFactory, SessionManager sessionManager) < this.sessionManager = sessionManager; this.service = new DocumentManagerService(hibernateSessionFactory); this.data = new DocumentManagerData(); >public boolean init() < boolean result = true; service.getData(data); if (data==null)< result = false; >return result; > public List getDocuments(String currentSessionID, String[] ids) < Listresult = new ArrayList<>(); Session session = sessionManager.getSession(currentSessionID); List userIDs = new ArrayList<>(); if(ids == null || ids.length == 0) < userIDs.add(session.currentUserID); >else < Collections.addAll(userIDs, ids); >if(session != null) < for(String userID : userIDs) < if(Objects.equals(userID, session.currentUserID)) < service.getDataByUserID(data,userID); result.addAll(data.documents); >> > return result; > public List getDocumentByID(String currentSessionID, String[] ids, String id) < Listresult = new ArrayList<>(); Session session = sessionManager.getSession(currentSessionID); List userIDs = new ArrayList<>(); if(ids == null || ids.length == 0) < userIDs.add(session.currentUserID); >else < Collections.addAll(userIDs, ids); >if(session != null) < for(String userID : userIDs) < if(Objects.equals(userID, session.currentUserID)) < service.getDataByID(data,id); result.addAll(data.documents); >> > return result; > public void save(Document document) < document.setId(CommonUtils.createID()); service.createDocument(document); >> DocumentManager работает со списком объектов класса Document, собранных в класс DocumentManagerData:
package core.documentManager; import dbclasses.Document; import java.util.ArrayList; import java.util.List; /** * Класс для хранения списка документов */ public class DocumentManagerData < public final Listdocuments; public DocumentManagerData() < documents = new ArrayList<>(); > public void clear() < documents.clear(); >>Кроме того, в DocumentManager используется класс-сервис DocumentManagerService для выполнения транзакций.
package db; import core.documentManager.DocumentManagerData; import dbclasses.Document; import org.hibernate.Session; import org.hibernate.SessionFactory; import org.hibernate.Transaction; import org.hibernate.query.Query; import java.util.List; public class DocumentManagerService < private final SessionFactory sessionFactory; public DocumentManagerService(SessionFactory sessionFactory) < this.sessionFactory = sessionFactory; >public void getData(DocumentManagerData data) < data.clear(); Session session = sessionFactory.openSession(); Transaction transaction = session.beginTransaction(); try < data.documents.addAll(session.createQuery("SELECT row FROM Document row", Document.class).list()); transaction.commit(); >catch (Exception e) < transaction.rollback(); throw e; >finally < session.close(); >> public void getDataByUserID(DocumentManagerData data, String id) < data.clear(); Session session = sessionFactory.openSession(); Transaction transaction = session.beginTransaction(); try < data.documents.addAll(session.createQuery("SELECT row FROM Document row WHERE row.userID= : userID", Document.class). setParameter("userID", id). list()); transaction.commit(); >catch (Exception e) < transaction.rollback(); throw e; >finally < session.close(); >> public void getDataByID(DocumentManagerData data, String id) < data.clear(); Session session = sessionFactory.openSession(); Transaction transaction = session.beginTransaction(); try < data.documents.addAll(session.createQuery("SELECT row FROM Document row WHERE row.id= : id", Document.class). setParameter("id", id). list()); transaction.commit(); >catch (Exception e) < transaction.rollback(); throw e; >finally < session.close(); >> public void createDocument(Document document) < Session session = sessionFactory.openSession(); Transaction transaction = session.beginTransaction(); try < session.persist(document); transaction.commit(); >catch (Exception e) < transaction.rollback(); throw e; >finally < session.close(); >> >Осталось привести код класса-сущности Document:
package dbclasses; import jakarta.persistence.Column; import jakarta.persistence.Entity; import jakarta.persistence.Table; @Entity @Table(name = "Documents") public class Document extends ObjectWithID < @Column(name = "userid") private String userID; @Column(name = "title") private String title; @Column(name = "filepdf") private byte[] filepdf; @Column(name = "filetext") private byte[] filetext; public String getUserID() < return userID; >public void setUserID(String userID) < this.userID = userID; >public String getTitle() < return title; >public void setTitle(String title) < this.title = title; >public byte[] getFilepdf() < return filepdf; >public void setFilepdf(byte[] filepdf) < this.filepdf = filepdf; >public byte[] getFiletext() < return filetext; >public void setFiletext(byte[] filetxt) < this.filetext = filetxt; >>Весь фронтэнд находится в пакете web (рисунок 3) и состоит из пяти страниц HTML, за внешний вид отвечают ассоциированные с ними файлы CSS, за функционал естественно файлы на JavaScript. Обмен данных с сервером проходит с помощью технологии AJAX, реализованной в буферном классе NetworkClient, через который проходят все запросы со всех страниц (экземпляр NetworkClient присутствует на каждом классе для страницы).
Например, реализация отправки данных для авторизации в NetworkClient выполнена следующим образом:
export default class NetworkClient < constructor(parent) < this._parent = parent; this._serverUrl = 'handler'; this._defaultTimeout = 30000; //миллисек >#executeCommand(commandName, commandParameters, onSuccess, onError) < let query = < method: 'POST', url: this._serverUrl, timeout: this._defaultTimeout, context: this._parent, success: onSuccess, error: onError >; let parameters = commandParameters; if (parameters instanceof FormData) < parameters.append("cmd", commandName); query.data = parameters; query.processData = false; query.contentType = false; >else < parameters.cmd = commandName; query.data = parameters; >$.ajax(query); > commandLogin(username, password, onSuccess, onError) < let command = "SESSION_OPEN"; let commandParameters = ; this.#executeCommand(command, commandParameters, onSuccess, onError); >Метод commandLogin принимает параметры от пользователя (логин и пароль), добавляет команду для сервера «SESSION_OPEN» и отправляет в метод executeCommand (принимающий и другие запросы). В executeCommand формируется POST запрос, который с использованием AJAX отправляется на сервер. В случае успеха информация далее поступает в соответствующий метод в контроллере страницы для авторизации, в случае ошибки данные уходят в другой метод, обычно показывающий соответствующее сообщение об ошибке.
В качестве итога — демонстрация работы приложения
Продемонстрирую кратко получившееся приложение в действии. При запуске приложения была настроена стартовая страница, startform.html (рисунок 5). Кроме запуска сервлета, необходимо параллельно запустить сервер на Python — файл cvserver.py.
Со стартовой страницы можно попасть либо на страницу для авторизации, либо на страницу регистрации (рисунок 6).
После успешного прохождения авторизации или регистрации пользователь попадает на главную страницу личного кабинета (рисунок 7), где он может загружать файлы формата *.pdf или *.wav.
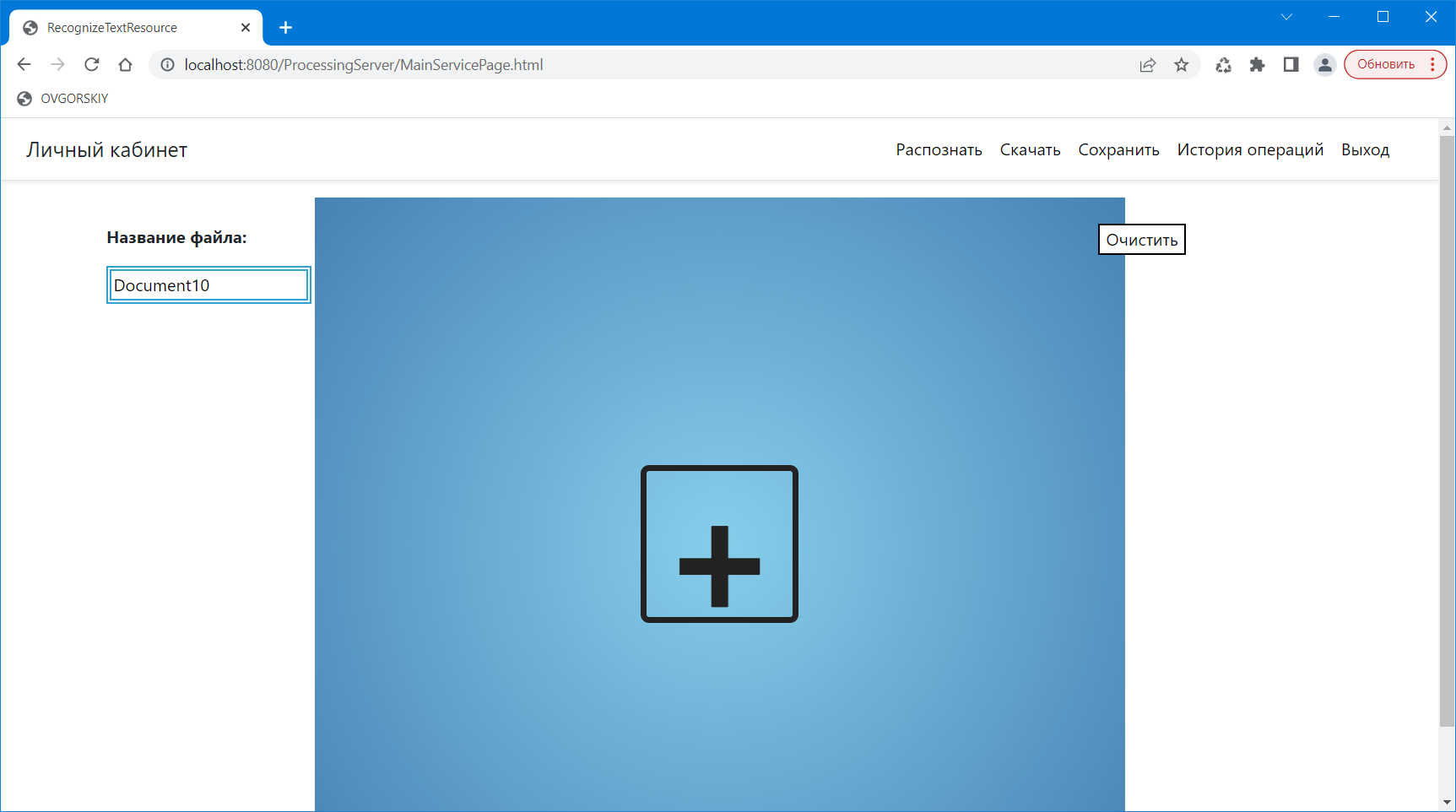
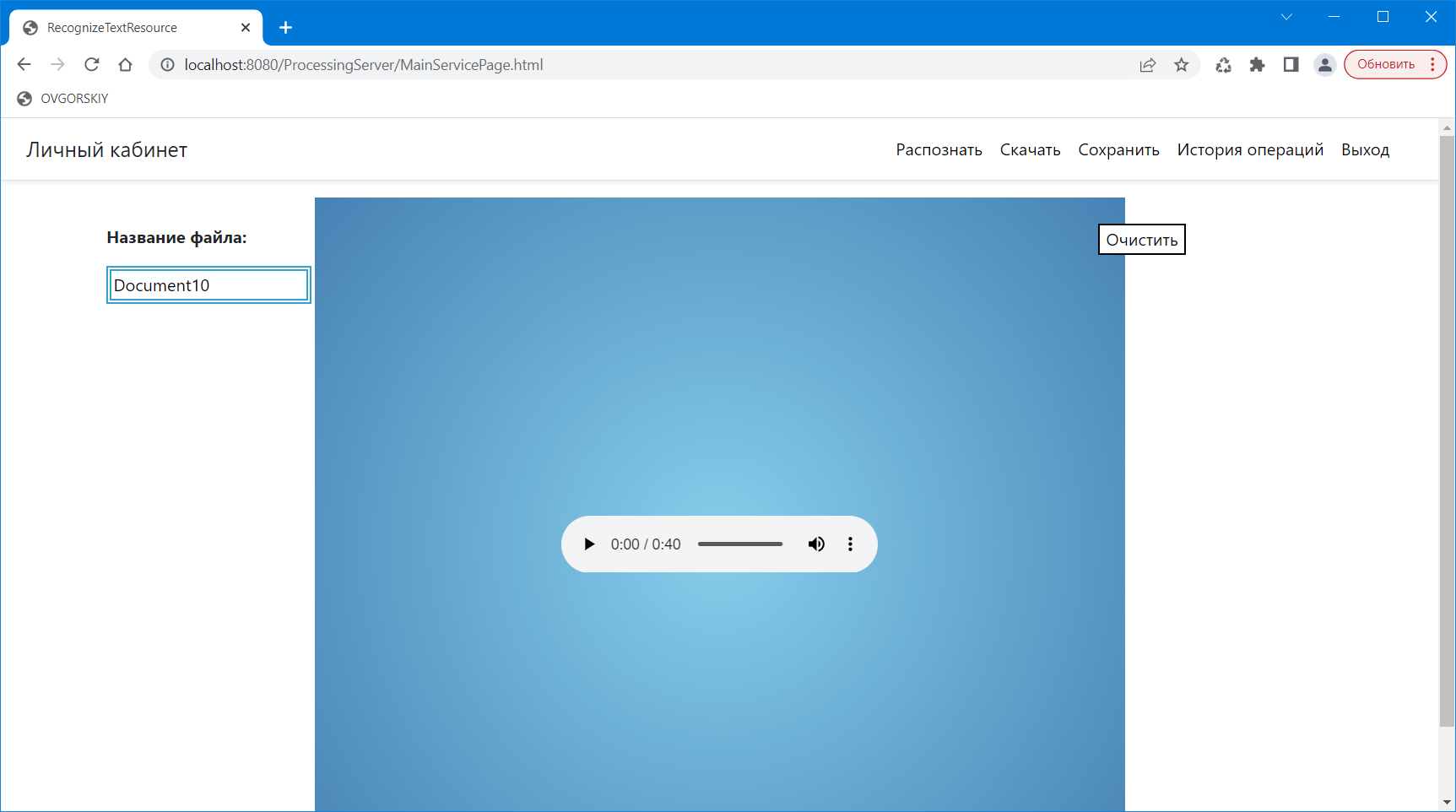
При загрузке соответствующих файлов для распознавания, они отображаются в форме загрузки в центре, либо в виде PDF (рисунок 8), либо в виде проигрывателя звука (рисунок 9).
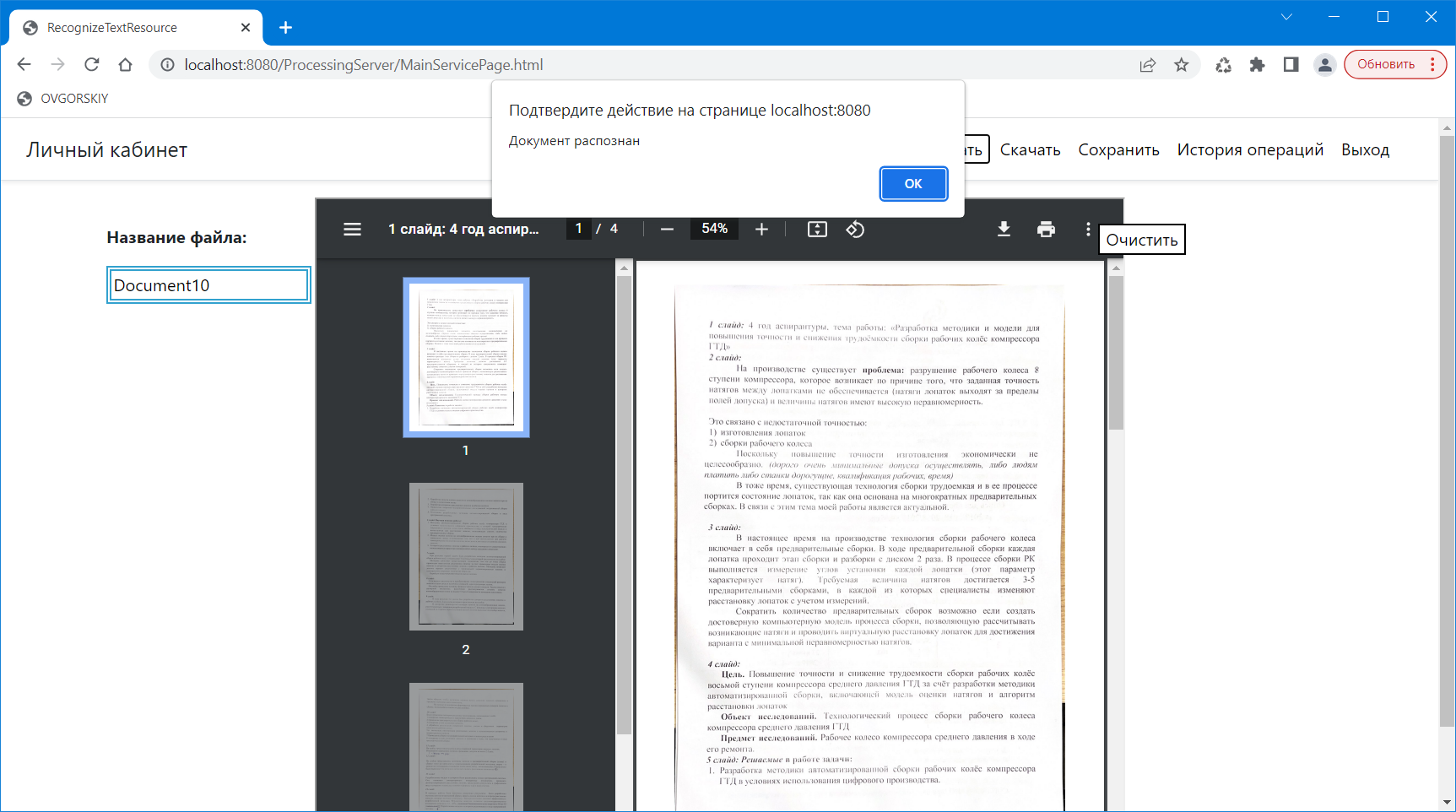
При нажатии на кнопку меню «Распознать» в случае успешной операции появляется сообщение о том, что документ распознан (рисунок 8). Текстовый документ с распознанным текстом можно скачать и сохранить в базу данных, задав при этом название файла.
Кроме того, пользователь может зайти на страницу «История операций» и выполнить загрузку исходного документа, скачать его и скачать результат распознавания (рисунок 10).
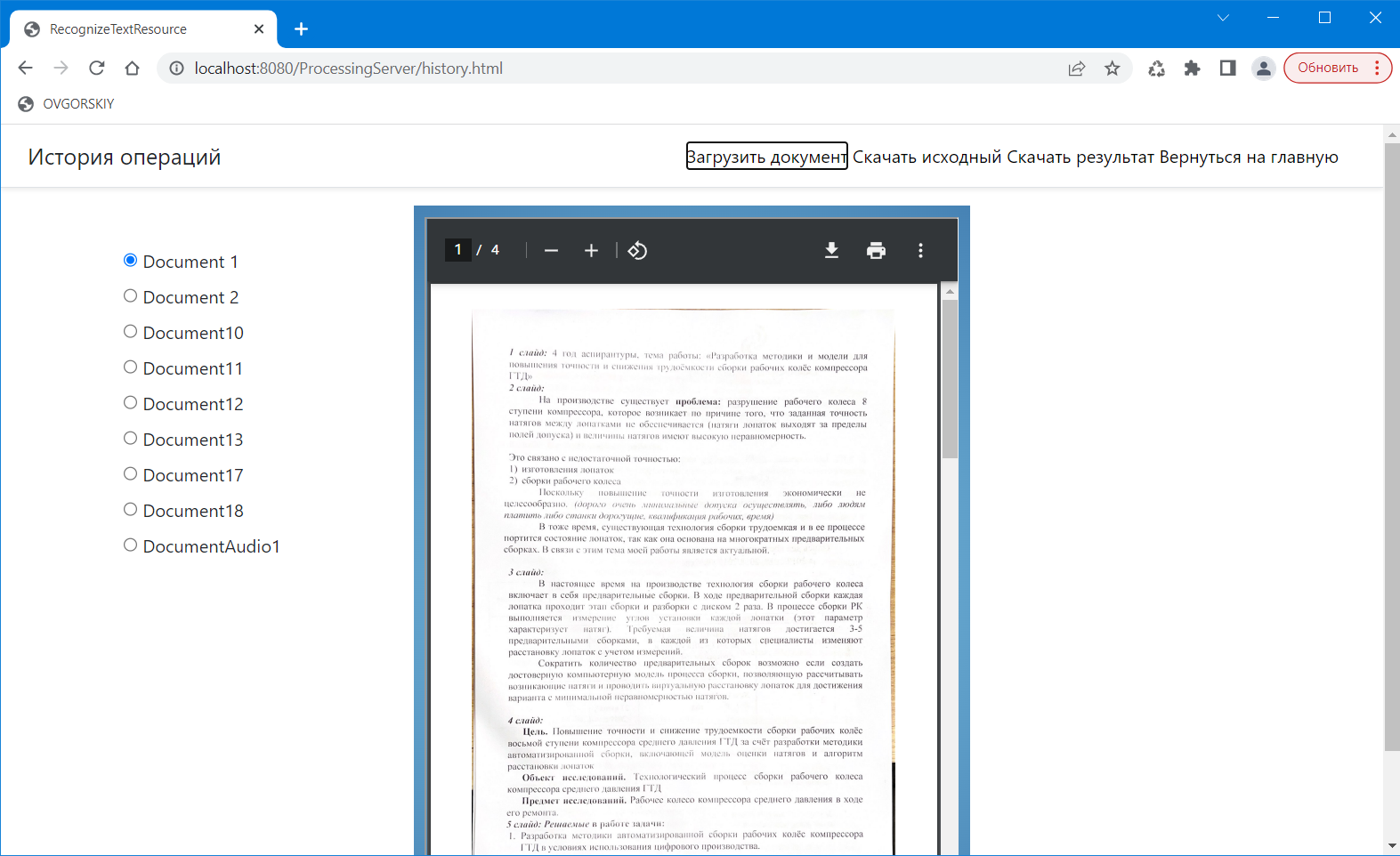
Таким образом пользователь может не только выполнять распознавание текущих документов, но и обращаться к истории лично им использованных документов, связанных с его профилем.
Ссылки
- LeCun, Y. Gradient-based learning applied to document recognition / Y. LeCun, L. Bottou, Y. Bengio, P. Haffner // Proceedings of the IEEE. – 1998. – Vol. 86, Issue 11. – P. 2278-2323.
- . Rabiner, L.R. A tutorial on hidden Markov models and selected applications in speech recognition / L.R. Rabiner // Proceedings of the IEEE. – 1989. – Vol. 77, issue 2. – P. 257 — 286.
- Hochreiter S. Long Short-term Memory / S. Hochreiter, J. Schmidhuber // Neural Computation. – 1997. – Vol. 9, no. 8. – P. 1735-80.
- обработка естественного языка
- mvc
- сервер
- база данных
- ocr-технологии
- Сезон java one love