Создание хранилища в Microsoft Fabric
В этой статье описывается, как приступить к работе с хранилищем в Microsoft Fabric с помощью портала Microsoft Fabric, включая обнаружение создания и потребления хранилища. Вы узнаете, как создать склад с нуля и примера вместе с другими полезными сведениями, чтобы ознакомиться с возможностями склада, предлагаемыми на портале Microsoft Fabric.
Важно отметить, что большая часть функциональных возможностей, описанных в этом разделе, также доступна пользователям с помощью подключения к конечной точке TDS и таких средств, как SQL Server Management Studio (SSMS) или Azure Data Studio (для пользователей, которые предпочитают использовать T-SQL для большинства своих потребностей в обработке данных). Дополнительные сведения см. в разделе Подключение ivity или Query a warehouse.
Вы можете продолжить работу с пустым хранилищем или примером хранилища, чтобы продолжить эту серию шагов по началу работы.
Создание хранилища
В этом разделе мы рассмотрим три различных интерфейса, доступные для создания хранилища с нуля на портале Microsoft Fabric.
Создание хранилища с помощью домашнего концентратора
Первый концентратор в меню навигации слева — главная . Вы можете начать создание хранилища из домашнего центра, выбрав карта складав разделе «Создать«. Пустое хранилище создается для начала создания объектов в хранилище. Вы можете использовать примеры данных, чтобы начать переход или загрузить собственные тестовые данные , если вы предпочитаете.

Создание хранилища с помощью центра создания
Другой вариант, доступный для создания хранилища, — это центр создания, который является вторым концентратором в меню навигации слева.
Вы можете создать хранилище из центра создания, выбрав карта хранилища в разделе Хранилище данных. При выборе карта пустое хранилище создается для начала создания объектов в хранилище или использования примера для начала работы, как раньше упоминание.

Создание хранилища из представления списка рабочих областей
Чтобы создать хранилище, перейдите в рабочую область, нажмите кнопку +Создать , а затем выберите «Склад «, чтобы создать склад.

После инициализации можно загрузить данные в хранилище. Дополнительные сведения о получении данных в хранилище см. в разделе приема данных.

Создание примера хранилища
В этом разделе мы рассмотрим два различных интерфейса, доступные для создания примера хранилища с нуля.
Создание примера хранилища с помощью домашнего концентратора
- Первый концентратор в меню навигации слева — главная . Вы можете начать создание примера хранилища из домашнего центра, выбрав пример хранилища карта в разделе «Создать«.

- Укажите имя примера хранилища и нажмите кнопку «Создать«.

- Действие создания создает хранилище и начинает загрузку примеров данных в него. Загрузка данных занимает несколько минут.

- После завершения загрузки примеров данных хранилище открывается с данными, загруженными в таблицы и представления для запроса.

Загрузка примеров данных в существующее хранилище
Дополнительные сведения о создании хранилища см. в статье «Создание хранилища данных Synapse».
- После создания хранилища можно загрузить образец данных в хранилище из примера базы данных карта.

- Загрузка данных занимает несколько минут.

- При завершении загрузки примеров данных хранилище отображает данные, загруженные в таблицы и представления для запроса.

Примеры сценариев
/************************************************* Get number of trips performed by each medallion **************************************************/ SELECT M.MedallionID ,M.MedallionCode ,COUNT(T.TripDistanceMiles) AS TotalTripCount FROM dbo.Trip AS T JOIN dbo.Medallion AS M ON T.MedallionID=M.MedallionID GROUP BY M.MedallionID ,M.MedallionCode /**************************************************** How many passengers are being picked up on each trip? *****************************************************/ SELECT PassengerCount, COUNT(*) AS CountOfTrips FROM dbo.Trip WHERE PassengerCount > 0 GROUP BY PassengerCount ORDER BY PassengerCount /********************************************************************************* What is the distribution of trips by hour on working days (non-holiday weekdays)? *********************************************************************************/ SELECT ti.HourlyBucket, COUNT(*) AS CountOfTrips FROM dbo.Trip AS tr INNER JOIN dbo.Date AS d ON tr.DateID = d.DateID INNER JOIN dbo.Time AS ti ON tr.PickupTimeID = ti.TimeID WHERE d.IsWeekday = 1 AND d.IsHolidayUSA = 0 GROUP BY ti.HourlyBucket ORDER BY ti.HourlyBucket
Вы можете продолжить работу с пустым хранилищем или примером хранилища, чтобы продолжить эту серию шагов по началу работы.
Создаем аналитическое хранилище данных командой из 2-3 спецов
Цепочка создания ценности в процессе работы с данными (источник):
Ценность создается только на последнем шаге цепочки. Вы можете извлекать данные, обрабатывать их как угодно: чистить, обогащать, маршрутизировать по системам, накапливать в хранилищах, заливать в витрины и т.д. Все эти операции ценности никакой не приносят.
Ценность создается при принятии правильных решений. Поэтому, мне кажется, в начале пути нужно как можно быстрее научиться получать профит из данных и DWH, а затем постепенно улучшать модели данных и процессы разработки DWH.

Сейчас часто собирается всё что можно собрать в озеро, а на втором этапе начинается детальная проработка результирующих витрин. Считаю, что нужно мыслить от показателей к источникам данных, а не наоборот. Чем лучше вы проработаете показатели необходимые для анализа, разрезы в которых нужно анализировать показатели, тем меньше работы будет у дата инженеров (DE), а значит вы быстрее получите нужный результат.
Подробнее на эту тему: Six Things You Need to Know About Data Governance, также в этой статье есть хороший раздел “Продуктовый подход к DWH” о том, какие вопросы нужно задавать пользователям при создании витрин.
Сначала логика и архитектура, потом инструменты
Часто на презентациях я вижу картинки наподобие этой →
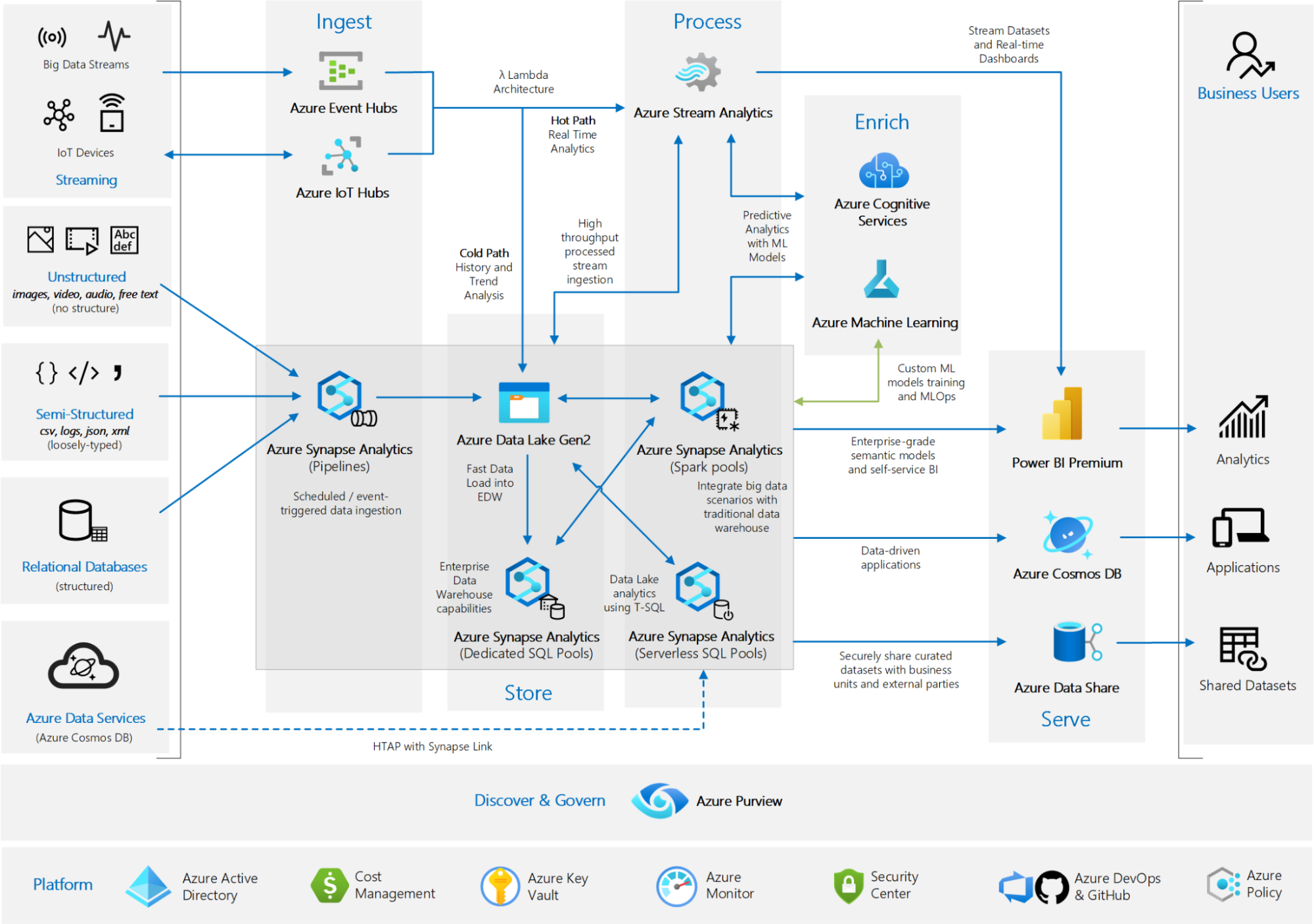
Важно помнить, что инструменты не дают методологии. Использование всего самого современного без проектирования увеличивает расходы и сложность системы.
Поэтому один из моих базовых принципов — сначала логика и архитектура, а потом инструменты. Именно логике построения DWH посвящена статья.
Основы логики и архитектуры DWH
Загрузить данные из источника А в результирующую таблицу (таргет) Б легко, но это нужно будет проделать для сотен таблиц: в стриминге и батче, инкрементами и полностью, с зависимостью одних таблиц от других, на тестовом и прод серверах и т.д. Таким образом, есть куча опций и если их не систематизировать, то скрипты загрузки DWH превратятся в страшный сон.
Поэтому, первая ключевая роль в создании DWH — архитектор, человек, который умеет думать и систематизировать. Через единообразие кода и правил нужно стремиться упростить жизнь DE. Большую часть времени DE должен тратить на создание продукта из данных.
- Подрезка (фильтрация) таблиц в источниках при получении инкремента.
- Типы загрузки таргета: append, upsert, full (snapshot), scd2, recreate.
- Типы таргетов: ods, mart, scd2, data vault сущности.
- Четко определить, что такое Джоб.
- Иметь возможность отлаживать любую джобу/расчет локально.
- Если есть ресурсы хранить “сырые данные” и историю их изменений, это упрощает исторические перерасчеты.
Джоба — основной кирпич системы. Джоба должна быть четко определена и проста.
Как лучше не делать джобы
- Большие джобы работают долго, а значит у вас меньше возможностей для маневров.
- При падении джобы её придется перезапускать полностью.
- Трудно дорабатывать джобу.
- Трудно развивать DWH.
- Частично или полностью недоступен Git: сравнение, слияние, версионность джобов и т.д.
- Ограничения на автогенерацию.
- Вендор-лок.
Первый принцип создания джоб (DAG’ов)
Одна джоба загружает один таргет (таблицу).
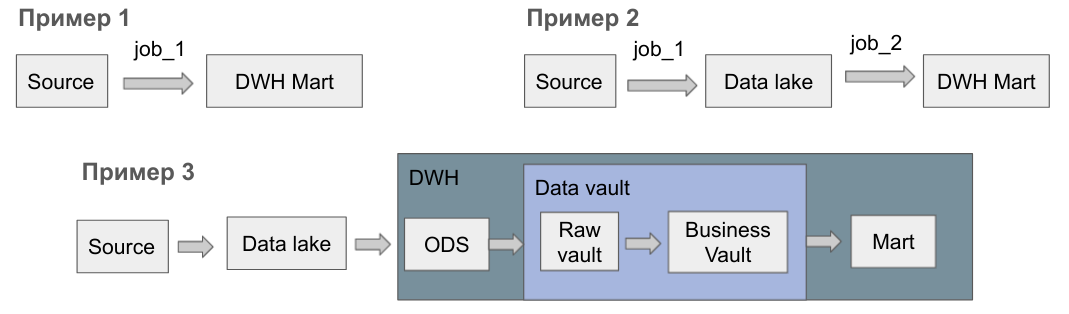
Преимущества:
- Простой перезапуск или пропуск упавших джобов.
- Разделяй и властвуй — зная входные таблицы и таргет, легко управлять порядком и параллельностью запуска джобов.
Этот принцип позволяет создавать действительно масштабируемые DWH, позволяя постепенно увеличивать число таблиц, слоев и DE.
Cколько джобов нужно для получения результата, полезного для бизнеса, зависит от числа слоев вашего DWH.
Пример 1. Данные из источника попадают сразу в витрину DWH, т.е. для одного таргета нужна одна джоба. Дополнительные слои не дают ценности бизнесу, поэтому для начала я рекомендую делать именно так. Разработка такой джобы займет не больше дня.
Пример 2. Данные из источников сначала складируются в озере данных. Такой подход лучше масштабируется по данным и разработчикам, однако разработка пары джоб в такой модели займет уже 2-3 дня.
Пример 3. Если делать всё правильно по популярной методологии Data Vault 2.0, то первого полезного результата можно ждать несколько недель. Мощь Data Vault 2.0 в том, что он позволяет прозрачно масштабировать DWH на любое число таблиц и DE.
С возрастанием числа источников, таблиц в DWH и DE нужно двигаться от примера 1 к 3.
Второй принцип создания джоб (DAG’ов)
- job.py – инструкции исполнителю.
- getdata.sql – получение данных.
- recreate.sql – пересоздание таргета.
Исполнитель джобы
Когда приходит очередь выполнить определенный джоб, запускается команда
launcher.run_job(job_name=’marts.crm_bill’, method=’increment’)
Исполнитель джобы читает файл job.py из папки marts.crm_bill. Получает объект класса JobDag, и дальше выполняет задачи из него. Поскольку одна джоба загружает один таргет, все джобы маленькие – от одного до пяти шагов.
Пример файла job.py с одной задачей:
from job_launcher_package import job_module def get_job_dag() -> job_module.JobDag(): j = job_module.JobDag() params = < "connection": "dwh_main", "get_data_sql": "get_data.sql", "recreate_target_sql": "recreate_target.sql", "target_table_name": "", "target_table_type": job_module.JobTargetTableType.MART, "increment": < # при получении данных в where есть , # движок его заменяет в зависимости настроек инкремент "target_load_type": job_module.JobTargetTableLoadType.UPSERT_ROWS_BY_PK, "target_pk_field": "crm_bill_id”, "target_checkpoint_name": "crm_bill_dttm", # MAX значение этого поля сохранится в системную таблицу "source_filtering_type": job_module.JobSourceFilteringType.MORE_THAN, "source_filtering_field": "crm_bil_dttm", "source_filtering_field_type": job_module.JobFieldType.TIMESTAMP>> j.add_task(id=1, order=1,# шаги выполняются по порядку, шаги с одинаковым step_order - параллельно func='vertica_elt.load_data_vertica_to_vertica', # вызов функции исполнителя джобов params=params) # параметры функции исполнителя джобов return j DE использует готовые функции движка, просто задавая параметры. Например: «target_load_type»: job_module.JobTargetTableLoadType.UPSERT_ROWS_BY_PK -тип загрузки данных в таргет.
Функция ‘vertica_elt.load_data_vertica_to_vertica’ — обычная python функция, которая должна иметь следующие входные атрибуты:
@core.lakehouse_function def load_data_vertica_to_vertica( launcher: job_launcher.JobLauncher,# connection strings и общие методы исполнителя джобов job_log: job_log_module.JobLog,# объект для логирования шагов task: job_module.JobTask, # данные по таску из job.py run_params, # параметры запуска, например method=’increment’ all_results): # результаты выполнения других шаговТаким образом, все ELT/ETL процессы у нас запускает один исполнитель джобов. В исполнителе есть несколько хорошо отлаженных, документированных функций, которые делают всю работу.
По сути DE создает джобу декларативно. Такой подход резко снижает барьер входа для создания джобов и в разы — вероятность возникновения ошибок.
Оркестрация джобов
От исполнителя одной джобы переходим к их оркестрации.
Вариант 1. Более правильный, но сложный в поддержке. Если на уровне метаданных для каждой джобы определить источники и таргет, то можно автоматически создавать граф. Допустим job_2 уже отработал, тогда если job_3 закончит работу быстрее, чем job_1, то оркестратор запустит job_5, иначе job_4.

Проблемы:
- Вариант 1 в идеальных условиях работает хорошо. Но бизнес может требовать много разных вещей типа “более приоритетных очередей”. Постоянное добавление логики в такую систему может сделать её очень непрозрачной.
- Одна джоба может сильно изменить граф.
Вариант 2. Разделяй и властвуй. Джобы объединяются в группы, у группы есть group_order. Внутри группы у джобы есть job_order. Оркестратор в порядке group_order выбирает группы, группы с одинаковым group_order запускаются параллельно. На уровне джобов и тасков такая же логика. 
В обоих вариантах есть глобальный параметр — Параллельность — количество джобов/тасков, которые можно выполнять одновременно.
Второй вариант проще в реализации и контроле, он лучше подходит на старте DWH, но глобально вариант 1 лучше, когда быстро увеличивается число таблиц и DE.
Инструменты и технологии
Данная статье не про инструменты, поэтому скажу лишь пару мыслей.
Если у вас меньше 4 терабайт данных, то не переусложняйте. Достаточно на мощном компьютере поднять PostgreSQL или ClickHouse для DWH. Плюс BI решение: Superset, Metabase или PowerBI.
Если данных больше 4 терабайт, или объемы быстро растут, то необходимо заложить горизонтальное масштабирование. Лучше, чтобы объем данных и вычислительные ресурсы можно было масштабировать по отдельности.
Hadoop — очень сложно и дорого. Почти всегда дешевле и быстрее облачная MPP + S3-совместимый storage.
Облачная MPP/Lakehouse система — ядро аналитического решения. Посмотрите на Google BigQuery, Snowflake, Databricks.
Итоги
В начале проекта как можно быстрее нужно создать ценность для бизнеса.
Сделайте хорошие витрины.
Учитесь получать профит из данных.
К более профессиональному моделированию DWH лучше переходить, когда есть первые успехи.
Сначала логика, потом инструменты – решите задачу на псевдокоде. Поймите и отработайте основные сценарии, а затем уже начинайте выбирать оркестраторы и всё остальное.
- Джоба — основной кирпич системы. Джоба должна быть четко определена и проста.
- Одна джоба загружает один таргет (таблицу).
- Джоба — это не визуальная схема, а код (мини-проект).
- job.py + унифицированный исполнитель джобов ускоряет разработку ELT/ETL процессов и снижает порог входа — инвестируйте в движок. Аналитики смогут делать джобы.
Приложение. Основные типы витрин.
- Транзакционная витрина – данные в строках не меняются.
- Витрина снимков – все данные на определенную дату.
- Накопительная витрина – у каждой строки есть дата начала и конца действия.
- Витрина на основе запроса.
Транзакционная витрина – данные в строках не меняются

Самая простая и популярная витрина. Записи из источника попадают в неё один раз и не меняются.
Преимущества этой витрины — по ней автоматически строятся правильные графики и считаются суммы, например, продажи товаров.
Витрина снимков – все данные на определенную дату
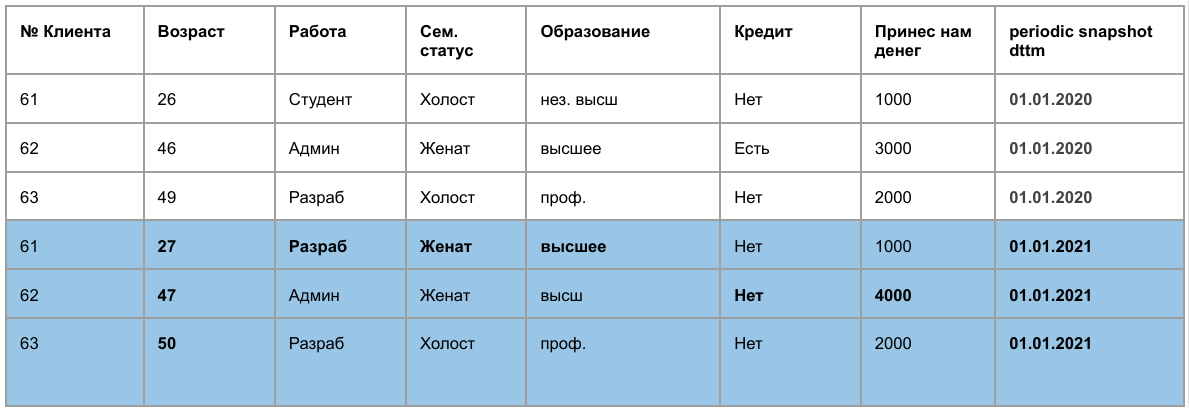
Раз в месяц/квартал/год в такую витрину добавляются все данные из источника. Такая витрина позволяет анализировать данные которые меняются со временем, например, данные о клиентах.
Накопительная витрина – у каждой записи есть интервал актуальности
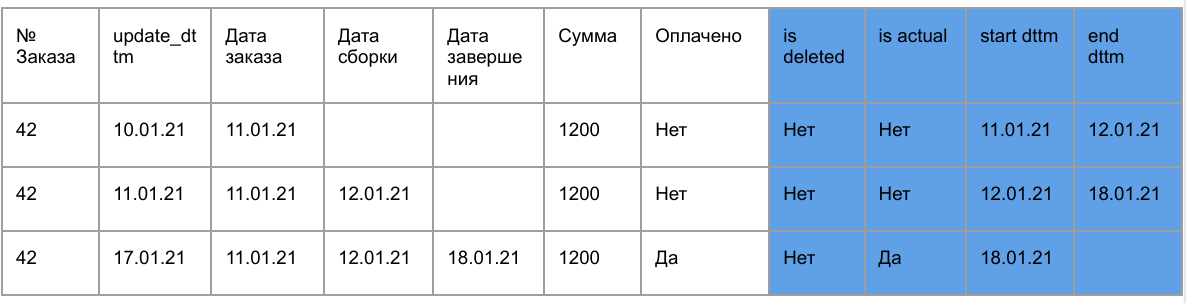
У накопительной витрины есть 4 дополнительных поля:
- start_dttm, end_dttm – время актуальности записи.
- is_actual – признак актуальности записи.
- is deleted – признак удаления из источника.
Данные из источника забираются раз в час или в день. После загрузки в метаданные хранилища записывается максимально значение поля update_dttm, в котором хранится время обновления записи. В следующий раз данные забираются из источника с фильтром where source_table.update_dttm > MAX(target_table.update_dttm), т.е. берутся только изменившиеся и новые записи.
Пример: Постепенное дополнение заказа в интернет магазине.
Если в новых данных из источника приходит запись, которая уже есть в таргет-таблице DWH, то у записи в DWH проставляется end_dttm = NOW(), is_actual = false и после добавляется новая актуальная запись.
Таким образом в DWH есть все изменения конкретной записи, что удобно для анализа.
Витрина на основе sql запроса к источнику
К источнику делается произвольный запрос с фильтром source_table.update_dttm > MAX(target_table.update_dttm)
Чтобы не было дублей, из таргет таблицы стираются строки с id, которые пришли из источника. Опционально также могут стираться записи, удаленные из источника. Затем делается вставка всех пришедших записей в таргет.
Итоги по витринам
Все запросы к источнику обычно делаются не к продакшен базе, а к её реплике.
На мой взгляд, на старте создания DWH, описанные 4 типа витрин закроют почти все нужды бизнеса.
По мере взросления DWH, лучше переходить сразу к Data Vault минуя 3NF. Для начала крутое видео.
P. S. Чтобы статья не стала бесконечной, я сознательно исключил ряд тем, таких как: управление метаданными, генерация суррогатных ключей.
Интересно мне сообщества:
Чем отличается ваш подход?
Какие вещи я раскрыл слабо?
- dwh
- etl-процессы
- архитектура системы
- Big Data
- Хранилища данных
- Data Engineering
Что такое data warehouse и как его построить
Компании получают данные из множества источников. Рекламная информация поступает из Google AdWords, сессии пользователей — из Google Analytics, данные продукта — из MySQL, MS Server или MongoDB. Информация о платежах — из 1C. Кроме этого, есть тикет-системы, чаты, CRMs и даже Excel-файлы.
Вручную обрабатывать и соединять эту информацию — нецелесообразно и дорого. Поэтому многие компании используют data warehouse (хранилище данных).
Оксана Носенко, лектор курса «SQL для аналитики» в robot_dreams, Senior Product Analyst в Jooble, объясняет, чем data warehouse отличается от базы данных и как создать собственное хранилище.

Хранение данных в «облаке»
Data warehouse — это система, которая хранит данные из разных источников для аналитики и составления отчетов.
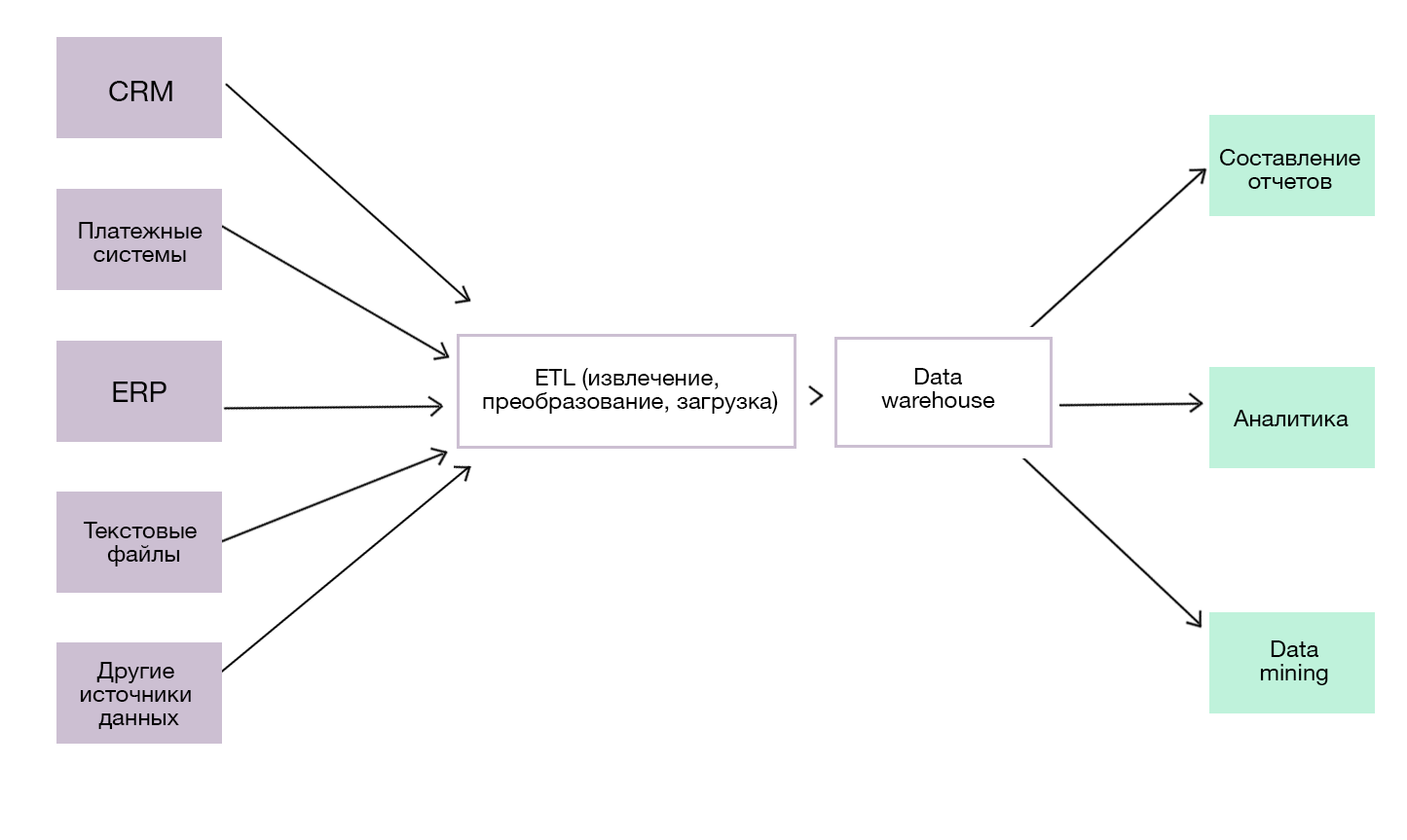
Схема хранилища данных
Хранилища отличаются от баз данных по ряду признаков:
- данные в warehouse не обязательно должны поступать в реальном времени (если иное не предусмотрено бизнес-задачей);
- данные могут иметь разную структуру (в зависимости от источников);
- хранилище не обязательно должно работать быстро. Главное, чтобы скорости хватало для решения всех аналитических задач.
Data warehouse подходит для сложных и комплексных вычислений лучше, чем база данных. Во время выполнения сложного запроса база данных может быть перегружена. Из-за этого вы рискуете потерять новую информацию — для ее обработки не хватит ресурсов.
Как создать data warehouse
Для хранения данных чаще всего используют cloud-решения. Их плюсы:
- поддержка и масштабируемость: не надо выделять комнату для серверов и подключать новые в случае роста нагрузки. Обычно облачное хранилище масштабируется автоматически;
- производительность: облачные решения работают быстрее традиционных и автоматически перераспределяют нагрузку;
- доступ к данным: чтобы попасть в облачное хранилище, не нужно устанавливать сервер на компьютер. Достаточно открыть браузер и войти в облако. SQL-запрос можно делать даже со смартфона.
Основные cloud warehouses — Amazon Redshift, Google BigQuery, Azure.
У них разная стоимость, производительность, экосистема, поддержка.
В продуктовых IT-компаниях, где я работала, мы выбирали Google Big Query по этим причинам:
- хранилище в GBQ запустить можно быстро и без помощи администраторов баз данных. Нужно только создать аккаунт в Google Cloud;
- формат pay-as-you-go: оплата по мере потребления только за те услуги, которые используем. Не нужно заранее выбирать самый оптимальный пакет;
- готовые pipeline-решения. Многие платформы предоставляют услуги трансфера данных в GBQ. Поэтому warehouse запускали только аналитики, без разработчиков и админов.
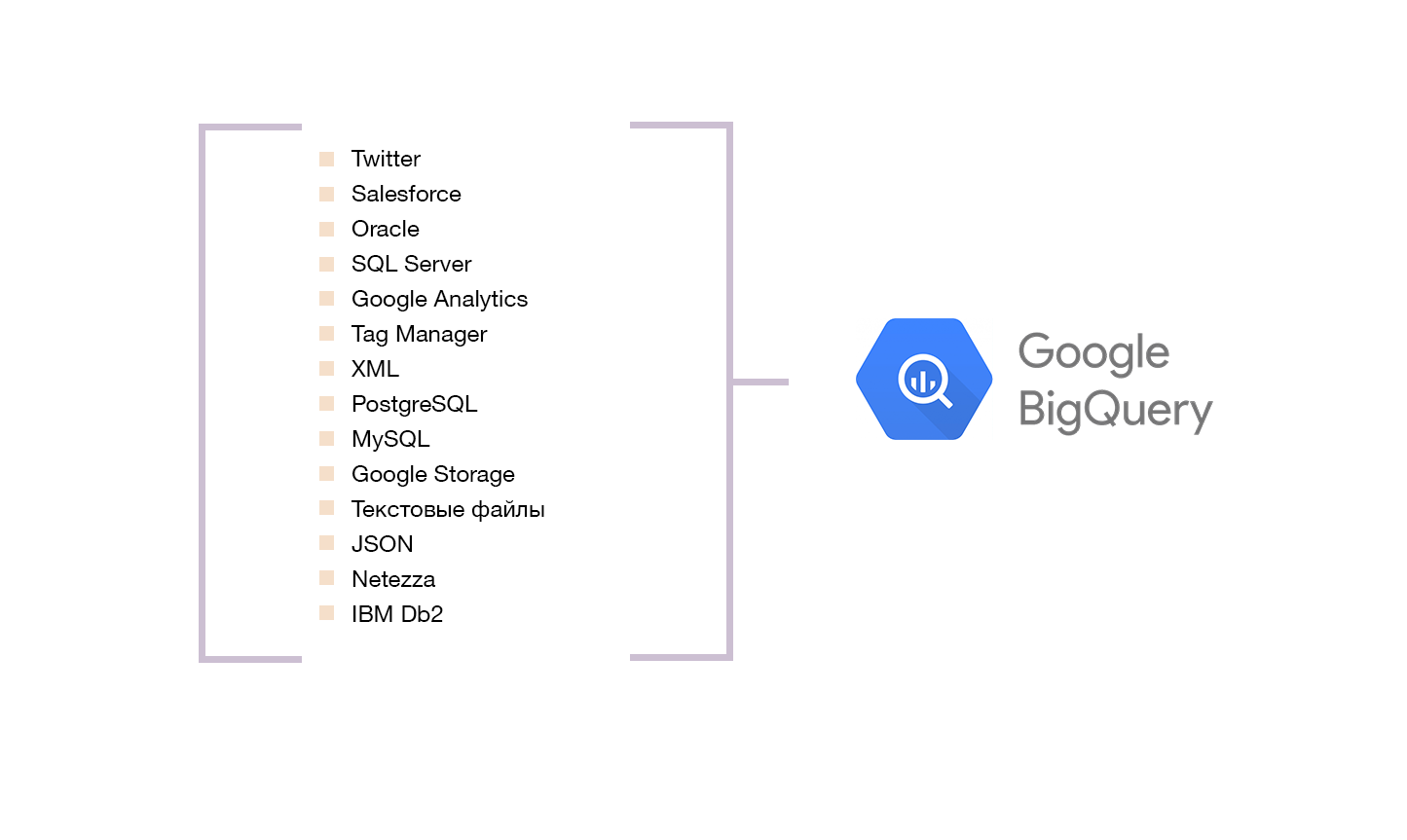
Пример GBQ Data Warehouse
Основной минус Big Query — плата за запросы. Каждый SQL-запрос использует определенный объем памяти, за который нужно платить в конце месяца. Поэтому советую поставить ограничение на количество запросов в день.
Создавая хранилище данных, нужно учитывать все сложности. Основная проблема — конструирование пайплайнов. Нужно настроить трансфер данных из всех источников в единое хранилище. Во время него придется столкнуться с несовершенными API, ограничениями по выгрузке или парсингом данных. Можно писать все соединения самостоятельно или использовать готовые решения (например, Owox, Alooma, Blendo). Тем, кто работает с большим объемом информации, лучше написать свои скрипты, которые будут синхронизировать данные каждый день.
Маленькому бизнесу без администратора баз данных стоит использовать pipeline-платформу. Ее стоимость зависит от объема информации и количества соединений.
Вторая сложность — качество данных. Трансфер данных может не выдавать ошибку. Но при этом информация может быть неполной (из-за ограничений в API). Также есть риск ошибки во время дальнейшего парсинга переменных (например, возникнут проблемы с кодировкой данных из 1С).
Следующий шаг после создания хранилища — выбор инструментов для разработки frontend-части. Бизнесу нужно видеть графики, срезы, сравнения и динамику.
курсы по теме:
SQL для аналитики и разработки
7 шагов успешного создания хранилища данных(DWH)
Проектирование и построение хранилища данных (data warehouse) – задача масштабная и длительная. Необходимо учесть много факторов и нюансов, рассчитать бюджет и только на последнем этапе создавать DWH.
Рассмотрим создание хранилища данных поэтапно, рассказав о каждом шаге и возможных подводных камнях.
Для чего нужно DWH
Хранилище данных представляет собой предметно-ориентированную БД, которая аккумулирует всю информацию внутри организации в единую систему.
Данные в DWH используются не только для хранения, но и для дальнейшего анализа информации и предоставления консолидированных отчетов. На их основе руководители бизнеса принимают важные стратегические и управленческие решения.
В хранилище данных находится информация в течение многих десятков лет, что позволяет проводить более точную аналитику. При этом сам процесс анализа не влияет на производительность информационных систем, как происходит в случае использования обычных баз данных.
Архитектура DWH
Хранилище данных, построенное любым из методов, обязательно состоит из нескольких компонентов:
- Ядро. Главная часть любой DWH – обеспечивает целостность входящих данных. Структурирует полученную информацию согласно заданным параметрам.
- Область сбора информации. Компонент, который собирает всю входящую информацию с разных источников.
- Аналитическая часть отвечает за предоставления отчетности по требованию владельца.
- Сервис. Компонент отвечает за управление и стабильное взаимодействие трех предыдущих. Мониторит в режиме онлайн состояние каждого компонента и оперативно устраняет ошибки.
Методы создания DWH
Построение хранилища данных происходит по разным методикам.
- Классический метод. В его основе лежит разделение данных на две группы: измерения и факты. Связь между ними представлена в виде классических таблиц с внешним ключом. Возникает неудобство при добавлении новой составляющей в таблице, поскольку жесткая привязка таблиц к внешнему ключу не позволяет гибко менять структура data warehouse.
- Метод Инмона. По задумке создателя способа, сначала проектируется централизованное хранилище данных, а дальше добавляются витрины с информацией. При таком подходе загрузка входящей информации в data warehouse значительно упрощается, но увеличивается время при обработке запросов.
- Метод Кимбалла. В отличие от предыдущего способа DWH создается на основе витрин. Другими словами, сначала они заполняются необходимой информацией, а после проектируется централизованное хранилище.
- Метод 7D. Назван так по названиям этапов, которые включены в него: Discover, Design, Develop, Deploy, Day to day, Defend и Decommission.
Проектирование DWH с помощью 7D
Этап 1. Discover
Сначала анализируются требования к создаваемому хранилищу данных. Менеджер проекта тесно сотрудничает с представителями бизнеса, так как необходимо учитывать их задачи.
Чтобы получить необходимые данные, следует ответить на шесть главных вопросов: Что? Как? Где? Кто? Когда? Зачем?. Ответы на вопросы являются фундаментом будущей DWH.
Менеджер проекта детерминирует роли и требования по визуализации данных для заказчиков и пользователей.
Это очень важный этап, поскольку малейшая ошибка на нем приводит к невозможности создания хранилища данных.
Этап 2. Design
На втором шаге проектируются семантические и схематические реализации DWH. Для проектирования можно воспользоваться двумя методами:
- Создать концептуальные и логические реализации DWH совместно с пространственными моделями в виде многомерных кубов данных.
- Воспользоваться матрицей принятия решений для вычисления четких требований бизнеса к хранилищу данных.
Информация, которая используется на втором этапе, аккумулируется с разных внешних и внутренних источников. При этом на втором шаге сразу задаются параметры, по которым информация будет импортироваться в data warehouse либо работать со ссылкой на внешний источник.
Разделение происходит по двум уровням. На технологическом вычисляется необходимый размер дискового пространства для хранения и обработки поступающей информации. Параллельно сразу рассчитываются вычислительные мощности, которые потребуются для стабильной и быстрой работы DWH.
Закладываются расчеты на вырост. Другими словами, планируется значение, на которое ежегодно будут расти требования DWH к дисковому пространству и вычислительным мощностям аппаратной части.
Коммуникации, инженерные системы, кабелирование – также закладываются на технологическом уровне второго этапа.
На уровне приложений составляется список программного обеспечения, которое будет использоваться в DWH как для администраторов, так и для пользователей. ПО также включает в себя информационно-аналитические системы для формирования отчетов.
На данном уровне рекомендуется создавать визуальное изображение будущей модели для более наглядного показа заказчикам.
Успешным считается проектирование, когда обе полученные модели соответствуют задачам ИС управления и отображают аналитику под бизнес-задачи. Созданные на втором этапе модели должны удовлетворять в полном объеме шести вопросам, которые были озвучены на первом этапе.
А в Вашей организации есть хранилище данных?