Режимы работы сетей в Docker¶
Используется для коммуникации контейнеров в пределах одного хоста.
По-умолчанию используется мост с названием bridge . Он не рекомендуется для использования в продакшене. Его настройки можно поменять при желании.
Можно сделать свою сеть данного типа и подключать к ней контейнеры. В docker CLI создать сеть можно командой docker network create my-net , а как сделать в Docker Compose будет описано далее.
Различия моста по-умолчанию и определенного пользователем¶
- Описанные пользователем контейнеры предоставляет лучшую изоляцию контейнеризированных приложений. Контейнеры, подключенные к пользовательскому мосту открывают все прокинутые порты внутри данного моста друг другу локально, но не в публичную сеть.
- Определенные пользователем мосты предоставляют автоматическое разрешение DNS имени между контейнерами. Контейнеры в стандартной сети моста могут обращаться к друг другу только по IP-адресам пока не указан параметр —link (так же поддерживается в Compose, но он признан устаревшим и использовать его больше не рекоммендуется ни в коем случае). В случае с пользовательской сетью типа мост можно обращаться к контейнеру по его имени или заданному alias .
- Контейнеры могут быть подключены и отключены от сети пользовательской сети на лету. Это позволяет не пересоздавая контейнер настроить его параметры в сети, например указать другой статический IP-адрес.
- Пользовательские мосты могут настраиваться. Пользовательские мосты настраиваются и управляются через docker network create или в Docker Compose файле. Настройки можно менять на лету. У родного моста менять настройки надо изменяя файл конфигурации daemon.json , а так же он использует единые настройки iptables и MTU.
- Связанные флагом —link контейнеры в родной сети «мост» делят переменные окружения. Так как после внедрения настраиваемых сетей режим —link устарел и не ркомендуется к использованию, то рассматривать подробности этого пункта смысла не имеет.
overlay 2 ¶
Распределенная сеть среди нескольких хостов Docker. Название сети происходит от слова «прослойка» (overlay), потому как потому как сеть является прослойкой для коммуникации контейнеров в распределенной сети.
Сеть типа overlay требует, чтобы хост был частью сети Swarm. В Swarm по умолчанию используется сеть типа overlay с именем ingress для распределения нагрузки, а так же сеть типа bridge с названием docker_gwbridge для коммуникации самих Docker daemon.
Для overlay сетей есть так же требования к фаерволу, то есть открытым в нем портам:
- TCP 2377 для коммуникации менеджмента кластера;
- TCP и UDP 7946 для коммуникации нод кластера;
- UDP 4789 для трафика сети overlay.
У пользовательской overlay сети есть несколько интересных параметров:
- —attachable : позволяет общаться не только сервисам, но и отдельным контейнерам с другими контейнерами в пределах swarm;
- —opt encrypted : включает шифрование AES в режиме GCM с ротацией ключей каждые 12 часов. К сожалению, так как используется виртуальная LAN (VxLAN), то нагрузка на ЦП сильно возрастает, потому опция может не подходить для продакшена. Windows хосты также не поддерживают опцию.
Для изменения настроек родных сетей ingress и docker_gwbridge их необходимо удалить и создать заново.
host 3 ¶
При использовании данного режима сети сетевой стек контейнера не изолирован от хоста Docker. аким образом если контейнер привязывается к 80 порту (например, nginx), то он будет доступен по порту 80 IP-адресу хоста.
При использовании режима в Docker swarm используется overlay сеть для управляющего трафика, а контейнер доступен только с одной машине, к которой привязался. Это создает ограничение, которое не позволяет использовать в swarm на машине с занятым портом приложение. Таким образом если в Swarm используется порт 80 в распределенной сети и на одной машине из swarm есть контейнер с host режимом, то на этой машине не будет доступно приложение из распределенной сети.
macvlan/ipvlan 4 ¶
Некоторые приложения, например для мониторинга трафика, должны быть напрямую покдлючены к физической сети. Это можно сделать с помощью режимов macvlan и ipvlan.
Необходимо понимать, что для этого режима используется физический сетевой интерфейс, который имеет доступ к физической сети. Для изоляции от основной сетинеобходимо использовать другой сетевой интерфейс или создать VLAN.
При использовании режима надо понимать, что
- можно нанести вред своей сети исчерпав запас IP-адресов или необдуманным созданием VLANов;
- сетевой интерфейс должен поддерживать использование нескольких MAC-адресов;
- если приложение может работать с bridge или overlay режимами, то лучше выбрать их.
macvlan может работать в двух режимах:
- сетевой мост, где трафик идет через физический адаптер хоста;
- сетевой мост с использованием стандарта 802.1Q, где тегируется трафик и показывается принадлежность к определенному VLAN. Docker создает сетевой «подинтерфейс» над основным, позволяя настраивать маршрутизацию и фильтрацию на более высоком уровне.
Если необходим более низкоуровневый чем L3 мост, то можно создать ipvlan.
Конфигурация данного вида сетей недоступна из docker compose.
- https://docs.docker.com/network/bridge/↩
- https://docs.docker.com/network/overlay/↩
- https://docs.docker.com/network/host/↩
- https://docs.docker.com/network/overlay/↩
Docker Tips: Очистите свою машину от хлама

Привет, Хабр! Представляю вашему вниманию перевод статьи «Docker Tips: Clean Up Your Local Machine» автора Luc Juggery.
Сегодня мы поговорим о том, как Docker использует дисковое пространство хостовой машины, а также разберемся в том, как это пространство освободить от ошметков неиспользуемых образов и контейнеров.
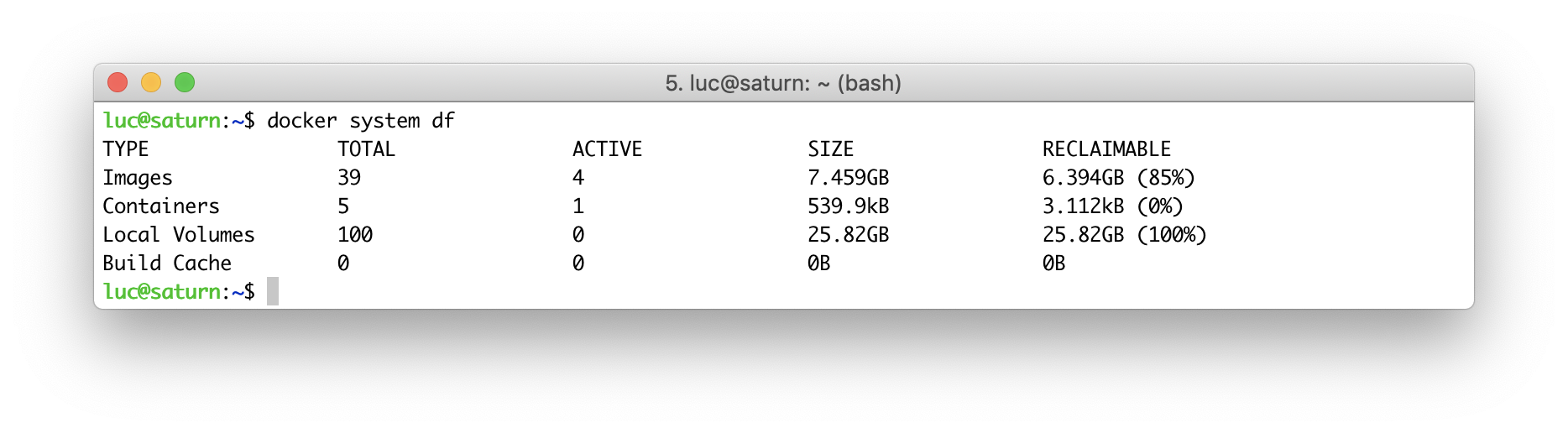
Общее потребление
Docker – крутая штука, наверное сегодня мало кто в этом сомневается. Всего несколько лет назад этот продукт предоставил нам совершенно новый способ построения, доставки и запуска любого окружения, позволяя значительно сэкономить ресурсы процессора и оперативной памяти. В дополнение к этому (а для кого-то это будет даже самым важным) Docker позволил нам невероятно упростить и унифицировать управление жизненным циклом используемых рабочих сред.
Однако, за все эти прелести современной жизни приходится платить. Когда мы запускаем контейнеры, скачиваем или создаем собственные образы, разворачиваем сложные экосистемы, нам приходится платить. И платим мы, в том числе, дисковым пространством.
Если вы никогда не задумывались о том, сколько же места реально занято на вашей машине Docker’ом, то можете быть неприятно удивлены выводом этой команды:
$ docker system df
Здесь отображено использование диска Docker’ом в различных разрезах:
- образы (images) – общий размер образов, которые были скачаны из хранилищ образов и построены в вашей системе;
- контейнеры (containers) – общий объем дискового пространства, используемый запущенными контейнерами (имеется ввиду общий объем слоев чтения-записи всех контейнеров);
- локальные тома (local volumes) – объем локальных хранилищ, примонтированных к контейнерам;
- кэш сборки (build cache) – временные файлы, сгенерированные процессом построения образов (при использовании инструмента BuildKit, доступного начиная с Docker версии 18.09).
Готов поспорить, что уже после этого простого перечисления вы горите желанием почистить диск от мусора и вернуть к жизни драгоценные гигабайты (прим. перев.: особенно, если за эти гигабайты вы ежемесячно перечисляете арендную плату).
Использование диска контейнерами
Каждый раз при создании контейнера на хостовой машине в каталоге /var/lib/docker создается несколько файлов и каталогов, среди которых стоит отметить следующие:
- Каталог /var/lib/docker/containers/ID_контейнера – при использовании стандартного драйвера логгирования именно сюда сохраняются журналы событий в JSON-формате. Слишком подробные логи, а также логи, которые никто не читает и не обрабатывает иными способами, часто становятся причиной переполнения дисков.
- Каталог /var/lib/docker/overlay2 – содержит слои чтения-записи контейнеров (overlay2 – предпочитаемые драйвер в большинстве дистрибутивов Linux). Если контейнер сохраняет данные в своей файловой системе, то именно в этом каталоге они и будут размещены.
Давайте представим себе систему, на которой установлен девственно чистый Docker, ни разу не участвовавший в запуске контейнеров и сборке образов. Его отчет об использовании дискового пространства будет выглядеть так:
$ docker system df TYPE TOTAL ACTIVE SIZE RECLAIMABLE Images 0 0 0B 0B Containers 0 0 0B 0B Local Volumes 0 0 0B 0B Build Cache 0 0 0B 0BЗапустим какой-нибудь контейнер, например, NGINX:
$ docker container run --name www -d -p 8000:80 nginx:1.16Что происходит с диском:
- образы (images) занимают 126 Мб, это тот самый NGINX, который мы запустили в контейнере;
- контейнеры (containers) занимают смешные 2 байта.
$ docker system df TYPE TOTAL ACTIVE SIZE RECLAIMABLE Images 1 1 126M 0B (0%) Containers 1 1 2B 0B (0%) Local Volumes 0 0 0B 0B Build Cache 0 0 0B 0BСудя по выводу, у нас еще нет пространства, которое мы могли бы высвободить. Так как 2 байта это совершенно несерьезно, давайте представим, что наш NGINX неожиданно для всех написал куда-то 100 Мегабайт данных и создал внутри себя файл test.img именно такого размера.
$ docker exec -ti www \ dd if=/dev/zero of=test.img bs=1024 count=0 seek=$[1024*100]Снова исследуем использование дискового пространства на хосте. Мы увидим, что контейнер (containers) занимает там 100 Мегабайт.
$ docker system df TYPE TOTAL ACTIVE SIZE RECLAIMABLE Images 1 1 126M 0B (0%) Containers 1 1 104.9MB 0B (0%) Local Volumes 0 0 0B 0B Build Cache 0 0 0B 0BДумаю, ваш пытливый мозг уже задается вопросом, где же находится наш файл test.img. Давайте его поищем:
$ find /var/lib/docker -type f -name test.img /var/lib/docker/overlay2/83f177. 630078/merged/test.img /var/lib/docker/overlay2/83f177. 630078/diff/test.imgНе вдаваясь в подробности можно отметить, что файл test.img удобно расположился на уровне чтения-записи, управляемом драйвером overlay2. Если же мы остановим наш контейнер, то хост подскажет нам, что это место, в принципе, можно высвободить:
# Stopping the www container $ docker stop www # Visualizing the impact on the disk usage $ docker system df TYPE TOTAL ACTIVE SIZE RECLAIMABLE Images 1 1 126M 0B (0%) Containers 1 0 104.9MB 104.9MB (100%) Local Volumes 0 0 0B 0B Build Cache 0 0 0B 0BКак мы можем это сделать? Удалением контейнера, которое повлечет за собой очистку соответствующего пространства на уровне чтения-записи.
С помощью следующей команды вы можете удалить все установленные контейнеры одним махом и очистить ваш диск от всех созданных ими на уровне чтения-записи файлов:
$ docker container prune WARNING! This will remove all stopped containers. Are you sure you want to continue? [y/N] y Deleted Containers: 5e7f8e5097ace9ef5518ebf0c6fc2062ff024efb495f11ccc89df21ec9b4dcc2 Total reclaimed space: 104.9MBИтак, мы высвободили 104,9 Мегабайта удалением контейнера. Но так как мы уже не используем скачанный ранее образ, то он тоже становится кандидатом на удаление и высвобождение наших ресурсов:
$ docker system df TYPE TOTAL ACTIVE SIZE RECLAIMABLE Images 1 0 126M 126M (100%) Containers 0 0 0B 0B Local Volumes 0 0 0B 0B Build Cache 0 0 0B 0BВнимание: до тех пор, пока образ используется хотя бы одним контейнером, вы не сможете использовать этот трюк.
Субкоманда prune, которую мы использовали выше, дает эффект только на остановленных контейнерах. Если мы хотим удалить не только остановленные, но и запущенные контейнеры, следует использовать одну из этих команд:
# Historical command $ docker rm -f $(docker ps –aq) # More recent command $ docker container rm -f $(docker container ls -aq)Заметки на полях: если при запуске контейнера использовать параметр —rm, то при его остановке будут высвобождено все дисковое пространство, которое он занимал.
Использование диска образами
Несколько лет назад размер образа в несколько сотен мегабайт был совершенно нормальным: образ Ubuntu весил 600 Мегабайт, а образ Microsoft .Net – несколько Гигабайт. В те лохматые времена скачивание одного только образа могло нанести большой урон вашему свободному месту на диске, даже если вы расшаривали уровни между образами. Сегодня – хвала великим – образы весят намного меньше, но даже в этом случае можно быстро забить имеющиеся ресурсы, если не принимать некоторых мер предосторожности.
Есть несколько типов образов, которые напрямую не видны конечному пользователю:
- intermediate образы, на основе которых собраны другие образы в – они не могут быть удалены, если вы используете контейнеры на базе этих самых «других» образов;
- dangling образы – это такие intermediate образы, на которые не ссылается ни один из запущенных контейнеров – они могут быть удалены.
- С помощью следующей команды вы можете проверить наличие в вашей системе dangling образов:
$ docker image ls -f dangling=true REPOSITORY TAG IMAGE ID CREATED SIZE none none 21e658fe5351 12 minutes ago 71.3MBУдалить их можно следующим способом:
$ docker image rm $(docker image ls -f dangling=true -q)Мы можем использовать также субкоманду prune:
$ docker image prune WARNING! This will remove all dangling images. Are you sure you want to continue? [y/N] y Deleted Images: deleted: sha256:143407a3cb7efa6e95761b8cd6cea25e3f41455be6d5e7cda deleted: sha256:738010bda9dd34896bac9bbc77b2d60addd7738ad1a95e5cc deleted: sha256:fa4f0194a1eb829523ecf3bad04b4a7bdce089c8361e2c347 deleted: sha256:c5041938bcb46f78bf2f2a7f0a0df0eea74c4555097cc9197 deleted: sha256:5945bb6e12888cf320828e0fd00728947104da82e3eb4452f Total reclaimed space: 12.9kBЕсли мы вдруг захотим удалить вообще все образы (а не только dangling) одной командой, то можно сделать так:
$ docker image rm $(docker image ls -q)Использование диска томами
Тома (volumes) применяются для хранения данных за пределами файловой системы контейнера. Например, если мы хотим сохранить результаты работы какого-либо приложения, чтобы использовать их как-то еще. Частым примером являются базы данных.
Давайте запустим контейнер MongoDB, примонтируем к нему внешний по отношению к контейнеру том, и восстановим из него бэкап базы данных (у нас он доступен в файле bck.json):
# Running a mongo container $ docker run --name db -v $PWD:/tmp -p 27017:27017 -d mongo:4.0 # Importing an existing backup (from a huge bck.json file) $ docker exec -ti db mongoimport \ --db 'test' \ --collection 'demo' \ --file /tmp/bck.json \ --jsonArrayДанные будут находиться на хостовой машине в каталоге /var/lib/docker/volumes. Но почему не на уровне чтения-записи контейнера? Потому что в Dockerfile образа MongoDB каталог /data/db (в котором MongoDB по умолчанию хранит свои данные) определен как том (volume).
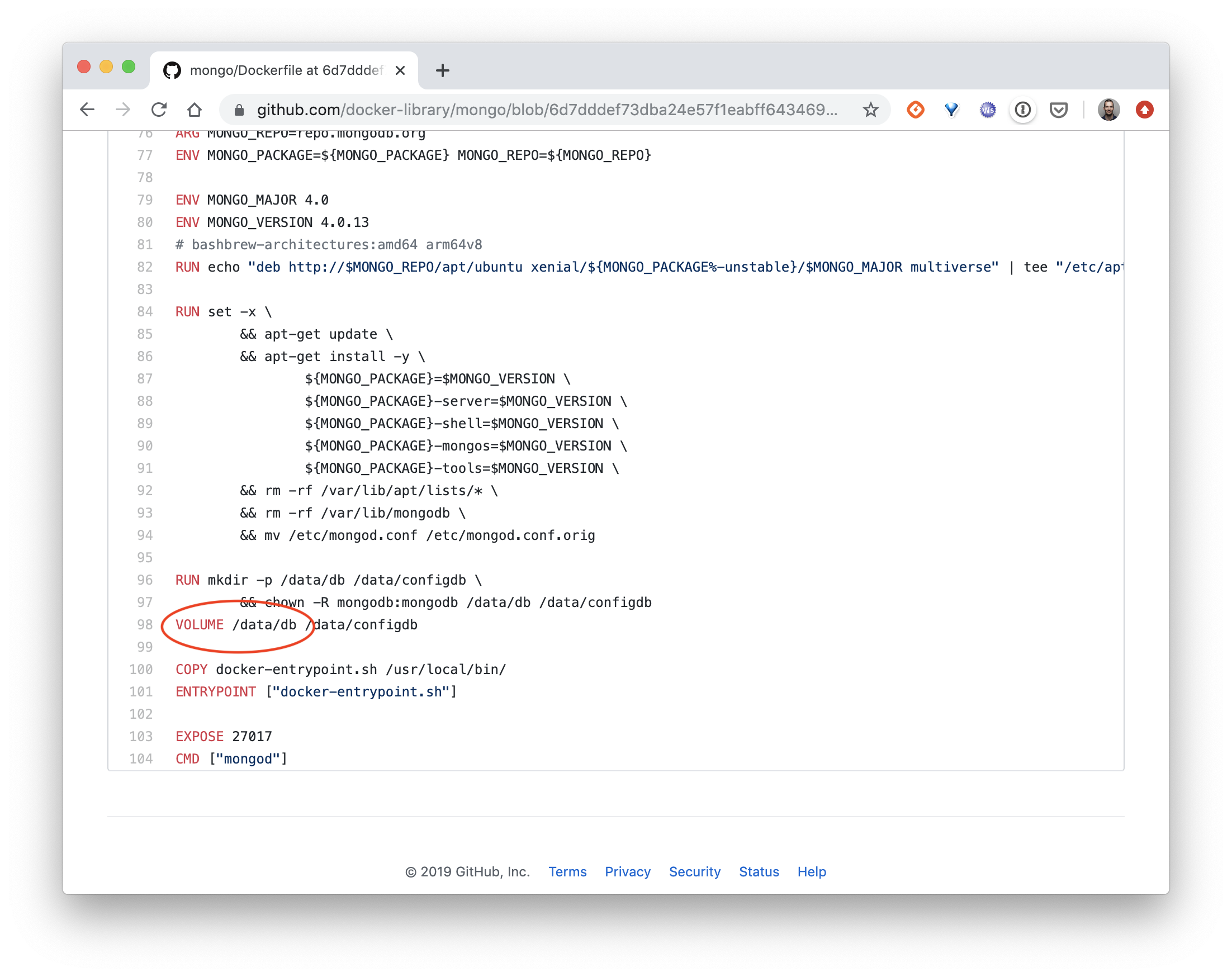
Заметки на полях: многие образы, в результате работы которых должны создаваться данные, используют тома (volumes) для сохранения этих самых данных.
Когда мы наиграемся с MongoDB и остановим (а может даже и удалим) контейнер, том не будет удален. Он продолжит занимать наше драгоценное дисковое пространство до тех пор, пока мы явно не удалим его такой командой:
$ docker volume rm $(docker volume ls -q)Ну или мы можем использовать уже знакомую нам субкоманду prune:
$ docker volume prune WARNING! This will remove all local volumes not used by at least one container. Are you sure you want to continue? [y/N] y Deleted Volumes: d50b6402eb75d09ec17a5f57df4ed7b520c448429f70725fc5707334e5ded4d5 8f7a16e1cf117cdfddb6a38d1f4f02b18d21a485b49037e2670753fa34d115fc 599c3dd48d529b2e105eec38537cd16dac1ae6f899a123e2a62ffac6168b2f5f . 732e610e435c24f6acae827cd340a60ce4132387cfc512452994bc0728dd66df 9a3f39cc8bd0f9ce54dea3421193f752bda4b8846841b6d36f8ee24358a85bae 045a9b534259ec6c0318cb162b7b4fca75b553d4e86fc93faafd0e7c77c79799 c6283fe9f8d2ca105d30ecaad31868410e809aba0909b3e60d68a26e92a094da Total reclaimed space: 25.82GB luc@saturn:~$Использование диска для кэша сборки образов
В Docker 18.09 процесс создания образов претерпел некоторые изменения благодаря инструменту BuildKit. С помощью этой штуки увеличивается скорость процесса, оптимизируется управление хранением данных и безопасностью. Здесь мы не будем рассматривать все детали этого замечательного инструмента, остановимся лишь нам том, как он затрагивает вопросы использования дискового пространства.
Предположим, что у нас есть совершенно простое приложение Node.Js:
- файл index.js запускает простой HTTP сервер, который отвечает строкой на каждый полученный запрос:
- файл package.json определяет зависимости, из которых используется только expressjs для запуска HTTP сервера:
$ cat index.js var express = require('express'); var util = require('util'); var app = express(); app.get('/', function(req, res) < res.setHeader('Content-Type', 'text/plain'); res.end(util.format("%s - %s", new Date(), 'Got Request')); >); app.listen(process.env.PORT || 80);$ cat package.json < "name": "testnode", "version": "0.0.1", "main": "index.js", "scripts": < "start": "node index.js" >, "dependencies": < "express": "^4.14.0" >>Dockerfile для сборки образа выглядит так:
FROM node:13-alpine COPY package.json /app/package.json RUN cd /app && npm install COPY . /app/ WORKDIR /app EXPOSE 80 CMD ["npm", "start"]Давайте соберем образ обычным способом, без использования BuildKit:
$ docker build -t app:1.0 .Если мы проверим использование дискового пространства, то увидим, что место занимают только базовый образ (node:13-alpine) и конечный образ (app:1.0):
TYPE TOTAL ACTIVE SIZE RECLAIMABLE Images 2 0 109.3MB 109.3MB (100%) Containers 0 0 0B 0B Local Volumes 0 0 0B 0B Build Cache 0 0 0B 0BДавайте соберем вторую версию нашего приложения, уже с использованием BuildKit. Для этого нам лишь необходимо установить переменную DOCKER_BUILDKIT в значение 1:
$ DOCKER_BUILDKIT=1 docker build -t app:2.0 .Если мы сейчас проверим использование диска, то увидим, что теперь там участвует кэш сборки (buid-cache):
$ docker system df TYPE TOTAL ACTIVE SIZE RECLAIMABLE Images 2 0 109.3MB 109.3MB (100%) Containers 0 0 0B 0B Local Volumes 0 0 0B 0B Build Cache 11 0 8.949kB 8.949kBДля его очистки воспользуемся следующей командой:
$ docker builder prune WARNING! This will remove all dangling build cache. Are you sure you want to continue? [y/N] y Deleted build cache objects: rffq7b06h9t09xe584rn4f91e ztexgsz949ci8mx8p5tzgdzhe 3z9jeoqbbmj3eftltawvkiayi Total reclaimed space: 8.949kBОчистить все!
Итак, мы рассмотрели очистку дискового пространства, занятого контейнерами, образами и томами. В этом нам помогает субкоманда prune. Но ее можно использовать и на системном уровне docker, и она очистит все, что только сможет:
$ docker system prune WARNING! This will remove: - all stopped containers - all networks not used by at least one container - all dangling images - all dangling build cache Are you sure you want to continue? [y/N]Если вы по каким-либо причинам экономите дисковое пространство на машине с Docker, то периодический запуск этой команды стоит ввести в привычку.
- docker
- системное администрирование
- tips
Хранение данных в Docker
Важная характеристика Docker-контейнеров — эфемерность. В любой момент контейнер может рестартовать: завершиться и вновь запуститься из образа. При этом все накопленные в нём данные будут потеряны. Но как в таком случае запускать в Docker приложения, которые должны сохранять информацию о своём состоянии? Для этого есть несколько инструментов.
В этой статье рассмотрим docker volumes, bind mount и tmpfs, дадим советы по их использованию, проведём небольшую практику.
Особенности работы контейнеров
Прежде чем перейти к способам хранения данных, вспомним устройство контейнеров. Это поможет лучше понять основную тему.
Контейнер создаётся из образа, в котором есть всё для начала его работы. Но там не хранится и тем более не изменяется ничего важного. В любой момент приложение в контейнере может быть завершено, а контейнер уничтожен, и это нормально. Контейнер отработал — выкидываем его и собираем новый. Если пользователь загрузил в приложение картинку, то при замене контейнера она удалится.
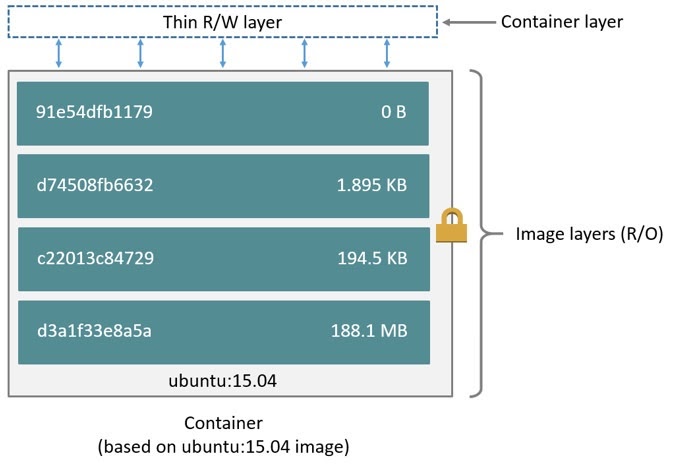
На схеме показано устройство контейнера, запущенного из образа Ubuntu 15.04. Контейнер состоит из пяти слоёв: четыре из них принадлежат образу, и лишь один — самому контейнеру. Слои образа доступны только для чтения, слой контейнера — для чтения и для записи. Если при работе приложения какие-то данные будут изменяться, они попадут в слой контейнера. Но при уничтожении контейнера слой будет безвозвратно потерян, и все данные вместе с ним.
В идеальном мире Docker используют только для запуска stateless-приложений, которые не читают и не сохраняют данные о своём состоянии и готовы в любой момент завершиться. Однако в реальности большинство программ относятся к категории stateful, то есть требуют сохранения данных между перезапусками.
Поэтому нужны способы сделать так, чтобы важные изменяемые данные не зависели от эфемерности контейнеров и, как бонус, были доступными сразу из нескольких мест.
В Docker есть несколько способов хранения данных. Наиболее распространенные:
- тома хранения данных (docker volumes),
- монтирование каталогов с хоста (bind mount).
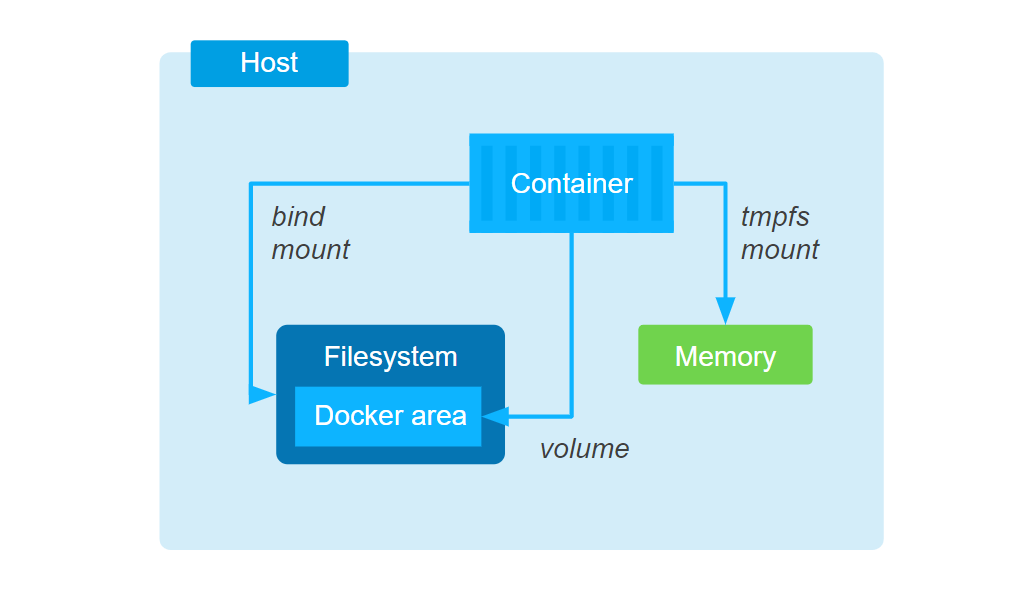
- именованные каналы (named pipes, только в Windows),
- монтирование tmpfs (только в Linux).
На схеме показаны самые популярные типы хранения данных для Linux: в памяти (tmpfs), в файловой системе хоста (bind mount), в томе Docker (docker volumes). Разберём каждый вариант.
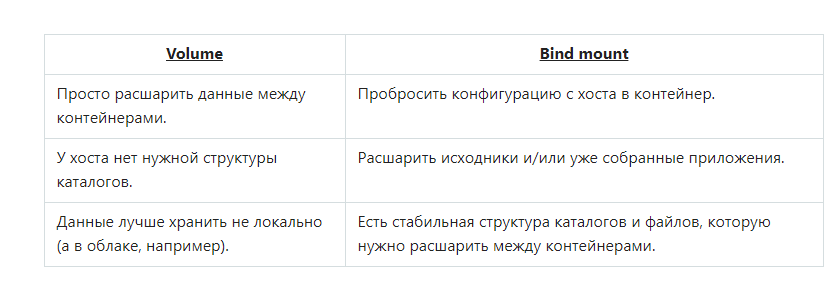
Тома (docker volumes)
Тома — рекомендуемый разработчиками Docker способ хранения данных. В Linux тома находятся по умолчанию в /var/lib/docker/volumes/. Другие программы не должны получать к ним доступ напрямую, только через контейнер.
Тома создаются и управляются средствами Docker: командой docker volume create, через указание тома при создании контейнера в Dockerfile или docker-compose.yml.
В контейнере том видно как обычный каталог, который мы определяем в Dockerfile. Тома могут быть с именами или без — безымянным томам Docker сам присвоит имя.
Один том может быть примонтирован одновременно в несколько контейнеров. Когда никто не использует том, он не удаляется, а продолжает существовать. Команда для удаления томов: docker volume prune.
Можно выбрать специальный драйвер для тома и хранить данные не на хосте, а на удалённом сервере или в облаке.
Для чего стоит использовать тома в Docker:
- шаринг данных между несколькими запущенными контейнерами,
- решение проблемы привязки к ОС хоста,
- удалённое хранение данных,
- бэкап или миграция данных на другой хост с Docker (для этого надо остановить все контейнеры и скопировать содержимое из каталога тома в нужное место).
Монтирование каталога с хоста (bind mount)
Это более простая концепция: файл или каталог с хоста просто монтируется в контейнер.
Используется, когда нужно пробросить в контейнер конфигурационные файлы с хоста. Например, именно так в контейнерах реализуется DNS: с хоста монтируется файл /etc/resolv.conf.
Другое очевидное применение — в разработке. Код находится на хосте (вашем ноутбуке), но исполняется в контейнере. Вы меняете код и сразу видите результат. Это возможно, так как процессы хоста и контейнера одновременно имеют доступ к одним и тем же данным.
Особенности bind mount:
- Запись в примонтированный каталог могут вести программы как в контейнере, так и на хосте. Это значит, есть риск случайно затереть данные, не понимая, что с ними работает контейнер.
- Лучше не использовать в продакшене. Для продакшена убедитесь, что код копируется в контейнер, а не монтируется с хоста.
- Для успешного монтирования указывайте полный путь к файлу или каталогу на хосте.
- Если приложение в контейнере запущено от root, а совместно используется каталог с ограниченными правами, то в какой-то момент может возникнуть проблема с правами на файлы и невозможность что-то удалить без использования sudo.
Монтирование tmpfs
Tmpfs — временное файловое хранилище. Это некая специально отведённая область в оперативной памяти компьютера. Из определения выходит, что tmpfs — не лучшее хранилище для важных данных. Так оно и есть: при остановке или перезапуске контейнера сохранённые в tmpfs данные будут навсегда потеряны.
На самом деле tmpfs нужно не для сохранения данных, а для безопасности, полученные в ходе работы приложения чувствительные данные безвозвратно исчезнут после завершения работы контейнера. Бонусом использования будет высокая скорость доступа к информации.
Например, приложение в контейнере тормозит из-за того, что в ходе работы активно идут операции чтения-записи, а диски на хосте не очень быстрые. Если вы не уверены, в какой каталог идёт эта нагрузка, можно применить к запущенному контейнеру команду docker diff. И вот этот каталог смонтировать как tmpfs, таким образом перенеся ввод-вывод с диска в оперативную память.
Такое хранилище может одновременно работать только с одним контейнером и доступно только в Linux.
Общие советы по использованию томов
Монтирование в непустые директории
Если вы монтируете пустой том в каталог контейнера, где уже есть файлы, то эти файлы не удалятся, а будут скопированы в том. Этим можно пользоваться, когда нужно скопировать данные из одного контейнера в другой.
Если вы монтируете непустой том или каталог с хоста в контейнер, где уже есть файлы, то эти файлы тоже не удалятся, а просто будут скрыты. Видно будет только то, что есть в томе или каталоге на хосте. Похоже на простое монтирование в Linux.
Монтирование служебных файлов
С хоста можно монтировать любые файлы, в том числе служебные. Например, сокет docker. В результате получится docker-in-docker: один контейнер запустится внутри другого. UPD: (*это не совсем так. mwizard в комментариях пояснил, что в таком случае родительский docker запустит sibling-контейнер). Выглядит как бред, но в некоторых случаях бывает оправдано. Например, при настройке CI/CD.
Монтирование /var/lib/docker
Разработчики Docker говорят, что не стоит монтировать с хоста каталог /var/lib/docker, так как могут возникнуть проблемы. Однако есть некоторые программы, для запуска которых это необходимо.
Практика: создадим тестовый том
Ключ командной строки для Docker при работе с томами.
Для volume или bind mount:
Команды для управления томами в интерфейсе CLI Docker:
Commands:
create Create a volume (Создать том)
inspect Display detailed information on one or more
volumes (Отобразить детальную информацию)
ls List volumes (Вывести список томов)
prune Remove all unused volumes (Удалить все неиспользуемые тома)
rm Remove one or more volumes (Удалить один или несколько томов)
Создадим тестовый том:
$ docker volume create slurm-storage
slurm-storage
Вот он появился в списке:
$ docker volume ls
DRIVER VOLUME NAME
local slurm-storage
Команда inspect выдаст примерно такой список информации в json:
Попробуем использовать созданный том, запустим с ним контейнер:
$ docker run —rm -v slurm-storage:/data -it ubuntu:20.10 /bin/bash
# echo $RANDOM > /data/file
# cat /data/file
13279
# exit
После самоуничтожения контейнера запустим другой и подключим к нему тот же том. Проверяем, что в нашем файле:
$ docker run —rm -v slurm-storage:/data -it centos:8 /bin/bash -c «cat /data/file»
13279
То же самое, отлично.
Теперь примонтируем каталог с хоста:
$ docker run -v /srv:/host/srv —name slurm —rm -it ubuntu:20.10 /bin/bash
Docker не любит относительные пути, лучше указывайте абсолютные!
Теперь попробуем совместить оба типа томов сразу:
$ docker run -v /srv:/host/srv -v slurm-storage:/data —name slurm —rm -it ubuntu:20.10 /bin/bash
Отлично! А если нам нужно передать ровно те же тома другому контейнеру?
$ docker run —volumes-from slurm —name backup —rm -it centos:8 /bin/bash
Вы можете заметить некий лаг в обновлении данных между контейнерами, это зависит от используемого Docker драйвера файловой системы.
Создавать том заранее необязательно, всё сработает в момент запуска docker run:
$ docker run -v newslurm:/newdata -v /srv:/host/srv -v slurm-storage:/data —name slurm —rm -it ubuntu:20.10 /bin/bash
Посмотрим теперь на список томов:
$ docker volume ls
DRIVER VOLUME NAME
local slurm-storage
local newslurm
Ещё немного усложним команду запуска, создадим анонимный том:
$ docker run -v /anonymous -v newslurm:/newdata -v /srv:/host/srv -v slurm-storage:/data —name slurm —rm -it ubuntu:20.10 /bin/bash
Такой том самоуничтожится после выхода из контейнера, так как мы указали ключ –rm.
Если этого не сделать, давайте проверим что будет:
$ docker run -v /anonymous -v newslurm:/newdata -v /srv:/host/srv -v slurm-storage:/data —name slurm -it ubuntu:20.10 /bin/bash
$ docker volume ls
DRIVER VOLUME NAME
local 04c490b16184bf71015f7714b423a517ce9599e9360af07421ceb54ab96bd333
local newslurm
local slurm-storage
Хозяйке на заметку: тома (как образы и контейнеры) ограничены значением настройки dm.basesize, которая устанавливается на уровне настроек демона Docker. Как правило, что-то около 10Gb. Это значение можно изменить вручную, но потребуется перезапуск демона Docker.
При запуске демона с ключом это выглядит так:
$ sudo dockerd —storage-opt dm.basesize=40G
Однажды увеличив значение, его уже нельзя просто так уменьшить. При запуске Docker выдаст ошибку.
Если вам нужно вручную очистить содержимое всех томов, придётся удалять каталог, предварительно остановив демон:
$ sudo service docker stop
$ sudo rm -rf /var/lib/docker
Может быть интересно:
- Интенсив по Python для инженеров и разработчиков
- Курс по GoLang для инженеров
Изучаем внутренние компоненты Docker — Объединённая файловая система

Создавать, запускать, просматривать, перемещать контейнеры и образы с помощью интерфейса командной строки Docker (Docker CLI) проще простого, но задумывались ли вы когда-нибудь, как на самом деле работают внутренние компоненты, обеспечивающие работу интерфейса Docker? За этим простым интерфейсом скрывается множество продвинутых технологий, и специально к старту нового потока курса по DevOps в этой статье мы рассмотрим одну из них — объединённую файловую систему, используемую во всех слоях контейнеров и образов. Маститым знатокам контейнеризации и оркестрации данный материал навряд ли откроет что-то новое, зато будет полезен тем, кто делает первые шаги в DevOps.
Что такое объединённая файловая система?
Каскадно-объединённое монтирование — это тип файловой системы, в которой создается иллюзия объединения содержимого нескольких каталогов в один без изменения исходных (физических) источников. Такой подход может оказаться полезным, если имеются связанные наборы файлов, хранящиеся в разных местах или на разных носителях, но отображать их надо как единое и совокупное целое. Например, набор пользовательских/корневых каталогов, расположенных на удалённых NFS-серверах, можно свести в один каталог или можно объединить разбитый на части ISO-образ в один целый образ.
Однако технологию объединённого монтирования (или объединённой файловой системы), по сути, нельзя считать отдельным типом файловой системы. Это, скорее, особая концепция с множеством реализаций. Некоторые реализации работают быстрее, некоторые медленнее, некоторые проще в использовании, некоторые сложнее — проще говоря, у разных реализаций разные цели и разные уровни зрелости. Поэтому, прежде чем углубиться в детали, ознакомимся с некоторыми наиболее популярными реализациями объединённой файловой системы:
- Начнём с исходной объединённой файловой системы, а именно UnionFS. На данный момент поддержка файловой система UnionFS прекращена, последнее изменение кода было зафиксировано в августе 2014 года. Более подробная информация об этой файловой системе приведена здесь: unionfs.filesystems.org.
- aufs — альтернативная версия исходной файловой системы UnionFS с добавлением множества новых функций. Данную файловую систему нельзя использовать в составе ванильного ядра Linux. Aufs использовалась в качестве файловой системы по умолчанию для Docker на Ubuntu/Debian, однако со временем она была заменена на OverlayFS (для ядра Linux >4.0). По сравнению с другими объединёнными файловыми системами эта система имеет ряд преимуществ, описанных в Docker Docs.
- Следующая система — OverlayFS — была включена в ядро Linux Kernel, начиная с версии 3.18 (26 октября 2014 года). Данная файловая система используется по умолчанию драйвером overlay2 Docker (это можно проверить, запустив команду docker system info | grep Storage). Данная файловая система в целом обеспечивает лучшую, чем aufs, производительность и имеет ряд интересных функциональных особенностей, например функцию разделения страничного кэша.
- ZFS — объединённая файловая система, разработанная Sun Microsystems (в настоящее время эта компания называется Oracle). В этой системе реализован ряд полезных функций, таких как функция иерархического контрольного суммирования, функция обработки снимков, функция резервного копирования/репликации или архивирования и дедупликации (исключения избыточности) внутренних данных. Однако, поскольку автором этой файловой системы является Oracle, её выпуск осуществлялся под общей лицензией на разработку и распространение (CDDL), не распространяемой на программное обеспечение с открытым исходным кодом, поэтому данная файловая система не может поставляться как часть ядра Linux. Тем не менее можно воспользоваться проектом ZFS on Linux (ZoL), который в документации Docker описывается как работоспособный и хорошо проработанный. но, увы, непригодный к промышленной эксплуатации. Если вам захочется поработать с этой файловой системой, её можно найти здесь.
- Btrfs — ещё один вариант файловой системы, представляющий собой совместный проект множества компаний, в том числе SUSE, WD и Facebook. Данная файловая система выпущена под лицензией GPL и является частью ядра Linux. Btrfs — файловая система по умолчанию дистрибутива Fedora 33. В ней также реализованы некоторые полезные функции, такие как операции на уровне блоков, дефрагментация, доступные для записи снимки и множество других. Если вас не пугают трудности, связанные с переходом на специализированный драйвер устройств памяти для Docker, файловая система Btrfs с её функциональными и производительными возможностями может стать лучшим вариантом.
Если вы хотите более глубоко изучить характеристики драйверов, используемых в Docker, в Docker Docs можно ознакомиться с таблицей сравнения разных драйверов. Если вы затрудняетесь с выбором файловой системы (не сомневаюсь, есть и такие программисты, которые знают все тонкости файловых систем, но эта статья предназначена не для них), возьмите за основу файловую систему по умолчанию overlay2 — именно её я буду использовать в примерах в оставшейся части данной статьи.
Почему именно она?
В предыдущем разделе мы рассказали о некоторых полезных возможностях файловой системы такого типа, но почему именно она является оптимальным выбором для работы Docker и контейнеров в целом?
Многие образы, используемые для запуска контейнеров, занимают довольно большой объём, например, ubuntu занимает 72 Мб, а nginx — 133 Мб. Было бы довольно разорительно выделять столько места всякий раз, когда потребуется из этих образов создать контейнер. При использовании объединённой файловой системы Docker создаёт поверх образа тонкий слой, а остальная часть образа может быть распределена между всеми контейнерами. Мы также получаем дополнительное преимущество за счёт сокращения времени запуска, так как отпадает необходимость в копировании файлов образа и данных.
Объединённая файловая система также обеспечивает изоляцию, поскольку контейнеры имеют доступ к общим слоям образа только для чтения. Если контейнерам когда-нибудь понадобится внести изменения в любой файл, доступный только для чтения, они используют стратегию копирования при записи copy-on-write (её мы обсудим чуть позже), позволяющую копировать содержимое на верхний слой, доступный для записи, где такое содержимое может быть безопасно изменено.
Как это работает?
Теперь вы вправе задать мне важный вопрос: как же это всё работает на практике? Из сказанного выше может создаться впечатление, что объединённая файловая система работает с применением некой чёрной магии, но на самом деле это не так. Сейчас я попытаюсь объяснить, как это работает в общем (неконтейнерном) случае. Предположим, нам нужно объединить два каталога (верхний и нижний) в одной точке монтирования и чтобы такие каталоги были представлены унифицированно:
. ├── upper │ ├── code.py # Content: `print("Hello Overlay!")` │ └── script.py └── lower ├── code.py # Content: `print("This is some code. ")` └── config.yamlВ терминологии объединённого монтирования такие каталоги называются ветвями. Каждой из таких ветвей присваивается свой приоритет. Приоритет используется для того, чтобы решить, какой именно файл будет отображаться в объединённом представлении, если в нескольких исходных ветках присутствуют файлы с одним и тем же именем. Если проанализировать представленные выше файлы и каталоги, станет понятно, что такой конфликт может возникнуть, если мы попытаемся использовать их в режиме наложения (файл code.py). Давайте попробуем и посмотрим, что у нас получится:
~ $ mount -t overlay \ -o lowerdir=./lower,\ upperdir=./upper,\ workdir=./workdir \ overlay /mnt/merged ~ $ ls /mnt/merged code.py config.yaml script.py ~ $ cat /mnt/merged/code.py print("Hello Overlay!")В приведённом выше примере мы использовали команду mount с type overlay, чтобы объединить нижний каталог (только для чтения; более низкий приоритет) и верхний каталог (чтение-запись; более высокий приоритет) в объединённое представление в каталоге /mnt/merged. Мы также включили опцию workdir=./workdir. Этот каталог служит местом для подготовки объединённого представления нижнего каталога (lowerdir) и верхнего каталога (upperdir) перед их перемещением в каталог /mnt/merged.
Если посмотреть на выходные данные команды cat, можно заметить, что в объединённом представлении приоритет получили файлы верхнего каталога.
Теперь мы знаем, как объединить два каталога и что произойдёт при возникновении конфликта. Но что произойдёт, если попытаться изменить определенные файлы в объединённом представлении? Здесь в игру вступает функция копирования при записи (CoW). Что именно делает эта функция? CoW — это способ оптимизации, при котором, если две вызывающих программы обращаются к одному и тому же ресурсу, можно дать им указатель на один и тот же ресурс, не копируя его. Копирование необходимо только тогда, когда одна из вызывающих программ пытается осуществить запись собственной «копии» — отсюда в названии способа появилось слово «копия», то есть копирование осуществляется при (первой попытке) записи.
В случае объединённого монтирования это означает, что, если мы пытаемся изменить совместно используемый файл (или файл только для чтения), он вначале копируется в верхнюю ветвь, доступную для записи (upperdir), имеющую более высокий приоритет, чем нижние ветви (lowerdir), доступные только для чтения. Когда файл попадает в ветвь, доступную для записи, его можно безопасно изменить, и его новое содержимое отобразится в объединённом представлении, так как верхний слой имеет более высокий приоритет.
Последняя операция, которую мы, возможно, захотим выполнить, — это удаление файлов. Чтобы «удалить» файл, в ветви, доступной для записи, создается файл whiteout для очистки «удаляемого» файла. На самом деле файл не будет удалён физически. Вернее сказать, что он будет скрыт в объединённом представлении.
Мы много говорили о принципах объединённого монтирования, но как все эти принципы работают на платформе Docker и её контейнерах? Рассмотрим многоуровневую архитектуру Docker. Песочница контейнера состоит из нескольких ветвей образа, или, как мы их называем, слоёв. Такими слоями являются часть объединённого представления, доступная только для чтения (lowerdir), и слой контейнера — тонкая верхняя часть, доступная для записи (upperdir).
Не считая терминологических различий, речь фактически идёт об одном и том же — слои образа, извлекаемые из реестра, представляют собой lowerdir, и, если запускается контейнер, upperdir прикрепляется поверх слоев образа, обеспечивая рабочую область, доступную для записи в контейнер. Звучит довольно просто, не так ли? Давайте проверим, как всё работает!
Проверяем
Чтобы показать, как Docker использует файловую систему OverlayFS, попробуем смоделировать процесс монтирования Docker контейнеров и слоев образа. Прежде чем мы приступим, нужно вначале очистить рабочее пространство и получить образ, с которым можно работать:
~ $ docker image prune -af . Total reclaimed space: . MB ~ $ docker pull nginx Using default tag: latest latest: Pulling from library/nginx a076a628af6f: Pull complete 0732ab25fa22: Pull complete d7f36f6fe38f: Pull complete f72584a26f32: Pull complete 7125e4df9063: Pull complete Digest: sha256:10b8cc432d56da8b61b070f4c7d2543a9ed17c2b23010b43af434fd40e2ca4aa Status: Downloaded newer image for nginx:latest docker.io/library/nginx:latestИтак, у нас имеется образ (nginx), с которым можно работать, далее нужно проверить его слои. Проверить слои образа можно, либо запустив проверку образа в Docker и изучив поля GraphDriver, либо перейдя в каталог /var/lib/docker/overlay2, в котором хранятся все слои образа. Выполним обе эти операции и посмотрим, что получится:
~ $ cd /var/lib/docker/overlay2 ~ $ ls -l total 0 drwx------. 4 root root 55 Feb 6 19:19 3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd drwx------. 3 root root 47 Feb 6 19:19 410c05aaa30dd006fc47d8c23ba0d173c6d305e4d93fdc3d9abcad9e78862b46 drwx------. 4 root root 72 Feb 6 19:19 685374e39a6aac7a346963bb51e2fc7b9f5e2bdbb5eac6c76ccdaef807abc25e brw-------. 1 root root 253, 0 Jan 31 18:15 backingFsBlockDev drwx------. 4 root root 72 Feb 6 19:19 d487622ece100972afba76fda13f56029dec5ec26ffcf552191f6241e05cab7e drwx------. 4 root root 72 Feb 6 19:19 fb18be50518ec9b37faf229f254bbb454f7663f1c9c45af9f272829172015505 drwx------. 2 root root 176 Feb 6 19:19 l ~ $ tree 3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/ 3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/ ├── diff │ └── docker-entrypoint.d │ └── 20-envsubst-on-templates.sh ├── link ├── lower └── work ~ $ docker inspect nginx | jq .[0].GraphDriver.Data < "LowerDir": "/var/lib/docker/overlay2/fb18be50518ec9b37faf229f254bbb454f7663f1c9c45af9f272829172015505/diff: /var/lib/docker/overlay2/d487622ece100972afba76fda13f56029dec5ec26ffcf552191f6241e05cab7e/diff: /var/lib/docker/overlay2/685374e39a6aac7a346963bb51e2fc7b9f5e2bdbb5eac6c76ccdaef807abc25e/diff: /var/lib/docker/overlay2/410c05aaa30dd006fc47d8c23ba0d173c6d305e4d93fdc3d9abcad9e78862b46/diff", "MergedDir": "/var/lib/docker/overlay2/3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/merged", "UpperDir": "/var/lib/docker/overlay2/3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/diff", "WorkDir": "/var/lib/docker/overlay2/3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/work" >Если внимательно посмотреть на полученные результаты, можно заметить, что они весьма похожи на те, что мы уже наблюдали после применения команды mount, не находите?
- LowerDir: это каталог, в котором слои образа, доступные только для чтения, разделены двоеточиями.
- MergedDir: объединённое представление всех слоев образа и контейнера.
- UpperDir: слой для чтения и записи, на котором записываются изменения.
- WorkDir: рабочий каталог, используемый Linux OverlayFS для подготовки объединённого представления.
Сделаем ещё один шаг — запустим контейнер и изучим его слои:
~ $ docker run -d --name container nginx ~ $ docker inspect container | jq .[0].GraphDriver.Data < "LowerDir": "/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4-init/diff: /var/lib/docker/overlay2/3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/diff: /var/lib/docker/overlay2/fb18be50518ec9b37faf229f254bbb454f7663f1c9c45af9f272829172015505/diff: /var/lib/docker/overlay2/d487622ece100972afba76fda13f56029dec5ec26ffcf552191f6241e05cab7e/diff: /var/lib/docker/overlay2/685374e39a6aac7a346963bb51e2fc7b9f5e2bdbb5eac6c76ccdaef807abc25e/diff: /var/lib/docker/overlay2/410c05aaa30dd006fc47d8c23ba0d173c6d305e4d93fdc3d9abcad9e78862b46/diff", "MergedDir": "/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/merged", "UpperDir": "/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/diff", "WorkDir": "/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/work" >~ $ tree -l 3 /var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/diff # The UpperDir /var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/diff ├── etc │ └── nginx │ └── conf.d │ └── default.conf ├── run │ └── nginx.pid └── var └── cache └── nginx ├── client_temp ├── fastcgi_temp ├── proxy_temp ├── scgi_temp └── uwsgi_tempИз представленных выше выходных данных следует, что те же каталоги, которые были перечислены в выводе команды docker inspect nginx ранее как MergedDir, UpperDir и WorkDir (с id 3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd), теперь являются частью LowerDir контейнера. В нашем случае LowerDir составляется из всех слоев образа nginx, размещённых друг на друге. Поверх них размещается слой в UpperDir, доступный для записи, содержащий каталоги /etc, /run и /var. Также, раз уж мы выше упомянули MergedDir, можно видеть всю доступную для контейнера файловую систему, в том числе всё содержимое каталогов UpperDir и LowerDir.
И, наконец, чтобы эмулировать поведение Docker, мы можем использовать эти же каталоги для ручного создания собственного объединённого представления:
~ $ mount -t overlay -o \ lowerdir=/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4-init/diff: /var/lib/docker/overlay2/3d963d191b2101b3406348217f4257d7374aa4b4a73b4a6dd4ab0f365d38dfbd/diff: /var/lib/docker/overlay2/fb18be50518ec9b37faf229f254bbb454f7663f1c9c45af9f272829172015505/diff: /var/lib/docker/overlay2/d487622ece100972afba76fda13f56029dec5ec26ffcf552191f6241e05cab7e/diff: /var/lib/docker/overlay2/685374e39a6aac7a346963bb51e2fc7b9f5e2bdbb5eac6c76ccdaef807abc25e/diff: /var/lib/docker/overlay2/410c05aaa30dd006fc47d8c23ba0d173c6d305e4d93fdc3d9abcad9e78862b46/diff,\ upperdir=/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/diff,\ workdir=/var/lib/docker/overlay2/59bcd145c580de3bb3b2b9c6102e4d52d0ddd1ed598e742b3a0e13e261ee6eb4/work \ overlay /mnt/merged ~ $ ls /mnt/merged bin dev docker-entrypoint.sh home lib64 mnt proc run srv tmp var boot docker-entrypoint.d etc lib media opt root sbin sys usr ~ $ umount overlayВ нашем случае мы просто взяли значения из предыдущего фрагмента кода и передали их в качестве соответствующих аргументов в команду mount. Разница лишь в том, что для объединённого представления вместо /var/lib/docker/overlay2/. /merged мы использовали /mnt/merged.
Именно к этому сводится действие файловой системы OverlayFS в Docker — на множестве уложенных друг на друга слоев может использоваться одна команда монтирования. Ниже приводится отвечающая за это часть кода Docker — заменяются значения lowerdir=. upperdir=. workdir=. после чего следует команда unix.Mount.
// https://github.com/moby/moby/blob/1ef1cc8388165b2b848f9b3f53ec91c87de09f63/daemon/graphdriver/overlay2/overlay.go#L580 opts := fmt.Sprintf("lowerdir=%s,upperdir=%s,workdir=%s", strings.Join(absLowers, ":"), path.Join(dir, "diff"), path.Join(dir, "work")) mountData := label.FormatMountLabel(opts, mountLabel) mount := unix.Mount mountTarget := mergedDir rootUID, rootGID, err := idtools.GetRootUIDGID(d.uidMaps, d.gidMaps) // . Заключение
Интерфейс Docker может показаться чёрным ящиком с большим количеством скрытых внутри непонятных технологий. Эти технологии — пусть непонятные — довольно интересны и полезны. Я вовсе не хочу сказать, что для эффективного использования Docker нужно досконально знать все их тонкости, но, на мой взгляд, если вы потратите немного времени и поймёте, как они работают, это пойдёт вам только на пользу. Ясное понимание принципов работы инструмента облегчает принятие правильных решений — в нашем случае речь идёт о повышении производительности и возможных аспектах, связанных с безопасностью. Кроме того, вы сможете ознакомиться с некоторыми продвинутыми технологиями, и кто знает, в каких областях знаний они могут вам пригодится в будущем!
В этой статье мы рассмотрели только часть архитектуры Docker — файловую систему. Есть и другие части, с которыми стоит ознакомиться более внимательно, например контрольные группы (cgroups) или пространства имен Linux. Если вы их освоите — можно уже задуматься о переходе в востребованный DevOps. А с остальными знаниями, необходимыми для данной профессии мы поможем на курсе по профессии DevOps-инженер.

Узнайте, как прокачаться в других специальностях или освоить их с нуля:
- Профессия Data Scientist
- Профессия Data Analyst
- Курс по Data Engineering
ПРОФЕССИИ
- Профессия Fullstack-разработчик на Python
- Профессия Java-разработчик
- Профессия QA-инженер на JAVA
- Профессия Frontend-разработчик
- Профессия Этичный хакер
- Профессия C++ разработчик
- Профессия Разработчик игр на Unity
- Профессия Веб-разработчик
- Профессия iOS-разработчик с нуля
- Профессия Android-разработчик с нуля
КУРСЫ
- Курс по Machine Learning
- Курс «Machine Learning и Deep Learning»
- Курс «Математика для Data Science»
- Курс «Математика и Machine Learning для Data Science»
- Курс «Python для веб-разработки»
- Курс «Алгоритмы и структуры данных»
- Курс по аналитике данных
- Курс по DevOps