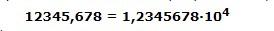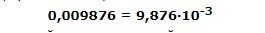Double c что это
Каждая переменная имеет определенный тип. И этот тип определяет, какие значения может иметь переменная, какие операции с ней можно производить и сколько байт в памяти она будет занимать. В языке C++ определены следующие базовые типы данных: логический тип bool , целочисленные типы, типа чисел с плавающей точкой, символьные типы. Рассмотрим эти группы по отдельности.
Логический тип
Логический тип bool может хранить одно из двух значений: true (истинно, верно) и false (неверно, ложно). Например, определим пару переменных данного типа и выведем их значения на консоль:
#include int main() < bool isAlive ; bool isDead ; std::cout
При выводе значения типа bool преобразуются в 1 (если true) и 0 (если false). Как правило, данный тип применяется преимущество в условных выражениях, которые будут далее рассмотрены.
Значение по умолчанию для переменных этого типа — false .
Целочисленные типы
Целые числа в языке C++ представлены следующими типами:
- signed char : представляет один символ. Занимает в памяти 1 байт (8 бит). Может хранить любой значение из диапазона от -128 до 127
- unsigned char : представляет один символ. Занимает в памяти 1 байт (8 бит). Может хранить любой значение из диапазона от 0 до 255
- char : представляет один символ в кодировке ASCII. Занимает в памяти 1 байт (8 бит). Может хранить любое значение из диапазона от -128 до 127, либо от 0 до 255 Несмотря на то, что данный тип представляет тот же диапазон значений, что и вышеописанный тип signed char , но они не эквивалентны. Тип char предназначен для хранения числового кода символа и в реальности может представлять как signed byte , так и unsigned byte в зависимости от конкретного компилятора.
- short : представляет целое число в диапазоне от –32768 до 32767. Занимает в памяти 2 байта (16 бит). Данный тип также имеет псевдонимы short int , signed short int , signed short .
- unsigned short : представляет целое число в диапазоне от 0 до 65535. Занимает в памяти 2 байта (16 бит). Данный тип также имеет синоним unsigned short int .
- int : представляет целое число. В зависимости от архитектуры процессора может занимать 2 байта (16 бит) или 4 байта (32 бита). Диапазон предельных значений соответственно также может варьироваться от –32768 до 32767 (при 2 байтах) или от −2 147 483 648 до 2 147 483 647 (при 4 байтах). Но в любом случае размер должен быть больше или равен размеру типа short и меньше или равен размеру типа long Данный тип имеет псевдонимы signed int и signed .
- unsigned int : представляет положительное целое число. В зависимости от архитектуры процессора может занимать 2 байта (16 бит) или 4 байта (32 бита), и из-за этого диапазон предельных значений может меняться: от 0 до 65535 (для 2 байт), либо от 0 до 4 294 967 295 (для 4 байт). Имеет псевдоним unsigned
- long : в зависимости от архитектуры может занимать 4 или 8 байт и представляет целое число в диапазоне от −2 147 483 648 до 2 147 483 647 (при 4 байтах) или от −9 223 372 036 854 775 808 до +9 223 372 036 854 775 807 (при 8 байтах). Занимает в памяти 4 байта (32 бита) или. Имеет псевдонимы long int , signed long int и signed long
- unsigned long : представляет целое число в диапазоне от 0 до 4 294 967 295. Занимает в памяти 4 байта (32 бита). Имеет синоним unsigned long int .
- long long : представляет целое число в диапазоне от −9 223 372 036 854 775 808 до +9 223 372 036 854 775 807. Занимает в памяти 8 байт (64 бита). Имеет псевдонимы long long int , signed long long int и signed long long .
- unsigned long long : представляет целое число в диапазоне от 0 до 18 446 744 073 709 551 615. Занимает в памяти, как правило, 8 байт (64 бита). Имеет псевдоним unsigned long long int .
Для представления чисел в С++ применятся целочисленные литералы со знаком или без, типа -10 или 10. Например, определим ряд переменных целочисленных типов и выведем их значения на консоль:
#include int main() < signed char num1< -64 >; unsigned char num2< 64 >; short num3< -88 >; unsigned short num4< 88 >; int num5< -1024 >; unsigned int num6< 1024 >; long num7< -2048 >; unsigned long num8< 2048 >; long long num9< -4096 >; unsigned long long num10< 4096 >; std::cout u или U. Литералы типовlongиlong longимеют суффиксы L/l и LL/ll соответственно:#include int main() < unsigned int num6< 1024U >; // U - unsigned int long num7< -2048L >; // L - long unsigned long num8< 2048UL >; // UL - unsigned long long long num9< -4096LL >; // LL - long long unsigned long long num10< 4096ULL >;// ULL - unsigned long long std::cout #include int main() < int num< 1'234'567'890 >; std::coutРазличные системы исчисления
По умолчанию все стандартные целочисленные литералы представляют числа в привычной нам десятичной системе. Однако C++ также позволяет использовать и числа в других системах исчисления.
Чтобы указать, что число - шестнадцатеричное, перед числом указывается префикс 0x или 0X . Например:
int num1< 0x1A>; // 26 - в десятичной int num2< 0xFF >; // 255 - в десятичной int num3< 0xFFFFFF >; //16777215 - в десятичнойЧтобы указать, что число - восьмеричное, перед числом указывается ноль 0 . Например:
int num1< 034>; // 26 - в десятичной int num2< 0377 >; // 255 - в десятичнойБинарные литералы предваряются префиксом 0b или 0B :
int num1< 0b11010>; // 26 - в десятичной int num2< 0b11111111 >; // 255 - в десятичнойВсе эти типы литералов также поддерживают суффиксы U/L/LL :
unsigned int num1< 0b11010U>; // 26 - в десятичной long num2< 0377L >; // 255 - в десятичной unsigned long num3< 0xFFFFFFULL >; //16777215 - в десятичнойЧисла с плавающей точкой
Для хранения дробных чисел в C++ применяются числа с плавающей точкой. Число с плавающей точкой состоит из двух частей: мантиссы и показателя степени . Оба могут быть как положительными, так и отрицательными. Величина числа – это мантисса, умноженная на десять в степени экспоненты.
Например, число 365 может быть записано в виде числа с плавающей точкой следующим образом:
3.650000E02В качестве разделителя целой и дробной частей используется символ точки. Мантисса здесь имеет семь десятичных цифр - 3.650000 , показатель степени - две цифры 02 . Буква E означает экспоненту, после нее указывается показатель степени (степени десяти), на которую умножается часть 3.650000 (мантисса), чтобы получить требуемое значение. То есть, чтобы вернуться к обычному десятичному представлению, нужно выполнить следующую операцию:
3.650000 × 102 = 365Другой пример - возьмем небольшое число:
-3.650000E-03В данном случае мы имеем дело с числом –3.65 × 10 -3 , что равно –0.00365 . Здесь мы видим, что в зависимости от значения показателя степени десятичная точка "плавает". Собственно поэтому их и называют числами с плавающей точкой.
Однако хотя такая запись позволяет определить очень большой диапазон чисел, не все эти числа могут быть представлены с полной точностью; числа с плавающей запятой в целом являются приблизительными представления точного числа. Например, число 1254311179 выглядело бы так: 1.254311E09 . Однако если перейти к десятичной записи, то это будет 1254311000 . А это не то же самое, что и 1254311179 , поскольку мы потеряли три младших разряда.
В языке C++ есть три типа для представления чисел с плавающей точкой:
- float : представляет вещественное число одинарной точности с плавающей точкой в диапазоне +/- 3.4E-38 до 3.4E+38. В памяти занимает 4 байта (32 бита)
- double : представляет вещественное число двойной точности с плавающей точкой в диапазоне +/- 1.7E-308 до 1.7E+308. В памяти занимает 8 байт (64 бита)
- long double : представляет вещественное число двойной точности с плавающей точкой не менее 8 байт (64 бит). В зависимости от размера занимаемой памяти может отличаться диапазон допустимых значений.
В своем внутреннем бинарном представлении каждое число с плавающей запятой состоит из одного бита знака, за которым следует фиксированное количество битов для показателя степени и набор битов для хранения мантиссы. В числах float 1 бит предназначен для хранения знака, 8 бит для экспоненты и 23 для мантиссы, что в сумме дает 32 бита. Мантисса позволяет определить точность числа в виде 7 десятичных знаков.
В числах double : 1 знаковый бит, 11 бит для экспоненты и 52 бит для мантиссы, то есть в сумме 64 бита. 52-разрядная мантисса позволяет определить точность до 16 десятичных знаков.
Для типа long double расклад зависит от конкретного компилятора и реализации этого типа данных. Большинство компиляторов предоставляют точность до 18 - 19 десятичных знаков (64-битная мантисса), в других же (как например, в Microsoft Visual C++) long double аналогичен типу double .
В C++ литералы чисел с плавающими точками представлены дробными числами, которые в качестве разделителя целой и дробной частей применяют точку:
double num ;
Даже если переменной присваивается целое число, чтобы показать, что мы присваиваем число с плавающей точкой, применяется точка:
double num1< 1 >; // 1 - целочисленный литерал double num2< 1. >; //1. - литерал числа с плавающей точкой
Так, здесь число 1. представляет литерал числа с плавающей точкой, и в принципе аналогичен 1.0 .
По умолчанию все такие числа с точкой расцениваются как числа типа double. Чтобы показать, что число представляет другой тип, для float применяется суффикс f / F , а для long double - l / L :
float num1< 10.56f >; // float long double num2< 10.56l >; // long double
В качестве альтернативы также можно применять экспоненциальную запись:
double num1< 5E3 >; // 5E3 = 5000.0 double num2< 2.5e-3 >; // 2.5e-3 = 0.0025
Размеры типов данных
При перечислении типов данных указывался размер, который он занимает в памяти. Но стандарт языка устанавливает лишь минимальные значения, которые должны быть. Например, для типов int и short минимальное значение - 16 бит, для типа long - 32 бита, для типа long double - 64 разряда. При этом размер типа long должен быть не меньше размера типа int, а размер типа int - не меньше размера типа short, а размер типа long double должен быть не меньше double . А разработчики компиляторов могут выбирать предельные размеры для типов самостоятельно, исходя из аппаратных возможностей компьютера.
К примеру, компилятор g++ Windows для long double использует 16 байт. А компилятор в Visual Studio, который также работает под Windows, и clang++ под Windows для long double используют 8 байт. То есть даже в рамках одной платформы разные компиляторы могут по разному подходить к размерам некоторых типов данных. Но в целом используются те размеры, которые указаны выше при описании типов данных.
Однако бывают ситуации, когда необходимо точно знать размер определенного типа. И для этого в С++ есть оператор sizeof() , который возвращает размер памяти в байтах, которую занимает переменная:
#include int main() < long double number ; std::coutsizeof(number) = 16Символьные типы
В C++ есть следующие символьные типы данных:
- char : представляет один символ в кодировке ASCII. Занимает в памяти 1 байт (8 бит). Может хранить любое значение из диапазона от -128 до 127, либо от 0 до 255
- wchar_t : представляет расширенный символ. На Windows занимает в памяти 2 байта (16 бит), на Linux - 4 байта (32 бита). Может хранить любой значение из диапазона от 0 до 65 535 (при 2 байтах), либо от 0 до 4 294 967 295 (для 4 байт)
- char8_t : представляет один символ в кодировке Unicode. Занимает в памяти 1 байт. Может хранить любой значение из диапазона от 0 до 256
- char16_t : представляет один символ в кодировке Unicode. Занимает в памяти 2 байта (16 бит). Может хранить любой значение из диапазона от 0 до 65 535
- char32_t : представляет один символ в кодировке Unicode. Занимает в памяти 4 байта (32 бита). Может хранить любой значение из диапазона от 0 до 4 294 967 295
char
Переменная типа char хранит числовой код одного символа и занимает один байт. Стандарт языка С++ не определяет кодировку символов, которая будет использоваться для символов char, поэтому производители компиляторов могут выбирать любую кодировку, но обычно это ASCII.
В качестве значения переменная типа char может принимать один символ в одинарных кавычках, либо числовой код символа:
#include int main() < char a1 ; char a2 ; std::cout
В данном случае переменные a1 и a2 будут иметь одно и то же значение, так как 65 - это числовой код символа "A" в таблице ASCII. При выводе на консоль с помощью cout по умолчанию отображается символ.
Кроме того, в C++ можно использовать специальные управляющие последовательности, которые предваряются слешем и которые интерпретируются особым образом. Например, "\n" представляет перевод строки, а "\t" - табуляцию.
Однако ASCII обычно подходит для наборов символов языков, которые используют латиницу. Но если необходимо работать с символами для нескольких языков одновременно или с символами языков, отличных от английского, 256-символьных кодов может быть недостаточно. И в этом случае применяется Unicode .
Unicode (Юникод) — это стандарт, который определяет набор символов и их кодовых точек, а также несколько различных кодировок для этих кодовых точек. Наиболее часто используемые кодировки: UTF-8, UTF-16 и UTF-32. Разница между ними заключается в том, как представлена кодовая точка символа; числовое же значение кода для любого символа остается одним и тем же в любой из кодировок. Основные отличия:
- UTF-8 представляет символ как последовательность переменной длины от одного до четырех байт. Набор символов ASCII появляется в UTF-8 как однобайтовые коды, которые имеют те же значения кодов, что и в ASCII. UTF-8 на сегодняшний день является самой популярной кодировкой Unicode.
- UTF-16 представляет символы как одно или два 16-битных значения.
- UTF-32 представляет все символы как 32-битные значения
В C++ есть четыре типа для хранения символов Unicode: wchar_t , char8_t , char16_t и char32_t ( char16_t и char32_t были добавлены в C+11, а char8_t - в C++20).
wchar_t
Тип wchar_t — это основной тип, предназначенный для наборов символов, размер которых выходит за пределы одного байта. Собственно отсюда и его название: wchar_t - wide (широкий) char. происходит от широкого символа, потому что этот символ «шире», чем обычный однобайтовый символ. Значения wchar_t определяются также как и символы char за тем исключением, что они предваряются символов "L":
wchar_t a1 ;
Также можно передать код символа
wchar_t a1 ;
Значение, заключенное в одинарные кавычки, представляет собой шестнадцатеричный код символа. Обратная косая черта указывает на начало управляющей последовательности, а x после обратной косой черты означает, что код шестнадцатеричный.
Стоит учитывать, что для вывода на консоль символов wchar_t следует использовать не std::cout , а поток std::wcout :
#include int main() < char h = 'H'; wchar_t i ; std::wcout
При этом поток std::wcout может работать как с char, так и с wchar_t. А поток std::cout для переменной wchar_t вместо символа будет выводить его числовой код.
Проблема с типом wchar_t заключается в том, что его размер сильно зависит от реализации и применяемой кодировки. Кодировка обычно соответствует предпочтительной кодировке целевой платформы. Так, для Windows wchar_t обычно имеет ширину 16 бит и кодируется с помощью UTF-16. Большинство других платформ устанавливают размер в 32 бита, а в качестве кодировки применяют UTF-32. С одной стороны, это позволяет больше соответствовать конкретной платформе. Но с другой стороны, затрудняет написание кода, переносимого на разные платформы. Поэтому в общем случае часто рекомендуется использовать типы char8_t , char16_t и char32_t . Значения этих типов предназначены для хранения символов в кодировке UTF-8, UTF-16 или UTF-32 соответственно, а их размеры одинаковы на всех распространенных платформах.
Для определения символов типов char8_t , char16_t и char32_t применяются соответственно префиксы u8, u и U:
char8_t c< u8'l' >; char16_t d< u'l' >; char32_t e< U'o' >;
Стоит отметить, что для вывода на консоль значений char8_t/char16_t/char32_t пока нет встроенных инструментов типа std:cout/std:wcout .
Спецификатор auto
Иногда бывает трудно определить тип выражения. В этом случае можно предоставить компилятору самому выводить тип объекта. И для этого применяется спецификатор auto . При этом если мы определяем переменную со спецификатором auto, эта переменная должна быть обязательно инициализирована каким-либо значением:
auto number = 5; // number имеет тип int auto sum ; // sum имеет тип double auto distance ; // distance имеет тип unsigned long
На основании присвоенного значения компилятор выведет тип переменной. Неинициализированные переменные со спецификатором auto не допускаются:
Переменные и типы данных в C++ — урок 2
Из школьного курса математики мы все знаем, что такое переменные. В программировании принципы довольно схожи. Переменная — это «ячейка» оперативной памяти компьютера, в которой может храниться какая-либо информация.
В программировании переменная, как и в математике, может иметь название, состоящее из одной латинской буквы, но также может состоять из нескольких символов, целого слова или нескольких слов.
- Типы данных
- Основные типы данных в C++
- Пример объявления переменных
- Разбор кода
Типы данных
В языке С++ все переменные имеют определенный тип данных. Например, переменная, имеющая целочисленный тип не может содержать ничего кроме целых чисел, а переменная с плавающей точкой — только дробные числа.
Тип данных присваивается переменной при ее объявлении или инициализации. Ниже приведены основные типы данных языка C++, которые нам понадобятся.
Основные типы данных в C++
- int — целочисленный тип данных.
- float — тип данных с плавающей запятой.
- double — тип данных с плавающей запятой двойной точности.
- char — символьный тип данных.
- bool — логический тип данных.
Объявление переменной
Объявление переменной в C++ происходит таким образом: сначала указывается тип данных для этой переменной а затем название этой переменной.
Пример объявления переменных
int a; // объявление переменной a целого типа. float b; // объявление переменной b типа данных с плавающей запятой. double c = 14.2; // инициализация переменной типа double. char d = 's'; // инициализация переменной типа char. bool k = true; // инициализация логической переменной k.- Заметьте, что в C++ оператор присваивания(=) — не является знаком равенства и не может использоваться для сравнения значений. Оператор равенства записывается как «двойное равно» — == .
- Присваивание используется для сохранения определенного значение в переменной. Например, запись вида a = 10 задает переменной a значение числа 10.
Простой калькулятор на C++
Сейчас мы напишем простую программу-калькулятор, которая будет принимать от пользователя два целых числа, а затем определять их сумму:
Double и типизация данных в C

Типы данных в программировании определяются выбранным языком разработки и позволяют выделять некоторое пространство в памяти оборудования под функции, переменные и иные объекты исходного кода. Это оказывает влияние и на особенности обработки данных.
В языках программирования СИ поддерживаются самые разные типы данных. Примеры – int, double, float. Далее предстоит поближе познакомиться с типизацией в информатике. Необходимо выяснить, что она собой представляет, как реализовывается в C, а также какими особенностями и нюансами обладает. Статья в большей степени ориентирована на начинающих программистов.
Ключевые определения
Перед более детальным изучением data type необходимо в первую очередь выучить несколько понятий. Они пригодятся каждому, кто планирует разрабатывать программное обеспечение. Типизация в соответствующем деле – это «база», без которой создавать сложные проекты не представляется возможным.
Каждый программист должен знать следующие определения:
- Алгоритм – набор инструкций, направленный на решение той или иной задачи.
- Переменная – именованная область памяти. Место, в котором хранятся переменные и другие кодовые компоненты.
- Оператор – объект, который способен управлять (манипулировать) операндами. Операнд обозначает компонент программного кода, которым допускается оперирование.
- Указатель – это переменная с адресом места в памяти.
- Тип данных – классификация информации схожего характера.
- Массив – списки или группы (множества) схожих типов значений. Они предварительно проходят этап группировки. Все значения в массиве будут иметь одни и те же data types, отличаясь исключительно своим местоположением.
- Константа – неизменное значение. Оно не меняется ни при каких обстоятельствах в процессе работы исходного кода программы.
- Петля – это цикл. Представляет собой последовательность инструкций, которые раз за разом повторяют один и тот же процесс. Это происходит до тех пор, пока приложение не выполнит установленное условие или не получит команду на остановку.
- Итерация – один проход приложения через имеющийся набор инструкций.
- Ключевые слова – слова, которые язык программирования зарезервировал синтаксисом. Используются для выполнения определенных задач, а также обозначения функций, инструментов и объектов.
- Класс – это набор связанных объектов, имеющих общие свойства.
Когда разработчик поймет, что значит каждый приведенный выше термин, он может приступить к более детальному изучению типов информации в программировании. Особое внимание рекомендуется уделить типу double в C. Он используется так же часто, как и int.
Типизация в информатике
Система типов – это совокупность правил в языках разработки, которые назначают свойства (они называются типами) разнообразных конструкциям, которые формируют исходный проект. К ним можно отнести:
- модули;
- функции;
- переменные;
- выражения.
Ключевая роль типизации – уменьшение количества ошибок в исходном коде за счет грамотного определения интерфейсов между разнообразными частями приложения и проверки согласованности взаимодействия «фрагментов» между собой. «Тестирование» может быть организовано статически (во время компиляции) или динамически (до формирования проекта в программу). Допускается сочетание соответствующих концепций.
Виды данных
Тип данных будет определять множество значений, набор операций, применяемых к соответствующим материалам, а также способ реализации хранения значений и выполнения операций. За счет этого «компонента» система сможет выделить тот или иной размер памяти на устройстве для нормального функционирования объекта кода.
Проверка и накладывание ограничений на виды используемых данных – это контроль типов или типизация. В языке C поддерживается ее статический вид. Это значит, что разработчик перед компиляцией должен самостоятельно определить виды используемой информации в задействованном проекте.
Рассматривая описание видов информации в IT и программировании, по умолчанию можно выделить следующие «классы»:
- простые;
- составные (сложные);
- иные.
Первая категория – это самый распространенный вариант. Он включает в себя целочисленные типы, типы с плавающей запятой (вещественные), символьные и логические. Соответствующий вариант будет рассмотрен более подробно далее. Он используется как в простых, так и в достаточно сложных проектах чаще всего.
К составным вариантам относят:
- массивы – индексированные наборы элементов одного и того же вида (пример – double);
- строки – массивы, включающие в себя символьные строки;
- структуры – наборы разнообразных элементов, который хранится в качестве единого целого и предусматривает доступ к отдельным полям.
Описание иных видов информации обычно ограничивается определением указателя и идентификатора.
Указатель – это компонент, который хранит адрес в памяти компьютера, указывающий на те или иные данные. Обычно работает с различными переменными.
Идентификатор – последовательность, размер которой составляет до 32 символов (латинский алфавит, подчеркивания, цифры). Является уникальным «именем» компонента в исходном программном коде.
Единицы измерения
Когда стало понятно, что означает типизация, а также какими условно бывают виды информации, некоторые из них (double и другие) могут быть изучены более подробно. Сначала нужно выяснить, в каких единицах измеряются данные в IT и информатике.
Минимальная единица измерения – это бит. Оно выражает информацию, которая выступает достаточно для установки различий между двумя явлениями одинаковой вероятности. 1 бит указывает на два понятия 0 и 1 (ложь и истина, неверно или верно, нет или да, zero или определенное значение).
Бит – самая маленькая единица измерения, с которой может работать оператор или функция. Она редко используется на практике. Чаще всего программистам приходится работать с другой единицей измерения – с байтами. 1 byte – это 8 бит.
Вот единицы измерения количества данных и их диапазон. Они представлены по возрастанию:
По представленному выше принципу обозначена измерительная система, которая является международным стандартом. В программировании при выяснении того, какой размер имеет функция или переменная, принято применять биты или байты. В них переводятся остальные единицы счисления.
Основные типы в C
Когда стало понятно, каким образом в информатике определяется размер (size) в файле или документе, а также ключевые единицы счисления в IT, можно более подробно изучить основные виды информации в C. К ним относят значение переменной типа «простое».
Целочисленные
Целочисленные – это целые числа. Они могут быть представлены в нескольких формах: беззнаковой и знаковой. В первом случае числа будут представлены в виде последовательности битов, диапазон которых составляет от 0 до 2 n -1, где n – это количество занимаемых битов. Во втором случае диапазон определяется как -2 n-1 …+2 n-1 -1. Старший бит будет отводится под знак. Здесь 0 значит положительное число, а 1 – означает отрицательное.
Ниже представлена таблица, помогающая запомнить описание целочисленных, с которыми работает C. Double и float в соответствующую категорию не относятся, но они тоже являются простыми:
Размер (sizes) в битах Беззнаковые Знаковые 8 Unsigned char – символы от 0 до 255. Char, -128 до 127 16 Unsigned short, от 0 до 65 535 Short, от -32 768 до 32 767 32 (или 4 байта) Unsigned int Int – обычное целое число. Максимальное значение – 32 767, минимальное – -32 767. 64 Unsigned long int Long int У каждого вида информации, не только целого, есть свой минимальный размер. Меньше соответствующего значения система не сможет выделить памяти на устройстве для нормальной работы элемента.
Вещественные
Сюда относят «числа с точкой». Это множество, которое включает в себя тип float в C (числа с плавающей запятой). К этой же категории относится double.
Вещественный тип (double и другие) используется для того, чтобы представлять в информатике действительные числа. Они представляются в разрядной сетке устройства в нормированной форме.
Нормированная форма числа с плавающей точкой – это наличие одной значащей цифры, отличной от нуля, до разделения целой и дробной части. Соответствующее представление умножается на основание системы счисления в соответствующей степени. Ниже – пример десятичных дробей:
В нормированной форме оно выглядит как:
В двоичной системе счисления значащий разряд, стоящий перед точкой (разделителем дробной и целой части) может быть равен только 1. Если число нельзя представить в нормированной форме, значащий размер перед разделителем целого и дроби будет равен нулю.
В C оператор может работать с тремя вещественными видами информации (включая double). Сюда относят:
- Float. Это простое вещественное число. Оно означает значение одинарной точности с плавающей запятой. Занимает 4 байта. Хранит в себе число с точкой от -3,4 *10 38 до 3,4*10 38 .
- Double – вещественный тип с плавающей точкой двойной точности. Double принимает значения в диапазоне от +-5*10 -324 до +-1,7*10 308 . Занимает 8 байтов.
- Long double – вещественное число двойной расширенной точности. Может быть 80-битным форматом. Встречается крайне редко.
Других вещественных вариаций язык программирования не предусматривает.
Логический
Логический тип добавлен в C99. Представлен ключевым словом _Bool. В отличие от double, может принимать всего два значения: истина и ложь.
Дополнительный заголовочный файл stdbool.h определяет для такого компонента псевдоним bool, а также макросы true и false. Ведет себя этот компонент точно так же, как встроенный тип (включая doubles), за исключением того, что любое ненулевое присваивание будет храниться в качестве единицы.
Здесь можно увидеть несколько наглядных примеров применения double и других типов информации в изученном языке.
P. S. Интересует разработка? Обратите внимание на курс «Программист C» . Также в Otus доступно множество других современных курсов.
Тип double
Значения типа double с двойной точностью имеют размер 8 байт. Формат напоминает формат чисел с плавающей запятой, за исключением того, что он имеет 11-разрядную экспоненту (ее значение может превышать 1023) и 52-разрядную мантиссу, а также еще один старший разряд. Значения типа double в этом формате могут находиться в диапазоне примерно от 1,7E–308 до 1,7E+308.
Блок, относящийся только к системам Microsoft
Тип double представлен 64 битами: 1 для знака, 11 для экспоненты и 52 для мантиссы. Он имеет диапазон +/–1,7E308 с точностью не менее 15 знаков.
Завершение блока, относящегося только к системам Майкрософт