Что такое Disaster Recovery
Disaster Recovery (аварийное восстановление) — это сервис восстановления ИТ-систем и данных после сбоя любого уровня. Как правило, предлагается облачными провайдерами как отдельная услуга или включается в состав крупного решения. Условно можно разбить на три составляющие: резервная площадка, программные решения и план восстановления.
Причины востребованности Disaster Recovery
Чем активнее компания использует ИТ-инфраструктуру, тем выше становится зависимость от её работоспособности. Сбои напрямую влияют на доходы организации, её репутацию. Они также негативно сказываются на эффективности сотрудников и комфорте клиентов. Поэтому компании тратят много ресурсов, чтобы снизить риск неполадок в работе инфраструктуры.
Помимо стабильности также необходимо обеспечить быстрое восстановление систем после сбоя. Чем скорее всё заработает, тем меньше негативных последствий для компании. Для этого существуют решения Disaster Recovery — системы аварийного восстановления ИТ-инфраструктуры после сбоя.
Disaster Recovery является частью плана обеспечения непрерывности бизнеса. Его идея в том, что компания должна работать, несмотря на внутренние сбои, кибератаки, другие инциденты. А в случае аварии — не потерять ценные данные и быстро восстановить работоспособность.
Для аварийного восстановления необходима параллельная IT-инфраструктура, которая будет использоваться для хранения данных и шаблонов виртуальных машин либо выступит в роли вспомогательной системы, которая возьмёт на себя рабочие задачи на время инцидента.
Чаще всего Disaster Recovery предлагают облачные провайдеры. Компании-клиенту предоставляются облачные мощности, на которых можно расположить резервную информационную систему (ИС). Основная же располагается в другом ЦОД. Между системами настраиваются каналы связи, чтобы данные одновременно поступали в основную и резервную ИС.
Важно понимать, что аварийное восстановление как сервис (DRaaS) отличается от бэкап-решений. Основная задача системы резервного копирования — сохранность данных в случае аварии. Disaster Recovery же отвечает за сокращение времени простоя ИТ-систем. Бэкап не даёт компании возможность продолжить работу на резервной платформе, пока будет восстанавливаться работоспособность основной. Услуга DRaaS гарантирует, что у компании будет площадка, идентичная основной, которая сможет сохранить непрерывность бизнес-процессов.
Ключевые параметры аварийного восстановления
У решений Disaster Recovery есть два основных параметра, которые влияют на стоимость катастрофоустойчивой системы и размер ущерба в случае инцидента: RTO и RPO.
RTO (recovery time objective) — период времени, за который ИТ-система должна восстановиться. Если RTO составляет четыре часа, то инфраструктура заработает не позже, чем за этот срок. Если RTO несколько секунд, то пользователи могут даже не заметить, что система «падала». Часть решений аварийного восстановления поддерживают автоматическое переключение трафика на резервную инфраструктуру. Это позволяет нивелировать последствия аварии, сделав их незаметными для пользователей. Длительность RTO определяется потребностями бизнеса. Например, сайту с маленьким трафиком большой RTO не повредит, а для крупного онлайн-магазина 2-3 часа RTO — это серьёзные убытки.
RPO (recovery point objective) — период времени, за который могут быть утеряны данные в результате аварии. Заявленные три часа RPO означают, что после восстановления системы могут быть утеряны данные не более чем за три часа до инцидента. А при RPO в несколько секунд сохранятся почти все данные, что особенно критично для банков, крупных девелоперов и других организаций, которым нельзя терять данные даже за минуту. Величина RPO влияет на частоту создания копий IT-инфраструктуры.
Очевидно, что стоимость решения Disaster Recovery будет тем дороже, чем меньше RTO/RPO. Подбирайте модель аварийного восстановления, стоимость которой не превышает размер убытков в случае простоя. Необходим баланс между затратами на катастрофоустойчивость и убытками из-за инцидента с учётом времени восстановления бизнес-процессов и объёма утерянных данных.
Получить консультацию об облачных сервисахЗаказать звонок
Что такое Disaster Recovery Plan
Disaster Recovery Plan (DRP) — это план аварийного восстановления всех ИТ-систем после катастрофы (который в идеале никогда не должен понадобиться). Представляет собой документ с детальным описанием всех действий по устранению последствий аварии и восстановлению данных. В плане указаны роли и обязанности ответственных сотрудников, последовательность предпринимаемых ими действий.
На каком этапе развития компании требуется DRP, сказать непросто. Можно сформулировать этот критерий следующим образом. Disaster Recovery Plan требуется компании, когда:
- Остановка сервера/приложения или потеря базы данных влечёт за собой значительные финансовые, репутационные или иные потери;
- В штате имеется полноценный IT-отдел со своим бюджетом;
- Есть реальная возможность выделить средства на полноценное или хотя бы частичное резервирование на случай возникновения аварии.
Если потеря БД за день ничего не меняет, а ИТ-отдел месяцами может ждать комплектующих к старому серверу, DRP вряд ли потребуется. Хотя этот документ способен выручить в трудной ситуации.
Основная цель Disaster Recovery Plan: создание пошаговой инструкции с указанием времени на выполнение отдельных процедур. С помощью плана компания:
- Сможет быстрее восстановить ИТ-инфраструктуру после сбоя;
- Сможет обеспечить работу критически важных процессов во время простоя основной площадки;
- Сможет сохранить важные данные компании.
План аварийного восстановления состоит из нескольких разделов. В первую очередь это цели разработки плана, факторы риска, список критически важных сервисов.
Целью DRP может являться:
- Подготовка сотрудников. Важно, чтобы в критической ситуации они не растерялись, а действовали чётко по инструкции.
- Сохранение работоспособности. Восстановление работы сервисов в короткий срок и сохранение данных.
- PR-контакты. Правильное взаимодействие со СМИ, клиентами партнёрами в момент аварии играет важную роль.
- Соблюдение стандартов. В ходе аварийного восстановления важно соблюдать корпоративные стандарты, чтобы избежать хаоса.
Факторы риска показывают, какие процессы требуют особого внимания в процессе аварийного восстановления. В документе прописываются действия по устранению этих рисков. Например, проверка корректности создания бэкапов, работы каналов резервной связи, тестирование резервной инфраструктуры, проверка наличия нужного оборудования.
Список критически важных сервисов определяет очерёдность процессов восстановления. Чем критичнее процесс, тем быстрее нужно восстановить его работоспособность. Режим аварийного восстановления предполагает, что критические сервисы переносятся на резервную платформу. Поэтому даже при серьёзном инциденте их работоспособность должна сохраняться. Но если и с резервной площадкой что-то не так, работы по восстановлению начинаются с наиболее критичных систем.
DRaaS от Cloud4Y
Корпоративный облачный провайдер Cloud4Y предлагает три модели аварийного восстановления:
- Backup. Резервное копирование данных осуществляется по схеме Active – Passive. RTO/RPO зависят от объёма данных, по срокам — от 1 часа. Модель подходит всем типам бизнеса, для которых срок восстановления некритичен, а также допускаются небольшие потери данных.
- VM Replication. Осуществляется репликация данных на удалённую площадку (Active – Standby). RTO/RPO составляют от 30 /15 минут соответственно. Вариант подходит для веб-платформ, e-commerce, BigData. Базовая отказоустойчивость SLA составляет 99.982%, обеспечивается непрерывность бизнес-процессов, упрощённый failover и failback, Near-CDP для любого виртуализованного приложения.
- SyncCluster. Синхронное зеркаливание данных по схеме Active – Active. RTO/RPO составляют от 30 секунд/от 0 секунд соответственно. Вариант подходит для банков, крупных ИТ-компаний, госучреждений, BigData. Репликация обеспечивается на уровне СХД. Отказоустойчивость SLA составляет 99.99%, гарантируется защита даже от природных катаклизмов. Расстояние между дублирующими ЦОД составляет 10 км.
Использование облачных решений Disaster Recovery проще с точки зрения организации и управления, а также дешевле, чем построение собственной инфраструктуры. Используя услугу DRaaS от Cloud4Y, вы гарантируете себе возможность вернуться к привычному функционированию в срок, установленный договором. Проработка схем взаимодействия, подключения и маршрутизации занимает немного времени, поэтому интегрировать решения аварийного восстановления может компания любого уровня.
О проведении DR-тестирования ИТ‑систем НРД
В субботу, 30 июля 2022 года, с 10:00 до 18:00 пройдет disaster-recovery тестирование систем НРД.
Цель работ — проверить переключения систем и пользователей на работу с резервным дата-центром.
При проведении тестирования возможна частичная недоступность ИТ-систем НРД:
- web-кабинеты НРДирект;
- cайт НРД — www.nsd.ru;
- ПО «Аламеда»;
- web-сервис «Onyx».
Приносим извинения за временные неудобства в работе.
Общий телефон
Подписка на новости НРД
Небанковская кредитная организация акционерное общество «Национальный расчетный депозитарий» (НКО АО НРД) – центральный депозитарий Российской Федерации. Статус центрального депозитария присвоен ФСФР России приказом № 12-2761/ПЗ-И от 6 ноября 2012 г. Лицензия № 045-12042-000100 от 19 февраля 2009 г. профессионального участника рынка ценных бумаг на осуществление депозитарной деятельности, выданная ФСФР России. Лицензия № 3294 на осуществление банковских операций, выданная 4 августа 2016 г. Банком России. Лицензия № 045-00004-000010 от 20 декабря 2012 г. на осуществление клиринговой деятельности, выданная ФСФР России. Лицензия № 045-01 от 28 декабря 2016 г. на осуществление репозитарной деятельности, выданная Банком России. Местонахождение: г. Москва, ул. Спартаковская, дом 12.
Обработка персональных данных на сайте осуществляется в соответствии с «Политикой обработки персональных данных». Настоящим, продолжая работу на сайте, вы подтверждаете, что ознакомились с Политикой обработки персональных данных НКО АО НРД, даете свое согласие НКО АО НРД на обработку ваших персональных данных в соответствии с условиями указанной политики, а также даете свое согласие на автоматизированную обработку ваших персональных данных (файлы cookie, сведения о действиях, которые вы совершаете на сайте, сведения об используемых для этого устройствах, дата и время сессии), в т.ч. с использованием метрических программ Яндекс.Метрика, путем совершения следующих действий: сбор, запись, систематизация, накопление, хранение, уточнение (обновление, изменение), извлечение, использование, блокирование, удаление, уничтожение, передача (предоставление, доступ) третьим лицам, предоставляющим НКО АО НРД сервис по метрическим программам.
Обработка данных осуществляется в целях улучшения работы сайта, совершенствования продуктов и услуг НКО АО НРД, определения предпочтений пользователя, предоставления целевой информации по продуктам и услугам НКО АО НРД. Настоящее согласие действует с момента его предоставления и в течение всего периода использования сайта.
В случае отказа от обработки данных метрическими программами вы проинформированы о необходимости прекратить использование сайта или отключить файлы cookie в настройках браузера.
Что такое Disaster Recovery: зачем нужно, как использовать, преимущества
Аварийное восстановление (от английского DR, Disaster Recovery) — набор политик и процедур, которые позволяют восстанавливаться после сбоя. Disaster — это катастрофа и ей может быть все, что нарушает нормальную работу IT-инфраструктуры компании, например, стихийное бедствие, отключение электроэнергии или кибератака.
Аварийное восстановление отличается от обычного своими масштабами: оно призвано локализовывать последствия крупных аварий, которые могут нанести серьезный ущерб. Обычные процедуры восстановления предназначены для устранения инцидентов меньшего масштаба (например, сбой одного сервера).
Простыми словами, аварийное восстановление — это процесс, при помощи которого компания может предсказать и локализовать аварии (приложения, сервера, иной IT-инфраструктуры).
Причины востребованности Disaster Recovery
- Растущая частота аномальных климатических явлений.
- Увеличивается зависимость от технологий.
- Постоянный рост изощренности кибератак..
- Необходимость соблюдения нормативных, законодательных актов.
- Усиление требований (регулирование) со стороны государства.
За рубежом стихийные бедствия распространены больше, но и в России ураганы, наводнения представляют определенную опасность для ЦОД, например. Еще большую угрозу несут землетрясения, которые случаются не только в Японии, Индонезии, Северной Америке. Фиксируются они даже в России. В последние годы частота этих и других стихийных бедствий значительно возросла. Это привело к росту спроса на услуги аварийного восстановления.
Компании больше не могут быть оторванными от IT. Диджитализация проникла во все сферы жизнедеятельности человека. Как следствие — малый, средний, крупный бизнес все больше полагаются на технологии. И сбой даже одного сервера или серьезная кибератака могут оказать значительное влияние на бизнес-процессы.
Кстати, о кибератаках: они становятся все более изощренными. Это означает, что бизнес должен быть быть более бдительным в защите своих данных Ведь за компрометацию персональных данных, например, юридическое лицо может сильно пострадать. Ну и в последние годы появляются дополнительные законодательные требования к работе IT-инфраструктуры. Вот почему нормативные акты теперь более строги, некоторые уже сейчас требуют от компаний наличия плана аварийного восстановления (пока что лишь для некоторых отраслей — финансы, медицинские услуги).
Ключевые параметры аварийного восстановления
При выборе решения для аварийного восстановления нужно учитывать разные требования. Вот минимальный набор параметров, которые нужно запомнить:
Целевое время восстановления (от английского Recovery time objective). Это количество времени, необходимое для восстановления критически важных бизнес-функций после сбоя.
Цель точки восстановления (от английского Recovery point objective). Это объем данных, который может быть потерян в результате аварии. Компания должна выбрать решение для аварийного восстановления, отвечающее ее конкретным требованиям по RTO (и RPO).
Стоимость решения. Должно укладываться в соответствующую статью расходов. Цена таких решений может варьироваться от 10 тысяч до миллионов рублей. Конечно, нужно выбирать платформу, которая соответствует бюджету.
Сложность решения. Внедрение чрезмерно сложных систем или инструментов потребует обучения персонала. Но лучше выбрать инструмент, с которым IT-сотрудники смогут справиться изначально.
Масштабируемость решения. В случае, если инфраструктура компании будет расширяться. Необходимо выбрать решение, которое может масштабироваться в соответствии с потребностями бизнеса по мере его роста.
Таким образом, RTO и RPO — два наиболее важных фактора, которые сверхважно учитывать при выборе решения для аварийного восстановления.
Преимущества Disaster Recovery для бизнеса
Наличие плана аварийного восстановления и сопутствующих инструментов важно по трем причинам:
1. Сокращается время простоя. План аварийного восстановления + инструменты Disaster Recovery помогают восстановиться даже в самых сложных сценариях аварии. Деятельность компании, ее бизнес-процессы — под защитой.
2. Уменьшается объем потерянных данных. Даже если какая-то часть их будет безвозвратно утеряна, большая часть — сохранится.
3. Улучшается соответствие техническим требованиям, политикам конфиденциальности и другим регламентам (см. выше).
Disaster Recovery — это своеобразная волшебная таблетка, но настроить ее, уметь пользоваться — также очень важно. Иначе эффекта от нее просто не будет.
Disaster Recovery от CloudMTS
Аварийное восстановление Cloud MTS — полностью управляемый сервис, который защищает все критически важные приложения, данные, иную IT-инфраструктуру от сбоев.
● 5 минут — развертывание инфраструктуры.
● от 15 минут — восстановление ИТ-систем после сбоя.
● 15 ЦОД, в том числе уровня Tier III.
● 99,95% доступность сервиса.
● 24/7 русскоговорящая техподдержка.
Disaster Recovery от CloudMTS обеспечивает непрерывную репликацию данных, в случае сбоя ваши приложения и другие данные можно будет восстановить за считанные секунды.
CloudMTS DR разработан для удовлетворения потребностей предприятий любого размера. Оно масштабируемо, надежно и безопасно. С CloudMTS DR можно быть уверенным даже в нестандартных ситуациях.
Коротко о главном
● Аварийное восстановление (DR) — набор политик и процедур, которые позволяют компании восстанавливаться после аварий, крупных сбоев.
● В качестве аварии может рассматриваться любое событие, если оно нарушает нормальную работу бизнеса (атаки, стихийные бедствия, обесточивание).
● Имея план аварийного восстановления, можно свести к минимуму последствия аварии, вернуть к жизни IT-инфраструктуру быстро, а в наиболее удачном случае — вообще без последствий.
● Планы Disaster Recovery обычно подразумевают не только создание бэкапов, но и перенос резервных копий в отдельное хранилище, регламент настройки, процедуры коммуникации с сотрудниками (и клиентами) во время аварии.
Disaster Recovery в облако: кому нужно и как его обеспечить
Рассказываем, кому стоит позаботиться об аварийном восстановлении инфраструктуры и какими способами можно реализовать DR.
Эта инструкция — часть курса «Начинаем работу с VMware».
Смотреть весь курс

Рассказываем, кому стоит позаботиться об аварийном восстановлении инфраструктуры и какими способами можно реализовать DR.
Что такое Disaster Recovery
Disaster Recovery, или аварийное восстановление, — это комплекс инструментов, обеспечивающих быстрое восстановление инфраструктуры, данных, работы всех систем в случае критических сбоев.
Причины сбоев могут быть как рядовыми — отключение электричества в районе размещения оборудования и проблемы с сетью, так и чрезвычайными. Например, DR готовит сервис к землетрясениям, пожарам, наводнениям. Любым событиям, которые серьезно навредят дата-центру с инфраструктурой компании, вплоть до полного уничтожения.
По сути, Disaster Recovery подразумевает резервную площадку для восстановления полного «клона» или части инфраструктуры компании. Чтобы отвечать требованиям DR, площадка должна:
→ быть географически удалена от основной (в таком случае ЧС, произошедшая в первом дата-центре, не затронет второй),
→ иметь хорошую сетевую связность с местом размещения инфраструктуры (чем выше пропускная способность канала, тем быстрее данные будут «добираться» до резервной площадки).
Способы организации DR
Disaster Recovery — концепция, которую можно реализовать разными способами.
Сделать самостоятельно на своей инфраструктуре (on-premises)
В таком случае не избежать капитальных затрат (всю инфраструктуру нужно будет умножать на два) и простаивания закупленного оборудования. Также Disaster Recovery собственными силами — это сложный проект, требующий серьезных компетенций сотрудников. Поэтому к CAPEX добавим еще и потребность в высококвалифицированных DevOps-, NetOps-специалистах и архитекторах инфраструктуры.
Построить Disaster Recovery на арендованных физических серверах
Сделать это можно за счет полного дубля инфраструктуры в концепции георепликации (размещения в другой географической точке). Такая реализация, впрочем, лишена гибкости — организация DR, как и внесение изменений в инфраструктуру, займет больше времени. Гибкости нет и в оплате резервной инфраструктуры — аренда минимум на месяц.
Развернуть Disaster Recovery в облако
На данный момент это наиболее оптимальный и распространенный сценарий в практике компаний. Облачную инфраструктуру легче создавать и масштабировать. Если компания использует Terraform или иные инструменты IaC-подхода, развернуть резервную площадку можно за несколько минут.
Также очевидным преимуществом является модель оплаты pay-as-you-go — оплата за потребленные ресурсы, которую поддерживают облака. Если компании не нужна активная репликация инфраструктуры 24/7/365, она может экономить на ресурсах.
Disaster Recovery as a service
В качестве альтернативы самостоятельному созданию резервной площадки в облаке можно рассмотреть готовый сервис по DR. Помимо перехода на OPEX-модель, он облегчит такие задачи, как поиск и — самое главное — настройка инфраструктуры в концепции Disaster Recovery. Также клиент, как правило, получает дополнительные «плюшки» в виде консультации экспертов и SLA. У Selectel в этом списке также защита от DDoS-атак и соответствие 152-ФЗ.
Аварийное восстановление в облако
Пользуйтесь вычислительными ресурсами в облаке на базе VMware в Selectel в случае аварии на вашей основной площадке.
Характеристики Disaster Recovery
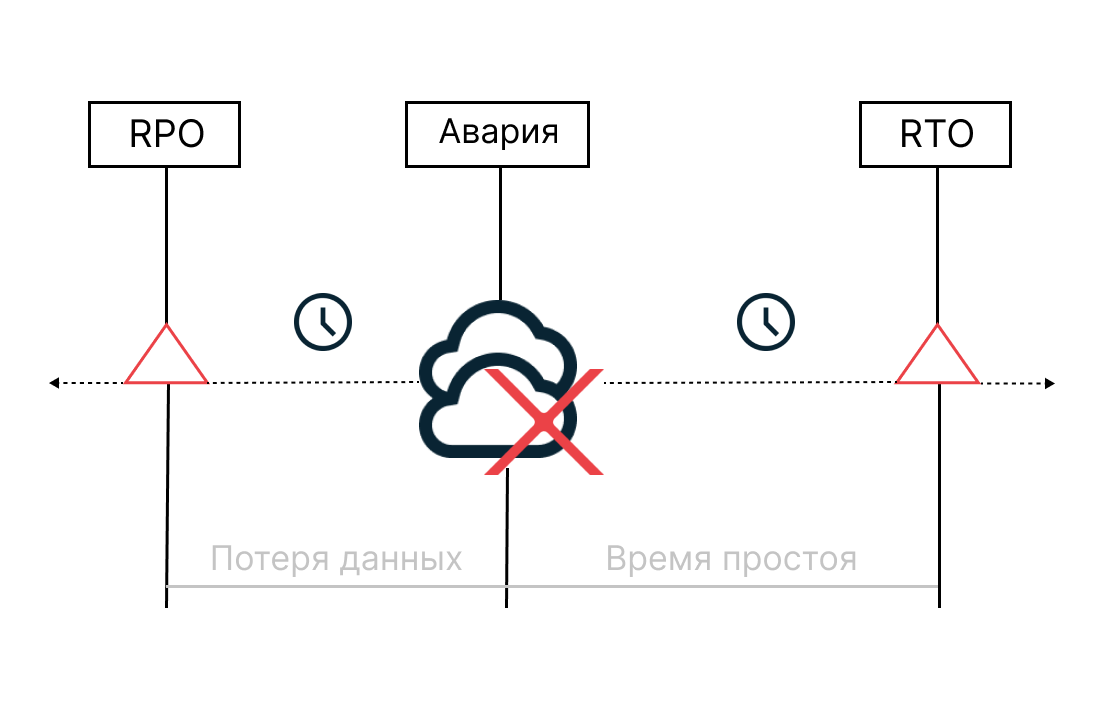
Основные характеристики, своеобразные метрики аварийного восстановления — это RPO (Recovery Point Objective) и RTO (Recovery Time Objective). В зависимости от их значений компания выбирает техническое решение, которое будет в основе Disaster Recovery.
RTO
Определяет максимальное время простоя, которое может позволить себе бизнес. Чем меньше этот показатель, тем незаметнее для конечного пользователя пройдет переключение на резервную площадку. Допустим, RTO установлен на 15 минут. В таком случае сервис начнет работать в штатном режиме не позже этого времени. В идеале — раньше.
Чем меньше RTO, тем больше это будет стоить бизнесу. Поскольку в реализации будут использовать более технологичные (и дорогие) решения, а резервную инфраструктуру нужно будет держать в состоянии active-active.
RPO
Определяет максимальный объем данных, который может позволить себе потерять компания в случае аварии и простоя. Чем меньше устанавливается показатель, тем чаще компания делает резервное копирование. Так, если RPO составляет 1 минуту, значит, резервная копия будет создаваться каждую минуту.
Все это также влияет на стоимость решения. Поэтому нет «золотых стандартов» RPO и RTO — каждая компания определяет эти показатели индивидуально. Обычно это консенсус между тем, что потеряет компания из-за простоя, и тем, что она потратит на достижение нужных метрик RPO и RTO.
Есть компании — например, крупные банки, чьи потенциальные репутационные и финансовые издержки в случае даунтайма всегда покроют затраты на организацию Disaster Recovery на высшем уровне. А есть бизнес, которому выгоднее «полежать», чем увеличивать чек за инфраструктуру.
Определение показателей RTO и RPO – это часть плана аварийного восстановления IT-систем (Disaster Recovery Plan, DRP). В идеале такой план должен быть у любой компании — вне зависимости от масштаба и специфики бизнеса. О нем мы еще напишем подробнее.
Всем ли нужен Disaster Recovery?
Аварийное восстановление нужно не всем. Оно необходимо компаниям, где репутационные и финансовые потери при простое сервисов недопустимы. Рассмотрим несколько примеров.
Крупный банк
На основной площадке случилась авария — клиенты не могут зайти в мобильное приложение и личные кабинеты. Сервис недоступен 30 минут: физлица не могут оплачивать покупки и переводить деньги близким, юрлица не могут совершать необходимые транзакции. При восстановлении системы оказалось, что данные о транзакциях за последний час потерян. Менеджеры хватаются за головы — клиенты уходят в другой банк.
Служба доставки еды
В районе ЦОД, где расположена инфраструктура сервиса, случился шатдаун. Пользователи не могут заказать продукты домой (допустим, сервис неудачно выбрал провайдера без ИБП и ДГУ). За час, ушедший на восстановление систем, несколько сотен клиентов не смогли выполнить свои заказы — финансовые убытки оцениваются в несколько сотен тысяч. Половина этих клиентов заказали доставку у конкурентов. Добила ситуацию потеря части данных о заказах клиентов — несколько десятков людей ждали свою пиццу в течение 4 часов. Еще один денежный транш ушел на сохранение лояльности клиентов.
В обоих случаях затраты на Disaster Recovery окупятся с лихвой. Компаниям, которым отзываются описанные кейсы, стоит задуматься о DR. В остальных случаях будет достаточно бэкапов. В отличие от аварийного восстановления резервные копии — безусловный мастхэв для компаний любого размера.
Чем отличаются бэкапы от Disaster Recovery?
В случае бэкапов вы делаете резервную копию данных. Если случается локальная авария, систему можно будет развернуть из бэкапа на новой инфраструктуре. В облаке это можно сделать достаточно быстро, если у вас один-два сервера. Если речь о восстановлении всей инфраструктуры — конфигураций серверов, сетевой обвязки, БД и т.д., восстановление займет непозволительные часы. Резервное копирование данных — обязательная часть Disaster Recovery, но это лишь часть.
Гайд по репликации инфраструктуры в облако
Итак, вы задумались об организации аварийного восстановления. С чего начать?
- Определите, какие проекты или сервисы нужно «продублировать» в облако. Клонировать инфраструктуру полностью не обязательно. Так, тестовое окружение или внутренние сервисы, некритичные для бизнеса, можно исключить из этого списка.
- Выберите провайдера. При выборе отталкивайтесь от того, где расположены дата-центры, на какие ресурсы в облаке вы можете рассчитывать, какая пропускная способность каналов связи и производительность инфраструктуры. Нелишним будет уточнить, есть ли тестовый период решений, сравнить цены на рынке, выяснить, подписывает ли провайдер соглашение об уровне услуг (SLA) с клиентом.
- Выберите техническое решение. Как правило, провайдер предлагает несколько решений по организации Disaster Recovery с разными значениями RTO и RPO. Ознакомьтесь со всеми и выберите наиболее подходящее. Если сомневаетесь в выборе, хороший провайдер всегда подскажет решение.
- Сформируйте план аварийного восстановления (DRP), если у вас его еще нет. Базово в нем должен быть прописан алгоритм действий в случае аварии: кому звонить, кого подключать, как распределяется ответственность за восстановление систем. Главная задача плана — исключить паническое накопление ошибок и неправильных действий в случае ЧС. В крупных компаниях в DRP прописывают даже порядок коммуникации со СМИ, чтобы отработать потенциальные риски.
- Преднастройте сетевую инфраструктуру, NAT, межсетевые экраны. Инфраструктура — это не только набор серверов. Если вы быстро восстановили сервер БД, но при этом не связали его с веб-сервером, полноценно приложение работать не будет. Настройка сети требует много времени, поэтому откладывает ее на последний момент не стоит. К слову, часто в готовых DR-сервисах это можно настроить в интерфейсе.
- Настройте техническое решение и DR для сервисов. Вне зависимости от выбранного решения (если это, конечно, не полная настройка DR под ключ) систему придется настраивать. Так, например, если вы выбрали Cloud Director Availability, нужно будет обеспечить управление инфраструктурой через плагин vSphere или Cloud Director. Опасаться этого пункта, впрочем, не нужно: если вы выбрали правильного провайдера, подробные инструкции по настройке вы найдете в его базе знаний.
- Протестируйте работоспособность системы. Просто настроить и забыть — не вариант. Настроенный Disaster Recovery нужно протестировать, то есть искусственно устроить отказ инфраструктуры на основной площадке и реализовать тот самый план Б. Это ваш шанс найти слабые места в DRP и засечь время восстановления. Действительно ли оно соответствует желаемым метрикам RPO и RTO? В Selectel протестировать настроенную систему для решения можно бесплатно.
- Установите периодичность тестирования DR. Рекомендуется повторять предыдущий пункт гайда хотя бы раз в два месяца, чтобы удостовериться в корректности восстановления в облако.
Технические решения для DR
Существует несколько технических решений, которые позволяют организовать аварийное восстановление в облако. Наиболее распространенные реализуются через Cloud Director Availability и Veeam Cloud Connect Replication (в связке с Veeam Backup & Replication). Эти решения предлагает и Selectel.
Cloud Director Availability
Это решение может быть использовано как для безопасной миграции в облако, так и для аварийного восстановления нагрузок между облаками VMware в облаке Selectel или из частного облака клиента.
Особенности
- минимальный RPO – 5 минут,
- можно управлять и основной инфраструктурой, и репликациями в единой панели управления Cloud Director,
- при настройке сетей не нужно открывать дополнительные порты (достаточно порта TCP 443),
- есть подробная документация по настройке и видеодемонстрация настройки.
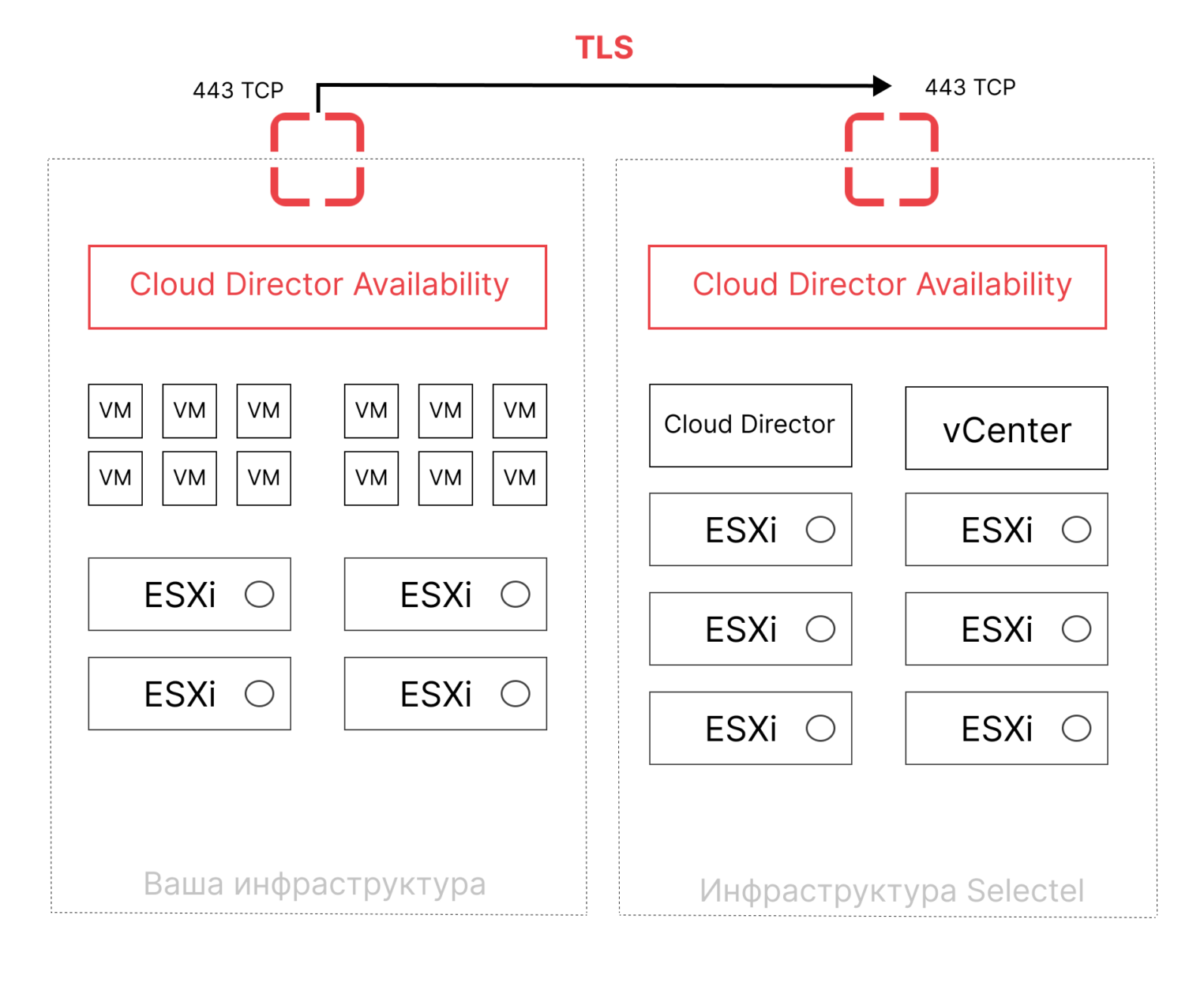
Кому подойдет
Решение более простое в настройке и не требует серьезной экспертизы. В среднем, развертывание системы занимает около 15 минут, но клиент должен иметь инфраструктуру в облаке VMware. Это может быть частное облако на собственной инфраструктуре, частное облако у другого провайдера, частное облако в Selectel. Подойдет компаниям, которые не хотят переплачивать за дополнительные лицензии.
Veeam Cloud Connect
Этот облачный репозиторий не только позволяет хранить бэкапы в облаке, но и восстанавливать данные в облако в случае критических сбоев.
Особенности
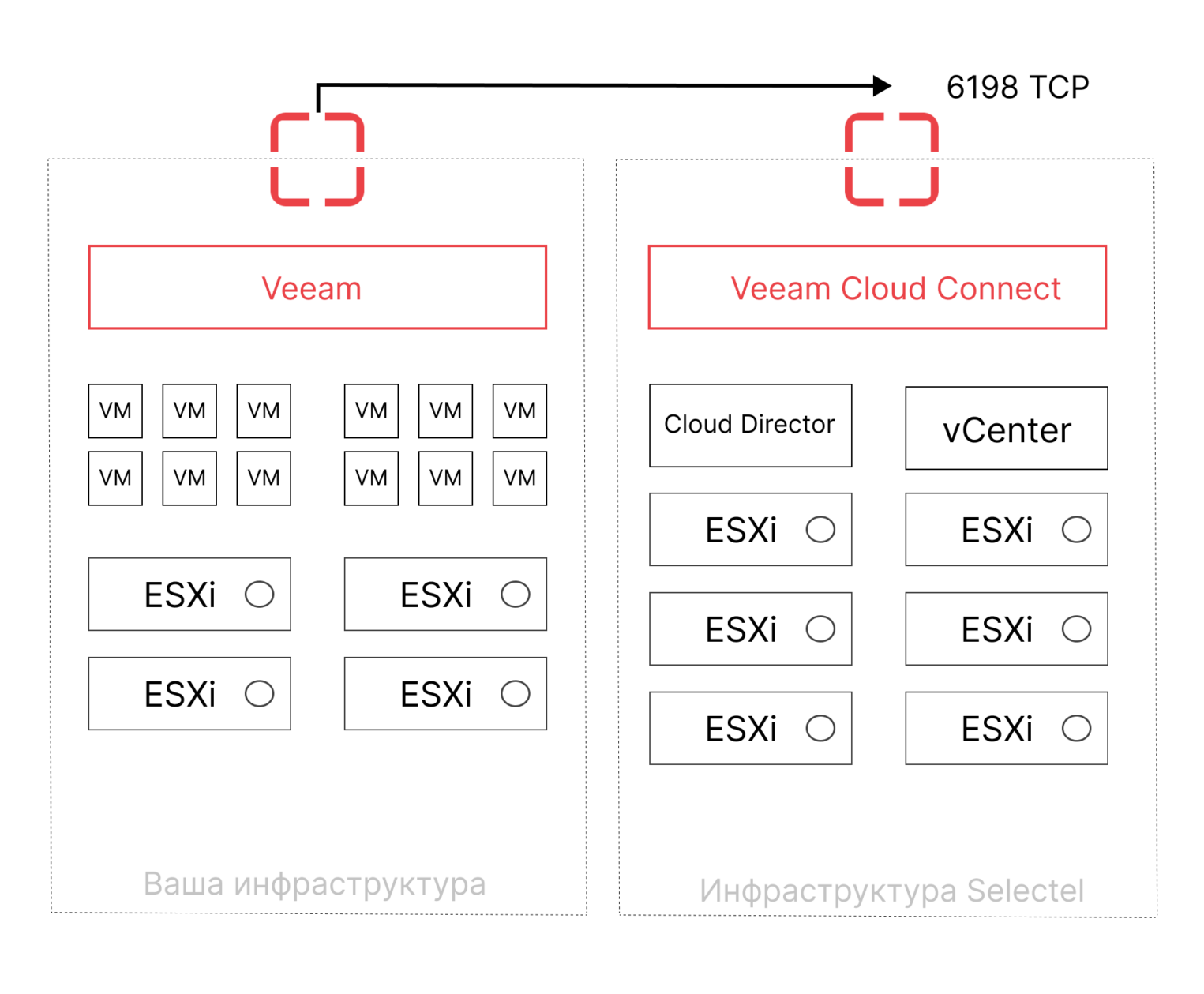
- минимальный PRO – 1 минута,
- необходимо иметь Veeam Backup & Replication (бесплатный Community Edition не подойдет, минимум — версия Standard, для сжатия трафика — Enterprise),
- тестировать настроенную систему придется вручную, автоматическое тестирование не поддерживается.
Кому подойдет
Решение больше подходит компаниям, которые уже использует платное ПО от Veeam в работе.
Если у вас остались вопросы по реализации Disaster Recovery для своего бизнеса, пишите на sales@selectel.ru.
Инструменты Veeam для резервного копирования — в чем разница?
Знакомство с публичным облаком на базе VMware в Selectel
Зарегистрируйтесь в панели управления
И уже через пару минут сможете арендовать сервер, развернуть базы данных или обеспечить быструю доставку контента.