Получение данных с сервера
Другой очень распространённой задачей в современных веб-сайтах и приложениях является получение отдельных элементов данных с сервера для обновления разделов веб-страницы без необходимости загрузки всей новой страницы. Эта, казалось бы, небольшая деталь оказала огромное влияние на производительность и поведение сайтов, поэтому в этой статье мы объясним концепцию и рассмотрим технологии, которые делают это возможным, например XMLHttpRequest и API Fetch.
| Необходимые условия: | Основы JavaScript (см. первые шаги, структурные элементы, объекты JavaScript), основы клиентских API |
|---|---|
| Задача: | Узнать, как извлекать данные с сервера и использовать их для обновления содержимого веб-страницы. |
В чем проблема?
Первоначальная загрузка страницы в Интернете была простой — вы отправляли запрос на сервер web-сайта, и если всё работает, как и должно, то вся необходимая информация о странице будет загружена и отображена на вашем компьютере.

Проблема с этой моделью заключается в том, что всякий раз, когда вы хотите обновить любую часть страницы, например, чтобы отобразить новый набор продуктов или загрузить новую страницу, вам нужно снова загрузить всю страницу. Это очень расточительно и приводит к плохому пользовательскому опыту, особенно по мере того, как страницы становятся все более сложными.
Появление Ajax
Это привело к созданию технологий, позволяющих веб-страницам запрашивать небольшие фрагменты данных (например, HTML, XML, JSON или обычный текст) и отображать их только при необходимости, помогая решать проблему, описанную выше.
Это достигается с помощью таких API, как XMLHttpRequest или — более новой — Fetch API. Эти технологии позволяют веб-страницам напрямую обрабатывать запросы HTTP для определённых ресурсов, доступных на сервере, и форматировать результирующие данные по мере необходимости перед их отображением.
Примечание: Вначале эта общая техника была известна как Асинхронный JavaScript и XML (Ajax), поскольку она, как правило, использовала XMLHttpRequest для запроса данных XML. В наши дни это обычно не так (вы, скорее всего, будете использовать XMLHttpRequest или Fetch для запроса JSON), но результат все тот же, и термин «Ajax» по-прежнему часто используется для описания этой техники.
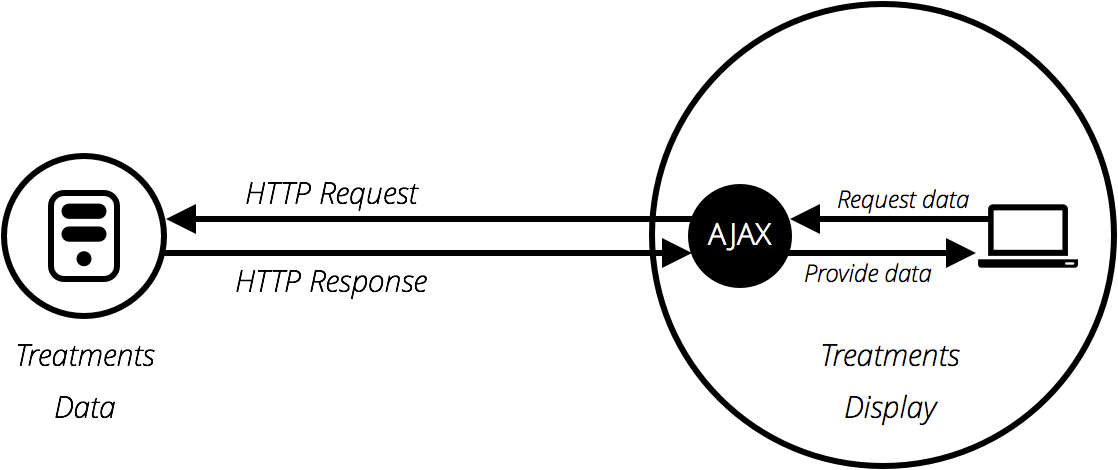
Модель Ajax предполагает использование веб-API в качестве прокси для более разумного запроса данных, а не просто для того, чтобы браузер перезагружал всю страницу. Давайте подумаем о значении этого:
- Перейдите на один из ваших любимых сайтов, богатых информацией, таких как Amazon, YouTube, CNN и т.д., и загрузите его.
- Теперь найдите что-нибудь, например, новый продукт. Основной контент изменится, но большая часть информации, подобной заголовку, нижнему колонтитулу, навигационному меню и т. д., останется неизменной.
Это действительно хорошо, потому что:
- Обновления страницы намного быстрее, и вам не нужно ждать перезагрузки страницы, а это означает, что сайт работает быстрее и воспринимается более отзывчивым.
- Меньше данных загружается при каждом обновлении, что означает меньшее потребление пропускной способности. Это не может быть такой большой проблемой на рабочем столе в широкополосном подключении, но это серьёзная проблема на мобильных устройствах и в развивающихся странах, которые не имеют повсеместного быстрого интернет-сервиса.
Чтобы ускорить работу, некоторые сайты также сохраняют необходимые файлы и данные на компьютере пользователя при первом обращении к сайту, а это означает, что при последующих посещениях они используют локальные версии вместо загрузки свежих копий, как при первой загрузке страницы. Содержимое загружается с сервера только при его обновлении.
Основной запрос Ajax
Давайте посмотрим, как обрабатывается такой запрос, используя как XMLHttpRequest , так и Fetch. В этих примерах мы будем запрашивать данные из нескольких текстовых файлов и использовать их для заполнения области содержимого.
Этот набор файлов будет действовать как наша поддельная база данных; в реальном приложении мы с большей вероятностью будем использовать серверный язык, такой как PHP, Python или Node, чтобы запрашивать наши данные из базы данных. Здесь, однако, мы хотим сохранить его простым и сосредоточиться на стороне клиента.
XMLHttpRequest
XMLHttpRequest (который часто сокращается до XHR) является довольно старой технологией сейчас — он был изобретён Microsoft в конце 1990-х годов и уже довольно долго стандартизирован в браузерах.
- Чтобы начать этот пример, создайте локальную копию ajax-start.html и четырёх текстовых файлов — verse1.txt, verse2.txt, verse3.txt и verse4.txt — в новом каталоге на вашем компьютере. В этом примере мы загрузим другое стихотворение (который вы вполне можете распознать) через XHR, когда он будет выбран в выпадающем меню.
- Внутри элемента добавьте следующий код. В нем хранится ссылка на элементы и в переменных и определяется onchange обработчика событий, так что, когда значение select изменяется, его значение передаётся вызываемой функции updateDisplay() в качестве параметра.
var verseChoose = document.querySelector("select"); var poemDisplay = document.querySelector("pre"); verseChoose.onchange = function () var verse = verseChoose.value; updateDisplay(verse); >;
function updateDisplay(verse) >
= verse.replace(" ", ""); verse = verse.toLowerCase(); var url = verse + ".txt";
var request = new XMLHttpRequest();
.open("GET", url);
.responseType = "text";
.onload = function () poemDisplay.textContent = request.response; >;
.send();
updateDisplay("Verse 1"); verseChoose.value = "Verse 1";
Обслуживание вашего примера с сервера
Некоторые браузеры (включая Chrome) не будут запускать запросы XHR, если вы просто запускаете пример из локального файла. Это связано с ограничениями безопасности (для получения дополнительной информации о безопасности в Интернете, ознакомьтесь с Website security).
Чтобы обойти это, нам нужно протестировать пример, запустив его через локальный веб-сервер. Чтобы узнать, как это сделать, прочитайте Как настроить локальный тестовый сервер?
Fetch
API-интерфейс Fetch — это, в основном, современная замена XHR — недавно он был представлен в браузерах для упрощения асинхронных HTTP-запросов в JavaScript, как для разработчиков, так и для других API, которые строятся поверх Fetch.
Давайте преобразуем последний пример, чтобы использовать Fetch!
- Сделайте копию своего предыдущего готового каталога примеров. (Если вы не работали над предыдущим упражнением, создайте новый каталог и внутри него создайте копии xhr-basic.html и четырёх текстовых файлов — verse1.txt, verse2.txt, verse3.txt и verse4.txt.)
- Внутри функции updateDisplay() найдите код XHR:
var request = new XMLHttpRequest(); request.open("GET", url); request.responseType = "text"; request.onload = function () poemDisplay.textContent = request.response; >; request.send();
fetch(url).then(function (response) response.text().then(function (text) poemDisplay.textContent = text; >); >);
Итак, что происходит в коде Fetch?
Прежде всего, мы вызываем метод fetch() , передавая ему URL-адрес ресурса, который мы хотим получить. Это современный эквивалент request.open() в XHR, плюс вам не нужен эквивалент .send() .
После этого вы можете увидеть метод .then() , прикреплённый в конец fetch() — этот метод является частью Promises — современная функция JavaScript для выполнения асинхронных операций. fetch() возвращает промис, который разрешает ответ, отправленный обратно с сервера, — мы используем .then() для запуска некоторого последующего кода после того, как промис будет разрешено, что является функцией, которую мы определили внутри неё. Это эквивалент обработчика события onload в XHR-версии.
Эта функция автоматически передаёт ответ от сервера в качестве параметра, когда обещает fetch() . Внутри функции мы берём ответ и запускаем его метод text() (en-US), который в основном возвращает ответ как необработанный текст. Это эквивалент request.responseType = ‘text’ в версии XHR.
Вы увидите, что text() также возвращает промис, поэтому мы привязываем к нему другой .then() , внутри которого мы определяем функцию для получения необработанного текста, который выполняет text() .
Внутри функции внутреннего промиса мы делаем то же самое, что и в версии XHR, — устанавливаем текстовое содержимое в текстовое значение.
Помимо промисов
Промисы немного запутывают первый раз, когда вы их встречаете, но не беспокойтесь об этом слишком долго. Через некоторое время вы привыкнете к ним, особенно, когда вы узнаете больше о современных JavaScript-API. Большинство из них в большей степени основаны на промисах.
Давайте посмотрим на структуру промисов сверху, чтобы увидеть, можем ли мы ещё немного понять это:
fetch(url).then(function (response) response.text().then(function (text) poemDisplay.textContent = text; >); >);
В первой строке говорится: «Получить ресурс, расположенный по адресу url» (fetch(url) ) и «затем запустить указанную функцию, когда промис будет разрешено» ( .then(function() < . >) ). «Resolve» означает «завершить выполнение указанной операции в какой-то момент в будущем». Указанная операция в этом случае заключается в извлечении ресурса с указанного URL (с использованием HTTP-запроса) и возврата ответа для нас, чтобы что-то сделать.
Фактически, функция, переданная в then() , представляет собой кусок кода, который не запускается немедленно — вместо этого он будет работать в какой-то момент в будущем, когда ответ будет возвращён. Обратите внимание, что вы также можете сохранить своё промис в переменной и цепочку .then() вместо этого. Ниже код будет делать то же самое:
var myFetch = fetch(url); myFetch.then(function (response) response.text().then(function (text) poemDisplay.textContent = text; >); >);
Поскольку метод fetch() возвращает промис, который разрешает HTTP-ответ, любая функция, которую вы определяете внутри .then() , прикованная к концу, будет автоматически передаваться как параметр. Вы можете вызвать параметр, который вам нравится — приведённый ниже пример будет работать:
fetch(url).then(function (dogBiscuits) dogBiscuits.text().then(function (text) poemDisplay.textContent = text; >); >);
Но имеет смысл называть параметр тем, что описывает его содержимое!
Теперь давайте сосредоточимся только на функции:
function(response) response.text().then(function(text) poemDisplay.textContent = text; >); >
Объект ответа имеет метод text() (en-US), который берёт необработанные данные, содержащиеся в теле ответа, и превращает его в обычный текст, который является форматом, который мы хотим в нем А также возвращает промис (который разрешает полученную текстовую строку), поэтому здесь мы используем другой .then() , внутри которого мы определяем другую функцию, которая диктует что мы хотим сделать с этой текстовой строкой. Мы просто устанавливаем свойство textContent элемента нашего стихотворения равным текстовой строке, так что это получается довольно просто.
Также стоит отметить, что вы можете напрямую связывать несколько блоков промисов ( .then() , но есть и другие типы) на конце друг друга, передавая результат каждого блока следующему блоку по мере продвижения по цепочке , Это делает промисы очень мощными.
Следующий блок делает то же самое, что и наш оригинальный пример, но написан в другом стиле:
fetch(url) .then(function (response) return response.text(); >) .then(function (text) poemDisplay.textContent = text; >);
Многие разработчики любят этот стиль больше, поскольку он более плоский и, возможно, легче читать для более длинных цепочек промисов — каждое последующее промис приходит после предыдущего, а не внутри предыдущего (что может стать громоздким). Единственное отличие состоит в том, что мы должны были включить оператор return перед response.text() , чтобы заставить его передать результат в следующую ссылку в цепочке.
Какой механизм следует использовать?
Это действительно зависит от того, над каким проектом вы работаете. XHR существует уже давно и имеет отличную кросс-браузерную поддержку. Fetch and Promises, с другой стороны, являются более поздним дополнением к веб-платформе, хотя они хорошо поддерживаются в браузере, за исключением Internet Explorer и Safari (которые на момент написания Fetch были доступны в своём предварительный просмотр технологии).
Если вам необходимо поддерживать старые браузеры, тогда может быть предпочтительным решение XHR. Если, однако, вы работаете над более прогрессивным проектом и не так обеспокоены старыми браузерами, то Fetch может быть хорошим выбором.
Вам действительно нужно учиться — Fetch станет более популярным, так как Internet Explorer отказывается от использования (IE больше не разрабатывается, в пользу нового браузера Microsoft Edge), но вам может понадобиться XHR ещё некоторое время.
Более сложный пример
Чтобы завершить статью, мы рассмотрим несколько более сложный пример, который показывает более интересные применения Fetch. Мы создали образец сайта под названием The Can Store — это вымышленный супермаркет, который продаёт только консервы. Вы можете найти этот пример в прямом эфире на GitHub и посмотреть исходный код.
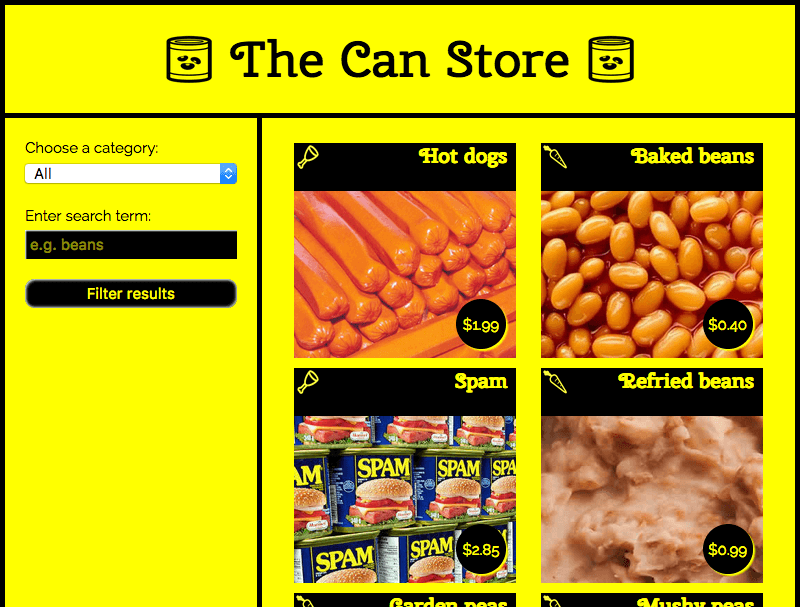
По умолчанию на сайте отображаются все продукты, но вы можете использовать элементы управления формы в столбце слева, чтобы отфильтровать их по категориям, поисковому запросу или и тому и другому.
Существует довольно много сложного кода, который включает фильтрацию продуктов по категориям и поисковым запросам, манипулирование строками, чтобы данные отображались правильно в пользовательском интерфейсе и т.д. Мы не будем обсуждать все это в статье, но вы можете найти обширные комментарии в коде (см. can-script.js).
Однако мы объясним код Fetch.
Первый блок, который использует Fetch, можно найти в начале JavaScript:
fetch("products.json").then(function (response) if (response.ok) response.json().then(function (json) products = json; initialize(); >); > else console.log( "Network request for products.json failed with response " + response.status + ": " + response.statusText, ); > >);
Это похоже на то, что мы видели раньше, за исключением того, что второй промис находится в условном выражении. В этом случае мы проверяем, был ли возвращённый ответ успешным — свойство response.ok (en-US) содержит логическое значение, которое true , если ответ был в порядке (например, 200 meaning «OK») или false , если он не увенчался успехом.
Если ответ был успешным, мы выполняем второй промис — на этот раз мы используем json() (en-US), а не text() (en-US), так как мы хотим вернуть наш ответ как структурированные данные JSON, а не обычный текст.
Если ответ не увенчался успехом, мы выводим сообщение об ошибке в консоль, в котором сообщается о сбое сетевого запроса, который сообщает о статусе сети и описательном сообщении ответа (содержащемся в response.status (en-US) и response.statusText (en-US), соответственно). Конечно, полный веб-сайт будет обрабатывать эту ошибку более грациозно, отображая сообщение на экране пользователя и, возможно, предлагая варианты для исправления ситуации.
Вы можете проверить сам случай отказа:
- Создание локальной копии файлов примеров (загрузка и распаковка the can-store ZIP file)
- Запустите код через веб-сервер (как описано выше, в Serving your example from a server)
- Измените путь к извлечённому файлу, например, «product.json» (т.е. убедитесь, что он написан неправильно)
- Теперь загрузите индексный файл в свой браузер (например, через localhost:8000 ) и посмотрите в консоли разработчика браузера. Вы увидите сообщение в строке «Запрос сети для продуктов.json не удалось с ответом 404: Файл не найден»
Второй блок Fetch можно найти внутри функции fetchBlob() :
fetch(url).then(function (response) if (response.ok) response.blob().then(function (blob) objectURL = URL.createObjectURL(blob); showProduct(objectURL, product); >); > else console.log( 'Network request for "' + product.name + '" image failed with response ' + response.status + ": " + response.statusText, ); > >);
Это работает во многом так же, как и предыдущий, за исключением того, что вместо использования json() (en-US) мы используем blob() (en-US) — в этом случае мы хотим вернуть наш ответ в виде файла изображения, а формат данных, который мы используем для этого — Blob — этот термин является аббревиатурой от« Binary Large Object »и может в основном использоваться для представляют собой большие файловые объекты, такие как изображения или видеофайлы.
После того как мы успешно получили наш blob, мы создаём URL-адрес объекта, используя createObjectURL() . Это возвращает временный внутренний URL-адрес, указывающий на объект, указанный в браузере. Они не очень читаемы, но вы можете видеть, как выглядит, открывая приложение Can Store, Ctrl-/щёлкнуть правой кнопкой мыши по изображению и выбрать опцию «Просмотр изображения» (которая может немного отличаться в зависимости от того, какой браузер вы ). URL-адрес объекта будет отображаться внутри адресной строки и должен выглядеть примерно так:
blob:http://localhost:7800/9b75250e-5279-e249-884f-d03eb1fd84f4
Вызов: XHR версия the Can Store
Мы хотели бы, чтобы вы решили преобразовать версию приложения Fetch для использования XHR в качестве полезной части практики. Возьмите копию ZIP файла и попробуйте изменить JavaScript, если это необходимо.
Некоторые полезные советы:
- Вы можете найти полезный справочный материал XMLHttpRequest .
- Вам в основном нужно использовать тот же шаблон, что и раньше, в примере XHR-basic.html.
- Однако вам нужно будет добавить обработку ошибок, которые мы показали вам в версии Fetch Can Store:
- Ответ найден в request.response после того, как событие load запущено, а не в промисе then() .
- О наилучшем эквиваленте Fetch’s response.ok в XHR следует проверить, является ли request.status равным 200 или если request.readyState равно 4.
- Свойства для получения статуса и сообщения состояния одинаковы, но они находятся на объекте request (XHR), а не в объекте response .
Примечание: Если у вас есть проблемы с этим, не стесняйтесь сравнить свой код с готовой версией на GitHub (см. исходник здесь, а также см. это в действии).
Резюме
Это завершает нашу статью по извлечению данных с сервера. К этому моменту вы должны иметь представление о том, как начать работать как с XHR, так и с Fetch.
Смотрите также
Однако в этой статье обсуждается много разных тем, которые только поцарапали поверхность. Для получения более подробной информации по этим темам, попробуйте следующие статьи:
- Введение в Ajax (en-US)
- Применение Fetch
- Promises
- Работа с JSON данными
- Обзор HTTP
- Программирование веб-сайта на стороне сервера
- Назад
- Обзор: Client-side web APIs
- Далее
Found a content problem with this page?
- Edit the page on GitHub.
- Report the content issue.
- View the source on GitHub.
This page was last modified on 2 дек. 2023 г. by MDN contributors.
Your blueprint for a better internet.
Как получить данные с сервера на чистом js?
Дело в том что данные XMLHttpRequest можно будет получить в onload методе. В вашем случае вы отправляете запрос и тут же хотите ответ это не php а JavaScript он хоть и однопоточный но все же асинхронный. Хотите синхронно то поставьте 3 параметр в open false.
request.open(«POST», url, false);
Отслеживать
ответ дан 7 июл 2020 в 19:29
Aziz Umarov Aziz Umarov
22.5k 2 2 золотых знака 10 10 серебряных знаков 33 33 бронзовых знака
Спасибо, помогло
7 июл 2020 в 20:05
Рад помочь. Изучайте дальше
7 июл 2020 в 20:19Не буду минусовать, но это плохое решение, т.к. «подвесит» весь скрипт. ТС лично оно подходит, но в нормальных системах его не нужно использовать. Хорошее решение — у @MoloF ru.stackoverflow.com/a/1150225/287469
8 июл 2020 в 9:30
Речь идёт не о хорошем решении. А о ситуации. По сути надо обрабатывать onload чтобы невешать скрипт я это написал
Использование JavaScript Fetch API для получения данных

Было время, когда для запросов API использовался XMLHttpRequest . В нем не было промисов, и он не позволял создавать чистый код JavaScript. В jQuery мы использовали более чистый синтаксис с jQuery.ajax() .
Сейчас JavaScript имеется собственный встроенный способ отправки запросов API. Это Fetch API, новый стандарт создания серверных запросов с промисами, также включающий много других возможностей.
В этом учебном модуле мы создадим запросы GET и POST, используя Fetch API.
Предварительные требования
Для этого обучающего модуля вам потребуется следующее:
- Последняя версия Node, установленная на вашем компьютере. Чтобы установить Node в macOS, выполните указания учебного модуля Установка Node.js и создание локальной среды разработки в macOS.
- Базовое понимание принципов программирования в JavaScript, о которых можно узнать более подробно в серии Программирование на JavaScript.
- Понимание понятия промисов в JavaScript. Прочитайте раздел «Промисы» этой статьи, чтобы узнать больше о циклах событий, обратных вызовах, промисах и асинхронном/ожидающем в JavaScript.
Шаг 1 — Введение в синтаксис Fetch API
Чтобы использовать Fetch API, вызовите метод fetch , который принимает URL API в качестве параметра:
fetch(url)После метода fetch() нужно включить метод промиса then() :
.then(function() >)Метод fetch() возвращает промис. Если возвращается промис resolve , будет выполнена функция метода then() . Эта функция содержит код для обработки данных, получаемых от API.
Под методом then() следует включить метод catch() :
.catch(function() >);API, вызываемый с помощью метода fetch() , может не работать или на нем могут возникнуть ошибки. Если это произойдет, будет возвращен промис reject . Метод catch используется для обработки reject . Код метода catch() выполняется в случае возникновения ошибки при вызове выбранного API.
В целом, использование Fetch API выглядит следующим образом:
fetch(url) .then(function() >) .catch(function() >);Теперь мы понимаем синтаксис использования Fetch API и можем переходить к использованию fetch() с реальным API.
Шаг 2 — Использование Fetch для получения данных от API
Следующие примеры кода основаны на Random User API. Используя API, вы получаете десять пользователей и выводите их на странице, используя Vanilla JavaScript.
Идея заключается в том, чтобы получить все данные от Random User API и вывести их в элементах списка внутри списка автора. Для начала следует создать файл HTML и добавить в него заголовок и неупорядоченный список с идентификатором authors :
h1>Authorsh1> ul id="authors">ul>Теперь добавьте теги script в конец файла HTML и используйте селектор DOM для получения ul . Используйте getElementById с аргументом authors . Помните, что authors — это идентификатор ранее созданного ul :
script> const ul = document.getElementById('authors'); script>Создайте постоянную переменную url , в которой будет храниться URL-адрес API, который вернет десять случайных пользователей:
const url = 'https://randomuser.me/api/?results=10';Теперь у нас есть ul и url , и мы можем создать функции, которые будут использоваться для создания элементов списка. Создайте функцию под названием createNode , принимающую параметр с именем element :
function createNode(element) >Впоследствии, при вызове createNode , вам нужно будет передать имя создаваемого элемента HTML.
Добавьте в функцию выражение return , возвращающее element , с помощью document.createElement() :
function createNode(element) return document.createElement(element); >Также вам нужно будет создать функцию с именем append , которая принимает два параметра: parent и el :
function append(parent, el) >Эта функция будет добавлять el к parent , используя document.createElement :
function append(parent, el) return parent.appendChild(el); >Теперь и createNode , и append готовы к использованию. Используя Fetch API, вызовите Random User API, добавив к fetch() аргумент url :
fetch(url)fetch(url) .then(function(data) >) >) .catch(function(error) >);В вышеуказанном коде вы вызываете Fetch API и передаете URL в Random User API. После этого поступает ответ. Однако ответ вы получите не в формате JSON, а в виде объекта с серией методов, которые можно использовать в зависимости от того, что вы хотите делать с информацией. Чтобы конвертировать возвращаемый объект в формат JSON, используйте метод json() .
Добавьте метод then() , содержащий функцию с параметром resp :
fetch(url) .then((resp) => )Параметр resp принимает значение объекта, возвращаемого fetch(url) . Используйте метод json() , чтобы конвертировать resp в данные JSON:
fetch(url) .then((resp) => resp.json())При этом данные JSON все равно необходимо обработать. Добавьте еще одно выражение then() с функцией, имеющей аргумент с именем data :
.then(function(data) >) >)Создайте в этой функции переменную с именем authors , принимающую значение data.results :
.then(function(data) let authors = data.results;Для каждого автора в переменной authors нам нужно создать элемент списка, выводящий портрет и имя автора. Для этого отлично подходит метод map() :
let authors = data.results; return authors.map(function(author) >)Создайте в функции map переменную li , которая будет равна createNode с li (элемент HTML) в качестве аргумента:
return authors.map(function(author) let li = createNode('li'); >)Повторите эту процедуру, чтобы создать элемент span и элемент img :
let li = createNode('li'); let img = createNode('img'); let span = createNode('span');Предлагает имя автора и портрет, идущий вместе с именем. Установите в img.src портрет автора:
let img = createNode('img'); let span = createNode('span'); img.src = author.picture.medium;Элемент span должен содержать имя и фамилию автора . Для этого можно использовать свойство innerHTML и интерполяцию строк:
img.src = author.picture.medium; span.innerHTML = `$author.name.first> $author.name.last>`;Когда изображение и элемент списка созданы вместе с элементом span , вы можете использовать функцию append , которую мы ранее добавили для отображения этих элементов на странице:
append(li, img); append(li, span); append(ul, li);Выполнив обе функции then() , вы сможете добавить функцию catch() . Эта функция поможет зарегистрировать потенциальную ошибку на консоли:
.catch(function(error) console.log(error); >);Это полный код запроса, который вы создали:
function createNode(element) return document.createElement(element); > function append(parent, el) return parent.appendChild(el); > const ul = document.getElementById('authors'); const url = 'https://randomuser.me/api/?results=10'; fetch(url) .then((resp) => resp.json()) .then(function(data) let authors = data.results; return authors.map(function(author) let li = createNode('li'); let img = createNode('img'); let span = createNode('span'); img.src = author.picture.medium; span.innerHTML = `$author.name.first> $author.name.last>`; append(li, img); append(li, span); append(ul, li); >) >) .catch(function(error) console.log(error); >);Вы только что успешно выполнили запрос GET, используя Random User API и Fetch API. На следующем шаге вы научитесь выполнять запросы POST.
Шаг 3 — Обработка запросов POST
По умолчанию Fetch использует запросы GET, но вы также можете использовать и все другие типы запросов, изменять заголовки и отправлять данные. Для этого нужно задать объект и передать его как второй аргумент функции fetch.
Прежде чем создать запрос POST, создайте данные, которые вы хотите отправить в API. Это будет объект с именем data с ключом name и значением Sammy (или вашим именем):
const url = 'https://randomuser.me/api'; let data = name: 'Sammy' >Обязательно добавьте постоянную переменную, хранящую ссылку на Random User API.
Поскольку это запрос POST, ее нужно будет указать явно. Создайте объект с именем fetchData :
let fetchData = >Этот объект должен содержать три ключа: method , body и headers . Ключ method должен иметь значение ‘POST’ . Для body следует задать значение только что созданного объекта data . Для headers следует задать значение new Headers() :
let fetchData = method: 'POST', body: data, headers: new Headers() >Интерфейс Headers является свойством Fetch API, который позволяет выполнять различные действия с заголовками запросов и ответов HTTP. Если вы захотите узнать об этом больше, вы можете найти более подробную информацию в статье под названием Определение маршрутов и методов запросов HTTP в Express.
С этим кодом можно составлять запросы POST, используя Fetch API. Мы добавим url и fetchData как аргументы запроса fetch POST:
fetch(url, fetchData)Функция then() будет включать код, обрабатывающий ответ, получаемый от сервера Random User API:
fetch(url, fetchData) .then(function() // Handle response you get from the server >);Есть и другая опция, позволяющая создать объект и использовать функцию fetch() . Вместо того, чтобы создавать такой объект как fetchData , вы можете использовать конструктор запросов для создания объекта запроса. Для этого нужно создать переменную с именем request :
const url = 'https://randomuser.me/api'; let data = name: 'Sara' > var request =Для переменной request следует задать значение new Request . Конструкт new Request принимает два аргумента: URL API ( url ) и объект. В объекте также должны содержаться ключи method , body и headers , как и в fetchData :
var request = new Request(url, method: 'POST', body: data, headers: new Headers() >);Теперь request можно использовать как единственный аргумент для fetch() , поскольку он также включает URL-адрес API:
fetch(request) .then(function() // Handle response we get from the API >)В целом код будет выглядеть следующим образом:
const url = 'https://randomuser.me/api'; let data = name: 'Sara' > var request = new Request(url, method: 'POST', body: data, headers: new Headers() >); fetch(request) .then(function() // Handle response we get from the API >)Теперь вы знаете два метода создания и выполнения запросов POST с помощью Fetch API.
Заключение
Хотя Fetch API поддерживается еще не всеми браузерами, он представляет собой отличную альтернативу XMLHttpRequest. Если вы хотите узнать, как вызывать Web API с помощью React, ознакомьтесь с этой статьей по данной теме.
Thanks for learning with the DigitalOcean Community. Check out our offerings for compute, storage, networking, and managed databases.
Как парсить сайты и материалы СМИ с помощью JavaScript и Node.js
Не надо тыкать мне в лицо своим питоном: простой парсинг сайтов на Node.js для тех, кто ничего об этом не знает.
Иллюстрация: Node.js / Colowgee для Skillbox Media

Евгений Колесников
Журналист, автор канала «Тёмный Лорд Коммуникаций».
Евгений Колесников
Журналист РИА «Новости», автор канала «Тёмный Лорд Коммуникаций».
Ссылки
Парсинг, также известный как веб-скрейпинг, — это автоматизированный сбор данных по Сети. И у него тысячи возможных способов применения в профессиях, связанных с постоянной работой с информацией. На примере парсинга статей с двух сайтов с помощью JavaScript и фреймворка Node.js я покажу, как он может помочь современному журналисту, пиарщику и маркетологу — тем, кто, казалось бы, далёк от программирования.
Предположим, у нас есть сайт-источник и мы хотим прочитать все статьи на нём, чтобы разобраться в определённой теме или сделать подборку новостей. Страниц на сайте много, и листать ленту очень долго. Что делать? Было бы удобно сначала получить список публикаций, а потом отфильтровать нужные.
Как устроен парсинг сайтов
Вкратце процедуру сбора данных с сайта можно описать следующим образом:
- Определяем сайт-источник и желаемые данные.
- Выясняем способ пагинации (перехода по страницам) и структуру кода сайта.
- Любым из множества возможных способов делаем последовательные сетевые запросы по каждой странице. Если у сайта есть API — используем API, если нет — другие инструменты.
- Переводим полученные данные в удобный формат.
- Записываем итоговые данные в файл.
Успех зависит от правильного анализа сайта. Нам нужно будет выяснить:
- Как происходит переход на следующую страницу. Это нужно, чтобы парсер делал всё автоматически, — в противном случае сбор завершится на первой же странице. Обычно это происходит при нажатии кнопки типа «Далее» или «Следующая страница» — а парсер имитирует нажатие.
- Правильное и точное место, где в HTML-разметке сайта содержатся нужные материалы. Для этого придётся определить местонахождение (вложенность) блоков, а также их селекторы.
Запросы нужно делать «вежливо», то есть с некоторой задержкой, чтобы не навредить сайту-источнику (например, не очень хорошо запускать цикл из сотни мгновенных запросов сразу ко всем страницам архива).
И категорически запрещено нарушать авторские права. Перед разработкой парсера стоит ознакомиться с пользовательским соглашением, которое может прямо запрещать автоматический сбор данных.
Для примера парсинга я взял два сайта, пагинация которых устроена по-разному: в первом случае это клик по кнопке «Следующая страница», а во втором — бесконечная подгрузка.
Устанавливаем необходимое ПО
Наш парсер будет работать на языке JavaScript и в среде выполнения Node.js с использованием дополнительных модулей axios и jsdom:
- С помощью языка JavaScript мы будем объявлять переменные и константы, а также запускать функции и циклы.
- Фреймворк Node.js позволит выполнять всё это не в браузере, а через командную строку Windows.
- Встроенный в Node.js модуль fs (сокращение от file system) позволит работать с файловой системой компьютера, чтобы создавать файлы с результатом.
- Дополнительно скачиваемый модуль axios позволит в удобном виде делать HTTP-запросы по ссылкам.
- Дополнительно скачиваемый модуль jsdom позволит разбирать получаемый результат в виде DOM‑дерева, как если бы это делалось в браузере.
Перейдём к установке. Для этого нужно скачать и установить любым из способов Node.js с официального сайта. После этого с JavaScript-кодом можно будет работать из командной строки, в том числе запускать JS-файлы и отдельные команды.
Вместе с Node.js устанавливается так называемый менеджер пакетов npm, он позволит установить модули axios и jsdom. Открываем командную строку и вводим по очереди команды npm install axios и npm install jsdom — после каждой нужно дождаться завершения установки пакета. Можно установить модули в папку по умолчанию или в папку со своим проектом, это на ваше усмотрение.
Обратите внимание, что в качестве дополнительных модулей мы выбрали одни из наиболее популярных решений — об этом говорит статистика их скачиваний за неделю в каталоге npm. Логика такая: если их так часто используют, значит, они проверены и работают более или менее надёжно.
Парсим сайт с первым типом пагинации: отдельные страницы, переход по кнопке
В классическом случае каждая страница с материалами сайта — отдельная, переход инициируется пользователем по клику. Для парсинга нужно по очереди перебрать все страницы, делая остановки на каждой и записывая необходимые данные, а затем переходить к следующей, пока доступные страницы не закончатся.
Посмотрим, как такой вид перехода реализован на сайте профессионального журнала «Журналист», и попробуем его спарсить. Этот сайт был выбран в качестве объекта для парсинга по следующим причинам:
- Во-первых, мы с редактором Skillbox Media «Код» согласились, что это классный журнал 🙂
- Во-вторых, структура пагинации журнала позволяет использовать его для демонстрации технологии.
- В-третьих, редакция «Журналиста» любезно согласилась нам помочь.
На сайте содержатся материалы примерно за шесть лет: больше 160 страниц, на каждой примерно пара десятков статей — итого почти 3000 материалов. Что получим на выходе: HTML-файл со списком названий статей и ссылками.
Определяем структуру сайта
Выясняем способ перехода между страницами. Здесь переход по страницам происходит по нажатию кнопки «Читать ещё» под статьями, которая отправляет на сервер запрос вида «https://jrnlst.ru/node?page=2" и таким образом подгружает на ту же страницу дополнительные материалы, относящиеся к следующей странице.
Но мы воспользуемся вторым способом, который есть на сайте: ссылками вида «https://jrnlst.ru/?page=[номер страницы]», которые загружают именно отдельные страницы со статьями. Нумерация идёт с нулевой страницы (главной), хотя это прямо и не указывается.
Находим последнюю страницу, на которой нужно завершить сбор. Экспериментально я установил, что на момент написания статьи последней была страница под номером 162: на ней под статьями вместо кнопки перехода находится лаконичная надпись «Пока что это всё».
Нашёл я её просто: переходил по ссылкам с произвольными номерами страниц, начав с «page=200» (выбрал как предположение) и постепенно сокращая цифры, — здесь всё зависит от сайта, времени его существования и предположительной частоты обновления. Получается, у нас 163 страницы, так как мы должны учесть и нулевую (главную).
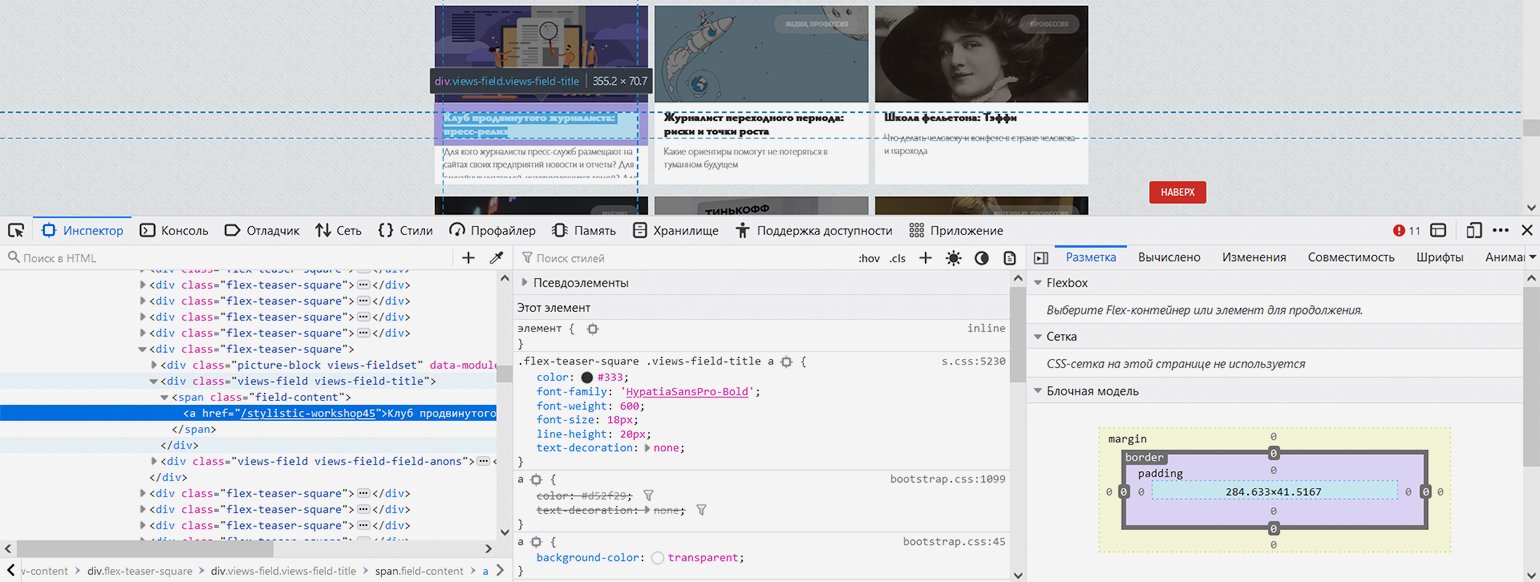
Показываем парсеру, где в HTML-коде находится нужная информация. С помощью встроенных в браузер инструментов веб-разработки изучаем структуру кода и выясняем — нужные нам заголовки в HTML‑иерархии находятся вот по какому пути: элемент с классом «block-views-articles-latest-on-front-block» → первый элемент с классом «view-content» → все элементы с классом «flex-teaser-square» (по очереди) → в каждом из них первый элемент с классом «views-field views-field-title» → в каждом из них первый элемент с тегом ‘a’ (то есть гиперссылка с названием статьи).
Теперь, когда у нас есть все необходимые данные для парсера, давайте автоматизируем процесс сборки материалов.
Пишем код парсера
Наш парсер будет состоять из двух файлов — JS-файл с собственно кодом и bat-файл для запуска по клику:
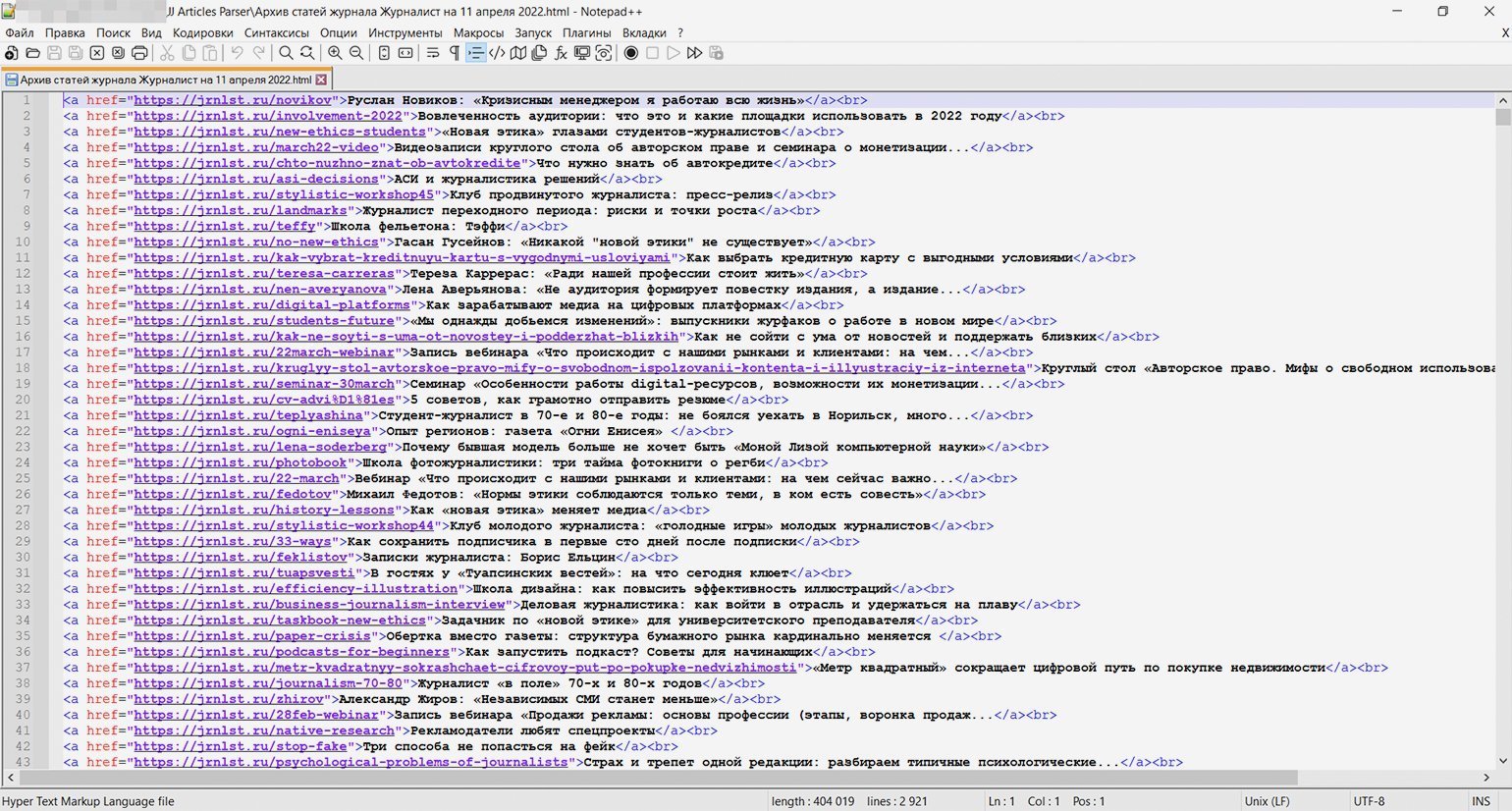
- Создадим файл с именем «JJ Articles Parser.js» (JJ — удобное сокращение от «журнал „Журналист“» — никакой магии). В этом файле будет практически весь наш исполняемый код.
- Создадим файл start.bat и пропишем в нём следующие команды:
Когда код написан и настроен, остаётся только запустить его кликом по батнику (start.bat) и наблюдать в реальном времени за выполнением. Примерно через полчаса мы получим HTML-файл со списком всех 2920 статей ссылками, как и планировалось.

В списке запросов можно увидеть POST-запрос к сайту skillbox.ru на выполнение PHP-файла с говорящим названием getArticlesIndex.php, ответ возвращается в часто используемом формате разметки данных JSON. URL запроса: https://skillbox.ru/local/ajax/getArticlesIndex.php — при этом на вкладке «Запрос» можно увидеть, что он передаётся с такими параметрами:
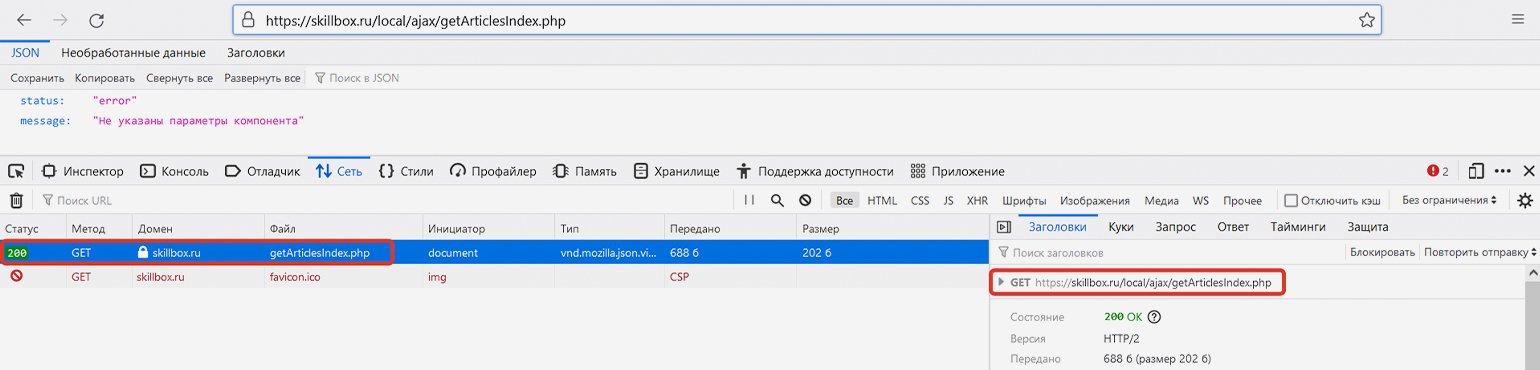
Если попробовать сделать прямой запрос по той же ссылке и с указанием правильных параметров, то опять же в результате GET-запроса получим JSON-ответ с HTML-кодом дополнительных статей и статусом «ok».
Например, соединим базовую ссылку и указанные выше параметры в единую строку — https://skillbox.ru/local/ajax/getArticlesIndex.php?params[SECTION_ID]=10& params[CODE_EXCLUDE]=news& params[FIRST_IS_FULL]=Y& params[COUNT]=7& params[PAGE_NUM]=2& params[FIELDS][]=PROPERTY_FAKE_COUNTER& params[CACHE_TYPE]=A& params[COMPONENT_TEMPLATE]=articles — и сделаем GET-запрос, перейдя по конечной ссылке. В ответ сайт отдаст данные в JSON-формате — это будет разметка списка статей на второй странице, в чём легко убедиться, найдя в этой мешанине через поиск доступные на сайте названия статей.
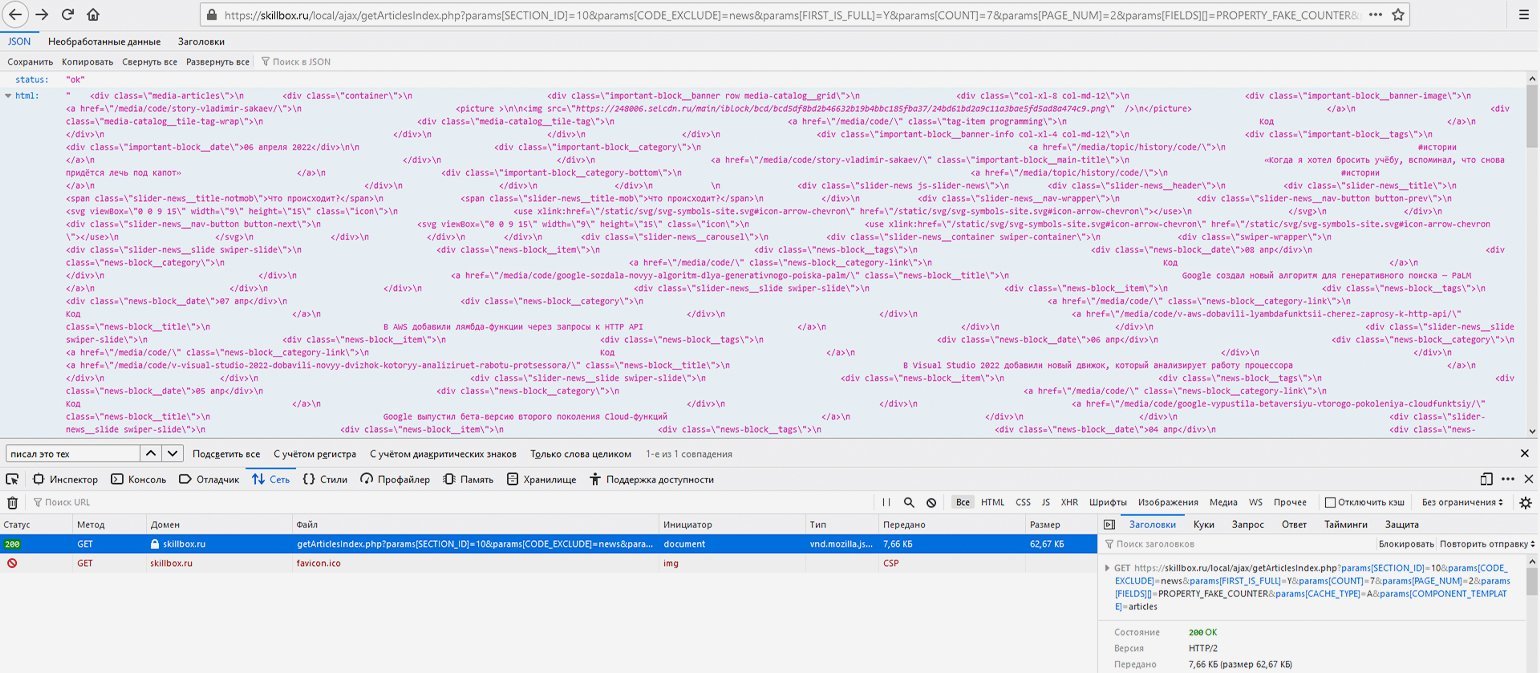
Теперь, когда мы примерно поняли структуру пагинации, нужно определиться, где же парсеру надо остановиться — где заканчиваются статьи.
Загуглив фразу «Skillbox запустил медиа», находим материал «Подборка статей Skillbox в честь запуска медиа» от 8 июля 2018 года в блоге Skillbox на Medium. Это уже что-то — теперь можно догадаться, что статьи на сайте появились примерно в первой половине 2018 года.
Как и в предыдущем примере, начинаем искать номер последней страницы перебором параметра «[PAGE_NUM]». Если введённого номера страницы нет, сайт отдаёт первую страницу — в таком случае номер нужно уменьшить.
На момент написания статьи последняя страница была под номером 101, на каждой — по семь материалов: исходя из этого было сделано предположение, что всего в рубрике «Код» должно быть примерно 707 статей (в реальности их оказалось 705, потому что на последней странице было только пять публикаций). В данном случае автор мог сверить подсчёты с редактором раздела, который подтвердил их правильность, — однако так везёт далеко не всегда. Судя по выданному сайтом результату, первая статья раздела — «Какой язык программирования учить новичку. Выбираем JavaScript» от 3 мая 2018 года.
Вернёмся к первой странице рубрики и попробуем с помощью инструментов веб-разработчика найти местонахождение ссылок на статьи, чтобы указать его парсеру.
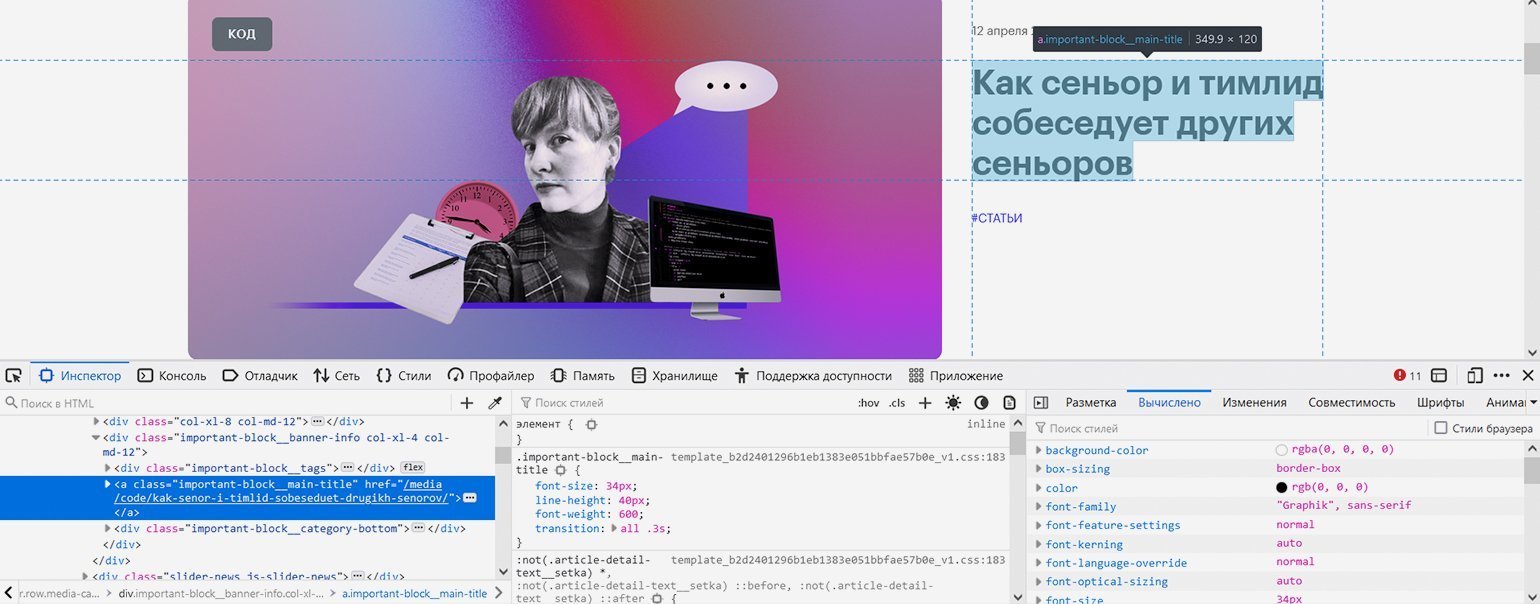
Со статьёй в закрепе проблем нет — она такая одна, это элемент с классом «important-block__main-title».
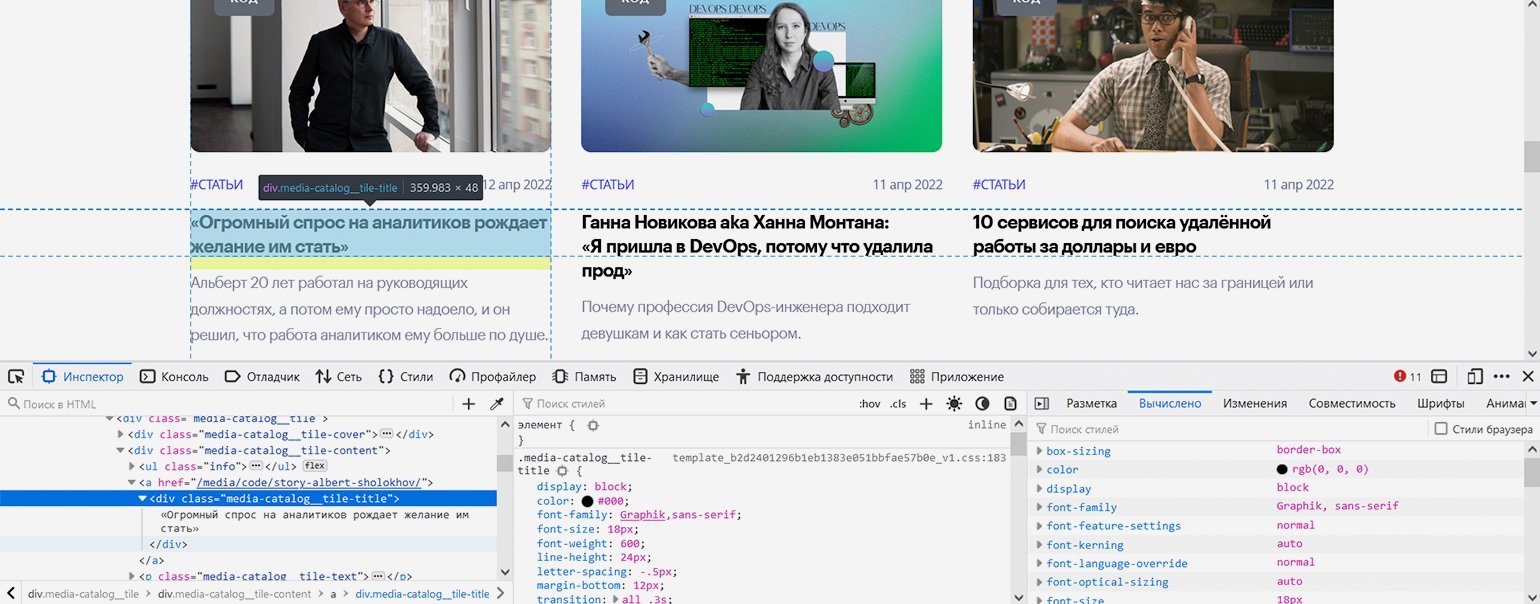
С остальными посложнее: блочный элемент с классом «media-catalog__tile-title» вложен в ссылку — элемент , что довольно необычно. содержит только текст заголовка, а у ссылки не указан класс — но всё это мы решим с помощью правильной навигации.
Пишем код парсера
Создаём два файла — skbx_code_articles_parser.js с кодом и start.bat для его запуска. Батник копируем почти без изменений — отличаться будут только путь и имя запускаемого скрипта. В JS-файл вставляем следующий код:
Как и в прошлом примере, запускаем парсер кликом на файл start.bat и примерно 17 минут ждём результата — HTML-файла со списком из 705 статей.
Ничто не вечно
И ваш парсер тоже. Вы можете читать этот материал через день или через год после выхода. На момент подготовки статьи сайт Skillbox Media выводил по семь статей на странице: одну в закрепе и шесть снизу. Впоследствии разработчики неожиданно удвоили выдачу — теперь уже выводится по 14 статей в следующем порядке: одна в закрепе, шесть снизу, снова одна в закрепе и ещё шесть снизу.
Мы решили оставить этот факт как часть урока о парсерах: сайт, который вы собираете, может в любой момент поменять дизайн и структуру материалов, поэтому не следует ожидать, что ваш сборщик будет работать вечно даже на одном и том же ресурсе.
В ходе теста выяснилось, что с выдачей 14 материалов вместо семи указанный выше код также справляется, поскольку параметры с номером страницы и количеством статей на ней взаимосвязаны и ответ сервера адаптируется под ваш запрос (даже если он построен по старому принципу).
Однако, если, как и раньше, подстраиваться под логику разработчиков, будет разумно поменять навигацию: указать в константе в два раза меньшее число страниц и поменять порядок перебора расположенных на них элементов — имея в два раза больше статей на каждой, для сохранения правильного порядка мы должны задать проход по алгоритму «первый закреп, обычные статьи с первой по шестую, второй закреп, обычные статьи с седьмой по 12-ю». Вы можете сделать это самостоятельно в качестве упражнения.
Заключение
Мы рассмотрели два рабочих способа автоматического сбора материалов на сайтах СМИ. Есть и другие варианты: парсить список материалов в Excel-таблицу, в файл закладок для импорта в браузер, сделать красивый дизайн, автоматически отправлять результат в Telegram-чат через бота, сортировать, проводить контент-анализ (рубрики, ключевые слова, частота публикации), вставлять галочки для отметки прочитанного и так далее — насколько хватит фантазии.
Вероятно, приведённый выше код не идеален, ведь он написан не профессиональным программистом, а журналистом, применяющим программирование в работе. Это важный момент: он показывает, что сейчас программирование нужно всем и доступно всем, если выйти за пределы привычных методов работы и изучить что-то новое.
Читайте также:
- Как добавить JavaScript без ожирения сайта
- Что такое фреймворк и как выбрать фреймворк для фронтенда: советы бывалых
- Гайд для начинающих: как написать JavaScript