Как сделать тепловые карты с Seaborn (с примерами)
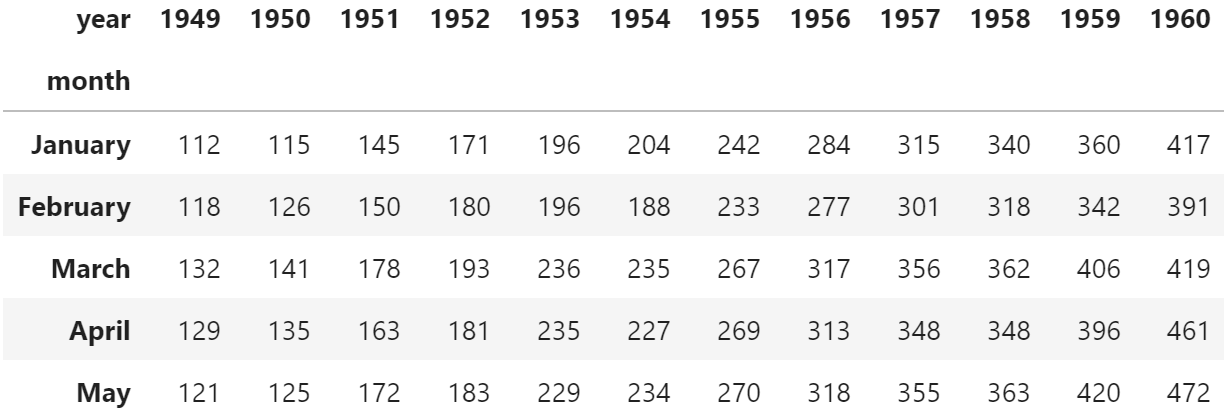
Тепловая карта — это тип диаграммы, в которой для представления значений данных используются разные оттенки цветов.
В этом руководстве объясняется, как создавать тепловые карты с помощью библиотеки визуализации Python Seaborn со следующим набором данных:
#import seaborn import seaborn as sns #load "flights" dataset data = sns.load_dataset("flights") data = data.pivot(" month", " year", " passengers ") #view first five rows of dataset data.head() 
Создайте базовую тепловую карту
Мы можем использовать следующий синтаксис для создания базовой тепловой карты для этого набора данных:
sns.heatmap(data) 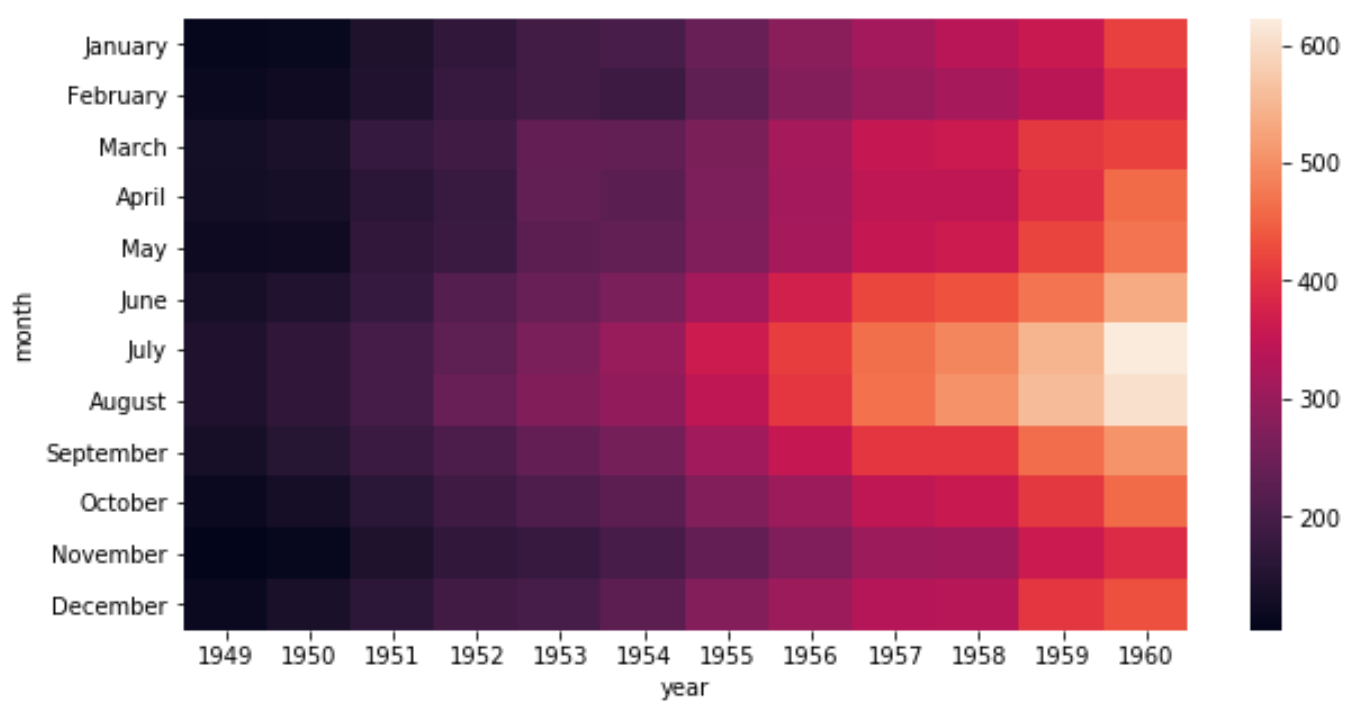
По оси X отображается год, по оси Y — месяц, а цвет квадратов на тепловой карте представляет количество полетов в этих конкретных комбинациях год-месяц.
Отрегулируйте размер тепловой карты
Мы можем использовать аргумент figsize для настройки общего размера тепловой карты:
#set heatmap size import matplotlib.pyplot as plt plt.figure(figsize = (12,8)) #create heatmap sns.heatmap(data) 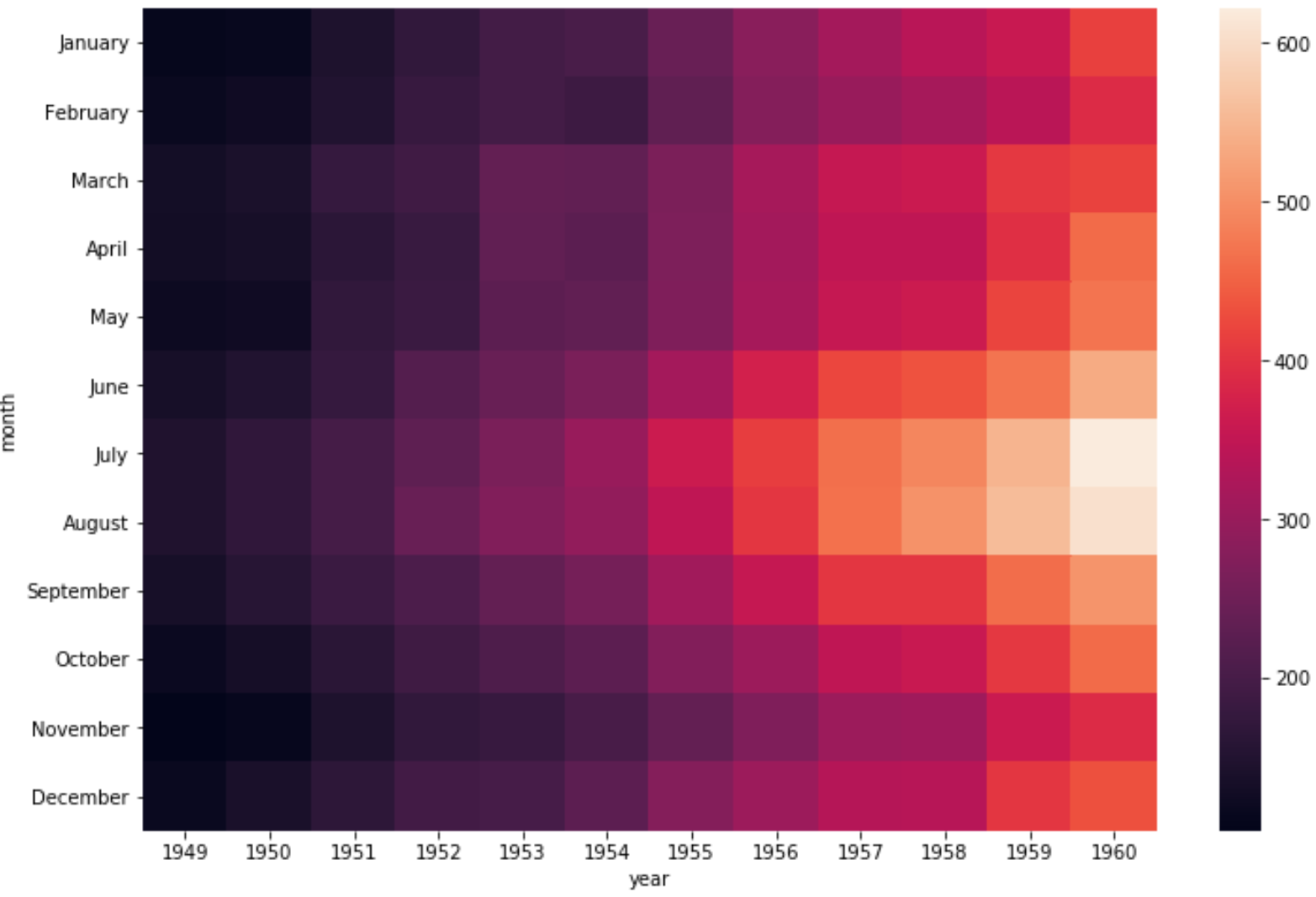
Изменить цвета тепловой карты
Мы можем использовать аргумент cmap , чтобы изменить цвета, используемые в тепловой карте. Например, мы могли бы выбрать цветовую карту «Спектральная»:
sns.heatmap(data, cmap=" Spectral ") 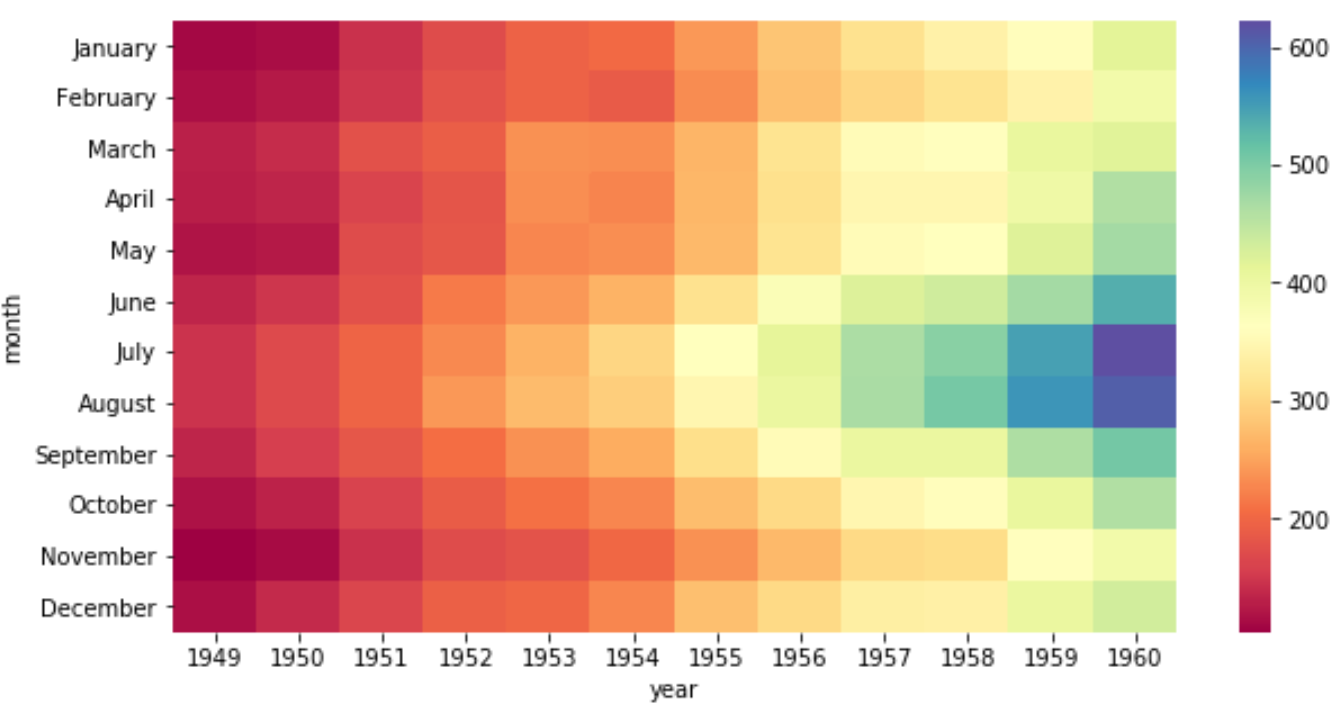
Или мы могли бы выбрать «холодную» цветовую карту:
sns.heatmap(data, cmap=" coolwarm ") 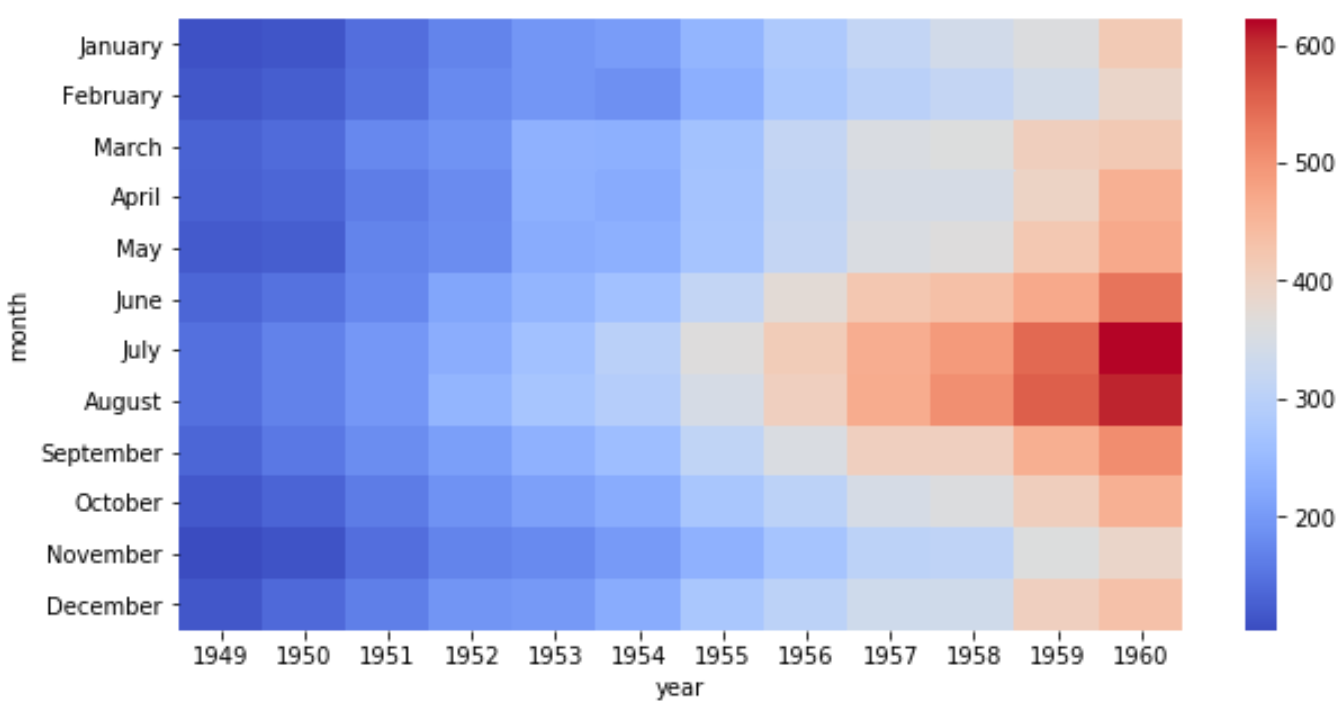
Полный список опций cmap доступен здесь .
Аннотировать тепловую карту
Мы можем использовать следующий синтаксис, чтобы аннотировать каждую ячейку в тепловой карте с целочисленным форматированием и указать размер шрифта:
sns.heatmap(data, annot= True , fmt=" d", annot_kws=) 
Изменить цветовую полосу тепловой карты
Наконец, мы можем отключить цветовую полосу, если хотим использовать аргумент cbar :
sns.heatmap(data, cbar= False ) 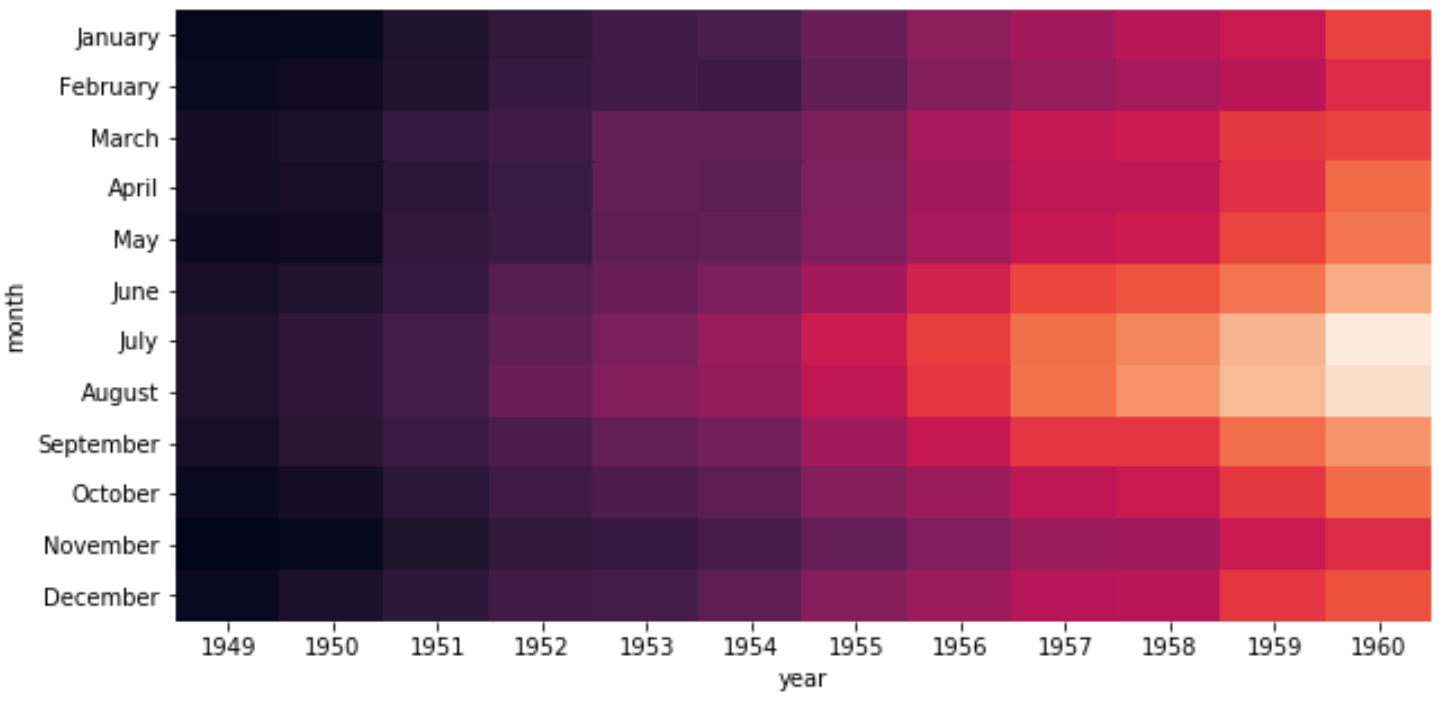
Найдите больше руководств Seaborn на этой странице .
Как легко создавать тепловые карты в Python
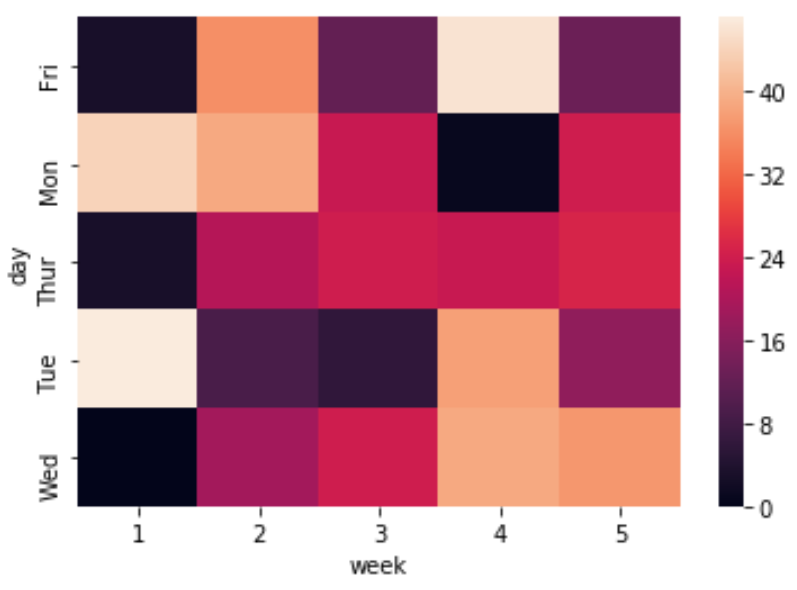
Предположим, у нас есть следующий набор данных на Python, который отображает количество продаж, совершаемых определенным магазином в каждый будний день в течение пяти недель:
import numpy as np import pandas as pd import seaborn as sns #create a dataset np.random.seed(0) data = df = pd.DataFrame(data,columns=['day','week','sales']) df = df.pivot('day', 'week', 'sales') view first ten rows of dataset df[:10] week 1 2 3 4 5 day Fri 3 36 12 46 13 Mon 44 39 23 1 24 Thur 3 21 24 23 25 Tue 47 9 6 38 17 Wed 0 19 24 39 37 Создать базовую тепловую карту
Мы можем создать базовую тепловую карту, используя функцию s ns.heatmap() :
sns.heatmap(df) 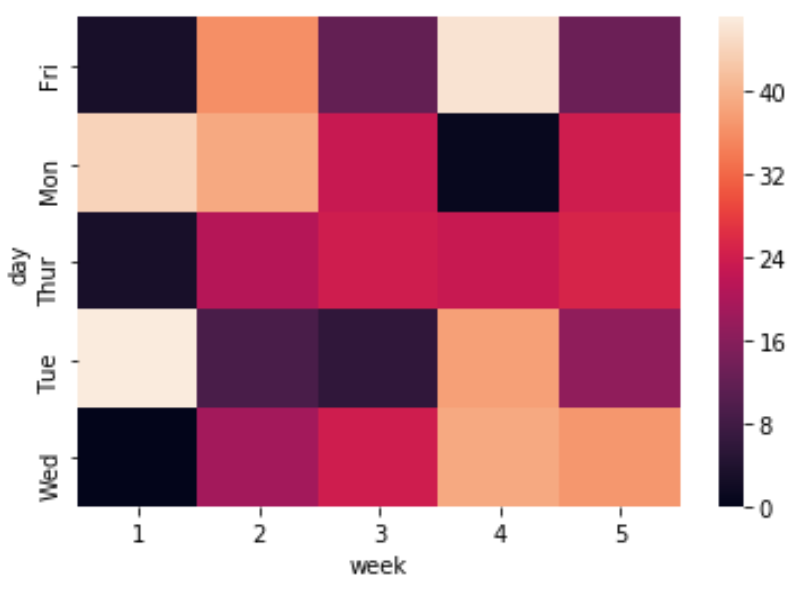
Цветовая полоса справа отображает легенду о том, какие значения представляют различные цвета.
Добавить линии на тепловую карту
Вы можете добавить линии между квадратами на тепловой карте, используя аргумент ширины линии :
sns.heatmap(df, linewidths=.5) 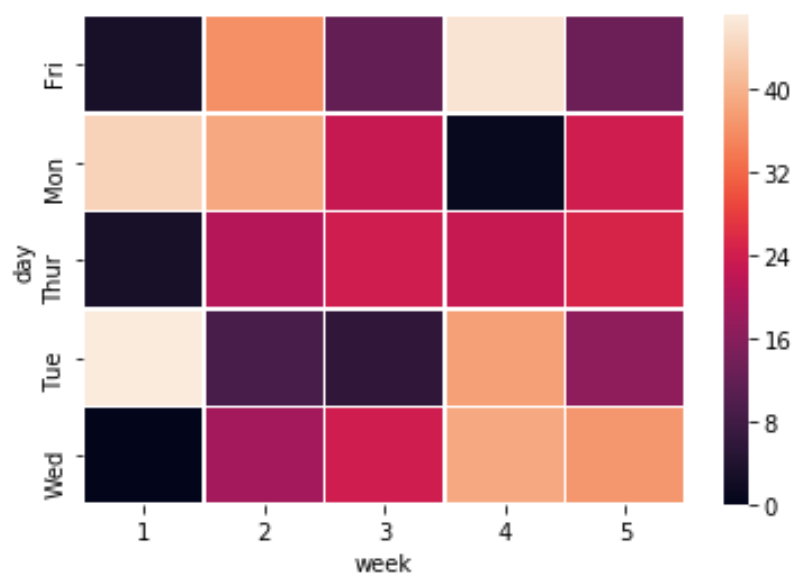
Добавьте аннотации к тепловой карте
Вы также можете добавить аннотации к тепловой карте, используя аргумент annot=True :
sns.heatmap(df, linewidths=.5, annot=True) 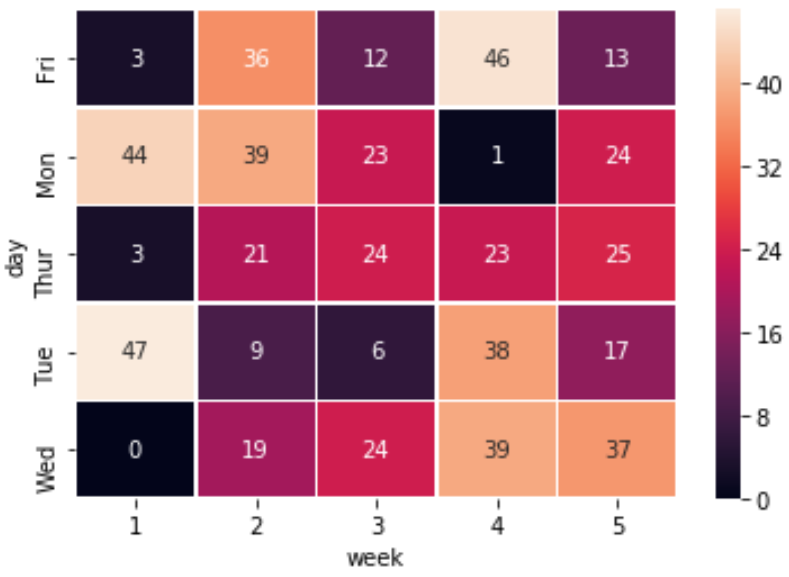
Скрыть Colorbar из тепловой карты
Вы также можете полностью скрыть цветовую полосу, используя параметр cbar=False :
sns.heatmap(df, linewidths=.5, annot=True, cbar=False) 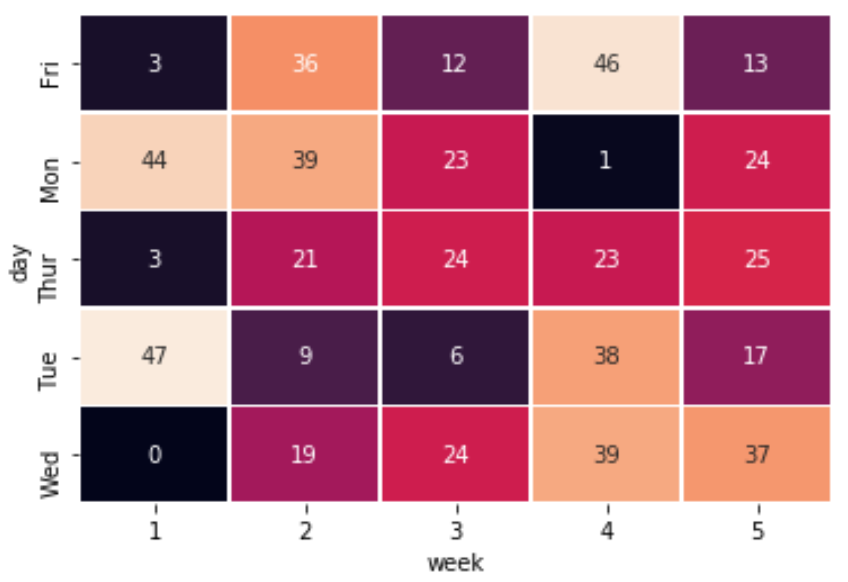
Изменить цветовую тему тепловой карты
Вы также можете изменить цветовую тему, используя аргумент cmap.Например, вы можете установить цвета в диапазоне от желтого до зеленого и синего:
sns.heatmap(df, cmap='YlGnBu') 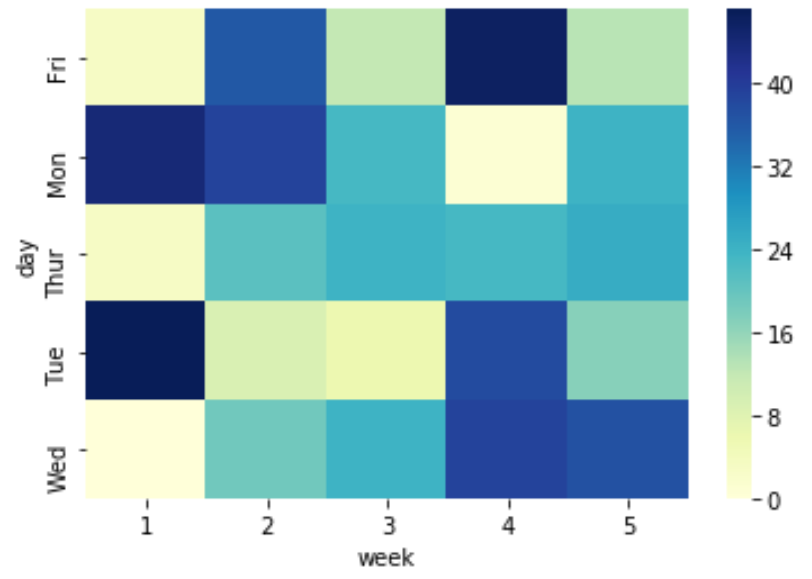
Или вы можете иметь диапазон цветов от красного до синего:
sns.heatmap(df, cmap='RdBu') python: построить тепловую карту (heatmap) с помощью matplotlib для данных, записанных в формате [x, y, z]
У меня есть данные некоторого 2D распределения, записанные в csv файле в виде списка x;y;z , при этом данные представляют собой разброс точек на плоскости
# считать данные из файла src_data = loadDataFromFile(file_path) # сформировать numpy массив x, y, z, = np.array([]), np.array([]), np.array([]) for record in src_data: x = np.append(x, record[0]) y = np.append(y, record[1]) z = np.append(z, record[2]) # создать сетку заданного размера с интерполяцией данных xi = np.linspace(x.min(), x.max(), 100) yi = np.linspace(y.min(), y.max(), 100) zi = griddata((x, y), z, (xi[None, :], yi[:, None]), method='cubic') # построить график px = 1 / plt.rcParams['figure.dpi'] fig, ax = plt.subplots(figsize=(1280 * px, 1024 * px)) plt.contourf(xi, yi, zi, 100, cmap=plt.cm.rainbow)
что работало, когда же пытался добавить время через
dates = [] for record in src_data: dates.append(datetime.datetime.fromtimestamp(record[0])) x = np.array(matplotlib.dates.date2num(x)) xfmt = matplotlib.dates.DateFormatter('%d.%m %H:%M') ax.xaxis.set_major_formatter(xfmt)
то получалась какая-то фигня с тепловой картой Как это все корректно сделать, подскажите пожалуйста?
Heatmap на интерактивной карте с помощью folium
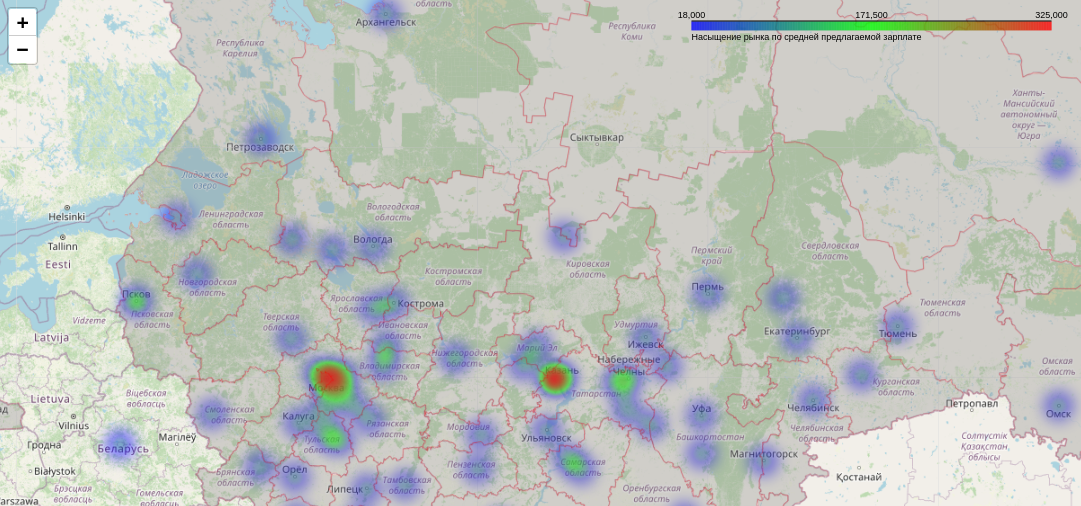
Возникла необходимость изобразить на интерактивной карте актуальное предложение вакансий в сфере Data Science с агрегацией по городам.
Действовать будем в 3 этапа:
- Парсинг вакансий с hh API
- Актуализация геолокаций каждой вакансии с точностью до населенного пункта
- Построение heatmap по количеству вакансий и по средней предлагаемой зарплате с помощью folium
1. Парсинг вакансий с hh API
Воспользуемся официальным API hh.ru (документация).
Основные параметры, которые мы будем передавать через API:
| Параметр | Описание |
|---|---|
| ‘text’ | Ключевое слово для поиска вакансий |
| ‘page’ | Номер страницы в списке поиска вакансий |
| ‘per_page’ | Количество вакансий на страницу (максимум 100) |
| ‘only_with_salary’ | Только с указание зарплаты (работает некорректно, просачиваются вакансии без указания зарплаты) |
def get_vacancies(skills, filename, pages=10): res = [] for indx, skill in enumerate(skills): print(f'\ncollecting > ( of )') for page in range(pages): params = < 'text': f'', 'page': page, 'per_page': 100, 'only_with_salary': 'true', > req = requests.get('https://api.hh.ru/vacancies', params).json() if 'items' in req.keys(): res.extend(req['items']) print('|', end='') df = pd.DataFrame(res) df.to_csv(filename, index=False)Функция создает в текущей дериктории файл с указанным названием.
Полный листинг парсинга с очисткой данных здесь.
В нашем примере используем ключевые слова, характерные для выбранной сферы. Результат сохраним в файл ‘data.csv’.
skill_list = ['machine AND learning', 'data AND science', 'NLP', 'spark', 'hadoop', 'pandas', 'dask', 'deep AND learning', 'pytorch', 'tensorflow', 'keras', 'ai AND developer', 'computer AND vision', 'нейронные AND сети', 'big AND data'] get_vacancies(skill_list, 'data.csv')В результате получаем такую таблицу:
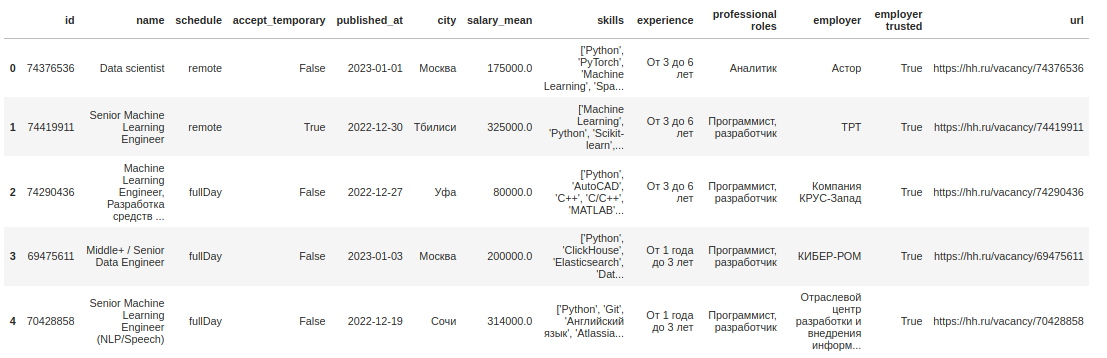
Нам понадобятся колонки ‘city’ и ‘salary_mean’.
2. Актуализация геолокаций каждой вакансии с точностью до населенного пункта
Хотя некоторые вакансии на hh.ru снабжены геометками, актуальность их сомнительна (на поверку некоторые города оказываются совсем не в положенном им месте, часть даже оказалась посреди Черного моря).
Для актуализации координат населенных пунктов, указанных в вакансиях, воспользуемся библиотекой geopy (документация).
from geopy.geocoders import Nominatim geolocator = Nominatim(user_agent="geo") def get_coords(city): geo = geolocator.geocode(city) if geo: return geo.longitude, geo.latitude else: return np.nan, np.nan coords = pd.DataFrame(data=df['city'].unique(), columns=['city']) coords['coords'] = (coords['city'] .apply(lambda x: get_coords(x))) df = df.merge(coords, on='city') df.head()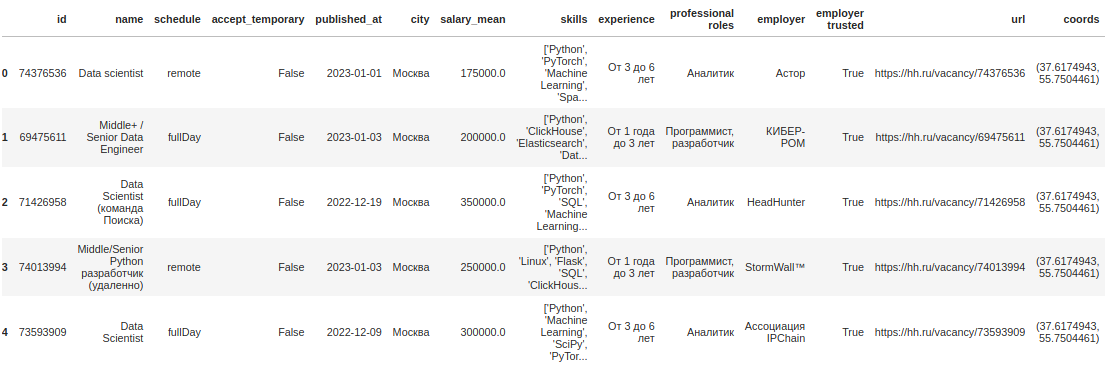
3. Построение heatmap по количеству вакансий и по средней предлагаемой зарплате с помощью folium
import folium from folium import plugins, brancaДля начала создаем объект класса Map для рисования карты. В него передаем для параметра: координаты локализации и степень приближения при загрузке карты.
mapObj = folium.Map(location=[57.23337810789467, 48.05744173358704], zoom_start=5)Лайфхак. Для определения координат и степени приближения можно сделать так:
Создаем объект класса Map с параметрами по-умолчанию, сохраняем в формат html.
mapObj = folium.Map() mapObj.save('output.html')Открываем сохраненный файл ‘output.html’. Перемещаемся в интересующее место на карте. Правая кнопка -> inspect -> Console. Вводим:
map_.getCenter() — получаем координаты центра текущего вида.
Мне было необходимо очертить границы регионов на карте. Для этого добавляем в нашу карту информацию из файла формата geojson. В параметр ‘style_function’ передаем словарь с характеристиками стиля изображения данных нашего geojson (цвет линий, их толщина, цвет заливки, прозрачность).
bordersStyle = < 'color': 'red', 'weight': 0.2, 'fillColor': 'grey', 'fillOpacity': 0.3 >folium.GeoJson('russia.geojson', name='Russia', style_function=lambda x: bordersStyle).add_to(mapObj)Создаем список координат и передаем его в класс HeatMap. Дабавляем HeatMap к нашему объекту карты.
heat_data = [[lat, lon] for lon, lat in df['coords']] plugins.HeatMap(heat_data, radius=18, gradient=).add_to(mapObj)Легенду можно создать с помощью класса LinearColormap:
colormap = branca.colormap.LinearColormap(['blue', 'lime', 'red'], vmin=1, vmax=df['city'].value_counts()[0], caption='Насыщение рынка по количеству вакансий') colormap.add_to(mapObj)Теперь карту можно сохранить в формат ‘html’.
mapObj.save('output1.html')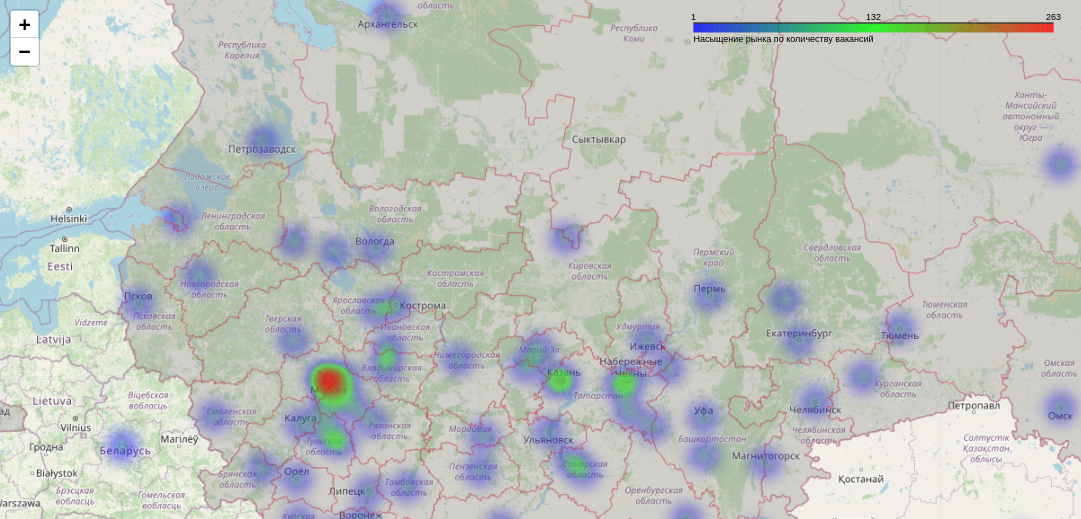
Тоже самое проделаем для данных о средней зарплате. Единственное отличие — в список heat_data помимо координат передаем третий параметр weight (им будут вычисленные в разрезе населенных пунктов средние зарплаты)
salary_mean = (df .groupby('city')[['salary_mean']] .agg('mean') ) salary_mean = coords.merge(salary_mean, on='city') mapObj = folium.Map(location=[57.23337810789467, 48.05744173358704], zoom_start=5) bordersStyle = < 'color': 'red', 'weight': 0.2, 'fillColor': 'grey', 'fillOpacity': 0.3 >folium.GeoJson('russia.geojson', name='Russia', style_function=lambda x: bordersStyle).add_to(mapObj) heat_data = [] for i in range(len(salary_mean)): heat_data.append([*reversed(salary_mean['coords'][i]), salary_mean['salary_mean'][i]]) plugins.HeatMap(heat_data, radius=18, gradient=).add_to(mapObj) colormap = branca.colormap.LinearColormap(['blue', 'lime', 'red'], vmin=salary_mean['salary_mean'].min(), vmax=salary_mean['salary_mean'].max(), caption='Насыщение рынка по средней предлагаемой зарплате') colormap.add_to(mapObj) mapObj.save('output2.html')
Полный листинг примера в репозитории Github