Создание прогноза в Excel для Windows
Если у вас есть статистические данные с зависимостью от времени, вы можете создать прогноз на их основе. При этом в Excel создается новый лист с таблицей, содержащей статистические и предсказанные значения, и диаграммой, на которой они отражены. С помощью прогноза вы можете предсказывать такие показатели, как будущий объем продаж, потребность в складских запасах или потребительские тенденции.
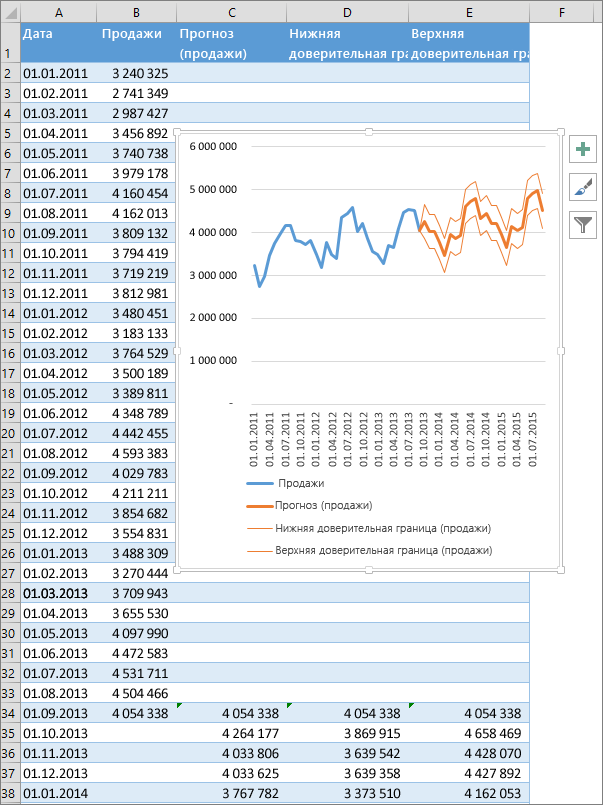
Создание прогноза
- На листе введите два ряда данных, которые соответствуют друг другу:
- ряд значений даты или времени для временной шкалы;
- ряд соответствующих значений показателя. Эти значения будут предсказаны для дат в будущем.
Примечание: Для временной шкалы требуются одинаковые интервалы между точками данных. Например, это могут быть месячные интервалы со значениями на первое число каждого месяца, годичные или числовые интервалы. Если на временной шкале не хватает до 30 % точек данных или есть несколько чисел с одной и той же меткой времени, это нормально. Прогноз все равно будет точным. Но для повышения точности прогноза желательно перед его созданием обобщить данные.
Совет: Если выделить ячейку в одном из рядов, Excel автоматически выделит остальные данные.

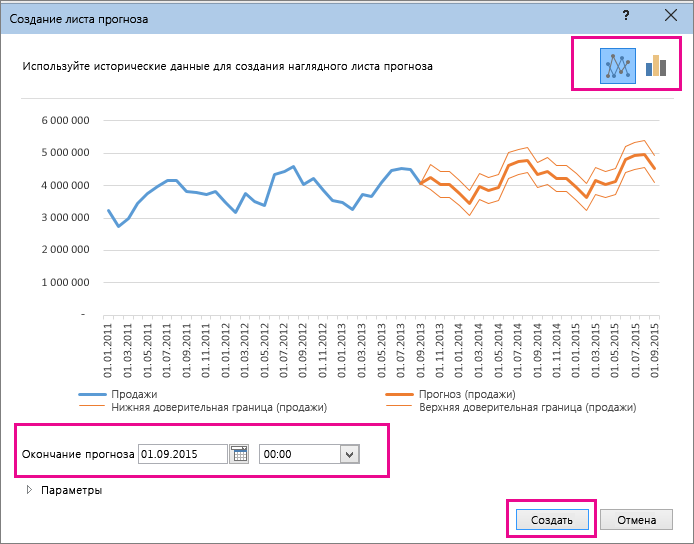
Настройка прогноза
Если вы хотите изменить дополнительные параметры прогноза, нажмите кнопку Параметры.
Сведения о каждом из вариантов можно найти в таблице ниже.
Параметры прогноза
Начало прогноза
Выберите дату, с которой должен начинаться прогноз. При выборе даты начала, которая наступает раньше, чем заканчиваются статистические данные, для построения прогноза используются только данные, предшествующие ей (это называется «ретроспективным прогнозированием»).
- Если вы начинаете прогноз перед последней точкой, вы сможете получить оценку точности прогноза, так как сможете сравнить прогнозируемый ряд с фактическими данными. Но если начать прогнозирование со слишком ранней даты, построенный прогноз может отличаться от созданного на основе всех статистических данных. При использовании всех статистических данных прогноз будет более точным.
- Если в ваших данных прослеживаются сезонные тенденции, то рекомендуется начинать прогнозирование с даты, предшествующей последней точке статистических данных.
Доверительный интервал
Установите или снимите флажок Доверительный интервал, чтобы показать или скрыть его. Доверительный интервал — это диапазон вокруг каждого предсказанного значения, в который в соответствии с прогнозом (при нормальном распределении) предположительно должны попасть 95 % точек, относящихся к будущему. Доверительный интервал помогает определить точность прогноза. Чем он меньше, тем выше достоверность прогноза для данной точки. Доверительный интервал по умолчанию определяется для 95 % точек, но это значение можно изменить с помощью стрелок вверх или вниз.
Сезонность — это число для длины (количества точек) сезонного шаблона и автоматически обнаруживается. Например, в ежегодном цикле продаж, каждый из которых представляет месяц, сезонность составляет 12. Автоматическое обнаружение можно переопрепредидить, выбрав установить вручную и выбрав число.
Примечание: Если вы хотите задать сезонность вручную, не используйте значения, которые меньше двух циклов статистических данных. При таких значениях этого параметра приложению Excel не удастся определить сезонные компоненты. Если же сезонные колебания недостаточно велики и алгоритму не удается их выявить, прогноз примет вид линейного тренда.
Диапазон временной шкалы
Здесь можно изменить диапазон, используемый для временной шкалы. Этот диапазон должен соответствовать параметру Диапазон значений.
Диапазон значений
Здесь можно изменить диапазон, используемый для рядов значений. Этот диапазон должен совпадать со значением параметра Диапазон временной шкалы.
Заполнить отсутствующие точки с помощью
Для обработки отсутствующих точек в Excel используется интерполяция, то есть отсутствующие точки будут заполнены в качестве взвешенного среднего значения соседних точек, если отсутствует менее 30 % точек. Чтобы нули в списке не были пропущены, выберите в списке пункт Нули.
Использование агрегатных дубликатов
Если данные содержат несколько значений с одной меткой времени, Excel находит их среднее. Чтобы использовать другой метод вычисления, например Медиана илиКоличество,выберите нужный способ вычисления из списка.
Включить статистические данные прогноза
Установите этот флажок, если хотите поместить на новом листе дополнительную статистическую информацию о прогнозе. При этом добавляется таблица статистики, созданная с помощью прогноза. Ets. Функция СТАТ и показатели, такие как коэффициенты сглаживания («Альфа», «Бета», «Гамма») и метрики ошибок (MASE, SMAPE, MAE, RMSE).
Формулы, используемые при прогнозировании
При использовании формулы для создания прогноза возвращаются таблица со статистическими и предсказанными данными и диаграмма. Прогноз предсказывает будущие значения на основе имеющихся данных, зависящих от времени, и алгоритма экспоненциального сглаживания (ETS) версии AAA.
Таблицы могут содержать следующие столбцы, три из которых являются вычисляемыми:
- столбец статистических значений времени (ваш ряд данных, содержащий значения времени);
- столбец статистических значений (ряд данных, содержащий соответствующие значения);
- столбец прогнозируемых значений (вычисленных с помощью функции ПРЕДСКАЗ.ЕTS);
- два столбца, представляющие доверительный интервал (вычисленные с помощью функции ПРЕДСКАЗ.ЕTS.ДОВИНТЕРВАЛ). Эти столбцы отображаются только при проверке доверительный интервал в разделе Параметры.
Скачивание образца книги
Дополнительные сведения
Вы всегда можете задать вопрос эксперту в Excel Tech Community или получить поддержку в сообществах.
Прогнозирование временных рядов в MS EXCEL (обзорная статья)
В первом разделе статьи модели для прогнозирования временных рядов сравниваются с моделями, построение которых основано на причинно-следственных закономерностях.
Во втором разделе приведен краткий обзор трендов временных рядов (линейный и сезонный тренд, стационарный процесс). Для каждого тренда предложена модель для прогнозирования.
Затем даны ссылки на сайты по теории прогнозирования временных рядов и содержащие базы статистических данных.
Disclaimer:
Напоминаем, что задача сайта excel2.ru (раздел Временные ряды ) продемонстрировать использование MS EXCEL для решения задач, связанных с прогнозированием временных рядов. Поэтому, статистические термины и определения приводятся лишь для логики изложения и демонстрации идей. Сайт не претендует на математическую строгость изложения статистики. Однако в наших статьях:
• ПОЛНОСТЬЮ описан встроенный в EXCEL инструментарий по анализу временных рядов (в составе надстройки Пакет анализа , различных типов Диаграмм ( гистограмма , линия тренда ) и формул);
• созданы файлы примера для построения соответствующих графиков, прогнозов и их интервалов предсказания, вычисления ошибок, генерации рядов (с трендами и сезонностью ) и пр.
Модели временных рядов и модели предметной области
Напомним, что временным рядом (англ. Time Series) называют совокупность наблюдений изучаемой величины, упорядоченную по времени. Наблюдения производятся через одинаковые периоды времени. Другой информацией, кроме наблюдений, исследователь не обладает.
Основной целью исследования временного ряда является его прогнозирование – предсказание будущих значений изучаемой величины. Прогнозирование основывается только на анализе значений ряда в предыдущие периоды, точнее — на идентификации трендов ряда. Затем, после определения трендов, производится моделирование этих трендов и, наконец, с помощью этих моделей — экстраполяция на будущие периоды.
Таким образом, прогнозирование основывается на фактических данных (значениях временного ряда) и модели ( скользящее среднее , экспоненциальное сглаживание , двойное и тройное экспоненциальное сглаживание и др.).
Примечание : Прогнозирование методом Скользящее среднее в MS EXCEL подробно рассмотрено в одноименной статье .
В отличие от методов временных рядов, где зависимости ищутся внутри самого процесса , в «моделях предметной области» (англ. «Causal Models») кроме самих данных используют еще и законы предметной области.
Примером построения «моделей предметной области» ( моделей строящихся на основе причинно-следственных закономерностей, априорно известных независимо от имеющихся данных ) может быть промышленный процесс изготовления защитной ткани. Пусть в таком процессе известно, что прочность материала ткани зависит от температуры в реакторе, в котором производится процесс полимеризации (температура — контролируемый фактор). Однако, прочность материала является все же случайной величиной, т.к. зависит помимо температуры также и от множества других факторов (качества исходного сырья, температуры окружающей среды, номера смены, умений аппаратчика реактора и пр.). Эти другие факторы в процессе производства стараются держать постоянными (сырье проходит входной контроль и его поставщик не меняется; в помещении, где стоит реактор, поддерживается постоянная температура в течение всего года; аппаратчики проходят обучение и регулярно проводится переаттестация). Задачей статистических методов в этом случае – предсказать значение случайной величины (прочности) при заданном значении изменяемого фактора (температуры).
Обычно для описания таких процессов (зависимость случайной величины от управляемого фактора) являются предметом изучения в разделе статистики « Регрессионный анализ », т.к. есть основания сделать гипотезу о существовании причинно-следственной связи между управляемым фактором и прогнозируемой величиной.
Модели, строящиеся на основе причинно-следственных закономерностей, упомянуты в этой статье для того чтобы акцентировать, что их изучение предшествует теме «временные ряды». Так, часть методов, например «Регрессионный анализ» (используется метод наименьших квадратов — МНК ), используется при анализе временных рядов, но изучаются в моделях предметной области, поэтому неподготовленным «пытливым умам» не стоит игнорировать раздел статистики « Статистический вывод », в котором проверяются гипотезы о равенстве среднего значения и строятся доверительные интервалы для оценки среднего , и упомянутый выше «Регрессионный анализ».
Кратко о типах процессов и моделях для их прогнозирования
Выбор подходящей модели прогнозирования делается с учетом типа моделируемого процесса (наличие трендов). Рассмотрим основные типы процессов.
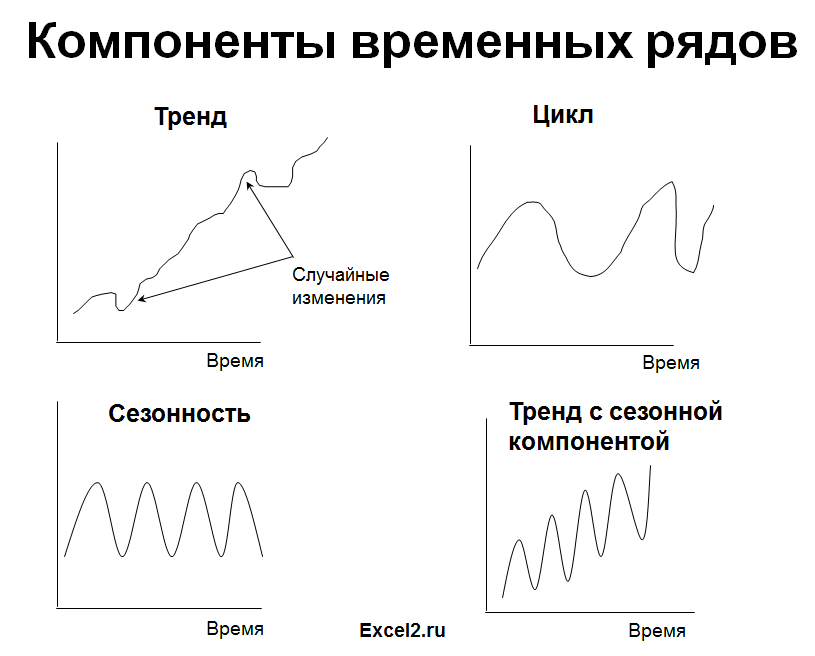
1. Стационарный процесс
Стационарный процесс – это случайный процесс чьи характеристики не зависят от времени их наблюдения. Этими характеристиками являются среднее значение , дисперсия и автоковариация. В стационарном процессе не могут быть выделены предсказуемые паттерны. Соответственно ряды демонстрирующие тренд и сезонность — не стационарны. А вот ряд с цикличностью (апериодической) является стационарным, т.к. на долгосрочном временном интервале появление циклов предсказать невозможно.
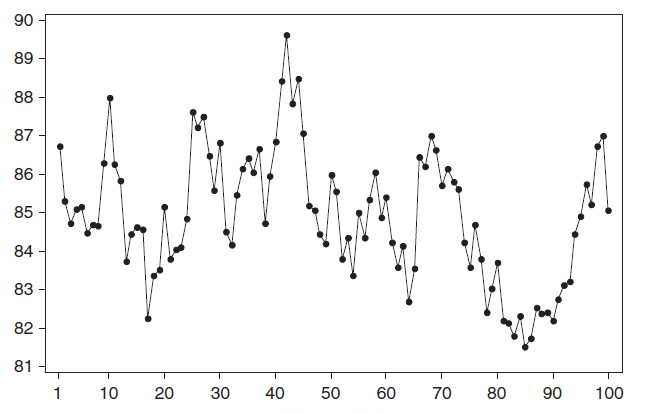
Почему стационарный процесс важен? Так как стационарность подразумевает нахождение процесса в состоянии статистической стабильности, то такие временные ряды имеют постоянное среднее значение и дисперсию, которые определяются стандартным образом.
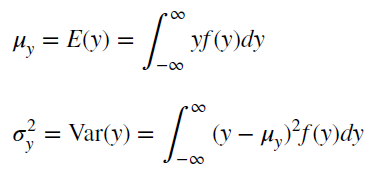
Также для стационарного процесса определяется функция автокорреляции – совокупность коэффициентов корреляции значений временного ряда с собственными значениями, сдвинутыми по времени на один или несколько периодов. Сдвиг на несколько временных периодов часто называется лагом (обозначается k).
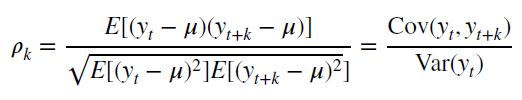
Функция автокорреляции является важным источником информации о временном ряде.
Примером стационарного процесса является колебания биржевого индекса, состоящего из стоимости акций нескольких компаний, около определённого значения (в период стабильности рынка).
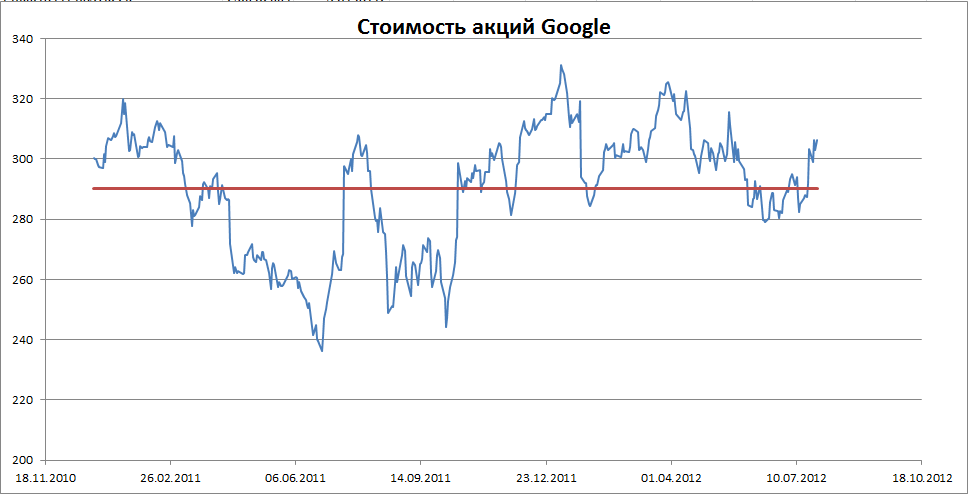
Примечание : график стоимости акций построен на реальных данных, см. файл примера Google .
Специальным видом стационарного процесса является белый шум. У этого процесса: среднее значений ряда равно 0, имеется конечная дисперсия и отсутствует корреляция между значениями исходного ряда и рядом сдвинутым на произвольное количество периодов (лагов). В MS EXCEL белый шум можно сгенерировать функцией СЛЧИС().
2. Линейный тренд
Некоторые процессы генерируют тренд (монотонное изменение значений ряда). Например, линейный тренд y=a*x+b, точнее y=a*t+b, где t – это время. Примером такого (не стационарного) процесса может быть монотонный рост стоимости недвижимости в некотором районе.
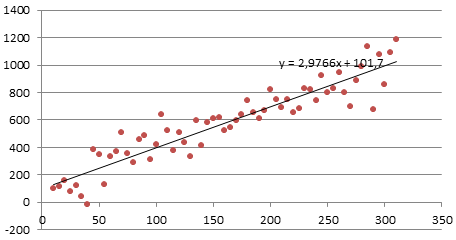
Для вычисления прогнозного значения можно воспользоваться методами Регрессионного анализа и подобрать параметры тренда: наклон и смещение по вертикали.
Примечание : Про генерацию случайных значений, демонстрирующих линейный тренд, можно посмотреть в статье Генерация данных для простой линейной регрессии в EXCEL .
3. Процессы, демонстрирующие сезонность
В сезонном процессе присутствует точно или примерно фиксированный интервал изменений, например, продажи некоторых товаров имеют четко выраженный пик в ноябре-декабре каждого года в связи с праздником.
Для прогнозирования вычисляется индекс сезонности, затем ряд очищается от сезонной компоненты. Если ряд также демонстрирует тренд, то после очистки от сезонности используются методы регрессионного анализа для вычисления тренда.
Примечание : Про генерацию случайных значений, демонстрирующих сезонность, можно посмотреть в статье Генерация сезонных трендов в EXCEL.
Часто на практике встречаются ряды, являющиеся комбинацией вышеуказанных типов тенденций.
О моделях прогнозирования
В качестве простейшей модели для прогноза можно взять последнее значение индекса. Этой модели соответствует следующий ход мысли исследователя: «Если значение индекса вчера было 306, то и завтра будет 306».
Этой модели соответствует формула Y прогноз(t) = Y t-1 (прогноз в момент времени t равен значению временного ряда в момент t-1).
Другой моделью является среднее за последние несколько периодов ( скользящее среднее ). Этой модели соответствует другой ход мысли исследователя: «Если среднее значение индекса за последние n периодов было 540, то и завтра будет 540». Этой модели соответствует формула Y прогноз(t) =(Y t-1 + Y t-2 +…+Y t-n )/n
Обратите внимание, что значения временного ряда берутся с одинаковым весом 1/n, то есть более ранние значения (в момент t-n) влияют на прогноз также как и недавние (в момент t-1). Конечно, в случае, если речь идет о стационарном процессе (без тренда), такая модель может быть приемлема. Чем больше количество периодов усреднения (n), тем меньше влияние каждого индивидуального наблюдения.
Третьей моделью для стационарного процесса может быть экспоненциальное сглаживание . В этом случае веса более ранних периодов будут меньше чем веса поздних. При этом учитываются все предыдущие наблюдения. Вес каждого последующего наблюдения больше на 1-α (Фактор затухания), где α (альфа) – это константа сглаживания (от 0 до 1).
Этой модели соответствует формула Y прогноз(t) =α*Y t-1 + α*(1-α)*Y t-2 + α*(1-α)2*Y t-3 +…)
Формулу можно переписать через предыдущий прогноз Y прогноз(t) =α*Y t-1 +(1- α)* Y прогноз(t-1) = α*(Y t-1 — Y прогноз(t-1) )+Y прогноз(t-1) = α*(ошибка прошлого прогноза)+ прошлый прогноз
При экспоненциальном сглаживании прогнозное значение равно сумме последнего наблюдения с весом альфа и предыдущего прогноза с весом (1-альфа). Этой модели соответствует следующий ход мысли исследователя: «Вчера рано утром я предсказывал, что индекс будет равен 500, но вчера в конце дня значение индекса составило 480 (ошибка составила 20). Поэтому за основу сегодняшнего прогноза я беру вчерашний прогноз и корректирую его на величину ошибки, умноженную на альфа. Параметр альфа (константа) я найду методом экспоненциального сглаживания».
Подробнее о методе прогнозирования на основе экспоненциального сглаживания можно найти в этой статье .
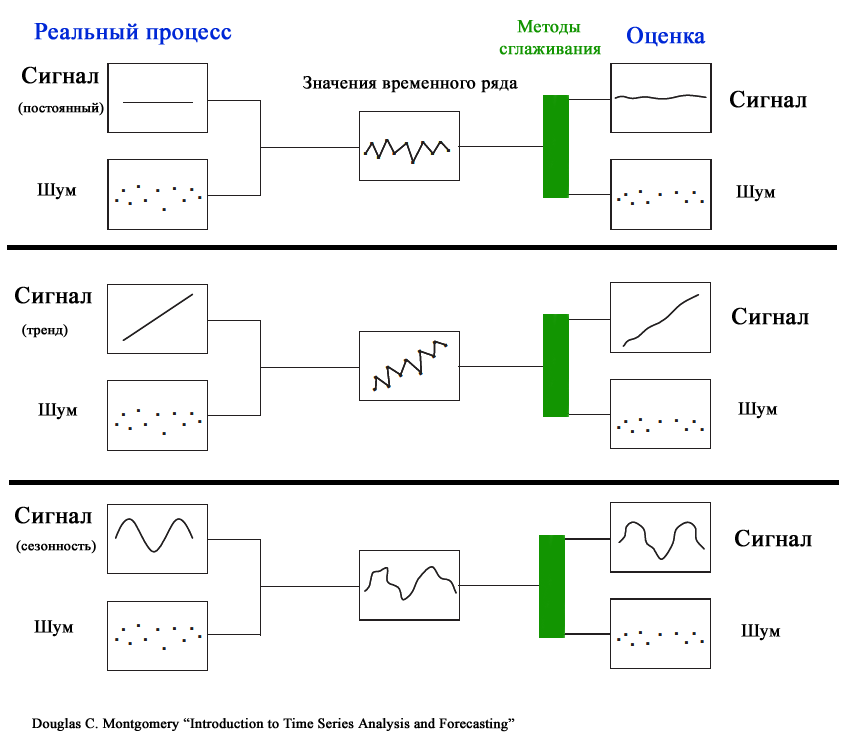
Полезный сигнал и шум
Из-за случайного разброса, присущему временному ряду, временной ряд представляют как комбинацию двух различных компонентов: полезного сигнала и шума (ошибки). Полезный сигнал следует одному из 3-х вышеуказанных типов процессов. Сигнал может быть смоделирован и соответственно спрогнозирован. Шум представляет собой случайные ошибки (со средним значением =0, отсутствием корреляции и с фиксированной дисперсией ).
Основной задачей моделирования идентификация полезного сигнала, имеющего определенный тренд, от непредсказуемого шума. Для этого как раз и используются Модели сглаживания.
Ссылки на источники статистических данных и обучающие материалы
Все источники англоязычные.
Анализ временных рядов, тренд ряда динамики, точечная оценка прогноза
Аннотация: Цель работы: научиться выполнять прогнозирование временного ряда данных с помощью средств Microsoft Excel и математически. Содержание работы: Анализ временных рядов. Прогноз, характеристики и параметры прогнозирования. Уравнение тренда временного ряда. Порядок выполнения работы: Изучить методические указания. Выполнить задания с использованием средств MS Excel. Оформить отчет, сделав выводы по заданиям.
МЕТОДИЧЕСКИЕ РЕКОМЕНДАЦИИ
Анализ временных рядов
Временной ряд (или ряд динамики) – это упорядоченная по времени последовательность значений некоторой произвольной переменной величины. Тем самым, временной ряд существенным образом отличается от простой выборки данных. Каждое отдельное значение данной переменной называется отсчётом (уровнем элементов) временного ряда.
Временные ряды состоят из двух элементов:
- периода времени, за который или по состоянию на который приводятся числовые значения;
- числовых значений того или иного показателя, называемых уровнями ряда.
Временные ряды классифицируются по следующим признакам:
- по форме представления уровней: ряды абсолютных показателей, относительных показателей, средних величин;
- по количеству показателей, когда определяются уровни в каждый момент времени: одномерные и многомерные временные ряды;
- по характеру временного параметра: моментные и интервальные временные ряды. В моментных временных рядах уровни характеризуют значения показателя по состоянию на определенные моменты времени. В интервальных рядах уровни характеризуют значение показателя за определенные периоды времени. Важная особенность интервальных временных рядов абсолютных величин заключается в возможности суммирования их уровней. Отдельные же уровни моментного ряда абсолютных величин содержат элементы повторного счета. Это делает бессмысленным суммирование уровней моментных рядов;
- по расстоянию между датами и интервалами времени выделяют равноотстоящие – когда даты регистрации или окончания периодов следуют друг за другом с равными интервалами и неполные (неравноотстоящие) – когда принцип равных интервалов не соблюдается;
- по наличию пропущенных значений: полные и неполные временные ряды. Временные ряды бывают детерминированными и случайными: первые получают на основе значений некоторой неслучайной функции (ряд последовательных данных о количестве дней в месяцах); вторые есть результат реализации некоторой случайной величины;
- в зависимости от наличия основной тенденции выделяют стационарные ряды – в которых среднее значение и дисперсия постоянны и нестационарные – содержащие основную тенденцию развития.
Временные ряды, как правило, возникают в результате измерения некоторого показателя. Это могут быть как показатели (характеристики) технических систем, так и показатели природных, социальных, экономических и других систем (например, погодные данные). Типичным примером временного ряда можно назвать биржевой курс, при анализе которого пытаются определить основное направление развития (тенденцию или тренда).
Анализ временных рядов – совокупность математико-статистических методов анализа, предназначенных для выявления структуры временных рядов и для их прогнозирования. Сюда относятся, в частности, методы регрессионного анализа. Выявление структуры временного ряда необходимо для того, чтобы построить математическую модель того явления, которое является источником анализируемого временного ряда. Прогноз будущих значений временного ряда используется для эффективного принятия решений.
Прогноз, характеристики и параметры прогнозирования
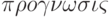
Прогноз (от греч. – предвидение, предсказание) – предсказание будущего с помощью научных методов, а также сам результат предсказания. Прогноз – это научная модель будущего события, явлений и т.п.
Прогнозирование, разработка прогноза; в узком значении – специальное научное исследование конкретных перспектив развития какого-либо процесса.
- по срокам: краткосрочные, среднесрочные, долгосрочные;
- по масштабу: личные, на уровне предприятия (организации), местные, региональные, отраслевые, мировые (глобальные).
К основным методам прогнозирования относятся:
- статистические методы;
- экспертные оценки (метод Дельфи);
- моделирование.
Прогноз – обоснованное суждение о возможном состоянии объекта в будущем или альтернативных путях и сроках достижения этих состояний. Прогнозирование – процесс разработки прогноза. Этап прогнозирования – часть процесса разработки прогнозов, характеризующаяся своими задачами, методами и результатами. Деление на этапы связано со спецификой построения систематизированного описания объекта прогнозирования, сбора данных, с построением модели, верификацией прогноза.
Прием прогнозирования – одна или несколько математических или логических операций, направленных на получение конкретного результата в процессе разработки прогноза. В качестве приема могут выступать сглаживание динамического ряда, определение компетентности эксперта, вычисление средневзвешенного значения оценок экспертов и т. д.
Модель прогнозирования – модель объекта прогнозирования, исследование которой позволяет получить информацию о возможных состояниях объекта прогнозирования в будущем и (или) путях и сроках их осуществления.
Метод прогнозирования – способ исследования объекта прогнозирования, направленный на разработку прогноза. Методы прогнозирования являются основанием для методик прогнозирования.
Методика прогнозирования – совокупность специальных правил и приемов (одного или нескольких методов) разработки прогнозов.
Прогнозирующая система – система методов и средств их реализации, функционирующая в соответствии с основными принципами прогнозирования. Средствами реализации являются экспертная группа, совокупность программ и т. д. Прогнозирующие системы могут быть автоматизированными и неавтоматизированными.
Прогнозный вариант – один из прогнозов, составляющих группу возможных прогнозов.
Объект прогнозирования – процесс, система, или явление, о состоянии которого даётся прогноз.
Характеристика объекта прогнозирования – качественное или количественное отражение какого-либо свойства объекта прогнозирования.
Переменная объекта прогнозирования – количественная характеристика объекта прогнозирования, которая является или принимается за изменяемую в течение периода основания и (или) периода упреждения прогноза.
Период основания прогноза – промежуток времени, за который используют информацию для разработки прогноза. Этот промежуток времени называют также периодом предыстории.
Период упреждения прогноза – промежуток времени, на который разрабатывается прогноз.
Прогнозный горизонт – максимально возможный период упреждения прогноза заданной точности.
Точность прогноза – оценка доверительного интервала прогноза для заданной вероятности его осуществления.
Достоверность прогноза – оценка вероятности осуществления прогноза для заданного доверительного интервала.
Ошибка прогноза – апостериорная величина отклонения прогноза от действительного состояния объекта.
Источник ошибки прогноза – фактор, способный привести к появлению ошибки прогноза. Различают источники регулярных и нерегулярных ошибок.
Верификация прогноза – оценка достоверности и точности или обоснованности прогноза.
Статистические методы прогнозирования – научная и учебная дисциплина, к основным задачам которой относятся разработка, изучение и применение современных математико-статистических методов прогнозирования на основе объективных данных; развитие теории и практики вероятностно-статистического моделирования экспертных методов прогнозирования; методов прогнозирования в условиях риска и комбинированных методов прогнозирования с использованием совместно экономико-математических и эконометрических (как математико-статистических, так и экспертных) моделей. Научной базой статистических методов прогнозирования является прикладная статистика и теория принятия решений.
Простейшие методы восстановления используемых для прогнозирования зависимостей исходят из заданного временного ряда, т. е. функции, определённой в конечном числе точек на оси времени. Временной ряд при этом часто рассматривается в рамках той или иной вероятностной модели, вводятся другие факторы (независимые переменные), помимо времени, например, объем денежной массы. Временной ряд может быть многомерным. Основные решаемые задачи – интерполяция и экстраполяция. Метод наименьших квадратов в простейшем случае (линейная функция от одного фактора) был разработан К. Гауссом в 1794–1795 гг. Могут оказаться полезными предварительные преобразования переменных, например, логарифмирование. Наиболее часто используется метод наименьших квадратов при нескольких факторах.
Оценивание точности прогноза (в частности, с помощью доверительных интервалов) – необходимая часть процедуры прогнозирования. Обычно используют вероятностно-статистические модели восстановления зависимости, например, строят наилучший прогноз по методу максимального правдоподобия. Разработаны параметрические (обычно на основе модели нормальных ошибок) и непараметрические оценки точности прогноза и доверительные границы для него (на основе Центральной Предельной Теоремы теории вероятностей). Применяются также эвристические приемы, не основанные на вероятностно-статистической теории: метод скользящих средних, метод экспоненциального сглаживания.
Многомерная регрессия, в том числе с использованием непараметрических оценок плотности распределения – основной на настоящий момент статистический аппарат прогнозирования. Нереалистическое предположение о нормальности погрешностей измерений и отклонений от линии (поверхности) регрессии использовать не обязательно; однако для отказа от предположения нормальности необходимо опереться на иной математический аппарат, основанный на многомерной Центральной Предельной Теореме теории вероятностей, технологии линеаризации и наследования сходимости. Он позволяет проводить точечное и интервальное оценивание параметров, проверять значимость их отличия от 0 в непараметрической постановке, строить доверительные границы для прогноза.
Уравнение тренда временного ряда
Рассматривая временной ряд как множество результатов наблюдений изучаемого процесса, проводимых последовательно во времени, в качестве основных целей исследования временных рядов можно выделить: выявление и анализ характерного изменения параметра у, оценка возможного изменения параметра в будущем (прогноз).
Значения временного ряда можно представить в виде: 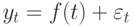 , где f (t) – неслучайная функция, описывающая связь оценки математического ожидания со временем,
, где f (t) – неслучайная функция, описывающая связь оценки математического ожидания со временем, 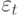 – случайная величина, характеризующая отклонение уровня от f(t ).
– случайная величина, характеризующая отклонение уровня от f(t ).
Неслучайная функция f (t) называется трендом. Тренд отражает характерное изменение (тенденцию) yt за некоторый промежуток времени. На практике в качестве тренда выбирают несколько возможных теоретических или эмпирических моделей. Могут быть выбраны, например, линейная, параболическая, логарифмическая, показательная функции. Для выявления типа модели на координатную плоскость наносят точки с координатами ( t, yt ) и по характеру расположения точек делают вывод о виде уравнения тренда. Для получения уравнения тренда применяют различные методы: сглаживание с помощью скользящей средней, метод наименьших квадратов и другие.
Уравнение тренда линейного вида будем искать в виде yt=f(t ), где f (t) = a0+a1(t ).
Пример 1. Имеется временной ряд:
| ti | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| xti | 2 | 1 | 4 | 4 | 6 | 8 | 7 | 9 | 12 | 11 |
Построим график xti во времени. Добавим на графике линию тренда исходных значений ряда. При этом, щелкнув правой кнопкой мыши по линии тренда, можно вызвать контекстное меню «Формат линии тренда», а в нем поставить флажок «показывать уравнение на диаграмме», тогда на диаграмме высветится уравнение линии тренда, вычисленное встроенными возможностями Excel .
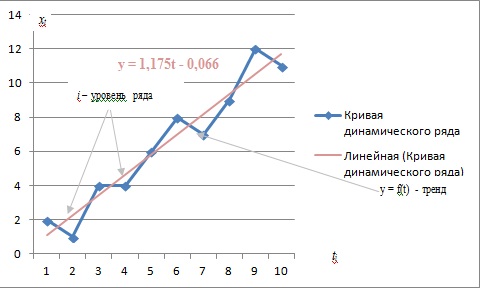
Рис. 14.1.
Чтобы определить уравнение тренда, необходимо найти значения коэффициентов а0 и а1. Эти коэффициенты следует определять, исходя из условия минимального отклонения значений функции f (t) в точках ti от значений исходного временного ряда в тех же точках ti . Это условие можно записать в виде (на основе метода наименьших квадратов):
![$\sum\limits_<t=1></p>
<p>^[x_-a_-a_t]^\rightarrow min\eqno(1)$» /></p>
<p>где n – количество значений временного ряда.</p>
<p><img decoding=](https://intuit.ru/sites/default/files/tex_cache/56404890c825202167c4ba34001e2250.png)
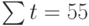
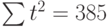
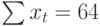
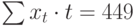
Рис. 14.2.
Временной ряд приведен в таблице. Используя средства MS Excel :
- построить график временного ряда;
- добавить линию тренда и ее уравнение;
- найти уравнение тренда методом наименьших квадратов, сравнить уравнения (выше на графике и полученное);
- построить график временного ряда и полученной функции тренда в одной системе координат.
1. Реализация аспирина по аптеке (у.е.) за последние 7 недель приведена в таблице:
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| хti | 3,2 | 3,3 | 2,9 | 2,2 | 1,6 | 1,5 | 1,2 |
2. Динамика потребления молочных продуктов (у.е.) по району за последние 7 месяцев:
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| хti | 30 | 29 | 27 | 24 | 25 | 24 | 23 |
3. Динамика числа работников, занятых в одной из торговых сетей города за последние 8 лет приведена в таблице:
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 280 | 361 | 384 | 452 | 433 | 401 | 512 | 497 |
4. Динамика потребления сульфаниламидных препаратов в клинике по годам (тыс. упаковок):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 14 | 21 | 29 | 33 | 38 | 44 | 46 | 50 |
5. Динамика продаж однокомнатных квартир в городе за последние 8 лет (тыс. ед.):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| уt | 39 | 40 | 36 | 34 | 36 | 37 | 33 | 35 |
6. Динамика потребления антибиотиков в клинике (тыс. упаковок):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 10 | 17 | 18 | 13 | 17 | 21 | 25 | 29 |
7. Динамика производства хлебобулочных изделий на хлебозаводе (тонн):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 510 | 502 | 564 | 680 | 523 | 642 | 728 | 665 |
8. Динамика потребления противовирусных препаратов по аптечной сети в начале эпидемии гриппа (тыс. единиц):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 36 | 42 | 34 | 38 | 12 | 32 | 26 | 20 |
9. Динамика потребления противовирусных препаратов по аптечной сети в конце эпидемии гриппа (тыс. единиц):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 46 | 52 | 44 | 48 | 32 | 42 | 36 | 30 |
10. Динамика потребления витаминов по аптечной сети в весенний период (с марта по апрель) в разные годы (у.е.):
| t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| хti | 0,9 | 1,7 | 1,5 | 1,7 | 1,5 | 2,1 | 2,5 | 3,6 |
Пример 2. Используя данные примера 1, приведенного выше, вычислить точечный прогноз исходного временного ряда на 5 шагов вперед.
Исходя из условия задачи, необходимо определить точечную оценку прогноза для t = 11, 12, 13, 14, 15, где t в данном случае – шаг упреждения.
Рассмотрим решение этой задачи средствами Microsoft Excel . При решении данной задачи следует так же, как и в примере 1, ввести исходные данные. Выделив данные, построить точечный график, щелкнув правой кнопкой мыши по ряду данных, вызвать контекстное меню и выбрать «Добавить линию тренда».
Щелкнув правой кнопкой мыши по линии тренда, вызвать контекстное меню, выбрать «Формат линии тренда», в окне Параметры линии тренда указать прогноз на 5 периодов и поставить флажок в окошке «Показывать уравнение на диаграмме (рис. 14.3 рис. 14.3.). В версии Excel ранее 2007 окно диалога представлено на рисунке 14.4 рис. 14.4.
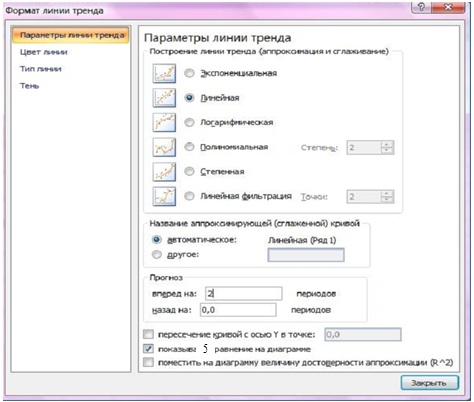
Рис. 14.3. Задание параметров тренда в MS Excel 2007
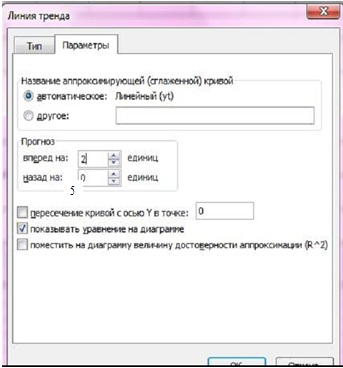
Рис. 14.4. Задание параметров тренда в версии ранее MS Excel 2007
Итоговый график представлен на рисунке 14.5 рис. 14.5.
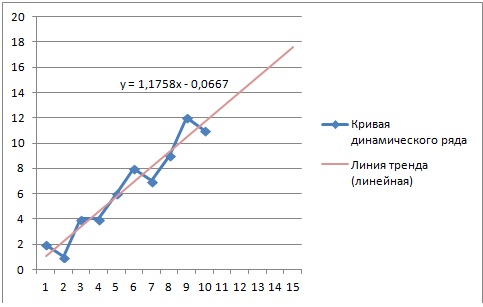
Рис. 14.5.
Значения прогноза для 11, 12, 13, 14 и 15 уровней получим, используя функцию ПРЕДСКАЗ( ). Данная функция позволяет получить значения прогноза линейного тренда. Вычисленные значения: 12,87, 14,04, 15,22, 16,39, 17,57.
Значения точечного прогноза для исходного временного ряда на 5 шагов вперед можно вычислить и с помощью уравнения функции тренда f(t ), найденного по методу наименьших квадратов. Для этого в полученное для f (t) выражение необходимо подставить значения t = 11, 12, 13, 14, 15. В результате получим (эти значения следует рассчитать, сформировав формулу в табличном процессоре MS Excel ):
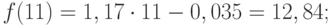
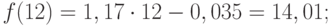
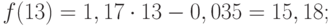
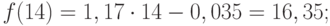
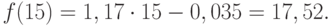
Научитесь использовать все прикладные инструменты из функционала MS Excel.
Любому бизнесу интересно заглянуть в будущее и правильно ответить на вопрос: «А сколько денег мы заработаем за следующий период?» Ответить на такого рода вопросы позволяют различные методики прогнозирования. В данной статье мы с вами рассмотрим несколько таких методик и произведем все необходимые расчеты в Excel. Еще больше про анализ данных в Excel мы рассказываем на нашем открытом курсе «Аналитика в Excel».
Постановка задачи
Исходные данные
Для начала, давайте определимся, какие у нас есть исходные данные и что нам нужно получить на выходе. Фактически, все что у нас есть, это некоторые исторические данные. Если мы говорим о прогнозировании продаж, то историческими данными будут продажи за предыдущие периоды.
Примечание. Собранные в разные моменты времени значения одной и той же величины образуют временной ряд. Каждое значение такого временного ряда называется измерением. Например: данные о продажах за последние 5 лет по месяцам — временной ряд; продажи за январь прошлого года — измерение.
Составляющие прогноза
Следующий шаг: давайте определимся, что нам нужно учесть при построении прогноза. Когда мы исследуем наши данные, нам необходимо учесть следующие факторы:
- Изменение нашей пронозируемой величины (например, продаж) подчиняется некоторому закону. Другими словами, в временном ряде можно проследить некую тенденцию. В математике такая тенденция называется трендом.
- Изменение значений в временном ряде может зависить от промежутка времени. Другими словами, при построении модели необходимо будет учесть коэффициент сезонности. Например, продажи арбузов в январе и августе не могут быть одинаковыми, т.к. это сезонный продукт и летом продажи значительно выше.
- Изменение значений в временном ряде периодически повторяется, т.е. наблюдается некоторая цикличность.
Эти три пункта в совокупность образуют регулярную составляющую временного ряда.
Примечание. Не обязательно все три элемента регулярной составляющей должны присутствовать в временном ряде.
Однако, помимо регулярной составляющей, в временном ряде присутствует еще некоторое случайное отклонение. Интуитивно это понятно – продажи могут зависеть от многих факторов, некоторые из которых могут быть случайными.
Вывод. Чтобы комплексно описать временной ряд, необходимо учесть 2 главных компонента: регулярную составляющую (тренд + сезонность + цикличность) и случайную составляющую.
Виды моделей
Следующий вопрос, на который нужно ответить при построении прогноза: “А какие модели временного ряда бывают?”
Обычно выделяют два основных вида:
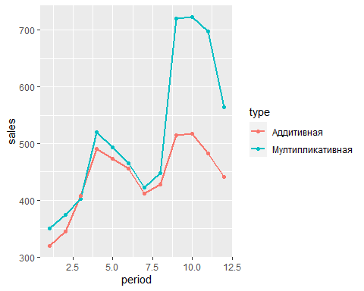
- Аддитивная модель: Уровень временного ряда = Тренд + Сезонность + Случайные отклонения
- Мультипликативная модель: Уровень временного ряда = Тренд X Сезонность X Случайные отклонения
Иногда также выделают смешанную модель в отдельную группу:
- Смешанная модель: Уровень временного ряда = Тренд X Сезонность + Случайные отклонения
С моделями мы определились, но теперь возникает еще один вопрос: «А когда какую модель лучше использовать?»
Классический вариант такой:
— Аддитивная модель используется, если амплитуда колебаний более-менее постоянная;
— Мультипликативная – если амплитуда колебаний зависит от значения сезонной компоненты.
Решение задачи с помощью Excel
Итак, необходимые теоретические знания мы с вами получили, пришло время применить их на практике. Мы будем с вами использовать классическую аддитивную модель для построения прогноза. Однако, мы построим с вами два прогноза:
- с использованием линейного тренда
- с использованием полиномиального тренда
Во всех руководствах, как правило, разбирается только линейный тренд, поэтому полиномиальная модель будет крайне полезна для вас и вашей работы!

Научитесь использовать все прикладные инструменты из функционала MS Excel.
Модель с линейным трендом
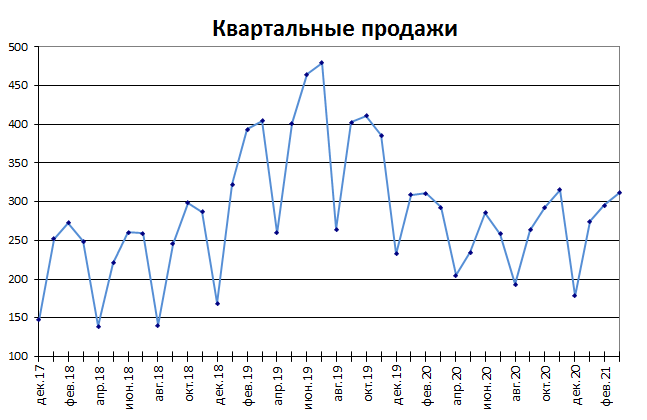
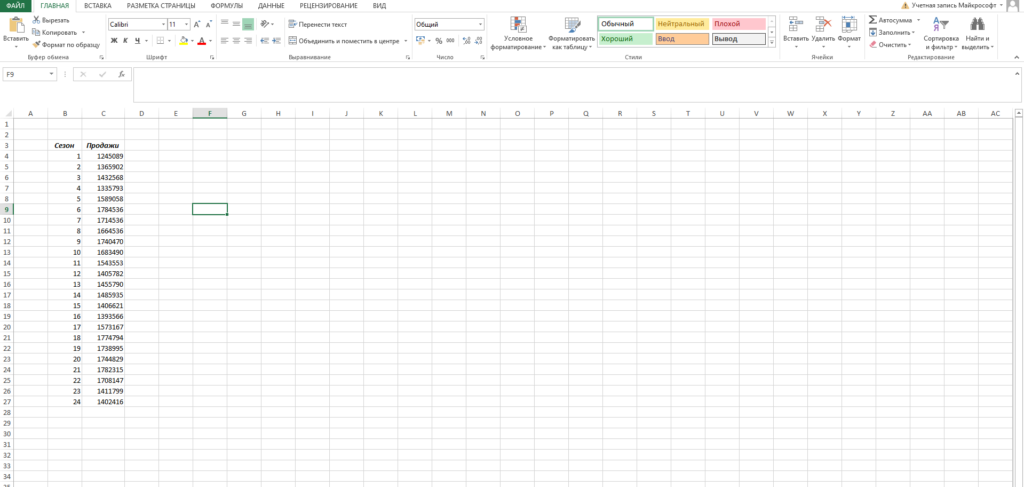
Пусть у нас есть исходная информация по продажам за 2 года:
Учитывая, что мы используем линейный тренд, то нам необходимо найти коэффициенты уравнения
- y – значения продаж
- x – номер периода
- a – коэффициент наклона прямой тренда
- b – свободный член тренда
Рассчитать коэффициенты данного уравнения можно с помощью формулы массива и функции ЛИНЕЙН. Нам необходимо будет сделать следующую последовательность действий:
- Выделяем две ячейки рядом
- Ставим курсор в поле формул и вводим формулу =ЛИНЕЙН(C4:C27;B4:B27)
- Нажимаем Ctrl+Shift+Enter, чтобы активировать формулу массива
На выходе мы получили 2 числа: первое — коэффициент a, второе – свободный член b.
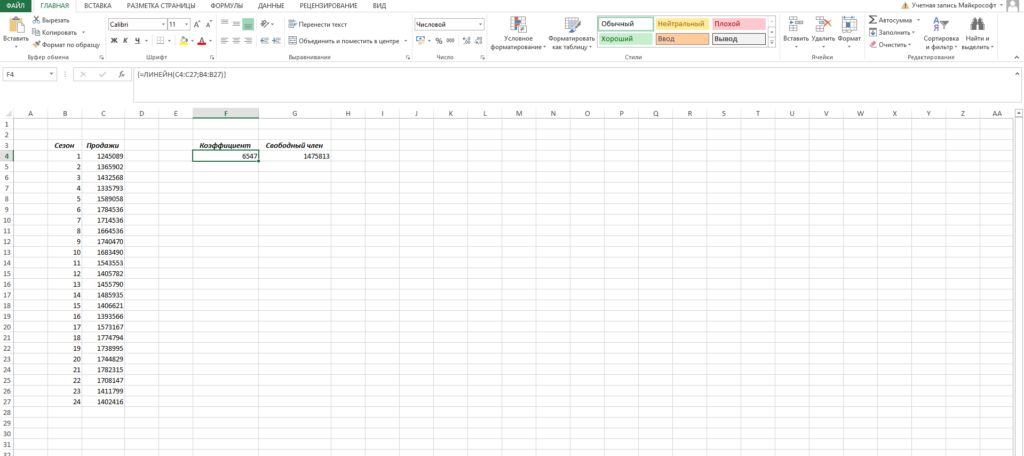
Теперь нам нужно рассчитать для каждого периода значение линейного тренда. Сделать это крайне просто — достаточно в полученное уравнение подставить известные номера периодов. Например, в нашем случае, мы прописываем формулу =B4*$F$4+$G$4 в ячейке I4 и протягиваем ее вниз по всем периодам.
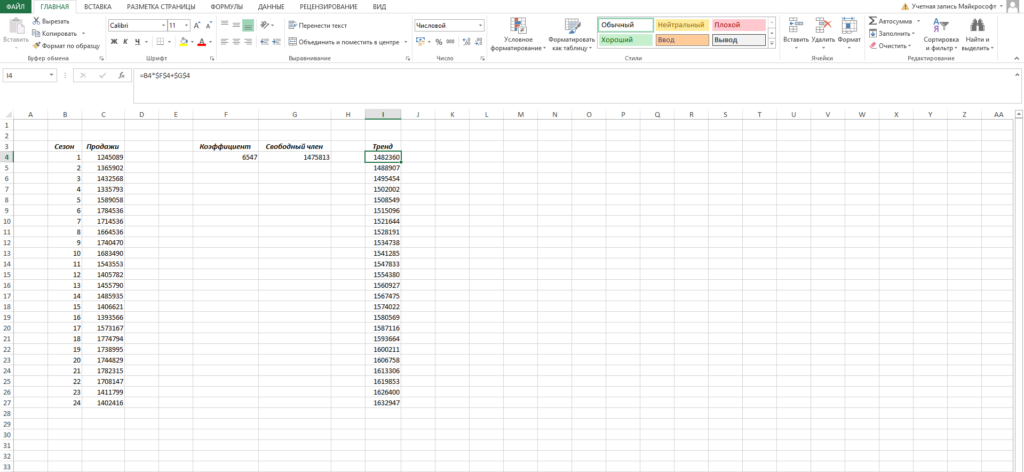
Нам осталось рассчитать коэффициент сезонности для каждого периода. Учитывая, что у нас есть исторические данные за два года, разумно будет учесть это при расчете. Можем сделать следующим образом: в ячейке J4 прописываем формулу =(C4+C16)/СРЗНАЧ($C$4:$C$27)/2 и протягиваем вниз на 12 месяцев (т.е. до J15).
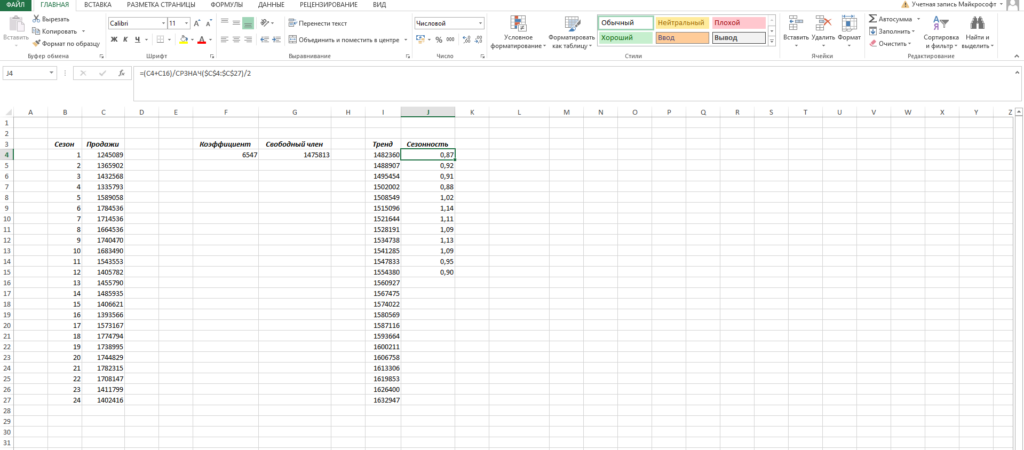
Что нам это дало? Мы посчитали, сколько суммарно продавалось каждый январь/каждый февраль и так далее, а потом разделили это на среднее значение продаж за все два периода.
То есть мы выяснили, как продажи двух январей отклонялись от средних продаж за два года, как продажи двух февралей отклонялись и так далее. Это и дает нам коэффициент сезонности. В конце формулы делим на 2, т.к. в расчете фигурировало 2 периода.
Примечание. Рассчитали только 12 коэффициентов, т.к. один коэффициент учитывает продажи сразу за 2 аналогичных периода.
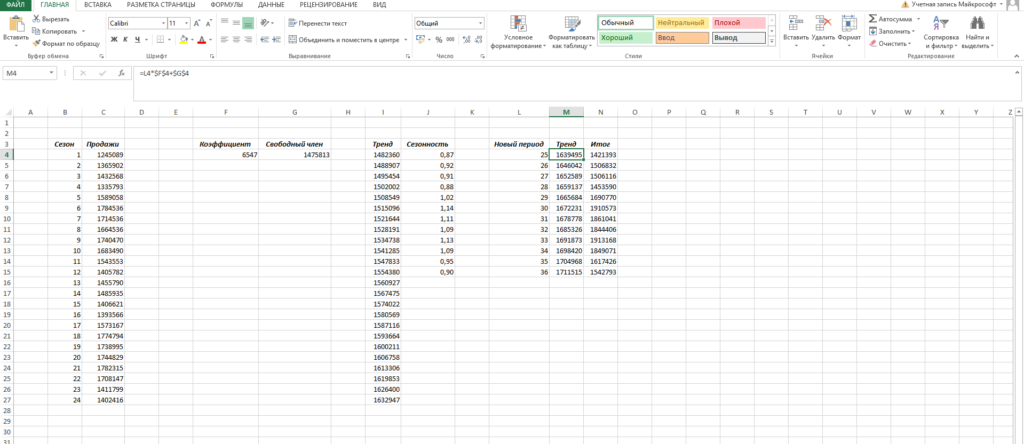
Итак, теперь мы на финишной прямой. Нам осталось рассчитать тренд для будущих периодов и учесть коэффициент сезонности для них. Давайте амбициозно построим прогноз на год вперед.
Сначала создаем столбец, в котором прописываем номера будущих периодов. В нашем случае нумерация начинается с 25 периода.
Далее, для расчета значения тренда просто прописываем уже известную нам формулу =L4*$F$4+$G$4 и протягиваем вниз на все 12 прогнозируемых периодов.
И последний штрих — умножаем полученное значение на коэффициент сезонности. Вуаля, это и есть итоговый ответ в данной модели!
Модель с полиномиальным трендом
Конструкция, которую мы только что с вами построили, достаточно проста. Но у нее есть один большой минус — далеко не всегда она дает достоверные результаты.
Посмотрите сами, какая модель более точно аппроксимирует наши точки — линейный тренд (прямая зеленая линия) или полиномиальный тренд (красная кривая)? Ответ очевиден. Поэтому сейчас мы с вами и разберем, как построить полиномиальную модель в Excel.
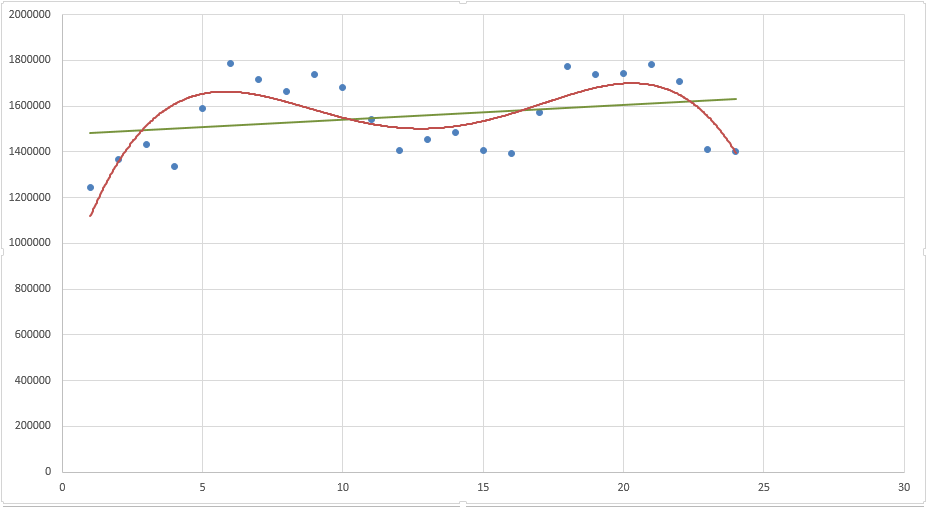
Пусть все исходные данные у нас будут такими же. Для простоты модели будем учитывать только тренд, без сезонной составляющей.
Для начала давайте определимся, чем полиномиальный тренд отличается от обычного линейного. Правильно — формой уравнения. У линейного тренда мы разбирали обычный график прямой:
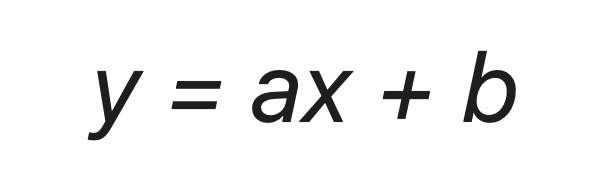
У полиномиального тренда же уравнение выглядит иначе:
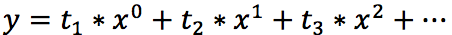
где конечная степень определяется степенью полинома.
Т.е. для полинома 4 степени необходимо найти коэффициенты уравнения:
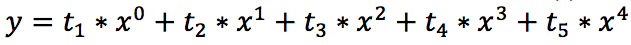
Согласитесь, выглядит немного страшно. Однако, ничего страшного нет, и мы с легкостью можем решить эту задачку с помощью уже известных нам методов.
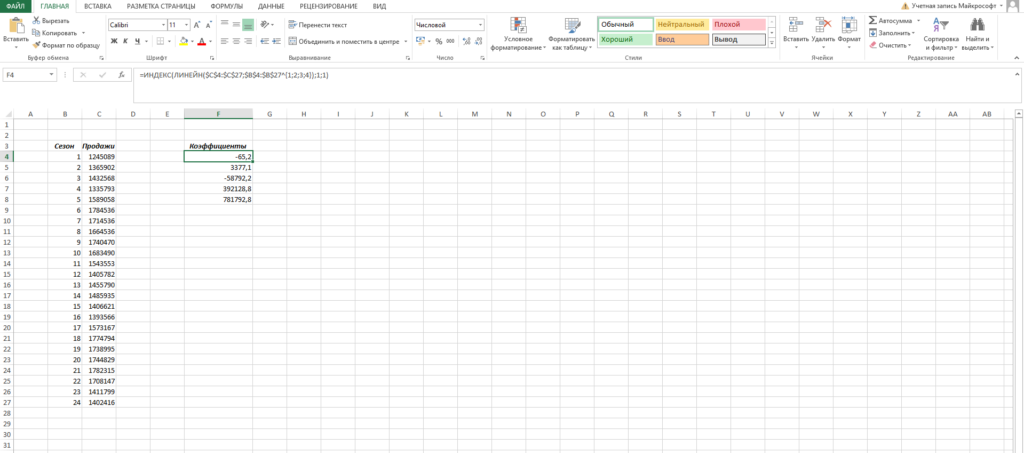
- Ставим в ячейку F4 курсор и вводим формулу =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^);1;1). Функция ЛИНЕЙН позволяет произвести расчет коэффициентов, а с помощью функции ИНДЕКС мы вытаскиваем нужный нам коэффициент. В данном случае за выбор коэффициента отвечает самый последний аргумент. У нас стоит 1 — это коэффициент при самой высокой степени (т.е. при 4 степени, коэффициент). Кстати, узнать о самых полезных математических формулах Excel можно в нашем бесплатном гайде «Математические функции Excel».
- Аналогично прописываем формулу =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^);1;2) в ячейке ниже.
- Делаем такие же действия, пока не найдем все коэффициенты.
Кстати говоря, мы можем легко сами себя проверить. Давайте построим график наших продаж и добавим к нему полиномиальный тренд.
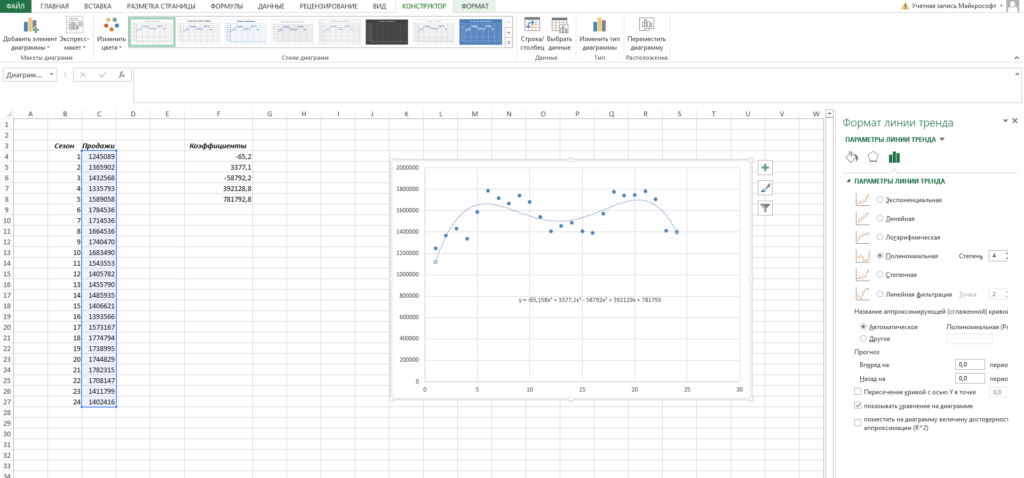
- Выделяем столбец с продажами
- Выбираем «Вставка» → «График» → «Точечный» → «Точечная диаграмма»
- Нажимаем на любую точку графика правой кнопкой мыши и выбираем «Добавить линию тренда»
- В открывшемся справа меню выбираем «Полиномиальная модель», меняем степень на 4 и ставим галочку на «Показывать уравнение на диаграмме»
Теперь вы наглядно можете видеть, как рассчитанный тренд аппроксимирует исходные данные и как выглядит само уравнение. Можно сравнить уравнение на графике с вашими коэффициентами. Сходится? Значит сделали все верно!
Помимо всего прочего, вы можете сразу оценить точность аппроксимации (не полностью, но хотя бы первично). Это делается с помощью коэффициента R^2. Тут у вас снова есть два пути:
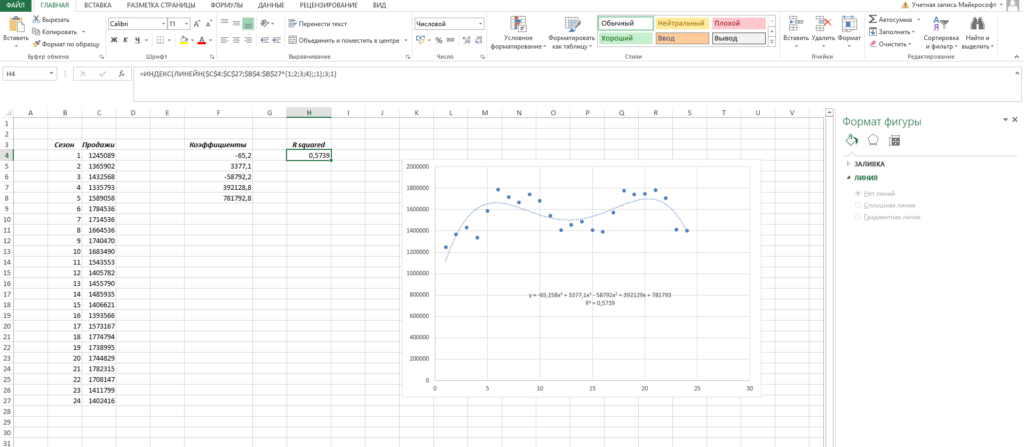
- Вы можете вывести коэффициент на график, поставив галочку «Поместить на диаграмму величину достоверности аппроксимации»
- Вы можете рассчитать коэффициент R^2 самостоятельно по формуле =ИНДЕКС(ЛИНЕЙН($C$4:$C$27;$B$4:$B$27^;;1);3;1)
Заключение
Мы с вами подробно разобрали вопрос прогнозирования — изучили необходимые термины и виды моделей, построили аддитивную модель в Excel с использованием линейного и полиномиального тренда, а также научились отображать результаты своих вычислений на графиках. Все это позволит вам эффективно внедрять полученные знания на работе, усложнять существующие модели и уточнять прогнозы. Чем большим количеством методов и инструментов вы будете владеть, тем выше будет ваш профессиональный уровень и статус на рынке труда.
Если вас интересуют еще какие-то модели прогнозирования — напишите нам об этом, и мы постараемся осветить эти темы в дальнейших своих статьях! Или запишитесь на курс «Excel Academy» от SF Education, где мы рассказываем про возможности Excel, необходимые для анализа.
Автор: Алексанян Андрон, эксперт SF Education
Научитесь использовать все прикладные инструменты из функционала MS Excel.