Как подсчитать пропущенные значения в Pandas DataFrame
Часто вас может заинтересовать подсчет количества пропущенных значений в кадре данных pandas.
В этом руководстве показано несколько примеров подсчета пропущенных значений с использованием следующего кадра данных:
import pandas as pd import numpy as np #create DataFrame with some missing values df = pd.DataFrame() #view DataFrame print(df) a b c 0 4.0 NaN 11.0 1 NaN 6.0 8.0 2 NaN 8.0 10.0 3 7.0 14.0 6.0 4 8.0 29.0 6.0 5 12.0 NaN NaN Подсчитайте общее количество пропущенных значений во всем DataFrame
В следующем коде показано, как рассчитать общее количество пропущенных значений во всем DataFrame:
df.isnull().sum().sum () 5 Это говорит нам о том, что всего пропущено 5 значений.
Подсчитайте общее количество пропущенных значений в столбце
В следующем коде показано, как рассчитать общее количество пропущенных значений в каждом столбце DataFrame:
df.isnull().sum () a 2 b 2 c 1 Это говорит нам:
- Столбец «а» имеет 2 пропущенных значения.
- Столбец «b» имеет 2 пропущенных значения.
- Столбец «c» имеет 1 пропущенное значение.
Вы также можете отобразить количество пропущенных значений в процентах от всего столбца:
df.isnull().sum ()/ len(df)\* 100 a 33.333333 b 33.333333 c 16.666667 Это говорит нам:
- 33,33% значений в столбце «а» отсутствуют.
- 33,33% значений в столбце «b» отсутствуют.
- 16,67% значений в столбце «c» отсутствуют.
Подсчитайте общее количество пропущенных значений в строке
В следующем коде показано, как рассчитать общее количество пропущенных значений в каждой строке DataFrame:
df.isnull().sum (axis= 1 ) 0 1 1 1 2 1 3 0 4 0 5 2 Это говорит нам:
- В строке 1 отсутствует 1 значение.
- В строке 2 отсутствует 1 значение.
- В строке 3 отсутствует 1 значение.
- В строке 4 пропущено 0 значений.
- Строка 5 имеет 0 пропущенных значений.
- В строке 6 есть 2 пропущенных значения.
Как подсчитать количество значений NaN в столбце DataFrame в pandas?

В работе с данными на Python, особенно с большими наборами данных, часто приходится сталкиваться с пропущенными или неполными данными. Эти данные обычно представлены как NaN (Not a Number) в DataFrame библиотеки pandas. Важным этапом предварительной обработки данных является обнаружение и обработка таких значений.
Рассмотрим следующий DataFrame в pandas:
import pandas as pd import numpy as np data = df = pd.DataFrame(data)
При выводе этого DataFrame на экран, значения NaN будут отображены, указывая на места пропущенных или недостающих данных.
Чтобы подсчитать количество значений NaN в каждом столбце DataFrame, можно использовать метод isnull() , который возвращает DataFrame того же размера, заполненный булевыми значениями. Этот метод возвращает True там, где первоначальные данные были NaN , и False в противном случае.
Затем, чтобы подсчитать количество True (то есть NaN в исходных данных) в каждом столбце, можно использовать метод sum() .
В итоге, для подсчета значений NaN в каждом столбце достаточно применить следующую команду:
df.isnull().sum()
Эта команда вернет серию, где индекс будет именами столбцов исходного DataFrame, а значения — количеством NaN в каждом столбце.
Важно помнить, что работа с пропущенными данными — важная часть предварительной обработки данных, и правильное обращение с ними может значительно повлиять на качество последующего анализа данных.
Как анализировать данные на Python с Pandas: первые шаги


Мария Жарова Эксперт по Python и математике для Data Science, ментор одного из проектов на курсе по Data Science.
Pandas — главная Python-библиотека для анализа данных. Она быстрая и мощная: в ней можно работать с таблицами, в которых миллионы строк. Вместе с Марией Жаровой, ментором проекта на курсе по Data Science, рассказываем про команды, которые позволят начать работать с реальными данными.
Среда разработки
Pandas работает как в IDE (средах разработки), так и в облачных блокнотах для программирования. Как установить библиотеку в конкретную IDE, читайте тут. Мы для примера будем работать в облачной среде Google Colab. Она удобна тем, что не нужно ничего устанавливать на компьютер: файлы можно загружать и работать с ними онлайн, к тому же есть совместный режим для работы с коллегами. Про Colab мы писали в этом обзоре. Пройдите тест и узнайте, какой вы аналитик данных и какие перспективы вас ждут. Ссылка в конце статьи.

Освойте профессию «Data Scientist» на курсе с МГУ
Data Scientist с нуля до PRO
Освойте профессию Data Scientist с нуля до уровня PRO на углубленном курсе совместно с академиком РАН из МГУ. Изучите продвинутую математику с азов, получите реальный опыт на практических проектах и начните работать удаленно из любой точки мира.

25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями
6 224 ₽/мес 11 317 ₽/мес

Анализ данных в Pandas
-
Создание блокнота в Google Colab На сайте Google Colab сразу появляется экран с доступными блокнотами. Создадим новый блокнот:
Импортирование библиотеки Pandas недоступна в Python по умолчанию. Чтобы начать с ней работать, нужно ее импортировать с помощью этого кода:
import pandas as pd
pd — это распространенное сокращенное название библиотеки. Далее будем обращаться к ней именно так.
И прочитать с помощью такой команды:
Это можно сделать через словарь и через преобразование вложенных списков (фактически таблиц).

Если нужно посмотреть на другое количество строк, оно указывается в скобках, например df.head(12) . Последние строки фрейма выводятся методом .tail() .
Также чтобы просто полностью красиво отобразить датасет, используется функция display() . По умолчанию в Jupyter Notebook, если написать имя переменной на последней строке какой-либо ячейки (даже без ключевого слова display), ее содержимое будет отображено.

Характеристики датасета Чтобы получить первичное представление о статистических характеристиках нашего датасета, достаточно этой команды: df.describe()
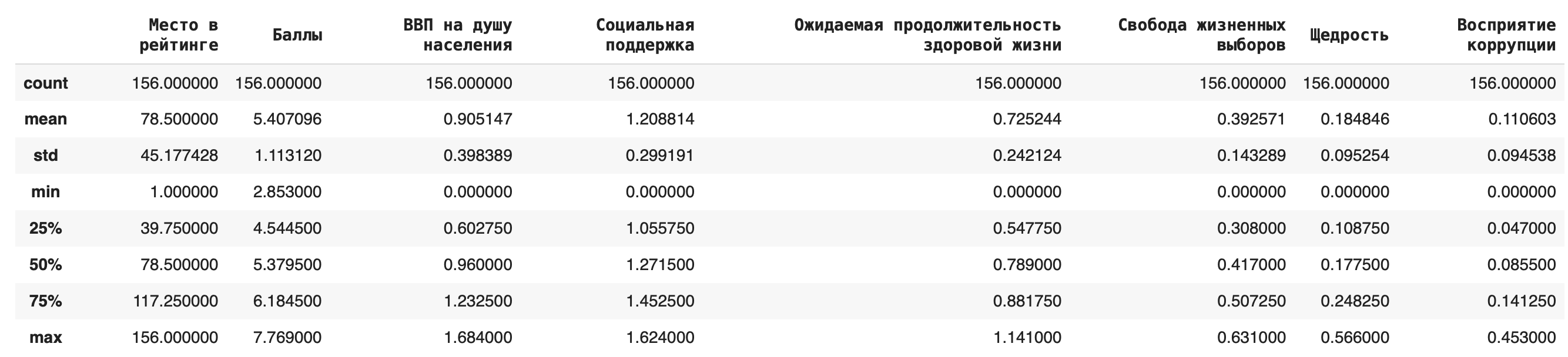

Обзор содержит среднее значение, стандартное отклонение, минимум и максимум, верхние значения первого и третьего квартиля и медиану по каждому столбцу.
Работа с отдельными столбцами или строками
Выделить несколько столбцов можно разными способами.
1. Сделать срез фрейма df[[‘Место в рейтинге’, ‘Ожидаемая продолжительность здоровой жизни’]]

Срез можно сохранить в новой переменной: data_new = df[[‘Место в рейтинге’, ‘Ожидаемая продолжительность здоровой жизни’]]
Теперь можно выполнить любое действие с этим сокращенным фреймом.
2. Использовать метод loc
Если столбцов очень много, можно использовать метод loc, который ищет значения по их названию: df.loc [:, ‘Место в рейтинге’:’Социальная поддержка’]
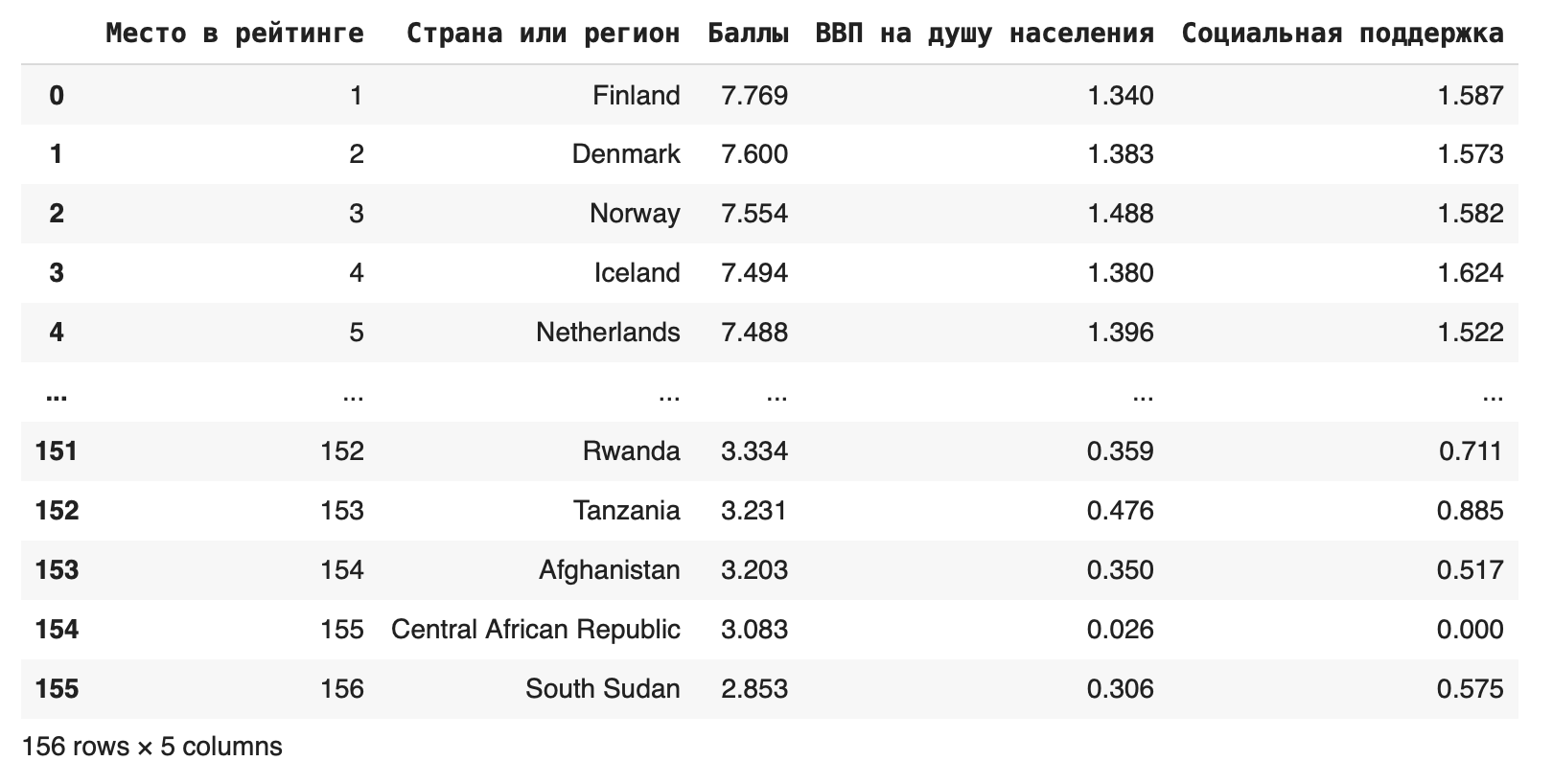
В этом случае мы оставили все столбцы от Места в рейтинге до Социальной поддержки.

Станьте дата-сайентистом на курсе с МГУ и решайте амбициозные задачи с помощью нейросетей
3. Использовать метод iloc
Если нужно вырезать одновременно строки и столбцы, можно сделать это с помощью метода iloc: df.iloc[0:100, 0:5]
Первый параметр показывает индексы строк, которые останутся, второй — индексы столбцов. Получаем такой фрейм:
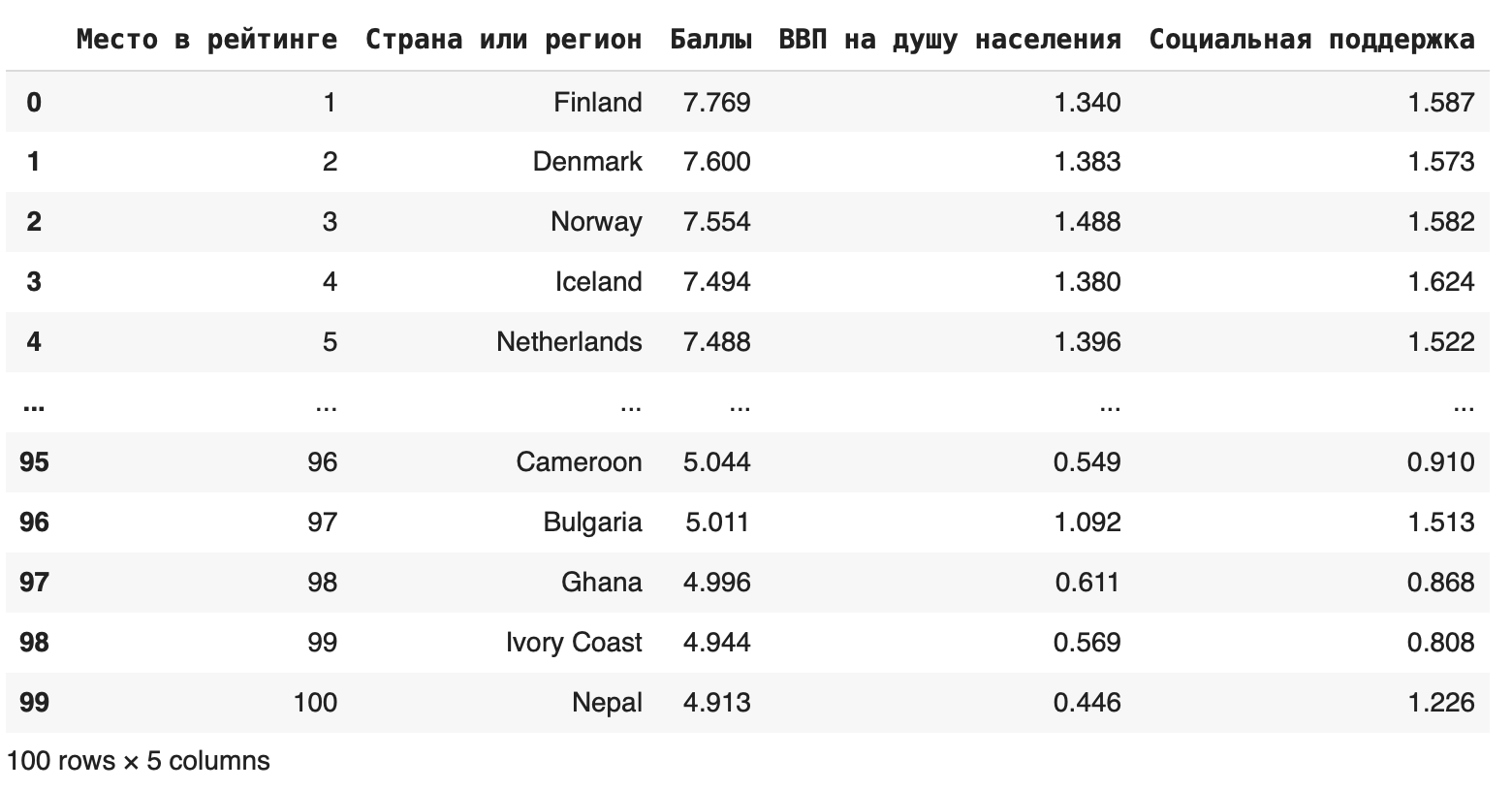
В методе iloc значения в правом конце исключаются, поэтому последняя строка, которую мы видим, — 99.
4. Использовать метод tolist()
Можно выделить какой-либо столбец в отдельный список при помощи метода tolist(). Это упростит задачу, если необходимо извлекать данные из столбцов: df[‘Баллы’].tolist()
Часто бывает нужно получить в виде списка названия столбцов датафрейма. Это тоже можно сделать с помощью метода tolist(): df.columns.tolist()

Добавление новых строк и столбцов
В исходный датасет можно добавлять новые столбцы, создавая новые «признаки», как говорят в машинном обучении. Например, создадим столбец «Сумма», в который просуммируем значения колонок «ВВП на душу населения» и «Социальная поддержка» (сделаем это в учебных целях, практически суммирование этих показателей не имеет смысла): df[‘Сумма’] = df[‘ВВП на душу населения’] + df[‘Социальная поддержка’]

Можно добавлять и новые строки: для этого нужно составить словарь с ключами — названиями столбцов. Если вы не укажете значения в каких-то столбцах, они по умолчанию заполнятся пустыми значениями NaN. Добавим еще одну страну под названием Country: new_row = df = df.append(new_row, ignore_index=True)
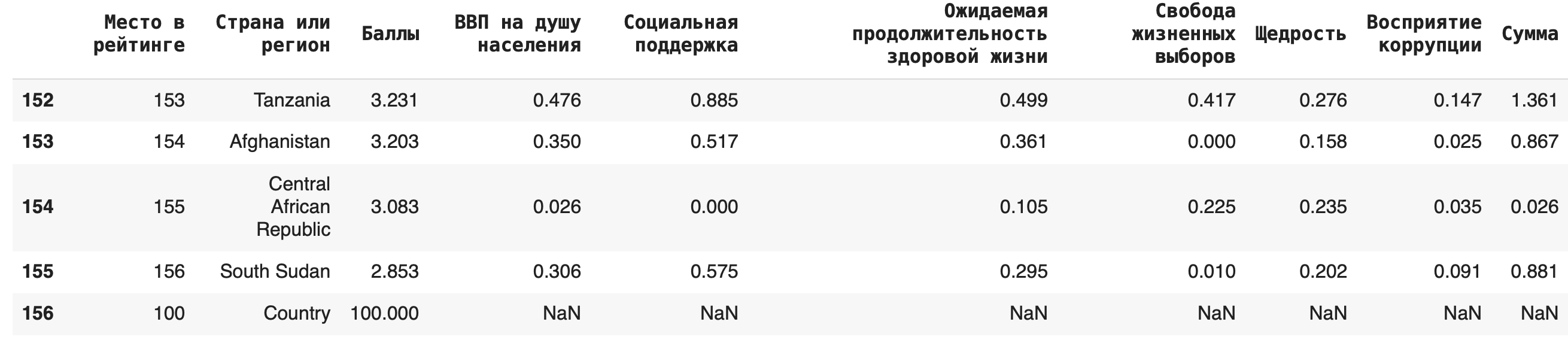
Важно: при добавлении новой строки методом .append() не забывайте указывать параметр ignore_index=True, иначе возникнет ошибка.
Иногда бывает полезно добавить строку с суммой, медианой или средним арифметическим) по столбцу. Сделать это можно с помощью агрегирующих (aggregate (англ.) — группировать, объединять) функций: sum(), mean(), median(). Для примера добавим в конце строку с суммами значений по каждому столбцу: df = df.append(df.sum(axis=0), ignore_index = True)
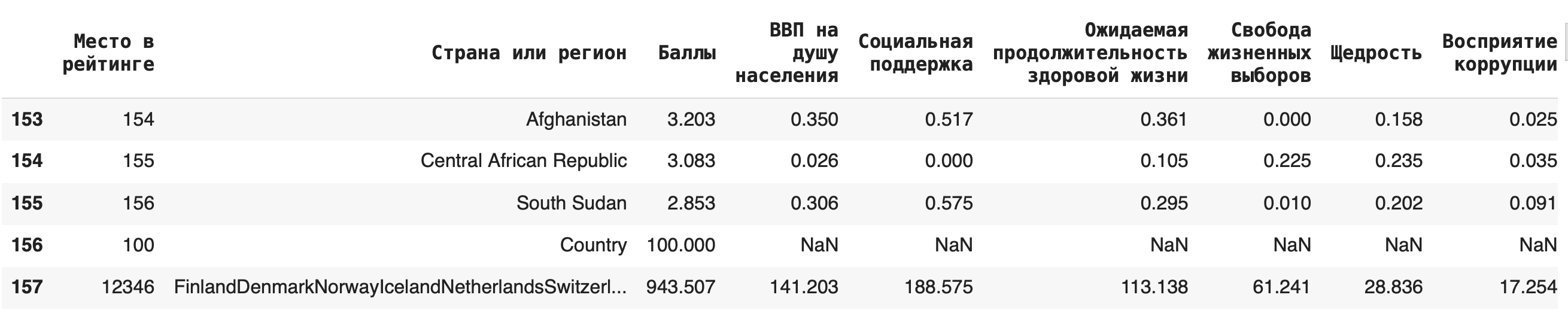
Удаление строк и столбцов
Удалить отдельные столбцы можно при помощи метода drop() — это целесообразно делать, если убрать нужно небольшое количество столбцов. df = df.drop([‘Сумма’], axis = 1)
В других случаях лучше воспользоваться описанными выше срезами.
Обратите внимание, что этот метод требует дополнительного сохранения через присваивание датафрейма с примененным методом исходному. Также в параметрах обязательно нужно указать axis = 1, который показывает, что мы удаляем именно столбец, а не строку.
Соответственно, задав параметр axis = 0, можно удалить любую строку из датафрейма: для этого нужно написать ее номер в качестве первого аргумента в методе drop(). Удалим последнюю строчку (указываем ее индекс — это будет количество строк): df = df.drop(df.shape[0]-1, axis = 0)
Копирование датафрейма
Можно полностью скопировать исходный датафрейм в новую переменную. Это пригодится, если нужно преобразовать много данных и при этом работать не с отдельными столбцами, а со всеми данными: df_copied = df.copy()
Уникальные значения
Уникальные значения в какой-либо колонке датафрейма можно вывести при помощи метода .unique(): df[‘Страна или регион’].unique()
Чтобы дополнительно узнать их количество, можно воспользоваться функцией len(): len(df[‘Страна или регион’].unique())
Подсчет количества значений
Отличается от предыдущего метода тем, что дополнительно подсчитывает количество раз, которое то или иное уникальное значение встречается в колонке, пишется как .value_counts(): df[‘Страна или регион’].value_counts()

Группировка данных
Некоторым обобщением .value_counts() является метод .groupby() — он тоже группирует данные какого-либо столбца по одинаковым значениям. Отличие в том, что при помощи него можно не просто вывести количество уникальных элементов в одном столбце, но и найти для каждой группы сумму / среднее значение / медиану по любым другим столбцам.
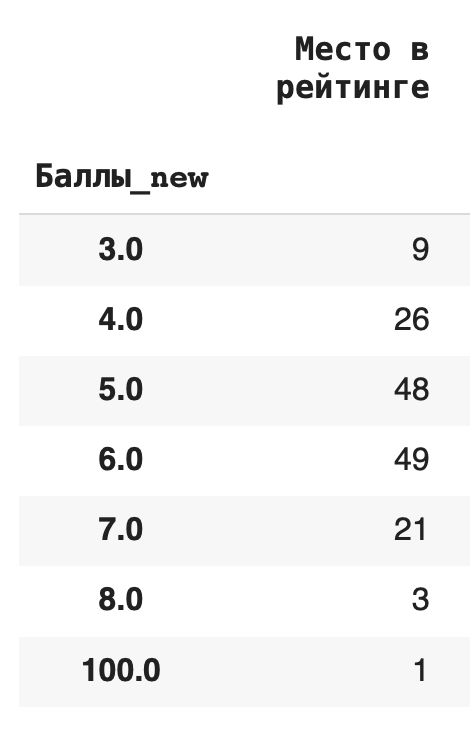
Рассмотрим несколько примеров. Чтобы они были более наглядными, округлим все значения в столбце «Баллы» (тогда в нем появятся значения, по которым мы сможем сгруппировать данные): df[‘Баллы_new’] = round(df[‘Баллы’])
1) Сгруппируем данные по новому столбцу баллов и посчитаем, сколько уникальных значений для каждой группы содержится в остальных столбцах. Для этого в качестве агрегирующей функции используем .count(): df.groupby(‘Баллы_new’).count()
Получается, что чаще всего страны получали 6 баллов (таких было 49):
2) Получим более содержательный для анализа данных результат — посчитаем сумму значений в каждой группе. Для этого вместо .count() используем sum(): df.groupby(‘Баллы_new’).sum()
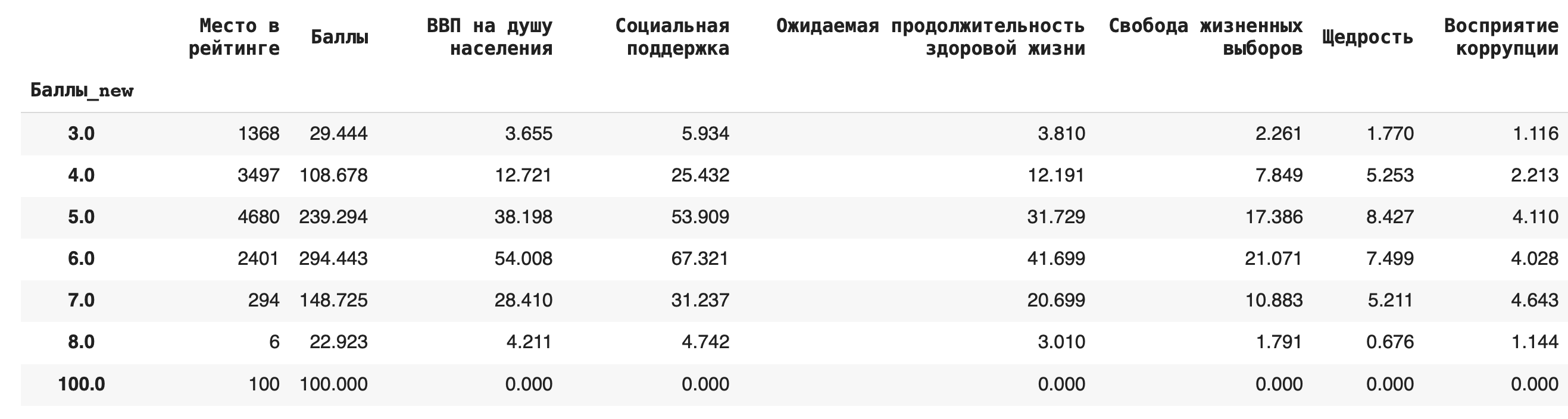
3) Теперь рассчитаем среднее значение по каждой группе, в качестве агрегирующей функции в этом случае возьмем mean(): df.groupby(‘Баллы_new’).mean()
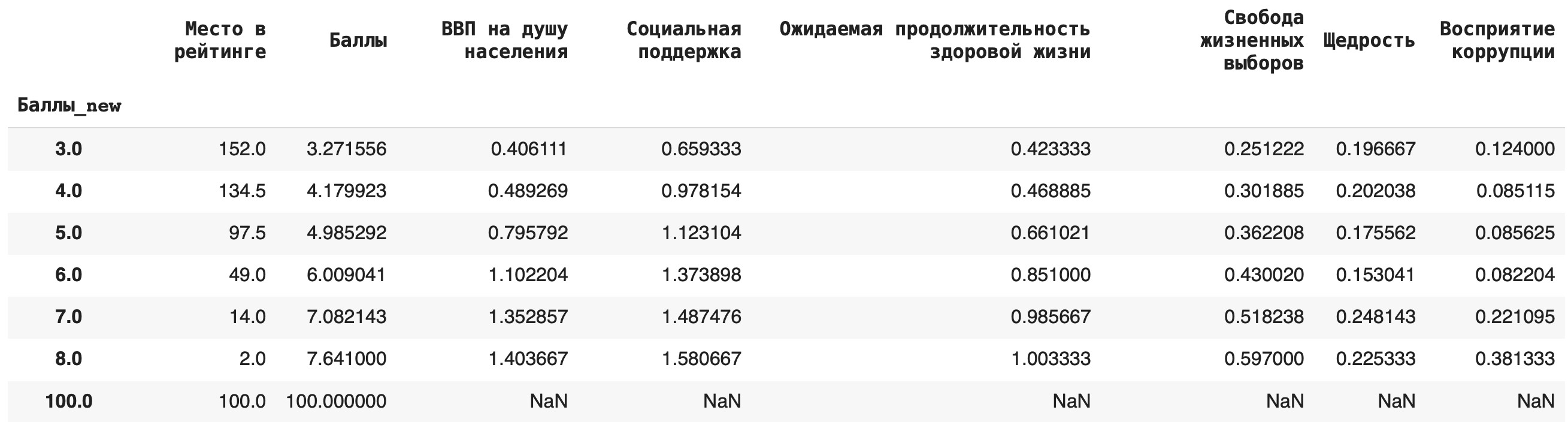
4) Рассчитаем медиану. Для этого пишем команду median(): df.groupby(‘Баллы_new’).median()
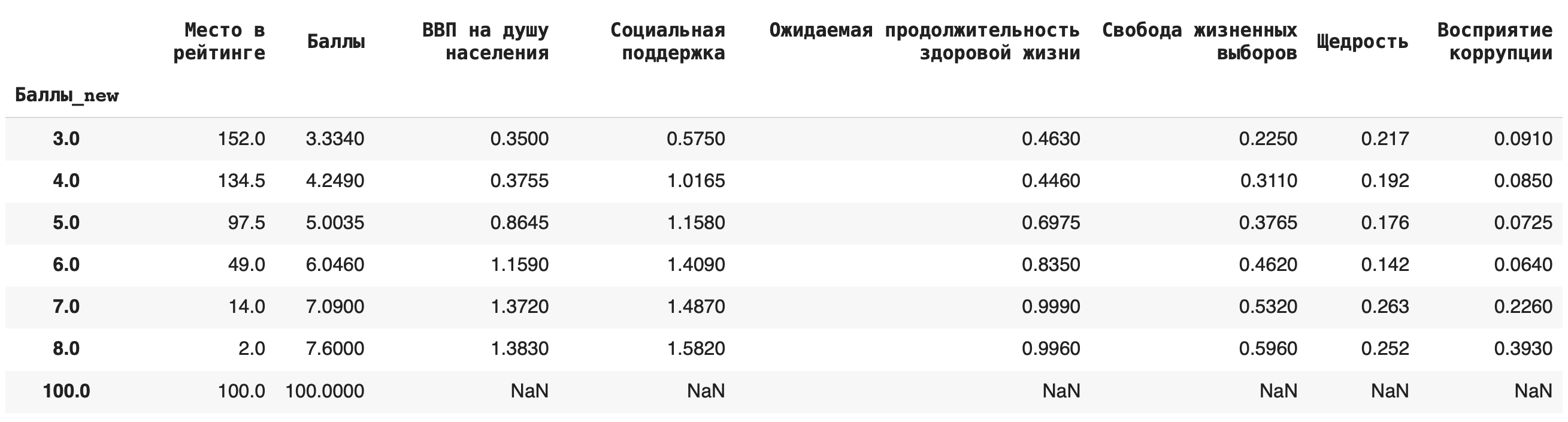
Это самые основные агрегирующие функции, которые пригодятся на начальном этапе работы с данными.
Вот пример синтаксиса, как можно сагрегировать значения по группам при помощи сразу нескольких функций:
df_agg = df.groupby(‘Баллы_new’).agg(< 'Баллы_new': 'count', 'Баллы_new': 'sum', 'Баллы_new': 'mean', 'Баллы_new': 'median' >)
Сводные таблицы
Бывает, что нужно сделать группировку сразу по двум параметрам. Для этого в Pandas используются сводные таблицы или pivot_table(). Они составляются на основе датафреймов, но, в отличие от них, группировать данные можно не только по значениям столбцов, но и по строкам.
В ячейки такой таблицы помещаются сгруппированные как по «координате» столбца, так и по «координате» строки значения. Соответствующую агрегирующую функцию указываем отдельным параметром.
Разберемся на примере. Сгруппируем средние значения из столбца «Социальная поддержка» по баллам в рейтинге и значению ВВП на душу населения. В прошлом действии мы уже округлили значения баллов, теперь округлим и значения ВВП: df[‘ВВП_new’] = round(df[‘ВВП на душу населения’])
Теперь составим сводную таблицу: по горизонтали расположим сгруппированные значения из округленного столбца «ВВП» (ВВП_new), а по вертикали — округленные значения из столбца «Баллы» (Баллы_new). В ячейках таблицы будут средние значения из столбца «Социальная поддержка», сгруппированные сразу по этим двум столбцам: pd.pivot_table(df, index = [‘Баллы_new’], columns = [‘ВВП_new’], values = ‘Социальная поддержка’, aggfunc = ‘mean’)
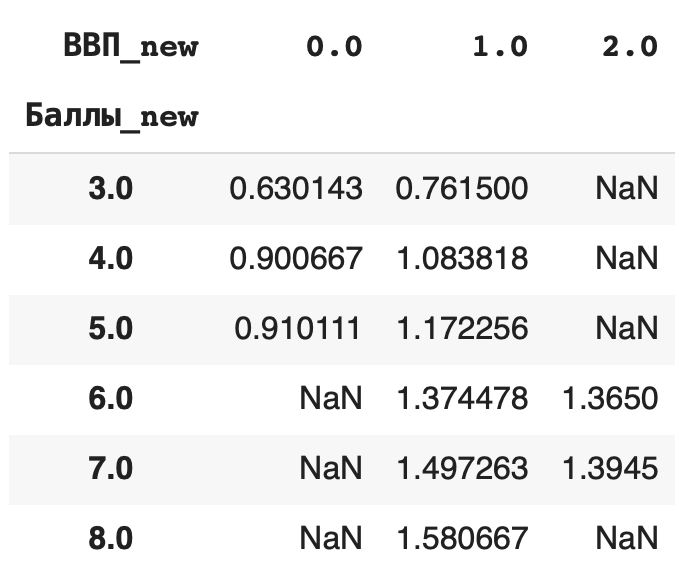
Сортировка данных
Строки датасета можно сортировать по значениям любого столбца при помощи функции sort_values(). По умолчанию метод делает сортировку по убыванию. Например, отсортируем по столбцу значений ВВП на душу населения: df.sort_values(by = ‘ВВП на душу населения’).head()
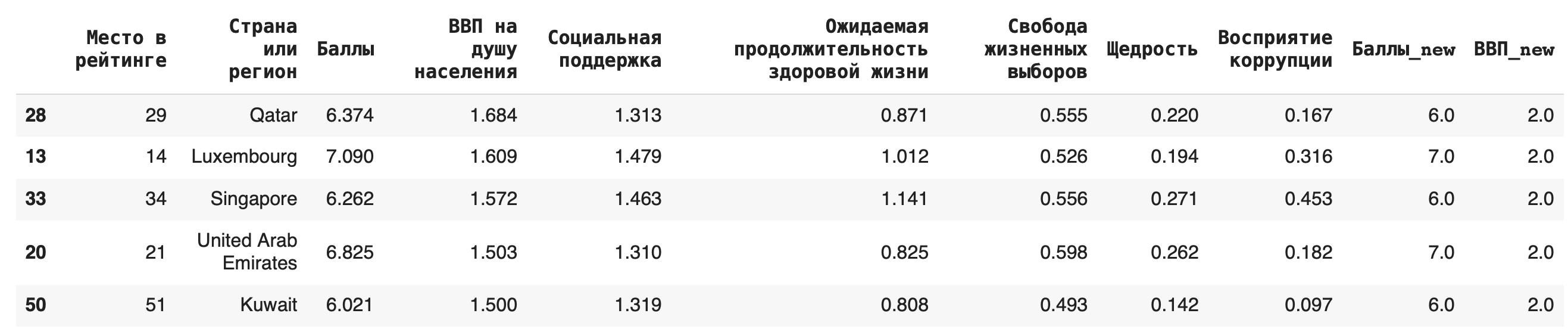
Видно, что самые высокие ВВП совсем не гарантируют высокое место в рейтинге.
Чтобы сделать сортировку по убыванию, можно воспользоваться параметром ascending (от англ. «по возрастанию») = False: df.sort_values(by = ‘ВВП на душу населения’, ascending=False)
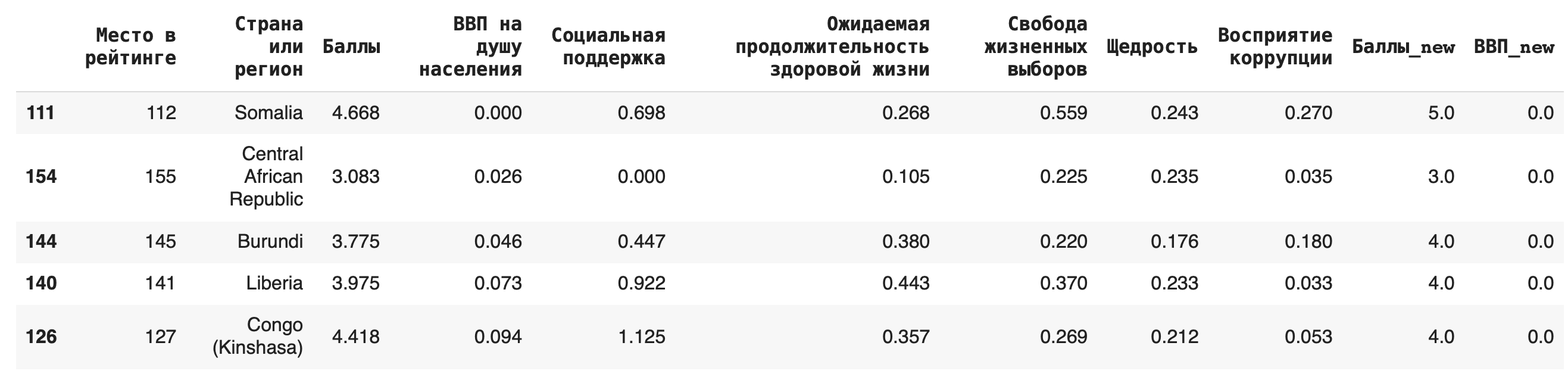
Фильтрация
Иногда бывает нужно получить строки, удовлетворяющие определенному условию; для этого используется «фильтрация» датафрейма. Условия могут быть самые разные, рассмотрим несколько примеров и их синтаксис:
1) Получение строки с конкретным значением какого-либо столбца (выведем строку из датасета для Норвегии): df[df[‘Страна или регион’] == ‘Norway’]

2) Получение строк, для которых значения в некотором столбце удовлетворяют неравенству. Выведем строки для стран, у которых «Ожидаемая продолжительность здоровой жизни» больше единицы:
df[df[‘Ожидаемая продолжительность здоровой жизни’] > 1]
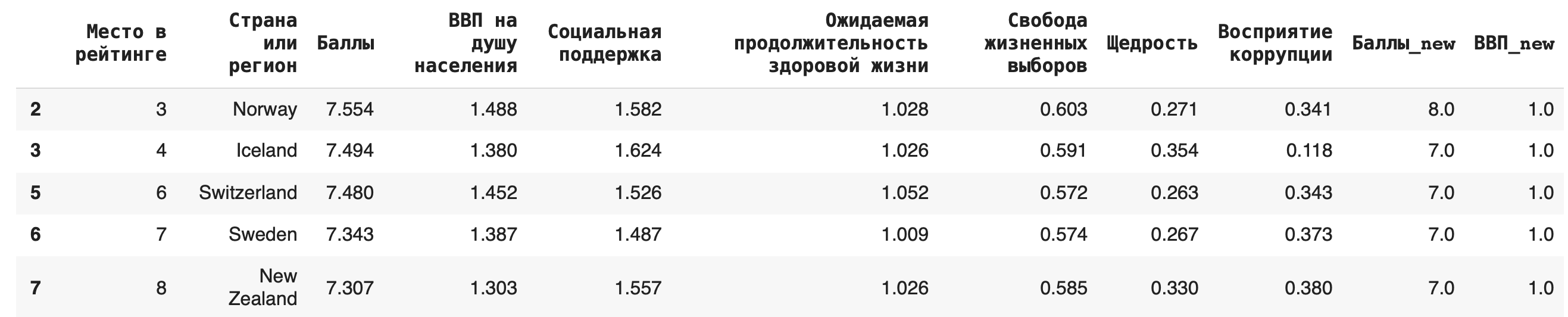
3) В условиях фильтрации можно использовать не только математические операции сравнения, но и методы работы со строками. Выведем строки датасета, названия стран которых начинаются с буквы F, — для этого воспользуемся методом .startswith():
df[df[‘Страна или регион’].str.startswith(‘F’)]

4) Можно комбинировать несколько условий одновременно, используя логические операторы. Выведем строки, в которых значение ВВП больше 1 и уровень социальной поддержки больше 1,5: df[(df[‘ВВП на душу населения’] > 1) & (df[‘Социальная поддержка’] > 1.5)]

Таким образом, если внутри внешних квадратных скобок стоит истинное выражение, то строка датасета будет удовлетворять условию фильтрации. Поэтому в других ситуациях можно использовать в условии фильтрации любые функции/конструкции, возвращающие значения True или False.
Применение функций к столбцам
Зачастую встроенных функций и методов для датафреймов из библиотеки бывает недостаточно для выполнения той или иной задачи. Тогда мы можем написать свою собственную функцию, которая преобразовывала бы строку датасета как нам нужно, и затем использовать метод .apply() для применения этой функции ко всем строкам нужного столбца.
Рассмотрим пример: напишем функцию, которая преобразует все буквы в строке к нижнему регистру, и применим к столбцу стран и регионов: def my_lower(row): return row.lower() df[‘Страна или регион’].apply(lower)

Очистка данных
Это целый этап работы с данными при подготовке их к построению моделей и нейронных сетей. Рассмотрим основные приемы и функции.
1) Удаление дубликатов из датасета делается при помощи функции drop_duplucates(). По умолчанию удаляются только полностью идентичные строки во всем датасете, но можно указать в параметрах и отдельные столбцы. Например, после округления у нас появились дубликаты в столбцах «ВВП_new» и «Баллы_new», удалим их: df_copied = df.copy() df_copied.drop_duplicates(subset = [‘ВВП_new’, ‘Баллы_new’])
Этот метод не требует дополнительного присваивания в исходную переменную, чтобы результат сохранился, — поэтому предварительно создадим копию нашего датасета, чтобы не форматировать исходный.
Строки-дубликаты удаляются полностью, таким образом, их количество уменьшается. Чтобы заменить их на пустые, можно использовать параметр inplace = True. df_copied.drop_duplicates(subset = [‘ВВП_new’, ‘Баллы_new’], inplace = True)
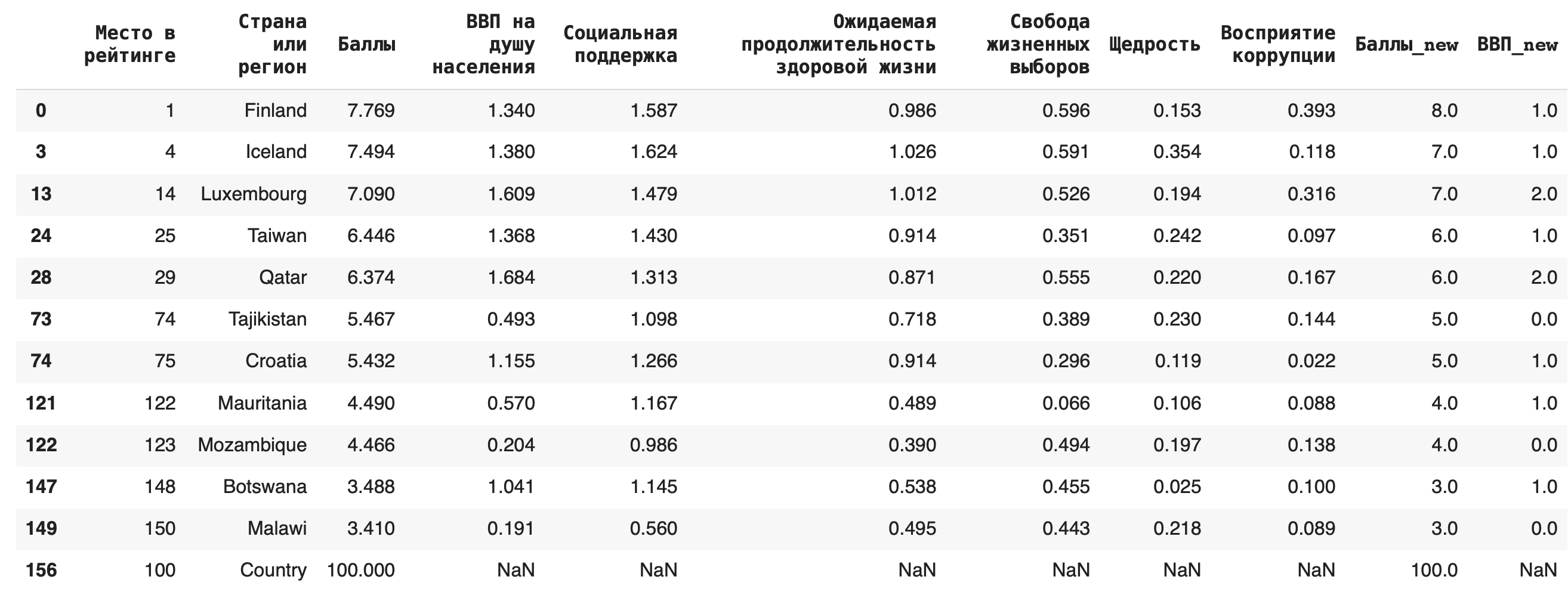
2) Для замены пропусков NaN на какое-либо значение используется функция fillna(). Например, заполним появившиеся после предыдущего пункта пропуски в последней строке нулями: df_copied.fillna(0)
3) Пустые строки с NaN можно и вовсе удалить из датасета, для этого используется функция dropna() (можно также дополнительно указать параметр inplace = True): df_copied.dropna()
Построение графиков
В Pandas есть также инструменты для простой визуализации данных.
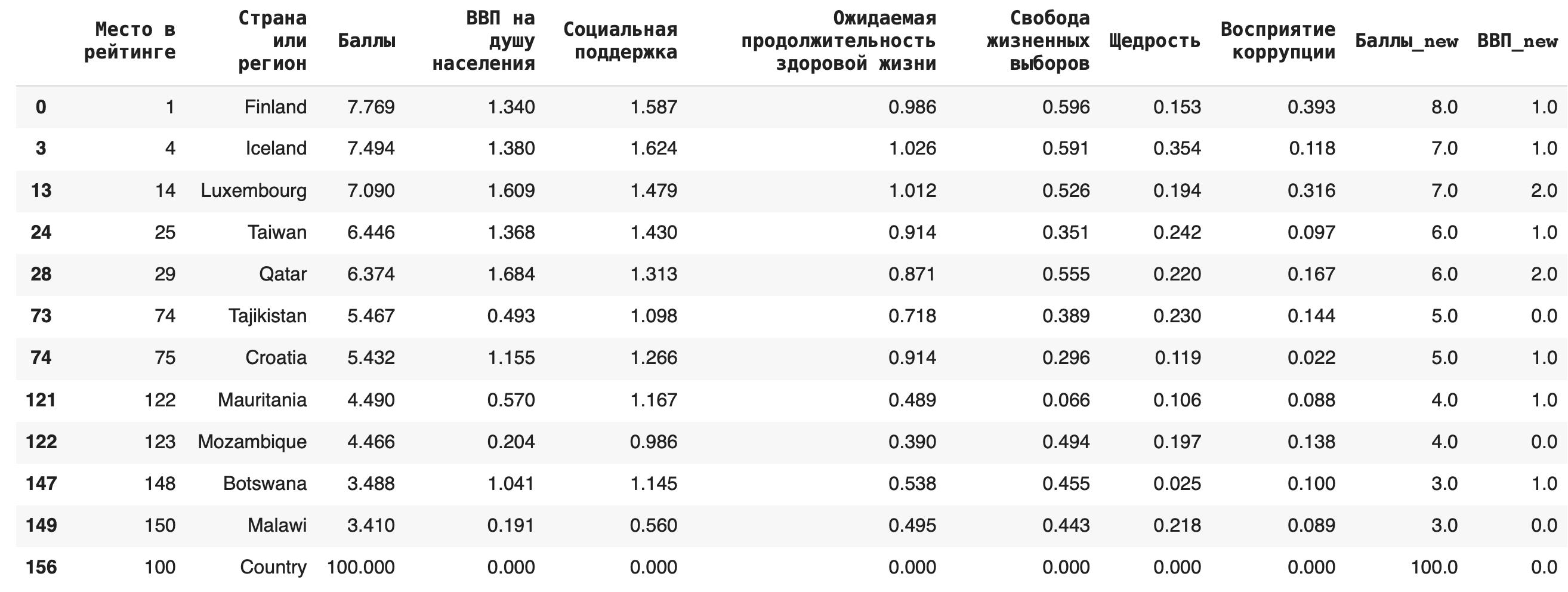
1) Обычный график по точкам.
Построим зависимость ВВП на душу населения от места в рейтинге: df.plot(x = ‘Место в рейтинге’, y = ‘ВВП на душу населения’)
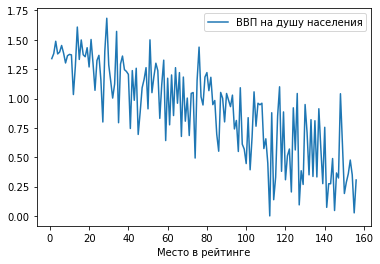
2) Гистограмма.
Отобразим ту же зависимость в виде столбчатой гистограммы: df.plot.hist(x = ‘Место в рейтинге’, y = ‘ВВП на душу населения’)
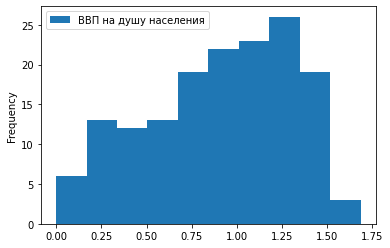
3) Точечный график.
df.plot.scatter(x = ‘Место в рейтинге’, y = ‘ВВП на душу населения’)
Мы видим предсказуемую тенденцию: чем выше ВВП на душу населения, тем ближе страна к первой строчке рейтинга.
Сохранение датафрейма на компьютер
Сохраним наш датафрейм на компьютер: df.to_csv(‘WHR_2019.csv’)
Теперь с ним можно работать и в других программах.
Блокнот с кодом можно скачать здесь (формат .ipynb).
Аналитикам: большая шпаргалка по Pandas
Привет. Я задумывал эту заметку для студентов курса Digital Rockstar, на котором мы учим маркетологов автоматизировать свою работу с помощью программирования, но решил поделиться шпаргалкой по Pandas со всеми. Я ожидаю, что читатель умеет писать код на Python хотя бы на минимальном уровне, знает, что такое списки, словари, циклы и функции.
- Что такое Pandas и зачем он нужен
- Структуры данных: серии и датафреймы
- Создаем датафреймы и загружаем в них данные
- Исследуем загруженные данные
- Получаем данные из датафреймов
- Считаем производные метрики
- Объединяем несколько датафреймов
- Решаем задачу
Что такое Pandas и зачем он нужен
Pandas — это библиотека для работы с данными на Python. Она упрощает жизнь аналитикам: где раньше использовалось 10 строк кода теперь хватит одной.
Например, чтобы прочитать данные из csv, в стандартном Python надо сначала решить, как хранить данные, затем открыть файл, прочитать его построчно, отделить значения друг от друга и очистить данные от специальных символов.
> with open('file.csv') as f: . content = f.readlines() . content = [x.split(',').replace('\n','') for x in content]В Pandas всё проще. Во-первых, не нужно думать, как будут храниться данные — они лежат в датафрейме. Во-вторых, достаточно написать одну команду:
> data = pd.read_csv('file.csv')Pandas добавляет в Python новые структуры данных — серии и датафреймы. Расскажу, что это такое.
Структуры данных: серии и датафреймы
Серии — одномерные массивы данных. Они очень похожи на списки, но отличаются по поведению — например, операции применяются к списку целиком, а в сериях — поэлементно.
То есть, если список умножить на 2, получите тот же список, повторенный 2 раза.
> vector = [1, 2, 3] > vector * 2 [1, 2, 3, 1, 2, 3]А если умножить серию, ее длина не изменится, а вот элементы удвоятся.
> import pandas as pd > series = pd.Series([1, 2, 3]) > series * 2 0 2 1 4 2 6 dtype: int64Обратите внимание на первый столбик вывода. Это индекс, в котором хранятся адреса каждого элемента серии. Каждый элемент потом можно получать, обратившись по нужному адресу.
> series = pd.Series(['foo', 'bar']) > series[0] 'foo'Еще одно отличие серий от списков — в качестве индексов можно использовать произвольные значения, это делает данные нагляднее. Представим, что мы анализируем помесячные продажи. Используем в качестве индексов названия месяцев, значениями будет выручка:
> months = ['jan', 'feb', 'mar', 'apr'] > sales = [100, 200, 300, 400] > data = pd.Series(data=sales, index=months) > data jan 100 feb 200 mar 300 apr 400 dtype: int64Теперь можем получать значения каждого месяца:
> data['feb'] 200Так как серии — одномерный массив данных, в них удобно хранить измерения по одному. На практике удобнее группировать данные вместе. Например, если мы анализируем помесячные продажи, полезно видеть не только выручку, но и количество проданных товаров, количество новых клиентов и средний чек. Для этого отлично подходят датафреймы.
Датафреймы — это таблицы. У их есть строки, колонки и ячейки.
Технически, колонки датафреймов — это серии. Поскольку в колонках обычно описывают одни и те же объекты, то все колонки делят один и тот же индекс:
> months = ['jan', 'feb', 'mar', 'apr'] > sales = < . 'revenue': [100, 200, 300, 400], . 'items_sold': [23, 43, 55, 65], . 'new_clients': [10, 20, 30, 40] . >> sales_df = pd.DataFrame(data=sales, index=months) > sales_df revenue items_sold new_clients jan 100 23 10 feb 200 43 20 mar 300 55 30 apr 400 65 40Объясню, как создавать датафреймы и загружать в них данные.
Создаем датафреймы и загружаем данные
Бывает, что мы не знаем, что собой представляют данные, и не можем задать структуру заранее. Тогда удобно создать пустой датафрейм и позже наполнить его данными.
> df = pd.DataFrame()А иногда данные уже есть, но хранятся в переменной из стандартного Python, например, в словаре. Чтобы получить датафрейм, эту переменную передаем в ту же команду:
> df = pd.DataFrame(data=sales, index=months))Случается, что в некоторых записях не хватает данных. Например, посмотрите на список goods_sold — в нём продажи, разбитые по товарным категориям. За первый месяц мы продали машины, компьютеры и программное обеспечение. Во втором машин нет, зато появились велосипеды, а в третьем снова появились машины, но велосипеды исчезли:
> goods_sold = [ . , . , . . ]Если загрузить данные в датафрейм, Pandas создаст колонки для всех товарных категорий и, где это возможно, заполнит их данными:
> pd.DataFrame(goods_sold) bicycles cars computers soft 0 NaN 1.0 10 3 1 1.0 NaN 4 5 2 NaN 2.0 6 3Обратите внимание, продажи велосипедов в первом и третьем месяце равны NaN — расшифровывается как Not a Number. Так Pandas помечает отсутствующие значения.
Теперь разберем, как загружать данные из файлов. Чаще всего данные хранятся в экселевских таблицах или csv-, tsv- файлах.
Экселевские таблицы читаются с помощью команды pd.read_excel() . Параметрами нужно передать адрес файла на компьютере и название листа, который нужно прочитать. Команда работает как с xls, так и с xlsx:
> pd.read_excel('file.xlsx', sheet_name='Sheet1')Файлы формата csv и tsv — это текстовые файлы, в которых данные отделены друг от друга запятыми или табуляцией:
# CSV month,customers,sales feb,10,200 # TSV month\tcustomers\tsales feb\t10\t200Оба читаются с помощью команды .read_csv() , символ табуляции передается параметром sep (от англ. separator — разделитель):
> pd.read_csv('file.csv') > pd.read_csv('file.tsv', sep='\t')При загрузке можно назначить столбец, который будет индексом. Представьте, что мы загружаем таблицу с заказами. У каждого заказа есть свой уникальный номер, Если назначим этот номер индексом, сможем выгружать данные командой df[order_id] . Иначе придется писать фильтр df[df[‘id’] == order_id ] .
О том, как получать данные из датафреймов, я расскажу в одном из следующих разделов. Чтобы назначить колонку индексом, добавим в команду read_csv() параметр index_col , равный названию нужной колонки:
> pd.read_csv('file.csv', index_col='id')После загрузки данных в датафрейм, хорошо бы их исследовать — особенно, если они вам незнакомы.
Исследуем загруженные данные
Представим, что мы анализируем продажи американского интернет-магазина. У нас есть данные о заказах и клиентах. Загрузим файл с продажами интернет-магазина в переменную orders . Раз загружаем заказы, укажем, что колонка id пойдет в индекс:
> orders = pd.read_csv('orders.csv', index_col='id')Расскажу о четырех атрибутах, которые есть у любого датафрейма: .shape , .columns , .index и .dtypes .
.shape показывает, сколько в датафрейме строк и колонок. Он возвращает пару значений (n_rows, n_columns) . Сначала идут строки, потом колонки.
> orders.shape (5009, 5)В датафрейме 5009 строк и 5 колонок.
Окей, масштаб оценили. Теперь посмотрим, какая информация содержится в каждой колонке. С помощью .columns узнаем названия колонок:
> orders.columns Index(['order_date', 'ship_mode', 'customer_id', 'sales'], dtype='object')Теперь видим, что в таблице есть дата заказа, метод доставки, номер клиента и выручка.
С помощью .dtypes узнаем типы данных, находящихся в каждой колонке и поймем, надо ли их обрабатывать. Бывает, что числа загружаются в виде текста. Если мы попробуем сложить две текстовых значения ‘1’ + ‘1’ , то получим не число 2, а строку ’11’ :
> orders.dtypes order_date object ship_mode object customer_id object sales float64 dtype: objectТип object — это текст, float64 — это дробное число типа 3,14.
C помощью атрибута .index посмотрим, как называются строки:
> orders.index Int64Index([100006, 100090, 100293, 100328, 100363, 100391, 100678, 100706, 100762, 100860, . 167570, 167920, 168116, 168613, 168690, 168802, 169320, 169488, 169502, 169551], dtype='int64', name='id', length=5009)Ожидаемо, в индексе датафрейма номера заказов: 100762, 100860 и так далее.
В колонке sales хранится стоимость каждого проданного товара. Чтобы узнать разброс значений, среднюю стоимость и медиану, используем метод .describe() :
> orders.describe() sales count 5009.0 mean 458.6 std 954.7 min 0.6 25% 37.6 50% 152.0 75% 512.1 max 23661.2Наконец, чтобы посмотреть на несколько примеров записей датафрейма, используем команды .head() и .sample() . Первая возвращает 6 записей из начала датафрейма. Вторая — 6 случайных записей:
> orders.head() order_date ship_mode customer_id sales id 100006 2014-09-07 Standard DK-13375 377.970 100090 2014-07-08 Standard EB-13705 699.192 100293 2014-03-14 Standard NF-18475 91.056 100328 2014-01-28 Standard JC-15340 3.928 100363 2014-04-08 Standard JM-15655 21.376Получив первое представление о датафреймах, теперь обсудим, как доставать из него данные.
Получаем данные из датафреймов
Данные из датафреймов можно получать по-разному: указав номера колонок и строк, использовав условные операторы или язык запросов. Расскажу подробнее о каждом способе.
Указываем нужные строки и колонки
Продолжаем анализировать продажи интернет-магазина, которые загрузили в предыдущем разделе. Допустим, я хочу вывести столбец sales . Для этого название столбца нужно заключить в квадратные скобки и поставить после них названия датафрейма: orders[‘sales’] :
> orders['sales'] id 100006 377.970 100090 699.192 100293 91.056 100328 3.928 100363 21.376 100391 14.620 100678 697.074 100706 129.440 . Обратите внимание, результат команды — новый датафрейм с таким же индексом.
Если нужно вывести несколько столбцов, в квадратные скобки нужно вставить список с их названиями: orders[[‘customer_id’, ‘sales’]] . Будьте внимательны: квадратные скобки стали двойными. Первые — от датафрейма, вторые — от списка:
> orders[['customer_id', 'sales']] customer_id sales id 100006 DK-13375 377.970 100090 EB-13705 699.192 100293 NF-18475 91.056 100328 JC-15340 3.928 100363 JM-15655 21.376 100391 BW-11065 14.620 100363 KM-16720 697.074 100706 LE-16810 129.440 . Перейдем к строкам. Их можно фильтровать по индексу и по порядку. Например, мы хотим вывести только заказы 100363, 100391 и 100706, для этого есть команда .loc[] :
> show_these_orders = ['100363', '100363', '100706'] > orders.loc[show_these_orders] order_date ship_mode customer_id sales id 100363 2014-04-08 Standard JM-15655 21.376 100363 2014-04-08 Standard JM-15655 21.376 100706 2014-12-16 Second LE-16810 129.440А в другой раз бывает нужно достать просто заказы с 1 по 3 по порядку, вне зависимости от их номеров в таблицемы. Тогда используют команду .iloc[] :
> show_these_orders = [1, 2, 3] > orders.iloc[show_these_orders] order_date ship_mode customer_id sales id 100090 2014-04-08 Standard JM-15655 21.376 100293 2014-04-08 Standard JM-15655 21.376 100328 2014-12-16 Second LE-16810 129.440Можно фильтровать датафреймы по колонкам и столбцам одновременно:
> columns = ['customer_id', 'sales'] > rows = ['100363', '100363', '100706'] > orders.loc[rows][columns] customer_id sales id 100363 JM-15655 21.376 100363 JM-15655 21.376 100706 LE-16810 129.440 . Часто вы не знаете заранее номеров заказов, которые вам нужны. Например, если задача — получить заказы, стоимостью более 1000 рублей. Эту задачу удобно решать с помощью условных операторов.
Если — то. Условные операторы
Задача: нужно узнать, откуда приходят самые большие заказы. Начнем с того, что достанем все покупки стоимостью более 1000 долларов:
> filter_large = orders['sales'] > 1000 > orders.loc[filter_slarge] order_date ship_mode customer_id sales id 101931 2014-10-28 First TS-21370 1252.602 102673 2014-11-01 Standard KH-16630 1044.440 102988 2014-04-05 Second GM-14695 4251.920 103100 2014-12-20 First AB-10105 1107.660 103310 2014-05-10 Standard GM-14680 1769.784 . Помните, в начале статьи я упоминал, что в сериях все операции применяются по-элементно? Так вот, операция orders[‘sales’] > 1000 идет по каждому элементу серии и, если условие выполняется, возвращает True . Если не выполняется — False . Получившуюся серию мы сохраняем в переменную filter_large .
Вторая команда фильтрует строки датафрейма с помощью серии. Если элемент filter_large равен True , заказ отобразится, если False — нет. Результат — датафрейм с заказами, стоимостью более 1000 долларов.
Интересно, сколько дорогих заказов было доставлено первым классом? Добавим в фильтр ещё одно условие:
> filter_large = df['sales'] > 1000 > filter_first_class = orders['ship_mode'] == 'First' > orders.loc[filter_large & filter_first_class] order_date ship_mode customer_id sales id 101931 2014-10-28 First TS-21370 1252.602 103100 2014-12-20 First AB-10105 1107.660 106726 2014-12-06 First RS-19765 1261.330 112158 2014-12-02 First DP-13165 1050.600 116666 2014-05-08 First KT-16480 1799.970 . Логика не изменилась. В переменную filter_large сохранили серию, удовлетворяющую условию orders[‘sales’] > 1000 . В filter_first_class — серию, удовлетворяющую orders[‘ship_mode’] == ‘First’ .
Затем объединили обе серии с помощью логического ‘И’: filter_first_class & filter_first_class . Получили новую серию той же длины, в элементах которой True только у заказов, стоимостью больше 1000, доставленных первым классом. Таких условий может быть сколько угодно.
Язык запросов
Еще один способ решить предыдущую задачу — использовать язык запросов. Все условия пишем одной строкой ‘sales > 1000 & ship_mode == ‘First’ и передаем ее в метод .query() . Запрос получается компактнее.
> orders.query('sales > 1000 & ship_mode == First') order_date ship_mode customer_id sales id 101931 2014-10-28 First TS-21370 1252.602 103100 2014-12-20 First AB-10105 1107.660 106726 2014-12-06 First RS-19765 1261.330 112158 2014-12-02 First DP-13165 1050.600 116666 2014-05-08 First KT-16480 1799.970 . Отдельный кайф: значения для фильтров можно сохранить в переменной, а в запросе сослаться на нее с помощью символа @: sales > @sales_filter .
> sales_filter = 1000 > ship_mode_filter = 'First' > orders.query('sales > @sales_filter & ship_mode > @ship_mode_filter') order_date ship_mode customer_id sales id 101931 2014-10-28 First TS-21370 1252.602 103100 2014-12-20 First AB-10105 1107.660 106726 2014-12-06 First RS-19765 1261.330 112158 2014-12-02 First DP-13165 1050.600 116666 2014-05-08 First KT-16480 1799.970 . Разобравшись, как получать куски данных из датафрейма, перейдем к тому, как считать агрегированные метрики: количество заказов, суммарную выручку, средний чек, конверсию.
Считаем производные метрики
Задача: посчитаем, сколько денег магазин заработал с помощью каждого класса доставки. Начнем с простого — просуммируем выручку со всех заказов. Для этого используем метод .sum() :
> orders['sales'].sum() 2297200.8603000003Добавим класс доставки. Перед суммированием сгруппируем данные с помощью метода .groupby() :
> orders.groupby('ship_mode')['sales'].sum() ship_mode First 3.514284e+05 Same Day 1.283631e+05 Second 4.591936e+05 Standard 1.358216e+063.514284e+05 — научный формат вывода чисел. Означает 3.51 * 10 5 . Нам такая точность не нужна, поэтому можем сказать Pandas, чтобы округлял значения до сотых:
> pd.options.display.float_format = ''.format > orders.groupby('ship_mode')['sales'].sum() ship_mode First 351,428.4 Same Day 128,363.1 Second 459,193.6 Standard 1,358,215.7Другое дело. Теперь видим сумму выручки по каждому классу доставки. По суммарной выручке неясно, становится лучше или хуже. Добавим разбивку по датам заказа:
> orders.groupby(['ship_mode', 'order_date'])['sales'].sum() ship_mode order_date First 2014-01-06 12.8 2014-01-11 9.9 2014-01-14 62.0 2014-01-15 149.9 2014-01-19 378.6 2014-01-26 152.6 . Видно, что выручка прыгает ото дня ко дню: иногда 10 долларов, а иногда 378. Интересно, это меняется количество заказов или средний чек? Добавим к выборке количество заказов. Для этого вместо .sum() используем метод .agg() , в который передадим список с названиями нужных функций.
> orders.groupby(['ship_mode', 'order_date'])['sales'].agg(['sum', 'count']) sum count ship_mode order_date First 2014-01-06 12.8 1 2014-01-11 9.9 1 2014-01-14 62.0 1 2014-01-15 149.9 1 2014-01-19 378.6 1 2014-01-26 152.6 1 . Ого, получается, что это так прыгает средний чек. Интересно, а какой был самый удачный день? Чтобы узнать, отсортируем получившийся датафрейм: выведем 10 самых денежных дней по выручке:
> orders.groupby(['ship_mode', 'order_date'])['sales'].agg(['sum']).sort_values(by='sum', ascending=False).head(10) sum ship_mode order_date Standard 2014-03-18 26,908.4 2016-10-02 18,398.2 First 2017-03-23 14,299.1 Standard 2014-09-08 14,060.4 First 2017-10-22 13,716.5 Standard 2016-12-17 12,185.1 2017-11-17 12,112.5 2015-09-17 11,467.6 2016-05-23 10,561.0 2014-09-23 10,478.6 Команда разрослась, и её теперь неудобно читать. Чтобы упростить, можно разбить её на несколько строк. В конце каждой строки ставим обратный слеш \ :
> orders \ . .groupby(['ship_mode', 'order_date'])['sales'] \ . .agg(['sum']) \ . .sort_values(by='sum', ascending=False) \ . .head(10) sum ship_mode order_date Standard 2014-03-18 26,908.4 2016-10-02 18,398.2 First 2017-03-23 14,299.1 Standard 2014-09-08 14,060.4 First 2017-10-22 13,716.5 Standard 2016-12-17 12,185.1 2017-11-17 12,112.5 2015-09-17 11,467.6 2016-05-23 10,561.0 2014-09-23 10,478.6 В самый удачный день — 18 марта 2014 года — магазин заработал 27 тысяч долларов с помощью стандартного класса доставки. Интересно, откуда были клиенты, сделавшие эти заказы? Чтобы узнать, надо объединить данные о заказах с данными о клиентах.
Объединяем несколько датафреймов
До сих пор мы смотрели только на таблицу с заказами. Но ведь у нас есть еще данные о клиентах интернет-магазина. Загрузим их в переменную customers и посмотрим, что они собой представляют:
> customers = pd.read_csv('customers.csv', index='id') > customers.head() name segment state city id CG-12520 Claire Gute Consumer Kentucky Henderson DV-13045 Darrin Van Huff Corporate California Los Angeles SO-20335 Sean O'Donnell Consumer Florida Fort Lauderdale BH-11710 Brosina Hoffman Consumer California Los Angeles AA-10480 Andrew Allen Consumer North Carolina ConcordМы знаем тип клиента, место его проживания, его имя и имя контактного лица. У каждого клиента есть уникальный номер id . Этот же номер лежит в колонке customer_id таблицы orders . Значит мы можем найти, какие заказы сделал каждый клиент. Например, посмотрим, заказы пользователя CG-12520 :
> cust_filter = 'CG-12520' > orders.query('customer_id == @cust_filter') order_date ship_mode customer_id sales id CA-2016-152156 2016-11-08 Second CG-12520 993.90 CA-2017-164098 2017-01-26 First CG-12520 18.16 US-2015-123918 2015-10-15 Same Day CG-12520 136.72Вернемся к задаче из предыдущего раздела: узнать, что за клиенты, которые сделали 18 марта заказы со стандартной доставкой. Для этого объединим таблицы с клиентами и заказами. Датафреймы объединяют с помощью методов .concat() , .merge() и .join() . Все они делают одно и то же, но отличаются синтаксисом — на практике достаточно уметь пользоваться одним из них.
Покажу на примере .merge() :
> new_df = pd.merge(orders, customers, how='inner', left_on='customer_id', right_index=True) > new_df.columns Index(['order_date', 'ship_mode', 'customer_id', 'sales', 'name', 'segment', 'state', 'city'], dtype='object')В .merge() я сначала указал названия датафреймов, которые хочу объединить. Затем уточнил, как именно их объединить и какие колонки использовать в качестве ключа.
Ключ — это колонка, связывающая оба датафрейма. В нашем случае — номер клиента. В таблице с заказами он в колонке customer_id , а таблице с клиентами — в индексе. Поэтому в команде мы пишем: left_on=’customer_id’, right_index=True .
Решаем задачу
Закрепим полученный материал, решив задачу. Найдем 5 городов, принесших самую большую выручку в 2016 году.
Для начала отфильтруем заказы из 2016 года:
> orders_2016 = orders.query("order_date >= '2016-01-01' & order_date orders_2016.head() order_date ship_mode customer_id sales id 100041 2016-11-20 Standard BF-10975 328.5 100083 2016-11-24 Standard CD-11980 24.8 100153 2016-12-13 Standard KH-16630 63.9 100244 2016-09-20 Standard GM-14695 475.7 100300 2016-06-24 Second MJ-17740 4,823.1Город — это атрибут пользователей, а не заказов. Добавим информацию о пользователях:
> with_customers_2016 = pd.merge(customers, orders_2016, how='inner', left_index=True, right_on='customer_id')Cруппируем получившийся датафрейм по городам и посчитаем выручку:
> grouped_2016 = with_customers_2016.groupby('city')['sales'].sum() > grouped_2016.head() city Akron 1,763.0 Albuquerque 692.9 Amarillo 197.2 Arlington 5,672.1 Arlington Heights 14.1 Name: sales, dtype: float64Отсортируем по убыванию продаж и оставим топ-5:
> top5 = grouped_2016.sort_values(ascending=False).head(5) > print(top5) city New York City 53,094.1 Philadelphia 39,895.5 Seattle 33,955.5 Los Angeles 33,611.1 San Francisco 27,990.0 Name: sales, dtype: float64Возьмите данные о заказах и покупателях и посчитайте:
- Сколько заказов, отправлено первым классом за последние 5 лет?
- Сколько в базе клиентов из Калифорнии?
- Сколько заказов они сделали?
- Постройте сводную таблицу средних чеков по всем штатам за каждый год.
Через некоторое время выложу ответы в Телеграме. Подписывайтесь, чтобы не пропустить ответы и новые статьи.
Кстати, большое спасибо Александру Марфицину за то, что помог отредактировать статью.