Как скачать защищенный от (Save file as) PDF, просматриваемый в браузере?
Как скачать защищенный от (Save file as) PDF, который просматривается браузером. Принцип защиты неизвестен (я не спец).
- Вопрос задан более трёх лет назад
- 10096 просмотров
1 комментарий
Простой 1 комментарий
purplepanda @purplepanda
Study from home or anywhere that suits you and your schedule.
Visit https://www.matric.co.za/courses/distance-learning. to learn more about our Distance Learning Courses.
Решения вопроса 1
PostgreSQL DBA
А в чём собственно заключается «защита»?
Прямая ссылка, файл отдаётся даже банальному wget. Мой firefox сам спросил сохранять ли файл. Может это у вас браузер себя ведёт неадекватно?
Как скачать защищенный PDF файл с Google Диска, за минуту


Добрый день! Уважаемые читатели и гости одного из крупнейших IT блогов в России Pyatilistnik.org. В прошлый раз мы с вами научились запрещать автовоспроизведение видео в браузере Chrome, так как все понимают на сколько это может раздражать, и может быть несвоевременно, на Youtube для этого была отдельная кнопка, а вот в плане всего интернета пришлось выбирать любой из понравившихся методов. Сегодня я хочу вас научить скачивать защищенный PDF файл с Google Drive (Google Диска). Под защищенным понимается, что у вас есть возможность читать его с правами только на чтение и скачать или сохранить себе на Google диск вы его не можете. Но как выяснилось все очень просто решается и уже все придумано за нас.
Постановка задачи
И так у нас с вами есть ссылка на PDF файл, который располагается на облачном хранилище Google Диск, вот пример ссылки:
https://drive.google.com/file/d/0B8pbiwdqmBuPa2xjNkItTHdWRW8/edit
Как вы можете обратить внимание, это книга «Дешифровка критской письменности (Пеластско-лезгинский язык)». Все, что вы можете сделать это вызвать панель с меню и выбрать свойства документа.
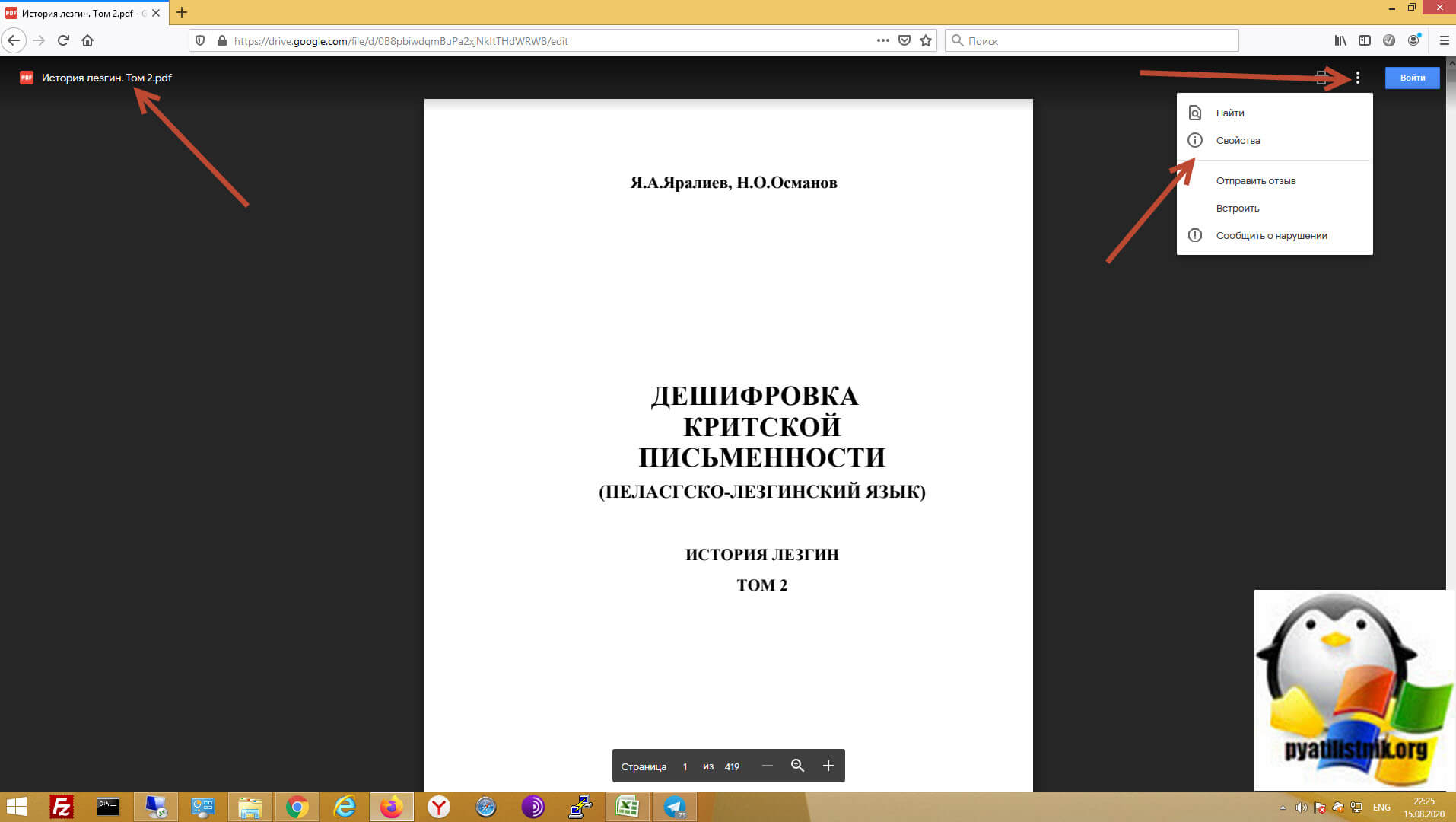
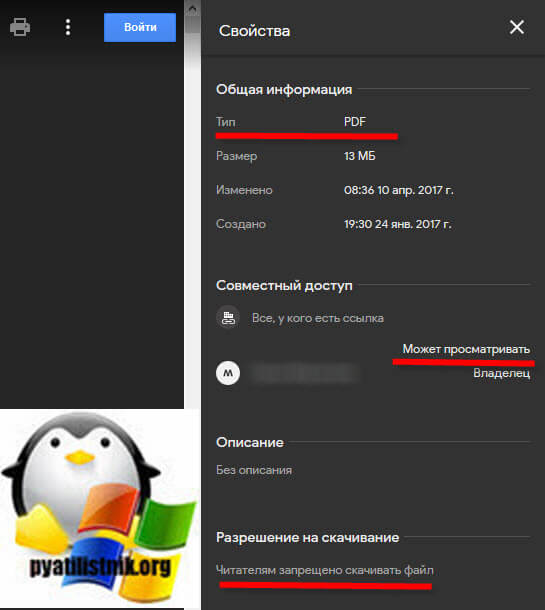
Суть метода по скачиванию ограниченного PDF файла на Гугл диске
Как оказалось Гугл диск хранит все PDF файлы в виде отдельных файлов картинок и когда пользователь начинает просматривать документ, его просто собирает в веб интерфейсе, на уровне файлового хранилище, это просто картинки. Проверить это легко, вы должны открыть защищенный PDF документ, вызвать режим разработчика, через клавишу «F11» и перейдя на вкладку «Network«, где после чего нужно обновить страницу с файлом. Делается это через клавишу «F5«. Теперь если вы зайдете в раздел «XHR», то увидите там кучу ссылок типа «xhr». Открыв любую из них вас перекинет на страницу, которую вы уже успели промотать в книжке.
Зная факт того, что это картинки и они попадают в кэш при просмотре, мы можем их вытащить из кэша и объединить в единый PDF файл
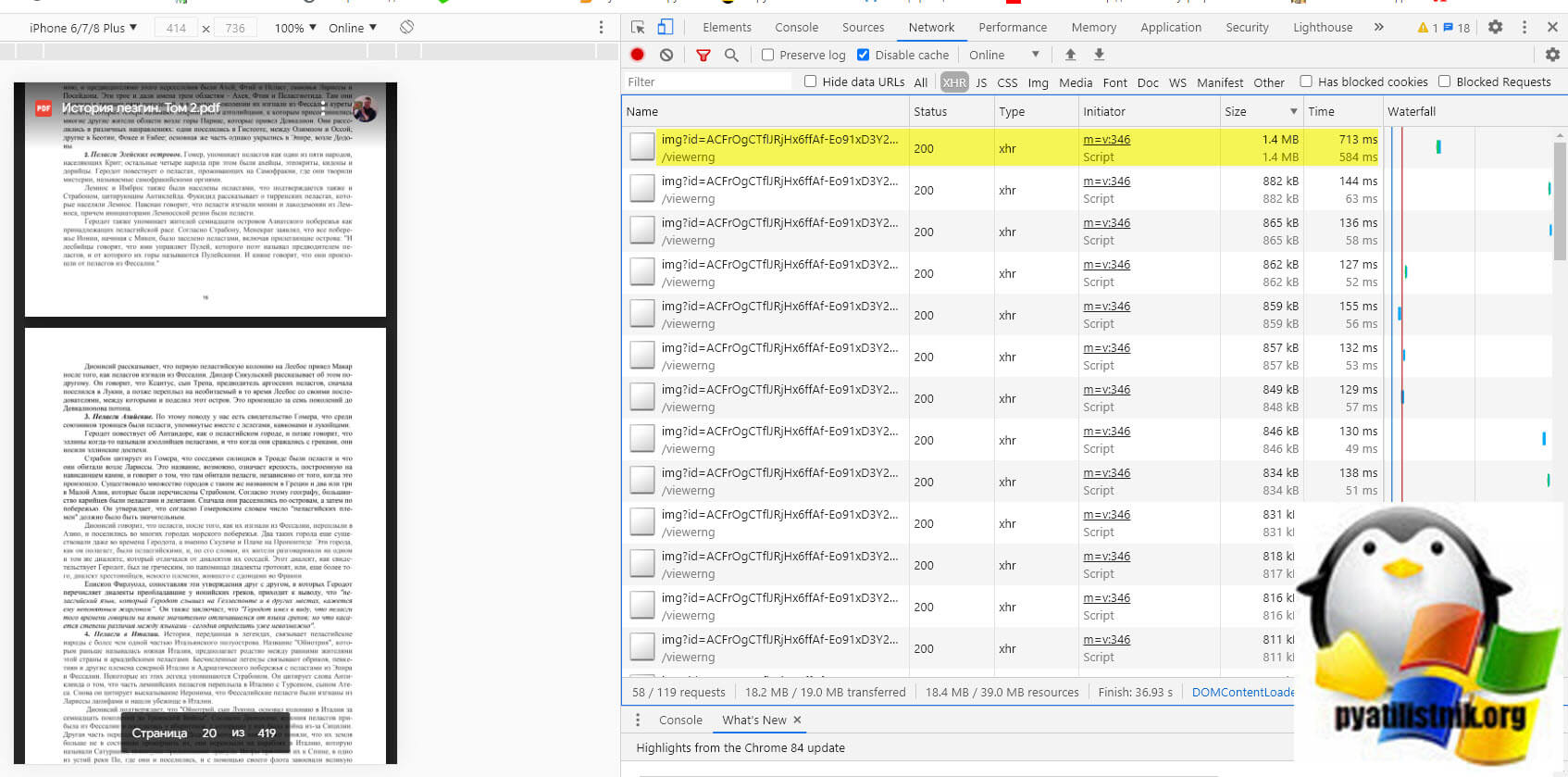
Теперь, что мы делаем поэтапно:
- Откройте ваш защищенный PDF документ, я покажу, как это делается в Mozilla Firefox и Google Chrome
- Перейдите в режим разработчика
- Нажмите клавишу F5 для обновления страницы
- Полностью пролистайте весь PDF документ, все страницы. Так как они должны попасть в локальный кэш вашего браузера
- Выполните специальный код, который объединит все страницы в кэше в единый PDF файл и позволит его загрузить на компьютер
Текст кода для скачивания защищенного PDF файла с Google Диска
let jspdf = document.createElement(«script»);
jspdf.onload = function () let pdf = new jsPDF();
let elements = document.getElementsByTagName(«img»);
for (let i in elements) let img = elements[i];
console.log(«add img «, img);
if (!/^blob:/.test(img.src)) console.log(«invalid src»);
continue;
>
let can = document.createElement(‘canvas’);
let con = can.getContext(«2d»);
can.width = img.width;
can.height = img.height;
con.drawImage(img, 0, 0, img.width, img.height);
let imgData = can.toDataURL(«image/jpeg», 1.0);
pdf.addImage(imgData, ‘JPEG’, 0, 0);
pdf.addPage();
>
pdf.save(«download.pdf»);
>;
jspdf.src = ‘https://cdnjs.cloudflare.com/ajax/libs/jspdf/1.5.3/jspdf.debug.js’;
document.body.appendChild(jspdf);
Как загрузить ограниченный PDF из Google Drive через Mozilla
- Откройте ваш защищенный PDF документ, я покажу, как это делается в Mozilla Firefox
- Перейдите в режим разработчика. В Mozilla Firefox это делается, через одновременное нажатие клавиш CTRL+Shift+I или вызов соответствующего меню «Веб разработка — Инструменты разработчика«

- Далее нажмите клавишу F5 и обновите страницу
- Полностью, по порядку пролистайте все страницы данного PDF файла
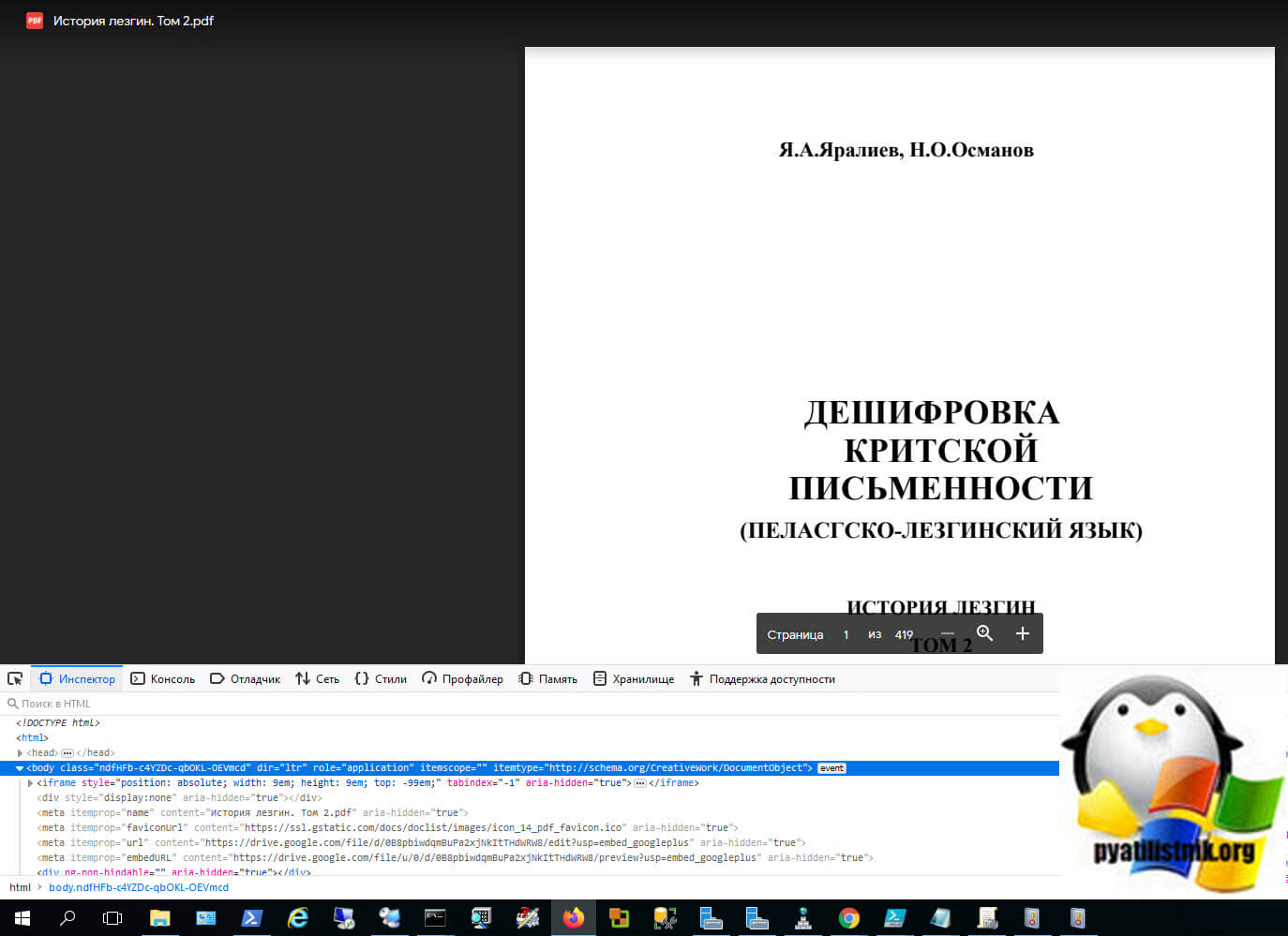
Перейдите на вкладку «Консоль«. Именно сюда нам нужно будет вставлять код, но по умолчанию политика безопасности Mozilla Firefox запрещает выполнение неподписанных скриптов. Чтобы это обойти вам нужно, это разрешить.
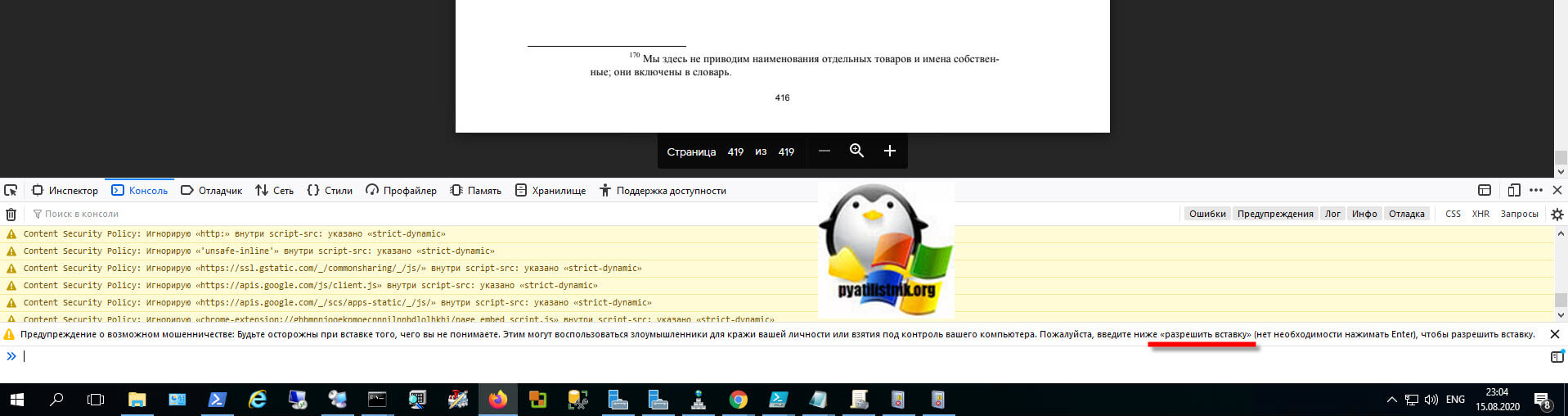
Вам нужно ввести «разрешить вставку» и нажать Enter.
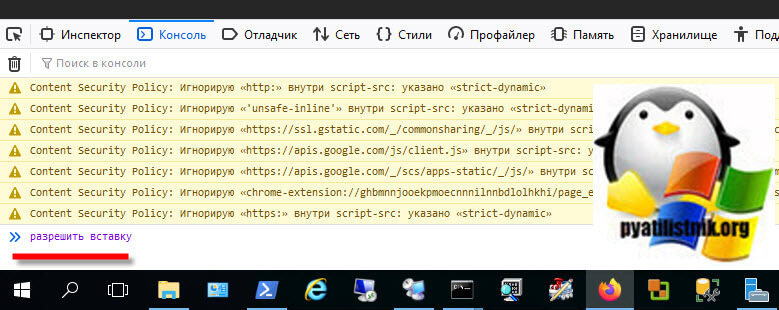
Теперь вставляем код. Для его выполнения нажмите одновременно CTRL и Enter.
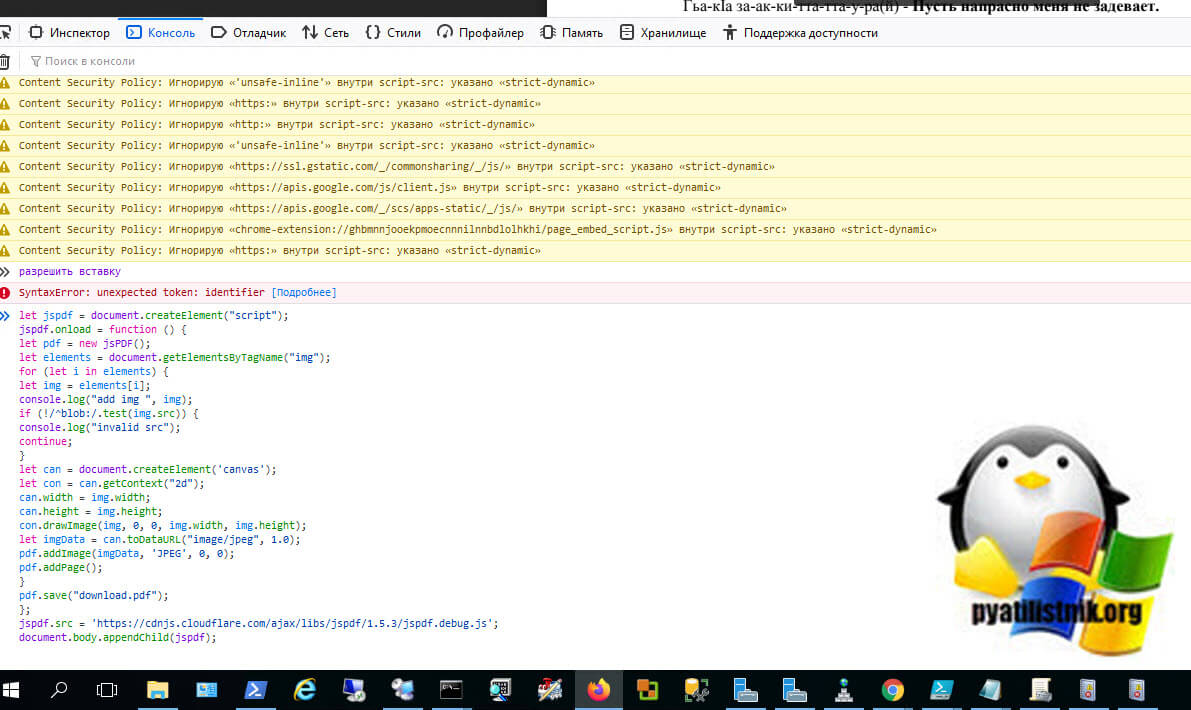
Начинается процесс скачивания картинок и объединение их в единый PDF-файл.
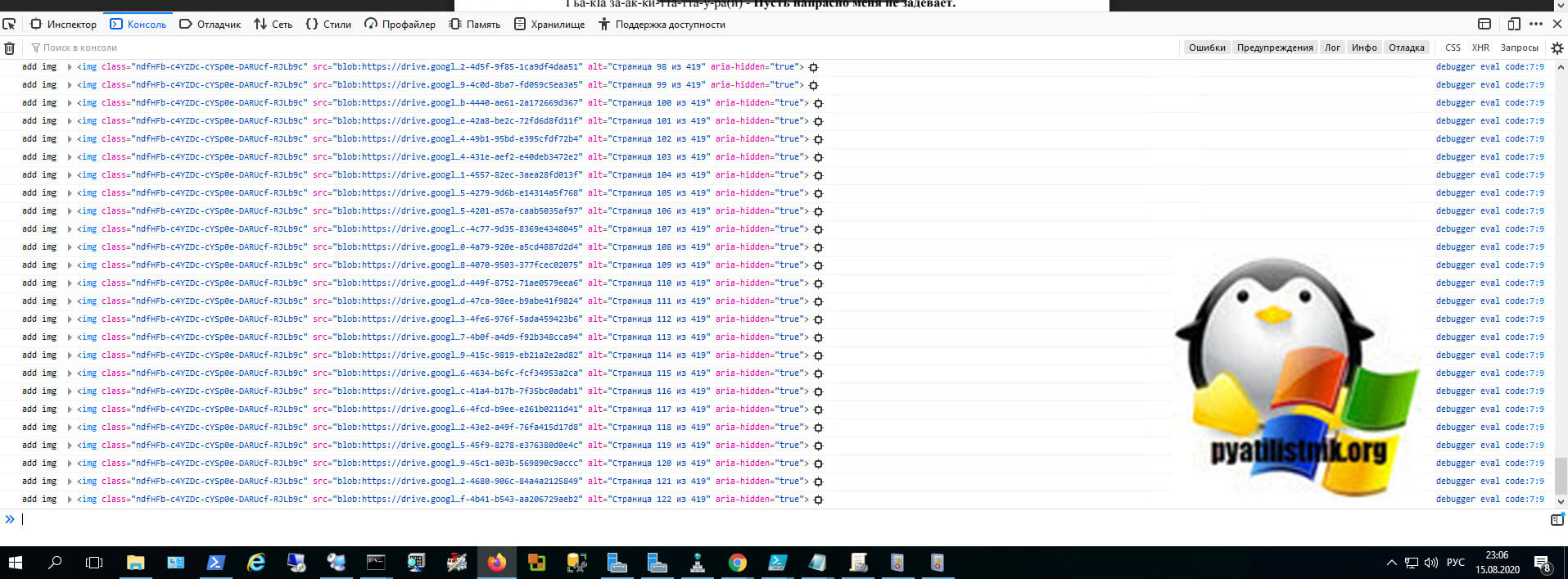
Через некоторое время браузер вам предложит сохранить DPF файл к вам на компьютер.
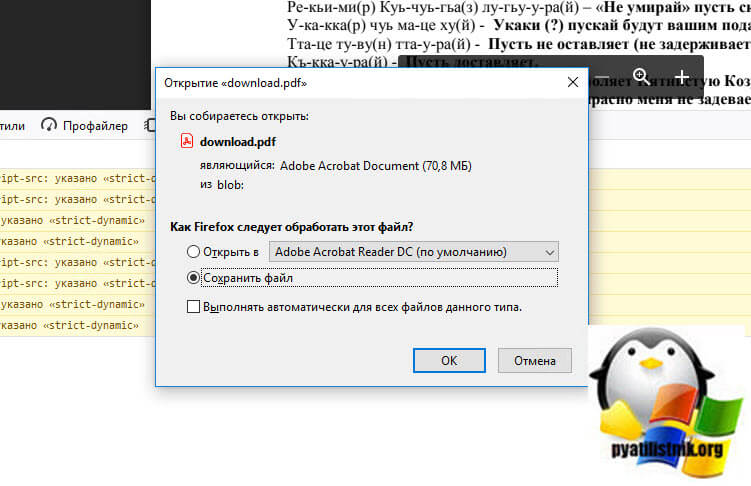
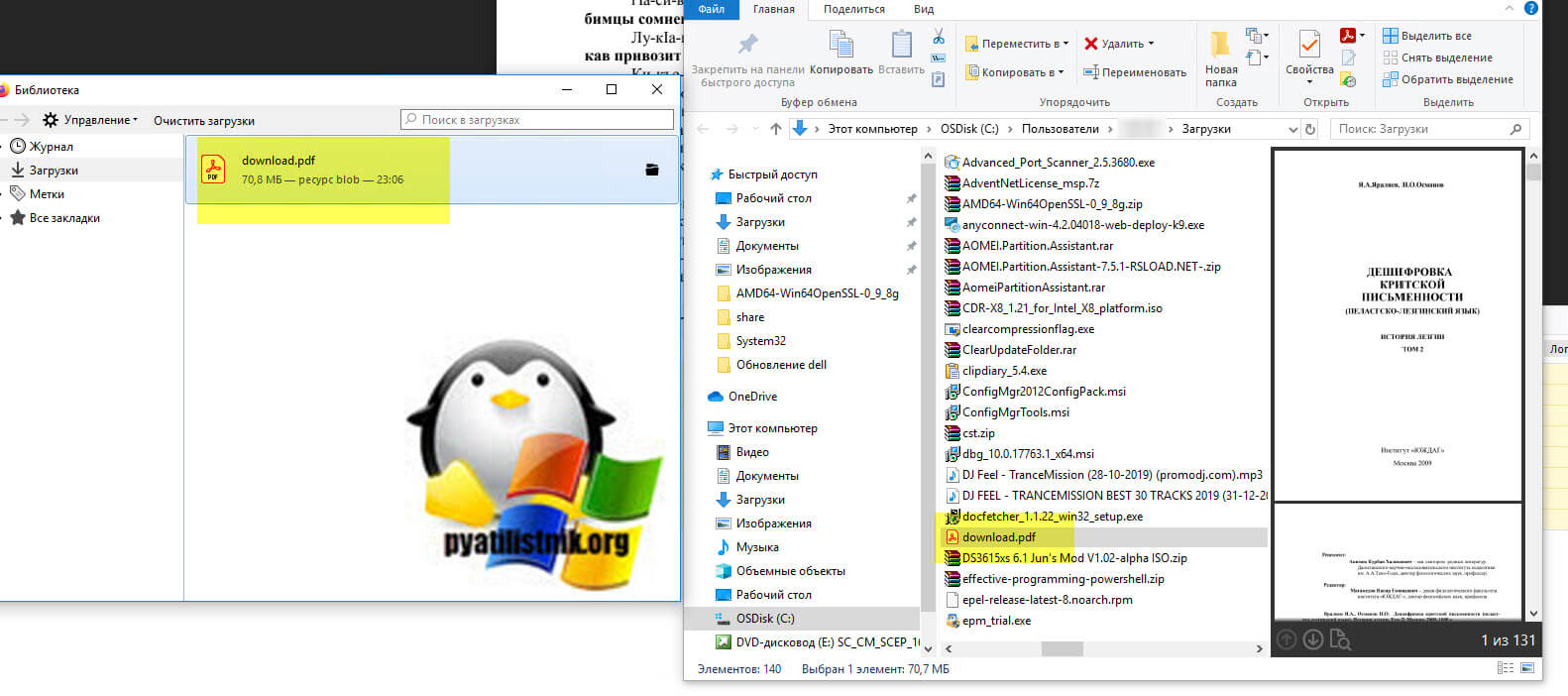
Как видите я успешно загрузил ограниченный владельцем PDF документ, все прекрасно работает.
Как загрузить ограниченный PDF из Google Drive через Chrome
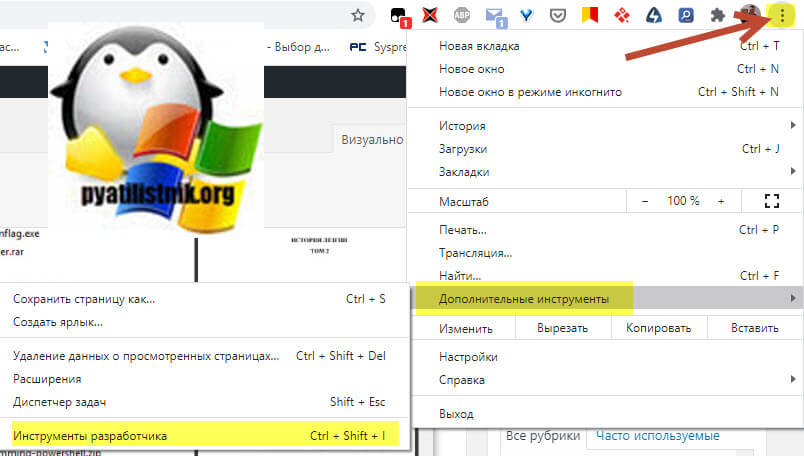
- Откройте ваш защищенный PDF документ, я покажу, как это делается в Google Chrome
- Перейдите в режим разработчика. В Google Chrome это делается, через нажатие клавиши F11 или вызов соответствующего меню «Дополнительные — Инструменты разработчика (CTRL+SHOFT+I)«
- Обязательно выберите режим iPad Pro для максимального разрешения и выставите масштаб 100%, в противном случае вы скачаете документ не с очень хорошим качеством. Далее нажмите клавишу F5 и обновите страницу
- Полностью, по порядку пролистайте все страницы данного PDF файла
- Далее перейдите на вкладку «Console»
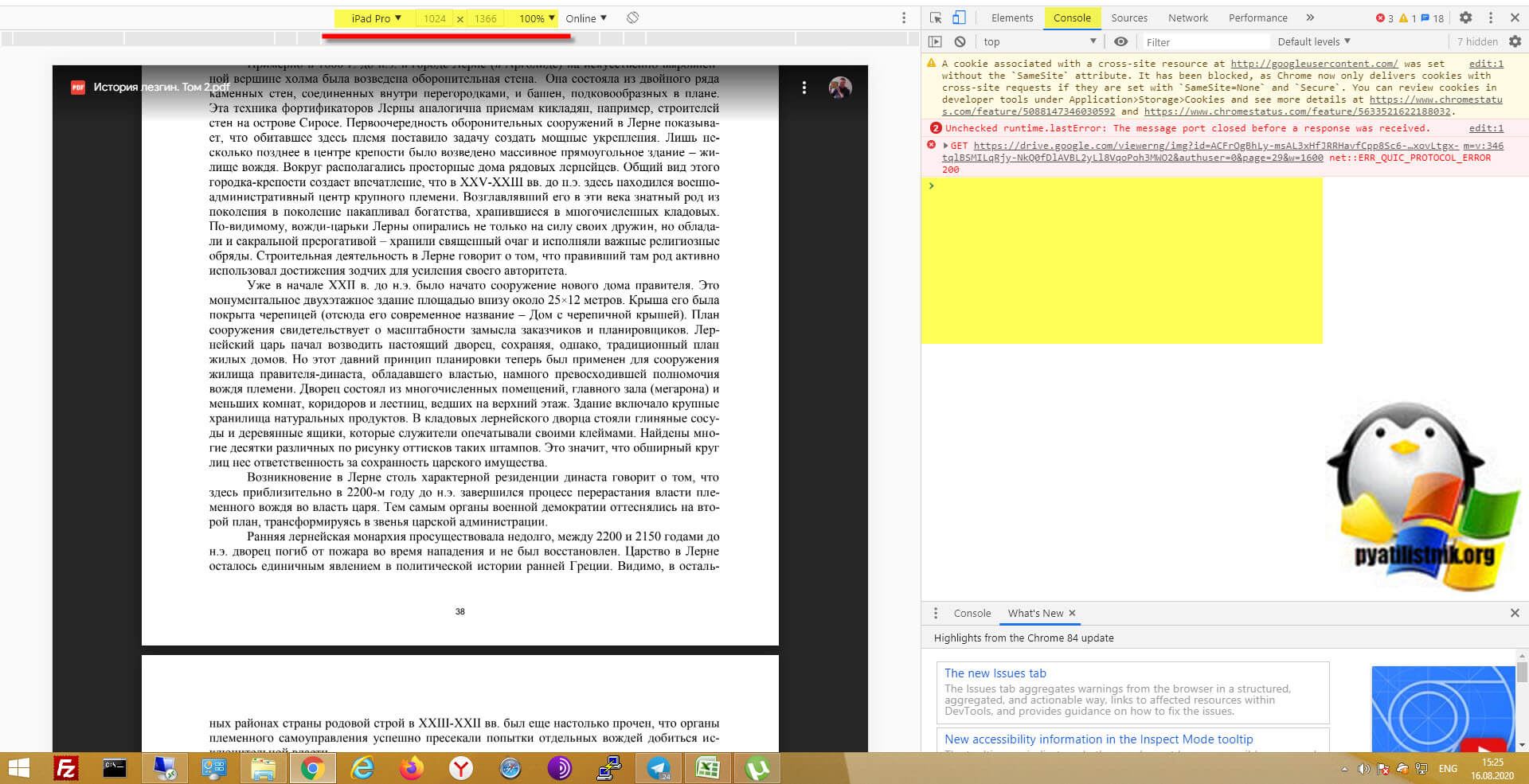
Вам необходимо вставить представленный выше код для скачивания ограниченного PDF файла, после чего просто нажать Enter.
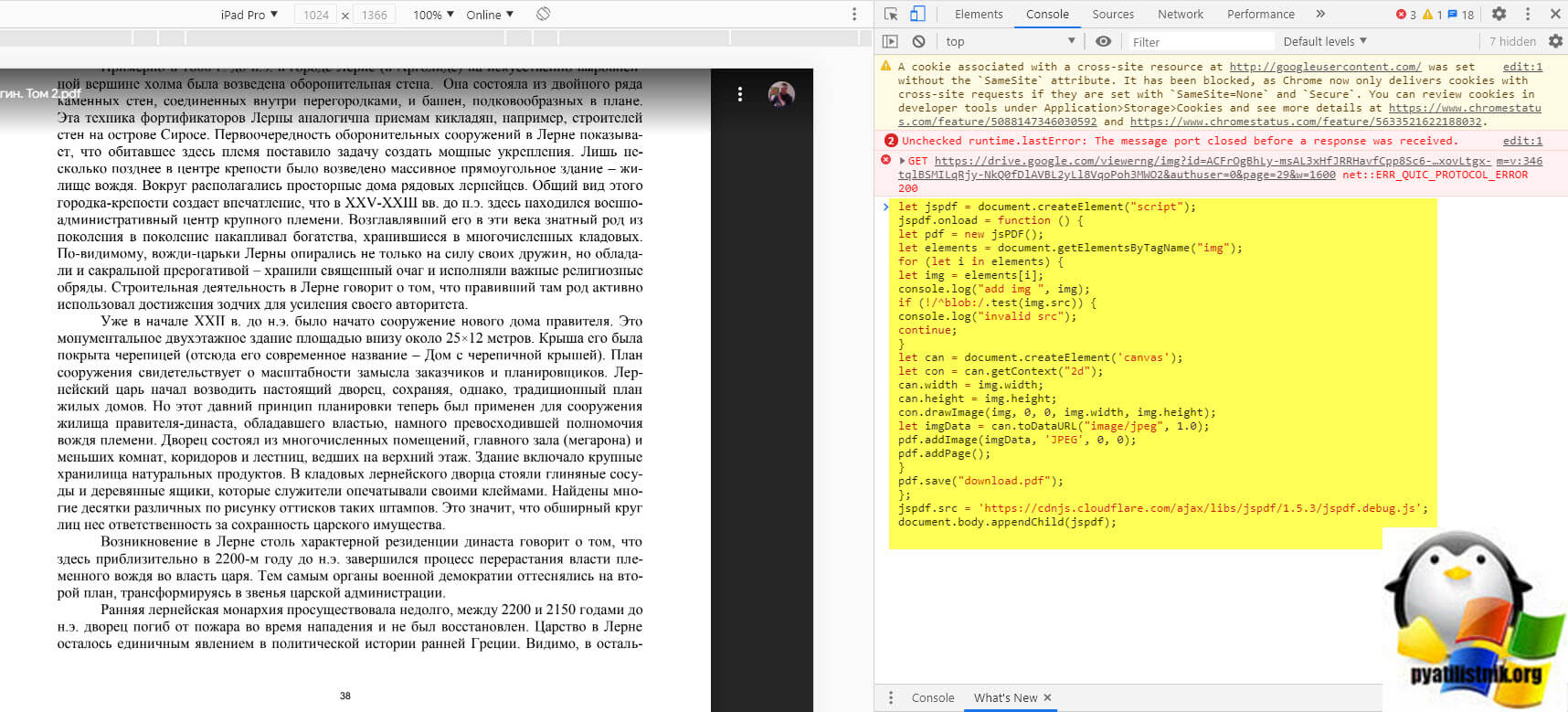
Начнется процесс сборки вашего PDF документа.
Через пару мгновений вы получите нужный вам PDF документ.
Что делать если не работает в Chrome
Тут я посоветую использовать Mozilla или же найдите версию Chrome до 100-110, главное у них отключить обновление, как вариант можно сделать из них и портативные версии.
На этом у меня все, скачивание ограниченных файлов с гугл диска через другие браузеры очень похоже, поэтому я не буду их описывать. С вами был Иван Семин, автор и создатель IT портала Pyatilistnik.org.
Популярные Похожие записи:
- Как скопировать защищенный docs файл с Google Диска
 Как скопировать защищенную Google таблицу
Как скопировать защищенную Google таблицу Импорт таблицы на веб-странице в Google Sheets
Импорт таблицы на веб-странице в Google Sheets Как ускорить Google и YouTube в России
Как ускорить Google и YouTube в России Управление Google диском в домене Active Directory
Управление Google диском в домене Active Directory- Страница с переадресацией в Search Console
Авг 9, 2020 01:11 Автор — Сёмин Иван
76 Responses to Как скачать защищенный PDF файл с Google Диска, за минуту
Очень хочется узнать как таким образом можно скачать презентацию а не pdf документ? В презентации есть много картинок+видео и текст
Иван Семин :
А это вызов, с вас пример ссылки
Спасибо большое!
Спасибо, очень круто, только не много качество хуже становиться
Просто шик, спасибо за подробную инструкцию! Очень пригодилось и заняло несколько минут. Качество на уровне.
все сделала по инструкции, файл сохраняется в плохом качестве в левом углу на листе, что то с кодом не так?
Иван Семин :
Увеличьте размер документа, поставьте 100-120%
Да ты неимоверно крут! Готов перечислить даже малость денег
Иван Семин :
Если хотите задонатить, то на странице об авторе есть реквизиты!
А ты хороший человек. )))
Хочется скачать вот такой документ
_ttps://docs.google.com/spreadsheets/u/0/d/1XMyVTv5hb9-nJZhHmHASHEyFDfpDneSfqu—mSlqJcU/htmlview#
Это гугл-таблицы. Возможно ли?
Иван Семин :
Нет не получиться, тут нет прав на это
Когда файл сохраняется, по низу обрезается 30% информации, по тексту это 4 строчки. От чего метод становится не рабочим, т.к. суть теряется на первом листе.
Иван Семин :
у меня такого нет, книжка скачивается на ура
У меня не получается — я вижу XHR — отдельные страницы, образуется
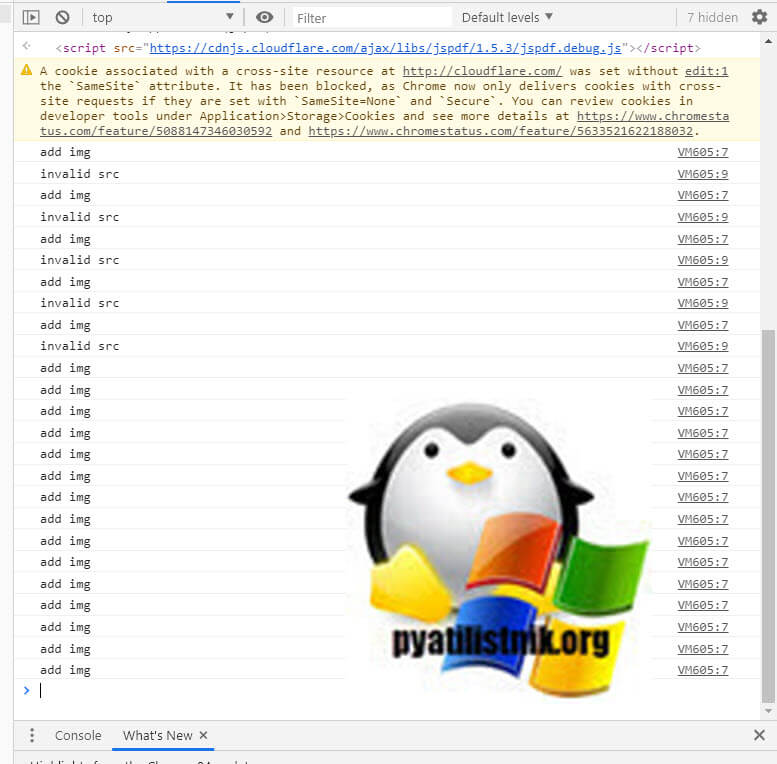
download.pdf — но он пустой — 1 страница пустая Google Chrome ubuntu 20.04 Да скрипт запускается в Tampermonkey — привязанного к веб странице с книжкой в момент refresh. add img 0
VM1068 userscript.html:24 invalid src
VM1068 userscript.html:22 add img ƒ item() < [native code] >
VM1068 userscript.html:24 invalid src
VM1068 userscript.html:22 add img ƒ namedItem() < [native code] >
VM1068 userscript.html:24
add img 0
VM943 userscript.html:24 invalid src
VM943 userscript.html:22 add img ƒ item() < [native code] >
VM943 userscript.html:24 invalid src
VM943 userscript.html:22 add img ƒ namedItem() < [native code] >
VM943 userscript.html:24 invalid src Navigated to _ttps://drive.google.com/file/d/0B5yKZ3bWyNe6SHB2T1BHYVdsT1k/view
VM1027 userscript.html:22 add img 0
VM1027 userscript.html:24
Получилось — но после некоторых усилий. На ubuntu 20.04 — у меня не работает из GOOGLE CHROME но работает из CHROMIUM и MOZILLA. Скрипт надо каждый раз руками копировать открыв инструменты разработчика и закладку консоль. Там нет надписи paste если правую кнопку мыши жать. Надо скопировать просто скрипт левой кнопкой мыши и нажать на среднюю — и RETURN. Ну конечно предварителино освежив, пролистав, перед этим настроив размер ctrl++. (извиняюсь за занудство).
Гениально просто!
И работает! Спасибо.
Виноват! Адрес страницы не гугл диск.
Доброго времени суток. Вопрос : а есть ли скрипт , чтобы проделать ту же операцию , только с дропбокс … тоже стоит запрет на скачивание и запрет на печать… а страниц много 150+ (я их вижу по отдельности и даже номера есть… но как их в кучку собрать и автоматически ? )
Подставлял ваш скрипт — выдает ошибку : мол дропбоксом запрещено использовать скрипты или чтото такое.
Refused to load the script ‘(тут ваш скрипт) ‘ because it violates the following Content Security Policy directive: «script-src ‘unsafe-eval'(и далее ссылки видимо на правила сервиса)
Для стандартной ориентации страниц работает супер! А для альбомной не получается ((( — обрезает.
Добрый день. А как excel файл скачать?
Тоже вопрос какую функцию в код добавить, что бы альбомная ориентация получилась пдф при скачивании
для альбомной ориентации ребят:
pdf.addPage(», ‘landscape’);
Вот это нужно вставить вместо
pdf.addPage();
Спасибо большое очень помог
не получается альбомный лист ввести pdf.addPage(», ‘landscape’); ошибка((
если вводить как вы писали(с книжным вариантом) все получается.
Спасибо
Спасибо за статью! Очень полезно. Есть еще вызов для Вас.
А можно сделать тоже самое, но для произвольного сайта? Чтобы скрипт сохранял все закешированные картинки при том, что они закачиваются не в виде BLOB, а в виде обычных файлов. Например, запускаем скрипт через консоль для новостного сайта и получаем все картинки со страницы. Сейчас скрипт работает только с гугл документами, а если запустить его на другом сайте, то сформируется пустой документ. И второе, тоже очень важное. Можно картинки не собирать в единый PDF, а сохранить в исходном виде (JPG) отдельным файлами и без запроса на сохранение каждого файла? Поясню для чего это нужно. Есть защищенный онлайн просмотрщик документов, в котором сделано все, чтобы пользователь не мог скачать просматриваемый материал. Смотреть можно, скачать нет. Но, по сути, этот сервис работает точно также, как и сервис гугла из Вашей статьи. При каждом нажатии на кнопку “следующая страница”, подгружается отдельная картинка и используется кеширование. Названия картинок и адреса меняются при каждой загрузке и состоят из сотни символов. Угадать адрес картинки не получается. Можно уже загруженные картинки скачивать из кэша. Вручную я из кэша картинки смог вытащить. Но нужно как-то автоматизировать процесс. В одном документе может быть 1000 страниц. А таких документов может быть много. Сами скачанные картинки удобней хранить отдельными файлами, чтобы их можно было переименовывать, пересылать, раскладывать по папочкам итп. При этом важно сохранить очерёдность скачивания файлов и при сохранении желательно называть их 0001, 0002, 0003 итп. Адрес для тестирования есть, но я его не хочу публиковать в открытом доступе. Если сделать универсальный скрипт для сохранения картинок произвольного сайта, то и для своей задачи я его смогу адаптировать. Некоторый опыт в программировании есть, но на других языках. Я пробовал решить задачу без скриптов, с помощью утилиты просмотра кэша браузера (MZCacheView). Частично работает, но не так как надо. Копировать выбранные файлы получается. Но утилита не умеет их в нужном порядке сохранять в папку, а это важно. Оригинальные названия файлов состоят из сотен символов. Утилита обрезает название файла до какой-то длинны. У них получается одинаковое называние и тогда каждому файлу добавляется числовой индекс. Вроде бы так и надо. Но проблема в том, что файлы сохраняются в последовательности по времени закачки с точностью до секунды. В одну секунду может быть закачано несколько файлов и в результате внутри каждого секундного интервала последовательность сохраненных файлов сбивается на произвольную.
Всё получилось, огромное спасибо.
Четко и быстро расписана методика , рекомендую!
Скачал пдф файл но он идет картинками не могу скопировать текст, как это исправить?
Иван Семин :
Не совсем понятно, что именно за проблема опишите подробнее или сделайте скриншот
При увеличении качество текста отличное, но режет картинку, в зависимости от приближения, иногда даже пополам( А без увеличения нормально, но качество не очень… Что посоветуете?
Иван Семин :
Даже не знаю, скиньте ссылку попробую посмотреть
Спасибо! Всё отлично скачалось на Гугл Хроме! Правда мне пришлось размер исходного файла на сайте поставить на 100%, иначе более крупный размер после сохранения урезается по краям. Качество сохранённого файла очень хорошее. Чёткость картинок и текст смотрибельно/читабельно. ��
Как скачать документ, книгу с защищенного сайта(только чтение) (Для примера взял книгу с открытым доступом)?
(заранее извиняюсь, что цитирую того человека, просто ту тему я найти не могу, она не высвечивается в браузере, как ранее. Некоторые важные моменты сохранились. Если вдруг автор скажет что-то удались — сразу удалю)
Буду раскрывать все карты — поэтапно, поскольку пока что вообще не разбираюсь коде, но один добрый человек вдохновил меня на поиски решения. Но пришлось на некоторое время забыть. Как видите — по итогу безуспешно, раз пишу сюда (потому что слишком туп). Теперь по существу: «предмет исследования» — книга-пример с открытым доступом из сайта юрайт: https://urait.ru/viewer/grazhdanskoe-pravo-i-proce. . «объект исследования» — возможность скачать ее любым способом (пожалуйста, только не надо предлагать нажать «сохранить как» правой кнопкой мыши несколько сотен раз.)
Так вот, внезапно тот добрый человек кидает результат через день: https://disk.yandex.ru/d/wOHMnfNx-rsxaQ (не в том порядке страницы, но меня удивил сам факт того, что это получилось). Я его стал расспрашивать что да как. Он отвечает, что в отладке (F12) увидел, что каждая страница качается в .svg по ссылке вида */page_N.svg.gz выкачал все страницы конвертировал в pdf и объединил. Далее он пишет что есть куча способов выкачать ссылку, от curl и wget, до python скрипта. Он использовал Download Master «добавить группу закачек» На сайтах, где требуется авторизация, он из консоли разработчика скрипт писал, чтобы ссылки выкачать.
Это все что тогда я успел взять с развития темы. После пост удален скорее всего. Сейчас появился CHAT GPT. Я в шоке с его возможностей, но из-за своего непонимания ситуации даже он мне не помог. Я ему предложил написать код для скачивания всех картинок на примере данных с этого URL: https://urait.ru/library/svobodnyy-dostup/pravo-yu. (уже другая книга, но тоже с открытым доступом) . Он мне скинул этот код:
for (let i = 1; i .svg.gz`; fetch(url) .then(res => res.arrayBuffer()) .then(data => < const blob = new Blob([data], < type: 'image/png' >); const link = document.createElement('a'); link.href = URL.createObjectURL(blob); link.download = `page$.png`; link.click(); >); >В этом коде, вы создаете цикл от 1 до 302, который загружает каждую страницу в формате .svg.gz. Затем, используя fetch API, вы загружаете этот файл в бинарный формат. Наконец, вы создаете ссылку на этот файл и скачиваете его с помощью метода click.
Я: Вставил эту команду, все 302 файла скачались, но формат файлов не поддерживается и они имеют одинаковый размер. Вылезала ошибка в консоли 302 раза: Failed to load resource: the server responded with a status of 404 ()
ЧатЖПТ: Судя по всему, сервер не поддерживает скачивание этих файлов или они просто не существуют. Возможно, эти файлы генерируются динамически при запросе или требуется определенный доступ для их загрузки. Попробуйте найти информацию об этом на сайте или у администратора сайта.
Я: забыл добавить еще ошибку: Не удалось загрузить карту исходного кода с помощью инструментов разработчика: Не удалось загрузить контент для https://static.isu.pub/fe/product-header-frontend/. : Ошибка HTTP. Код статуса 403, net::ERR_HTTP_RESPONSE_CODE_FAILURE.
ЧатЖПТ: Эти ошибки говорят о том, что ваш браузер не может загрузить какие-либо файлы, потому что сервер вернул статус ошибки 404 или 403. Ошибка 404 означает, что сервер не нашел файл, который вы запрашиваете. Ошибка 403 означает, что ваш доступ к файлу запрещен. В этом случае, вам нужно обратиться к владельцу сайта или администратору, чтобы убедиться, что у вас есть необходимые права доступа.
Если у кого-то есть опыт, сообщите, пожалуйста!
- Вопрос задан 06 февр. 2023
- 6237 просмотров
3 комментария
Простой 3 комментария
Ошибка «Не удалось скачать» при скачивании файлов с защищенных веб-сайтов в Internet Explorer 9 и более поздних версиях
Устаревшее и не поддерживаемое классическое приложение Internet Explorer 11 было окончательно отключено с помощью обновления Microsoft Edge в некоторых версиях Windows 10. Дополнительные сведения см. в статье Часто задаваемые вопросы о прекращении использования классических приложений Internet Explorer 11.
В этой статье содержатся сведения об устранении ошибки Не удалось скачать , которая возникает при попытке скачать файлы с помощью Internet Explorer 9 или более поздней версии.
Исходная версия продукта: Internet Explorer 9 и более поздних версий
Исходный номер базы знаний: 2549423
Симптомы
Вы не можете скачивать файлы или просматривать файлы с веб-сайта при подключении к сайту по протоколу HTTPS (безопасные сайты) с помощью Internet Explorer 9 или более поздней версии. Например, вы посещаете безопасный веб-сайт, например банк или другое финансовое учреждение, и пытаетесь скачать или просмотреть PDF-файл. Файл не отображается в Internet Explorer, и может появиться сообщение об ошибке, похожее на следующее:
Сообщение об ошибке 1
Internet Explorer не удается скачать
Сообщение об ошибке 2
Эта проблема возникает, если в Internet Explorer выбран параметр Не сохранять зашифрованные страницы на диск .
Причина
Чтобы скачать файлы, Internet Explorer должен создать кэш или временный файл. В Internet Explorer 9 или более поздней версии, если файл доставляется по протоколу HTTPS и все заголовки ответов настроены для предотвращения кэширования, а если установлен параметр Не сохранять зашифрованные страницы на диск , файл кэша не создается. Поэтому скачивание завершается сбоем.
Решение — метод 1
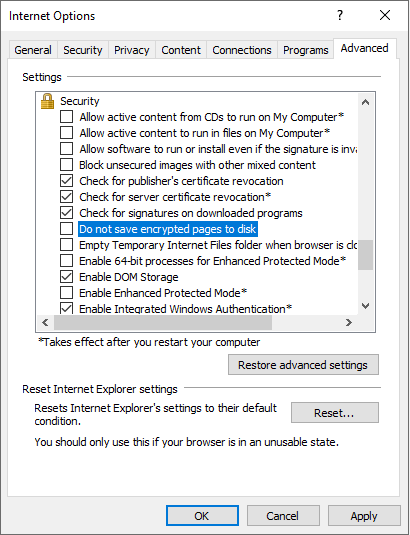
Чтобы устранить эту проблему, сначала попробуйте метод 1. Если метод 1 завершается ошибкой, перейдите к методу 2.
- В меню Сервис в Internet Explorer 9 или более поздней версии выберите пункт Свойства браузера, а затем перейдите на вкладку Дополнительно .
- Щелкните, чтобы снять флажок Не сохранять зашифрованные страницы на диск в области Безопасность , а затем нажмите кнопку ОК. (Это параметр Internet Explorer по умолчанию.)
Решение — метод 2
- Откройте редактор реестра.
- Для параметра для пользователя найдите следующий раздел реестра:
HKEY_CURRENT_USER\SOFTWARE\Microsoft\Windows\CurrentVersion\Internet Settings Для параметра для каждого компьютера найдите следующий раздел реестра:
HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Windows\CurrentVersion\Internet Settings - В меню Правка выберите команду Добавить значение, а затем добавьте следующее значение:
BypassSSLNoCacheCheck =Dword:00000001 - Закройте редактор реестра.
Обратная связь
Были ли сведения на этой странице полезными?