Как в Адоб Ридере выделить текст колонкой?
Выделяется в таблице — если в виде текста, то строками, или столбец, но тогда в виде изображения. Может, я какого-то инструмента (команды) просто не знаю? Подскажите, пожалуйста!
Лучший ответ
PDF формат вообще не предназначен для копирования\редактирования, и, каких-то удобных инструментов для обработки, Adobe Reader изначально не имеет. Дальше, как обычно, есть 3 варианта достичь цели:
1. Взять программу, которая может реактировать PDF-файлы. Тогда можно «убрать ненужные» столбцы, после чего, легко копировать и вставить, а также работать с таблицей как с таблицей. . Называется такая программа Adobe Acrobat 8.0 Pro (RUS), а, вот, самоучититель по нему.
2. Состоит в том, чтобы преобразовть PDF в картинку, которую потом распознать с помощью ABBYY FineReader 9.0.0.662 PRO Midnight Special Edition (Not Neeeded Activation), у которого есть определение и восстановление логической структуры документа:
ABBYY FineReader 9.0 представляет революционную технологию адаптивного распознавания документов — ADRT™ (Adaptive Document Recognition Technology). Теперь документ анализируется и обрабатывается как единое целое, а не постранично.
Технология ADRT позволяет ABBYY FineReader определить элементы «логической» структуры документа: верхние и нижние колонтитулы, сноски, подписи к картинкам и диаграммам, стили, шрифты, нумерацию страниц. Теперь ABBYY FineReader реконструирует документ так, как будто это сделал человек.
Т. е. , появляется возможность получить нормальную таблицу в Word’e, после чего ее можно импортировать в Excel для дальнейшей нормальной работы со столбцами.
3. Впрочем, есть более простой вариант, это
ABBYY PDF Transformer 2.0 Multilingual. ABBYY PDF Transformer 2.0 – универсальный инструмент для работы с PDF-файлами. Он не только преобразует PDF-файлы в привычные, удобные для редактирования форматы – Microsoft Word, Excel, HTML и TXT, но также позволяет создавать PDF прямо из приложений Microsoft Office одним щелчком мыши. Кроме того, программа позволяет создавать PDF-документы практически из любого приложения, поддерживающего вывод документа на печать (это делается при помощи драйвера принтера ABBYY PDF Transformer 2.0).
Источник: Личный опыт
—Мыслитель (7332) 15 лет назад
Большое спасибо за проявленное Вами внимание к моему вопросу и за подробный, подкрепленный личным опытом ответ, снабженный к тому же приятными ссылками!
Импорт данных из PDF в Excel через Power Query
Задача переноса данных из таблицы в PDF-файле на лист Microsoft Excel — это всегда «весело». Особенно если у вас нет дорогих программ распознавания типа FineReader или чего-то подобного. Прямое копирование обычно ни к чему хорошему не приводит, т.к. после вставки скопированных данных на лист, они, скорее всего, «слипнутся» в один столбец. Так что их потом придется кропотливо разделять с помощью инструмента Текст по столбцам с вкладки Данные (Data — Text to Columns) . И само-собой, копирование возможно только для тех PDF-файлов, где есть текстовый слой, т.е. с только что отсканированным с бумаги в PDF документом это не сработает в принципе. Но все не так грустно, на самом деле 🙂 Если у вас Office 2013 или 2016, то за пару минут без дополнительных программ вполне можно реализовать перенос данных из PDF в Microsoft Excel. А помогут нам в этом Word и Power Query.
Для примера, давайте возьмем вот такой PDF-отчет с кучей текста, формул и таблиц с сайта Европейской Экономической Комиссии: 
. и попробуем вытащить из него в Excel, скажем первую таблицу: 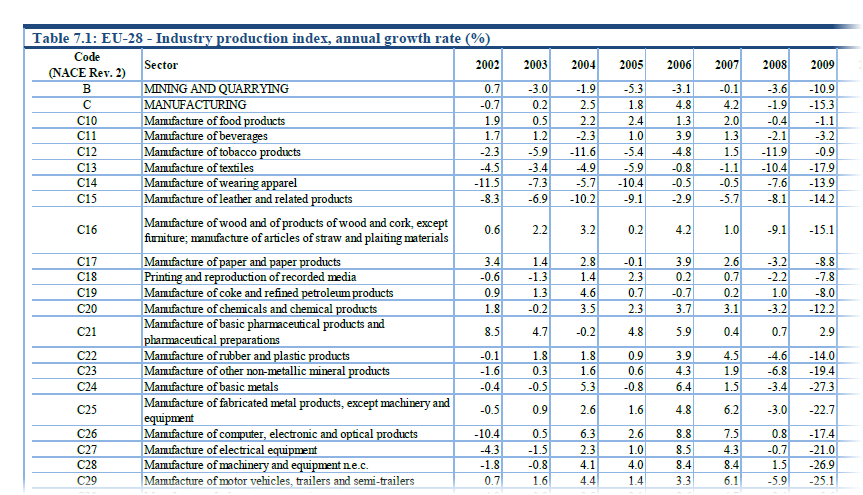
Поехали!
Шаг 1. Открываем PDF в Word
Почему-то мало кто знает, но начиная с 2013 года Microsoft Word научился открывать и распознавать PDF файлы (даже отсканированные, т.е. без текстового слоя!). Делается это совершенно стандартным образом: открываем Word, жмем Файл — Открыть (File — Open) и уточняем PDF-формат в выпадающем списке в правом нижнем углу окна. Затем выбираем нужный нам PDF-файл и жмем Открыть (Open) . Word сообщает нам, что собирается запустить распознавание этого документа в текст: 
Соглашаемся и через несколько секунд увидим наш PDF открытым для редактирования уже в Word: 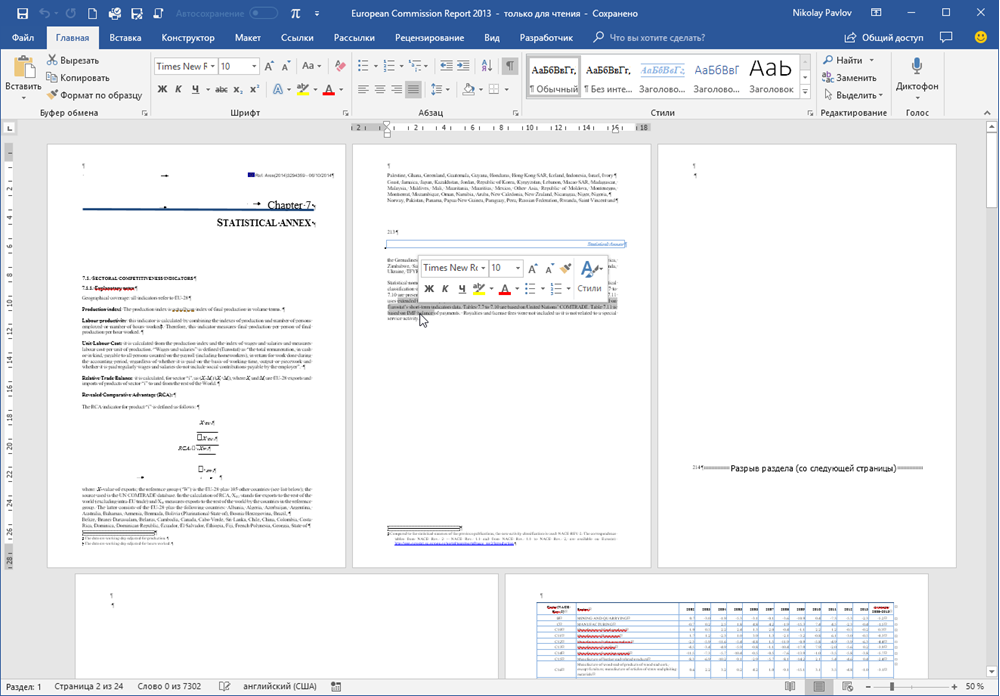
Само-собой, у документа частично слетит дизайн, стили, шрифты, колонтитулы и т.п., но для нас это не важно — нам нужны только данные из таблиц. В принципе, на этом этапе уже возникает соблазн дальше просто скопировать таблицу из распознанного документа в Word и просто вставить ее в Excel. Иногда это срабатывает, но чаще приводит ко всевозможным искажениям данных — например числа могут превратиться в даты или остаться текстом, как в нашем случае, т.к. в PDF используется не российские разделители: 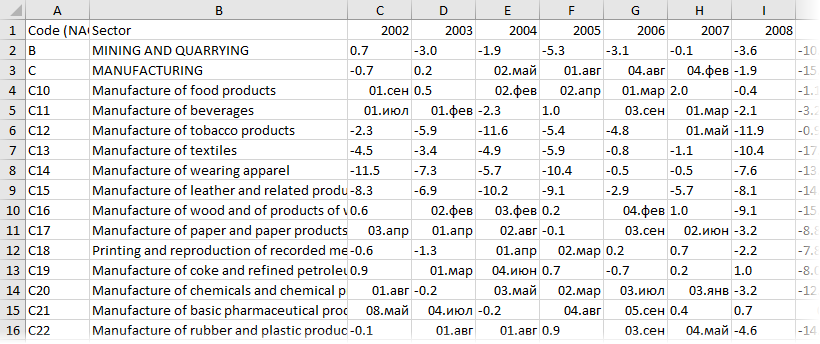 Так что давайте не будем срезать углы, а сделаем все чуть сложнее, но правильно.
Так что давайте не будем срезать углы, а сделаем все чуть сложнее, но правильно.
Этап 2. Сохраняем документ как веб-страницу
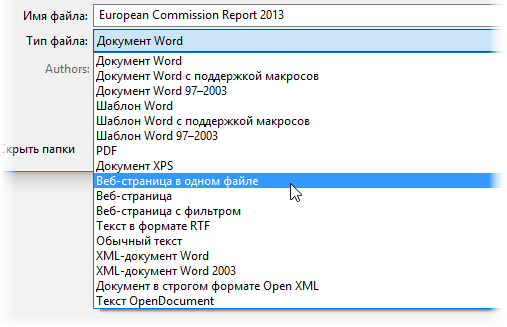
Чтобы потом загрузить полученные данные в Excel (через Power Query), наш документ в Word нужно сохранить в формате веб-страницы — этот формат является, в данном случае, неким общим знаменателем между Word’ом и Excel’ем. Для этого идем в меню Файл — Сохранить как (File — Save As) или жмем клавишу F12 на клавиатуре и в открывшемся окне выбираем тип файла Веб-страница в одном файле (Webpage — Single file) : После сохранения должен получиться файл с расширением mhtml (если у вас в Проводнике видны расширения файлов).
Этап 3. Загружаем файл в Excel через Power Query
Можно открыть созданный MHTML-файл в Excel напрямую, но тогда мы получим, во-первых сразу все содержимое PDF вместе текстом и кучей ненужных таблиц, а, во-вторых, опять потеряем данные из-за неправильных разделителей. Поэтому импорт в Excel мы будем делать через надстройку Power Query. Это совершенно бесплатная надстройка, с помощью которой можно загружать в Excel данные практически из любых источников (файлов, папок, баз данных, ERP-систем) и всячески затем полученные данные трансформировать, придавая им нужную форму.
Если у вас Excel 2010-2013, то скачать Power Query можно с официального сайта Microsoft — после установки у вас появится вкладка Power Query. Если у вас Excel 2016 или новее, то качать ничего не нужно — весь функционал уже встроен в Excel по-умолчанию и находится на вкладке Данные (Data) в группе Загрузить и преобразовать (Get & Transform) . Так что идем либо на вкладку Данные, либо на вкладку Power Query и выбираем команду Получить данные или Создать запрос — Из файла — Из XML. Чтобы были видны не только XML-файлы — меняем в выпадающем списке в правом нижнем углу окна фильтры на Все файлы (All files) и указываем наш MHTML-файл: 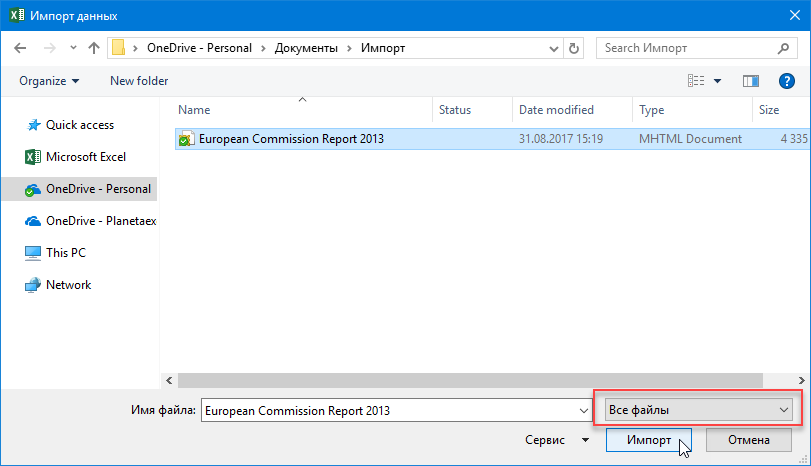
Обратите внимание, что импорт успешно не завершится, т.к. Power Query ждет от нас XML, а у нас, на самом деле, HTML-формат. Поэтому в следующем появившемся окне нужно будет щелкнуть правой кнопкой мыши по непонятному для Power Query файлу и уточнить его формат: 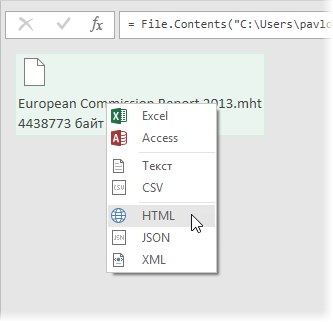 После этого файл будет корректно распознан и мы увидим список всех таблиц, которые в нем есть:
После этого файл будет корректно распознан и мы увидим список всех таблиц, которые в нем есть: 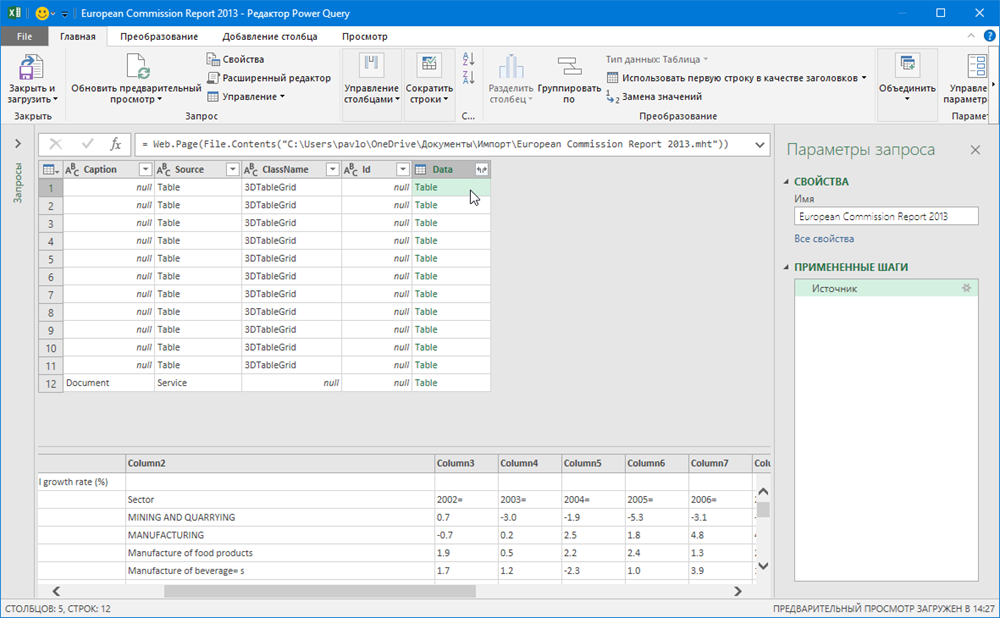
Посмотреть содержимое таблиц можно, если щелкать левой кнопкой мыши в белый фон (не в слово Table!) ячеек в столбце Data. Когда нужная таблица определена, щелкните по зеленому слову Table — и вы «провалитесь» в её содержимое: 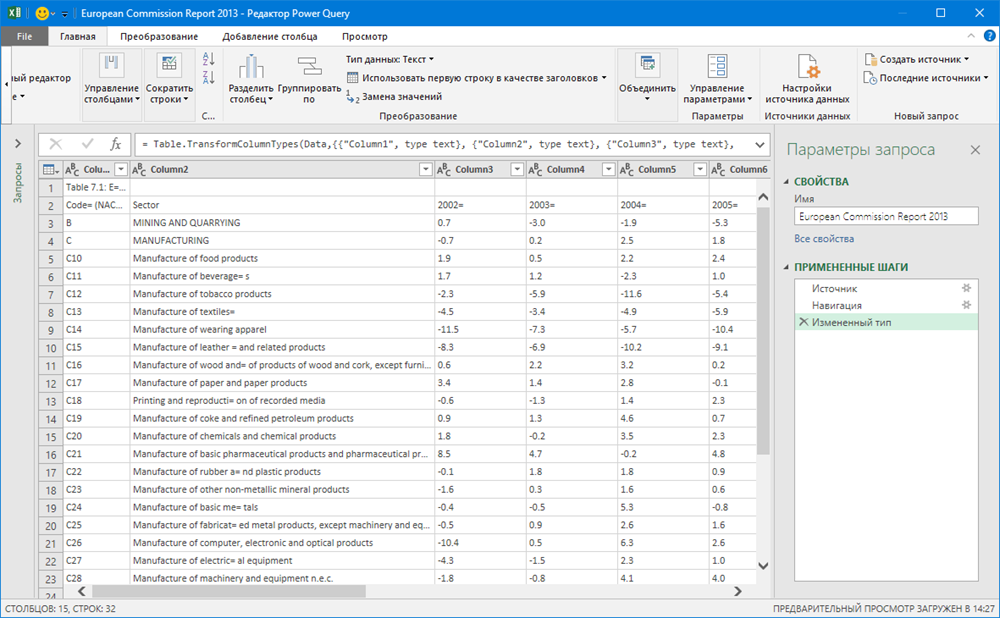
Останется проделать несколько простых действий, чтобы «причесать» ее содержимое, а именно:
- удалить ненужные столбцы (правой кнопкой мыши по заголовку столбца — Удалить)
- заменить точки на запятые (выделить столбцы, щелкнуть правой — Замена значений)
- удалить знаки равно в шапке (выделить столбцы, щелкнуть правой — Замена значений)
- удалить верхнюю строку (Главная— Удалить строки — Удаление верхних строк)
- удалить пустые строки (Главная — Удалить строки — Удаление пустых строк)
- поднять первую строку в шапку таблицы (Главная — Использовать первую строку в качестве заголовков)
- отфильтровать лишние данные с помощью фильтра
Когда таблица будет приведена в нормальный вид, ее можно выгрузить на лист командой Закрыть и загрузить (Close & Load) на Главной вкладке. И мы получим вот такую красоту, с которой уже можно работать:
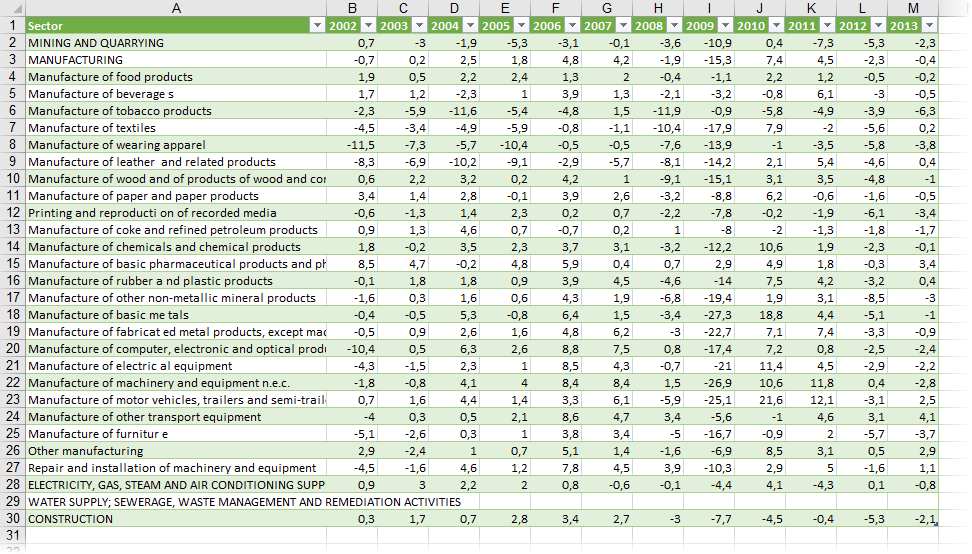
Ссылки по теме
- Трансформация столбца в таблицу с помощью Power Query
- Разделение слипшегося текста по столбцам
Как извлечь страницы из PDF документа для создания нового PDF документа
wikiHow работает по принципу вики, а это значит, что многие наши статьи написаны несколькими авторами. При создании этой статьи над ее редактированием и улучшением работали, в том числе анонимно, 28 человек(а).
Количество просмотров этой статьи: 285 831.
В этой статье:
Иногда нам не нужен весь документ, а некоторые из них такие огромные, что не помещаются на флеш-накопителе. Возможно, в документе всего несколько интересных страниц, поэтому лучше сохранить их как отдельный небольшой PDF-файл.
Метод 1 из 6:
С помощью программы Acrobat Professional (в Windows и macOS)

Запустите программу Adobe Acrobat Professional, а затем откройте нужный PDF-документ.
Откройте панель «Страницы» слева в окне Acrobat. На этой панели отобразятся миниатюры (маленькие изображения) страниц PDF-документа.
- Например, если нужно извлечь первую и третью страницу, переместите миниатюру третьей страницы вверх так, чтобы над миниатюрой второй страницы отобразилась синяя полоска, которая указывает, где разместится перетаскиваемая страница.
- Теперь третья страница будет расположена непосредственно после первой.
- Появится окно «Извлечение страниц».
Укажите диапазон страниц. Если в окне «Извлечение страниц» отображается не тот диапазон страниц, введите нужный вам диапазон.
- Чтобы каждая извлекаемая страница сохранилась как отдельный файл, установите флажок у «Извлечь страницы в отдельные файлы». В противном случае все извлекаемые страницы будут сохранены в одном файле.
Щелкните по «ОК». Программа извлечет нужные страницы и сохранит их в новом PDF-документе.
Сохраните и закройте новый документ. Можно ввести имя нового файла и выбрать папку для его сохранения, а затем вернуться к оригинальному документу. Нажмите «Сохранить», чтобы сохранить файл в формате PDF, или щелкните по «Сохранить как», чтобы выбрать один из множества форматов, например, PDF, PNG, JPEG, Word и так далее.
Восстановите оригинальный файл. Если извлеченные страницы не были удалены из оригинального документа, и вы хотите упорядочить страницы так, как было, откройте меню «Файл» и выберите «Восстановить». В любом другом случае сохраните измененный документ как обычно.
Метод 2 из 6:
С помощью браузера Google Chrome

Запустите Google Chrome.

Нажмите клавиши Ctrl + О. Откроется окно, в котором можно найти нужный PDF-файл.
Найдите или введите имя нужного файла, а затем щелкните по «Открыть». PDF-документ откроется в окне браузера.
Щелкните по значку, который выглядит как три точки и находится в верхнем правом углу. Откроется меню.
Нажмите «Печать».
Щелкните по «Изменить» в меню «Принтер».
Нажмите «Сохранить как PDF».
Установите флажок у опции, которая находится под опцией «Все», а затем введите нужный диапазон страниц.
Щелкните по «Сохранить».
Введите имя нового файла, выберите папку для сохранения, а затем щелкните по «Сохранить» (все это сделайте в открывшемся окне).
Метод 3 из 6:
С помощью программы «Просмотр» (в macOS)

Запустите программу «Просмотр». Теперь откройте нужный PDF-документ и щелкните по кнопке «Миниатюры» вверху окна. Появится панель с миниатюрами (маленькими изображениями) страниц PDF-документа.
Переместите страницы. Переместите миниатюры страниц, которые нужно извлечь, так, чтобы они находились друг за другом. Также можно удерживать клавишу Shift и щелкнуть по каждой нужной миниатюре, чтобы выделить их.
Откройте меню «Файл» и нажмите «Печать». В окне «Печать» введите нужный диапазон страниц. Если миниатюры нужных страниц уже выделены, на панели миниатюр нажмите «Выбранные страницы».
Сохраните выбранные страницы в формате PDF. В левом нижнем углу окна «Печать» щелкните по «PDF» и нажмите «Сохранить как PDF».
Введите имя файла. Откройте папку, в которой файл будет сохранен, введите имя файла, а затем сохраните его.
Метод 4 из 6:
С помощью онлайн-сервиса SmallPDF (на любой платформе)

Откройте сайт сервиса Smallpdf. Перейдите на страницу https://smallpdf.com/ru/merge-pdf в веб-браузере.
Загрузите нужный PDF-документ. Для этого просто перетащите PDF-файл(ы) на фиолетовое поле «Перетяните PDF сюда».
Измените расположение страниц. Нажмите «Режим страницы», чтобы на экране отобразились миниатюры всех страниц документа. Под каждой миниатюрой есть номер страницы (буква перед номером указывает на документ). Чтобы удалить ненужные страницы, щелкните по значку «Х» в правом верхнем углу миниатюры (чтобы он отобразился, наведите указатель мыши на миниатюру)
Объедините нужные страницы в один документ. Для этого нажмите «Объединить PDF» справа и под миниатюрами страниц. Новый PDF-документ будет автоматически скачан на компьютер; вы найдете его в папке для загрузок.
Метод 5 из 6:
С помощью программы CutePDF Writer

Перейдите на сайт CutePDF. Теперь нажмите «CutePDF Writer». Вы перейдете на страницу загрузки бесплатной программы CutePDF Writer.
Как скопировать только один столбец в пдф
Шаг 1.
Скачайте и установите последнюю версию оригинального просмотрщика Adobe Reader. Шаг 2.
Запустите Adobe Reader и откройте в нем форму для заполнения. Одновременно откройте любой редактор, предназначенный для работы с документами в формате «только текст», например, в Linux — KWrite или Geany, в Windows — «Блокнот» или MS Word. Шаг 3.
Введите данные, которые должны располагаться в полях формы в документе, не непосредственно в них, а в текстовый редактор. Для каждого нового поля используйте отдельную строку. Документ сохраните. Шаг 4.
Используя буфер обмена (копировать — «Control»+»C», вставить — «Control»+»V»), перенесите данные из строк в текстовом документе в соответствующие поля формы в PDF-документе. Удостоверьтесь, что, во-первых, поля заполнены правильно, а во-вторых, все данные находятся именно в тех полях, которые для них предназначены. При заполнении форм используйте примеры заполнения во втором справа столбце таблицы. Шаг 5
Нажмите, чтобы выбрать нужные параметры, например, переключатели. Нажмите внутри текстового поля для ввода текста.
В ситуациях, при которых возможен ввод текста в поле формы, инструмент «Рука» превращается в I-образный курсор. Некоторые текстовые поля являются динамическими. Это означает, что для того чтобы вместить все вводимые данные, они могут изменять свои размеры и переноситься на другую страницу. Заполняемые поля формы выделены цветом (по умолчанию светло-синим). Все обязательные поля обведены тонкой рамкой другого цвета (по умолчанию красный цвет). Нажмите на клавиатуре клавишу Tab, чтобы перейти к следующему полю, или клавиши Shift+Tab, чтобы перейти к предыдущему полю. Шаг 6
Сохраните PDF-форму. Чтобы сохранить заполненную форму, выберите Файл > Сохранить как и переименуйте файл. Шаг 7
Печать PDF-форм
7.1. Нажмите кнопку Печать или выберите команду Файл > Печать.
7.2. Выберите принтер из меню в верхней части диалогового окна «Печать».
7.3. В диалоговом окне выберите необходимые вам параметры, а затем нажмите кнопку «ОК» (Печать). Шаг 8
Подайте документы в Роспатент Электронная подача заявки
Через сайт ФИПС
Через Портал «Госуслуги» Неэлектронная подача заявки
Непосредственно в пункт приема заявок:
Москва, Бережковская наб., д. 30, корп. 1
понедельник – четверг: 9:30–17:45; пятница: 9:30–16:45; перерыв: 12:30–13:00;
Почтовым отправлением по адресу:
Роспатент, Бережковская наб., д. 30, корп. 1, Москва, Г-59, ГСП-3, 125993, Российская Федерация. Госуслуги Роспатента
Меню раздела
- Устав
- Структура и руководство
- История
- Деятельность
- Вакансии
- Закупки
- Всероссийская патентно-техническая библиотека
- Центры поддержки технологий и инновации
- Мероприятия
- Мультимедиа
- Палата по патентным спорам
- Противодействие коррупции
- Приволжский центр ФИПС
Навигация по странице
Бережковская наб., д. 30, корп. 1, Москва, Г-59, ГСП-3, 125993, РФ
E-mail: fips@rupto.ru
Тел.: +7 (499) 240-6015, факс: +7 (495) 531-6336
Время работы:
Режим рабочего времени ФИПС:
Понедельник — Четверг: 9:30 – 18:15
Пятница: 9:30 – 17:00
Суббота, воскресенье, нерабочие и
праздничные дни – выходные дни.
Режим работы окон приема документов:
Понедельник – Четверг: 9:00 – 17:45
Пятница: 9:00 – 16:30
Без перерыва на обед