Пример построения кластера надежности и его тестирование
В качестве примера построим кластер, состоящий из двух узлов и одного внешнего массива данных с интерфесом Fiber Channel. Подключим к нему несколько рабочих станций и проведем тестирование возможных точек отказа кластера.
Используемое оборудование:
Узлы кластера — два сервера Team Server серии 1500A в составе:
- Intel Server Board S5000PAL;
- Intel Xeon 5130 Processor;
- 2Gb Fully Buffered ECC SDRAM DDR2-667;
- HBA QLogic QLE2462;
Дисковый массив Dot Hill R/Evolution 2730 в составе:
- Два Raid контроллера (двухпортовых);
- Два блока питания;
- 12 жестких дисков объемом 146Gb каждый;
Система хранения данных в нашем случае представляет собой полностью продублированную систему в одном общем корпусе. Все узлы дискового массива (контроллеры, блоки питания, жесткие диски) постоянно находятся в активном состоянии и подменяют друг друга в случае отказа незаметно для кластерной службы. Эти компоненты допускают «горячую» замену, т.е. замену без выключения массива.
На каждый узел кластера установлена операционная система Windows Server 2003 R2 Enterprise.
Схема кластера
Настройка сетевых параметров
При построении кластера необходимо, чтобы все узлы находились в одной подсети. Внутренняя (Private Network) сеть не должна иметь соединений с общей (Public Network) сетью независимо от того, сколько узлов применяется в кластере.
IP адреса, примененные нами, показаны на схеме кластера.
После настройки сети необходимо сделать каждый узел контроллером домена и убедиться в том, что они видны в сети как друг для друга, так и для клиентских компьютеров. Перед началом конфигурирования внешнего массива и установкой службы кластеров Microsoft требуется выключить все узлы кроме первого.
Настройка дискового массива данных
В нашем примере система хранения данных представляет собой устройство SAN, его конфигурирование происходит с помощью веб интерфейса. Каждый узел кластера подключается с помощью двухпортового HBA (Host Bus Adapter) контроллера к обоим контроллерам массива.
После того, как подключение и настройка массива и FC HBA контроллеров выполнена, необходимо убедиться в том, что все созданные через веб интерфейс диски видны в Windows, после чего создать на них один или несколько логических дисков и отформатировать в NTFS.
Один из логических дисков будет использоваться для кластерного кворума. Объем его, как правило, небольшой (минимум 50MB). На нем будет храниться конфигурационная информация и служебные данные для функционирования службы кластеров.
После настройки первого узла его необходимо выключить, после чего включить второй узел, чтобы убедиться, что все созданные и отформатированные разделы корректно отображаются и на нем. В случае большего количества узлов такую операцию придется проделать с каждым узлом, включая его отдельно от остальных. По окончании проверки всех узлов они должны быть в выключенном состоянии, чтобы можно было приступить к установке самой службы кластеров на первом узле.
Установка службы кластеров
Служба кластеров устанавливается по умолчанию при установке Windows Server, найти ее можно в Administrative Tools/Cluster Administrator (Администрирование/Администратор кластеров).
Процесс установки кластерной службы не представляет собой сложной задачи и подробно описан в инструкции по Windows Server на сайте Microsoft. После его окончания необходимо включить следующий узел и добавить его в кластер с помощью консоли Cluster Administrator (Администратор кластеров).
Создание кластерного ресурса для тестирования
Теперь имея функционирующий кластер, можно создать на нем кластерный ресурс для доступа к файлам на логическом диске массива. Сделать это можно, выбрав нужную группу в панели управления Cluster Administrator (Администратор кластеров) и затем через меню Файл-Создать-Ресурс выбрать нужный тип ресурса. Он отображается как ресурс с заданным именем и типом File Share. Теперь к нему можно обратиться по сети с клиентских компьютеров как к общей папке.
Тестирование отказоустойчивости кластера
Проверим доступность кластерного сервиса на примере копирования большого объема информации компьютерами клиентами как на кластер, так и с него.
Возможные точки отказа кластера:
Обрыв (отключение) одного из кабелей связи дискового массива с активным узлом.
На графике представлена сетевая активность одного из клиентских компьютеров при копировании файлов. На практике это выразилось в остановке копирования на время перевода связи узла с одного Fiber Channel порта на другой. После чего копирование продолжилось.
Обрыв (отключение) сети Private Cluster Network (Heartbeat).
Потеря внутрикластерной связи никак не сказывается на клиентских компьютерах. Но, если при установке службы кластера для внешней клиентской сети было указано, что ее нельзя использовать для внутренней связи узлов кластера между собой, то пассивный узел кластера будет недоступен и, в случае выхода из строя активного узла, ресурсы не смогут быть перезапущены для обеспечения доступности.
Обрыв (отключение) клиентской сети от активного узла.
График ниже также представляет сетевую активность одного из клиентских компьютеров. Здесь можно заметить, что время недоступности сервиса по сравнению с первым случаем увеличилось примерно в два раза и составило 52 секунды.
Отказ активного узла или отключение его от сети электропитания.
Отключение электропитания от активного в данный момент узла или его отказ приводит к результатам, аналогичным предыдущему пункту потери связи с активным узлом. Т.е. копирование файлов приостановится на время перевода ресурсов с первого узла на второй.
Обозначения «Тим Компьютерс» , «Team Computers» , Runbook , логотип «Team Computers» являются зарегистрированными товарными знаками компании «Тим Компьютерс».
Обозначения Celeron, Celeron Inside, Centrino, Centrino logo, Core Inside, Intel, Intel Core, Intel logo, Intel Inside, Intel Inside logo, Intel SpeedStep, Intel Xeon, Intel Inside Xeon Phi logo, Intel Xeon Phi, Pentium и Pentium Inside являются товарными знаками, либо зарегистрированными товарными знаками, права на которые принадлежат корпорации Intel или ее подразделениям на территории США и других стран.
Политика в отношении обработки персональных данных
Как создать кластер из двух ноутбуков?

У меня родилась «гениальная» идея: создать соединить мощности двух компов.
Погуглил, такая технология есть, существует и активно используется людьми со всего мира.
Погуглил ещё, оказывается, что это можно сделать на Windows Server и Linux
Ну и соответственно, вопросы:
1.1 Можно ли комфортно работать на Сервере — играть в игры, отвечать на Тостере, смотреть кино? В том числе на кластеризированном?
1.2 Будет ли на кластеризированном линуксе нормально работать Wine и\или подобные средства запуска windows — программ?
Погуглил еще — оказывается, что скорости моего инета для нормального функционирования кластера не хватит, а надо для таких вещей кабельного сообщения компьютеров.
Ну и вопросы:
2.1 Можно ли просто напрямую соединить два компа каким-нибудь таким lan кабелем?
2.2 Если я захочу к этой бандуре подключить еще нетбук, то можно ли просто всё присоединить к подобному свитчу и радоваться жизни?
Хар-ки компьютеров:
2.40 Ghz | 2.27 Ghz — оба двухядерные, от intel
4 Gb RAM- одинаково
512 Mb GPU — одинаково, от nvidia
Dell|Asus
- Вопрос задан более трёх лет назад
- 13395 просмотров
Комментировать
Решения вопроса 2
Для того, для чего вы хотите — никак не создать.
Кластер — это даже согласно статье из Википедии, которую вы приводите — это слабо связанная вычислительная система.
Попробую объяснить, используя аналогию.
Вы считаете, что компьютеры можно объединять также, как можно объединять усилия людей, наполняющих бочку водой, таская ее ведрами. Один человек наполнит за час, два — за полчаса, и так далее. Но это процесс, который распараллеливается элементарно.
А на самом деле, кластер работает подобно команде сценаристов, которые пишут сценарий сериала из двадцати серий, работая удаленно по бумажной почте: сначала главный сценарист придумывает персонажей и общий сюжет, записывает это, потом ему нужно разбить его на серии и отослать каждому из сценаристов, указав, какую серию тому нужно прописать в подробностях. Если бы он писал все сам, ему бы понадобилось по неделе на серию, итого — двадцать недель. А съемки можно начинать, когда готова первая серия (через неделю). Поскольку съемки одной серии занимают три дня, съемочная группа будет простаивать четыре дня из каждой недели, пока не будет готова следующая серия (деньги во время простоя тоже расходуются, хотя ничего не производится). Съемки будут, таким образом, завершены через 20*7+3=143 дня.
Наемным сценаристам тоже нужно по неделе на написании серий, но начальная работа главного сценариста тоже занимает неделю, плюс — три дня на доставку «каркаса сценария» наемным сценаристам, три дня на доставку сценария серий обратно, еще пять дней на проверку и исправление нестыковок. Итог — начинать съемки можно только через 25 дней, а не через семь, но продолжать их можно уже непрерывно. Съемки будут завершены через 25+3*20=85 дней.
Ровно как здесь нельзя ускорить процесс еще больше, заставив больше сценаристов писать по половине серии (потому что при этом растет сложность стыковки кусков сюжета, которые написаны разными людьми, потому им придется переписываться, теряя время), так и пытаясь запустить на кластере условную игру, придется просадить кучу времени на медленное общение узлов между собой по сети.
Чтобы всё «летало» в реальном времени в игре, вам нужен один мощный компьютер с многоядерным процессором, мощной видеокартой и быстрой шиной, которая всех их объединяет. А собрать кластер из сотни древних ноутов на медленном Ethernet и получить производительность в сто раз больше в играх — это фантастика из дурацких фильмов про хакеров.
PARALLEL.RU — Информационно-аналитический центр по параллельным вычислениям
Для начинающих пользователей вычислительных кластеров
Данная страница написана с таким расчетом, чтобы она могла быть полезной не только пользователям вычислительных кластеров НИВЦ, но и всем, желающим получить представление о работе вычислительного кластера. Решение типичных проблем пользователей кластера НИВЦ изложено на отдельной странице.
Что такое вычислительный кластер?
В общем случае, вычислительный кластер — это набор компьютеров (вычислительных узлов), объединенных некоторой коммуникационной сетью. Каждый вычислительный узел имеет свою оперативную память и работает под управлением своей операционной системы. Наиболее распространенным является использование однородных кластеров, то есть таких, где все узлы абсолютно одинаковы по своей архитектуре и производительности.
Подробнее о том, как устроен и работает вычислительный кластер можно почитать в книге А.Лациса «Как построить и использовать суперкомпьютер».
Как запускаются программы на кластере?
Для каждого кластера имеется выделенный компьютер — головная машина (front-end). На этой машине установлено программное обеспечение, которое управляет запуском программ на кластере. Собственно вычислительные процессы пользователей запускаются на вычислительных узлах, причем они распределяются так, что на каждый процессор приходится не более одного вычислительного процесса. Запускать вычислительные процессы на головной машине кластера нельзя.
Пользователи имеют терминальный доступ на головную машину кластера, а входить на узлы кластера для них нет необходимости. Запуск программ на кластере осуществляется в т.н. «пакетном» режиме — это значит, что пользователь не имеет непосредственного, «интерактивного» взаимодействия с программой, программа не может ожидать ввода данных с клавиатуры и выводить непосредственно на экран. Более того, программа пользователя может работать тогда, когда пользователь не подключен к кластеру.
Какая установлена операционная система?
Вычислительный кластер, как правило, работает под управлением одной из разновидностей ОС Unix — многопользовательской многозадачной сетевой операционной системы. В частности, в НИВЦ МГУ кластеры работают под управлением ОС Linux — свободно распространяемого варианта Unix. Unix имеет ряд отличий от Windows, которая обычно работает на персональных компьютерах, в частности эти отличие касаются интерфейса с пользователем, работы с процессами и файловой системы.
Более подробно об особенностях и командах ОС UNIX можно почитать здесь:
- Инсталляция Linux и первые шаги (книга Matt Welsh, перевод на русский язык А.Соловьева).
- Учебник по Unix для начинающих.
- Энциклопедия Linux.
- Операционная система UNIX (информационно-аналитические материалы на сервере CIT-Forum).
Как хранятся данные пользователей?
Все узлы кластера имеют доступ к общей файловой системе, находящейся на файл-сервере. То есть файл может быть создан, напрмер, на головной машине или на каком-то узле, а затем прочитан под тем же именем на другом узле. Запись в один файл одновременно с разных узлов невозможна, но запись в разные файлы возможна. Кроме общей файловой системы, могут быть локальные диски на узлах кластера. Они могут использоваться программами для хранения временных файлов. После окончания (точнее, непосредственно перед завершением) работы программы эти файлы должны удаляться.
Какие используются компиляторы?
Никаких специализированных параллельных компиляторов для кластеров не существует. Используются обычные оптимизирующие компиляторы с языков Си и Фортран — GNU, Intel или другие, умеющие создавать исполняемые программы ОС Linux. Как правило, для компиляции параллельных MPI-программ используются специальные скрипты (mpicc, mpif77, mpif90 и др.), которые являются надстройками над имеющимися компиляторами и позволяют подключать необходимые библиотеки.
Как использовать возможности кластера?
Существует несколько способов задействовать вычислительные мощности кластера.
1. Запускать множество однопроцессорных задач. Это может быть разумным вариантом, если нужно провести множество независимых вычислительных экспериментов с разными входными данными, причем срок проведения каждого отдельного расчета не имеет значения, а все данные размещаются в объеме памяти, доступном одному процессу.
2. Запускать готовые параллельные программы. Для некоторых задач доступны бесплатные или коммерческие параллельные программы, которые при необходимости Вы можете использовать на кластере. Как правило, для этого достаточно, чтобы программа была доступна в исходных текстах, реализована с использованием интерфейса MPI на языках С/C++ или Фортран. Примеры свободно распространяемых параллельных программ, реализованных с помощью MPI: GAMESS-US (квантовая химия), POVRay-MPI (трассировка лучей).
3. Вызывать в своих программах параллельные библиотеки. Также для некоторых областей, таких как линейная алгебра, доступны библиотеки, которые позволяют решать широкий круг стандартных подзадач с использованием возможностей параллельной обработки. Если обращение к таким подзадачам составляет большую часть вычислительных операций программы, то использование такой параллельной библиотеки позволит получить параллельную программу практически без написания собственного параллельного кода. Примером такой библиотеки является SCALAPACK. Русскоязычное руководство по использованию этой библиотеки и примеры можно найти на сервере по численному анализу НИВЦ МГУ. Также доступна параллельная библиотека FFTW для вычисления быстрых преобразований Фурье (БПФ). Информацию о других параллельных библиотеках и программах, реализованных с помощью MPI, можно найти по адресу http://www-unix.mcs.anl.gov/mpi/libraries.html.
4. Создавать собственные параллельные программы. Это наиболее трудоемкий, но и наиболее универсальный способ. Существует два основных варианта. 1) Вставлять параллельные конструкции в имеющиеся параллельные программы. 2) Создавать «с нуля» параллельную программу.
Как работают параллельные программы на кластере?
Параллельные программы на вычислительном кластере работают в модели передачи сообщений (message passing). Это значит, что программа состоит из множества процессов, каждый из которых работает на своем процессоре и имеет свое адресное пространство. Причем непосредственный доступ к памяти другого процесса невозможен, а обмен данными между процессами происходит с помощью операций приема и посылки сообщений. То есть процесс, который должен получить данные, вызывает операцию Receive (принять сообщение), и указывает, от какого именно процесса он должен получить данные, а процесс, который должен передать данные другому, вызывает операцию Send (послать сообщение) и указывает, какому именно процессу нужно передать эти данные. Эта модель реализована с помощью стандартного интерфейса MPI. Существует несколько реализаций MPI, в том числе бесплатные и коммерческие, переносимые и ориентированные на конкретную коммуникационную сеть.
Как правило, MPI-программы построены по модели SPMD (одна программа — много данных), то есть для всех процессов имеется только один код программы, а различные процессы хранят различные данные и выполняют свои действия в зависимости от порядкового номера процесса.
Более подробно об MPI можно почитать здесь:
- Курс Вл.В.Воеводина «Параллельная обработка данных». Лекция 5. Технологии параллельного программирования. Message Passing Interface.
- Вычислительный практикум по технологии MPI (А.С.Антонов).
- А.С.Антонов «Параллельное программирование с использованием технологии MPI».
- MPI: The Complete Reference (на англ.яз.).
- Глава 8: Message Passing Interface в книге Яна Фостера «Designing and Building Parallel Programs» (на англ.яз.).
Где можно посмотреть примеры параллельных программ?
Схематичные примеры MPI-программ можно посмотреть здесь:
- Курс Вл.В.Воеводина «Параллельная обработка данных». Приложение к лекции 5.
- Примеры из пособия А.С.Антонова «Параллельное программирование с использованием технологии MPI».
Примеры простейших работающих MPI-программ доступны в составе пакета MPICH, свободно распространяемой реализации MPI. Для пользователей НИВЦ МГУ простейшие примеры MPI-программ на Си и Фортране доступны в директории /home/examples/mpi. Примеры использования конструкций MPI в программах на языке Си можно посмотреть в тестах производительности для параллельных компьютеров. Примеры программ на Фортране с комментариями можно посмотреть в англоязычном документе «MPI User’s Guide in Fortran» (формат Word).
Можно ли отлаживать параллельные программы на персональном компьютере?
Разработка MPI-программ и проверка функциональности возможна на обычном ПК. Можно запускать несколько MPI-процессов на однопроцессорном компьютере и таким образом проверять работоспособность программы. Желательно, чтобы это был ПК с ОС Linux, где можно установить пакет MPICH. Это возможно и на компьютере с Windows, но более затруднительно.
Насколько трудоемко программировать вычислительные алгоритмы c помощью MPI и есть ли альтернативы?
Набор функций интерфейса MPI иногда называют «параллельным ассемблером», т.к. это система программирования относительно низкого уровня. Для начинающего пользователя-вычислителя может быть достаточно трудоемкой работой запрограммировать сложный параллельный алгоритм с помощью MPI и отладить MPI-программу. Существуют и более высокоуровневые системы программирования, в частности российские разработки — DVM и НОРМА, которые позволяют пользователю записать задачу в понятных для него терминах, а на выходе создают код с использованием MPI, и поэтому могут быть использованы практически на любом вычислительном кластере.
Как ускорить проведение вычислений на кластере?
Во-первых, нужно максимально ускорить вычисления на одном процессоре, для чего можно принять следующие меры.
1. Подбор опций оптимизации компилятора. Подробнее об опциях компиляторов можно почитать здесь:
- Компиляторы Intel C++ и Fortran (русскоязычная страница на нашем сайте).
- GCC online documentation.
2. Использование оптимизированных библиотек. Если некоторые стандартные действия, такие как умножение матриц, занимают значительную долю времени работы программы, то имеет смысл использовать готовые оптимизированные процедуры, выполняющие эти действия, а не программировать их самостоятельно. Для выполнения операций линейной алгебры над матричными и векторными величинами была разработана библиотека BLAS («базовые процедуры линейной алгебры»). Интерфейс вызова этих процедур стал уже фактически стандартом и сейчас существуют несколько хорошо оптимизированных и адаптированных к процессорным архитектурам реализаций этой библиотеки. Одной из таких реализаций является свободно распространяемая библиотека ATLAS, которая при установке настраивается с учетом особенностей процессора. Компания Интел предлагает библиотеку MKL — оптимизированную реализацию BLAS для процессоров Intel и SMP-компьютеров на их основе. Тут статья про подбор опций MKL.
Подробнее о библиотеках линейной алгебры (BLAS) можно почитать здесь:
3. Исключение своппинга (автоматического сброса данных из памяти на диск). Каждый процесс должен хранить не больше данных, чем для него доступно оперативной памяти (в случае двухпроцессорного узла это примерно половина от физической памяти узла). В случае необходимости работать с большим объемом данных может быть целесообразным организовать работу со временными файлами или использовать несколько вычислительных узлов, которые в совокупности предоставляют необходимый объем оперативной памяти.
4. Более оптимальное использование кэш-памяти. В случае возможности изменять последовательность действий программы, нужно модифицировать программу так, чтобы действия над одними и те же или подряд расположенными данными данными выполнялись также подряд, а не «в разнобой». В некоторых случаях может быть целесообразно изменить порядок циклов во вложенных циклических конструкциях. В некоторых случаях возможно на «базовом» уровне организовать вычисления над такими блоками, которые полностью попадают в кэш-память.
5. Более оптимальная работа с временными файлами. Например, если программа создает временные файлы в текущем каталоге, то более разумно будет перейти на использование локальных дисков на узлах. Если на узле работают два процесса и каждый из них создает временные файлы, и при этом на узле доступны два локальных диска, то нужно, чтобы эти два процесса создавали файлы на разных дисках.
6. Использование наиболее подходящих типов данных. Например, в некоторых случаях вместо 64-разрядных чисел с плавающей точкой двойной точности (double) может быть целесообразным использовать 32-разрядные числа одинарной точности (float) или даже целые числа (int).
Более подробно о тонкой оптимизации программ можно почитать в руководстве по оптимизации для процессоров Intel и в других материалах по этой теме на веб-сайте Intel.
Как оценить и улучшить качество распараллеливания?
Для ускорения работы параллельных программ стоит принять меры для снижения накладных расходов на синхронизацию и обмены данными. Возможно, приемлемым подходом окажется совмещение асинхронных пересылок и вычислений. Для исключения простоя отдельных процессоров нужно наиболее равномерно распределить вычисления между процессами, причем в некоторых случаях может понадобиться динамическая балансировка.
Важным показателем, который говорит о том, эффективно ли в программе реализован параллелизм, является загрузка вычислительных узлов, на которых работает программа. Если загрузка на всех или на части узлов далека от 100% — значит, программа неэффективно использует вычислительные ресурсы, т.е. создает большие накладные расходы на обмены данными или неравномерно распределяет вычисления между процессами. Пользователи НИВЦ МГУ могут посмотреть загрузку через веб-интерфейс для просмотра состояния узлов.
В некоторых случаях для того, чтобы понять, в чем причина низкой производительности программы и какие именно места в программе необходимо модифицировать, чтобы добиться увеличения производительности, имеет смысл использовать специальные средства анализа производительности — профилировщики и трассировщики. На кластере Ant установлена система для отладки MPI-программ deb-MPI. Краткую информацию по системе можно найти по адресу http://parallel.ru/cluster/deb-MPI-UG.html .—>
Подробнее об улучшении производительности параллельных программ можно почитать в книге В.В.Воеводина и Вл.В.Воеводина «Параллельные вычисления».
Подготовка кластерных объектов-компьютеров в доменных службах Active Directory
В этом разделе показан порядок подготовки кластерных объектов-компьютеров в доменных службах Active Directory (AD DS). Эту процедуру можно использовать, чтобы дать возможность пользователю или группе создавать отказоустойчивые кластеры, если у них нет разрешений на создание объектов-компьютеров в AD DS.
Когда вы создаете отказоустойчивый кластер с помощью мастера создания кластеров или Windows PowerShell, необходимо указать имя кластера. Если при создании кластера у вас достаточно разрешений, процесс создания кластера автоматически создает объект-компьютер в AD DS с соответствующим именем кластера. Этот объект называется объектом имени кластера или CNO. Посредством CNO при настройке кластерных ролей, использующих точки доступа клиентов, автоматически создаются виртуальные объекты-компьютеры (VCO). Например, если вы создали файловый сервер высокой надежности с точкой доступа клиента с именем FileServer1, CNO создаст соответствующий VCO в AD DS.
Существует возможность создать отсоединяемый от Active Directory кластер, где в AD DS не создаются CNO или VCOS. Эта возможность предназначена для определенных типов развертывания кластера. Дополнительные сведения см. в разделе Deploy an Active Directory-Detached Cluster.
Для автоматического создания CNO у пользователя, создающего отказоустойчивый кластер, должно быть разрешение на создание объектов-компьютеров для подразделения или контейнера, в которых размещаются серверы, которые войдут в кластер. Чтобы позволить пользователям и группам, не имеющим разрешения, создавать кластеры, пользователь с соответствующими разрешениями в AD DS (обычно администратор домена) может подготовить CNO в AD DS. Это также обеспечивает администратору домена больший контроль над именами, используемыми для кластера, и над тем, в каких подразделениях можно создавать кластерные объекты.
Шаг 1. Подготовка CNO в AD DS
Перед началом работы убедитесь, что знаете следующее:
- Имя, которое нужно назначить кластеру
- Имя учетной записи пользователя или группы, которой требуется предоставить права на создание кластера.
Мы рекомендуем создать подразделение для кластерных объектов. Если подразделение, которое вы хотите использовать, уже существует, для завершения этого шага требуется членство в группе Операторы учета . Если подразделение для кластерных объектов необходимо создать, для завершения этого шага требуется членство в группе Администраторы домена или аналогичной группе.
Если вы создали CNO в контейнере компьютеров по умолчанию, а не в подразделении, вам не нужно выполнять шаг 3 этого раздела. В этом сценарии администратор кластера может создать до 10 VCO без какой-либо дополнительной настройки.
Подготовка CNO в AD DS
- На компьютере с установленными средствами AD DS из средств удаленного администрирования сервера или на контроллере домена откройте Пользователи и компьютеры Active Directory. Чтобы сделать это на сервере, запустите диспетчер сервера, а затем в меню «Сервис» выберите Пользователи и компьютеры Active Directory.
- Чтобы создать подразделение для объектов компьютера кластера, щелкните правой кнопкой мыши доменное имя или существующее подразделение, наведите указатель мыши на новое и выберите подразделение. В поле «Имя» введите имя подразделения и нажмите кнопку «ОК«.
- В дереве консоли щелкните правой кнопкой мыши подразделение, в котором нужно создать CNO, наведите указатель мыши на «Создать» и выберите «Компьютер».
- В поле «Имя компьютера» введите имя, которое будет использоваться для отказоустойчивого кластера, а затем нажмите кнопку «ОК«.
Примечание. Это имя кластера, которое пользователь, создающий кластер, укажет в мастере создания кластеров на странице Точка доступа для администрирования кластера или укажет как значение параметра –Name для командлета New-Cluster Windows PowerShell.
Примечание. Учетную запись необходимо отключить, чтобы во время создания кластера соответствующий процесс подтвердил, что учетная запись не используется в данный момент существующим компьютером или кластером в домене.
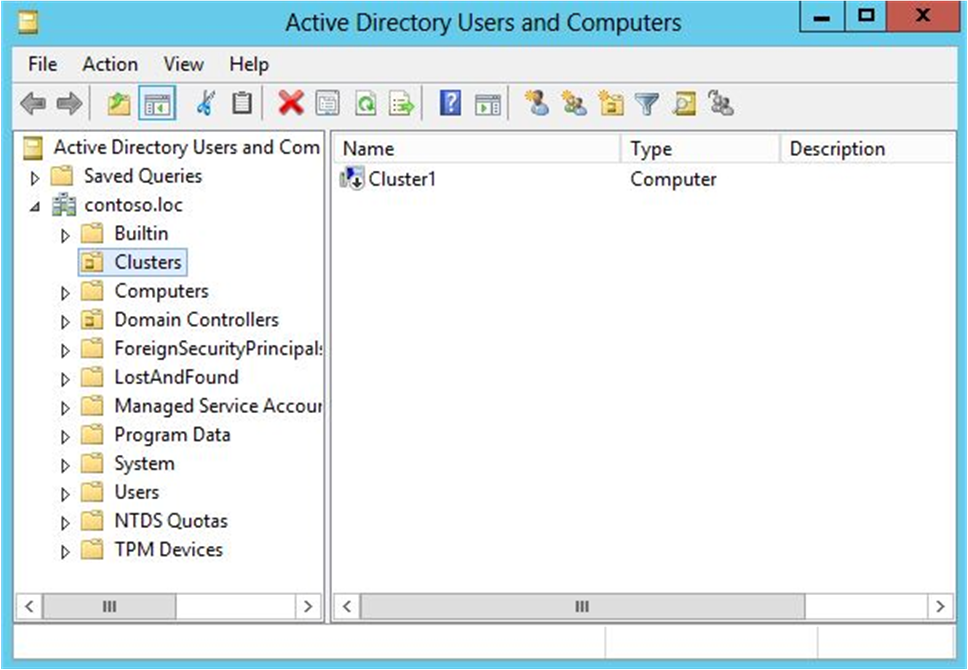
Рисунок 1. Отключенный CNO в примере подразделения кластеров
Шаг 2. Предоставление пользователю разрешений на создание кластера
Необходимо настроить разрешения, чтобы учетная запись пользователя, которая будет использоваться для создания отказоустойчивого кластера, имела полный доступ к CNO.
Минимальное требование для выполнения этого шага — членство в группе Операторы учета .
Вот как предоставить пользователю разрешения на создание кластера:
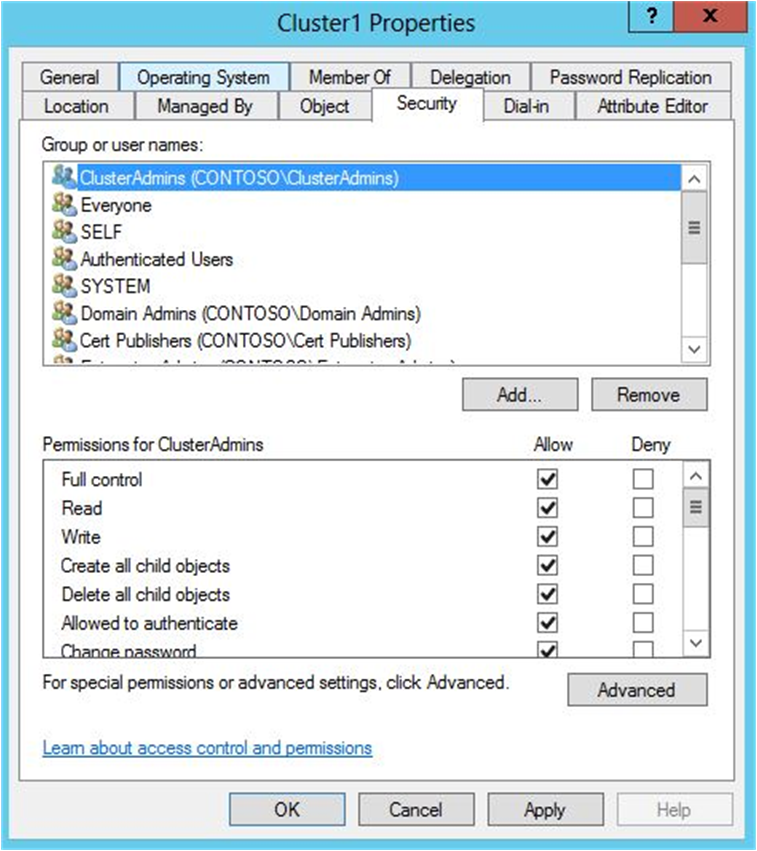
- На странице «Пользователи и компьютеры Active Directory» в меню Вид убедитесь, что выбран пункт Дополнительные параметры .
- Найдите и щелкните правой кнопкой мыши CNO, а затем выберите «Свойства«.
- На вкладке Безопасность щелкните Добавить.
- В диалоговом окне выбора пользователей, компьютеров или групп укажите учетную запись пользователя или группу, которой требуется предоставить разрешения, а затем нажмите кнопку «ОК«.
- Выберите добавленную учетную запись пользователя или группу и около пункта Полный доступустановите флажок Разрешить . Рисунок 2. Предоставление полного доступа пользователю или группе, которые будут создавать кластер
- Нажмите ОК.
После завершения этого шага пользователь, которому вы предоставили разрешение, сможет создать отказоустойчивый кластер. Однако если CNO расположен в подразделении, до завершения вами шага 3 пользователь не сможет создавать кластерные роли, которые требуют точку доступа клиента.
Если CNO находится в контейнере компьютеров по умолчанию, администратор кластера может создать до 10 VCO без какой-либо дополнительной настройки. Чтобы добавить более 10 VCO, необходимо явно предоставить разрешение на создание объектов-компьютеров объекту имени кластера для контейнера компьютеров.
Шаг 3. Предоставление разрешений CNO подразделению или подготовка VCO для кластерных ролей
Когда вы создаете кластерную роль с точкой доступа клиента, кластер создает VCO в том же подразделении, что и CNO. Чтобы это происходило автоматически, CNO должен иметь разрешения на создание объектов-компьютеров в подразделении.
Если вы подготовили CNO в AD DS, для создания VCO можно сделать следующее.
- Вариант 1: Grant the CNO permissions to the OU. Если вы воспользуетесь этим вариантом, кластер сможет автоматически создавать VCO в AD DS. Таким образом, администратор отказоустойчивого кластера сможет создавать кластерные роли, не отправляя вам запрос на подготовку VCO в AD DS.
Необходимым минимумом для выполнения шагов этого варианта является членство в группе Администраторы домена или эквивалентной группе.
- Вариант 2. Подготовка виртуальной машины для кластеризованной роли. Используйте этот вариант, если есть необходимость в подготовке учетных записей для кластерных ролей из-за требований в вашей организации. Например, если вы хотите контролировать использование имен или создание кластерных ролей.
Необходимым минимумом для выполнения шагов этого варианта является членство в группе Операторы учета .
Предоставление разрешений CNO подразделению
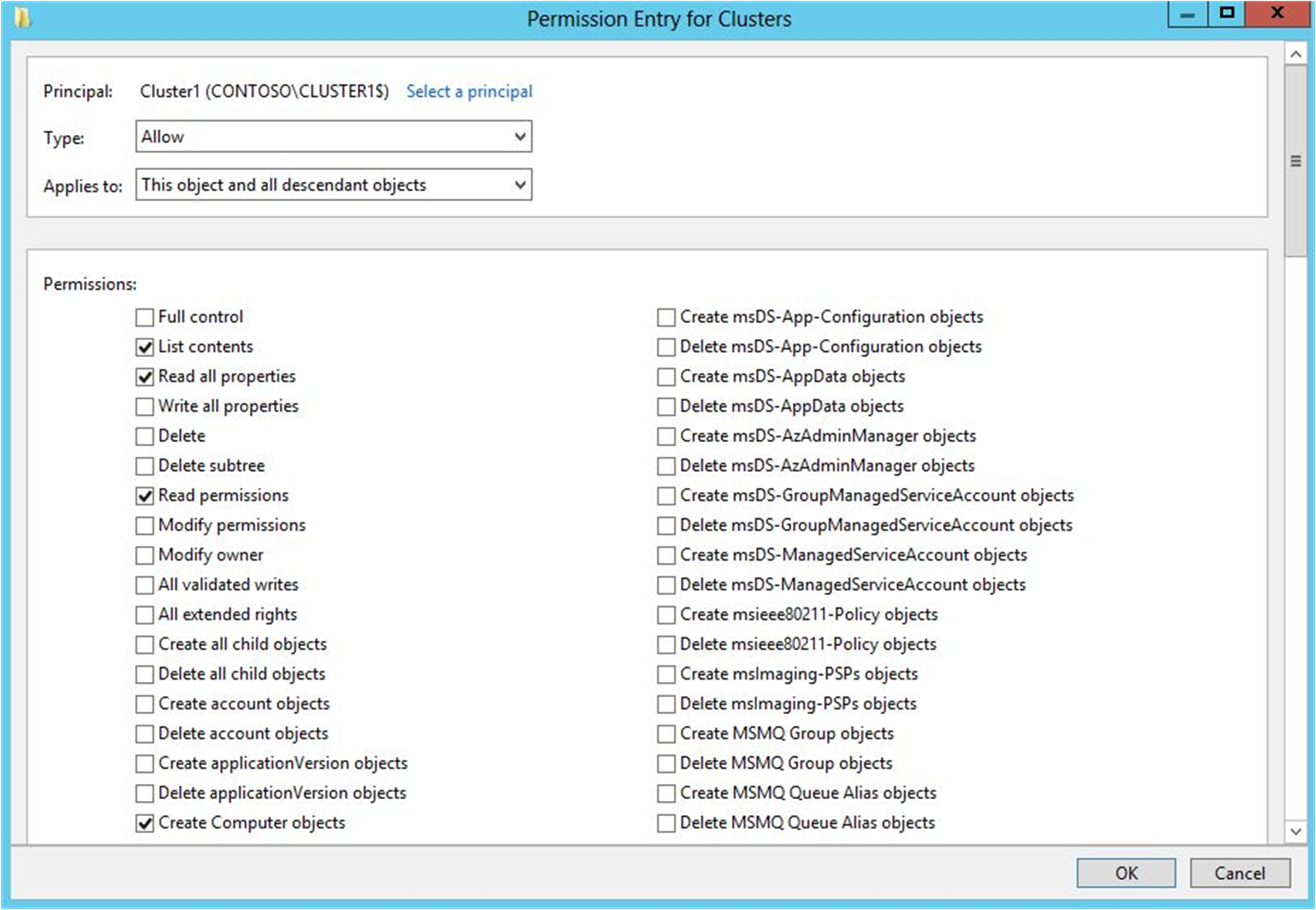
- На странице «Пользователи и компьютеры Active Directory» в меню Вид убедитесь, что выбран пункт Дополнительные параметры .
- Щелкните правой кнопкой мыши подразделение, в котором вы создали CNO на шаге 1. Подготовка CNO в AD DS и выберите пункт «Свойства«.
- На вкладке Безопасность нажмите кнопку Дополнительно.
- В диалоговом окне «Расширенная безопасность» Параметры нажмите кнопку «Добавить«.
- Рядом с субъектом выберите пункт «Выбрать субъект«.
- В диалоговом окне «Выбор пользователя, компьютера, учетной записи службы» или «Группы» выберите «Типы объектов», «Компьютеры» проверка и нажмите кнопку «ОК«.
- В разделе «Введите имена объектов» для выбора, введите имя CNO, выберите «Проверить имена» и нажмите кнопку «ОК«. В ответ на предупреждение, которое говорит, что вы хотите добавить отключенный объект, нажмите кнопку «ОК«.
- В диалоговом окне Запись разрешения убедитесь, что для списка Тип установлено значение Разрешить, а для списка Применяется к — значение Этот объект и все дочерние объекты.
- В разделе Разрешенияустановите флажок Создание объектов-компьютеров . Рисунок 3. Предоставление CNO разрешения на создание объектов-компьютеров
- Нажмите кнопку «ОК«, пока не вернеесь к оснастке Пользователи и компьютеры Active Directory.
Теперь администратор отказоустойчивого кластера может создать кластерные роли с точкой доступа клиента и подключить ресурсы.
Подготовка виртуальной машины для кластеризованной роли
- Прежде чем начать подготовку, убедитесь, что знаете имя кластера и имя, которое будет иметь кластерная роль.
- На странице «Пользователи и компьютеры Active Directory» в меню Вид убедитесь, что выбран пункт Дополнительные параметры .
- В Пользователи и компьютеры Active Directory щелкните правой кнопкой мыши подразделение, в котором находится CNO для кластера, наведите указатель на «Создать» и выберите «Компьютер«.
- В поле «Имя компьютера» введите имя, которое будет использоваться для кластеризованной роли, а затем нажмите кнопку «ОК«.
- В качестве рекомендации щелкните правой кнопкой мыши созданную учетную запись компьютера, выберите «Свойства» и выберите вкладку «Объект«. На вкладке «Объект» установите флажок «Защитить объект от случайного удаления» проверка и нажмите кнопку «ОК«.
- Щелкните правой кнопкой мыши созданную учетную запись компьютера и выберите пункт «Свойства«.
- На вкладке Безопасность щелкните Добавить.
- В диалоговом окне «Выбор пользователя, компьютера, учетной записи службы» или «Группы» выберите «Типы объектов», «Компьютеры» проверка и нажмите кнопку «ОК«.
- В разделе «Введите имена объектов» для выбора, введите имя CNO, выберите «Проверить имена» и нажмите кнопку «ОК«. Если появится предупреждение о том, что вы хотите добавить отключенный объект, нажмите кнопку «ОК«.
- Убедитесь, что CNO выделен, после чего рядом с полем Полный доступустановите флажок Разрешить .
- Нажмите ОК.
Теперь администратор отказоустойчивого кластера может создать кластерную роль с точкой доступа клиента, которая соответствует подготовленному имени VCO, и подключить ресурсы.
Дополнительные сведения
- Отказоустойчивая кластеризация
- Настройка учетных записей кластеров в Active Directory