Как создать пустой динамический массив питон
Часто в задачах приходится хранить прямоугольные таблицы с данными. Такие таблицы называются матрицами или двумерными массивами. В языке программирования Питон таблицу можно представить в виде списка строк, каждый элемент которого является в свою очередь списком, например, чисел. Например, приведём программу, в которой создаётся числовая таблица из двух строк и трех столбцов, с которой производятся различные действия.
a = [[1, 2, 3], [4, 5, 6]] print(a[0]) print(a[1]) b = a[0] print(b) print(a[0][2]) a[0][1] = 7 print(a) print(b) b[2] = 9 print(a[0]) print(b)
Здесь первая строка списка a[0] является списком из чисел [1, 2, 3] . То есть a[0][0] == 1 , значение a[0][1] == 2 , a[0][2] == 3 , a[1][0] == 4 , a[1][1] == 5 , a[1][2] == 6 .
Для обработки и вывода списка, как правило, используют два вложенных цикла. Первый цикл перебирает номер строки, второй цикл бежит по элементам внутри строки. Например, вывести двумерный числовой список на экран построчно, разделяя числа пробелами внутри одной строки, можно так:
a = [[1, 2, 3, 4], [5, 6], [7, 8, 9]] for i in range(len(a)): for j in range(len(a[i])): print(a[i][j], end=' ') print()
Однажды мы уже пытались объяснить, что переменная цикла for в Питоне может перебирать не только диапазон, создаваемый с помощью функции range() , но и вообще перебирать любые элементы любой последовательности. Последовательностями в Питоне являются списки, строки, а также некоторые другие объекты, с которыми мы пока не встречались. Продемонстрируем, как выводить двумерный массив, используя это удобное свойство цикла for :
a = [[1, 2, 3, 4], [5, 6], [7, 8, 9]] for row in a: for elem in row: print(elem, end=' ') print()
Естественно, для вывода одной строки можно воспользоваться методом join() :
for row in a: print(' '.join([str(elem) for elem in row]))
Используем два вложенных цикла для подсчета суммы всех чисел в списке:
a = [[1, 2, 3, 4], [5, 6], [7, 8, 9]] s = 0 for i in range(len(a)): for j in range(len(a[i])): s += a[i][j] print(s)
Или то же самое с циклом не по индексу, а по значениям строк:
a = [[1, 2, 3, 4], [5, 6], [7, 8, 9]] s = 0 for row in a: for elem in row: s += elem print(s)
2. Создание вложенных списков
Пусть даны два числа: количество строк n и количество столбцов m . Необходимо создать список размером n × m , заполненный нулями.
Очевидное решение оказывается неверным:
a = [[0] * m] * n
В этом легко убедиться, если присвоить элементу a[0][0] значение 5 , а потом вывести значение другого элемента a[1][0] — оно тоже будет равно 5. Дело в том, что [0] * m возвращает ccылку на список из m нулей. Но последующее повторение этого элемента создает список из n элементов, которые являются ссылкой на один и тот же список (точно так же, как выполнение операции b = a для списков не создает новый список), поэтому все строки результирующего списка на самом деле являются одной и той же строкой.
В визуализаторе обратите внимание на номер id у списков. Если у двух списков id совпадает, то это на самом деле один и тот же список в памяти.
n = 3 m = 4 a = [[0] * m] * n a[0][0] = 5 print(a[1][0])
Таким образом, двумерный список нельзя создавать при помощи операции повторения одной строки. Что же делать?
Первый способ: сначала создадим список из n элементов (для начала просто из n нулей). Затем сделаем каждый элемент списка ссылкой на другой одномерный список из m элементов:
n = 3 m = 4 a = [0] * n for i in range(n): a[i] = [0] * m
Другой (но похожий) способ: создать пустой список, потом n раз добавить в него новый элемент, являющийся списком-строкой:
n = 3 m = 4 a = [] for i in range(n): a.append([0] * m)
Но еще проще воспользоваться генератором: создать список из n элементов, каждый из которых будет списком, состоящих из m нулей:
n = 3 m = 4 a = [[0] * m for i in range(n)]
В этом случае каждый элемент создается независимо от остальных (заново конструируется список [0] * m для заполнения очередного элемента списка), а не копируются ссылки на один и тот же список.
3. Ввод двумерного массива
Пусть программа получает на вход двумерный массив в виде n строк, каждая из которых содержит m чисел, разделенных пробелами. Как их считать? Например, так:
3 1 2 3 4 5 6 7 8 9
# в первой строке ввода идёт количество строк массива n = int(input()) a = [] for i in range(n): a.append([int(j) for j in input().split()])
Или, без использования сложных вложенных вызовов функций:
3 1 2 3 4 5 6 7 8 9
# в первой строке ввода идёт количество строк массива n = int(input()) a = [] for i in range(n): row = input().split() for i in range(len(row)): row[i] = int(row[i]) a.append(row)
Можно сделать то же самое и при помощи генератора:
3 1 2 3 4 5 6 7 8 9
# в первой строке ввода идёт количество строк массива n = int(input()) a = [[int(j) for j in input().split()] for i in range(n)]
4. Пример обработки двумерного массива
Пусть дан квадратный массив из n строк и n столбцов. Необходимо элементам, находящимся на главной диагонали, проходящей из левого верхнего угла в правый нижний (то есть тем элементам a[i][j] , для которых i==j ) присвоить значение 1 , элементам, находящимся выше главной диагонали – значение 0, элементам, находящимся ниже главной диагонали – значение 2. То есть необходимо получить такой массив (пример для n==4 ):
1 0 0 0 2 1 0 0 2 2 1 0 2 2 2 1
Рассмотрим несколько способов решения этой задачи. Элементы, которые лежат выше главной диагонали – это элементы a[i][j] , для которых ij . Таким образом, мы можем сравнивать значения i и j и по ним определять значение A[i][j] . Получаем следующий алгоритм:
n = 4 a = [[0] * n for i in range(n)] for i in range(n): for j in range(n): if i < j: a[i][j] = 0 elif i >j: a[i][j] = 2 else: a[i][j] = 1 for row in a: print(' '.join([str(elem) for elem in row]))
Данный алгоритм плох, поскольку выполняет одну или две инструкции if для обработки каждого элемента. Если мы усложним алгоритм, то мы сможем обойтись вообще без условных инструкций.
Сначала заполним главную диагональ, для чего нам понадобится один цикл:
for i in range(n): a[i][i] = 1
Затем заполним значением 0 все элементы выше главной диагонали, для чего нам понадобится в каждой из строк с номером i присвоить значение элементам a[i][j] для j = i+1 , . n-1 . Здесь нам понадобятся вложенные циклы:
for i in range(n): for j in range(i + 1, n): a[i][j] = 0
Аналогично присваиваем значение 2 элементам a[i][j] для j = 0 , . i-1 :
for i in range(n): for j in range(0, i): a[i][j] = 2
Можно также внешние циклы объединить в один и получить еще одно, более компактное решение:
n = 4 a = [[0] * n for i in range(n)] for i in range(n): for j in range(0, i): a[i][j] = 2 a[i][i] = 1 for j in range(i + 1, n): a[i][j] = 0 for row in a: print(' '.join([str(elem) for elem in row]))
А вот такое решение использует операцию повторения списков для построения очередной строки списка. i -я строка списка состоит из i чисел 2 , затем идет одно число 1 , затем идет n-i-1 число 0 :
n = 4 a = [0] * n for i in range(n): a[i] = [2] * i + [1] + [0] * (n - i - 1) for row in a: print(' '.join([str(elem) for elem in row]))
А можно заменить цикл на генератор:
n = 4 a = [0] * n a = [[2] * i + [1] + [0] * (n - i - 1) for i in range(n)] for row in a: print(' '.join([str(elem) for elem in row]))
5. Вложенные генераторы двумерных массивов
Для создания двумерных массивов можно использовать вложенные генераторы, разместив генератор списка, являющегося строкой, внутри генератора всех строк. Напомним, что сделать список из n строк и m столбцов можно при помощи генератора, создающего список из n элементов, каждый элемент которого является списком из m нулей:
[[0] * m for i in range(n)]
Но при этом внутренний список также можно создать при помощи, например, такого генератора: [0 for j in range(m)] . Вложив один генератор в другой, получим вложенные генераторы:
[[0 for j in range(m)] for i in range(n)]
Но если число 0 заменить на некоторое выражение, зависящее от i (номер строки) и j (номер столбца), то можно получить список, заполненный по некоторой формуле.
Например, пусть нужно задать следующий массив (для удобства добавлены дополнительные пробелы между элементами):
0 0 0 0 0 0 0 1 2 3 4 5 0 2 4 6 8 10 0 3 6 9 12 15 0 4 8 12 16 20
В этом массиве n = 5 строк, m = 6 столбцов, и элемент в строке i и столбце j вычисляется по формуле: a[i][j] = i * j .
Для создания такого массива можно использовать генератор:
[[i * j for j in range(m)] for i in range(n)]
Реализация динамического массива на Python
Мы продолжаем курс по структурам данных. Пришло время посмотреть, как реализуется динамический массив в языках Python и С++. И начнем с языка Python.
Динамический массив в Python
Всем питонистам известна коллекция типа list, которая позволяет создавать список из разных объектов. Например, так:
marks = [2, 2, 3, 4]
lst = [True, "Истина", 1, 1.0]
Можно ли считать такие списки динамическими массивами? Строго говоря, лишь с некоторым приближением, так как в массивах все элементы должны иметь единый тип данных. А во втором списке мы видим и булево значение и строку и целое число, то есть, разные типы. Но если мы посмотрим внутрь этой структуры, то увидим, что на самом деле списки в Python реализованы как динамические массивы ссылок. И эти ссылки могут быть связаны с любым объектом, любого типа.
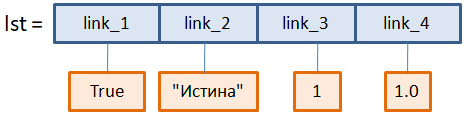
Отсюда и получается эффект, словно список содержит разные типы. На самом деле в нем хранятся только ссылки, ведущие на те или иные объекты и не более того. То есть, сам динамический массив содержит данные одного типа – ссылки на объекты.
Число хранимых элементов в списке можно определить командой:
n = len(lst)
Если требуется добавить новый элемент в этот список, то используется команда:
lst.append(5)
В результате в конец списка будет добавлена новая ссылка, связанная с целым значением 5. Скорость этой операции с точки зрения О большого составляет O(1). То есть, добавление нового значения в конец списка – это относительно быстрая операция.
Если же мы хотим вставить новое промежуточное значение, например, в середину или начало списка, то это делается с помощью команды:
lst.insert(0, 'First')
Здесь первое значение – это индекс вставляемого элемента, а второй аргумент – значение вставляемого элемента. В итоге получаем список из шести элементов со скоростью выполнения операции O(n), где n – общее число элементов в списке.
Как видите, скорость выполнения операции вставки элементов в список существенно выше, чем операция добавления последнего элемента. Поэтому вставок лучше избегать при использовании списков.
Далее, для доступа к отдельным элементам списков используется оператор квадратные скобки:
el_1 = marks[2] # чтение значения 3-го элемента marks[1] = 3 # запись значения во 2-й элемент
Так как динамический массив в своей основе использует обычный статический массив, то доступ к произвольному его элементу осуществляется мгновенно (за константное время) O(1).
Я напомню, что имя самого массива хранит адрес первой ячейки. Зная этот начальный адрес и размер одного элемента в байтах:
k – число байт для одного элемента
мы легко можем вычислить адрес любого j-го элемента по формуле:
p = marks + (j-1) ∙ k
Поэтому операции чтения/записи отдельного элемента выполняются за время O(1).
Таким образом, если нам нужен список разумной длины, к элементам которого предполагается частое обращение, то динамический массив (список языка Python) будет хорошим выбором. Также мы вполне можем использовать операции добавления последнего элемента в список, увеличивая общее число элементов. Но операций вставки новых элементов и удаления промежуточных лучше избегать, т.к. они требуют линейного времени выполнения. Вот общие рекомендации по использованию списков языка Python.
Объединение списков и срезы
Довольно часто в Python используется операция объединения списков. Например, мы можем соединить два списка в нашем примере следующим образом:
lj = marks + lst
Что происходит в этот момент, какие действия? И какова вычислительная сложность такой операции с точки зрения О большого?
Начнем с первого вопроса, что происходит в момент объединения двух динамических массивов. Создается новый массив, размером достаточным для хранения всех объединяемых элементов, а затем, в него копируется информация из первого и второго массивов:

Если принять число элементов первого массива за n, а во втором – за m, то вычислительная сложность такой операции с точки зрения О большого составляет:
Другая распространенная операция со списками – это взятие срезов. Давайте предположим, что у нас имеется список:
lst = [1, 2, 3, 4, 5, 6, 7, 8]
и мы берем от него срез:
lst2 = lst[1:6]
Что происходит с динамическим массивом в этом случае? Как мы знаем, срез в списках создает новый список с соответствующим набором элементов. В данном случае список lst2 будет состоять из значений:
lst2 = [2, 3, 4, 5, 6]
То есть, при взятии среза создается новый динамический массив и в него копируются данные из первого массива. Сложность этой операции составляет O(n).
Видео по теме

#1. О большое (Big O) — верхняя оценка сложности алгоритмов

#2. О большое (Big O). Случаи логарифмической и факториальной сложности

#3. Статический массив. Структура, его преимущества и недостатки

#4. Примеры реализации статических массивов на C++

#5. Динамический массив. Принцип работы

#6. Реализация динамического массива на Python

#7. Реализация динамического массива на С++ с помощью std::vector

#8. Односвязный список. Структура и основные операции

#9. Делаем односвязный список на С++

#10. Двусвязный список. Структура и основные операции

#11. Делаем двусвязный список на С++

#12. Двусвязный список (list) в STL на С++

#13. Очереди типов FIFO и LIFO

#14. Очередь collections.deque на Python

#15. Очередь deque библиотеки STL языка C++

#16. Стек. Структура и принцип работы

#17. Реализация стека на Python и C++

#18. Бинарные деревья. Начало

#19. Бинарное дерево. Способы обхода и удаления вершин

#20. Реализация бинарного дерева на Python

#21. Множества (set). Операции над множествами

#22. Множества set и multiset в C++

#23. Контейнер map библиотеки STL в C++

#24. Префиксное (нагруженное, Trie) дерево. Ассоциативные массивы

#25. Хэш-таблицы. Что это такое и как работают

#26. Хэш-функции. Универсальное хэширование

#27. Метод открытой адресации. Двойное хэширование

#28. Использование хэш-таблиц в Python и С++
© 2024 Частичное или полное копирование информации с данного сайта для распространения на других ресурсах, в том числе и бумажных, строго запрещено. Все тексты и изображения являются собственностью сайта
Динамические массивы данных: теория веб-разработки

Рассказываем об одной из основных структур данных в веб-разработке — динамических массивах данных (dynamic arrays). В отличие от простых массивов, их размер определяется при выполнении кода, что избавляет программиста от утомительной необходимости планировать распределение памяти. Эти знания помогут всем желающим выбрать оптимальный инструмент для решения множества типичных проблем и изучить (самостоятельно или на нашем курсе) программирование на Python.
Введение в динамические массивы
Динамические массивы применяются в ситуациях, когда разработчик не знает точно, сколько памяти ему потребуется в тот или иной момент. Они позволяют гибко менять используемый объем ресурсов и освобождать ненужные ячейки. Эти процессы происходят автоматически, поэтому такие массивы и называются динамическими.

Освойте профессию
«Fullstack-разработчик на Python»
Fullstack-разработчик на Python
Fullstack-разработчики могут в одиночку сделать IT-проект от архитектуры до интерфейса. Их навыки востребованы у работодателей, особенно в стартапах. Научитесь программировать на Python и JavaScript и создавайте сервисы с нуля.

Профессия / 12 месяцев
Fullstack-разработчик на Python
Создавайте веб-проекты самостоятельно
4 116 ₽/мес 7 483 ₽/мес

Благодаря этой структуре данных программа может занимает в памяти ровно тот объем, который ей необходим для хранения конкретных данных. Представим, что вам нужно сгенерировать список пользователей, которые соответствуют каким-то критериям. Вы не знаете, сколько их будет — 10, 50, 100? Если ошибиться в меньшую сторону, код не будет работать. Если перестраховаться и зарезервировать избыточное место (например, сразу на 1000 пользователей), без ресурсов могут остаться приложения, которым они действительно нужны. Однако с использованием динамических массивов вы забываете обо всех трудностях. Еще одна проблема, которую решается таким образом — это фрагментация памяти. В своей работе веб-разработчики нередко сталкиваются с ситуацией, когда ресурсов вроде бы должно быть достаточно, однако программа начинает сбоить. Причина в том, что в какой-то момент ей нужен один большой кластер памяти, а свободные ячейки оказываются распределены по нескольким участкам. При использовании динамических массивов система оптимально формирует блоки и эффективно освобождает ненужные площади.
Вопросы производительности
Функционально динамический массив соответствует статистическому, открывая при этом ряд удобных возможностей. Время уточнения или изменения значения любого элемента массива не зависит от его расположения. При последовательном переборе элементов, время операции возрастает в линейной прогрессии, а ресурсы кеша расходуются максимально эффективно. То же самое справедливо для добавления или удаления элементов в середине массива. На проведение этих же операций с элементами в конце массива уходит постоянное амортизированное время, то есть в отдельные моменты скорость падает, однако общая производительность остается на уровне константы. Если вы уже проштудировали руководство по веб-разработке, вы наверняка сравните динамические массивы со связными списками — они также позволяют менять содержимое без лишних затрат ресурсов. Однако массивы обеспечивают лучшие показатели индексирования и перебора элементов. С другой стороны, они несколько проигрывают в скорости добавления данных — если в списке достаточно изменить внутренние ссылки, то содержимое массива приходится двигать в памяти целиком. Для решения этих проблем применяются буферные окна (gap buffers) и многоуровневые векторы (tiered vectors).

Станьте Fullstack-разработчик на Python и найдите стабильную работу
на удаленке
Взгляд за кулисы
Теперь рассмотрим, какая механика стоит за всеми этими операциями — как именно Python создает динамические массивы и как меняет их размер. Для начала практическая демонстрация этого механизма. import sys # этот модуль позволит нам использовать функцию для определения точного объема, который программа занимает в памяти n = 10 # задаем пороговое значение
data = [] # создаем пустой список
for i in range(n):
a = len(data) # количество элементов
b = sys.getsizeof(data) # объем памяти
print (‘Length:; Size of bytes:’.format(a, b))
data.append(n) # увеличиваем размер на единицу После выполнения кода мы видим следующую картину (рамками обозначены границы выделенных блоков памяти): 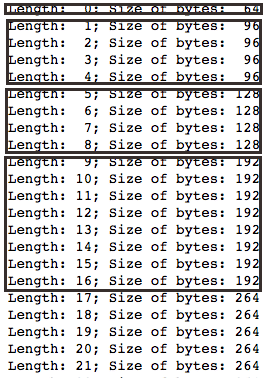 По этой таблице можно понять принцип, которому Python следует при выделении ресурсов. Первые два дополнительных блока содержат по четыре ячейки. После того, как программа последовательно занимает эти пространства, интерпретатор делает вывод о ее ресурсоемкости и сразу предоставляет в два раза больше места. В дальнейшем он будет поступать так же — каждый новый блок будет вдвое превышать предыдущий. Помните, мы говорили про постоянное амортизированное время при добавлении элементов в конец массива? Падение производительности происходит как раз в тот момент, когда нужно выделить новый, в два раза больший блок памяти. Остальные операции занимают одинаковый период. Этот принцип позволяет программе быстро добрать небольшое количество ресурсов, которых ей не хватает в начале работы. Если же ее аппетиты продолжают расти, она обращается за помощью все реже. Алгоритм, который позволяет переносить данные из блока A в блок B, выглядит следующим образом:
По этой таблице можно понять принцип, которому Python следует при выделении ресурсов. Первые два дополнительных блока содержат по четыре ячейки. После того, как программа последовательно занимает эти пространства, интерпретатор делает вывод о ее ресурсоемкости и сразу предоставляет в два раза больше места. В дальнейшем он будет поступать так же — каждый новый блок будет вдвое превышать предыдущий. Помните, мы говорили про постоянное амортизированное время при добавлении элементов в конец массива? Падение производительности происходит как раз в тот момент, когда нужно выделить новый, в два раза больший блок памяти. Остальные операции занимают одинаковый период. Этот принцип позволяет программе быстро добрать небольшое количество ресурсов, которых ей не хватает в начале работы. Если же ее аппетиты продолжают расти, она обращается за помощью все реже. Алгоритм, который позволяет переносить данные из блока A в блок B, выглядит следующим образом:
- Выделить участок B с нужным объемом памяти, в соответствии с описанным выше методом.
- Установить, что B[i] = A[i], i=0,….,n-1, где n — это текущий номер последнего элемента.
- Установить, что A = B.
- Добавить элементы в новый массив.
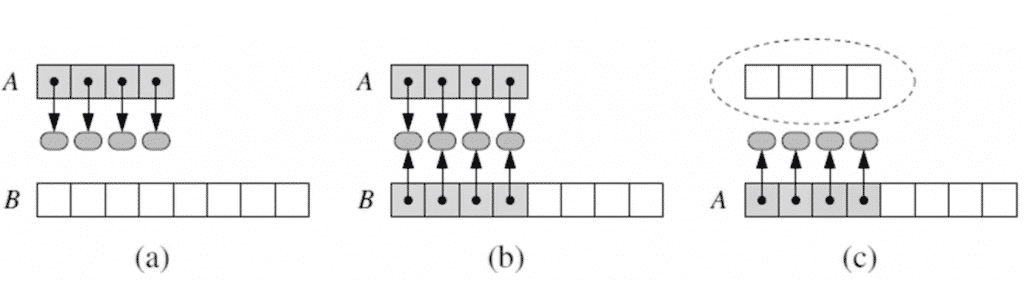
Другими словами, с того момента, как Python создает новый массив B и копирует в него данные, он считает его массивом A. Именно такая элегантная эффективность и снискала этому языку признание тысяч и тысяч программистов по всему миру.
Перламутровые пуговицы
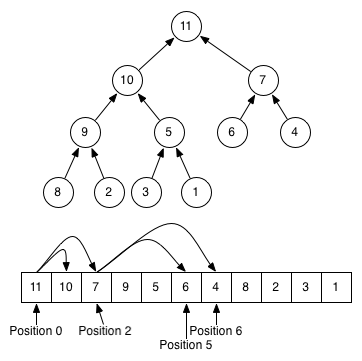
Что ещё можно делать с массивами? Например, структура под названием “куча” (heap) позволяет программисту в любой момент определить в ряду значений минимальное.
Функционально “куча” представляет собой бинарное дерево, где каждый родитель больше двух своих наследников. Таким образом, верхний узел (heap[0]) всегда оказывается самым меньшим из всего массива.

Список доступных в Python операций с “кучей” включает определение наименьшего элемента, его добавление или удаление, слияние нескольких массивов и др. С помощью “кучи” вы можете, например, выстроить приоритетную очередь для нескольких равноправных процессов, объединить записи двух журналов и выставить их в хронологическом порядке.
Как и другие бинарные деревья, “кучу” может быть сохранить в массиве, но при этом она оказывается компактнее. Дело в том, что в этом случае не требуется пространство для указателей — родителя и его наследников можно найти арифметически по индексам.
Ещё одна вариация структуры на основе массива — двухсторонняя очередь (double-ended queue, deque). Она объединяет в себе функции стека и, собственно, очереди. Как вы помните, главное отличие между этими двумя структурами — порядок получения сохранённых данных. В очереди первыми предоставляются те данные, которые были раньше в ней сохранены (принцип First-In-First-Out). В стеке — наоборот, как в стопке книг или тарелок, сверху оказываются самые новые элементы (First-In-Last-Out).
Двусторонняя очередь позволяет работать с данными с обеих сторон массива — добавлять и удалять элементы как в начале, так и в конце. Классический пример практического применения — планировщик задач для параллельных вычислений. Для каждого участвующего процессора формируется отдельная deque, в которую потоки сохраняются по принципу FIFO. Освободившийся процессор забирает первую задачу в своей очереди. Если она пуста, он обращается к deque другого процессора и забирает себе задачу, которая стоит там последней.
На этом сегодняшний теоретический экскурс окончен. Надеемся, что эти знания помогут вам в изучении Python и покорении новых вершин веб-разработки.
Двумерные массивы в Python и методы работы с ними

Иногда нам приходится использовать таблицы с данными для решения своих задач. Такие таблицы называются матрицами или двумерными массивами.
В Python подобные таблицы можно представить в виде списка, элементы которого являются другими списками. Для примера создадим таблицу с тремя столбцами и тремя строками, заполненными произвольными буквами:
mas = [['й', 'ц', 'у'], ['к','е','н'], ['г', 'ш', 'щ']] #Вывод всего двумерного массива print(mas) #Вывод первого элемента в первой строке print(mas[0][0]) # Выведет й #Вывод третьего элемента в третьей строке print(mas[2][2]) # Выведет щ
Создание двумерных массивов
Создать такой массив в Python можно разными способами. Разберем первый:
# Создание таблицы с размером 3x3, заполненной нулями a = 3 mas = [0] * a for i in range(a): mas[i] = [0] * a print(mas) # Выведет [[0, 0, 0], [0, 0, 0], [0, 0, 0]]
Второй способ предполагает создание пустого списка с добавлением в него новых списков. Рассмотрим на примере:
# Создание таблицы с размером 2x2, заполненной единицами
a = 2 mas = [] for i in range(a): mas.append([0] * a) print(mas) # Выведет [[1, 1, 1], [1, 1, 1], [1, 1, 1]]
Третьим и самым простым способом является генератор списков с x строками, которые будут состоять из y элементов. Пример:
# Создание таблицы с размером 3x3, заполненной двойками a = 3 mas = [[2] * a for i in range(a)] print(mas) # Выведет [[2, 2, 2], [2, 2, 2], [2, 2, 2]]
Комьюнити теперь в Телеграм
Подпишитесь и будьте в курсе последних IT-новостей
Способы ввода двумерных массивов
Допустим, нам нужно ввести двумерный массив после запуска нашей программы. Для этого мы можем создать программу, которая будет построчно считывать значения нашего массива, а также количество строк в нем. Рассмотрим на примере:
a=int(input()) mas = [] for i in range(a): mas.append(list(map(int, input().split()))) print(mas)
Запускаем программу и сначала вводим количество строк в массиве (допустим, 3). Далее вводим строки в порядке их очереди. Например:
1 1 1 1 1 1 1 1 1
После этого данная программа выведет наш двумерный массив: [[1, 1, 1], [1, 1, 1], [1, 1, 1]].
То же самое можно сделать с помощью генератора двумерных массивов:
mas = [list(map(int, input().split())) for i in range(int(input()))] # Вводим 3 1 1 1 1 1 1 1 1 1 print(mas) # Выведет [[1, 1, 1], [1, 1, 1], [1, 1, 1]]
Вывод двумерных массивов
Для обработки и вывода списков используются два вложенных цикла. Первый цикл – по порядковому номеру строки, второй – по ее элементам. Например, вывести массив можно так:
mas = [[1, 1, 1], [1, 1, 1], [1, 1, 1]] for i in range(0, len(mas)): for i2 in range(0, len(mas[i])): print(mas[i][i2], end=' ') print() # Выведет 1 1 1 1 1 1 1 1 1
То же самое можно сделать не по индексам, а по значениям массива:
mas = [[1, 1, 1], [1, 1, 1], [1, 1, 1]] for i in mas: for i2 in i: print(i2, end=' ') print() # Выведет 1 1 1 1 1 1 1 1 1
Способ с использованием метода join():
mas = [[1, 1, 1], [1, 1, 1], [1, 1, 1]] for i in mas: print(' '.join(list(map(str, i)))) # Выведет 1 1 1 1 1 1 1 1 1
Вывод одной из строк двумерного массива можно осуществить с помощью цикла и того же метода join(). Для примера выведем вторую строку в произвольном двумерном массиве:
mas = [[1, 1, 1], [2, 2, 2], [3, 3, 3]] string = 2 for i in mas[string-1]: print(i, end=' ') # Выведет 1 1 1
Для вывода определенного столбца в двумерном массиве можно использовать такую программу:
mas = [[1, 2, 3], [4, 5, 6], [7, 8, 9]] column = 2 for i in mas: print(i[column-1], end=' ') # Выведет 2 5 8
Обработка двумерных массивов
Составим произвольный двумерный массив с числами и размерностью 4×4:
2 4 7 3 4 5 6 9 1 0 4 2 7 8 4 7
Теперь поставим числа в каждой строке по порядку:
mas = [[2, 4, 7, 3], [4, 5, 6, 9], [1, 0, 4, 2], [7, 8, 4, 7]] mas2 = [] for i in mas: mas2.append(sorted(i)) print(mas2) # Выведет [[2, 3, 4, 7], [4, 5, 6, 9], [0, 1, 2, 4], [4, 7, 7, 8]]
А теперь расставим все числа по порядку, вне зависимости от их нахождения в определенной строке:
mas = [[2, 4, 7, 3], [4, 5, 6, 9], [1, 0, 4, 2], [7, 8, 4, 7]] mas2 = [] for i in mas: for i2 in i: mas2.append(i2) mas=sorted(mas2) for x in range(0, len(mas), 4): e_c = mas[x : 4 + x] if len(e_c) < 4: e_c = e_c + [None for y in range(n - len(e_c))] print(list(e_c)) # Выведет [0, 1, 2, 2] [3, 4, 4, 4] [4, 5, 6, 7] [7, 7, 8, 9]
Итог
Мы разобрались в основах двумерных массивов в Python, научились создавать, вводить и выводить их, а также рассмотрели примеры обработки. Надеюсь, статья оказалась полезной для вас!