Редактирование таблиц данных в R
В прошлый раз мы говорили о том, как загрузить данные в среду R. Следующим важным этапом является их подготовка к визуализации и статистическому анализу. Для этого нам, как правило, необходимо внести некоторые изменения в таблицу, например: удалить столбец или строку, переименовать колонку, произвести сортировку или фильтрацию данных. Многие из этих операций можно сделать в Excel. Однако, зачастую возникают ситуации, когда необходимо изменить структуру или содержание таблицы прямо в ходе анализа. И вот тут у начинающих пользователей R могут возникнуть проблемы. В этой статье мы научимся их решать.
Структура таблицы и изменение типов данных
Лучший способ для закрепления новых знаний — это практика. Поэтому мы продолжим работать с таблицей физических данных студентов одного из военных вузов «voenvuz». Итак, загрузим знакомую уже нам таблицу в Rgui (таблицу можно скачать здесь).
Функции head и str
Для того, чтобы посмотреть правильно ли загрузились данные, введем команду head(voenvuz) , которая покажет первые 6 строчек нашей таблицы. Если все загрузилось нормально, то переходим к команде str(voenvuz) , которая выведет в консоль структуру таблицы.

Итак, в поле «data.frame» мы видим, что наша таблица состоит из 20 строк и 6 столбцов. Под ним располагается список названий столбцов, тип данных и первые шесть элементов каждого столбца. Обратите внимание, что колонки «Name» и «Rhesus.factor» сейчас хранят в себе категориальный тип данных (Factor), а остальные — целочисленный. Компьютер вычислил это автоматически, но в нашем случае — вычислил неверно. Прежде чем мы исправим типы этих данных, немного теоретической информации.
О типах данных
Почему важно правильно распознать тип данных в столбцах таблицы? Потому что при проведении статистических тестов, информация о типе данных учитывается и влияет на результат.
В языке R можно выделить 5 основных типов данных, хранящихся в столбцах таблицы:
- числовой (numeric);
- целочисленный (integer);
- текстовый (character);
- категориальный (Factor);
- логический (logical).
Есть также комплексный (complex) и сырой (raw) типы данных, но они редко встречаются, и поэтому я о них здесь писать не буду. Пропущенные данные обозначаются как «NA» (от англ. not available — недоступно), и тогда R игнорирует их.
Изменим типы данных на практике
Посмотрим еще раз на таблицу. Логично предположить, что столбец «Name» с именами студентов не содержит никаких категорий, поэтому, преобразуем эту колонку в обычный текстовый тип данных:
voenvuz$NameИдем дальше, столбец "Age" был правильно идентифицирован как целочисленный. А вот столбцы "Height" и "Weight" являются скорее числовыми, т.к. могут содержать промежуточные значения, например 182.5. Переделаем их из типа Integer в тип Numeric:
voenvuz$Height
voenvuz$WeightПоследнее, что нам нужно - это изменить тип данных в столбце "Blood.group". Каждый из студентов так или иначе имеет одну из 4 групп крови, соответственно, этот столбец содержит четыре категории: "1", "2", "3", "4". Другими словами, в нем должен находиться категориальный тип данных:
voenvuz$Blood.groupВ итоге, повторив команду str(voenvuz) , мы должны получить вот такую картинку.
Редактирование элементов таблицы
Иногда возникают ситуации, когда необходимо вставить в таблицу столбец или строку, изменить значение элемента или название колонки. Наша таблица - не исключение и нуждается в доработке.
Добавление строк
Добавим в таблицу данные о двух новых студентах: Иване и Олеге. Для этого необходимо создать новую структуру - список (list) , В список мы по порядку вносим параметры, совпадающие со структурой таблицы (напомню, что в кавычках мы пишем нечисловые типы данных):
Ivan
OlegПосле, при помощи функции rbind (от англ. row bind, что дословно означает "связать строчки") мы объединим эти два списка с нашей таблицей:
voenvuzДобавление столбцов
Теперь у нас в таблице два Ивана и два Олега. В данном случае хорошо было бы прописать для каждого студента свой идентификационный номер (ID), чтобы не запутаться, кто есть кто. Для этого создадим структуру, которая называется вектор (последовательность элементов одного типа). В него мы запишем последовательность от 1 до 22, так, чтобы у каждого из наших 22 студентов был свой уникальный ID:
Теперь объединим наш вектор с таблицей, воспользовавшись функцией cbind (от англ. column bind):
voenvuzНе забудьте поменять тип данных нового столбца на символьный:
voenvuz$IDВ качестве еще одного примера добавления новых столбцов с данными в таблицу, рассчитаем индекс массы тела (BMI) для каждого студента. Для этого, мы воспользуемся новым способом: напишем математическую формулу индекса на языке R и присвоим ей новое имя столбца "BMI" внутри нашей таблицы:
voenvuz$BMIПроверьте, что получилось, используя уже знакомые нам функции head и str
Удаление строк и столбцов
Существует относительно "универсальная формула" для удаления элементов таблицы: new.data
Для того, чтобы корректно ее использовать необходимо запомнить несколько правил:
- После имени таблицы пространство внутри квадратных скобок следует разделить на две части запятой.
- Все, что находится до запятой, относится к строчкам, все что после - к столбцам.
- Поставьте минус перед номером столбца или номером строки, которую собираетесь удалить.
- Если таких элементов несколько, используйте функцию c(. ) : внутри скобок перечисление элементов через запятую.
В нашем случае, удалять из таблицы ничего не надо, но я покажу пару примеров, назвав "укороченные" таблицы именами "trash1", "trash2", "trash3", "trash4":
trash1 # удалим раннее созданный столбец "ID"
trash2 # удалим строку под номером 2 (данные Петра)
trash3 # удалим первые десять строк
trash4 # то же самое, только код корочеИзменение имен столбцов и данных в ячейках:
Переименуем колонку "Rhesus.factor" на укороченное "Rhesus". Для этого нужно вызвать функцию names , написать в параметрах функции имя таблицы и номер столбца, и присвоить ему новое имя :
names(voenvuz)[6]Изменение данные в ячейках таблицы не представляет особой сложности. В квадратных скобках прописываем координаты нужной ячейки (до запятой - строка, после запятой - столбец) и присваиваем новое значение:
voenvuz[1, "Name"]
После всех наших манипуляций мы должны получить вот такую таблицу данных:
Фильтрация и сортировка данных
В качестве примера, исключим из таблицы данных студентов, чей возраст больше 23 лет. Существует множество способов решения подобного рода задач, включая циклы if-else, for или while (о них будет написана отдельная статья). Однако в нашем случае хватит простого фильтра, основанного на логическом операторе " < wp-block-preformatted">voenvuz.final
Того же результата мы добьемся, если будем использовать логические операторы ">" (больше) и "!" (исключить):
voenvuz.final 23, ]Итак, мы получили финальную версию таблицы "voenvuz.final ". Осталось лишь упорядочить столбцы:
voenvuz.finalИ произвести сортировку данных по имени студентов, используя функцию order :
voenvuz.final
После завершения редактирования таблицы, обновим имена строк, т.к. сейчас они не соответствуют действительности, и выведем таблицу на экран, введя имя таблицы в консоль:
rownames(voenvuz.final) = c(1:length(voenvuz.final$ID))
voenvuz.finalЗаключение
Описанные выше способы редактирования данных в таблице не уникальны, существует множество других методов и команд, позволяющих получить желаемый результат. Я рассказал лишь о наиболее простых и часто используемых. Для более детального ознакомления с этой темой я хотел бы порекомендовать два источника на английском языке:
- сайт http://stackoverflow.com/ (уже подробно разобраны тысячи вопросов по этой теме)
- книгу-справочник "R book" by Michael J. Crawley (легко найти бесплатную PDF версию в интернете).
Если у Вас возникли вопросы или проблемы с редактированием таблиц данных, Вы всегда можете оставить комментарий под этой статьей, и он не останется без внимания. А в качестве продолжения, читайте следующую статью, посвященную сохранению данных в среде R.
Комментарии: 41
Февраль 21, 2021 в 13:52 ВладимирЗдравствуйте! Хотел отфильтровать записи в своем файле ничего не получилось. Тогда взял Ваш пример и попытался отфильтровать записи прямо по Вашему примеру, но получил тоже самое. Вот R-файл
voenvuz=read.csv(«D:/progaR/voenvuz_clean.csv»,sep=»;»)
voenvuz.fin=voenvuz[voenvuz$age=23]
Это текст на консоли(фрагмент) voenvuz voenvuz=read.csv(«D:/progaR/voenvuz_clean.csv»,sep=»;»)
> voenvuz.fin=voenvuz[voenvuz$age voenvuz
Name Age Height Weight Blood.group Rhesus.factor
1 Ivan 23 178 80 2 +
2 Peter 18 169 62 1 —
3 Oleg 22 185 77 2 +
4 Sergey 19 182 73 2 —
5 Dmitriy 25 190 93 3 +
6 Vladimir 20 166 65 1 +
7 Alexey 19 185 90 1 +
8 Alexandr 21 182 89 2 +
9 Boris 18 172 59 4 +
10 Igor 23 175 75 3 +
11 Artem 18 176 69 2 +
12 Andrey 20 184 81 3 —
ENVIRONMENT
voenvuz 20 obs of 6 variables
voenvuz.fin 0 obs of 6 variables
voenvuz.fin1 20 obs of 0 variables
с уважением ВладимирАпрель 20, 2020 в 16:49 Олег
kod col.x col.y delta
1 00046949 1,000 1,000 2
2 00047069 3,000 3,000 2
3 00047070 19,000 19,000 2
4 00047071 49,000 49,000 2
5 00047072 21,000 21,000 2
356 CB128164 2,000 2
252 CB164884 1,000 2
Всем привет! Только начал изучать R и столкнулся с некой проблемой: Есть такая волшебная таблица. И задача, вывести в последний столбец разницу 2 и 3 го, и с учетом того что данные в последних строках NA, соответственно вывести в последний столбец NA2 или NA3, в зависимости от того где стоит NA. Проблема в том, что стандартные функции(о которых я еще мало знаю) удаляют строки с NA, а мне важно их сохранить и обработать.
Если у кого то будут мысли по теме, буду рад помощи. Да и еще, у меня типы данных факторы в первых трех столбцах, а последний число.Апрель 21, 2020 в 11:47 Samoedd (Автор записи)
https://samoedd.comПривет, Олег! А где у тебя NA?
Столбец со значениями 1,2,3,4,5,356,252 — это что?
delta — это столбец со значениями 2?Апрель 10, 2020 в 18:46 Данила
Здравствуйте! Подскажите, пожалуйста, что я делаю не так.
У меня есть данные, записанные в одну строку «tree» в таком виде: ((ETH1567:0.07723012967,((ETH1478:0.03477412382,ETH1481:0.03998172409)100:0.01982264043,(LAV2470:0.04453502013,LAV2519:0.04666678739) и т.д. без пробелов. Мне нужно извлечь блоки содержащие буквы и последующие цифры до знака двоеточия, т.е.: ETH1567 ETH1478 ETH1481 LAV2470 LAV2519 Я подобрал регулярку для этого: ([A-z][0-9]*) Но мой код: treenames named character(0) Перерыд весь stackoverflow и иже с ним, но ответа не нашел.
Буду благодарен за подсказку.Апрель 11, 2020 в 20:07 Samoedd (Автор записи)
https://samoedd.comЗдравствуйте, Данила! Вот одно из возможных решений Вашей задачи: tree
tree1
tree2
tree3
tree4
tree4 # Your result! P.S. я мало анализирую текстовые данные, поэтому это решение вероятно не самое элегантное, но должно работать.5 Работа со строками
Мы будем пользоваться в основном пакетами stingr и stringi , так как они в большинстве случаях удобнее. К счастью функции этих пакетов легко отличить от остальных: функции пакет stringr всегда начинаются с str_ , а функции пакета stringi — c stri_ .
5.2 Как получить строку?



- следите за кавычками
"the quick brown fox jumps over the lazy dog"## [1] "the quick brown fox jumps over the lazy dog" 'the quick brown fox jumps over the lazy dog'## [1] "the quick brown fox jumps over the lazy dog" "the quick 'brown' fox jumps over the lazy dog"## [1] "the quick 'brown' fox jumps over the lazy dog" 'the quick "brown" fox jumps over the lazy dog'## [1] "the quick \"brown\" fox jumps over the lazy dog"- пустая строка
character(3)- преобразование
typeof(4:7)## [1] "integer" as.character(4:7)## [1] "4" "5" "6" "7"- встроенные векторы
letters## [1] "a" "b" "c" "d" "e" "f" "g" "h" "i" "j" "k" "l" "m" "n" "o" "p" "q" "r" "s" ## [20] "t" "u" "v" "w" "x" "y" "z" LETTERS## [1] "A" "B" "C" "D" "E" "F" "G" "H" "I" "J" "K" "L" "M" "N" "O" "P" "Q" "R" "S" ## [20] "T" "U" "V" "W" "X" "Y" "Z" month.name## [1] "January" "February" "March" "April" "May" "June" ## [7] "July" "August" "September" "October" "November" "December"- помните, что функции data.frame() , read.csv() , read.csv2() , read.table() из базового R всегда по-умолчанию преобразуют строки в факторы, и чтобы это предотвратить нужно использовать аргумент stringsAsFactors . Это много обсуждалось в сообществе R, можно, например, почитать про это вот этот блог пост Роджера Пенга.
str(data.frame(letters[6:10], LETTERS[4:8]))## 'data.frame': 5 obs. of 2 variables: ## $ letters.6.10.: chr "f" "g" "h" "i" . ## $ LETTERS.4.8. : chr "D" "E" "F" "G" . str(data.frame(letters[6:10], LETTERS[4:8], stringsAsFactors = FALSE))## 'data.frame': 5 obs. of 2 variables: ## $ letters.6.10.: chr "f" "g" "h" "i" . ## $ LETTERS.4.8. : chr "D" "E" "F" "G" . Но этом курсе мы учим использовать сразу tibble() , read_csv() , read_csv2() , read_tsv() , read_delim() из пакета readr (входит в tidyverse ).
- Создание рандомных строк
set.seed(42) stri_rand_strings(n = 10, length = 5:14)## [1] "uwHpd" "Wj8ehS" "ivFSwy7" "TYu8zw5V" ## [5] "OuRpjoOg0" "p0CubNR2yQ" "xtdycKLOm2k" "fAGVfylZqBGp" ## [9] "gE28DTCi0NV0a" "9MemYE55If0Cvv"- Перемешивает символы внутри строки
stri_rand_shuffle("любя, съешь щипцы, — вздохнёт мэр, — кайф жгуч")## [1] ",цо м,пюзгу сл аиъ—в кжряд,ыщьчебэн х—штё фй" stri_rand_shuffle(month.name)## [1] "aJayunr" "eyrbraFu" "achMr" "Aplri" "ayM" "Jnue" ## [7] "uJly" "usuAgt" "tpebermSe" "tOecrbo" "oeNembvr" "Dmceerbe"- Генерирует псевдорандомный текст 1
stri_rand_lipsum(nparagraphs = 2)## [1] "Lorem ipsum dolor sit amet, donec sit nunc urna sed ultricies ac pharetra orci luctus iaculis, ac tincidunt cum. Neque eu semper at sociosqu hendrerit. Eu aliquet lacus, eu hendrerit donec aliquam eros. Risus nibh, quam in sit facilisi ipsum. Amet sem sed donec sed molestie scelerisque tincidunt. Nisl donec et facilisis interdum non sed dolor purus. In ipsum dignissim torquent velit nec aliquam pellentesque. Ac, adipiscing, neque et at torquent, vestibulum ullamcorper. Ad dictumst enim velit non nulla felis habitant. Egestas placerat consectetur, dictum nostra sed nec. Erat phasellus dolor libero aliquam viverra. Vestibulum leo et. Suscipit egestas in in montes, sapien gravida? Conubia purus varius ut nec feugiat." ## [2] "Risus eleifend magnis neque diam, suspendisse ullamcorper nulla adipiscing malesuada massa, nisi sociosqu velit id et. Aliquam facilisis et aenean. Parturient vel ac in convallis, massa diam nibh. Nulla interdum cursus et. Natoque amet, ut praesent. Tortor ultrices a consectetur, augue natoque class faucibus? Ut sed arcu elementum magna. Dignissim ac facilisi quis ut nisl eu, massa."5.3 Соединение и разделение строк
Соединенить строки можно используя функцию str_c() , в которую, как и в функции с() , можно перечислять элементы через запятую:
tibble(upper = rev(LETTERS), smaller = letters) %>% mutate(merge = str_c(upper, smaller))Кроме того, если хочется, можно использовать особенный разделитель, указав его в аргументе sep :
tibble(upper = rev(LETTERS), smaller = letters) %>% mutate(merge = str_c(upper, smaller, sep = "_"))Аналогичным образом, для разделение строки на подстроки можно использовать функцию separate() . Это функция разносит разделенные элементы строки в соответствующие столбцы. У функции три обязательных аргумента: col — колонка, которую следует разделить, into — вектор названий новых столбец, sep — разделитель.
tibble(upper = rev(LETTERS), smaller = letters) %>% mutate(merge = str_c(upper, smaller, sep = "_")) %>% separate(col = merge, into = c("column_1", "column_2"), sep = "_")Кроме того, есть инструмент str_split() , которая позволяет разбивать строки на подстроки, но возвращает список.
str_split(month.name, "r")## [[1]] ## [1] "Janua" "y" ## ## [[2]] ## [1] "Feb" "ua" "y" ## ## [[3]] ## [1] "Ma" "ch" ## ## [[4]] ## [1] "Ap" "il" ## ## [[5]] ## [1] "May" ## ## [[6]] ## [1] "June" ## ## [[7]] ## [1] "July" ## ## [[8]] ## [1] "August" ## ## [[9]] ## [1] "Septembe" "" ## ## [[10]] ## [1] "Octobe" "" ## ## [[11]] ## [1] "Novembe" "" ## ## [[12]] ## [1] "Decembe" ""5.4 Количество символов
5.4.1 Подсчет количества символов
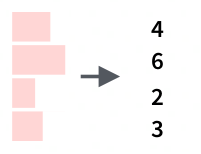
tibble(mn = month.name) %>% mutate(n_charactars = str_count(mn))5.4.2 Подгонка количества символов
Можно обрезать строки, используя функцию str_trunc() :
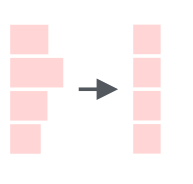
tibble(mn = month.name) %>% mutate(mn_new = str_trunc(mn, 6))Можно решить с какой стороны обрезать, используя аргумент side :
tibble(mn = month.name) %>% mutate(mn_new = str_trunc(mn, 6, side = "left")) tibble(mn = month.name) %>% mutate(mn_new = str_trunc(mn, 6, side = "center"))Можно заменить многоточие, используя аргумент ellipsis :
tibble(mn = month.name) %>% mutate(mn_new = str_trunc(mn, 3, ellipsis = ""))Можно наоборот “раздуть” строку:
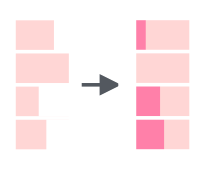
tibble(mn = month.name) %>% mutate(mn_new = str_pad(mn, 10))Опять же есть аргумент side :
tibble(mn = month.name) %>% mutate(mn_new = str_pad(mn, 10, side = "right"))Также можно выбрать, чем “раздувать строку”:
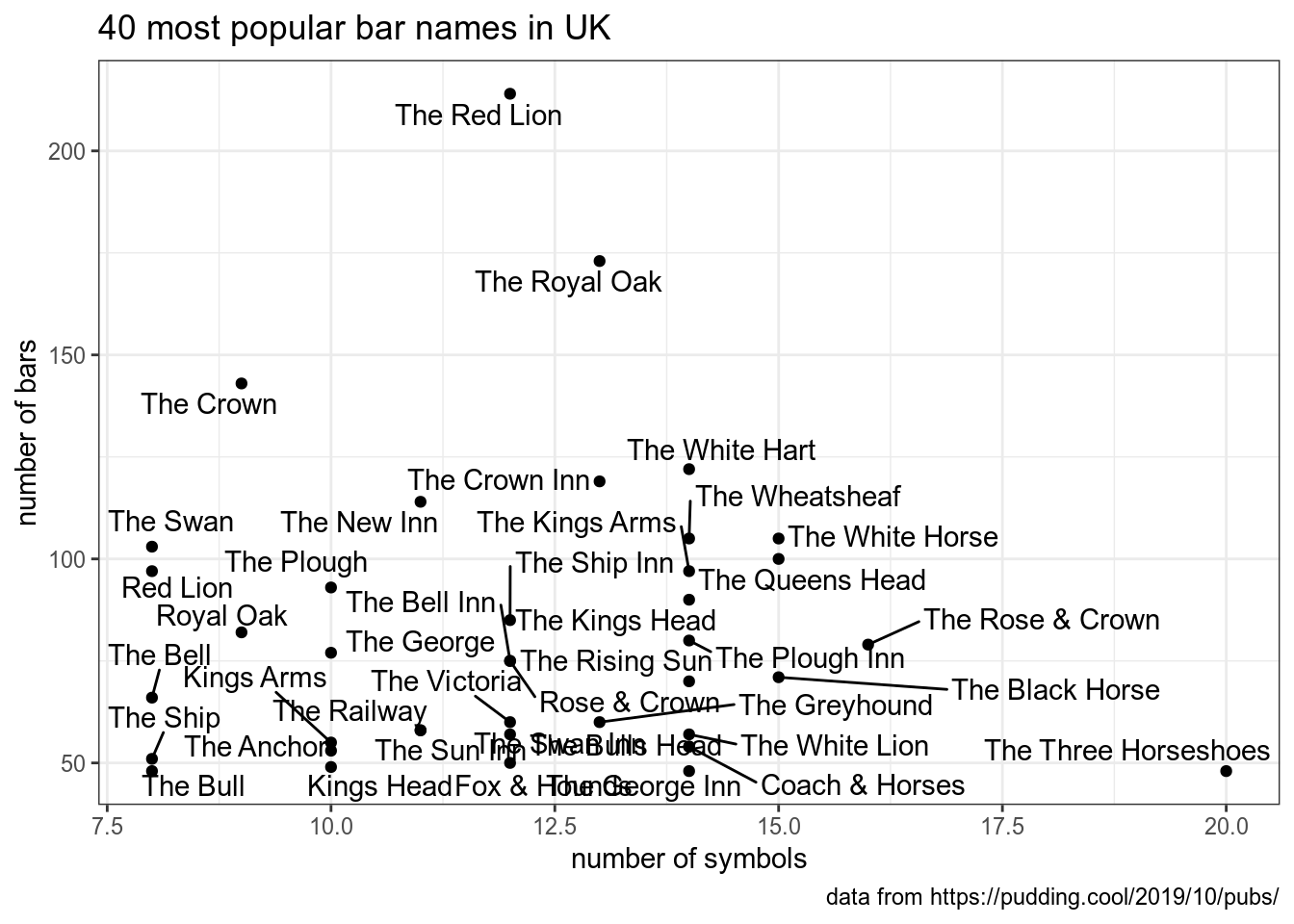
tibble(mn = month.name) %>% mutate(mn_new = str_pad(mn, 10, pad = "."))На Pudding вышла статья про английские пабы. Здесь лежит немного обработанный датасет, которые они использовали. Визуализируйте 40 самых частотоных названий пабов в Великобритании, отложив по оси x количество символов, а по оси y – количество баров с таким названием.
�� Датасет скачался, что дальше? ➡ Перво-наперво следует создать переменную, в которой бы хранилось количество каждого из баров.
�� А как посчитать количество баров? ➡ Это можно сделать при помощи функции count() .
�� Бары пересчитали, что дальше? ➡ Теперь нужно создать новую переменную, где бы хранилась информация о количестве символов.
�� Все переменные есть, теперь рисуем? ➡ Не совсем. Перед тем как рисовать нужно отфильтровать 50 самых популярных.
�� Так, все готово, а какие geom_() ? ➡ На графике geom_point() и geom_text_repel() из пакета ggrepel .
�� А-а-а-а! could not find function "geom_text_repel" ➡ А вы включили библиотеку ggrepel ? Если не включили, то функция, естественно будет недоступна.
�� А-а-а-а! geom_text_repel requires the following missing aesthetics: label" ➡ Все, как написала программа: чтобы писать какой-то текст в функции aes() нужно добавить аргумент label = pub_name . Иначе откуда он узнает, что ему писать?
�� Фуф! Все готово! ➡ А оси подписаны? А заголовок? А подпись про источник данных?
5.5 Сортировка
Для сортировки существует базовая функция sort() и функция из stringr str_sort() :
unsorted_latin c("I", "♥", "N", "Y") sort(unsorted_latin)## [1] "♥" "I" "N" "Y" str_sort(unsorted_latin)## [1] "♥" "I" "N" "Y" str_sort(unsorted_latin, locale = "lt")## [1] "♥" "I" "Y" "N" unsorted_cyrillic c("я", "i", "ж") str_sort(unsorted_cyrillic)## [1] "i" "ж" "я" str_sort(unsorted_cyrillic, locale = "ru_UA")## [1] "ж" "я" "i"Список локалей на копмьютере можно посмотреть командой stringi::stri_locale_list() . Список всех локалей вообще приведен на этой странице. Еще полезные команды: stringi::stri_locale_info и stringi::stri_locale_set .
Не углубляясь в разнообразие алгоритмов сортировки, отмечу, что алгоритм по-умолчанию хуже работает с большими данными:
set.seed(42) huge sample(letters, 1e7, replace = TRUE) head(huge)## [1] "q" "e" "a" "y" "j" "d" system.time( sort(huge) )## user system elapsed ## 7.359 0.024 7.383 system.time( sort(huge, method = "radix") )## user system elapsed ## 0.330 0.028 0.358 system.time( str_sort(huge) )## user system elapsed ## 6.566 0.072 6.679 huge_tbl tibble(huge) system.time( huge_tbl %>% arrange(huge) )## user system elapsed ## 3.404 0.064 3.468Предварительный вывод: для больших данных – sort(. method = "radix") .
5.6 Поиск подстроки
Можно использовать функцию str_detect() :
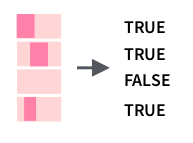
tibble(mn = month.name) %>% mutate(has_r = str_detect(mn, "r"))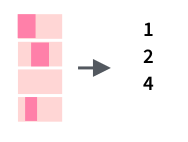
Кроме того, существует функция, которая возвращает индексы, а не значения TRUE / FALSE :
tibble(mn = month.name) %>% slice(str_which(month.name, "r"))Также можно посчитать количество вхождений какой-то подстроки:
tibble(mn = month.name) %>% mutate(has_r = str_count(mn, "r"))5.7 Изменение строк
5.7.1 Изменение регистра
latin "tHe QuIcK BrOwN fOx JuMpS OvEr ThE lAzY dOg" cyrillic "лЮбЯ, сЪеШь ЩиПцЫ, — вЗдОхНёТ мЭр, — кАйФ жГуЧ" str_to_upper(latin)## [1] "THE QUICK BROWN FOX JUMPS OVER THE LAZY DOG" str_to_lower(cyrillic)## [1] "любя, съешь щипцы, — вздохнёт мэр, — кайф жгуч" str_to_title(latin)## [1] "The Quick Brown Fox Jumps Over The Lazy Dog"5.7.2 Выделение подстроки
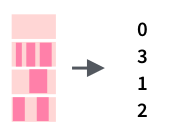
Подстроку в строке можно выделить двумя способами: по индексам функцией str_sub() , и по подстроке функцией str_png() .
tibble(mn = month.name) %>% mutate(mutate = str_sub(mn, start = 1, end = 2))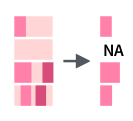
tibble(mn = month.name) %>% mutate(mutate = str_extract(mn, "r"))По умолчанию функция str_extract() возвращает первое вхождение подстроки, соответствующей шаблону. Также существует функция str_extract_all() , которая возвращает все вхождения подстрок, соответствующих шаблону, однако возвращает объект типа список.
str_extract_all(month.name, "r")## [[1]] ## [1] "r" ## ## [[2]] ## [1] "r" "r" ## ## [[3]] ## [1] "r" ## ## [[4]] ## [1] "r" ## ## [[5]] ## character(0) ## ## [[6]] ## character(0) ## ## [[7]] ## character(0) ## ## [[8]] ## character(0) ## ## [[9]] ## [1] "r" ## ## [[10]] ## [1] "r" ## ## [[11]] ## [1] "r" ## ## [[12]] ## [1] "r"5.7.3 Замена подстроки
Существует функция str_replace() , которая позволяет заменить одну подстроку в строке на другую:
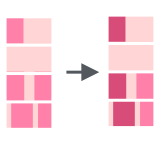
tibble(mn = month.name) %>% mutate(mutate = str_replace(mn, "r", "R"))Как и другие функции str_replace() делает лишь одну замену, чтобы заменить все вхождения подстроки следует использовать функцию str_replace_all() :
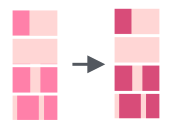
tibble(mn = month.name) %>% mutate(mutate = str_replace_all(mn, "r", "R"))5.7.4 Удаление подстроки
Для удаления подстроки на основе шаблона, используется функция str_remove() и str_remove_all()
tibble(month.name) %>% mutate(mutate = str_remove(month.name, "r")) tibble(month.name) %>% mutate(mutate = str_remove_all(month.name, "r"))5.7.5 Транслитерация строк
В пакете stringi сууществует достаточно много методов транслитераций строк, которые можно вывести командой stri_trans_list() . Вот пример использования некоторых из них:
stri_trans_general("stringi", "latin-cyrillic")## [1] "стринги" stri_trans_general("сырники", "cyrillic-latin")## [1] "syrniki" stri_trans_general("stringi", "latin-greek")## [1] "στριγγι" stri_trans_general("stringi", "latin-armenian")## [1] "ստրինգի"Вот два датасета:
- список городов России
- частотный словарь русского языка [Шаров, Ляшевская 2011]
Определите сколько городов называется обычным словом русского языка (например, город Орёл)? Не забудьте поменять ё на е.
�� Датасеты скачались, что дальше? ➡ Надо их преобразовать к нужному виду и объединить.
�� А как их соединить? Что у них общего? ➡
В одном датасете есть переменная city , в другом – переменная lemma . Все города начинаются с большой буквы, все леммы с маленькой буквы. Я бы уменьшил букву в датасете с городами, сделал бы новый столбец в датасете с городами (например, town ), соединил бы датасеты и посчитал бы сколько в результирующем датасете значений town .
�� А как соеднить? ➡ Я бы использовал dict %>% . %>% inner_join(cities) . Если в датасетах разные названия столбцов, то следует указывать какие столбцы, каким соответствуют: dict %>% . %>% inner_join(cities, by = c("lemma" = "city"))
�� Соединилось вроде… А как посчитать? ➡ Я бы, как обычно, использовал функцию count() .
5.8 Регулярные выражения
Большинство функций из раздела об операциях над векторами ( str_detect() , str_extract() , str_remove() и т. п.) имеют следующую структуру:
- строка, с которой работает функция
- образец (pattern)
Дальше мы будем использовать функцию str_view_all() , которая позволяет показывать, выделенное образцом в исходной строке.
str_view_all("Я всегда путаю с и c", "c") # я ищу латинскую c5.8.1 Экранирование метасимволов
a "Всем известно, что 4$\\2 + 3$ * 5 = 17$? Да? Ну хорошо (а то я не был уверен). [|>^<|]" str_view_all(a, "$") str_view_all(a, "\\$") str_view_all(a, "\\.") str_view_all(a, "\\*") str_view_all(a, "\\+") str_view_all(a, "\\?") str_view_all(a, "\\(") str_view_all(a, "\\)") str_view_all(a, "\\|") str_view_all(a, "\\^") str_view_all(a, "\\[") str_view_all(a, "\\]") str_view_all(a, "\\) str_view_all(a, "\\>") str_view_all(a, "\\\\")5.8.2 Классы знаков
- \\d – цифры. \\D – не цифры.
str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\d") str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\D")- \\s – пробелы. \\S – не пробелы.
str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\s") str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\S")- \\w – не пробелы и не знаки препинания. \\W – пробелы и знаки препинания.
str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\w") str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "\\W")- произвольная группа символов и обратная к ней
str_view_all("Умей мечтать, не став рабом мечтанья", "[оауиыэёеяю]") str_view_all("И мыслить, мысли не обожествив", "[^оауиыэёеяю]")- встроенные группы символов
str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "[0-9]") str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "[а-я]") str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "[А-Я]") str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "[А-я]") str_view_all("The quick brown Fox jumps over the lazy Dog", "[a-z]") str_view_all("два 15 42. 42 15. 37 08 5. 20 20 20!", "[^0-9]")
- выбор из нескольких групп
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "лар|рал|арл")- произвольный символ
str_view_all("Везет Сенька Саньку с Сонькой на санках. Санки скок, Сеньку с ног, Соньку в лоб, все — в сугроб", "[Сс].н")- знак начала и конца строки
str_view_all("от топота копыт пыль по полю летит.", "^о") str_view_all("У ежа — ежата, у ужа — ужата", "жата$")- есть еще другие группы и другие обозначения уже приведенных групп, см. ?regex

5.8.3 Квантификация
- ? – ноль или один раз
str_view_all("хорошее длинношеее животное", "еее?")- * – ноль и более раз
str_view_all("хорошее длинношеее животное", "ее*")- + – один и более раз
str_view_all("хорошее длинношеее животное", "е+") str_view_all("хорошее длинношеее животное", "е")- – n раз и более
str_view_all("хорошее длинношеее животное", "е")- – от n до m . Отсутствие пробела важно: – правильно, – неправильно.
str_view_all("хорошее длинношеее животное", "е")- группировка символов
str_view_all("Пушкиновед, Лермонтовед, Лермонтововед", "(ов)+") str_view_all("беловатый, розоватый, розововатый", "(ов)+")- жадный vs. нежадный алоритмы
str_view_all("Пушкиновед, Лермонтовед, Лермонтововед", "в.*ед") str_view_all("Пушкиновед, Лермонтовед, Лермонтововед", "в.*?ед")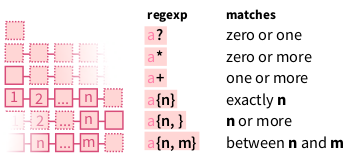
5.8.4 Позиционная проверка (look arounds)
Позиционная проверка – выглядит достаточно непоследовательно даже в свете остальных регулярных выражений.
Давайте найдем все а перед р:
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "а(?=р)")А теперь все а перед р или л:
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "а(?=[рл])")Давайте найдем все а после р
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "(?<=р)а")А теперь все а после р или л:
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "(?<=[рл])а")Также у этих выражений есть формы с отрицанием. Давайте найдем все р не перед а:
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "р(?!а)")А теперь все р не после а:
str_view_all("Карл у Клары украл кораллы, а Клара у Карла украла кларнет", "(?)Запомнить с ходу это достаточно сложно, так что подсматривайте сюда:
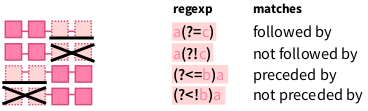
Вот отсюда можно скачать файл с текстом стихотворения Н. Заболоцкого “Меркнут знаки задиака”. Посчитайте долю женских (ударение падает на предпоследний слог рифмующихся слов) и мужских (ударение падает на последний слог рифмующихся слов) рифм в стихотворении.
�� Датасеты скачивается с ошибкой, почему? ➡ Дело в том, что исходный файл в формате .txt , а не .csv . Его нужно скачивать, например, командой read_lines()
�� Ошибка: . applied to an object of class "character" ➡
Скачав файл Вы получили вектор со строками, где каждая элимент вектора – строка стихотворения. Создайте tibble() , тогда можно будет применять стандартные инструменты tidyverse .
�� Хорошо, tibble() создан, что дальше? ➡ Дальше нужно создать переменную, из которой будет понятно, мужская в каждой строке рифма, или женская.
�� А как определить, какая рифма? Нужно с словарем сравнивать? ➡ Формально говоря, определять рифму можно по косвенным признакам. Все стихотворение написано четырехстопным хореем, значит в нем либо 7, либо 8 слогов. Значит, посчитав количество слогов, мы поймем, какая перед нами рифма.
�� А как посчитать гласные? ➡ Нужно написать регулярное выражение… вроде бы это тема нашего занятия…
�� Гласные посчитаны. А что дальше? ➡ Ну теперь нужно посчитать, сколько каких длин (в количестве слогов) бывает в стихотворении. Это можно сделать при помощи функции count() .
�� А почему у меня есть строки длины 0 слогов ➡ Ну, видимо, в стихотворении были пустые строки. Они использовались для разделения строф.
�� А почему у меня есть строки длины 6 слогов ➡ Ну, видимо, Вы написали регулярное выражение, которое не учитывает, что гласные буквы могут быть еще и в начале строки, а значит написаны с большой буквы.
В ходе анализа данных чаще всего бороться со строками и регулярными выражениями приходится в процессе обработки неаккуратнособранных анкет. Предлагаю обработать переменные sex и age такой вот неудачно собранной анкеты и построить следующий график:
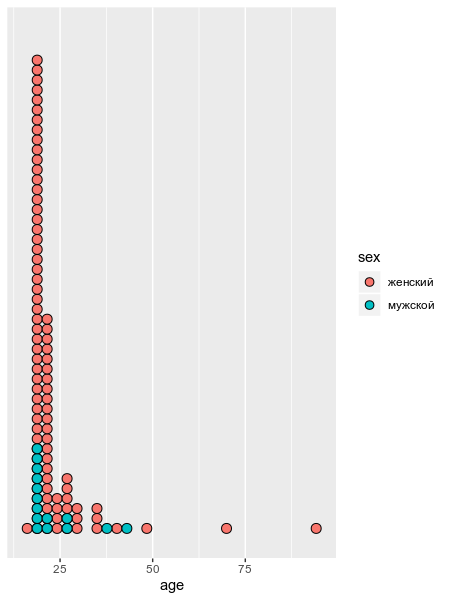
�� А что это за geom_. () ? ➡ Это geom_dotplot() с аргументом method = "histodot" и с удаленной осью y при помощи команды scale_y_continuous(NULL, breaks = NULL)
�� Почему на графике рисутеся каждое значение возраста? ➡ Если Вы все правильно преобразовали, должно помочь преобразование строковой переменной age в числовую при помощи функции as.integer().
5.9 Определение языка
Для определения языка существует два пакета cld2 (вероятностный) и cld3 (нейросеть).
udhr_24 read_csv("https://raw.githubusercontent.com/agricolamz/DS_for_DH/master/data/article_24_from_UDHR.csv")## Parsed with column specification: ## cols( ## article_text = col_character() ## ) udhr_24 cld2::detect_language(udhr_24$article_text)## [1] "ru" "en" "fr" "es" "ar" "zh" cld2::detect_language(udhr_24$article_text, lang_code = FALSE)## [1] "RUSSIAN" "ENGLISH" "FRENCH" "SPANISH" "ARABIC" "CHINESE" cld3::detect_language(udhr_24$article_text)## [1] "ru" "en" "fr" "es" "ar" "zh" cld2::detect_language("Ты женат? Говорите ли по-английски?")## [1] "bg" cld3::detect_language("Ты женат? Говорите ли по-английски?")## [1] NA cld2::detect_language("Варкалось. Хливкие шорьки пырялись по наве, и хрюкотали зелюки, как мюмзики в мове.")## [1] "ru" cld3::detect_language("Варкалось. Хливкие шорьки пырялись по наве, и хрюкотали зелюки, как мюмзики в мове.")## [1] "ru" cld2::detect_language("Варчилось… Хлив'язкі тхурки викрули, свербчись навкрузі, жасумновілі худоки гривіли зехряки в чузі.")## [1] "uk" cld3::detect_language("Варчилось… Хлив'язкі тхурки викрули, свербчись навкрузі, жасумновілі худоки гривіли зехряки в чузі.")## [1] "uk" cld2::detect_language_mixed("Многие в нашей команде OpenDataScience занимаются state-of-the-art технологиями машинного обучения: DL-фреймворками, байесовскими методами машинного обучения, вероятностным программированием и не только.")## $classificaton ## language code latin proportion ## 1 RUSSIAN ru FALSE 0.87 ## 2 ENGLISH en TRUE 0.11 ## 3 UNKNOWN un TRUE 0.00 ## ## $bytes ## [1] 353 ## ## $reliabale ## [1] TRUE cld3::detect_language_mixed("Многие в нашей команде OpenDataScience занимаются state-of-the-art технологиями машинного обучения: DL-фреймворками, байесовскими методами машинного обучения, вероятностным программированием и не только.")5.10 Расстояния между строками
Существует много разных метрик для измерения расстояния между строками (см. ?`stringdist-metrics` ), в примерах используется расстояние Дамерау — Левенштейна. Данное расстояние получается при подсчете количества операций, которые нужно сделать, чтобы перевести одну строку в другую.
- вставка ab → aNb
- удаление aOb → ab
- замена символа aOb → aNb
- перестановка символов ab → ba
library(stringdist)## ## Attaching package: 'stringdist'## The following object is masked from 'package:tidyr': ## ## extract stringdist("корова","корова") stringdist("коровы", c("курица", "бык", "утка", "корова", "осел"))## [1] 4 6 6 1 5 amatch(c("быки", "коровы"), c("курица", "бык", "утка", "корова", "осел"), maxDist = 2)## [1] 2 4- Lorem ipsum — классический текст-заполнитель на основе трактата Марка Туллия Цицерона “О пределах добра и зла”. Его используют, чтобы посмотреть, как страница смотриться, когда заполнена текстом↩︎
Урок 1 Функции select(), rename_with() и relocate()
Первый урок курса посвящён таким операциям, как продвинутый выбор столбцов, их переименование и изменения порядка столбцов таблицы.
В этом видео уроке мы познакомимся с такими функциями как: select() , rename_with() , relocate() , any_of() , all_of() .
1.2 Видео
1.3 Код
#devtools::install_github("tidyverse/dplyr") library(dplyr, warn.conflicts = FALSE) # rename # Переименовать столбцы для устранение дублирования их имён df1 tibble(a = 1:5, a = 5:1, .name_repair = "minimal") df1 df1 %>% rename(b = 2) # select # обращение к столбцам по типу df2 tibble(x1 = 1, x2 = "a", x3 = 2, y1 = "b", y2 = 3, y3 = "c", y4 = 4) # числовые столбцы df2 %>% select(is.numeric) # НЕ текстовые столбцы df2 %>% select(!is.character) # смешанный тип обращения # числовые стобцы, название которых начинается на X df2 %>% select(starts_with("x") & is.numeric) # выбор полей с помощью функций any_of и all_of vars c("x1", "x2", "y1", "z") df2 %>% select(any_of(vars)) df2 %>% select(all_of(vars)) # функция rename_with df2 %>% rename_with(toupper) df2 %>% rename_with(toupper, starts_with("x")) df2 %>% rename_with(toupper, is.numeric) # relocate для изменения порядка стобцов df3 tibble(w = 0, x = 1, y = "a", z = "b") # переместить столбцы y, z в начало df3 %>% relocate(y, z) # переместить текстовые столбцы вначало df3 %>% relocate(is.character) # поместить столбец w после y df3 %>% relocate(w, .after = y) # поместить столбец w перед y df3 %>% relocate(w, .before = y) # переместить w в конец df3 %>% relocate(w, .after = last_col())1.4 Упражнения
Для примера мы будем использовать встроенный набор данных iris , выполните следующие действия:
- Выберите все столбцы, которые заканчиваются на Width .
- Переместите с помощью функции relocate() единственный текстовый столбец в левую часть таблицы.
- Замените с помощью функции rename_with() в названии столбцов точку на нижнее подчёркивание, и преобразуйте имена в нижний регистр.
3 Семантика ссылок
В этой виньетке обсуждается семантика ссылок в data.table, которая позволяет добавлять/обновлять/удалять столбцы в data.table по ссылке, а также комбинирование с i и by . Она предназначена для тех, кто уже знаком с синтаксисом data.table, его общим видом, способом выбора строк в i , выбором и вычислением столбцов, выполнением агрегирования по группам. Если вы не знакомы с этими концепциями, пожалуйста, прочтите сперва виньетку “Введение в data.table”.
3.1 Данные
Мы будем использовать набор данных flights , так же как в виньетке “Введение в data.table”.
flights fread("https://raw.githubusercontent.com/wiki/arunsrinivasan/flights/NYCflights14/flights14.csv") flights # year month day dep_time dep_delay arr_time arr_delay cancelled carrier tailnum flight # 1: 2014 1 1 914 14 1238 13 0 AA N338AA 1 # 2: 2014 1 1 1157 -3 1523 13 0 AA N335AA 3 # 3: 2014 1 1 1902 2 2224 9 0 AA N327AA 21 # 4: 2014 1 1 722 -8 1014 -26 0 AA N3EHAA 29 # 5: 2014 1 1 1347 2 1706 1 0 AA N319AA 117 # --- # 253312: 2014 10 31 1459 1 1747 -30 0 UA N23708 1744 # 253313: 2014 10 31 854 -5 1147 -14 0 UA N33132 1758 # 253314: 2014 10 31 1102 -8 1311 16 0 MQ N827MQ 3591 # 253315: 2014 10 31 1106 -4 1325 15 0 MQ N511MQ 3592 # 253316: 2014 10 31 824 -5 1045 1 0 MQ N813MQ 3599 # origin dest air_time distance hour min # 1: JFK LAX 359 2475 9 14 # 2: JFK LAX 363 2475 11 57 # 3: JFK LAX 351 2475 19 2 # 4: LGA PBI 157 1035 7 22 # 5: JFK LAX 350 2475 13 47 # --- # 253312: LGA IAH 201 1416 14 59 # 253313: EWR IAH 189 1400 8 54 # 253314: LGA RDU 83 431 11 2 # 253315: LGA DTW 75 502 11 6 # 253316: LGA SDF 110 659 8 24 dim(flights) # [1] 253316 173.2 Введение
В этой виньетке мы:
- сперва коротко обсудим семантику ссылок и рассмотрим две разные формы использования оператора :=
- затем увидим, как мы можем добавлять/обновлять/удалять столбцы по ссылке в j с использованием := , и как это комбинировать с i и by
- и, наконец, мы увидим, как использовать оператор := ради его побочного эффекта, и как мы можем его избежать при помощи copy() .
3.3 1. Семантика ссылок
Результатом всех операций, которые мы видели в предыдущей виньетке, был новый набор данных. Мы увидим, как добавлять новые столбцы, обновлять или удалять существующие столбцы в исходных данных.
3.3.1 a) Бэкграунд
Прежде чем заняться семантикой ссылок, рассмотрим следующую таблицу data.frame:
DF = data.frame(ID = c("b","b","b","a","a","c"), a = 1:6, b = 7:12, c=13:18) DF # ID a b c # 1 b 1 7 13 # 2 b 2 8 14 # 3 b 3 9 15 # 4 a 4 10 16 # 5 a 5 11 17 # 6 c 6 12 18Когда вы выполняем:
DF$c 18:13 # (1) -- replace entire column # or DF$c[DF$ID == "b"] 15:13 # (2) -- subassign in column 'c'и (1), и (2) приводят к созданию глубокой копии всей таблицы data.frame в R версии < 3.1 . Данные копируются больше одного раза. Для увеличения производительности путем избегания этих ненужных копий data.table использует доступный, но неиспользуемый в R оператор := .
Большое увеличение производительности было сделано в R v3.1 , в результате чего в случае (1) создается поверхностная, а не глубокая копия. Тем не менее, для (2) по-прежнему создается глубокая копия всего столбца даже в R v3.1+ . Это означает, что чем больше столбцов участвуют в частичном присвоении в одном запросе, тем более глубокие копии создает R.
3.3.1.1 Поверхностная копия против глубокой копии
Поверхностная копия является всего лишь копией вектора-указателя столбцов (в соответствии со столбцами в data.frame или data.table). Настоящие данные физически не копируются в памяти.
С другой стороны, глубокая копия создает новую копию всех данных в новой области памяти.
С использованием оператора := в data.table никакие копии не создаются ни в случае (1), ни в случае (2) независимо от используемой версии R. Причина этого в том, что оператор := на месте обновляет столбцы data.table (по ссылке).
3.3.2 b) Оператор :=
Может быть использован в j двумя способами:
- Форма LHS := RHS
DT[, c("colA", "colB", . ) := list(valA, valB, . )] # when you have only one column to assign to you # can drop the quotes and list(), for convenience DT[, colA := valA]- Функциональная форма
DT[, `:=`(colA = valA, # valA is assigned to colA colB = valB, # valB is assigned to colB . )]Обратите внимаени, что приведенныый выше код объясняет, как можно использовать := . Это не рабочие примеры. Мы начнем использовать этот оператор с таблицей data.table flights в следующем разделе.
- Форма (a) удобна для программирования и особенно полезна, когда вы не знаете заранее столбцы для присваивания значений.
- С другой стороны, форма (b) удобна, когда вы хотите записать комментарии на будущее.
- Результат возвращается скрыто.
- Поскольку оператор := доступен в j , мы можем комбинировать его с операциями i и by , подобно операциям агрегирования, которые мы видели в предыдущей виньетке.
Обратите внимание, что в двух формах := , показанных выше, мы не присваиваем результат переменной, потому что не нуждаемся в этом. Исходная таблица data.table изменяется по ссылке. Давайте рассмотрим примеры, чтобы понять, что под этим подразумевается.
В оставшейся части виньетки мы будем работать с набором данных flights .
3.4 2. Добавление/обновление/удаление столбцов по ссылке
3.4.1 a) Добавление столбцов по ссылке
3.4.1.0.1 - Как мы можем добавить столбцы скорость и общая задержка каждого рейса в таблицу data.table flights ?
flights[, `:=`(speed = distance / (air_time/60), # speed in km/hr delay = arr_delay + dep_delay)] # delay in minutes head(flights) # year month day dep_time dep_delay arr_time arr_delay cancelled carrier tailnum flight origin # 1: 2014 1 1 914 14 1238 13 0 AA N338AA 1 JFK # 2: 2014 1 1 1157 -3 1523 13 0 AA N335AA 3 JFK # 3: 2014 1 1 1902 2 2224 9 0 AA N327AA 21 JFK # 4: 2014 1 1 722 -8 1014 -26 0 AA N3EHAA 29 LGA # 5: 2014 1 1 1347 2 1706 1 0 AA N319AA 117 JFK # 6: 2014 1 1 1824 4 2145 0 0 AA N3DEAA 119 EWR # dest air_time distance hour min speed delay # 1: LAX 359 2475 9 14 413.6490 27 # 2: LAX 363 2475 11 57 409.0909 10 # 3: LAX 351 2475 19 2 423.0769 11 # 4: PBI 157 1035 7 22 395.5414 -34 # 5: LAX 350 2475 13 47 424.2857 3 # 6: LAX 339 2454 18 24 434.3363 4 ## alternatively, using the 'LHS := RHS' form # flights[, c("speed", "delay") := list(distance/(air_time/60), arr_delay + dep_delay)]3.4.1.1 Обратите внимание
- Мы не присвоили разультат переменной flights .
- Таблица flights теперь содержит два новых столбца. Это то, что мы подразумеваем под добавлением по ссылке.
- Мы использовали функциональную форму, так что мы можем добавлять комментарии сбоку для объяснения, что делают эти вычисления. Вы также можете видеть форму LHS := RHS (закомментированную).
3.4.2 b) Обновление некоторых строк в столбцах по ссылке - частичное присваивание по ссылке
Давайте взглянем на все значения hours , доступные в таблице data.table flights :
# get all 'hours' in flights flights[, sort(unique(hour))] # [1] 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24Мы видим, что имеется 25 уникальных значений - есть и 0, и 24. Давайте заменим 24 на 0.
3.4.2.1 – Заменить строки, где hour == 24 , на 0
# subassign by reference flights[hour == 24L, hour := 0L]- Мы можем использовать i вместе с := в j тем же способом, как мы видели в виньетке “Введение в data.table”.
- Столбец hour заменяется 0 только для индексов строк, для которых условие hour == 24L , определенное в i , возвращает TRUE .
- := возвращает результат скрыто. Иногда бывает нужно увидеть результат после присваивания. Мы можем добиться этого, добавив пустой оператор [] в конце запроса, как показано ниже:
flights[hour == 24L, hour := 0L][] # year month day dep_time dep_delay arr_time arr_delay cancelled carrier tailnum flight # 1: 2014 1 1 914 14 1238 13 0 AA N338AA 1 # 2: 2014 1 1 1157 -3 1523 13 0 AA N335AA 3 # 3: 2014 1 1 1902 2 2224 9 0 AA N327AA 21 # 4: 2014 1 1 722 -8 1014 -26 0 AA N3EHAA 29 # 5: 2014 1 1 1347 2 1706 1 0 AA N319AA 117 # --- # 253312: 2014 10 31 1459 1 1747 -30 0 UA N23708 1744 # 253313: 2014 10 31 854 -5 1147 -14 0 UA N33132 1758 # 253314: 2014 10 31 1102 -8 1311 16 0 MQ N827MQ 3591 # 253315: 2014 10 31 1106 -4 1325 15 0 MQ N511MQ 3592 # 253316: 2014 10 31 824 -5 1045 1 0 MQ N813MQ 3599 # origin dest air_time distance hour min speed delay # 1: JFK LAX 359 2475 9 14 413.6490 27 # 2: JFK LAX 363 2475 11 57 409.0909 10 # 3: JFK LAX 351 2475 19 2 423.0769 11 # 4: LGA PBI 157 1035 7 22 395.5414 -34 # 5: JFK LAX 350 2475 13 47 424.2857 3 # --- # 253312: LGA IAH 201 1416 14 59 422.6866 -29 # 253313: EWR IAH 189 1400 8 54 444.4444 -19 # 253314: LGA RDU 83 431 11 2 311.5663 8 # 253315: LGA DTW 75 502 11 6 401.6000 11 # 253316: LGA SDF 110 659 8 24 359.4545 -4Давайте взглянем на все значения hours для проверки.
# check again for '24' flights[, sort(unique(hour))] # [1] 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 233.4.3 c) Удаление столбца по ссылке
3.4.3.1 – Удаление столбца delay
flights[, c("delay") := NULL] head(flights) # year month day dep_time dep_delay arr_time arr_delay cancelled carrier tailnum flight origin # 1: 2014 1 1 914 14 1238 13 0 AA N338AA 1 JFK # 2: 2014 1 1 1157 -3 1523 13 0 AA N335AA 3 JFK # 3: 2014 1 1 1902 2 2224 9 0 AA N327AA 21 JFK # 4: 2014 1 1 722 -8 1014 -26 0 AA N3EHAA 29 LGA # 5: 2014 1 1 1347 2 1706 1 0 AA N319AA 117 JFK # 6: 2014 1 1 1824 4 2145 0 0 AA N3DEAA 119 EWR # dest air_time distance hour min speed # 1: LAX 359 2475 9 14 413.6490 # 2: LAX 363 2475 11 57 409.0909 # 3: LAX 351 2475 19 2 423.0769 # 4: PBI 157 1035 7 22 395.5414 # 5: LAX 350 2475 13 47 424.2857 # 6: LAX 339 2454 18 24 434.3363 ## or using the functional form # flights[, `:=`(delay = NULL)]- Присвоение значения NULL столбцу удаляет его. И это происходит мгновенно.
- Мы можем такое передавать имена столбцов вместо их имен в LHS , хотя хорошая практика программирования заключается в использовании имен.
- Когда нужно удалить всего один столбец, мы можем опустить c() и двойные кавычки и использовать для удобства просто имя столбца. Эквивалент кода выше:
flights[, delay := NULL]3.4.4 d) := вместе с группировкой при помощи by
В разделе 2b мы уже видели, как использовать := совместно с i . Давайте посмотрим, как мы можем использовать := в сочетании с by .
3.4.4.1 - Как мы можем добавить новый столбец, содержащий максимальную скорость для каждой пары origin, dest ?
flights[, max_speed := max(speed), by=.(origin, dest)] head(flights) # year month day dep_time dep_delay arr_time arr_delay cancelled carrier tailnum flight origin # 1: 2014 1 1 914 14 1238 13 0 AA N338AA 1 JFK # 2: 2014 1 1 1157 -3 1523 13 0 AA N335AA 3 JFK # 3: 2014 1 1 1902 2 2224 9 0 AA N327AA 21 JFK # 4: 2014 1 1 722 -8 1014 -26 0 AA N3EHAA 29 LGA # 5: 2014 1 1 1347 2 1706 1 0 AA N319AA 117 JFK # 6: 2014 1 1 1824 4 2145 0 0 AA N3DEAA 119 EWR # dest air_time distance hour min speed max_speed # 1: LAX 359 2475 9 14 413.6490 526.5957 # 2: LAX 363 2475 11 57 409.0909 526.5957 # 3: LAX 351 2475 19 2 423.0769 526.5957 # 4: PBI 157 1035 7 22 395.5414 517.5000 # 5: LAX 350 2475 13 47 424.2857 526.5957 # 6: LAX 339 2454 18 24 434.3363 518.4507- Мы добавляем новый столбец max_speed по ссылке, используя оператор := .
- Мы задаем столбцы для группировки, как было показано в виньетке “Введение в data.table”. Для каждой группы было вычислено выражение max(speed) , которое возвращает единственное значение. Это выражение повторяется, чтобы соответствовать длине группы. Еще раз: никакие копии не создаются. Таблица data.table flights изменяется на месте.
- Мы также можем задать by как символьный вектор, как мы видели в виньетке “Введение в data.table”, например, by = c("origin", "dest") .
3.4.5 e) Множественные столбцы и :=
3.4.5.1 - Как мы может добавить еще две колонки, рассчитав max() для dep_delay и arr_delay для каждого месяца, используя .SD ?
in_cols = c("dep_delay", "arr_delay") out_cols = c("max_dep_delay", "max_arr_delay") flights[, c(out_cols) := lapply(.SD, max), by = month, .SDcols = in_cols] head(flights) # year month day dep_time dep_delay arr_time arr_delay cancelled carrier tailnum flight origin # 1: 2014 1 1 914 14 1238 13 0 AA N338AA 1 JFK # 2: 2014 1 1 1157 -3 1523 13 0 AA N335AA 3 JFK # 3: 2014 1 1 1902 2 2224 9 0 AA N327AA 21 JFK # 4: 2014 1 1 722 -8 1014 -26 0 AA N3EHAA 29 LGA # 5: 2014 1 1 1347 2 1706 1 0 AA N319AA 117 JFK # 6: 2014 1 1 1824 4 2145 0 0 AA N3DEAA 119 EWR # dest air_time distance hour min speed max_speed max_dep_delay max_arr_delay # 1: LAX 359 2475 9 14 413.6490 526.5957 973 996 # 2: LAX 363 2475 11 57 409.0909 526.5957 973 996 # 3: LAX 351 2475 19 2 423.0769 526.5957 973 996 # 4: PBI 157 1035 7 22 395.5414 517.5000 973 996 # 5: LAX 350 2475 13 47 424.2857 526.5957 973 996 # 6: LAX 339 2454 18 24 434.3363 518.4507 973 996- Мы используем форму LHS := RHS . Сохраняем имена исходных и результирующих столбцов в отдельных переменных и передаем их в SDcols и LHS (для лучшей читаемости).
- Отметим, что поскольку мы допускаем присваивание по ссылке без заключения имени столбца в кавычки для случая отдельного столбца, как объясняется в разделе 2c, мы не можем записать out_cols := lapply(.SD, max) . Это приведет к добавлению единственного столбца с именем out_col . Вместо этого мы должны использовать c(out_cols) или просто (out_cols) . Использования ( вокруг имени переменной достаточно, чтобы различать эти два случая.
- Форма LHS := RHS позволяет нам работать с несколькими столбцами. В RHS для расчета max для столбцов, заданных в .SDcols , мы используем базовую функцию lapply() вместе с .SD тем же способом, как мы видели ранее в виньетке “Введение в data.table”. Возвращается список из двух элементов, содержащих максимальные значения dep_delay и arr_delay для каждой группы.
Прежде чем перейти к следующему разделу, давайте удалим новые столбцы speed , max_speed , max_dep_delay и max_arr_delay .
# RHS gets automatically recycled to length of LHS flights[, c("speed", "max_speed", "max_dep_delay", "max_arr_delay") := NULL] head(flights) # year month day dep_time dep_delay arr_time arr_delay cancelled carrier tailnum flight origin # 1: 2014 1 1 914 14 1238 13 0 AA N338AA 1 JFK # 2: 2014 1 1 1157 -3 1523 13 0 AA N335AA 3 JFK # 3: 2014 1 1 1902 2 2224 9 0 AA N327AA 21 JFK # 4: 2014 1 1 722 -8 1014 -26 0 AA N3EHAA 29 LGA # 5: 2014 1 1 1347 2 1706 1 0 AA N319AA 117 JFK # 6: 2014 1 1 1824 4 2145 0 0 AA N3DEAA 119 EWR # dest air_time distance hour min # 1: LAX 359 2475 9 14 # 2: LAX 363 2475 11 57 # 3: LAX 351 2475 19 2 # 4: PBI 157 1035 7 22 # 5: LAX 350 2475 13 47 # 6: LAX 339 2454 18 243.5 3 := и copy()
:= изменяет исходный объект по ссылке. Помимо возможностей, которые мы уже обсудили, иногда мы можем захотеть использовать возможность обновления по ссылке ради его побочного эффекта. А в других случаях может быть нежелательно изменять исходный объект, и тогда мы можем использовать функцию copy() , как мы сейчас увидим.
3.5.1 a) Использование оператора := ради его побочного эффекта
Скажем, мы хотели бы создать функцию, которая будет возвращать максимальную скорость для каждого месяца. Но, в то же время, мы хотели бы добавить столбец speed в таблицу flight . Мы можем написать следующую простую функцию:
foo function(DT) < DT[, speed := distance / (air_time/60)] DT[, .(max_speed = max(speed)), by=month] > ans = foo(flights) head(flights) # year month day dep_time dep_delay arr_time arr_delay cancelled carrier tailnum flight origin # 1: 2014 1 1 914 14 1238 13 0 AA N338AA 1 JFK # 2: 2014 1 1 1157 -3 1523 13 0 AA N335AA 3 JFK # 3: 2014 1 1 1902 2 2224 9 0 AA N327AA 21 JFK # 4: 2014 1 1 722 -8 1014 -26 0 AA N3EHAA 29 LGA # 5: 2014 1 1 1347 2 1706 1 0 AA N319AA 117 JFK # 6: 2014 1 1 1824 4 2145 0 0 AA N3DEAA 119 EWR # dest air_time distance hour min speed # 1: LAX 359 2475 9 14 413.6490 # 2: LAX 363 2475 11 57 409.0909 # 3: LAX 351 2475 19 2 423.0769 # 4: PBI 157 1035 7 22 395.5414 # 5: LAX 350 2475 13 47 424.2857 # 6: LAX 339 2454 18 24 434.3363 head(ans) # month max_speed # 1: 1 535.6425 # 2: 2 535.6425 # 3: 3 549.0756 # 4: 4 585.6000 # 5: 5 544.2857 # 6: 6 608.5714- Обратите внимание, что новый столбец speed был добавлен в таблицу data.table flights , поскольку := выполняет операции по ссылке. Поскольку DT (аргумент функции) и flights ссылаются на один и тот же объект в памяти, изменение DT также отражается на flights.
- ans содержит максимальную скорость для каждого месяца.
3.5.2 b) Функция copy()
В предыдущем разделе мы использовали оператор := ради его побочного эффекта. Но, разумеется, это не всегда может быть желательно. Иногда мы хотели бы передать объект data.table функции и использовать оператор := , но не хотели бы обновлять исходный объект. Мы можем достичь этого, используя функцию copy() .
Функция copy() создает глубокую копию исходного объекта, и поэтому любые последующие операции обновления по ссылке, выполняемые на скопированном объекте, не влияют на исходный объект.
Есть два конкретных случая, когда функция copy() имеет важное значение:
- В отличие от ситуации, которую мы видели в предыдущем пункте, мы можем не хотеть, чтобы таблица data.table, передаваемая функции, изменялась по ссылке. В качестве примера давайте рассмотрим задачу из предыдущего раздела, за исключением того, что не хотим изменять flights по ссылке.
Сперва удалим столбец speed , созданный в предыдущем разделе.
flights[, speed := NULL]Теперь мы можем выполнить задачу следующим образом:
foo function(DT) copy(DT) ## deep copy DT[, speed := distance / (air_time/60)] ## doesn't affect 'flights' DT[, .(max_speed = max(speed)), by=month] > ans foo(flights) head(flights) # year month day dep_time dep_delay arr_time arr_delay cancelled carrier tailnum flight origin # 1: 2014 1 1 914 14 1238 13 0 AA N338AA 1 JFK # 2: 2014 1 1 1157 -3 1523 13 0 AA N335AA 3 JFK # 3: 2014 1 1 1902 2 2224 9 0 AA N327AA 21 JFK # 4: 2014 1 1 722 -8 1014 -26 0 AA N3EHAA 29 LGA # 5: 2014 1 1 1347 2 1706 1 0 AA N319AA 117 JFK # 6: 2014 1 1 1824 4 2145 0 0 AA N3DEAA 119 EWR # dest air_time distance hour min # 1: LAX 359 2475 9 14 # 2: LAX 363 2475 11 57 # 3: LAX 351 2475 19 2 # 4: PBI 157 1035 7 22 # 5: LAX 350 2475 13 47 # 6: LAX 339 2454 18 24 head(ans) # month max_speed # 1: 1 535.6425 # 2: 2 535.6425 # 3: 3 549.0756 # 4: 4 585.6000 # 5: 5 544.2857 # 6: 6 608.5714- Использование функции copy() не обновляет по ссылке таблицу data.table flights . Эта таблица не содержит столбца speed .
- ans содержит максимальную скорость, соответствующую каждому месяцу.
Однако мы могли еще улучшить эту функциональность, делая поверхностное копирование вместо глубокого. На самом деле, мы бы очень хотели обеспечить эту функциональность в v1.9.8 . Мы коснемся этой темы еще раз в виньетке “data.table design”.
- Когда мы сохраняем имена столбцов в переменной, например, DT_n = names(DT) , а затем добавляем/обновляем/удаляем столбцы по ссылке, это также изменит DT_n , если мы не выполним copy(names(DT)) .
DT = data.table(x=1, y=2) DT_n = names(DT) DT_n # [1] "x" "y" ## add a new column by reference DT[, z := 3] ## DT_n also gets updated DT_n # [1] "x" "y" "z" ## use `copy()` DT_n = copy(names(DT)) DT[, w := 4] ## DT_n doesn't get updated DT_n # [1] "x" "y" "z"3.6 Резюме
3.6.0.1 - Оператор :=
- Используется для добавления/обновления/удаления столбцов по ссылке.
- Мы также увидели, как использовать := вместе с i и by таким же образом, как мы видели в виньетке “Введение в data.table”. Еще мы можем использовать keyby , цепочечные операции, передавать выражения в by . Синтаксис согласован.
- Мы можем использовать оператор := ради его побочного эффекта, или использовать copy() , чтобы не изменять исходный объект при обновлении по ссылке.
Пока что мы увидели много всего, что может j , как это комбинировать с by , а также немного возможностей i . Давайте обратим наше внимание на i в следующей виньетке “Keys and fast binary search based subset” для выполнения молниеносного создания поднаборов при помощи установки ключей (keying) в data.tables.