Увеличить список его содержимым в N раз
Операция позволяет расширить последовательность ее же содержимым. Операция sequence *= n производит расширение последовательности sequence ее же содержимым, повторенным n раз.
Значение n является целым числом или объектом, реализующим метод __index__() . Нулевые и отрицательные значения n очищают последовательность.
Если значение n не является целым числом, то поднимается исключение TypeError
Элементы в последовательности не копируются, а на них проставляются ссылки, как описано для s * n — Повторение последовательности N раз в разделе Общие операции с последовательностями.
Эта операция поддерживаются изменяемыми типами последовательностей.
Примеры увеличения списка его содержимым.
>>> x = [12, 15, 18] >>> x *= 3 >>> x # [12, 15, 18, 12, 15, 18, 12, 15, 18] >>> x = ['one','two','three'] >>> x *= 2 >>> x # ['one','two','three', 'one','two','three'] >>> x = ['one','two','three'] >>> x *= -2 >>> x # [] >>> x = ['one','two','three'] >>> x *= 0 >>> x # [] # Внимание! >>> x = [[]] >>> x *= 4 >>> x # [[], [], [], []] >>> x[0].append(9) >>> x # [[9], [9], [9], [9]]
- ОБЗОРНАЯ СТРАНИЦА РАЗДЕЛА
- Изменение/замена элемента списка по индексу
- Изменение части списка операцией среза
- Изменение списка срезом c заданным шагом
- Удаление части списка операцией среза
- Удаление части списка по срезу с заданным шагом
- Метод list.append(), добавляет значение в конец списка
- Метод list.clear(), очищает список
- Метод list.copy(), копия списка
- Метод list.extend(), расширяет список другой последовательностью
- Расширение списка его содержимым
- Метод list.insert(), вставить элемент по индексу
- Метод list.pop(), получение с удалением элемент списка
- Метод list.remove(), удаление элемента списка по значению
- Метод list.reverse(), разворачивает элементы списка
- Удаление элемента списка по индексу
- Удаление дубликатов из списка Python с сохранением очередности
Задача на питоне Все сразу
Заменил второй элемент списка на 17;
Добавил числа 4, 5 и 6 в конец списка;
Удалил первый элемент списка;
Удвоил список;
Вставил число 25 по индексу 3;
Вывел список, с помощью функции print()
сам код:
numbers = [8, 9, 10, 11]
Голосование за лучший ответ
numbers = [8, 9, 10, 11]
numbers[1] = 17
numbers += [4, 5, 6]
del numbers[0]
numbers *= 2
numbers.insert(3, 25)
print(*numbers)
Увеличение двумерного списка?

RimMirK, задание заключается в следующем: Реализуйте функцию enlarge(), которая принимает изображение в виде двумерного списка строк и увеличивает его в два раза, то есть удваивает каждый символ по горизонтали и вертикали.
Собственно, у меня получилось, но тесты не проходит:
def enlarge(list_arr): second_list = [] if len(list_arr) == 0: return list_arr else: for i in range(len(list_arr)): second_list.extend(list_arr[i] * 2) return ''.join(second_list) print(enlarge([''])) print(enlarge([])) print(enlarge(['aaaa', 'bb', 'c'])) print(enlarge(['1', '22', '333']))Всё ломается на print(enlarge([»])), не получается удвоить.
goryay, добавь исключение. тут не понятно что должно получится в результате удвоения пустоты. напиши если на входе пустота то сразу вернуть удвоенную пустоту
то есть буквально
def enlarge(list_arr): if list_arr == '': return '' second_list = [] if len(list_arr) == 0: return list_arr else: for i in range(len(list_arr)): second_list.extend(list_arr[i] * 2) return ''.join(second_list)goryay @goryay Автор вопроса
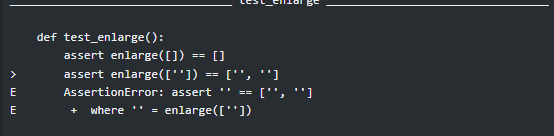
be52,
Всё равно не пропускает
Как удвоить список python

На позапрошлом уроке мы узнали, как работать со списками в Python. Теперь изучим, как можно создавать списки более быстрым и красивым с точки зрения синтаксиса способом.
Съемка, монтаж: Глеб Лиманский
Для решения одной практической задачи, нам нужно создать список с годами с 2000 по 2019. Мы можем сделать это так:
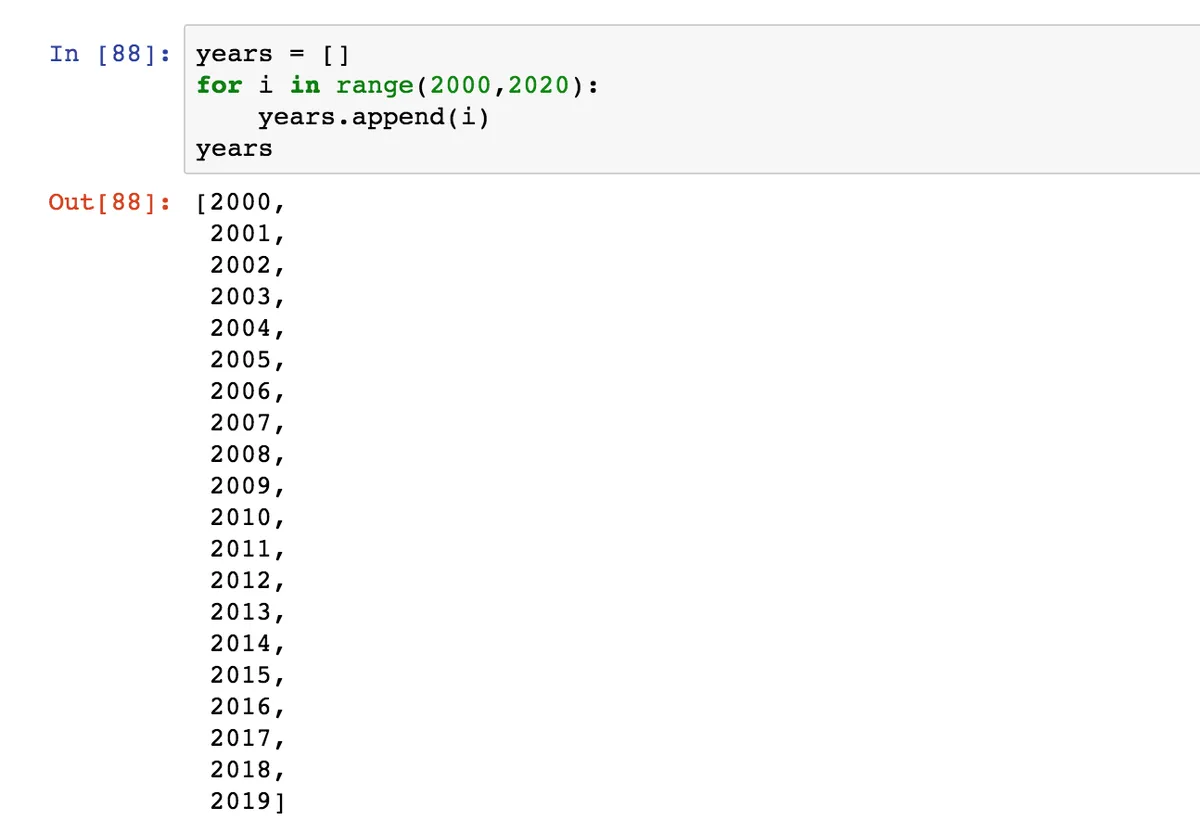
Помним, что по правилам срезов в Питоне к последнему элементу нужно прибавлять +1.
Нам понадобилось написать три строчки кода, чтобы решить эту задачи. Но можно сделать тоже самое с помощью одной строки. Для этого мы будем использовать то, что в Python называется List comprehensions, а по-русски их называют списковыми включениями или генераторами списков.
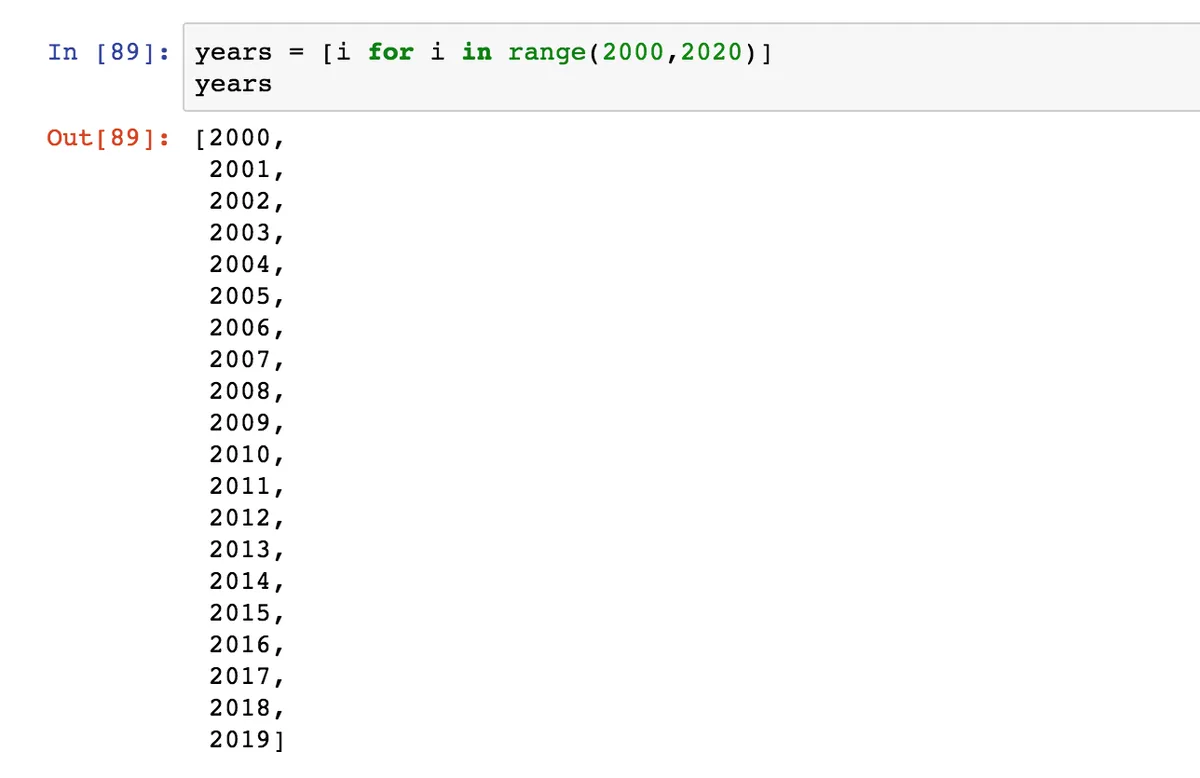
Строка, которую мы написали, и есть генератор списка. Заключается она в квадратные скобки: так мы всегда создаем списки. Первая часть — это, что мы делаем с элементом. В данном случае мы его просто добавляем в список. Но могли бы, например, еще удвоить:
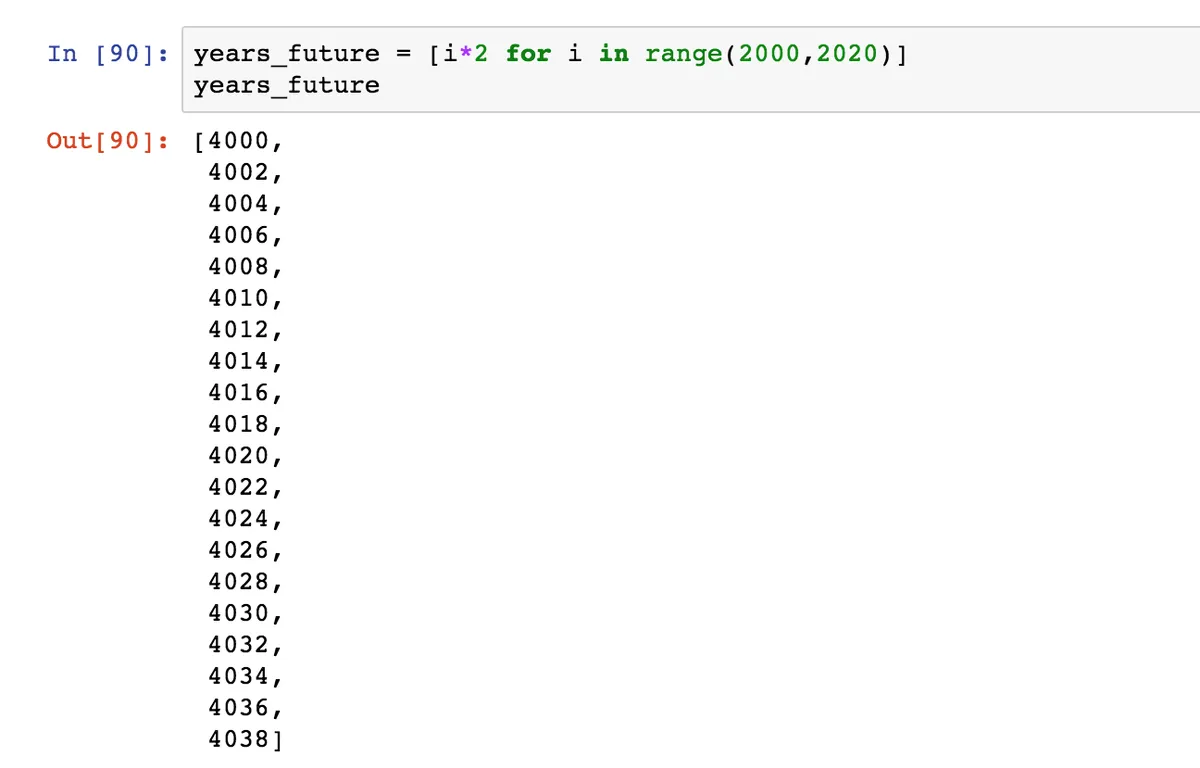
Дальше повторяем наш элемент, с которым работаем, и указываем, откуда мы его берем: то есть прописываем одной строкой весь цикл for с функцией range.
Поддержите Мастерскую
Если вам нравятся наши уроки, помогите нам продолжать их готовить
Поддержать «Важные истории»
Давайте поработаем теперь с реальными данными. Возьмем с сайта федеральной службы государственной статистики данные о количестве населения в России, которое живет за чертой прожиточного минимума — то есть количество бедного населения. Доступные года за 21 век есть с 2001 по 2019. С сайта можно скачать таблицу в формате эксель. Пока мы перенесем вручную нужные там данные. А на следующем уроке расскажем, как работать с файлами на вашем компьютере в Python.
Теперь у нас есть список с годами, который мы создали ранее, и список с количеством бедных россиян в миллионах человек. Логично будет сделать из этих данных словарь. Мы уже с вами учили функцию zip, давайте используем ее и генератор словарей для создания словаря.
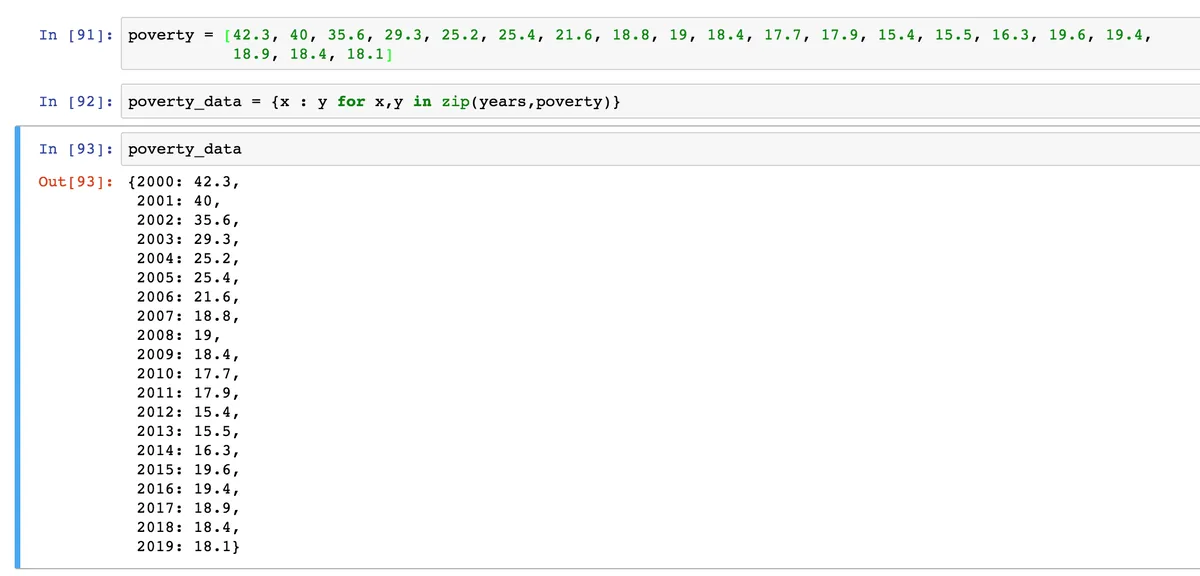
Генераторы словарей это по сути то же самое, что и генераторы списков, только, во –первых, мы используем фигурные скобочки для их создания, а не квадратные (так как для создания словарей всегда используются фигурные). А, во вторых, добавляем двоеточие после первого элемента, который будет ключем словаря.
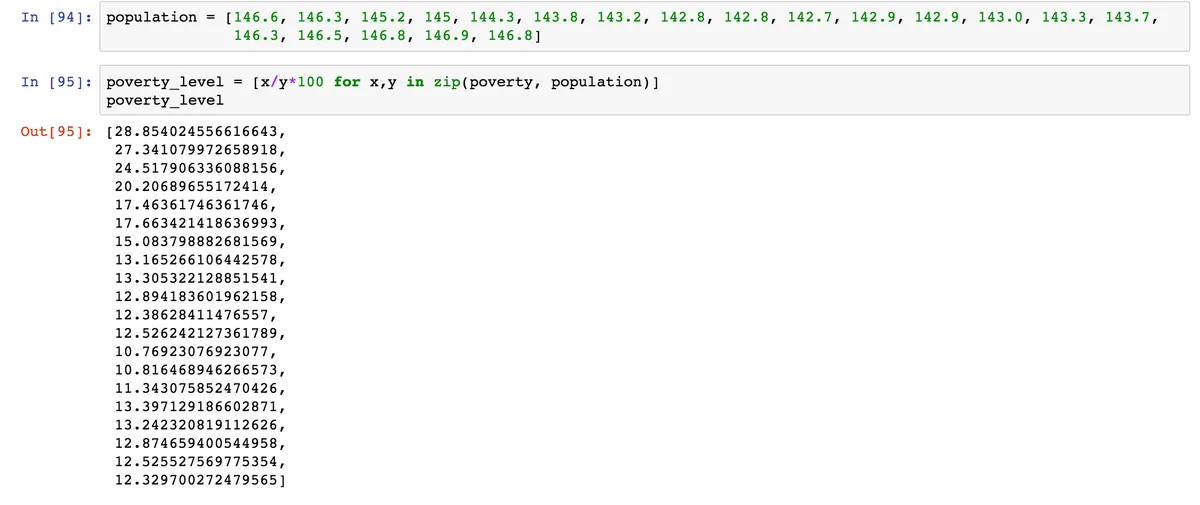
Смотреть на количество человек за чертой бедности в абсолютных значения не совсем корректно. Ведь численность населения в разные года была разная. Поэтому для того, чтобы сравнить уровень бедности в России по годам, нам нужно узнать процентное соотношение бедных к численности населения. Для этого с сайта Федстата мы берем данные о населении также в миллионах человек.
И считаем уровень бедности в процентах одной строкой.
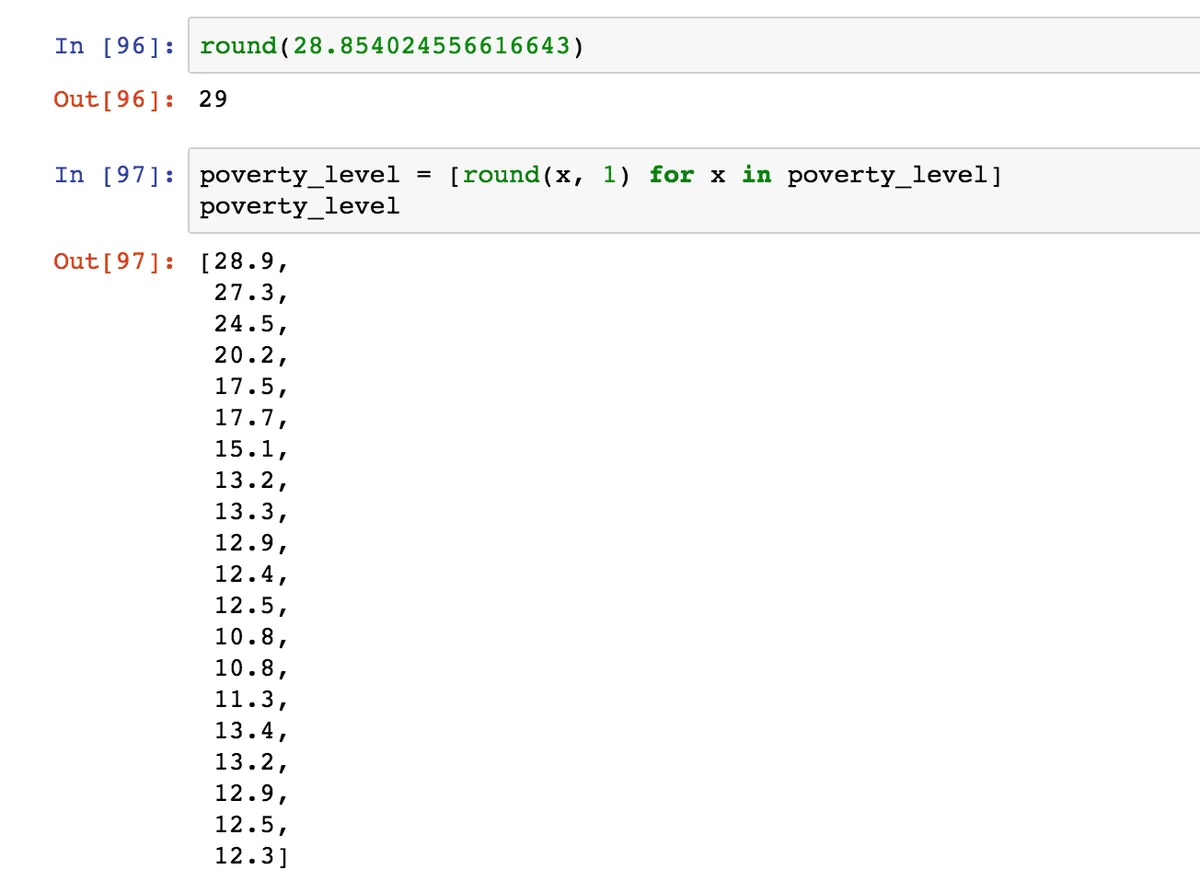
Теперь нам стоит округлить числа, но не до целого, а с десятичными. Чтобы мы могли видеть разницу между годами. Используем функцию round. Ей нужно отдать в скобках само число и через запятую, если нужно, количество знаков, которое оставляем после запятой. Используем генераторы списков для этого.
Давайте сравним, сколько нам понадобилось строчек кода для этих подсчетов без генераторов списков.
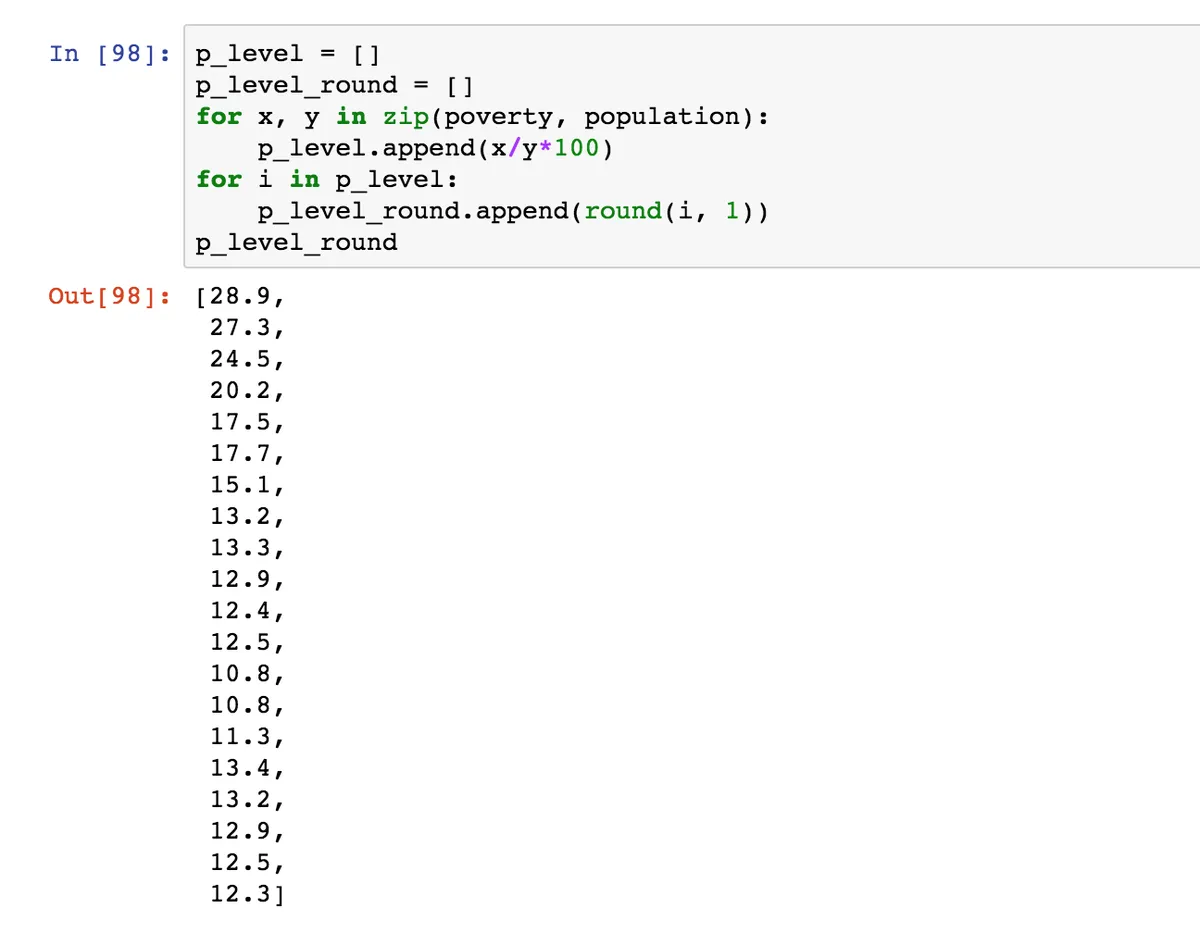
Такой код выглядит более громоздким. Но самое главное преимущество генераторов списков: они работают быстрее.
Давайте теперь создадим новый словарь с полученными данными.
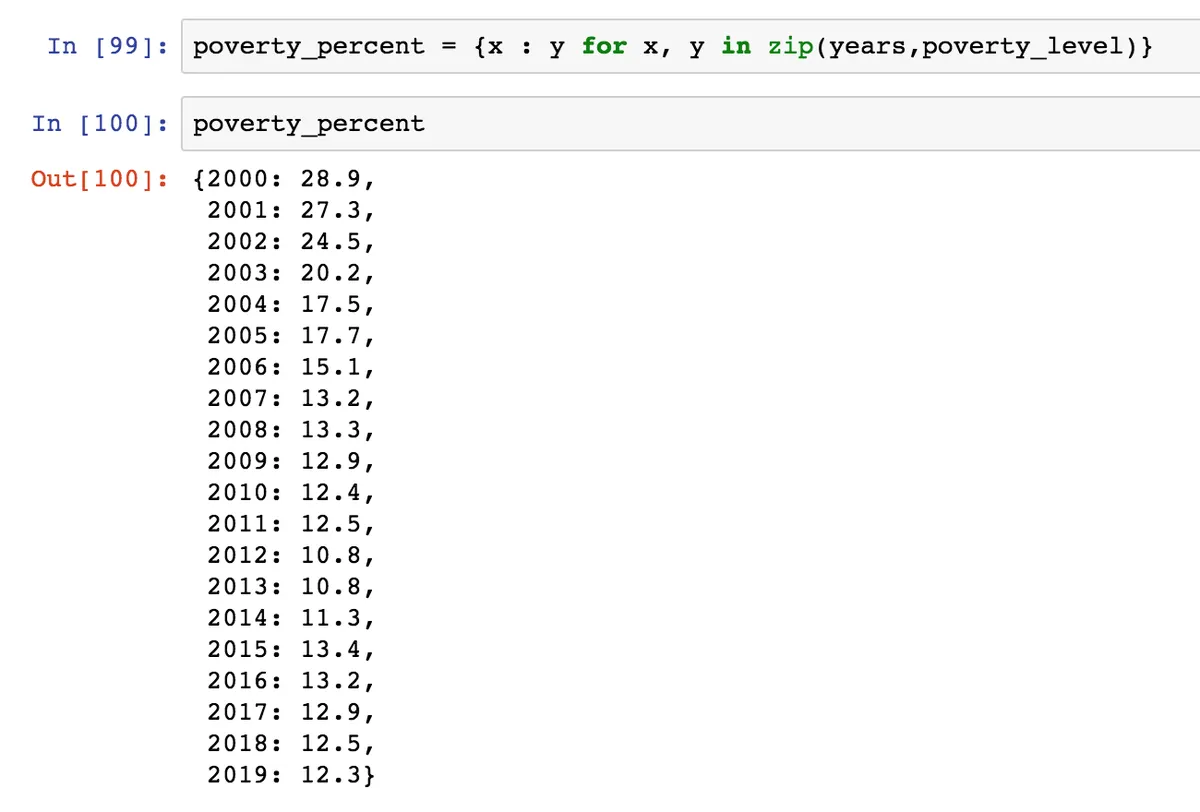
И отсортируем его по убыванию значений, чтобы узнать в какие года был максимальный уровень бедности в России. Для этого вспомним предыдущие уроки по функциям и сортировке. С помощью функций sorted и lambda отсортируем наш словарь.
Mетод items дает нам ключи и значения. В параметр функции сортировки key кладем функцию lambda. В ней прописываем, что хотим сделать с аргументом x (в данном случае с элементами словаря): мы хотим взять значения с индексом 1. Так как мы кладем lambda в параметр key, то сортировка будет по значению словаря, как мы и хотели. Затем можем указать в параметре reverse True, чтобы сортировка была по убыванию. Получили отсортиванный список.
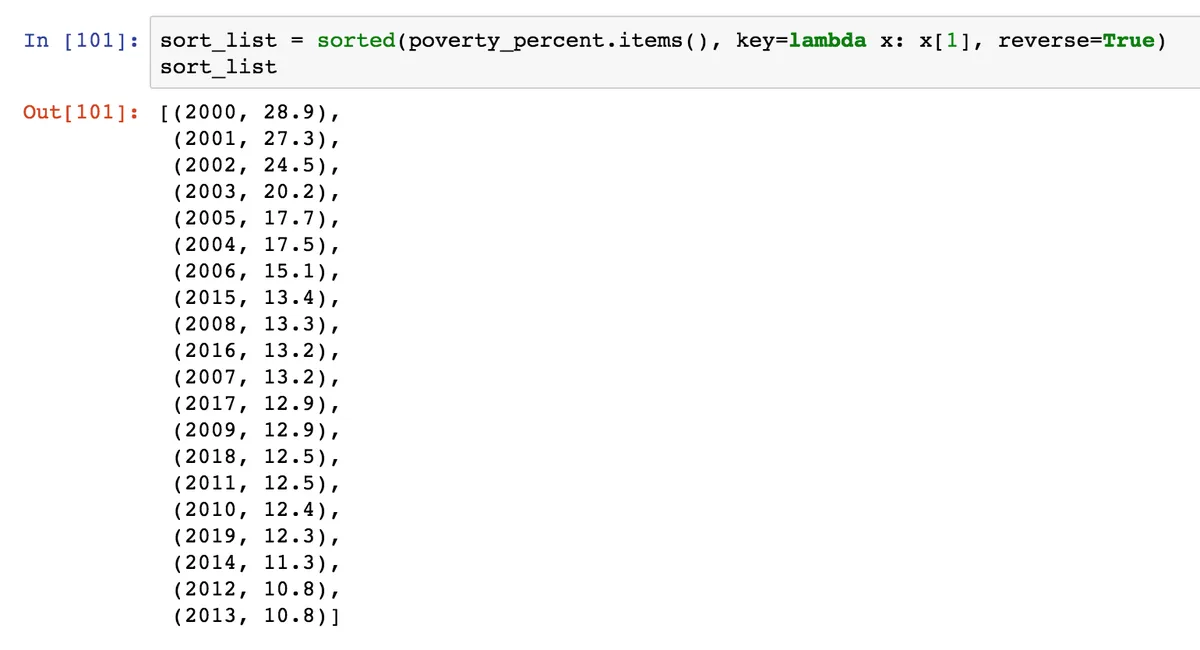
Давайте посмотри, какой год был худшим за последние 5 лет (к 2019 году). Для этого нам пригодится еще одна возможность генераторов списков: с их помощью можно производить фильтрацию. Используем для этого оператор if.
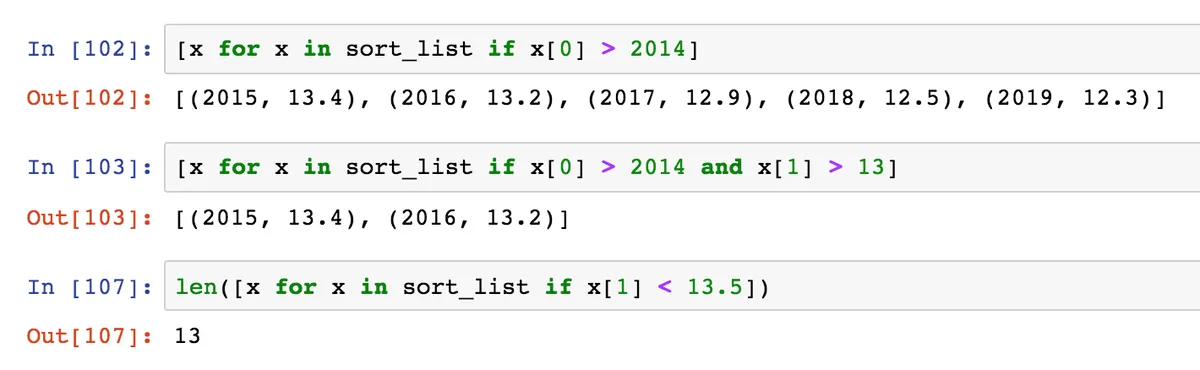
Также можем поставить два условия и узнаем, какие года стали рекордными по уровню бедности (когда он был выше 13%.) Данные Федстат за 2020 год еще не выложил, но Владимир Путин объявил, что уровень бедности упал до 13,5 % в прошлом году. Это рекордно большое значение за 14 лет (включая 2020).
Тетрадка Jupyter Notebook с этого урока доступна на нашем GitHub. А здесь можно почитать, какие еще показатели побили рекорды в 2020 году.