Как узнать тип данных в postgresql
При определении таблицы для всех ее столбцов необходимо указать тип данных. Тип данных определяет диапазон значений, которые могут храниться в столбце, сколько они будут занимать места в памяти. PostgreSQL поддерживает богатую палитру различных типов данных, среди которые условно можно разделить на подгруппы: числовые, символьные, логические, дата и время, бинарные и ряд других.
Числовые типы данных
- serial : представляет автоинкрементирующееся числовое значение, которое занимает 4 байта и может хранить числа от 1 до 2147483647. Значение данного типа образуется путем автоинкремента значения предыдущей строки. Поэтому, как правило, данный тип используется для определения идентификаторов строки.
- smallserial : представляет автоинкрементирующееся числовое значение, которое занимает 2 байта и может хранить числа от 1 до 32767. Аналог типа serial для небольших чисел.
- bigserial : представляет автоинкрементирующееся числовое значение, которое занимает 8 байт и может хранить числа от 1 до 9223372036854775807. Аналог типа serial для больших чисел.
- smallint : хранит числа от -32768 до +32767. Занимает 2 байта. Имеет псевдоним int2 .
- integer : хранит числа от -2147483648 до +2147483647. Занимает 4 байта. Имеет псевдонимы int и int4 .
- bigint : хранит числа от -9223372036854775808 до +9223372036854775807. Занимает 8 байт. Имеет псевдоним int8 .
- numeric : хранит числа с фиксированной точностью, которые могут иметь до 131072 знаков в целой части и до 16383 знаков после запятой. Данный тип может принимать два параметра precision и scale: numeric(precision, scale) . Параметр precision указывает на максимальное количество цифр, которые может хранить число. Параметр scale представляет максимальное количество цифр, которые может содержать число после запятой. Это значение должно находиться в диапазоне от 0 до значения параметра precision. По умолчанию оно равно 0. Например, для числа 23.5141 precision равно 6, а scale — 4.
- decimal : хранит числа с фиксированной точностью, которые могут иметь до 131072 знаков в целой части и до 16383 знаков в дробной части. То же самое, что и numeric .
- real : хранит числа с плавающей точкой из диапазона от 1E-37 до 1E+37. Занимает 4 байта. Имеет псевдоним float4 .
- double precision : хранит числа с плавающей точкой из диапазона от 1E-307 до 1E+308. Занимает 8 байт. Имеет псевдоним float8 .
Id SERIAL, TotalWeight NUMERIC(9,2), Age INTEGER, Surplus REAL
Типы для работы с валютой (денежными единицами)
Для работы с денежными единицами определен тип money , который может принимать значения в диапазоне от -92233720368547758.08 до +92233720368547758.07 и занимает 8 байт.
Символьные типы
- character(n) : представляет строку из фиксированного количества символов. С помощью параметра задается задается количество символов в строке. Имеет псевдоним char(n) .
- character varying(n) : представляет строку из переменной длины. С помощью параметра задается задается максимальное количество символов в строке. Имеет псевдоним varchar(n) .
- text : представляет текст произвольной длины.
Бинарные данные
Для хранения бинарных данных определен тип bytea . Он хранит данные в виде бинарных строк, которые представляют последовательность октетов или байт.
Типы для работы с датами и временем
- timestamp : хранит дату и время. Занимает 8 байт. Для дат самое нижнее значение — 4713 г до н.э., самое верхнее значение — 294276 г н.э.
- timestamp with time zone : то же самое, что и timestamp , только добавляет данные о часовом поясе.
- date : представляет дату от 4713 г. до н.э. до 5874897 г н.э. Занимает 4 байта.
- time : хранит время с точностью до 1 микросекунды без указания часового пояса. Принимает значения от 00:00:00 до 24:00:00. Занимает 8 байт.
- time with time zone : хранит время с точностью до 1 микросекунды с указанием часового пояса. Принимает значения от 00:00:00+1459 до 24:00:00-1459. Занимает 12 байт.
- interval : представляет временной интервал. Занимает 16 байт.
Распространенные форматы дат:
- yyyy-mm-dd — 1999-01-08
- Month dd, yyyy — January 8, 1999
- mm/dd/yyyy — 1/8/1999
Распространенные форматы времени:
- hh:mi — 13:21
- hh:mi am/pm — 1:21 pm
- hh:mi:ss — 1:21:34
Логический тип
Тип boolean может хранить одно из двух значений: true или false.
Вместо true можно указывать следующие значения: TRUE, ‘t’, ‘true’, ‘y’, ‘yes’, ‘on’, ‘1’.
Вместо false можно указывать следующие значения: FALSE, ‘f’, ‘false’, ‘n’, ‘no’, ‘off’, ‘0’.
Типы для представления интернет-адресов
- cidr : интернет-адрес в формате IPv4 и IPv6. Например, 192.168.0.1 . Занимает от 7 до 19 байт.
- inet : интернет-адрес в формате cidr/y , где cidr это адрес в формате IPv4 или IPv6, а /y — количество бит в адресе (если этот параметр не указан, то используется 34 для IPv4, 128 для IPv6). Например, 192.168.0.1/24 или 2001:4f8:3:ba:2e0:81ff:fe22:d1f1/128 . Занимает от 7 до 19 байт.
- macaddr : хранит MAC-адрес. Занимает 6 байт.
- macaddr8 : хранит MAC-адрес в формате EUI-64. Занимает 8 байт.
Геометрические типы
- point : представляет точку на плоскости в формате (x,y) . Занимает 16 байт.
- line : представляет линию неопределенной длины в формате . Занимает 32 байта.
- lseg : представляет отрезок в формате ((x1,y1),(x2,y2)) . Занимает 32 байта.
- box : представляет прямоугольник в формате ((x1,y1),(x2,y2)) . Занимает 32 байта.
- path : представляет набор содиненных точек. В формате ((x1,y1). ) путь является закрытым (первая и последняя точка соединяются линией) и фактически представляет многоугольник. В формате [(x1,y1). ] путь является открытым Занимает 16+16n байт.
- polygon : представляет многоугольник в формате ((x1,y1). ) . Занимает 40+16n байт.
- circle : представляет окружность в формате . Занимает 24 байта.
Остальные типы данных
- json : хранит данные json в текстовом виде.
- jsonb : хранит данные json в бинарном формате.
- uuid : хранит универсальный уникальный идентификатор (UUID), например, a0eebc99-9c0b-4ef8-bb6d-6bb9bd380a11 . Занимает 32 байта.
- xml : хранит даные в формате XML.
SQL-Ex blog

Массив и пользовательские типы данных в PostgreSQL
Добавил Sergey Moiseenko on Суббота, 5 марта. 2022
Введение
Как и всякая другая база данных, PostgreSQL имеет свой собственный набор базовых типов данных, таких как Boolean, Varchar, Text, Date, Time и т.д. Мы можем легко хранить такие типы как числа, дату, время и т.п., используя эти поддерживаемые типы данных, но что если нам требуется хранить несколько элементов данных в единственном столбце?
Предположим, что мы сохраняем данные сотрудников организации, и очевидно, что большинство сотрудников будет иметь несколько контактных номеров, альтернативных контактных номеров. Как нам хранить их в одном столбце, а не создавать разные столбцы для всех этих номеров? В PostgreSQL можно использовать тип данных ARRAY, который мы собираемся подробно рассмотреть.
PostgreSQL также поддерживает различные формы проверок и ограничений, накладываемых на столбец в скриптах DDL. Что если мы захотим иметь похожие ограничения для столбцов нескольких таблиц? Вместо повторяющейся записи избыточной логики ограничений в каждом скрипте DDL, мы можем использовать здесь пользовательский тип данных. Мы так же рассмотрим пользовательские типы данных позже в этой статье.
Сценарий
Предположим, что сотрудник может добавить несколько контактных номеров в свою запись. Нам требуется хранить эти контактные номера в единственном столбце в базе данных. Пусть первый контактный номер является первичным, а остальные все — альтернативными контактными номерами. Мы будем использовать тип данных array, чтобы разместить столбец, содержащий контактный номер для хранения нескольких номеров.
Давайте создадим таблицу сотрудников со столбцом contact_number, имеющим тип данных ARRAY. Для создания таблицы мы можем выполнить следующий запрос :
CREATE TABLE employee_info (
employee_id serial PRIMARY KEY,
employee_full_name VARCHAR (100),
contact_number TEXT []
);
После создания таблицы мы можем записать туда некоторые данные. Мы имеем трех сотрудников, которые имеют несколько контактных номеров. Добавим их с помощью следующего запроса:
INSERT INTO employee_info (employee_full_name, contact_number)
VALUES('Sabyasachi Mukherjee',ARRAY [ '+91-1234567890','+91-0987654321' ]);
INSERT INTO employee_info (employee_full_name, contact_number)
VALUES('Pawel Smith',ARRAY [ '+1-1234567','+1-0987654' ]);
INSERT INTO employee_info (employee_full_name, contact_number)
VALUES('Steven Hopkins',ARRAY [ '+91-55667890' ]);
Если проверить теперь содержимое таблицы employee_info, то мы увидим:
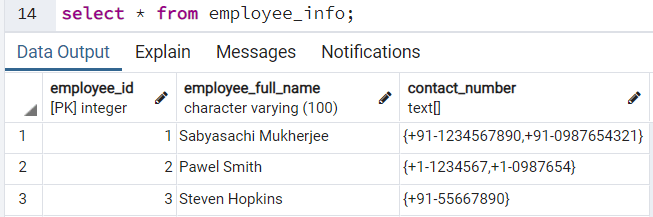
Выборка конкретных данных из массива
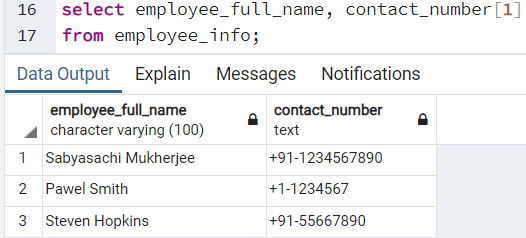
Мы можем получить доступ к элементам массива, используя индекс в квадратных скобках, []. Мы просто предполагали, что первый номер телефона каждого сотрудника является его первичным контактным номером, поэтому используемым индексом должен быть «1». Если мы хотим запросить первичный контактный номер каждого сотрудника в организации, то можем выполнить следующий запрос:
select employee_full_name, contact_number[1]
from employee_info;
Мы получаем следующий результат:
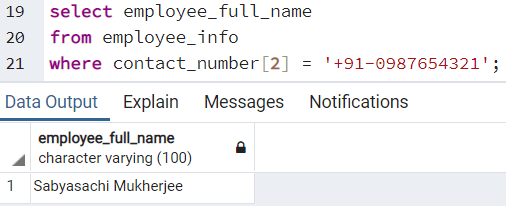
Можно выполнять также много других операций с типом данных array, так же, как мы можем это делать со столбцами других типов данных. Мы можем проверить информацию о сотруднике, у которого вторым контактным номером является «+91-0987654321», выполнив следующий запрос:
select employee_full_name
from employee_info
where contact_number[2] = '+91-0987654321';
При этом будет выполнен поиск всех тех записей в таблице, для которых второй контактный номер (второй элемент массива) совпадает с заданным номером. Будет возвращен следующий результат:
Что если мы пытаемся получить доступ к индексу массива, который не существует?
Что если мы в нижеприведенном наборе данных попытаемся обратиться к третьему контактному номеру сотрудника Sabyasachi Mukherjee, который не существует?
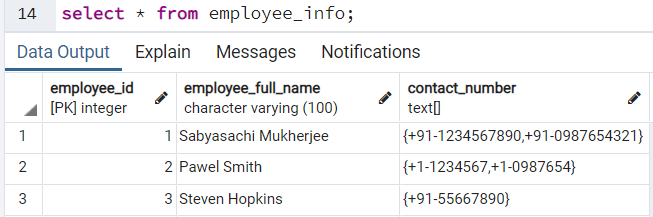
Запрос для получения третьего контактного номера Sabyasachi должен выглядеть так:
select employee_full_name, contact_number[3]
from employee_info
where employee_full_name = 'Sabyasachi Mukherjee';
Однако, если выполнить это запрос, мы получим в ответ NULL-значение, поскольку у данного сотрудника только 2 контактных номера. В большинстве языков, если попытаться получить доступ к элементу, индекс которого превышает размер массива, обычно возникает соответствующее исключение. Но здесь мы получаем только NULL.
Поиск конкретных данных в записи массивов
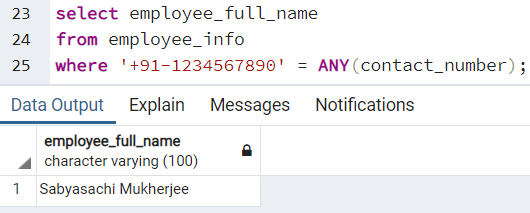
Предположим, что нам нужно выяснить имя сотрудника, имеющего конкретный номер телефона. Это потребует доступа к каждой записи в таблице и проверки того, удовлетворяет ли «какой-нибудь» контактный номер искомому. Тут мы используем функцию ANY(). В случае, если несколько сотрудников имеют один и тот же номер телефона (чего не должно быть в идеале), в результате будут напечатаны имена нескольких сотрудников.
В подобном случае мы можем выполнить следующий запрос:
select employee_full_name
from employee_info
where '+91-1234567890' = ANY(contact_number);
Это дает нам следующий вывод:
Мы увидели, как тип данных массива на самом деле может пригодиться, когда нам требуется сохранить множество информации одной категории в одной записи.
Пользовательский тип данных
Помимо использования встроенных типов данных, гибкость PostgreSQL придает возможность создания типов данных, определяемых пользователем. Мы можем создать пользовательский тип данных, используя либо CREATE DOMAIN, либо CREATE TYPE. CREATE DOMAIN создает пользовательский тип данных с поддержкой использования ограничений типа NOT NULL, CHECK и т.д.. CREATE TYPE создает составной пользовательский тип данных, который используется в хранимых процедурах в качестве типа данных возвращаемого значения.
Мы увидим, как использовать оба варианта — DOMAIN и TYPE — для создания пользовательских типов данных и понимания необходимости их использования в некоторых базовых сценариях, с которыми мы можем столкнуться в ежедневной работе.
Пользовательский домен
Все мы знаем, что во многих формах мы должны вводить имя и фамилию отдельно. В идеале они не должны содержать пробелов или быть пустыми/NULL. Предположим, у нас есть база данных для хранения данных кандидатов, и нам необходимо гарантировать, что ни пробелов, ни пустых значений нельзя будет ввести в столбцы имени и фамилии. Для достижения этого мы можем использовать следующий запрос создания таблицы:
CREATE TABLE candidate_data (
candidate_id SERIAL PRIMARY KEY,
first_name VARCHAR NOT NULL,
last_name VARCHAR NOT NULL,
email_id VARCHAR NOT NULL,
CHECK (
first_name !~ '\s'
AND last_name !~ '\s'
)
);
Но возможен случай, когда у нас может быть много подобных таблиц, в которых хранится имя и фамилия, и везде мы должны обеспечить подобную проверку. В этой ситуации вместо наличия ограничения CHECK в каждом запросе CREATE TABLE разумно рекомендуется иметь домен, который будет выполнять проверку этих ограничений, и мы сможем повторно использовать повсюду один и тот же код.
Мы можем создать домен с подобной проверкой таким образом:
CREATE DOMAIN candidate_name AS
VARCHAR NOT NULL CHECK (value !~ '\s');
Теперь мы так можем использовать этот домен в таблице candidate_data:
CREATE TABLE candidate_data (
candidate_id SERIAL PRIMARY KEY,
first_name candidate_name,
last_name candidate_name,
email_id VARCHAR NOT NULL
)
Теперь, если мы попытаемся ввести имя с пробелами, система выдаст нам соответствующее сообщение об ошибке:
INSERT INTO candidate_data (first_name, last_name, email_id)
VALUES('Sabya sachi','Mukherjee','sabya.mukherjee@company.com');

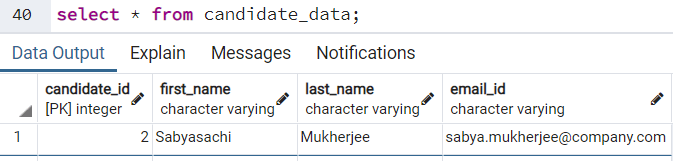
Однако если вставить данные без пробелов, запрос успешно сохранит запись:
INSERT INTO candidate_data (first_name, last_name, email_id)
VALUES('Sabyasachi','Mukherjee','sabya.mukherjee@company.com');
Мы можем создать наш пользовательский домен, и использовать его, когда нам нужно иметь подобные ограничения и проверку в нескольких столбцах многих таблиц в базе данных. Это помогает сделать запросы DDL аккуратней и легче в обслуживании.
Дополнительная информация о пользовательских доменах
Нам может понадобиться информация об именах доменов в схеме, чтобы повторно их использовать. В таком случае мы можем выполнить следующий код в терминале psql:
Эта команда выведет список доменов, созданных в базе данных текущего подключения:

Пользовательский тип данных
CREATE TYPE позволяет создать пользовательский тип данных, который будет использоваться как тип данных, возвращаемого функцией значения. Предположим, нам нужно получить имя сотрудника и первичный контактный номер из таблицы employee_info по заданному значению employee_id. Для этого мы можем создать функцию, которая будет принимать employee_id и возвращать имя и контактный номер как пользовательский тип данных.
Для начала нам нужно создать подходящий тип данных, используя следующий запрос:
CREATE TYPE employee_data AS (
employee_name VARCHAR,
contact_no VARCHAR
);
Мы создали составной тип данных, который включает информацию о двух различных столбцах. В этом случае также имеется два различных типа данных. Один — VARCHAR, а другой — INT. Затем нам нужно определить функцию, которая будет принимать employee_id и возвращать имя и контактный номер, соответственно. Тело функции будет выглядеть так:
CREATE OR REPLACE FUNCTION get_employee_snapshot (e_id INT)
RETURNS employee_data AS
$$
SELECT
employee_full_name,
contact_number[1]
FROM
employee_info
WHERE
employee_id = e_id ;
$$
LANGUAGE SQL;
Оператор RETURN содержит новый тип данных, который мы создали как тип возвращаемого значения.
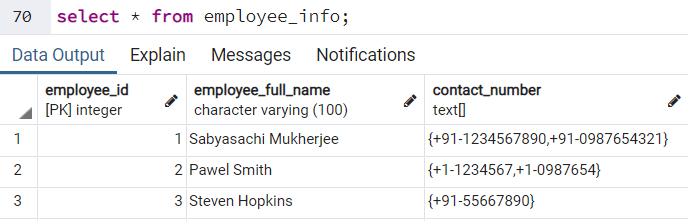
Теперь, если мы проверим информацию, содержащуюся в таблице employee_info, то увидим:
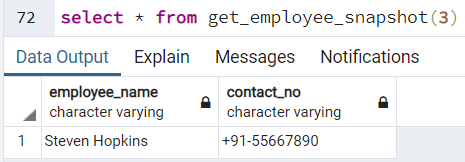
Если мы захотим получить информации о сотруднике с employee_id = 2, мы можем вызвать функцию и получить следующий результат:
Поскольку пользовательские типы данных являются составными, нам может потребоваться отредактировать их в будущем. Что если нам так же потребуется вернуть employee_id? Для редактирования существующего пользовательского типа данных мы можем использовать ключевые слова ALTER TYPE следующим образом:
ALTER TYPE employee_data ADD ATTRIBUTE employee_number INT;
Замечание. Поскольку вы меняете число полей пользовательского типа данных, вы также должны изменить функцию, чтобы она возвращала то же самое число полей, в противном случае возникнет ошибка.
Чтобы удалить любой атрибут, вы можете выполнить:
ALTER TYPE employee_data DROP ATTRIBUTE employee_number;
Вы можете также переименовать тип данных с помощью ALTER:
ALTER TYPE employee_data RENAME TO EMPLOYEE_SNAPSHOT_DATA;
Опять таки после переименования пользовательского типа данных, не забудьте изменить ссылку на тип в каждой функции, чтобы не возникали ошибки.
Для удаления пользовательского типа данных, мы можем использовать:
DROP TYPE EMPLOYEE_SNAPSHOT_DATA;
Замечание. Вы сможете только тогда удалить пользовательский тип данных, если на него нет никаких ссылок в функциях или еще где-нибудь.
Заключение
В этой статье мы узнали, как использовать тип данных ARRAY для хранения множества данных одного типа в одной столбце записи. Мы узнали, как использовать пользовательские домены, чтобы избежать создания одинаковых ограничений во множестве операторов DDL. Мы также научились использовать пользовательские типы данных, чтобы вернуть многие детали как единое целое.
Обратные ссылки
Нет обратных ссылок
Комментарии
Показывать комментарии Как список | Древовидной структурой
Автор не разрешил комментировать эту запись
Глава 8. Типы данных
PostgreSQL предоставляет пользователям богатый ассортимент встроенных типов данных. Кроме того, пользователи могут создавать свои типы в PostgreSQL , используя команду CREATE TYPE.
Таблица 8-1 содержит все встроенные типы данных общего пользования. Многие из альтернативных имён, приведённых в колонке «Псевдонимы» , используются внутри PostgreSQL по историческим причинам. В этот список не включены некоторые устаревшие типы и типы для внутреннего применения.
Таблица 8-1. Типы данных
| Имя | Псевдонимы | Описание |
|---|---|---|
| bigint | int8 | знаковое целое из 8 байт |
| bigserial | serial8 | восьмибайтное целое с автоувеличением |
| bit [ (n) ] | битовая строка фиксированной длины | |
| bit varying [ (n) ] | varbit | битовая строка переменной длины |
| boolean | bool | логическое значение (true/false) |
| box | прямоугольник в плоскости | |
| bytea | двоичные данные ( «массив байт» ) | |
| character [ (n) ] | char [ (n) ] | символьная строка фиксированной длины |
| character varying [ (n) ] | varchar [ (n) ] | символьная строка переменной длины |
| cidr | сетевой адрес IPv4 или IPv6 | |
| circle | круг в плоскости | |
| date | календарная дата (год, месяц, день) | |
| double precision | float8 | число двойной точности с плавающей точкой (8 байт) |
| inet | адрес узла IPv4 или IPv6 | |
| integer | int, int4 | знаковое четырёхбайтное целое |
| interval [ поля ] [ (p) ] | интервал времени | |
| json | текстовые данные JSON | |
| jsonb | двоичные данные JSON, разобранные | |
| line | прямая в плоскости | |
| lseg | отрезок в плоскости | |
| macaddr | MAC-адрес | |
| money | денежная сумма | |
| numeric [ (p, s) ] | decimal [ (p, s) ] | вещественное число заданной точности |
| path | геометрический путь в плоскости | |
| pg_lsn | Последовательный номер в журнале PostgreSQL | |
| point | геометрическая точка в плоскости | |
| polygon | замкнутый геометрический путь в плоскости | |
| real | float4 | число одинарной точности с плавающей точкой (4 байта) |
| smallint | int2 | знаковое двухбайтное целое |
| smallserial | serial2 | двухбайтное целое с автоувеличением |
| serial | serial4 | четырёхбайтное целое с автоувеличением |
| text | символьная строка переменной длины | |
| time [ (p) ] [ without time zone ] | время суток (без часового пояса) | |
| time [ (p) ] with time zone | timetz | время суток с учётом часового пояса |
| timestamp [ (p) ] [ without time zone ] | дата и время (без часового пояса) | |
| timestamp [ (p) ] with time zone | timestamptz | дата и время с учётом часового пояса |
| tsquery | запрос текстового поиска | |
| tsvector | документ для текстового поиска | |
| txid_snapshot | снимок идентификатора транзакций | |
| uuid | универсальный уникальный идентификатор | |
| xml | XML-данные |
Совместимость: В стандарте SQL описаны следующие типы (или их имена): bigint, bit, bit varying, boolean, char, character varying, character, varchar, date, double precision, integer, interval, numeric, decimal, real, smallint, time (с часовым поясом и без), timestamp (с часовым поясом и без), xml.
Каждый тип данных имеет внутреннее представление, скрытое функциями ввода и вывода. При этом многие встроенные типы стандартны и имеют очевидные внешние форматы. Однако есть типы, уникальные для PostgreSQL , например геометрические пути, и есть типы, которые могут иметь разные форматы, например, дата и время. Некоторые функции ввода и вывода не являются в точности обратными друг к другу, то есть результат функции вывода может не совпадать со входным значением из-за потери точности.
| Пред. | Начало | След. |
| Запросы WITH (Общие табличные выражения) | Уровень выше | Числовые типы |
Как узнать версию PostgreSQL
В этой инструкции учим смотреть версию PostgreSQL в командной строке и с помощью клиентской оболочки PSQL.
Эта инструкция — часть курса «PostgreSQL для новичков».
Смотреть весь курс
Введение
PostgreSQL — объектно-реляционная система управления базами данных с открытым исходным кодом. Есть несколько способов узнать версию PostgreSQL, установленную на сервере. Технические специалисты должны располагать такими сведениями, например, чтобы своевременно производить обновление программного обеспечения, понимать, насколько текущая версия совместима для интеграции с той или иной службой, и для выполнения иных административных задач. Будем считать, что PostgreSQL уже установлена на сервере и работает. Если на этапе установки и настройки возникли какие-либо сложности, у нас в блоге есть статья, в которой рассмотрены базовые функции по работе с СУБД. В нашем случае, в качестве операционной системы выбрана Ubuntu Linux 22.04 и версия PostgreSQL 14.5, установленная из репозитория.
PostgreSQL как сервис
Обозначение версий PostgreSQL
Разработчики придерживаются следующей схемы нумерации версий продукта: MAJOR.MINOR, где major — основная версия, которая снабжается новым функционалом, исправляет ошибки обновляет систему безопасности. Такой релиз выпускается примерно раз в год и поддерживается ближайшие 5 лет. Minor — дополнительная версия, выпускается не реже одного раза в три месяца и содержит в основном обновления системы безопасности.
Проверить версии PostgreSQL из командной строки
Для отображения версии PostgreSQL, нужно любым удобным способом подключиться к серверу и в терминале выполнить команду:
pg_config --version postgres (PostgreSQL) 14.5 (Ubuntu 14.5-0ubuntu0.22.04.1) Из вывода команды видно, что используется версия PostgreSQL 14.5.
Есть и другие варианты проверки, но с ними не всегда удается сделать все с ходу:
postgres --version Или используя короткую версию параметра -V:
postgres -V Обратите внимание, что в первом случае применяется длинная версия параметра —version, а во втором короткая -V, результат выполнения во всех трех случаях абсолютно одинаковый.
На этом этапе некоторые операционные системы могут сообщить об ошибке: Command ‘postgres’ not found, это не проблема, и связано с тем, что разработчики данного программного продукта по каким-либо причинам не размещают двоичный исполняемый файл postgres ни в одну из папок, прописанных в переменной окружения $PATH. В таком случае, найдем его самостоятельно:
sudo find / -type f -iwholename "*/bin/postgres" Результат выполнения команды в нашем случае:
/usr/lib/postgresql/14/bin/postgres Файл найден. Повторяем вышеописанные действия, используя абсолютный путь:
/usr/lib/postgresql/14/bin/postgres --version /usr/lib/postgresql/14/bin/postgres -V Результат выполнения обеих команд будет идентичный, что был описан выше.
Узнать версию сервера PostgreSQL, используя оболочку
Также есть возможность определить версию СУБД непосредственно из оболочки самого сервера. На практике такой подход применим при написании SQL-запросов. Переходим в интерактивный терминал PostgreSQL от имени пользователя postgres:
sudo -u postgres psql Система попросит ввести свой пароль для использования функционала sudo. После ввода пароля должно появиться приглашение интерпретатора SQL-запросов в виде:
postgres=# Для отображения версии установленного сервера вводим запрос:
SELECT version(); В ответ получим:
--------------------------------------------------------------------------------------------------------------------------------- PostgreSQL 14.5 (Ubuntu 14.5-0ubuntu0.22.04.1) on x86_64-pc-linux-gnu, compiled by gcc (Ubuntu 11.2.0-19ubuntu1) 11.2.0, 64-bit (1 row) Из вывода команды видно, что установлена версия 14.5, а также другие технические данные о сервере.
Если необходимо запросить версию и менее детализированный вывод, используем конструкцию:
SHOW server_version; Тогда ответ от сервера будет выглядеть следующим образом:
server_version ------------------------------------- 14.5 (Ubuntu 14.5-0ubuntu0.22.04.1) (1 row) Запущенный сервер сообщает номер версии — 14.5. Для выхода из SQL shell нужно ввести команду \q и нажать Enter.
Посмотреть версию утилиты PSQL
PSQL — утилита, служащая интерфейсом между пользователем и сервером, она принимает SQL-запросы, затем передает их PostgreSQL серверу и отображает результат выполнения. Данный инструмент предоставляет очень мощный функционал для автоматизации и написания скриптов под широкий спектр задач. Для получения информации о версии установленной утилиты, нужно выполнить команду:
psql -V Или используя длинную версию параметра –version:
psql --version Вывод в обоих случаях будет одинаковый:
psql (PostgreSQL) 14.5 (Ubuntu 14.5-0ubuntu0.22.04.1) Терминальная утилита PSQL имеет версию 14.5.
Заключение
В этой инструкции мы:
- разобрались в схеме управления версиями разработчиками продукта;
- научились смотреть версию PostgreSQL в командной строке и с помощью клиентской оболочки PSQL;
Стоит добавить, что данная инструкция охватывает лишь часть функционала по работе с PostgreSQL, за дополнительной информацией всегда можно обратиться к документации на официальном сайте.
Как создать пользователя в PostgreSQL
DBaaS: что такое облачные базы данных
Зарегистрируйтесь в панели управления
И уже через пару минут сможете арендовать сервер, развернуть базы данных или обеспечить быструю доставку контента.
Читайте также:
Инструкция
Как создать веб-приложение на базе Telegram Mini Apps
Инструкция
Что делает команда chmod и как ее использовать в Linux
Инструкция
Как разработать gRCP-сервис на Go