Как исправить: нет модуля с именем pandas
Одна распространенная ошибка, с которой вы можете столкнуться при использовании Python:
no module named ' pandas ' Эта ошибка возникает, когда Python не обнаруживает библиотеку pandas в вашей текущей среде.
В этом руководстве представлены точные шаги, которые вы можете использовать для устранения этой ошибки.
Шаг 1: pip установить Pandas
Поскольку pandas не устанавливается автоматически вместе с Python, вам нужно будет установить его самостоятельно. Самый простой способ сделать это — использовать pip , менеджер пакетов для Python.
Вы можете запустить следующую команду pip для установки панд:
pip install pandas В большинстве случаев это исправит ошибку.
Шаг 2: Установите пип
Если вы все еще получаете сообщение об ошибке, вам может потребоваться установить pip. Используйте эти шаги , чтобы сделать это.
Вы также можете использовать эти шаги для обновления pip до последней версии, чтобы убедиться, что он работает.
Затем вы можете запустить ту же команду pip, что и раньше, для установки pandas:
pip install pandas На этом этапе ошибка должна быть устранена.
Шаг 3: Проверьте версии pandas и pip
Если вы все еще сталкиваетесь с ошибками, возможно, вы используете другую версию pandas и pip.
Вы можете использовать следующие команды, чтобы проверить, совпадают ли ваши версии pandas и pip:
which python python --version which pip Если две версии не совпадают, вам нужно либо установить более старую версию pandas, либо обновить версию Python.
Шаг 4: Проверьте версию панд
После того, как вы успешно установили pandas, вы можете использовать следующую команду, чтобы отобразить версию pandas в вашей среде:
pip show pandas Name: pandas Version: 1.1.5 Summary: Powerful data structures for data analysis, time series, and statistics Home-page: https://pandas.pydata.org Author: None Author-email: None License: BSD Location: /srv/conda/envs/notebook/lib/python3.6/site-packages Requires: python-dateutil, pytz, numpy Required-by: Note: you may need to restart the kernel to use updated packages. Примечание. Самый простой способ избежать ошибок с версиями pandas и Python — просто установить Anaconda , набор инструментов, предустановленный вместе с Python и pandas и бесплатный для использования.
Дополнительные ресурсы
В следующих руководствах объясняется, как исправить другие распространенные проблемы в Python:
Введение в библиотеку pandas: установка и первые шаги / pd 1
Библиотека pandas в Python — это идеальный инструмент для тех, кто занимается анализом данных, используя для этого язык программирования Python.
В этом материале речь сначала пойдет об основных аспектах библиотеки и о том, как установить ее в систему. Потом вы познакомитесь с двумя структурам данных: series и dataframes . Сможете поработать с базовым набором функций, предоставленных библиотекой pandas, для выполнения основных операций по обработке. Знакомство с ними — ключевой навык для специалиста в этой сфере. Поэтому так важно перечитать материал до тех, пока он не станет понятен на 100%.
А на примерах сможете разобраться с новыми концепциями, появившимися в библиотеке — индексацией структур данных. Научитесь правильно ее использовать для управления данными. В конце концов, разберетесь с тем, как расширить возможности индексации для работы с несколькими уровнями одновременно, используя для этого иерархическую индексацию.
Библиотека Python для анализа данных
Pandas — это библиотека Python с открытым исходным кодом для специализированного анализа данных. Сегодня все, кто использует Python для изучения статистических целей анализа и принятия решений, должны быть с ней знакомы.
Библиотека была спроектирована и разработана преимущественно Уэсом Маккини в 2008 году. В 2012 к нему присоединился коллега Чан Шэ. Вместе они создали одну из самых используемых библиотек в сообществе Python.
Pandas появилась из необходимости в простом инструменте для обработки, извлечения и управления данными.
Этот пакет Python спроектирован на основе библиотеки NumPy. Такой выбор обуславливает успех и быстрое распространение pandas. Он также пользуется всеми преимуществами NumPy и делает pandas совместимой с большинством другим модулей.
Еще одно важное решение — разработка специальных структур для анализа данных. Вместо того, чтобы использовать встроенные в Python или предоставляемые другими библиотеками структуры, были разработаны две новых.
Они спроектированы для работы с реляционными и классифицированными данными, что позволяет управлять данными способом, похожим на тот, что используется в реляционных базах SQL и таблицах Excel.
Дальше вы встретите примеры базовых операций для анализа данных, которые обычно используются на реляционных или таблицах Excel. Pandas предоставляет даже более расширенный набор функций и методов, позволяющих выполнять эти операции эффективнее.
Основная задача pandas — предоставить все строительные блоки для всех, кто погружается в мир анализа данных.
Установка pandas
Простейший способ установки библиотеки pandas — использование собранного решения, то есть установка через Anaconda или Enthought.
Установка в Anaconda
В Anaconda установка занимает пару минут. В первую очередь нужно проверить, не установлен ли уже pandas, и если да, то какая это версия. Для этого введите следующую команду в терминале:
conda list pandas Если модуль уже установлен (например в Windows), вы получите приблизительно следующий результат:
# packages in environment at C:\Users\Fabio\Anaconda: # pandas 0.20.3 py36hce827b7_2 Если pandas не установлена, ее необходимо установить. Введите следующую команду:
conda install pandas Anaconda тут же проверит все зависимости и установит дополнительные модули.
Solving environment: done ## Package Plan ## Environment location: C:\Users\Fabio\Anaconda3 added / updated specs: - pandas The following new packages will be installed: Pandas: 0.22.0-py36h6538335_0 Proceed ([y]/n)? Press the y key on your keyboard to continue the installation. Preparing transaction: done Verifying transaction: done Executing transaction: done Если требуется обновить пакет до более новой версии, используется эта интуитивная команда:
conda update pandas Система проверит версию pandas и версию всех модулей, а затем предложит соответствующие обновления. Затем предложит перейти к обновлению.
Установка из PyPI
Pandas можно установить и с помощью PyPI, используя эту команду:
pip install pandas Установка в Linux
Если вы работаете в дистрибутиве Linux и решили не использовать эти решения, то pandas можно установить как и любой другой пакет.
В Debian и Ubuntu используется команда:
sudo apt-get install python-pandas А для OpenSuse и Fedora — эта:
zypper in python-pandas Установка из источника
Если есть желание скомпилировать модуль pandas из исходного кода, тогда его можно найти на GitHub по ссылке https://github.com/pandas-dev/pandas:
git clone git://github.com/pydata/pandas.git cd pandas python setup.py install Убедитесь, что Cython установлен. Больше об этом способе можно прочесть в документации: (http://pandas.pydata.org/pandas-docs/stable/install.html).
Репозиторий для Windows
Если вы работаете в Windows и предпочитаете управлять пакетами так, чтобы всегда была установлена последняя версия, то существует ресурс, где всегда можно загрузить модули для Windows: Christoph Gohlke’s Python Extension Packages for Windows (www.lfd.uci.edu/~gohlke/pythonlibs/). Каждый модуль поставляется в формате WHL для 32 и 64-битных систем. Для установки нужно использовать приложение pip:
pip install SomePackage-1.0.whl Например, для установки pandas потребуется найти и загрузить следующий пакет:
pip install pandas-0.22.0-cp36-cp36m-win_amd64.whl При выборе модуля важно выбрать нужную версию Python и архитектуру. Более того, если для NumPy пакеты не требуются, то у pandas есть зависимости. Их также необходимо установить. Порядок установки не имеет значения.
Недостаток такого подхода в том, что нужно устанавливать пакеты отдельно без менеджера, который бы помог подобрать нужные версии и зависимости между разными пакетами. Плюс же в том, что появляется возможность освоиться с модулями и получить последние версии вне зависимости от того, что выберет дистрибутив.
Проверка установки pandas
Библиотека pandas может запустить проверку после установки для верификации управляющих элементов (документация утверждает, что тест покрывает 97% всего кода).
Во-первых, нужно убедиться, что установлен модуль nose . Если он имеется, то тестирование проводится с помощью следующей команды:
nosetests pandas Оно займет несколько минут и в конце покажет список проблем.
Модуль Nose
Этот модуль спроектирован для проверки кода Python во время этапов разработки проекта или модуля Python. Он расширяет возможности модуль unittest . Nose используется для проверки кода и упрощает процесс.
Здесь о нем можно почитать подробнее: _http://pythontesting.net/framework/nose/nose-introduction/.
Первые шаги с pandas
Лучший способ начать знакомство с pandas — открыть консоль Python и вводить команды одна за одной. Таким образом вы познакомитесь со всеми функциями и структурами данных.
Более того, данные и функции, определенные здесь, будут работать и в примерах будущих материалов. Однако в конце каждого примера вы вольны экспериментировать с ними.
Для начала откройте терминал Python и импортируйте библиотеку pandas. Стандартная практика для импорта модуля pandas следующая:
>>> import pandas as pd >>> import numpy as np Теперь, каждый раз встречая pd и np вы будете ссылаться на объект или метод, связанный с этими двумя библиотеками, хотя часто будет возникать желание импортировать модуль таким образом:
>>> from pandas import * В таком случае ссылаться на функцию, объект или метод с помощью pd уже не нужно, а это считается не очень хорошей практикой в среде разработчиков Python.
Установка Jupyter и Pandas в MacOS
Это краткая инструкция по установке Jupyter Notebook в MacOS. Cразу будут установлены инструменты для аналитики данных.
Требования — у вас на Mac должен быть установлен Python + Virtualenv, если таковых нет в системе — в этой статье представлена подробная информация о том как установить Python на Mac.
В этой статье я просто напишу кратко команды для установки и настройки окружения.
1) Проверить есть ли python3 (если нет — инструкция выше)
python3 --version
2) Установка virtualenv. Для этого в терминале просто выполнить команду:
sudo pip3 install virtualenv
3) Инициализация виртуального окружения (перед выполнением команды нужно быть в дериктории вашего проекта, куда нужно установить Jupyter)
virtualenv venv -p python3 # инициализация source venv/bin/activate # активация
4) Далее последовательно выполнить команды:
pip install numpy pip install opencv-python pip install matplotlib pip install jupyterlab pip install pandas pip install pivottablejs
5) Запуск Jupyter, просто запустить в консоли команду:
Библиотека Pandas Profiling: делаем первичный анализ данных в одну строку

Кандидат философских наук, специалист по математическому моделированию. Пишет про Data Science, AI и программирование на Python.
Python-библиотека pandas — незаменимый инструмент для работы с табличными данными. Команды и функции из этой библиотеки — практически всегда первое, что исполняет дата-сайентист в своём Jupyter-блокноте.
Мы будем запускать наш блокнот в среде Google Colab, которая работает прямо в браузере. Прочитайте небольшую статью об этом популярном сервисе.
Мы будем запускать наш блокнот в среде Google Colab, которая работает прямо в браузере. Прочитайте небольшую статью об этом популярном сервисе.
Выглядит это так:
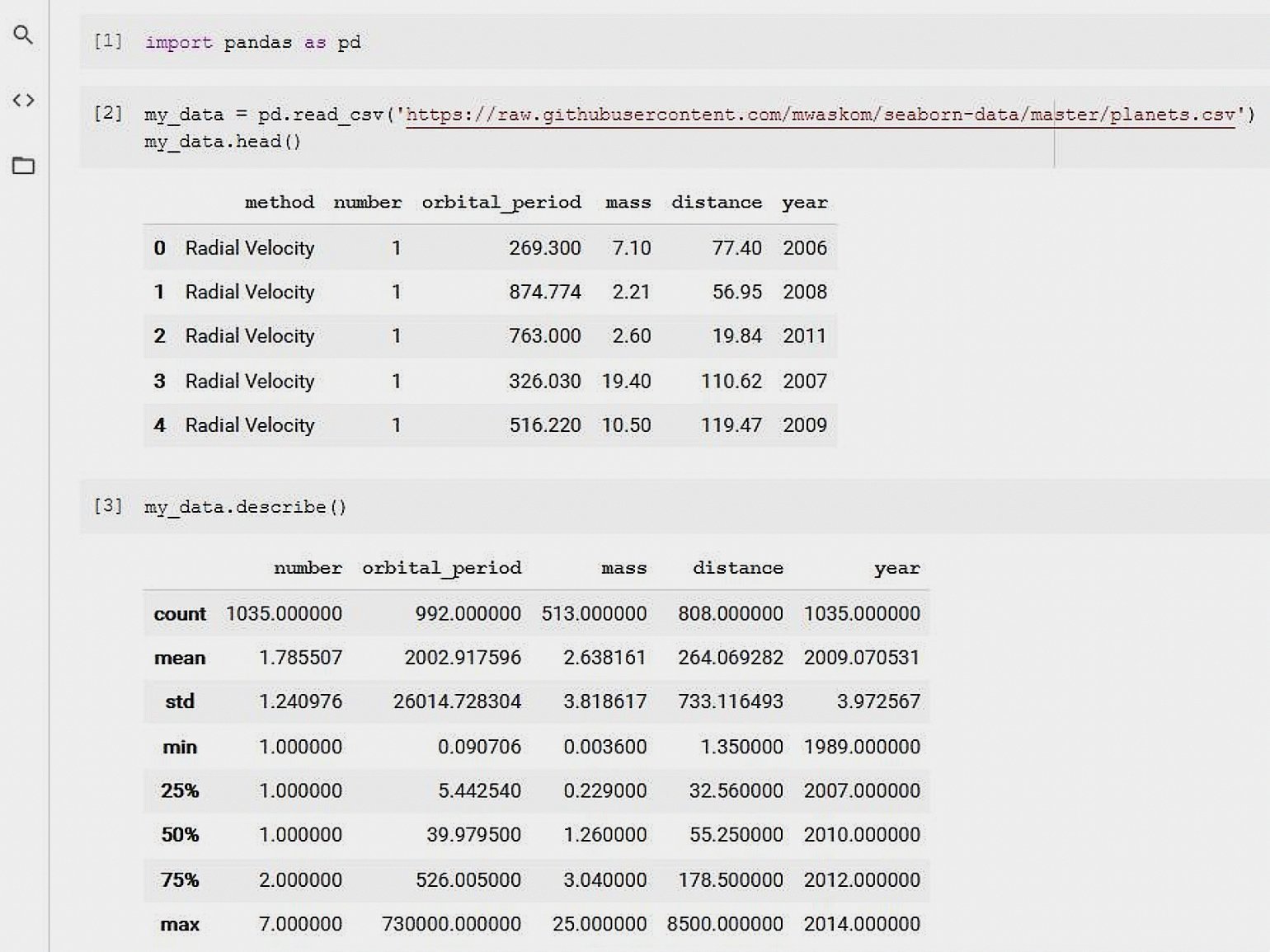
В первой ячейке мы импортировали библиотеку pandas. Во второй:
- прочитали таблицу planets.csv из коллекции seaborn-data, содержащую данные наблюдений за экзопланетами;
- сохранили её в переменную my_data;
- а также посмотрели первые пять строк датасета с помощью метода .head(), чтобы убедиться, что данные прочитались корректно.
В третьей ячейке с помощью .describe() были получены основные количественные характеристики нашего датасета: количество строк (наблюдений) count, среднее mean, величина стандартного отклонения std и так далее. На вид всё вполне солидно, но:
- результат — сплошные цифры, надо разбираться и вникать в каждую строчку;
- куда-то делась колонка method, содержащая категориальные (не числовые) переменные.
Неужели характеристики датасета (часто говорят «профиль данных») нельзя представить полнее и нагляднее? Оказывается, можно.

Pandas Profiling спешит на помощь
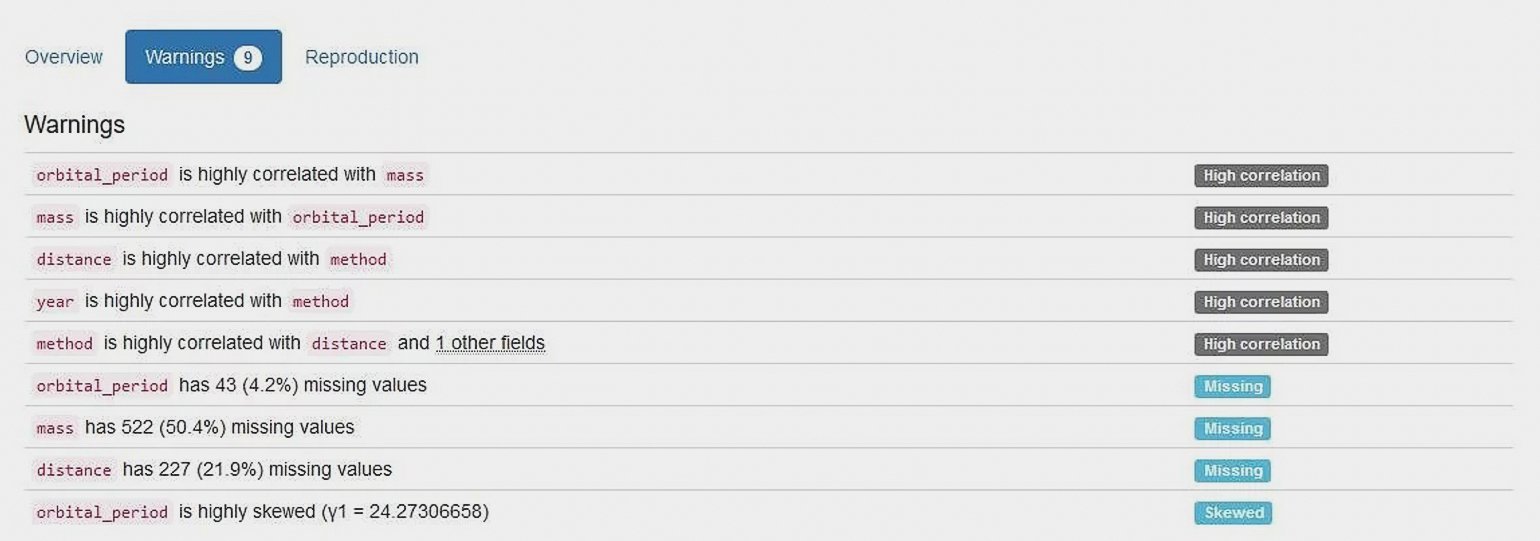
Создатели библиотеки пишут прямо: функция .describe() в Pandas отличная, но не покрывает современных требований к первичному исследовательскому (разведочному) анализу данных.
Pandas Profiling выдаёт в своём отчёте следующие параметры датасета:
- тип данных в каждой колонке;
- пропущенные и уникальные значения (количество и процент);
- описательную статистику: квартили, медиану, межквартильный размах, среднее, моду, абсолютное и относительное стандартное отклонение, медианное абсолютное отклонение, коэффициенты асимметрии и эксцесса;
Уфф! А ведь это только середина неполного списка. Пора сделать перерыв на статью о базовых статистических понятиях, необходимых для дата-сайентиста.
- график в виде гистограммы;
- корреляции между значениями (Пирсона, Спирмена и Кендалла);
- матрицу пропущенных значений;
- анализ текста в категориальных значениях;
- а также метаданные файлов и изображений: размеры файлов, даты создания, высоту и ширину.
Это практически исчерпывающее описание имеющихся данных. Причём оформленное в наглядный отчёт прямо в вашем блокноте.
Давайте разбираться, как заполучить себе такую красоту.
Отчёт о данных в одну (почти) строчку
Для установки библиотеки в Colab запускаем в отдельной ячейке одну из двух команд:
Чтобы сохранить отчёт в html-файл, воспользуйтесь командой .to_file():
profile.to_file("my_report.html")
Файл my_report.html появится в меню колаба слева, и оттуда его можно будет скачать себе на компьютер.
Посмотрите, как выглядят отчёты по разным датасетам на странице библиотеки на GitHub:
- отчёт по классическому датасету про пассажиров «Титаника»;
- отчёт по данным NASA о падениях метеоритов;
- отчёт по данным о 1000 самых употребительных слов русского языка;
- ну, и, конечно, куда без котиков и собачек.
Что дальше
Библиотека Pandas Profiling поможет как начинающим, так и опытным дата-сайентистам быстро понять, что за данные перед ними, оценить их качество и полноту. Скопируйте наш колаб-ноутбук себе с помощью команды меню «Файл» → «Сохранить копию на диске» и испытайте её в деле.
На курсе «Профессия Data Scientist» вы познакомитесь со множеством других, не менее мощных, быстрых и полезных инструментов специалиста по данным. Приходите, чтобы получить модную, интересную и востребованную профессию!