Повышение эффективности взаимодействия проектировщиков бортовой радиоэлектронной аппаратуры космических аппаратов на базе интеграции информационных систем Текст научной статьи по специальности «Компьютерные и информационные науки»
Аннотация научной статьи по компьютерным и информационным наукам, автор научной работы — Аметова Эвелина Серверовна, Гаврилов Дмитрий Викторович, Савенко Игорь Игоревич, Цапко Сергей Геннадьевич
Предложен подход реализации информационного взаимодействия проектировщиков бортовой радиоэлектронной аппаратуры , повышающий эффективность использования ресурсов и управление производственными процессами. Представлена концепция практической реализации предложенного подхода в среде PLM-системы Enovia SmarTeam . Разработан алгоритм сохранения данных проектов EDA-системы Altium Designer в хранилище данных PLM-системы Enovia SmarTeam . Сформирован механизм генерации конструкторских документов на базе формата хранения данных JSON.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по компьютерным и информационным наукам , автор научной работы — Аметова Эвелина Серверовна, Гаврилов Дмитрий Викторович, Савенко Игорь Игоревич, Цапко Сергей Геннадьевич
Особенности интеграции информационных систем автоматизированного проектирования и систем управления данными
Разработка модели данных информационной системы поддержки жизненного цикла изделий для задач космического приборостроения
Проблемы сквозного проектирования печатных узлов для изделий электронных средств
Жизненный цикл документа в информационных системах управления данными
Plm-cmctema Enovia SmarTeam в задачах реализации интегрированной информационной среды вуза
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Текст научной работы на тему «Повышение эффективности взаимодействия проектировщиков бортовой радиоэлектронной аппаратуры космических аппаратов на базе интеграции информационных систем»
Аметова Эвелина Серверовна,
магистрант кафедры автоматики и компьютерных систем Института кибернетики ТПУ, программист научно-образовательного
центра по CALS-технологиям Института кибернетики ТПУ. E-mail: zlatco@mail2000.ru Область научных интересов: автоматизация жизненного цикла конструкторских документов. Гаврилов Дмитрий Викторович, магистрант, учебный мастер кафедры автоматики и компьютерных систем Института кибернетики ТПУ.
mrdimagavrilov@gmail.com Область научных интересов: программирование, автоматизация жизненного цикла конструкторских документов.
Савенко Игорь Игоревич, магистрант, учебный мастер кафедры автоматики и компьютерных систем Института кибернетики ТПУ.
Область научных интересов: программирование, автоматизация жизненного цикла конструкторских документов.
Цапко Сергей Геннадьевич, канд. техн. наук, доцент докторант кафедры автоматики и компьютерных систем Института кибернетики ТПУ.
E-mail: serg@aics.ru Область научных интересов: информационная поддержка жизненного цикла изделий и услуг.
ПОВЫШЕНИЕ ЭФФЕКТИВНОСТИ ВЗАИМОДЕЙСТВИЯ ПРОЕКТИРОВЩИКОВ БОРТОВОЙ РАДИОЭЛЕКТРОННОЙ АППАРАТУРЫ КОСМИЧЕСКИХ АППАРАТОВ НА БАЗЕ ИНТЕГРАЦИИ ИНФОРМАЦИОННЫХ СИСТЕМ
Э.С. Аметова, Д.В. Гаврилов, И.И. Савенко, С.Г. Цапко
Томский политехнический университет E-mail: serg@aics.ru
Предложен подход реализации информационного взаимодействия проектировщиков бортовой радиоэлектронной аппаратуры, повышающий эффективность использования ресурсов и управление производственными процессами. Представлена концепция практической реализации предложенного подхода в среде PLM-системы Enovia SmarTeam. Разработан алгоритм сохранения данных проектов EDA-системы Altiivm Designer в хранилище данных PLM-системы Enovia SmarTeam. Сформирован механизм генерации конструкторских документов на базе формата хранения данных JSON.
Интеграция, радиоэлектронная аппаратура, Altium Designer, SmarTeam, структура изделия.
Развитие ракетно-космической промышленности обеспечивает национальный технологический прогресс. В связи с этим главными управленческими задачами на ракетно-космических предприятиях становятся эффективное управление производственными процессами, грамотное и экономичное использование ресурсов, в том числе временных и человеческих, накопление знаний и опыта.
Для решения перечисленных задач используются CALS-технологии. CALS (от англ. Continuous Acquisition and Life cycle Support) — совокупность базовых принципов, управленческих и информационных технологий, обеспечивающая поддержку жизненного цикла изделий (ЖЦИ) на всех его стадиях. CALS базируется на использовании единого информационного пространства (ЕИП), в котором посредством электронного обмена данными реализуется взаимодействие всех участников ЖЦИ: заказчиков продукции, разработчиков, производителей продукции, эксплуатантов [1]. Правила указанного взаимодействия регламентированы международными стандартами.
Интеграция различных систем автоматизации производства в ЕИП является составной задачей внедрения CALS-технологий. Эта задача становится особенно актуальной для космического приборостроения, учитывая современные тенденции к постоянному усложнению технических проектов, инженерных расчетов и увеличению количества элементов.
Бортовая радиоэлектронная аппаратура (РЭА) — это сложное наукоемкое изделие, включающее в себя как электрическую, так и механическую части. Для автоматизации проектирования используются соответственно EDA (от англ. Electronic Design Automation — автоматизация проектирования электронных приборов) и CAD (от англ. Computer-Aided Design — система автоматизированного проектирования) системы. Объединить все данные об изделии и автоматизировать производственные процессы позволяет PLM система (от англ. Product Lifecycle Management — система управления жизненным циклом изделия). От эффективности функционирования и взаимодействия этих систем зависит эффективность и качество проектирования изделия. Связывание систем в единое целое, то есть их интеграция, позволяет сократить цикл проектирования, исключить ручной перевод данных из одной системы в другую, тем самым сократить количество ошибок, и обеспечить актуальность и целостность данных. Таким образом, разработка интеграций становится важной и актуальной задачей [2].
В данной статье рассматривается подход к реализации интеграции между EDA-системой Altium Designer (далее по тексту Altium Designer) и PLM-системой SmarTeam (далее по тексту SmarTeam) и автоматической генерации некоторых конструкторских документов в рамках внедрения ЕИП в приборостроительном направлении ОАО «Информационные спутниковые системы им. академика М. Решетнева» (ОАО «ИСС»).
Методологические основы интеграции информационных систем
Базовая система SmarTeam обеспечивает хранение и управление данными об изделии на всех этапах ЖЦИ. Модель базы данных (БД) SmarTeam основана на объектно-ориентированной методологии. Фундаментальными понятиями объектно-ориентированной методологии являются понятия класса и объекта. При этом под классом понимают некоторую абстракцию совокупности объектов, которые имеют общий набор свойств (атрибутов) и обладают одинаковым поведением и функционалом (методами). Каждый объект в этом случае рассматривается как экземпляр соответствующего класса [3]. Важной особенностью классов является возможность их организации в виде некоторой иерархической структуры.
В модели БД SmarTeam на высшем уровне иерархии классов находится суперкласс, который является абстрактным — имеет наибольший объем и наименьшее содержание. Суперкласс конкретизируется — уменьшается его объем и увеличивается содержание до уровня класса. Этот процесс конкретизации понятий может быть продолжен до тех пор, пока на самом нижнем уровне не будет получено понятие, дальнейшая конкретизация которого в данном контексте либо невозможна, либо нецелесообразна
Модель БД строится на основе анализа и инжиниринга бизнес-процессов предприятия, в результате которых выявляются требования к интеграции систем автоматизации предприятия. SmarTeam предоставляет готовые шаблоны моделей БД, которые в дальнейшем могут быть адоптированы к нуждам предприятия путем изменения атрибутов, добавления собственных классов. Главным классом в структуре данных SmarTeam является обязательный класс «Проекты», и все данные организованы вокруг него. Проекты обычно содержат набор, суперклассов, классов и подклассов для представления состава изделия или других базовых объектов.
Одними из основных суперклассов SmarTeam являются Электронная структура изделия (Items) и Документы (Documents). Электронная структура изделия описывает иерархические связи внутри изделия и содержит ассоциативные ссылки на данные, описывающие изделия, то есть ссылки на классы Документы, Материалы и др. Суперкласс Документы содержит как непосредственно конструкторские документы (в doc, pdf и других форматах), так и информационные модели изделия (результаты проектирования в различных CAD-, EDA- системах, программные модули). Следовательно, файлы, полученные в процессе проектирования Altium Designer, должны быть помещены в суперкласс Документы, а ассоциативные ссылки на них
должны быть созданы в классе Электронная структура изделия. Здесь следует отметить, что прибор состоит из сборочных единиц более низкого уровня, которые и описываются проектами Altium Designer.
Одна из особенностей проектирования бортовой РЭА — наличие ограничительного перечня электрорадиоизделий (ЭРИ), которые могут быть использованы при проектировании электрической схемы. Это дает возможность создания справочника ЭРИ внутри SmarTeam. Так как SmarTeam позволяет связывать ассоциативными ссылками объекты не только внутри одного проекта, но и для разных проектов, то было предложено создать проект, содержащий полный перечень-справочник элементов, а при помещении проекта Altium Designer в SmarTeam должны создаваться ассоциативные ссылки между элементами суперкласса Электронная структура изделия и элементами проекта справочника [4].
Практическая реализации механизма интеграции
В ОАО «ИСС» была создана и поддерживается справочная БД ЭРИ в системе управления БД (СУБД) MySQL. Эта база содержит полное описание всех элементов (порядка 20 атрибутов). Исходя из вышеизложенного, был предложен подход к реализации интеграции между EDA- и PLM-системой. Предлагаемый подход к реализации интеграции включает в себя решение нескольких задач.
1. Организация справочника ЭРИ в SmarTeam, то есть, по сути, репликация БД MySQL. Для формирования справочника ЭРИ в SmarTeam в модели БД SmarTeam был создан специальный класс ЭРИ, далее была реализована связка между БД MySQL и классом ЭРИ в SmarTeam в среде Visual Studio на языке C# с использованием бесплатных библиотек. Для поддержания информации в актуальном состоянии и предотвращения возможных конфликтов при добавлении проектов Altium Designer в интерфейс пользователя была добавлена кнопка «Обновить».
2. Заполнение параметров в свойствах элементов в Altium Designer. Эта задача была решена с помощью API Altium Designer. В состав Altium Designer входит средство расширения функционала — интерфейс прикладного программирования API (от англ. англ. application programming interface). API — это набор готовых классов, процедур, функций, структур и констант, предоставляемых приложением (библиотекой, сервисом) для использования во внешних программных продуктах. Благодаря этому полностью снимаются ограничения на дальнейшее развитие Altium Designer.
Таким образом, была решена задача соответствия описаний элементов в SmarTeam и Altium Designer.
3. Выгрузка данных о проекте из Altium Designer и загрузка их в SmarTeam, то есть реализация односторонней интеграции между системами. Обмен данными между SmarTeam и Altium Designer, а именно выгрузка данных обо всех ЭРИ и файлах, входящих в состав проекта Altium Designer, был реализован через передачу данных в JSON формате. JSON (от англ. JavaScript Object Notation) — текстовый формат обмена данными, основанный на JavaScript. Несмотря на происхождение от JavaScript, формат считается языконезависимым и может использоваться практически с любым языком программирования. Для многих языков существуют функции для создания и обработки данных в формате JSON. Авторами статьи был выбран этот формат, так как он отлично подходит для описания сложных структур в силу удобочитаемости и лаконичности, а также полученный файл имеет меньший размер (по сравнению с XML). Решение задач 1-3 графически проиллюстрировано на рис. 1.
Класс Электронная структура изделия
— Элемент 1 Элемент 2 1- Элемент 3
-Схема 1.3сИОос —Схема 1.8сИОос -Схема З.РсЬйос
Данные в JSON формате
Файлы Altium Designer
Схема электрическая принципиальная
Рис. 1. Схема взаимодействия SmarTeam и Altium Designer
На панель управления в Altium Designer была добавлена кнопка «Сохранить в Smarteam». При нажатии на кнопку запускается программа, которая работает согласно алгоритму, приведенному на рис. 2.
Благодаря тому, что при помещении проекта Altium Designer в SmarTeam сохраняется целостность проекта и происходит построение электронной структуры, появилась возможность
автоматического формирования некоторых конструкторских документов. Так как файл JSON содержит полное описание всех элементов изделия/сборочной единицы, он может быть использован для формирования конструкторской документации: ведомости покупных изделий (ВП) и перечня элементов принципиальной электрической схемы (ПЭ3).
Для обработки файла JSON было решено применять язык C#. C# — объектноориентированный язык программирования. В основе концепции объектно-ориентированного программирования лежит понятие объекта — некоторая сущность, которая имеет некоторые характеристики (атрибуты) и поведение (методы). Язык позволяет как самостоятельно написать алгоритм обработки данных, так и использовать стандартные средства языка. Первый способ весьма трудоемкий и неэффективный, поэтому был выбран второй путь.
Авторами статьи выделены основные этапы формирования конструкторского документа (рис. 3).
1. Преобразование JSON файла в объектную модель, содержащую коллекцию из ЭРИ и их характеристик.
Часть атрибутов не нужны для формирования документа, поэтому данные, полученные из файла JSON, обрабатываются в объект, который непосредственно используется при генерации документа.
2. Описание метода класса.
Бизнес-логика по генерации документа инкапсулирована в библиотеку классов, то есть класс включает описание алгоритма, который обрабатывает всю коллекцию ЭРИ. Первый шаг работы алгоритма — это обработка входных данных, выделение необходимых свойств данных и приведение их в более удобный для обработки вид. Второй шаг — группировка и сортировка элементов.
3. Формирование документа.
Первоначально было решено генерировать файл в doc формате, так как существует хороший API между C# и Microsoft Office, что значительно облегчает генерацию файлов. Но при этом были учтены и недостатки, такие как большие аппаратные и временные затраты, вероятность утечки памяти из-за ошибки. Поэтому было решено отказаться от генерации документа напрямую в Microsoft Word. Также пришлось отказаться от идеи конвертации doc файлов в PDF формат, так как во время анализа конвертеров не было найдено бесплатных утилит, которые бы позволяли это делать напрямую. А при использование промежуточных утилит типа doPDF (бесплатный конвертер в PDF формат производства Softland SRL) понадобилось бы устанавливать у заказчика дополнительное ПО, что является не совсем оптимальным подходом.
Далее в результате поиска качественных и бесплатных библиотек, которые бы позволили напрямую работать с PDF форматом, была найдена многофункциональная библиотека.
Следует отметить, что библиотеки позволили работать с преобразованным из doc формата в PDF шаблоном основной надписи чертежа (то есть заполнять ее).
Коллекция из ЭРИ и их характеристик
Документ в PDF-формате
Рис. 3. Основные этапы работы при генерации документов
Генерация документов происходит по запросу пользователя. ВП формируется на прибор в целом, ПЭ3 на сборочные единицы и прибор.
Для генерации документов в корректной форме были учтены требования ГОСТ 2.1042006 «Основные надписи», ГОСТ 2.106-96 «Текстовые документы», 2.701-2008 «Схемы. Виды
и типы. Общие требования к выполнению», ГОСТ 2.304-81 «Шрифты чертежные», а также стандарты предприятия.
Достоинства предложенного подхода:
• при выделении элемента на вкладке Связи «Links» можно просмотреть все проекты и сборочные единицы, в которых использовался данный элемент;
• так как в дереве Электронная структура изделия появляются лишь ссылки на справочник, а не копии элементов, это предупреждает разрастание базы данных;
• в SmarTeam хранятся не только логические файлы (схемы), но и сгенерированные файлы (отчеты), что обеспечивает целостность проекта;
• есть возможность отслеживания изменений в различных версиях проекта.
Altium Designer и SmarTeam взаимодействуют через файл в формате JSON. Этот файл содержит все описание схемы, на основе него формируется документация, отслеживается вер-сионность. Файл скрыт для пользователя, чтобы избежать некорректных изменений файла.
Предложенная концепция интеграции между PLM и EDA системами позволит сократить временные издержки, уменьшить количество ошибок на этапе электрического проектирования, а также будет способствовать накоплению знаний и опыта. Это приведет к улучшению качества выпускаемой продукции и повышению конкурентоспособности предприятия.
1. Информационное обеспечение, поддержка и сопровождение жизненного цикла изделия / Бакаев В.В., Судов Е.В., Гомозов В.А. и др. / под ред. В.В. Бакаева. — М.: Машиностроение-1, 2005. — 624 с.
2. Ершова Т.Б. Организационные аспекты создания единого информационного пространства предприятия // Транспортное дело России. — 2009. — № 2. — C. 62-65.
3. Гайсарян С.С. Объектно-ориентированные технологии проектирования прикладных программных систем. Центр информационных технологий // IT-портал CITForum.ru. 2012. URL: http://citforum.ru/programming/oop_rsis/ (дата обращения: 25.02.2012).
4. Сабунин А.Е. Altium Designer. Новые решения в проектировании электронных устройств. -М.: Изд-во «Солон-пресс», 2009. — 432 с.
Поступила 17.04.2012 г.
JSON
JSON (JavaScript Object Notation) — это формат передачи данных, который используется при взаимодействии веб-сервера и браузера.

Освойте профессию «Frontend-разработчик»
До создания формата JSON веб-сайты работали медленно. Каждый запрос пользователя к серверу требовал повторной отправки в браузер обновленной HTML-страницы. AJAX-запрос, использующий формат JSON, выполняется в фоновом режиме, поэтому страница не перезагружается. Сегодня JSON — это стандарт передачи данных в интернете.
Основа JSON — это синтаксис объектов JavaScript, которые используются в языке для представления данных. Данные в формате JSON хранятся как пары «ключ:значение» и упорядоченные списки.
Значениями в JSON могут быть:
- JSON-объекты — неупорядоченные множества пар «ключ:значение», разделенные запятыми;
- массивы — упорядоченные коллекции значений, заключенные в квадратные скобки, значения разделены запятыми;
- числа — целые или с плавающей запятой;
- логический тип данных — true и false;
- строки — заданные последовательности из символов Юникода (стандарт кодирования символов), заключенные в две двойные кавычки;
- значение Null — показывает отсутствие информации.
JSON поддерживают большинство современных языков программирования. Он доступен либо по умолчанию, либо с помощью специальных библиотек.
Профессия / 9 месяцев
Frontend-разработчик
Создавайте интерфейсы сервисов, которыми пользуются все

Структура JSON
JSON-файл — это строка. Для работы с данными в этом формате нужно использовать методы глобального объекта JSON.
Чтобы отправить по сети объект JavaScript, его нужно преобразовать в JSON (строку). Для этого используется метод stringify(), который принимает объект в качестве параметра и возвращает строку JSON.
let student = name: ‘Max’,
age: 28,
isAdmin: false,
courses: [‘html’, ‘css’, ‘js’],
wife: null
>;
let json = JSON.stringify(student);
alert(json);
/* выведет объект в формате JSON:
«name»: «Max»,
«age»: 28,
«isAdmin»: false,
«courses»: [«html», «css», «js»],
«wife»: null
>
*/
Для превращения данных, полученных в JSON-формате от сервера, в объект JavaScript применяется метод parse(). Он работает по аналогии со stringify(), принимая строку в качестве аргумента и возвращая объект.
Общие правила создания JSON-файла описывает RFC-стандарт:
- данные записаны в виде пар «ключ:значение»;
- данные разделены запятыми;
- объект находится внутри фигурных скобок <>;
- массив находится внутри квадратных скобок [].

Станьте Frontend-разработчиком
и создавайте интерфейсы сервисов, которыми пользуются все
Есть и другие моменты:
- В JSON-формате используют двойные кавычки (“), одиночные кавычки (‘) не подходят. Но кавычки не нужны для любых значений, не являющихся строкой, — чисел, массивов, булевых значений.
- Одна лишняя или пропущенная запятая или скобка могут привести к сбою работы JSON-файла.
- JSON-формат не поддерживает комментарии. Добавление комментария вызовет ошибку.
- Автоматически сгенерированный JSON-файл не должен содержать ошибок, его лучше тоже проверить с помощью валидатора JSONLint.
Эти правила JSON обеспечивают надежность и скорость реализации алгоритма кодирования и чтения.
Способы хранения данных JSON
Хранимые данные могут быть организованы в виде объекта и массива. Базовый формат — это объект, на что указывают фигурные скобки:
В этом объекте три пары ключей и значений, разделенные запятыми. Значения в этом примере — строки, поэтому они заключены в кавычки, так же как и ключи.
Массив — это способ хранения данных с более сложной структурой. Вот пример:
В четвертой паре ключей “hobby” — это ключ, а значение — массив в квадратных скобках.
Массивы поддерживают цикл for, с помощью которого можно быстро найти нужные данные.
Принцип работы JSON
Данные в формате JSON передаются с сервера в браузер с помощью таких API (Application Programming Interface), как XMLHttpRequest или более современная Fetch API. Вот как это работает:
- Пользователь кликает по заголовку или карточке товара и отправляет запрос на сервер.
- API генерирует запрос с использованием JavaScript.
- Сервер обрабатывает полученный запрос и формирует ответ в виде данных в JSON-формате.
- Получив данные от сервера, браузер с помощью JavaScript оборачивает эти данные в HTML-теги и обновляет страницу в фоновом режиме, без перезагрузки.
Преимущества использования JSON
- JSON — это компактный формат. С ним большие объемы данных быстро обмениваются между браузером и веб-сервером.
- С JSON-файлами можно работать не только методами JavaScript. Почти у всех языков есть инструменты для чтения и генерации данных JSON.
- Хранение и экспорт данных в JSON поддерживают современные реляционные базы данных, такие как PostgreSQL и MySQL.
Как открыть JSON-файл на компьютере
Открыть, посмотреть или отредактировать файл с расширением .json можно с помощью любого текстового редактора, Notepad++, Sublime Text, Atom и других. Самый простой вариант — использовать Блокнот, встроенный в операционную систему Windows, или Apple TextEdit на МасOS.
Чтобы создать файл, нужно при сохранении выбрать тип файла «Все файлы» и самостоятельно дописать нужное расширение — .json.
Более подробная информация есть на официальном сайте JSON или на популярных ресурсах, посвященных веб-разработке, таких как Developer.mozilla или Хабр.
Frontend-разработчик
Научитесь создавать удобные и эффектные сайты, сервисы и приложения, которые нужны всем. Сегодня профессия на пике актуальности: в России 9000+ вакансий, где требуется знание JavaScript.
Что такое JSON
Если вы тестируете API, то должны знать про два основных формата передачи данных:
- XML — используется в SOAP (всегда) и REST-запросах (реже);
- JSON — используется в REST-запросах.
Сегодня я расскажу вам про JSON. И расскажу в основном с точки зрения «послать запрос в Postman или прочитать ответ», потому что статья рассчитана на студентов, впервые работающих с Postman.
JSON (англ. JavaScript Object Notation) — текстовый формат обмена данными, основанный на JavaScript. Но при этом формат независим от JS и может использоваться в любом языке программирования.
JSON используется в REST API. По крайней мере, тестировщик скорее всего столкнется с ним именно там.
См также:
Что такое API — общее знакомство с API
Что такое XML — второй популярный формат
Введение в SOAP и REST: что это и с чем едят — видео про разницу между SOAP и REST
В SOAP API возможен только формат XML, а вот REST API поддерживает как XML, так и JSON. Разработчики предпочитают JSON — он легче читается человеком и меньше весит. Так что давайте разберемся, как он выглядит, как его читать, и как ломать!
Как устроен JSON
В качестве значений в JSON могут быть использованы:
- JSON-объект
- Массив
- Число (целое или вещественное)
- Литералы true (логическое значение «истина»), false (логическое значение «ложь») и null
- Строка
Я думаю, с простыми значениями вопросов не возникнет, поэтому разберем массивы и объекты. Ведь если говорить про REST API, то обычно вы будете отправлять / получать именно json-объекты.

JSON-объект
Как устроен
И разберемся, что означает эта запись.
Объект заключен в фигурные скобки <>

JSON-объект — это неупорядоченное множество пар «ключ:значение».
Ключ — это название параметра, который мы передаем серверу. Он служит маркером для принимающей запрос системы: «смотри, здесь у меня значение такого-то параметра!». А иначе как система поймет, где что? Ей нужна подсказка!
Вот, например, «Виктор Иван» — это что? Ищем описание параметра «query» в документации — ага, да это же запрос для подсказок!

Это как если бы мы вбили строку «Виктор Иван» в GUI (графическом интерфейсе пользователя):
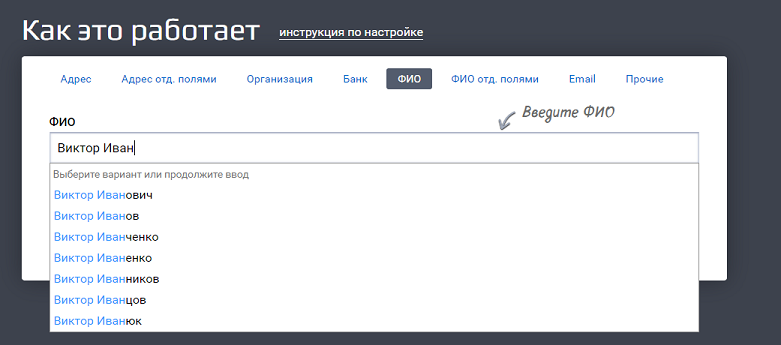
Когда пользователь начинает вводить данные в формочку, то сразу видит результат — появляется список подсказок. Это значит, что разработчик прописал в коде условие — делать некое действие на каждый ввод символа в это поле. Какое действие? Можно увидеть через f12.
Открываем вкладку Network, вбиваем «Виктор Иван» и находим запрос, который при этом уходит на сервер. Ого, да это тот самый пример, что мы разбираем!

Клиент передает серверу запрос в JSON-формате. Внутри два параметра, две пары «ключ-значение»:
- query — строка, по которой ищем (то, что пользователь вбил в GUI);
- count — количество подсказок в ответе (в Дадате этот параметр зашит в форму, всегда возвращается 7 подсказок. Но если дергать подсказки напрямую, значение можно менять!)
Пары «ключ-значение» разделены запятыми:

Строки берем в кавычки, числа нет:

Конечно, внутри может быть не только строка или число. Это может быть и другой объект! Или массив. Или объект в массиве, массив в объекте. Любое количество уровней вложенности =))
Объект, массив, число, булево значение (true / false) — если у нас НЕ строка, кавычки не нужны. Но в любом случае это будет значение какого-то ключа:
НЕТ
ДА
Переносы строк делать необязательно. Вообще пробелы и переносы строк нужны только человеку для читабельности, система поймет и без них:
Так правильно
Так тоже правильно
Ключ — ВСЕГДА строка, но мы все равно берем его в кавычки. В JavaScript этого можно не делать, в JSON нельзя.
Так правильно
Так правильно в JS, но неправильно в JSON
По крайней мере, если вы работаете с простыми значениями ключей, а несколько слов записываете в верблюжьемРегистре или в змеином_регистре. Если вы хотите написать в ключе несколько слов через пробел, ключ нужно взять в кавычки.
НЕТ
ДА
my query: «Виктор Иван»
«my query»: «Виктор Иван»
И все же я рекомендую использовать простые названия ключей, или использовать snake_case.
Писать ключи можно в любом порядке. Ведь JSON-объект — это неупорядоченное множество пар «ключ:значение».
Так правильно
Так тоже правильно
query: «Виктор Иван»
Очень важно это понимать, и тестировать! Принимающая запрос система должна ориентировать на название ключей в запросе, а не на порядок их следования. Ключевое слово «должна» )) Хотя знаю примеры, когда от перестановки ключей местами всё ломалось, ведь «первым должен идти запрос, а не count!».
Ключ или свойство?
Вот у нас есть JSON-объект:
Что такое «query»? Если я хочу к нему обратиться, как мне это сказать? Есть 2 варианта, и оба правильные:
— Обратиться к свойству объекта;
— Получить значение по ключу.

То есть «query» можно назвать как ключом, так и свойством. А как правильно то?

Правильно и так, и так! Просто есть разные определения объекта:
Объект
В JS объект — это именно объект. У которого есть набор свойств и методов:
- Свойства — описывают, ЧТО мы создаем.
- Методы — что объект умеет ДЕЛАТЬ.
То есть если мы хотим создать машину, есть два пути:
- Перечислить 10 разных переменных — модель, номер, цвет, пробег.
- Создать один объект, где будут все эти свойства.
Аналогично с кошечкой, собачкой, другом из записной книжки.

Объектно-ориентированное программирование (ООП) предлагает мыслить не набором переменных, а объектом. Хотя бы потому, что это логичнее. Переменных в коде будет много, как понять, какие из них взаимосвязаны?
Вот если я создаю машину, сколько переменных мне надо заполнить? А если меняю данные? А если удаляю? Когда переменные разбросаны по коду, можно забыть про какую-то и получить ошибку в интерфейсе. А если у нас есть цельный объект, всегда можно посмотреть, какие у него есть свойства и методы.
Например, создадим кошечку:
var cat = < name: “Pussy”, year: 1, sleep: function() < // sleeping code >>
В объекте cat есть:
- Свойства — name, year (что это за кошечка)
- Функции — sleep (что она умеет делать, описание поведения)
По коду сразу видно, что у кошечки есть имя и возраст, она умеет спать. Если разработчик решит добавить новые свойства или методы, он дополнит этот объект, и снова всё в одном месте.
Если потом нужно будет получить информацию по кошечке, разработчик сделает REST-метод getByID, searchKitty, или какой-то другой. А в нем будет возвращать свойства объекта.
То есть метод вернет
И при использовании имени вполне уместно говорить «обратиться к свойству объекта». Это ведь объект (кошечка), и его свойства!
Набор пар «ключ:значение»
Второе определение объекта — неупорядоченное множество пар ключ:значение, заключенное в фигурные скобки <>.
Оно применимо тогда, когда внутри фигурных скобок приходит не конкретный целостный объект, а просто набор полей. Они могут быть связаны между собой, а могут относится к совершенно разным объектам внутри кода:
- client_fio (в коде это свойство fio объекта client)
- kitty_name (в коде это свойство name объекта cat)
- car_model (в коде это свойство model объекта car)
- …
В таком случае логично называть эти параметры именно ключами — мы хотим получить значение по ключу.

Но в любом случае, и «ключ», и «свойство» будет правильно. Не пугайтесь, если в одной книге / статье / видео увидели одно, в другой другое. Это просто разные трактовки ¯\_(ツ)_/¯
Итого
Json-объект — это неупорядоченное множество пар «ключ:значение», заключённое в фигурные скобки «< >». Ключ описывается строкой, между ним и значением стоит символ «:». Пары ключ-значение отделяются друг от друга запятыми.
Значения ключа могут быть любыми:
И только строку мы берем в кавычки!
JSON-массив
Как устроен
Давайте снова начнем с примера. Это массив:
[ "MALE", "FEMALE" ]Массив заключен в квадратные скобки []

Внутри квадратных скобок идет набор значений. Тут нет ключей, как в объекте, поэтому обращаться к массиву можно только по номеру элемента. И поэтому в случае массива менять местами данные внутри нельзя. Это упорядоченное множество значений.

Значения разделены запятыми:

Значения внутри
Внутри массива может быть все, что угодно:
Цифры
[ 1, 5, 10, 33 ]Строки
[ "MALE", "FEMALE" ]Смесь
[ 1, "Андрюшка", 10, 33 ]Объекты
Да, а почему бы и нет:
[1, , "такой вот массивчик"]Или даже что-то более сложное. Вот пример ответа подсказок из Дадаты:
Система возвращает массив подсказок. Сколько запросили в параметре count, столько и получили. Каждая подсказка — объект, внутри которого еще один объект. И это далеко не самая сложная структура! Уровней вложенности может быть сколько угодно — массив в массиве, который внутри объекта, который внутри массива, который внутри объекта.
Ну и, конечно, можно и наоборот, передать массив в объекте. Вот пример запроса в подсказки:
Это объект (так как в фигурных скобках и внутри набор пар «ключ:значение»). А значение ключа «parts» — это массив элементов!
Итого
Массив — это просто набор значений, разделенных запятыми. Находится внутри квадратных скобок [].
А вот внутри него может быть все, что угодно:
- числа
- строки
- другие массивы
- объекты
- смесь из всего вышеназванного
JSON vs XML
В SOAP можно применять только XML, там без вариантов.
В REST можно применять как XML, так и JSON. Разработчики отдают предпочтение json-формату, потому что он проще воспринимается и меньше весит. В XML есть лишняя обвязка, название полей повторяется дважды (открывающий и закрывающий тег).
Сравните один и тот же запрос на обновление данных в карточке пользователя:
XML
Иванов Иван Иванович 01.01.1990 Москва 8 926 766 48 48 JSON
За счет того, что мы не дублируем название поля каждый раз «surname – surname», читать JSON проще. И за счет этого же запрос меньше весит, что при плохом интернете бывает важно. Или при большой нагрузке.
Well Formed JSON
Разработчик сам решает, какой JSON будет считаться правильным, а какой нет. Но есть общие правила, которые нельзя нарушать. Наш JSON должен быть well formed, то есть синтаксически корректный.
Чтобы проверить JSON на синтаксис, можно использовать любой JSON Validator (так и гуглите). Я рекомендую сайт w3schools. Там есть сам валидатор + описание типичных ошибок с примерами.
Но учтите, что парсеры внутри кода работают не по википедии или w3schools, а по RFC, стандарту. Так что если хотите изучить «каким должен быть JSON», то правильнее открывать RFC и искать там JSON Grammar. Однако простому тестировщику хватит набора типовых правил с w3schools, их и разберем.
Правила well formed JSON:

- Данные написаны в виде пар «ключ:значение»
- Данные разделены запятыми
- Объект находится внутри фигурных скобок <>
- Массив — внутри квадратных []
1. Данные написаны в виде пар «ключ:значение»
"name":"Ольга"В JSON название ключа нужно брать в кавычки, в JavaScript не обязательно — он и так знает, что это строка. Если мы тестируем API, то там будет именно JSON, так что кавычки обычно нужны.
Но учтите, что это правило касается JSON-объекта. Потому что json может быть и числом, и строкой. То есть:
"Ольга"Это тоже корректный json, хоть и не в виде пар «ключ:значение».
И вот если у вас по ТЗ именно json-объект на входе, попробуйте его сломать, не передав ключ. Ещё можно не передать значение, но это не совсем негативный тест — система может воспринимать это нормально, как пустой ввод.
2. Данные разделены запятыми
Пары «ключ:значение» в объекте разделяются запятыми. После последней пары запятая не нужна!
Типичная ошибка: поставили запятую в конце объекта:

Это последствия копипасты. Взяли пример из документации, подставили в постман (ну или разработчик API подставил в код, который будет вызывать систему), а потом решили поменять поля местами.
В итоге было так:
Смотрим на запрос — ну, query то важнее чем count, надо поменять их местами! Копипастим всю строку ««count»: 7,», вставляем ниже. Перед ней запятую добавляем, а «лишнюю» убрать забываем. По крайней мере у меня это частая ошибка, когда я «кручу-верчу, местами поменять хочу».
Другой пример — когда мы добавляем в запрос новое поле. Примерный сценарий:
- У меня уже есть работающий запрос в Postman-е. Но в нем минимум полей.
- Я его клонирую
- Копирую из документации нужное мне поле. Оно в примере не последнее, так что идёт с запятой на конце.
- Вставляю себе в конце запроса — в текущий конец добавляю запятую, потом вставляю новую строку.
- Отправляю запрос — ой, ошибка! Из копипасты то запятую не убрала!
Я на этот сценарий постоянно напарываюсь при тестировании перестановки полей. А ведь это нужно проверять! Хороший запрос должен быть как в математической присказке: «от перемены мест слагаемых сумма не меняется».

Не зря же определение json-объекта гласит, что «это неупорядоченное множество пар ключ:значение». Раз неупорядоченное — я могу передавать ключи в любом порядке. И сервер должен искать по запросу название ключа, а не обращаться к индексу элемента.
Разработчик, который будет взаимодействовать с API, тоже человек, который может ошибиться. И если система будет выдавать невразумительное сообщение об ошибке, можно долго думать, где конкретно ты налажал. Поэтому ошибки тоже тестируем.
Чтобы протестировать, как система обрабатывает «плохой json», замените запятую на точку с запятой:
Или добавьте лишнюю запятую в конце запроса — эта ошибка будет встречаться чаще!
Или пропустите запятую там, где она нужна:
Аналогично с массивом. Данные внутри разделяются через запятую. Хотите попробовать сломать? Замените запятую на точку с запятой! Тогда система будет считать, что у вас не 5 значений, а 1 большое:
[1, 2, 3, 4, 5] [1; 2; 3; 4; 5] !*Я добавила комментарии внутри блока кода. Но учтите, что в JSON комментариев нет. Вообще. Так что если вы делаете запрос в Postman, не получится расставить комментарии у разных строчек в JSON-формате.
3. Объект находится внутри фигурных скобок <>
Чтобы сломать это условие, уберите одну фигурную скобку:
a: 1, b: 2>Или попробуйте передать объект как массив:
[ a: 1, b: 2 ]Ведь если система ждет от вас в запросе объект, то она будет искать фигурные скобки.

4. Массив — внутри квадратных []
Чтобы сломать это условие, уберите одну квадратную скобку:
Или попробуйте передать массив как объект, в фигурных скобках:
Ведь если система ждет от вас в запросе массив, то она будет искать квадратные скобки.
Итого
JSON (JavaScript Object Notation) — текстовый формат обмена данными, основанный на JavaScript. Легко читается человеком и машиной. Часто используется в REST API (чаще, чем XML).

Корректные значения JSON:
- JSON-объект — неупорядоченное множество пар «ключ:значение», заключённое в фигурные скобки «< >».
- Массив — упорядоченный набор значений, разделенных запятыми. Находится внутри квадратных скобок [].
- Число (целое или вещественное).
- Литералы true (логическое значение «истина»), false (логическое значение «ложь») и null.
- Строка
При тестировании REST API чаще всего мы будем работать именно с объектами, что в запросе, что в ответе. Массивы тоже будут, но обычно внутри объектов.
Комментариев в JSON, увы, нет.
Правила well formed JSON:
- Данные в объекте написаны в виде пар «ключ:значение»
- Данные в объекте или массиве разделены запятыми
- Объект находится внутри фигурных скобок <>
- Массив — внутри квадратных []
См также:
+комментарии к этой статье =)
какой язык программирования лежит в основе json
Важным фактором является тип используемых накопителей. Наши VPS/VDS серверы, работающие как на Windows, так и на Linux, предоставляют доступ к накопителям SSD eMLC. Эти накопители обеспечивают высокую производительность и надежность, что гарантирует бесперебойную работу ваших приложений независимо от выбранной операционной системы.
Защита от DDoS В современном мире виртуальные серверы (VPS/VDS) стали неотъемлемой частью развития бизнеса и онлайн-проектов. Выбор правильной операционной системы — важный шаг в процессе создания надежной и эффективной инфраструктуры. Наше предложение VPS/VDS серверов Windows, доступных уже от 13 рублей, сочетает в себе множество преимуществ и становится незаменимым инструментом для развития вашего проекта, будь то на Windows или Linux.
Преимущества SSD eMLC: производительность и надежность
Одним из основных факторов, которые следует учитывать при выборе виртуальных серверов, является тип используемых накопителей. Наши VPS/VDS серверы, работающие как на Windows, так и на Linux, предоставляют доступ к накопителям SSD eMLC. Эти накопители обеспечивают высокую производительность и надежность, что гарантирует бесперебойную работу ваших приложений независимо от выбранной операционной системы.
Защита от DDoS: ваша безопасность на первом месте
Другой важный аспект — защита от DDoS-атак. Независимо от того, работаете ли вы на Windows или Linux, наши VPS/VDS серверы предоставляют встроенную защиту от DDoS, обеспечивая непрерывную работу вашего проекта даже в условиях массированных атак.
Надежная инфраструктура: ЦОД TIER III
Центры обработки данных (ЦОД) играют важную роль в обеспечении надежности вашего сервера. Наши VPS/VDS серверы, поддерживающие как Windows, так и Linux, размещаются в ЦОД уровня TIER III. Это гарантирует вам надежность и доступность вашего сервера на уровне 99,982%. Вне зависимости от выбранной операционной системы, вы можете быть уверены в надежности инфраструктуры.
Высокоскоростной интернет: до 1000 Мбит/с
Скорость Интернет-соединения — еще один важный фактор для успешной работы вашего проекта. Наши VPS/VDS серверы, поддерживающие Windows и Linux, предоставляют доступ к интернету со скоростью до 1000 Мбит/с, обеспечивая быструю загрузку веб-страниц и высокую производительность онлайн-приложений на обеих операционных системах.
Центры обработки данных (ЦОД) играют важную роль в обеспечении надежности вашего сервера. Наши VPS/VDS серверы, поддерживающие как Windows, так и Linux, размещаются в ЦОД уровня TIER III. Это гарантирует надежность и доступность сервера на уровне 99,982%.
Мы предоставляем скидку 10% от существующей цены на все VPS/VDS серверы Windows и Linux.
Высокая производительность, надежная защита, надежная инфраструктура и высокоскоростной интернет — все это доступно по доступной цене, с