Что такое динамическое программирование
Работу разработчика часто можно сравнить с решением головоломок. Как в настоящей головоломке, разработчику приходится тратить существенные ресурсы не столько на реализацию конкретного решения, сколько на выбор оптимального подхода. Иногда задача решается легко и эффективно, а порой — только полным перебором всех возможных вариантов. Такой подход часто называют наивным решением. Он имеет существенный минус — временные затраты.
Представим хакера, который пытается взломать какой-то пароль перебором всех комбинаций символов. Если пароль допускает 10 цифр, 26 маленьких букв, 26 больших букв и 32 специальных символа (например, значок доллара), то для каждого символа в пароле есть 94 кандидата. Значит, чтобы взломать перебором пароль, состоящий из одного символа, потребуется 94 проверки. Если в пароле два символа — 94 кандидата на первую позицию, 94 кандидата на вторую позицию — то придется перебрать аж 94*94 = 8836 возможных пар. Для пароля из десяти символов потребуется уже перебор 94^10 комбинаций.
Если обобщить, то для взлома пароля с произвольной длиной N требуется O(94^N) операций. Такие затраты часто называют «экспоненциальными»: появление каждой новой позиции влечёт за собой увеличение количества операций в 94 раза. Взлом пароля может показаться чем-то экзотическим, но задачи, требующие полного перебора всех вариантов — совсем не экзотика, скорее угрюмая реальность.
Экспоненциальное время — это долго. Даже O(2^N) — это просто непозволительно долго. Настолько долго, что никому и в голову не придет запустить подобный алгоритм даже на простых данных — ведь на решение такой задачи с сотней элементов потребуются тысячи, миллионы или миллиарды лет вычислений. А в реальной жизни нужно решать задачи с намного большим количеством элементов. Как же быть?
Дело в том, что многие задачи без эффективного алгоритма решения можно решить за привлекательное время с помощью одной хитрости — динамического программирования.
- Динамическое программирование
- Пример решения задачи
- Итог
- Области применения
Динамическое программирование
Динамическое программирование — это особый подход к решению задач. Не существует какого-то единого определения динамическому программированию, но все-таки попробуем её сформировать. Идея заключается в том, что оптимальное решение зачастую можно найти, рассмотрев все возможные пути решения задачи, и выбрать среди них лучшее.
Работа динамического программирования очень похожа на рекурсию с запоминанием промежуточных решений — такую рекурсию еще называют мемоизацией. Рекурсивные алгоритмы, как правило, разбивают большую задачу на более мелкие подзадачи и решают их. Динамические алгоритмы делят задачу на кусочки и вычисляют их по очереди, шаг за шагом наращивая решения. Поэтому динамические алгоритмы можно представить как рекурсию, работающую снизу вверх.
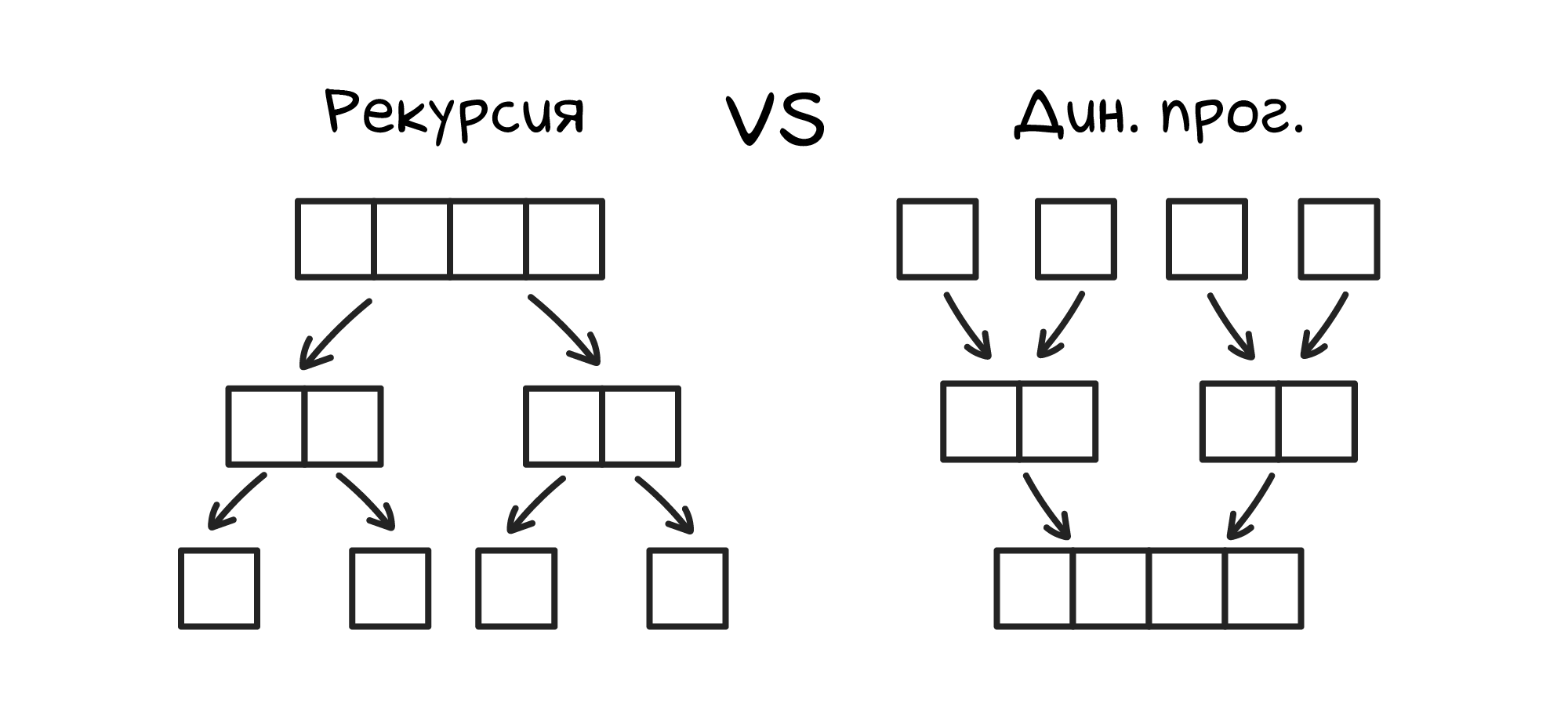
Магия динамического программирования заключается в умном обращении с решениями подзадач. «Умный» в этом контексте значит «не решающий одну и ту же подзадачу дважды». Для этого решения мелких подзадач должны где-то сохраняться. Для многих реальных алгоритмов динамического программирования этой структурой данных является таблица.
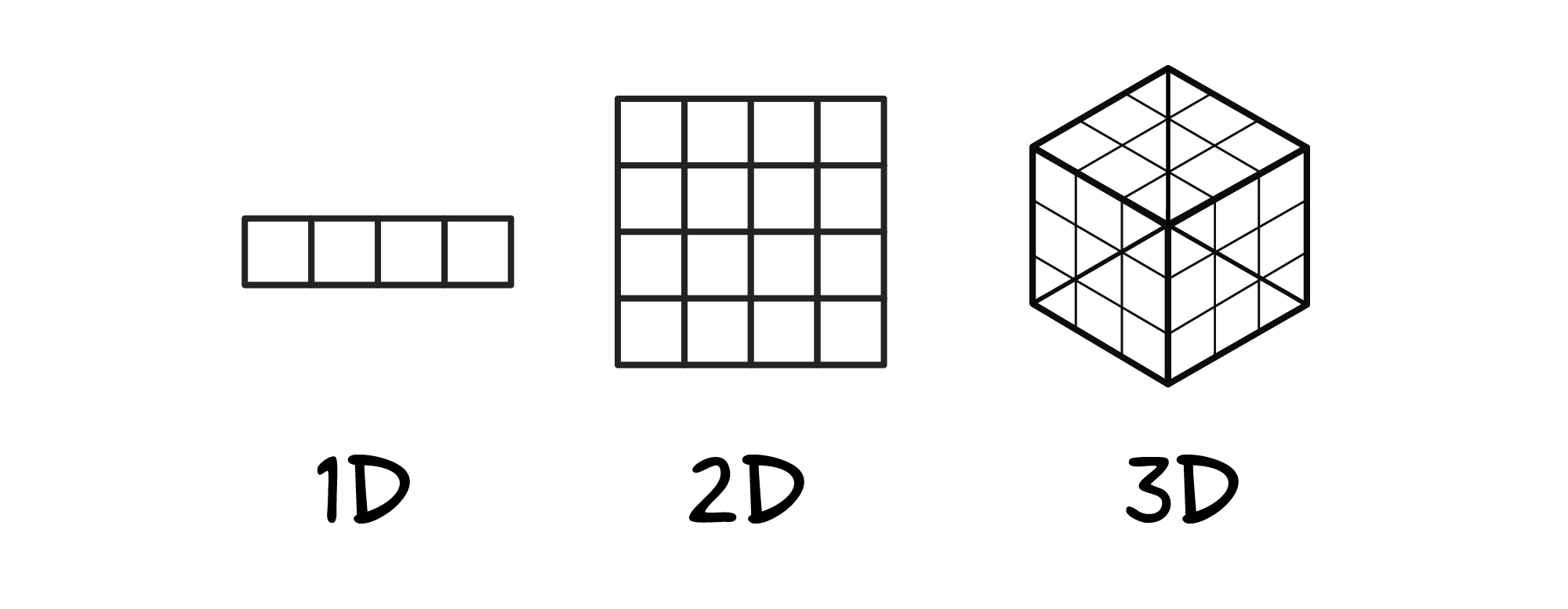
В самых простых случаях эта таблица будет состоять только из одной строки — аналогично обычному массиву. Эти случаи будут называться одномерным динамическим программированием, и потреблять O(n) памяти. Например, алгоритм эффективного вычисления чисел Фибоначчи использует обычный массив для запоминания вычисленных промежуточных результатов. Классический рекурсивный алгоритм делает очень много бессмысленный работы — он по миллионному разу рассчитывает то, что уже было рассчитано в соседних ветках рекурсии.
В самых распространённых случаях эта таблица будет выглядеть привычно и состоять из строчек и столбиков. Обычная таблица, похожая на таблицы из Excel. Это называется двумерным динамическим программированием, которое при n строках и n столбцах таблицы потребляет O(n*n) = O(n^2) памяти. Например, квадратная таблица из 10 строк и 10 столбцов будет содержать 100 ячеек. Чуть ниже будет подробно разобрана именно такая задача.
Бывают и более запутанные задачи, использующие для решения трехмерные таблицы, но это редкость — решение задачи с использованием трехмерной таблицы зачастую просто нельзя себе позволить. Небольшая двухмерная таблица на 1024 строки и 1024 столбца может потребовать несколько мегабайт памяти. Трехмерная таблица с такими же параметрами будет занимать уже несколько гигабайт.
Что нужно, чтобы решить задачу динамически, помимо ее исходных данных? Всего три вещи:
- Таблица, в которую будут вноситься промежуточные результаты. Один из них будет выбран в конце работы алгоритма в качестве ответа
- Несколько простых правил по заполнению пустых ячеек таблицы, основанных на значениях в уже заполненных ячейках. Универсального рецепта тут нет и к каждой задаче требуется свой подход
- Правило выбора финального решения после заполнения таблицы
Разберем эти принципы на примере.
Пример решения задачи
Демонстрационным подопытным выступит классическая задача динамического программирования — Расстояние Левенштейна. Несмотря на кажущееся сложным название, в действительности это задача о трансформации одного слова в другое путем добавления, удаления и замены букв с минимальным количеством операций.
Эта задача может быть сформулирована так: найти минимальное «расстояние» между двумя словами. Расстоянием в этом случае будет минимальное количество операций, которые нужно применить к первому слову, чтобы получить второе (или наоборот).
Доступных операции у нас три:
- insert — добавить одну букву в любое место в слове, в том числе в самое начало и в конец
- delete — удалить одну букву из любого места в слове
- replace — заменить одну букву в определенном месте на другую букву
Все эти операции имеют равную стоимость: +1 к расстоянию между словами.
Возьмем для примера два простых слова, MONEY и MONKEY. Какое минимальное количество операций необходимо, чтобы превратить MONEY в MONKEY? Находчивый человеческий глаз быстро смекнет, что одна: добавить букву K после между третьей и четвертой буквой.
Возьмем случай посложнее. Попробуем превратить слово SUNDAY в слово SATURDAY, и увидим, что количество комбинаций, которые нужно перебрать, потенциально очень велико. Если решать задачу перебором, то можно рассмотреть все возможные комбинации, как в примере со взломом пароля. Вместо возможных 94 символов-кандидатов у нас есть три операции — insert, delete, replace. Три комбинации для первой буквы, 3*3 для двух букв, 3*3*3 для трех букв, 3^N для N букв. Комбинаторный взрыв.
Динамическое решение
Приступим к динамическому решению. Для начала, создадим таблицу и разместим исходные слова на ее краях, оставив немного свободного места. Второй столбик и вторую строчку буем использовать для пустых строк — их часто обозначают символом ε, читается epsilon. Аналог того, что вы имеете в виду, когда используете пустую строку на своем языке программирования: String eps = “”.
| ε | S | A | T | U | R | D | A | Y |
|---|---|---|---|---|---|---|---|---|
| ε | ||||||||
| S | ||||||||
| U | ||||||||
| N | ||||||||
| D | ||||||||
| A | ||||||||
| Y |
Теперь заполним второй столбик и вторую строчку, руководствуясь абсолютно интуитивными соображениями: как превратить пустую строку в какую-то строку? Конечно же, добавить в нее нужные символы! Например, чтобы перевести ε в SATU, необходимо добавить букву S, букву A, букву T и букву U. Четыре операции. Что делать с превращением ε в ε (вторая строка, второй столбец)? Элементарно — ничего делать не нужно, ноль действий.
| ε | S | A | T | U | R | D | A | Y | |
|---|---|---|---|---|---|---|---|---|---|
| ε | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| S | 1 | ||||||||
| U | 2 | ||||||||
| N | 3 | ||||||||
| D | 4 | ||||||||
| A | 5 | ||||||||
| Y | 6 |
Теперь нужна система простых правил, с помощью которой мы сможем заполнить таблицу. Таблица будет именоваться D, а первая строчка и столбик останутся на ее полях. Работать с таблицей мы будем, как с двухмерным массивом: D[0, 2] означают ячейку на пересечении нулевой строки и второго столбика. В нашем примере D[0, 2] = 2.
Также назовём слово по вертикали A, а слово по горизонтали B. Эта парочка нам нужна, чтобы иметь доступ к оригинальным словам на полях. Из-за дополнительных колонок в для ε индексы в A и B отличаются от индексов в таблице. Если быть точнее — они сдвинуты на единицу. A[0] = S, A[1] = U, A[2] = N, B[7] = Y, и так далее.
Наконец, создадим наше правило заполнения таблицы. Для каждой новой ячейки мы проверяем верхнюю, левую или лево верхнюю по диагонали соседние ячейки. Из трех чисел будет выбрано наименьшее и записано в новую ячейку.
D[i, j] = minimum( D[i-1, j] + 1, // delete D[i, j-1] + 1, // insert D[i-1, j-1] + (A[i-1] == B[j-1] ? 0 : 1) // replace ) Это важный момент в динамическом программировании: правила кажутся бессмысленными, а собрать общую картину происходящего в голове сложно. Давайте посмотрим на маленький кусочек таблицы — возможно, он прольет свет на некоторые детали.
| ε | S | A | |
|---|---|---|---|
| ε | 0 | 1 | 2 |
| S | 1 | ||
| U | 2 |
Что следует записать в ячейку D[1,1] как результат перехода из S в S? Интуитивно ясно, что для этого ничего делать и не нужно, ноль операций. Запишем в ячейку ноль. На что похоже это значение, учитывая, что вычитать ничего нельзя? Среди соседей ноль есть только по диагонали.
| ε | S | A | |
|---|---|---|---|
| ε | 0 | 1 | 2 |
| S | 1 | 0 | |
| U | 2 |
Что записать в ячейку D[2,1] как результат перехода из SU в S? Нужно удалить букву U — значит, это одна операция. По-сути, стоимость перехода из SU в S будет равно стоимости удаления буквы U и перехода из S в S (чья стоимость уже была посчитана и лежит в ячейке D[1,1]).
| ε | S | A | |
|---|---|---|---|
| ε | 0 | 1 | 2 |
| S | 1 | 0 | |
| U | 2 | 1 |
Теперь посмотрим на ячейку D[1,2], переход из S в SA. Да, именно, стоимость перехода будет равна стоимости добавления буквы A и перехода из S в S, итого единица.
| ε | S | A | |
|---|---|---|---|
| ε | 0 | 1 | 2 |
| S | 1 | 0 | 1 |
| U | 2 | 1 |
Последняя ячейка, D[2,2], переход из SU в SA. Самым оптимальным решением было бы заменить букву U на букву A, плюс цена бесплатного перехода из S в S.
| ε | S | A | |
|---|---|---|---|
| ε | 0 | 1 | 2 |
| S | 1 | 0 | 1 |
| U | 2 | 1 | 1 |
В самой правой нижней ячейке содержится финальная стоимость перехода из слова SU в слово SA. Аналогичным образом можно заполнить всю таблицу. Из ячейки D[6,8] мы узнали, что переход из слова SUNDAY в слово SATURDAY стоит минимум три операции. Жирным шрифтом выделим оптимальный путь.
Давайте проследим его по шагам. Переход из S в S ничего не стоит. Переход из S в SA стоит одну операцию. Переход из S в SAT стоит две операции. Переход из SU в SATU стоит две операции. Переход из SUN в SATUR стоит три операции. Переход из SUND в SATURD стоит три операции (стоимость предыдущего перехода плюс нулевая цена перехода из D в D). Переход из SUNDA в SATURDA стоит три операции. Наконец, переход из SUNDAY в SATURDAY требует тех же трёх операций.
Кстати, если присмотреться к таблице, можно заметить, что оптимальных решений несколько: из D[1,2] можно перейти как в D[1,3], так и в D[2,2]. В этой постановке задачи нас интересует только минимальное количество, а не список всех возможных путей решения, так что это не существенно.
| ε | S | A | T | U | R | D | A | Y | |
|---|---|---|---|---|---|---|---|---|---|
| ε | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| S | 1 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| U | 2 | 1 | 1 | 2 | 2 | 3 | 4 | 5 | 6 |
| N | 3 | 2 | 2 | 2 | 3 | 3 | 4 | 5 | 6 |
| D | 4 | 3 | 3 | 3 | 3 | 4 | 3 | 4 | 5 |
| A | 5 | 4 | 3 | 4 | 4 | 4 | 4 | 3 | 4 |
| Y | 6 | 5 | 4 | 4 | 5 | 5 | 5 | 4 | 3 |
Вот так, собственно, и выглядит большинство решений из мира динамического программирования. Кстати, это решение имеет название — алгоритм Вагнера-Фишера. Забавный факт: этот алгоритм практически параллельно опубликовали разные группы незнакомых ученых с разных концов планеты в эпоху, когда еще не был интернета. Товарищи Вагнер и Фишер, кстати, были далеко не первыми.
Давайте теперь рассмотрим, в чем отличия применения этого алгоритма от решения перебором.
Анализ решения
Как уже было сказано, решение перебором этой задачи простой рекурсией имеет временную сложность O(3^n), но не требует лишней памяти — значит, O(1) операций в памяти.
Какие издержки у динамического решения? Давайте представим, что сравниваются слова равной длины, по n символов в слове. Все решение сводится к заполнению таблицы с n+1 строчками (отдельная для пустой строки ε), и n+1 столбиками. Значит, используется (n+1)^2 ячеек. Не будем считать копейки, и округлим количество ячеек до n^2. Для каждой ячейки мы будем проверять трех ее соседей, что требует константного времени O(1). Значит, на заполнение всей таблицы потребуется O(n^2) операций.
Какой будет расход памяти? Для таблицы с n^2 ячеек нам нужно O(n^2) памяти.
Если слова разной длины, то можно либо смотреть по самому длинному, либо несколько повысить степень сложности формулы. Например, если первое слово имеет длину n, а второе — m, то потребуется O(nm) времени и O(nm) памяти.
Итог
Основная идея динамического программирования должна прослеживаться в представленном примере: мы жертвуем солидным количеством памяти (O(nm) вместо O(1)), но получаем просто сумасшедший выигрыш во времени (O(nm) против O(3^n)).
Перечислим все ключевые особенности динамического программирования.
Преимущества:
- Скорость. Главное достоинство динамического программирования. Нерешаемые задачи становятся решаемыми, в большинстве случаев — за квадратичное время! Одна операция на заполнение каждой ячейки таблицы — и вопрос закрыт.
- Универсальность. One Ring to rule them all — создание компактной системы из нескольких правил для заполнения таблицы гарантирует решение задачи на любых данных. Ни исключений, ни пограничных случаев, несколько строчек, — и сложная проблема решена.
- Точность. Поскольку алгоритм динамического программирования рассматривает абсолютно все возможные варианты и сценарии, он гарантированно обнаружит самое оптимальное решение. Никакой потери точности, никаких приблизительных ответов. Если решение существует — оно будет найдено.
Недостатки:
- Память. В большинстве случаев алгоритмы динамического программирования требуют времени на построение и заполнение таблиц. Таблицы потребляют память. Это может стать проблемой: в случае, если сами таблицы очень большие, или если для решения какой-то задачи нужно построить очень много таких таблиц и держать их всех в памяти.
- Когнитивная нагрузка. Решение запутанной задачи с помощью компактной системы правил — очень заманчивая идея. Но тут есть один нюанс: для составления или хотя бы для понимания этих систем правил необходимо научиться «думать на динамическом программировании». Это является причиной довольно спорной репутации динамического программирования.
Области применения
Динамическое программирование — не теоретическая конструкция, которая не выходит за рамки научных работ. Оно пользуется популярностью во многих прикладных областях. Их достаточно много: прикладная математика, машиностроение, теории управления или прогнозирование финансовых данных. Но мы остановимся на одной — на биоинформатике.
Ученые в этой области занимаются «оцифровыванием» биологического материала, а так же хранением и анализом полученной информации. В этой науке сотни захватывающих аспектов, и она ставит перед разработчиками очень серьезные задачи, ведь данных невероятно много. Например, в геноме человека около трех миллиардов пар нуклеотидов (кирпичиков ДНК). Одна пара обычно кодируется одним байтом, в итоге выходит около трех миллиардов байт информации на один-единственный геном — три гигабайта данных на одного человека.
Один геном не создает серьезных проблем, но геномы сами по себе малоинтересны: чтобы обнаружить мутации в геноме конкретного человека, нужно сначала «выровнять» его с другими, референсными геномами (выровненными и размеченными заранее). Возможных вариантов этого выравнивания может быть огромное количество, но нужно найти самый правдоподобный из них. То есть вариант, у которого максимальная вероятность возникновения. Например, вариант с наименьшим количеством мутаций. Если принять во внимание, что генетический код обычно хранятся в виде очень длинных строк, состоящих из разных букв, то пример с Расстоянием Левенштейна начинает играть новыми красками. Эта задача, потенциально приводящая к комбинаторному взрыву (прямо как перебор всех комбинаций символов для взлома пароля), замечательно решается методами динамического программирования!
Это только один пример. Биоинформатика буквально живет динамическим программированием — вот еще несколько примеров:
- Построение молекулярных деревьев для определения последовательности эволюционных изменений
- Эффективный перевод генетической информации (например, из кусочка кожи) в длинную строку в базе данных
Если 15 лет назад полное считывание генома (секвенирование) имело себестоимость в десятки миллионов долларов, то сегодня эта услуга стоит одну-две тысячи долларов, и постепенно дешевеет. Этот скачок произошел не столько за счет роста вычислительных мощностей, сколько за счет появления эффективных алгоритмов.
Динамическое программирование для начинающих
Разбираем классические задачи на последовательности, одномерную и двумерную динамику с обоснованием разных подходов к реализации. Примеры кода на Java.
Динамическое программирование — тема, которой в рунете посвящено довольно мало статей, поэтому мы решили ею заняться. В этой статье будут разобраны классические задачи на последовательности, одномерную и двумерную динамику, будет дано обоснование решениям и описаны разные подходы к их реализации. Весь приведённый в статье код написан на Java.
О чём вообще речь? Что такое динамическое программирование?
Динамическое программирование — метод решения задачи путём её разбиения на несколько одинаковых подзадач, рекуррентно связанных между собой. Самым простым примером будут числа Фибоначчи — чтобы вычислить некоторое число в этой последовательности, нам нужно сперва вычислить третье число, сложив первые два, затем четвёртое таким же образом на основе второго и третьего, и так далее (да, мы слышали про замкнутую формулу).
Хорошо, как это использовать?
Решение задачи динамическим программированием должно содержать следующее:
- Зависимость элементов динамики друг от друга. Такая зависимость может быть прямо дана в условии (так часто бывает, если это задача на числовые последовательности). В противном случае вы можете попытаться узнать какой-то известный числовой ряд (вроде тех же чисел Фибоначчи), вычислив первые несколько значений вручную. Если вам совсем не повезло — придётся думать ?
- Значение начальных состояний. В результате долгого разбиения на подзадачи вам необходимо свести функцию либо к уже известным значениям (как в случае с Фибоначчи — заранее определены первые два члена), либо к задаче, решаемой элементарно.
И что, мне для решения рекурсивный метод писать надо? Я слышал, они медленные.
Конечно, не надо, есть и другие подходы к реализации динамики. Разберём их на примере следующей задачи:
Идея решения
Здесь нам даны и начальные состояния (a0 = a1 = 1), и зависимости. Единственная сложность, которая может возникнуть — понимание того, что 2n — условие чётности числа, а 2n+1 — нечётности. Иными словами, нам нужно проверять, чётно ли число, и считать его в зависимости от этого по разным формулам.
Рекурсивное решение
Очевидная реализация состоит в написании следующего метода:
private static int f(int n)< if(n==0 || n==1) return 1; // Проверка на начальное значение if(n%2==0)< //Проверка на чётность return f(n/2)+f(n/2-1); // Вычисляем по формуле для чётных индексов, // ссылаясь на предыдущие значения >else < return f((n-1)/2)-f((n-1)/2-1); // Вычисляем по формуле для нечётных // индексов, ссылаясь на предыдущие значения >> И она отлично работает, но есть нюансы. Если мы захотим вычислить f(12) , то метод будет вычислять сумму f(6)+f(5) . В то же время, f(6)=f(3)+f(2) и f(5)=f(2)-f(1) , т.е. значение f(2) мы будем вычислять дважды. Спасение от этого есть — мемоизация (кеширование значений).
Рекурсивное решение с кэшированием значений
Идея мемоизации очень проста — единожды вычисляя значение, мы заносим его в какую-то структуру данных. Перед каждым вычислением мы проверяем, есть ли вычисляемое значение в этой структуре, и если есть, используем его. В качестве структуры данных можно использовать массив, заполненный флаговыми значениями. Если значение элемента по индексу N равно значению флага, значит, мы его ещё не вычисляли. Это создаёт определённые трудности, т.к. значение флага не должно принадлежать множеству значений функции, которое не всегда очевидно. Лично я предпочитаю использовать хэш-таблицу — все действия в ней выполняются за O(1), что очень удобно. Однако, при большом количестве значений два числа могут иметь одинаковый хэш, что, естественно, порождает проблемы. В таком случае стоит использовать, например, красно-чёрное дерево.
Для уже написанной функции f(int) кэширование значений будет выглядеть следующим образом:
private static HashMap cache = new HashMap(); private static int fcashe(int n) < if(!cache.containsKey(n))return cache.get(n); > Не слишком сложно, согласитесь? Зато это избавляет от огромного числа операций. Платите вы за это лишним расходом памяти.
Последовательное вычисление
Теперь вернёмся к тому, с чего начали — рекурсия работает медленно. Не слишком медленно, чтобы это приносило действительные неприятности в настоящей жизни, но на соревнованиях по спортивному программированию каждая миллисекунда на счету.
Метод последовательного вычисления подходит, только если функция ссылается исключительно на элементы перед ней — это его основной, но не единственный минус. Наша задача этому условию удовлетворяет.
Суть метода в следующем: мы создаём массив на N элементов и последовательно заполняем его значениями. Вы, наверное, уже догадались, что таким образом мы можем вычислять в том числе те значения, которые для ответа не нужны. В значительной части задач на динамику этот факт можно опустить, так как для ответа часто бывают нужны как раз все значения. Например, при поиске наименьшего пути мы не можем не вычислять путь до какой-то точки, нам нужно пересмотреть все варианты. Но в нашей задаче нам нужно вычислять приблизительно log2(N) значений (на практике больше), для 922337203685477580-го элемента (MaxLong/10) нам потребуется 172 вычисления.
private static int f(int n)< if(n<2) return 1; //Может, нам и вычислять ничего не нужно? int[] fs = int[n]; //Создаём массив для значений fs[0]=fs[1]=1; //Задаём начальные состояния for(int i=2; ielse < fs[i]=fs[(i-1)/2]+fs[(i-1)/2-1] >> return fs[n-1]; > Ещё одним минусом такого подхода является сравнительно большой расход памяти.
Создание стека индексов
Сейчас нам предстоит, по сути, написать свою собственную рекурсию. Идея состоит в следующем — сначала мы проходим «вниз» от N до начальных состояний, запоминая аргументы, функцию от которых нам нужно будет вычислять. Затем возвращаемся «вверх», последовательно вычисляя значения от этих аргументов, в том порядке, который мы записали.
Зависимости вычисляются следующим образом:
LinkedList stack = new LinkedList(); stack.add(n); < LinkedListqueue = new LinkedList(); //Храним индексы, для которых ещё не вычислены зависимости queue.add(n); int dum; while(queue.size()>0)< //Пока есть что вычислять dum = queue.removeFirst(); if(dum%2==0)< //Проверяем чётность if(dum/2>1) < //Если вычисленная зависимость не принадлежит начальным состояниям stack.addLast(dum/2); //Добавляем в стек queue.add(dum/2); //Сохраняем, чтобы //вычислить дальнейшие зависимости >if(dum/2-1>1) < //Проверяем принадлежность к начальным состояниям stack.addLast(dum/2-1); //Добавляем в стек queue.add(dum/2-1); //Сохраняем, чтобы //вычислить дальнейшие зависимости >>else< if((dum-1)/2>1) < //Проверяем принадлежность к начальным состояниям stack.addLast((dum-1)/2); //Добавляем в стек queue.add((dum-1)/2); //Сохраняем, чтобы //вычислить дальнейшие зависимости >if((dum-1)/2-1>1) < //Проверяем принадлежность к начальным состояниям stack.addLast((dum-1)/2-1); //Добавляем в стек queue.add((dum-1)/2-1); //Сохраняем, чтобы //вычислить дальнейшие зависимости >> /* Конкретно для этой задачи есть более элегантный способ найти все зависимости, здесь же показан достаточно универсальный */ > > Полученный размер стека — то, сколько вычислений нам потребуется сделать. Именно так я получил упомянутое выше число 172.
Теперь мы поочередно извлекаем индексы и вычисляем для них значения по формулам — гарантируется, что все необходимые значения уже будут вычислены. Хранить будем как раньше — в хэш-таблице.
HashMap values = new HashMap(); values.put(0,1); //Важно добавить начальные состояния //в таблицу значений values.put(1,1); while(stack.size()>0)< int num = stack.removeLast(); if(!values.containsKey(num))< //Эту конструкцию //вы должны помнить с абзаца о кешировании if(num%2==0)< //Проверяем чётность int value = values.get(num/2)+values.get(num/2-1); //Вычисляем значение values.add(num, value); //Помещаем его в таблицу >else < int value = values.get((num-1)/2)-values.get((num-1)/2-1); //Вычисляем значение values.add(num, value); //Помещаем его в таблицу >> Все необходимые значения вычислены, осталось только написать
return values.get(n); Конечно, такое решение гораздо более трудоёмкое, однако это того стоит.
Хорошо, математика — это красиво. А что с задачами, в которых не всё дано?
Для большей ясности разберём следующую задачу на одномерную динамику:
Идея решения
На первую ступеньку можно попасть только одним образом — сделав прыжок с длиной равной единице. На вторую ступеньку можно попасть сделав прыжок длиной 2, или с первой ступеньки — всего 2 варианта. На третью ступеньку можно попасть сделав прыжок длиной три, с первой или со втрой ступенек. Т.е. всего 4 варианта (0->3; 0->1->3; 0->2->3; 0->1->2->3). Теперь рассмотрим четвёртую ступеньку. На неё можно попасть с первой ступеньки — по одному маршруту на каждый маршрут до неё, со второй или с третьей — аналогично. Иными словами, количество путей до 4-й ступеньки есть сумма маршрутов до 1-й, 2-й и 3-й ступенек. Математически выражаясь, F(N) = F(N-1)+F(N-2)+F(N-3). Первые три ступеньки будем считать начальными состояниями.
Реализация через рекурсию
private static int f(int n)
Здесь ничего хитрого нет.
Реализация через массив значений
Исходя из того, что, по большому счёту, простое решение на массиве из N элементов очевидно, я продемонстрирую тут решение на массиве всего из трёх.
int[] vars = new int[3]; vars[0]=1;vars[1]=2;vars[2]=4; for(int i=3; i > System.out.println(vars[(N-1)%3]); Так как каждое следующее значение зависит только от трёх предыдущих, ни одно значение под индексом меньше i-3 нам бы не пригодилось. В приведённом выше коде мы записываем новое значение на место самого старого, не нужного больше. Цикличность остатка от деления на 3 помогает нам избежать кучи условных операторов. Просто, компактно, элегантно.
Там вверху ещё было написано про какую-то двумерную динамику.
С двумерной динамикой не связано никаких особенностей, однако я, на всякий случай, рассмотрю здесь одну задачу и на неё.
Идея решения
Логика решения полностью идентична таковой в задаче про мячик и лестницу — только теперь в клетку (x,y) можно попасть из клеток (x-1,y) или (x, y-1). Итого F(x,y) = F(x-1, y)+F(x,y-1). Дополнительно можно понять, что все клетки вида (1,y) и (x,1) имеют только один маршрут — по прямой вниз или по прямой вправо.
Реализация через рекурсию
Ради всего святого, не нужно делать двумерную динамику через рекурсию. Уже было упомянуто, что рекурсия менее выгодна, чем цикл по быстродействию, так двумерная рекурсия ещё и читается ужасно. Это только на таком простом примере она смотрится легко и безобидно.
private static int f(int i, int j)
Реализация через массив значений
int[][] dp = new int[Imax][Jmax]; for(int i=0; ielse < dp[i][j]=dp[i-1][j]+dp[i][j-1]; >> > System.out.println(dp[Imax-1][Jmax-1]); Классическое решение динамикой, ничего необычного — проверяем, является ли клетка краем, и задаём её значение на основе соседних клеток.
Отлично, я всё понял. На чём мне проверить свои навыки?
В заключение приведу ряд типичных задач на одномерную и двумерную динамику, разборы прилагаются.
Методы разбиения задач на подзадачи. Рекурсия, «Разделяй и властвуй» динамическое программирование Текст научной статьи по специальности «Математика»
В статье рассматриваются способы решения задачи путем разбиения ее на «меньшие» подзадачи, которые решаются легче. Автор рассматривает три способа: рекурсия, «разделяй и властвуй», динамическое программирование. Некоторые задачи подробно разобраны, некоторые предлагаются школьникам для самостоятельного решения.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Похожие темы научных работ по математике , автор научной работы — Наумов Лев Александрович
Математические методы анализа рекурсивных алгоритмов
Разбор задач финала международного студенческого чемпионата мира 2003 года по программированию АСМ
Асимптотические свойства решений специального типа рекуррентных соотношений
Разбор задач третьей Всероссийской командной олимпиады школьников по программированию
Задачи международных студенческих олимпиад
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
i Надоели баннеры? Вы всегда можете отключить рекламу.
Текст научной работы на тему «Методы разбиения задач на подзадачи. Рекурсия, «Разделяй и властвуй» динамическое программирование»
Наумов Лев Александрович
МЕТОДЫ РАЗБИЕНИЯ ЗАДАЧ НА ПОДЗАДАЧИ. РЕКУРСИЯ, «РАЗДЕЛЯЙ И ВЛАСТВУЙ» ДИНАМИЧЕСКОЕ ПРОГРАММИРОВАНИЕ
Какие задачи решать труднее всего? Глупый вопрос, конечно же — сложные. За этим вопросом напрашивается другой, не менее глупый: решать то их, конечно, сложно, но, все-таки, как? На него ответить вообще нельзя. Все зависит от конкретной задачи. Однако мы попытаемся здесь описать один наиболее общий метод: их можно разбивать на «меньшие» подзадачи, которые уже решаются легче. В начале необходимо оговорить, что под словом «сложные» в данном случае мы будем понимать не сложные для программиста, а сложные для компьютера, трудоемкие задачи.
Мы предложим различные методы разбиения задачи на подзадачи. Причем это разбиение должно, очевидно, характеризоваться следующим свойством: решив все получившиеся подзадачи, мы должны получить решение исходной. Как же этого достичь? Основной принцип заключается в явном выделении рекуррентных соотношений, зависимостей от уже полученных результатов. А может быть, просто, удастся выделить подзадачи, которые работают лишь с подмножеством исходных данных, а не со всем набором. Вариантов много. Однако основное внимание будет уделено одному из таких приемов — методу динамического программирования.
Прежде, чем перейти к основной части повествования, введем обозначение. Если в тексте Вы встретите такую запись: < к >(где к — на-
. ч^йма или /еосЗеННа обрщае&ся слмл « себе.
туральное число), то это будет означать, что Вам был изложен весь материал, достаточный для решения задачи к. Список задач приведен в крнце статьи.
Начнем, пожалуй, с самого простого приема, с рекурсии. Скорее всего, Вы с ним уже знакомы, но так как мы в дальнейшем будем активно его использовать, то позвольте все-таки о нем рассказать.
Этот механизм основан на использовании так называемой рекурсивной функции. Она обладает тем свойством, что прямо или косвенно обращается сама к себе. Рекурсией полезно пользоваться, если задачу можно разбить на подзадачи, решаемые за «разумное время», и если при этом суммарный размер подзадач — «небольшой». В предыдущем предложении так много кавычек из-за того, что общего определения «разумного времени» и «небольшого размера» дать нельзя. Значения, вкладываемые в эти понятия, зависят от задачи, целей, которые преследуются, приоритетов при построении решения и многого другого.
Когда и как использовать этот метод? Как правило, поступают так: рекурсивная функция принимает ряд параметров, описывающих те действия, которые ей надлежит выполнить. Ее «рекурсивность» обеспечивается тем, что из нее вызывается она же, но с другими значениями пара-
.рл^мигяш мо&а^м разбиений уадлги На
метров. Главное — не забыть проконтролировать, чтобы процесс когда-нибудь закончился. Для этого нужно, чтобы при некоторых значениях параметров функция больше не вызывала себя. Эти значения называются терминальными.
Продемонстрируем работу рекурсивного метода. В качестве примера рассмотрим вычисление суммы всех целых степеней x от 0 до некоторого n, сосчитаем значение функции f(х,n) = xn + xn-1 +. + x +1. Эта функция обладает определенный свойством, позволяющим нам применить рекурсию. Оно выражается в следующем равенстве: f (х,n) = х• (xn-1 + xn-2. + х +1) +1. Вы убедитесь в этом, если просто вынесете x за скобку из всех слагаемых, кроме последнего. Фактически, оно означает, что f (x, n) = x • f (x, n -1) +1, а это и есть рекуррентное соотношение, позволяющее перейти от решения задачи для n -1 к решению для n.
Остается один вопрос: а какое значение n считать терминальным? Ну, подумайте сами, результат возведения в какую степень нам всегда известен заранее, независимо от числа x? Конечно — в нулевую. Так пусть терминальным значением и будет n = 0.
Соответствующая рекурсивная процедура будет иметь вид:
function f(x:real; n:integer):real; begin
if n=0 then begin f:=1; exit;
На самом деле Вас «обманули», и мы надеемся, что Вы это уже заметили сами. Мотивация выбора нуля, как терминального значения параметра, совсем иная. Действительно, мы всегда знаем, что f (x,0) = 1. Но, посудите сами, разве нам не известно, что f (x,1) = x +1 ?, что f (x,2) = x2+x +1 ? Конечно, известно! Просто если бы мы выбрали, например, двойку как терминальное значение, то подсчитать f (x, 0) и f (x, 1) мы бы уже не смогли. В этой задаче стоило выбирать наименьшее n, для которого мо-
. fteKCffefeefa&ftoe cooHftoaeftue, ftefeeu&u лН решения ^л^лис n —1 e feeweftoa n.
жет потребоваться вычисление значения функции.
Помимо того, что терминальные значения должны быть предусмотрены, они должны еще и достигаться при рекурсивном вычислении. В приведенном выше примере это, очевидно, выполняется. Ведь начав с любого n, мы, постоянно вычитая из него единицу, рано или поздно, доберемся до нуля. Тем самым, «глубина рекурсии» у нас ограничена и равна n + 1. Вызов f (n) приведет к вычислению значения требуемой функции посредством вызова f самой из себя, n раз. То есть для всех значений второго параметра от n — 1 до 0. При этом глубина рекурсии равна n + 1, так как надо посчитать еще и сам первый вызов f (n). 3 1, 2 4
А вообще говоря, почему глубина рекурсии должна быть ограничена? Дело в том, что при программировании нужно исходить из того, что чрезмерная глубина может вызвать ошибку. Если функция будет бесконечно вызывать и вызывать себя же, то на определенном этапе это приведет к переполнению стека. При этом, выполнение программы, несомненно, не сможет продолжаться. О подробностях природы этого эффекта мы здесь говорить не будем. Однако, наверное, будет полезно упомянуть, что, например, в среде программирования Borland
. аагему гл^бсЯл fezKipfecuu далфЯя быНь o-tfeaftaiefta?
Pascal 7.0 есть средства, позволяющие следить и предотвратить возникновение этой ошибки. Открыв при отладке программы окно Call stack (это можно сделать через главное меню Debug I Call stack или сочетанием клавиш + ) Вы сможете наблюдать за последовательностью вызовов функций и изменением их параметров. Если при определенных обстоятельствах возникает ошибка «Stack overflow error», значит, Вам есть еще над чем поработать в реализуемом рекурсивном алгоритме. Или, как минимум, нужно наложить некоторые ограничения на область значений параметров. 3 3 ►
Следующий метод называется «разделяй и властвуй». Он заключается также в разбиении задачи на части, каждая из которых решается отдельно. Затем решения объединяются, и получается решение всей задачи. Это — очень общее определение механизма «разделяй и властвуй». Отметим один частный случай: один из вариантов довольно эффективного использования данной методики, а именно, ее применение к задачам, подзадачи которой являются ее же «уменьшенными версиями», причем такими, что их, в свою очередь, можно решать рекурсивно. Под «уменьшенными версиями», как говорилось выше, имеются в виду задачи, аналогичные исходной, только обрабатывающие не все множество входных данных, а лишь некоторое его подмножество. Принципиально она не меняется, но за счет этого «уменьшения» она может упроститься и алгоритмически.
Рассмотрим сказанное выше поподробнее. Например, пусть какая-то задача оперирует с набором из n элементов. Было бы здорово разбить его на q наборов из меньшего числа элементов. Причем так, чтобы ни один из элементов не принадлежал более чем одному набору.
Итак, предположим, что набор разделяется на q непустых поднаборов, содержа-
6ft ^мсмоше&ся 6 рл^биеНии
,n элементов, соответствен-
но. Так как п, + п + . + п = п, то п. < п
для любого г от 1 до д. Если исходную задачу переформулировать таким образом в д подзадач (по одной для каждого поднабо-ра), решить каждую из них отдельно и объединить решения, то получится результат, построенный методом «разделяй и властвуй».
Упомянутый выше частный случай достигается, когда каждую из сформулированных задач для (г = 1, 2, . д) можно также решить разбиением соответствующих поднаборов на более мелкие. Проделывая такую операцию рекурсивно до определенного предела (терминального значения длины поднабора), Вы можете получить решения подзадач для наборов из нескольких элементов. Затем уже легко построить решение всей задачи как некое объединение этих решений.
Рассмотрим пример применения данного механизма. Обсудим, так называемую сортировку слиянием. Пусть, например, нам дан набор из восьми чисел Т = . Наша задача заключается в том, чтобы отсортировать их, скажем, по возрастанию. Согласно методу «разделяй и властвуй», разделим его пополам, получим два поднабора Т1 = и Т2 = и будем над ними властвовать! А точнее, будем сортировать уже их, каждый отдельно. Как мы будем это делать? Конечно же, опять поделив и тот и другой наборы пополам (таким образом, мы получим Т11 = , Т12 = , Т21 = и Т22 = ). Деление продолжим рекурсивно до того момента, пока не получим наборы из одного единственного элемента (Тш = , Т112 = , Т121 = ,
и Т222 = ). Естественно, такие наборы можно сразу считать отсортированными. Тогда объединим два упорядоченных набора. Причем так, чтобы их объединение опять было упорядоченным 3 4 ► . Проделаем это рекурсивно до тех пор, пока снова не получим набор, равный по длине исходному. На-
деемся, рисунок 1 поможет Вам понять, как именно должно осуществляться объединение наборов.
Механизм слияния наборов мы рассматривать не будем, так как он не имеет непосредственного отношения к обсуждаемой теме. 3 5 ►
Выше мы рассказывали о том, что при решении задач рекурсивным методом существует опасность вызвать переполнение стека. Поэтому нужно стараться минимизировать глубину рекурсии. Читатель, наверное, согласится с тем, что разбивать исходный набор вплоть до поднаборов длины 1 вряд ли имеет смысл. Ведь набор из двух элементов уже можно упорядочить, проверив одно условие. Конечно, можно проверкой некоторого количества разных условий отсортировать и набор из четырех элементов. Однако это, пожалуй, уже лишнее. Так можно «вручную» сортировать наборы из любого наперед заданного числа элементов. 3 6 ► Механизм сортировки наборов с длиной, меньшей терминального значения, тоже можно предусмотреть.
А вот другой пример применения принципа «разделяй и властвуй». Рассмотрим часто встречаемую в программировании задачу о выпуклой оболочке на плоскости. Для конечного множества точек Q выпук-
. рл^би&Аеиь «сх&рМж Ллбор . .
лой оболочкой называется наименьший по площади выпуклый многоугольник, содержащий все точки из Q. Фактически, задача заключается в отыскании некоего подмножества Q (обозначим его S), все точки которого являются вершинами упомянутого многоугольника. Поясним сказанное выше примером. Пусть Q = (здесь числа — номера, индексы, идентификаторы точек, не более того). Точки располагаются так, как указано на рисунке 2. Их координаты задают их расположение. Вряд ли стоит приводить здесь некие конкретные числа, так как наша задача заключается в том, чтобы объяснить принцип, алгоритм решения.
Итак, выпуклой оболочкой является многоугольник, вершинами которого являются точки множества S. В данном случае 5 = . Соответствующий многоугольник показан на рисунке 3. Все оставшиеся точки (то есть те, которые принадлежат Q, но не принадлежат 5) располагаются внутри этого многоугольника.
Для построения выпуклой оболочки существует множество методов: просмотр
Грэхема, проход Джарвиса, метод добавления точек, «метод стрижки и поиска». Если Вас это заинтересовало, то о них Вы можно узнать из книги [1]. Мы же остановимся лишь на решении задачи приемом «разделяй и властвуй». Все происходит абсолютно так же, как при сортировке слиянием. Сначала необходимо разделить имеющееся множество точек на два подмножества, приблизительно равных по мощности (числу элементов). Причем сделать это нужно так, чтобы ни один из многоугольников, построенных на неких точках одной половинки как на вершинах, не пересекался ни с каким многоугольником, построенным на точках другой половинки. Достичь этого можно, разделив плоскость вертикальной прямой на две зоны.
Затем следует получить решение для обеих половинок. Результат представлен на рисунке 4.
Естественно, что задачу для каждой зоны нужно решать так же, разделяя ее на две подзоны. Разделение следует продолжать рекурсивно до тех пор, пока в одной зоне
не окажется лишь 3 точки, для которых выпуклая оболочка получается простым их соединением. Конечно, если в зоне было, например, всего 5 точек, то отделив 3, Вы получите зону в которой — 2 точки. Что же делать? Прочитайте описание излагаемого метода до конца и подумайте, является ли это проблемой.
Теперь остается объединить решения, что на самом деле не очень просто. Для двух зон, изображенных на рисунке 4, получим рисунок 5.
Здесь результирующий прямоугольник обведен сплошными отрезками. Трудность
. улдлгу для клфдай уаЯи НуфНа реалЛ-ь ен
. рлудемий-ь имеющееся . Ял дбл
при объединении заключается в выборе соединяемых точек. Почему мы предпочли отрезок 9-4 отрезкам 9-3, 9-10 и остальным? Дело в том, что нужно производить соединения так, чтобы все точки объединяемых многоугольников лежали по одну сторону от проводимой прямой, и чтобы получающийся многоугольник был минимален. Над этим правилом Вам предстоит подумать в задаче 7.
Ранее говорилось, что задача о выпуклой оболочке «часто встречается в программировании». Не надо из этого делать вывод, что программисты нередко решают задачи планиметрии. Просто многие проблемы из самых разных областей сводятся к построению выпуклой оболочки для некоторого множества, природа которого далека от геометрической, и понятие координат его элементов заменено на что-то специфические для данной задачи. 3 7, 8, 9, 10 ►
Нельзя не отметить, что применительно к задаче 8 этот метод дает существенный выигрыш в эффективности. А именно, он требует 1,5п -2 сравнений, в то время как обычный способ вычисления в цикле требует 2п — 3 (п — 1 на поиск минимума и п — 2 на поиск максимума; минимум в рассмотрении уже не участвует).
Метод «разделяй и властвуй» зачастую повышает эффективность на порядки. Чтобы познакомится с примерами, можно обратиться к книге [2]. Мы же переходим к основной теме — динамическому программированию.
Рекурсия, как уже говорилось, полезна, когда задачу можно разбить на подзадачи, решаемые за «разумное время», причем так, чтобы суммарный размер этих подзадач был «небольшим». Но что делать, если разбиения задачи размера п приводит к п задачам, размера п -1? В таких ситуациях зачастую можно получить более эффектив-
.¿лулгу мо^Но рл^бш&ь Ял по/^лфлш, решаемые «рл^ужНое бремя».
ные алгоритмы методом динамического программирования.
Как и техника «разделяй и властвуй», динамическое программирование позволяет построить решение общей задачи, разбивая ее на подзадачи и объединяя их решения. Однако, как было продемонстрировано выше, при использовании метода «разделяй и властвуй» нужно производить разбиение на системы независимых подзадач. А при динамическом программировании необходимо разделение на взаимосвязанные подзадачи. Дробить следует так, чтобы у подзадач были общие части, общие «подподзадачи», если угодно. Если бы в такой ситуации мы использовали метод «разделяй и властвуй», то эти самые «подподзадачи» решались бы по нескольку раз. Динамический метод, решив ее однажды, запоминает результат в специальном хранилище, как правило, -таблице. Когда этот результат понадобится, будет достаточно лишь обратиться к соответствующей ее ячейке.
Давайте вместе рассмотрим следующую задачу. Пусть нам дана таблица ¥, состоящая из п строк и т столбцов. В каждой ячейке таблицы может содержаться либо «0», либо «1». От нас требуется найти сторону наибольшего квадрата из единиц, который есть в этой таблице.
Поясним сказанное примером ¥ для п и т равных 6.
. ЛребуеЛся Лай&и ойораЛу Камбал-шего коядра,* едиЛщ.
Если бы на вход алгоритма, который мы должны построить, подали бы такую таблицу, то для нее нужно было бы получить ответ 3. Искомый квадрат выделен в таблице.
Как же ее решать? Очевидно, полный перебор всевозможных вариантов — дело не очень перспективное, особенно при больших п и т.
Предлагается следующее решение: заведем таблицу D, равную по размеру К В каждую ее клетку [г, у] поместим величину стороны квадрата из единиц, имеющего нижний правый угол в клетке ^[г, у]. Ясно, что там, где в ^ были нули, там и в D будут нули.
Для приведенной выше исходной таблицы вспомогательная таблица D должна выглядеть так:
просто переносятся из ^ в Д — очевиден. Ведь на них мы можем обнаружить либо квадрат со стороной равной единице (то есть просто -«1»), либо ноль, который вообще не может являться «нижним правым углом квадрата из единиц».
Теперь сведем имеющиеся результаты относительно D воедино. Получим:
^[г, у], при г = 1 или у = 1 0, если ^[г, у] = 0
т1п(Дг — 1, у], Дг, у — 1], Дг — 1, у — 1]) + 1 ,
Очевидно, наша задача свелась к вычислению наибольшего значения в таблице D. Очень хорошо! Но для начала не мешало бы выяснить, как эта таблица строится. Это делается очень просто. Надеемся, тот факт, что первая строка и первый столбец
i Не можете найти то, что вам нужно? Попробуйте сервис подбора литературы.
Как реализовать вычисление D на компьютере? Сначала — заполнить первую строку и столбец. А затем — вычислять в двойном цикле по г и у от меньших индексов — к большим. При таком подходе Вы защищены от того, что может потребоваться значение из ячейки, которое еще не вычислялось. 3 11 ►
Продемонстрированный только что метод решения задачи, иллюстрировал прием динамического программирования «снизу вверх» (явное указание на это заключено во фразе «от меньших индексов — к большим»). Если есть такой способ, то должен быть и способ «сверху вниз»? Совершенно верно. Его отличие состоит в методе работы с таблицей полученных результатов подзадач. А именно: изначально все клетки таблицы инициализируются неким значением, сигнализирующем о том, что информация для данной клетки еще не вычислялась. Условно обозначим его как ¥ По ходу решения задачи, естественно, происходит обращение к определенным ячейкам таблицы. Если значение в требуемой ячейке равно ¥, то вызывается рекурсивная функция, вычисляющая это значение. В противном случае просто берется соответствующая информация из определенной клетки таблицы. Такой метод больше тяготеет к названию «рекурсия с сохранением результатов», чем «динамическое программирование сверху вниз», но с классической терминологией спорить не будем.
Как правило, метод «снизу вверх» более или, по крайней мере, не менее эффективен, чем «сверху вниз», если каждая из подзадач должна быть решена несколько раз. Просто метод «сверху вниз» требует много дополнительного времени на разнообразные проверки наличия информации в таблице и тому подобное. К тому же, он увеличивает глубину рекурсии. Ведь на любом ее уровне может внезапно потребоваться еще более глубокое «погружение» для дополнения таблицы требуемой информацией. В то время как метод «снизу вверх»
. обращение а определенным ячейкам Ллёмщи.
характеризуется тем, что мы гарантированно на каждом шаге имеем всю необходимую для дальнейших вычислений информацию.
Тем не менее, если метод «сверху вниз» существует, значит он кому-нибудь нужен. Дело в том, что получаемый алгоритм будет несколько понятнее. Он позволит однозначно ответить на вопрос «откуда что берется». Какие значения, на каком этапе выполнения вычисляются. Это особенно актуально, если последовательность вычисления значений сложна.
Сказанное выше не означает, что этот метод не стоит использовать. Наоборот, предыдущий абзац, скорее, — лишний аргумент в пользу его применения. К тому же, он полезен, когда не все подзадачи решаются несколько раз. 3 12 ►
На практике очень часто встречается задача о выделении наибольшей общей подпоследовательности. Давайте рассмотрим и ее решение методом динамического программирования. Основное свойство этой задачи, которое мы будем при этом использовать, заключается в следующем:
Для нахождения наибольшей общей подпоследовательности последовательностей X и У нужно:
1) Если последний элемент последовательности X совпадает с последним элементом последовательности У, то решать задачу для этих последовательностей без последних элементов, а
потом приписать этот элемент к результату.
2) Если последний элемент последовательности X не совпадает с последним элементом последовательности У, решать две задачи. Первая — для последовательности X без последнего элемента
и последовательности У. Вторая — для последовательности У без последнего элемента и последовательности X. Наибольший из результатов и будет наибольшей общей подпоследовательностью.
Таким образом, получилось очевидное перекрытие подзадач: ведь наибольшую общую подпоследовательность для X и У без последних элементов придется искать, как в случае 1, так, вероятно, и в случае 2. Очевидно, что в этой ситуации имеет смысл сохранять результаты вычислений в таблице. Обозначим за с [г, у] длину наибольшей общей подпоследовательности для последовательности X, состоящей из г элементов, и последовательности У — из у элементов. Тогда приходим к соотношению:
с[г — 1, у — 1] + 1, если г, у > 0
и последние элементы совпадают, тах(с[г, у — 1], с[г — 1, у]), если г, у > 0 и последние элементы не совпадают.
Как Вы, должно быть, уже догадались, с [г, у’] и составляет содержание одноименной таблицы, необходимой для корректной работы метода динамического программирования. Здесь г = 0, 1, . , т, а у = 0, 1, . , п.
Кроме того, потребуется вторая таблица Ь, в которой Ь [г, у] хранит «происхождение» с [г, у]. Ведь возможны 3 варианта появления конкретного значения с [г, у]: от с[г — 1, у — 1], от с[г, у — 1] или от с[г — 1, у]. Очень красивым и экономичным решением для организации Ь было бы такое, при котором на каждую ячейку отводилось бы 2 бита. Таким образом, одна ячейка могла бы хранить значения от 0 до 3. Этого было бы вполне достаточно (даже одно — лишнее), а интерпретировать их можно было бы так:
0 — значение для инициализации ячеек Ь. На самом деле, конечно, оно не нужно, но что ему без дела пропадать ©.
1 — с [г,у] «произошло» от с [г — 1,у — 1].
2 — с [г, у] «произошло» от с [г, у — 1].
3 — с [г, у] «произошло» от с [г — 1, у].
Теперь, пусть алгоритм выполнен и
таблицы Ь и с заполнены. Как получить Z? Нужно из клетки Ь [т, п] проделать путь до
^уфЯо Ь [т, п] проф&хо&ь до
ЯекоЛорой кле&ки. Ь [ 0, р].
некоторой клетки Ь [0, р] или Ь [г, 0] (для какого-нибудь р или г), выписывая одинаковые члены последовательностей X и У. Звучит угрожающе, не правда ли? Посмотрите на рисунок 6, и, надеемся, Вам станет понятнее.
На рисунке представлено некое совмещение информации таблиц Ь и с для X = и У = . Число в каждой клетке соответствует значению с [г, у] для нее. Стрелочка — некое наглядное представление информации ячейки Ь [г, у]. Она указывает на ту ячейку, от которой «произошло» с [г, у]. Такое представление очень удобно для построения пути из Ь [т, п]. Оно просто заключается в прохождении по этим стрелкам до тех пор, пока не будет достигнута граница матрицы. Клет-
Всё, что вы хотели знать о динамическом программировании, но боялись спросить
Я был крайне удивлён, найдя мало статей про динамическое программирование (далее просто динамика) на хабре. Мне всегда казалось, что эта парадигма довольно сильно распространена, в том числе и за пределами олимпиад по программированию. Поэтому я постараюсь закрыть этот пробел своей статьёй.
# Весь код в статье написан на языке Python Основы
Пожалуй, лучшее описание динамики в одно предложение, которое я когда либо слышал:
Динамическое программирование — это когда у нас есть задача, которую непонятно как решать, и мы разбиваем ее на меньшие задачи, которые тоже непонятно как решать. (с) А. Кумок.
Чтобы успешно решить задачу динамикой нужно:
1) Состояние динамики: параметр(ы), однозначно задающие подзадачу.
2) Значения начальных состояний.
3) Переходы между состояниями: формула пересчёта.
4) Порядок пересчёта.
5) Положение ответа на задачу: иногда это сумма или, например, максимум из значений нескольких состояний.
Порядок пересчёта
Существует три порядка пересчёта:
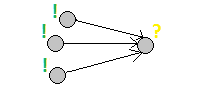
1) Прямой порядок:
Состояния последовательно пересчитывается исходя из уже посчитанных.
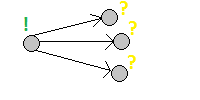
2) Обратный порядок:
Обновляются все состояния, зависящие от текущего состояния.
3) Ленивая динамика:
Рекурсивная мемоизированная функция пересчёта динамики. Это что-то вроде поиска в глубину по ацикличному графу состояний, где рёбра — это зависимости между ними.
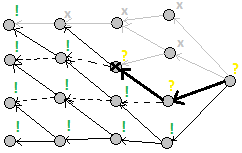
Элементарный пример: числа Фибоначчи. Состояние — номер числа.
fib[1] = 1 # Начальные значения fib[2] = 1 # Начальные значения for i in range(3, n + 1): fib[i] = fib[i - 1] + fib[i - 2] # Пересчёт состояния i Обратный порядок:
fib[1] = 1 # Начальные значения for i in range(1, n): fib[i + 1] += fib[i] # Обновление состояния i + 1 fib[i + 2] += fib[i] # Обновление состояния i + 2 Ленивая динамика:
def get_fib(i): if (i Все три варианта имеют права на жизнь. Каждый из них имеет свою область применения, хотя часто пересекающуюся с другими.
Многомерная динамика
Пример одномерной динамики приведён выше, в «порядке пересчёта», так что я сразу начну с многомерной. Она отличается от одномерной, как вы уже наверно догадались, количеством измерений, то есть количеством параметров в состоянии. Классификация по этому признаку обычно строится по схеме «один-два-много» и не особо принципиальна, на самом деле.
Многомерная динамика не сильно отличается от одномерной, в чём вы можете убедиться взглянув на пару примеров:
Пример №1: Количество СМСок
Раньше, когда у телефонов были кнопки, их клавиатуры выглядели примерно так:
Требуется подсчитать, сколько различных текстовых сообщений множно написать используя не более k нажатий на такой клавиатуре.
Решение
1) Состояние динамики: dp[n][m] — количество различных сообщений длины n , использующих m нажатий.
2) Начальное состояние: есть одно сообщение длины ноль, использующее ноль нажатий — пустое.
3) Формулы пересчёта: есть по восемь букв, для написания которых нужно одно, два и три нажатия, а так же две буквы требующие 4 нажатия.
dp[n][m] = (dp[n - 1][m - 1] + dp[n - 1][m - 2] + dp[n - 1][m - 3]) * 8 + dp[n - 1][m - 4] * 2 Обратный пересчёт:
dp[n + 1][m + 1] += dp[n][m] * 8 dp[n + 1][m + 2] += dp[n][m] * 8 dp[n + 1][m + 3] += dp[n][m] * 8 dp[n + 1][m + 4] += dp[n][m] * 2 4) Порядок пересчёта:
Если писать прямым методом, то надо отдельно подумать о выходе за границу динамики, к примеру, когда мы обращаемся к dp[n - 1][m - 4] , которого может не существовать при малых m . Для обхода этого можно или ставить проверки в пересчёте или записать туда нейтральные элементы (не изменяющие ответа).
При использовании обратного пересчёта всё проще: мы всегда обращаемся вперёд, так что в отрицательные элементы мы не уйдём.
5) Ответ — это сумма всех состояний.
UPD:
К сожалению, я допустил ошибку — задачу можно решить и одномерно, просто убрав из состояния длину сообщения n .
1) Состояние: dp[m] — количество различных собщений, которые можно набрать за m нажатий.
2) Начальное состояние: dp[0] = 1 .
3) Формула пересчёта:
dp[m] = (dp[m - 1] + dp[m - 2] + dp[m - 3]) * 8 + dp[m - 4] * 2 4) Порядок: все три варианта можно использовать.
5) Ответ — это сумма всех состояний.
Пример №2: Конь
Шахматный конь стоит в клетке (1, 1) на доске размера N x M . Требуется подсчитать количество способов добраться до клетки (N, M) передвигаясь четырьмя типами шагов:
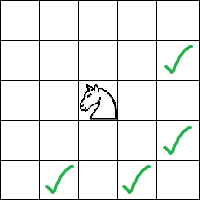
Решение
1) Состояние динамики: dp[i][j] — количество способов добраться до (i, j) .
2) Начальное значение: В клетку (1, 1) можно добраться одним способом — ничего не делать.
3) Формула пересчёта:
Для прямого порядка:
dp[i][j] = dp[i - 2][j - 1] + dp[i - 2][j + 1] + dp[i - 1][j - 2] + dp[i + 1][j - 2] Для обратного порядка:
dp[i + 1][j + 2] += dp[i][j] dp[i + 2][j + 1] += dp[i][j] dp[i - 1][j + 2] += dp[i][j] dp[i + 2][j - 1] += dp[i][j] 4) А теперь самое интересное в этой задаче: порядок. Здесь нельзя просто взять и пройтись по строкам или по столбцам. Потому что иначе мы будем обращаться к ещё не пересчитанным состояниям при прямом порядке, и будем брать ещё недоделанные состояния при обратном подходе.
Есть два пути:
1) Придумать хороший обход.
2) Запустить ленивую динамику, пусть сама разберётся.
Если лень думать — запускаем ленивую динамику, она отлично справится с задачей.
Если не лень, то можно придумать обход наподобие такого:
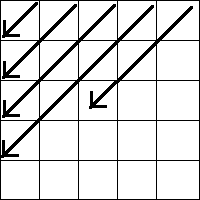
Этот порядок гарантирует обработанность всех требуемых на каждом шаге клеток при прямом обходе, и обработанность текущего состояния при обратном.
5) Ответ просто лежит в dp[n][m] .
Динамика и матрица переходов
Если никогда не умножали матрицы, но хотите понять этот заголовок, то стоит прочитать хотя бы вики.
Допустим, есть задача, которую мы уже решили динамическим программированием, например, извечные числа Фибоначчи.
Давайте немного переформулируем её. Пусть у нас есть вектор , из которого мы хотим получить вектор . Чуть-чуть раскроем формулы: . Можно заметить, что из вектора можно получить вектор путем умножения на какую-то матрицу, ведь в итоговом векторе фигурируют только сложенные переменные из первого вектора. Эту матрицу легко вывести, вот она: . Назовём её матрицей перехода.
Это значит, что если взять вектор и умножить его на матрицу перехода n - 1 раз, то получим вектор , в котором лежит fib[n] — ответ на задачу.
А теперь, зачем всё это надо. Умножение матриц обладает свойством ассоциативности, то есть (но при этом не обладает коммутативностью, что по-моему удивительно). Это свойство даёт нам право сделать так: .
Это хорошо тем, что теперь можно применить метод быстрого возведения в степень, который работает за . Итого мы сумели посчитать N -ое число Фибоначчи за логарифм арифметических операций.
А теперь пример посерьёзнее:
Пример №3: Пилообразная последовательность

Обозначим пилообразную последовательность длины N как последовательность, у которой для каждого не крайнего элемента выполняется условие: он или меньше обоих своих соседей или больше. Требуется посчитать количество пилообразных последовательностей из цифр длины N . Выглядит это как-то так:
Решение
Для начала решение без матрицы перехода:
1) Состояние динамики: dp[n][last][less] — количество пилообразных последовательностей длины n , заканчивающихся на цифру last . Причём если less == 0 , то последняя цифра меньше предпоследней, а если less == 1 , значит больше.
2) Начальные значения:
for last in range(10): dp[2][last][0] = 9 - last dp[2][last][1] = last 3) Пересчёт динамики:
for prev in range(10): if prev > last: dp[n][last][0] += dp[n - 1][prev][1] if prev < last: dp[n][last][1] += dp[n - 1][pref][0] 4) Порядок пересчёта: мы всегда обращаемся к предыдущей длине, так что просто пара вложенных for 'ов.
5) Ответ — это сумма dp[N][0..9][0..1] .
Теперь надо придумать начальный вектор и матрицу перехода к нему. Вектор, кажется, придумывается быстро: все состояния, обозначающие длину последовательности N . Ну а матрица перехода выводится, смотря на формулы пересчёта.
Вектор и матрица перехода
Динамика по подотрезкам
Это класс динамики, в котором состояние — это границы подотрезка какого-нибудь массива. Суть в том, чтобы подсчитать ответы для подзадач, основывающихся на всех возможных подотрезках нашего массива. Обычно перебираются они в порядке увеличения длины, и пересчёт основывается, соответственно на более коротких отрезках.
Пример №4: Запаковка строки
Вот Развернутое условие. Я вкратце его перескажу:
Определим сжатую строку:
1) Строка состоящая только из букв — это сжатая строка. Разжимается она в саму себя.
2) Строка, являющаяся конкатенацией двух сжатых строк A и B . Разжимается она в конкатенацию разжатых строк A и B .
3) Строка D(X) , где D — целое число, большее 1 , а X — сжатая строка. Разжимается она в конкатенацию D строк, разжатых из X .
Пример: “3(2(A)2(B))C” разжимается в “AABBAABBAABBC” .
Необходимо по строке s узнать длину самой короткой сжатой строки, разжимающийся в неё.
Решение
Решается эта задача, как вы уже наверняка догадались, динамикой по подотрезкам.
1) Состояние динамики: d[l][r] — сжатая строка минимальной длины, разжимающаяся в строку s[l:r]
2) Начальные состояния: все подстроки длины один можно сжать только в них самих.
3) Пересчёт динамики:
У лучшего ответа есть какая-то последняя операция сжатия: либо это просто строка из заглавных букв, или это конкатенация двух строк, или само сжатие. Так давайте переберём все варианты и выберем лучший.
dp_len = r - l dp[l][r] = dp_len # Первый вариант сжатия - просто строка. for i in range(l + 1, r): dp[l][r] = min(dp[l][r], dp[l][i] + dp[i][r]) # Попробовать разделить на две сжатые подстроки for cnt in range(2, dp_len): if (dp_len % cnt == 0): # Если не делится, то нет смысла пытаться разделить good = True for j in range(1, (dp_len / cnt) + 1): # Проверка на то, что все cnt подстрок одинаковы good &= s[l:l + dp_len / cnt] == s[l + (dp_len / cnt) * j:l + (dp_len / cnt) * (j + 1)] if good: # Попробовать разделить на cnt одинаковых подстрок и сжать dp[l][r] = min(dp[l][r], len(str(cnt)) + 1 + dp[l][l + dp_len / cnt] + 1) 4) Порядок пересчёта: прямой по возрастанию длины подстроки или ленивая динамика.
5) Ответ лежит в d[0][len(s)] .
Пример №5: Дубы
Динамика по поддеревьям
Параметром состояния динамики по поддеревьям обычно бывает вершина, обозначающая поддерево, в котором эта вершина — корень. Для получения значения текущего состояния обычно нужно знать результаты всех своих детей. Чаще всего реализуют лениво — просто пишут поиск в глубину из корня дерева.
Пример №6: Логическое дерево
Дано подвешенное дерево, в листьях которого записаны однобитовые числа — 0 или 1 . Во всех внутренних вершинах так же записаны числа, но по следующему правилу: для каждой вершины выбрана одна из логических операций: «И» или «ИЛИ». Если это «И», то значение вершины — это логическое «И» от значений всех её детей. Если же «ИЛИ», то значение вершины — это логическое «ИЛИ» от значений всех её детей.
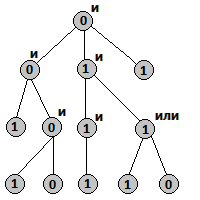
Требуется найти минимальное количество изменений логических операций во внутренних вершинах, такое, чтобы изменилось значение в корне или сообщить, что это невозможно.
Решение
1) Состояние динамики: d[v][x] — количество операций, требуемых для получения значения x в вершине v . Если это невозможно, то значение состояния — +inf .
2) Начальные значения: для листьев, очевидно, что своё значение можно получить за ноль изменений, изменить же значение невозможно, то есть возможно, но только за +inf операций.
3) Формула пересчёта:
Если в этой вершине уже значение x , то ноль. Если нет, то есть два варианта: изменить в текущей вершине операцию или нет. Для обоих нужно найти оптимальный вариант и выбрать наилучший.
Если операция «И» и нужно получить «0», то ответ это минимум из значений d[i][0] , где i — сын v .
Если операция «И» и нужно получить «1», то ответ это сумма всех значений d[i][1] , где i — сын v .
Если операция «ИЛИ» и нужно получить «0», то ответ это сумма всех значений d[i][0] , где i — сын v .
Если операция «ИЛИ» и нужно получить «1», то ответ это минимум из значений d[i][1] , где i — сын v .
4) Порядок пересчёта: легче всего реализуется лениво — в виде поиска в глубину из корня.
5) Ответ — d[root][value[root] xor 1] .
Динамика по подмножествам
В динамике по подмножествам обычно в состояние входит маска заданного множества. Перебираются чаще всего в порядке увеличения количества единиц в этой маске и пересчитываются, соответственно, из состояний, меньших по включению. Обычно используется ленивая динамика, чтобы специально не думать о порядке обхода, который иногда бывает не совсем тривиальным.
Пример №7: Гамильтонов цикл минимального веса, или задача коммивояжера
Задан взвешенный (веса рёбер неотрицательны) граф G размера N . Найти гамильтонов цикл (цикл, проходящий по всем вершинам без самопересечений) минимального веса.
Решение
Так как мы ищем цикл, проходящий через все вершины, то можно выбрать за «начальную» вершину любую. Пусть это будет вершина с номером 0 .
1) Состояние динамики: dp[mask][v] — путь минимального веса из вершины 0 в вершину v , проходящий по всем вершинам, лежащим в mask и только по ним.
2) Начальные значения: dp[1][0] = 0 , все остальные состояния изначально — +inf .
3) Формула пересчёта: Если i -й бит в mask равен 1 и есть ребро из i в v , то:
dp[mask][v] = min(dp[mask][v], dp[mask - (1 Где w[i][v] — вес ребра из i в v .
4) Порядок пересчёта: самый простой и удобный способ — это написать ленивую динамику, но можно поизвращаться и написать перебор масок в порядке увеличения количества единичных битов в ней.
5) Ответ лежит в d[(1
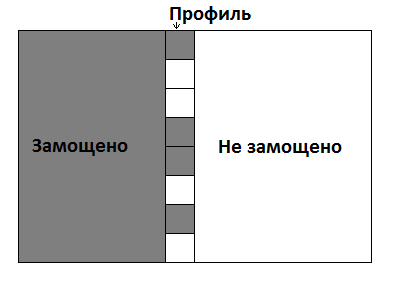
Динамика по профилю
Классическими задачами, решающимися динамикой по профилю, являются задачи на замощение поля какими-нибудь фигурами. Причём спрашиваться могут разные вещи, например, количество способов замощения или замощение минимальным количеством фигур.
Эти задачи можно решить полным перебором за , где a — количество вариантов замощения одной клетки. Динамика по профилю же оптимизирует время по одной из размерностей до линейной, оставив от себя в экспоненте только коэффициент. Получится что-то такое: .
Профиль — это k (зачастую один) столбцов, являющиеся границей между уже замощённой частью и ещё не замощённой. Эта граница заполнена только частично. Очень часто является частью состояния динамики.
Почти всегда состояние — это профиль и то, где этот профиль. А переход увеличивает это местоположение на один. Узнать, можно ли перейти из одного профиля в другой можно за линейное от размера профиля время. Это можно проверять каждый раз во время пересчёта, но можно и предподсчитать. Предподсчитывать будем двумерный массив can[mask][next_mask] — можно ли от одной маски перейти к другой, положив несколько фигурок, увеличив положение профиля на один. Если предподсчитывать, то времени на выполнение потребуется меньше, а памяти — больше.
Пример №8: Замощение доминошками
Найти количество способов замостить таблицу N x M с помощью доминошек размерами 1 x 2 и 2 x 1 .
Решение
Здесь профиль — это один столбец. Хранить его удобно в виде двоичной маски: 0 — не замощенная клетка столбца, 1 — замощенная. То есть всего профилей .
0) Предподсчёт (опционально): перебрать все пары профилей и проверить, что из одного можно перейти в другой. В этой задаче это проверяется так:
Если в первом профиле на очередном месте стоит 1 , значит во втором обязательно должен стоять 0 , так как мы не сможем замостить эту клетку никакой фигуркой.
Если в первом профиле на очередном месте стоит 0 , то есть два варианта — или во втором 0 или 1 .
Если 0 , это значит, что мы обязаны положить вертикальную доминошку, а значит следующую клетку можно рассматривать как 1 . Если 1 , то мы ставим вертикальную доминошку и переходим к следующей клетке.
Примеры переходов (из верхнего профиля можно перейти в нижние и только в них):
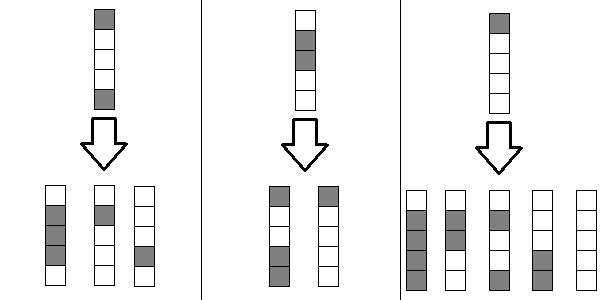
После этого сохранить всё в массив can[mask][next_mask] — 1 , если можно перейти, 0 — если нельзя.
1) Состояние динамики: dp[pos][mask] — количество полных замощений первых pos - 1 столбцов с профилем mask .
2) Начальное состояние: dp[0][0] = 1 — левая граница поля — прямая стенка.
3) Формула пересчёта:
dp[pos][mask] += dp[pos - 1][next_mask] * can[mask][next_mask] 4) Порядок обхода — в порядке увеличения pos .
5) Ответ лежит в dp[pos][0].
Динамика по изломанному профилю
Это очень сильная оптимизация динамики по профилю. Здесь профиль — это не только маска, но ещё и место излома. Выглядит это так:
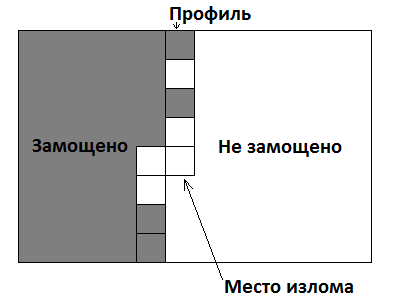
Теперь, после добавления излома в профиль, можно переходить к следующему состоянию, добавляя всего одну фигурку, накрывающую левую клетку излома. То есть увеличением числа состояний в N раз (надо помнить, где место излома) мы сократили число переходов из одного состояния в другое с до . Асимптотика улучшилась с до .
Переходы в динамике по изломанному профилю на примере задачи про замощение доминошками (пример №8):
Восстановление ответа
Иногда бывает, что просто знать какую-то характеристику лучшего ответа недостаточно. Например, в задаче «Запаковка строки» (пример №4) мы в итоге получаем только длину самой короткой сжатой строки, но, скорее всего, нам нужна не её длина, а сама строка. В таком случае надо восстановить ответ.
В каждой задаче свой способ восстановления ответа, но самые распространенные:
- Рядом со значением состояния динамики хранить полный ответ на подзадачу. Если ответ — это что-то большое, то может понадобиться чересчур много памяти, поэтому если можно воспользоваться другим методом, обычно так и делают.
- Восстанавливать ответ, зная предка(ов) данного состояния. Зачастую можно восстановить ответ, зная только как он был получен. В той самой «Запаковке строки» можно для восстановления ответа хранить только вид последнего действия и то, из каких состояний оно было получено.
- Есть способ, вообще не использующий дополнительную память — после пересчёта динамики пойти с конца по лучшему пути и по дороге составлять ответ.
Небольшие оптимизации
Память
Зачастую в динамике можно встретить задачу, в которой состояние требует быть посчитанными не очень большое количество других состояний. Например, при подсчёте чисел Фибоначчи мы используем только два последних, а к предыдущим уже никогда не обратимся. Значит, можно про них забыть, то есть не хранить в памяти. Иногда это улучшает асимптотическую оценку по памяти. Этим приёмом можно воспользоваться в примерах №1, №2, №3 (в решении без матрицы перехода), №7 и №8. Правда, этим никак не получится воспользоваться, если порядок обхода — ленивая динамика.
Время
Иногда бывает так, что можно улучшить асимптотическое время, используя какую-нибудь структуру данных. К примеру, в алгоритме Дейкстры можно воспользоваться очередью с приоритетами для изменения асимптотического времени.
Замена состояния
В решениях динамикой обязательно фигурирует состояние — параметры, однозначно задающие подзадачу, но это состояние не обязательно одно единственное. Иногда можно придумать другие параметры и получить с этого выгоду в виде снижения асимптотического времени или памяти.
Пример №9: Разложение числа
- 7
- 3 + 4
- 2 + 5
- 1 + 7
- 1 + 2 + 4
Два решения с различными состояниями
Решение №1:
1) Состояние динамики: dp[n][k] — количество разложений числа n на числа, меньшие или равные k . Параметр k нужен, чтобы брать всегда только большие числа, чем уже имеющиеся.
2) Начальные значения: dp[1][1] = 1 , dp[1][i] = 0 .
3) Формула пересчёта:
for last_summand in range(1, k + 1): dp[n][k] += dp[n - last_summand][last_summand] 4) Порядок: прямой, в порядке увеличения n .
5) Ответ — сумма dp[N][1..N] .
Состояний: , переходов: . Асимптотика: .
Решение №2:
1) Поменяем состояние. Теперь dp[n][k] — это количество разложений числа n на k различных чисел. Казалось бы незачем, но сейчас будет понятно.
2) Начальные значения: dp[1][1] = 1 , dp[1][i] = 0 .
3) Формула пересчёта:
dp[n][k] = dp[n - k][k] + dp[n - k][k - 1] - Все уже имеющиеся числа увеличить на 1 .
- Все уже имеющиеся числа увеличить на 1 . Добавить число 1 в разложение.
Строки здесь обозначают слагаемые.
Первое решение последовательно добавляет по одной строчке внизу таблицы, а второе — по одному столбцу слева таблицы. Вариантов размера следующей строчки много — главное, чтобы она была больше предыдущей, а столбцов — только два: такой же как предыдущий и на единичку больше.
4) Порядок пересчёта: прямой, в порядке увеличения n .
Невооруженным взглядом кажется, что у этого решения асимптотика , ведь есть два измерения в состоянии и переходов. Но это не так, ведь второй параметр — k ограничен сверху не числом N , а формулой (сумма чисел от 1 до k меньше или равна разлагаемого числа). Из этой формулы видно, что количество состояний .
5) Ответ — это сумма dp[N][1..k_max] .
Заключение
Основным источником была голова, а туда информация попала с лекций в Летней Компьютерной Школе (для школьников), а также кружка Андрея Станкевича и спецкурса Михаила Дворкина (darnley).
Спасибо за внимание, надеюсь эта статья кому-нибудь пригодится! Хотя мне уже пригодилась — оказывается, написание статьи это хороший способ всё вспомнить.
- динамическое программирование
- динамика
- дп
- dynamic programming
- dynamic
- dp
- как ещё можно обозвать динамику?
- динамика по подотрезкам
- динамика по поддеревьям
- динамика по подмножествам
- динамика по профилю
- динамика по изломанному профилю
- матрица перехода