CPU Load: когда начинать волноваться?
Данная заметка является переводом статьи из блога компании Scout. В статье дается простое и наглядное объяснение такого понятия, как load average . Статья ориентирована на начинающих Linux-администраторов, но, возможно, будет полезна и более опытным админам. Заинтересовавшимся добро пожаловать под кат.
Вероятно, Вы уже знакомы с понятием load average . Load average — это три числа, отображаемые при выполнении команд top и uptime . Выглядят они примерно так:
load average: 0,35, 0,32, 0,41 Большинство интуитивно понимают, что эти три числа обозначают средние значения загрузки процессора на прогрессивно увеличивающихся временных промежутках (одна, пять и пятнадцать минут) и чем меньше их значения — тем лучше. Большие числа свидетельствуют о слишком большой нагрузке на сервер. Но какие значения считать предельными? Какие значения являются «плохими», а какие — «хорошими»? Когда Вам следует просто волноваться о занчениях средней загрузки, а когда следует бросать другие дела и решать проблему так быстро, как это возможно?
Для начала, давайте разберемся, что же означает load average . Рассмотрим простейший случай: предположим, что у нас в наличии один сервер с одноядерным процессором.
Аналогия транспортного потока
Одноядерный процессор похож на дорогу с одной полосой движения. Представьте себе, что Вы управяете движением машин по мосту. Иногда, Ваш мост загружен настолько сильно, что машинам приходится ждать в очереди чтобы проехать по нему. Вы хотите дать людям понять, как долго им придется ждать чтобы перебраться на другую сторону реки. Хорошим способом сделать это будет показать как много машин ждут в очереди в конкретный момент времени. Если машин в очереди нет, подъезжающие водители будут знать, что они сразу смогут проехать по мосту. В противном случае, они будут понимать, что придется ждать своей очереди.
Итак, Управляющий Мостом, какую систему обозначений Вы будете использовать? Как насчет такой:
- 0.00 означает, что на мосту нет ни одной машины. Фактически, значения от 0.00 до 1.00 означают отсутствие очереди. Подъезжающая машина может воспользоваться мостом без ожидания;
- 1.00 означает, что на мосту находится как раз столько автомобилей, сколько он может вместить. Все еще идет хорошо, но, в случае увеличения потока машин, возможны проблемы;
- Значения, превышающие 1.00 означают наличие очереди на въезде. Насколько большой? Например, значение 2.00 показывает, что в очереди стоит столько же автомобилей, сколько движется по мосту. 3.00 означает, что мост полностью занят и в очереди ожидает в два раза больше машин, чем он может вместить. И так далее.
 load average = 1.00
load average = 1.00  load average = 0.50
load average = 0.50  load average = 1.70
load average = 1.70
Вот базовое значение загрузки процессора. «Машины» обрабатываются с использованием промежутков процессорного времени («пересекают мост»), либо ставятся в очередь. В Unix это называется длина очереди выполнения: количество всех процессов, выполняемых в данный момент времени, плюс количество процессов, ожидающих в очереди.
Вам, как управляющему мостом, хотелось бы, чтобы машины-процессы никогда не ждали в очереди. Таким образом, предпочтительно, чтобы загрузки процессора была всегда ниже 1.00. Периодически возможны всплески трафика, когда загрузка будет превышать 1.00, но если она постоянно превышает данное значение — это повод начать волноваться.
Так Вы говорите, 1.00 — идеальное значание load average?
- Практическое правило «Требуется присмотр»: 0.70. Если среднее значение загрузки постоянно превышает 0.70, следует выяснить причину такого поведения системы во избежании проблем в будущем;
- Практическое правило «Почини это немедленно!»: 1.00. Если средняя загрузка системы превышает 1.00, необходимо срочно найти причину и устранить ее. В противном случае, Вы рискуете быть разбуженным посреди ночи и это точно не будет весело;
- Практическое правило «Щас же 3 ночи. ШОЗАНАХ. »: 5.00. Если среднее значение загрузки процессора превышает 5.00, у Вас серьезные проблемы. Сервер может подвисать или работать очень медленно. Скорее всего, это произойдет в худший из возможных моментов. Например, посреди ночи или когда Вы выступаете с докладом на конференции.
Что насчет многопроцессорных систем? Мой сервер показывает загрузку 3.00 и все ОК!
У Вас четырехпроцессорная система? Все в порядке, если load average равен 3.00.
В мультипроцессорных системах загрузка вычисляется относительно количества доступных процессорных ядер. 100% загрузка обозначается числом 1.00 для одноядерной машины, числом 2.00 для двуядерной, 4.00 для четырехъядерной и т.д.
Если вернуться к нашей аналогии с мостом, 1.00 означает «одну полностью загруженную полосу движения». Если на мосту всего одна полоса, 1.00 означает, что мост загружен на 100%, если же в наличии две полосы, он загружен всего на 50%.
То же самое с процессорами. 1.00 означает 100% загрузки одноядерного процессора. 2.00 — 100% загрузки двуядерного и т.д.
Многоядерность vs. многопроцессорность
- «Количество ядер = максимальная загрузка». На многоядерной системе, загрузка не должна превышать количества доступных ядер;
- «Ядра — они и в Африке ядра». То, как ядра распределены по процессорам — неважно. Два четырехъядерных = четыре двуядерных = восем одноядерных процессоров. Имеет значение лишь общее число ядер.
Сведем все вместе
Давайте посмотрим на средние значения загрузки с помощью команды uptime :
~$ uptime 09:14:44 up 1:20, 5 users, load average: 0,35, 0,32, 0,41 Здесь представлены показатели для системы с четырехъядерным процессором и мы видим, что имеется большой запас по нагрузке. Я даже не буду задумываться о ней, пока load average не превысит 3.70.
Какое среднее значение мне следует контролировать? Для одной, пяти или 15 минут?
Для значений, о которых мы говорили раньше (1.00 — почини это немедленно и т.д.), следует рассматривать временные промежутки в пять и 15 минут. Если загрузка Вашей системы превышает 1.00 на интервале в одну минуту, все в порядке. Если же загрузка превышает 1.00 на пяти- или 15-минутном интервале, Вам следует начать принимать меры (конечно, Вам следует также принимать во внимание количество ядер в Вашей системе).
Количество ядер важно для правильно понимания load average. Как мне его узнать?
Команда cat /proc/cpuinfo выводит информацию обо всех процессорах в вашей системе. Чтобы узнать количество ядер, «скормите» ее вывод утилите grep :
~$ cat /proc/cpuinfo | grep 'cpu cores' cpu cores : 4 cpu cores : 4 cpu cores : 4 cpu cores : 4 Примечания переводчика
Выше представлен перевод самой статьи. Также много интересной информации можно почерпнуть из комментариев к ней. Так, один из комментаторов говорит о том, что не для каждой системы важно иметь запас по производтельности и не допускать значения загрузки выше 0.70 — иногда нам нужно чтобы сервер работал «на всю катушку» и в таких случаях load average = 1.00 — то, что доктор прописал.
PS
Хабраюзер dukelion добавил в комментариях ценное замечание, что в некоторых сценариях, для достижения максимального КПД «железа», стоит держать значение load average несколько выше 1.00 в ущерб эффективности работы каждого отдельного процесса.
PPS
Хабраюзер enemo в комментариях добавил замечание о том, что высокий показатель load average может быть вызван большим количеством процессов, выполняющих в данный момент операции чтения/записи. То есть, load average > 1.00 на одноядерной машине не всегда говорит о том, что в Вашей системе отсутствует запас по загрузке процессора. Требуется более внимательное изучение причин такого показателя. Кстати, это хорошая тема для нового поста на Хабре 🙂
PPPS
Хабраюзер esvaf в комментариях интересуется, как интерпретировать значения load average в случае использования процессора с технологией HyperThreading. Однозначного ответа на данный момент я не нашел. В данной статье утверждается, что процессор, который имеет два виртуальных ядра при одном физическом, будет на 10-30% более производительным, чем простой одноядерный. Если принимать такое допущение за истину, считаю, при интерпретации load average стоит брать в расчет только количество физических ядер.
- linux
- перевод с английского
30 инструментов мониторинга системы Linux, которые должен знать каждый сисадмин

Visitors have accessed this post 18363 times.
Ищете способы, как контролировать производительность сервера Linux? В большинстве дистрибутивов Linux уже встроены разные инструменты мониторинга. Используя их, можно посмотреть метрики с информацией о системных процессах. Эти инструменты можно использовать для поиска возможных причин возникновения проблем с производительностью. Команды, которые мы будем обсуждать в этой статье, относятся к самым фундаментальным. Они нужны для системного анализа и отладки проблем сервера Linux, таких как:
- Выявление узких мест в системе
- Проблемы производительности диска (хранилища)
- Проблемы производительности памяти и процессора
- Узкие места в сети
1. top — мониторинг активности процессов
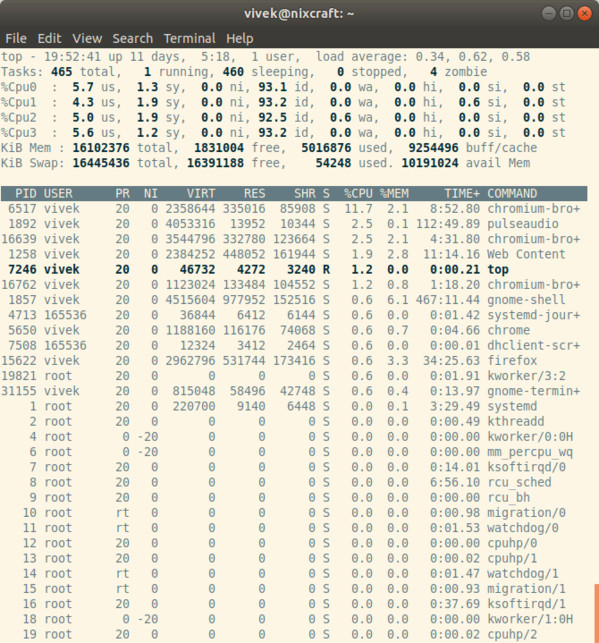
Команда top отображает процессы Linux. Она позволяет представить работающую систему в реальном времени, то есть в момент фактической активности процесса. По умолчанию она отображает наиболее ресурсоемкие задачи, выполняемые на сервере, и обновляет их список каждые пять секунд.
Часто используемые горячие клавиши с лучшими инструментами мониторинга Linux
Ниже приведен список полезных горячих клавиш:
| Горячая клавиша | Применение |
| t | Отображает, включена или выключена опция представления сводных данных |
| m | Отображает, включена или выключена опция представления информации о памяти |
| A | Сортирует задачи по активности потребления различных системных ресурсов. Полезно для быстрой идентификации задач, требующих высокой производительности в системе. |
| f | Вход в интерактивный экран конфигурации для команды top. Полезно для настройки top под конкретную задачу. |
| o | Позволяет выбрать способ упорядочивания информации для команды top. |
| r | Выполняет команду renice. |
| k | Выполняет команду kill. |
| z | Включает или выключает цвет/моно |
2. vmstat — статистика виртуальной памяти
Команда vmstat сообщает информацию о процессах, памяти, подгрузке страниц, блочном вводе-выводе, прерываниях и активности процессора.
# vmstat 3
Примеры выводов:
procs ————memory———- —swap— ——io—- —system— ——cpu——
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 2540988 522188 5130400 0 0 2 32 4 2 4 1 96 0 0
1 0 0 2540988 522188 5130400 0 0 0 720 1199 665 1 0 99 0 0
0 0 0 2540956 522188 5130400 0 0 0 0 1151 1569 4 1 95 0 0
0 0 0 2540956 522188 5130500 0 0 0 6 1117 439 1 0 99 0 0
0 0 0 2540940 522188 5130512 0 0 0 536 1189 932 1 0 98 0 0
0 0 0 2538444 522188 5130588 0 0 0 0 1187 1417 4 1 96 0 0
0 0 0 2490060 522188 5130640 0 0 0 18 1253 1123 5 1 94 0 0
Использование памяти дисплея Slabinfo
Получить информацию об активных/неактивных страницах памяти
3. w — узнайте, кто вошел в систему и какие действия производит
Команда who (w) отображает информацию о пользователях, находящихся в данный момент в системе, и их процессах.
# w username
# w vivek
Примеры выводов:
17:58:47 up 5 days, 20:28, 2 users, load average: 0.36, 0.26, 0.24
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root pts/0 10.1.3.145 14:55 5.00s 0.04s 0.02s vim /etc/resolv.conf
root pts/1 10.1.3.145 17:43 0.00s 0.03s 0.00s w
4. uptime — узнайте, сколько уже работает система Linux
Команда uptime используется, чтобы узнать, как долго, с момента последней перезагрузки, работает после сервер. Текущее время, сколько времени система работает, сколько пользователей в системе на данный момент и средняя загрузка системы за последние 1, 5 и 15 минут.
# uptime
Вывод:
18:02:41 up 41 days, 23:42, 1 user, load average: 0.00, 0.00, 0.00
1 пользователь в системе считается оптимальным значением нагрузки. Нагрузка может меняться от системы к системе. Для систем с одним ЦП приемлемо значение нагрузки 1–3, для систем SMP — 6–10.
5. ps — отображает процессы Linux
Команда ps сообщает о текущих процессах. Чтобы выбрать все процессы, используйте опцию -A или -e:
# ps -A
Примеры выводов:
PID TTY TIME CMD
1 ? 00:00:02 init
2 ? 00:00:02 migration/0
3 ? 00:00:01 ksoftirqd/0
4 ? 00:00:00 watchdog/0
5 ? 00:00:00 migration/1
6 ? 00:00:15 ksoftirqd/1
.
.
4881 ? 00:53:28 java
4885 tty1 00:00:00 mingetty
4886 tty2 00:00:00 mingetty
4887 tty3 00:00:00 mingetty
4888 tty4 00:00:00 mingetty
4891 tty5 00:00:00 mingetty
4892 tty6 00:00:00 mingetty
4893 ttyS1 00:00:00 agetty
12853 ? 00:00:00 cifsoplockd
12854 ? 00:00:00 cifsdnotifyd
14231 ? 00:10:34 lighttpd
14232 ? 00:00:00 php-cgi
54981 pts/0 00:00:00 vim
55465 ? 00:00:00 php-cgi
55546 ? 00:00:00 bind9-snmp-stat
55704 pts/1 00:00:00 ps
Команда ps чем-то напоминает top, но предоставляет больше информации.
Полноформатный вывод
# ps -Al
Чтобы вывести дополнительную информацию о процессе (он показывает аргументы командной строки, которые передаются процессу):
# ps -AlF
Вывод потоков ( LWP и NLWP)
Просмотр потоков после процессов
Вывод всех процессов на сервере
Вывод дерева процессов
# ps -ejH
# ps axjf
# pstree
Получить информацию о безопасности процесса Linux
# ps -eo euser,ruser,suser,fuser,f,comm,label
# ps axZ
# ps -eM
Давайте выведем каждый процесс, запущенный от имени пользователя Vivek
# ps -U vivek -u vivek u
Конфигурация вывода команды ps в пользовательском формате
# ps -eo pid,tid,class,rtprio,ni,pri,psr,pcpu,stat,wchan:14,comm
# ps axo stat,euid,ruid,tty,tpgid,sess,pgrp,ppid,pid,pcpu,comm
# ps -eopid,tt,user,fname,tmout,f,wchan
Попробуем отобразить только идентификаторы процессов Lighttpd
# ps -C lighttpd -o pid=
ИЛИ
# pgrep lighttpd
ИЛИ
# pgrep -u vivek php-cgi
Вывод имени PID 55977
# ps -p 55977 -o comm=
Топ 10 процессов, потребляющих память
# ps -auxf | sort -nr -k 4 | head -10
Отобразить Топ 10 процессоров с максимальным потреблением ресурсов системы
# ps -auxf | sort -nr -k 3 | head -10
6. free — отображает использование памяти Linux-сервером
Команда free показывает общий объем свободной и используемой физической памяти в системе, а также буферы, используемые ядром.
# free
Пример вывода:
total used free shared buffers cached
Mem: 12302896 9739664 2563232 0 523124 5154740
-/+ buffers/cache: 4061800 8241096
Swap: 1052248 0 1052248
7. iostat — отслеживает среднюю загрузку процессора и активность диска на Linux
Команда iostat предоставляет отчет по статистике центрального процессора (ЦП) и статистике ввода/вывода для устройств, директорий и сетевых файловых систем (NFS).
# iostat
Примеры выводов:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
avg-cpu: %user %nice %system %iowait %steal %idle
3.50 0.09 0.51 0.03 0.00 95.86
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 22.04 31.88 512.03 16193351 260102868
sda1 0.00 0.00 0.00 2166 180
sda2 22.04 31.87 512.03 16189010 260102688
sda3 0.00 0.00 0.00 1615 0
8. sar — мониторинг, сбор и отчетность о деятельности системы Linux
Команду sar используют для сбора, представления и сохранения информации о деятельности системы. Чтобы увидеть сетевой контроллер, введите:
# sar -n DEV | more
Сетевые контроллеры, начиная с 24:
# sar -n DEV -f /var/log/sa/sa24 | more
Вы также можете настроить отображение в реальном времени, используя команду sar:
# sar 4 5
Примеры выводов:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
06:45:12 PM CPU %user %nice %system %iowait %steal %idle
06:45:16 PM all 2.00 0.00 0.22 0.00 0.00 97.78
06:45:20 PM all 2.07 0.00 0.38 0.03 0.00 97.52
06:45:24 PM all 0.94 0.00 0.28 0.00 0.00 98.78
06:45:28 PM all 1.56 0.00 0.22 0.00 0.00 98.22
06:45:32 PM all 3.53 0.00 0.25 0.03 0.00 96.19
Average: all 2.02 0.00 0.27 0.01 0.00 97.70
9. mpstat — отслеживает использование мультипроцессора в Linux
Команда mpstat отображает действия для каждого доступного процессора. Процессор 0 является первым. mpstat -P ALL отображает среднюю загрузку ЦП/процессора:
# mpstat -P ALL
Пример вывода:
Linux 2.6.18-128.1.14.el5 (www03.nixcraft.in) 06/26/2009
06:48:11 PM CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
06:48:11 PM all 3.50 0.09 0.34 0.03 0.01 0.17 0.00 95.86 1218.04
06:48:11 PM 0 3.44 0.08 0.31 0.02 0.00 0.12 0.00 96.04 1000.31
06:48:11 PM 1 3.10 0.08 0.32 0.09 0.02 0.11 0.00 96.28 34.93
06:48:11 PM 2 4.16 0.11 0.36 0.02 0.00 0.11 0.00 95.25 0.00
06:48:11 PM 3 3.77 0.11 0.38 0.03 0.01 0.24 0.00 95.46 44.80
06:48:11 PM 4 2.96 0.07 0.29 0.04 0.02 0.10 0.00 96.52 25.91
06:48:11 PM 5 3.26 0.08 0.28 0.03 0.01 0.10 0.00 96.23 14.98
06:48:11 PM 6 4.00 0.10 0.34 0.01 0.00 0.13 0.00 95.42 3.75
06:48:11 PM 7 3.30 0.11 0.39 0.03 0.01 0.46 0.00 95.69 76.89
10. pmap — отслеживает использование памяти процессом в Linux
Команда pmap показывает использование памяти процессом. Используйте эту команду, чтобы выяснить проблемы с потреблением памяти.
# pmap -d PID
Чтобы отобразить информацию о памяти процесса для pid # 47394, введите:
# pmap -d 47394
Примеры выводов:
47394: /usr/bin/php-cgi
Address Kbytes Mode Offset Device Mapping
0000000000400000 2584 r-x— 0000000000000000 008:00002 php-cgi
0000000000886000 140 rw— 0000000000286000 008:00002 php-cgi
00000000008a9000 52 rw— 00000000008a9000 000:00000 [ anon ]
0000000000aa8000 76 rw— 00000000002a8000 008:00002 php-cgi
000000000f678000 1980 rw— 000000000f678000 000:00000 [ anon ]
000000314a600000 112 r-x— 0000000000000000 008:00002 ld-2.5.so
000000314a81b000 4 r—- 000000000001b000 008:00002 ld-2.5.so
000000314a81c000 4 rw— 000000000001c000 008:00002 ld-2.5.so
000000314aa00000 1328 r-x— 0000000000000000 008:00002 libc-2.5.so
000000314ab4c000 2048 —— 000000000014c000 008:00002 libc-2.5.so
.
..
00002af8d48fd000 4 rw— 0000000000006000 008:00002 xsl.so
00002af8d490c000 40 r-x— 0000000000000000 008:00002 libnss_files-2.5.so
00002af8d4916000 2044 —— 000000000000a000 008:00002 libnss_files-2.5.so
00002af8d4b15000 4 r—- 0000000000009000 008:00002 libnss_files-2.5.so
00002af8d4b16000 4 rw— 000000000000a000 008:00002 libnss_files-2.5.so
00002af8d4b17000 768000 rw-s- 0000000000000000 000:00009 zero (deleted)
00007fffc95fe000 84 rw— 00007ffffffea000 000:00000 [ stack ]
ffffffffff600000 8192 —— 0000000000000000 000:00000 [ anon ]
mapped: 933712K writeable/private: 4304K shared: 768000K
Последняя строка очень важна:
- mapped: 933712K общий объем памяти, сопоставленный с файлами;
- writeable/private: 4304K объем недоступного адресного пространства;
- shared: 768000K объем адресного пространства, который этот процесс делит с другими.
11. Команда netstat — инструмент для мониторинга сети и статистики Linux
Команда netstat отображает состояние TCP-соединений (как входящих, так и исходящих), таблицы маршрутизации, число сетевых интерфейсов и сетевую статистику по протоколам.
# netstat -tulpn
# netstat -nat
12. ss — статистика сети
Команда ss используется для вывода статистики сокетов. Позволяет отображать информацию, аналогичную netstat. Обратите внимание, что команда netstat считается устаревшей. Лучше использовать команду ss. Чтобы посмотреть все сокеты TCP и UDP в Linux:
# ss -t -a
ИЛИ
# ss -u -a
13. iptraf — получение сетевой статистики в реальном времени в Linux
Команда iptraf — это интерактивный цветной IP-дисплей. Генерирует различную сетевую статистику, включая информацию TCP, UDP-счетчики, информацию о ICMP и OSPF, о нагрузке Ethernet, статистику узлов, ошибки контрольной суммы IP и другое. Она может предоставить следующую информацию в удобочитаемом формате:
- Статистика сетевого трафика по TCP-соединению
- Статистика IP-трафика по сетевому интерфейсу
- Статистика сетевого трафика по протоколу
- Статистика сетевого трафика по TCP/UDP-порту и размеру пакета
- Статистика сетевого трафика по адресу Layer2
14. tcpdump — детальный анализ сетевого трафика
Команда tcpdump — это простая команда, которая создает дамп трафика в сети. Тем не менее, вам нужно хорошо понимать принцип работы протокола TCP/IP, чтобы использовать этот инструмент. Например, для отображения информации о трафике DNS введите:
# tcpdump -i eth1 ‘udp port 53’
Для просмотра всех HTTP-пакетов IPv4 через порт 80 введите:
# tcpdump ‘tcp port 80 and (((ip[2:2] — ((ip[0]&0xf)<<2)) - ((tcp[12]&0xf0)>>2)) != 0)’
Показать все сеансы FTP до 202.54.1.5:
# tcpdump -i eth1 ‘dst 202.54.1.5 and (port 21 or 20’
Вывести всю сессию HTTP на 192.168.1.5:
# tcpdump -ni eth0 ‘dst 192.168.1.5 and tcp and port http’
Чтобы использовать wireshark для просмотра подробной информации о файлах, введите:
# tcpdump -n -i eth1 -s 0 -w output.txt src or dst port 80
15. iotop — монитор ввода-вывода Linux
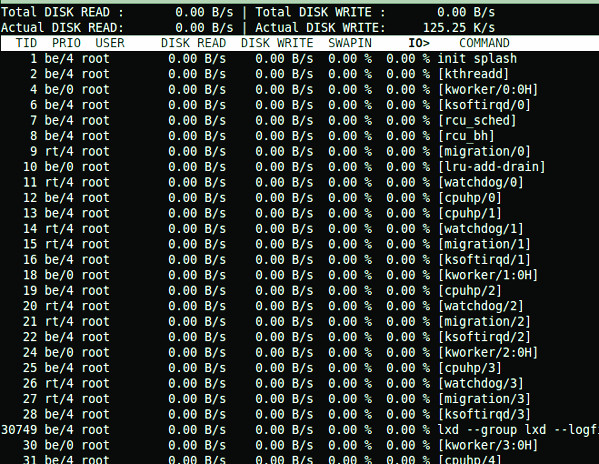
Команда iotop показывает таблицу текущего использования ввода-вывода, отсортированную по процессам или потокам на сервере.
$ sudo iotop
Пример выводов:
16. htop — интерактивный просмотрщик процессов
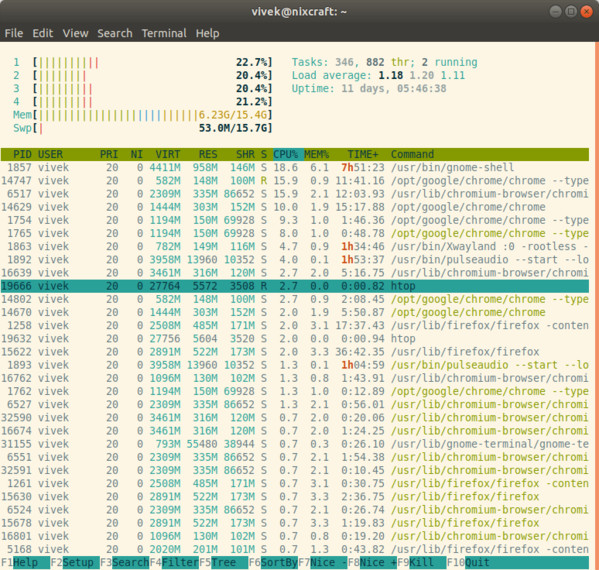
htop — это бесплатная программа с открытым исходным кодом на базе ncurses для просмотра процессов для Linux. Она очень проста в использовании. Вы можете выбрать процессы для команд kill или renice, не используя их PID и не выходя из интерфейса htop.
$ htop
Пример выводов:
17. atop — мониторинг процессов
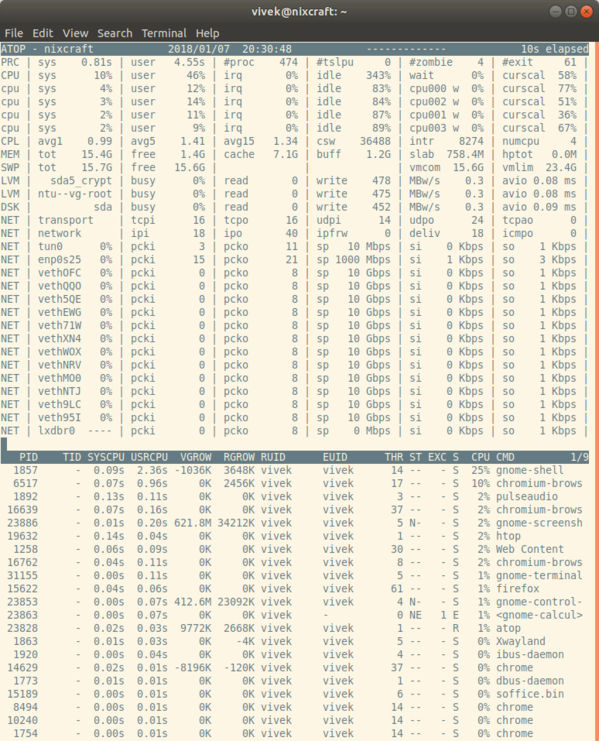
atop — очень мощный и интерактивный монитор для просмотра нагрузки в системе Linux. Он отображает наиболее важные аппаратные ресурсы с точки зрения производительности. Вы можете посмотреть производительность процессора, памяти, диска и сети. Команда показывает, какие процессы ответственны за указанную нагрузку относительно загрузки процессора и памяти.
$ atop
18. Команды ac и lastcomm
Вы можете отслеживать процессы и вход в систему на вашем сервере Linux. Пакет psacct или acct содержит несколько утилит для мониторинга процессов, в том числе:
- Команда AC: статистика о времени подключения пользователей
- Команда lastcomm: информация о ранее выполненных командах
- Команда accton: включает или выключает учет процессов
- Команда sa: обобщает учетную информацию
19. monit — контроль процессов
Monit — это бесплатное программное обеспечение с открытым исходным кодом, которое выполняет функции контроля за процессом. В нем встроена возможность перезапуска служб. Вы можете использовать Systemd, daemontools или любой другой подобный инструмент для той же цели.
20. nethogs — узнайте PID, которые используют наибольшую пропускную способность в Linux
NetHogs — это небольшой, но удобный инструмент для работы с сетью. Он группирует пропускную способность по имени процесса, например, Firefox, wget и так далее. В случае внезапного всплеска сетевого трафика, запустите NetHogs. Вы увидите, какой PID вызывает скачок пропускной способности.
$ sudo nethogs
21. iftop — показывает использование полосы пропускания на интерфейсе хоста
Команда iftop слушает сетевой трафик с заданным именем интерфейса, например, eth0. Она отображает таблицу текущего использования полосы пропускания парами узлов.
$ sudo iftop
22. vnstat — консольный монитор сетевого трафика
vnstat — это простой в использовании консольный монитор сетевого трафика для Linux. Он ведет журнал почасового, ежедневного и ежемесячного сетевого трафика для выбранного интерфейса.
$ vnstat
23. nmon — мониторинг серверов
nmon — это утилита, которая может показывать процессор, память, сеть, диски, файловые системы, NFS, основные ресурсы процесса и информацию о разделах из Cli.
$ nmon
24. glances — отслеживание системы Linux
glances — это кроссплатформенный инструмент мониторинга с открытым исходным кодом. Он предоставляет тонны информации на маленьком экране. Он также может работать в режиме клиент/сервер.
$ glances
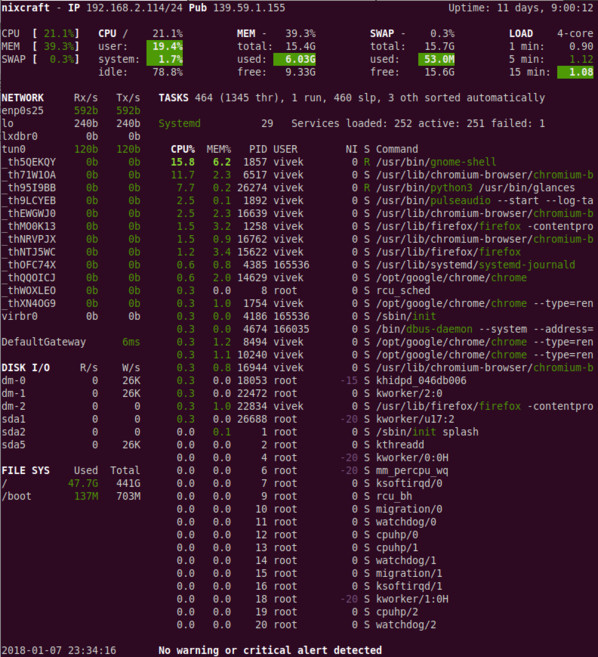
25. strace — отслеживает системные запросы в Linux
Strace позволяет отслеживать системные запросы и сигналы Linux. Это пригодится при отладке веб-сервера и решении других проблем с ним.
26. /proc /file system — статистика ядра Linux
Файловая система /proc предоставляет подробную информацию о различных аппаратных устройствах и другие данные об ядре Linux. Типичные примеры /proc:
# cat /proc/cpuinfo
# cat /proc/meminfo
# cat /proc/zoneinfo
# cat /proc/mounts
27. Nagios — мониторинг серверов Linux и сетей
Nagios — это популярная программа с открытым исходным кодом для мониторинга сети. С ней вы можете контролировать все хосты, сетевое оборудование и сервисы. Она может отправлять оповещения, когда что-то идет не так и когда все стабилизируется.
28. Cacti — веб-инструмент для мониторинга Linux
Cacti — это комплексное решение для построения сетевых графиков, предназначенное для использования возможностей RRDTool по хранению и графическому отображению данных. В Cacti есть функционал для обследования сети, расширенные шаблоны графиков, несколько методов сбора данных и функции управления пользователями. Все это сведено в интуитивно понятный и простой в использовании интерфейс, который подходит даже для сложных сетей с сотнями устройств. Он может предоставлять данные о сети, процессоре, памяти, пользователях вошедших в систему, Apache, DNS-серверах и многое другое.
29. KDE System Guard — системы и отчеты Linux в режиме реального времени
KSysguard — это приложение для мониторинга системы для рабочего стола KDE. Его можно запускать через сессию ssh. Оно обеспечивает мониторинг локальных и удаленных хостов. Графический интерфейс использует так называемые датчики для извлечения отображаемой информации. Датчик может возвращать простые значения или более сложную информацию, например, таблицы. Для каждого типа информации предоставляется один или несколько дисплеев. Дисплеи организованы в виде листов, которые можно сохранять и загружать независимо друг от друга. Таким образом, KSysguard — это не только простой диспетчер задач, но и очень мощный инструмент для управления большими пулами серверов.
30. Системный монитор Gnome Linux
Приложение System Monitor позволяет отображать основную системную информацию и отслеживать системные процессы, использование системных ресурсов и файловых систем. Его также можно использовать для изменения поведения вашей системы. Хотя он и не такой мощный, как KDE System Guard, но зато он предоставляет основную информацию, которая может быть полезна для новых пользователей:
- Отображение основной информации об аппаратном и программном обеспечении компьютера.
- Версия ядра Linux
- Версия GNOME
- Аппаратные средства
- Встроенная память
- Процессоры и скорость работы
- Состояние системы
- Доступное дисковое пространство
- Процессы
- Память
- Использование сети
- Файловые системы
- Список всех файловых систем с основной информацией о каждой.
Бонус: дополнительные инструменты
Еще немного инструментов:
- nmap – сканирует сервер на наличие открытых портов.
- lsof – список открытых файлов, сетевых подключений и многое другое.
- ntop — веб-инструмент для наблюдения за использованием сети, программное обеспечение для мониторинга сетевого трафика. Вы можете видеть состояние сети, распределение трафика по протоколам для UDP, TCP, DNS, HTTP и других протоколов.
- Conky – еще один классный инструмент мониторинга для системы X Window. Он легко настраивается и способен отслеживать многие системные переменные, включая состояние процессора, памяти, места подкачки, дискового пространства, температуры, процессов, сетевых интерфейсов, заряда батареи, системных сообщений, почтовых ящиков и т. д.
- GKrellM – этот инструмент можно использовать для мониторинга состояния процессоров, основной памяти, жестких дисков, сетевых интерфейсов, локальных и удаленных почтовых ящиков и многого другого.
- mtr – mtr объединяет функциональность программ traceroute и ping в одном инструменте диагностики сети.
- vtop – графический монитор активности терминала в Linux.
- gtop – панель мониторинга системы для терминала Linux/macOS Unix.
Каждую неделю мы в live режиме решаем кейсы на наших открытых онлайн-практикумах, присоединяйтесь к нашему каналу в Телеграм, вся информация там.
Если вы хотите освоить функционал системного администратора Linux на практике, приглашаем на наш практикум Linux by Rebrain.
Мониторинг температуры и нагрузки процессора в Windows
Компьютер — это ваш рабочий инструмент, где необходимо поддерживать порядок, чтобы он работал стабильно, и процесс обучения проходил максимально комфортно.
Если вы замечаете, что ваш компьютер очень медленно работает или тормозит, проверьте, что нагружается в нем до критичной отметки.
Инструкция для Windows
№1. Загрузка центрального процессора
1. Нажмите на клавиатуре одновременно клавиши Ctrl+Alt+Del и выберите «Диспетчер задач».
2. Выберите закладку «Производительность» → «ЦП» и «Память».
Если ваш компьютер загружен на 90-100% по одному из этих параметров, рекомендуем:
- закрыть некоторые программы и процессы, чтобы снизить нагрузку;
- задуматься над увеличением производительности компьютера.
№2. Температура процессора
- Перейдите по ссылке → «Download» → установите программу Speecy на свой компьютер.
- Перейдите по ссылке и зайдите в свой личный кабинет.
- Откройте любой урок в Виртуальном классе.
Если перегрев вашего процессора более 60℃, то мы настоятельно рекомендуем отнести ваш компьютер в чистку (чтобы почистили систему охлаждения и заменили термопасту). Запускать это нельзя, если процессор выйдет из строя из-за перегрева, придется менять всю материнскую плату.
№3. Дополнительные рекомендации: про автозагрузку
Часто происходит, что устанавливаемые программы добавляют себя в список автозапуска.
С некоторыми программами это удобно, если вы пользуетесь им каждый день. Но такие программы, как Torrent или Team Viewer, вы не захотите видеть постоянно включенными сразу при запуске. Тем более это сильно замедляет включение компьютера.
Как их отключить:
- Нажмите на клавиатуре одновременно клавиши Ctrl+Alt+Del и выберите «Диспетчер задач».
- Выберите закладку «Автозагрузка».
- Выберите нужные вам приложения и нажмите «Отключить».
№4. Дополнительные рекомендации: про статистику
Как сама система, так и большинство программ, которыми вы пользуетесь, ведут статистику работы, сохраняют временные файлы, кэш, отчеты и прочее.
Со временем это начинает замедлять работу системы. Что можно с этим сделать? Регулярно чистить систему от временных файлов и ошибок реестра следующим способом:
- Перейдите по ссылке → «Скачать» → «Скачать CCleaner» → «Скачать бесплатно» → установите программу на свой компьютер.
- Во вкладке «Реестр» запустите поиск проблем, когда наберется 100% нажмите «Исправить» → «Исправить отмеченные».
Вы нашли ответ на свой вопрос?
1 CPU 1 Гб – а я хочу мониторинг, как у больших дядей

Я обожаю читать на хабре статьи про то, как устроены системы больших интернет-компаний. Кластеры SQL-серверов, монг и редисов. Тут у нас кластер ELK собирает трейсинг, там – сборка логов, здесь балансер выдает входящим запросам traceID и можно отслеживать, как запрос ходит по всем нашим микросервисам. Класс. Но, допустим, у вас совсем маленький проект и вы можете себе позволить лишь VPS минимальной конфигурации. Реально ли на ней сделать мониторинг не хуже, чем у больших проектов? Я решил – надо попробовать.
Создаем VPS
Сразу оговорюсь, что я ни разу не devops и не особо глубоко разбираюсь в Linux, поэтому, если что-то сделал неправильно, или у вас есть идеи, как можно было сделать то, что я делаю в этой статье проще и лучше – пишите в комментариях, буду рад любым вашим советам и замечаниям!
Для экспериментов я создал на Маклауде VPS следующей конфигурации: 1 CPU, 1 Гб RAM и 20 Гб диск.
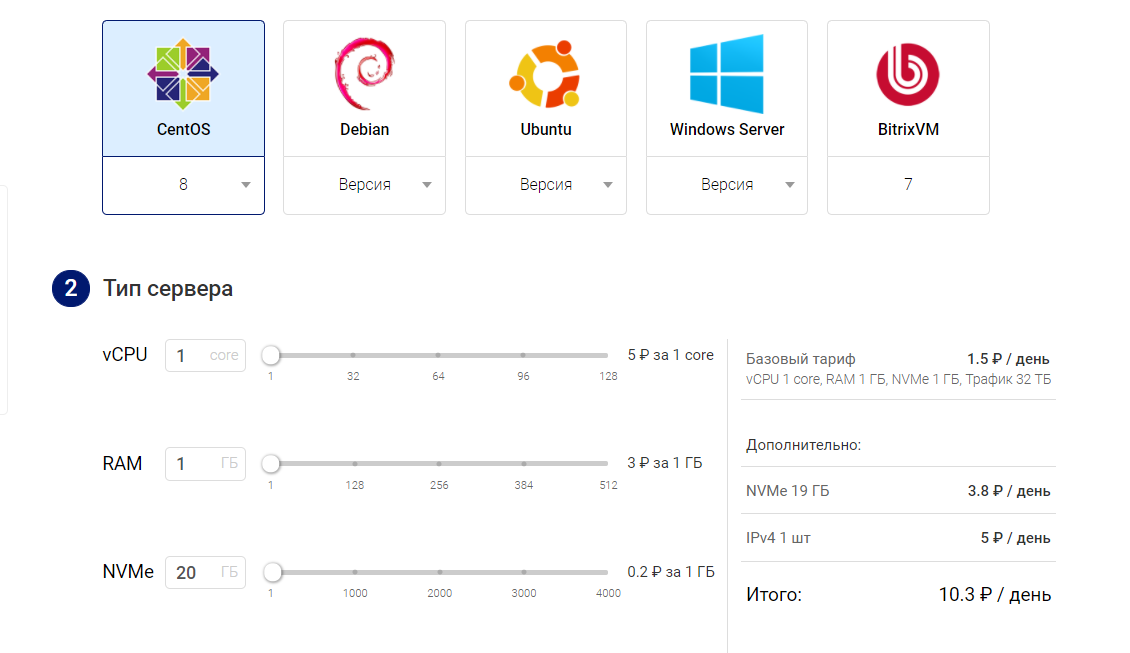
Для удобства я загрузил свой SSH ключ, и мог заходить в консоль сразу после запуска сервера. Также по умолчанию включено резервное копирование, я его отключил, так как в целях эксперимента мне оно было не нужно. Далее требовалось выбрать ОС. Для этого хотелось понять, какие ресурсы будут доступны на VPS сразу после создания. Меня интересовала свободная память и место на диске. Для этого, в панели управления можно инициировать переустановку ОС. Я поочередно установил доступные ОС и для каждой посмотрел, какие параметры она дает на старте:
[root@v54405 ~]# df Filesystem 1K-blocks Used Available Use% Mounted on devtmpfs 406744 0 406744 0% /dev tmpfs 420480 0 420480 0% /dev/shm tmpfs 420480 5636 414844 2% /run tmpfs 420480 0 420480 0% /sys/fs/cgroup /dev/vda1 20582864 1395760 18300472 8% / tmpfs 84096 0 84096 0% /run/user/0 [root@v54405 ~]# free total used free shared buff/cache available Mem: 840960 106420 525884 5632 208656 600868 Swap: 0 0 0root@v54405:~# df Filesystem 1K-blocks Used Available Use% Mounted on udev 490584 0 490584 0% /dev tmpfs 101092 1608 99484 2% /run /dev/vda1 20608592 1001560 18736224 6% / tmpfs 505448 0 505448 0% /dev/shm tmpfs 5120 0 5120 0% /run/lock tmpfs 505448 0 505448 0% /sys/fs/cgroup tmpfs 101088 0 101088 0% /run/user/0 root@v54405:~# free total used free shared buff/cache available Mem: 1010900 43992 903260 1608 63648 862952 Swap: 0 0 0root@v54405:~# df Filesystem 1K-blocks Used Available Use% Mounted on udev 473920 0 473920 0% /dev tmpfs 100480 592 99888 1% /run /dev/vda1 20575824 1931420 17757864 10% / tmpfs 502396 0 502396 0% /dev/shm tmpfs 5120 0 5120 0% /run/lock tmpfs 502396 0 502396 0% /sys/fs/cgroup tmpfs 100476 0 100476 0% /run/user/0 root@v54405:~# free total used free shared buff/cache available Mem: 1004796 65800 606824 592 332172 799692 Swap: 142288 0 142288 Итак, в CentOS не доложили оперативной памяти (кстати почему – хороший вопрос сервису), а Убунту занял на гигабайт больше места на диске. Так что я остановил свой выбор на Debian 10.
Для начала обновим систему:
apt-get update apt-get upgrade Также установим sudo
apt-get install sudoДля того, чтобы реализовать мою задумку первым делом я установил докер по инструкции с официального сайта.
Проверяем, что докер установлен
# docker -v Docker version 20.10.6, build 370c289Также понадобится docker-compose. Процесс установки можно посмотреть тут.
Проверим, что докер установился:
# docker-compose -v docker-compose version 1.29.1, build c34c88b2 Итак, все приготовления выполнены, посмотрим, сколько места осталось на диске:
Filesystem 1K-blocks Used Available Use% Mounted on udev 490584 0 490584 0% /dev tmpfs 101092 2892 98200 3% /run /dev/vda1 20608592 1781756 17956028 10% / tmpfs 505448 0 505448 0% /dev/shm tmpfs 5120 0 5120 0% /run/lock tmpfs 505448 0 505448 0% /sys/fs/cgroup tmpfs 101088 0 101088 0% /run/user/0 Запускаем проект
Для эксперимента я написал на NestJS небольшой веб-сервис, который работает с изображениями. Он позволяет загружать изображения на сервер, извлекает из них метаданные, записывает их в MongoDB, а информация о сохраненных изображениях пишется в Postgres. Для каждого загруженного изображения можно получить метаданные и скачать само изображение. Изображения, к которым не обращались более 10 минут удаляются с сервера при помощи функции очистки, которая запускается раз в минуту.
Исходный код проекта на github.
Я клонировал его на сервер при помощи команды:
git clone https://github.com/debagger/observable-backend.git Чтобы было удобно разворачивать сервис на сервере я написал файл docker-compose.nomon.yml следующего содержания:
version: "3.9" volumes: imagesdata: grafanadata: postgresdata: mongodata: tempodata: services: backend: image: node:lts volumes: - ./backend:/home/backend - imagesdata:/images working_dir: /home/backend environment: OT_TRACING_ENABLED: "false" PROM_METRICS_ENABLE: "false" ports: - 3000:3000 entrypoint: ["/bin/sh"] command: ["prod.sh"] restart: always db: image: postgres restart: always expose: - "5432" volumes: - postgresdata:/var/lib/postgresql/data environment: POSTGRES_PASSWORD: password POSTGRES_USER: images adminer: image: adminer restart: always ports: - 8080:8080 mongo: image: mongo restart: always volumes: - mongodata:/data/db mongo-express: image: mongo-express restart: always ports: - 8081:8081 Для запуска проекта переходим в его директорию
cd observable-backenddocker-compose -f docker-compose.nomon.yml up -dСервису понадобится некоторое время чтобы стартовать, я настроил его таким образом, чтобы он при запуске автоматически загружал зависимости и собирался.
После запуска можно проверить что он работает в браузере по ссылке
http://:3000/
Должна вывестись строка Hello World!
Для того, чтобы испытывать производительность сервиса при помощи библиотеки autocannon я написал нагрузочный тест. Он находится в том же репозитории, в директории autocannon. Его надо запускать на машине с установленным node.js предварительно установив адрес сервера, где запущен проект в .env файле.
После запуска двухминутного теста я получил следующий результат:

В процессе теста я мог наблюдать за поведением системы при помощи стандартной команды linux — top , а также docker stats . Помимо этого можно смотреть логи, при помощи команды docker logs . Но этого недостаточно, хочется лучше понимать, что происходит с моим сервисом под нагрузкой. Поэтому следующим шагом я решил добавить к проекту сбор метрик.
Настраиваем метрики
После недолгого гугления решений для сбора метрик я остановил свой выбор на связке Prometheus + Grafana.
Для использования этой связки я добавил в конфигурацию docker-compose следующее:
prometheus: image: prom/prometheus ports: - 9090:9090 volumes: - ./prometheus.yml:/etc/prometheus/prometheus.yml mongo-exporter: image: bitnami/mongodb-exporter ports: - 9091:9091 command: [«--mongodb.uri=mongodb://mongo», «--web.listen-address=0.0.0.0:9091»] pg-exporter: image: bitnami/postgres-exporter ports: - 9092:9092 environment: DATA_SOURCE_NAME: sslmode=disable user=images password=password host=db PG_EXPORTER_WEB_LISTEN_ADDRESS: 0.0.0.0:9092 grafana: image: grafana/grafana ports: - 3001:3000 volumes: - grafanadata:/var/lib/grafana
Здесь минимальная конфигурация для запуска Prometheus и Grafana, а также экспортеры для метрик из Postgres и Mongo. Для Prometheus я написал конфиг prometheus.yml со следующим содержимым.
global: scrape_interval: 10s scrape_configs: - job_name: 'nodejs' honor_labels: true static_configs: - targets: ['backend:3000'] - job_name: «mongodb» honor_labels: true static_configs: - targets: ['mongo-exporter:9091'] - job_name: «postgres» scrape_timeout: 9s honor_labels: true static_configs: - targets: ['pg-exporter:9092'] Чтобы собирать метрики из своего приложения я использовал библиотеку express-prom-bundle , которая позволяет собирать стандартные метрики и создавать свои собственные. Также я добавил в свой сервис переменную окружения PROM_METRICS_ENABLE для того, чтобы можно было включать и отключать метрики из конфигурации контейнера. Если активировать данную функцию, метрики, собираемые приложением, будут доступны по адресу http://:3000/metrics .
Я включил сбор дефолтных системных метрик, метрики по запросам, обрабатываемым сервером Express, а также несколько своих, которые позволяют контролировать скорость и количество загружаемых и скачиваемых изображений, количество хранимых изображений и занимаемое ими место на диске.
Получившуюся конфигурацию я сохранил под именем docker-compose.metrics.yml .
Запустить эту конфигурацию можно командой
docker-compose -f docker-compose.metrics.yml up -dПосле запуска можно зайти в интерфейс Grafana по адресу http://:3001/
Логин/пароль по умолчанию admin/admin.
Здесь в настройках я добавил источник данных Prometheus

После этого нам доступны все метрики, которые собирает Prometheus.
Для примера выведем графики загрузки процессора по всем сервисам:

Для своих целей я настроил такую панель:

Теперь мне стало гораздо проще разобраться, что происходит с сервисом.
ELK – неудача
Итак, я настроил метрики, и теперь мне хотелось заняться сбором логов. Я решил попробовать поднять для этих целей связку Elasticsearch + Logstash. Это просто первое, что пришло в голову, ибо читал много хорошего про эти инструменты. Особенно интересовало, удастся ли сделать сбор логов прямо с контейнеров, потому что у докера для этой целей есть встроенный плагин, позволяющий экспортировать вывод консоли сервисов в формате gelf, который поддерживает Logstash. Я добавил в docker-compose следующее
elasticsearch: image: elasticsearch:7.12.1 environment: - discovery.type=single-node - ES_JAVA_OPTS=-Xms250m -Xmx250m ports: - 9200:9200 - 9300:9300 logstash: image: logstash:7.12.1 links: - elasticsearch volumes: - ./logstash.conf:/etc/logstash/logstash.conf command: logstash -f /etc/logstash/logstash.conf ports: - 12201:12201/udp depends_on: - elasticsearch
Также для начала настроил экспорт логов из Mongo. Для этого описание сервиса mongo в файле docker-compose я дополнил следующим образом:
mongo: image: mongo restart: always logging: driver: gelf options: gelf-address: "udp://localhost:12201"
Когда я запустил новую конфигурацию – я понял, что это конец. Ничего не работало. Сервер стал жутко тормозить, а kswapd0 периодически выходил на первое место по загрузке процессора, а свободная память была почти на нуле. Памяти для такой конфигурации явно не хватало.
Забегая вперед, когда я активировал файл подкачки, мне удалось запустить проект. Но все равно всё работало очень медленно, причем дольше всего запускался Logstash. Инструмент, задача которого всего лишь на всего грузить логи – стартовал минут 20. Хотя, когда он наконец запустился, работал как предполагалось, и я даже смог посмотреть в Grafana кусочек лога Mongo, так что, в принципе решение работало, просто для системы с таким объемом оперативной памяти оно не подходило, что не удивительно, ведь если погуглить, каковы минимальные требования для Elasticsearch, то ответ будет таким:

Я действительно этого не знал, поэтому немного приуныл, поскольку я хотел позже использовать Elasticsearch в качестве хранилища данных для jaeger, чтобы реализовать сбор трейсов приложения и поставить Kibana чтобы добить ELK стек. Но, как говорится, на нет и суда нет, поэтому я стал искать альтернативу.
Loki
И альтернатива нашлась! Искать, к слову, долго не пришлось, потому что в списке поддерживаемых источников данных Grafana обнаружился зверь под названием Loki. Это сборщик логов из той же эко-системы, что Prometheus и Grafana. Напомню, что моя идея была в том, чтобы писать логи из стандартного потока контейнеров. И для этого сценария тоже быстро нашлось решение. Оказалось, для докера есть плагин, который позволяет делать именно то, что мне надо – отправлять потоки стандартного вывода в Loki. Поставить его можно следующей командой:
# docker plugin install grafana/loki-docker-driver:latest --alias loki --grant-all-permissions
Я добавил в конфигурацию docker-compose сервис loki:
loki: image: grafana/loki:2.0.0 ports: - «3100:3100» command: -config.file=/etc/loki/local-config.yaml
Кроме этого, я добавил ко всем сервисам, логи с которых хотел собрать, следующую секцию:
logging: driver: loki options: loki-url: «http://localhost:3100/loki/api/v1/push»
А к своему приложению добавил еще
loki-pipeline-stages: | - json: expressions: output: msg level: level timestamp: time pid: pid hostname: hostname context: context traceID: traceID
Чтобы из лога, который у меня в формате json парсились важные поля.
Получившийся конфиг я сохранил под именем docker-compose.metrics_logs.yml .
Теперь результат можно запустить при помощи команды
docker-compose -f docker-compose.metrics_logs.yml up -d После запуска я понял, что что-то идет не так, потому что команда вылетела с сообщением Killed. Я попробовал еще раз – сервисы запустились частично. На третий раз все заработало, но когда я заглянул в top то увидел, что там периодически проскакивает kswapd0 , а это значило, что системе жестко не хватало памяти.

Простой выход – добавить в конфигурацию хотя бы гигабайт оперативной памяти, но по условиям эксперимента я хотел запустить все на VPS минимальной конфигурации. Поэтому я решил активировать swap-файл, который в системе по умолчанию отключен. Сколько было эпичных баттлов в комментариях про то, нужен ли файл подкачки в Linux, но у меня выбора особо не было. Заодно я решил проверить, как будет влиять наличие файла подкачки на производительность системы.
# sudo fallocate -l 1G /swapfile # sudo chmod 600 /swapfile # sudo mkswap /swapfile # sudo swapon /swapfile Проверяем про помощи команды free :
total used free shared buff/cache available Mem: 1010900 501760 202344 26500 306796 353952 Swap: 4194300 0 4194300
В системе появился файл подкачки размером 4Гб. Должно хватить!
Снова пытаемся запустить нашу систему:
# docker-compose -f docker-compose.metrics_logs.yml up -dВсе работает! Теперь в Grafana добавляем в качестве источника логов Loki

Идем в Explore и видим, что логи начали подгружаться.

Проверим, что стало с производительностью.

Раз все работает, осталось закрепить файл подкачки в системе. Для этого надо в файле /etc/fstab добавить строку
/swapfile swap swap defaults 0 0
После этого файл подкачки останется в системе даже после перезагрузки.
Добавляем сбор трейсов при помощи Tempo
Для полного счастья мне нужна была система сбора трейсов. Чтобы не мудрить, раз уж так вышло, что я использую стек Grafana, можно добавить в качестве сборщика данных еще один инструмент от Grafana Lab – сервер для сбора трейсов Tempo. Он из коробки поддерживается Grafana, поэтому попробуем добавить его в систему.
Для того, чтобы приложение стало генерировать трейсы, его надо специальным образом инструментировать. Для этого есть замечательный проект под названием OpenTelemetry, который развивает систему спецификаций и библиотек для реализации трейсинга под различные платформы и системы. В нем есть готовые библиотеки для автоматической инструментации Node.js и сервера express.js, который работает под капотом у nest.js. Их я и добавил в свой проект.
Tempo может принимать трейсы про всем распространённым протоколам. Я выбрал протокол Jagger Trift binary – простой двоичный формат, передаваемый по UDP. Также, как и в случае с метриками, я в своем приложение я добавил переменную окружения OT_TRACING_ENABLED , которая, если ее установить в true включает в приложении телеметрию.
Для запуска Tempo я добавил в файл конфигурации docker-compose следующее:
tempo: image: grafana/tempo:latest command: [«-config.file=/etc/tempo.yaml»] volumes: - ./tempo-local.yaml:/etc/tempo.yaml - tempodata:/tmp/tempo ports: - «6832/udp» # Jaeger - Thrift Binary
и сохранил его под названием docker-compose.metrics_logs_tempo.yml
Для настройки Tempo я создал файл конфигурации tempo-local.yaml (на самом деле просто скопировал из репозитория Tempo подходящий и немного поправил). Запустим его командой
docker-compose -f docker-compose.metrics_logs_tempo.yml up -dТеперь осталось в Grafana настроить источник данных:

Чтобы было удобно переходить к просмотру трейсов из логов надо настроить источник данных Loki:

После такой настройки рядом с полем traceID появится ссылка:

По этой ссылке будет открываться окно с данным трейсом:

Испытываем производительность нашего сервиса.

Здесь уже видно заметное падение производительности сервиса, но надо понимать, что эта плата за детальную телеметрию.
Дополнение: уже когда я прогнал нагрузочные тесты, результаты которых приведены ниже и дописывал статью, изучая документацию Jaeger я выяснил, что он может использовать для хранения данных локальное хранилище на основе key-value базы данных Badger, и, таким образом, может работать без Elasticsearch. Я добавил в репозиторий файл конфигурации для docker-compose где вместо tempo используется jaeger ( docker-compose.metrics_logs_jaeger.yml ), но не проводил всего набора тестов. Я запустил тест производительности только на базовой конфигурации, и в этом режиме получилось 19,92 запроса в секунду, что несколько больше по сравнению с вариантом, где используется tempo — 18,84.
В отличии от tempo, который позволяет искать трейсы только по traceID, jeaeger дает возможность поиска по различным параметрам и у него есть собственный, достаточно удобный интерфейс для просмотра трейсов.
Результаты тестов
Итак, мне удалость запустить все необходимые компоненты мониторинга и телеметрии. Осталось понять, насколько использование различных компонентов влияет на производительность системы.
Для каждого из перечисленных выше вариантов я запускал нагрузочный тест продолжительностью 20 минут. Для того, чтобы задействовать все компоненты системы, включая сетевой интерфейс я запускал тест autocannon со своей VPS размещённой у другого провайдера, предварительно проверив скорость соединения при помощи iperf – она составила 90 Мбит/сек. Так же между запусками тестов я дожидался, пока отработает функция удаления старых изображений, полностью удалив загруженные в предыдущем тесте файлы с диска и информацию из баз данных.
Результаты я свел в таблицу. Для оценки производительности я решил ориентироваться на число запросов в секунду, которое может обрабатывать система. Конечно, есть куча других метрик, но именно эта наиболее наглядно, на мой взгляд, показывает общее влияние различных факторов на производительность системы. Вот что получилось.
| Запросов в секунду | Снижение производительности | |
| Без мониторинга | 28,07 | 100% |
| Prometheus | 27,19 | 97% |
| Prometheus+Loki | 25,47 | 91% |
| Prometheus+Loki+Tempo | 18,84 | 67% |
Выходит, что только использование трейсинга приводит к значительным потерям производительности, а в случае со сбором метрик и логов потери составляют менее 10%.
Добавляем ядра и память
Также я решил посмотреть, как будет влиять на производительность сервиса увеличение объема памяти и количества ядер процессора. Macloud.ru позволяет менять параметры тарифа и я решил посмотреть как работает эта функция. Первым делом я добавил еще 1 Гб оперативной памяти.

После нажатия кнопки «Сменить тариф» сервер перезагрузился и вот что получилось:
total used free shared buff/cache available Mem: 2043092 309876 1190416 14284 542800 1576804 Swap: 4194300 0 4194300
Все правильно. Теперь можно отключить файл подкачки.
Посмотрим, что покажут тесты:
| Запросов в секунду | Снижение производительности | |
| Без мониторинга | 27,52 | 100% |
| Prometheus | 24,78 | 90% |
| Prometheus+Loki | 21,58 | 78% |
| Prometheus+Loki+Tempo | 21,44 | 78% |
Почему-то производительность в целом стала немного ниже, но не так сильно зависит от включения функций мониторинга. Я предположил, что может быть дело все-таки в файле подкачки и включил его обратно. Вот что получилось:
| Запросов в секунду | Снижение производительности | |
| Без мониторинга | 29,64 | 100% |
| Prometheus | 26,97 | 91% |
| Prometheus+Loki | 25,7 | 87% |
| Prometheus+Loki+Tempo | 22,95 | 77% |
Выводы такие – добавление памяти улучшает производительность системы, наличие файла подкачки также влияет положительно. Почему так происходит, требует более детального изучения, могу лишь предположить, что менеджер памяти при наличии файла подкачки имеет возможность вытеснить на диск малоиспользуемые данные чтобы дать больше места активным приложениям. Я оставил файл подкачки включенным несмотря на то, что памяти в принципе хватало для работы системы и без него.
После этого мне стало интересно – а как повлияет на производительность добавление второго ядра CPU? Сказано-сделано:

После добавления второго ядра я погнал всё те же тесты и вот какой результат получился.
| Запросов в секунду | Снижение производительности | |
| Без мониторинга | 49,05 | 100% |
| Prometheus | 44,52 | 91% |
| Prometheus+Loki | 45,64 | 93% |
| Prometheus+Loki+Tempo | 40,34 | 82% |
Производительность увеличилась в 1,75 раза если сравнивать с базовым вариантом. Это хорошо, ведь если нагрузка на сервер будет расти, я могу просто докупить второе ядро, когда в этом появится необходимость.
Дальше я экспериментировать не стал, мне понятно, что, если продолжить добавлять память и процессорные ядра, производительность системы не будет расти так заметно. Чтобы обеспечить прирост производительности в этом случае нужно будет организовать запуск приложения в режиме кластера и внести еще ряд архитектурных изменений.
Выводы
Начиная этот эксперимент, я задался целью проверить, возможно ли на VPS c очень ограниченными ресурсами (я знаю, что можно найти предложения с еще более скромными параметрами, но 1 CPU + 1 Гб RAM – это доступный минимум у большей части провайдеров) запустить полноценную систему мониторинга для приложения. Как видите, это оказалось вполне возможно. Конечно, не все инструменты, которые используют крупные компании, применимы, но вполне можно найти такой набор, который позволит организовать мониторинг вашей системы не сильно влияя на ее производительность.
Также в ходе эксперимента я смог ответить для себя на ряд вопросов:
Стоит ли заморачиваться с настройкой мониторинга для совсем небольшого проекта?
Я считаю, что да, стоит. Мониторинг помогает понять, как ведет себя ваш проект в рабочей среде и дает информацию для дальнейшего улучшения качества кода. Я в процессе данного эксперимента, благодаря изучению данных мониторинга я смог заметить ряд недостатков в своем приложении, которые мне бы вряд ли удалось выявить другим способом.
Нужно ли делать нагрузочное тестирование?
Однозначно да. Во-первых, это позволяет найти узкие места в вашем приложении. Во-вторых, позволяет оценить, с какой нагрузкой сможет справиться система. Ну и в-третьих, имея настроенный мониторинг очень интересно наблюдать как система ведет себя под нагрузкой, это дает очень много пищи для размышлений и позволяет улучшить понимание того, как взаимодействуют компоненты системы.
Сложно ли настроить мониторинг
Ох, хотел бы я сказать, что это просто, но нет. Если делаешь это впервые, скорее всего придется вдоволь походить по граблям. Тут нет единого рецепта, как построить работающую систему, которая будет делать то, что вам нужно. Часто приходится собирать необходимую информацию по крупицам, и действовать интуитивно, потому что какие-то важные для тебя моменты не озвучиваются в документации. Если вы решите пойти этим путем, надеюсь, что данная статья и прилагающийся репозиторий поможет вам пройти его быстрее, чем мне.
А почему не облачные решения?
Мне просто спокойней платить фиксированную сумму и иметь в своем распоряжении все ресурсы, которые дает VPS. Истории, как разработчик что-то сделал неправильно и получил многотысячный счет – пугают. Хотя возможно, что в облаке все, что я описываю в этой статье настраивается за пару кликов мышкой, и тогда это, конечно, огромный плюс.
В заключении хотелось бы сказать – даже если у вас небольшой проект, и еще нет мониторинга, имеет смысл задуматься о его внедрении. Если вы опасаетесь, что это сложно сделать, или что у вашей системы недостаточно ресурсов для его реализации – можете использовать в качестве отправной точки материалы данной статьи и пример реализации, который я разместил в репозитории.
Репозиторий можно посмотреть по этому адресу: github.com/debagger/observable-backend
Облачные серверы от Маклауд быстрые и безопасные.
Зарегистрируйтесь по ссылке выше или кликнув на баннер и получите 10% скидку на первый месяц аренды сервера любой конфигурации!