Позовите преподавателя для проверки работы
Цель работы: изучить и освоить возможности MS Word при работе с колонками и списками.
Задание 1. Установка параметров страницы
Установим поля страницы. Для этого выберите вкладку Разметка страницы ® Параметры страницы.

Откроется окно Параметры страницы:

Установите поля страницы: Верхнее – 2 см, Нижнее – 2 см, Левое – 2 см, Правое – 2 см.
Обратите внимание, что в этом же окне можно поменять ориентацию страницы с книжной (по умолчанию) на альбомную.
Задание 2. Создание колонок (3 колонки)
Наберите текст по образцу (тип шрифта Times New Roman, размер – 12):
Распознавание текстов — очень важная задача, которая возникает во многих областях деятельности человека. Заполняя бюллетень на выборах, бланк во время переписи населения, карточку в поликлинике, бланк теста на экзамене, мы знаем, что обработку информации с этих носителей будет выполнять компьютер, а вернее специальная программа распознавания текста. Но прежде специальное устройство сканер поможет ввести данные с бланков в память компьютера. Сканер предназначен для преобразования информации с бумажного носителя в графический файл, с которым и будет работать программа.
Внимание: после напечатанного абзаца обязательно нажмите несколько раз , иначе не получатся три колонки.
Выделите напечатанный текст и выберите вкладку Разметка страницы ® Колонки ® Другие колонки.

Откроется окно Колонки:

Заполните поля диалогового окна: Тип (количество колонок) – 3, промежуток – 0,5 см. Нажмите ОК. Получится так:
Распознавание текстов — очень важная задача, которая возникает во многих областях деятельности человека. Заполняя бюллетень на выборах, бланк во время переписи населения, карточку в поликлинике, бланк теста на экзамене, мы знаем, что обработку информации с этих носителей будет выполнять компьютер, а вернее специальная программа распознавания текста. Но прежде специальное устройство сканер поможет ввести данные с бланков в память компьютера. Сканер предназначен для преобразования информации с бумажного носителя в графический файл, с которым и будет работать программа.
Задание 3. Создание колонок (2 колонки с разделителем)
Скопируйте и вставьте образец текста еще раз. Расположите его в две колонки с интервалом между колонками 1 см, поставьте галочку в окошке Разделитель. Получится так:
Распознавание текстов — очень важная задача, которая возникает во многих областях деятельности человека. Заполняя бюллетень на выборах, бланк во время переписи населения, карточку в поликлинике, бланк теста на экзамене, мы знаем, что обработку информации с этих носителей будет выполнять компьютер, а вернее специальная программа распознавания текста. Но прежде специальное устройство сканер поможет ввести данные с бланков в память компьютера. Сканер предназначен для преобразования информации с бумажного носителя в графический файл, с которым и будет работать программа.
Задание 4. Списки
Списки используют для автоматической нумерации абзацев. Элементом списка может быть только абзац. Списки могут быть нумерованные, маркированные и многоуровневые.

Списки можно создавать двумя способами:
1. Набрать текст из последовательности абзацев, выделить его и выбрать вид списка.
2. Выбрать вид списка и только после этого набрать текст из последовательности абзацев.
Результат будет одинаковым.
Нумерованные списки
Для создания нумерованного списка выберите вкладку Главная ® Абзац ® Нумерация.
Если щелкнуть по стрелке, появится окно, в котором можно выбрать форматы нумерации. Выберите указанный вид нумерованного списка и создайте список:

1. Сайгутина Светлана
2. Асадова Светлана
3. Козырева Юлия
4. Сакаева Ирина
5. Кузнецова Кристина
6. Балахонова Дарья
7. Пономарева Лидия

Расположите фамилии студенток по алфавиту. Для этого: выделите список и щелкните по пиктограмме Сортировка:
Появится окно Сортировка текста. Нажмите ОК. Получится так:
1. Асадова Светлана
2. Балахонова Дарья
3. Козырева Юлия
4. Кузнецова Кристина
5. Пономарева Лидия
6. Сайгутина Светлана
7. Сакаева Ирина
Скопируйте и вставьте полученный список, выберите другой вид нумерованного списка. Например:
1) Асадова Светлана
2) Балахонова Дарья
3) Козырева Юлия
4) Кузнецова Кристина
5) Пономарева Лидия
6) Сайгутина Светлана
7) Сакаева Ирина
Если список начинается не с 1, а продолжается, выделите первую фамилию, нажмите правую кнопку мыши (контекстное меню) и выберите Начать заново с 1. Создайте другие виды нумерованных списков.
Маркированные списки
Для создания маркированного списка выберите вкладку Главная ® Абзац ® Маркеры:

Создайте маркированный список:
Функции процессора:
ü обработка данных по заданной программе путем выполнения арифметических и логических операций;
ü программное управление работой устройств компьютера.
Функции памяти:
ü прием информации из других устройств;
ü запоминание информации;
ü выдача информации по запросу в другие устройства машины.

Многоуровневые списки
Первоначально список не имеет уровней. Для понижения уровня списка следует увеличить отступ:
Для повышения уровня списка – уменьшите отступ:
Создайте многоуровневые списки:
Список 1
1. Компьютерное оборудование
1.1. Системный блок:
1.1.1. материнская плата;
1.1.2. жесткий диск;
1.1.4. блок питания;
Список 2
1. В современном документообороте чаще всего используется:
1) Microsoft Word
2) StarOffice Writer
3) Windows Блокнот
2. Преобразование документа, обеспечивающее вставку, удаление, перемещение его фрагментов (объектов) – это:
3. Часть текста, представляющая собой законченный по смыслу фрагмент произведения, окончание которого служит естественной паузой для перехода к новой мысли:
Сохраните работу в своей папке под именем Практическая работа 3.
Позовите преподавателя для проверки работы
Практическое занятие № 4
Создание и форматирование таблиц
Цель работы: изучить и освоить возможности MS Word при работе с таблицами.
Таблицы в документах используют для представления структурированной информации.
Задание 1. Создание таблицы
Образец: Таблица истинности для основных логических функций
| A | B | A Ù B конъюнкция | A Ú B дизъюнкция | ØA инверсия |
| 0 | 0 | 0 | 0 | 1 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 | 0 |
Для создания таблицы используется вкладка Вставка ® Таблица

Посчитайте количество столбцов в таблице – 5. Количество строк считать необязательно, т.к. они легко добавляются и удаляются. Щелкните по пиктограмме Таблица и, удерживая левую кнопку мыши нажатой, выделите 5 клеточек по горизонтали и 5 клеточек по вертикали. Щелкните левой кнопкой мыши.

Заполните таблицу. Для ввода символов конъюнкции, дизъюнкции, инверсии используйте вкладку Вставка ® Символ.

| A | B | A Ù B конъюнкция | A Ú B дизъюнкция | ØA инверсия |
| 0 | 0 | 0 | 0 | 1 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 | 0 |
Выделите всю таблицу и щелкните правой кнопкой мыши. Появится контекстное меню:

Выберите Автоподбор ® Автоподбор по содержимому. Получится так:
| A | B | A Ù B конъюнкция | A Ú B дизъюнкция | ØA инверсия |
| 0 | 0 | 0 | 0 | 1 |
| 0 | 1 | 0 | 1 | 1 |
| 1 | 0 | 0 | 1 | 0 |
| 1 | 1 | 1 | 1 | 0 |
Расположите таблицу по центру. Расположите надписи в ячейках по центру. Напечатайте название таблицы. Должно получиться, как на образце.
Задание 2. Конструктор. Создайте таблицу:
| Вид рекламы | Эффективность рекламы (%) |
| Телевидение | 40 |
| Радио | 20 |
| Средства печати | 26 |
| Транспорт | 7 |
| Уличные щиты | 2 |
| Прочие | 5 |
Установите курсор в любой ячейке таблицы и найдите вкладку РАБОТА С ТАБЛИЦАМИ Конструктор:

Откройте окно, где Вы можете выбрать стиль оформления таблицы или создать свой стиль. Выберите один из стилей.
Задание 3. Объединение ячеек Образец:
Единицы измерения информации
Для того, чтобы записать название таблицы Единицы измерения информации, необходимо выделить ячейки первой строки, щелкнуть правой кнопкой мыши (появится контекстное меню), выбрать: Объединить ячейки:

Расположите текст внутри ячеек По центру, введите название таблицы Единицы измерения информации. Объедините 4-ую и 5-ую ячейки второй строки (где будет напечатано Приставка), затем разбейте ее на 2 столбца, 2 строки.


Единицы измерения информации
Две верхние ячейки объедините. Заполните таблицу. Используйте надстрочные и подстрочные знаки.
Задание 4. Создайте таблицу самостоятельно. Образец:
Дата добавления: 2020-04-08 ; просмотров: 2763 ; Мы поможем в написании вашей работы!
Поделиться с друзьями:
© 2014-2024 — Студопедия.Нет — Информационный студенческий ресурс. Все материалы представленные на сайте исключительно с целью ознакомления читателями и не преследуют коммерческих целей или нарушение авторских прав (0.033)
Распознавание текстов очень важная задача которая возникает
Государственная публичная научно-техническая библиотека СО РАН
Г.Б. Паршукова
Научная работа библиотекарей на персональном компьютере
Глава 18 Система распознавания текста FineReader
Система распознавания � одна из наиболее перспективных областей применения искусственного интеллекта. Существует решение, максимально приближенное к человеческой способности читать: оно построено на принципах, сформулированных в результате наблюдений за поведением животных и человека. Это технология целостного, целенаправленного и адаптивного восприятия.
Процесс обработки FineReader осуществляется в несколько этапов:
2. Выделение блоков на изображении.
Затем нужно проверить ошибки и сохранить результат распознавания (передать его в другое приложение, например в текстовый редактор WORD , в Буфер и т.п.).
FineReader � это система оптического распознавания текстов. Она преобразует полученное с помощью сканера графическое изображение (картинку) в текст (то есть в коды букв, «понятные» компьютеру). Основные модификации � Standard, Professional, Рукопись.
Функции, обеспечиваемые модификациями FineReader
Печатные, рукописные
В библиотеках следует, конечно, применять профессиональные версии программ (это замечание касается любых программ). Если есть возможность, а главное уровень решаемых задач, то необходимо приобретать модификацию Рукопись.
Выбор сканера
Библиотекарям приходится сканировать именно тексты, которые должны быть потом распознаны и превращены в текстовый файл. Если же сканер используется для выполнения платных услуг по сканированию и распознавание не требуется, то можно использовать программы, предназначенные только для сканирования и сохранения картинки.
Для большего комфорта работы необходимо, чтобы программа была связана с подключенным к ней сканером: меню Сервис � Выбор сканера.
О планшетных сканерах
Наиболее универсальный и наиболее распространенный тип сканера. Как правило, обеспечивает высокое разрешение при средней и высокой скорости сканирования.
Планшетные сканеры делятся на две группы:
1. Для работы в офисе и дома.
Как правило, эти сканеры обладают максимальным оптическим разрешением 300 dpi, обычно достаточным для систем распознавания текстов и проведения простых работ по вводу фотографий для любительских фотоальбомов или дизайна страниц в Интернете. Они могут подключаться через параллельный порт, собственную ISA или PSI карту, или SCSI. Обычно имеют максимальную область сканирования A4.
2. Профессиональные сканеры.
Цветные. Оптическое разрешение 600 dpi и выше. Имеют SCSI интерфейс. Зачастую комплектуются модулем для сканирования слайдов. Область сканирования � от Legal до A3.
Некоторые модели сканеров могут дополнительно комплектоваться устройством автоматической подачи бумаги (Automat Document Feeder � ADF). Как правило, они производятся только для моделей, имеющих либо SCSI, либо другой достаточно быстрый интерфейс с компьютером.
При выборе модели сканера необходимо обращать внимание на следующие моменты:
1. Если предполагается сканировать толстые книги, желательно, чтобы крышка сканера это позволяла � не была жестко закреплена, а могла выдвигаться.
2. Если сканер снабжен автоподатчиком, необходимо проследить, как сканер и его драйвер обрабатывают ситуацию перекоса бумаги в лотке автоподатчика. Сканер должен позволять легко разрешать эту проблему.
3. Следует обращать внимание на шум, производимый при сканировании. Некоторые дешевые сканеры довольно шумные, что может доставить массу неудобств при работе в офисе или дома.
О листовых сканерах
Применяются обычно в офисе или дома для сканирования отдельных листов. Однако существуют модели, у которых снимается нижняя часть, что позволяет сканировать книги и журналы, но при этом качество изображения, как правило, резко снижается. Из-за невысокой скорости и среднего качества изображения применяются при эпизодической работе.
До недавнего времени листовые сканеры служили дешевой альтернативой планшетным. Дополнительным стимулом при покупке может служить экономное использование рабочего пространства. Существуют модели для сканирования как черно-белых, так и цветных изображений. Обычно максимальная область сканирования � A 4.
При выборе данной модели сканера необходимо обращать внимание на следующие моменты:
1. Сканер должен легко «захватывать» бумагу из лотка.
2. Как сканер и его драйвер обрабатывают ситуацию перекоса бумаги в лотке. Сканер должен позволять легко разрешать эту проблему.
3. Часто бывает полезной способность TWAIN-драйвера сканера сканировать в автоматическом режиме всю стопку документов, вставленную в лоток, а не ждать команды после сканирования каждого листа. Как правило, эта способность связана с другой не менее важной � автоматическое определение того, кончилась ли бумага в лотке.
О ручных сканерах
Из-за невысокого качества получаемого изображения ручные сканеры применяются обычно дома. В отличие от других типов сканеров, позволяют получать хорошее изображение области около корешка книг в жестком переплете.
До недавнего времени они служили дешевой альтернативой планшетным сканерам.
Модели с мотором иногда позволяют достигать лучшего качества сканирования за счет более равномерного перемещения сканера.
Дополнительным стимулом при покупке может служить экономное использование рабочего пространства. Существуют модели, предназначенные для сканирования черно-белых и модели для сканирования цветных изображений. Обычно максимальная ширина сканируемой области � 10 см.
При выборе модели сканера необходимо обращать внимание на следующие моменты:
1. Качество отсканированного изображения (лучше всего � текста). Качество изображения не должно страдать при более или менее равномерном перемещении сканера. Обычно запоминается скорость сканирования на разных этапах и происходит программная компенсация неизбежных вертикальных искажений. Если драйвер сканера не умеет компенсировать вертикальные искажения, то получить качественное изображение текста практически невозможно.
2. Проверьте, позволяет ли сканер указывать направление сканирования: слева направо, сверху вниз, справа налево.
3. Часто бывает полезной способность TWAIN-драйвера склеивать куски изображений. К сожалению, ею не всегда можно реально воспользоваться.
Некоторые общие советы на применение сканеров при вводе документов:
1. Документация сканера и сопровождающего программного обеспечения должна быть на русском языке.
2. В документации должны быть указаны адреса центров технического обслуживания.
3. Сканер должен иметь в комплекте TWAIN-драйвер совместимый с той операционной системой, в которой вы будете его использовать. Обычно на коробке сканера при этом присутствует логотип Twain-compliant или Twain-compatible. Как правило, все современные сканеры имеют TWAIN-драйвер, совместимый с MS Windows’95, 98. Кроме того, все сканеры подключаемые через SCSI, одинаково успешно работают в MS Windows’95, 98 и Windows NT 4.0. Проблему могут составить только сканеры, подключаемые через параллельный порт или специальные карты, при работе в MS Windows NT 4.0.
4. Обратите внимание на диалог с опциями сканера, который возникает перед сканированием. Желательно, чтобы в этом окне была легко доступна опция выбора типа сканируемого изображения (черно-белый, серый, цветной). В идеале еще и серый с 16 градациями (обычно только с 256 градациями) � это позволит включать встроенный в систему FineReader автоматический подбор яркости при сканировании в сером (обычно серое изображение с 16 градациями сканируется быстрее за счет меньшего объема информации, чем с 256 градациями). Возможность работать с серым изображением особенно важна для библиотек, так как очень часто возникает необходимость сканирования печатных текстов разного качества (бумага, шрифт и т.д.).
Окно программы
Окно программы FineReader имеет сложную структуру (оно разбито на несколько кадров, в которых отражаются результаты сканирования, страницы, которые необходимо распознать, результаты распознавания).
Сканировани е
Нажмите кнопку с изображением сканера на панели инструментов (сканировать).
Вы можете добавлять отсканированные страницы в пакет, по умолчанию создаваемый при запуске программы, или открыть другой пакет (нажмите кнопку) и записывать отсканированные страницы в него.
Нажмите стрелку справа от кнопки и из локального меню выберите пункт Сканировать и распознать.
Система отсканирует изображение, выделит на нем блоки, а затем распознает его.
Если у Вас отмечен пункт Открывать последний пакет (меню Сервис, пункт Опции. закладка Установки), то при загрузке программа будет открывать последний пакет, с которым вы работали в предыдущей сессии.
Параметры сканирования:
Яркость: для светлых документов необходимо уменьшить яркость (сделать их темнее), для темных � увеличить (сделать их светлее).
Разрешение: 300 dpi � для большинства документов; 400�600 dpi � для документов, набранных мелким шрифтом.
Выбор разрешения � это регулировка яркости у всех типов изображения. Часто у черно-белых изображений регулировка яркости осуществляется не выбором яркости (brigthness), а выбором порога (threshold). Это ничем не хуже, однако, если вы потом отключите опцию Показ диалога TWAIN-драйвера , то скорее всего не сможете регулировать яркость.
| Особенности входного изображения | Что сделать |
| Светлые или тонкие буквы | Уменьшить яркость (сделать темнее) |
| Темные или толстые буквы | Увеличить яркость (сделать светлее) |
| Глянцевая бумага | Уменьшить яркость |
| Слипшиеся символы | Увеличить яркость |
| Разрывы | Уменьшить яркость |
| Смазанные или заполненные контуры букв | Увеличить яркость |
Обратите внимание на скорость сканирования в режиме черно-белого изображения (300 dpi). Желательно, чтобы это время не превышало 1�2 минуты.
Обратите внимание на скорость сканирования в режиме цветного изображения (300 dpi). Желательно, чтобы это время не превышало 5�6 минут. В некоторых дешевых моделях, подключаемых через параллельный порт, это время может достигать огромных значений.
Некоторые TWAIN-драйверы при запуске сканирования показывают окно с сообщением о том, что идет разогрев (Warming �) или калибровка (Calibrating �). Как правило, это занимает около минуты. Иногда эта операция происходит при каждом запуске сканирования, даже если оно идет практически непрерывно или сканируется предварительное изображение (Preview�). Как утверждают разработчики сканеров, это необходимо для более корректной цветопередачи. Желательно, чтобы этого режима не было вообще или чтобы он был отключаемым.
Повернуть изображение
Распознаваемое изображение должно иметь стандартную ориентацию: текст должен читаться сверху вниз и строки должны быть параллельны нижнему краю экрана.
Вы можете указать программе, чтобы она автоматически подбирала ориентацию страницы.
Если ориентация не подбирается автоматически, повернуть изображение можно вручную:
1. Выделите нужные изображения.
Выделить одну страницу � Нажмите на нее мышью.
Выделить несколько страниц подряд � Удерживая клавишу SHIFT, нажмите мышью на первую страницу выборки, а затем � на последнюю.
2. Выделить несколько страниц не подряд
Удерживая клавишу CTRL, последовательно нажимайте на интересующие страницы.
Нажмите кнопку, с изображением направления, чтобы повернуть изображение на 90�.
Из меню Изображение выберите пункт Повернуть на 180�, чтобы перевернуть изображение вверх ногами.
Таким же образом можно повернуть активное открытое изображение.
Распознавание
Язык распознавания и тип текста являются главными параметрами распознавания.
Языки, которые имеют словарную поддержку: английский, голландский, датский, испанский, итальянский, немецкий, норвежский, польский, португальский, русский, украинский, финский французский, шведский.
При распознавании текста на том или ином языке выберите нужный язык из списка на панели Распознавание.
Если нужного языка нет в списке, то выберите значение Другой. и в открывшемся списке найдите нужный язык или выберите несколько языков, слова которых встречаются в распознаваемом тексте.
Тип текста определяется в системе автоматически. Однако для распознавания текстов, напечатанных на пишущей машинке или матричном принтере в черновом режиме, чтобы повысить надежность и скорость распознавания, выберите соответствующее значение в списке на панели инструментов.
Если вы распознавали тексты, напечатанные на пишущей машинке или матричном принтере, то при возвращении к типографскому тексту не забудьте снова выбрать значение Авто .
Открытие изображения:
- Меню Файл � Открыть.
- Выберите диск и папку, где находятся нужные файлы.
- Выберите нужные файлы и нажмите OK.
- Выбранные файлы копируются в текущий пакет.
- Вы можете указать, чтобы выбранные изображения не копировались, а перемещались в пакет (отметьте пункт Перемещать файлы в пакет).
Тогда при загрузке в текущий пакет выбранные файлы будут копироваться туда, где находится ваш пакет и удаляться оттуда.
Также можно добавлять изображения из буфера или через drag-&-drop.
Запуск распознавания:
- Выделите нужные страницы в окне пакета. Подведите курсор и щелкните 1 раз левой кнопкой мыши.
- Нажмите кнопку Распознать открытую страницу. Активизируйте открытое изображение и нажмите кнопку � Распознать.
Распознать все нераспознанные страницы:
- Нажмите стрелку справа от кнопки � Распознать и из открывшегося меню выберите пункт Распознать все нераспознанные страницы.
- Программа выделяет блоки (если они еще не выделены) и распознает изображения.
Установить расположение текста на странице :
Программа FineReader автоматически определяет раскладку текста на странице. Для книг, газет, факсов, отчетов и т.п. подходит положение Автоматическое определение. И только в редких случаях, например при распознавании оглавлений и листингов программ, нужно специально указывать программе, что текст напечатан в одну колонку.
1. Меню Сервис � Опции�
2. В диалоге Опции выберите закладку Сегментация.
3. В группе Число колонок выберите пункт Одна колонка (для текста, напечатанного в одну колонку с большими промежутками между словами) или Автоматическое определение.
С охранить результаты распознавания в файл:
1. Если Вы хотите сохранить не все страницы пакета, то выделите нужные в окне Пакет.
2. Нажмите стрелку справа от кнопки Сохранить и в открывшемся меню выберите пункт Сохранить в файл.
3. В открывшемся диалоговом окне выберите диск, каталог и укажите имя и расширение файла, в который хотите экспортировать распознанный текст.
4. Установите переключатель Какие страницы сохранять в положение Все распознанные или Только выделенные.
5. Чтобы записывать каждую страницу в отдельный файл, отметьте пункт Записывать каждую страницу в отдельный файл. Тогда имена, которые эти файлы получат, будут состоять из заданного имени и порядкового номера (1, 2, и т.д.).
Вы можете передать результаты распознавания в одно из следующих приложений: MS Word, MS Excel, Corel WordPerfect, Lotus Word Pro или PROMT:
1. Активизируйте окно пакета (нажмите в нем мышью) и нажмите стрелку справа от кнопки Сохранить.
2. В открывшемся меню выберите пункт Передать в Word, Передать в Excel и т.п.
Для выделенных страниц:
1. Если вы хотите передать в другое приложение не все страницы, а только некоторые, то выделите нужные страницы в окне Пакет.
2. Нажмите на стрелку справа от кнопки � Сохранить и выберите пункт Мастер сохранения результатов.
3. В открывшемся списке выберите нужное приложение и отметьте пункт Сохранять только выделенные страницы. По нажатию Готово в этом диалоге результаты распознавания передаются в выбранное приложение.
Что такое OCR? Зачем нужно оптическое распознавание символов в современном мире мобильных технологий?
Говоря простым языком, OCR (optical character recognition, оптическое распознавание символов) – это процесс перевода текста на изображениях в текстовый формат. Основное применение технологии OCR находят в различных задачах, связанных с оцифровкой данных. Для отдельных подзадач OCR иногда используют названия наподобие “умное распознавание символов” (intelligent character recognition, ICR) или “распознавание визитных карточек” (business card recognition, BCR).

Первые системы оптического распознавания символов появились практически одновременно с первыми компьютерами. В 50-х годах прошлого столетия с помощью коммерческих OCR системы начали обрабатывать отчеты о продажах, набранные на печатной машинке, и переводили их в перфокарты. С тех пор OCR пережил много изменений, главным из которых стала замена применяемых в алгоритмах распознавания разнообразных классификаторов символов искусственными нейронными сетями (ИНС, ANN).
Вызовы современных OCR технологий
Сейчас технологиям распознавания брошен серьезный вызов, когда все чаще речь идет о распознавании изображений с камер мобильных устройств или обычных веб-камер. Это могут фотографии или кадры из видеопотока. Чтобы лучше понять сложность поставленной задачи, давайте начнем с примера. Изображение документа для распознавания можно получить разными способами, и мы выбрали три из них:
1) взяли Canon CanoScan LiDE 300, отсканировали документ с разрешением 300dpi и бинаризовали результат;
2) сфотографировали документ на iPhone 11 при комнатном освещении;
3) сняли видео веб-камерой и взяли из него один кадр.
Как видно на картинке, системы распознавания в наши дни должны быть устойчивы к самым разнообразным условиям съемки. Очевидно, качество изображений может существенно различаться.
| Binarized scan |  |
| Photo with iPhone 11 |  |
| Web camera video frame |  |
Вот так может выглядеть рабочий процесс системы оптического распознавания.

Большинство подходов начинаются с предобработки изображения, которая, как правило, включает бинаризацию изображение для упрощения последующей сегментации на символы. Алгоритм сегментации делит изображение строки на изображения отдельных символов, которые подаются классификатору. Иногда, для улучшения качества распознавания к результату классификации могут применяться алгоритмы постобработки.
В случае mobile optical character recognition или мобильного OCR (на Android, iOS или иных системах), или же распознавания на мобильном устройстве, возникают две трудности: ограничения на вычислительные мощности и неконтролируемые условия съемки. При работе с персональными документами, банковскими бумагами или, например, результатами теста на COVID-19 важно обеспечить максимум конфиденциальности и минимизировать риск утечки данных, так что распознавание “в облаке” сразу отпадает. Распознавание непосредственно на устройстве накладывает ограничения на вычислительную сложность алгоритмов, ведь система должна работать быстро и энергоэффективно. С другой стороны, меньшие ограничения на условия съемки значительно расширяют диапазон возможных искажений. Появляются проективные искажения, смазывание, перепады яркости, блики и многое другое. Все это существенно влияет на этап предобработки.
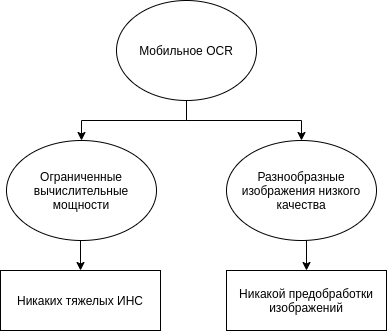
В результате при мобильном распознавании, с одной стороны, возникает множество ошибок у стандартных подходов к сегментации, а с другой – из-за ограничения на вычислительные ресурсы многие современные нейросетевые модели, например, рекуррентные сети (RNN) или LSTM-сети становятся неэффективными или же излишне ресурсозатратными. Таким образом, для успешного распознавания изображений, снятых на камеры мобильных устройств (работающих на Android или iOS), необходимо придумывать абсолютно новые алгоритмы и переосмысливать уже известные подходы.
Примером переосмысления старых подходов можно считать замену алгоритмов сегментации, основанных на обработке изображений, на сегментирующие нейронные сети, как это уже когда-то произошло с классификаторами. Наиболее многообещающей моделью для такие подходов представляется полносверточная сеть (fully convolutional network, FCN).

Замена отдельного изображения на видеопоток приводит к появлению концепции 4D OCR и новым возможностям распознавания, прежде всего, к алгоритмам межкадровой интеграции результатов распознавания. Более того, при обработке видео можно рассматривать процесс распознавания как anytime алгоритм, готовый в любой момент дать ответ. Выбор оптимального числа кадров можно осуществлять, решая задачу остановки.
В каких процессах применяются системы оптического распознавания (OCR)
Давайте приведем несколько примеров. Все ниже перечисленные процессы можно улучшить и ускорить с помощью OCR системы.
Платежи и переводы могут стать гораздо быстрее с добавлением распознавания банковской карты. Замена ручного ввода данных на сканирование QR, AZTEC, PDF 417 или другого типа штрихкода вместе с распознаванием карты поможет избежать раздражающих ошибок во введенных данных и улучшить впечатление конечного пользователя от банковского приложения, онлайн-магазина или даже офлайн магазина.
При продаже билетов и регистрации на рейс пассажирам требуется вводить свои личные данные. Автоматическое сканирование МЧЗ (машиночитаемой зоны) или паспорта позволит сделать эти процессы более удобными для пользователей и минимизировать число ошибок в данных.
Удаленная идентификация клиента – популярная и крайне важная опция для многих задач, включая проверку возраста, онлайн-регистрацию, активацию сим-карты, бронирование номеров в отелях и предварительную запись на медицинские услуги. С ее помощью можно упростить жизнь пользователю, а также оптимизировать работу персонала и в результате избежать очередей в офисах, магазинах, фойе отелей и других местах скопления людей.
Отдельно стоит выделить банковские услуги, где применение OCR для распознавания документов и удостоверений личности является must-have функцией. В этой сфере любые ошибки в данных приводят к проблемам для клиентов, оставляя у них плохое впечатление от банка и влияя на решение о дальнейшем обслуживании. Встроенное распознавание ID карт, паспортов, водительских прав и других документов ускоряет процесс открытия счета новым клиентам, упрощает аутентификацию текущих клиентов и предоставляет возможности развития кросс-продаж.
А что об общедоступных OCR решениях?
В наше время существует много общедоступных open-source распознавателей текста. Такие решения могут быть очень полезны в образовательных целях или для учебного демонстрационного приложения. Однако они могут быть не просто бесполезны, а опасны для настоящих “боевых” коммерческих систем. При этом, их существенным недостатком окажется не только точность и скорость распознавания, но и уязвимость для внешних атак.
Атаки на нейронные сети – это популярная тема для научных исследований. Главные типы атак – отправление данных и атака уклонением с помощью состязательных примеров. При отравлении данных ошибки вводятся в сеть на этапе обучения. А при применении сети распознаватель может совершить специфические серьезные ошибки. Единственный способ избежать такой атаки – быть уверенными в своих данных. А как можно быть уверенным в данных, которых вы никогда не видели? При атаке уклонением злоумышленник пытается заставить сеть дать неверный ответ. Иногда он даже может предопределить этот ответ. Для открытых систем оптического распознавания текста и символов (OCR) такие примеры можно посчитать, так как эти системы общедоступны. Можно просто скачать модель и подобрать нужные примеры.
Теперь чуть больше об OCR сервисах Smart Engines
В Smart Engines мы разрабатываем OCR решения, которые могут работать с изображениям, фотографиями, сканами или видеопотоком в реальном времени. Условия съемки могут быть самыми разными – не нужно специально фокусировать камеру или же искать хорошо освещенное место. Наше ПО работает автономно на конечном устройстве, никуда не передает данные клиента, не хранит их и не требует интернет-соединения. При разработке нашего OCR модуля мы активно пользуемся генерацией искусственных данных и не используем предобученные модели. Таким образом, наше решение оказывается гораздо более устойчивым для внешних атак.
Программные продукты Smart Engines, в которых мы применяем собственные технологии OCR
– Smart ID Engine – SDK для сканирования более чем 2427 типов удостоверяющих личность документов со всего мира, напечатанных с использованием латиницы, кириллицы, арабицы и других письменностей;
– Smart Code Engine – решение для распознавания банковских карт, одномерных и двумерных штрихкодов, МЧЗ и других кодированных объектов;
– Smart Document Engine – система автоматического анализа и распознавания деловых документов, форм и анкет.
– Сканеры Smart Engines – программно-аппаратные комплексы для распознавания и проверки подлинности паспортов и других удостоверений личности
Как работают наши OCR технологии в мобильных приложениях Android и iOS
Чтобы бесплатно попробовать наши продукты в действии, вы можете скачать демоприложение из App Store или Google Play.
Если же вы хотите узнать больше о научных разработках, стоящих за нашими продуктами, можете почитать разделы Наука и Блог на нашем сайте, наш блог на хабре или просто поискать нас в Google Scholar.
Блог
Заказать продукт
Быстрая интеграция технологии распознавания документов в бизнес-процессы вашей компании
Распознавание текстов очень важная задача которая возникает
УПС, страница пропала с радаров.
*размещая тексты в комментариях ниже, вы автоматически соглашаетесь с пользовательским соглашением
Вам может понравиться Все решебники
Мерзляк, Полонская, Якир
Пасечник, Каменский, Швецов
Арсентьев, Данилов, Курукин
Юлия Ваулина, Джунни Дули
Комарова, Ларионова
©Reshak.ru — сборник решебников для учеников старших и средних классов. Здесь можно найти решебники, ГДЗ, переводы текстов по школьной программе. Практически весь материал, собранный на сайте — авторский с подробными пояснениями профильными специалистами. Вы сможете скачать гдз, решебники, улучшить школьные оценки, повысить знания, получить намного больше свободного времени.
Главная задача сайта: помогать школьникам и родителям в решении домашнего задания. Кроме того, весь материал совершенствуется, добавляются новые сборники решений.