Stop the world в Kafka или спасти рядового consumer 🙂

Меня зовут Андрей Бугаков, разработчик в компании Datanomica. Я решил написать эту статью после ошибки в production, думаю, она может оказаться полезной другим разработчикам. Ниже рассказал, как в рамках разработки нового сервиса мы выбирали оптимальный вариант стратегии ребалансировки и изучали влияние различных стратегий ребалансировки на потерю сообщений.
Kafka — достаточно популярная потоковая платформа, которая позволяет хранить, обрабатывать и доставлять данные в высоконагруженных проектах. Kafka разработана так, что ее можно использовать и как транспорт для передачи информации, и как хранилище. Так же архитектура предоставляет возможности по довольно удобному горизонтальному масштабированию.
В Kafka используется publish-subscribe модель распространения сообщений. Основные сущности: topic, partition, producer, consumer, consumer group. Ниже объясню термины подробнее, если вы уже знаете их — пролистните таблицу.
Topic
Ключевое понятие в архитектуре Kafka. Это канал, который используется для организации или хранения потоков данных.
Producer
Приложение или компонент, отправляющие (публикующие) сообщения в topic Kafka.
Consumer
Приложение или компонент, читающее сообщения из topic Kafka.
Partition
Физическое и упорядоченное хранилище сообщений внутри topic. Каждый topic может быть разделен на одну или несколько partition. Внутри partition сообщения являются логической последовательностью, упорядоченной по времени или ключам сообщений.
Consumer Group
Логическая группа, состоящая из одного или нескольких consumers, которые работают совместно для чтения сообщений из topics Kafka. Каждая consumer group обрабатывает набор partitions в topic, причем каждая partition обрабатывается только одним consumer из группы (это довольно важно в контексте статьи).
Как все начиналось
Какое-то время мы разрабатывали решение на микросервисах, которым должны были заменить старое монолитное решение в нашей компании.
Прежде, чем перейти дальше, уточню — для развертывания в production у нас используется подход canary release (канареечный релиз). Таким образом, сначала происходит установка одного экземпляра сервиса, проверяются ошибки интеграции, потребителей и далее приложение раскатывается на весь входящий трафик.
Нам нужно было постепенно включать потребителей в рамках миграции со старого решения на новое. Большинство из них были готовы перейти на взаимодействие с использованием Rest, но были и те, кто не был готов, поэтому в качестве транспорта была выбрана Kafka.
Особенность этих интеграций заключается в том, что подразумевается ограниченное время на запросы потребителя с таймаутом от 3 до 20 секунд, в зависимости от конкретного потребителя. Нагрузка по этому каналу интеграции предполагалась около 500-800 RPS, общая нагрузка же около 1,5-2 тысяч запросов в секунду.
На тот момент опыта работы с Kafka с нагрузкой выше 50 запросов в секунду не было, и раньше мы с командой не сталкивались с требованием связанным с ограничением по времени ответа.
Для разработки была использована библиотека spring-kafka и наработки по предыдущим сервисам работавшим с Kafka. Далее, реализовали сервис, успешно прошли нагрузочное тестирование и установили сервис в production среду. Сервис успешно работал и в production проблем не вызывал. Также, первое время данный сервис обновлялся во время технического окна, в которое нагрузка на topics снижалась до нуля и переводилась на старое решение, поэтому все обновления происходили без каких либо проблем. Первый звонок прозвенел после того, как мы вывели старую систему из эксплуатации и сервис, читающий из Kafka, потребовал установки доработок.
И тут произошло самое интересное ��
На мониторинге коллеги от команды сопровождения увидели примерно такую картину:
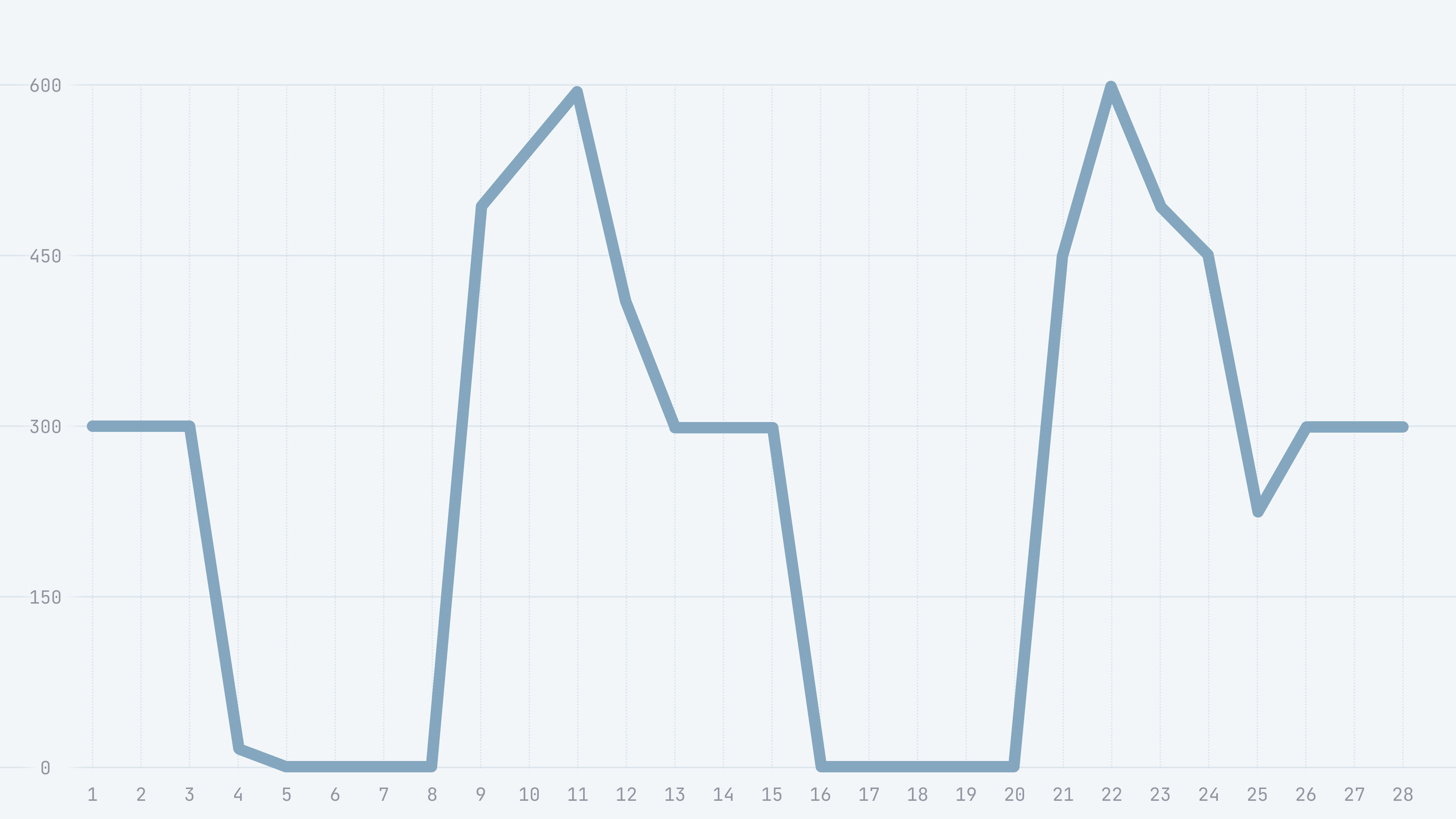
График сделан от руки, чтобы показать влияние обновления системы на получение ответов внешней системой.
Рассмотрим график подробнее и попробуем сопоставить интервалы на графиках с имеющейся информацией от команды сопровождения:
Т1-Т3: нормальная обработка сообщений, новый экземпляр приложения еще не запущен,
Т3-Т4: отсутствует обработка сообщений,
Т8-Т13: повышение количества обработанных сообщений,
Т13-Т15: стабилизация количества ответов,
Т15-Т20: отсутствует обработка сообщений,
Т20-Т26: всплеск количества обработанных сообщений,
Т26-Т28 и далее: нормальная работа приложения.
Обновление приложения происходило в два этапа в связи с установкой при режиме canary release, временной интервал Т3 соответствует включению одного приложения новой версии и добавлению нескольких новых consumers в consumer group. Далее, в момент времени Т15-Т16 добавляется еще несколько consumers и в этот момент происходит переключение кластера на новую версию приложения, старые версии приложения выключаются.
Таким образом, как видно по графику, происходит полная остановка обработки сообщений, потом происходит всплеск, и нагрузка возвращается к стандартным значениям.
Что произошло
Добавление новых consumers запускало механизм ребалансировки. Ребалансировка consumers Kafka — процесс, который происходит, когда новый consumer добавляется в consumer group Kafka или удаляется из нее, а так же, когда существующий consumer в consumer group дает сбой или перезапускается.
В это время Kafka перераспределяет partitions между активными consumers в consumer group, чтобы гарантировать, что каждая partition обрабатывается только одним consumer. После завершения перебалансировки consumers возобновляют обработку сообщений. Этот процесс помогает обеспечить равномерное распределение работы по потреблению сообщений между членами consumer group.
Далее, думаю, стоит разобраться какие стратегии ребалансировки существуют и как они работают.
Стратегии ребалансировки
Выбор стратегии ребалансировки задается параметром:
partition.assignment.strategyKafka clients предоставляет четыре стратегии ребалансировки: RangeAssignor, RoundRobinAssignor, StickyAssignor и CooperativeStickyAssignor.
В случае необходимости смены стратегии требуется задать перечень стратегий для перехода на необходимую стратегию, в порядке приоритета использования, например, если изначально использовался режим балансировки по умолчанию — RangeAssignor, и требуется перейти на стратегию CooperativeStickyAssignor то требуется указать полное имя класса, имплементирующего класс PartitionAssignor:
partition.assignment.strategy: org.apache.kafka.clients.consumer.CooperativeStickyAssignor,org.apache. kafka.clients.consumer.RangeAssignorВсе consumers внутри consumer group должны использовать одну и ту же стратегию, в случае, если в группе будут указаны разные стратегии, то будут возникать ошибки вида:
org.apache.kafka.common.errors.InconsistentGroupProtocolException: The group member's supported protocols are incompatible with those of existing members or first group member tried to join with empty protocol type or empty protocol listВзглянем на стратегии перебалансировки и их влияние на распределение partitions:
Как работает: назначает partitions consumers на основе диапазона идентификаторов. Сначала сортирует partitions и consumers по их идентификаторам, а затем назначает разделы каждому consumer на основе диапазона идентификаторов partitions. Данная стратегия используется по-умолчанию.
Что гарантирует: каждому consumer будет назначен ряд смежных partitions.
- Round Robin Assignor.
Как работает: назначает partitions consumers в стиле round-robin. Сортирует partitions и consumers по их идентификаторам, а затем назначает каждый раздел следующему доступному consumer циклически. Звучит очень похоже на стратегию выше, данный способ позволяет задействовать большее количество consumers, но не минимизирует перемещения partitions в consumer group.
Что гарантирует: каждый consumer имеет равное количество partitions и также в случаях использования одной consumer group для чтения из нескольких topics, также может позволить более равномерно распределить нагрузку между consumers в consumer group, задействовав большее количество consumers.
- Sticky Assignor.
Как работает: стратегия предназначена, чтобы минимизировать количество partitions, которые перемещаются между consumers во время перебалансировки. Он назначает partitions consumers на основе хэша идентификатора partition и идентификатора consumer.
Что гарантирует: каждая partition всегда назначается одному и тому же consumer, если этот consumer все еще является частью consumer group. Если consumer покидает consumer group, его partitions перераспределяются между оставшимися членами consumer group.
- Cooperative Sticky Assignor.
Появился в kafka-clients версии 2.7.0.
Как работает: стратегия перебалансировки точно такая же как Sticky Assignor, но она предназначена для работы с протоколом кооперативной балансировки consumers Kafka. Кооперативный протокол позволяет consumers обмениваться информацией об их текущем состоянии, такой как количество partitions, которые они обрабатывают, и объем данных, которые они получают. Cooperative Sticky Assignor использует эту информацию для оптимизации назначения partitions на основе балансировки нагрузки.
Тестирование стратегий ребалансировки
Чтобы проиллюстрировать влияние различных стратегий ребалансировки на распределение partitions и на обработку сообщений, мы можем использовать два смоделированных сценария.
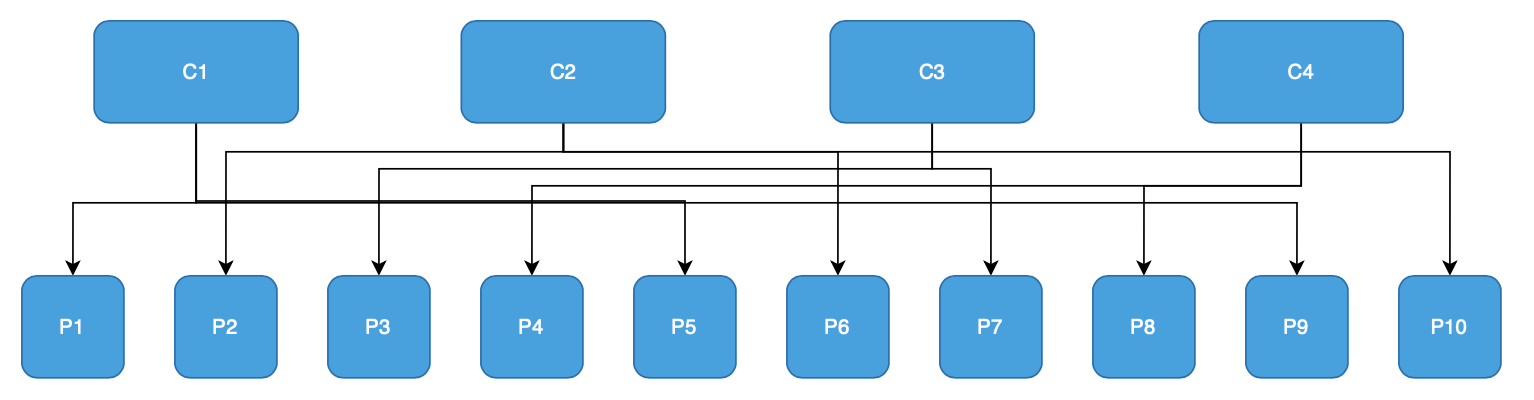
Первый сценарий
Данный сценарий позволит оценить изменения при перераспределении partitions.
- topic Kafka с 10 partitions;
- consumer group с 4 consumers (C1, C2, C3 и C4), подписавшихся на этот topic.
- оценить первоначальное распределение partitions между consumers;
- добавить новый consumer (C5) в группу и оценить перебалансировку partition между всеми 5 consumers.
Ниже описано влияние на распределение partitions в зависимости от выбранной стратегии:
Ниже можно увидеть как при воспроизведении первого тестового сценария распределяются partitions:
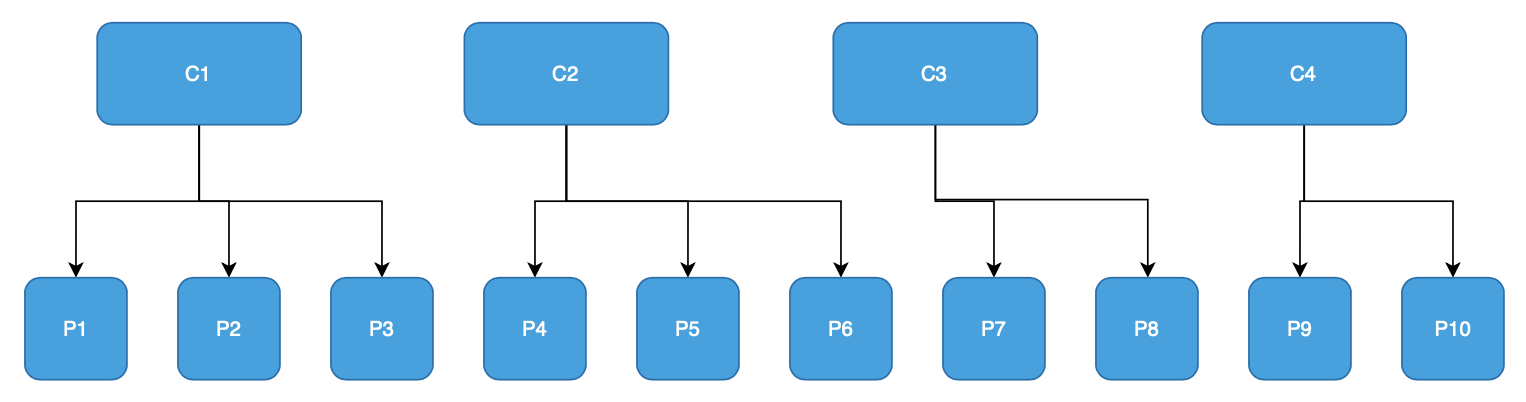
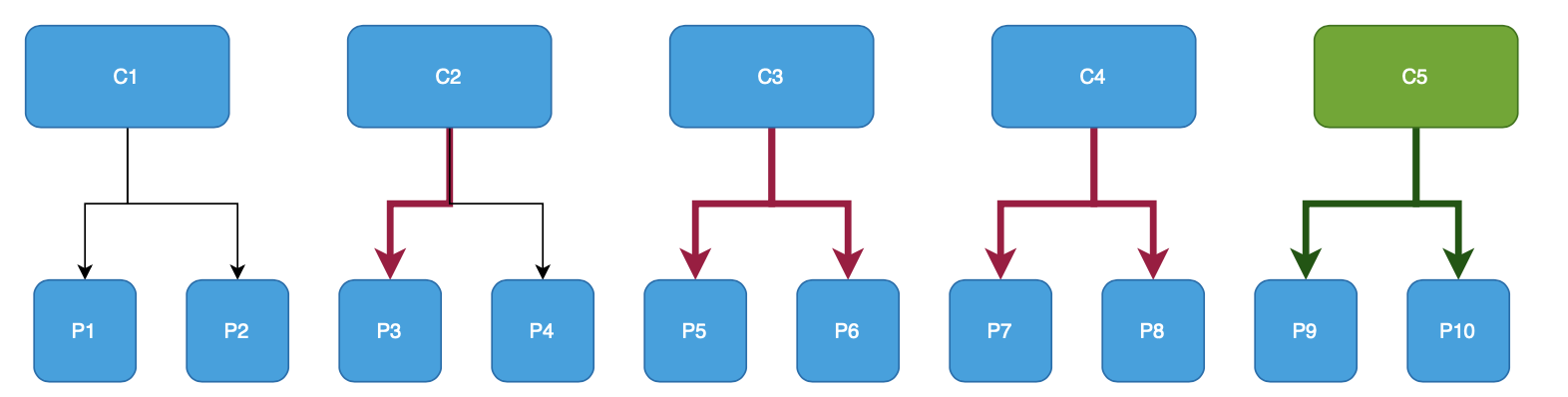
На втором графике стрелками красного цвета отображены изменения назначений partitions для consumers, зелеными стрелками — назначение partitions для нового consumer (далее буду использовать подобный подход для отображения изменений состояний consumers).
Исходя из результатов становится очевидно, что для этого примера ребалансировка затрагивает минимум 7 partitions, это довольно много, но тем не менее ребалансировка равномерно распределила partitions между consumers.
Когда стоит выбрать: Стоит выбрать данную стратегию если время на ребалансировку и количество переназначенных partitions не имеет значения.
- Round Robin Assignor
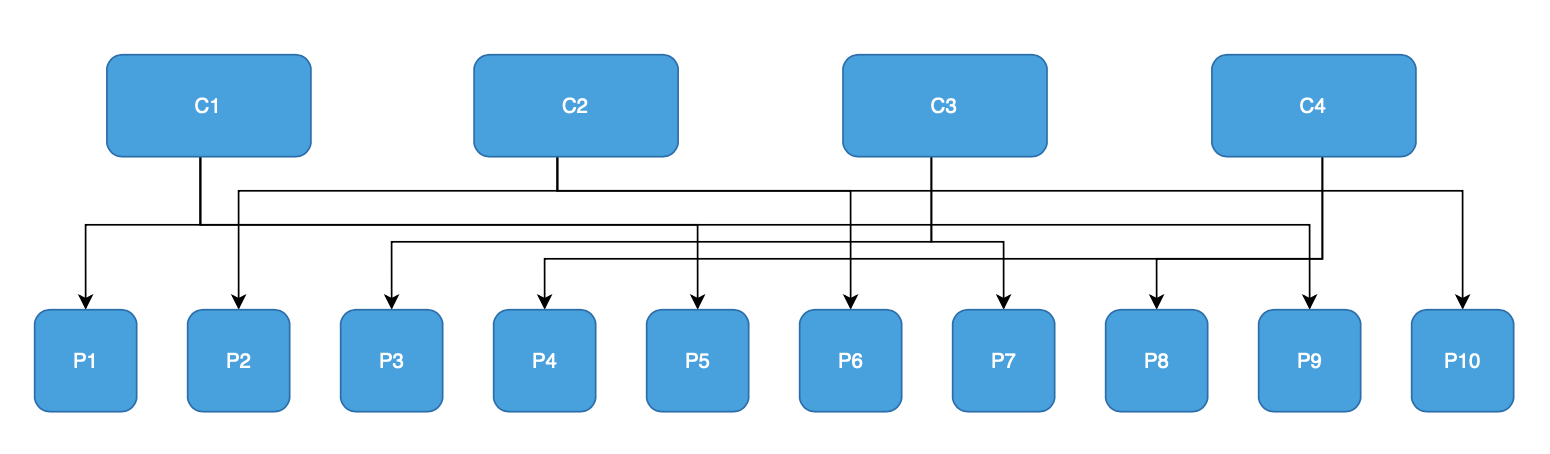
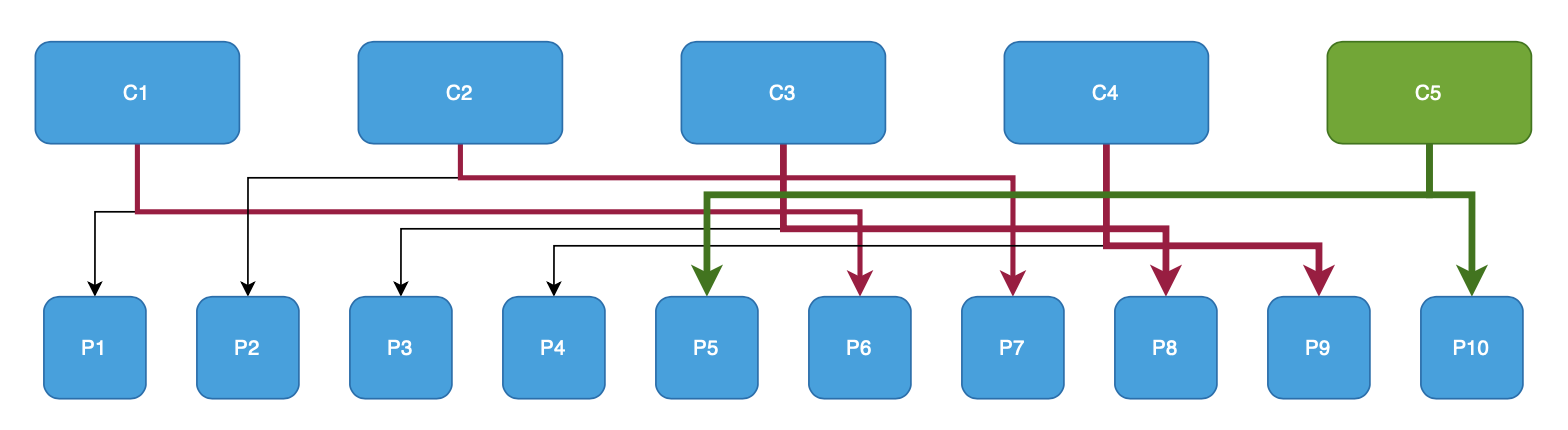
Исходя из результатов становится очевидно, что для этого примера ребалансировка затрагивает минимум 6 partitions, это довольно много, но тем не менее ребалансировка равномерно распределила partitions между consumers.
Когда стоит выбрать: если время на ребалансировку и количество переназначенных partitions не имеет значения и требуется максимально равномерное распределение partitions.
- Sticky Assignor
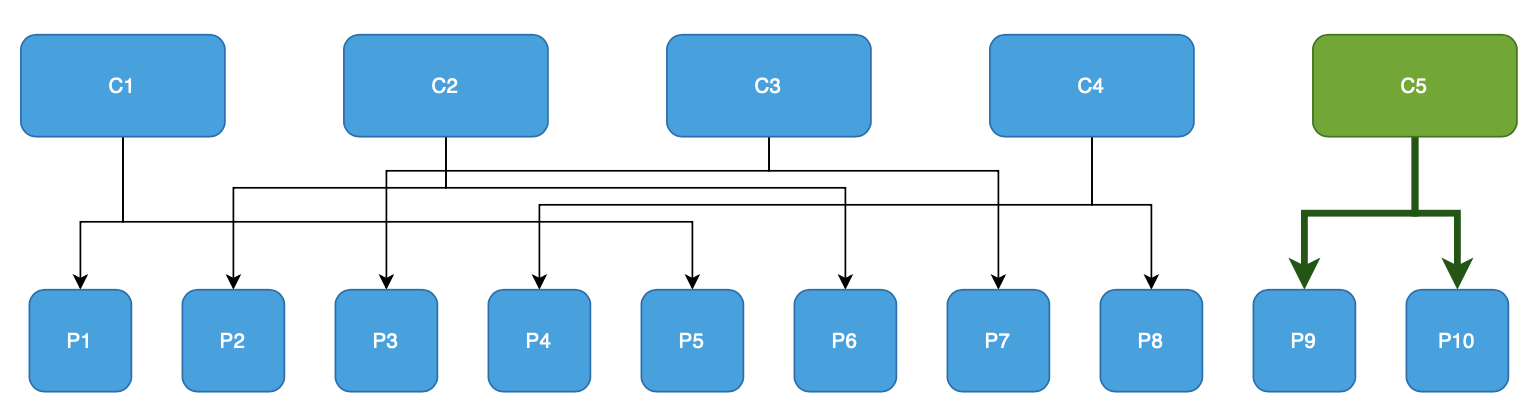
Исходя из результатов становится очевидно, что для этого примера ребалансировка затрагивает 2 partitions. Это очень хороший результат, и преимущество данной ребалансировки в том, что consumers C1, C2, C3, C4 не прекращают обработку сообщений из partitions во время ребалансировки, таким образом сокращается время простоя и влияния ребалансировки на обработку входящих сообщений.
Когда стоит выбрать: Стоит выбрать данную стратегию если требуется минимизация времени простоя при обновлении приложения и минимизации перемещений partitions между consumers.
- Cooperative Sticky Assignor.
Пример ребалансировки аналогичен StickyAssignor.
Когда стоит выбрать: аналогично рекомендациям по StickyAssignor и в случае, если может пригодиться динамическое перераспределение partitions внутри consumer group, даже если не был изменен состав consumer group.
Второй сценарий
Сценарий для оценки влияния перебалансировки на обработку сообщений под нагрузкой.
- topic кафка с 50 partitions;
- нагрузка 600 RPS.
- начало теста с 50 consumers;
- повышение количества consumers в два раза (до 100 consumers);
- снижение количества consumers до 50 consumers;
- рестарт 10 consumers;
- остановка теста.
Для этого сценария будем считать «потерянными» сообщения между отправкой и получением которых прошло более 3 секунд.
Мы можем смоделировать эти сценарии, используя различные стратегии перебалансировки и наблюдать результирующие назначения partitions и оценить время затрачиваемое на перебалансировку и количество «потерянных» сообщений.
Для этого сценария я составил сравнительную таблицу для оценки влияния обновления приложения на количество потерянных сообщений и времени затрачиваемого на ребалансировку.
Apache Kafka Consumer Lag Monitoring: How to Check and Fix It to Stream Data Smoothly
The world lives by processing the data. Humans process the data – each sound we hear, each picture we see – everything is data for our brain. The same goes for modern applications and algorithms – the data is the fuel that allows them to function and provide useful features.
Even though such thinking is not new, what is new in recent years is the requirement of near-real-time processing of large quantities of events processed by our systems. That’s why the technological stack grew from simple applications to whole processing pipelines. And the more complex the systems become, the less visibility into its working we have – at least when not using proper tools.
One system that allows us to process large amounts of data is Apache Kafka – an open-source, distributed event streaming platform designed to stream massive amounts of data. However, as with everything, we need to monitor it to ensure that everything works well and is healthy. One of the most crucial metrics for Kafka and the systems using it is consumer lag. In this blog post, we will learn how to check, fix and monitor it.
What Is Consumer Lag in Kafka?
Kafka Consumer Lag indicates the difference between the last offset stored by the broker and the last offset committed for that partition.how much lag there is between Kafka producers and consumers.
You can think of a Kafka Broker as a server in Kafka. It is what actually stores and serves Kafka messages. Kafka Producers are applications that write messages into Brokers. Kafka Consumers are applications that read messages from Brokers.
Data is stored inside Brokers in one or more Topics, each Topic consisting of one or more Partitions. When writing data, a Broker writes it into a specific Partition. As it writes data, it keeps track of the last “write position” in each Partition. This is called the Latest Offset, also known as Log End Offset. Each Partition has its own independent Latest Offset.
Consumer Group Offset
Just like Brokers keep track of their write position in each Partition, each Consumer keeps track of “read position” in each Partition whose data it is consuming. That is, it keeps track of which data it has read. This is known as Consumer Offset. This Consumer Offset is periodically persisted (to ZooKeeper or a special topic in Kafka itself), so it can survive Consumer crashes or unclean shutdowns and avoid re-consuming too much old data.
When a new consumer group is created, so when we start consuming data from Kafka, it is set to zero and the group offset is increased when the data is read and the offset is committed, so that the consumer knows when it ended.
Why Is Consumer Lag Important?
Many applications today are based on processing (near) real-time data. Think about performance monitoring systems like Sematext Monitoring or log management tools like Sematext Logs. They continuously process infinite streams of near real-time data. If they were to show you metrics or logs with too much delay – if the Consumer Lag were too big – they’d be nearly useless. This Consumer Lag tells us how far behind each Consumer (Group) is in each Partition. The smaller the lag, the more real-time the data consumption.
How Is Kafka Consumer Lag Calculated?
The rate at which Brokers are writing messages created by Producers should be roughly equal to the orange bars representing the rate at which Consumers are consuming messages from Brokers. Otherwise, the Consumers will fall behind. However, there will always be some delay between the moment a message is written and the moment it is consumed. Reads will always lag behind writes – that is what we call Consumer Lag. The Consumer Lag is simply the delta between the Broker Latest Offset and Consumer Offset.
What Causes Kafka Consumer Lag?
There are many things that can be causing the Kafka Consumer Lag, including:
- big jump in traffic resulting in producing way more Kafka messages
- poorly written code
- various software bugs and issues resulting in slow processing
- issues with the pipeline elements
- uneven load in Kafka partitions
Of course, the above list is just an example, but let’s look at one of the mentioned causes a bit deeper, the one about issues with the pipeline elements. Let’s imagine a very simplified architecture that looks like this:
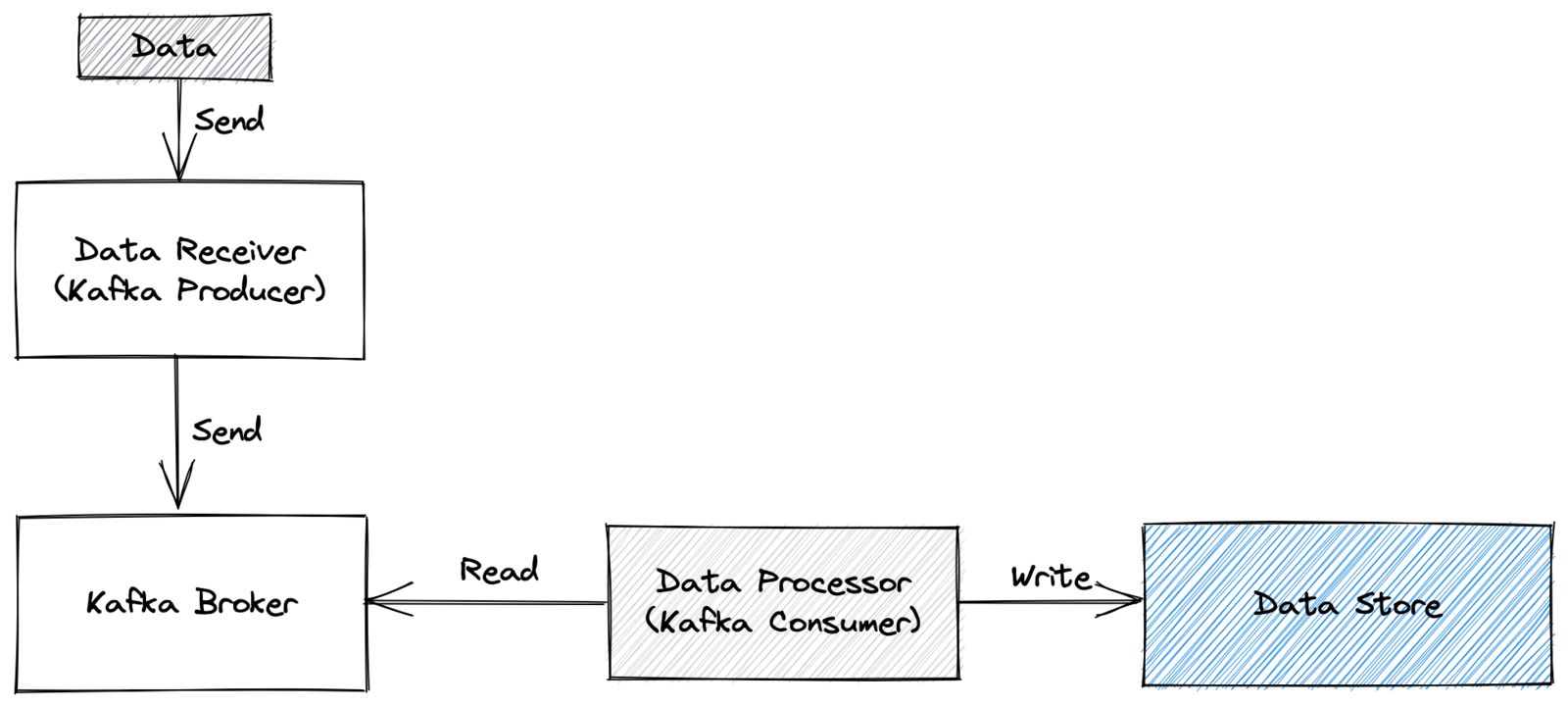
We have the data sent to the Data Receiver that works as the Kafka Producer and sends the data to our Kafka Broker. Next, the Data Processor reads the messages from the Kafka Broker. The data process is in fact, the Kafka Consumer which, in addition to reading the data, also enriches it and finally writes it to the Data Store.
What can cause the Kafka Consumer Lag in this scenario? From a technical point of view, the cause can be in almost every part of this architecture, but to be very strict, the Consumer Lag is only present when the consumer cannot keep up. So in our case, if the Data Processor cannot read, process, and write the data to the Data Store faster or at the same pace as it is written to the Kafka Broker by our Data Receiver, the Consumer Lag will start to grow. The reasons for that may vary from inefficient processing to issues with the Data Store, network issues, and many more. Basically, anything that can slow down consuming data from the Kafka Broker will cause the Consumer Lag making the processing fall behind in processing the data.
Sematext Infrastructure Monitoring
Effortlessly monitor your entire infrastructure in minutes.
How to Fix Consumer Lag in Kafka?
There isn’t a simple answer to how to fix consumer lag in Kafka. There may not even be a general answer because it all depends on why the lag happened in the first place. We know of a few common causes, and I’ll try to discuss them and tell you what you can do in each case.
Poorly Written Code
If you know that the code responsible for consuming data from Kafka is poorly written, and you need a reliable solution that reads data from Kafka fast and without issues, then this won’t surprise you – you need to at least refactor the code.
There are various resources on how to approach that – one of them is, for example, the introduction to the New Consumer Client introduced with Kafka 0.9. It provides insights into how things work if you don’t know that and shows code fragments that can be incorporated. It is based on Kafka 0.9, though, so you may need to adjust when using recent Kafka versions, but at least you know where to start.
Software Bugs and Issues
Similar to the above point, you need to find and fix the issues in your code if they are the ones that are responsible for the Kafka Consumer lag. If you can’t find any other reasons – if everything works well and Kafka’s number of messages is similar to what we expect – you may have bugs. As developers know all that, I know, but unit tests, pair programming, and code reviews really help find issues and correct them. So keep that in mind, and good luck!
Big Jump in Traffic
In some cases, we are not the ones to blame – the code works well, the whole pipeline works as intended, but still, issues may happen. You may be very successful and receive traffic far beyond what you ever imagined. In such cases, you may not be prepared to process such a tremendous amount of data and need to scale up. You will probably need more Kafka Consumers.
However, keep in mind that the reads parallelization may be limited by the number of partitions or the consumer implementation. If you can’t increase the number of partitions in your Kafka topic and introduce new consumers to parallelize the processing, maybe you should have a look at the Parallel Consumer implementation?
Pipeline Issues
If the issues are in the pipeline, the key is to fix the issue. For example, even if your Kafka consumers are doing an amazing job and process everything in real time, you may not be able to write data to the data store that fast, so you must pause reading. First, make sure that your pipeline works again, and then think if you need to catch up faster or not. If you don’t, just wait for things to settle after fixing the pipeline. If you do need to catch up, you may need additional resources, just as mentioned in the Big Jump in Traffic section.
Uneven Load in Kafka Partitions
If the messages you are writing to Kafka use a key, the partition that will store the data is determined by the hash calculated based on the message key.
Suppose such a key is based on an identifier associated with the source, like the user identifier. It may happen because one of the sources is very noisy and may cause one of the partitions to be loaded more than the others and be processed slower. The risks of such a situation aren’t significant, but they can happen. Luckily you can mitigate such issues, for example, by using the Parallel Consumer or trying to repartition the Kafka topic even more to isolate the noisy data source.
How to Monitor Kafka Consumer Lag?
The basic way to monitor Kafka Consumer Lag is to use the Kafka command line tools and see the lag in the console. We can use the kafka-consumer-groups.sh script provided with Kafka and run a lag command similar to this one:
$ bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --describe --group console-consumer-15340
The result would be the lag for the provided consumer group. Here is a very simple example that uses the console consumer:
GROUP TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID console-consumer-8551 example_blog 0 - 26 - consumer-console-consumer-8551-1-4f57353f-a040-4b4d-a13a-6514e9a245ec /127.0.0.1 consumer-console-consumer-8551-1
The thing you are most interested in is the current offset. If the offset is positive, that means that there is a lag. In most cases, if your Kafka Producer is actively producing messages and the Kafka Consumers are actively consuming, you will have a small lag here. This is expected. The problems start when the lag is significant or is constantly growing. That means that the data is not processed fast enough.
Using the console tools is possible and a viable solution if we have access to Kafka brokers, we are online when the issues are happening, and we know that the issues are happening. But without a proper monitoring solution, users may see the issues way before we will notice them. By then, it may be too late to react and prevent the disaster quickly. That’s why we need an observability solution like Sematext Monitoring.
Sematext Monitoring is one of the most comprehensive Kafka monitoring tools, capturing a number of the 200+ Kafka metrics, including Kafka Broker, Producer, and Consumer metrics. If the 200 Kafka metrics sound scary and overwhelming, you shouldn’t worry. Sematext Monitoring includes pre-built dashboards with metrics that you should really take care of and keep a close eye on. If you want to see everything, you can create a custom dashboard and choose the Kafka metrics you want and need to monitor.
To start monitoring, just create a Kafka monitoring application and follow the instructions in the documentation or the ones displayed on the screen. You’ll have your monitoring setup in seconds.
However, keep in mind that it is crucial to have full visibility into what is happening when using Kafka. To achieve that, monitoring your Kafka Producers, Kafka Brokers, and Kafka Consumers in a single Sematext Monitoring App is the optimal way to get the most out of the monitoring solution.
Look Beyond Kafka Consumer Lag
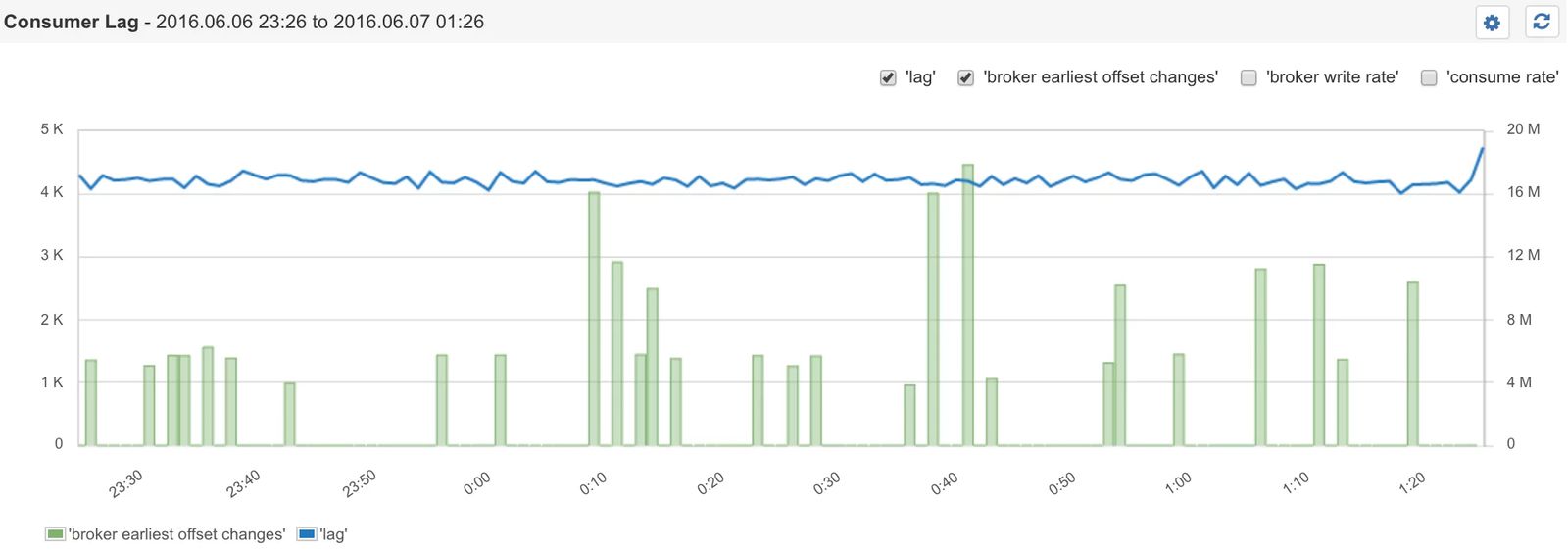
Kafka Consumer Lag and Broker Offset Changes
As we’ve just learned, the delta between the Latest Offset and the Consumer Offset is what gives us the Consumer Lag. But there is more to monitoring Kafka than the lag itself. In the above chart from Sematext, you may have noticed a few other metrics:
- Broker Write Rate
- Consume Rate
- Broker Earliest Offset Changes
The rate metrics are derived metrics. If you look at Kafka’s metrics, you won’t find them there. Under the hood, the open source Sematext agent collects a few Kafka metrics with various offsets from which these rates are computed. You can use the Sematext flexible dashboarding and the awesome chart builder to derive new metrics from the ones gathered by Sematext Agent to get even more visibility into what is happening in your environment.
Avoid Consumer Lag with Sematext’s Kafka Monitoring Tools
There are several Kafka monitoring tools out there, like LinkedIn’s Burrow, whose Kafka Offset monitoring and Consumer Lag monitoring approach is used in Sematext. Check out this short video on Sematext Infrastructure Monitoring to see exactly how it can help you monitor Kafka:
If you need a good Kafka monitoring tool, give Sematext Monitoring a go. Ship your Kafka and other logs into Sematext Logs and you’ve got yourself a comprehensive DevOps solution that will make troubleshooting easy instead of dreadful. Read how to choose the best monitoring software for your use case from our alerting and monitoring guide.
Understanding the Lag in Your Kafka Cluster

At Acceldata we spend a lot of time working with enterprises to optimize high throughput, low latency data streaming applications using Apache Kafka.
Some of our customers include ad networks with over 100 billion events a day on their Kafka infrastructure. Amongst various metrics that Kafka monitoring includes consumer lag is nearly the most important of them all.
In this blog we will explore potential reasons for Kafka consumer lag and what you could do when you experience lag.
Kafka – Past and Present
Apache Kafka is no longer used just by the Internet hyperscalers. Apache Kafka is used in the enterprise to deal with exploding streaming data. It powers compelling consumer experiences such as real-time personalization, recommendation and next best action.
Kafka allows low latency ingestion of large amounts of data into data lakes or data warehouses. Kafka allows businesses to get real-time intelligence into their business operations that allows them to react in real -time to changing business conditions.
Mission critical business processes are plagued by consumer lags, and experienced practitioners agree that preventing consumer lag is the biggest challenge in Kafka.
How does Kafka Work?
Kafka is a distributed, partitioned, replicated commit log service. Kafka is run as a cluster of multiple servers or containers.The cluster stores streams of records in categories called topics with each record consisting of a key, value and a timestamp.
Kafka Producers are processes that publish data into Kafka topics, while Consumers are processes that read messages off a Kafka topic.Topics are divided into partitions which contain messages in an append-only sequence. Each message in a partition is assigned and identified by its unique offset.
Partitions can hold multiple partition logs allowing consumers to read from in parallel.These partitions are replicated across multiple Kafka clusters for resilience. A variety of applications could produce data and send them towards the Kafka broker.
Consumers are applications that read messages from such Kafka brokers. Consumers read messages from a specific offset and are allowed to read from any offset point they choose. Consumer groups include a set of consumer processes subscribing to a given topic.Each consumer group is assigned a set of partitions to consume from.
They will receive messages from a different subset of the partitions in the topic. Kafka guarantees that the message is only read by a single consumer in the group. This philosophy is called exactly once delivery.
What is Kafka Consumer Lag?
Consumer lag indicates the lag between Kafka producers and consumers. If the rate of production of data far exceeds the rate at which it is getting consumed, consumer groups will exhibit lag.
It can be understood very succinctly as the gap between the difference between the latest offset and consumer offset. In general, enterprises talk about Kafka but they are referring to the physical Kafka brokers — a server either physical or container that runs Kafka. Brokers are the physical repositories of logs that store and serve Kafka messages.
Data storage inside a Kafka broker is done through topics. Topics are divided into partitions and brokers write data into specific partitions. As the broker writes data — it keeps track of the last offset and records it as the log end offset.

Kafka Consumers
Consumers on the other end may have complex application logic embedded inside the consumer processes. If there are way too many producers writing data to the same topic when there are a limited number of consumers then then the reading processes will always be slow. The real time objectives are lost.
So just like multiple producers which can write to the same topic, multiple consumers can read from the same topic, by getting data from one of the partitions inside the topic. It is common for consumer groups to have equal numbers of consumers as partitions, since they are doing low-latency operations. Good design includes the creation of a large number of partitions and is a fundamental way of scaling.
Just like Brokers keep track of their write position in each Partition, each Consumer keeps track of “read position” in each partition whose data it is consuming. It is the only way to keep track of the data that it has read, this is periodically persisted to Zookeeper or a Kafka Topic itself.
It’s possible that some consumer groups exhibit more lag than others, because they may have more complex logic. It can also occur because of stuck consumers, slow message processing, incrementally more messages produced than consumed.
Rebalance events can also be unpleasant contributors to consumer lag. In real time conditions, new addition of new consumers to the consumer group causes partition ownership to change — this is helpful if it’s done to increase parallelism.
However, such changes are undesirable when triggered due to a consumer process crashing down. During this event, consumers can’t consume messages, and hence consumer lag occurs. Also, when partitions are moved from one consumer to another, the consumer loses its current state including caches.
Monitoring Tools
There are several Kafka monitoring tools both in the open-source community and commercially. We’ve provided end-to-end visibility into Kafka and allow enterprises to scale technology adoption without worrying about operational blindness.
Kafka — для самых маленьких
В интырнете тыщщи миллионов статей на тему Kafka. И даже не смотря на это я все равно хочу поделиться своими знаниями в области этой замечательной штуки.
Сейчас ни одно интервью на позицию backend developer не обходится без знаний брокеров сообщений, и в большинстве случаев это Kafka.
Давайте разберем основные моменты с самого нуля для тех, кто никогда не работал и не был знаком с Kafka, а затем углубимся более детальней.
А уже в следующей статье поговорим про Kafka Streams.
Что такое Kafka?
Для начала максимально кратко, а потом уже остановимся на каждой детали и все будет понятно.
Kafka — это распределенный брокер сообщений, который работает по принципу Издатель-Подписчик.
Kafka нужна для организации потоковой обработки данных.
Состоит из двух типов компонентов:
- кластер zookeeper (zookeeper встраивается в брокер в последних версиях)
- кластер брокеров
Очередь в Kafka всегда однонаправленная! Нельзя сделать двунаправленную!
Данные в Kafka представлены в виде пар ключ-значение.
Kafka гарантирует, что все сообщения будут упорядочены именно в той последовательности, в которой поступили.
Kafka хранит прочитанные сообщения определенный период времени (не удаляет их после прочтения — по умолчанию хранит 1 неделю).
Kafka хранит свои записи на диске и ничего не держит в оперативной памяти.
Особенности:
- Конкретной партицией владеет один брокер-лидер (остальные брокеры, у которых также размещена эта партиция — реплики).
- По умолчанию создается одна партиция на топик.
- Сообщения в партициях строго упорядочены, но не упорядочены между партициями одного топика, потому что запись сообщений в партиции происходит параллельно.
- Сообщения в партиции сохраняются до накопления определенного объема или периода хранения.
- Если consumer объединены в consumer group, то в каждой consumer group каждая партиция принадлежит только одному consumer (т.е. consumer может читать несколько партиций, но одна партиция не может читаться несколькими consumer). Если количество consumer больше количества партиций, то часть consumer будет простаивать.
- Если consumers не объединены в consumer group, они читают независимо (т.е. каждый consumer, не объединенный в consumer group, читает из всех партиций).
- Consumer может подписываться на топики по regular expression, в этом случае при создании соответствующего топика произойдет rebalance и consumer начнет читать также этот топик.
- Consumer может читать только после того, как сообщение запишется на все не отстающие реплики, для того чтобы гарантировать, что прочитанные сообщения не пропадут из Kafka при сбое (из-за выхода из строя лидера, если сообщения есть только на нем) и смогут быть прочитаны всеми consumers. Чем больше реплике позволено отставать и при этом все еще считаться “не отстающей”, тем больше может быть пауза между записью producer и чтением consumer (потому что consumer сможет читать только после записи сообщения на самую отстающую реплику, которая все еще считается “не отстающей”).
- Для того, чтобы при выходе consumer из строя было известно, какие сообщения он успел прочитать, consumer делает commit offset — записывает оффсет последнего записанного сообщения. Раньше consumer записывал оффсеты прямо в zookeeper.
- Consumer может вручную подписаться на определенные партиции топика (например все), не входя в consumer group, но в этом случае он должен периодически уточнять, не появились ли новые партиции, потому что в случае ручной подписки добавление партиций не приведет к ребалансировке.
- Порядок внутри партиции: если сообщение А записано в партицию после сообщения Б, то они будут прочитаны из этой партиции в том же порядке и сообщение А будет иметь меньший оффсет.
- Поддерживается атомарная запись в несколько топиков в рамках одной транзакции.
Consumer может читать в режимах:
- read_committed — в этом режиме consumer прочтет сообщения, записанные в рамках транзакции, только после коммита транзакции.
- read_uncommitted — в этом режиме consumer прочтет сообщения, записанные в рамках транзакции сразу после их записи, не дожидаясь коммита транзакции.
Принцип работы
- Издатель посылает сообщение в Kafka
Эти сообщения обрабатываются другими приложениями (Consumer = Потребителями).
- Сообщения сохраняются в Topic
- Потребители сами опрашивают Kafka, не появилось ли у него новых сообщений, и указывают, какие записи им нужно прочесть.
Очередь может работать в 2 режимах: push и pull.
Push — когда Topic сам рассылает сообщения всем, кто на него подписан.
Pull — когда Потребители сами опрашивают Topic в надежде получить новое сообщение. Потребители подписываются на тему чтобы получить новые сообщения.
Также можно построить систему, в которой будет 1 главный (ведущий) брокер Kafka и также будут дополнительные (запасные) брокеры. В случае неработоспособности главного брокера, дополнительные будут работать. Все взаимодействие происходит через Zookeeper (аналоги Eureka, Consul).
Как происходит добавление брокера ?
Дополнительные брокеры добавляются в список ISR и контроллер начинает производить балансировку этих брокеров (например на одном 4 partitions, на другом 2 или 3. В этом случае Kafka второму добавит пару штук чтобы разбалансировать нагрузку).
Topic
Теперь более детально и по порядку, чтобы все понять.
Topic — это поток сообщений (неограниченная последовательность key-value пар). Мысленно можете представить что это труба, по которой текут данные.
Ключи и значения — обычные массивы байтов, т.е.
- имеет имя
- можно создавать сколько угодно топиков
- данные в топике хранятся 1 неделю (по дефолту)
- нельзя удалить одно сообщение из топика (в таком случае лучше сделать новый топик, скопировать все сообщения из старого топика кроме того, которое хотим удалить, и затем просто удалить старый топик)
Данные в Topic хранятся в Log-файлах! В файловой системе Kafka есть папка logs -> в ней есть папки для каждой partitions. В каждой папке будет 3 файла: .log, .index, .timeindex.
.log -> тут сами данные в формате: offset (номер сообщения в partition), position (смещение в байтах в файле), timestamp, message.
Лимит log файла = 1 Гб (при достижении лимита старый останавливается и больше не изменяется и создается новый).
.index -> маппинг offset на позицию.
.timeindex -> маппинг timestamp на offset.
Compacted topic
Это значит, что для такого Topic для каждого ключа нам важно знать только самое последнее значение!
т.е. если есть несколько значений с одним и тем же ключом, то Kafka их выкинет и оставит только самые свежие значение для этого ключа.
Если Topic помечен compacted, то время от времени Kafka будет заниматься его компактификацией, т.е. будет удалять те значения, которые уже переписаны более новым.
Никаких гарантий нет — Kafka будет делать это когда ей вздумается (как GC в Java).
Работает в параллельном потоке.
Partition
Topic делится на партиции.
Когда мы кидаем сообщение в Topic, то на самом деле это сообщение попадает в Partition внутри Topic.
Мы представляли что Topic — это труба. Так вот представьте теперь что Partition — это маленькая трубка, которая находится внутри большой трубы (Topic).
- Каждый Partition сохраняет порядок сообщений (сообщения упорядочены только в рамках одной partition)
- Каждое сообщение в Partition получает номер или offset (номер сообщения)
Broker
Это сервер. У него есть имя. Каждый Broker хранит несколько Partitions.
Kafka состоит из нескольких Broker.
Например, если у нас в кластере есть 3 broker, есть 1 topic и в нем 3 partitions -> то можно сказать что каждый partition будет храниться на своем broker.
Когда Kafka соединяется с broker, это означает что Kafka соединяется сразу со всем кластером!
Визуально вот так представляйте себе
А если чуть более детальней, то вот так
Заметили что добавилось ? Внутри Broker мы видим Topics.
Ну а если еще детальней и наглядней, то вот так это выглядит
Внутри Broker мы видим Topics, а внутри Topics лежат наши Partitions.
Думаю теперь стало понятней. Идем дальше.
Topic replication
Итак, в итоге наша картинка имеет вид
Что такое replication?
Это копирование данных с одного partition одного broker на другой для надежности.
Если у нас есть несколько одинаковых копий для partition, то среди них есть главная — Leader.
Producer записывает сообщения именно в Leader какого-либо partition, остальные partition только копируют данные из Leader (синхронизируются с ним)!
Leader-ом может быть только одна копия!
ISR (in-sync replicas)
Когда пишем сообщения в leader, то также синхронно пишем и в ISR-follower-ы, для надежности, если вдруг leader упадет.
Когда leader падает, Kafka переизбирает leader (при этом ВСЕГДА будет потеря данных!)
Producer
Producer пишет сообщения в Topic в partition в порядке отправки.
Producer сам определяет в какие Partitions он будет писать.
НЕ Kafka определяет, а он сам!
Он реализован как клиент, который работает отдельно от Kafka.
Он автоматически понимает в какой partition и broker (leader) писать.
При коннекте к broker он узнает состояние всего Kafka кластера => например если один broker упал, то producer подключится к другому и т.д.
При отправке сообщения он идет в Broker, а Broker идет в ZooKeeper чтобы узнать, какие реплики являются leader чтобы в них писать (ведь Producer пишет ТОЛЬКО в leader!)
Если вдруг broker, в который producer пишет сообщение, упал, то Kafka автоматически исправит ситуацию: нагрузка балансируется по разным broker и partition.
Например если надо записать миллионы сообщений в секунду в один Topic, то это легко: данные будут писаться в разные partition, которые физически располагаются на разных брокерах.
Отправка:
Когда Producer шлет сообщение в Topic происходит следующее:
- fetch metadata (происходит синхронно!)
Из чего состоит кластер, какие реплики leader и где они находятся и т.д.
2. сериализация сообщения в нужный формат
Параметры: key.serializer и value.serializer
3. выбор partition в который будем слать сообщение
- можно указать в какую конкретную partition
- или указать чтобы Kafka выбрала сама (параметр round robin)
- partition определяется по ключу (если мы отправляем сообщение с одним и тем же ключом, то оно всегда будет попадать в одну и ту же partition)
4. компрессия сообщения с помощью кодеков
5. accumulate batch для повышения производительности
batch.size — по дефолту 16 кб. Если превысили размер 16 кб то сообщения отправляются батчем в брокер
linger.ms — если мы копим батч продолжительное время, которое превышает заданный параметр, то сообщения отправляются батчем в брокер
Если же batch.size и linger.ms не превышены, то мы все равно можем отправить сообщения в брокер.
Например у нас есть Broker и у него 2 partitions. Мы накапливаем 2 батча данных для отправки и если же эти 2 батча суммарно превышают batch.size, то сообщения отправляются этими батчами в брокер, даже если эти батчи еще не заполнены до конца.
6. отправка сообщений батчем в брокер
Режимы подтверждения записи сообщений:
В конфиг файле есть параметр acks
- acks=0 не ждем подтверждения
- acks=1 ждем от лидера
- acks=all ждем от всех (нет потерь 100%)
Message key
Key — часть сообщения (может быть = null)
- если НЕ null -> то все сообщения с этим key будут писаться в один и тот же partition
- если null -> то выбирается partition по round robin
Consumer
Читает сообщения по порядку из topic из partition.
Kafka сама определяет из каких Partitions будет читать Consumer! (НЕ Consumer, а Kafka)! НО в случае с Producer, как вы помните, сам Producer определяет, куда писать, не Kafka!
т.е. Producer сам решает, куда писать и Kafka сама решает, откуда Consumer будет читать!
Также как и Producer, Consumer узнает о всех Broker в кластере, когда подключается к Broker.
Consumer знает из какого Broker (leader) читать сообщения.
При падении Broker, Consumer переключится на другой.
Сообщения из partition читаются по правилу FIFO (First in First out — первый пришел, первый обработан).
Данные из разных partition в рамках одного Consumer могут перемешиваться любым способом.
Consumer должен коммитить свой offset (он получает сообщение и подтверждает, что оно прочитано).
Если Consumer упал после того, как прочитал сообщение, но перед тем, как отправил подтверждение, то Kafka отправит это сообщение еще раз либо этому же Consumer либо другому Consumer в этой же группе, т.к. Kafka следит за offset.
Если Consumer упал, то когда поднимется, он может продолжить читать с того сообщения, на котором упал, зная offset!
Прием сообщений:
Читаем не по одному сообщению, а сразу пачку сообщений!
- fetch metadata
- устанавливается коннект на необходимый Broker-Topic-partition для чтения данных (подключение к leader репликам!)
Гарантия доставки:
- at most once: коммит сразу после получения (но если Consumer упадет после получения, но перед обработкой сообщения, то сообщение будет не обработано и потеряно)
- at least once: коммит сразу после обработки:
Если Consumer упадет во время обработки, то Kafka отправит это же сообщение еще раз или другому Consumer из группы.
Если Consumer упадет сразу после обработки, но до отправки уведомления, то Kafka отправит это же сообщение уже другому Consumer из группы.
Может быть проблема, когда сообщение может быть отправлено несколько раз.
Нужен идемпотентный Consumer, чтобы он мог дважды присланный один и тот же запрос запрос обработать 1 раз!
- exactly once: коммит сразу после обработки (доставка гарантируется) + получатель получит сообщение ровно 1 раз
Внутри системы exactly once гарантировать можно (что мы не обработаем одни и те же данные 2 раза)!
Но на входе в топик и на выходе из топика это гарантировать невозможно!
т.е. мы даем гарантию ТОЛЬКО ВНУТРИ самой Kafka, но не за ее пределами!
Consumer Group
Это несколько Consumer, которые объединены в группу.
Каждый Consumer из своей группы читает из собственного поднабора partition этого Topic.
Если много Producer-ов будут слать сообщения в Kafka, то есть вероятность, что 1 Consumer может не справиться с такой нагрузкой.
Если для Consumer в группе не хватило partition, то он будет неактивный.
Kafka сохраняет offset для каждой группы для каждой partition — это указатель на то, какое сообщение читать дальше.
- Если несколько Consumer в одной группе, то каждому из них будет назначен свой partition!
- Если несколько Consumer в разных группах, то они будут читать одновременно и Kafka для каждого из них будет сохранять свой offset!
Offset
Например в каком-то определенном Topic в partition лежит 5 сообщений.
Допустим Consumer прочитал из Topic из partition 2 сообщения и упал, то другой Consumer из этой же группы начнет читать эти сообщения из этого же Topic из этой же partition.
Но это лишняя работа, т.к. мы уже прочитали первые 2 сообщения, зачем их еще раз читать.
Тот Consumer, который прочитал 2 сообщений и упал, после чтения второго сообщения сделал commit и указал offset = 2.
В Kafka есть специальный Topic с названием “__consumer_offsets”, который хранит offset для каждой группы для каждой partition.
В этом топике хранится сообщение в виде Field-Value
И теперь другой Consumer из этой же группы обратится к Topic “__consumer_offsets” за информацией и будет читать с partition с 3-го сообщения.
виды commit:
at most once: коммит сразу после получения (но если Consumer упадет после получения, но перед обработкой сообщения, то сообщение будет не обработано и потеряно)
at least once: коммит сразу после обработки:
Если Consumer упадет во время обработки, то Kafka отправит это же сообщение еще раз или другому Consumer из группы
Если Consumer упадет сразу после обработки, но до отправки уведомления, то Kafka отправит это же сообщение уже другому Consumer из группы
Может быть проблема, когда сообщение может быть отправлено несколько раз.
Нужен идемпотентный Consumer, чтобы он мог дважды присланный один и тот же запрос запрос обработать 1 раз!
Retention
Kafka пишет логи на диск.
Retention помогает указать какое кол-во логов мы сохраняем, а какое удаляем.
Например записи недельной давности уже удаляем или все что больше 100 Гб не храним.
Когда Kafka пишет данные на диск, она пишет их в файловый сегмент (по дефолту 4 Гб). Когда этот сегмент переполняется, он начинает писать во второй сегмент (первый сегмент закрывается на запись и его всегда можно прочитать). Когда второй переполняется, то аналогично начинает писать в третий и т.д.
Пишет в конец!
И потом Kafka понимает, что например 1 сегмент уже не актуален по лимиту места или времени и удаляет его.
Kafka Broker Discovery
Каждый Broker — это bootstrap сервер.
Каждый Broker знает обо всех остальных в кластере, их Topic и partitions.
Bootstraping — это когда клиент подключается к одному из них и узнает о всех остальных.
ZooKeeper
Это часть кластера Kafka.
Это распределенный кластер, который обеспечивает хранение конфигураций и уведомлений о том, что эта конфигурация изменилась.
Обычно должен состоять из нечетного кол-ва узлов (3,5,7 узлов).
Содержит актуальный список всех Broker, topics, partitions.
Kafka vs RabbitMQ
Теперь давайте сравним Kafka и наиболее популярный аналог RabbitMQ.
- Kafka более масштабируема, нежели RabbitMQ
- Другой подход к работе
RabbitMQ:
1) Publisher отправляет сообщение на exchange
2) exchange отправляет сообщение в Очередь
3) RabbitMQ отправляет подтверждения паблишерам при получении сообщения
4) Сonsumers поддерживают постоянные TCP-соединения с RabbitMQ
5) RabbitMQ проталкивает (push) сообщения получателям
6) Получатели отправляют подтверждения успеха/ошибки
7) После успешного получения, сообщения удаляются из очередей
Kafka:
- Producer публикует сообщение в Broker
- Сообщение сохраняется в Topic -> Partition
3) Consumer подписывается на Topic для получения сообщений
4) Consumer запрашивает у Kafka новые сообщения и указывает, какие записи ему нужно прочитать.
— В Kafka легко добавить еще один Broker в систему (т.к. Kafka брокер — это кластер), в rabbitMQ это сделать сложнее.
— В Kafka Topics с сообщениями можно разбить на разделы (partition) и распределить внутри кластера (внутри брокера) и сделать реплику.
Получается что несколько брокеров обслуживают 1 Topic. Если 1 брокер умрет, то данные не будут потеряны.
Другими словами Kafka умеет дробить свои очереди на части и распределять по кластеру.
- Kafka работает в памяти (по умолчанию), RabbitMQ с диском
- Kafka горизонтально масштабируема, RabbitMQ только вертикально
- В Kafka есть возможность реализовывать что-то вроде шардирования за счет consumer groups, которые гарантируют что одна partition (считай шард) будет читаться только одним Consumer-ом
Масштабирование
1) Больше Brokers
2) Больше partitions
3) Больше replication factor (т.е. сколько реплик в каждой partition) — для надежности
replication factor — позволяет указать сколько падений реплик partition мы можем пережить.
Если factor = N, то сможем пережить N-1 падений брокеров одновременно.
Плюсы
- позволяет хранить большой объем данных (большая пропускная способность)
- высокодоступность
Выход из строя одного узла не нарушает доступ к данным
- отказоустойчивость
- распределенность
Это множество сервером, объединенных вместе
- надежность и согласованность данных
Поддерживает C и A из CAP теоремы:
- согласованность (consistency) — во всех вычислительных узлах в один момент времени данные не противоречат друг другу
- доступность (availability) — любой запрос к распределённой системе завершается корректным откликом, однако без гарантии, что ответы всех узлов системы совпадают
- высокая производительность
- горизонтальное масштабирование
- интегрируемость с различными системами и БД
Выводы
- Пока количество partition остается постоянным, то один и тот же ключ пишется в один и тот же replication factor.
- Удалить данные из Topic нельзя!
В таком случае лучше сделать новый Topic, скопировать все сообщения из старого Topic кроме того, которое хотим удалить, и затем просто удалить старый Topic.
3. Поддерживается автоматическое удаление данных по TTL (time-to-live):
- удаляются целиком сегменты партиций (не отдельные сообщения)
4. Вы можете начать обработку ваших данных с использованием Kafka, затем продолжить работу с Kafka Streams, а затем опять вернуться к Kafka.
Независимо от того, используете вы Kafka Streams или просто Kafka, благодаря Kafka вы получите гибкую масштабируемую и отказоустойчивую распределенную потоковую обработку данных, которая работает везде (в docker контейнераз, на виртуальных машинах, локально, удаленно, в облаках и т.д.).
Если вы нашли неточности в описании данной статьи, вы можете написать мне на email и я с радостью вам отвечу.
Kirill Sereda