Как работать с bias в нейросети
Как правильно работать с нейросетью с использованием bias если я делаю ее самостоятельно(разбираю чужой код,но без bias). Я делал так:для каждого слоя выделяю лишнюю связь с весом(это вес для bias). При прямом передачи сигнала по сети на данном слое при взвешивании сигналов учитываю сигнал bias,например 1.0 и его вес про который я говорил выше. Но когда я вычисляю вектор ошибок для данного слоя и чтобы его же передать пред-слою,я получаю вектор не учитывающий вес к bias.Как автор говорит «Нейрону смещения не нужна ошибка».В результате например для матрицы данного слоя (3,5) (с учетом bias) получаю вектор ошибок (4,1).Т.е. вес bias нельзя исправить,хотя его нужно исправлять. Похоже такой код не работает. Как нужно правильно работать с bias?
Отслеживать
9,491 8 8 золотых знаков 50 50 серебряных знаков 103 103 бронзовых знака
задан 25 июн 2019 в 7:33
Константин Константин
895 4 4 серебряных знака 16 16 бронзовых знаков
Нейронные сети: теория и практика

В рамках изучения темы искусственного интеллекта мне повстречался такой термин, как искусственная нейронная сеть. Изучив несколько десятков статей и пару книг, я хочу поделится своим кратким опытом. Я думаю, что данная статья будет полезна тем, кто захочет начать свой путь в изучении нейросетей.
Из литературы и статей единственное что я понял, так это то, что намного проще описать нейросети как математические функции, которые взаимосвязаны между собой и на выходе каждой из них мы получаем либо «да», либо «нет», либо «что-то посередине». Эти функции работают вместе, а чем лучше они обучены на взаимодействие друг с другом, тем «умнее» система и будет, т.е. нейронную сеть нужно тренировать.
Нейронные сети состоят из:
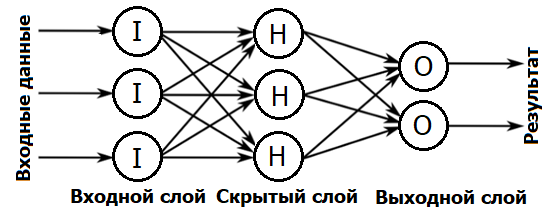
- входного слоя I (input)
- произвольного количества скрытых слоев H (hidden)
- выходного слоя O (output)
- набора весов W (weight) и смещений B (bias) между каждым слоем
- функции активации f для каждого из скрытых слоев
У каждого из нейронов есть 2 основных параметра: входные данные (input data) и выходные данные (output data). В случае входного нейрона эти параметры равны, а в остальных случаях, в поле input попадает суммарная информация всех нейронов с предыдущего слоя, после чего, она нормализуется относительно функции активации и результат подает output.
Синапс – это связь между двумя нейронами. У синапсов есть только один параметр – вес, благодаря которому, входная информация изменяется при передаче от одного нейрона к другому. Следует отметить, что информация нейрона, вес которого будет больше, и будет доминирующей в следующем нейроне. Именно благодаря весам, входная информация обрабатывается и превращается в результат.
Про нейрон смещения могу сказать, что он необходим для смещения (кто бы подумал) графика активации.
Для наилучшего понимания давайте разберем это на примере. Скажем у нас есть искусственный нейрон с двумя входными данными I1 = 2, I2 = 1. В нейроне происходят три вещи.
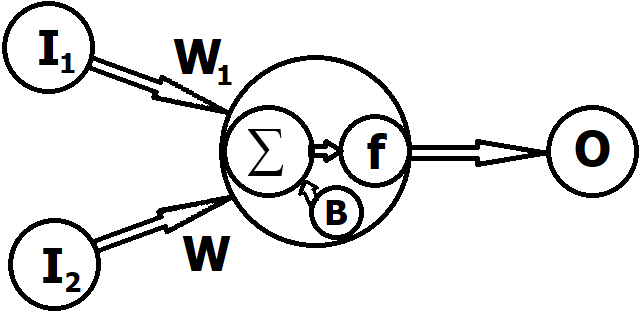
- Каждый вход умножается на вес и в нашем случае пусть веса будут следующими W1 = 4, W2 = 3:
- Полученные результаты складываем со смещением B (Скажем B = –9):
- Данную сумму мы передаем через функцию активации:
Но что же такое функция активации? Функция активации используется для подключения несвязанных входных данных с выводом, у которого простая и предсказуемая форма. То есть, если на входе у вас будет большое число, пропустив его через функцию активации, мы получим выход в нужном нам диапазоне. Функций активации достаточно много, но, как правило, чаще всего в качестве функцией активации берется функция сигмоида, т.к. она позволяет удобно работать со значениями от 0 до 1:
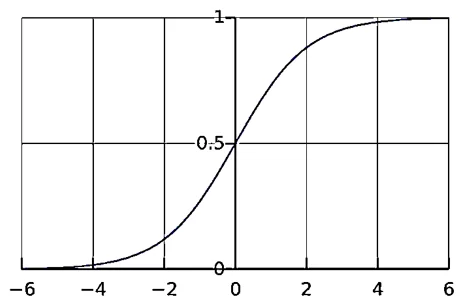
Теперь, когда у нас есть входные данные, мы можем получить выходные данные, подставив входное значение в функцию активации. И в итоге мы получаем что f(2) = 0,87 и так, мы повторяем для всех слоев, пока не дойдем до выходного нейрона. А весь этот процесс получения из входных данных результат называется прямым распространением.
Есть возможность «натренировать» нейрон, для того чтобы изменить веса и получить более близкий к идеалу результат. Все завязано на определении ошибки, которая нейронная сеть допускает во время тренировки, и ее уменьшении корректировав веса.
Попробуем на практике реализовать работу одного нейрона в рамках задачи Классификации – распределения данных по заданным параметрам.
Практика
Представим, что у нас стоит задача определить какая из компаний подходит под наше спецпредложение по кредиту. Само спецпредложение хоть и выдумал из головы, но в работе применяли реальные варианты. И да, мы не будем разворачивать слишком большую сеть, используем только один скрытый нейрон, т.к. у нас параметров мало.
В качестве параметров мы рассмотрим:
- размер компании (маленькая (0), средняя (0.5), крупная (1));
- уже существующую кредитную историю (1 – отличная, 0 – нет кредитной истории, -1 – еще те плохиши);
- рейтинг 1-10 (чем меньше, тем лучше);
- срок ведения деятельности (больше или меньше года).
Ну, соответственно дадим для нашего нейрона тренировочные данные и ручками сами определим получат ли компании спецпредложение или нет.
| Кредитная история | Размер компании | Срок ведения деятельности | Рейтинг | Спецпредложение |
| -1 | 0 | 1 | 1 | Нет |
| -1 | 0.5 | 0 | 2 | Нет |
| -1 | 1 | 1 | 5 | Нет |
| 0 | 0 | 0 | 7 | Нет |
| 0 | 0 | 1 | 8 | Нет |
| 0 | 0.5 | 1 | 10 | Да |
| 0 | 0.5 | 0 | 4 | Нет |
| 0 | 0.5 | 1 | 3 | Да |
| 0 | 1 | 1 | 8 | Нет |
| 0 | 1 | 1 | 1 | Да |
| 0 | 1 | 1 | 4 | Да |
| 1 | 0 | 0 | 3 | Нет |
| 1 | 0.5 | 0 | 8 | Нет |
| 1 | 0.5 | 1 | 1 | Да |
| 1 | 1 | 0 | 4 | Да |
| 1 | 1 | 1 | 3 | Да |
Реализуем на python’e:

Вы спросите, что такое np? Да-да, держите:

Далее мы объявим переменные класса, да собственно сам класс тоже, и зададим случайные первоначальные веса, которые после тренировки изменятся.

Почему нужно выбирать случайные первоначальные веса? Как я понял, что основной смысл состоит в нахождении идеальных весов, довольно близких к оптимальным. Однако, я еще не нашел (или плохо искал) универсального метода подбора весов, и потому будем считать, что случайность иногда может попасть в тот самый идеальный результат, который мы ищем.
Определим функцию активации (сигмоиду) и ее производную:

Производная нам понадобится для обратного тестирования. Не люблю расписывать много формул, но скажу, что если производная от ошибки (чтобы ее посчитать и нужна производная от функции активации) будет положительная, то уменьшится вес и сама ошибка и наоборот, при отрицательной производной от ошибки увеличится вес и ошибка соответственно
Ах, да. Забыл еще рассказать, что такое эпоха. Эпоха это один переход туда (прямое распространение) и обратно (обратное распространение). Вот собственно то, как происходит прямое и обратное распространение, да и сама тренировка:
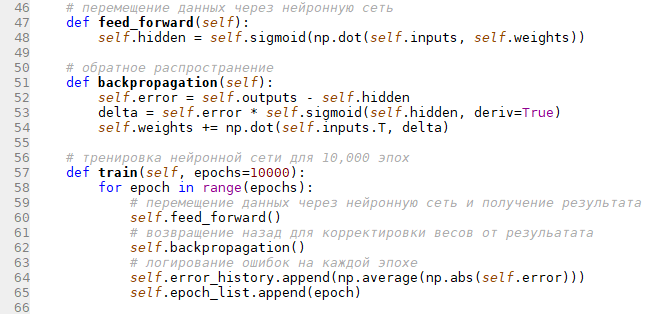
Вот такие изменения весов после тренировки мы получили (не забывайте, что первоначальные веса случайны):

Теперь проверим то, что мы получили на новых данных, которые не использовались во время тренировки.
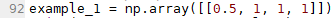

Скажу заранее, что мы получим какие-то значения от 0 до 1 (спасибо сигмоиде). Попробуем условно сказать, что они означают:

Собственно, вот что мы получили:
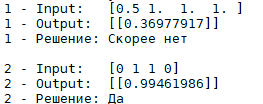
Хочу также показать Вам график зависимости ошибки от эпохи (для этого мы ошибки и логировали):
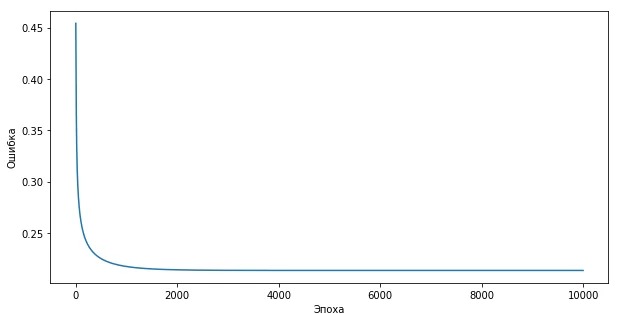
Из графика видно, что чем больше будет количество эпох, тем меньше будет ошибка. А вот что будет с результатом и графиком, если во время тренировки будет всего 100 эпох:
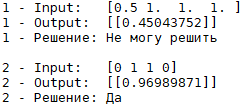
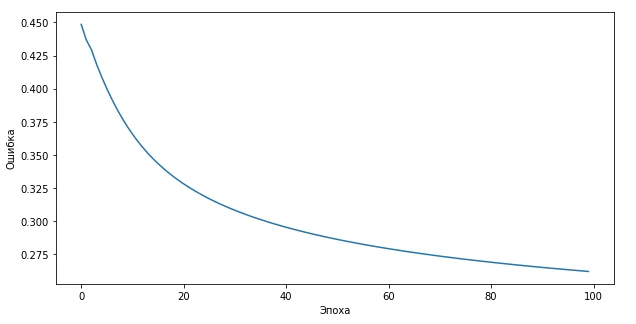
А что если тренировочные данные будут недобросовестными, скомпрометированными или вообще они сделаны наугад без какой-либо логики? А вот что:

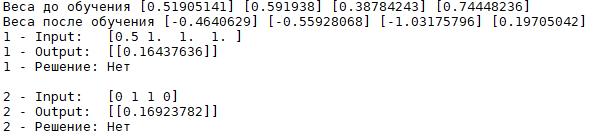
И график будет выглядеть так:
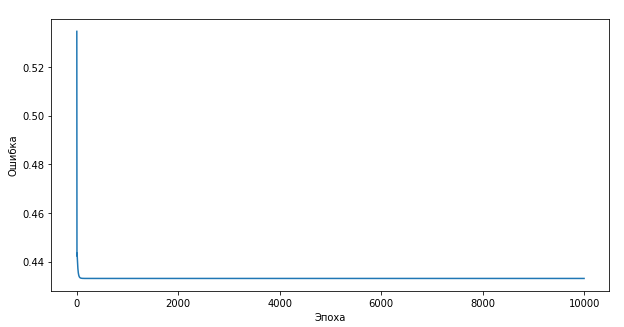
Следовательно, для тренировки нейрона важны как качество тренировочных данных, так и количество эпох, и тогда результат не заставит себя ждать.
Заключение
По итогу скажу, что хоть нейронные сети хорошо справляются со сложными данными, но они все еще далеки от имитации человеческого мозга, однако они постепенно движутся в этом направлении постоянно совершенствуясь и обучаясь, ведь перспективы искусственных нейронных сетей практически безграничны. Меня заинтересовали нейросети и возможности их практического применения. В следующий раз я постараюсь реализовать определение рукописных букв или цифр с помощью нейросети.
P.S.: Если Вы заинтересованы в теме нейросетей или у Вас есть замечания/пожелания/советы, то оставляйте обратную связь в комментариях.
Переобучение
Переобучение (англ. overfitting) — негативное явление, возникающее, когда алгоритм обучения вырабатывает предсказания, которые слишком близко или точно соответствуют конкретному набору данных и поэтому не подходят для применения алгоритма к дополнительным данным или будущим наблюдениям.
Недообучение (англ. underfitting) — негативное явление, при котором алгоритм обучения не обеспечивает достаточно малой величины средней ошибки на обучающей выборке. Недообучение возникает при использовании недостаточно сложных моделей.
Примеры
На примере линейной регрессии
Представьте задачу линейной регрессии. Красные точки представляют исходные данные. Синие линии являются графиками полиномов различной степени M, аппроксимирующих исходные данные.
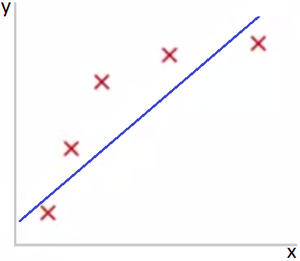
Рис 1. Недообучение. M=1
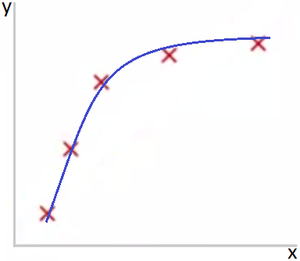
Рис 2. Норма. M=2
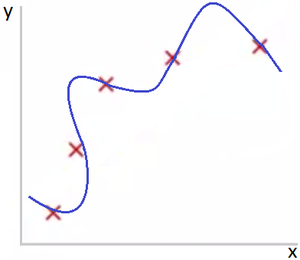
Рис 3. Переобучение. M=4
Как видно из Рис. 1, данные не поддаются линейной зависимости при небольшой степени полинома и по этой причине модель, представленная на данном рисунке, не очень хороша.
На Рис. 2 представлена ситуация, когда выбранная полиномиальная функция подходит для описания исходных данных.
Рис. 3 иллюстрирует случай, когда высокая степень полинома ведет к тому, что модель слишком заточена на данные обучающего датасета.
На примере логистической регрессии
Представьте задачу классификации размеченных точек. Красные точки представляют данные класса 1. Голубые круглые точки — класса 2. Синие линии являются представлением различных моделей, которыми производится классификация данных.
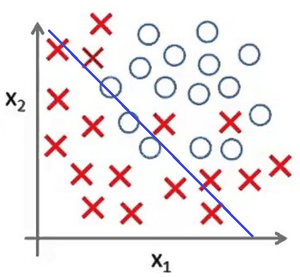
Рис 4. Недообучение
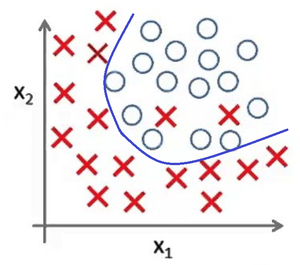
Рис 5. Подходящая модель
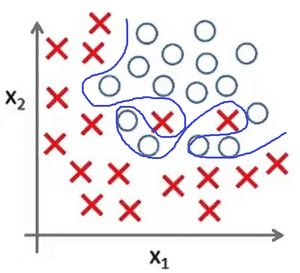
Рис 6. Переобучение
Рис. 4 показывает результат использования слишком простой модели для представленного датасета
Кривые обучения
Кривая обучения — графическое представление того, как изменение меры обученности (по вертикальной оси) зависит от определенной единицы измерения опыта (по горизонтальной оси) [1] . Например, в примерах ниже представлена зависимость средней ошибки от объема датасета.
Кривые обучения при переобучении
При переобучении небольшая средняя ошибка на обучающей выборке не обеспечивает такую же малую ошибку на тестовой выборке.
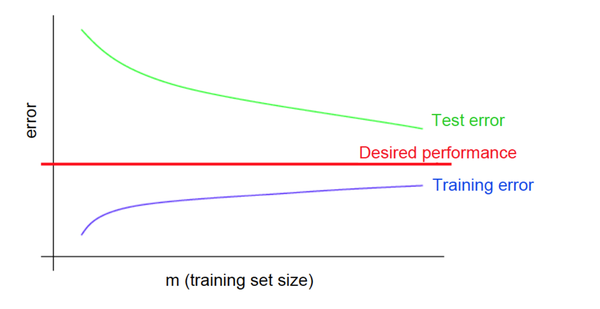
Рис 7. Кривые обучения при переобучении
Рис. 7 демонстрирует зависимость средней ошибки для обучающей и тестовой выборок от объема датасета при переобучении.
Кривые обучения при недообучении
При недообучении независимо от объема обучающего датасета как на обучающей выборке, так и на тестовой выборке небольшая средняя ошибка не достигается.
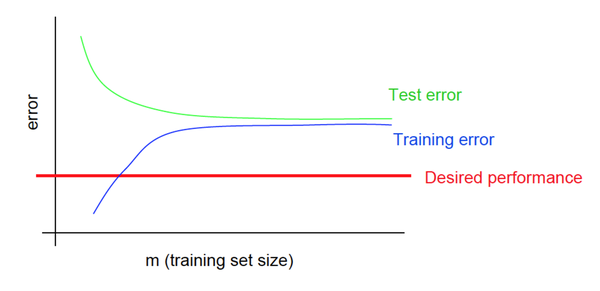
Рис 8. Кривые обучения при недообучении
Рис. 8 демонстрирует зависимость средней ошибки для обучающей и тестовой выборок от объема датасета при недообучении.
High variance и high bias
Bias — ошибка неверных предположений в алгоритме обучения. Высокий bias может привести к недообучению.
Variance — ошибка, вызванная большой чувствительностью к небольшим отклонениям в тренировочном наборе. Высокая дисперсия может привести к переобучению.
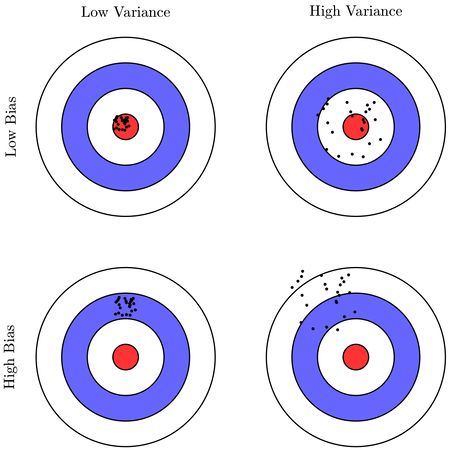
Рис 9. High variance и high bias
При использовании нейронных сетей variance увеличивается, а bias уменьшается с увеличением количества скрытых слоев.
Для устранения high variance и high bias можно использовать смеси и ансамбли. Например, можно составить ансамбль (boosting) из нескольких моделей с высоким bias и получить модель с небольшим bias. В другом случае при bagging соединяются несколько моделей с низким bias, а результирующая модель позволяет уменьшить variance.
Дилемма bias–variance
Дилемма bias–variance — конфликт в попытке одновременно минимизировать bias и variance, тогда как уменьшение одного из негативных эффектов, приводит к увеличению другого. Данная дилемма проиллюстрирована на Рис 10.
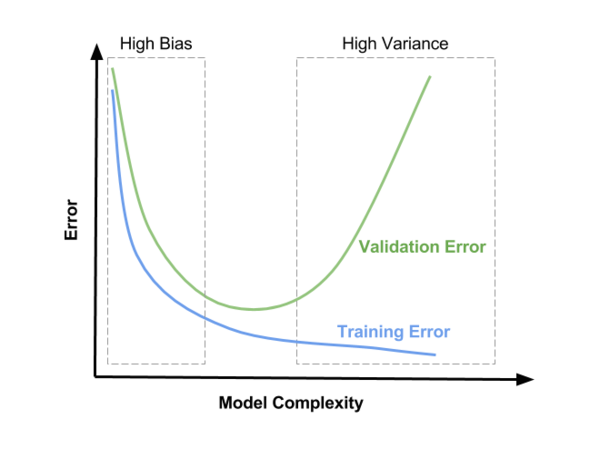
Рис 10. Дилемма bias–variance
При небольшой сложности модели мы наблюдаем high bias. При усложнении модели bias уменьшается, но variance увеличится, что приводит к проблеме high variance.
Возможные решения
Возможные решения при переобучении
- Увеличение количества данных в наборе;
- Уменьшение количества параметров модели;
- Добавление регуляризации / увеличение коэффициента регуляризации.
Возможные решения при недообучении
- Добавление новых параметров модели;
- Использование для описания модели функций с более высокой степенью;
- Уменьшение коэффициента регуляризации.
См. также
- Модель алгоритма и ее выбор
- Оценка качества в задачах классификации и регрессии [на 28.01.19 не создан]
- Оценка качества в задаче кластеризации
Примечания
Источники информации
- The Problem of Overfitting on Coursera, Andrew Ng
- Overfitting: when accuracy measure goes wrong
- The Problem of Overfitting Data
- Overfitting in Machine Learning
- Overfitting — статься на Википедии
- Переобучение — вводная статься на MachineLearning.ru
- The Problem of Overfitting — курс Andrew Ng
- Hastie, T., Tibshirani, R., Friedman, J.The Elements of Statistical Learning, 2nd edition. — Springer, 2009. — 533 p.
- Vapnik V.N.Statistical learning theory. — N.Y.: John Wiley & Sons, Inc., 1998.
- Воронцов, К. В.Комбинаторная теория надёжности обучения по прецедентам: Дис. док. физ.-мат. наук: 05-13-17. — Вычислительный центр РАН, 2010. — 271 с.
Сексизм и шовинизм искусственного интеллекта.
Почему так сложно его побороть?

Что такое «предвзятость искусственного интеллекта» (AI bias)? С чем связано возникновение этого явления и как с ним бороться? В материале, подготовленном специально для TAdviser, на эти вопросы отвечает журналист Леонид Черняк.
В основе всего того, что является практикой ИИ (машинный перевод, распознавание речи, обработка текстов на естественных языках, компьютерное зрение, автоматизация вождения автомобилей и многое другое) лежит глубинное обучение. Это подмножество машинного обучения, отличающееся использованием моделей нейронных сетей, о которых можно сказать, что они имитируют работу мозга, поэтому их с натяжкой можно отнести к ИИ. Любая модель нейронной сети обучается на больших наборах данных, таким образом, она обретает некоторые «навыки», но то, как она ими пользуется — для создателей остается не ясным, что в конечном счете становится одной из важнейших проблем для многих приложений глубинного обучения. Причина в том, что такая модель работает с образами формально, без какого-либо понимания того, что она делает. Является ли такая система ИИ и можно ли доверять системам, построенным на основе машинного обучения? Значение ответа на последний вопрос выходит за пределы научных лабораторий.

Причина высокого интереса к AI bias объясняется тем, что результаты внедрения технологий ИИ в ряде случаев нарушают принципы расового и гендерного равенства
Вот почему за последние пару лет заметно обострилось внимание средств массовой информации к явлению, получившему название AI bias. Его можно перевести как «необъективность ИИ» или «пристрастность ИИ». О расизме и сексизме, свойственном ИИ, пишут не только профессиональные издания как Engadget [1] или TechTolks [2] но и массовые журналы и газеты, например Forbes [3] , The Guardian [4] , The New York Times [5] .
Причина столь высокого интереса к AI bias объясняется тем, что результаты внедрения технологий ИИ в ряде случаев задевают основные ценности современного общества. Они проявляются в нарушении таких важных принципов как расовое и гендерное равенства.
Внешне AI bias проявляется в том, что многие аналитические системы, созданные на основе глубинного обучения, неожиданным образом демонстрируют склонность к принятию, скажем так, пристрастных выводов, таких, которые в последующем могут привести к ошибочным решениям, сделанным на их основе. Решения, страдающие AI bias, стали причиной общественных возмущений в связи с несправедливостью некоторых действий пенитенциарной системы США по отношению к афро-американцам, они были вызваны ошибками в распознавании лиц этнических меньшинств. Хорошо известен скандал с запуском корпорацией Microsoft голосового помощника Tay, вскорости замененного на Zo [6] .
Проявление относительно несложными системами якобы «человеческих качеств» оказалась лакомым куском для тех, кто склонен антропоморфизировать ИИ. Вполне естественно, что первыми на возможные пагубные последствия AI bias обратили внимание философствующие защитники «Азиломарских принципов искусственного интеллекта» [7] . Среди этих 23 положений есть совершенно здравые (с 1 по 18), но другие (с 19 по 23), принятые под влиянием Илона Маска, Рея Курцвейла и покойного Стивена Хокинга носят, скажем так, общеразговорный характер. Они распространяются в область сверхразума и сингулярности, которыми регулярно и безответственно пугают наивное народонаселение.
Возникают естественные вопросы – откуда взялась AI bias и что с этой предвзятостью делать? Справедливо допустить, что предвзятость ИИ не вызвана какими-то собственными свойствами моделей, а является прямым следствием двух других типов предвзятостей – хорошо известной когнитивной и менее известной алгоритмической. В процессе обучения сети они складываются в цепочку и в итоге возникает третье звено – AI bias.
Трехзвенная цепочка предвзятостей:
- Разработчики, создающие системы глубинного обучения являются обладателями когнитивных предвзятостей.
- Они с неизбежностью переносят эти предвзятости в разрабатываемые ими системы и создают алгоритмические предвзятости.
- В процессе эксплуатации системы демонстрируют AI bias.
Начнем с когнитивных. Разработчики систем на принципах глубинного обучения, как и все остальные представители человеческой расы, являются носителями той или иной когнитивной пристрастности (cognitive bias). У каждого человека есть свой жизненный путь, накопленный опыт, поэтому он не в состоянии быть носителем абсолютной объективности. Индивидуальная пристрастность является неизбежной чертой любой личности. Психологи стали изучать когнитивную пристрастность как самостоятельное явление в семидесятых годах ХХ века, в отечественной психологической литературе ее принято называть когнитивным искажением.
«Когнитивные искажения являются примером эволюционно сложившегося ментального поведения. Некоторые из них выполняют адаптивную функцию, поскольку они способствуют более эффективным действиям или более быстрым решениям. Другие, по-видимому, происходят из отсутствия соответствующих навыков мышления или из-за неуместного применения навыков, бывших адаптивными в других условиях» [8] . Существует также сложившиеся направления как когнитивная психология и когнитивно-бихевиоральная терапия (КБТ). На февраль 2019 года выделено порядка 200 типов различных когнитивных искажений.
Пристрастности и предвзятости — это часть человеческой культуры. Любой создаваемый человеком артефакт является носителем тех или иных когнитивных пристрастностей его создателей. Можно привести множество примеров, когда одни и те же действия приобретают в разных этносах собственный характер, показательный пример – пользованием рубанком, в Европе его толкают от себя, а в Японии его тянут на себя.
Системы, построенные на принципах глубинного обучения в этом смысле не являются исключением, их разработчики не могут быть свободны от присущих им пристрастностей, поэтому с неизбежностью будут переносить часть своей личности в алгоритмы, порождая, в конечном итоге, AI bias. То есть AI bias не собственное свойство ИИ, о следствие переноса в системы качеств, присущих их авторам.
Существование алгоритмической пристрастности (Algorithmic bias) нельзя назвать открытием. Об угрозе возможного «заражения машины человеческими пристрастиями» много лет назад впервые задумался Джозеф Вейценбаум, более известный как автор первой способной вести диалог программы Элиза, написанной им в еще 1966 году. Название программы адресует нас к Элизе Дулиттл, героине «Пигмалиона» Бернарда Шоу. С ней Вейценбаум одним из первых предпринял попытку пройти тест Тьюринга, но он изначально задумывал Элизу как средство для демонстрации возможности имитационного диалога на самом поверхностном уровне. Это был академический розыгрыш высочайшего уровня. Совершенно неожиданно для себя он обнаружил, что к его «разговору с компьютером», в основе которого лежала примитивная пародия, основанная на принципах клиент-центрированной психотерапии Карла Роджерса, многие, в том числе и специалисты, отнеслись всерьез с далеко идущими выводами.
В современности мы называем такого рода технологии чат-ботами. Тем, кто верит в их интеллектуальность, стоит напомнить, что эти программы не умнее Элизы. Вейценбаум наряду с Хьюбертом Дрейфусом и Джоном Серлем вошел в историю ИИ как один из основных критиков утверждений о возможности создания искусственного мозга и тем более искусственного сознания, сравнимого с человеческим по своим возможностям. В переведенной на русский язык в 1982 году книге «Возможности вычислительных машин и человеческий разум» Вейценбаум предупреждал об ошибочности отождествления естественного и искусственного разума, основываясь на сравнительном анализе фундаментальных представлений психологии и на наличии принципиальных различий между человеческим мышлением и информационными процессами в компьютере. А возвращаясь к AI bias заметим, что более тридцати лет назад Вейценбаум писал о том, что предвзятость программы может быть следствием ошибочно использованных данных и особенностей кода этой самой программы. Если код не тривиален, скажем, не формула записанная на Fortran, то такой код так или иначе отражает представления программиста о внешнем мире, поэтому не следует слепо доверять машинным результатам.
А в далеко не тривиальных по своей сложности приложениях глубинного обучения алгоритмическая пристрастность тем более возможна. Она возникает в тех случаях, когда система отражает внутренние ценности ее авторов, на этапах кодирования, сбора и селекции данных, используемых для тренировки алгоритмов.
Алгоритмическая пристрастность возникает не только вследствие имеющихся культурных, социальных и институциональных представлений, но и из-за возможных технических ограничений. Существование алгоритмической предвзятости находится в противоречии с интуитивным представлением, а в некоторых случаях с мистической убежденностью в объективности результатов, полученных в результате обработки данных на компьютере.
Хорошее введение в тематику, связанную с алгоритмическими пристрастностями, можно найти в статье The Foundations of Algorithmic Bias [9] .
В статье «Вот почему возникают ИИ-привязанности и почему с ними сложно бороться» [10] , опубликованной в феврале 2019 года в MIT Review, выделяются три момента, способствующие возникновению AI bias. Однако, как не странно, их не связывают когнитивными предвзятостями, хотя нетрудно заметить, что в корне всех трех лежат именно они.
- Постановка задачи (Framing the problem). Проблема состоит в том, что методами машинного обучения обычно хочется опередить нечто, не имеющее строгого определения. Скажем банк хочет определить кредитные качества заемщика, но это весьма размытое понятие и результат работы модели будет зависеть от того, как разработчики, в силу своих личных представлений, смогут это качество формализовать.
- Сбор данных для обучения (Collecting the data). На данном этапе может быть два источника предвзятости: данные могут быть не репрезентативны или же могут содержать предрассудки. Известный прецедент, когда система лучше различала светлокожих по сравнению с темнокожими, был связан с тем, что в исходных данных светлокожих было больше. А не менее известная ошибка в автоматизированных рекрутинговых службах, которые отдавали предпочтения мужской половине, была связаны с тем, что они были обучены на данных, страдающих мужским шовинизмом.
- Подготовка данных (Preparing the data). Когнитивная предвзятость может просочиться при выборе тех атрибутов, которые алгоритм будет использовать при оценке заемщика или кандидата на работу. Никто не может дать гарантии объективности избранного набора атрибутов.
Бороться с AI bias «в лоб» практически невозможно, в той же статье в MIT Review называются основные причины этого:
- Нет понятных методов для исправления модели. Если, например, модель страдает гендерной предвзятостью, то недостаточно просто удалить слово «женщина», поскольку есть еще огромное количество гендерноориентированных слов. Как их все обнаружить?
- Стандартные практики обучения и модели не принимают в расчет AI-bias.
- Создатели моделей являются представителями определенных социальных групп, носителями тех или иных социальных взглядов, их самих объективизировать невозможно.
- А главное, не удается понять, что такое объективность, поскольку компьютерные науки с этим явлением еще не сталкивались.
Какие же выводы можно сделать из факта существования феномена AI bias?
- Вывод первый и самый простой – не верить тем, кого классик советской фантастики Кир Булычев называл птицами-говорунами, а читать классику, в данном случае работы Джозефа Вейценбаума, и к тому же Хьюберта Дрейфуса и Джона Серля. Очень способствует развитию трезвости сознания и пониманию роли человека в сложных системах.
- Вывод второй, следующий из первого – системы, построенные на принципах глубинного обучения не обладают ИИ, это ни что иное, как новый и более сложный, чем программирование, способ использования компьютеров в качестве инструмента для анализа данных. Не исключено, что мощности современных и будущих компьютеров позволят предавать условия и методы решения задач еще в каких-то иных, отличных от программирование формах. Сегодня это обучение с учителем, а завтра могут быть и другие подходы к машинному обучению или что-то новое, более совершенное.
- Вывод третий, возможно самый важный – компьютер был и будет инструментом для расширения интеллектуального потенциала человека, и главная задача заключается не в создании искусственного разума AI, а в развитии систем, которые называют Intelligence amplification (усиление интеллекта), Сognitive augmentation (когнитивное усиление) или Machine augmented intelligence (машинное усиление интеллекта). Этот путь хорошо и давно известен. Еще в 1945 году Ванневар Буш написал не устаревшую по сути программную статью «Как мы можем мыслить». Об усилении интеллекта писал великий кибернетик Уильям Росс Эшби. Человеко-компьютерному симбиозу посвятил свои работы Джозеф Ликлайдер, автор идеи Интернета. Практические подходы к усилению человеческого интеллекта (от мышки до основ человеко-машинного интерфейса) разработал Дуглас Энгельбарт. Эти первопроходцы наметили столбовую дорогу, по ней и следует идти. От популярных творцов ИИ их отличает то, что все задуманное ими успешно работает и составляет важную часть нашей жизни.
- Вывод четвертый и последний. Обнаружение и анализ феномена AI bias позволяет утверждать, что никакой собственной предвзятостью искусственный интеллект в форме глубинного обучения не обладает, а некорректность, как обычно, объясняется человеческим фактором.
Робототехника
- Роботы (робототехника)
- Робототехника (мировой рынок)
- Обзор: Российский рынок промышленной робототехники 2019
- Карта российского рынка промышленной робототехники
- Промышленные роботы в России
- Каталог систем и проектовРоботы Промышленные
- Топ-30 интеграторов промышленных роботов в России
- Карта российского рынка промышленной робототехники: 4 ключевых сегмента, 170 компаний
- Технологические тенденции развития промышленных роботов
- В промышленности, медицине, боевые (Кибервойны)
- Сервисные роботы
- Каталог систем и проектовРоботы Сервисные
- Collaborative robot, cobot (Коллаборативный робот, кобот)
- IoT — IIoT — Цифровой двойник (Digital Twin)
- Компьютерное зрение (машинное зрение)
- Компьютерное зрение: технологии, рынок, перспективы
- Как роботы заменяют людей
- Секс-роботы
- Роботы-пылесосы
- Искусственный интеллект (ИИ, Artificial intelligence, AI)
- Обзор: Искусственный интеллект 2018
- Искусственный интеллект (рынок России)
- Искусственный интеллект (мировой рынок)
- Искусственный интеллект (рынок Украины)
- В банках, медицине, радиологии, ритейле, ВПК, производственной сфере, образовании, Автопилот, транспорте, логистике, спорте, СМИ и литература, видео (DeepFake, FakeApp), музыке
- Национальная стратегия развития искусственного интеллекта
- Национальная Ассоциация участников рынка робототехники (НАУРР)
- Российская ассоциация искусственного интеллекта
- Национальный центр развития технологий и базовых элементов робототехники
- Международный Центр по робототехнике (IRC) на базе НИТУ МИСиС
- Машинное обучение, Вредоносное машинное обучение, Разметка данных (data labeling)
- RPA — Роботизированная автоматизация процессов
- Видеоаналитика (машинное зрение)
- Машинный интеллект
- Когнитивный компьютинг
- Наука о данных (Data Science)
- DataLake (Озеро данных)
- BigData
- Нейросети
- Чатботы
- Умные колонки Голосовые помощники