Структуры данных: бинарные деревья. Часть 1
Этой статьей я начинаю цикл статей об известных и не очень структурах данных а так же их применении на практике.
В своих статьях я буду приводить примеры кода сразу на двух языках: на Java и на Haskell. Благодаря этому можно будет сравнить императивный и функциональный стили программирования и увидить плюсы и минусы того и другого.
Начать я решил с бинарных деревьев поиска, так как это достаточно базовая, но в то же время интересная штука, у которой к тому же существует большое количество модификаций и вариаций, а так же применений на практике.
Зачем это нужно?
Бинарные деревья поиска обычно применяются для реализации множеств и ассоциативных массивов (например, set и map в с++ или TreeSet и TreeMap в java). Более сложные применения включают в себя ropes (про них я расскажу в одной из следующих статей), различные алгоритмы вычислительной геометрии, в основном в алгоритмах на основе «сканирующей прямой».
В этой статье деревья будут рассмотрены на примере реализации ассоциативного массива. Ассоциативный массив — обобщенный массив, в котором индексы (их обычно называют ключами) могут быть произвольными.
Ну-с, приступим
Двоичное дерево состоит из вершин и связей между ними. Конкретнее, у дерева есть выделенная вершина-корень и у каждой вершины может быть левый и правый сыновья. На словах звучит несколько сложно, но если взглянуть на картинку все становится понятным:
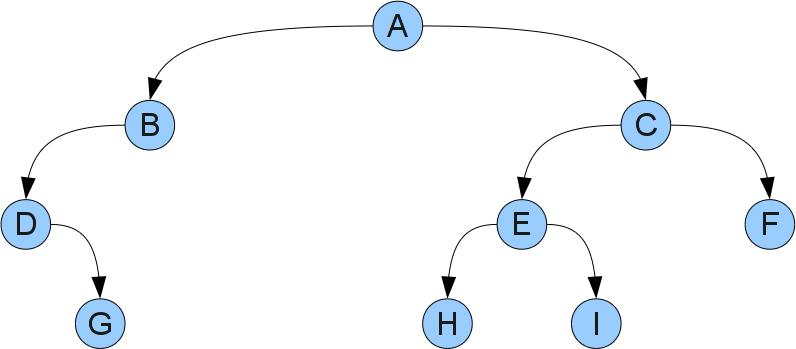
У этого дерева корнем будет вершина A. Видно, что у вершины D отсутствует левый сын, у вершины B — правый, а у вершин G, H, F и I — оба. Вершины без сыновей принято называть листьями.
Каждой вершине X можно сопоставить свое дерево, состоящее из вершины, ее сыновей, сыновей ее сыновей, и т.д. Такое дерево называют поддеревом с корнем X. Левым и правым поддеревьями X называют поддеревья с корнями соответственно в левом и правом сыновьях X. Заметим, что такие поддеревья могут оказаться пустыми, если у X нет соответствующего сына.
Данные в дереве хранятся в его вершинах. В программах вершины дерева обычно представляют структурой, хранящей данные и две ссылки на левого и правого сына. Отсутствующие вершины обозначают null или специальным конструктором Leaf:
data Ord key => BSTree key value = Leaf | Branch key value (BSTree key value) (BSTree key value) deriving (Show) static class Node < T1 key; T2 value; Nodeleft, right; Node(T1 key, T2 value) < this.key = key; this.value = value; >> Как видно из примеров, мы требуем от ключей, чтобы их можно было сравнивать между собой ( Ord a в haskell и T1 implements Comparable в java). Все это не спроста — для того, чтобы дерево было полезным данные должны храниться в нем по каким-то правилам.
Какие же это правила? Все просто: если в вершине X хранится ключ x, то в левом (правом) поддереве должны храниться только ключи меньшие (соответственно большие) чем x. Проиллюстрируем:
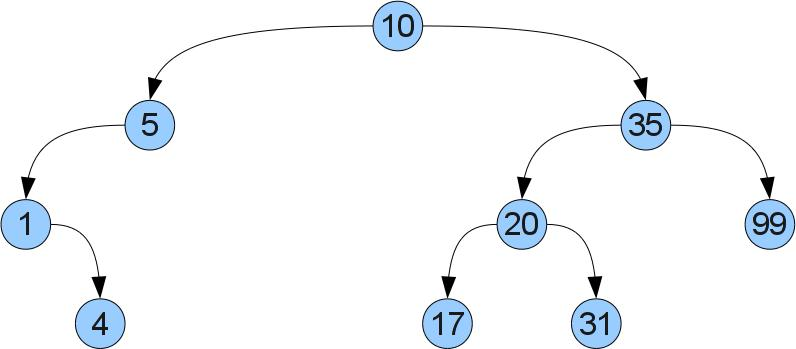
Что же нам дает такое упорядочевание? То, что мы легко можем отыскать требуемый ключ x в дереве! Просто сравним x со значением в корне. Если они равны, то мы нашли требуемое. Если же x меньше (больше), то он может оказаться только в левом (соответственно правом) поддереве. Пусть например мы ищем в дереве число 17:
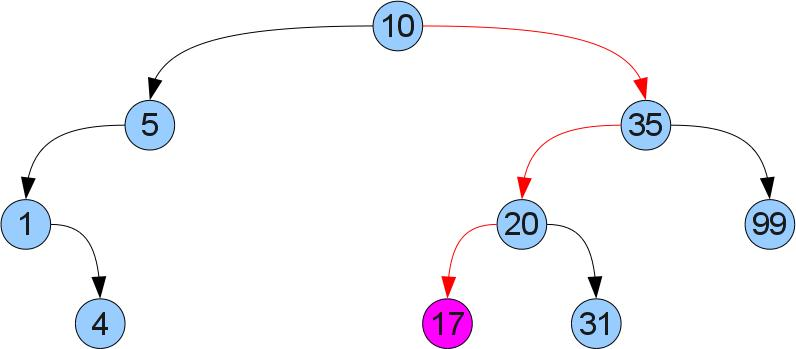
Функция, получающая значение по ключу:
get :: Ord key => BSTree key value -> key -> Maybe value get Leaf _ = Nothing get (Branch key value left right) k | k < key = get left k | k >key = get right k | k == key = Just value public T2 get(T1 k) < Nodex = root; while (x != null) < int cmp = k.compareTo(x.key); if (cmp == 0) < return x.value; >if (cmp < 0) < x = x.left; >else < x = x.right; >> return null; > Добавление в дерево
Теперь попробуем сделать операцию добавления новой пары ключ/значение (a,b). Для этого будем спускаться по дереву как в функции get, пока не найдем вершину с таким же ключем, либо не дойдем до отсутсвующего сына. Если мы нашли вершину с таким же ключем, то просто меняем соответствующее значение. В противно случае легко понять что именно в это место следует вставить новую вершину, чтобы не нарушить порядок. Рассмотрим вставку ключа 42 в дерево на прошлом рисунке:
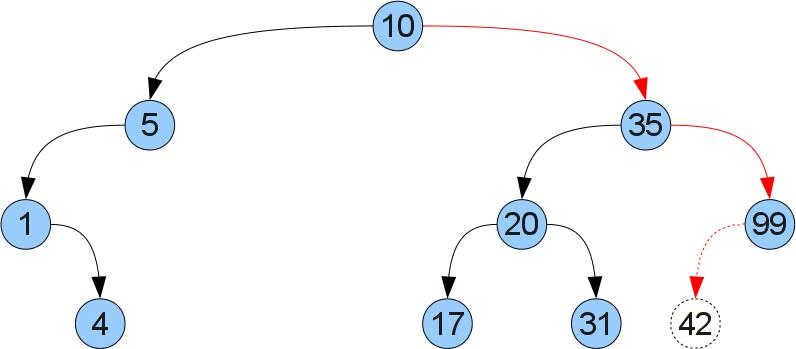
add :: Ord key => BSTree key value -> key -> value -> BSTree key value add Leaf k v = Branch k v Leaf Leaf add (Branch key value left right) k v | k < key = Branch key value (add left k v) right | k >key = Branch key value left (add right k v) | k == key = Branch key value left right public void add(T1 k, T2 v) < Nodex = root, y = null; while (x != null) < int cmp = k.compareTo(x.key); if (cmp == 0) < x.value = v; return; >else < y = x; if (cmp < 0) < x = x.left; >else < x = x.right; >> > Node newNode = new Node(k, v); if (y == null) < root = newNode; >else < if (k.compareTo(y.key) < 0) < y.left = newNode; >else < y.right = newNode; >> > Лирическое отступление о плюсах и минусах функционального подхода
Если внимательно рассмотреть примеры на обоих языках, можно увидеть некоторое различие в поведении функциональной и императивной реализаций: если на java мы просто модифицируем данные и ссылки в имеющихся вершинах, то версия на haskell создает новые вершины вдоль всего пути, пройденного рекурсией. Это связано с тем, что в чисто функциональных языках нельзя делать разрушающие присваивания. Ясно, что это ухудшает производительность и увеличивает потребляемую память. С другой стороны, у такого подхода есть и положительные стороны: отсутствие побочных эффектов сильно облегчает понимание того, как функционирует программа. Более подробно об этом можно прочитать в практически любом учебнике или вводной статье про функциональное программирование.
В этой же статье я хочу обратить внимание на другое следствие функционального подхода: даже после добавления в дерево нового элемента старая версия останется доступной! За счет этого эффекта работают ropes, в том числе и в реализации на императивных языках, позволяя реализовывать строки с асимптотически более быстрыми операциями, чем при традиционном подходе. Про ropes я расскажу в одной из следующих статей.
Вернемся к нашим баранам
Теперь мы подобрались к самой сложной операции в этой статье — удалению ключа x из дерева. Для начала мы, как и раньше, найдем нашу вершину в дереве. Теперь возникает два случая. Случай 1 (удаляем число 5):

Видно, что у удаляемой вершины нет правого сына. Тогда мы можем убрать ее и вместо нее вставить левое поддерево, не нарушая упорядоченность:
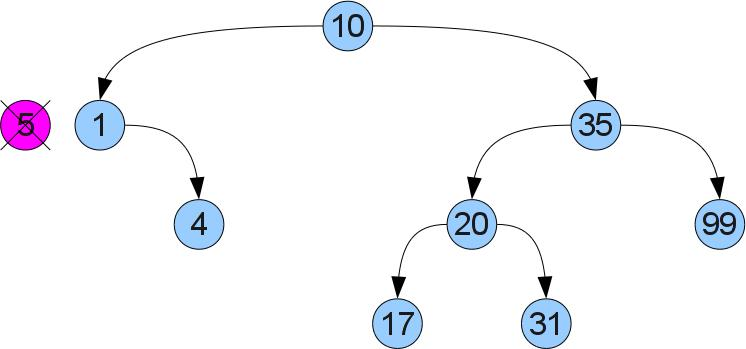
Если же правый сын есть, налицо случай 2 (удаляем снова вершину 5, но из немного другого дерева):
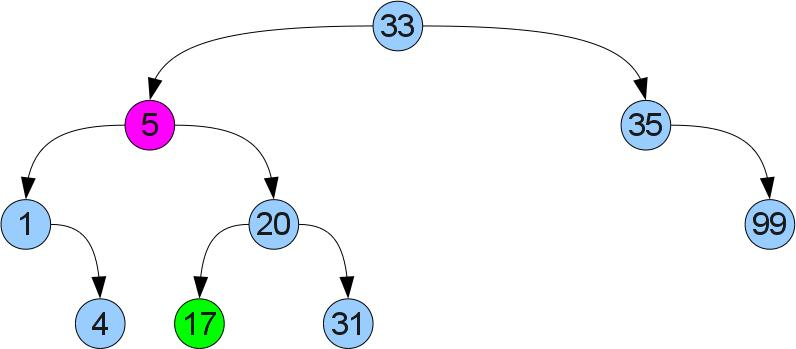
Тут так просто не получится — у левого сына может уже быть правый сын. Поступим по-другому: найдем в правом поддереве минимум. Ясно, что его можно найти если начать в правом сыне и идти до упора влево. Т.к у найденного минимума нет левого сына, можно вырезать его по аналогии со случаем 1 и вставить его вместо удалеемой вершины. Из-за того что он был минимальным в правом поддереве, свойство упорядоченности не нарушится:
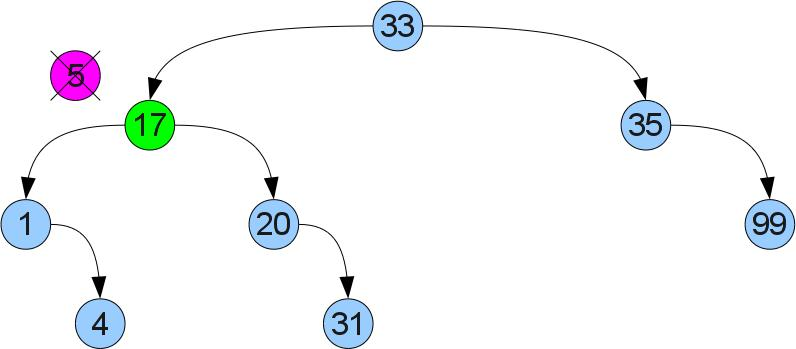
remove :: Ord key => BSTree key value -> key -> BSTree key value remove Leaf _ = Leaf remove (Branch key value left right) k | k < key = Branch key value (remove left k) right | k >key = Branch key value left (remove right k) | k == key = if isLeaf right then left else Branch leftmostA leftmostB left right' where isLeaf Leaf = True isLeaf _ = False ((leftmostA, leftmostB), right') = deleteLeftmost right deleteLeftmost (Branch key value Leaf right) = ((key, value), right) deleteLeftmost (Branch key value left right) = (pair, Branch key value left' right) where (pair, left') = deleteLeftmost left public void remove(T1 k) < Nodex = root, y = null; while (x != null) < int cmp = k.compareTo(x.key); if (cmp == 0) < break; >else < y = x; if (cmp < 0) < x = x.left; >else < x = x.right; >> > if (x == null) < return; >if (x.right == null) < if (y == null) < root = x.left; >else < if (x == y.left) < y.left = x.left; >else < y.right = x.left; >> > else < NodeleftMost = x.right; y = null; while (leftMost.left != null) < y = leftMost; leftMost = leftMost.left; >if (y != null) < y.left = leftMost.right; >else < x.right = leftMost.right; >x.key = leftMost.key; x.value = leftMost.value; > > На десерт, пара функций, которые я использовал для тестирования:
fromList :: Ord key => [(key, value)] -> BSTree key value fromList = foldr (\(key, value) tree -> add tree key value) Leaf toList :: Ord key => BSTree key value -> [(key, value)] toList tree = toList' tree [] where toList' Leaf list = list toList' (Branch key value left right) list = toList' left ((key, value):(toList' left list)) Чем же все это полезно?
У читателя возможно возникает вопрос, зачем нужны такие сложности, если можно просто хранить список пар [(ключ, значение)]. Ответ прост — операции с деревом работают быстрее. При реализации списком все функции требуют O(n) действий, где n — размер структуры. (Запись O(f(n)) грубо говоря означает «пропорционально f(n)», более корректное описание и подробности можно почитать тут). Операции с деревом же работают за O(h), где h — максимальная глубина дерева (глубина — расстояние от корня до вершины). В оптимальном случае, когда глубина всех листьев одинакова, в дереве будет n=2^h вершин. Значит, сложность операций в деревьях, близких к оптимуму будет O(log(n)). К сожалению, в худшем случае дерево может выродится и сложность операций будет как у списка, например в таком дереве (получится, если вставлять числа 1..n по порядку):
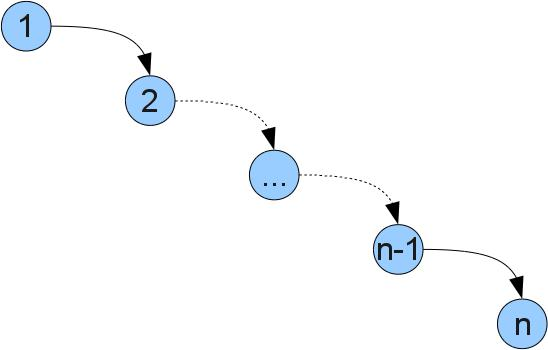
К счастью, существуют способы реализовать дерево так, чтобы оптимальная глубина дерева сохранялась при любой последовательности операций. Такие деревья называют сбалансированными. К ним например относятся красно-черные деревья, AVL-деревья, splay-деревья, и т.д.
Анонс следующих серий
В следующей статье я сделаю небольшой обзор различных сбалансированных деревьев, их плюсы и минусы. В следующих статьях я расскажу о каком-нибудь (возможно нескольких) более подробно и с реализацией. После этого я расскажу о реализации ropes и других возможных расширениях и применениях сбалансированных деревьев.
Оставайтесь на связи!
Полезные ссылки
Исходники примеров целиком:
Также очень советую почитать книгу Кормен Т., Лейзерсон Ч., Ривест Р.: «Алгоритмы: построение и анализ», которая является прекрасным учебником по алгоритмам и структурам данных
Деревья
Дерево — это нелинейная иерархическая структура данных. Она состоит из узлов и ребер, которые соединяют узлы.
Вот так выглядят деревья:

Зачем нужны деревья
Другие структуры данных, например, массивы, списки, стеки и очереди, линейные. Это значит, что данные в них хранятся последовательно. Когда мы выполняем любую операцию в линейной структуре данных, временная сложность растет с увеличением размера данных. В современном мире это не очень круто.
Разные древовидные структуры позволяют быстрее и легче получать доступ к данным, поскольку дерево — структура нелинейная.
Части дерева
- Узел — это объект, в котором есть ключ или значение и указатели на дочерние узлы.
Узлы, у которых нет дочерних узлов, называют листами или терминальными узлами.
Узлы, у которых есть хотя бы один дочерний узел, называются внутренними. - Ребро связывает два узла.
- Корень — это самый верхний узел дерева. Его ещё иногда называют корневым узлом.
.png)
Другие понятия
- Высота узла — это максимальная длина пути от этого узла к самому нижнему узлу (листу).
- Глубина вложенности узла — длина пути от корня до этого узла.
- Высота дерева — это высота корневого узла или глубина самого глубокого узла.
- Степень узла — это общее количество ребер, которые соединены с этим узлом.

- Лес — множество непересекающихся деревьев. Например, если «срезать» корень, получится лес.

Виды деревьев
- Двоичное дерево.
- Дерево двоичного поиска.
- АВЛ-дерево.
- B-дерево.
Обход дерева
Чтобы выполнить какую-либо операцию с деревом, нужно добраться до определенного узла. Для этого и существуют алгоритмы обхода дерева. Они помогают «дойти» до необходимого узла.
Где используются
- Деревья двоичного поиска помогают быстро проверить наличие элемента в наборе.
- Куча — это тоже своеобразное дерево. Кучи используют в алгоритме сортировки кучей.
- Префиксные деревья используются в маршрутизаторах, они хранят информацию о маршруте.
- Большинство популярных баз данных основаны на B-деревья и T-деревья.
- Компиляторы используют абстрактное синтаксическое дерево, чтобы находить синтаксические ошибки в ваших программах.
СodeСhick.io — простой и эффективный способ изучения программирования.
2024 © ООО «Алгоритмы и практика»
Деревья как концепция — Алгоритмы на деревьях
Иерархические структуры окружают нас везде — например, структура управления предприятием, адреса, содержания в книгах. Иерархия встречается и в программировании, например, в работе со стандартными типами данных, такими как массивы. Так как такие данные нельзя разместить линейно, программисты используют деревья. Они считаются одной из важнейших нелинейных структур, которые встречаются при работе с алгоритмами.
В этом уроке мы поговорим о деревьях, узнаем, какие проблемы они решают, и какие характеристики и способы представления деревьев существуют.
Что такое деревья и для чего они нужны
Деревья используют, чтобы отразить в памяти компьютера иерархические взаимосвязи. Их применяют для реестра Windows, XML-документов, DOM-структур HTML-страниц, родословных, каталогов запчастей или файловых систем. Например, так файловую структуру видят конечные пользователи:
При этом для программистов она выглядит иначе:
Это древовидное представление структуры. Из этой схемы можно сделать вывод, что дерево — это конечное множество, которое состоит из вершин или узлов, а еще есть выделенный узел — корень дерева. В примере выше вершины — это все папки, а корень дерева — «Новая папка».
Каждый узел содержит данные и ссылки на другие непересекающиеся между собой деревья. В этом случае каждая папка в дереве, от которой исходят другие данные, является для них корневым узлом. При этом эти данные образуют поддерево основного дерева.
Помимо представления иерархических взаимосвязей, деревья применяют в следующих случаях:
- Организация быстрого поиска в отсортированных данных, например, в индексах баз данных
- Кластеризация данных. Возможность разбивать данные на кластеры применяется в базах данных и машинном обучении
- Решение сложных арифметических выражений. Дерево используется, чтобы хранить порядок выполнения операций, значений аргументов и промежуточных результатов
- Алгоритмы принятия решений. Дерево решений — инструмент интеллектуального анализа данных и проведения предсказаний. Он считается более простым в работе инструментом, чем нейросети, так как формулирует правила на естественном языке
- Сетевое взаимодействие. Деревья используют для маршрутизации и работы механизмов определения IP-адресов по URL сайта, например, DNS-сервера
Деревья часто используют в проектах по разработке программ. Как результат — разработчики выделили терминологию описания узлов и формы деревьев.
Какие узлы есть в деревьях
Так как внешний вид дерева схож с генеалогическим деревом, термины генеалогии применяются и в программировании. Например, в отношении алгоритмических деревьев можно услышать такие термины, как «основатель династии», «мама», «ребенок», «брат», «двоюродный дядя». При этом существуют стандартизированные именования для отношений узлов:
- Родительский узел или предок — узел, который находится на первом уровне иерархии
- Дочерний узел или потомок — узел, на который есть ссылки из рассматриваемого узла
- Корневой узел — узел, на который нет ссылок из других узлов
- Сестринские узлы — два узла, у которых общие родители
- Листовой узел, лист дерева или терминальный узел — узел, у которого количество поддеревьев равно нулю
- Узел ветвления или внутренняя вершина — узел, у которого есть дочерние структуры
Количество поддеревьев у узла называется его степенью. Максимальное значение степени узла — степень дерева. Если степень дерева равна двум, значит, у каждого узла может быть не более двух потомков:
Какие формы деревьев бывают
Из-за определенных особенностей задач и алгоритмов, разработчики применяют разные формы деревьев со своими особенностями организации вершин:
- Упорядоченное дерево — дерево, в котором все вершины отсортированы. Такие деревья еще называются плоскими, так как при последовательном обходе вершин получится отсортированный массив:
Далее в курсе мы будем считать все деревья упорядоченными, если в условии не сказано обратное.
- Полное дерево — дерево, в котором количество дочерних узлов у каждой внутренней вершины равно степени дерева:
- Завершенное дерево – дерево, у которого каждый уровень, кроме последнего, является полным:
- Идеальное дерево — полное дерево, у которого все терминальные узлы располагаются на одном уровне:
Мы познакомились с основной терминологией, которая используется при работе с деревьями. Теперь рассмотрим, какие есть способы представления деревьев в графическом виде и в коде.
Как могут выглядеть деревья
Чтобы изображать иерархические структуры, используют следующие варианты:
- Древовидное схематическое представление
- Круги Эйлера
- Списки с отступами
- Код
Разберем каждый способ изображения дерева.
Древовидное схематическое представление
В качестве основного способа представления деревьев используют имена, номера вершин или содержимое полезных данных узла. Они соединяются линиями, которые обозначают связи между вершинами:
Этот способ похож на природные деревья, только в информатике корень дерева обычно рисуется вверху схемы.
Круги Эйлера
Мы можем изобразить алгоритмическое дерево по правилам теории множеств с помощью кругов Эйлера:
Данный способ на практике встречается достаточно редко, так как поддеревья обычно не пересекаются между собой. В такой ситуации использование схематичного представления более наглядно для человека.
Списки с отступами
Иерархическую связь можно изображать через пронумерованный список с отступами, где отступ или номер строки будут означать ее уровень:
Такой формат используют при работе с книгой, так как оглавление — это дерево.
Код
Чтобы работать с деревьями, их нужно уметь не только рисовать, но и хранить в памяти компьютера.
В виде кода мы получаем следующий класс узла:
class BinaryTreeNode constructor(value, parent) this.child1 = null; this.child2 = null; this.parent = parent; this.value = value; > >class BinaryTreeNode public BinaryTreeNode child1 = null; public BinaryTreeNode child2 = null; public BinaryTreeNode parent; public Object value; BinaryTreeNode(Object value, BinaryTreeNode parent) this.parent = parent; this.value = value; > >class BinaryTreeNode: def __init__(self, value, parent=None): self.child1 = None self.child2 = None self.parent = parent self.value = valueparent = $parent; $this->value = $value; > >Чтобы организовать из узла дерево, нужно добавить методы, которые заполняют ссылки на поддеревья child1 и child2 . Как реализуются деревья в коде, разберем подробно в следующих уроках.
Прежде чем писать код дерева, разработчики часто изображают иерархию графически, чтобы видеть полную картину взаимосвязей.
Дерево как структура данных
Какую выгоду можно извлечь из такой структуры данных, как дерево? В этой статье мы расскажем о данных в виде дерева, рассмотрим основные определения, которые следует знать, а также узнаем, как и зачем используется дерево в программировании. Спойлер: бинарные деревья часто применяют для поиска информации в базах данных, для сортировки данных, для проведения вычислений, для кодирования и в других случаях. Но давайте обо всем по порядку.
Основные термины
Дерево — это, по сути, один из частных случаев графа. Древовидная модель может быть весьма эффективна в случае представления динамических данных, особенно тогда, когда у разработчика стоит цель быстрого поиска информации, в тех же базах данных, к примеру. Еще древом называют структуру данных, которая представляет собой совокупность элементов, а также отношений между этими элементами, что вместе образует иерархическую древовидную структуру.
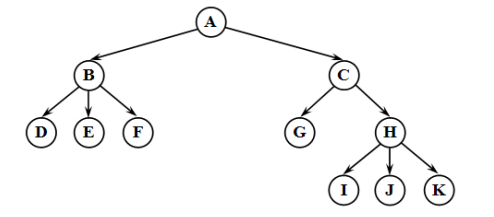
Каждый элемент — это вершина или узел дерева. Узлы, соединенные направленными дугами, называются ветвями. Начальный узел — это корень дерева (корневой узел). Листья — это узлы, в которые входит 1 ветвь, причем не выходит ни одной.
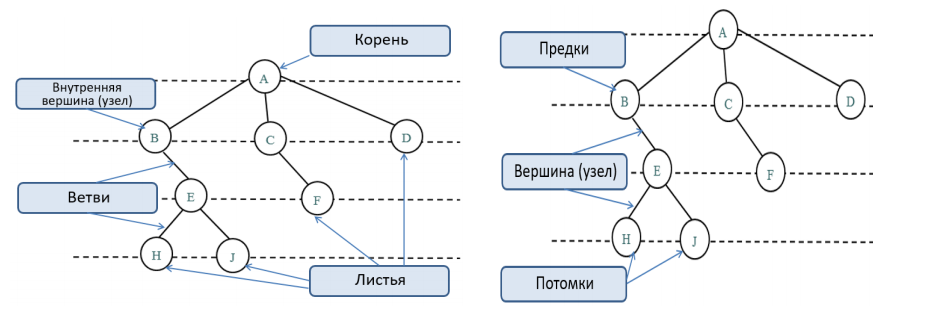
Общую терминологию можно посмотреть на левой и правой части картинки ниже:
Какие свойства есть у каждого древа:
— существует узел, в который не входит ни одна ветвь;
— в каждый узел, кроме корневого узла, входит 1 ветвь.
На практике деревья нередко применяют, изображая различные иерархии. Очень популярны, к примеру, генеалогические древа — они хорошо известны. Все узлы с ветвями, исходящими из единой общей вершины, являются потомками, а сама вершина называется предком (родительским узлом). Корневой узел не имеет предков, а листья не имеют потомков.
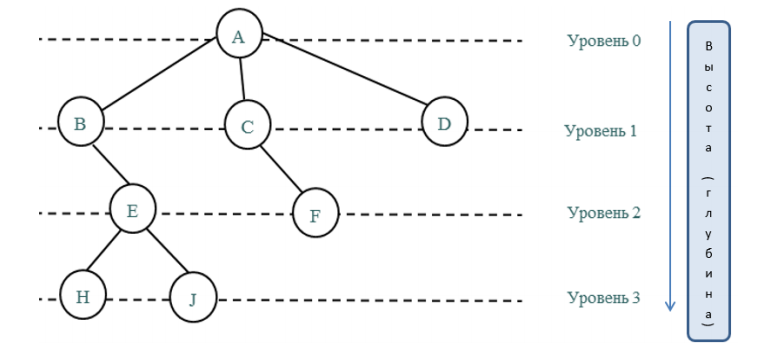
Также у дерева есть высота (глубина). Она определяется числом уровней, на которых располагаются узлы дерева. Глубина пустого древа равняется нулю, а если речь идет о дереве из одного корня, тогда единице. В данном случае на нулевом уровне может быть лишь одна вершина – корень, на 1-м – потомки корня, на 2-м – потомки потомков корня и т. д.
Ниже изображен графический вывод древа с 4-мя уровнями (дерево имеет глубину, равную четырем):
Следующий термин, который стоит рассмотреть, — это поддерево. Поддеревом называют часть древообразной структуры, которую можно представить в виде отдельного дерева.
Идем дальше. Древо может быть упорядоченным — в данном случае ветви, которые исходят из каждого узла, упорядочены по некоторому критерию.
Степень вершины в древе — это число ветвей (дуг), выходящих из этой вершины. Степень равняется максимальной степени вершины, которая входит в дерево. В этом случае листьями будут узлы, имеющие нулевую степень. По величине степени деревья бывают:
— двоичные (степень не больше двух);
— сильноветвящиеся (степень больше двух).
Деревья — это рекурсивные структуры, ведь каждое поддерево тоже является деревом. Каждый элемент такой рекурсивной структуры является или пустой структурой, или компонентом, с которым связано конечное количество поддеревьев.
Когда мы говорим о рекурсивных структурах, то действия с ними удобнее описывать посредством рекурсивных алгоритмов.
Обход древа
Чтобы выполнить конкретную операцию над всеми вершинами, надо все эти узлы просмотреть. Данную задачу называют обходом дерева. То есть обход представляет собой упорядоченную последовательность узлов, в которой каждый узел встречается лишь один раз.
В процессе обхода все узлы должны посещаться в некотором, заранее определенном порядке. Есть ряд способов обхода, вот три основные:
— прямой (префиксный, preorder);
— симметричный (инфиксный, inorder);
— обратный (постфиксный, postorder).
Существует много древовидных структур данных: двоичные (бинарные), красно-черные, В-деревья, матричные, смешанные и пр. Поговорим о бинарных.
Бинарные (двоичные) деревья
Бинарные имеют степень не более двух. То есть двоичным древом можно назвать динамическую структуру данных, где каждый узел имеет не большое 2-х потомков. В результате двоичное дерево состоит из элементов, где каждый из элементов содержит информационное поле, а также не больше 2-х ссылок на различные поддеревья. На каждый элемент древа есть только одна ссылка.
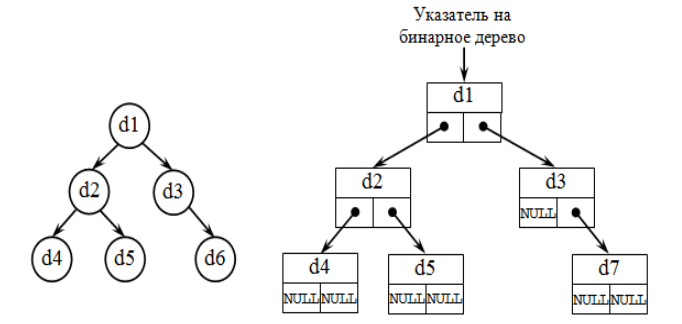
У бинарного древа каждый текущий узел — это структура, которая состоит из 4-х видов полей. Какие это поля:
— информационное (ключ вершины);
— служебное (включена вспомогательная информация, однако таких полей может быть несколько, а может и не быть вовсе);
— указатель на правое поддерево;
— указатель на левое поддерево.
Самый удобный вид бинарного древа — бинарное дерево поиска.
Что значит древо в контексте программирования?
Мы можем долго рассуждать о математическом определении древа, но это вряд ли поможет понять, какие именно выгоды можно извлечь из древовидной структуры данных. Тут важно отметить, что древо является способом организации данных в форме иерархической структуры.
В каких случаях древовидные структуры могут быть полезны при программировании:
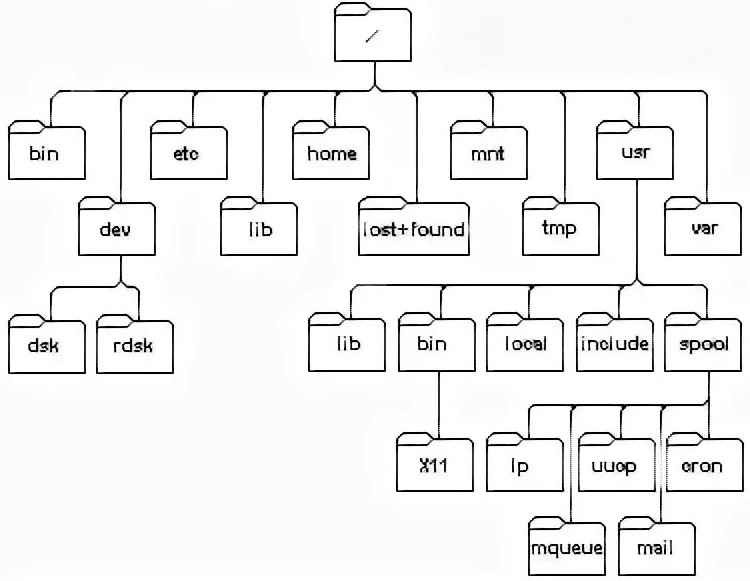
- Когда данная иерархия существует в предметной области разрабатываемой программы. К примеру, программа должна обрабатывать генеалогическое древо либо работать со структурой каталогов. В таких ситуациях иногда есть смысл сохранять между объектами программы существующие иерархические отношения. В качестве примера можно вывести древо каталогов операционной системы UNIX:
- Когда между объектами, которые обрабатывает программа, отношения иерархии не заданы явно, но их можно задать, что сделает обработку данных удобнее. Как тут не вспомнить разработку парсеров либо трансляторов, где весьма полезным может быть древо синтаксического разбора?
- А сейчас очевидная вещь: поиск объектов более эффективен, когда объекты упорядочены, будь то те же базы данных. К примеру, поиск значения в неструктурированном наборе из тысячи элементов потребует до тысячи операций, тогда как в упорядоченном наборе может хватить всего дюжины. Вывод прост: раз иерархия — эффективный способ упорядочивания объектов, почему же не использовать древовидную иерархию для ускорения поиска узлов со значениями? Так и происходит: если вспомнить бинарные деревья, то на практике их можно применять в следующих целях:
— поиск данных в базах данных (специально построенных деревьях);
— сортировка и вывод данных;
— вычисления арифметических выражений;
— кодирование по методу Хаффмана и пр.