Моки — JS: Продвинутое тестирование
В тестировании очень популярен мокинг. Технически он похож на стабинг, и из-за этого их часто путают (специально или ненамеренно). Но все же они служат разным целям и используются в разных ситуациях. Разберемся, что это такое, и когда он нужен.
До этого момента мы рассматривали побочные эффекты как помеху тестирования нашей логики. Для их изоляции использовались стабы или прямое выключение логики в тестовой среде. После этого можно было спокойно проверять правильность работы функции.
В некоторых ситуациях требуется кое-что другое. Не результат работы функции, а то, что она выполняет нужное нам действие, например, шлет правильный HTTP-запрос с правильными параметрами. Для этого понадобятся моки. Моки проверяют, как выполняется код.
HTTP
import nock from 'nock'; import getPrivateForkNames > from '../src.js'; // Предотвращение случайных запросов nock.disableNetConnect(); test('getPrivateForkNames', async () => // Полное название домена const scope = nock('https://api.github.com') // Полный путь .get('/orgs/hexlet/repos/?private=true') .reply(200, [ fork: true, name: 'one' >, fork: false, name: 'two' >]); await getPrivateForkNames('hexlet'); // Метод `scope.isDone()` возвращает `true` только тогда, // когда соответствующий запрос был выполнен внутри `getPrivateForkNames` expect(scope.isDone()).toBe(true); >); Это и называется мокинг. Мок проверяет, что какой-то код выполнился определенным образом. Это может быть вызов функции, HTTP-запрос и тому подобное. Задача мока убедиться в том, что это произошло, и в том, как конкретно это произошло, например, что в функцию были переданы конкретные данные.
Что дает нам такая проверка? В данном случае — мало что. Да, мы убеждаемся, что вызов был, но само по себе это еще ни о чем не говорит. Так когда же полезны моки?
Представьте, что мы бы разрабатывали библиотеку @octokit/rest, ту самую, что выполняет запросы к GitHub API. Вся суть этой библиотеки в том, чтобы выполнить правильные запросы с правильными параметрами. Поэтому там нужно обязательно проверять выполнение запросов с указанием точных URL-адресов. Только в таком случае можно быть уверенными, что она выполняет верные запросы.
В этом ключевое отличие мока от стаба. Стаб устраняет побочный эффект, чтобы не мешать проверке результата работы кода, например, возврату данных из функции. Мок фокусируется на том, как конкретно работает код, что он делает внутри. При этом чисто технически мок и стаб создаются одинаково, за исключением того, что на мок вешают ожидания, проверяющие вызовы. Это приводит к путанице, потому что часто моками называют стабы. С этим ничего уже не поделать, но для себя всегда пытайтесь понять, о чем идет речь. Это важно, от этого зависит фокус тестов.
Функции
Моки довольно часто используют с функциями (методами). К примеру, они могут проверять:
- Что функция была вызвана
- Сколько раз она была вызвана
- Какие аргументы мы использовали
- Сколько аргументов было передано в функцию
- Что вернула функция
Предположим, что мы хотим протестировать функцию forEach . Она вызывает колбек для каждого элемента коллекции:
[1, 2, 3].forEach((v) => console.log(v)); // или проще [1, 2, 3].forEach(console.log) Эта функция ничего не возвращает, поэтому напрямую ее не протестировать. Можно попробовать сделать это с помощью моков. Проверим, что она вызывает переданный колбек и передает туда нужные значения.
Так как мы изучаем Jest, то для создания моков воспользуемся встроенным механизмом Jest. В других фреймворках могут быть свои встроенные механизмы. Кроме того, как мы убедились выше, существуют специализированные библиотеки для моков и стабов.
test('forEach', () => // Моки функций в Jest создаются с помощью функции jest.fn // Она возвращает функцию, которая запоминает все свои вызовы и переданные аргументы // Потом это используется для проверок const callback = jest.fn(); [1, 2, 3].forEach(callback); // Теперь проверяем, что она была вызвана с правильными аргументами нужное количество раз expect(callback.mock.calls).toHaveLength(3); // Первый аргумент первого вызова expect(callback.mock.calls[0][0]).toBe(1); // Первый аргумент второго вызова expect(callback.mock.calls[1][0]).toBe(2); // Первый аргумент третьего вызова expect(callback.mock.calls[2][0]).toBe(3); >); С помощью моков мы проверили, что функция была вызвана ровно три раза, и ей, последовательно для каждого вызова, передавался новый элемент коллекции. В принципе, можно сказать, что этот тест действительно проверяет работоспособность функции forEach() . Но можно ли сделать это проще, без мока и без завязки на внутреннее поведение? Оказывается, можно. Для этого достаточно использовать замыкание:
test('forEach', () => const result = []; const numbers = [1, 2, 3]; numbers.forEach((x) => result.push(x)); expect(result).toEqual(numbers); >); Объекты
Jest позволяет создавать моки и для объектов. Они создаются с помощью функции jest.spyOn() , напоминающей уже известную нам jest.fn() . Эта функция принимает на вход объект и имя метода в этом объекте, и отслеживает вызовы этого метода. Отследим, в качестве примера, вызов console.log() :
test('logging something', () => const spy = jest.spyOn(console, 'log'); console.log(12); expect(spy).toHaveBeenCalled(); // => true, т.к. метод log был вызван expect(spy).toHaveBeenCalledTimes(1); // => true, т.к. метод был вызван 1 раз expect(spy).toHaveBeenCalledWith(12); // true, т.к. log был вызван с аргументом 12 expect(spy.mock.calls[0][0]).toBe(12); // проверка, идентичная предыдущей >); Кроме того, Jest позволяет создавать свою реализацию сбора данных о вызовах отслеживаемой функции при помощи метода mockImplementation(fn) . Колбэком этого метода будет функция, которая выполняется после каждого вызова отслеживаемой функции. Возьмем предыдущий пример, но теперь соберем аргументы каждого вызова console.log() в отдельный массив:
test('logging something', () => const logCalls = []; // Здесь функция внутри mockImplementation принимает на вход аргумент(ы), // с которым был вызван console.log, и сохраняет его в заранее созданный массив const spy = jest.spyOn(console, 'log').mockImplementation((. args) => logCalls.push(args)); console.log('one'); console.log('two'); expect(logCalls.join(' ')).toBe('one two'); >); Преимущества и недостатки
Несмотря на то, что существуют ситуации, в которых моки нужны, в большинстве ситуаций их нужно избегать. Моки слишком много знают о том, как работает код. Любой тест с моками из черного ящика превращается в белый ящик. Повсеместное использование моков приводит к двум вещам:
- После рефакторинга приходится переписывать тесты (много тестов!), даже если код работает правильно. Происходит это из-за завязки на то, как конкретно работает код
Открыть доступ
Курсы программирования для новичков и опытных разработчиков. Начните обучение бесплатно
- 130 курсов, 2000+ часов теории
- 1000 практических заданий в браузере
- 360 000 студентов
Наши выпускники работают в компаниях:
Что такое тестирование с использованием моков

Тестирование с использованием моков (mock testing) – это метод, при котором вместо реальных компонентов системы используются их имитационные заместители, называемые моками (mocks). Это позволяет упростить процесс тестирования, изолировать тестируемый компонент от внешних зависимостей и контролировать поведение зависимых компонентов в ходе тестирования.
Виды заглушек (стабов)
Моки – это лишь один из видов заглушек, используемых при тестировании. В общем случае, заглушки могут быть разделены на следующие виды:
- Стабы (stubs) – простейшие заглушки, которые возвращают заранее определенные значения на определенные входные данные.
- Моки (mocks) – более продвинутые заглушки, которые позволяют контролировать вызов методов, передачу аргументов и проверку ожидаемого поведения тестируемой системы.
- Фейки (fakes) – имитационные объекты, которые имитируют поведение реальных компонентов, но с упрощенной реализацией.
- Спайы (spies) – специальные объекты, которые записывают информацию о своем использовании (количество вызовов, переданные аргументы и т. д.), что позволяет анализировать их поведение после выполнения теста.
Пример использования моков
Допустим, у нас есть система, которая отправляет электронные письма пользователям. Вот упрощенный код нашей системы:
class EmailSender: def send_email(self, recipient, subject, message): # Отправка письма с использованием внешнего сервиса pass class NotificationSystem: def __init__(self, email_sender): self.email_sender = email_sender def notify_user(self, user): self.email_sender.send_email(user.email, "Уведомление", "Приветствуем вас в нашей системе!")
В этом примере, если бы мы хотели протестировать метод notify_user класса NotificationSystem , нам бы пришлось использовать реальный сервис отправки писем. Однако с помощью моков мы можем создать имитационный объект EmailSender и контролировать его поведение:
from unittest.mock import Mock # Создаем мок-объект для EmailSender mock_email_sender = Mock(spec=EmailSender) # Создаем экземпляр системы уведомлений с моком вместо реального отправителя писем notification_system = NotificationSystem(mock_email_sender) # Тестируем метод notify_user notification_system.notify_user(test_user) # Проверяем, что метод send_email мок-объекта был вызван с правильными аргументами mock_email_sender.send_email.assert_called_with(test_user.email, "Уведомление", "Приветствуем вас в нашей системе!")
Таким образом, с помощью моков мы смогли протестировать поведение системы уведомлений, не завися от реального сервиса отправки писем.
Моки и явные контракты
Наверное каждый, кто начинал писать юнит и интеграционные тесты, сталкивался с проблемой злоупотребления моками, которая приводит к хрупким тестам. Последние, в свою очередь, создают у программиста неверное убеждение в том, что тесты только мешают работать.
Ниже представлен вольный перевод статьи, в которой José Valim — создатель языка Elixir — высказал своё мнение на проблему использования моков, с которым я полностью согласен.
Несколько дней назад я поделился своими мыслями по поводу моков в Twitter:
Мок — полезный инструмент в тестировании, но имеющиеся тестовые библиотеки и фреймворки зачастую приводят к злоупотреблению этим инструментом. Ниже мы рассмотрим лучший способ использования моков.
Что такое мок?
Воспользуемся определением из англоязычной википедии: мок — настраиваемый объект, который имитирует поведение реального объекта. Я сделаю акцент на этом позже, но для меня мок — это всегда существительное, а не глагол [для наглядности, глагол mock везде будет переводиться как «замокать» — прим. перев.].
На примере внешнего API
Давайте рассмотрим стандартный пример из реальной жизни: внешнее API.
Представьте, что вы хотите использовать Twitter API в веб-приложении на фреймворке Phoenix или Rails. В приложение приходит запрос, который перенаправляется в контроллер, который, в свою очередь, делает запрос к внешнему API. Вызов внешнего API происходит прямо в контроллере:
defmodule MyApp.MyController do def show(conn, % username>) do # . MyApp.TwitterClient.get_username(username) # . end endСтандартным подходом при тестирования такого кода будет замокать (опасно! замокать в данном случае является глаголом!) HTTPClient , которым пользуется MyApp.TwitterClien :
mock(HTTPClient, :get, to_return: % "josevalim", . >)Далее вы используете такой же подход в других частях приложения и добиваетесь прохождения юнит и интеграционных тестов. Время двигаться дальше?
Не так быстро. Основная проблема при моке HTTPClient заключается в создании сильной внешней зависимости [англ. coupling везде переведена как «зависимость» — прим. перев.] к конкретному HTTPClient . Например, если вы решите использовать новый более быстрый HTTP-клиент, не изменяя поведение приложения, большая часть ваших интеграционных тестов упадет, потому что все они зависят от конкретного замоканного HTTPClient . Другими словами, изменение реализации без изменения поведения системы все равно приводит к падению тестов. Это плохой знак.
Кроме того, так как мок, показанный выше, изменяет модуль глобально, вы больше не сможете запустить эти тесты в Elixir параллельно.
Решение
Вместо того, чтобы мокать HTTPClient , мы можем заменить MyApp.TwitterClient чем-нибудь другим во время тестов. Давайте посмотрим, как решение может выглядеть на Elixir.
В Elixir все приложения имеют конфигурационные файлы и механизм для их чтения. Используем этот механизм, чтобы настроить клиент Twitter’a для различных окружений. Код контроллера теперь будет выглядеть следующим образом:
defmodule MyApp.MyController do @twitter_api Application.get_env(:my_app, :twitter_api) def show(conn, % username>) do # . @twitter_api.get_username(username) # . end endСоответствующие настройки для различных окружений:
# config/dev.exs config :my_app, :twitter_api, MyApp.Twitter.Sandbox # config/test.exs config :my_app, :twitter_api, MyApp.Twitter.InMemory # config/prod.exs config :my_app, :twitter_api, MyApp.Twitter.HTTPClientСейчас мы можем выбрать лучшую стратегию получения данных из Twitter для каждого из окружений. Sandbox может быть полезен, если Twitter предоставляет какой-нибудь sandbox для разработки. Наша замоканная версия HTTPClient позволяла избежать реальных HTTP-запросов. Реализация этой же функциональности в данном случае:
defmodule MyApp.Twitter.InMemory do def get_username("josevalim") do %MyApp.Twitter.User < username: "josevalim" >end endКод получился простым и чистым, а сильной внешней зависимости от HTTPClient больше нет. MyApp.Twitter.InMemory является моком, то есть существительным, и для его создания вам не нужны никакие библиотеки!
Необходимость явных контрактов
Мок предназначен для замены реального объекта, а значит будет эффективен только в том случае, когда поведение реального объекта определено явно. Иначе, вы можете оказаться в ситуации, когда мок начнет становиться все сложнее, увеличивая зависимость между тестируемыми компонентами. Без явного контракта заметить это будет сложно.
Мы уже имеем три реализации Twitter API и лучше сделать их контракты явными. В Elixir описать явный контракт можно с помощью behaviour:
defmodule MyApp.Twitter do @doc ". " @callback get_username(username :: String.t) :: %MyApp.Twitter.User<> @doc ". " @callback followers_for(username :: String.t) :: [%MyApp.Twitter.User<>] endТеперь добавьте @behaviour MyApp.Twitter в каждый модуль, который реализует этот контракт, и Elixir поможет вам создать ожидаемый API.
В Elixir мы полагаемся на такие behaviours постоянно: когда используем Plug, когда работаем с базой данных в Ecto, когда тестируем Phoenix channels и так далее.
Тестирование границ
Сначала, когда явные контракты отсутствовали, границы приложения выглядели так:
[MyApp] -> [HTTPClient] -> [Twitter API]
Поэтому изменение HTTPClient могло приводить к падению интеграционных тестов. Сейчас приложение зависит от контракта и только одна реализация этого контракта работает с HTTP:
[MyApp] -> [MyApp.Twitter (contract)]
[MyApp.Twitter.HTTP (contract impl)] -> [HTTPClient] -> [Twitter API]
Тесты такого приложения изолированы от HTTPClient и от Twitter API. Но как нам протестировать MyApp.Twitter.HTTP ?
Сложность тестирования больших систем заключается в определение четких границ между компонентами. Слишком высокий уровень изоляции при отсутствии интеграционных тестов сделает тесты хрупкими, а большинство проблем будут обнаруживаться только на production. С другой стороны, низкий уровень изоляции увеличит время прохождения тестов и сделает тесты сложными в сопровождении. Единственного верного решения нет, и уровень изоляции будет изменяться в зависимости от уверенности команды и прочих факторов.
Лично я бы протестировал MyApp.Twitter.HTTP на реальном Twitter API, запуская эти тесты по-необходимости во время разработки и каждый раз при сборке проекта. Система тегов в ExUnit — библиотеке для тестирования в Elixir — реализует такое поведение:
defmodule MyApp.Twitter.HTTPTest do use ExUnit.Case, async: true # Эти тесты будут работать с Twitter API @moduletag :twitter_api # . endИсключим тесты с Twitter API:
ExUnit.configure exclude: [:twitter_api]При необходимости включим их в общий тестовый прогон:
mix test —include twitter_api
Также можно запустить их отдельно:
mix test —only twitter_api
Хотя я предпочитаю такой подход, внешние ограничения, вроде максимального количества запросов к API, могут сделать его бесполезным. В таком случае, возможно, действительно нужно использовать мок HTTPClient , если его использование не нарушает определенных ранее правил:
- Изменение в HTTPClient приводит только к падению тестов на MyApp.Twitter.HTTP
- Вы не мокаете (осторожно! мок в данном случае является глаголом!) HTTPClient . Вместо этого, вы передаете его как зависимость через файл конфигурации, подобно тому, как мы делали для Twitter API
- Вам все еще нужен способ протестировать работу вашего клиента до выкатки в production.
Вместо создания мока HTTPClient можно поднять dummy-сервер, который будет эмулировать Twitter API. bypass — один из проектов, который может в этом помочь. Все возможные варианты вы должны обсудить со своей командой.
Примечания
Я бы хотел закончить эту статью разбором нескольких общих проблем, которые всплывают практически в каждом обсуждении моков.
Создание «тестируемого» кода
Получается, предложенное решение делает production-код более «тестируемым», но создает необходимость ходить в конфигурацию приложения на каждый вызов функции? Наличие ненужного оверхэда, чтобы сделать что-то «тестируемым», не похоже на хорошее решение.
Я бы сказал, что речь идет не о создании «тестируемого» кода, а об улучшении дизайна [от англ. design of your code — прим. перев.].
Тест — это пользователь вашего API, как и любой другой код, который вы пишите. Одна из идей TDD заключается в том, что тесты — это код и ничем не отличаются от кода. Если вы говорите: «Я не хочу делать мой код тестируемым», это означает «Я не хочу уменьшать зависимость между компонентами» или «Я не хочу думать о контракте (интерфейсе) этих компонентов».
Нет ничего плохого в нежелании уменьшать зависимость между компонентами. Например, если речь идет о модуле работы с URI [имеется ввиду модуль URI для Elixir — прим. перев.]. Но если мы говорим о чем-то таком же сложном, как внешнее API, определение явного контракта и наличие возможности заменять реализацию этого контракта сделает ваш код удобным и простым в сопровождении.
Кроме того, оверхэд минимален, так как конфигурация Elixir-приложения хранится в ETS, а значит вычитывается прямо из памяти.
Локальные моки
Хотя мы и использовали конфигурацию приложения для решения проблемы с внешним API, иногда проще передать зависимость как аргумент. Например, некоторая функция выполняет долгие вычисления, которые вы хотите изолировать в тестах:
defmodule MyModule do def my_function do # . SomeDependency.heavy_work(arg1, arg2) # . end endМожно избавиться от зависимости, передав её как аргумент. В данном случае будет достаточно передачи анонимной функции:
defmodule MyModule do def my_function(heavy_work \\ &SomeDependency.heavy_work/2) do # . heavy_work.(arg1, arg2) # . end endТест будет выглядеть следующим образом:
test "my function performs heavy work" do # Симулируем долгое вычисление с помощью отправки сообщения тесту heavy_work = fn(_, _) -> send(self(), :heavy_work) end MyModule.my_function(heavy_work) assert_received :heavy_work endИли, как было описано ранее, можно определить контракт и передать модуль целиком:
defmodule MyModule do def my_function(dependency \\ SomeDependency) # . dependency.heavy_work(arg1, arg2) # . end endtest "my function performs heavy work" do # Симулируем долгое вычисление с помощью отправки сообщения тесту defmodule TestDependency do def heavy_work(_arg1, _arg2) do send self(), :heavy_work end end MyModule.my_function(TestDependency) assert_received :heavy_work endВы также можете представить зависимость в виде data structure и определить контракт с помощью protocol.
Передать зависимость как аргумент намного проще, поэтому, если возможно, такой способ должен быть предпочтительнее использования конфигурационного файла и Application.get_env/3 .
Мок — это существительное
Лучше думать о моках как о существительных. Вместо того, чтобы мокать API (мокать — глагол), нужно создать мок (мок — существительное), который реализует необходимый API.
Большинство проблем от использования моков возникают, когда они используются как глаголы. Если вы мокаете что-то, вы изменяете уже существующие объекты, и зачастую эти изменения являются глобальными. Например, когда мы мокаем модуль SomeDependency , он изменится глобально:
mock(SomeDependency, :heavy_work, to_return: true)При использовании мока как существительного, вам необходимо создать что-то новое, и, естественно, это не может быть уже существующий модуль SomeDependency . Правило «мок — это существительное, а не глагол» помогает находить «плохие» моки. Но ваш опыт может отличаться от моего.
Библиотеки для создания моков
После прочитанного у вас может возникнуть вопрос: «Нужно ли отказываться от библиотек для создания моков?»
Все зависит от ситуации. Если библиотека подталкивает вас на подмену глобальных объектов (или на использование моков в качестве глаголов), изменение статических методов в объектно-ориентированном или замену модулей в функциональном программировании, то есть на нарушение описанных выше правил создания моков, то вам лучше отказаться от неё.
Однако, есть библиотеки для создания моков, которые не подталкивают вас на использование описанных выше анти-паттернов. Такие библиотеки предоставляют «мок-объекты» или «мок-модули», которые передаются в тестируемую систему в качестве аргумента и собирают информацию о количестве вызовов мока и о том, с какими аргументами он был вызван.
Заключение
Одна из задач тестирования системы — нахождение правильных контрактов и границ между компонентами. Использование моков только в случае наличия явного контракта позволит вам:
- Защититься от засилья моков, так как контракты будут создаваться только для необходимых частей системы. Как было упомянуто выше, вряд ли вы захотите прятать взаимодействие со стандартными модулями URI и Enum за контрактом.
- Упростить поддержку компонентов. При добавлении новой функциональности к зависимости, вам нужно обновить контракт (добавить новый @callback в Elixir). Бесконечный рост @callback укажет на зависимость, которая берет на себя слишком много ответственности, и вы сможете раньше расправиться с проблемой.
- Сделать вашу систему пригодной для тестирования, потому что взаимодействие между сложными компонентами будет изолировано.
Явные контракты позволяют увидеть сложность зависимостей в вашем приложении. Сложность присутствует в каждом приложении, поэтому всегда старайтесь делать её настолько явной, насколько это возможно.
- Тестирование IT-систем
- Совершенный код
- Elixir/Phoenix
Когда использовать mocks в юнит-тестировании
Использование моков в модульном тестировании является спорной темой. Автор оригинала заметил, что на протяжении всей своей карьеры в программировании он сначала перешел от моков почти над каждой зависимостью к политике «без моков», а затем к «только моки для внешних зависимостей».
Ни одна из этих практик не является достаточно хорошей. В этой статье Владимир Хориков покажет, какие зависимости следует мокать, а какие использовать как есть в тестах.
Что такое mock (мок, от англ. «пародия», «имитация»)?
Прежде чем перейти к теме того, когда использовать моки, давайте обсудим, что такое мок. Люди часто используют термины тестовый двойник (test double) и мок (mock) как синонимы, но технически это не так:
- Тестовый двойник — это всеобъемлющий термин, который описывает все виды фальшивых (fake) зависимостей, непригодных к использованию в конечном продукте (non-production-ready), в тестах. Такая зависимость выглядит и ведет себя как ее аналог, предназначенный для production, но на самом деле является упрощенной версией, которая снижает сложность и облегчает тестирование. Этот термин был введен Джерардом Месаросом в его книге «xUnit Test Patterns: Refactoring Test Code». Само название происходит от понятия дублера в кино.
- Мок – это лишь один из видов таких зависимостей.
Согласно Жерару Месарошу, существует 5 видов тестовых двойников:
- Пустышка (dummy)
- Стаб (stub)
- Шпион (spy)
- Мок (mock)
- Фейк (fake)
Такое разнообразие может показаться пугающим, но на самом деле все они могут быть сгруппированы всего в два типа: моки и стабы.
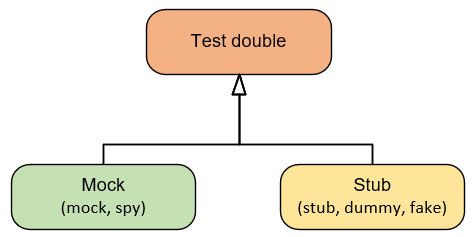
Разница между этими двумя типами сводится к следующему:
- Моки помогают имитировать и изучать исходящие (outcoming) взаимодействия. То есть вызовы, совершаемые тестируемой системой (SUT) к ее зависимостям для изменения их состояния.
- Стабы помогают имитировать входящие (incoming) взаимодействия. То есть вызовы, совершаемые SUT к ее зависимостям для получения входных данных.
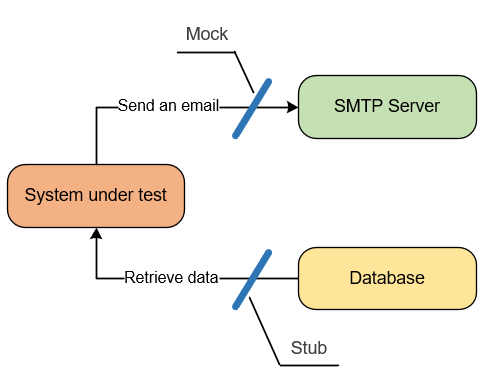
Например, отправка электронной почты является исходящим (outcoming) взаимодействием: это взаимодействие приводит к побочному эффекту на SMTP-сервере. Тестовый двойник, имитирующий такое взаимодействие, — это мок.
Извлечение данных из БД является входящим (incoming) взаимодействием — оно не приводит к побочному эффекту. Соответствующий тестовый двойник является стабом.
Все остальные различия между пятью типами тестовых двойников являются незначительными деталями реализации:
- Spies (шпионы) выполняют ту же роль, что и моки. Отличие в том, что spies пишутся вручную, а моки создаются с помощью готовых инструментов. Иногда spies называют рукописными моками.
С другой стороны, разница между стабами, dummy (пустышками) и фейками заключается в том, насколько они умны:
- Dummy — это простое, жестко закодированное значение, такое как null значение или выдуманная строка. Он используется для удовлетворения сигнатуры метода SUT и не участвует в получении конечного результата.
- Стаб посложнее. Это полноценная зависимость, которую вы настраиваете для возврата разных значений для разных сценариев.
- Фейк — это то же самое, что и стаб для большинства целей. Разница заключается в причинах его создания: фейк обычно используется для замены еще не существующей зависимости.
Обратите внимание на разницу между моками и стабами (помимо исходящих и входящих взаимодействий). Моки помогают эмулировать и изучать взаимодействия между SUT и его зависимостями, в то время как стабы помогают только эмулировать эти взаимодействия. Это важное различие.
Мок-как-инструмент vs. мок-как-тестовый-двойник
Термин мок перегружен и может означать разные вещи в разных обстоятельствах. В статье уже упоминалось, что люди часто используют этот термин для обозначения любого тестового двойника, тогда как моки — это всего лишь подмножество тестовых двойников.
Но у термина мок есть и другое значение. Вы также можете ссылаться на классы из библиотек (для создания моков) как на моки. Эти классы помогают вам создавать настоящие моки, но сами по себе они не являются моками как таковыми:
[Fact] public void Sending_a_greetings_email() < // Using a mock-the-tool to create a mock-the-test-double var mock = new Mock(); var sut = new Controller(mock.Object); sut.GreetUser("user@email.com"); // Examining the call from the SUT to the test double mock.Verify( x => x.SendGreetingsEmail("user@email.com"), Times.Once); >В этом тесте используется класс Mock из библиотеки Moq. Этот класс представляет собой инструмент, который позволяет вам создавать тестовый двойник — мок. Другими словами, класс Mock (или Mock ) является мок-как-инструмент, в то время как экземпляр этого класса является мок-как-тестовый-двойник.
Важно не смешивать мок-как-инструмент с мок-как-тестовый-двойник, потому что вы можете использовать мок-как-инструмент для создания обоих типов тестовых двойников: моков и стабов.
Вот еще один пример теста, в котором используется класс Mock. Экземпляр этого класса — стаб, а не мок:
[Fact] public void Creating_a_report() < // Using a mock-the-tool to create a stub var stub = new Mock(); // Setting up a canned answer stub.Setup(x => x.GetNumberOfUsers()).Returns(10); var sut = new Controller(stub.Object); Report report = sut.CreateReport(); Assert.Equal(10, report.NumberOfUsers); >Этот тестовый двойник имитирует входящее взаимодействие – вызов, который предоставляет SUT входные данные. С другой стороны, в предыдущем примере вызов SendGreetingsEmail() является исходящим взаимодействием. Его единственная цель — вызвать побочный эффект — отправить электронное письмо.
Не проверяйте взаимодействия со стабами
Как уже упоминал выше, моки помогают эмулировать и изучать исходящие взаимодействия между SUT и его зависимостями, в то время как стабы помогают только эмулировать входящие взаимодействия, а не изучать их.
Из этого следует, что вы никогда не должны проверять взаимодействие со стабами. Вызов от SUT к стабу не является частью конечного результата, который выдает SUT. Такой вызов — это всего лишь средство для получения конечного результата; это деталь реализации. Проверка взаимодействий со стабами является распространенным анти-паттерном, который приводит к хрупким тестам.
Единственный способ избежать хрупкости тестов — это заставить эти тесты проверять конечный результат (который в идеале должен иметь значение для непрограммиста), а не детали реализации.
В приведенных выше примерах проверка
mock.Verify(x => x.SendGreetingsEmail("user@email.com"))соответствует фактическому результату, и этот результат имеет значение для специалиста в предметной области: отправка приветственного электронного письма — это то, что такой специалист хотели бы, чтобы система делала.
В то же время вызов GetNumberOfUsers() вообще не является результатом. Это внутренняя деталь реализации, касающаяся того, как SUT собирает данные, необходимые для создания отчета. Следовательно, проверка этого вызова приведет к уязвимости теста. Неважно, как SUT генерирует конечный результат, если этот результат правильный.
Вот пример такого хрупкого теста:
[Fact] public void Creating_a_report() < var stub = new Mock(); stub.Setup(x => x.GetNumberOfUsers()).Returns(10); var sut = new Controller(stub.Object); Report report = sut.CreateReport(); Assert.Equal(10, report.NumberOfUsers); // Asserting an interaction with a stub stub.Verify( x => x.GetNumberOfUsers(), Times.Once);Такая практика проверки того, что не является частью конечного результата, также называется чрезмерной спецификацией.
Моки — это более сложная тема: не все их использования приводят к уязвимости теста, но многие из них делают это. Вы скоро поймете почему.
Совместное использование моков и стабов
Иногда нужно создать тестовый двойник, который проявляет свойства как мока, так и стаба:
[Fact] public void Purchase_fails_when_not_enough_inventory() < var storeMock = new Mock(); // Setting up a canned answer storeMock .Setup(x => x.HasEnoughInventory(Product.Shampoo, 5)) .Returns(false); var sut = new Customer(); bool success = sut.Purchase(storeMock.Object, Product.Shampoo, 5); Assert.False(success); // Examining a call from the SUT to the mock storeMock.Verify( x => x.RemoveInventory(Product.Shampoo, 5), Times.Never); >Этот тест использует storeMock для двух целей: он возвращает шаблонный ответ и проверяет вызов метода, сделанный SUT.
Однако обратите внимание, что это два разных метода: тест устанавливает ответ от HasEnoughInventory(), но затем проверяет вызов RemoveInventory(). Таким образом, здесь не нарушается правило не проверять взаимодействия со стабами.
Когда тестовый двойник является одновременно и моком, и стабом, он все равно называется моком. Это в основном потому, что нужно выбрать одно имя, но также и потому, что являться моком — более важный факт.
Mocks vs. stubs и commands vs. queries
Понятие моков и стабов связано с принципом command-query separation (CQS). Принцип CQS гласит, что каждый метод должен быть либо командой, либо запросом, но не обоими:
- Команды — это методы, которые вызывают побочные эффекты и не возвращают никакого значения. Примеры побочных эффектов включают изменение состояния объекта, изменение файла в файловой системе и т. д.
- Запросы противоположны этому — они не имеют побочных эффектов и возвращают значение.
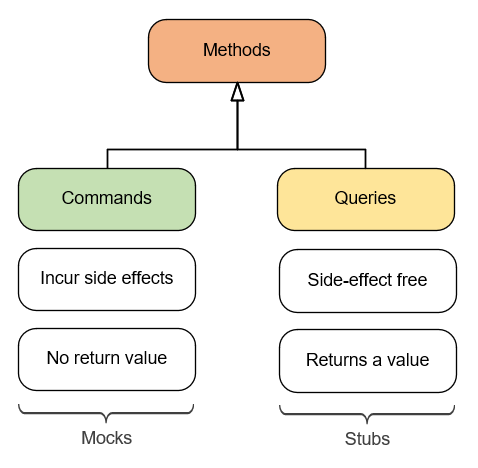
Другими словами, задавая вопрос, вы не должны менять ответ. Код, который поддерживает такое четкое разделение, становится легче для чтения. Тестовые двойники, заменяющие команды, становятся моками. Аналогично, тестовые двойники, заменяющие запросы, являются стабами:
Посмотрите еще раз на два теста из предыдущих примеров:
var mock = new Mock(); mock.Verify(x => x.SendGreetingsEmail("user@email.com")); var stub = new Mock(); stub.Setup(x => x.GetNumberOfUsers()).Returns(10);SendGreetingsEmail() — это команда, побочным эффектом которой является отправка электронного письма. Тестовый двойник, который заменяет эту команду, является моком.
С другой стороны, GetNumberOfUsers() — это запрос, который возвращает значение и не изменяет состояние базы данных. Соответствующий тестовый двойник — стаб.
Когда мокать?
Разобравшись со всеми этими определениями, давайте поговорим о том, когда вам следует использовать моки.
Очевидно, что вы не хотите мокать саму тестируемую систему (SUT), поэтому вопрос «Когда мокать?» сводится к следующему: «Какие типы зависимостей вы должны заменять на моки, а какие использовать в тестах?»
Вот все типы зависимостей модульного тестирования, которые автор оригинала перечислил в своей предыдущей статье:

- Совместная зависимость (shared dependency) — это зависимость, которая является общей между тестами и с помощью нее тесты могут влиять на результаты друг друга.
- Приватная зависимость (private dependency) — это любая зависимость, которая не является совместной.
Совместная зависимость соответствует изменяемой внепроцессорной зависимости (mutable out-of-process dependency) в подавляющем большинстве случаев, поэтому автор оригинала использует здесь эти два понятия как синонимы. (Ознакомьтесь с предыдущим постом Владимира Хорикова, чтобы узнать больше: Unit Testing Dependencies: The Complete Guide.)
Существуют две школы модульного тестирования с собственными взглядами на то, какие типы зависимостей следует заменять на моки:
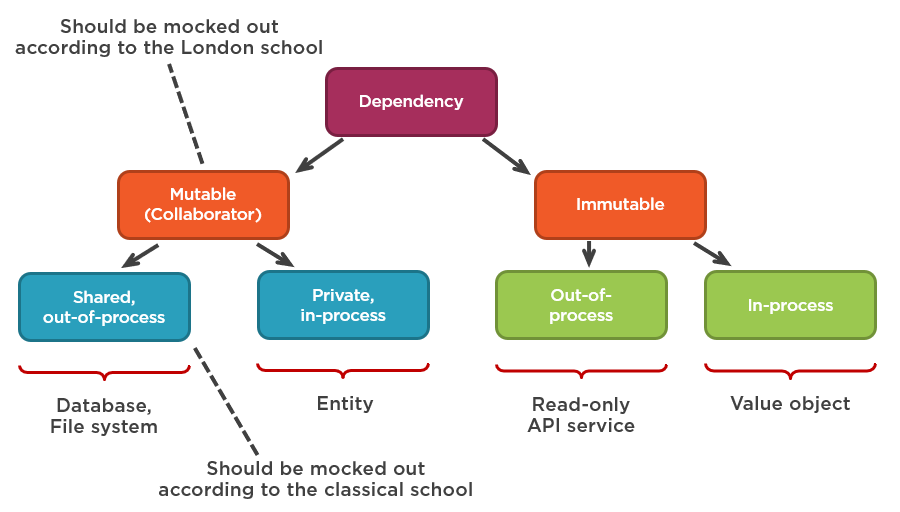
- Лондонская школа (также известная как школа mockist) выступает за замену всех изменяемых зависимостей на моки.
- Классическая школа (также известная как школа Детройта) выступает за замену только общих (изменяемых внепроцессорных) зависимостей.
Обе школы ошибаются в своем отношении к мокам, хотя классическая школа меньше, чем лондонская.
Моки и неизменяемые внепроцессорные зависимости.
А как насчет иммутабельных внепроцессорных (immutable out-of-process) зависимостей? Разве их не стоит мокать, по крайней мере, по мнению одной из школ? Неизменяемые внепроцессорные зависимости (например, служба API только для чтения) следует заменить тестовым двойником, но этот тестовый двойник будет стабом, а не моком.
Это опять же из-за различий между моками и стабами:
· Моки предназначены для исходящих взаимодействий (команд) — взаимодействий, которые оставляют побочный эффект в зависимости.
· Стабы предназначены для входящих взаимодействий (запросов) — взаимодействий, которые не оставляют побочных эффектов в зависимости.
Взаимодействия с иммутабельными внепроцессорными зависимостями по определению являются входящими и, следовательно, не должны проверяться в тестах, а только заменяться шаблонными ответами (обе школы с этим согласны).
Сначала Владимир Хориков опишет, почему лондонская школа ошибочна, а затем — почему классический подход тоже неверен.
Не мокайте все изменяемые зависимости
Не стоит мокать все изменяемые зависимости. Чтобы понять, почему, нам нужно рассмотреть два типа коммуникаций в типичном приложении: внутрисистемный и межсистемный.
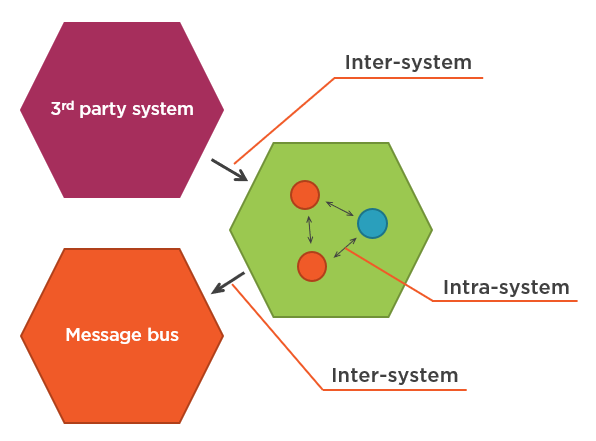
- Внутрисистемные (Intra-system) коммуникации — это коммуникации между классами внутри вашего приложения.
- Межсистемные (Inter-system) коммуникации — это когда ваше приложение взаимодействует с другими приложениями.
Между ними существует огромная разница: внутрисистемные коммуникации являются деталями реализации; межсистемные коммуникации — нет.
Внутрисистемные коммуникации являются деталями реализации, поскольку взаимодействие, через которое проходят ваши доменные классы для выполнения операции, не является частью их наблюдаемого поведения. Это взаимодействие не имеет непосредственной связи с целью клиента. Таким образом, связь с таким взаимодействием приводит к хрупким тестам.
Межсистемные коммуникации — это совсем другое дело. В отличие от взаимодействия между классами внутри вашего приложения, то, как ваша система взаимодействует с внешним миром, формирует наблюдаемое поведение этой системы в целом. Это часть контракта, который ваше приложение должно соблюдать в любое время.
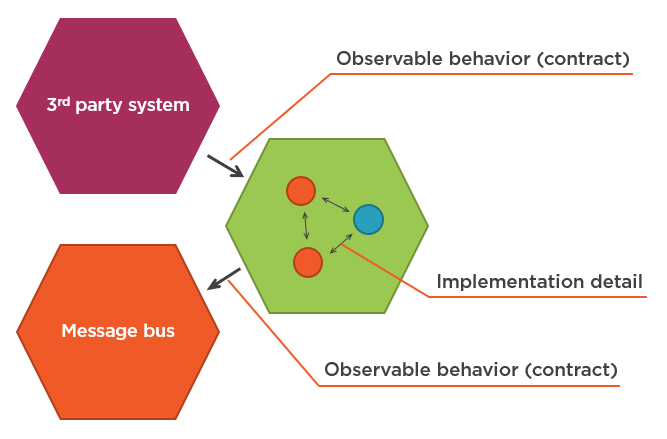
Это свойство межсистемных коммуникаций проистекает из того, как отдельные приложения развиваются вместе. Один из основных принципов такой эволюции – обеспечение обратной совместимости. Независимо от рефакторинга, который вы выполняете внутри своего приложения, паттерн взаимодействия, который оно использует для взаимодействия с внешними приложениями, должен всегда оставаться на месте, чтобы внешние приложения могли его понять. Например, сообщения, отправляемые вашим приложением по шине, должны сохранять свою структуру и так далее.
Использование моков закрепляет контракт взаимодействия между тестируемой системой и зависимостью. Это именно то, что вам нужно при проверке связи между вашей системой и внешними приложениями. И наоборот, использование моков для проверки связи между классами внутри вашей системы связывает ваши тесты с деталями реализации, делая их хрупкими. Внутрисистемные связи соответствуют изменяемым внутрипроцессорным зависимостям:

Итак, лондонская школа ошибается, потому что она поощряет использование моков для всех изменяемых зависимостей и не проводит различия между внутрисистемными (внутрипроцессорными) и межсистемными (внепроцессорными) коммуникациями.
В результате тесты проверяют связь между классами точно так же, как они проверяют связь между вашим приложением и внешними системами. Это неизбирательное использование моков является причиной того, что следование лондонской школе часто приводит к хрупким тестам — тестам, которые связаны с деталями реализации.
Не мокайте все внепроцессорные зависимости
Классическая школа лучше справляется с этим вопросом, потому что она выступает за замену только внепроцессорных зависимостей, таких как служба SMTP, шина сообщений и т. д. Но классическая школа также не идеальна по отношению к межсистемным коммуникациям. Эта школа также поощряет чрезмерное использование моков, хотя и не так сильно, как лондонская школа.
Не все внепроцессорные зависимости следует мокать. Если внепроцессорная зависимость доступна только через ваше приложение, то связь с такой зависимостью не является частью наблюдаемого поведения вашей системы. Внепроцессорная зависимость, которая не может наблюдаться извне, по сути, действует как часть вашего приложения. Связи с такой зависимостью становятся деталями реализации: они не должны оставаться неизменными после рефакторинга и, следовательно, не должны проверяться с помощью моков.

Помните, что требование всегда сохранять схему взаимодействия между вашим приложением и внешними системами проистекает из необходимости поддерживать обратную совместимость. Вы должны поддерживать способ взаимодействия вашего приложения с внешними системами. Это потому, что вы не можете изменять эти внешние системы одновременно с вашим приложением; они могут следовать другому циклу развертывания, или вы можете просто не контролировать их.
Но когда ваше приложение действует как прокси-сервер для внешней системы, и ни один клиент не может получить к ней прямой доступ, требование обратной совместимости исчезает. Теперь вы можете развернуть свое приложение вместе с этой внешней системой, и это не повлияет на клиентов. Схема взаимодействия с такой системой становится деталью реализации.
Хорошим примером здесь является БД приложения: БД, которая используется только вашим приложением. Ни одна внешняя система не имеет доступа к этой БД. Таким образом, вы можете изменить схему взаимодействия между вашей системой и БД приложения любым удобным вам способом, если это не ломает существующую функциональность. Поскольку эта БД полностью скрыта от глаз клиентов, вы даже можете заменить ее совершенно другим механизмом хранения, и никто этого не заметит.
Использование моков для внепроцессорных зависимостей, которые вы полностью контролируете, также приводит к хрупким тестам. Вы не хотите, чтобы ваши тесты становились красными каждый раз, когда вы разбиваете таблицу в БД или изменяете тип одного из параметров в хранимой процедуре. БД и ваше приложение должны рассматриваться как одна система.
Это различие разделяет внепроцессорные зависимости на две подкатегории:
- Управляемые (managed) зависимости — внепроцессорные зависимости, над которыми вы имеете полный контроль. Эти зависимости доступны только через ваше приложение; взаимодействия с ними не видны внешнему миру. Типичным примером является БД приложения. Внешние системы не имеют прямого доступа к вашей БД; они делают это через API, предоставляемый вашим приложением.
- Неуправляемые (unmanaged) зависимости — внепроцессорные зависимости, над которыми у вас нет полного контроля. Взаимодействия с такими зависимостями наблюдаются извне. Примеры — SMTP-сервер и шина сообщений: оба они создают побочные эффекты, видимые для других приложений.
Только неуправляемые зависимости должны быть заменены моками. Используйте реальные экземпляры управляемых зависимостей в тестах.

Резюме
Тестовый двойник — это всеобъемлющий термин, который описывает все виды непригодных к использованию в конечном продукте (non-production-ready), фейковых зависимостей в тестах.
- Существует пять вариантов тестовых двойников — dummy (манекен), стаб, spy (шпион), мок и фейк, которые можно сгруппировать всего в два типа: моки и стабы.
- Spies функционально такие же, как и моки; dummy и фейки выполняют ту же роль, что и стабы.
Различия между моками и стабами:
- Моки помогают имитировать и изучать исходящие взаимодействия: вызовы от SUT к его зависимостям, которые изменяют состояние этих зависимостей.
- Стабы помогают имитировать входящие взаимодействия: для получения входных данных SUT обращается к своим зависимостям.
- Проверка взаимодействия со стабами всегда приводит к хрупким тестам.
- Тестовые двойники, заменяющие команды CQS, являются моками. Тестовые двойники, заменяющие запросы CQS, являются стабами.
Мок-как-инструмент — это класс из библиотеки моков, который вы можете использовать для создания мока-как-тестовый-двойник или стаба.
Внепроцессорные зависимости можно разделить на 2 подкатегории: управляемые и неуправляемые зависимости.
- Управляемые зависимости — это внепроцессорные зависимости, доступные только через ваше приложение. Взаимодействия с управляемыми зависимостями не наблюдаются извне. Типичным примером является БД приложения.
- Неуправляемые зависимости — это внепроцессорные зависимости, к которым имеют доступ другие приложения. Взаимодействия с неуправляемыми зависимостями наблюдаются извне. Типичные примеры — SMTP-сервер и шина сообщений.
- Связь с управляемыми зависимостями — это детали реализации; связь с неуправляемыми зависимостями является частью наблюдаемого поведения вашей системы.
- Используйте реальные экземпляры управляемых зависимостей в интеграционных тестах; замените неуправляемые зависимости моками.
- и
- автоматическое тестирование
- юнит-тесты
- юнит-тестирование
- моки
- стабы
- Тестирование IT-систем
- Программирование
- Анализ и проектирование систем
- Проектирование и рефакторинг
- Тестирование веб-сервисов