Префикс-функция
Определение. Префикс-функцией от строки $s$ называется массив $p$, где $p_i$ равно длине самого большого префикса строки $s_0 s_1 s_2 \ldots s_i$, который также является и суффиксом $i$-того префика (не считая весь $i$-й префикс).
Например, самый большой префикс, который равен суффиксу для строки «aataataa» — это «aataa»; префикс-функция для этой строки равна $[0, 1, 0, 1, 2, 3, 4, 5]$.
Этот алгоритм пока что работает за $O(n^3)$, но позже мы его ускорим.
#Как это поможет решить исходную задачу?
Давайте пока поверим, что мы умеем считать префикс-функцию за линейное от размера строки, и научимся с помощью нее искать подстроку в строке.
Соединим подстроки $s$ и $t$ каким-нибудь символом, который не встречается ни там, ни там — обозначим пусть этот символ # . Посмотрим на префикс-функцию получившейся строки s#t .
Видно, что все места, где значения равны 6 (длине $s$) — это концы вхождений $s$ в текст $t$.
Такой алгоритм (посчитать префикс-функцию от s#t и посмотреть, в каких позициях она равна $|s|$) называется алгоритмом Кнута-Морриса-Пратта.
#Как её быстро считать
Рассмотрим ещё несколько примеров префикс-функций и попытаемся найти закономерности:
Можно заметить следующую особенность: $p_$ максимум на единицу превосходит $p_i$.
Доказательство. Если есть префикс, равный суффиксу строки $s_$, длины $p_$, то, отбросив последний символ, можно получить правильный суффикс для строки $s_$, длина которого будет ровно на единицу меньше.
Попытаемся решить задачу с помощью динамики: найдём формулу для $p_i$ через предыдущие значения.
Заметим, что $p_ = p_i + 1$ в том и только том случае, когда $s_ =s_$. В этом случае мы можем просто обновить $p_$ и пойти дальше.
Например, в строке $\underbracet\overbrace$ выделен максимальный префикс, равный суффиксу: $p_ = 5$. Если следующий символ равен будет равен $t$, то $p_ = p_ + 1 = 6$.
Но что происходит, когда $s_\neq s_$? Пусть следующий символ в этом же примере равен не $t$, а $b$.
- $\implies$ Длина префикса, равного суффиксу новой строки, будет точно меньше 5.
- $\implies$ Помимо того, что искомый новый супрефикс является суффиксом «aabaab», он ещё является префиксом подстроки «aabaa».
- $\implies$ Значит, следующий кандидат на проверку — это значение префикс-функции от «aabaa», то есть $p_4 = 2$, которое мы уже посчитали.
- $\implies$ Если $s_2 = s_$ (т. е. новый символ совпадает с идущим после префикса-кандидата), то $p_ = p_2 + 1 = 2 + 1 = 3$.
В данном случае это действительно так (нужный префикс — «aab»). Но что делать, если, в общем случае, $p_ \neq p_$? Тогда мы проводим такое же рассуждение и получаем нового кандидата, меньшей длины — $p_>$. Если и этот не подошел — аналогично проверяем меньшего, пока этот индекс не станет нулевым.
Асимптотика. В худшем случае этот while может работать $O(n)$ раз за одну итерацию, но в среднем каждый while работает за $O(1)$.
Префикс-функция каждый шаг возрастает максимум на единицу и после каждой итерации while уменьшается хотя бы на единицу. Значит, суммарно операций будет не более $O(n)$.
Префиксы и постфиксы в PHP (и CSS)
Ещё давно я взял практику использовать префиксы и постфиксы в PHP и в CSS. Особенно это актуально, когда что-то выходит за рамки локальной видимости и находится в глобальном пространстве, взять те же модели в Yii.
Префиксы и постфиксы несут основную задачу – сделать сущность максимально уникальной, причём настолько, чтобы её можно было без проблем найти любым текстовым редактором. На сегодняшний день IDE поддерживают отличную вещь – «Find Usages» (поиск использований), но это не всегда помогает, и об этом я напишу чуть ниже.
Именование в стиле Венгерской нотации мне не пришлось по душе. Такой подход мне не нравился ещё со времён C++ / Delphi – я считал его избыточном и не всегда понятным. Мне понравилась реализация БЭМ, но в полной мере я её тоже не использую. Я постарался вычленить и объединить наиболее понравившиеся мне методы, о них и расскажу.
CSS
Все CSS классы я начинаю с префикса «cl_», идентификаторы с префикса «id_». Если класс или идентификатор относится к блоку, добавляю после префикса «b_», если к модулю – «m_». Какие-либо внутренние состояния или мини-блоки я также указываю с префиксами.
.cl_b_promoblock <> #id_m_user_list <> #id_m_order_preview .cl_b_user_info <> .cl_user_list_item .cl_visible <> #id_b_main_menu .cl_main_menu_item.cl_selected <> Таким образом, у меня всегда уникальные и структурно понятные названия. Да и найти такие названия куда проще, если надо, например, провести рефакторинг и посмотреть, где это может отразиться.
Кстати, такой код легче прогнать через сжатие и обфускацию. Причём, не надо никаких анализаторов – ищи регуляркой по префиксам и сжимай. Собственно, поэтому и используются разные префиксы для идентификаторов и классов. Я думаю, статья про сжатие и обфускацию будет интересна аудитории Хабра, постараюсь её оформить, как появится время.
PHP (Yii)
Как-то неправильно, что контроллеры, валидаторы и т.п. имеют дополнительные префиксы и постфиксы, а модели не имеют. Я решил, что ввиду «магии» Yii тяжело будет найти, где используется класс User, а простым поиском по тексту слово User будет встречаться везде, где только можно.
- Wb: идентификатор проекта (сокращение от названия);
- User: собственно, модель;
- Model: означает, что это модель, а не что-то другое.
Под такой шаблон попали также валидаторы (WbExistsByPkValidator, WbCensureValidator) и собственные вспомогательные библиотеки (LArray, LTime, LString), где префикс «L» – сокращение от Library. Что касается библиотек, то можно использовать также и StringLib или ArrayLib, однако моё мнение – префикс «L» ставит их в списке файлов друг за другом, что удобно. К слову, для методов «scope» я также добавляю префиксы, например, ScopePublished() или ScopeLast(int $limit), чтобы отличать их от «обычных» методов.
Использование таких наименований придаёт уникальности, и в случае чего я могу даже без IDE найти все использования того или иного класса. Также я всячески старюсь отойти от использования текстового представления классов и атрибутов, особенно считаю большим злом, когда ссылка на класс генерируется из объединения строк – это нельзя найти ни через «Find Usages», ни через поиск по тексту. Например:
public function actionGetData($object_type)
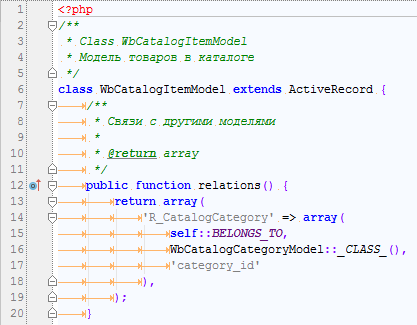
Для именования relations в Yii я также использую специальный префикс – «R_» (сокращение от Relation). Таким образом, при взгляде сразу уже понятно, что это не атрибут модели, а именно связь с другой моделью. Хотя по концепции Yii это преподносится как одно и то же (атрибут модели), всё же я считаю, что это разные вещи. Помимо добавления префикса, я всегда добавляю также и название класса модели. Да, этот подход может и менее красив, зато сух и конкретен – при взгляде на код я сразу же понимаю, что от чего зависит, и откуда взялись данные.
public function relations() < return array( 'R_PriceItems' =>array(self::HAS_MANY, WbCatalogPriceItemModel::CLASS, 'category_id'), 'R_CategoryParent' => array(self::BELONGS_TO, WbCatalogCategoryModel::CLASS, array('parent_id' => 'id'), ) > public function RecalculatePriceItems() < foreach ($this->R_PriceItems as $price_item) < $price_item->price = $price_item->new_price; > > Как можно заметить в коде выше (метод relations), я определяю классы для связанных моделей динамически, а не текстом. Но это возможно только для PHP > 5.5. Если же (а скорей всего так и есть) сервер не поддерживает такую версию PHP, можно расширить ActiveRecord и вместо CLASS использовать метод _CLASS_(). Потом после перехода на PHP > 5.5 можно будет без проблем заменить _CLASS_() на CLASS простым «Find And Replace».
class ActiveRecord extends CActiveRecord < public static function _CLASS_() < return get_called_class(); >> «ЗА» или «ПРОТИВ»
В моём окружении есть сторонники как «ЗА», так и «ПРОТИВ» такого подхода к именованию.
В частности, используют же для приватных свойств и методов префикс «_» ($_items, $_version). Нередки случаи, когда для таблиц в БД указывают префикс проекта, например, wb_catalog_item. Исходный код страниц YouTube повсеместно содержит в HTML и CSS префикс «yt-» (это, скорей всего ещё и для того, чтобы при подключении на сторонних сайтах не было конфликтов).
Против такой схемы именования можно привести то, что эта информация является излишней, и (как бы) не стоит мусорить код префиксами и постфиксами. К тому же, необходимо научить других (и новых) сотрудников разбираться, как и что надо именовать (хотя лично я не вижу в этом проблемы).
Да, префиксы и постфиксы несколько замедляют написание кода, но код пишется один раз, а читается и рефакторится далеко не один. Как по мне, так значительно проще читать код, в котором можно сразу определить по префиксам и регистру, где атрибут модели, где метод, а где scope или relation. Префикс «R_» явно даёт понять, что это связь, а постфикс «Model», что это модель. Например, есть класс WebUser – это компонент (extends CWebUser), а есть класс User – и это уже модель.
И напоследок… В Yii повсеместно используются цепочки вызовов. Например, $category->first_item->store. В данном случае, store – это relation, означающий связь со складом. Но в один прекрасный момент необходимо в таблицу catalog_item добавить новый столбец с названием store. Тут и начинается проблема, потому как при обычном подходе без анализа кода нельзя взять и заменить связь store на что-то другое, чтобы не было конфликта имён. В случае же с использованием префиксов всё решится на уровне «Find And Replace» за 1-2-3 минуты.
Мне хочется услышать от аудитории Хабра именно конструктивного обсуждения такого подхода. Возможно, есть иные варианты решения проблем с неуникальными именами.
Префикс-функция
Здесь и далее считаем, что символы в строках нумеруются с [math]0[/math] .
Определим префикс-функцию от строки [math]s[/math] в позиции [math]i[/math] следующим образом: [math]\pi(s, i) = \max\limits_ \[/math] . Если мы не нашли такого [math]k[/math] , то [math]\pi(s, i)=0[/math] .
Наивный алгоритм
Наивный алгоритм вычисляет префикс-функцию непосредственно по определению, сравнивая префиксы и суффиксы строк. Обозначим длину строки за [math]n[/math] . Будем считать, что префикс-функция хранится в массиве [math] p [/math] .
Псевдокод
int[] prefixFunction(string s): int[] p = int[s.length] fill(p, 0) for i = 0 to s.length - 1 for k = 0 to i - 1 if s[0..k] == s[i - k..i] p[i] = k return p
Пример
Рассмотрим строку [math]abcabcd[/math] , для которой значение префикс-функции равно [math][0,0,0,1,2,3,0][/math] .
| Шаг | Строка | Значение функции |
|---|---|---|
| [math]1[/math] | a | 0 |
| [math]2[/math] | ab | 0 |
| [math]3[/math] | abc | 0 |
| [math]4[/math] | abca | 1 |
| [math]5[/math] | abcab | 2 |
| [math]6[/math] | abcabc | 3 |
| [math]7[/math] | abcabcd | 0 |
Время работы
Всего [math]O(n^2)[/math] итераций цикла, на каждой из который происходит сравнение строк за [math]O(n)[/math] , что дает в итоге [math]O(n^3)[/math] .
Эффективный алгоритм
Вносятся несколько важных замечаний:
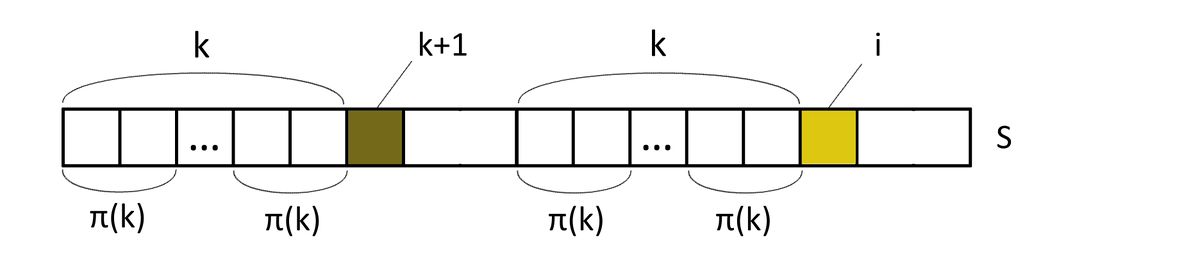
- Заметим, что [math]p[i + 1] \leqslant p[i] + 1[/math] . Чтобы показать это, рассмотрим суффикс,оканчивающийся на позиции [math]i + 1[/math] и имеющий длину [math]p[i + 1][/math] , удалив из него последний символ, мы получим суффикс, оканчивающийся на позиции [math]i[/math] и имеющий длину [math]p[i + 1] — 1[/math] , следовательно неравенство [math]p[i + 1] \gt p[i] + 1[/math] неверно.
- Избавимся от явных сравнений строк. Пусть мы вычислили [math]p[i][/math] , тогда, если [math]s[i + 1] = s[p[i]][/math] , то [math]p[i + 1] = p[i] + 1[/math] . Если окажется, что [math]s[i + 1] \ne s[p[i]][/math] , то нужно попытаться попробовать подстроку меньшей длины. Хотелось бы сразу перейти к такому бордеру наибольшей длины, для этого подберем такое [math]k[/math] , что [math]k = p[i] — 1[/math] . Делаем это следующим образом. За исходное [math]k[/math] необходимо взять [math]p[i — 1][/math] , что следует из первого пункта. В случае, когда символы [math]s[k][/math] и [math]s[i][/math] не совпадают, [math]p[k — 1][/math] — следующее потенциальное наибольшее значение [math]k[/math] , что видно из рисунка. Последнее утверждение верно, пока [math]k\gt 0[/math] , что позволит всегда найти его следующее значение. Если [math]k=0[/math] , то [math]p[i]=1[/math] при [math]s[i] = s[1][/math] , иначе [math]p[i]=0[/math] .
Псевдокод
int[] prefixFunction(string s): p[0] = 0 for i = 1 to s.length - 1 k = p[i - 1] while k > 0 and s[i] != s[k] k = p[k - 1] if s[i] == s[k] k++ p[i] = k return p
Время работы
Время работы алгоритма составит [math]O(n)[/math] . Для доказательства этого нужно заметить, что итоговое количество итераций цикла [math]\mathrm[/math] определяет асимптотику алгоритма. Теперь стоит отметить, что [math]k[/math] увеличивается на каждом шаге не более чем на единицу, значит максимально возможное значение [math]k = n — 1[/math] . Поскольку внутри цикла [math]\mathrm[/math] значение [math]k[/math] лишь уменьшается, получается, что [math]k[/math] не может суммарно уменьшиться больше, чем [math]n-1[/math] раз. Значит цикл [math]\mathrm[/math] в итоге выполнится не более [math]n[/math] раз, что дает итоговую оценку времени алгоритма [math]O(n)[/math] .
Построение префикс-функции по Z-функции
Постановка задачи
Дан массив с корректной Z-функцией для строки [math]s[/math] , получить за [math]O(n)[/math] массив с префикс-функцией для строки [math]s[/math] .
Описание алгоритма
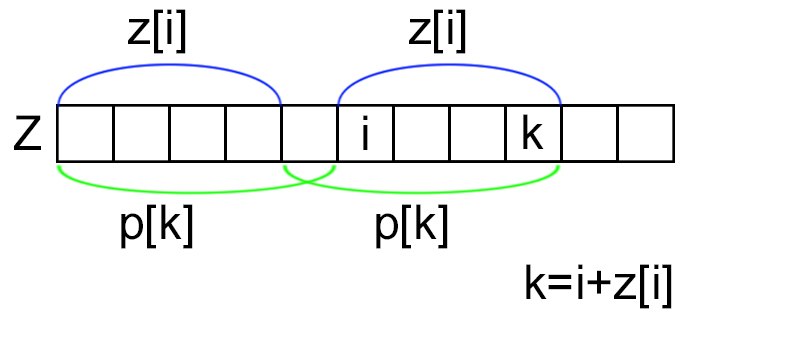
Пусть Z-функция хранится в массиве [math]z[0 \ldots n-1][/math] . Префикс-функцию будем записывать в массив [math]p[0 \ldots n-1][/math] . Заметим, что если [math]z[i] \gt 0, [/math] то для всех элементов с индексом [math]i + j[/math] , где [math]0 \leqslant j \lt z[i] [/math] , значение [math]p[i + j] [/math] будет не меньше, чем длина подстроки с [math] i [/math] по [math] i + j[/math] , что равно [math]j + 1[/math] (как изображено на рисунке).
Также заметим, что если мы уже установили в какую-то позицию значение [math] j [/math] с позиции [math] i [/math] , а потом пытаемся установить значение [math] j’ [/math] c позиции [math] i’ [/math] , причём [math] i \lt i’ [/math] и [math] i + j = i’ + j’ [/math] , то изменение с позиции [math] i’ [/math] только уменьшит значение [math] p[i + j][/math] . Действительно, значение после первого присвоения [math]p[i + j] = j \gt j’ = p[i’ + j’][/math] . В итоге получаем алгоритм: идем слева направо по массиву [math]z[/math] и, находясь на позиции [math]i[/math] , пытаемся записать в [math]p[/math] от позиции [math]i + z[i] — 1 [/math] до [math]i[/math] значение [math] j + 1,[/math] где [math]j[/math] пробегает все значения [math] 0 \dots z[i] — 1[/math] , пока не наткнемся на уже инициализированный элемент. Слева от него все значения тоже нет смысла обновлять, поэтому прерываем эту итерацию.
Убедимся, что алгоритм работает за линейное время (см. псевдокод). Каждый элемент устанавливается ровно один раз. Дальше на нем может случиться только [math]\mathrm[/math] . Поэтому в итоге внутренний цикл суммарно отработает за количество установленных значений и количество [math]\mathrm[/math] . Количество установленных значений — [math] n[/math] . А число [math]\mathrm[/math] тоже будет не больше [math]n[/math] , так как каждый [math]\mathrm[/math] переводит внешний цикл на следующую итерацию, откуда получаем итоговую асимптотику [math]O(n)[/math] .
Псевдокод
int[] buildPrefixFunctionFromZFunction(int[] z): int[] p = int[z.length] fill(p, 0) for i = 1 to z.length - 1 for j = z[i] - 1 downto 0 if p[i + j] > 0 break else p[i + j] = j + 1 return p
Построение строки по префикс-функции
Постановка задачи
Восстановить строку по префикс-функции за [math]O(n)[/math] , считая алфавит неограниченным.
Описание алгоритма
Пусть в массиве [math]p[/math] хранятся значения префикс-функции, в [math]s[/math] будет записан ответ. Пойдем по массиву [math]p[/math] слева направо.
Пусть мы хотим узнать значение [math]s[i][/math] . Для этого посмотрим на значение [math]p[i][/math] : если [math]p[i] =0[/math] , тогда в [math]s[i][/math] запишем новый символ, иначе [math]s[i] = s[p[i] — 1][/math] . Обратим внимание, что [math]s[p[i] — 1][/math] нам уже известно, так как [math]p[i] — 1 \lt i[/math] .
Реализация
string buildFromPrefix(int[] p): s = "" for i = 0 to p.length - 1 if p[i] == 0 s += new character else s += s[p[i] - 1] return s
Доказательство корректности алгоритма
Докажем, что если нам дали корректную префикс-функцию, то наш алгоритм построит строку с такой же префикс-функцией. Также заметим, что строк с такой префикс-функцией может быть много, и алгоритм строит только одну из них.
Пусть [math]p[/math] — данная префикс-функция, строку [math]s[/math] построил наш алгоритм, [math] q [/math] — массив значений префикс-функции для [math]s[/math] .
Докажем корректность индукцией по длине массива префикс-функции полученной строки. Для начала заметим, что на предыдущие значения массива [math] q [/math] прибавление нового символа не влияет, так как при подсчёте префикс-функции на [math] i [/math] -ой позиции рассматриваются символы на позициях не больше [math] i [/math] . Поэтому достаточно показать, что очередное значение префикс-функции будет вычислено правильно.
- База очевидна для строки длины [math]1[/math] .
- Переход: пусть до [math]n[/math] -ой позиции мы построили строку, что [math]p[0 \ldots n — 1] = q[0 \ldots n — 1][/math] . Возможны два случая:
- [math]p[n] = 0[/math] . Тогда мы добавляем новый символ, поэтому [math]q[n][/math] тоже будет равно [math]0[/math] .
- [math]p[n] \gt 0[/math] . Бордер строки [math] s[0 \ldots n — 1] [/math] имеет длину [math] p[n-1] = q[n-1] [/math] . Поэтому если дописать к строке [math] s [/math] символ [math] s[q[n] — 1] [/math] , то бордер нашей новой строки [math] s[0 \ldots n] [/math] станет равен [math] p[n] [/math] , как можно увидеть на рисунке.
Критерий корректности значений префикс-функции
Задача: Дан массив значений префикс-функции некоторой строки [math]s[/math] , необходимо проверить, корректен ли он за [math]O(|s|)[/math] . Так же узнать размер минимального алфавита, при котором он корректен. Решение
Если выполняется неравенство [math]0 \leqslant p[i + 1] \leqslant p[i] + 1[/math] , то мы можем построить строку из алгоритма выше, значит префикс-функция корректна.
Найдем минимальный алфавит, при котором префикс-функция корректна. Если значение префикс-функции в текущей ячейке больше нуля, буква известна и алфавит не нуждается в добавлении новой буквы. Иначе, необходимо исключить все ранее известные буквы, возвращаясь и проверяя для меньших префиксов. Если все уже известные буквы использованы, понятно что, необходимо добавить новую букву.
Доказательство корректности
Докажем, что найденнный выше алфавит минимален от противного. Допустим, существует строка, использующая алфавит меньшей мощности. Рассмотрим первое вхождение буквы, которая есть в нашем алфавите, а в их отсутствует. Понятно, что для этого символа префикс-функция равна 0, т.к. мы добавили новую букву. Пройдемся циклом [math]\mathrm[/math] по подпрефиксам. Т.к. в меньшем решении буква не новая, то она увеличит подпрефикс и префикс-функция в новой строке будет отличаться от нуля в этом символе, а должна равняться нулю. Противоречие, следовательно не существует алфаивта меньшей мощности, чем найденный алгоритмом выше.
Псевдокод
bool is_correct(int[] p): for i = 0 to p.length - 1 if i > 0 && p[i] > p[i - 1] + 1 || p[i] < 0 return false return true
int minimal_alphabet(int[] p): c = 1 s[0] = 0 for i = 1 to p.length - 1 if p[i] == 0 fill(used, false) k = p[i - 1] while k > 0 used[s[k]] = true k = p[k - 1] s[i] = -1 for j = 1 to c if !used[j] s[i] = j; break if s[i] == -1 s[i] = c++ else s[i] = s[p[i] - 1] return c
См. также
- Z-функция
- Алгоритм Кнута-Морриса-Пратта
Источники информации
- Википедия — Префикс-функция
- MAXimal :: algo :: Префикс-функция
- Кормен Т., Лейзерсон Ч., Ривест Р. Алгоритмы: построение и анализ. — 2-е изд. — М.: Издательский дом «Вильямс», 2007. — С. 1296 ISBN 978-5-8459-0857-5
- Алгоритмы и структуры данных
- Поиск подстроки в строке
- Точный поиск
в чем отличия между аффиксами, суффиксами и префиксами ?
Аффикс — морфема, которая присоединяется к корню и служит для образования слов.
Суффиксы и префиксы являются аффиксами: префикс идёт перед корнем, суффикс — после.Это же просто. Аффикс — общее слова для суффикса, префикса и инфикса. Суффикс — морфема, стоящая после корня в слове: чита-л (суффикс прошедшего времени) , префикс -(или приставка по русски) морфема, находящаяся перед корнем слова: про- читать.
Похожие вопросы