Реактивное программирование — Reactive programming
Реактивное программирование было впервые разработано Гленном Вадденом в 1986 году как язык программирования (VTScript) в системе диспетчерского управления и сбор данных (SCADA ).
В вычислениях, реактивное программирование — это декларативная парадигма программирования, связанная с потоками данных и распространение изменений. С помощью этой парадигмы можно с легкостью выразить статические (например, массивы) или динамические (например, источники событий) потоки данных, а также сообщить, что предполагаемая зависимость в связанной модели выполнения существует, что облегчает автоматическое распространение измененных данных. поток.
Например, в настройке императивного программирования a: = b + c будет означать, что a < \ displaystyle a>присваивается результат b + c в момент вычисления выражения, а затем значения b и c можно изменить без влияния на значение a . С другой стороны, при реактивном программировании значение a автоматически обновляется всякий раз, когда значения b или c изменение без необходимости повторного выполнения инструкции программе a: = b + c для определения присвоенного в настоящее время значения a.
Другим примером является язык описания оборудования, такой как Verilog, где реактивное программирование позволяет моделировать изменения по мере их распространения по схемам.
Реактивное программирование было предложено как способ упростить создание интерактивных пользовательских интерфейсов и системной анимации в режиме, близком к реальному времени.
Например, в модель – представление – контроллер ( MVC), реактивное программирование может облегчить изменения в базовой модели, которые автоматически отражаются в связанном представлении.
- 1 Подходы к созданию языков реактивного программирования
- 2 Модели и семантика программирования
- 3 Методы реализации и проблемы
- 3.1 Суть реализаций
- 3.1.1 Алгоритмы распространения изменений
- 3.1.2 Что подтолкнуть?
- 3.2.1 Сбои
- 3.2.2 Циклические зависимости
- 3.2.3 Взаимодействие с изменяемым состоянием
- 3.2.4 Динамическое обновление графика зависимостей
- 4.1 Степени ясности
- 4.2 Статическое или динамическое
- 4.3 Реактивное программирование высшего порядка
- 4.4 Дифференциация потоков данных
- 4.5 Модели оценки реактивного программирования
- 4.5.1 Сходства с шаблоном наблюдателя
- 5.1 Императив
- 5.2 Объектно-ориентированный
- 5.3 Функциональный
- 5.4 Основанный на правилах
Подходы к созданию реактивных языков программирования
При создании реактивных языков программирования используются несколько популярных подходов. Спецификация выделенных языков, специфичных для различных ограничений домена. Такие ограничения обычно характеризуются описанием встроенных вычислений или оборудования в реальном времени. Другой подход включает в себя спецификацию языков общего назначения, которые включают поддержку реактивности. Другие подходы сформулированы в определении и использовании программных библиотек или встроенных предметно-ориентированных языков, которые обеспечивают реактивность наряду с языком программирования или поверх него. Спецификация и использование этих различных подходов приводит к компромиссу языковых возможностей. В целом, чем более ограничен язык, тем больше связанные с ним компиляторы и инструменты анализа могут информировать разработчиков (например, при выполнении анализа того, могут ли программы выполняться в реальном времени). Функциональные компромиссы в специфичности могут привести к ухудшению общей применимости языка.
Модели и семантика программирования
Семейство реактивного программирования управляется множеством моделей и семантики. Мы можем условно разделить их по следующим параметрам:
- Синхронность: является ли лежащая в основе модель времени синхронным или асинхронным?
- Детерминизм: детерминированный или недетерминированный как в процессе оценки, так и в результатах
- Процесс обновления: обратные вызовы по сравнению с потоком данных по сравнению с субъектом
Методы и проблемы реализации
Суть реализаций
Среда выполнения реактивного языка программирования представлена графиком, который определяет зависимости между задействованные реактивные значения. В таком графе узлы представляют собой процесс вычисления, а отношения зависимости модели ребер. Такая среда выполнения использует упомянутый граф, чтобы отслеживать различные вычисления, которые должны быть выполнены заново, как только задействованный ввод изменяет значение.
Алгоритмы распространения изменений
Наиболее распространенные подходы к распространению данных:
- Извлечение : Потребитель значения фактически является проактивным, поскольку он регулярно запрашивает значения у наблюдаемого источника. и реагирует всякий раз, когда доступно соответствующее значение. Эта практика регулярной проверки событий или изменений значений обычно называется опросом.
- Push : Потребитель значения получает значение из источника всякий раз, когда значение становится доступным. Эти значения самодостаточны, например они содержат всю необходимую информацию, и у потребителя нет необходимости запрашивать дополнительную информацию.
- Push-pull : Потребитель значения получает уведомление об изменении, которое является кратким описанием изменения, например «какое-то значение изменено» — это нажимная часть. Однако уведомление не содержит всей необходимой информации (т.е. не содержит фактических значений), поэтому потребитель должен запросить у источника дополнительную информацию (конкретное значение) после того, как он получит уведомление — это извлекающая часть. Этот метод обычно используется, когда существует большой объем данных, которые могут быть потенциально интересны потребителям. Таким образом, чтобы уменьшить пропускную способность и задержку, отправляются только легкие уведомления; а затем те потребители, которым требуется дополнительная информация, будут запрашивать эту конкретную информацию. У этого подхода также есть недостаток, заключающийся в том, что источник может быть перегружен множеством запросов на дополнительную информацию после отправки уведомления.
Что отправлять?
На уровне реализации реакция на событие состоит из распространения информации на графике, которая характеризует наличие изменения. Следовательно, вычисления, на которые влияет такое изменение, затем становятся устаревшими и должны быть помечены для повторного выполнения. Такие вычисления обычно характеризуются переходным замыканием изменения в ассоциированном с ним источнике. Распространение изменений может затем привести к обновлению значения стоков графа.
Информация, распространяемая графиком, может состоять из полного состояния узла, то есть результата вычислений задействованного узла. В таких случаях предыдущий вывод узла игнорируется. Другой метод включает в себя распространение дельты, то есть постепенное распространение изменений. В этом случае информация распространяется по ребрам графа, которые состоят только из дельт, описывающих, как был изменен предыдущий узел. Этот подход особенно важен, когда узлы содержат большие объемы данных о состоянии, которые в противном случае было бы дорого пересчитывать с нуля.
Дельта-распространение — это, по сути, оптимизация, которая была тщательно изучена с помощью дисциплины инкрементных вычислений, подход которой требует удовлетворения во время выполнения, включая проблему обновления представления. Эта проблема, как известно, характеризуется использованием сущностей базы данных, которые отвечают за поддержку изменяющихся представлений данных.
Другой распространенной оптимизацией является использование унарного накопления изменений и пакетного распространения. Такое решение может быть более быстрым, поскольку оно сокращает обмен данными между задействованными узлами. Затем можно использовать стратегии оптимизации, которые определяют характер изменений, содержащихся внутри, и вносят соответствующие изменения. например два изменения в пакете могут отменять друг друга и, таким образом, просто игнорироваться. Еще один доступный подход описан как распространение уведомления о недействительности. Этот подход заставляет узлы с недопустимыми входными данными извлекать обновления, что приводит к обновлению их собственных выходных данных.
Существует два основных способа построения графа зависимостей:
- Граф зависимостей поддерживается неявно внутри цикла событий. Регистрация явных обратных вызовов приводит к созданию неявных зависимостей. Следовательно, инверсия управления, которая вызывается обратным вызовом, остается на месте. Однако выполнение функций обратного вызова (т.е. возврат значения состояния вместо значения единицы) требует, чтобы такие обратные вызовы стали композиционными.
- График зависимостей зависит от программы и создается программистом. Это облегчает адресацию инверсии управления обратным вызовом двумя способами: либо граф указывается явно (обычно с использованием предметно-ориентированного языка (DSL), который может быть встроен), либо граф неявно определяется с помощью выражение и генерация с использованием эффективного архетипического языка.
Проблемы реализации в реактивном программировании
Сбои
При распространении изменений можно выбрать порядок распространения таким образом, чтобы значение выражения было не естественное следствие исходной программы. Мы можем легко проиллюстрировать это на примере. Предположим, секунд — это реактивное значение, которое изменяется каждую секунду, чтобы представить текущее время (в секундах). Рассмотрим это выражение:
t = секунды + 1 g = (t>секунды)
Поскольку t всегда должно быть больше, чем секунд , это выражение всегда должно оценить истинное значение. К сожалению, это может зависеть от порядка оценки. При изменении секунд необходимо обновить два выражения: секунд + 1 и условное. Если первое выполняется раньше второго, то этот инвариант будет сохраняться. Если, однако, условие обновляется первым, используя старое значение t и новое значение секунд , тогда выражение будет оцениваться как ложное значение. Это называется глюк.
Некоторые реактивные языки не содержат сбоев и подтверждают это свойство. Обычно это достигается путем топологической сортировки выражений и обновления значений в топологическом порядке. Однако это может иметь последствия для производительности, например задержку доставки значений (из-за порядка распространения). Поэтому в некоторых случаях реактивные языки допускают сбои, и разработчики должны знать о возможности того, что значения могут временно не соответствовать исходному тексту программы и что некоторые выражения могут оцениваться несколько раз (например, t>секунды может оцениваться дважды: один раз при поступлении нового значения секунд и еще раз при обновлении t ).
Циклические зависимости
Топологическая сортировка зависимостей зависит от того, является ли граф зависимостей направленным ациклическим графом (DAG). На практике программа может определять граф зависимостей с циклами. Обычно языки реактивного программирования ожидают, что такие циклы будут «прерваны» путем размещения некоторого элемента вдоль «заднего края», чтобы разрешить завершение реактивного обновления. Как правило, языки предоставляют такой оператор, как delay , который используется механизмом обновления для этой цели, поскольку delay подразумевает, что последующее должно быть оценено на «следующем временном шаге» (позволяя текущую оценку прекратить).
Взаимодействие с изменяемым состоянием
Реактивные языки обычно предполагают, что их выражения чисто функциональны. Это позволяет механизму обновления выбирать разные порядки для выполнения обновлений и оставлять конкретный порядок неуказанным (тем самым обеспечивая оптимизацию). Однако, когда реактивный язык встроен в язык программирования с состоянием, программисты могут выполнять изменяемые операции. Как сделать это взаимодействие гладким, остается открытой проблемой.
В некоторых случаях возможны принципиальные частичные решения. Два таких решения включают:
- Язык может предлагать понятие «изменяемая ячейка». Изменяемая ячейка — это ячейка, о которой знает система реактивного обновления, поэтому изменения, внесенные в ячейку, распространяются на остальную часть реактивной программы. Это позволяет нереактивной части программы выполнять традиционную мутацию, в то же время позволяя реактивному коду узнавать об этом обновлении и реагировать на него, таким образом поддерживая согласованность отношений между значениями в программе. Примером реактивного языка, который предоставляет такую ячейку, является FrTime.
- Правильно инкапсулированные объектно-ориентированные библиотеки предлагают инкапсулированное понятие состояния. В принципе, таким образом, такая библиотека может беспрепятственно взаимодействовать с реактивной частью языка. Например, обратные вызовы могут быть установлены в геттерах объектно-ориентированной библиотеки для уведомления механизма реактивного обновления об изменениях состояния, а изменения в реактивном компоненте могут быть переданы объектно-ориентированной библиотеке через геттеры. Такую стратегию использует FrTime.
Динамическое обновление графа зависимостей
В некоторых реактивных языках граф зависимостей статичен, то есть граф фиксируется на протяжении всего выполнения программы. В других языках граф может быть динамическим, то есть он может изменяться по мере выполнения программы. В качестве простого примера рассмотрим этот иллюстративный пример (где секунд — реактивное значение):
t = if ((seconds mod 2) == 0): секунды + 1 else: секунды - 1 end t + 1
Каждую секунду значение этого выражения изменяется на другое реактивное выражение, от которого затем зависит t + 1 . Поэтому график зависимостей обновляется каждую секунду.
Разрешение динамического обновления зависимостей обеспечивает значительную выразительную мощность (например, динамические зависимости обычно возникают в программах графического интерфейса пользователя (GUI)). Однако механизм реактивного обновления должен решить, восстанавливать ли выражения каждый раз или оставить узел выражения созданным, но неактивным; в последнем случае убедитесь, что они не участвуют в вычислениях, когда они не должны быть активными.
Концепции
Степени явности
Реактивные языки программирования могут варьироваться от очень явных, где потоки данных настраиваются с помощью стрелок, до неявных, где потоки данных происходят из языковые конструкции, похожие на конструкции императивного или функционального программирования. Например, в неявно поднятом функциональном реактивном программировании (FRP) вызов функции может неявно вызывать создание узла в графе потока данных. Библиотеки реактивного программирования для динамических языков (например, библиотеки Lisp «Cells» и Python «Trellis») могут создавать граф зависимостей на основе анализа значений, считываемых во время выполнения функции, во время выполнения, что позволяет спецификациям потока данных быть как неявными, так и динамическими.
Иногда термин реактивное программирование относится к архитектурному уровню разработки программного обеспечения, где отдельные узлы в графе потока данных представляют собой обычные программы, которые взаимодействуют друг с другом.
Статическое или динамическое
Реактивное программирование может быть чисто статическим, если потоки данных настроены статически, или динамическим, когда потоки данных могут изменяться во время выполнения программы.
Использование переключателей данных в графе потока данных может в некоторой степени сделать статический граф потока данных динамическим и слегка размыть различия. Однако истинное динамическое реактивное программирование может использовать императивное программирование для восстановления графа потока данных.
Реактивное программирование высшего порядка
Можно сказать, что реактивное программирование относится к более высокому порядку, если оно поддерживает идею о том, что потоки данных могут использоваться для построения других потоков данных. То есть результирующее значение из потока данных представляет собой другой граф потока данных, который выполняется с использованием той же модели оценки, что и первый.
Дифференциация потока данных
В идеале все изменения данных распространяются мгновенно, но на практике этого нельзя гарантировать. Вместо этого может потребоваться дать разным частям графа потока данных разные приоритеты оценки. Это можно назвать дифференцированным реактивным программированием .
. Например, в текстовом процессоре маркировка орфографических ошибок не обязательно должна полностью синхронизироваться с вставкой символов. Здесь потенциально можно использовать дифференцированное реактивное программирование, чтобы придать программе проверки орфографии более низкий приоритет, что позволяет отложить ее выполнение, сохраняя при этом другие потоки данных мгновенными.
Однако такое различие вносит дополнительную сложность в конструкцию. Например, решение о том, как определять различные области потока данных и как обрабатывать передачу событий между различными областями потока данных.
Модели оценки реактивного программирования
Оценка реактивных программ не обязательно основана на том, как оцениваются языки программирования на основе стека. Вместо этого, когда некоторые данные изменены, изменение распространяется на все данные, которые частично или полностью получены из данных, которые были изменены. Это распространение изменений может быть достигнуто несколькими способами, из которых, возможно, наиболее естественным способом является схема недействительности / ленивого повторного подтверждения.
Может быть проблематично просто наивно распространять изменение с использованием стека из-за потенциальной экспоненциальной сложности обновления, если структура данных имеет определенную форму. Одна такая форма может быть описана как «повторяющаяся форма ромбов» и имеет следующую структуру: A n→Bn→An + 1, A n→Cn→An + 1, где n = 1,2. Эту проблему можно преодолеть, распространяя аннулирование только тогда, когда некоторые данные еще не признаны недействительными, и позже повторно проверяйте данные, когда это необходимо, используя ленивую оценку.
. Одна неотъемлемая проблема для реактивного программирования заключается в том, что большинство вычислений, которые будут оцениваться и забытые в обычном языке программирования, должны быть представлены в памяти как структуры данных. Это потенциально может сделать реактивное программирование очень затратным по памяти. Однако исследование того, что называется понижением, потенциально могло бы преодолеть эту проблему.
С другой стороны, реактивное программирование — это форма того, что можно было бы описать как «явный параллелизм», и поэтому оно может быть полезным для использования мощности параллельного оборудования.
Сходства с шаблоном наблюдателя
Реактивное программирование имеет принципиальное сходство с шаблоном наблюдателя , обычно используемым в объектно-ориентированном программировании. Однако интеграция концепций потока данных в язык программирования упростит их выражение и, следовательно, может увеличить степень детализации графа потока данных. Например, шаблон наблюдателя обычно описывает потоки данных между целыми объектами / классами, тогда как объектно-ориентированное реактивное программирование может быть нацелено на члены объектов / классов.
Подходы
Императив
Можно объединить реактивное программирование с обычным императивным программированием. В такой парадигме императивные программы работают с реактивными структурами данных. Такая установка аналогична; однако, в то время как императивное программирование с ограничениями управляет двунаправленными ограничениями, реактивное императивное программирование управляет односторонними ограничениями потока данных.
Объектно-ориентированное
Объектно-ориентированное реактивное программирование (OORP) — это комбинация объектно-ориентированного программирования и реактивного программирования. Возможно, наиболее естественный способ создать такую комбинацию заключается в следующем: вместо методов и полей у объектов есть реакции, которые автоматически переоцениваются, когда другие реакции, от которых они зависят, были изменены.
Если язык OORP поддерживает его императивные методы, он также подпадал бы под категорию императивного реактивного программирования.
Функциональный
На основе правил
Относительно новая категория языков программирования использует ограничения (правила) в качестве основной концепции программирования. Он состоит из реакций на события, которые удовлетворяют все ограничения. Это не только облегчает реакции, основанные на событиях, но и делает реактивные программы инструментом правильности программного обеспечения. Примером языка реактивного программирования на основе правил является Ampersand, который основан на алгебре отношений.
См. Также
- Реактивные расширения, API для реализации реактивного программирования с потоками, наблюдаемыми объектами и операторами с несколькими языками. реализации, включая RxJs, RxJava, RxPy и RxSwift.
- Elm (язык программирования) Реактивная композиция веб-интерфейса пользователя.
- Реактивные потоки, стандарт JVM для обработки асинхронных потоков с неблокирующим противодавлением
- Наблюдаемое, наблюдаемое в реактивном программировании.
Ссылки
- ^«О трехграннике». VTScada от Трехгранного. Проверено 2020-10-20.
- ^«SCADA Scripting Language». VTScada от Трехгранного. Проверено 20 октября 2020 г.
- ^Trellis, Модель-представление-контроллер и шаблон наблюдателя, Tele community.
- ^«Встраивание динамического потока данных в язык вызова по значению». cs.brown.edu. Проверено 9 октября 2016 г.
- ^«Пересечение границ состояний: адаптация объектно-ориентированных структур к функциональным реактивным языкам». cs.brown.edu. Проверено 9 октября 2016 г.
- ^«Реактивное программирование — Искусство обслуживания | Руководство по управлению ИТ». theartofservice.com. Проверено 2 июля 2016.
- ^Берчетт, Кимберли; Купер, Грегори Х; Кришнамурти, Шрирам, «Понижение: метод статической оптимизации для прозрачной функциональной реактивности», Труды симпозиума ACM SIGPLAN 2007 года по частичной оценке и манипулированию программами на основе семантики (PDF), стр. 71–80.
- ^Деметреску, Камил; Финокки, Ирэн; Рибичини, Андреа, «Реактивное императивное программирование с ограничениями потока данных», Труды международной конференции ACM 2011 года по системным языкам и приложениям объектно-ориентированного программирования, стр. 407–26.
- ^Йостен, Стеф (2018), «Алгебра отношений как язык программирования с использованием компилятора Ampersand», Журнал логических и алгебраических методов программирования, 100, стр. 113–29, doi : 10.1016 / j. jlamp.2018.04.002.
Внешние ссылки
- Обзор реактивного программирования Статья Э. Байномугиши, А. Ломбида Карретона, Т. Ван Катсема, С. Мостинкса и В. Де Мойтера, в которой исследуются и обеспечивает систематизацию существующих подходов к реактивному программированию.
- Проект MIMOSA INRIA — ENSMP, общий сайт о реактивном программировании.
- Эксперименты с ячейками Демонстрация простого приложения реактивного программирования на Лиспе с использованием Библиотека ячеек
- REScala Реактивное программирование для объектно-ориентированных приложений.
- Устарел шаблон наблюдателя A 2010 статья Инго Майера, Тиарка Ромпфа и Мартина Одерски, описывающая структуру реактивного программирования для языка программирования Scala.
- Устарение шаблона наблюдателя с помощью Scala.React Статья Инго * RxJS, библиотека Reactive Extensions для «составления асинхронных [. ] программ с использованием наблюдаемых последовательностей»
Реактивность в программировании
Как устроены системы, которые обновляются автоматически при изменении состояния приложения.
Время чтения: 7 мин
Открыть/закрыть навигацию по статье
- Кратко
- Что такое реактивность?
- Типы реактивности
- Push-реактивность
- Pull реактивность
Обновлено 13 октября 2022
Кратко
Реактивность – это способ автоматически обновлять систему в зависимости от изменения потока данных.
Поток данных – любая последовательность событий из любого источника, упорядоченная во времени. Например, в кейлогере — приложении, которое записывает нажатие клавиш на клавиатуре, потоком данных будут сигналы нажатия клавиш.
Реактивное программирование – парадигма в программировании, в которой программа больше сосредоточена на управлении потоками данных, таким образом описывая взаимосвязи между ними.
Что такое реактивность?
Давайте вспомним, как пользователь представляет себе работу с интерфейсом. Мы ожидаем, что интерфейс будет мгновенно реагировать на наши действия. Начали вводить текст, он сразу же появляется в поле. Нажали на кнопку, форма тут же изменилась, появились лоадеры, а затем выпрыгнуло радостное сообщение об успехе. С точки зрения пользователя реактивность – это мгновенная реакция на его действия.
Для разработчика этот термин имеет немного другое значение. Когда речь заходит о реактивности, фокус смещается на данные. Для примера напишем код, чтобы сложить два числа:
let a = 3let b = 4 const sum = a + b console.log(sum)// 7let a = 3 let b = 4 const sum = a + b console.log(sum) // 7В переменной sum теперь хранится сумма чисел, и мы знаем, что она никогда не изменится. Если изменить значения переменных a и b после сложения, это уже не повлияет на результат:
// . продолжение предыдущего примера // Меняем значения слагаемыхa = 10b = 8 console.log(sum)// Все еще 7// . продолжение предыдущего примера // Меняем значения слагаемых a = 10 b = 8 console.log(sum) // Все еще 7Чтобы получить новую сумму, нужно заново сложить эти числа. Кажется, что все логично, но что, если эти числа вводит пользователь, и они могут меняться? В таком случае было бы удобнее, если бы программа могла самостоятельно обновлять значение.
// ☝️ это псевдокод, настоящий код так не работает!let $a = 3let $b = 4 const $sum = a + bconsole.log($sum)// 7 $a = 2$b = 9console.log($sum)// 11 $a = -4console.log($sum)// 5// ☝️ это псевдокод, настоящий код так не работает! let $a = 3 let $b = 4 const $sum = a + b console.log($sum) // 7 $a = 2 $b = 9 console.log($sum) // 11 $a = -4 console.log($sum) // 5Пример выше ненастоящий, он не будет работать таким образом, но он даёт возможность понять, какую проблему может решать реактивность.
Во фронтенде мы можем связать любое изменение в интерфейсе с изменениями данных внутри программы. Реактивность с точки зрения фреймворков – это обновление интерфейса на основе изменений состояния.
В реактивности данные часто представляются в виде потока – последовательности событий, упорядоченной по времени.
Поток данных можно начать обрабатывать в любой момент времени, и все новые события могут быть обработаны. Таким образом, реактивность – это удобный способ синхронизировать данные, например, с интерфейсом, который видит пользователь. Реактивность помогает сосредоточиться на данных, как они связаны между собой, что гораздо ближе к бизнес-логике.
Типы реактивности
Основная идея реактивности строится на паттерне «Наблюдатель» (Observer). Это поведенческий паттерн проектирования, который создаёт механизм подписки, позволяющий другим следить и реагировать на события, происходящие в источнике. А вот в какой момент подписчики узнают об обновлениях, зависит от типа реактивности. Она бывает двух типов: push и pull.
Push-реактивность
Когда в реактивной системе по методу push происходит изменение, она самостоятельно проталкивает (от англ. push – «толкать») это изменение всем подписчикам. При таком типе реактивности все подписчики будут получать актуальные изменения сразу, как только они произошли.
Если мы подписываемся на событие (например, клик), то браузер сразу же уведомит всех подписчиков, когда оно случится.
document.addEventListener('click', () => console.log('Я среагировал на клик!')>)document.addEventListener('click', () => console.log('Я среагировал на клик!') >)В реальном мире можно подписаться на уведомления в приложении. Когда случится обновление, мы получим на телефон push-уведомление.
В экосистеме JavaScript самый популярный способ использовать push-реактивность — это использовать библиотеку RxJs.
// создаем источникconst $clicks = Rx.Observable.fromEvent(document, 'click') $clicks.subscribe(event => console.log('Я среагировал на клик реактивно!')>)// создаем источник const $clicks = Rx.Observable.fromEvent(document, 'click') $clicks.subscribe(event => console.log('Я среагировал на клик реактивно!') >)Недостатком push-реактивности могут быть повторяющиеся вычисления, так как при изменении данных все подписчики могут заново проделывать свою работу с этими данными. Это может быть проблемой при частых обновлениях, когда система может быть просто завалена большим потоком данных, а все подписчики без конца делают вычисления.
Предположим, что есть приложение-дашборд, на котором выводится актуальная информация с графиками и изменениями. Страница может состоять из множества различных блоков, и каждому нужна информация. Когда данные приходят непрерывно, вся страница будет постоянно обновляться в разных местах. Одни вычисления могут быть сложнее и дольше других, из-за чего в очереди будут скапливаться новые данные, которые нужно посчитать.
В JavaScript-коде, в котором используются библиотеки для реактивности, часто можно встретить обозначения переменных через знак доллара $, как в примере выше. Таким образом переменной дают специальный префикс, показывая, что в ней находится поток (stream) и на него можно подписаться. Вторым вариантом может быть добавление в конце буквы S: clicks S = Rx . Observable . from Event ( . . . ) .
Pull реактивность
Реактивность по методу pull работает противоположно push-реактивности. Вычисления, вызванные изменением данных в источнике, здесь откладываются до тех пор, пока не будут нужны. При таком типе реактивности подписчики вытянут (от англ. «pull» – тянуть) новые данные, только когда обновится вся система.
Примером из реальной жизни может быть паттерн pull-to-refresh из мобильных приложений. Например, в Twitter пользователь может потянуть контент с верхнего края немного вниз, а затем отпустить. Такое действие заставит ленту твитов обновиться, и пользователь сможет увидеть актуальные данные. При push-подходе лента обновлялась бы каждый раз самостоятельно, как только появляется новый твит.
Pull-механику редко можно встретить в библиотеках, потому часто она лишь частично присутствует в некоторых местах, например в MobX.
Недостатком pull-подхода являются проблемы с производительностью — каждый раз обновлять всю систему, чтобы уведомить подписчиков о новых данных, может быть затратным.
Реактивное программирование
Идеи реактивности в итоге привели к появлению новой парадигмы, которая базируется на асинхронном управлении потоками данных. Хотя ранее уже было сказано, что подписки на события в браузере тоже являются реактивной моделью, реактивное программирование возводит эти идеи в абсолют. Это значит, что потоки данных можно создавать из чего угодно и как угодно ими управлять: скрещивать, трансформировать, фильтровать и так далее. Например, в приложении, написанном с использованием подхода MVC, с помощью реактивного программирования можно создать автоматическое отражение изменений из Model во View, и наоборот, из View в Model.
Реактивное программирование помогает абстрагироваться от описания действий в коде напрямую и сосредоточиться на взаимосвязи данных. Оно создано, чтобы упростить создание программ с большим количеством связей.
В современном фронтенде можно встретить сложные клиентские приложения, где изменение значений в полях ведёт к целому ряду обновлений интерфейса. Реактивное программирование может облегчить создание таких систем. Существует даже целый манифест Реактивных Систем, описывающий, как должна себя вести реактивная система.
Само по себе реактивное программирование редко встречается в чистом виде. Часто оно объединено с другими парадигмами. Так появились такие смешения, как императивное реактивное программирование, объектно-ориентированное реактивное программирование и функциональное реактивное программирование. Последнее наиболее популярно, а язык Elm считается одним из главных его представителей.
Реактивное программирование на Java. Будущее, настоящее и прошлое
Разберемся с парадигмой реактивного программирования. Какие есть плюсы и минусы по сравнению с императивным подходом.
28 мая 2023 · 14 минуты на чтение
В современном мире разработки, где требования к производительности и отзывчивости системы становятся все более строгими, реактивное программирование выделяется как ключевой подход.
Что же такое реактивное программирование, и почему оно становится всё более популярным? В чём недостаток императивного подхода? И, что самое важное, как реактивные потоки помогают нам создавать более производительные и эффективные системы?
Целью статьи является погружение в контекст реактивной разработки и объяснение основных механик. Это не гайд по написанию реактивных приложений. Это будет в следующих статьях.
Спонсор поста
Реактивная система
Так как реактивный подход помогает создавать реактивные системы, неплохо сначала разобраться, что это за системы такие.
Представим себе систему управления таксопарка. Владелец таксопарка идёт в ногу со временем и решил заказать разработку системы для управления заказами. Система включает в себя множество подсистем: работа с заказами, управлением автопарком и так далее.
Перед разработкой владелец подсчитал среднее количество заказов в день, аналитики по этим данным рассчитали необходимое количество железа, заложили в эти данные избыток в 50% на будущий рост и закупили сервера. Система была написана и введена в эксплуатацию.
Всё было хорошо, пока в городе не объявили проведение чемпионата мира по футболу. Толпы туристов, многие из которых решили воспользоваться удобным способом заказа такси. В какой-то момент нагрузка превзошла все самые смелые ожидания и система полностью развалилась. В итоге таксопарк потерял клиентов и прибыль, а его рейтинг в AppStore обвалился.
Кажется, что было бы неплохо, чтобы система как-то динамически реагировала на изменения, будь то резко выросшая нагрузка или недоступность внешних служб.
В этом примере стоит задуматься об увеличении эластичности. Пропускная способность вашей системы должна автоматически увеличиваться при увеличении нагрузки, и автоматически уменьшаться со снижением нагрузки.
Это одно из свойств, которыми должна обладать реактивная система. Поговорим обо всех характеристиках.
Отзывчивость
Система способна быстро обрабатывать запросы пользователей даже при высокой нагрузке. Это требует соблюдения нескольких ключевых принципов проектирования.
Неблокирующий ввод/вывод: Использование неблокирующего ввода-вывода, позволит минимизировать время, которое потоки тратят на ожидание завершения операций ввода-вывода. Более эффективное использование потоков снижает вероятность «голодания» потоков и увеличивает производительность сервиса.
Про неблокирующий ввод/вывод я расскажу ниже более подробно.
Балансировка нагрузки гарантирует, что ни один экземпляр не будет перегружен трафиком. Таким образом увеличивая пропускную способность и производительность системы.
Существуют различные алгоритмы распределения запросов, но их цель одна: распределить запросы равномерно на существующие и работоспособные экземпляры системы.
Кэширование: система должна использовать методы кэширования для сокращения времени, затрачиваемого на обработку запросов, и повышения общей производительности системы.
Допустим, у вас есть сервис справочников, который содержит значения для различных списков: статусы заказа, названия категорий товаров. Нет смысла каждый раз обращаться в сервис справочной информации, если данные там меняются нечасто. Кэширование этой информации позволит снизить затраты на межсервисное взаимодействие, а также позволит сервису продолжить работу, даже если сервис справочников будет недоступен.
Для больших систем отличным решением будет использование CDN для кэширования статического контента и снижения сетевых задержек.
Устойчивость
Система должна продолжать работать во время сбоев и автоматически восстанавливаться после ошибок, а не полностью выходить из строя.
Существует несколько ключевых стратегий, которые могут помочь обеспечить устойчивость:
Отказоустойчивость: Реактивная система должна быть спроектирована таким образом, чтобы выдерживать сбои на всех уровнях, включая аппаратные, сетевые и программные сбои. Это может быть достигнуто благодаря избыточности, репликации и механизмов автоматического распределения нагрузки с отказавших экземпляров сервисов на здоровые экземпляры.
Автоматическое восстановление: Реактивная система должна уметь автоматически обнаруживать и диагностировать ошибки, а также предпринимать корректирующие действия для восстановления после сбоев без вмешательства разработчиков.
Вынужденная деградация (Graceful degradation): Система должна продолжать работать, даже если некоторые её компоненты или функции недоступны или работают неправильно.
Вместо того чтобы полностью разрушиться, система плавно деградирует, отключая несущественные функции, снижая функциональность или предоставляя запасные варианты. Это позволяет системе продолжать работать, хотя и с ограниченными возможностями, пока проблема не будет устранена.
Предохранители (Circuit breakers): Модель проектирования, которая может помочь предотвратить каскадные отказы в системе. Работает путём мониторинга количества отказов, происходящих в сервисе за определённый период времени, и автоматически отключает предохранитель, если количество отказов превышает заданный порог.
Можно реализовать различные предохранители. Например, если сервис не отвечает на запрос, начать возвращать дефолтное значение или кэшированное значение. Все зависит от ваших сценариев.
Контроль потока данных (Backpressure): Механизм, позволяющий получателю управлять скоростью получения данных от отправителя. Иными словами, это метод контроля потока информации между отправителем и получателем.
Включив эти стратегии в конструкцию реактивной системы, можно достичь высокого уровня устойчивости и гарантировать, что система способна быстро восстанавливаться после ошибок и продолжать бесперебойную работу.
Эластичность
Реактивная система должна иметь возможность масштабирования для обработки растущих рабочих нагрузок без снижения производительности и доступности.
Существует несколько методов, которые могут быть использованы для достижения эластичности в реактивной системе:
Горизонтальное масштабирование: Предполагает добавление дополнительных экземпляров сервиса для распределения рабочей нагрузки на несколько машин или узлов.
Этот подход может использоваться для обработки растущего трафика или запросов пользователей и может быть достигнут при использовании технологий контейнеризации, таких как Docker, и инструментов оркестрации, таких как Kubernetes.
Вертикальное масштабирование: Предполагает добавление дополнительных ресурсов (процессор, память или дисковое пространство) к существующему сервису для увеличения его мощности.
Этот подход может быть использован для обработки возросших объёмов данных или требований к обработке, и может быть реализован с помощью облачных инфраструктурных сервисов, таких как Amazon EC2 или Microsoft Azure.
Автомасштабирование: Предполагает использование автоматизированных инструментов или алгоритмов для динамической корректировки количества экземпляров или ресурсов, выделяемых сервису, на основе показателей, собираемых в реальном времени, таких как использование процессора, памяти или сетевого трафика.
Динамическая корректировка может увеличить количество экземпляров сервиса при увеличении количества запросов, а также уменьшить количество экземпляров при уменьшении нагрузки. Увеличение позволяет обработать непредсказуемый рост нагрузки, а уменьшение позволяет эффективнее потреблять доступные ресурсы и не платить накладные расхода за не используемые.
Достижение эластичности в реактивной системе требует сочетания архитектурного проектирования, управления инфраструктурой и инструментов автоматического масштабирования для обеспечения того, чтобы система могла адаптироваться к изменяющимся рабочим нагрузкам и поддерживать свою производительность и доступность в течение долгого времени.
Управление сообщениями
Message Driven — шаблон проектирования, используемый в реактивных системах для обеспечения асинхронной связи между различными компонентами. Этот паттерн позволяет сервисам отправлять и получать сообщения без блокировки, ожидания или удержания ресурсов, что помогает минимизировать потребление ресурсов и максимизировать пропускную способность.
Для обеспечения коммуникации на основе сообщений реактивные системы обычно используют брокер сообщений или очередь сообщений, которая выступает в качестве посредника между различными сервисами. Когда сервис посылает сообщение другому сервису, он помещает его в очередь сообщений, а принимающий компонент может получить сообщение асинхронно, когда он будет готов обработать его.
Такой подход позволяет сервисам работать независимо друг от друга, без необходимости знать о состоянии или доступности других сервисов. Он также позволяет сервисам обрабатывать большие объёмы сообщений или событий, не перегружаясь и не блокируясь входящим трафиком.
Некоторые популярные брокеры сообщений и системы очередей, используемые в реактивных системах: Apache Kafka, RabbitMQ и AWS SQS.
Подписывайся на Telegram
Реактивное программирование
Манифест реактивных систем гласит: «Большие системы состоят из подсистем, имеющих те же свойства и, следовательно, зависят от их реактивных характеристик. Это означает, что принципы Реактивных Систем применяются на всех уровнях.» Таким образом, каждый отдельный сервис должен также следовать принципам реактивной системы.
Реактивное программирование — это парадигма программирования, ориентированная на работу с потоками данных и распространение изменений в этих потоках. Какие-то данные поступают в систему, и как реакция на них, система выполняет какие-то действия. Вот отсюда и название — «реактивное».
Хотя реактивное программирование часто используется для создания реактивных систем, технически возможно достичь определённой степени реактивности системы, используя другие методы программирования, такие как многопоточность, асинхронное программирование и событийно-ориентированные архитектуры. Эти методы могут помочь улучшить отзывчивость и масштабируемость системы, но они могут не обеспечить тот уровень устойчивости и отказоустойчивости, который призваны обеспечить реактивные системы.
Проблемы императивного программирования
Разберёмся в недостатках императивного подхода. Зачем понадобилось выдумывать какое-то реактивное программирование, почему сложно написать реактивную систему на существующих технологиях?
Реализуем небольшой пример, который состоит из двух сервисов.
@Service @RequiredArgsConstructor public class PassengerServiceImpl implements PassengerService < private final RideService rideService; @Override public void requestRide(Location pickupLocation, Location dropoffLocation) < RideRequest rideRequest = new RideRequest(pickupLocation, dropoffLocation); Ride ride = rideService.processRideRequest(rideRequest); // other logic >>PassengerServiceImpl представляет API для запроса поездки, ориентированный на пассажира. Метод requestRide() принимает в качестве параметров место посадки и высадки пассажира и инициирует процесс запроса поездки.
@Service @RequiredArgsConstructor public class RideServiceImpl implements RideService < private final DriverService driverService; @Override public Ride processRideRequest(RideRequest rideRequest) < Driver driver = driverService.findAvailableDriver(rideRequest.getPickupLocation()); // other logic Ride ride = new . return ride; >>RideServiceImpl представляет внутреннюю службу, которая обрабатывает запросы на поездки. Метод processRideRequest() принимает объект RideRequest в качестве параметра и инициирует процесс поиска водителя и назначения поездки.
Представим, что DriverService при вызове метода findAvailableDriver() обращается к базе данных или посылает сетевой запрос в другой сервис. Что будет, если БД будет выполнять запрос 30 секунд или другой сервис ответит спустя 5 минут?
Одна из основных проблем императивного подхода это ожидание потоков выполнения какой-либо задачи, то есть блокировка. Например, для выполнения запроса к БД из пула потоков берётся поток, далее он ожидает , пока БД выполнит запрос и вернёт результат. Если вычисление результата займёт 5 минут, то поток всё это время будет недоступен для других операций.
Это может привести к снижению производительности сервиса, особенно если многие потоки будут блокироваться в ожидании завершения долго выполняющихся запросов к базе данных. В какой-то момент у вас просто могут закончиться потоки в пуле, и обработка новых запросов просто остановится.
Такая же проблема может возникнуть, когда выполняется запрос к внешнему сервису. Например, вы посылаете запрос используя RestTemplate . Если внешний ресурс будет отвечать 5 минут, то всё это время поток будет находится в ожидании ответа, то есть простаивать.
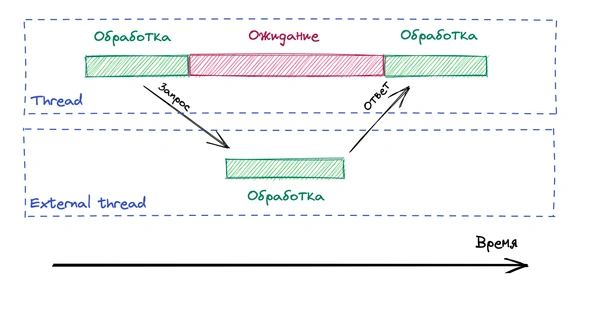
Почему простаивание потока — это проблема?
Каждый поток нуждается в памяти для хранения своего стека вызовов и других связанных с ним структур данных. Когда поток простаивает, он продолжает потреблять ресурсы для поддержания своего состояния.
Кроме того, процессорное время, которое выделяется неработающим потокам, могло бы быть использовано для других задач. Если большое количество потоков простаивает, это может привести к увеличению загрузки процессора и снижению производительности, так как операционная система будет тратить больше времени на переключение между потоками.
Попробуем решить проблему блокировки потоков доступными способами. Добавим ExecutorService в RideService и будем возвращать не Ride , а Future .
public inteface RideService < public FutureprocessRideRequest(RideRequest rideRequest); >@Service public class PassengerServiceImpl implements PassengerService < private final RideService rideService; @Override public void requestRide(Location pickupLocation, Location dropoffLocation) < RideRequest rideRequest = new RideRequest(pickupLocation, dropoffLocation); Futurefuture = rideService.processRideRequest(rideRequest); // other logic Ride ride = future.get(); // other logic > >Теперь мы выполняем асинхронный вызов к RideService и получаем объект Future . Далее мы можем продолжить выполнять другие операции, пока выполняется обработка Future .
Мы можем выполнить какую-то другую логику, но в какой-то момент необходимо вызывать метод Future.get() , который потенциально также является блокирующим, если Future ещё не закончил работу, то мы заблокируем поток.
Эта реализация позволила нам сократить время блокировки потока, однако полностью эта проблема не решена, мы всё ещё с большой вероятностью будем получать блокировку потока.
Более высокоуровневым решением может быть использование CompletionStage и его реализации CompletableFuture . CompletionStage позволяет писать код в функциональном стиле, который выполняется асинхронно.
public inteface RideService < public CompletionStageprocessRideRequest(RideRequest rideRequest); >@Service public class PassengerServiceImpl implements PassengerService < private final RideService rideService; public PassengerServiceImpl(RideService rideService) < this.rideService = rideService; >@Override public void requestRide(Location pickupLocation, Location dropoffLocation) < RideRequest rideRequest = new RideRequest(pickupLocation, dropoffLocation); rideService.processRideRequest(rideRequest) .thenApply(a ->< . >) .thenCombine(b -> < . >) .thenAccept(c -> < . >) > >Однако, реализации с использованием Future , CompletionStage и им подобных требуют от разработчика глубокого понимания многопоточного программирования: доступ к общей памяти, синхронизация, обработка ошибок и так далее.
Но и это ещё не всё. Дизайн многопоточности в Java не предполагает, что мы будем создавать поток на каждый чих. Создание потока дорогостоящая операция. Да, пул потоков частично решает эту проблему, но есть ещё одна проблема: несколько потоков могут использовать один процессор для выполнения задач одновременно. При такой ситуации, процессорное время распределяется между несколькими потоками, что вызывает необходимость переключения контекста. Для возобновления выполнения потока позже, необходимо сохранять и загружать регистры, карты памяти и выполнить другие операции с высоким объёмом вычислений. Из-за этого снижается эффект от использования большого количества потоков при небольшом количестве процессоров.
Паттерн Наблюдатель (Observer Pattern)
Вспомним паттерн «Наблюдатель». Он поможет нам лучше понять концепцию реактивных потоков.
Наблюдатель — это поведенческий паттерн проектирования, который создаёт механизм подписки, позволяющий одним объектам следить и реагировать на события, происходящие в других объектах.
В этом паттерне есть два ключевых участника: Издатель и Подписчик (Наблюдатель). Издатель обновляет состояние и оповещает всех своих подписчиков об этих изменениях. Подписчики, в свою очередь, реагируют на эти уведомления.
Ключевые характеристики
- Декаплинг: Субъекты и наблюдатели функционируют независимо друг от друга. Это означает, что они не должны знать друг о друге. Субъекты просто отправляют уведомления, а наблюдатели просто реагируют на них.
- Динамичность: Подписчики могут подписываться и отписываться от субъектов в любое время.
- Многопоточность: Паттерн Наблюдатель позволяет обрабатывать события асинхронно и в различных потоках исполнения.
В контексте реактивного программирования паттерн Наблюдатель становится основой для создания реактивных потоков, обеспечивающих эффективную обработку данных и событий. Это также служит фундаментом для различных библиотек и фреймворков, таких как RxJava и Project Reactor.
Реактивные потоки (стримы)
Спецификация Reactive Streams впервые была опубликована в 2015 году. Она была разработана для стандартизации модели асинхронного потокового программирования с контролем потока данных в JVM и была принята в качестве основы для обработки асинхронного потока в JDK 9.
В отличие от обычных Java Stream не было предоставлено стандартных реализаций реактивных стримов, поэтому в последующие годы в Java-сообществе появилось несколько библиотек и фреймворков, которые реализуют и расширяют спецификацию Reactive Streams, таких как: RxJava, Vert.x, ProjectReactor, Akka Streams.
Базовая схема работы стримов
Рекомендую посмотреть доклад «Олег Докука — Реактивный хардкор: как построить свой Publisher», который закрепит понимание данного механизма взаимодействия.
Продолжая историю с паттерном Наблюдатель, теперь у нас есть интерфейсы Publisher , представляет источник данных, и Subscriber — наблюдатель, который подписывается на поток и получает уведомления об изменении состояния потока. Есть ещё один важный интерфейс, который является «посредником» между первыми двумя — это Subscription .
Давайте взглянем, как выглядят данные интерфейсы:
package org.reactivestreams; public interface Publisher < public void subscribe(Subscribers); >package org.reactivestreams; public interface Subscriber
package org.reactivestreams; public interface Subscription
Все начинается с подписки Subscriber на Publisher посредством вызова метода Publisher.subscribe() . Publisher использует переданный объект Subscriber , вызывая метод onSubscribe() , передавая в Subscriber объект Subscription . Через этот объект Subscriber будет взаимодействовать с Publisher .
Теперь Subscriber , используя полученный Subscription , будет запрашивать значения у Publisher . Это важный момент, не Publisher инициализирует отправку данных подписчикам когда хочет, это подписчики запрашивают необходимое количество данных у Publisher . Таким образом реализуется контроль потока данных (Backpressure).
Метод onNext(T t) вызывается, когда Subcriber запрашивает значения у Publisher , используя метод Subscription.request() . Он передаёт данные по одному, но не больше, чем было запрошено подписчиком.
Метод onError() вызывается, когда ошибка происходит на стороне Publisher , оповещая таким образом о проблеме Subscriber , передавая объект исключения.
Метод onComplete() оповещает подписчиков, что у Publisher не осталось элементов для передачи. Данный метод, как и onError() вызывается лишь один раз.
Пример реактивного потока
Представим, что у нас есть набор чисел, и мы хотим получить квадрат каждого числа. При этом числа для расчёта могут поступать из разных систем или из бд, или из БД редиса и других систем.
В императивном стиле программирования мы бы обработали эти данные следующим образом:
List numbers = externalServices.getNumbers(); for (int number : numbers)
Код обрабатывает данные в определённом порядке и от начала до конца. Мы должны дождаться пока метод getNumbers() отправит нам все данные для расчёта.
Давайте рассмотрим тот же пример с использованием Project Reactor:
Flux numbers = externalServices.getNumber(); // Flux это реализация Publisher numbers .map(number -> number * number) .subscribe( data -> System.out.println("Получены данные: " + data), error -> System.out.println("Произошла ошибка: " + error), () -> System.out.println("Поток данных завершен") );Этот код напоминает Stream API. Только вместо Stream используется Flux — это тип данных из Project Reactor, который представляет собой поток данных.
Мы используем метод map , чтобы преобразовать каждое число в его квадрат, и затем подписываемся на поток, чтобы вывести результат. Подписка очень важна, без неё ничего не произойдёт. Только в отличие от Stream API на Flux можно подписаться несколько раз.
В данном примере мы будем обрабатывать данные асинхронно по мере их поступления. Одна система ответила быстрее другой, сразу обработали эту часть данных.
Ограничения и недостатки
Не бывает идеального решения и реактивные потоки не исключение.
Чтобы получить преимущество реактивных потоков, весь стек должен быть реактивным: доступ к БД, операции чтения/записи файлов и так далее. Всё должно работать в реактивной парадигме, иначе вы получите блокировки, которые ухудшат производительность всей системы.
Например, стандартный JDBC не является реактивным. Если использовать его в реактивном сервисе, то придётся ждать ответ, когда мы отправляем запрос в базу данных. Соответственно, вся реактивность тут же ломается.
Весь технологический стек должен быть реактивным
Сложность: Реактивное программирование может быть сложным для понимания, особенно для новичков. Это связано с необходимостью работы с асинхронностью, обработкой ошибок и механизмами подобными backpressure.
Отладка и тестирование: Отладка и тестирование реактивных систем сложная задача, так как асинхронная природа реактивного кода делает отслеживание исполнения программы менее прямолинейным и понятным.
Требования к проектированию: Реактивные системы требуют продуманного проектирования, чтобы обеспечить их эффективность. Без правильного проектирования система может столкнуться с проблемами производительности или недостаточной отзывчивости.
Поддержи автора
Event Loop
Рассуждая на тему реактивного программирования, нельзя пройти мимо такого понятия, как Event Loop.
Это реактивная асинхронная модель программирования для серверов. Она позволяет достичь более высокого уровня параллелизма при меньшем количестве потоков.
По сути, Event Loop — это реализация шаблона Reactor. Является неблокирующим потоком ввода-вывода, который работает непрерывно. Его основная задача — проверка новых событий. И как только событие пришло перенаправлять его тому, кто в данный момент может его обработать. Иногда их может быть несколько для увеличения производительности.
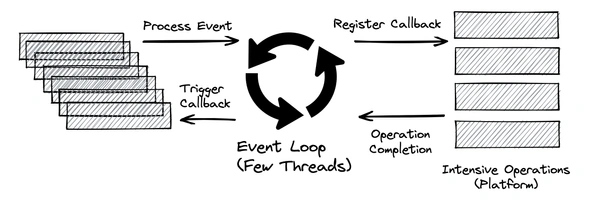
Выше приведён абстрактный дизайн цикла событий, который представляет идеи реактивного асинхронного программирования:
- Цикл событий выполняется непрерывно в одном потоке, хотя у нас может быть столько циклов событий, сколько доступно ядер.
- Цикл событий последовательно обрабатывает события из очереди событий и возвращается сразу после регистрации обратного вызова в платформе.
- Платформа может инициировать завершение операции, такой как вызов базы данных или вызов внешней службы.
- Цикл событий может запускать обратный вызов при уведомлении о завершении операции и отправлять результат обратно исходному вызывающему.
В своей работе механизм Event Loop использует Netty — клиент-серверная среда ввода-вывода для разработки сетевых приложений Java. Также этот механизм использует Vert.x – это полифункциональная библиотека для построения реактивных приложений на JVM.
Реактивные фреймворки в Java
Теперь немного поговорим про имплементации реактивной спецификации, коих уже появилось достаточное количество.
Spring WebFlux (Project Reactor)
Project Reactor – это библиотека для реактивного программирования на Java, которая полностью поддерживает Reactive Streams. Она предлагает два основных типа данных – Flux и Mono .
Flux представляет поток ноль или более элементов, а Mono представляет один или ноль элементов. Оба типа предоставляют обширный набор операторов для трансформации и комбинирования этих потоков.
Spring WebFlux – это веб-фреймворк, который является частью экосистемы Spring и использует Project Reactor для обработки реактивных потоков. В отличие от Spring MVC, который предназначен для синхронного веб-программирования и блокирования I/O, Spring WebFlux предназначен для асинхронного и неблокирующего веб-программирования.
Вместо Tomcat используется неблокирующий Netty. Сервлеты тоже ушли в прошлое.

Quarkus (Vert.x)
Не спрингом единым. Активно использую его в работе и в пет-проектах.
Реактивное программирование в Quarkus основано на библиотеке SmallRye Mutiny. Mutiny предлагает два основных типа: Uni и Multi , которые представляют собой типы реактивных потоков, обеспечивающих обработку одного или множества элементов соответственно.
Множество знакомых коллег, которым довелось поработать и со Spring WebFlux и с Quarkus, отмечают, что реактивный Quarkus API более приятный для работы.
Quarkus также оптимизирован для работы в контейнеризированных средах и облачных приложениях, что, в сочетании с его реактивной моделью программирования, делает его отличным выбором для создания современных микросервисов.
Кроме того, Quarkus предоставляет возможность компиляции приложений в нативный код при помощи GraalVM, что позволяет уменьшить время запуска и использование памяти, что является ещё одним преимуществом при использовании в облачных средах.
Project Loom
Некоторые разработчики предрекают скорую смерть таким проектам, как Project Reactor, ведь уже близится релиз Project Loom. Давайте порассуждаем на эту тему.
Цель Project Loom добавить в Java так называемые виртуальные потоки или нити (fibers). Одной из ключевых особенностей виртуальных потоков является их «непрерывность». Виртуальный поток может быть приостановлен, а его ресурсы могут быть возвращены в пул потоков, что позволяет использовать поток операционной системы для другой работы. Когда придёт ответ от внешнего сервиса, виртуальный поток может быть возобновлен и продолжить свою работу.
Хотя такие реактивные библиотеки предоставляют мощные абстракции для управления асинхронным и неблокирующим кодом, они всё ещё полагаются на традиционную модель потоков Java, которая может быть сложной и трудной для понимания. С Project Loom разработчики получат более простой способ написания неблокирующего кода, без необходимости использования сложных абстракций или пулов потоков.
Однако, на данный момент Project Loom находится в разработке, а вот реактивные фреймворки уже есть и успешно используются.
Вот аргументы, почему существующие фреймворки останутся в строю:
- Project Loom находится в разработке, и его окончательная форма и влияние на экосистему Java не полностью понятны.
- Ничто не мешает реактивным фреймворкам использовать под капотом новые виртуальные потоки. Предоставляя мощные абстракции и API для работы.
- Когда требуется тип обработки в стиле событий (Event-Driven Architecture), то их API очень удобен, странно от него отказываться.
Рекомендую посмотреть следующие доклады на тему Project Loom:
- Иван Углянский — Thread Wars: проект Loom наносит ответный удар
- Олег Докука, Андрей Родионов — Project Loom — друг или враг Reactive?
Заключение
Мы разобрались, что такое реактивные системы, и какими свойствами система должна обладать, чтобы называться реактивной. Разработка реактивной системы — сложный процесс и очевидно, что не каждой системе необходимо быть реактивной.
Однако, системы написанные с применением реактивных подходов и реактивного стека позволяют выдерживать большую нагрузку, чем системы, написанные на стандартном императивном стеке, а также быть более эффективными с точки зрения потребления ресурсов системы и дальнейшего её масштабирования.
Создать реактивную систему проще всего с помощью реактивных фремворков, которые позволяют не блокировать потоки и обрабатывать данные по мере их поступления.
Дополнительные материалы
- Зачем нам Reactive и как его готовить. Команда разработки делится своим опытом перевода сервисов на реактивный стек. Они используют Spring WebFlux.
Реактивное программирование на Java: как, зачем и стоит ли? Часть II
Реактивное программирование — один из самых актуальных трендов современности. Обучение ему — сложный процесс, особенно если нет подходящих материалов. В качестве своеобразного дайджеста может выступить эта статья. На конференции РИТ++ 2020 эксперт и тренер Luxoft Training Владимир Сонькин рассказал о фишках управления асинхронными потоками данных и подходах к ним, а также показал на примерах, в каких ситуациях нужна реактивность, и что она может дать.
В первой части статьи рассказывалось о том, что привело к появлению реактивного программирования, где оно применяется, и что нам может дать асинхронность. Пришло время рассказать о следующем шаге, позволяющем получить максимум преимуществ от асинхронности, и это — реактивное программирование.
Reactivity
Реактивное программирование — это асинхронность, соединенная с потоковой обработкой данных. То есть если в асинхронной обработке нет блокировок потоков, но данные обрабатываются все равно порциями, то реактивность добавляет возможность обрабатывать данные потоком. Помните тот пример, когда начальник поручает задачу Васе, тот должен передать результат Диме, а Дима вернуть начальнику? Но у нас задача — это некая порция, и пока она не будет сделана, дальше передать ее нельзя. Такой подход действительно разгружает начальника, но Дима и Вася периодически простаивают, ведь Диме надо дождаться результатов работы Васи, а Васе — дождаться нового задания.

А теперь представьте, что задачу разбили на множество подзадач. И теперь они плывут непрерывным потоком:

Говорят, когда Генри Форд придумал свой конвейер, он повысил производительность труда в четыре раза, благодаря чему ему удалось сделать автомобили доступными. Здесь мы видим то же самое: у нас небольшие порции данных, а конвейер с потоком данных, и каждый обработчик пропускает через себя эти данные, каким-то образом их преобразовывая. В качестве Васи и Димы у нас выступают потоки выполнения (threads), обеспечивая, таким образом, многопоточную обработку данных.

На этой схеме показаны разные технологии распараллеливания, добавлявшиеся в Java в разных версиях. Как мы видим, спецификация Reactive Streams на вершине — она не заменяет всего, что было до нее, но добавляет самый высокий уровень абстракции, а значит ее использование просто и эффективно. Попробуем в этом разобраться.
Идея реактивности построена на паттерне проектирования Observer.

Давайте вспомним, что это за паттерн. У нас есть подписчики и то, на что мы подписываемся. В качестве примера здесь рассмотрен Твиттер, но подписаться на какое-то сообщество или человека, а потом получать обновления можно в любой соцсети. После подписки, как только появляется новое сообщение, всем подписчикам приходит notify, то есть уведомление. Это базовый паттерн.
В данной схеме есть:
- Publisher — тот, кто публикует новые сообщения;
- Observer — тот, кто на них подписан. В реактивных потоках подписчик обычно называется Subscriber. Термины разные, но по сути это одно и то же. В большинстве сообществ более привычны термины Publisher/Subscriber.
Это базовая идея, на которой все строится.
Один из жизненных примеров реактивности — система оповещения при пожаре. Допустим, нам надо сделать систему, включающую тревогу в случае превышения задымленности и температуры.

У нас есть датчик дыма и градусник. Когда дыма становится много и/или температура растет, на соответствующих датчиках увеличивается значение. Когда значение и температура на датчике дыма оказываются выше пороговых, включается колокольчик и оповещает о тревоге.
Если бы у нас был традиционный, а не реактивный подход, мы бы писали код, который каждые пять минут опрашивает детектор дыма и датчик температуры, и включает или выключает колокольчик. Однако в реактивном подходе за нас это делает реактивный фреймворк, а мы только прописываем условия: колокольчик активен, когда детектор больше X, а температура больше Y. Это происходит каждый раз, когда приходит новое событие.
От детектора дыма идет поток данных: например, значение 10, потом 12, и т.д. Температура тоже меняется, это другой поток данных — 20, 25, 15. Каждый раз, когда появляется новое значение, результат пересчитывается, что приводит к включению или выключению системы оповещения. Нам достаточно сформулировать условие, при котором колокольчик должен включиться.
Если вернуться к паттерну Observer, у нас детектор дыма и термометр — это публикаторы сообщений, то есть источники данных (Publisher), а колокольчик на них подписан, то есть он Subscriber, или наблюдатель (Observer).

Немного разобравшись с идеей реактивности, давайте углубимся в реактивный подход. Мы поговорим об операторах реактивного программирования. Операторы позволяют каким-либо образом трансформировать потоки данных, меняя данные и создавая новые потоки. Для примера рассмотрим оператор distinctUntilChanged. Он убирает одинаковые значения, идущие друг за другом. Действительно, если значение на детекторе дыма не изменилось — зачем нам на него реагировать и что-то там пересчитывать:

Reactive approach
Рассмотрим еще один пример: допустим, мы разрабатываем UI, и нам нужно отслеживать двойные нажатия мышкой. Тройной клик будем считать как двойной.

Клики здесь — это поток щелчков мышкой (на схеме 1, 2, 1, 3). Нам нужно их сгруппировать. Для этого мы используем оператор throttle. Говорим, что если два события (два клика) произошли в течение 250 мс, их нужно сгруппировать. На второй схеме представлены сгруппированные значения (1, 2, 1, 3). Это поток данных, но уже обработанных — в данном случае сгрупированных.
Таким образом начальный поток преобразовался в другой. Дальше нужно получить длину списка ( 1, 2, 1, 3). Фильтруем, оставляя только те значения, которые больше или равны 2. На нижней схеме осталось только два элемента (2, 3) — это и были двойные клики. Таким образом, мы преобразовали начальный поток в поток двойных кликов.
Это и есть реактивное программирование: есть потоки на входе, каким-то образом мы пропускаем их через обработчики, и получаем поток на выходе. При этом вся обработка происходит асинхронно, то есть никто никого не ждет.
Еще одна хорошая метафора — это система водопровода: есть трубы, одна подключена к другой, есть какие-то вентили, может быть, стоят очистители, нагреватели или охладители (это операторы), трубы разделяются или объединяются. Система работает, вода льется. Так и в реактивном программировании, только в водопроводе течет вода, а у нас — данные.
Можно придумать потоковое приготовление супа. Например, есть задача максимально эффективно сварить много супа. Обычно берется кастрюля, в нее наливается порция воды, овощи нарезаются и т.д. Это не потоковый, а традиционный подход, когда мы варим суп порциями. Сварили эту кастрюлю, потом нужно ставить следующую, а после — еще одну. Соответственно, надо дождаться, пока в новой кастрюле снова закипит вода, растворится соль, специи и т.д. Все это занимает время.
Представьте себе такой вариант: в трубе нужного диаметра (достаточного, чтобы заполнялась кастрюля) вода сразу подогревается до нужной температуры, есть нарезанная свекла и другие овощи. На вход они поступают целыми, а выходят уже шинкованными. В какой-то момент все смешивается, вода подсаливается и т.д. Это максимально эффективное приготовление, супоконвейер. И именно в этом идея реактивного подхода.
Observable example
Теперь посмотрим на код, в котором мы публикуем события:

Observable.just позволяет положить в поток несколько значений, причем если обычные реактивные потоки содержат значения, растянутые во времени, то тут мы их кладем все сразу — то есть синхронно. В данном случае это названия городов, на которые в дальнейшем можно подписаться (тут для примера взяты города, в которых есть учебный центр Люксофт).
Девушка (Publisher) опубликовала эти значения, а Observers на них подписываются и печатают значения из потока.
Это похоже на потоки данных (Stream) в Java 8. И тут, и там синхронные потоки. И здесь, и в Java 8 список значений нам известен сразу. Но если бы использовался обычный для Java 8 поток, мы не могли бы туда что-то докладывать. В стрим ничего нельзя добавить: он синхронный. В нашем примере потоки асинхронные, то есть в любой момент времени в них могут появляться новые события — скажем, если через год откроется учебный центр в новой локации — она может добавиться в поток, и реактивные операторы правильно обработают эту ситуацию. Мы добавили события и сразу же на них подписались:
Мы можем в любой момент добавить значение, которое через какое-то время выводится. Когда появляется новое значение, мы просим его напечатать, и на выходе получаем список значений:

При этом есть возможность не только указать, что должно происходить, когда появляются новые значения, но и дополнительно отработать такие сценарии, как возникновение ошибок в потоке данных или завершение потока данных. Да-да, хотя часто потоки данных не завершаются (например, показания термометра или датчика дыма), многие потоки могут завершаться: например, поток данных с сервера или с другого микросервиса. В какой-то момент сервер закрывает соединение, и появляется потребность на это как-то отреагировать.
Implementing and subscribing to an observer
В Java 9 нет реализации реактивных потоков — только спецификация. Но есть несколько библиотек — реализаций реактивного подхода. В этом примере используется библиотека RxJava. Мы подписываемся на поток данных, и определяем несколько обработчиков, то есть методы, которые будут запущены в начале обработки потока (onSubscribe), при получении каждого очередного сообщения (onNext), при возникновении ошибки (onError) и при завершении потока (onComplete):

Давайте посмотрим на последнюю строчку.
locations.map(String::length).filter(l -> l >= 5).subscribe(observer);
Мы используем операторы map и filter. Если вы работали со стримами Java 8, вам, конечно, знакомы map и filter. Здесь они работают точно так же. Разница в том, что в реактивном программировании эти значения могут появляться постепенно. Каждый раз, когда приходит новое значение, оно проходит через все преобразования. Так, String::length заменит строчки на длину в каждой из строк.
В данном случае получится 5 (Minsk), 6 (Krakow), 6 (Moscow), 4 (Kiev), 5 (Sofia). Фильтруем, оставляя только те, что больше 5. У нас получится список длин строк, которые больше 5 (Киев отсеется). Подписываемся на итоговый поток, после этого вызывается Observer и реагирует на значения в этом итоговом потоке. При каждом следующем значении он будет выводить длину:
public void onNext(Integer value) <
System.out.println(«Length: » + value);То есть сначала появится Length 5, потом — Length 6. Когда наш поток завершится, будет вызван onComplete, а в конце появится надпись «Done.»:
public void onComplete() System.out.println(«Done.»);
Не все потоки могут завершаться. Но некоторые способны на это. Например, если мы читали что-то из файла, поток завершится, когда файл закончится.
Если где-то произойдет ошибка, мы можем на нее отреагировать:
public void onError(Throwable e) e.printStackTrace();
Таким образом мы можем реагировать разными способами на разные события: на следующее значение, на завершение потока и на ошибочную ситуацию.
Reactive Streams spec
Реактивные потоки вошли в Java 9 как спецификация.
Если предыдущие технологии (Completable Future, Fork/Join framework) получили свою имплементацию в JDK, то реактивные потоки имплементации не имеют. Есть только очень короткая спецификация. Там всего 4 интерфейса:

Если рассматривать наш пример из картинки про Твиттер, мы можем сказать, что:
Publisher — девушка, которая постит твиты;
Subscriber — подписчик. Он определяет , что делать, если:
- Начали слушать поток (onSubscribe). Когда мы успешно подписались, вызовется эта функция;
- Появилось очередное значение в потоке (onNext);
- Появилось ошибочное значение (onError);
- Поток завершился (onComplete).
Subscription — у нас есть подписка, которую можно отменить (cancel) или запросить определенное количество значений (request(long n)). Мы можем определить поведение при каждом следующем значении, а можем забирать значения вручную.
Processor — обработчик — это два в одном: он одновременно и Subscriber, и Publisher. Он принимает какие-то значения и куда-то их кладет.
Если мы хотим на что-то подписаться, вызываем Subscribe, подписываемся, и потом каждый раз будем получать обновления. Можно запросить их вручную с помощью request. А можно определить поведение при приходе нового сообщения (onNext): что делать, если появилось новое сообщение, что делать, если пришла ошибка и что делать, если Publisher завершил поток. Мы можем определить эти callbacks, или отписаться (cancel).
PUSH / PULL модели
Существует две модели потоков:
- Push-модель — когда идет «проталкивание» значений.
Например, вы подписались на кого-то в Telegram или Instagram и получаете оповещения (они так и называются — push-сообщения, вы их не запрашиваете, они приходят сами). Это может быть, например, всплывающее сообщение. Можно определить, как реагировать на каждое новое сообщение.
- Pull-модель — когда мы сами делаем запрос.
Например, мы не хотим подписываться, т.к. информации и так слишком много, а хотим сами заходить на сайт и узнавать новости.
Для Push-модели мы определяем callbacks, то есть функции, которые будут вызваны, когда придет очередное сообщение, а для Pull-модели можно воспользоваться методом request, когда мы захотим узнать, что новенького.
Pull-модель очень важна для Backpressure — «напирания» сзади. Что же это такое?
Вы можете быть просто заспамленными своими подписками. В этом случае прочитать их все нереально, и есть шанс потерять действительно важные данные — они просто утонут в этом потоке сообщений. Когда подписчик из-за большого потока информации не справляется со всем, что публикует Publisher, получается Backpressure.
В этом случае можно использовать Pull-модель и делать request по одному сообщению, прежде всего из тех потоков данных, которые наиболее важны для вас.
Implementations
Давайте рассмотрим существующие реализации реактивных потоков:
- RxJava. Эта библиотека реализована для разных языков. Помимо RxJava существует Rx для C#, JS, Kotlin, Scala и т.д.
- Reactor Core. Был создан под эгидой Spring, и вошел в Spring 5.
- Akka-стримы от создателя Scala Мартина Одерски. Они создали фреймворк Akka (подход с Actor), а Akka-стримы — это реализация реактивных потоков, которые дружат с этим фреймворком.
Во многом эти реализации похожи, и все они реализуют спецификацию реактивных потоков из Java 9.
Посмотрим подробнее на Spring’овский Reactor.
Function may return…
Давайте обобщим, что может возвращать функция:

- Single/Synchronous;
Обычная функция возвращает одно значение, и делает это синхронно.
- Multipple/Synchronous;
Если мы используем Java 8, можем возвращать из функции поток данных Stream. Когда вернулось много значений, их можно отправлять на обработку. Но мы не можем отправить на обработку данные до того, как все они получены — ведь Stream работают только синхронно.
- Single/Asynchronous;
Здесь уже используется асинхронный подход, но функция возвращает только одно значение:
- либо CompletableFuture (Java), и через какое-то время приходит асинхронный ответ;
- либо Mono, возвращающая одно значение в библиотеке Spring Reactor.
- Multiple/Asynchronous.
А вот тут как раз — реактивные потоки. Они асинхронные, то есть возвращают значение не сразу, а через какое-то время. И именно в этом варианте можно получить поток значений, причем эти значения будут растянуты во времени Таким образом, мы комбинируем преимущества потоков Stream, позволяющих вернуть цепочку значений, и асинхронности, позволяющей отложить возврат значения.
Например, вы читаете файл, а он меняется. В случае Single/Asynchronous вы через какое-то время получаете целиком весь файл. В случае Multiple/Asynchronous вы получаете поток данных из файла, который сразу же можно начинать обрабатывать. То есть можно одновременно читать данные, обрабатывать их, и, возможно, куда-то записывать. . Реактивные асинхронные потоки называются:
- Publisher (в спецификации Java 9);
- Observable (в RxJava);
- Flux (в Spring Reactor).
Netty as a non-blocking server
Рассмотрим пример использования реактивных потоков Flux вместе со Spring Reactor. В основе Reactor лежит сервер Netty. Spring Reactor — это основа технологии, которую мы будем использовать. А сама технология называется WebFlux. Чтобы WebFlux работал, нужен асинхронный неблокирующий сервер.

Схема работы сервера Netty похожа на то, как работает Node.js. Есть Selector — входной поток, который принимает запросы от клиентов и отправляет их на выполнение в освободившиеся потоки. Если в качестве синхронного сервера (Servlet-контейнера) используется Tomcat, то в качестве асинхронного используется Netty.
Давайте посмотрим, сколько вычислительных ресурсов расходуют Netty и Tomcat на выполнение одного запроса:

Throughput — это общее количество обработанных данных. При небольшой нагрузке, до первых 300 пользователей у RxNetty и Tomcat оно одинаковое, а после Netty уходит в приличный отрыв — почти в 2 фраза.

Blocking vs Reactive
У нас есть два стека обработки запросов:

- Традиционный блокирующий стек.
- Неблокирующий стек — в нем все происходит асинхронно и реактивно.
В блокирующем стеке все строится на Servlet API, в реактивном неблокирующем стеке — на Netty.
Сравним реактивный стек и стек Servlet.
В Reactive Stack применяется технология Spring WebFlux. Например, вместо Servlet API используются реактивные стримы.

Чтобы мы получили ощутимое преимущество в производительности, весь стек должен быть реактивным. Поэтому чтение данных тоже должно происходить из реактивного источника.
Например, если у нас используется стандартный JDBC, он является не реактивным блокирующим источником, потому что JDBC не поддерживает неблокирующий ввод/вывод. Когда мы отправляем запрос в базу данных, приходится ждать, пока результат этого запроса придет. Соответственно, получить преимущество не удается.
В Reactive Stack мы получаем преимущество за счет реактивности. Netty работает с пользователем, Reactive Streams Adapters — со Spring WebFlux, а в конце находится реактивная база: то есть весь стек получается реактивным. Давайте посмотрим на него на схеме:
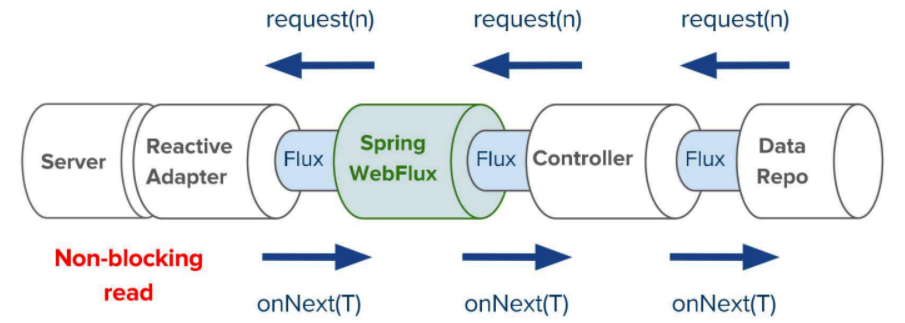
Data Repo — репозиторий, где хранятся данные. В случае, если есть запросы, допустим, от клиента или внешнего сервера, они через Flux поступают в контроллер, обрабатываются, добавляются в репозиторий, а потом ответ идет в обратную сторону.
При этом все это делается неблокирующим способом: мы можем использовать либо Push-подход, когда мы определяем, что делать при каждой следующей операции, либо Pull-подход, если есть вероятность Backpressure, и мы хотим сами контролировать скорость обработки данных, а не получать все данные разом.
Операторы
В реактивных потоках огромное количество операторов. Многие из них похожи на те, которые есть в обычных стримах Java. Мы рассмотрим только несколько самых распространенных операторов, которые понадобятся нам для практического примера применения реактивности.
Filter operator
Скорее всего, вы уже знакомы с фильтрами из интерфейса Stream.

По синтаксису этот фильтр точно такой же, как обычный. Но если в стриме Java 8 все данные есть сразу, здесь они могут появляться постепенно. Стрелки вправо — это временная шкала, а в кружочках находятся появляющиеся данные. Мы видим, что фильтр оставляет в итоговом потоке только значения, превышающие 10.

Take 2 означает, что нужно взять только первые два значения.
Map operator
Оператор Map тоже хорошо знаком:

Это действие, происходящее с каждым значением. Здесь — умножить на десять: было 3, стало 30; было 2, стало 20 и т.д.
Delay operator

Задержка: все операции сдвигаются. Этот оператор может понадобиться, когда значения уже генерируются, но подготовительные процессы еще происходят, поэтому приходится отложить обработку данных из потока.
Reduce operator
Еще один всем известный оператор:

Он дожидается конца работы потока (onComplete) — на схеме она представлена вертикальной чертой. После чего мы получаем результат — здесь это число 15. Оператор reduce сложил все значения, которые были в потоке.
Scan operator
Этот оператор отличается от предыдущего тем, что не дожидается конца работы потока.

Оператор scan рассчитывает текущее значение нарастающим итогом: сначала был 1, потом прибавил к предыдущему значению 2, стало 3, потом прибавил 3, стало 6, еще 4, стало 10 и т.д. На выходе получили 15. Дальше мы видим вертикальную черту — onComplete. Но, может быть, его никогда не произойдет: некоторые потоки не завершаются. Например, у термометра или датчика дыма нет завершения, но scan поможет рассчитать текущее суммарное значение, а при некоторой комбинации операторов — текущее среднее значение всех данных в потоке.
Merge operator
Объединяет значения двух потоков.

Например, есть два температурных датчика в разных местах, а нам нужно обрабатывать их единообразно, в общем потоке .
Combine latest
Получив новое значение, комбинирует его с последним значением из предыдущего потока.

Если в потоке возникает новое событие, мы его комбинируем с последним полученным значением из другого потока. Скажем, таким образом мы можем комбинировать значения от датчика дыма и термометра: при появлении нового значения температуры в потоке temperatureStream оно будет комбинироваться с последним полученным значением задымленности из smokeStream. И мы будем получать пару значений. А уже по этой паре можно выполнить итоговый расчет:
temperatureStream.combineLatest(smokeStream).map((x, y) -> x > X && y > Y)
В итоге на выходе у нас получается поток значений true или false — включить или выключить колокольчик. Он будет пересчитываться каждый раз, когда будет появляться новое значение в temperatureStream или в smokeStream.
FlatMap operator
Этот оператор вам, скорее всего, знаком по стримам Java 8. Элементами потока в данном случае являются другие потоки. Получается поток потоков. Работать с ними неудобно, и в этих случаях нам может понадобиться «уплостить» поток.

Можно представить такой поток как конвейер, на который ставят коробки с запчастями. До того, как мы начнем их применять, запчасти нужно достать из коробок. Именно это делает оператор flatMap.
Flatmap часто используется при обработке потока данных, полученных с сервера. Т.к. сервер возвращает поток, чтобы мы смогли обрабатывать отдельные данные, этот поток сначала надо «развернуть». Это и делает flatMap.
Buffer operator
Это оператор, который помогает группировать данные. На выходе Buffer получается поток, элементами которого являются списки (List в Java). Он может пригодиться, когда мы хотим отправлять данные не по одному, а порциями.
Мы с самого начала говорили, что реактивные потоки позволяют разбить задачу на подзадачи, и обрабатывать их маленькими порциями. Но иногда лучше наоборот, собрать много маленьких частей в блоки. Скажем, продолжая пример с конвейером и запчастями, нам может понадобиться отправлять запчасти на другой завод (другой сервер). Но каждую отдельную запчасть отправлять неэффективно. Лучше их собрать в коробки, скажем по 100 штук, и отправлять более крупными партиями.
На схеме выше мы группируем отдельные значения по три элемента (так как всего их было пять, получилась «коробка» из трех, а потом из двух значений). То есть если flatMap распаковывает данные из коробок, buffer, наоборот, упаковывает их.
Всего существует более сотни операторов реактивного программирования. Здесь разобрана только небольшая часть.
Итого
Есть два подхода:

- Spring MVC — традиционная модель, в которой используется JDBC, императивная логика и т.д.
- Spring WebFlux, в котором используется реактивный подход и сервер Netty.
Есть кое-что, что их объединяет. Tomcat, Jetty, Undertow могут работать и со Spring MVC, и со Spring WebFlux. Однако дефолтным сервером в Spring для работы с реактивным подходом является именно Netty.
Конференция HighLoad++ Весна 2021 пройдет 20 и 21 мая 2021 года. Приобрести билеты можно уже сейчас.
А совсем скоро состоится еще одно интересное событие, на сей раз онлайн: 18 марта в 17:00 МСК пройдет митап «Как устроена самая современная платежная система в МИРе: архитектура и безопасность».
Вместе с разработчиками Mир Plat.Form будем разбираться, как обеспечить устойчивость работы всех сервисов уже на этапе проектирования и как сделать так, чтобы система могла развиваться, не затрагивая бизнес-процессы. Митап будет интересен разработчикам, архитекторам и специалистам по безопасности.
Хотите бесплатно получить материалы конференции мини-конференции Saint HighLoad++ 2020? Подписывайтесь на нашу рассылку.
- реактивное программирование
- java
- конференция
- highload
- Блог компании Конференции Олега Бунина (Онтико)
- Высокая производительность
- Программирование
- Java
- Параллельное программирование
- 3.1 Суть реализаций