Методика расследования причин медленной работы Microsoft SQL Server
При оценке текущей нагрузки на Microsoft SQL Server, стандартные средства мониторинга (например, Task Manager) могут отобразить неверный результат. Microsoft SQL Server содержит в себе подсистему SQLOS – это надстройка над операционной системой (фактически ОС внутри Windows). SQLOS сама управляет: распределением памяти, состоянием процессов… Таким образом, оценка загрузки СУБД стандартными средствами Windows не отобразит реальной ситуации.
Подробнее про SQLOS:
Более правильный подход – оценивать проблему исходя из анализа «ожиданий».
Механизм ожиданий
Механизм ожиданий был изначально придуман разработчиками Microsoft SQL Server для того, чтобы самим понимать в каком месте проблема, т.е. это был некий отладочный механизм. По данной причине, ожидания были малоизвестны и практически не документированы.
Сейчас ситуация исправляется. Ожидания выходят на первый план при анализе работы Microsoft SQL Server.
Что внутри
Операции в Microsoft SQL Server (например, запросы) никогда не исполняются непрерывно от начала и до конца. Операция разбивается на мелкие кванты (около 4-х миллисекунд). Microsoft SQL Server циклично бежит по всем соединениям и исполняет по одному кванту из каждого. Данный подход обеспечивает работоспособность сервера при огромном количестве соединений.
Перед тем, как выполнить очередной квант, проверяется доступность необходимых ресурсов: диск, процессор, память, сеть, блокировки… Если необходимый ресурс недоступен, то соединение переходит в режим ожидания. При переходе в режим ожидания, соединение сигнализирует о том, какой ресурс ему необходим. Для каждого такого ожидания накапливается время простоя.
Когда ресурс будет освобожден, то процесс, освободивший ресурс, сигнализирует об этом. Выбирается следующий квант из очереди ожиданий данного ресурса, ресурс блокируется и квант исполняется.
Соответственно, собрав статистику по ожидаемым ресурсам, можно определить узкие места в работе СУБД.
Activity Monitor
Самым простым способом просмотра текущих ожиданий в Microsoft SQL Server, является утилита — «Activity Monitor». Открыть ее можно с помощью Management Studio.
Период обновления данных задается путем нажатия правой клавиши мыши в группе «Overview».
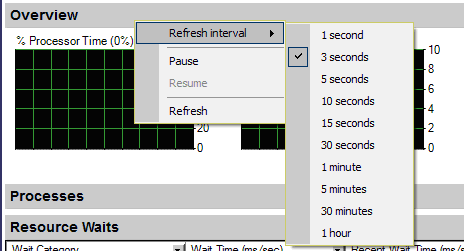
Overview
В группе «Overview» отображается информация:
• количество задач в состоянии ожидания ресурсов
• нагрузка на подсистему ввода-вывода
• число запросов в секунду
О проблемах в работе Microsoft SQL Server свидетельствует наличие значений на графике Waiting Tasks. Если значения есть, то необходимо раскрыть группу «Resource Waits».
Resource Waits
В группе «Resource Waits» отображаются типы ресурсов на которых возникают ожидания.
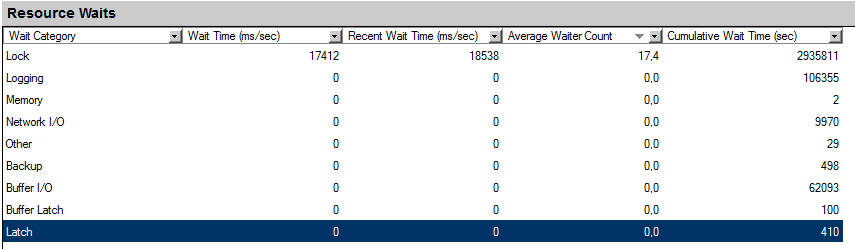
Таблицу необходимо упорядочить по убыванию значений колонки «Average Waiter Count».
Wait Time (ms/sec)
Время ожидания в «миллисекундах в секунду» с момента последнего обновления.
Recent Wait Time (ms/sec)
Самое большое среднее время ожидания ресурса в «миллисекундах в секунду» с момента последнего обновления.
Average Waiter Count
Среднее количество задач ждущих ресурсы данной категории за период перед последним обновлением Activity Monitor
Cumulative Wait Time (sec)
Накопленное время (в секундах) ожидания ресурсов данной категории с момента старта SQL Server или с момента принудительной очистки статистики по ожиданиям.
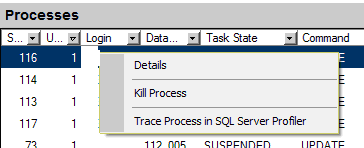
После определения категории проблемы, необходимо открыть группу «Processes».
Processes
В группе «Processes» отображается список текущих подключений к серверу БД и их состояние.
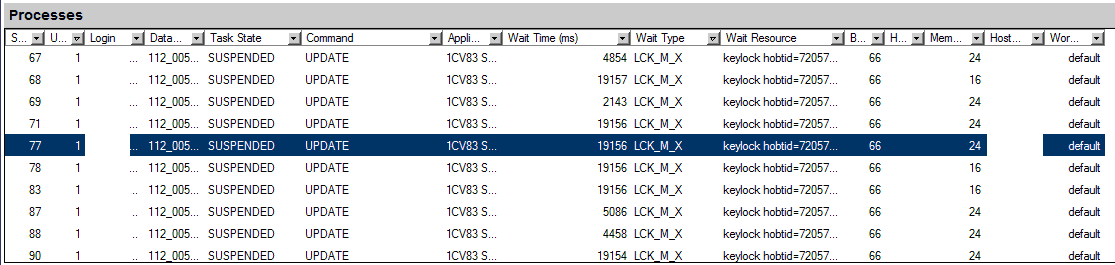
Необходимо установить отбор по колонке Wait Type в значение (NonBlanks). В таблице останутся только соединения, ожидающие освобождения ресурсов.
- dormant – идет перезапуск сессии.
- running – процесс сейчас работает (исполняет запросы).
- background – фоновый процесс (например, анализ deadlock graph)
- rollback – откат транзакции
- pending – ожидает предоставления рабочего потока
- runnable – стоит в очереди на исполнение
- suspended – ожидает ответа от ресурса, чтобы завершиться (например, ждет окончания записи данных на диск)
Колонка «Wait Time (ms)» показывает сколько миллисекунд соединение находилось в режиме ожидания ресурсов за период обновления.
Колонка «Wait Type» содержит имя ожидаемого ресурса.
По нажатию правой кнопки мыши на строке соединения, можно посмотреть текущий запрос или завершить это соединение
Для детального расследования причин медленной работы приложения с Microsoft SQL Server, необходимо ориентироваться на значение в колонке «Wait Type».
Разберем подробно основные типы ожиданий, характерные для 1С-Предприятия.
Типы ожиданий
Процессор
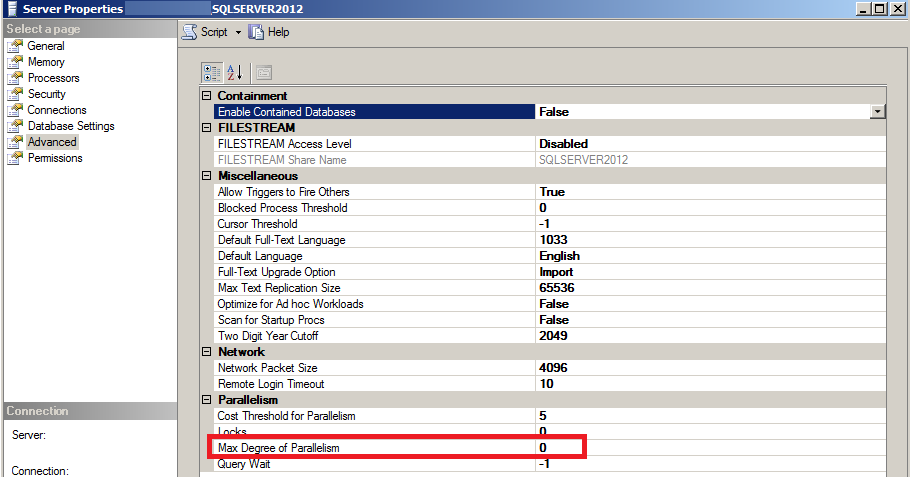
Ожидание CXPACKET в большинстве случаев возникает из-за настройки max degree of parallelism = 0. Значение настройки равное 0 устанавливается по умолчанию.
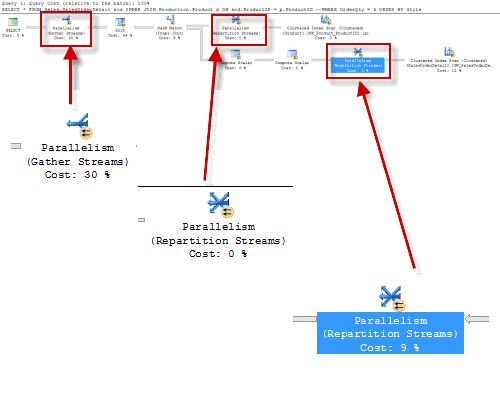
В этом случае, операции в плане запроса могут быть разбиты на несколько параллельных потоков. Каждый поток исполняется на отдельном ядре процессора. После того, как поток отработал, он отдает результат в операцию сведения потоков (Gather Streams), сервер не может исполнять запрос дальше, пока все остальные потоки не придут в операцию сведения. Ожидание запаздывающих потоков отображается как CXPACKET.
При этом ,стоит учесть, что запаздывающий поток может работать медленно, например, из-за того, что он выбрал обход сильно фрагментированной части индекса или ожидает отклика от системы ввода-вывода. Т.е. источником проблем может являться совсем не процессор. Однако, для более предсказуемого поведения сервера, стоит уменьшить параллельность операций, а потом разбираться с первопричиной возникновения ожидания CXPACKET (если в этом будет необходимость).
При возникновении данного типа ожидания, первым делом необходимо установить настройку max degree of parallelism = 1. Значение данной настройки большее 1 может быть полезно в системах, где нет большого числа мелких операций, а есть большие запросы, исполняемые небольшим количеством соединений (например, OLAP системы).
Внутренние ресурсы
Ожидания вида LATCH_* относятся к внутренним механизмам работы Microsoft SQL Server. Механизм latch (защелки) обеспечивает целостность внутренних структур данных, необходимых для работы сервера, путем наложения кратковременных блокировок.
Данный тип ожиданий плохо описан. В случае, когда ожидание LATCH_* является проблемой, можно попытаться найти его описание в интернете. Если описание не найдено, то необходимо обращаться в службу тех. поддержки Microsoft.
Подсистема ввода-вывода
PAGEIOLATCH_* — Соединение пытается заблокировать страницу данных (в буферном пуле), которая в этот момент либо обновляется с диска, либо сбрасывается на диск. Кратковременные ожидания не являются проблемой. Длительное время ожидания указывает на проблему в дисковой подсистеме, на которой расположены файлы данных (.mdf).
Длительное ожидание WRITELOG указывает на медленную работу дисковой подсистемы, где расположен журнал транзакций.
Очень часто встречается ошибочное мнение, что скорость дисковой подсистемы для журнала транзакций не важна. Однако, согласно рекомендации от Microsoft время отклика «диска» с файлами базы данных должно составлять 10-20 миллисекунд, а «диска» с файлами журнала транзакций 1-5 мс (подробнее про оценку скорости отклика дисковой подсистемы см. http://social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx).
Ожидание LOGBUFFER это следствие ожидания WRITELOG. После COMMIT TRANSACTION необходимая информация, для записи в журнал, помещается в буфер (LOGBUFFER). Из этого буфера она должна быть сброшена на диск. Если Microsoft SQL Server не успевает сбрасывать транзакции из буфера на диск (ожидание WRITELOG), то буфер переполняется и транзакции не могут поместить в него новые данные. В этот момент весь сервер «останавливается» и начинает заниматься только сбросом буфера транзакций на диск.
IO_COMPLETION появляется, чаще всего, если дисковая подсистема работает недостаточно быстро при операциях:
• создание базы данных
• операция Sort при исполнении запроса
Большое значение ASYNC_IO_COMPLETION может указывать, что происходит слишком частое расширение файлов журналов транзакций (см. свойства базы данных).
Операция расширения файлов (Autogrows) – крайне затратная. После того, как выделено новое место на диске, Microsoft SQL Server начинает «забивать» это пространство нулями. В этот момент ни одна транзакция не может изменить данные в базе.
Чтобы избежать операции очистки нового пространства, необходимо использовать механизм мгновенной инициализации файлов (Instant File Initialization
https://msdn.microsoft.com/en-us/library/ms175935.aspx). Instant File Initialization не работает при расширении журнала транзакций, поэтому размер журнала транзакций следует устанавливать достаточным для накопления в нем информации о транзакциях (без расширения файла) до выполнения операции backup, которая уберет из журнала все «старые» транзакции.
Для того, чтобы определить файлы с максимальной нагрузкой, можно воспользоваться группой Data File I/O в Activity Monitor.
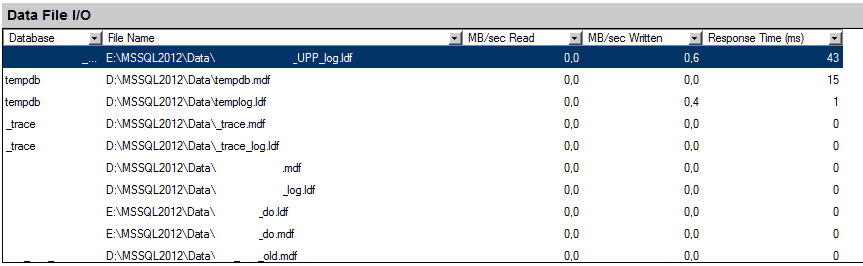
Сеть
Ожидание ASYNC_NETWORK_IO появляются когда Microsoft SQL Server отдает результат запроса приложению, но приложение забирает его медленно. Это может указывать как на проблемы с сетью, так и на проблемы с производительностью приложения. Для начала необходимо посмотреть загрузку канала между сервером баз данных и приложением. Если канал не загружен, то разбираться с приложением.
Блокировки
Ожидания LCK_* указывают на конфликты блокировок. Методы устранения конфликтов блокировок описаны в статьях :
Память
RESOURCE_SEMAPHORE возникает, чаще всего, когда в запросе есть операции Hash или Sort и сервер решает, что для выполнения этой операции необходимо дополнительно выделить память. Постоянное наличие данного типа ожидания может свидетельствовать о нехватке оперативной памяти.
«Не опасные» ожидания
Существует множество ожиданий, наличие которых не является проблемой. Например, SLEEP_TASK означает, что задача находится в неактивном состоянии и ждет события на «пробуждение». Такие типы ожиданий, как правило, имеют огромное время ожидания, что вызывает беспокойство у начинающих администраторов баз данных.
Примерный перечень таких ожиданий:
BROKER_TASK_STOP, BROKER_TO_FLUSH, BROKER_TRANSMITTER, CHECKPOINT_QUEUE, CHKPT, CLR_AUTO_EVENT, CLR_MANUAL_EVENT, CLR_SEMAPHORE, DBMIRROR_DBM_EVENT, DBMIRROR_EVENTS_QUEUE, DBMIRROR_WORKER_QUEUE, DBMIRRORING_CMD, DIRTY_PAGE_POLL, DISPATCHER_QUEUE_SEMAPHORE, EXECSYNC, FSAGENT, FT_IFTS_SCHEDULER_IDLE_WAIT, FT_IFTSHC_MUTEX, HADR_CLUSAPI_CALL, HADR_FILESTREAM_IOMGR_IOCOMPLETION, HADR_LOGCAPTURE_WAIT, HADR_NOTIFICATION_DEQUEUE, HADR_TIMER_TASK, HADR_WORK_QUEUE, KSOURCE_WAKEUP, LAZYWRITER_SLEEP, LOGMGR_QUEUE, ONDEMAND_TASK_QUEUE, PWAIT_ALL_COMPONENTS_INITIALIZED, QDS_PERSIST_TASK_MAIN_LOOP_SLEEP, QDS_CLEANUP_STALE_QUERIES_TASK_MAIN_LOOP_SLEEP, REQUEST_FOR_DEADLOCK_SEARCH, RESOURCE_QUEUE, SERVER_IDLE_CHECK, SLEEP_BPOOL_FLUSH, SLEEP_DBSTARTUP, SLEEP_DCOMSTARTUP, SLEEP_MASTERDBREADY, SLEEP_MASTERMDREADY, SLEEP_MASTERUPGRADED, SLEEP_MSDBSTARTUP, SLEEP_SYSTEMTASK, SLEEP_TASK, SLEEP_TEMPDBSTARTUP, SNI_HTTP_ACCEPT, SP_SERVER_DIAGNOSTICS_SLEEP, SQLTRACE_BUFFER_FLUSH, SQLTRACE_INCREMENTAL_FLUSH_SLEEP, SQLTRACE_WAIT_ENTRIES, WAIT_FOR_RESULTS, WAITFOR, WAITFOR_TASKSHUTDOWN, WAIT_XTP_HOST_WAIT, WAIT_XTP_OFFLINE_CKPT_NEW_LOG, WAIT_XTP_CKPT_CLOSE, XE_DISPATCHER_JOIN, XE_DISPATCHER_WAIT, XE_TIMER_EVENT
Получение статистики по ожиданиям запросом
WITH ByWaitTypes([Тип ожидания], [ожидания сигнала %], [ожидания ресурса %], [ожидания ms]) AS ( SELECT TOP 20 wait_type , cast(100.0 * sum(signal_wait_time_ms)/sum(wait_time_ms) AS NUMERIC (20,2)) , cast(100.0 * sum(wait_time_ms - signal_wait_time_ms)/sum(wait_time_ms) AS NUMERIC(20,2)) , sum(wait_time_ms) FROM sys.dm_os_wait_stats WHERE wait_time_ms > 0 AND wait_type NOT LIKE '%SLEEP%' GROUP BY wait_type ORDER BY sum(wait_time_ms) DESC ) SELECT TOP 1 'Тип ожидания' = N'BCE!' , 'ожидания сигнала %' = (SELECT cast(100.0 * sum(signal_wait_time_ms)/ sum (wait_time_ms) AS NUMERIC (20,2)) FROM sys.dm_os_wait_stats) , 'ожидания ресурса %' =(SELECT cast(100.0 * sum(wait_time_ms - signal_wait_time_ms)/ sum(wait_time_ms) AS NUMERIC(20,2)) FROM sys.dm_os_wait_stats) , 'ожидания ms' =(SELECT sum(wait_time_ms) FROM sys.dm_os_wait_stats) FROM sys.dm_os_wait_stats UNION SELECT [Тип ожидания], [ожидания сигнала %], [ожидания ресурса %], [ожидания ms] FROM ByWaitTypes ORDER BY [ожидания ms] DESC
Ожидания, полученные данным запросом, являются накопительными, т.е. данные по ним суммируются с момента старта Microsoft SQL Server.
Чтобы сбросить статистику по ожиданиям, необходимо выполнить команду:
DBCC SQLPERF ('sys.dm_os_wait_stats', CLEAR); GO
Административное подключение
В ситуации, когда Microsoft SQL Server критично загружен и нет возможности подключиться, однако необходимо диагностировать проблему или удалить соединение, создавшее нагрузку, можно воспользоваться выделенным административным подключением «diagnostic connection for administrators (DAC)». Под это подключение выделены отдельные ресурсы, которые не могут быть заняты ни каким другим соединением. По умолчанию, соединение разрешено только из клиента, запущенного на сервере. Сетевые подключения не разрешаются, пока они не включены с помощью хранимой процедуры sp_configure с параметром «remote admin connections».
EXEC sp_configure ‘remote admin connections’
При разрешенных сетевых административных подключениях, к Microsoft SQL Server можно подключиться через Management Studio, указав в имени сервера префикс «admin:» (admin:).
Перевод: Как MS SQL Server выполняет запросы. Часть 3
Завершающая часть перевода – здесь будут разобраны блокировки, процесс записи изменённых данных, а также дополнительные команды SQL Server.
Предыдущие части перевода:
- Перевод: Как MS SQL Server выполняет запросы. Часть 1
- Перевод: Как MS SQL Server выполняет запросы. Часть 2
«латчи» (Latches): защита конкурентного доступа к страницам.
Перед тем, как разбираться с механизмом записи данных, важно изучить механизм, призванный гарантировать, что с диска всегда будут считаны корректные данные. В многопоточной среде всегда важно следить за тем, чтобы «читатели» не могли увидеть данные из незавершённой транзакции записи. Всем программистам знакомы примитивы, реализующие такие проверки: мютексы, семафоры, критические секции. В терминах баз данных устоялся термин «латч» («защёлка», latch). Латчи – это структуры, которые контролируют конкурентный доступ к ресурсам. Например, каждая страница в Buffer pool должна иметь латч для контроля доступа и поддержания консистентности данных.
Латчи поддерживают несколько видов доступа: разделённый (shared), эксклюзивный (exclusive), доступ для обновления (update), удерживающий доступ (keep) и доступ для удаления (destroy). Ниже приведена таблица совместимости видов доступа.
KP
SH
UP
EX
DT
KP
SH
UP
EX
DT
Когда оператору доступа к данным требуется получить доступ к странице (например, чтобы сравнить значения ключей или чтобы прочитать строку), он должен получить латч в SH-режиме. Несколько операторов могут прочитать одну и ту же страницу одновременно, поскольку все они могут обратиться к странице в SH-режиме, не блокируя друг друга.
Любой оператор, которому потребуется изменить содержимое страницы, должен получить EX-латч. В каждый момент времени только один оператор может менять содержимое страницы – и ни один оператор не может прочитать её содержимое, пока изменение не будет завершено.
Эти два типа латчей будут отражены в статистике ожиданий как PAGELATCH_SH и PAGELATCH_EX. В статье Diagnosing and Resolving Latch Contention on SQL Server разобрано больше деталей этого механизма, в том числе:
- как латчи защищают обращения ввода-вывода (в результате страница считывается с диска только один раз, даже не смотря на то, что нескольким потокам может потребоваться считать её с диска одновременно)
- а также как в многопроцессорных системах суперлатчи (superlatches) используются для защиты от порчи процессорного кэша.
Важно не путать защиту физических ресурсов, которой занимаются латчи, с логической защитой, которой занимаются блокировки (locks). Клиент может управлять блокировками (например, с помощью выбора уровня изоляции транзакций), в то время, как латчи будут накладываться в любом случае.
Блокировки.
В то время, как латчи реализуют физическую защиту конкурентного доступа между потоками, блокировки отвечают за логическую защиту доступа между транзакциями:
Логическая и физическая защита:
Блокировки описывают заблокированную сущность, но сами они не являются сущностью. Это всего лишь 6-байтовая строка, которая описывает, что именно было заблокировано. Латчи – это самые настоящие объекты в памяти, которые могут быть заблокированы. Для того, чтобы получить, «захватить», латч, выполняемый код должен каким-то образом получить ссылку (указатель, адрес) на нужный объект латча. А для того, чтобы выполнить блокировку, коду достаточно сконструировать 6-байтовую строку, описывающую блокируемый объект, и затем запросить блокировку у менеджера блокировок.
Потоки и транзакции:
Латчи захватываются и освобождаются потоками (thread), существующими в рамках процесса. Блокировки захватываются и освобождаются транзакциями. Это важное отличие, поскольку транзакция может состоять из нескольких запросов, кроме того, транзакция может выполняться в контексте разных потоков (thread): либо одновременных, если мы говорим о параллельном выполнении, либо последовательных, если каждый из последовательных запросов транзакции был «подхвачен» разными рабочими потоками (workers)
Блокировки организованы более сложно, чем латчи. Не в последнюю очередь потому, что существует 22 типа блокировок, описанных в статье на Microsoft Docs. Добавьте сюда загадочные названия, наподобие SCH-S, SIX или RX-U – и станет понятно, почему тема блокировок кажется такой сложной. Попробуем немного прояснить, что именно означают эти множества видов блокировок.
Стабильность схемы (Schema Stability)
Во время выполнения плана запроса СУБД ожидает, что объекты, на которые ссылается план (т.е. таблицы, представления и т.п.) не будут менять свою структуру и не будут удалены кем-нибудь. Для того, чтобы гарантировать, что такие изменения не случатся, каждый запрос ещё до начала выполнения накладывает упреждающие блокировки «стабильности схемы» на все объекты, упоминаемые в плане. Это и есть SCH-S— блокировки.
DDL-команды (то есть, команды, изменяющие метаданные) будут накладывать блокировку модификации схемы: SCH-M. Это самая мощная блокировка (т.е. с максимальными ограничениями и с минимальной совместимостью). Эта блокировка гарантирует, что ни одна другая сессия не сможет даже ссылаться на изменяемый объект.
На практике большинство запросов не накладывает SCH-S блокировку, вместо этого используются аналоги – блокировки намерения (см. ниже, например *_IS)
Разделяемые блокировки, блокировки обновления и эксклюзивные блокировки (Shared, Update, Exclusive)
Это базовые режимы блокировок: S (shared, разделяемая), U (update, обновления) и X (eXclusive, исключительная). S- и X-блокировки самоочевидны. U-блокировка накладывается на данные, которые могут быть позже изменены или удалены (соответственно, при этом блокировка будет обновлена до X).
Наложение U-блокировки не блокирует другие чтения (S-блокировки), но не позволяет наложить U-блокировку из другой сессии. Если бы U-блокировок не было, две сессии могли бы попасть в дедлок в тот момент, когда пробовали бы одновременно обновить S-блокировку до X-блокировки. С другой стороны, если бы оператор UPDATE сразу накладывал X-блокировку на все считываемые записи, даже на те, которые потом не придётся изменять – мы бы получили избыточные блокировки других читающих сессий.
Иерархия блокировок и блокировки намерения.
Все блокировки, в названии которых есть буква I – это блокировки намерения (intent). Для того, чтобы понять их назначение, необходимо разобраться в иерархии блокировок.
Предположим, у нас есть запрос, который собирается просканировать всю таблицу, содержащую несколько миллионов строк. Если бы этот запрос накладывал блокировки на каждую из считываемых строк, пришлось бы выполнить несколько миллионов обращений за блокировками – а это довольно расточительно с точки зрения потребляемых ресурсов. Да, наложение блокировки – это быстро, но даже «быстро» суммируется в заметное время, если повторить это миллион раз. Поэтому запрос решает «сэкономить» и вместо блокировки отдельных строк накладывает всего одну S-блокировку, но сразу на объект таблицы.
Другой запрос, работающий параллельно, хочет удалить одну строку из таблицы – поэтому он запрашивает X-блокировку на эту строку. И вот тут возникает проблема: каким образом менеджер блокировок должен понять, что нельзя предоставлять X-блокировку на строку, т.к. другая сессия уже запросила S-блокировку на всю таблицу? Мы ведь помним, что блокировки – это просто строки, которые описывают, что было заблокировано. И по содержимому этих строк менеджер блокировок никак не может узнать, что строка, запрашиваемая для X-блокировки принадлежит таблице, на которую наложена S-блокировка. Строки, описывающие эти блокировки, описывают объекты на разных уровнях иерархии.
Тут и пригождаются блокировки намерения. Начнём с того, что операторы доступа к данным, которые запрашивают блокировки, знают иерархию блокируемых элементов. Тот же оператор изменения знает, что изменяемая строка принадлежит определённой таблице. Поэтому в обязанности оператора доступа к данным входит запрос блокировки намерения к родительскому объекту (или объектам) в иерархии. Получается, оператор изменения сначала запросит IX-блокировку на объект таблицы. Такая блокировка будет означать буквально следующее: «я не буду блокировать всю таблицу, но где-то внутри неё могут быть строки, на которые я наложу X-блокировку». IX-блокировка несовместима с S-блокировкой, которую наложила первая сессия. Проблема решена: «скрытый» конфликт блокировок становится явным, соответственно, одна сессия блокирует другую, пока не выполнит все свои действия. И теперь когда вы увидите, например, «SIX-блокировку», вы поймёте, что это означает: «Я выполнил S-блокировку на объект таблицы, но вместе с тем я могу заблокировать какие-то отдельные строки в X-режиме»
Блокировки диапазонов ключей (Key-range locks)
Режимы блокировок, содержащие в названии R – это блокировки диапазонов (range). Такие блокировки защищают строки, которые ещё не существуют. SQL Server использует блокировки диапазонов чтобы реализовать последовательный (SERIALIZABLE) уровень изоляции транзакций. Дело в том, что уровень SERIALIZABLE требует, чтобы два вызова одного и того же запроса в транзакции возвращали одинаковый результат: никаких новых или потерянных строк. Получается, нужно контролировать не только считанные строки, но и интервалы между ними – чтобы никакой INSERT не смог «протащить» новые строки в диапазон, уже считанный в нашей транзакции. Именно для этого и применяются блокировки диапазона. Больше подробностей о таких блокировках — в статье Key-Range Locking
Запись данных
Операторы изменения данных на самом деле во многом схожи с операторами чтения, разобранными нами ранее. Каждый раз, когда у такого оператора вызывают метод next(), он должен найти нужную строку (или, для INSERT, найти позицию для вставки новой строки) – и затем выполнить необходимые изменения. Когда next() вызовут в следующий раз – выполнить модификацию следующей строки. И так далее.
Операторы удаления (delete) и изменения (update) обычно управляются другими операторами чтения, которые находят нужные строки и передают оператору изменения указатели на конкретную строку.
Сами по себе операции вставки, удаления или изменения строк несколько более сложны, чем операции чтения. Это связано с тем, что SQL Server использует упреждающее логирование изменений (Write Ahead Logging). Любая операция модификации данных должна быть в первую очередь записана в лог транзакций.
Грубо говоря, все изменения происходят в следующей последовательности:
- Оператор изменения «позиционируется» на странице, которую он должен изменить (то есть, строка должна быть добавлена, удалена или изменена именно на этой странице). Для этого нужная страница должна оказаться в Buffer pool.
- Оператор изменения получает эксклюзивный латч на изменяемую страницу. Это означает, что ни один другой оператор не сможет считать изменяемую страницу.
- Оператор изменения добавляет в лог транзакций запись, в точности описывающую, что и как оператор собирается изменить на странице.
- После этого оператор может изменить страницу в памяти (Buffer pool). Страница на диске в этот момент не меняется!
- В момент создания записи в логе транзакций оператор получает LSN (Log sequence number) – номер операции внутри лога транзакций. Этот LSN записывается в заголовок изменяемой страницы в поле «LSN последнего изменения» (last modified LSN)
- В момент создания записи в логе транзакций оператор получает LSN (Log sequence number) – номер операции внутри лога транзакций. Этот LSN записывается в заголовок изменяемой страницы в поле «LSN последнего изменения» (last modified LSN)
- Снимается эксклюзивный латч на страницу. Теперь страница может быть прочитана другими транзакциями (например, в режиме Read Uncommitted). Важно понимать, что до сих пор ни одного байта не было записано на диск – все изменения происходили в памяти.
- Перед тем, как изменяющая транзакция будет завершена, она должна создать новую запись лога, фиксирующую факт, что транзакция зафиксирована (committed). Эта запись добавляется в лог транзакций и после этого она и все предшествующие записи лога (в рамках транзакции) должны быть записаны на диск – в файл лога транзакций. Изменяемая страница в этот момент всё еще не записана на диск, её изменения остаются только в памяти. Но сама транзакция с этого момента становится надёжной (durable): даже если служба SQL Server упадёт, информация об изменениях на странице хранятся в логе транзакций, процесс запуска БД прочитает её и повторит нужные действия
- Периодически (но не сразу по окончании транзакции) изменения в страницах записываются на диск, в файл данных. Эта операция называется CHECKPOINT.
Кроме того, есть отдельный вид операции записи, который работает по другому алгоритму: операции с минимальным логированием. Так могут работать только операции, вставляющие новые данные: INSERT или синтаксис .WRITE(@value, NULL) оператора UPDATE (и то, только в случае добавления BLOB-полей). Для того, чтобы транзакция могла использовать минимальное логирование, она должна отвечать дополнительным условиям, см. «Operations that can be minimally logged» и «Data loading performance guide».
Последовательность операций при записи с минимальным логированием будет примерно следующей:
- Оператор, выполняющий операцию вставки, выделяет место под новую страницу. Для понимания процесса выделения места под страницы можно изучить статью Managing Extent Allocations and Free Space
- Оператор помещает страницу в Buffer pool и получает эксклюзивный латч на неё.
- Создаётся запись лога транзакций, фиксирующая, что новая страница используется для операции вставки с минимальным логированием. Эта запись добавляется в лог (в памяти), а LSN записи помещается в заголовок новой страницы как LSN последнего изменения.
- Страница добавляется в список страниц с минимальным логированием, связанных с текущей транзакцией.
- Теперь оператор может добавить на страницу столько строк, сколько поместится. Ему не требуется создавать записи лога для каждой добавляемой записи. В этот момент изменяется только образ новой страницы в памяти, на диск пока ничего не пишется.
- Когда страница заполняется, выделяется новая страница – и описанные выше шаги повторяются.
- Перед тем как транзакция с минимальным логированием будет зафиксирована, все страницы, изменённые с минимальным логированием, должны быть записаны на диск. Только после того, как все эти страницы будут записаны, создаётся новая запись лога, подтверждающая, что транзакция зафиксирована. И после этого все записи лога, описывающие транзакцию, должны быть записаны на диск, в файл лога.
- Для того, чтобы массовая запись страниц на диск не положила дисковую подсистему специальный фоновый процесс «жадной записи» переносит их на диск ещё до завершения транзакции.
Операции с минимальным легированием остаются полностью транзакционными, целостными и надёжными. В любой момент выполнения такая операция может быть отменена (откачена, rolled back). Сервер СУБД может даже завершиться крэшем во время выполнения такой операции – и всё равно база останется в целостном состоянии (после завершения recovery, восстановления во время запуска)
Точно так же, как и обычные операции, операции с минимальным логированием детально описаны в статье SQL Server 2000 I/O Basics.
DDL
Не все T-SQL-выражения выполняются как последовательный перебор операторов из плана выполнения. Типичный пример такого исключения – DDL-команды (например, CREATE TABLE).
Для понимания того, как работают DDL-команды важно знать, что SQL Server сохраняет все метаданные о существующих объектах в специальных служебных таблицах. Получается, что вставка новой строки в, скажем, таблицу, хранящую список пользовательских таблиц, приведёт к тому, что SQL Server узнает о существовании новой таблицы. Вставка строки в таблицу, хранящую сведения о колонках таблиц, приведёт к появлению новой колонки у нашей новой таблицы. Выполнение команды DROP приведёт к удалению строк из соответствующих системных таблиц. Все объекты, с которыми работает SQL Server, описаны в таких системных таблицах. Более 80 таких таблиц содержат сведения о таблицах, колонках, индексах, схемах, процедурах, представлениях и т.д. – то есть, буквально, о каждом аспекте SQL Server. Получается, что всё, что требуется от DDL-команд – это поддерживать актуальность таких системных таблиц. CREATE TABLE нужно добавить строку в таблицу, описывающую пользовательские объекты (ведь таблица – это не единственный возможный вид объекта) и несколько строк в таблицы, описывающие колонки – вуаля, новая таблица готова! (Помните, что здесь я сильно упрощаю весь процесс).
Несмотря на то, что DDL-команды не используют операторы доступа или изменения данных, которые мы рассмотрели ранее, внутри DDL-команд используется точно такой же код, который находит и изменяет нужные строки в таблицах. Когда DDL-команда выполняется, она не будет вызывать метод next() у оператора поиска — вместо этого она использует точно такой же код, что и у оператора Seek, чтобы найти нужную строку в системной таблице.
Большинство DDL-команд выполняют свою полезную работу просто добавляя, удаляя или изменяя записи в системных таблицах. Но есть отдельные операторы, которые не только работают с системными таблицами, но и, например, обращаются к файловой системе, чтобы выделить место для новой базы данных. Или обращаются к API кластеризации Windows чтобы настроить группу доступности AlwaysOn. И отдельные команды могут обращаться к самим пользовательским таблицам чтобы установить значения по умолчанию или проверить, отвечают ли существующие значения новым ограничениям (check constraint)
BACKUP, RESTORE и DBCC
После того, как мы рассмотрели основные группы операторов – DDL и DML – осталось несколько специальных команд.
BACKUP и RESTORE в своей работе не учитывают практически ничего из того, что мы обсуждали в этой статье. Если смотреть с высоты птичьего полёта, всё, что они делают – просто копируют данные из одних файлов в другие. BACKUP читает данные из файлов данных и логов транзакций и записывает их в файл бэкапа, RESTORE – ровно наоборот. В своей работе эти команды обращаются и к некоторым системным таблицам, но большую часть времени они просто копируют данные из одного файла в другой. Важно, что это копирование происходит без участия Buffer Pool – то есть, бэкап не сможет выдавить из кэша накопленные данные.
(прим. переводчика: на самом деле RESTORE – это не только ценный мех копирование данных; RESTORE запускает процесс восстановления (recovery) базы данных, о котором тоже есть что рассказать. К счастью, всё уже подробно описано в Microsoft Docs – рекомендую изучить эту статью чтобы понимать, из чего складывается время запуска базы данных).
Что же до команд DBCC – каждая из них работает по-своему и выполняет разные задачи. Для примера можно изучить описание работы DBCC CHECKDB в цикле статей CHECKDB from every angle.
Как я могу использовать эту информацию?
У разработчиков, взаимодействующих с базами данных, обычно две главных проблемы: производительность запросов и сохранность данных в случае сбоя. Эта статья никак не поможет со второй проблемой – если у вас нет бэкапа, ничто вас не спасёт. Но, я надеюсь, что понимание того, как работает SQL Server прольёт свет на проблемы производительности.
Как только вы поймёте, что клиент отправляет запрос к СУБД и на каждый запрос создаётся своя задача, весь гордиев узел проблем производительности сильно упростится: в любой момент ваша задача либо выполняется (то есть, использует процессорное время), либо ждёт. И каждый раз, когда задача чего-то ждёт, информация об этом ожидании (чего именно ждали и как долго) попадает во внутреннюю статистику ожиданий, собираемую SQL Server. Есть отличная методичка о том, как использовать эту статистику ожиданий для расследования проблем производительности: Waits and Queries. Если из всех упомянутых ссылок из этой статьи вы откроете только одну – я бы хотел, чтобы это была ссылка на эту методичку.
- sql server
- query performance
Oracle latches. Как узнать количество защелок в запросах?
Защелки — это блокировка словарей данных. И также как и обычная блокировка строки влияет на время выполнения запроса. Чем больше защелок — тем дольше выполняется запрос.
Далее мы разберем как узнать их количество — эта информация поможет в анализе производительности запросов, поможет выявить слабые места.
Описание компонентов
v$latch
Представление выводит информацию о защелках по последней выполненной транзакции. Группируя информацию о родительской и дочерней защелке. Состоит из следующих полей:
| Поле | Тип | Описание |
|---|---|---|
| addr | raw(4|8) | адрес защелки |
| latch# | number | идентификатор защелки |
| level# | number | уровент защелки |
| name | varchar2(64) | имя защелки |
| hash | number | хэш защелки |
| gets | number | количество запросов на защелку в режиме ожидания |
| misses | number | cколько раз была запрошена защелка в режиме ожидания, и запрашивающая сторона должна была ждать |
| sleeps | number | количество раз, когда запрос защелки с ожиданием приводил к спящему сеансу в ожидании защелки |
| immediate_gets | number | количество запросов на защелку в режиме без ожидания |
| immediate_misses | number | количество раз, когда запрос блокировки без ожидания не удался (то есть был пропущен) |
| waiters_woken | number | неподдерживаемый Oracle столбец, всегда будет равен 0 |
| waits_holding_latch | number | неподдерживаемый Oracle столбец, всегда будет равен 0 |
| spin_gets | number | запросы с готовностью подождать защелки, которые пропустили первую попытку, но были успешными во время вращения |
| sleep1-11 | number | неподдерживаемые Oracle столбцы, всегда будут равны 0 |
| wait_time | number | время ожидания защелки (в микросекундах) |
| con_id | number | идентификатор контейнера (для мультиарендной контейнерной базы данных CDB) |
Права
Для выполнения представления у пользователя (в моем случае PROD) должен быть доступ на все таблицы, подключаемся к БД с помощью пользователя SYS с ролью SYSDBA и выполняем скрипты ниже:
grant select on v_$latch to prod;
Пример измерения количества защелок
Получение количества одной защелки
Рассмотрим как узнать конкретную защелку DML lock allocation (Распределение блокировки DML). В примере показанном ниже, будут меняться ранее сгенерированные данные, умышленно будет добавлен rollback в цикл, чтобы увидеть защелки.
—включаем вывод данных в output set serveroutput on; declare v_get_before number; —количество защелок ДО v_get_after number; —количество защелок ПОСЛЕ v_get_result number; —разница защелок ДО и ПОСЛЕ, итог v_latch_name varchar2(255 char) := ‘DML lock allocation’; —имя защелки begin —фиксируем количество защелок ДО select l.gets into v_get_before from v$latch l where l.name = v_latch_name; —запустим 1000 раз цикл, который обновит дату у первых попавшихся строк for rec in 1..1000 loop update prod.operation set op_date = trunc(sysdate) where rownum = 1 and op_date != trunc(sysdate); —сразу откатываем изменения rollback; end loop; —фиксируем количество защелок ДО select l.gets into v_get_after from v$latch l where l.name = v_latch_name; —считаем общее время выполнения в сотых долях секунды v_get_result := v_get_after — v_get_before; —выводим результат на экран dbms_output.put_line(‘Зарос 1.’ || v_latch_name || ‘: ‘ || to_char(v_get_result)); —ДАЛЕЕ ВСЕ ТОЖЕ САМОЕ ТОЛЬКО УБИРАЕМ ROLLBACK ИЗ ЦИКЛА select l.gets into v_get_before from v$latch l where l.name = v_latch_name; for rec in 1..1000 loop update prod.operation set op_date = trunc(sysdate) where rownum = 1 and op_date != trunc(sysdate); end loop; rollback; select l.gets into v_get_after from v$latch l where l.name = v_latch_name; v_get_result := v_get_after — v_get_before; dbms_output.put_line(‘Зарос 2.’ || v_latch_name || ‘: ‘ || to_char(v_get_result)); end;

Результат:
Получение количества всех защелок
Усложним задачу, чтобы видеть все защелки по двум запросам и сразу выводить по ним разницу для этого:
- Необходимо добавить себе программу по сбору и сравнению статистики, если уже есть, идем далее.
- Расширим наше представление prod.stats_vw , добавив в конце 4-й скрипт вывода информации о защелках:
create or replace view prod.stats_vw as —первый скрипт по выводу статистики select ‘STAT’ as inf_type, — для inf_type в stats_tbl a.name as name, — для name в stats_tbl b.value as value — для value в stats_tbl from v$statname a join v$mystat b on a.statistic# = b.statistic# —команда объединения union all —второй скрипт по фиксации общего времени select ‘ETIME’, — сокращенно от Elapsed time (общее время) ‘Elapsed Time’, hsecs from v$timer —команда объединения union all —третий скрипт по фиксации времени CPU select ‘CTIME’, —сокращенно от CPU time (время ЦПУ) ‘CPU Time’, dbms_utility.get_cpu_time from dual —команда объединения union all —четвертый скрипт по фиксации защелок select ‘LATCH’, —сокращенно от CPU time (время ЦПУ) l.name, l.gets from v$latch l;
begin —фиксируем начало работы fix_inf_prc(1,’before’); —ROLLBACK в конце for rec in 1..1000 loop update prod.operation set op_date = trunc(sysdate) where rownum = 1 and op_date != trunc(sysdate); end loop; rollback; —фиксируем завершение работы fix_inf_prc(1,’after’); —фиксируем начало работы fix_inf_prc(2,’before’); —ROLLBACK в цикле for rec in 1..1000 loop update prod.operation set op_date = trunc(sysdate) where rownum = 1 and op_date != trunc(sysdate); rollback; end loop; rollback; —фиксируем завершение работы fix_inf_prc(2,’after’); —вывести отчет stats_report_prc(1000); —показывать значение, отличающиеся на 1000 end;

Результат:
Статистика и виды ожиданий. День № 12 (PAGELATCH)


«PAGELATCH_DT, PAGELATCH_EX, PAGELATCH_KP, PAGELATCH_SH, PAGELATCH_UP»
Я часто вижу людей, которые не могут объяснить разницы в PAGEIOLATCH_X и PAGELATCH_X. А правильный ответ состоит в том, что PAGEIOLATCH относится к дисковым операциям, а PAGELATCH к памяти. Прежде чем пойдём дальше, позвольте мне объяснить что такое блокировки (latches).
Lathes — внутренние блокировки SQL Server, которые должны быть очень лёгкими и короткими. Lathes созданы не для блокировки данных на диске, а для распределения доступа к данных в памяти.
Lathes и Locks это два понятия, которые сильно могут поменять производительность сервера. Lathes происходят в страницах памяти, в то время как Locks накладывают блокировки на таблицы, строки и так далее.
ИЗ Book On-Line:
PAGELATCH_DT
Имеет место, когда задача ожидает кратковременной блокировки буфера, находящегося не в состоянии запроса ввода-вывода. Запрос на кратковременную блокировку производится в режиме удаления.
PAGELATCH_EX
Имеет место, когда задача ожидает кратковременной блокировки буфера, находящегося не в состоянии запроса ввода-вывода. Запрос на кратковременную блокировку производится в исключительном режиме.
PAGELATCH_KP
Имеет место, когда задача ожидает кратковременной блокировки буфера, находящегося не в состоянии запроса ввода-вывода. Запрос на кратковременную блокировку производится в режиме удержания.
PAGELATCH_SH
Имеет место, когда задача ожидает кратковременной блокировки буфера, находящегося не в состоянии запроса ввода-вывода. Запрос на кратковременную блокировку производится в режиме общего доступа.
PAGELATCH_UP
Имеет место, когда задача ожидает кратковременной блокировки буфера, находящегося не в состоянии запроса ввода-вывода. Запрос на кратковременную блокировку производится в режиме обновления.
Объяснение:
Когда происходит конкуренция доступа к страницам в памяти, появляется данный вид ожиданий. Скорее всего эта страница в памяти очень часто используется. SQL Server ждёт доступа к этим данным, чтобы положить latch. Часто такой вид блокировок может наблюдаться когда происходит конкуренция внутри TempDb. Если существуют индексы, которые очень часто используются, данный вид ожиданий так же может появиться.
Уменьшение ожиданий PAGELATCH_X:
Следующие виды конкуренции помогут понять ожидания PAGELATCH:
1. Average Latch Wait Time (ms): Время ожидания для запросов latch
2. Latch Waits/sec: Количество запросов latch, которые не могут быть наложены в данный момент
3. Total Latch Wait Time (ms): Общее количество latch в прошлую секунду
Если данные ожидания обнаружены в TempDb, то вам может помочь пост Pail Randal, который объяснит оптимальные настройки для данной базы (перейти). Флаг трассировки 1118 может помочь, но пользуйтесь им очень осторожно.
Заметка: Представленная тут информация является только моим опытом. Я настраиваю, чтобы вы читали Books On-Line. Все мои обсуждения ожиданий здесь носят общий характер и изменяются от системы к системе. Я рекомендую сначала тестировать всё на сервере разработки, прежде чем применять это на рабочем сервере.
Автор: Pinal Dave
Ссылка на наш канал YouTube