Упр. 8. Стр. 47
Слово теперь выводится по 2 буквы в каждую строку, поскольку в программу добавлено условие if i mod 2 = 0 then для переноса строки. Таким образом, перенос строки происходит только каждую вторую букву.
2. Измените программу из примера 8.3 так, как указано ниже.
1. Каждая буква должна выводиться своим цветом (можно использовать случайное задание цветов).
В цикле for будем задавать случайный цвет для буквы с помощью SetFontColor() , rgba() и random(255) .
uses GraphABC;
var
s: string; n: integer;
begin
writeln('Введи слово');
readln(s); writeln(s);
n := length(s);
for var i := 1 to n do
begin
SetFontColor(rgb(random(255), random(255), random(255)));
writeln(s[i]);
end;
end.
2. Буквы, стоящие на четных местах, должны выводиться одним цветом, а на нечетных — другим.
Изменим программу, чтобы буквы на чётных местах выводились красным цветом, а на нечётных — синим:
uses GraphABC;
var
s: string; n: integer;
begin
writeln('Введи слово');
readln(s); writeln(s);
n := length(s);
for var i := 1 to n do
begin
if i mod 2 = 0 then
begin
SetFontColor(clRed);
end
else
begin
SetFontColor(clBlue);
end;
writeln(s[i]);
end;
end.
3. Измените программу из примера 8.4 так, чтобы на экран выводился символ введенного слова, стоящий посередине (для слов с четным количеством букв — символ справа от середины).
Определим позицию середины с помощью целочисленного деления и прибавления единицы c := n div 2 + 1; .
var s: string; n, c: integer;
begin
writeln('Введи слово');
readln(s); n := length(s);
writeln('Символов: ', n);
c := n div 2 + 1;
writeln('Позиция середины: ', c);
writeln('Средний символ - ', s[c]);
end.
1-2. Проверьте правильность работы своей программы на предложенных примерах. Откройте файл с таблицей и запишите результаты. Допишите в таблицу два своих примера.
| Слово | Результат |
| Школа | о |
| гимназия | а |
| форма | р |
| Интернет | р |
| клавиатура | а |
| Деревня | е |
3. Что будет выведено, если ничего не вводить, просто нажать Enter?
Произойдёт ошибка, т.к. мы не сделали проверку ввода.
4. Проверьте, встречается ли выведенный символ в слове еще раз.
Проверка на существование ещё одного символа из примера 8.4 нам не подходит, т.к. в примере искался последний символ, а у нас нужно найти средний. Это значит, что для проверки существования ещё одного символа нужно проверить первой вхождение символа Pos() и последнее LastPos() , а потом сравнить полученные два значения: если они равны — значит мы нашли только наш средний символ и больше он не встречается в слове, если не равны — значит где-то существует ещё один символ.
var s: string; n, k, l, c, m: integer;
begin
writeln('Введи слово');
readln(s); n := length(s);
writeln('Символов: ', n);
c := n div 2 + 1;
writeln('Позиция середины: ', c);
writeln('Средний символ - ', s[c]);
k := Pos(s[c], s);
l := LastPos(s[c], s);
if k <> l then
writeln('Средний символ встречается ещё раз ')
else
writeln('Символ один')
end.
5. Выведите позиции всех символов, совпадающих с символом слова, находящимся посередине.
Будем записывать количество встречающихся символов в переменную m , не учитывая среднюю позицию — её записывать не будем. При каждой встрече нашего символа будем выводить соответствующее сообщение, а в конце, если символов не было найдено, т.е. если m = 0 , то выводим сообщение «Символ один».
var s: string; n, k, c, m: integer;
begin
writeln('Введи слово');
readln(s); n := length(s);
writeln('Символов: ', n);
c := n div 2 + 1;
writeln('Позиция середины: ', c);
writeln('Средний символ - ', s[c]);
for var i := 1 to n do
begin
if s[i] = s[c] then
begin
if c <> i then
begin
m := m + 1;
writeln('Символ встречается ещё раз на позиции ', i);
end
end
end;
if m = 0 then
writeln('Символ один')
end.
4. Измените программу из примера 8.4 так, чтобы строчные и заглавные буквы анализировались программой одинаково (например, для слова «Анна» ответ должен быть следующим: «Последний символ — а, символ встретился на месте 1»).
Слегка изменим нашу программу из примера 8.4 и при поиске других вхождение последнего символа обернём сам символ и строку в функцию LowerCase() , которая всегда возвращает строку в нижнем регистре (без больших букв). Таким образом, при поиске регистр букв для нас не будет иметь значения. Вместо функции LowerCase() можно использовать и UpperCase() , которая возвращает строку в верхнем регистре (заглавные буквы) — разницы нет.
var s: string; n, k: integer;
begin
writeln('Введи слово');
readln(s); n := length(s);
write('Последний символ - ', s[n], ', ');
k := pos(LowerCase(s[n]), LowerCase(s));
if k = n then
writeln('символ один')
else
writeln('символ встретился на месте ', k)
end.
5. Даны два слова. Верно ли, что одно из слов начинается на ту же букву, на которую заканчивается другое? (Первая буква одного из слов может быть заглавной.) Если да, то вывести букву, иначе — соответствующее сообщение.
Будем сравнивать последний символ первого слова с первым символом второго и наоборот.
var s1, s2: string; n1, n2: integer;
begin
writeln('Введи первое слово');
readln(s1); n1 := length(s1);
writeln('Введи второе слово');
readln(s2); n2 := length(s2);
if LowerCase(s1[n1]) = LowerCase(s2[1]) then
writeln('Второе слово начинается на ту же букву, на которую заканчивается первое: ', s2[1])
else if LowerCase(s1[1]) = LowerCase(s2[n2]) then
writeln('Первое слово начинается на ту же букву, на которую заканчивается второе: ', s1[1])
else
writeln('Неверно');
end.
1-2. Проверьте правильность работы своей программы на предложенных примерах. Откройте файл с таблицей и запишите результаты. Допишите в таблицу два своих значения.
| Слово 1 | Слово 2 | Результат |
| array | yellow | y |
| apple | auto | неверно |
| Рыба | Арбуз | а |
| школа | академия | а |
| Дом | комод | д |
3*. Если ответ «верно», указать, принадлежат ли буквы одному регистру.
Для выполнения этого задания нам нужно дополнительно сравнивать буквы без использования LowerCase() или UpperCase() .
var s1, s2: string; n1, n2: integer;
begin
writeln('Введи первое слово');
readln(s1); n1 := length(s1);
writeln('Введи второе слово');
readln(s2); n2 := length(s2);
if LowerCase(s1[n1]) = LowerCase(s2[1]) then
begin
writeln('Второе слово начинается на ту же букву, на которую заканчивается первое: ', s2[1]);
if s1[n1] = s2[1] then
writeln('Буквы принадлежат одинаковым регистрам')
else
writeln('Буквы принадлежат разным регистрам')
end
else if LowerCase(s1[1]) = LowerCase(s2[n2]) then
begin
writeln('Первое слово начинается на ту же букву, на которую заканчивается второе: ', s1[1]);
if s1[1] = s2[n2] then
writeln('Буквы принадлежат одинаковым регистрам')
else
writeln('Буквы принадлежат разным регистрам')
end
else
writeln('Неверно');
end.
6. Измените программу из примера 8.8 так, чтобы при k = 0 выводилось сообщение ‘Подстрока в строке не встречается’.
Для решения задачи добавим ещё одно условие для k = 0 .
var s, p, t: string;
n1, n2, k: integer;
begin
writeln('Cтрока s');
readln(s);
writeln('Подстрока p');
readln(p);
n1 := length(s);
n2 := length(p);
k := 0;
for var i := 1 to n1 - n2 + 1 do
begin
t := copy(s, i, n2);
if t = p then
k := k + 1;
end;
if k > 0 then
writeln('Встречается ', k, ' раз(-а)')
else
writeln('Подстрока в строке не встречается')
end.
7. Программу из примера 8.8 записали следующим образом:
var s, p, t: string;
k, i: integer;
begin
writeln('Строка s');
readln(s);
writeln('Подстрока p');
readln(p);
k := 0; i := 1;
while PosEx(p, s, i) <> 0 do
begin
i := PosEx(p, s, i) + 1; k := k + 1;
end;
writeln('Встречается', k, 'раз(-а)');
end.
Сравните эту программу и программу из примера 8.8, определив, сколько раз выполнится команда цикла в каждой из программ для перечисленных случаев.
- Строка s := «Не слово хозяин хозяину, а хозяин слову хозяин» , подстрока p := «хозяин» .
- Строка s := «Не слово хозяин хозяину, а хозяин слову хозяин» , подстрока p := «хозяйка» .
В первом случае цикл выполняется 41 раз в программе из примера 8.8, а в изменённой программе — всего 4 раза. Во втором случае цикл выполняется 40 раз в программе из примера 8.8, а в изменённой — ни одного раза.
*Можно ли подобрать тест, для которого количество выполнений цикла будет одинаковым для обеих программ? Если да, то какой?
Можно. Для этого нужно, чтобы строка s состояла только из подстрок p , например s := «ааааа» , подстрока p := «а» или s := «ааааа» , подстрока p := «аа» и т.д.
8. Получите из слова «ТЕСТИРОВАНИЕ» указанные слова. Для этого используйте команды: copy, delete, insert и операцию сложения строк.
var s, s1, s2, s3, s4, s5, s6: string;
begin
s := 'ТЕСТИРОВАНИЕ';
s1 := copy(s, 6, 2) + copy(s, 3, 2);
s2 := copy(s, 10, 2) + copy(s, 8, 2);
insert(s[3], s, 8);
insert(s[4], s, 9);
insert(s[2], s, 10);
insert(s[6], s, 11);
delete(s, 2, 5);
delete(s, 7, 6);
s4 := s;
s3 := copy(s, 1, 2) + copy(s2, 3, 2) + copy(s1, 1, 1);
delete(s, 10, 3);
insert(s[6], s, 10);
delete(s, 2, 5);
s5 := copy(s1, 2, 1) + copy(s1, 4, 1) + copy(s2, 3, 1) + copy(s4, 5, 2) + copy(s1, 3, 2) + copy(s2, 2, 1) + copy(s4, 5, 1);
s6 := copy(s3, 1, 2) + copy(s1, 3, 2);
writeln('1. ', s1);
writeln('2. ', s2);
writeln('3. ', s3);
writeln('4. ', s4);
writeln('5. ', s5);
writeln('6. ', s6);
end.
Присоединяйтесь к Telegram-группе @superresheba_9, делитесь своими решениями и пользуйтесь материалами, которые присылают другие участники группы!
9 алгоритмов сортировки и поиска для JS, о которых вас спросят на собеседовании
Меня зовут Илья, я frontend-разработчик SimbirSoft. Долгое время вопрос изучения алгоритмов был холиварным. Со временем я убедился, что ни одно современное собеседование в крупную компанию не обходится без вопросов про алгоритмы, и в последний год их всё больше.
Даже если ты frontend-разработчик и решаешь прикладные задачи, тебе в любом случае придётся знать алгоритмы хотя бы на базовом уровне. Но статей на русском с объяснением алгоритмов и тем, как их реализовать на JavaScript, крайне мало. Поэтому хочу поделиться некоторыми алгоритмами сортировки и поиска, и немного рассказать про структуры данных. Знание алгоритмов и структур данных поможет вам в оптимизации приложений.
Статья будет полезна разработчикам любых направлений, которые начали свой путь к крепкому уровню middle.
Что такое алгоритмы?
Для начала давай разберёмся с базовыми определениями.
Алгоритм — набор инструкций описывающий порядок действий для достижения определённых целей или решения конкретных задач.
Из этого определения можно подметить такой факт, что любой код, который решает какую-либо задачу, может считаться алгоритмом.
Структура данных — способ организации и хранения данных, устроенный максимально эффективным способом.
Алгоритмы и структуры данных неотделимы друг от друга, так как структуры данных — содержат информацию, а алгоритмы — это инструкции по работе с этой информацией.
Пара слов о нотации Big O
Для измерения эффективности необходимо позвать на помощь арбитра, который сможет максимально критично оценить производительность алгоритма.
Big O — нотация, которая позволяет определить верхнюю границу скорости работы алгоритма. Как справедливо отметил один из комментаторов, это асимптотическая сложность, которая описывает верхнюю границу сложности алгоритма при увеличении размера входных данных, или то, как рост размера входных данных влияет на количество операций.

Чтобы было понятнее, рассмотрим на примере:
Обычный обход по массиву имеет сложность O(n), где n — количество элементов массива. Если внутри этого цикла добавить ещё один, который также будет проходить по всем элементам массива, то сложность внешнего цикла возрастёт до O(n 2 ).
В Big O константы откидываются, представим ситуацию, что у нас существует функция, в которой существуют 2 одинаковых цикла.
const func = (arr) => < for(let i = 0; i < arr.length; i++) < . >for(let j = 0; j < arr.length; j++) < . >>Сложность её будет не O(2n) , как может вполне логично показаться, а O(n). Нотация Big O обращает внимание конкретно на число входных элементов — n, также на степени, логарифмы, факториалы и экспоненты этого числа.
Поначалу может показаться нелогичным, что функция с один циклом и функция с двумя циклами оцениваются по Big O как эквивалентные по временной сложности, но хочу подчеркнуть — Big O нотация показывает зависимость алгоритма от входных данных. Именно поэтому Big O не гарантирует, что алгоритм O(1) будет самым быстрым, но даёт понять, что скорость работы этого алгоритма не будет зависеть от входных данных.
Немного про структуры данных
Поговорим немного о тех структурах данных, которые будем использовать дальше в ходе статьи.
Граф. Структура данных, состоящая из «вершин» и «ребёр». Вершины имеют значение, именуемое «вес», рёбра соединяют вершины друг с другом. Получается своего рода сущность в виде сетки. Графом можно наглядно описать любые взаимосвязи в природе.

Дерево. При тщательном рассмотрении может показаться, что дерево очень похоже на граф, и так оно и есть. Это структура данных, представляющая собой связанный граф, не имеющий циклов.

Стек. Базовая структура данных, в которой реализовано только добавление и удаление элементов. Данные в этой структуре организованы по принципу LIFO (Last In First Out) «Последним зашёл, первым вышел». Такой способ организации можно сравнить со стопкой тарелок.
Очередь. Структура данных, название которой говорит само за себя. В ней также реализованы лишь методы добавления и удаления элементов. В этой структуре данные организованы по принципу FIFO (First In First Out) «Первым зашёл, первым вышел». Яркий пример — очередь в магазине.
Понимание вышеописанных структур данных даст нам понимание работы алгоритмов, которые на первый взгляд кажутся сложными и тяжёлыми к восприятию.
Алгоритмы сортировки
Переходим к разговору об алгоритмах сортировки. В этом разделе вы узнаете про такие алгоритмы, как:
- Сортировка пузырьком;
- Сортировка выбором;
- Циклическая сортировка;
- Быстрая сортировка;
Рассмотрим, чем они отличаются друг от друга, для чего применяются и где используются. Также мы рассмотрим на их имплементацию и визуализацию, и разберёмся, как реализовать их шаг за шагом.
Перед тем, как перейдём к изучению алгоритмов сортировки, надо уточнить, что алгоритмы сортировки подразделяют на стабильные и нестабильные.
Алгоритм является стабильным только в том случае, если он не меняет порядок элементов с одинаковыми значениями относительно друг друга. Соответственно, нестабильный алгоритм — наоборот.
При сортировки списка чисел на этот параметр можно не обращать внимания, а если мы собираемся сортировать массив/объект данных, то этот показатель может сыграть злую шутку.
Например, существует такой список:
const users = [ < number: 4, name: "Николай" >, < number: 2, name: "Анастасия" >, < number: 1, name: "Тимур" >, < number: 2, name: "Евгений" >, < number: 3, name: "Катерина" >]После сортировки стабильным алгоритмом этот список будет выглядеть следующим образом:
const users = [ < number: 1, name: "Тимур" >, < number: 2, name: "Анастасия" >, < number: 2, name: "Евгений" >, < number: 3, name: "Катерина" > < number: 4, name: "Николай" >]Пользователь «Анастасия» гарантированно будет находиться выше пользователя «Евгений», так как это было в исходном массиве. Нестабильный алгоритм гарантировать это не может.
Сортировка пузырьком
Сортировка пузырьком — самый примитивный и базовый алгоритм сортировки. Он является основой для некоторых других алгоритмов. Этот алгоритм является стабильным. Сортировка пузырьком перебирает весь массив элементов, сравнивая два соседних элемента друг с другом и меняя их местами в соответствии с условиями. Элементы с большим значением опускаются вниз массива, а элементы с наименьшим значением поднимаются вверх, подобно пузырькам газа.
Сложность алгоритма: O(n 2 ), где n — количество элементов массива. Так как мы запускаем вложенный цикл, сложность алгоритма равна O(n 2 )
- Запускаем цикл i по массиву.
- Запускаем внутренний цикл j , который идёт от 0 до arr.length — i . Это ускоряет алгоритм, так как он не проходит по уже отсортированным элементам.
- Во внутреннем цикле проверяем соседние элементы и меняем их местами, если сосед слева больше соседа справа.
const bubbleSort = (arr) => < for (let i = 0; i < arr.length; i++) < for (let j = 0; j < arr.length - i; j++) < if (arr[j] >arr[j + 1]) < [arr[j], arr[j + 1]] = [arr[j + 1], arr[j]]; // Меняем значения переменных >> > >;Алгоритм следует использовать в следующем случае:
- Когда количество входных данных невелико, так как его временная сложность составляет O(n 2 ).
Задачи для тренировки:
- https://leetcode.com/problems/sort-colors/
- https://leetcode.com/problems/height-checker
Сортировка выбором
Этот алгоритм сортировки при каждой итерации проходит по неотсортированной части массива, находит минимальный элемент и переносит его в начало массива.
Может быть как стабильным, так и нестабильным алгоритмом, в зависимости от реализации. В данном примере приведена стабильная реализация.
Сложность алгоритма: O(n 2 ).
- Запускаем цикл i по массиву.
- Внутри цикла создаём переменную, равную итерации цикла min = i .
- Запускаем внутренний цикл j по оставшимся элементам массива до его конца.
- Если элемент arr[min] > arr[j] , то присваиваем min значение j .
- По окончании внутреннего цикла j переменная min хранит индекс наименьшего неотсортированного элемента массива.
- Меняем местами элементы с индексами i и min .
const selectedSort = (arr) => < for (let i = 0; i < arr.length; i++) < let min = i; for (let j = i + 1; j < arr.length; j++) < if (arr[min] >arr[j]) < min = j; // Меняем значение переменной на наибольшее значение >> [arr[i], arr[min]] = [arr[min], arr[i]]; // Меняем значения переменных > >;Алгоритм следует использовать в следующем случае:
- Когда количество входных данных невелико, так как его временная сложность составляет O(n 2 ).
Задачи для тренировки:
- https://leetcode.com/problems/queue-reconstruction-by-height/
- https://leetcode.com/problems/third-maximum-number/
Циклическая сортировка
Основной идеей алгоритма циклической сортировки является разложение массива на циклы. Затем, внутри этих циклов происходят перестановки элементов до тех пор, пока все циклы не завершатся и массив не будет отсортирован.
Алгоритм циклической сортировки является нестабильным.
Хотя алгоритм циклической сортировки не является простым в понимании, он ценится за то, что изменения элементов массива происходят только тогда, когда элемент ставится на своё место. Это особенно важно, если изменение элементов массива является затратным.
Сложность алгоритма: O(n 2 ).
- Запускаем цикл i , который должен пройти по всему массиву.
- Создаём временную переменную position , которая будет равна i .
- Запускаем внутренний цикл j , который перебирает всех соседей справа.
- Когда внутри цикла j находим элемент, который меньше arr[i] , увеличиваем position на единицу.
- Если значение position равно i , переходим к следующей итерации внешнего цикла i .
- Пропускаем дубликаты, сравнивая значения элементов под индексами position и i с помощью цикла.
- Меняем местами элементы под индексами i и position .
- Запускаем цикл, пока position не будет ссылаться на i .
- Повторяем все операции, описанные внутри цикла j .
function cycleSort(arr) < for (let i = 0; i < arr.length; i++) < let value = arr[i]; let position = i; for (let j = i + 1; j < arr.length; j++) < if (arr[j] < value) < position++; >> if (position === i) < continue; >while (value === arr[position]) < // Избавляемся от дубликатов position++; >[arr[position], value] = [value, arr[position]]; // Меняем значения переменных while (position !== i) < // Запускаем цикл в обратную сторону position = i; for (let k = i + 1; k < arr.length; k++) < if (arr[k] < value) < position++; >> while (value === arr[position]) < // Избавляемся от дубликатов position++; >[arr[position], value] = [value, arr[position]]; // Меняем значения пременных > > return arr; >Алгоритм следует использовать в следующем случае:
- Когда запись в сортируемый набор данных очень дорога. Задачи для тренировки:
- https://leetcode.com/problems/missing-number
- https://leetcode.com/problems/check-if-array-is-good
Быстрая сортировка
Алгоритм быстрой сортировки работает следующим образом: он определяет так называемый «стержень» и разбивает массив на подмассивы относительно «стержня», которые затем сортируются.
Этот алгоритм сортировки является нестабильным.
Сложность алгоритма в среднем: O(n * log n).
Сложность алгоритма в худшем случае: O(n 2 ). Худшим для алгоритма быстрой сортировки можно назвать случай, когда опорный элемент pivot имеет максимальное или минимальное значение во всём массиве.
- Проверяем что указатель на начало массива start не совпадает с указателем на конец массива end .
- Если условие выполняется, находим индекс элемента, который разделяет массив на две части pi .
- Когда pi найден, рекурсивно запускаем quickSort для каждой из получившихся частей (от start до pi — 1 ) и (от pi + 1 до end ).
- При нахождении pi мы определяем pivot — опорный элемент и i — индекс, по которому будем делить массив.
- Запускаем цикл по массиву j до предпоследнего элемента. При нахождении элемента, который меньше или равен pivot меняем местами arr[i] и arr[j] и инкрементируем i .
- После завершения цикла меняем местами arr[i] и arr[end] и возвращаем i .
const partition = (arr, start, end) => < const pivot = arr[end]; // Определяем опорный элемент let i = start; // Определяем индекс, по которому делим массив на две части for (let j = start; j > [arr[i], arr[end]] = [arr[end], arr[i]]; // Меняем значения переменных return i; >; const quickSort = (arr, start, end) => < if (start < end) < // Условия запуска рекурсии const pi = partition(arr, start, end); // Получаем индекс quickSort(arr, start, pi - 1); quickSort(arr, pi + 1, end); >>;Алгоритм следует использовать в следующих случаях:
- При обработке большого объема входных данных.
- Когда требуется использовать наиболее быстрый алгоритм (в среднем этот алгоритм быстрее, чем рассмотренные ранее, но необходимо учитывать возможные негативные сценарии).
Задачи для тренировки:
- https://leetcode.com/problems/sort-an-array/
- https://leetcode.com/problems/merge-sorted-array/
Алгоритмы поиска
Переходим к разговору об алгоритмах поиска. В этом разделе вы узнаете про такие алгоритмы, как:
- Линейный поиск
- Бинарный поиск
- Поиск в ширину и глубину
- Алгоритм Дейкстры
Аналогично алгоритмам сортировки рассмотрим их имплементацию и визуализацию, также разберём, для чего они были придуманы, как и где применяются.
Линейный поиск
Линейный поиск — это самый примитивный алгоритм поиска, который работает как с отсортированными, так и с не отсортированными массивами.
Сложность алгоритма: О(n).
- Запускаем цикл по массиву i .
- Проверяем текущий элемент на соответствие искомому элементу, в случае не соответствия идём дальше. Если элемент соответствует искомому, возвращаем его индекс.
- Если элемента нет в массиве, возвращаем -1 .
const linearSearch = (arr, findEl) => < for (let i = 0; i < arr.length; i++) < if (arr[i] === findEl) < return i >> return -1 >Алгоритм следует использовать в следующих случаях:
- Когда массив входных данных невелик.
- Если массив данных неупорядоченный. На случай если входной массив отсортирован, лучше будет использовать алгоритм, который мы рассмотрим далее.
Задачи для тренировки:
- https://leetcode.com/problems/intersection-of-two-arrays/
- https://leetcode.com/problems/intersection-of-two-arrays-ii/
Бинарный поиск
Основная идея бинарного поиска заключается в делении массива по полам и отсеивании не подходящей части. Алгоритм имеет смысл использовать только с отсортированными массивами.
Сложность алгоритма в лучшем случае: O(1).
Сложность алгоритма в среднем: O(logn).
- Создаём два указателя на начало массива и конец массива.
- Запускаем цикл, который итерируется до тех пор, пока указатель на начало не совпадает с указателем на конец массива.
- Внутри цикла создаём указатель на середину массива.
- Проверяем, если элемент по середине равен искомому элементу, возвращаем его индекс.
- Если средний элемент меньше искомого элемента, тогда указатель на начало смещаем на mid + 1 . Иначе указатель на конец смещаем на mid — 1 .
- В случае если искомого элемента в массиве нет, возвращаем -1 .
const binarySearch = (arr, findItem) => < let start = 0; let end = arr.length - 1; while (start if (arr[mid] < findItem) < start = mid + 1; // Отбрасываем левую часть массива >else < end = mid - 1; // Отбрасываем правую часть массива >> return -1; >;Алгоритм следует использовать в следующих случаях:
- Когда входной массив отсортирован.
- Когда нам необходимо максимально производительное решение.
Задачи для тренировки:
- https://leetcode.com/problems/minimum-common-value/
- https://leetcode.com/problems/find-the-longest-equal-subarray/
Поиск в глубину (Depth-First Search)
Поиск в глубину — это алгоритм обхода или поиска в таких структурах данных, как деревья или графы. Основан на такой структуре данных, как стек. Алгоритм начинает работу с корневого узла (в случае графа в качестве корневого узла выбирается какой-либо произвольный узел) и прежде чем вернуться назад, проходит как можно дальше по каждой ветви.
Сложность алгоритма: O(V + E).
- В случае обхода графа необходимо проинициализировать объект visited , который будет хранить вершины, которые прошёл алгоритм во избежание попадания в бесконечный цикл. В случае обхода по дереву этот шаг можно пропустить.
- Создаём массив stack , который будет исполнять роль стека, сразу заполняем его значением вершины, с которой начнём обход.
- Запускаем цикл, который будет итерироваться до тех пор, пока стек не опустеет.
- Достаём первое значение из стека и помещаем его в переменную vert .
- Проверяем, имеет ли эта вершина дочерние вершины.
- В случае если дочерние вершины найдены, добавляем их в начало стека.
- В случае обхода графа запускаем цикл, который будет проходить по дочерним вершинам, и если они не были пройдены алгоритмом ранее, класть их в стек.
Пример кода в дереве:
const dfs = (tree, start) => < const stack = [start]; while (stack.length >0) < const vert = stack.shift(); // Выбираем первую вершину из стека if (tree[vert]) < stack.unshift(. tree[vert]); // Добавляем вершины в начало стека >> >;Пример кода в графе:
const dfs = (graph, start) => < const visited = <>; const stack = [start]; while (stack.length !== 0) < const vert = stack.shift(); // Выбираем первую вершину из стека if (!visited[vert]) < visited[vert] = true; // Отмечаем вершину как пройденую, если ранее не проходили её >if (graph[vert]) < for (let subVert of graph[vert]) < if (!visited[subVert]) < stack.unshift(subVert); // Добавляем вершину в начало стека >> > > >;Алгоритм следует использовать в следующих случаях:
- Когда мы знаем, что искомая вершина находится дальше всего от стартовой, или если граф имеет большую ширину.
- Когда нам необходимо найти пути между вершинами.
Задачи для тренировки:
- https://leetcode.com/problems/sum-of-left-leaves/
- https://leetcode.com/problems/second-minimum-node-in-a-binary-tree/
Поиск в ширину (Breadth-First Search)
Алгоритм поиска в ширину очень похож на описанный выше алгоритм поиска в глубину, отличается лишь тем, что в начале проходит все соседние узлы начальной вершины, потом все соседние узлы соседних вершин, и так далее, пока не пройдёт весь граф или не найдёт искомую вершину. Ещё одно отличие заключается в том, что основан этот алгоритм на такой структуре данных, как очередь.
Сложность алгоритма: O(V + E).
- В случае обхода графа создаём объект visited , который будет хранить в себе информацию о пройденных вершинах, чтобы избежать бесконечного цикла.
- Создаём массив queue , который будет исполнять роль очереди.
- Запускаем цикл, который будет итерироваться до тех пор, пока очередь не опустеет.
- Достаём первый элемент из очереди и помещаем его в переменную vert .
- Проверяем, имеет ли эта вершина дочерние вершины.
- Если дочерние вершины имеются, добавляем их в конец очереди.
- В случае обхода графа запускаем цикл, который будет проходить по дочерним вершинам текущей вершины vert , и если алгоритм не проходил их ранее, добавляем их в конец очереди.
Пример кода в дереве:
const bfs = (tree, start) => < const queue = [start]; while (queue.length !== 0) < const vert = queue.shift(); // Выбираем первую вершину из очереди if (tree[vert]) < queue.push(. tree[vert]); // Добавляем вершины в конец очереди >> >;Пример кода в графе:
const bfs = (graph, start) => < const visited = <>; const queue = [start]; while (queue.length !== 0) < const vert = queue.shift(); // Выбираем первую вершину из очереди if (!visited[vert]) < visited[vert] = true; // Отмечаем вершину как пройденую, если ранее не проходили её >if (graph[vert]) < for (let subVert of graph[vert]) < if (!visited[subVert]) < queue.push(subVert); // Добавляем вершину в конец очереди >> > > >;Алгоритм следует использовать в следующих случаях:
- Когда мы знаем, что искомая вершина находится близко к стартовой, или если граф имеет большую глубину.
- Когда нам необходимо найти кратчайшее расстояние в невзвешенном графе.
Задачи для тренировки:
- https://leetcode.com/problems/merge-two-binary-trees/
- https://leetcode.com/problems/cousins-in-binary-tree/
Алгоритм Дейкстры
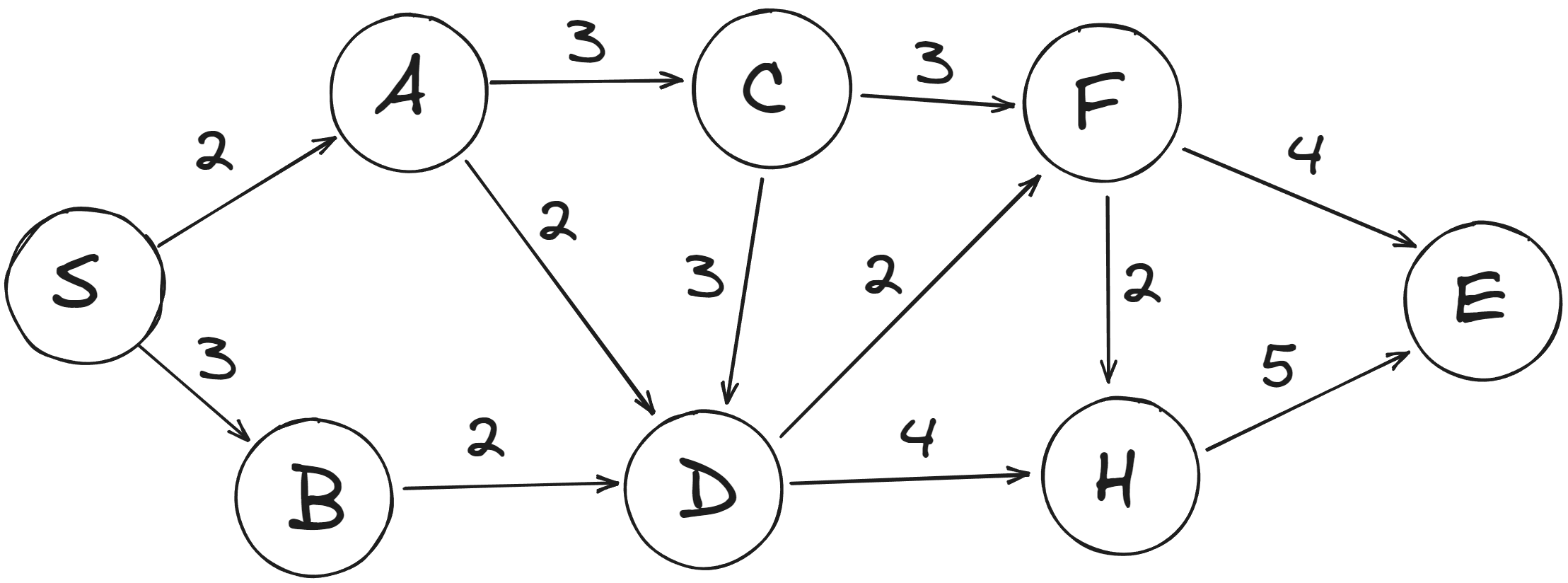
Основная идея алгоритма — создание дерева кратчайших путей с заданным источником в качестве корня. Алгоритм Дейкстры — один из самых популярных алгоритмов для нахождения короткого пути в взвешенном графе. Незаменим в работе GPS-навигации.
Сложность алгоритма: O(E * log V)
- Создаём объект parents , который будет хранить историю переходов по графу, объект costs , который будет хранить стоимости переходов, массив queue — очередь обхода вершин.
- Запускаем цикл, который проходит по вершинам графа и заполняет стартовыми значениями объект стоимости и очередь.
- Стоимость перехода в стартовую вершину равна 0, для остальных вершин Infinity .
- Запускаем цикл по очереди, находим элемент с наименьшей стоимостью перехода и помещаем её в переменную.
- Если элемент с наименьшей стоимостью существует и значение перехода в него не равно Infinity , запускаем цикл по дочерним вершинам.
- Находим новую стоимость, складывая стоимость перехода в родительскую и дочернюю вершину.
- Если стоимость перехода в дочернюю вершину больше новой стоимости, то обновляем стоимость для дочерней вершины в объекте стоимости, в истории переходов для дочерней вершины устанавливаем значение родительской вершины и добавляем дочернюю вершину с новой стоимостью в конец очереди.
- Повторяем шаги 4-7, пока очередь не опустеет.
const getLowestCostNode = (queue) => < let min = Infinity; let lowIndex; for (let i = 0; i < queue.length; i++) < const [, value] = queue[i]; if (value < min) < min = value; lowIndex = i; >> const lowestNode = queue.splice(lowIndex, 1)[0]; return lowestNode; >; const dijkstra = (graph, start) => < const parents = <>; const costs = <>; const queue = []; for (let vert in graph) < if (vert === start) < costs[vert] = 0; queue.push([vert, 0]); >else < costs[vert] = Infinity; queue.push([vert, Infinity]); >parents[vert] = null; > while (queue.length) < const node = getLowestCostNode(queue); let [vert, value] = node; const cost = costs[vert]; if (node || value !== Infinity) < for (let subNode in graph[vert]) < const nextSubNodeValue = graph[vert][subNode]; const newCost = cost + nextSubNodeValue; if (costs[subNode] >newCost) < costs[subNode] = newCost; parents[subNode] = vert; queue.push([subNode, newCost]); >> > > >;Алгоритм следует использовать в следующих случаях:
- Когда необходимо найти кратчайший путь в взвешенном графе.
- Когда граф не имеет отрицательных весов.
Задачи для тренировки:
Подводим итоги
Мир алгоритмов очень большой и насыщенный, существует огромное множество различных алгоритмов, каждый из которых решает какую-то конкретную задачу в определённой среде.
Алгоритмы, которые мы с вами рассмотрели, являются базовыми, возможно, они не всем пригодятся в повседневной работе, но тем не менее знать и понимать, как они работают будет полезно. Особенно, если вы хотите окунуться в этот мир алгоритмов с головой.
Спасибо что дочитали до конца. Буду благодарен, если поделитесь этой статьей с коллегами. Пишите в комментариях, о работе каких ещё алгоритмов вам было бы интересно узнать! Всем приятной работы/учёбы, и не забывайте, что алгоритмы окружают нас 🙂
Использованные источники:
- https://algorithm-visualizer.org/
- https://www.geeksforgeeks.org/fundamentals-of-algorithms/
- https://excalidraw.com/
Спасибо за внимание!
Больше авторских материалов для frontend-разработчиков от моих коллег читайте в соцсетях SimbirSoft – ВКонтакте и Telegram.
Алгоритмы быстрого вычисления факториала
Понятие факториала известно всем. Это функция, вычисляющая произведение последовательных натуральных чисел от 1 до N включительно: N! = 1 * 2 * 3 *… * N. Факториал — быстрорастущая функция, уже для небольших значений N значение N! имеет много значащих цифр.
Попробуем реализовать эту функцию на языке программирования. Очевидно, нам понадобиться язык, поддерживающий длинную арифметику. Я воспользуюсь C#, но с таким же успехом можно взять Java или Python.
Наивный алгоритм
Итак, простейшая реализация (назовем ее наивной) получается прямо из определения факториала:
static BigInteger FactNaive(int n)
На моей машине эта реализация работает примерно 1,6 секунд для N=50 000.
Далее рассмотрим алгоритмы, которые работают намного быстрее наивной реализации.
Алгоритм вычисления деревом
Первый алгоритм основан на том соображении, что длинные числа примерно одинаковой длины умножать эффективнее, чем длинное число умножать на короткое (как в наивной реализации). То есть нам нужно добиться, чтобы при вычислении факториала множители постоянно были примерно одинаковой длины.
Пусть нам нужно найти произведение последовательных чисел от L до R, обозначим его как P(L, R). Разделим интервал от L до R пополам и посчитаем P(L, R) как P(L, M) * P(M + 1, R), где M находится посередине между L и R, M = (L + R) / 2. Заметим, что множители будут примерно одинаковой длины. Аналогично разобьем P(L, M) и P(M + 1, R). Будем производить эту операцию, пока в каждом интервале останется не более двух множителей. Очевидно, что P(L, R) = L, если L и R равны, и P(L, R) = L * R, если L и R отличаются на единицу. Чтобы найти N! нужно посчитать P(2, N).
Посмотрим, как будет работать наш алгоритм для N=10, найдем P(2, 10):
P(2, 10)
P(2, 6) * P(7, 10)
( P(2, 4) * P(5, 6) ) * ( P(7, 8) * P(9, 10) )
( (P(2, 3) * P(4) ) * P(5, 6) ) * ( P(7, 8) * P(9, 10) )
( ( (2 * 3) * (4) ) * (5 * 6) ) * ( (7 * 8) * (9 * 10) )
( ( 6 * 4 ) * 30 ) * ( 56 * 90 )
( 24 * 30 ) * ( 5 040 )
720 * 5 040
3 628 800
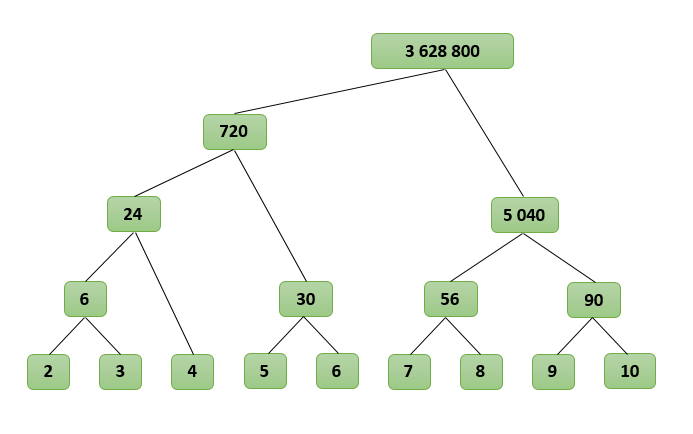
Получается своеобразное дерево, где множители находятся в узлах, а результат получается в корне
Реализуем описанный алгоритм:
static BigInteger ProdTree(int l, int r) < if (l >r) return 1; if (l == r) return l; if (r - l == 1) return (BigInteger)l * r; int m = (l + r) / 2; return ProdTree(l, m) * ProdTree(m + 1, r); > static BigInteger FactTree(int n)
Для N=50 000 факториал вычисляется за 0,9 секунд, что почти вдвое быстрее, чем в наивной реализации.
Алгоритм вычисления факторизацией
Второй алгоритм быстрого вычисления использует разложение факториала на простые множители (факторизацию). Очевидно, что в разложении N! участвуют только простые множители от 2 до N. Попробуем посчитать, сколько раз простой множитель K содержится в N!, то есть узнаем степень множителя K в разложении. Каждый K-ый член произведения 1 * 2 * 3 *… * N увеличивает показатель на единицу, то есть показатель степени будет равен N / K. Но каждый K 2 -ый член увеличивает степень еще на единицу, то есть показатель становится N / K + N / K 2 . Аналогично для K 3 , K 4 и так далее. В итоге получим, что показатель степени при простом множителе K будет равен N / K + N / K 2 + N / K 3 + N / K 4 +…
Для наглядности посчитаем, сколько раз двойка содержится в 10! Двойку дает каждый второй множитель (2, 4, 6, 8 и 10), всего таких множителей 10 / 2 = 5. Каждый четвертый дает четверку (2 2 ), всего таких множителей 10 / 4 = 2 (4 и 8). Каждый восьмой дает восьмерку (2 3 ), такой множитель всего один 10 / 8 = 1 (8). Шестнадцать (2 4 ) и более уже не дает ни один множитель, значит, подсчет можно завершать. Суммируя, получим, что показатель степени при двойке в разложении 10! на простые множители будет равен 10 / 2 + 10 / 4 + 10 / 8 = 5 + 2 + 1 = 8.
Если действовать таким же образом, можно найти показатели при 3, 5 и 7 в разложении 10!, после чего остается только вычислить значение произведения:
10! = 2 8 * 3 4 * 5 2 * 7 1 = 3 628 800
Осталось найти простые числа от 2 до N, для этого можно использовать решето Эратосфена:
static BigInteger FactFactor(int n) < if (n < 0) return 0; if (n == 0) return 1; if (n == 1 || n == 2) return n; bool[] u = new bool[n + 1]; // маркеры для решета Эратосфена List> p = new List>(); // множители и их показатели степеней for (int i = 2; i 0) < c += k; k /= i; >// запоминаем множитель и его показатель степени p.Add(new Tuple(i, c)); // просеиваем составные числа через решето int j = 2; while (i * j > // вычисляем факториал BigInteger r = 1; for (int i = p.Count() - 1; i >= 0; --i) r *= BigInteger.Pow(p[i].Item1, p[i].Item2); return r; > Эта реализация также тратит примерно 0,9 секунд на вычисление 50 000!
Библиотека GMP
Как справедливо отметил pomme скорость вычисления факториала на 98% зависит от скорости умножения. Попробуем протестировать наши алгоритмы, реализовав их на C++ с использованием библиотеки GMP. Результаты тестирования приведены ниже, по ним получается что алгоритм умножения в C# имеет довольно странную асимптотику, поэтому оптимизация дает относительно небольшой выигрыш в C# и огромный в C++ с GMP. Однако этому вопросу вероятно стоит посвятить отдельную статью.
Сравнение производительности
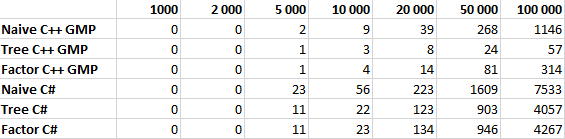
Все алгоритмы тестировались для N равном 1 000, 2 000, 5 000, 10 000, 20 000, 50 000 и 100 000 десятью итерациями. В таблице указано среднее значение времени работы в миллисекундах.
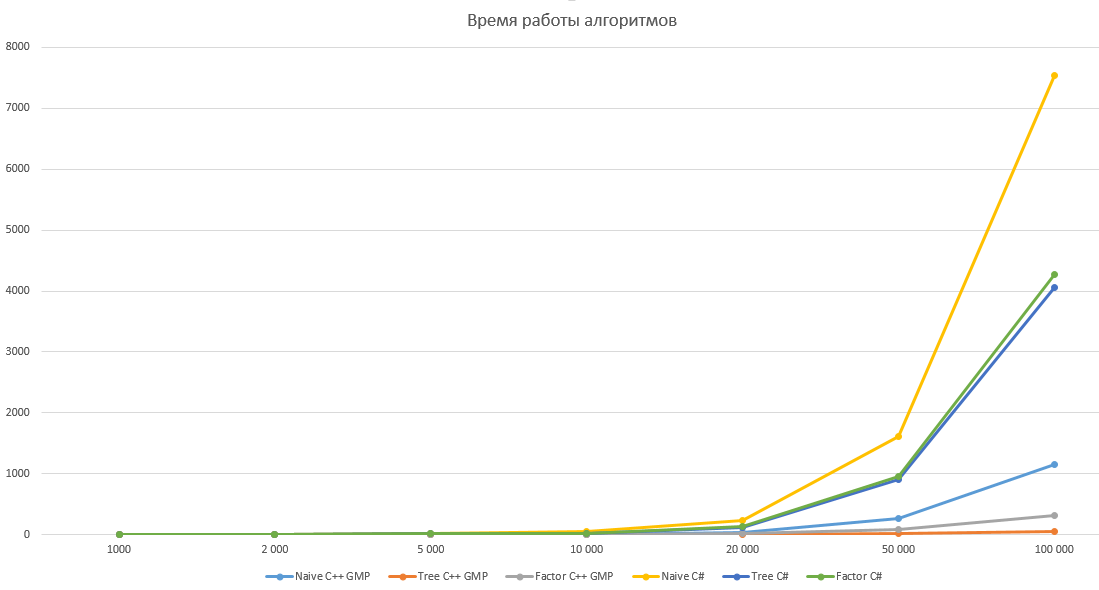
График с линейной шкалой
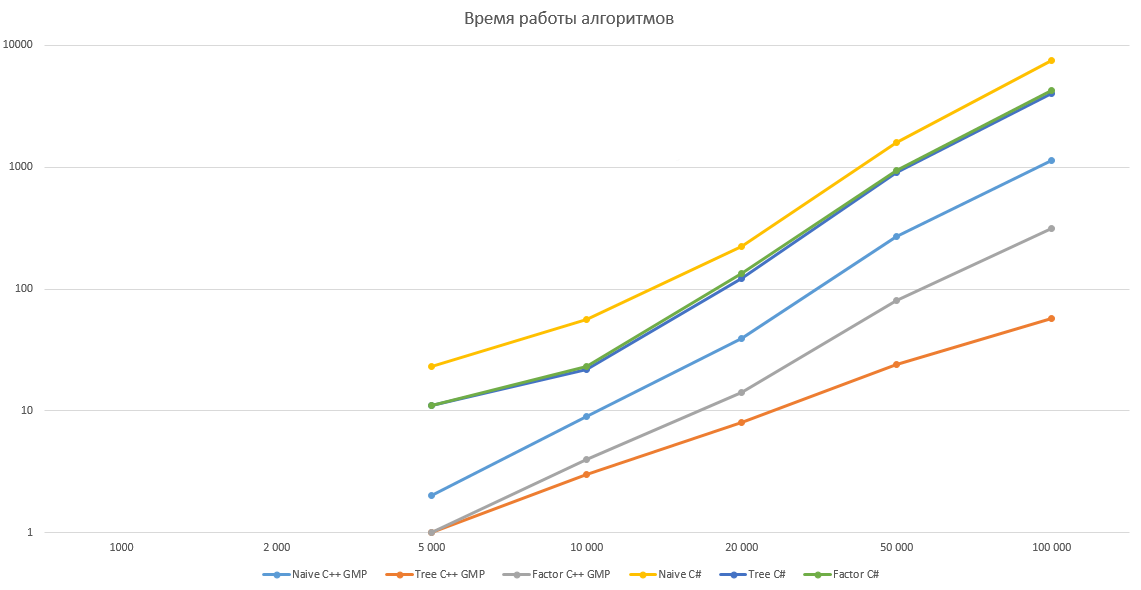
График с логарифмической шкалой
Идеи и алгоритмы из комментариев
Хабражители предложили немало интересных идей и алгоритмов в ответ на мою статью, здесь я оставлю ссылки на лучшие из них
Исходные коды
Исходные коды реализованных алгоритмов приведены под спойлерами
using System; using System.Linq; using System.Text; using System.Numerics; using System.Collections.Generic; using System.Collections.Specialized; namespace BigInt < class Program < static BigInteger FactNaive(int n) < BigInteger r = 1; for (int i = 2; i static BigInteger ProdTree(int l, int r) < if (l >r) return 1; if (l == r) return l; if (r - l == 1) return (BigInteger)l * r; int m = (l + r) / 2; return ProdTree(l, m) * ProdTree(m + 1, r); > static BigInteger FactTree(int n) < if (n < 0) return 0; if (n == 0) return 1; if (n == 1 || n == 2) return n; return ProdTree(2, n); >static BigInteger FactFactor(int n) < if (n < 0) return 0; if (n == 0) return 1; if (n == 1 || n == 2) return n; bool[] u = new bool[n + 1]; List> p = new List>(); for (int i = 2; i 0) < c += k; k /= i; >p.Add(new Tuple(i, c)); int j = 2; while (i * j > BigInteger r = 1; for (int i = p.Count() - 1; i >= 0; --i) r *= BigInteger.Pow(p[i].Item1, p[i].Item2); return r; > static void Main(string[] args) < int n; int t; Console.Write("n = "); n = Convert.ToInt32(Console.ReadLine()); t = Environment.TickCount; BigInteger fn = FactNaive(n); Console.WriteLine("Naive time: ms", Environment.TickCount - t); t = Environment.TickCount; BigInteger ft = FactTree(n); Console.WriteLine("Tree time: ms", Environment.TickCount - t); t = Environment.TickCount; BigInteger ff = FactFactor(n); Console.WriteLine("Factor time: ms", Environment.TickCount - t); Console.WriteLine("Check: ", fn == ft && ft == ff ? "ok" : "fail"); > > > C++ с GMP
#include #include #include #include #include using namespace std; mpz_class FactNaive(int n) < mpz_class r = 1; for (int i = 2; i mpz_class ProdTree(int l, int r) < if (l >r) return 1; if (l == r) return l; if (r - l == 1) return (mpz_class)r * l; int m = (l + r) / 2; return ProdTree(l, m) * ProdTree(m + 1, r); > mpz_class FactTree(int n) < if (n < 0) return 0; if (n == 0) return 1; if (n == 1 || n == 2) return n; return ProdTree(2, n); >mpz_class FactFactor(int n) < if (n < 0) return 0; if (n == 0) return 1; if (n == 1 || n == 2) return n; vectoru(n + 1, false); vector > p; for (int i = 2; i 0) < c += k; k /= i; >p.push_back(make_pair(i, c)); int j = 2; while (i * j > mpz_class r = 1; for (int i = p.size() - 1; i >= 0; --i) < mpz_class w; mpz_pow_ui(w.get_mpz_t(), mpz_class(p[i].first).get_mpz_t(), p[i].second); r *= w; >return r; > mpz_class FactNative(int n) < mpz_class r; mpz_fac_ui(r.get_mpz_t(), n); return r; >int main() < int n; unsigned int t; cout
- длинная арифметика
- факториал
- оптимизация
Как сюда добавить проверку на равенство строк?
во вторых оператор должен возвращать не ссылку на объект, а логическое значение : правда / ложь.
bool operator==(String,String); Аргументы и сам объект не должны изменятся, по-этому константность объекту и аргументы нужно выставлять обязательно.
bool operator==(String const,String const); так как аргументы передаются как копии, желательно их передавать ссылкой, без лишнего копирования :
bool operator==(String const & ,String const & ); и наконец, этот оператор можно определить, как член класса :
class String < .. bool operator==(String const & x )const; .. >; bool String::operator==(String const & x )const
так и статическим оператором :
class String < .. friend bool operator==(String const & th,String const & x ); .. >; bool operator==(String const & th,String const & x )
Отслеживать
ответ дан 3 дек 2022 в 11:20
17.2k 1 1 золотой знак 9 9 серебряных знаков 33 33 бронзовых знака
Спасибо,но после того как я воспользовался вашим решением, у меня теперь ошибка "String::operator == не должен быть статическим членом" , знаете как исправить?
3 дек 2022 в 11:37
первый коммент забудьте. попробуйте то, что в ответе
3 дек 2022 в 11:39
А как использовать эту перегрузку?
3 дек 2022 в 11:41
Извиняюсь за столько вопросов,это последний
3 дек 2022 в 11:42
String s1 , s2 ; if ( s1 == s2 ) ..
3 дек 2022 в 11:42
А с какими двумя строками Вы собираетесь сравнивать? Условие-то хорошо себе представляете? if (s1==s2, s3) – это что? Если s1 равно и s2, и s3? Если s2 не равна s3, то это не возможно, а если нет, то нет смысла сравнивать s1 с обеими, так как s1 или равна обеим и это можно узнать, сравнив её с любой из строк, или не равна ни одной и это можно узнать, сравнив её с любой из строк. И зачем возвращать ссылку на объект? Что с ней иф делать будет?
bool String::operator==(const String &Right) const < const char *l; const char *r; bool Result=true; if ((&Right)!=this) < if (size==(Right.size)) < for (l=(((const char*)str)+size-1), r=(((const char *)(Right.str))+size-1); l>=((const char *)str); --l, --r) < if ((*l)!=(*r)) < Result=false; break; >> > else < Result=false; >> return Result; > И причём здесь клавиша перезагрузки?
Отслеживать
ответ дан 3 дек 2022 в 12:46
Тарас Атавин Тарас Атавин
204 1 1 серебряный знак 9 9 бронзовых знаков
-
Важное на Мете
Похожие
Подписаться на ленту
Лента вопроса
Для подписки на ленту скопируйте и вставьте эту ссылку в вашу программу для чтения RSS.
Дизайн сайта / логотип © 2024 Stack Exchange Inc; пользовательские материалы лицензированы в соответствии с CC BY-SA . rev 2024.1.3.2953
Нажимая «Принять все файлы cookie» вы соглашаетесь, что Stack Exchange может хранить файлы cookie на вашем устройстве и раскрывать информацию в соответствии с нашей Политикой в отношении файлов cookie.