Механизмы контейнеризации: cgroups
Продолжаем цикл статей о механизмах контейнеризации. В прошлый раз мы говорили об изоляции процессов с помощью механизма «пространств имён» (namespaces). Но для контейнеризации одной лишь изоляции ресурсов недостаточно. Если мы запускаем какое-либо приложение в изолированном окружении, мы должны быть уверены в том, что этому приложению выделено достаточно ресурсов и что оно не будет потреблять лишние ресурсы, нарушая тем самым работу остальной системы. Для решения этой задачи в ядре […]

Продолжаем цикл статей о механизмах контейнеризации. В прошлый раз мы говорили об изоляции процессов с помощью механизма «пространств имён» (namespaces). Но для контейнеризации одной лишь изоляции ресурсов недостаточно. Если мы запускаем какое-либо приложение в изолированном окружении, мы должны быть уверены в том, что этому приложению выделено достаточно ресурсов и что оно не будет потреблять лишние ресурсы, нарушая тем самым работу остальной системы. Для решения этой задачи в ядре Linux имеется специальный механизм — cgroups (сокращение от control groups, контрольные группы). О нём мы расскажем в сегодняшней статье.
Тема cgroups сегодня особенно актуальна: в ядро версии 4.5, вышедшей в свет в январе текущего года, была официально добавлена новая версия этого механизма — group v2 .
В ходе работы над ней cgroups был по сути переписан заново.
Почему потребовались столь радикальные изменения? Чтобы ответить на этот вопрос, рассмотрим в деталях, как была реализована первая версия cgroups.
Cgroups: краткая история
Разработка cgroups была начата в 2006 году сотрудниками Google Полом Менеджем и Рохитом Сетом. Термин «контрольная группа» тогда ещё не использовался, а вместо него употреблялся термин « контейнеры процессов » (process containers). Собственно, сначала они и не ставили перед собой цели создать cgroups в современном понимании. Изначальный замысел был гораздо скромнее: усовершенствовать механизм cpuset , предназначенный для распределения процессорного времени и памяти между задачами. Но со временем всё переросло в более масштабный проект.
В конце 2007 года название process containers было заменено на control groups. Это было сделано, чтобы избежать разночтений в толковании термина «контейнер» (в то время уже активно развивался проект OpenVZ, и слово «контейнер» стало употребляться в новом, современном значении).
В 2008 году механизм cgroups был официально добавлен в ядро Linux (версия 2.6.24). Что нового появилось в этой версии ядра по сравнению с предыдущими?
Ни одного системного вызова, предназначенного специально для работы с cgroups, добавлено не было. В числе главных изменений следует назвать файловую систему cgroups, известную также под названием cgroupfs.
В init/main.c были были добавлены отсылки к функциям для активации cgoups во время загрузки: cgroup_init и cgroup_init_early. Были незначительно изменены функции, используемые для порождения и завершения процесса — fork() и exit().
В виртуальной файловой системе /proc появились новые директории: /proc//сgroup (для каждого процесса) и /proc/cgroups (для системы в целом).
Архитектура
Механизм cgroups состоит из двух составных частей: ядра ( cgroup core ) и так называемых подсистем. В ядре версии 4.4.0.21 таких подсистем 12:
| Имя | Модуль ядра | Функция |
|---|---|---|
| blkio | block/blkcroup.c | Устанавливает лимиты на чтение и запись с блочных устройств |
| cpuacct | kernel/sched/cpuacct.c | Предназначен для генерации отчётов об использовании ресурсов процессора |
| cpu | kernel/sched/core.c | Обеспечивает доступ процессов в рамках контрольной группы к CPU |
| cpuset | kernel/cpuset.c | Распределяет задачи в рамках контрольной группы между процессорными ядрами |
| devices | security/device_cgroup.c | Разрешает или блокирует доступ к устройствам |
| freezer | kernel/cgroup_freezer.c | Приостанавливает и возобновляет выполнение задач в рамках контрольной группы |
| hugetlb | mm/hugetlb_cgroup.c | Активирует поддержку больших страниц памяти для контрольных групп |
| memory | mm/memcontrol.c | Управляет выделением памяти для групп процессов |
| net_cls | net/core/netclassid_cgroup.c | Помечает сетевые пакеты специальным тэгом, что позволяет идентифицировать пакеты, порождаемые определённой задачей в рамках контрольной группы |
| net_prio | net/core/netprio_cgroup.c | Используется для динамической установки приоритетов по трафику |
| perf_event | evens/kernel.c | Обеспечивает доступ контрольных групп к perf_events |
| pids | kernel/cgroup_pids.c | Используется для ограничения количества процессов в рамках контрольной группы |
Вывести список подсистем на консоль можно с помощью команды:
$ ls /sys/fs/cgroup/ blkio cpu,cpuacct freezer net_cls perf_event cpu cpuset hugetlb net_cls,net_prio pids cpuacct devices memory net_prio systemd Каждая подсистема представляет собой директорию с управляющими файлами, в которых прописываются все настройки. В каждой из этих директорий имеются следующие управляющие файлы:
- cgroup.clone_children — позволяет передавать дочерним контрольным группам свойства родительских;
- tasks — содержит список PID всех процессов, включённых в контрольные группы;
cgroup.procs — содержит список TGID групп процессов, включённых в контрольные группы; - cgroup.event_control — позволяет отправлять уведомления в случае изменения статуса контрольной группы;
- release_agent — содержится команда, которая будет выполнена, если включена опция notify_on_release. Может использоваться, например, для автоматического удаления пустых контрольных групп;
- notify_on_release — содержит булеву переменную (0 или 1), включающую (или наоборот отключающую), выполнение команду, указанной в release_agent.
У каждой подсистемы имеются также собственные управляющие файлы. О некоторых из них мы расскажем ниже.
Чтобы создать контрольную группу, достаточно создать вложенную директорию в любой из подсистем. В эту вложенную директорию будут автоматически добавлены управляющие файлы (ниже мы расскажем об этом более подробно). Добавить процессы в группу очень просто: нужно просто записать их PID в управляющий файл tasks.
Совокупность контрольных групп, встроенных в подсистему, называется иерархией.Попробуем разобрать принципы функционирования cgroups на простых практических примерах.
Иерархия cgroups: практическое знакомство
Пример 1: управление процессорными ресурсами
$ mkdir /sys/fs/cgroup/cpuset/group0 С помощью этой команды мы создали контрольную группу, в которой содержатся следующие управляющие файлы:
$ ls /sys/fs/cgroup/cpuset/group0 group.clone_children cpuset.memory_pressure cgroup.procs cpuset.memory_spread_page cpuset.cpu_exclusive cpuset.memory_spread_slab cpuset.cpus cpuset.mems cpuset.effective_cpus cpuset.sched_load_balance cpuset.effective_mems cpuset.sched_relax_domain_level cpuset.mem_exclusive notify_on_release cpuset.mem_hardwall tasks cpuset.memory_migrate Пока что в нашей группе никаких процессов нет. Чтобы добавить процесс, нужно записать его PID в файл tasks, например:
$ echo $$ > /sys/fs/cgroup/cpuset/group0/tasks Cимволами $$ обозначается PID процесса, выполняемого текущей командной оболочкой.
Этот процесс не закреплён ни за одним ядром CPU, что подтверждает следующая команда:
$ cat /proc/$$/status |grep '_allowed' Cpus_allowed: 2 Cpus_allowed_list: 0-1 Mems_allowed: 00000000,00000001 Mems_allowed_list: 0 Вывод этой команды показывает, что для интересующего нас процесса доступны 2 ядра CPU с номерами 0 и 1.
Попробуем «привязать» этот процесс к ядру с номером 0:
$ echo 0 >/sys/fs/cgroup/cpuset/group0/cpuset.cpus Проверим, что получилось:
$ cat /proc/$$/status |grep '_allowed' Cpus_allowed: 1 Cpus_allowed_list: 0 Mems_allowed: 00000000,00000001 Mems_allowed_list: 0 Пример 2: управление памятью
Встроим созданную в предыдущем примере группу ещё в одну подсистему:
$ mkdir /sys/fs/cgroup/memory/group0 $ echo $$ > /sys/fs/cgroup/memory/group0/tasks Попробуем ограничить для контрольной группы group0 потребление памяти. Для этого нам понадобится прописать соответствующий лимит в файле memory.limit_in_bytes:
$ echo 40M > /sys/fs/cgroup/memory/group0/memory.limit_in_bytes Механизм cgroups предоставляет очень обширные возможности управления памятью. Например, с его помощью мы можем оградить критически важные процессы от попадания под горячую руку OOM-killer’a:
$ echo 1 > /sys/fs/cgroup/memory/group0/memory.oom_control $ cat /sys/fs/cgroup/memory/group0/memory.oom_control oom_kill_disable 1 under_oom 0 Если мы поместим в отдельную контрольную группу, например, ssh-демон и отключим для этой группы OOM-killer, то мы можем быть уверены в том, что он не будет «убит» при преувеличении потребления памяти.
Пример 3: управление устройствами
Добавим нашу контрольную группу ещё в одну иерархию:
$ mkdir /sys/fs/cgroup/devices/group0 По умолчанию у группы нет никаких ограничений доступа к устройствам:
$ cat /sys/fs/cgroup/devices/group0/devices.list a *:* rwm Попробуем выставить ограничения:
$ echo 'c 1:3 rmw' > /sys/fs/cgroup/devices/group0/devices.deny Эта команда включит устройство /dev/null в список запрещённых для нашей контрольной группы. Мы записали в управляющий файл строку вида ‘c 1:3 rmw’. Сначала мы указываем тип устройства — в нашем случае это символьное устройство, обозначаемое буквой с (сокращение от character device). Два других типа устройств — это блочные (b) и все возможные устройства (а). Далее следуют мажорный и минорный номера устройства. Узнать номера можно с помощью команды вида:
$ ls -l /dev/null Вместо /dev/null, естественно, можно указать любой другой путь. Вывод этой команды выглядит так:
crw-rw-rw- 1 root root 1, 3 May 30 10:49 /dev/null Первая цифра в выводе — это мажорный, а вторая — минорный номер.
Три последние буквы означают права доступа: r — разрешение читать файлы с указанного устройства, w — разрешение записывать на указанное устройство, m — разрешение создавать новые файлы устройств.
$ echo $$ > /sys/fs/cgroup/devices/group0/tasks $ echo "test" > /dev/null При выполнении последней команды система выдаст сообщение об ошибке:
-bash: /dev/null: Operation not permitted С устройством /dev/null мы никак взаимодействовать не можем, потому что доступ закрыт.
$ echo a > /sys/fs/cgroup/devices/group0/devices.allow В результате выполнения этой команды в файл /sys/fs/cgroup/devices/group0/devices.allow будет добавлена запись a *:* rwm, и все ограничения будут сняты.
Cgroups и контейнеры
Из приведённых примеров понятно, в чём заключается принцип работы cgroups: мы помещаем определённые процессы в группу, которую затем «встраиваем» в подсистемы. Разберём теперь более сложные примеры и рассмотрим, как cgroups используются в современных инструментах контейнеризации на примере LXC.
Установим LXC и создадим контейнер:
$ sudo apt-get install lxc debootstrap bridge-utils $ sudo lxc-create -n ubuntu -t ubuntu -f /usr/share/doc/lxc/examples/lxc-veth.conf $ lxc-start -d -n ubuntu Посмотрим, что изменилось в директории cgroups после создания и запуска контейнера:
$ ls /sys/fs/cgroup/memory cgroup.clone_children memory.limit_in_bytes memory.swappiness cgroup.event_control memory.max_usage_in_bytes memory.usage_in_bytes cgroup.procs memory.move_charge_at_immigrate memory.use_hierarchy cgroup.sane_behavior memory.numa_stat notify_on_release lxc memory.oom_control release_agent memory.failcnt memory.pressure_level tasks memory.force_empty memory.soft_limit_in_bytes Как видим, в каждой иерархии появилась директория lxc, которая в свою очередь содержит поддиректорию Ubuntu. Для каждого нового контейнера в директории lxc будет создаваться отдельная поддиректория. PID всех запускаемых в этом контейнере процессов будут записываться в файл /sys/fs/cgroup/cpu/lxc/[имя контейнера]/tasks
Выделять ресурсы для контейнеров можно как с помощью управляющих файлов cgroups, так и с помощью специальных команд lxc, например:
$ lxc-cgroup -n [имя контейнера] memory.limit_in_bytes 400 Аналогичным образом дело обстоит с контейнерами Docker, systemd-nspawn и другими.
Недостатки cgroups
На протяжении почти 10 лет существования механизм cgroups неоднократно подвергался критике. Как отметил автор одной статьи на LWN.net , разработчики ядра cgroups активно не любят. Причины такой нелюбви можно понять даже из приведённых в этой статье примеров, хоть мы и старались подавать их максимально нейтрально, без эмоций: встраивать контрольную группу в каждую подсистему по отдельности очень неудобно. Присмотревшись повнимательней, мы увидим, что такой подход отличается крайней непоследовательностью.
Если мы, например, создаём вложенную контрольную группу, то в некоторых подсистемах настройки родительской группы наследуются, а в некоторых — нет.
В подсистеме cpuset любое изменение в родительской контрольной группе автоматически передаётся вложенным группам, а в других подсистемах такого нет и нужно активировать параметр clone.children.
Об устранении этих и других недостатков cgroups разговоры в сообществе разработчиков ядра шли очень давно: один из первых текстов на эту тему датируется началом 2012 года.
Автор этого текста, инженер Facebook Течжен Хе, прямо указал, что главная проблема cgroups заключается в неправильной организации, при которой подсистемы подключаются к многочисленным иерархиям контрольных групп. Он предложил использовать одну и только одну иерархию, а подсистемы добавлять для каждой группы отдельно. Такой подход повлёк за собой серьёзные изменения вплоть до смены названия: механизм изоляции ресурсов теперь называется cgroup (в единственном числе), а не cgroups.
Разберёмся более подробно в сути реализованных нововведений.
Cgroup v2: что нового
Как уже было отмечено выше, сgroup v2 был включён в ядро Linux начиная с версии ядра 4.5. При этом старая версия поддерживается тоже. Для версии 4.6 уже существует патч, с помощью которого можно отключить поддержку первой версии при загрузке ядра.
На текущий момент в cgroup v2 можно работать только с тремя подсистемами: blkio, memory и PID. Уже появились (пока что в тестовом варианте) патчи, позволяющие управлять ресурсами CPU.
Cgroup v2 монтируется при помощи следующей команды:
$ mount -t cgroup2 none [точка монтирования] Предположим, мы смонтировали cgroup 2 в директорию /cgroup2. В этой директории будут автоматически созданы следующие управляющие файлы:
- cgroup.controllers — содержит список поддерживаемых подсистем;
- cgroup.procs — по завершении монтирования содержит список всех выполняемых процессов в системе, включая процессы-зомби. Если мы создадим группу, то для неё тоже будет создан такой файл; он будет пустым, пока в группу не добавлены процессы;
- cgroup.subtree_control — содержит список подсистем, активированных для данной контрольной группы; по умолчанию пуст.
Эти же самые файлы создаются в каждой новой контрольной группе. Также в группу добавляется файл cgroup.events, который в корневой директории отсутствует.
Новая группа создаётся так:
$ mkdir /cgroup2/group1 Чтобы добавить для группы подсистему, нужно записать имя этой подсистемы в файл cgroup.subtree_control:
$ echo "+pid" > /cgroup2/group1/cgroup.subtree_control Для удаления подсистемы используется аналогичная команда, только на место плюса ставится минус:
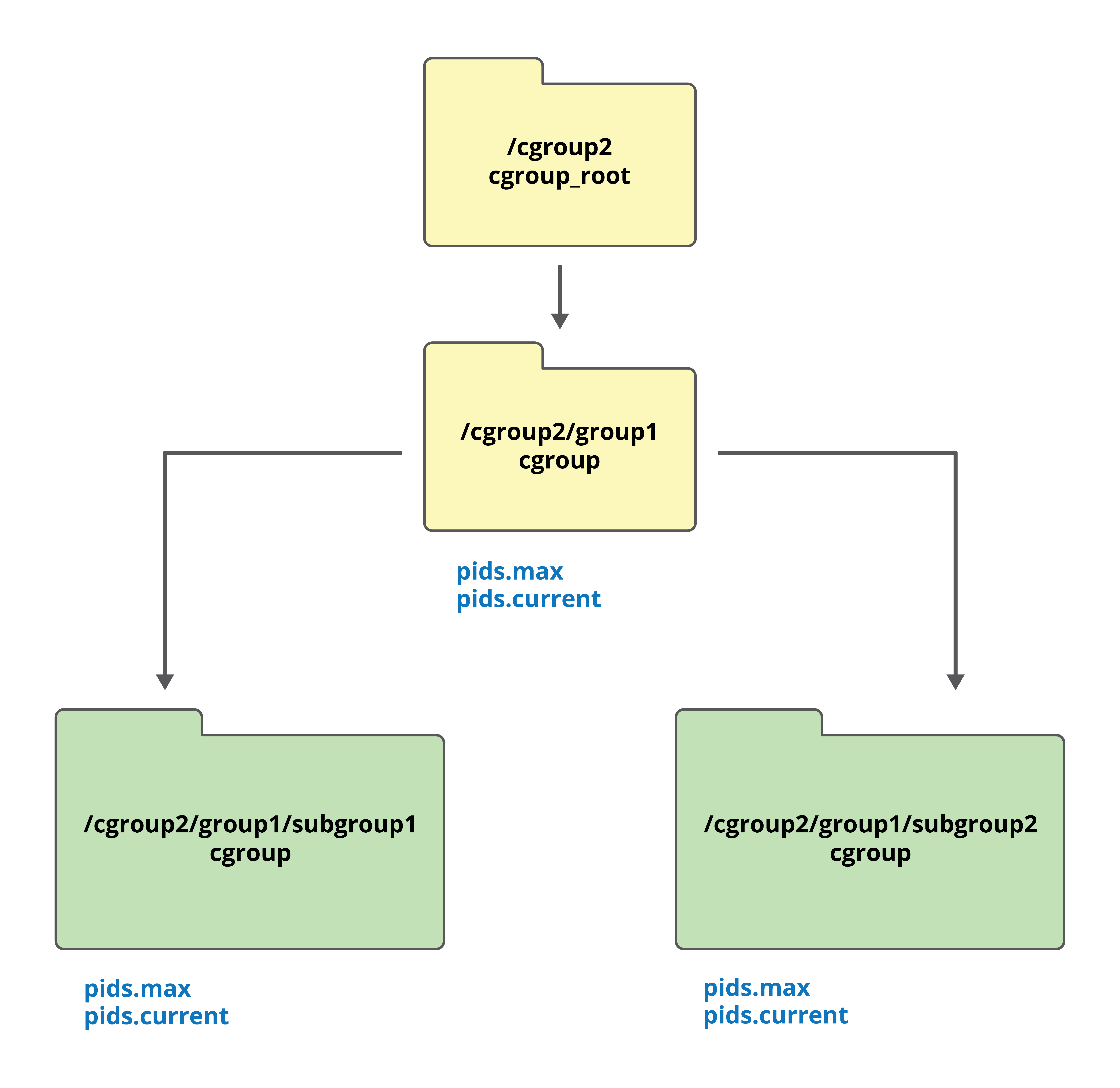
$ echo "-pid" > /cgroup2/group1/cgroup.subtree_control Когда для группы активируется подсистема, в ней создаются дополнительные управляющие файлы. Например, после активации подсистемы PID в директории появятся файлы pids.max и pids.current. Первый из этих файлов используется для ограничения числа процессов в группе, а второй — содержит информацию о числе процессов, включённых в группу на текущий момент.
Внутри уже имеющихся групп можно создавать подгруппы:
$ mkdir /cgroup2/group1/subgroup1 $ mkdir /cgroup2/group1/subgroup2 $ echo "+memory" > /cgroup2/group1/cgroup.subtree_control, Все подгруппы наследуют характеристики родительской группы. В только что приведённом примере подсистема PID будет активирована как для группы group1, так и для обеих вложенных в неё подгрупп; в них также будут добавлены файлы pids.max и pids.current. Сказанное можно проиллюстрировать с помощью схемы:
Чтобы избежать недоразумений с вложенными группами (см. выше), в cgroup v2 действует следующее правило: нельзя добавить процесс во вложенную группу, если в ней уже активирована какая-либо подсистема:
В первой версии cgroups процесс мог входить в несколько подгрупп одновременно, если эти подгруппы входили в разные иерархии, встроенные в разные подсистемы. Во второй версии один процесс может принадлежать только к одной подгруппе, что позволяет избежать путаницы.
Заключение
В этой статье мы рассказали, как устроен механизм cgroups и какие изменения были внесены в его новую версию. Если у вас есть вопросы и дополнения — добро пожаловать в комментарии.
Для всех, кто хочет глубже погрузиться в тему, приводим список ссылок на интересные материалы:
- https://www.kernel.org/doc/Documentation/cgroup-v1/cgroups.txt — документация первой версии cgroups;
- https://www.kernel.org/doc/Documentation/cgroup-v2.txt — документация cgroup v2;
- https://www.youtube.com/watch?v=PzpG40WiEfM — лекция Течжена Хе о нововведениях cgroup v2;
- https://events.linuxfoundation.org/sites/events/files/slides/2014-KLF.pdf — презентация доклада о cgroup v2 с подробными разъяснениями всех нововведений и изменений.
История контейнеризации

Контейнер — это изолированная рабочая среда, содержащая все зависимости, конфигурационные и исполняемые файлы необходимые для работы программы или пользователя, находящегося в контейнере. Для работы контейнера ОС выделяет пул изолированных ресурсов: ядра ЦП, оперативная память, диск и сеть. Важно понять, что контейнер работает на ядре хостовой ОС и изолируется средствами операционной системы, а не возможностями железа, как виртуальная машина. Пока в Linux существуют всего несколько инструментов ядра, которыми можно изолировать процессы и ограничить доступ к ресурсам. С помощью Namespaces (неймспейсы) процессы можно объединить в группы и изолировать, а с помощью Cgroups можно задать лимиты по ресурсам. Namespaces и Cgroups мы разберём чуть позже, а пока взглянем на функцию изоляции процессов на уровне ядра ОС, которой пользовались задолго до появления Namespaces и Cgroups — chroot.
Первый механизм изоляции процессов — chroot
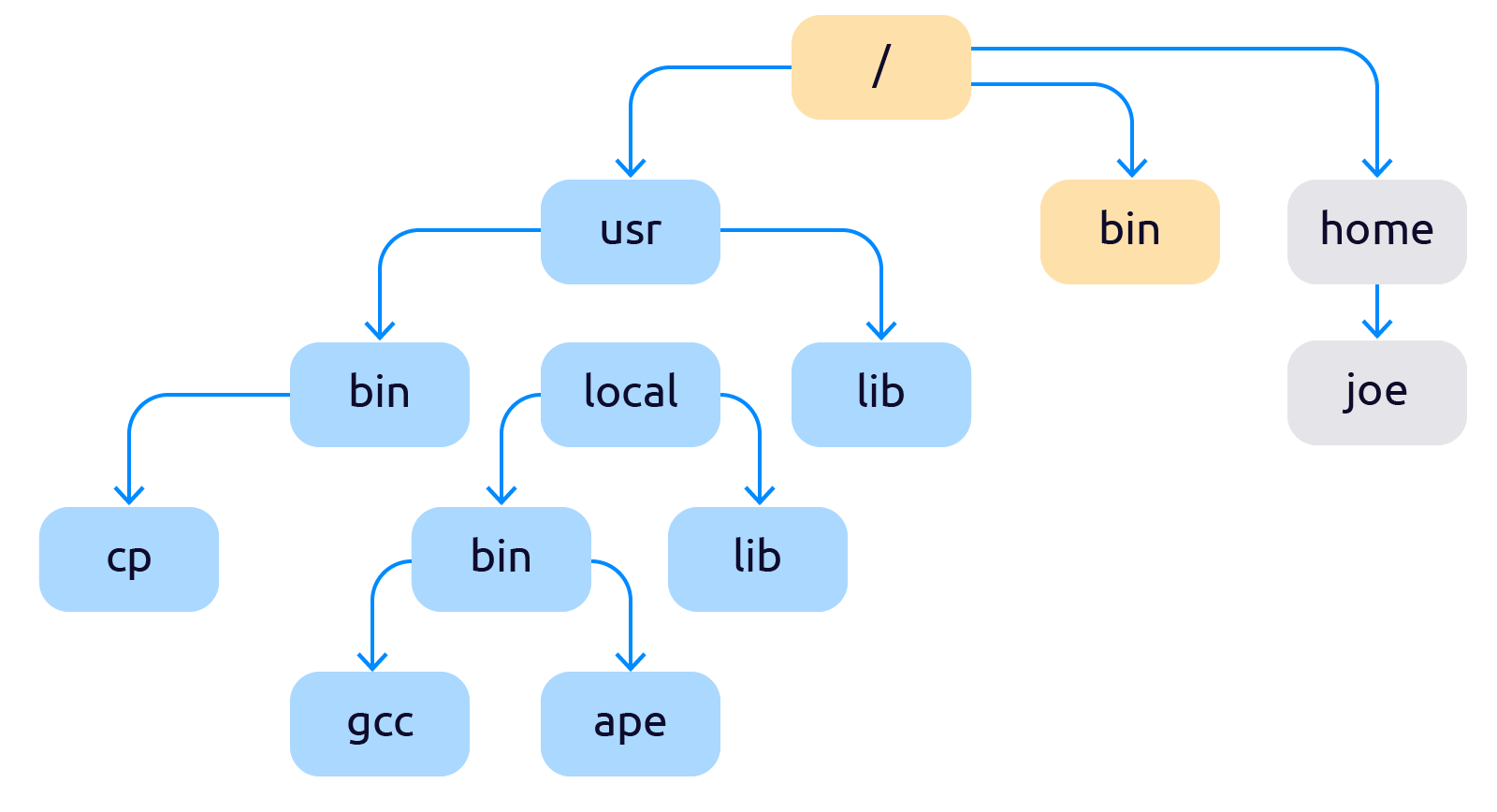 Про механизмы разделения процессов на изолированные окружения начали думать ещё в конце 70-х. Первым механизмом управления изоляцией процессов стал — chroot (чрут). Chroot — это подмена корня файловой системы для группы процессов или временная смена корня и контекста для запуска выбранных процессов. Точнее сказать так: chroot добавляет в систему второй корневой каталог «/», который с точки зрения пользователя ничем не будет отличаться от первого. После применения чрута файловая система начинает выглядеть как-то так:
Про механизмы разделения процессов на изолированные окружения начали думать ещё в конце 70-х. Первым механизмом управления изоляцией процессов стал — chroot (чрут). Chroot — это подмена корня файловой системы для группы процессов или временная смена корня и контекста для запуска выбранных процессов. Точнее сказать так: chroot добавляет в систему второй корневой каталог «/», который с точки зрения пользователя ничем не будет отличаться от первого. После применения чрута файловая система начинает выглядеть как-то так: 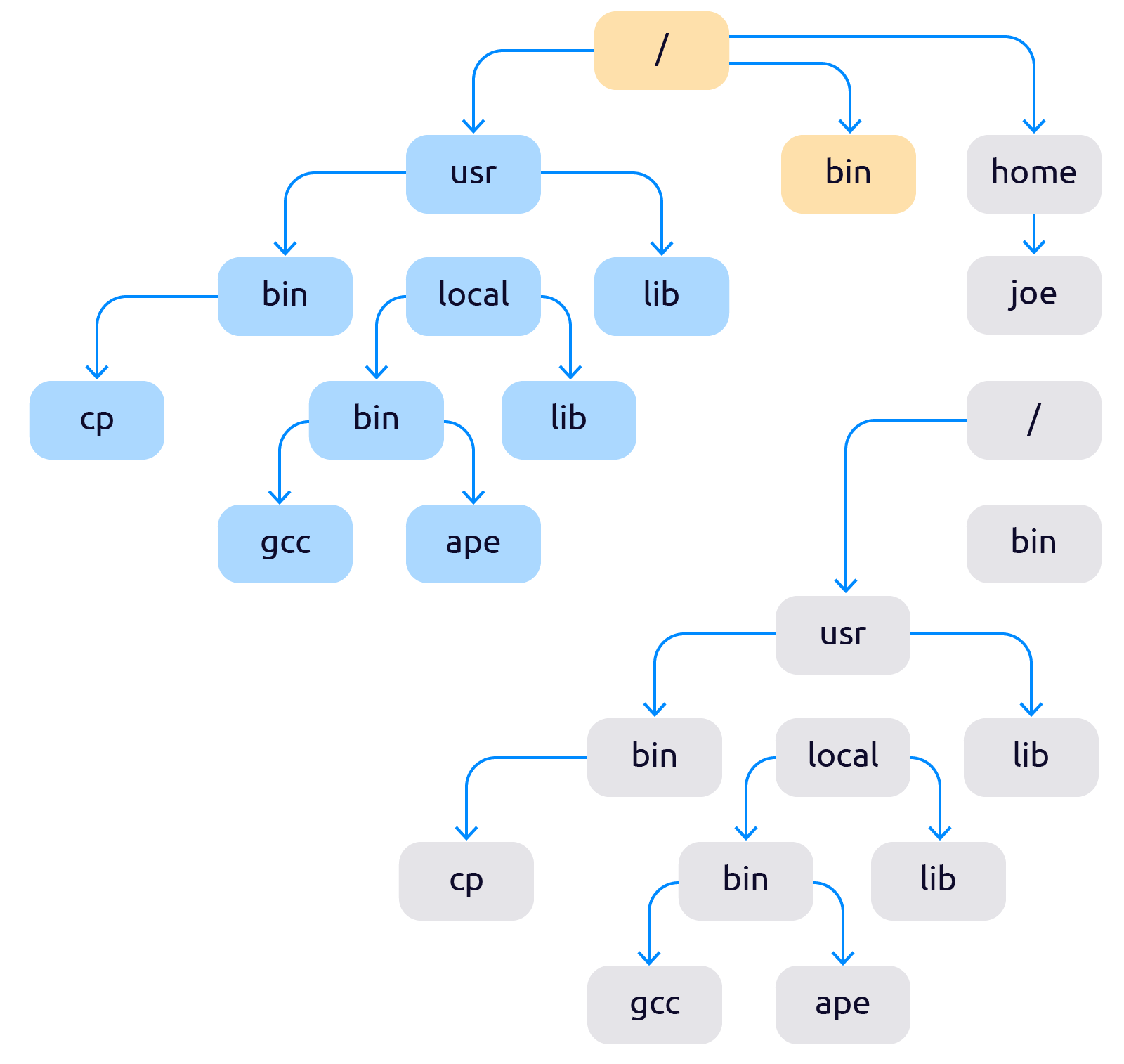 Теперь файловая система разделена на две не влияющие друг на друга части. Сейчас chroot стандартная функция любой *nix-ОС. Появившись впервые в 1982, в BSD 4.2, он почти не изменился, отсюда такое обилие недостатков:
Теперь файловая система разделена на две не влияющие друг на друга части. Сейчас chroot стандартная функция любой *nix-ОС. Появившись впервые в 1982, в BSD 4.2, он почти не изменился, отсюда такое обилие недостатков:
- Общие пространство процессов — процесс запущенный в chroot видит все остальные процессы.
- Сеть общая — невозможно запустить изолированные серверы в разных чрутах.
- Нельзя назначить лимиты по ресурсам — в любой момент процесс из чрута может так же, как и любой другой процесс в системе аллоцировать все ресурсы.
В каких задачах chroot применяется до сих пор:
- ограничение прав анонимных пользователей, подключившихся по ftp-протоколу
- управление правами пользователей, подключившихся по ssh-протоколу.
Chroot служит для изоляции процессов. Например, bind во многих дистрибутивах Linux запускается в chroot, многие демоны перед понижением привилегий делают chroot в пустую директорию. Также chroot может изолировать пользователей — демоны ftp и ssh через chroot ограничивают права анонимных пользователей.
Если вам хочется попробовать chroot на практике и поупражняться в Linux-администрировании. Рекомендуем прочесть эту статью.
Chroot был самым простым и единственным способом изоляции процессов в течение 15 лет, пока не появился jail.
Первый контейнер — технология jail в FreeBSD 4.0
Jail появился в 1999-2000 годах, в FreeBSD 4.0. По факту jail — это тот же chroot только посложнее. В jail появилась изоляция сети. Однако во FreeBSD, это изоляция была половинчатой — сетевые интерфейсы были видны в любом окружении, но в зависимости от окружения были видны только определённые IP-адреса, которые были присвоены определенным интерфейсам. При этом loopback был общим.
Jail был уже намного продвинутее чрута, и на нём даже строили хостинги, однако ограничения ресурсов в нём по-прежнему не было. Назначать лимиты на ресурсы стало возможно лишь в FreeBSD версии 9.0, с появлением механизма управления ресурсами RCTL. Эта система позволяет ограничивать ресурсы как отдельным пользователям и процессам, так и целым jail.
Интересный факт
В мире кроме всем нам хорошо известных Linux и Windows есть много самописных ОС, которые, конечно, в качестве основы брали уже что-то готовое от других ОС, но при этом приносили и что-то неожиданное и оригинальное.
Такой ОС непохожей на все остальные была Plan9. Это ОС разработана в Bell labs. Её исходники опубликованы на рубеже 00-х.
Фишка Plan9 в отношении к идеологии *NIX. Постулат *NIX — «всё есть файл».

Однако сокеты в *NIX-системах не вписываются в эту абстракцию, а вот в Plan9, сокет — это тоже файл.
Разработчики Plan9 возвели идеологию *NIX-систем в абсолют. В будущем Plan9 вдохновит немало других ОС, таких, как Harvey OS и Jehanne OS.
Примерно в то же время, в начале 2000 на свет появилась Virtuozzo в качестве коммерческой контейнеризации и openvz. Однако неудачные попытки коммерциализации продукта сильно затормозили приход новой системы контейнеризации в массы.
Немного о свободном ПО и коммерциализации
Если бы Parallels, Inc последовали бы сразу заветам Ричарда Столлмана, о коммерциализации open source-проектов, исходя из его заветов: зарабатывать open source может только на платном суппорте и платной доработке фич, возможно, судьба Virtuozzo сложилась бы по другому.
Кстати, Столлман ещё тот олдфаг. На своих выступлениях и лекциях он часто призывает отказаться от сотовых телефонов и передачи своих личных данных третьим сторонам.

Вообще мировоззрения Ричарда сегодня могут многим показаться устаревшими и недееспособными, однако на фоне этого, все же невозможно отрицать его огромный вклад в развитие свободного ПО.
Ознакомиться с биографией Ричарда Мэттью Столмана можно в Википедии.
К тому же, в те же годы к разработчикам стало приходить понимание, что все существующие инструменты изоляции — это костыли и палки проросшие глубоко в ядро ОС, и нужно радикально менять подход.
Для более глубокого погружения в jail рекомендуем прочесть вот эту статью на Хабре. Внутри много кода и подробная инструкция по настройке jail.
Переломный момент — появление Namespaces
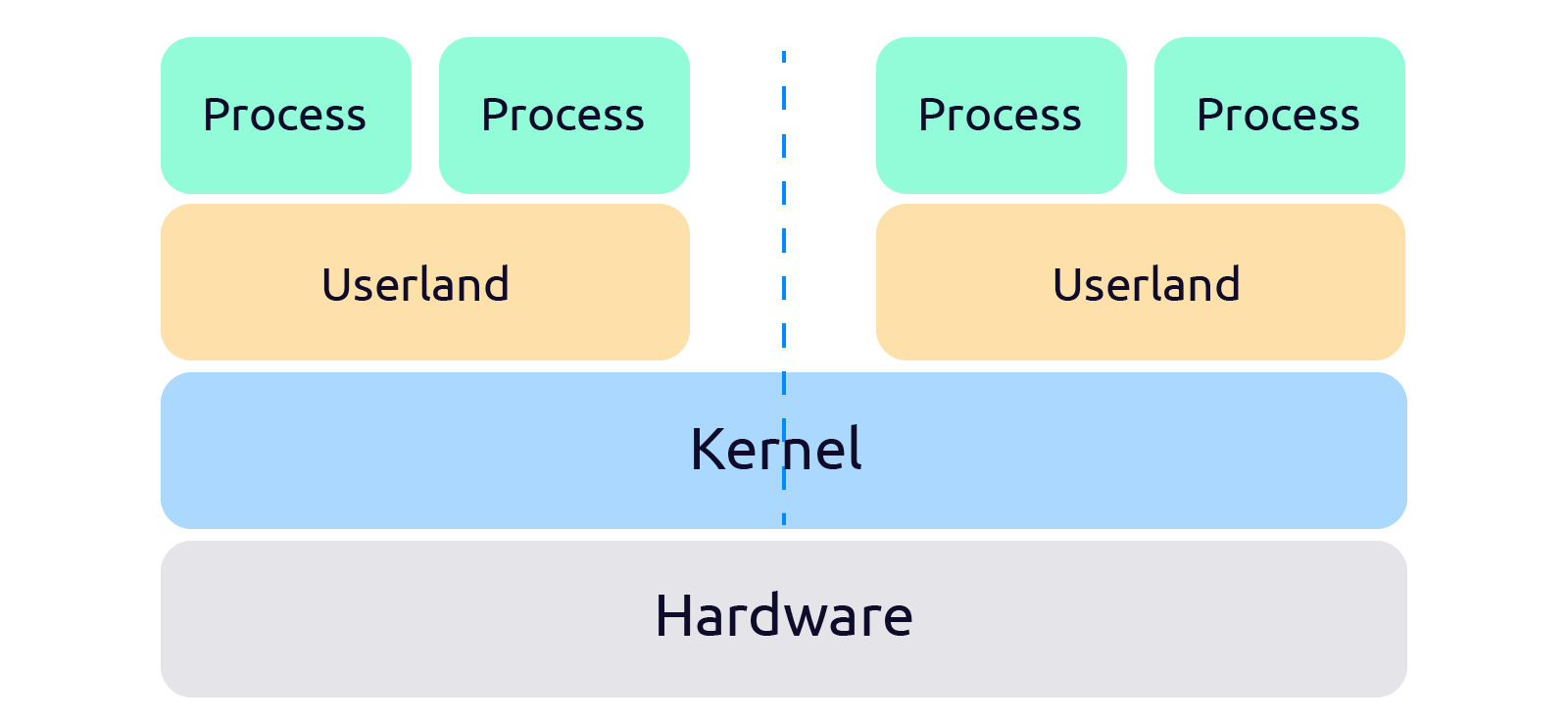
Свежим глотком воздуха стало появление в 2002 году, в ядре Linux версии 2.4.19 нового API для создания абстракции контроля над общими ресурсами — Namespaces API.
Namespaces (пространства имен) — это абстракция (программная прослойка) над физическими ресурсами. Если раньше процессы обращались напрямую к ресурсам, то с появлением namespaces, все запросы проходят через этот дополнительный слой абстракции.
С появлением namespace в ядро было добавлено 3 новых функции, которые отвечают за управление атрибутами namespace:
- clone() — аналог fork() с возможностью выделения частей общих ресурсов в отдельные namespaces.
- setns() — подключает указанный процесс к заданному namespace.
- unshare() — изменение контекста текущего процесса.
В результате вызовов перечисленных функций ядра, namespaces становятся новыми атрибутами процессов. Это позволяет разным процессам иметь разное представление о тех глобальных ресурсах, которыми они распоряжаются.
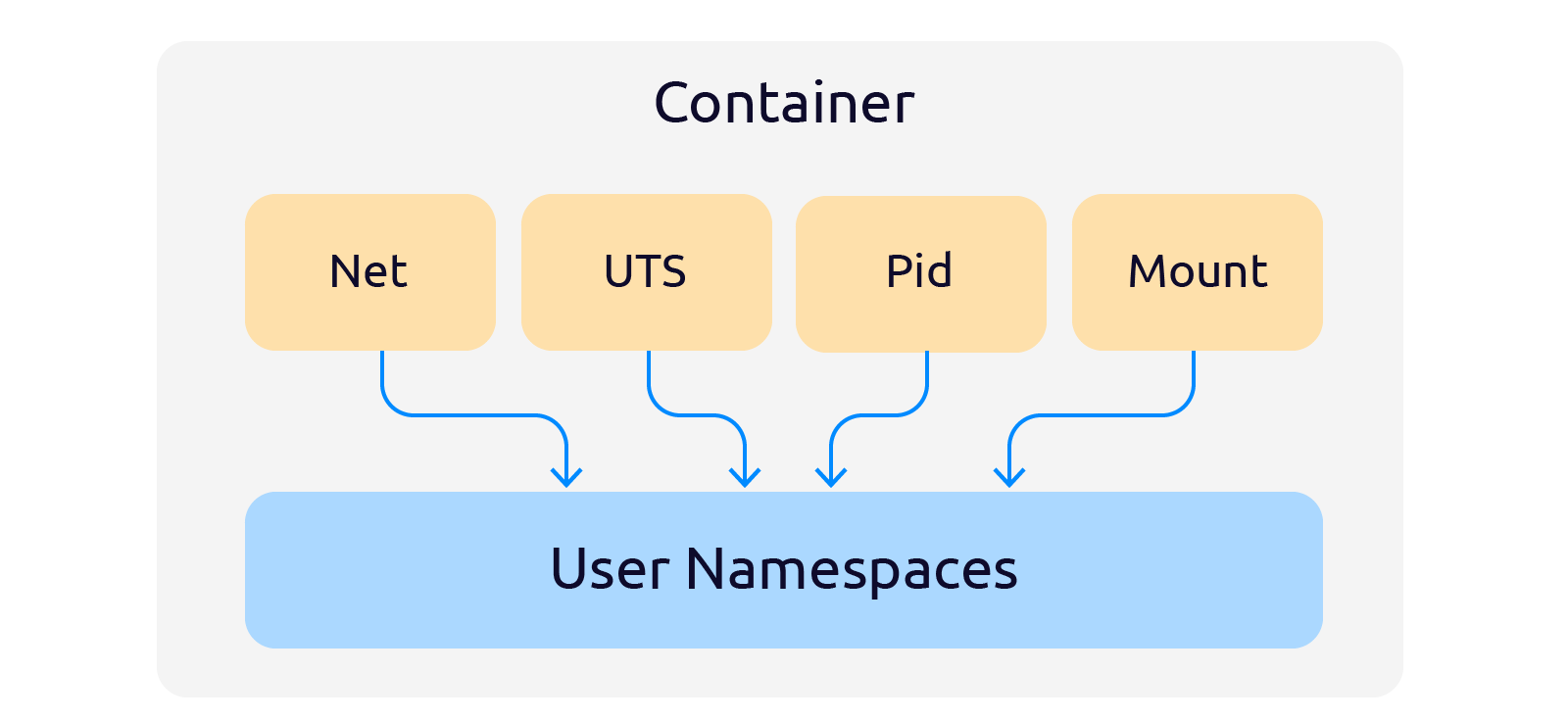
Существуют следующие пространства имён:
- Mount — абстракция над пространством имен для файловых систем. Mount позволяет сразу монтировать новое устройство в несколько пространств имён файловой системы, вместо монтирования в каждом отдельном пространстве.
- Network — абстракция над сетью: интерфейсы, таблицы маршрутизации и т.д. Пространство имен Network по сути выполняет роль туннеля между разными пространствами имён сети.
- IPC — абстракция над межпроцессным взаимодействием. Процесс в пространстве имен IPC не может писать или читать IPC ресурсы, принадлежащие другому пространству имен. Так процессы в одном контейнере не могут вмешиваться в другие контейнеры.
- PID — абстракция над пространством номеров процессов. PID изолирует пространство ID процессов. Процессы в различных пространствах могут иметь одинаковые ID.
- User — абстракция над пространством пользователей. User изолирует ID пользователей и групп, корневой каталог, ключи и capabilities.
- UTS (Unix Time Sharing) — абстракция над пространством hostname и NIS. UTS позволяет контейнерам иметь собственные доменные имена NIS domainname и имена контейнеров nodename.
- Cgroup — используется как атрибут, корневой узел дерева cgroup.
Перечисленные неймспейсы появлялись постепенно, по-мере необходимости решения определенных технических задач. Контейнер, по сути можно назвать квинтэссенцией неймспейсов. Вообще, тема неймспейсов очень обширна. Если вы хотите разобраться в ней лучше — почитайте этот отличный цикл статей на Хабре.
Неймспейсы решили вопросы изоляции, однако вопрос ограничения ресурсов для изолированных процессов оставался открытым. Решение этого вопроса появилось с выходом ядра версии 2.6.20 в 2008 году — в нём появился механизм Cgroups.
Ограничение ресурсов — Cgroups
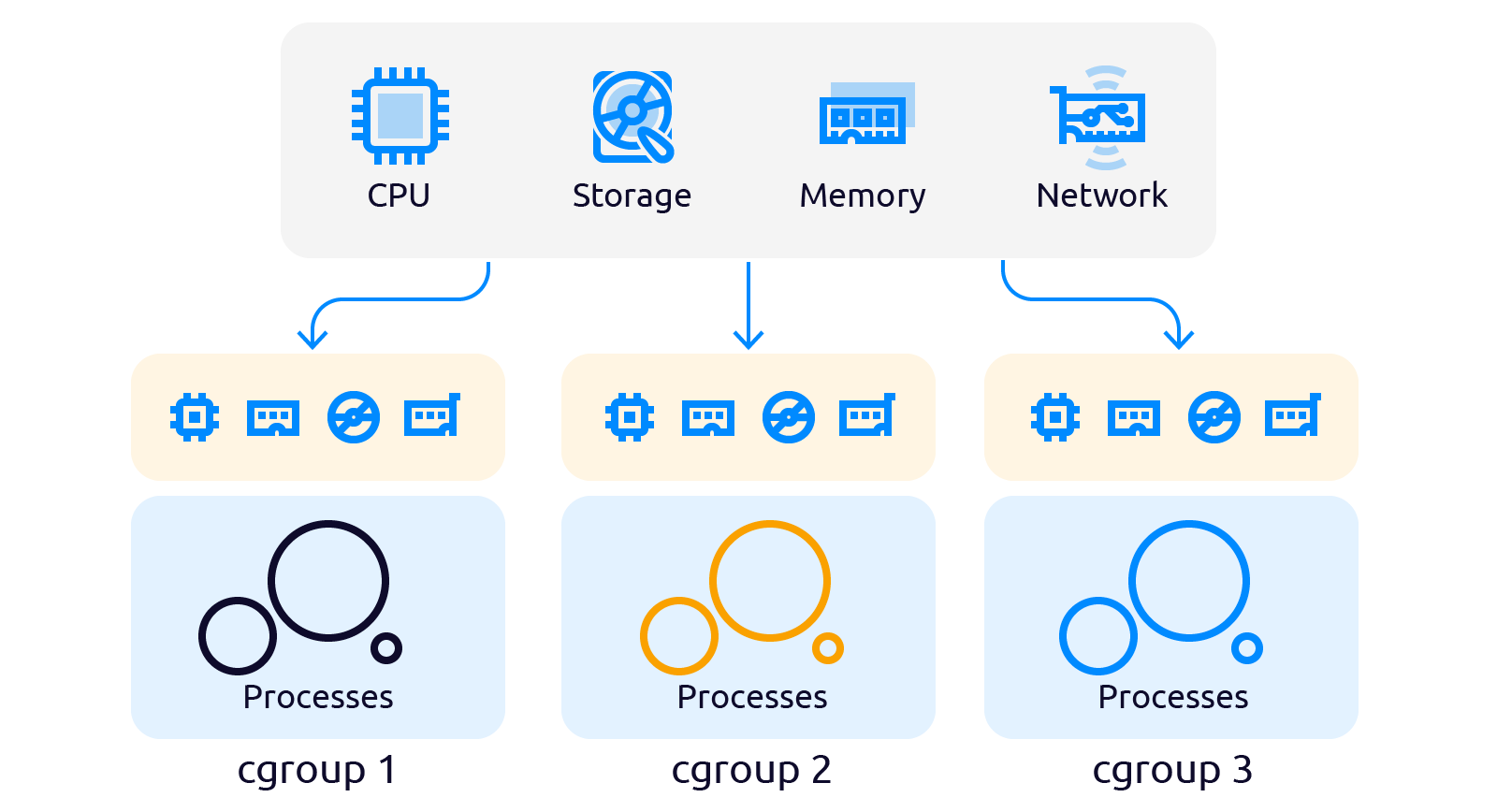
Cgroups (control group) — группа процессов Linux, на которые наложена изоляция и установлены ограничения на вычислительные ресурсы (процессорные, сетевые, ресурсы памяти, ресурсы ввода-вывода) со стороны ядра Linux.
Cgroups — было отличное самодостаточное решение, которое сильно продвинуло технологии контейнеризации вперед. Первой попыткой создания подобного механизма лимитирования ресурсов для изолированных процессов был process accounting, появившийся в 1999 году.
Опять же не обошлось без Google
Google — компания, которая умеет идти своей дорогой, даже там, где дороги вроде бы и нет.
В 2006 году Google взялась за разработку собственного механизма управления ресурсами контейнеров — process containers. Разрабатывали механизм Пол Менедж и Рохит Сет.
Замысел был скромен — усовершенствовать механизм cpuset, предназначенный для распределения процессорного времени и памяти между задачами. Но обыкновенная палка в руках опытных разработчиков выстрелила!
В итоге в конце 2007 года название process containers было заменено на control groups, а в 2008 году cgroups был официально добавлен в ядро Linux (версия 2.6.24).
Разработанные в Google и, включенные в ядро в 2008 году Cgroup стали новой абстракцией над управлением ресурсами. Cgroups состоит из двух частей: cgroup core (ядро cgroup) и подсистем (директории с управляющими файлами).
Количество подсистем может отличаться в зависимости от версии ядра. Так в ядре версии 4.4.0.21 таких подсистем 12, в ядре версии 5.10.16.3, которое содержится в Ubuntu 20 TLS, подсистем уже 13:
- blkio — управляет лимитами чтения и записи на блочных устройствах;
- cpu — управляет доступом к ресурсам процессора;
- cpuset — выделяет отдельных процессоров группе;
- cpuacct — управляет ресурсами cpu (работает совместно с cpu);
- devices — ограничивает доступ к устройствам;
- hugetlb — управляет работой групп с большими страницами памяти (huge pages);
- net_cls — размечает спец. тегами сетевые пакеты, что позволяет процессам генерирующим их определять какие процессы их сгенерировали;
- perf_event rdma — предоставляет интерфейс для инструмента анализа производительности в Linux (perf);
- freezer — управляет приостановкой и возобновлением процессов выполнения задач внутри контрольной группы;
- memory — управляет выделением памяти для групп процессов;
- net_prio — управляет динамическим назначением приоритета трафика;
- pids — ограничивает количество процессов в рамках контрольной группы;
- unified — автоматически монтирует файловую систему в каталог /sys/fs/cgroup/unified при запуске системы.
Вывести список подсистем в вашей версии ядра можно следующей командой:
$ ls /sys/fs/cgroup/
blkio cpuacct devices hugetlb net_cls perf_event rdma cpu cpuset freezer memory net_prio pids unified
Посмотреть к каким контрольным группам принадлежит процесс можно так:
- вызовите утилиту htop
- найдите нужный вам PID процесса
- перейдите в каталог /proc и найдите там директорию с нужным вам PID
- вызовите команду cat и передайте ей cgroup
Как работать с Cgroups
Работать с cgroups можно двумя способами:
- Стандартным способ — работать с cgroups как с файлами. Вносить записи групп с помощью echo в нужный контроллер.
- С помощью cgroup-tools — работать с cgroups через набор утилит, которые облегчают взаимодействие с cgroups.
Первый способ более предпочтительный, но более трудозатратный для пользователей, имеющих не богатый опыт администрирования Linux, поэтому мы пойдем вторым путем — будем использовать cgroup-tools.
Поместить процесс в контрольную группу просто. Достаточно выполнить команду cgcreate, передать ей следующие параметры:
- -t uid:gid — пользователи, получающие права на перемещение заданий в (из) группы.
- -a uid:gid — пользователи, получающие права на управление параметрами группы (опциональный параметр).
- -g список подсистем:путь.
Пример создания контрольной группы по памяти и процессору:
$ sudo cgcreate -t root:root -g memory,cpu:/mycgroup
Теперь в нашу вновь созданную группу нужно переместить процессы. Для этого есть команда cgclassify, в которую с помощью ключа g передается группа, её название и пиды процессов:
$ sudo cgclassify -g cpu:/mycgroup 7
Убедится, что процесс попал в новую группу можно с помощью команды cat:
Удалить процесс из группы можно также одной командой:
$ sudo cgdelete -g memory,cpu:/mycgroup
До этого мы умели лишь создавать группы и помещать в них процессы. Теперь научимся задавать ограничение ресурсов. Делается это командой cgset с параметром -r:
$ cgset -r cpu.shares=1 /mycgroup
Мы рассмотрели несколько основных инструментов управления контрольными группами из пакета cgroups-tools. Их там конечно же куда больше. Полное описание всех утилит пакета можно посмотреть тут.
Кстати, есть и альтернативный способ управления и настройки cgroups, о нём можно узнать из этой статьи:

Итак, мы кратко рассмотрели историю контейнеризации до этапа появления namespaces и cgroups, рассмотрели эти механизмы и теперь можно подвести итог.
Что же такое контейнер в итоге?

По сути контейнер — это определенные пространства имён (Namespaces) и наборы контрольных групп (Control groups), удобно управляемые с помощью сторонних утилит. Например, с помощью Docker.
Namespace — механизм изоляции процессов. Мы можем создавать пространства имён процессов (группы процессов) помещать туда нужные нам процессы по их идентификаторам — пидам (PID) и эти процессы не могут обращаться к процессам вне своего пространства имён.
Control groups — механизм определения количества выдаваемых ресурсов процессам.
Контейнеры обладают следующими важными преимуществами:
- Они легковесные и быстро выполняются, так как содержат только всё необходимое для работы контейнера: исполняемые и конфигурационные файлы, прочие зависимости.
- Хостовая ОС может смотреть внутрь контейнера и видеть дерево процессов. Когда мы смотрим на процесс виртуальной машины с хоста, мы видим один процесс.
- Появляется возможность использовать микросервисную архитектуру. Каждый сервис можно поместить в свой контейнер, назначить ему ресурсы, запускать и останавливать их независимо друг от друга.
- Можно быстрее развертывать приложения, легче масштабировать их горизонтально, проще находить в них ошибки.
- Выход из строя одного контейнера не влияет на дальнейшую работу других контейнеров.
Контейнеры нужны там, где требуется скорость разворачивания приложений и низкий уровень потребления системы виртуализации. Контейнеры подходят:
- для упрощения процесса развертывания приложений;
- для тестирования или отладки кода;
- для запуска приложений, требующих другого дистрибутива ОС (системные контейнеры);
- для микросервисов, которые можно разрабатывать и обновлять независимо;
- для горизонтально масштабируемых приложений — когда запускается несколько одинаковых контейнеров на текущих ресурсах без увеличения стоимости этих ресурсов;
- для модернизации и миграции существующих приложений в более современные среды.
Контейнеризация не подходит, если для работы приложения требуется другая ОС, а не та, что установлена на сервере.
И в конце, мы хотим оставить ссылку на интервью, того, без кого не было бы ни контейнеров, ни Линукса, ни системы контроля версий GIT, да и вообще, не было бы того технологического мира, в котором мы все с вами живём:
В следующих публикациях мы погрузимся в Docker и посмотрим на Docker-контейнеры через уже полученные знания о контейнеризации.
ОПИСАНИЕ¶
Управляемые cgroup-ы, обычно называемые cgroups, это свойство ядра Linux, которое позволяет объединять процессы в иерархические группы, и в этих группах отслеживать и ограничивать разные типы ресурсов. Ядро предоставляет интерфейс работы с cgroup-ами через псевдо-файловую систему, называемую cgroupfs. Группировка реализована в базовой части ядра cgroup, а слежение за ресурсами и ограничениями — в подсистемах самих ресурсов (память, ЦП и т. п.).
Терминология¶
cgroup — это набор процессов, которые связаны с набором ограничений или параметров, определяемых через файловую систему cgroup.
subsystem — компонент ядра, который изменяет поведение процессов в cgroup-у. Реализованы различные подсистемы, они позволяют делать разные вещи, например ограничивать количество времени ЦП и память доступную для cgroup-ы, подсчитывать время ЦП, используемое группой и останавливать и возобновлять выполнение процессов в cgroup-е. Подсистемы иногда также называют контроллерами ресурсов (или просто, контроллерами).
Для контроллера cgroup-ы упорядочены в иерархию. Иерархия определяется посредством создания, удаления и переименования подкаталогов в файловой системе cgroup. На каждом уровне иерархии можно задать атрибуты (например, ограничения). Если атрибуты назначены, то ограничение, контроль и учёт, предоставляемый cgroup-ами, обычно, распространяется в иерархии по всем нижестоящим элементам. То есть, например, ограничение, заданное на cgroup на высшем уровне иерархии не может быть превышено в дочерних cgroup-ах.
Cgroups версии 1 и 2¶
The initial release of the cgroups implementation was in Linux 2.6.24. Over time, various cgroup controllers have been added to allow the management of various types of resources. However, the development of these controllers was largely uncoordinated, with the result that many inconsistencies arose between controllers and management of the cgroup hierarchies became rather complex. A longer description of these problems can be found in the kernel source file Documentation/admin-guide/cgroup-v2.rst (or Documentation/cgroup-v2.txt in Linux 4.17 and earlier).
Because of the problems with the initial cgroups implementation (cgroups version 1), starting in Linux 3.10, work began on a new, orthogonal implementation to remedy these problems. Initially marked experimental, and hidden behind the -o __DEVEL__sane_behavior mount option, the new version (cgroups version 2) was eventually made official with the release of Linux 4.5. Differences between the two versions are described in the text below. The file cgroup.sane_behavior, present in cgroups v1, is a relic of this mount option. The file always reports «0» and is only retained for backward compatibility.
Хотя cgroups v2 создавалась как замена cgroups v1, старая система всё ещё существует (и для обеспечения совместимости её не хотелось бы удалять). В настоящее время, в cgroups v2 реализованы не все контроллеры, доступные в cgroups v1. Эти две системы реализованы таким образом, что контроллеры v1 и v2 можно монтировать одновременно. То есть, например, можно не только использовать контроллеры, поддерживаемые версией 2, но и использовать контроллеры версии 1, которые пока не поддерживаются версией 2. Единственным ограничением является то, что один и тот же контроллер не может быть запущен одновременно в иерархии cgroups v1 и cgroups v2.
CGROUPS ВЕРСИИ 1¶
В cgroups v1 каждый контроллер можно смонтировать в отдельную файловую систему cgroup, которая представляет собой собственную иерархию процессов в системе. Также возможно совместное монтирование нескольких (или даже всех) контроллеров cgroups v1 в единую файловую систему cgroup, при этом совместно смонтированные контроллеры управляют одной иерархией процессов.
Для каждой смонтированной иерархии дерево каталогов отражает иерархию управляемой группы. Каждая управляемая группа представляется каталогом, каждый её потомок управляемой cgroups представляется дочерним каталогом. Например, /user/joe/1.session представляет управляемую группу 1.session, которая является потомком cgroup joe, которая является потомком /user. В каждом каталоге cgroup есть набор файлов, доступных на чтение и запись, через которые доступны ограничения ресурсов и другие общие свойства cgroup.
Задачи (нити) и процессы¶
В cgroups v1 процессы и задачи различаются. Процесс может состоять из нескольких задач (чаще всего называемых нитями, если смотреть из пользовательского пространства, и так они будут называться далее в этой справочной странице). В cgroups v1 возможно независимо управлять членством cgroup для нитей процесса.
В некоторых случаях способность cgroups v1 разделять нити по разным cgroups вызывает проблемы. Например, это не имеет смысла для контроллера memory, так как все нити процесса находятся в одном адресном пространстве. Из-за таких проблем способность независимого управления членством cgroup для нитей процесса была удалена в первой реализации cgroups v2, но позже восстановлена в более ограниченном виде (смотрите описание «режим нитей» ниже).
Монтирование контроллеров v1¶
Для использования cgroups требуется собрать ядро с параметром CONFIG_CGROUP. Также с каждым контроллером v1 связан параметр настройки, который должен быть задан, если нужно работать с этим контроллером.
Чтобы использовать контроллер a v1, его нужно смонтировать в файловую систему cgroup. Обычно для этого используют файловую систему tmpfs(5), смонтированную в /sys/fs/cgroup. Таким образом, можно смонтировать контроллер cpu следующим образом:
mount -t cgroup -o cpu none /sys/fs/cgroup/cpu
Можно смонтировать несколько контроллеров вместе в одной иерархии. Например, так контроллеры cpu и cpuacct одновременно монтируются в одной иерархии:
mount -t cgroup -o cpu,cpuacct none /sys/fs/cgroup/cpu,cpuacct
Для одновременно смонтированных контроллеров процесс находится в одной cgroup всех одновременно смонтированных контроллеров. Отдельно смонтированные контроллеры позволяют процессу находиться в cgroup /foo1 одного контроллера и в /foo2/foo3 другого.
Можно смонтировать все контроллеры v1 вместе в одной иерархии:
mount -t cgroup -o all cgroup /sys/fs/cgroup
(Параметр -o all можно опустить, так как по умолчанию монтируются все контроллеры, если ни один не указан явно)
It is not possible to mount the same controller against multiple cgroup hierarchies. For example, it is not possible to mount both the cpu and cpuacct controllers against one hierarchy, and to mount the cpu controller alone against another hierarchy. It is possible to create multiple mount with exactly the same set of comounted controllers. However, in this case all that results is multiple mount points providing a view of the same hierarchy.
Note that on many systems, the v1 controllers are automatically mounted under /sys/fs/cgroup; in particular, systemd(1) automatically creates such mounts.
Размонтирование контроллеров v1¶
Смонтированная файловая система cgroup может быть размонтирована с помощью команды umount(8) как показано в этом примере:
umount /sys/fs/cgroup/pids
But note well: a cgroup filesystem is unmounted only if it is not busy, that is, it has no child cgroups. If this is not the case, then the only effect of the umount(8) is to make the mount invisible. Thus, to ensure that the mount is really removed, one must first remove all child cgroups, which in turn can be done only after all member processes have been moved from those cgroups to the root cgroup.
Контроллеры cgroups версии 1¶
Все контроллеры cgroups версии 1 управляются параметрами настройки ядра (список далее). Также, включение свойства cgroups управляется параметром настройки ядра CONFIG_CGROUPS.
cpu (начиная с Linux 2.6.24; CONFIG_CGROUP_SCHED) Cgroups can be guaranteed a minimum number of «CPU shares» when a system is busy. This does not limit a cgroup’s CPU usage if the CPUs are not busy. For further information, see Documentation/scheduler/sched-design-CFS.rst (or Documentation/scheduler/sched-design-CFS.txt in Linux 5.2 and earlier). In Linux 3.2, this controller was extended to provide CPU «bandwidth» control. If the kernel is configured with CONFIG_CFS_BANDWIDTH, then within each scheduling period (defined via a file in the cgroup directory), it is possible to define an upper limit on the CPU time allocated to the processes in a cgroup. This upper limit applies even if there is no other competition for the CPU. Further information can be found in the kernel source file Documentation/scheduler/sched-bwc.rst (or Documentation/scheduler/sched-bwc.txt in Linux 5.2 and earlier). cpuacct (начиная с Linux 2.6.24; CONFIG_CGROUP_CPUACCT) Включает учёт использования ЦП группами процессов. Further information can be found in the kernel source file Documentation/admin-guide/cgroup-v1/cpuacct.rst (or Documentation/cgroup-v1/cpuacct.txt in Linux 5.2 and earlier). cpuset (начиная с Linux 2.6.24; CONFIG_CPUSETS) Эту cgroup можно использовать для привязки процессов в cgroup к указанному набору ЦП и узлов NUMA. Further information can be found in the kernel source file Documentation/admin-guide/cgroup-v1/cpusets.rst (or Documentation/cgroup-v1/cpusets.txt in Linux 5.2 and earlier). memory (начиная с Linux 2.6.25; CONFIG_MEMCG) Контроллер памяти поддерживает учёт и ограничение памяти процесса, памяти ядра и подкачки, используемой cgroups. Further information can be found in the kernel source file Documentation/admin-guide/cgroup-v1/memory.rst (or Documentation/cgroup-v1/memory.txt in Linux 5.2 and earlier). devices (начиная с Linux 2.6.26; CONFIG_CGROUP_DEVICE) This supports controlling which processes may create (mknod) devices as well as open them for reading or writing. The policies may be specified as allow-lists and deny-lists. Hierarchy is enforced, so new rules must not violate existing rules for the target or ancestor cgroups. Further information can be found in the kernel source file Documentation/admin-guide/cgroup-v1/devices.rst (or Documentation/cgroup-v1/devices.txt in Linux 5.2 and earlier). freezer (начиная с Linux 2.6.28; CONFIG_CGROUP_FREEZER) freezer cgroup может приостанавливать и возобновлять работу всех процессов в cgroup. Заморозка cgroup /A также влияет на её потомков, например, процессы в /A/B тоже приостанавливаются. Further information can be found in the kernel source file Documentation/admin-guide/cgroup-v1/freezer-subsystem.rst (or Documentation/cgroup-v1/freezer-subsystem.txt in Linux 5.2 and earlier). net_cls (начиная с Linux 2.6.29; CONFIG_CGROUP_NET_CLASSID) Помещает classid, задаваемые для cgroup, в сетевые пакеты, создаваемые cgroup. Эти classid затем можно использовать в правилах межсетевого экрана, а также для ограничения трафика с помощью tc(8). Применяется только к пакетам, выходящим из cgroup, и не применяется к входящему трафику cgroup. Further information can be found in the kernel source file Documentation/admin-guide/cgroup-v1/net_cls.rst (or Documentation/cgroup-v1/net_cls.txt in Linux 5.2 and earlier). blkio (начиная с Linux 2.6.33; CONFIG_BLK_CGROUP) blkio cgroup контролирует и ограничивает доступ к заданным блочным устройствам, применяет управление вводом-выводом посредством пропусков (throttling) и ограничения сверху листовых узлов и и промежуточных узлов в иерархии хранилища. Доступно две стратегии. Первая: пропорционально взвешенное повременное разделение диска, реализованная посредством CFQ. Влияет на листовые узлы с помощью CFQ. Вторая: стратегия пропусков, которая задаётся верхним ограничением скорости обмена с устройством. Further information can be found in the kernel source file Documentation/admin-guide/cgroup-v1/blkio-controller.rst (or Documentation/cgroup-v1/blkio-controller.txt in Linux 5.2 and earlier). perf_event (начиная с Linux 2.6.39; CONFIG_CGROUP_PERF) Этот контроллер позволяет выполнять слежение perf за набором процессов, сгруппированных в cgroup. Further information can be found in the kernel source files net_prio (начиная с Linux 3.3; CONFIG_CGROUP_NET_PRIO) Позволяет для cgroups задавать свой приоритет на каждый интерфейс. Further information can be found in the kernel source file Documentation/admin-guide/cgroup-v1/net_prio.rst (or Documentation/cgroup-v1/net_prio.txt in Linux 5.2 and earlier). hugetlb (начиная с Linux 3.5; CONFIG_CGROUP_HUGETLB) Поддерживает ограничение cgroups на использование огромных страниц. Further information can be found in the kernel source file Documentation/admin-guide/cgroup-v1/hugetlb.rst (or Documentation/cgroup-v1/hugetlb.txt in Linux 5.2 and earlier). pids (начиная с Linux 4.3; CONFIG_CGROUP_PIDS) Этот контроллер позволяет ограничивать количество процессов, которые могут быть созданы в cgroup (и её потомках). Further information can be found in the kernel source file Documentation/admin-guide/cgroup-v1/pids.rst (or Documentation/cgroup-v1/pids.txt in Linux 5.2 and earlier). rdma (начиная с Linux 4.11; CONFIG_CGROUP_RDMA) Контроллер RDMA позволяет ограничивать использование ресурсов RDMA/IB определённой cgroup. Further information can be found in the kernel source file Documentation/admin-guide/cgroup-v1/rdma.rst (or Documentation/cgroup-v1/rdma.txt in Linux 5.2 and earlier).
Создание cgroups и перемещение процессов¶
Первоначально, в файловой системе cgroup содержится только корневая cgroup, «/», которой принадлежат все процессы. Новая cgroup создаётся посредством создания каталога в файловой системе cgroup:
mkdir /sys/fs/cgroup/cpu/cg1
Данная команда создаёт новую пустую cgroup.
Помещение процесса в эту cgroup выполняется с помощью записи его PID в файл cgroup cgroup.procs:
echo $$ > /sys/fs/cgroup/cpu/cg1/cgroup.procs
В этот файл единовременно должен записываться только один PID.
Запись в файл cgroup.procs значения 0 приводит к помещению в соответствующую cgroup записывающего процесса.
При записи PID в cgroup.procs в новую cgroup одновременно перемещаются все нити процесса.
Внутри иерархии процесс может быть членом только одной cgroup. Запись PID процесса в файл cgroup.procs автоматически удаляет его из cgroup, в которой он числился до этого.
Для получения списка процессов, числящихся в cgroup, можно прочитать файл cgroup.procs. Возвращаемый список PID не обязательно упорядочен. Также PID могут повторяться (например, во время чтения списка PID может использоваться повторно).
В cgroups v1 отдельные нити могут перемещаться в другую cgroup посредством записи ID нити (т. е., ядерный ID нити, возвращаемый clone(2) и gettid(2)) в файл tasks из каталога cgroup. Этот файл можно прочитать, чтобы получить набор нитей, принадлежащих cgroup.
Удаление cgroups¶
Удаляемая cgroup не должна содержать дочерних cgroups и процессов (не зомби). Если это соблюдается, то можно просто удалить соответствующий каталог. Заметим, что файлы в каталоге cgroup невозможно и ненужно удалять.
Выпуск уведомлений cgroups v1¶
Для определения того, как ядро выполняет уведомления об опустевших cgroup, можно использовать два файла. Cgroup считается пустой, если не содержит дочерних cgroup и процессов.
Специальный файл в корневом каталоге каждой иерархии cgroup, release_agent, можно использовать для регистрации программы, которая будет вызываться всякий раз, когда cgroup в иерархии становится пустой. При вызове программы release_agent в единственной аргументе командной строки передаётся путь (относительно точки монтирования cgroup) только что опустевшей cgroup. Программа release_agent может удалить удалить каталог cgroup или, возможно, повторно добавить в него процесс.
По умолчанию файл release_agent пуст, то есть агент освобождения не вызывается.
Содержимое файла release_agent также можно задать в параметре монтирования при монтировании файловой системы cgroup:
mount -o release_agent=файл …
Будет ли программа release_agent вызываться для определённой ставшей пустой cgroup, задаётся значением файла notify_on_release в каталоге, соответствующем cgroup. Если этот файл содержит значение 0, то программа release_agent не вызывается. Если он содержит 1, то программа release_agent вызывается. По умолчанию в этом файле содержится 0 для корневой cgroup. В момент, когда создаётся новая cgroup, значение в этом файле наследуется из соответствующего файла родительской cgroup.
Именованные иерархии cgroup v1¶
В cgroups v1 возможно монтирование иерархии cgroup, у которой нет присоединённых контроллеров:
mount -t cgroup -o none,name=какое-то_имя none /some/mount/point
Можно смонтировать несколько экземпляров таких иерархий; каждая иерархия должна иметь уникальное имя. Единственной целью таких иерархий является слежение за процессами (смотрите описание о выдаче уведомлений ниже). В пример можно привести иерархию cgroup name=systemd, которая используется systemd(1) для слежения за службами и пользовательскими сеансами.
Начиная с Linux 5.0, параметром ядра cgroup_no_v1 (описан ниже) можно выключить иерархию cgroup v1 с определённым именем: cgroup_no_v1=named.
CGROUPS ВЕРСИИ 2¶
В cgroup v2 все смонтированные контроллеры располагаются в единой унифицированной иерархии. Хотя (различные) контроллеры могут одновременно монтироваться в иерархиях v1 и v2, невозможно одновременное монтирование одного контроллера в обеих иерархиях v1 и v2.
Далее приведено краткое описание новых правил поведения cgroups v2, и в некоторых случаях, расширено в последующих подразделах.
• Cgroups v2 предоставляет унифицированную иерархию всех смонтированных контроллеров. • «Внутренние» процессы запрещены. За исключением корневой группы cgroup, процессы могут располагаться только в крайних узлах (группа cgroup, которая не содержит дочерних групп cgroup). Подробности несколько более тонкие, чем эти и описаны ниже. • Требуется указывать активные cgroup-ы через файлы cgroup.controllers и cgroup.subtree_control. • Удалён файл tasks. Также удалён файл cgroup.clone_children, использовавшийся контроллером cpuset. • Улучшенный механизм уведомлений о пустых cgroup доступен через файл cgroup.events.
For more changes, see the Documentation/admin-guide/cgroup-v2.rst file in the kernel source (or Documentation/cgroup-v2.txt in Linux 4.17 and earlier).
Некоторые новые упомянутые выше функциональные возможности появились с добавлением в Linux 4.14 «режима нитей» (смотрите далее).
Унифицированная иерархия cgroups v2¶
В cgroups v1, способность монтировать различные контроллеры в разные иерархии предназначалась для повышения гибкости при разработки приложения. Однако на практике выяснилось, что гибкость не так полезна как ожидалось, и во многих случаях добавляет сложности. Поэтому в cgroups v2, все доступные контроллеры монтируются в одну иерархию. Доступные контроллеры монтируются автоматически, то есть не нужно (но можно) указывать контроллеры при монтировании файловой системы cgroup v2 с помощью команды вида:
mount -t cgroup2 none /mnt/cgroup2
Контроллер cgroup v2 доступен только, если он уже не смонтирован в иерархии cgroup v1. Или, иначе говоря, невозможно использовать тот же контроллер одновременно в иерархии v1 и унифицированной иерархии v2. Это означает, что сначала может потребоваться размонтировать контроллер v1 (как описано выше), чтобы он стал доступен в v2. Так как systemd(1) по умолчанию интенсивно использует некоторые контроллеры v1, в некоторых случаях проще загрузить систему с отключёнными контроллерами v1. Для этого укажите параметр cgroup_no_v1=список в командной строке загрузки ядра; в списке через запятую перечисляются имена отключаемых контроллеров или указывается слово all для выключения всех контроллеров v1 (этот вариант корректно отрабатывается systemd(1) и она начинает работать без указанных контроллеров).
Заметим, что во многих современных системах systemd(1) автоматически монтирует файловую систему cgroup2 в каталог /sys/fs/cgroup/unified при запуске системы.
Cgroups v2 mount options¶
The following options (mount -o) can be specified when mounting the group v2 filesystem:
nsdelegate (начиная с Linux 4.15) Treat cgroup namespaces as delegation boundaries. For details, see below. memory_localevents (since Linux 5.2) The memory.events should show statistics only for the cgroup itself, and not for any descendant cgroups. This was the behavior before Linux 5.2. Starting in Linux 5.2, the default behavior is to include statistics for descendant cgroups in memory.events, and this mount option can be used to revert to the legacy behavior. This option is system wide and can be set on mount or modified through remount only from the initial mount namespace; it is silently ignored in noninitial namespaces.
Контроллеры cgroups v2¶
The following controllers, documented in the kernel source file Documentation/admin-guide/cgroup-v2.rst (or Documentation/cgroup-v2.txt in Linux 4.17 and earlier), are supported in cgroups version 2:
cpu (начиная с Linux 4.15) Приемник контроллеров cpu и cpuacct версии 1. cpuset (since Linux 5.0) This is the successor of the version 1 cpuset controller. freezer (since Linux 5.2) This is the successor of the version 1 freezer controller. hugetlb (since Linux 5.6) This is the successor of the version 1 hugetlb controller. io (начиная с Linux 4.5) Приемник контроллера blkio версии 1. memory (начиная с Linux 4.5) Приемник контроллера memory версии 1. perf_event (начиная с Linux 4.11) Совпадает с контроллером perf_event версии 1. pids (начиная с Linux 4.5) Совпадает с контроллером pids версии 1. rdma (начиная с Linux 4.11) Совпадает с контроллером rdma версии 1.
There is no direct equivalent of the net_cls and net_prio controllers from cgroups version 1. Instead, support has been added to iptables(8) to allow eBPF filters that hook on cgroup v2 pathnames to make decisions about network traffic on a per-cgroup basis.
The v2 devices controller provides no interface files; instead, device control is gated by attaching an eBPF (BPF_CGROUP_DEVICE) program to a v2 cgroup.
Управление поддеревом cgroups v2¶
Каждая cgroup в иерархии v2 содержит следующие два файла:
cgroup.controllers Доступный только для чтения файл со списком контроллеров, доступных в этой cgroup. Содержимое этого файла совпадает с содержимым файла cgroup.subtree_control в родительской cgroup. cgroup.subtree_control Список контроллеров, активных (включённых) в cgroup. Набор контроллеров в этом файле является поднабором cgroup.controllers этой cgroup. Изменение набора активных контроллеров выполняется записью строк в этот файл с именами контроллеров через пробел; перед именами указывается «+» (включить контроллер) или «-» (выключить контроллер), как в следующем примере:
echo '+pids -memory' > x/y/cgroup.subtree_control
Попытка включить контроллер, который отсутствует в cgroup.controllers, приводит к ошибке ENOENT при записи в файл cgroup.subtree_control.
Так как список контроллеров в cgroup.subtree_control является поднабором из cgroup.controllers, то контроллер, отключённый в иерархии cgroup, невозможно включить в поддереве ниже этой cgroup.
Файл cgroup cgroup.subtree_control определяет набор контроллеров, которые выполняются в дочерних cgroup. Когда контроллер (например pids), есть в файле cgroup.subtree_control родительской cgroup, то соответствующие файлы интерфейса контроллера (например pids.max) автоматически создаются в дочерних cgroup и могут использоваться для влияния на управление ресурсами в дочерних cgroup.
Правило cgroups v2 «нет внутренним процесса컶
Cgroups v2 вводит так называемое правило «нет внутренним процессам». Грубо говоря, это правило означает, что за исключением корневой cgroup, процессы могут располагаться только в краевых узлах (cgroup, которая не содержит дочерних cgroup). Это позволяет не решать как делить ресурсы между процессами, которые являются членами cgroup A и процессами в дочерних cgroup-ах A.
Например, если существует cgroup /cg1/cg2, то процесс может располагаться в /cg1/cg2, но не в /cg1. Это решает проблему с неясностью в cgroups v1 в плане разделения ресурсов между процессами в /cg1 и её дочерних cgroup-ах. Рекомендуемый подход в cgroups v2 — создать подкаталог leaf для всех конечных cgroup, в котором будут содержаться только процессы и отсутствовать дочерние cgroup-ы. То есть процессы, которые раньше находились в /cg1 теперь должны помещаться в /cg1/leaf. Преимуществом этого является явное указание родства между процессами в /cg1/leaf и в других потомках /cg1.
The «no internal processes» rule is in fact more subtle than stated above. More precisely, the rule is that a (nonroot) cgroup can’t both (1) have member processes, and (2) distribute resources into child cgroups—that is, have a nonempty cgroup.subtree_control file. Thus, it is possible for a cgroup to have both member processes and child cgroups, but before controllers can be enabled for that cgroup, the member processes must be moved out of the cgroup (e.g., perhaps into the child cgroups).
С добавлением в Linux 4.14 «режима нитей» (смотрите далее) для некоторых случаев применение правила «не внутренних процессов» было ослаблено.
Файл cgroup.events в cgroups v2¶
Each nonroot cgroup in the v2 hierarchy contains a read-only file, cgroup.events, whose contents are key-value pairs (delimited by newline characters, with the key and value separated by spaces) providing state information about the cgroup:
$ cat mygrp/cgroup.events populated 1 frozen 0
The following keys may appear in this file:
populated The value of this key is either 1, if this cgroup or any of its descendants has member processes, or otherwise 0. frozen (since Linux 5.2) The value of this key is 1 if this cgroup is currently frozen, or 0 if it is not.
The cgroup.events file can be monitored, in order to receive notification when the value of one of its keys changes. Such monitoring can be done using inotify(7), which notifies changes as IN_MODIFY events, or poll(2), which notifies changes by returning the POLLPRI and POLLERR bits in the revents field.
Cgroup v2 release notification¶
Cgroups v2 provides a new mechanism for obtaining notification when a cgroup becomes empty. The cgroups v1 release_agent and notify_on_release files are removed, and replaced by the populated key in the cgroup.events file. This key either has the value 0, meaning that the cgroup (and its descendants) contain no (nonzombie) member processes, or 1, meaning that the cgroup (or one of its descendants) contains member processes.
The cgroups v2 release-notification mechanism offers the following advantages over the cgroups v1 release_agent mechanism:
• It allows for cheaper notification, since a single process can monitor multiple cgroup.events files (using the techniques described earlier). By contrast, the cgroups v1 mechanism requires the expense of creating a process for each notification. • Notification for different cgroup subhierarchies can be delegated to different processes. By contrast, the cgroups v1 mechanism allows only one release agent for an entire hierarchy.
Файл cgroup.stat в cgroups v2¶
Каждая cgroup в иерархии v2 содержит файл cgroup.stat, доступный только для чтения (появился в Linux 4.14), который состоит из строк с парами ключ-значение. В этом файле появляются следующие ключи:
nr_descendants Общее количество видимых (т. е., живых) cgroups — потомков этой cgroup. nr_dying_descendants Общее количество прекративших работу cgroups — потомков этой cgroup. cgroups входит в состояния прекращения жизнедеятельности после удаления. Она остаётся в таком состоянии на неопределённых срок (зависит от системной нагрузки), хотя ресурсы освобождаются до уничтожения cgroup. Заметим, что существование несколькими cgroups в состоянии прекращения жизнедеятельности нормально и не указывает на проблему. Процесс не может стать членом прекратившей работу cgroup, и такая cgroup не может опять заработать.
Ограничение на количество дочерних cgroups¶
Каждая cgroup в иерархии v2 содержит следующие файлы, которые можно использовать для просмотра и изменения количества дочерних cgroup в cgroup:
cgroup.max.depth (начиная с Linux 4.14) Этим файлом задаётся ограничение глубины вложенности дочерних cgroup. Значение 0 означает запрет на создание дочерних cgroup. Попытка создать потомка, чья глубина вложенности превышает ограничение, завершается ошибкой (mkdir(2) завершается ошибкой EAGAIN). Writing the string «max» to this file means that no limit is imposed. The default value in this file is «max» . cgroup.max.descendants (начиная с Linux 4.14) Этим файлом задаётся ограничение на количество действующих дочерних cgroup, которое может иметь cgroup. Попытка создать больше потомков, чем разрешено, приводит к ошибке (mkdir(2) завершается ошибкой EAGAIN). Запись строки «max» в этот файл означает, что ограничение отсутствует. Значением по умолчанию для файла является «max».
ДЕЛЕГИРОВАНИЕ CGROUPS: ДЕЛЕГИРОВАНИЕ ИЕРАРХИИ МЕНЕЕ ПРИВИЛЕГИРОВАННОМУ ПОЛЬЗОВАТЕЛЮ¶
В контексте cgroups, делегирование означает передачу управления частью поддерева иерархии cgroup непривилегированному пользователю. Cgroups v1 предоставляют поддержку делегирования на основе файловых прав доступа в иерархии cgroup, но эти правила менее ограничительны по сравнению с v2 (смотрите далее). Поддержка делегирования в cgroups v2 планировалась изначально. В основном, этот раздел описывает делегирование для cgroups v2, попутно указывая различия с cgroups v1.
Для описания делегирования необходима некоторая терминология. Делегирующий это привилегированный пользователь (т.е., корневой объект), которому принадлежит родительская группа cgroup. Делегат это непривилегированный пользователь, которому будут предоставлены права, необходимые для управления некоторой субиерархией в родительской группе cgroup, также называемой делегированным поддеревом.
Для делегирования, делегирующий создает определённые каталоги и файлы, доступные на запись делегату, обычно, назначая владельцем объектов идентификатором пользователя-делегата. Предполагая, что нужно делегировать иерархию с корнем (например) /dlgt_grp и что пока нет каких-либо дочерних cgroups в cgroup, меняем владельца на идентификатор пользователя-делегата у следующего:
/dlgt_grp Смена владельца корня поддерева означает, что любые новые cgroups, созданные в поддереве (и файлы, которые они содержат), также будут принадлежать делегату. /dlgt_grp/cgroup.procs Смена владельца этого файла означает, что делегат может перемещать процессы в корень делегированного ему поддерева. /dlgt_grp/cgroup.subtree_control (только cgroups v2) Смена владельца этого файла означает, что делегат сможет включать контроллеры (которые имеются в /dlgt_grp/cgroup.controllers), чтобы в дальнейшем распределять ресурсы на более низких уровнях поддерева (вместо изменения прав владения данным файлом делегирующий может добавить нужные контроллеры в этот файл). /dlgt_grp/cgroup.threads (только cgroups v2) Смена владельца этого файла требуется для делегирования поддерева с нитями (смотрите описание «режима нитей» далее). Это позволяет делегату записывать в файл ID нитей (также может быть изменён владелец файла для делегирования поддерева домена, но пока это ни к чему не приводит, так как, судя по описанному далее, невозможно перемещать нить между cgroup домена просто записывая ID нити в файл cgroup.threads). В cgroups v1 соответствующим файлом вместо делегируемого должен быть файл tasks.
Делегирующий не должен изменять владельцев файлов интерфейса контроллера (например, pids.max, memory.high) в dlgt_grp. Эти файлы используются со следующего уровня над делегируемым поддеревом, чтобы распределить ресурсы в поддерево, и делегат не должен иметь права изменять ресурсы, распределённые в делегируемое поддерево.
Информацию о других делегируемых файлах cgroups v2 смотрите описание файла /sys/kernel/cgroup/delegate в ЗАМЕЧАНИЯХ.
После выполнения вышеуказанных шагов делегат может создавать подгруппы cgroups в рамках делегированного поддерева (подкаталоги cgroup и файлы в них будут принадлежать делегату) и перемещать процессы между группами cgroup в поддереве. Если в dlgt_grp/cgroup.subtree_control есть контроллеры, или право владения этим файлом перешло к делегату, то делегат также может управлять дальнейшим распределением соответствующих ресурсов в делегированном ему поддереве.
Делегирование cgroups v2: nsdelegate и пространство имён cgroup¶
Начиная с Linux 4.13 появился второй способ делегирования cgroup в иерархии cgroups v2. Этого можно достичь монтированием или перемонтированием файловой системы cgroup v2 с параметром монтирования nsdelegate. Например, если файловая система cgroup v2 уже смонтирована, то её можно перемонтировать с параметром nsdelegate следующим образом:
mount -t cgroup2 -o remount,nsdelegate \
none /sys/fs/cgroup/unified
Данный параметр монтирования заставляет пространства имён cgroup автоматически устанавливать границы делегирования. При этом на процессы внутри пространства имён cgroup накладываются следующие ограничения:
• Запись в файлы интерфейса к контроллерам в корневом каталоге пространства имён завершаются ошибкой EPERM. Процессы внутри пространства имён cgroup по-прежнему могут писать в делегированные файлы корневого каталога пространства имён cgroup (такие как cgroup.procs и cgroup.subtree_control) и могут создавать новые иерархии в корневом каталоге. • Попытки переноса процессов за границу пространства имён пресекаются (с ошибкой ENOENT). Процессы внутри пространства имён cgroup по-прежнему могут (цель сдерживающих правил описана ниже) перемещать процессы между cgroup внутри иерархий корневого каталога.
Возможность определения пространств имён cgroup для границ делегирования делает пространства имён cgroup ещё более полезными. Чтобы понять почему, предположим, что у нас уже есть одна иерархия cgroup, которая была делегирована непривилегированному пользователю, cecilia, посредством старого способа делегирования, описанного выше. Также предположим, что cecilia тоже хочет делегировать одну иерархий из имеющихся в делегированной иерархии (например, делегированная иерархия может быть связана с непривилегированным контейнером, запущенным cecilia). Даже, если пространство имён cgroup namespace было передано, так как обе иерархии принадлежат непривилегированному пользователю cecilia, могут быть выполнены следующие неправомерные действия:
• Процесс в нижележащей иерархии может изменять настройки контроллера ресурсов в корневом каталоге этой иерархии (предполагается, что данными настройками контроллера ресурсов управляют из родительской cgroup; процесс внутри дочерней cgroup не должен быть способен изменять их). • Процесс в нижележащей иерархии может перемещать процессы в и из нижележащей иерархии, если cgroup вышестоящей иерархии видима откуда-то ещё.
Использование параметра монтирования nsdelegate предотвращает обе эти возможности.
Параметр монтирования nsdelegate действует только, когда применяется к начальному пространству имён монтирования; для других пространств имён монтирования он игнорируется.
Замечание: в некоторых системах systemd(1) автоматически монтирует файловую систему cgroup v2. Чтобы попробовать работу с nsdelegate , может быть полезно загрузить ядро с следующими параметрами командной строки:
cgroup_no_v1=all systemd.legacy_systemd_cgroup_controller
Эти параметры заставляют ядро загружаться с выключенными контроллерами cgroups v1 (т. е., контроллеры доступны из иерархии v2) и указывают systemd(1) не монтировать и использовать иерархию cgroup v2, таким образом позволяя вручную смонтировать иерархию v2 с желаемыми параметрами после загрузки.
Сдерживающие правила делегирования cgroup¶
Некоторые сдерживающие правила делегирования обеспечивает то, что делегат может перемещать процессы в рамках делегированного поддерева, но не сможет перемещать процессы извне делегированного поддерева в поддерево и наоборот. Непривилегированный процесс (т. е., делегат) может записать PID «целевого» процесса в файл cgroup.procs только, если всё следующее верно:
• Писатель имеет права на запись в файл cgroup.procs в группе назначения cgroup. • Писатель имеет права на запись в файл cgroup.procs в ближайшем общем предке для cgroups источника и назначения. Заметим, что в некоторых случаях, ближайшим общим предком может быть сама cgroup источника или назначения. Это требование не выполняется в иерархиях cgroups v1, в следствие чего сдерживание в v1 менее ограничительно, чем v2 (например, в cgroups v1 пользователь, которому принадлежат две разных делегированных подиерархий, может перемещать процесс между этими иерархиями). • Если файловая система cgroup v2 смонтирована с параметром nsdelegate, то писатель способен видеть cgroup источника и приёмника из своего пространства имён cgroup. • В cgroups v1: эффективный UID писателя (т. е., делегата) совпадает с реальным пользовательским ID или сохранённым set-user-ID процесса назначения. До Linux 4.11 это требование также применялось к cgroups v2 (это исторически сложившиеся требование, унаследовано от cgroups v1, которое позднее сочли ненужным, так как достаточно других сдерживающих правил cgroups v2).
Замечание: одним из следствий этих сдерживающих правил является то, что непривилегированный делегат не может поместить первый процесс в делегированное поддерево; вместо этого делегирующему необходимо поместить первый процесс (процесс, принадлежащей делегату) в делегированное поддерево.
РЕЖИМ НИТЕЙ CGROUPS ВЕРСИИ 2¶
Ограничения, налагаемые cgroups v2, но отсутствующие в cgroups v1:
• Нет понитевого управления: все нити процесса должны быть в одной cgroup. • Нет внутренних процессов: cgroup не может иметь одновременно процессов-членов и выполняемых контроллеров в дочерних cgroup.
Эти ограничения добавлены из-за того, что их отсутствие вызывало проблемы в cgroups v1. В частности, возможность понитевого контроля членства в cgroups v1 приводило к бессмысленности некоторых контроллеров (особенно это касалось контроллера memory: так как нити используют одно адресное пространство, нет смысла разделять нити по разным memory cgroup).
В первоначальном решении проекта cgroups v2 не учитывалось, что для некоторых контроллеров, таких как cpu, было бы важным и полезным задействовать понитевое управление. Чтобы приспособиться под такие случаи, в Linux 4.14 для cgroups v2 добавлен режим нитей.
Режим нитей позволяет следующее:
• Создание поддеревьев нитей, в которых нити процесса могут размещаться по нескольким cgroup внутри дерева (поддерево нитей может содержать несколько многонитевых процессов). • Концепцию контроллеров нитей, которые могут распределять ресурсы между cgroup в поддереве нитей. • Ослабление «правила отсутствия внутренних процессов», то есть внутри поддерева нитей cgroup может одновременно содержать нити и контроль ресурсов над дочерними cgroup.
Также, в режиме нитей каждая не корневая cgroup теперь содержит новый файл, cgroup.type, который отражает и, в некоторых случаях, может использоваться для изменения «типа» cgroup. Этот файл содержит одно из следующих значений типа:
domain Обычная cgroup v2, предоставляющая попроцессное управление. Если процесс является членом этой cgroup, то все нити процесса (по определению) находятся в одной cgroup. Это тип cgroup по умолчанию, предоставляет такое же поведение, обеспечиваемое для cgroup начальной реализацией cgroups v2. threaded Данная cgroup является членом поддерева нитей. В эту cgroup нити могут добавляться, а контроллеры cgroup включаться. domain threaded Доменная cgroup, которая служит корнем поддерева нитей. Этот тип cgroup также называется «корнем нитей». domain invalid Эта cgroup находится внутри поддерева нитей в «некорректном» состоянии. В cgroup невозможно добавлять процессы, а контроллеры cgroup включать. Единственным действием с этой cgroup (помимо удаления) является преобразование в группу с типом threaded посредством записи строки «threaded» в файл cgroup.type. Обоснованием сущестования этого «переходного» типа при создании поддерева нитей (вместо того, чтобы ядро сразу преобразовывало все cgroup в корне нитей в тип threaded) является задел для возможных будущих расширений модели режима нитей.
Сравнение контроллеров домена и нитей¶
С добавлением режима нитей теперь в cgroups v2 различают два типа контроллеров ресурсов:
• Контроллеры нитей: эти контроллеры поддерживают понитевое управление ресурсами и могут включаться в поддеревья нитей; в результате появляются соответствующие файлы интерфейса контроллера внутри cgroup в поддереве нитей. В Linux 4.19 имеются следующие контроллеры нитей: cpu, perf_event и pids. • Контроллеры домена: эти контроллеры поддерживают только попроцессное управление ресурсами. С точки зрения контроллера домена все нити процесса всегда находятся в одной группе. Контроллеры домена нельзя включить внутри поддерева нитей.
Создание поддерева нитей¶
Существует два способа создания поддерева нитей. Первый:
(1) Записываем строку «threaded» в файл cgroup.type из cgroup y/z, которая в этот момент имеет тип domain. При этом происходит следующее:
• Типом cgroup y/z становится threaded. • Типом родительской cgroup, y, становится domain threaded. Родительская cgroup является корнем поддерева нитей (также называемая «корнем нитей»). • Все остальные cgroup в y, которые ещё не относятся к типу threaded преобразуются в тип domain invalid (так как они внутри уже существующих поддеревьев нитей с новом корне нитей). Все в дальнейшем создаваемые cgroup в y также будут иметь тип domain invalid.
(2) Записываем строку «threaded» в каждую cgroup с domain invalid в y, чтобы преобразовать их в тип threaded. В результате этого шага все нити в корне нитей теперь имеют тип threaded и поддерево нитей теперь полностью работоспособно. Требование записи «threaded» в каждую такую cgroup несколько обременительно, но это позволит расширить модель режима нитей в будущем.
Второй способ создания поддерева нитей:
(1) In an existing cgroup, z, that currently has the type domain, we (1.1) enable one or more threaded controllers and (1.2) make a process a member of z. (These two steps can be done in either order.) This has the following consequences:
• Типом z становится domain threaded. • Все дочерние cgroup x, не имеющие типа threaded, преобразуются в тип domain invalid.
(2) Как и ранее, делаем работоспособным поддерево нитей записывая строку «threaded» в каждую cgroup с domain invalid в y, чтобы преобразовать их в тип threaded.
Следствием одного из этих путей создания поддерева нитей является то, что cgroup корня нитей может быть родителем только cgroup с типом threaded (и domain invalid). cgroup корня нитей не может быть родителем cgroup с типом domain и cgroup с типом threaded не может быть на одном уровне с cgroup с типом domain.
Использование поддерева нитей¶
В поддереве нитей можно включать контроллеры нитей для каждой подгруппы, чей тип был изменён на threaded; после того, как это сделано, файлы интерфейса соответствующего контроллера появятся в дочерних cgroup.
Процесс можно перемещать в поддерево нитей посредством записи его PID в файл cgroup.procs одной из cgroup внутри дерева. В результате все нити процесса становятся членами соответствующей cgroup,а процесс — членом поддерева нитей. После этого нити процесса можно размещать по поддереву нитей посредством записи ID нитей (смотрите gettid(2)) в файлы cgroup.threads различных cgroup внутри поддерева. Все нити процесса должны быть расположены в одном поддереве нитей.
Как и при записи в cgroup.procs, при записи в файл cgroup.threads накладываются некоторые сдерживающие правила:
• Писатель должен иметь права на запись в файл cgroup.threads целевой cgroup. • Писатель должен иметь права на запись в файл cgroup.procs в общем предке для cgroups источника и назначения (в некоторых случаях, общим предком может быть сама cgroup источника или назначения). • Целевая и cgroup назначения должны быть в одном поддереве нитей (попытка переместить нить вне поддерева нитей посредством записи ID этой нити в файл cgroup.threads другой cgroup с типом domain завершится ошибкой EOPNOTSUPP).
Файл cgroup.threads существует в каждой cgroup (включая cgroup c типом domain) и может быть прочитан для нахождения набора нитей, представленных в группе. Для набора ID нитей, получаемых при чтении этого файла, не гарантируется порядок и отсутствие повторов.
Файл cgroup.procs в корне нитей отражает PID всех процессов, являющихся членами поддерева нитей. Файлы cgroup.procs других cgroup в поддереве недоступны для чтения.
Доменные контроллеры невозможно включить в поддереве нитей; в cgroup ниже корня нитей отсутствуют интерфейсные файлы контроллера. С точки зрения доменного контроллера поддеревья нитей невидимы: многонитевые процессы внутри поддерева нитей видятся доменным контроллером как процесс, расположенный в cgroup корня нитей.
В поддереве нитей правило «нет внутренних процессов» не применяется: cgroup может иметь одновременно процессы-члены (или нить) и выполняемые контроллеры в дочерних cgroup.
Правила записи в cgroup.type и создание поддеревьев нитей¶
При записи в файл cgroup.type накладывается несколько правил:
• Можно записать только строку «threaded». Другими словами, единственный возможный переход это преобразование domain cgroup к типу threaded. • Последствия от записи «threaded» зависит от текущего значения в cgroup.type:
• domain или domain threaded: начинается создание поддерева нитей (корнем будет родитель этой cgroup) посредством первого способа, описанного выше; • domain invalid: эта cgroup (находящаяся внутри поддерева нитей) переводится в работоспособное состояние (т. е., threaded); • threaded: ничего не происходит («нет действия»).
• Нельзя писать в файл cgroup.type, если тип родителя domain invalid. Иначе говоря, все cgroup поддерева нитей должны быть преобразованы в состояние threaded по нисходящей.
Также для создания поддерева нитей с корнем cgroup x требуется выполнить несколько условий:
• Не должно быть процессов-членов в дочерних cgroup x (сама cgroup x может иметь процессы-члены). • Не должно быть включённых доменных контроллеров для x в файле cgroup.subtree_control.
Если какое-либо из этих ограничений нарушено, то попытка записи «threaded» в файл cgroup.type завершится ошибкой ENOTSUP.
Тип cgroup «domain threaded»¶
Согласно способам, описанным выше, тип cgroup можно измениться на domain threaded в следующих случаях:
• В дочернюю cgroup записывается строка «threaded». • Внутри cgroup включён контроллер нитей и процесс стал членом cgroup.
A domain threaded cgroup, x, can revert to the type domain if the above conditions no longer hold true—that is, if all threaded child cgroups of x are removed and either x no longer has threaded controllers enabled or no longer has member processes.
Когда cgroup x с типом domain threaded возвращается к типу domain:
• Все потомки x с domain invalid, находящиеся не ниже уровня поддеревьев нитей, получают тип domain. • Корневым cgroup, находящимся ниже поддеревьев нитей возвращается тип domain threaded.
Исключения для корневой cgroup¶
Корневая cgroup иерархии v2 рассматривается отдельно: она может быть родителем cgroup сразу обоих типов: domain и threaded. Если строка «threaded» записывается в файл cgroup.type одного из потомков корневой cgroup, то
• Типом этой cgroup становится threaded. • Тип всех потомков этой cgroup, не являющихся частью уровня ниже поддеревьев нитей, изменяется на domain invalid.
Заметим, что в этом случае нет cgroup, чей тип стал domain threaded (в принципе, корневая cgroup может рассматриваться как корень нитей для cgroup, чей тип был изменён на threaded).
Данное исключение для корневой cgroup позволяет cgroup нитей, запускающей контроллер cpu, быть помещённой выше всех насколько возможно в иерархии, для того, чтобы минимизировать ущерб (маленький) от обхода иерархии cgroup.
Контроллер «cpu» cgroups v2 и нити реального времени¶
Начиная с Linux 4.19, контроллер cgroups v2 cpu не поддерживает управление нитями реального времени(нити, запланированные к выполнению планировщиками SCHED_FIFO, SCHED_RR, SCHED_DEADLINE; смотрите sched(7)). Поэтому контроллер cpu можно включить в корневую cgroup только, если все нити реального времени находятся в корневой cgroup (если есть нити реального времени вне корневой cgroups, то запись (write(2)) строки «+cpu» в файл cgroup.subtree_control завершится ошибкой EINVAL).
В некоторых системах systemd(1) помещает определённые нити реального времени в некорневую cgroups иерархии v2. В таких системах такие нити должны помещаться раньше в корневую cgroup, до включения контроллера cpu.
ОШИБКИ¶
Следующие ошибки могут возникать при mount(2):
EBUSY При монтировании файловой системы cgroup версии 1 не указан параметр name= (для монтирования именованной иерархии) или имя контроллера (или all).
ЗАМЕЧАНИЯ¶
Дочерний процесс, созданный fork(2), наследует членство родителя в cgroup. Членство в cgroup сохраняется при execve(2).
The clone3(2) CLONE_INTO_CGROUP flag can be used to create a child process that begins its life in a different version 2 cgroup from the parent process.
Файлы в /proc¶
/proc/cgroups (начиная с Linux 2.6.24) В этом файле содержится информация о контроллерах, с которыми было собрано ядро. Пример содержимого файла (переформатирован для читабельности):
#subsys_name hierarchy num_cgroups enabled cpuset 4 1 1 cpu 8 1 1 cpuacct 8 1 1 blkio 6 1 1 memory 3 1 1 devices 10 84 1 freezer 7 1 1 net_cls 9 1 1 perf_event 5 1 1 net_prio 9 1 1 hugetlb 0 1 0 pids 2 1 1
Поля файла, слева направо:
[1] Имя контроллера. [2] Уникальный ID иерархии cgroup, на которой смонтирован контроллер. Если к одной иерархии привязано несколько контроллеров cgroups v1, то для каждого в этом поле будет показан одинаковый ID иерархии. Значение поля равно 0, если:
• контроллер не смонтирован на иерархию cgroups v1; • контроллер привязан к унифицированной иерархии cgroups v2; или • контроллер отключён (смотрите ниже).
[3] Количество контролируемых групп в этой иерархии, использующих этот контроллер. [4] В этом поле содержится значение 1, если этот контроллер включён, или 0, если он выключен (с помощью параметра cgroup_disable командной строки загрузки ядра).
/proc/[pid]/cgroup (начиная с Linux 2.6.24) Этот файл описывает управляемые группы, которым принадлежит процесс с соответствующим PID. Отображаемая информация отличается для иерархий cgroups версии 1 и 2. Для каждой иерархии cgroup, членом которой является процесс, существует одна запись, состоящая из трёх полей через двоеточие:
ID иерархии:список контроллеров:путь cgroup
5:cpuacct,cpu,cpuset:/daemons
Поля, разделяемые двоеточием, слева направо:
[1] Для иерархии cgroups версии 1 это поле содержит уникальный ID номер иерархии, который может совпадать с ID иерархии в /proc/cgroups. Для иерархии cgroups версии 2 это поле содержит значение 0. [2] Для иерархии cgroups версии 1 это поле содержит список контроллеров, привязанных к иерархии, перечисленных через запятую. Для иерархии cgroups версии 2 это поле пусто. [3] Это поле содержит путь управляемой группы в иерархии, которой принадлежит процесс. Путь является относительным точки монтирования иерархии.
Файлы /sys/kernel/cgroup¶
/sys/kernel/cgroup/delegate (начиная с Linux 4.15) Этот файл экспортирует список файлов cgroups v2 (один на строку), которые можно делегировать (т. е., у которых можно изменить владельца на пользовательских ID делегата). В будущем, наборов доступных для делегирования файлов может измениться или вырасти, а этот файл предоставляет способ, которым ядро информирует приложения пользовательского пространства о необходимых для делегирования файлах. В Linux 4.15 в этом файле можно увидеть следующее:
$ cat /sys/kernel/cgroup/delegate cgroup.procs cgroup.subtree_control cgroup.threads
/sys/kernel/cgroup/features (начиная с Linux 4.15) Со временем набор возможностей cgroups v2, предоставляемых ядром, может измениться или вырасти, или некоторые возможности по умолчанию могут быть отключены. Этот файл предоставляет способ, которым приложения пользовательского пространства могут узнать о том, какие возможности поддерживает работающее ядро и какие из них включены. Возможности перечисляются по одной на строку:
$ cat /sys/kernel/cgroup/features nsdelegate memory_localevents
В этом файле может появляться следующее:
memory_localevents (since Linux 5.2) The kernel supports the memory_localevents mount option. nsdelegate (начиная с Linux 4.15) Поддержка параметра монтирования nsdelegate ядром. memory_recursiveprot (since Linux 5.7) The kernel supports the memory_recursiveprot mount option.
СМ. ТАКЖЕ¶
The kernel source file Documentation/admin-guide/cgroup-v2.rst.
ПЕРЕВОД¶
Русский перевод этой страницы руководства был сделан Azamat Hackimov , Dmitriy S. Seregin , Dmitry Bolkhovskikh , Katrin Kutepova , Yuri Kozlov и Иван Павлов
Этот перевод является бесплатной документацией; прочитайте Стандартную общественную лицензию GNU версии 3 или более позднюю, чтобы узнать об условиях авторского права. Мы не несем НИКАКОЙ ОТВЕТСТВЕННОСТИ.
Если вы обнаружите ошибки в переводе этой страницы руководства, пожалуйста, отправьте электронное письмо на man-pages-ru-talks@lists.sourceforge.net.
| 5 февраля 2023 г. | Linux man-pages 6.03 |
| Source file: | cgroups.7.ru.gz (from manpages-ru 4.21.0-2) |
| Source last updated: | 2023-12-18T19:28:31Z |
| Converted to HTML: | 2024-01-03T15:55:30Z |
cgroups — cgroups
cgroups (сокращенно от control groups ) — это функция ядра Linux, которая ограничивает, учитывает и изолирует использование ресурсов (ЦП, память, дисковый ввод-вывод, сеть и т. д.) коллекции процессы.
Инженеры Google (в первую очередь и) начали работу над этой функцией в 2006 году под названием «контейнеры процессов». В конце 2007 года номенклатура была изменена на «контрольные группы», чтобы избежать путаницы, вызванной множеством значений термина «контейнер » в контексте ядра Linux, а функциональные возможности контрольных групп были объединены в Linux. kernel mainline в версии ядра 2.6.24, выпущенной в январе 2008 года. С тех пор разработчики добавили много новых функций и контроллеров, таких как поддержка kernfs в 2014 году, firewalling и единой иерархии. cgroup v2 была объединена с ядром Linux 4.5 со значительными изменениями интерфейса и внутренней функциональности.
- 1 Версии
- 2 Функции
- 3 Использование
- 4 Редизайн
- 4.1 Изоляция пространства имен
- 4.2 Единая иерархия
- 4.3 Группы управления памятью ядра (kmemcg)
- 4.4 Осведомленность cgroup об убийце OOM
Версии
Есть две версии контрольных групп.
Cgroups были первоначально написаны Полом Менеджем и Рохитом Сетом и включены в ядро Linux в 2007 году. Впоследствии это называется cgroups version 1.
Затем разработка и обслуживание cgroups были взяты на себя. Теджун Хо переработал и переписал контрольные группы. Эта перезапись теперь называется версией 2, документация по cgroups-v2 впервые появилась в ядре Linux 4.5, выпущенном 14 марта 2016 года.
В отличие от v1, cgroup v2 имеет только одну иерархию процессов и различает процессы, а не потоки.
Возможности
Одна из целей разработки контрольных групп — предоставить единый интерфейс для множества различных вариантов использования, от управления отдельными процессами (с помощью nice, например) до полной виртуализации на уровне операционной системы (как предусмотрено OpenVZ, Linux-VServer или LXC, для пример). Cgroups обеспечивает:
Ограничение ресурсов группы могут быть настроены так, чтобы не превышать сконфигурированный предел памяти, который также включает кэш файловой системы Приоритизация некоторые группы могут получить большую долю использования ЦП или пропускной способности дискового ввода-вывода Учет измеряет использование ресурсов группой, что может использоваться, например, для выставления счетов Управление замораживание групп процессов, их контрольная точка и перезапуск
Использование
В качестве примера косвенного использования systemd предполагает монопольный доступ к средству cgroups
Контрольная группа (сокращенно cgroup) — это совокупность процессов, которые связаны одними и теми же критериями и связаны с набором параметров или ограничений. Эти группы могут быть иерархическими, что означает, что каждая группа наследует ограничения от своей родительской группы. Ядро предоставляет доступ к нескольким контроллерам (также называемым подсистемами) через интерфейс cgroup; например, контроллер «памяти» ограничивает использование памяти, «cpuacct» учитывает использование ЦП и т. д.
Управляющие группы могут использоваться несколькими способами:
- путем доступа к виртуальной файловой системе cgroup вручную.
- Создавая группы и управляя ими на лету с помощью таких инструментов, как cgcreate, cgexecи cgclassify(из libcgroup).
- Через «демон механизма правил», который может автоматически перемещать процессы определенных пользователей, групп или команд в контрольные группы, как указано в его конфигурации.
- Косвенно через другое программное обеспечение, использующее контрольные группы, такое как Docker, LXC, libvirt, systemd, Open Grid Scheduler / Grid Engine и несуществующий lmctfy.
Linux Документация ядра содержит некоторые технические подробности настройки и использования групп управления версии 1 и версии 2. Команда systemd-cgtop может использоваться для отображения верхних групп управления по их использованию ресурсов.
Редизайн
Редизайн cgrou ps начался в 2013 году, с дополнительными изменениями, внесенными в версии ядра Linux 3.15 и 3.16.
Изоляция пространства имен
Хотя технически это не является частью работы cgroups, связанная функция ядра Linux — это изоляция пространства имен, когда группы процессов разделены так, что они не могут «видеть» ресурсы в других группах. Например, пространство имен PID предоставляет отдельное перечисление идентификаторов процессов в каждом пространстве имен. Также доступны пространства имен mount, user, UTS, network и SysV IPC.
- Пространство имен PID обеспечивает изоляцию для выделения идентификаторов процессов (PID), списков процессов и их деталей. Хотя новое пространство имен изолировано от других братьев и сестер, процессы в его «родительском» пространстве имен по-прежнему видят все процессы в дочерних пространствах имен, хотя и с разными номерами PID.
- Сетевое пространство имен изолирует контроллеры сетевого интерфейса (физический или виртуальный), iptables правила брандмауэра, таблицы маршрутизации и т. д. Сетевые пространства имен могут быть связаны друг с другом с помощью виртуального устройства Ethernet «veth».
- Пространство имен «UTS» позволяет изменять hostname.
- Mount пространство имен позволяет создать другую структуру файловой системы или сделать определенные точки монтирования доступными только для чтения.
- Пространство имен IPC изолирует межпроцессное взаимодействие System V между пространствами имен.
- Пространство имен пользователя изолирует идентификаторы пользователей между пространствами имен.
- Пространство имен Cgroup
Пространства имен создаются с помощью команды «unshare» или системного вызова, или как новые флаги в системном вызове «clone».
Подсистема «ns» была добавлена на ранней стадии разработки cgroups для интеграции пространств имен и групп управления. Если была смонтирована контрольная группа «ns», каждое пространство имен также создавало бы новую группу в иерархии контрольных групп. Это был эксперимент, который позже был признан плохо подходящим для cgroups API и удален из ядра.
Пространства имен Linux были вдохновлены более общей функциональностью пространств имен, широко используемой в Plan 9 от Bell Labs.
Унифицированная иерархия
Kernfs была введена в ядро Linux с версией 3.14 в марте 2014 г., главный автор — Теджун Хео. Одним из главных мотиваторов для отдельного kernfs является файловая система cgroups. Kernfs в основном создается путем разделения части логики sysfs на независимый объект, что упрощает для других подсистем ядра реализацию собственной виртуальной файловой системы с обработкой подключения и отключения устройств, динамического создания и удаления, и другие атрибуты. Редизайн продолжился в версии 3.15 ядра Linux.
Группы управления памятью ядра (kmemcg)
Группы управления памятью ядра (kmemcg) были объединены в версию 3.8 (18 февраля 2013 г.; 7 лет назад ( 18-02-2013)) основной ветки ядра Linux. Контроллер kmemcg может ограничивать объем памяти, который ядро может использовать для управления собственными внутренними процессами.
осведомленность cgroup об убийце OOM
ядро Linux 4.19 (октябрь 2018 г.) представила cgroup осведомленность о реализации OOM killer, которая добавляет возможность убивать cgroup как единое целое, что гарантирует целостность рабочей нагрузки.
Adoption
Различные проекты используют cgroups в качестве своей основы, включая CoreOS, Docker (в 2013 г.), Hadoop, Jelastic, Kubernetes, lmctfy (Позвольте мне содержать это для вас), LXC (Контейнеры LinuX), systemd, Mesos и Mesosphere и HTCondor. Основные дистрибутивы Linux также приняли его, например, Red Hat Enterprise Linux (RHEL) 6.0 в ноябре 2010 года, три года спустя принятие основным ядром Linux.
29 октября 2019 года Проект Fedora модифицировал Fedora 31 для использования CgroupsV2 по умолчанию
См. Также
- Портал бесплатного программного обеспечения с открытым исходным кодом
- Портал Linux
- Реализации виртуализации на уровне операционной системы
- Процесс group
- Tc (Linux) — утилита управления трафиком, которая имеет небольшое функциональное перекрытие с сетевыми настройками контрольной группы
Ссылки
Внешние ссылки
- Документация ядра Linux по контрольным группам
- Пространства имен и контрольные группы ядра Linux от Рами Розена
- Пространства имен и контрольные группы, основа контейнеров Linux (включая контрольные группы v2), слайды выступления Рами Розена, Netdev 1.1, Севилья, Испания, 2016
- Понимание API новых групп управления, LWN.net, Рами Розен, март 2016 г.
- Управление крупномасштабными кластерами в Google с помощью Borg, апрель 2015 г., Абхишек Вер ma, Луис Педроса, Мадукар Коруполу, Дэвид Оппенгеймер, Эрик Тьюн и Джон Уилкс
- Job Objects, аналогичная функция в Windows