Записки IT специалиста
Linux — начинающим. Что такое Load Average и какую информацию он несет
- Автор: Уваров А.С.
- 29.06.2016
С необходимостью правильно оценить нагрузку на систему сталкивается каждый системный администратор. Если говорить о Linux-системах, то одним из основных терминов, с которым придется столкнуться начинающему администратору окажется Load Average (средняя загрузка). Однако, если говорить о русскоязычном сегменте сети интернет, описание данного параметра сводится к общим малозначащим фразам, в то время как за этими простыми цифрами кроется глубокий пласт информации о работе системы.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Если обратиться к популярным источникам (Википедия), то можно найти примерно следующее:
Средняя загрузка — среднее значение загрузки системы за некоторый период времени, как правило, отображается в виде трёх значений, которые представляют собой усредненные величины за последние 1, 5 и 15 минут, чем ниже, тем лучше. В UNIX это среднее значение вычислительной работы, которую выполняет система.
После прочтения данного абзаца никаких новых знаний, кроме того, что масло таки масляное (средняя загрузка — среднее значение загрузки) не возникает и понимания ситуации не прибавляется. Чем ниже, тем лучше, но насколько ниже и относительно чего.
Посмотреть текущую загрузку системы можно командной
uptimeТакже ее значения выводят утилиты top и htop, а также множество других инструментов. В ответ мы получим что-то вроде:
load average: 0,12, 0,10, 0,03Много это или мало? Хорошо или плохо? Давайте разбираться.
Чтобы понять, что такое загрузка системы следует обратиться к логике работы центрального процессора. Вне зависимости от того, мощный у вас процессор или слабый, многоядерный или нет, он выполняет некий программный код для некоторых процессов. Если процесс один, то вопросов нет, а вот когда их несколько? Надо как-то распределять ресурсы между ними и, желательно, равномерно, чтобы один процесс, «дорвавшись» до CPU, не оставил без вычислений другие.
Здесь можно провести аналогию, когда несколько игроков хотят поиграть на одной приставке. Что обычно делают в таких случаях? Договариваются о времени, скажем каждый играет по 15 минут, затем дает поиграть другому.
Процессор поступает аналогичным образом. Каждому нуждающемуся в вычислениях процессу выделяется некий промежуток времени, который зависит от типа процессора и системы, если говорить о современных процессорах Intel, то это значение обычно составляет 10 мс и называется тиком. Каждый тик процессорное время отдается какому-то одному процессу в порядке очереди, но если процесс имеет повышенный или пониженный приоритет, то он, соответственно получит большее или меньшее количество тиков.
Количество использованных тиков, в первом приближении, и представляет загрузку системы. В Linux для оценки загрузки используется интервал в 500 тиков (5 секунд), при этом учитываются как работающие процессы (использованные тики), так и ожидающие (которым не хватило тика, либо они не смогли его использовать, ожидая завершения иной операции).
Если мы используем все тики за указанный промежуток времени и у нас не будет ожидающих сводного тика процессов, то мы получим загрузку процессора на 100% или load average (LA) равное 1.
Давайте рассмотрим следующую схему:
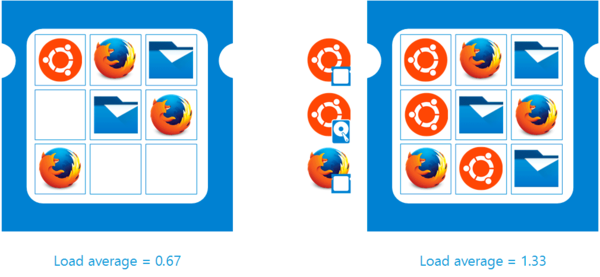
Для простоты мы будем использовать в расчетах более короткий интервал — 9 тиков. На схеме слева мы видим, что процессорные ресурсы сначала понадобились системе, затем браузеру и файловому менеджеру, потом активности в системе не было, затем еще один тик взял файловый менеджер и еще два браузер, последние два тика также не понадобились никому. Несложные расчеты показывают, что мы использовали 67% процессорного времени или load average системы составил 0,67.
Справа показана ситуация, когда каждый тик был занят своим процессом, но некоторые процессы так и не получили своего тика или не смогли получить, например, ждали окончания операции ввода-вывода. В таком случае загрузка процессора составит все те же 100%, но load average вырастет до 1,33, указывая на наличие очереди.
Чтобы лучше понять ситуацию давайте представим себе небольшой супермаркет, касса представляет собой аналог процессора, тик — среднее время обслуживания покупателя (скажем, 1 минута), а процессы — это покупатели. В разгар рабочего дня людей в магазине немного, и вы спокойно прошли на свободную кассу, рассчитались и пошли по своим делам. Это хорошо, но как оценить нагрузку на кассу? Для этого нужно взять некий промежуток времени, допустим 10 минут. Если за 10 минут в магазине кроме вас было еще три человека, то средняя загрузка составит 0,4.
А теперь зайдем в магазин вечером, все кассы заняты, и чтобы оплатить покупки придется ждать. Теперь если за 10 минут касса обслужила 10 человек и еще 10 стоят в очереди, то средняя загрузка будет равна 2, хотя касса загружена всего на 100%.
Вернемся к процессору и еще одному моменту, процессам, ожидающим окончания операций ввода-вывода (диск, сеть и т.п.). Во многих источниках указывается, что такие процессы искажают результат load average и мы можем получить высокие значения LA при отсутствии загрузки процессора. Да, это так. Посмотрим на еще одну схему ниже:
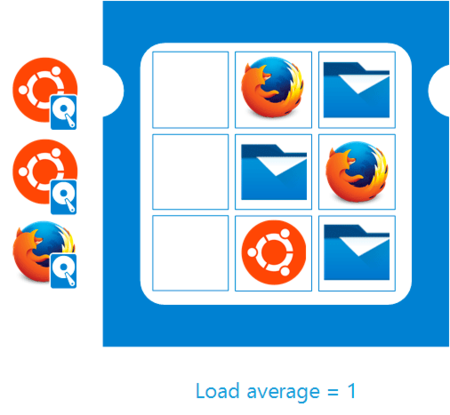
Как видим, из 9 тиков было использовано только 6, т.е. процессор загружен всего на 67%, но так как три процесса ждут данные от диска, то load average по-прежнему равен 1.
Если продолжать аналогию с супермаркетом, то похожая ситуация возникает, когда вы уже подошли к кассе и уже собрались выгружать продукты на ленту, но ваша супруга говорит вам, что она забыла купить хлеб, и вы тут стойте, а она сбегает. Собственно, все что вам остается до того, как она принесет хлеб, это стоять рядом с кассой и ждать, пропуская тех, кто находится в очереди позади вас.
Искажают ли такие процессы значение load average? На наш взгляд нет. Следует понимать, что средняя загрузка — это не показатель производительности процессора, не результат бенчмарка, не текущая нагрузка, а отношение числа процессов, которым требуются вычислительные ресурсы системы к имеющимся в наличии ресурсам.
Т.е. если у нас имеется 1 процессор и 500 тиков, но за это время процессорные ресурсы требуются тысяче процессов, то нагрузка у нас явно вдвое превышает имеющиеся ресурсы. И то, что часть процессов ждут жесткий диск и процессор работает вхолостую, не говорит о том, что система находится в простое, наоборот, она не может обработать нагрузку, правда по другой, не зависящей от процессора причине.
Пользователю ведь все равно по какой причине тормозит сайт или приложение, тем более что недостаток дисковых ресурсов обычно выражается подвисании приложения, в то время как при недостатке процессорных оно просто начинает тормозить.
Подведем промежуточный итог. Load average показывает отношение имеющихся запросов на вычислительные ресурсы к количеству этих самых ресурсов (тиков). Для одного процессора (одного процессорного ядра) использование всех имеющихся ресурсов обозначает load average = 1. Причем это будет справедливо и для Core i7 и для Pentium I, хотя производительность у этих двух процессоров разная.
Теперь перейдем к многопроцессорности и многоядерности. При появлении второго процессора или второго ядра у нас появляются дополнительные вычислительные ресурсы, т.е. же самые 500 тиков. Но за эти 500 тиков система уже может обработать уже 1000 запросов, что покажет нам load average = 2.
Значит ли это, что производительность выросла в два раза? Нет! Производительность зависит от того, сколько вычислений способен произвести процессор в течении одного тика. Понятно, что более мощный процессор выполнит за этот промежуток времени больше вычислений, но оба из них сделают одинаковое число тиков (для каждого процессорного ядра). В многопроцессорных (многоядерных) системах часть процессорного времени вместо вычислений занимают задачи межпроцессорного взаимодействия, переключения контекста и т.д. Поэтому появление второго ядра никогда не даст 100% прироста производительности, но всегда позволяет обработать вдвое большее количество запросов.
Это хорошо видно на примере технологии Hyper-threading, которая позволяет сделать из одного физического ядра процессора два виртуальных. Физическая производительность ядра процессора, т.е. количество производимых им вычислений в единицу времени не меняется, но появляется, хоть и виртуальное, но второе ядро, а это еще 500 тиков. Как показывают тесты, прирост производительности от Hyper-threading составляет 15-30%, что еще раз подтверждает старую поговорку, что лучше плохо ехать, чем хорошо стоять. Второе ядро, хоть и виртуальное, позволяет обрабатывать вычислительные запросы тех процессов, которые в одноядерном варианте стояли бы в очереди.
Непонимание этого момента приводит к тому, что load average ошибочно связывают не с доступностью и достаточностью вычислительных ресурсов, а с производительностью процессора, что приводит к неверным выводам.
Например, переводчик довольно неплохой статьи на Хабре делает ошибочный вывод в отношении Hyper-threading:
Хабраюзер esvaf в комментариях интересуется, как интерпретировать значения load average в случае использования процессора с технологией HyperThreading. Однозначного ответа на данный момент я не нашел. В данной статье утверждается, что процессор, который имеет два виртуальных ядра при одном физическом, будет на 10-30% более производительным, чем простой одноядерный. Если принимать такое допущение за истину, считаю, при интерпретации load average стоит брать в расчет только количество физических ядер.
А Википедия вообще написала полную ерунду (что для технических статей там совсем не редкость):
Средняя нагрузка — это не очень точная характеристика (хотя бы потому, что она определяет усреднённые значения). И если на компьютере есть несколько процессоров, то такой характеристике верить нельзя. Располагая двумя процессорами, можно (теоретически) одновременно выполнять в два раза большее число программ. Это означает, что средняя нагрузка 2.00 (на двухпроцессорном компьютере) будет эквивалентна средней нагрузке 1.00 (на однопроцессорном компьютере). На самом деле это не совсем так. Из-за дополнительной нагрузки, вызванной планированием и некоторыми другими факторами, двухпроцессорный компьютер не обеспечивает удвоения быстродействия по сравнению с однопроцессорным вариантом.
Убедиться, что это не так довольно легко. Если запустить бесконечный цикл командой
perl -e 'while(1)<>'
то мы обеспечим полную загрузку одного процессорного ядра и load average = 1 (в данный момент смотрим только на первые, минутные показания данного параметра).

Два процесса:
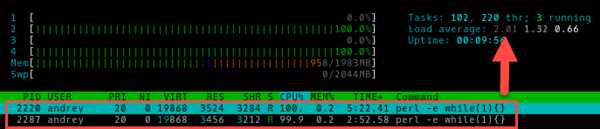
Четыре:
Мы не знаем, сколько именно операций в единицу времени выполняет наш процессор, но нам и не нужно знать это, гораздо важнее понимать, что на текущий момент все вычислительные ресурсы системы задействованы, но недостатка в них нет.
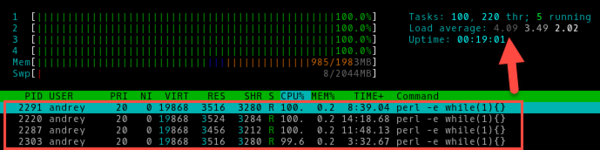
Запустим пятый процесс:
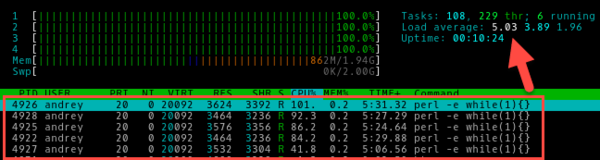
Что изменилось? Загрузка процессора осталась на уровне 100%, это и понятно, выше головы не прыгнешь, но load average вырос до 5, что означает нехватку вычислительных ресурсов примерно на 20%. Таким образом понимание сути значения средней загрузки позволяет администратору однозначно сделать выводы о текущей ситуации, чего не скажешь, глядя просто на индикатор загрузки CPU.
Теперь касательно HyperThreading, виртуализации и т.п. случаев, когда процессор, с которым работает система далеко не соответствует физическому процессору, искусственно создадим данную ситуацию. Для этого запустим на хосте параллельно с виртуальной машиной какой-нибудь ресурсоемкий процесс, например, кодирование видео. Виртуальная машина будет рассчитывать на 4 полных процессорных ядра, а по факту получит в лучшем случае половину их производительности. Проверим?
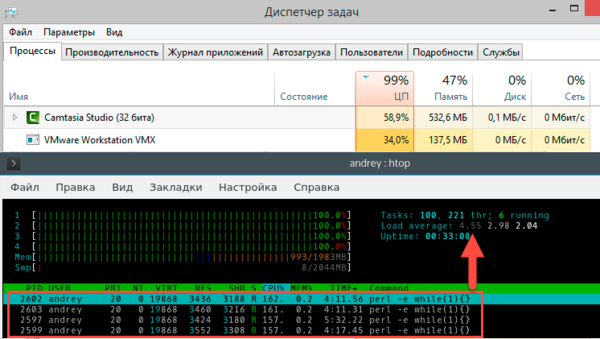
На что следует обратить внимание? В текущих условиях виртуальная машина получает примерно 30-40% загрузки физического процессора. Внутри виртуалки мы видим ожидаемые 100% загрузки процессора, однако если обратить внимание на колонку CPU%, то мы увидим там весьма интересные значения 157-162% загрузки процессора. Почему так происходит? Внутри виртуальной системы тиков CPU хватает всем, но реально гипервизор не выделяет виртуалке процессорного времени. Но это все лирика, что нам показывает load average? Налицо недостаток вычислительных ресурсов — 4,55. Соответствует это реальному положению дел? Да. Нужно ли вносить какие-то коррективы? На наш взгляд — нет.
Теперь уберем стороннюю нагрузку. Гипервизор тут же передаст максимум ресурсов виртуальной машине.
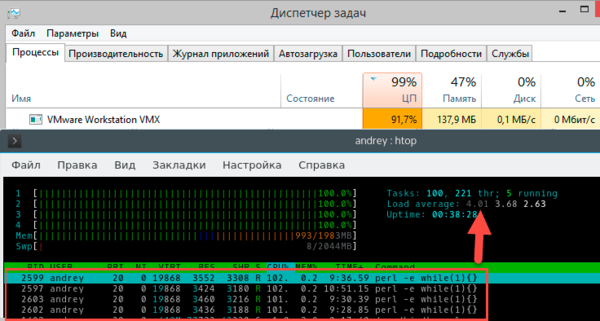
Как видим, вычислительных ресурсов снова стало достаточно и load average опустился до значения 4.
Какие выводы мы можем сделать из этого примера? Что значение load average корректно отражает загрузку системы даже в тех условиях, когда иные показатели не дают корректного представления о происходящих процессах. Так нагрузка на CPU в 157% явно противоречит здравому смыслу, а вот LA = 4,55 вполне реально отражает ситуацию. Поэтому никаких корректив на виртуальные ядра, виртуализацию и т.п. вносить не надо. Load average является относительной величиной и от реальной производительности CPU не зависит в тоже время показывая наличие или дефицит вычислительных ресурсов.
Теперь разберемся с самими цифрами. Мы получаем три значения load average для промежутков в 1, 5 и 15 минут. Как гласит та же Википедия — это средние значения за указанный промежуток времени, что снова неправильно. Для отображения load average используется экспоненциально взвешенная скользящая средняя, подобный тип кривых используется для для сглаживания краткосрочных колебаний и выделения основных тенденций или циклов.
Например, скользящие средние широко применяются в финансовом анализе, для выделения общих тенденций движения курсов валют и акций, позволяя отбросить так называемый «биржевой шум» и понять общие тренды рынка.
То, что подходит финансисту, наверняка подойдет и системному администратору. В чем основное преимущество скользящих средних? В том, что они позволяют выделить основные тенденции, отбросив кратковременные колебания. Это достоинство, а не недостаток, как пытается убедить нас Википедия:
Средняя нагрузка — это не очень точная характеристика (хотя бы потому, что она определяет усреднённые значения).
Именно усредненные по особому алгоритму значения позволяют нам окинуть ситуацию взглядом вширь и вглубь и разглядеть за деревьями лес. В этом отношении временные значения load average представляют собой не время, за которое посчитали среднее значение, а период времени относительно которого проводится усреднение.
Благодаря автору Хабра ZloyHobbit, который не поленился изучить исходный код Linux, можно точно смоделировать различные значения load average при заданной модели нагрузки. Мы смоделировали ситуацию, когда первые 30 минут единственное ядро CPU было нагружено на 100%, без ждущих в очереди процессов, в последующие полчаса нагрузка была полностью снята.
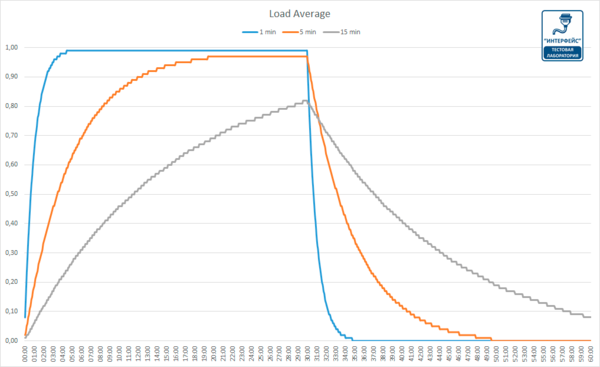
Как видим, разные периоды усреднения дают совершенно различные результаты, так LA 1 (1 min), начинает показывать реальные значения где-то через 4 минуты, LA 5 для отражения текущей нагрузки потребовалось уже 20 минут, а LA 15 за полчаса полной загрузки вышла только на 0,8.
О чем это говорит и как интерпретировать данные значения? Можно сказать, что LA 1 представляет собой недавнее прошлое (несколько минут назад), LA 5 прошлое (полчаса-час) и LA 15 отдаленное прошлое (несколько часов).
Теперь, располагая этим багажом знаний, мы можем правильно интерпретировать простые, на первый взгляд, три числа load average.
Для примера возьмем такое значение:
load average: 0.99 0.75 0.35Это говорит о том, что имеет место достаточно кратковременный (около десятка минут) всплеск нагрузки, при этом вычислительных ресурсов пока достаточно.
load average: 0.00 0.36 0.59Говорит о том, что не так давно система испытывала значительные нагрузки в течении довольно продолжительного времени (полчаса-час).
А вот такая картина:
load average: 4.55 4.22 4.18
Для четырехядерного процессора означает, что он работает на пределе своих возможностей в течении длительного времени (несколько часов).
Как видим, load average, несмотря всего на три цифры, способна представить системному администратору огромный пласт информации о фактической загрузке системы на протяжении последних нескольких часов.
Теперь самое время дать ответы на вопросы, поставленные нами в начале статьи: «Много это или мало? Хорошо или плохо? » Для одного ядра мы считаем приемлемыми следующие значения:
- LA 1 — может превышать 1.00, свидетельствуя о кратковременной пиковой нагрузке на систему.
- LA 5 — не должен превышать 1.00, в противном случае налицо явный недостаток вычислительных ресурсов.
- LA 15 — максимальное значение 0.7 — 0.8, но в любом случае не выше 1.0, в противном случае вы можете получить в три часа ночи звонок от руководства с вопросом: » А что это с нашим сервером. «
На многоядерной (многопроцессорной) системе значения load average следует откорректировать пропорционально числу ядер. Узнать их количество можно командой
nproccat /proc/cpuinfo | grep "cpu cores"Так, например, с учетом вышесказанного, для четырехядерной системы LA 15 не должен превышать 3.00, для двухядерной 1.5, а для одноядерной 0.75.
Теперь, понимая, что такое load average и каким образом формируются его значения вы всегда сможете быстро оценить производительность собственной системы и вовремя принять меры если в работе вашего сервера возникнут узкие места.
Научиться настраивать MikroTik с нуля или систематизировать уже имеющиеся знания можно на углубленном курсе по администрированию MikroTik. Автор курса, сертифицированный тренер MikroTik Дмитрий Скоромнов, лично проверяет лабораторные работы и контролирует прогресс каждого своего студента. В три раза больше информации, чем в вендорской программе MTCNA, более 20 часов практики и доступ навсегда.
Дополнительные материалы:
- Linux — начинающим. Часть 1. Первое знакомство
- Linux — начинающим. Часть 2. Установка Ubuntu Server
- Linux — начинающим. Часть 3. Установка Debian 7 для сервера
- Linux — начинающим. Часть 4. Работаем с файловой системой. Теория
- Linux — начинающим. Часть 4. Работаем с файловой системой. Практика
- Linux — начинающим. Часть 5. Управление пакетами в Debian и Ubuntu
- Linux — начинающим. Часть 6. Управление пользователями и группами. Теория
- Linux — начинающим. Часть 6. Управление пользователями и группами. Практика
- Linux — начинающим. Часть 7. Потоки, перенаправление потоков, конвейер
- Настройка языка и региональных стандартов в Ubuntu Server/Debian
- Используем APT Pinning для закрепления пакетов в Debian и Ubuntu
- Linux — начинающим. Что такое Load Average и какую информацию он несет
- Обновляем снятый с поддержки дистрибутив Ubuntu
- Linux — начинающим. Обновление Debian до следующего выпуска
- Осваиваем эффективную работу в Midnight Commander
- Linux — начинающим. Что такое пространства подкачки и как они работают
- Linux — начинающим. Screen — многозадачность в терминале и ни единого разрыва!
- Linux — начинающим. Как узнать температуру процессора и накопителей
- Linux — начинающим. Как получить информацию об оборудовании ПК
- Linux — начинающим. Установка и первоначальная настройка Debian 11 для сервера
Помогла статья? Поддержи автора и новые статьи будут выходить чаще:
![]()
![]()
Или подпишись на наш Телеграм-канал:
Linux: CPU Load – когда пора волноваться или что значит Load Average
Скорее всего – вы уже знакомы с понятием Load Average. LA представляет собой три числа, которые отображаются в утилитах uptime и top , и выглядят примерно так:
load average: 0.09, 0.05, 0.01
Большинство людей знают, что обозначают эти цифры: они отображают среднюю нагрузку за определённое время (1, 5 и 15 минут), и знают, что чем меньшее значение – тем лучше. Большие же значения означают какие-то проблемы с нагрузкой на процессор. Но – какой порог? как выглядит “хорошее” и “плохое” значение Load Average? Когда начинать беспокоиться – а когда пора уже паниковать и срочно фиксить проблему?
Для начала – давайте рассмотрим, что именно обозначает Load Average. Начнём с простого примера – машина с одноядерным процессором.
Пример с движением по дороге
Одноядерный процессор можно представить себе как дорогу с однополосным движением. Представьте себе, что вы – оператор моста, по которому проходит эта дорога. Иногда движение по ней такое интенсивное, что машины выстраиваются в очередь для переезда. Вы хотите, что бы водители знали – какова скорость прохождения машин по вашему мосту. Самое простое решение – определить, сколько машин уже ожидают очереди на переезд моста: если машин в очереди нет – то водители будут знать, что могут проехать без проблем, а если машины скапливаются в очереди на подъезде к мосту – водители будут видеть, что им придётся простоять в этой очереди.
И так, оператор – какую систему измерения вы выберете? Как на счёт такой:
- 0.00 означает что движения по мосту нет вообще. В действительности – значения между 0.00 и 1.00 будет обозначать, что очереди нет и движение свободно;
- 1.00 означает, что мост уже занят практически на полную пропускную способность. Всё ещё в порядке, но если движение ещё немного увеличится – то продвижение машин уже замедлится;
- свыше 1.00 уже означает образование очереди. Насколько большая? Например, 2.00 будет обозначать, что заняты две полосы – одна уже на мосту, и одна – на подъездной дороге. 3.00 означает, что заняты уже три полосы – одна на самом мосту, и две – в очереди на дороге.
![]()
= load of 0.50
![]()
= load of 1.00
![]()
= load of 1.70
Это пример того, чем является загрузка процессора. “Машины” тут – процессы, занимающие процессорное время (“переезжают мост“), или стоящие в очереди на подъезде к нему. UNIX считает загрузку, как “длина в очереди на выполнение“: сумма процессов, которые в настоящие момент выполняются + количество процессов в очереди на обработку:
Tasks: 213 total, 1 running, 212 sleeping, 0 stopped, 0 zombie
Как оператор моста, вы бы хотели, что бы машины (процессы) никогда не стояли в очереди. Так же и ваш процессор, в идеале, должен оставаться ниже 1.00. Так же, вы можете быть спокойны, если иногда возникают пики немного выше 1.00 – но вы должны начинать волноваться, если это происходит постоянно.
Так что – Load Average 1.00 является идеальным показателем?
Не совсем. Проблема нагрузки 1.00 в том, что у вас не остаётся “просвета” (запаса). На практике, многие системные администраторы придерживаются оптимального значения в 0.70:
- “Пора обратить внимание“: полезное правило 0.70 – если Load Average постоянно выше 0.70 – время искать причину прежде, чем это станет настоящей проблемой;
- “Пора исправлять это“: полезное правило 1.00 – если Load Average становится выше 1.00 – найдите причину и исправьте её уже сейчас. В противном случае – вы рискуете быть разбуженным среди ночи – и ничего прикольного в этом уже не будет;
- “Чёрт, 3 часа ночи – WTF?“: полезное правило 5.00 – если Load Average становится выше 5.00 – у вас могут быть серьёзные проблемы, и ваша машина либо уже зависла, либо уже работает намного медленнее, и это случится (неожиданно!) в самое неподходящее время, например – среди ночи или во время конференции. Не позволяйте этому произойти.
А как на счёт многоядерных процессоров? У меня Load Average 3.00 – но всё работает отлично!
У вас четырёхъядерный процессор? Тогда – Load Average в 3.00 совершенно нормальное значение.
На многоядерных процессорах значение LA взаимосвязано с количеством процессоров. Использование на 100% отображается как 1.00 на одноядерной системе, 2.00 на двухъядерной, 4.00 на четырёх и так далее.
Если мы вернёмся к аналогии с мостом, то 1.00 значит, что одна полоса движения на мосту полностью занята. На мосту с одной полосой – это и будет 100% его “пропускной способности”. На двухполосном мосту – это уже 50%, т.к. только одна полоса занята полностью – но есть ещё одна, полностью свободная.
То же самое и с процессором – нагрузка в 1.00 будет 100% на одноядерной системе, а на двухъядерной – значение 2.00 будет 100% нагрузки.
Многоядерность vs многопроцессорность
Раз уж мы затронули эту тему – давайте поговорим о разнице между многоядерными и многопроцессорными системами. С точки зрения производительности – равна ли машина с одним двухъядерным процессоров – машине с двумя процессорами по одному ядру? Грубо говоря – да. Есть много тонкостей, связанных с кешированием, передачей процессов между процессорами и так далее. Несмотря на это, в целях вычисления итоговой нагрузки на процессор(ы) – важно общее количество ядер, независимо от того, на сколько физических процессоров они распределены.
Это приводит нас к ещё двум правилам:
- “Количество ядер = максимальной нагрузке“: на многоядерных системах, Load Average не должен превышать количество ядер;
- “Ядра есть ядра“: не важно, как распределены ядра по процессорам. Два четырёхъядерных процессора == четырём двухъядерным == восьми одноядерным процессорам.
Подведём итог
Давайте посмотрим на Load Average в выводе утилиты uptime :
# uptime 23:05 up 14 days, 6:08, 7 users, load averages: 0.65 0.42 0.36
Это двухъядерный процессор, значит у нас имеется большой запас производительности, и можно даже не задумываться о нагрузке, пока значение не достигнет хотя бы 1.7.
Далее, как на счёт остальных значений? 0.65 значит нагрузку за последнюю минуту, 0.42 – за последние 5 минут и 0.36 – за прошедшие 15 минут. Это приводит нас к вопросу:
За каким именно значением наблюдать? 1, 5 или 15 минут?
Помня правила, которые мы обсудили (1.00 == “Пора исправлять это“) – вам необходимо обращать внимание на значения 5 и 15 минут. Т.е., если на вашей машине бывают пики нагрузки за 1 минуту – это нормально. Если же значение 15-ти минут поднимается выше 1.00 и остаётся таким – пора заняться этим вопросом (конечно, учитывая момент, касающийся количества ядер в системе).
Значит, количество ядер в системе важный вопрос для выяснения реальной нагрузки. Как мне узнать – сколько ядер в моей системе?
# cat /proc/cpuinfo
так вы получите полную информацию о процессоре(ах).
А что бы получить просто число, без другой информации – выполните:
# grep 'model name' /proc/cpuinfo | wc -l 16
Оригинал статьи взят отсюда>>>. Замечания/предложения к переводу категорически приветствуются.
Hive OS – майнинг на Linux и мониторинг
Зарегистрируйте новую учётную запись в нашем сообществе. Это очень просто!
Войти
Уже есть аккаунт? Войти в систему.
Поделиться
Последние посетители 0 пользователей онлайн
- Ни одного зарегистрированного пользователя не просматривает данную страницу
Similar Topics
Во Франции арестован предполагаемый оператор вируса-вымогателя Hive
Парижская полиция арестовала гражданина России по обвинению в причастности к группе хакеров-вымогателей Hive. У него было обнаружено более 570 000 евро в различных криптовалютах. Hive шифрует данные зараженных компьютеров, а хакеры вымогают средства в криптовалютах за расшифровку данных. Жертвами вируса-вымогателя во Франции стали более 60 компаний и частных лиц, в том числе Altice, Damart и некоторые муниципальные ведомства. Арестованному россиянину, по данным радио RMC.BFMTV, око
13 Dec 2023, 07:22 в Новости криптовалют
Майнинговая компания Hive Digital строит центр обработки данных в Швеции
Майнинговая компания Hive Digital Technologies заявила о планах расширения своего бизнеса за счет приобретения объекта недвижимости и строительства нового центра обработки данных в Швеции. В Hive Digital говорят, что центр обработки данных в шведском Бодене будет оснащен ASIC-майнерами нового поколения. Помимо этого, у компании есть парк из 38 000 графических процессоров Nvidia, мощности которых она намерена предложить частным пользователям в рамках программы развития экологически чистого о
27 Nov 2023, 15:30 в Новости криптовалют
Майнинговая компания HIVE намерена увеличить свою производительность до 6 EH/s
Майнинговая компания HIVE заявила, что планирует достигнуть производственной мощности в 4 EH/s к концу текущего года, а затем увеличить ее до 6 EH/s. Это почти вдвое больше, чем текущая мощность фирмы. В HIVE объяснили, что компания планирует достичь этой цели, используя новую партию ASIC-майнеров следующего поколения и разогнав уже работающий парк, который состоит из 4 769 установок S19j Pro+ и Pro, 1 100 S19 XP и 5 000 BuzzMiner Plus. Кроме того, компания собирается выпустить ак
15 May 2023, 06:40 в Новости криптовалют
ФБР ликвидировало международную сеть вымогателей Hive
Правоохранители США совместно с Германией и Нидерландами ликвидировали одну из крупнейших сетей вымогателей Hive, вернув украденные активы большей части жертв. Министерство юстиции США отчиталось о завершении совместной с Федеральным бюро расследований операции, в ходе которой была ликвидирована международная группа вымогателей Hive. Злоумышленники атаковали школы, банки и больницы в более 80 странах. С июня 2021 года их жертвами стали примерно 1 500 учреждений по всему миру, а вымогатели з
27 Jan 2023, 09:59 в Новости криптовалют
Hive Blockchain тестирует добычу различных монет с помощью видеокарт
Майнинговая компания Hive Blockchain начала тестирование своего оборудования для добычи различных монет – фирма ищет замену эфиру, добывать который после перехода на PoS будет невозможно. Hive Blockchain сообщила, что общая мощность видеокарт в ее распоряжении составляет 21.5 МВт – это 16% от мощностей фирмы. При этом большая часть – 14.8 МВт – это уже устаревшее оборудование, в основном, видеокарты AMD Radeon RX580. Они работают с 2018 года и «многократно окупились». Оставшиеся 6.7 МВт пот
8 Sep 2022, 06:38 в Новости криптовалют
- Ответов 4.2 тыс
- Создана 3 Nov 2017, 02:23
- Последний ответ 26 Dec 2022, 14:39
GPU FAQ
The farm is constantly rebooting. If I turn logs-on via Hive Shell, what should I pay attention to?
Pay attention to the log lines that appear right before the rig goes offline. Apart from this, you can launch this command via Hive Shell: tail -f /var/log/syslog (you can interrupt the command by pressing the keys Ctrl-C).
When the rig goes offline, Hive Shell will disconnect, and you will see the required lines on the screen.
How to reduce the GPU power consumption?
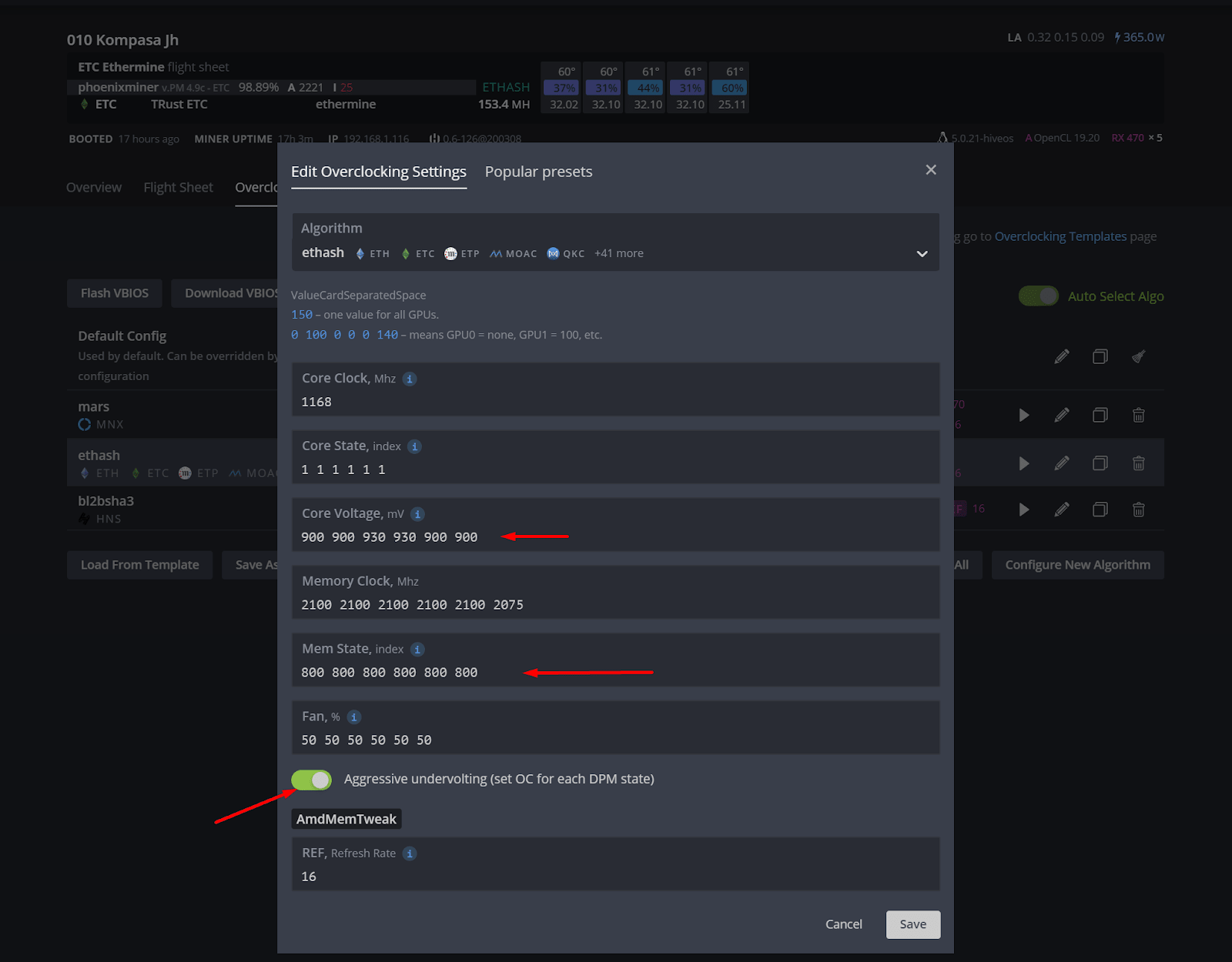
To reduce the consumption of your GPUs (when using Hiveon OS), you can specify the parameters of the core voltage and memory individually for each card.
To do this, go to the Overclocking section on your worker and specify the necessary values in the overclocking profile. Please note that in the Memory Status column you can indicate both the status index 0, 1, or 2, and the voltage in mW.
Also, to reduce power consumption, you can use the aggressive undervolting mode:
How to check internet on GPU rig?
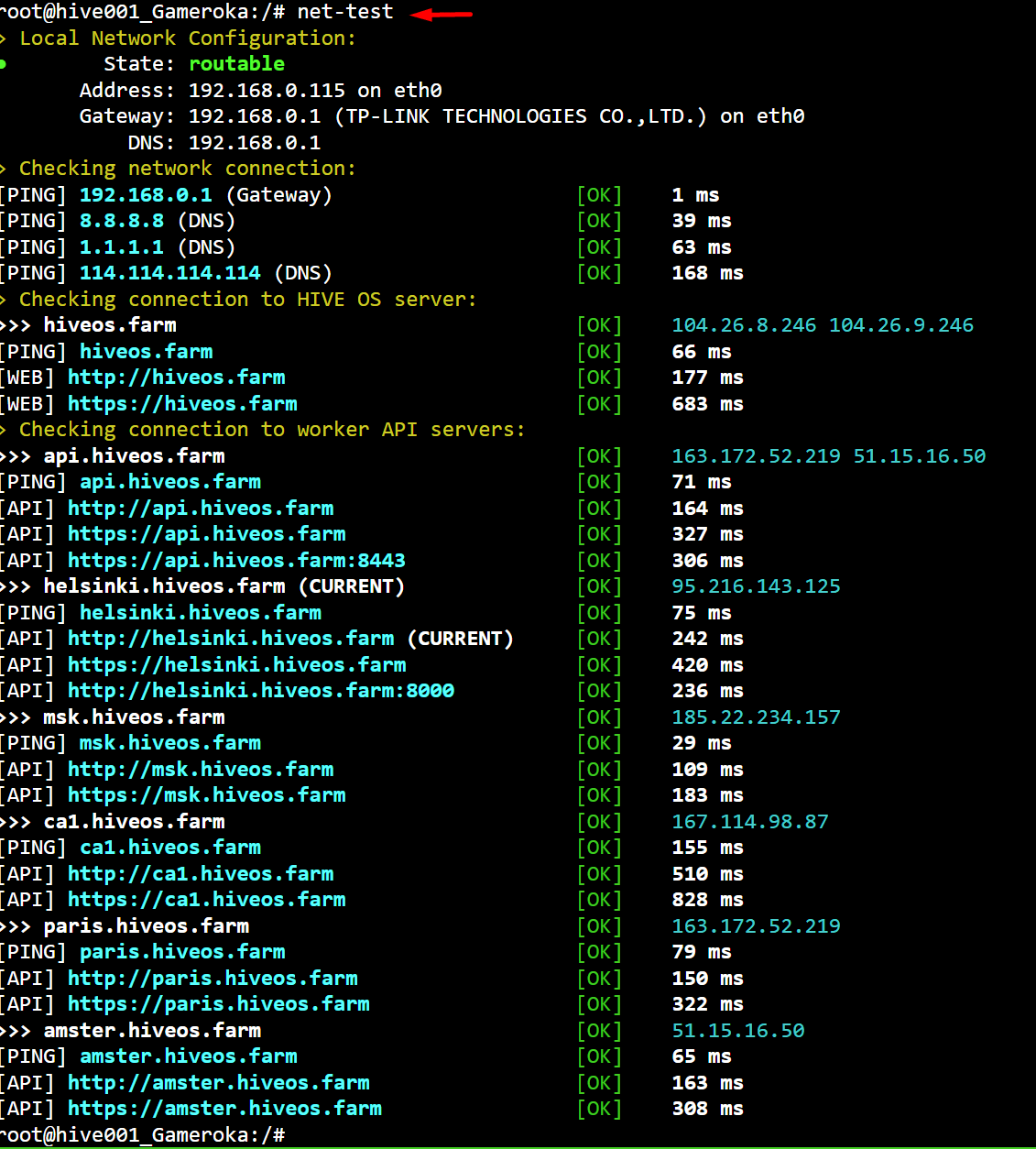
In order to check the availability of the Internet on your rig, you need a screen and a keyboard for a physical connection to the rig. After the Hiveon OS loading is complete, enter the command net-test . After you apply it, you will see the availability status of Hiveon OS servers.
What is error 511?
In most cases, this error occurs due to the malfunctioning of the video card’s riser. Please check the power connector on the riser for a burnt wire, and replace the riser.
What is DPM on AMD video cards?
DPM is a table of core frequencies and the corresponding voltages of these frequencies. This information can be checked with the amd-info command. The video card changes the core frequencies in steps according to this table.
The manufacturer with a large margin sets the voltages for each stage of the core frequency. Our task is to select the lowest voltage value for the selected core frequency specified in DPM, but at the same time to ensure that the card continues to mine steadily. In this way we get reduced consumption without losing performance. This is downvolt. Here are the examples:
- DPM 3 825
- DPM 4 875
- DPM 5 925
By default, Hiveon OS uses the value DPM 5. The factory value on Windows is DPM 7 Windows. Specifying core frequency works, but not on all the cards. But using the DPM value definitely works on all video cards.
How can rigs be merged /moved to another farm?
Go to the rig’s Settings:

Scroll down and click the Advanced settings button:

Select the desired farm from the drop-down list and click the Transfer button.:

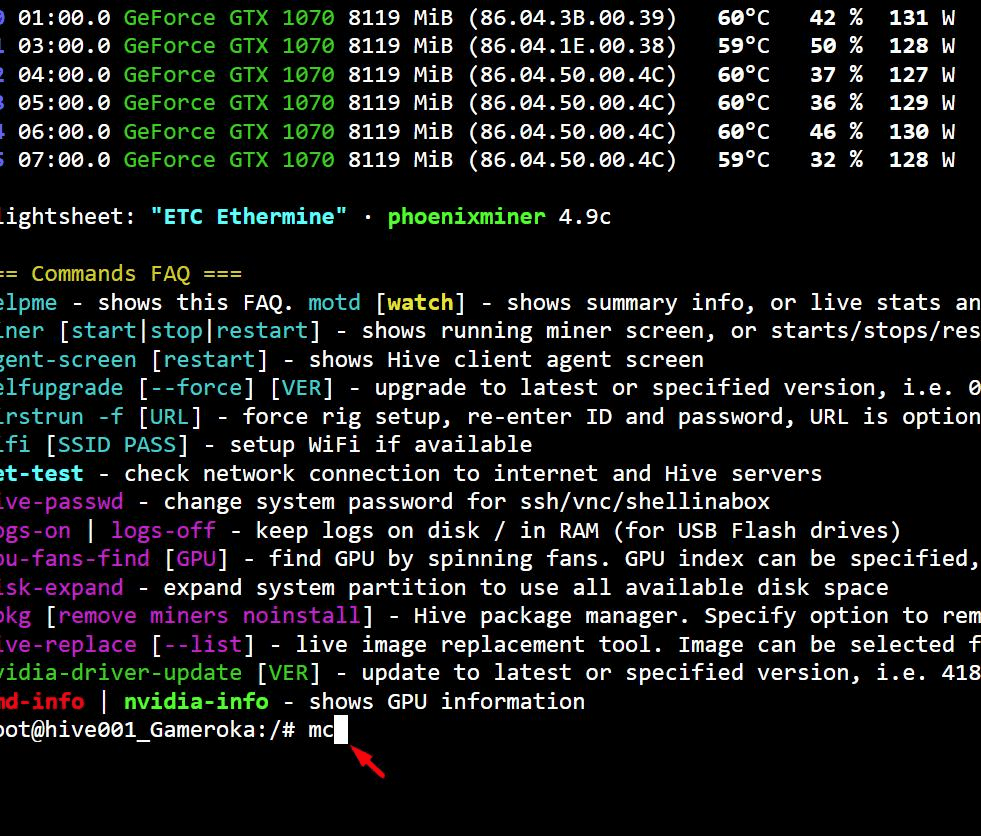
How to launch mc on the rig
To start the mc editor, launch Hive Shell on your worker. Then enter the mc command.
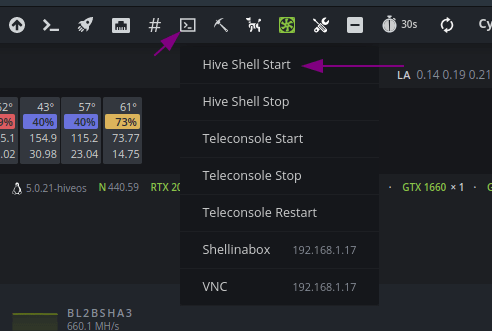
How can I check if the rig is really frozen using Hive-Shell?
Using Hive Shell, enter the working rig located in the same local network as the frozen one.
Enter this command: ssh user@”Ip_address_of_the_frozen_rig” :
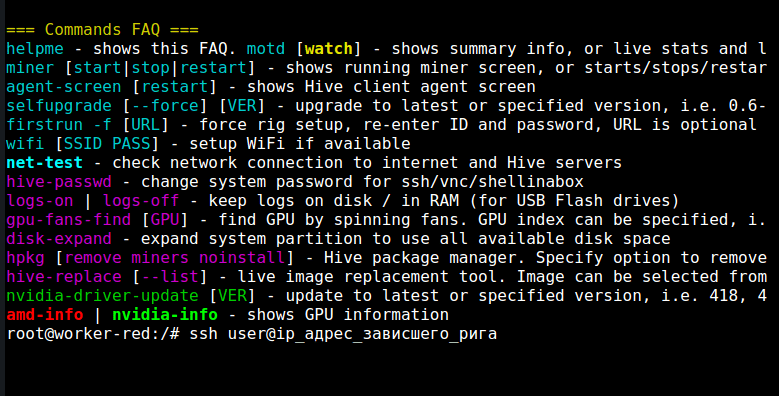
Then enter your password for this rig. The latest IP address of the rig can be checked in the Hiveon OS dashboard . Now you can check if the rig has really frozen or turned off, or if it is a glitch of the web-server.
The exit command will every time bring you back in the chain.
What is LA (Load Average)?
Load Average is the average number of executable processes over a given time. For example, if the hourly load average is 10, this means (for a uniprocessor system) that at any given time during that hour, 1 process is running, and 9 are ready to run (not blocked for input/output) and are waiting for the processor to become «free».
If you have Celeron G3930 with two cores, then LA 2 indicates 100% system load. For Ethash, this is very abnormal, but for modern algorithms — it is okay.
The maximum value of LA can be anything. This is the length of the queue to the processor, expressed in the number of cores of this processor. LA has always been counted as the number of computing devices required to complete the entire current task queue.
When mining Beam and Cuckoo on weak processors, LA can reach up to 3-4. If you don’t like the red color of the indicator, you can always set the threshold value here:
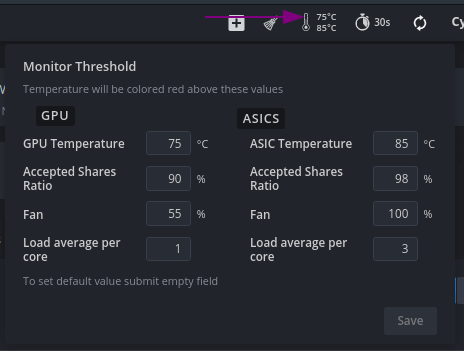
Three values: LA now / average LA per 5 minutes / average LA per 15 minutes .