Что такое Machine Learning и стоит ли его изучать
Зачем бизнесу нейросети и можно ли освоить ML без математической подготовки.

Иллюстрация: Dalee / Openai / Tong / Rawpixel / Annie для Skillbox Media

Мария Даровская
Журналист, коммерческий автор и редактор. Пишет про IT, цифровой маркетинг и бизнес.
Сайт: darovska.com.

Александр Белоусов
Разработчик приложений, использующих ML. IT‑консультант, основатель и СTO в ML‑проекте Giftbox. Создал русскоязычную версию Wordle.
Ссылки
Заниматься машинным обучением я начал ещё в университете и даже использовал его в дипломном проекте. Позже работал в аутсорс-агентстве, которое специализировалось на заказной разработке нейросетей, что помогло узнать массу нюансов. Например, даже развернуть модель в продакшен — непростая задача.
Позже я решил создать собственный сервис, в котором нейросеть будет помогать выбирать подарки. Впрочем, давайте по порядку.
Разберёмся с терминами
Машинное обучение — часть Computer Science, объекты изучения и разработки в которой — алгоритмы, способные обучаться за счёт анализа данных. Эти алгоритмы применяют для решения задач довольно широкого спектра: классификации, прогнозирования, регрессии и так далее. А самая продвинутая методика на сегодняшний день — использование нейросетей, поэтому под ML чаще всего подразумевают именно работу с нейросетями.
Сейчас использование нейросетей стало повсеместным, и встретить их можно даже в популярных текстовых и табличных редакторах. Простейший пример — парсинг и выгрузка с сайтов в Google-таблицы картинок и другого контента. Можно даже не писать код: достаточно просто ввести в ячейки то, что вам нужно (название, цену товара в магазине и так далее), — и все данные подтянутся сами, как на видео:

У этих сервисов большой потенциал: возможно, в будущем они сильно упростят работу с Photoshop и прочими графическими редакторами, позволят заметно ускорить работу дизайнеров, иллюстраторов, да и обычных пользователей. Больше не нужно будет искать исполнителя, согласовывать с ним техзадание и долго спорить с ним в духе: «Я вам не это заказывал! — Я художник, я так вижу!» Сравнительно несложные картинки и коллажи можно теперь сделать самостоятельно за несколько минут.
Точно так же нейросети могут стать мощным инструментом для создания собственных продуктов, выполнения ежедневных рутинных операций, облегчения жизни людей. Например, недавно я работал над заказом одной крупной зарубежной компании. В их CRM-систему поступали тысячи обращений разной тематики в день. Нужно было разделить их по категориям, не привлекая менеджеров, — то есть сделать что-то, похожее на классификатор «Яндекс.Новостей». И таких задач с каждым днём всё больше.
Бизнес ловит нейросетью
Думаю, со временем создание нейросетей станет гораздо проще и даже человек без навыков программирования сможет дообучать готовые нейросети под свои задачи. Если провести аналогию с сайтами, то раньше сайт мог сделать только программист. А сейчас есть большое количество no-code-конструкторов сайтов, с помощью которых сайт может сделать даже человек без навыков программирования.
Аналогично и с нейросетями: большой популярностью будут пользоваться сервисы, которые позволят обучить нейросеть под свои задачи, собирая различные готовые модели как кубики лего и настраивая их под себя. Это поможет даже малому бизнесу эффективнее автоматизировать свою работу.
Например, маркетологи будут загружать свои данные в готовую нейросеть, чтобы извлекать ценные данные о поведении клиентов и использовать их для улучшения своего продукта или сервиса.
Но если вернуться в текущие реалии, то использование нейросетей — дорогое удовольствие. Чтобы понять, стоит ли компании сейчас вкладываться в машинное обучение, определите, оправданно ли это финансово, насколько дешевле или дороже будет сделать это вручную или с использованием более простых алгоритмов.
Важный нюанс заключается в том, что нейросети обучаются на больших коллекциях данных, а их нужно где-то взять. Поэтому основная часть работы специалистов по ML — это сбор данных, очистка их от ненужного, не влияющего ни на что «белого шума» и правильная разметка. Процесс занимает много времени.
Если компания, которая никогда не работала с крупными массивами данных, попытается создать нейросеть, первое время будет сложновато: много времени уйдёт на эксперименты и подготовку данных.
В США и Европе есть большие стартапы, которые предоставляют бизнесу инструменты для разметки данных. В основном их клиенты — крупные компании, которые уже собрали большое количество данных и как-то с ними взаимодействуют: банки, телеком-операторы, медицинские сети и так далее.
Чтобы разметить данные, сейчас уже не нужно самостоятельно писать ПО для разметки или искать людей на подобную работу — можно использовать «Яндекс.Толоку» или другие платформы.
Как освоить машинное обучение
Специалист в нашей отрасли не должен всё время писать код, но нужно владеть базовой статистикой и теорией вероятностей. Чем глубже вы хотите погрузиться в технологию, тем больше математических знаний и навыков потребуется.
Начать стоит с простых туториалов. Если человек владеет основами программирования, он сможет создать свою нейросеть. Раньше их приходилось писать самому с нуля, а сейчас есть готовые фреймворки: TensorFlow от Google или Hydra от «Фейсбука»*. Они позволяют быстрее обучать нейросети.
Проблема в том, где взять данные и мощности, чтобы их обучить. Например, сделать такие мощные нейросети, как GPT-3 или mGPT от «Сбера», на локальном компьютере сложно. Впрочем, есть сервис Google Colab, который бесплатно предоставляет виртуальную машину для обучения нейросетей в исследовательских целях. Многие используют её для быстрого тестирования, обучения и демонстрации возможностей нейросети. В интернете довольно много готовых решений, которые тоже можно запускать, тестировать и изменять через Google Colab.
Сейчас основной язык для машинного обучения — Python. Большинство курсов и книг по ML, а также основные фреймворки заточены под него. Но тот же TensorFlow от Google можно запускать даже в браузере, то есть использовать JavaScript.
Фундаментальные знания лучше получить в приличном университете. Скажем, топовые компании вроде «Сбера» или «Яндекса» на проекты с нейросетями и машинным обучением ищут стажёров в рейтинговых технических вузах — МФТИ, Бауманке и так далее. Если вы там отучились, это станет преимуществом. Вам будет легче «попасть на радары» и получить достойные предложения ещё во время учёбы.
Впрочем, если профильного высшего образования нет, выучиться можно и самостоятельно. Сейчас для этого существует довольно много бесплатных ресурсов — например, курсы на Coursera, Stepik и других платформах.
Например, могу порекомендовать курс «Специализация. Глубокое обучение». Его авторы — ведущие учёные в области ML.
Для начала попробуйте использовать готовые модели и фреймворки — многие из них можно запустить на домашнем компьютере. Потренируйтесь, чтобы понять, к чему лежит душа.
А вот без чего точно не получится вкатиться в ML, так это без основ программирования. Работа с нейросетями скорее подойдёт уверенным джунам, которым не нужно объяснять азы программирования и Computer Science.
Тем, кто решился погрузиться в машинное обучение, рекомендую читать и смотреть такие ресурсы:
- Telegram-канал «Мишин Лернинг» — там делятся новостями, открытиями в ML, готовыми моделями;
- Telegram-канал Machine Learning in Art — здесь собраны колабы и освещаются значимые события из мира машинного обучения в изобразительном искусстве;
- Telegram-канал Дениса Ширяева, в котором он делится новостями из мира ML;
- ветка о машинном обучении на Reddit;
- новости на Y Combinator.
Как я запустил собственный ML-стартап
Сейчас я развиваю собственные проекты, связанные с машинным обучением и не только, — среди них русскоязычная версия игры Wordle, приложение для подбора подарков на основе интересов из «ВКонтакте» с помощью нейросети и другие.
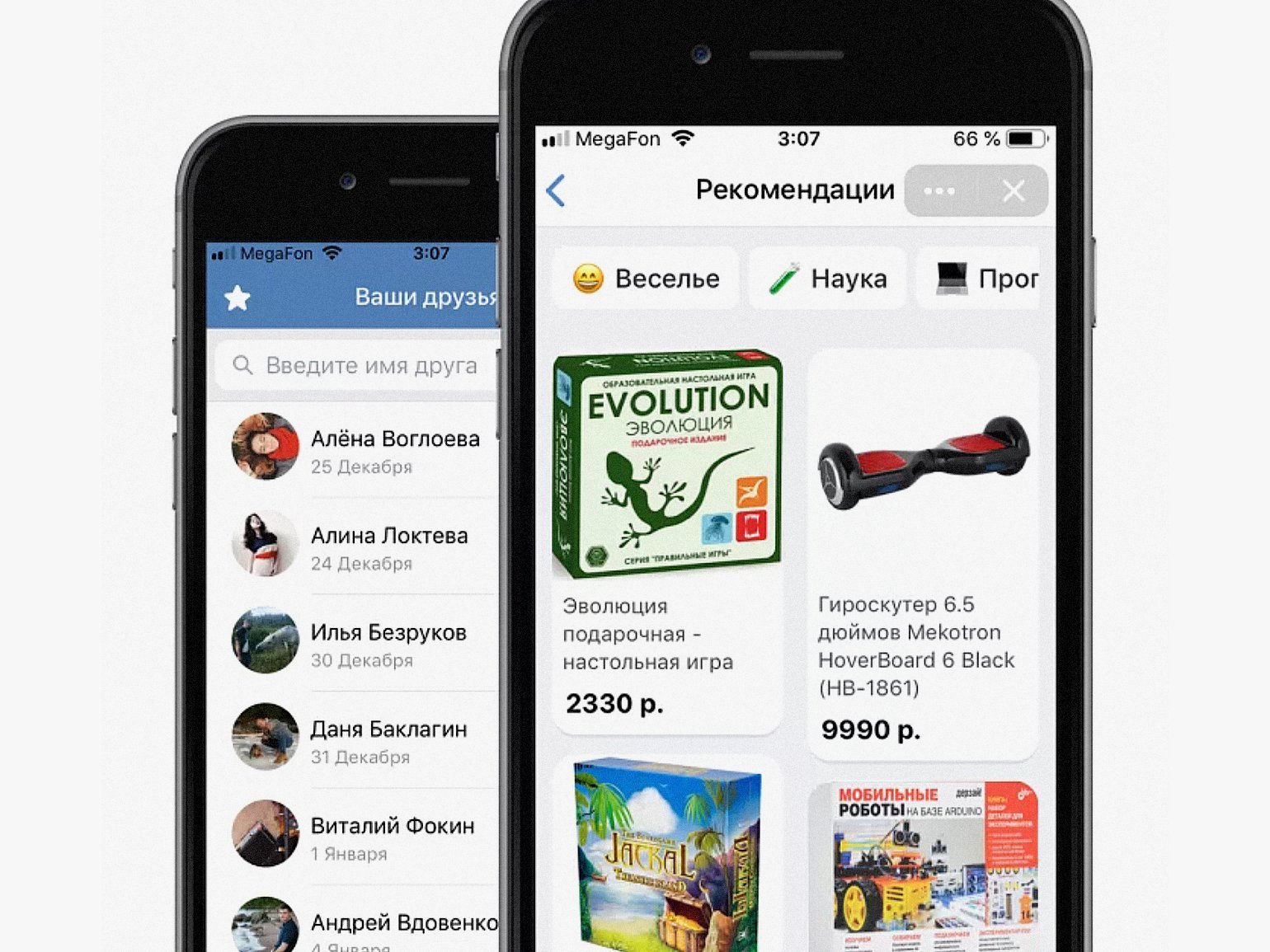
Идея создать Giftbox пришла ещё несколько лет назад. Дело в том, что в декабре и январе у многих моих близких дни рождения. Выбор подарков для них отнимал много времени. Я человек ленивый, поэтому решил сделать приложение, которое автоматически подбирает идеи. Занимался им около месяца по вечерам после работы.
Из ML-фреймворков использовал TensorFlow, дополнительно разобрался с MLflow — это такой опенсорс-инструмент для запуска ML-моделей в продакшен.
Я определил около 80 интересов, сделал список групп и подписок и собрал нейросеть через VK API по ключевым словам, которые соответствуют каждому интересу. Потом с помощью фрилансеров распределил группы по темам (разметил данные). Например, ключевое слово «дизайн» может относиться к веб-дизайну, а может к дизайну интерьеров — это разные темы. Также я поручил фрилансерам проверить работу друг друга.
Всего было обработано около 40 тысяч источников.
Чтобы людям было проще, я сразу выгрузил все нужные данные в CSV . Это позволило делать всё прямо в «Google Таблицах», что существенно ускорило процесс. Часть данных использовалась для обучения классификационной нейросети, а часть — для оценки качества обучения. Приложение Giftbox работает в партнёрстве с онлайн-магазинами. Нейросеть подбирает подарок исходя из действий пользователя на его странице и его интересов.
Любой из выбранных подарков можно купить на сайте партнёра. Сервис входит в сеть партнёрских приложений социальной сети «ВКонтакте». Его использует 150 тысяч покупателей ежемесячно.
Стартапов на основе ИИ в России будет меньше
Мои проекты позволяли мне не работать по найму. Вместо этого я развиваю свои сервисы, занимаюсь поддержкой пользователей и маркетингом. По моим ощущениям, в течение следующего года число стартапов с ML в России станет меньше. Крупные компании от этого выиграют и смогут занять нишу, которую раньше занимали западные конкуренты. А вот маленьким проектам найти финансирование станет гораздо сложнее. Сейчас многие венчурные фонды перестали рассматривать инвестиции в Россию, что негативно скажется на появлении новых инновационных продуктов.
Читайте также:
- Искусственный интеллект, машинное обучение и глубокое обучение: в чём разница
- Тест: ИИ на столе — пересол на спине. Распознай, какое блюдо придумал компьютер
- Какой язык программирования выбрать специалисту по машинному обучению?
* Решением суда запрещена «деятельность компании Meta Platforms Inc. по реализации продуктов — социальных сетей Facebook и Instagram на территории Российской Федерации по основаниям осуществления экстремистской деятельности».
API «ВКонтакте» — интерфейс, который позволяет получать информацию из базы данных vk.com с помощью HTTP-запросов к специальному серверу.
CSV-файлы (файлы данных с разделителями-запятыми) — файлы особого типа, которые можно создавать и редактировать в Excel. Данные в них не хранятся в столбцах, а разделяются запятыми.
Что такое машинное обучение?

Машинное обучение – это наука о разработке алгоритмов и статистических моделей, которые компьютерные системы используют для выполнения задач без явных инструкций, полагаясь вместо этого на шаблоны и логические выводы. Компьютерные системы используют алгоритмы машинного обучения для обработки больших объемов статистических данных и выявления шаблонов данных. Таким образом, системы могут более точно прогнозировать результаты на основе заданного набора входных данных. Например, специалисты по работе с данными могут обучить медицинское приложение диагностировать рак по рентгеновским изображениям, сохраняя миллионы отсканированных изображений и соответствующие диагнозы.
Почему машинное обучение так важно?
Машинное обучение помогает компаниям стимулировать рост, открывать новые источники дохода и решать сложные проблемы. Данные являются важной движущей силой принятия бизнес-решений, но традиционно компании использовали данные из различных источников, таких как отзывы клиентов, сотрудников и финансов. Исследования в области машинного обучения автоматизируют и оптимизируют этот процесс. Используя ПО, которое анализирует очень большие объемы данных на высокой скорости, компании могут быстрее достигать результатов.
Где используется машинное обучение?
Ключевые области использования машинного обучения см. ниже.
Производство
Машинное обучение может поддерживать профилактическое обслуживание, контроль качества и инновационные исследования в производственном секторе. Технология машинного обучения также помогает компаниям улучшать логистические решения, включая активы, цепочки поставок и управление запасами. Например, крупномасштабная компания-производитель 3M использует AWS Machine Learning для инновации шлифовальной бумаги. Алгоритмы машинного обучения позволяют исследователям 3M анализировать, как незначительные изменения формы, размера и ориентации улучшают абразивность и долговечность. Эти предложения влияют на производственный процесс.
Здравоохранение и медико‑биологические разработки
Распространение носимых датчиков и устройств породило значительный объем данных о здоровье. Программы машинного обучения могут анализировать эту информацию и помогать врачам в диагностике и лечении в режиме реального времени. Исследователи машинного обучения разрабатывают решения, которые обнаруживают раковые опухоли и диагностируют глазные заболевания, что значительно влияет на показатели здоровья человека. Например, компания Cambia Health Solutions использовала машинное обучение AWS для поддержки стартапов в области здравоохранения с целью автоматизации и персонализации лечения беременных женщин.
Финансовые услуги
Проекты финансового машинного обучения улучшают аналитику рисков и регулирование. Технология машинного обучения может позволить инвесторам выявлять новые возможности путем анализа движений фондового рынка, оценки хедж-фондов или калибровки финансовых портфелей. Кроме того, это может помочь выявить кредитных клиентов с высоким уровнем риска и смягчить признаки мошенничества. Лидирующий поставщик финансового ПО Intuit использует подсистему AWS Machine Learning, Amazon Textract,чтобы обеспечить более персонализированное управление финансами и помочь конечным пользователям улучшить финансовое положение.
Розничная торговля
В розничной торговле машинное обучение может использоваться для улучшения обслуживания клиентов, управления запасами, дополнительных продаж и многоканального маркетинга. Например, Amazon Fulfillment (AFT) удалось сократить расходы на инфраструктуру на 40 %, используя модель машинного обучения для выявления неуместных запасов. Это позволяет выполнять обещание Amazon в отношении предоставления клиентам простого доступа к товару и своевременной доставки такого товара, несмотря на обработку миллионов поставок ежегодно.
Мультимедиа и развлечения
Компании в индустрии развлечений обращаются к машинному обучению, чтобы лучше понимать целевую аудиторию и предоставлять иммерсивный персонализированный контент по запросу. Алгоритмы машинного обучения используются для разработки трейлеров и другой рекламы, предоставления потребителям персонализированных рекомендаций по контенту и даже оптимизации производства.
Например, Disney использует глубокое обучение AWS для архивирования медиатеки. Инструменты машинного обучения AWS автоматически маркируют, описывают и сортируют медиаконтент, позволяя писателям и аниматорам Disney быстро искать персонажей Disney и знакомиться с ними.
Как работает машинное обучение?
Центральной идеей машинного обучения является существующая математическая связь между любой комбинацией входных и выходных данных. Модель машинного обучения не имеет сведений об этой взаимосвязи заранее, но может сгенерировать их, если будет предоставлено достаточное количество наборов данных. Это означает, что каждый алгоритм машинного обучения строится вокруг модифицируемой математической функции. Описание основополагающего принципа см. ниже.
- Мы «обучаем» алгоритм, давая ему следующие комбинации ввода-вывода [input / output (i,o)]: (2,10), (5,19) и (9,31).
- Алгоритм вычисляет соотношение между входом и выходом следующим образом: o = 3 × i + 4.
- Затем мы задаем ввод 7 и просим предсказать результат. Алгоритм может автоматически определить выход как 25.
Хотя это базовое понимание, машинное обучение фокусируется на том принципе, что все сложные точки данных могут быть математически связаны компьютерными системами, если у них достаточно данных и вычислительной мощности для обработки этих данных. Следовательно, точность выходных данных прямо пропорциональна величине входных данных.
Какие типы алгоритмов машинного обучения существуют?
Алгоритмы можно разделить на четыре стиля обучения в зависимости от ожидаемого результата и типа ввода.
- Машинное обучение с учителем
- Машинное обучение без учителя
- Машинное обучение с частичным привлечением учителя
- Машинное обучение с подкреплением
1. Машинное обучение с учителем
Специалисты по работе с данными предоставляют алгоритмам помеченные и определенные обучающие данные для оценки корреляций. Демонстрационные данные определяют как входные данные, так и выходные данные алгоритма. Например, изображения рукописных цифр аннотируются, чтобы указать, какому числу они соответствуют. Система обучения с учителем может распознавать кластеры пикселей и фигур, связанных с каждым числом, при наличии достаточного количества примеров. Со временем система распознает написанные от руки цифры, стабильно различая числа 9 и 4 или 6 и 8.
Сильные стороны машинного обучения с учителем – простота и легкость структуры. Такая система полезна при прогнозировании возможного ограниченного набора результатов, разделении данных на категории или объединении результатов двух других алгоритмов машинного обучения. Однако маркировка миллионов немаркированных наборов данных является сложной задачей. Давайте рассмотрим это подробнее.
Что такое маркировка данных?
Маркировка данных – это процесс категоризации входных данных с соответствующими им определенными выходными значениями. Помеченные обучающие данные необходимы для обучения с учителем. Например, миллионы изображений яблок и бананов должны быть помечены словами «яблоко» или «банан». Затем приложения машинного обучения могли бы использовать эти обучающие данные, чтобы угадывать название фрукта по изображению фрукта. Однако маркировка миллионов новых данных может быть трудоемкой и сложной задачей. Сервисы коллективной работы, такие как Amazon Mechanical Turk, могут в некоторой степени преодолеть это ограничение алгоритмов обучения с учителем. Эти сервисы обеспечивают доступ к большому количеству доступным рабочим ресурсам по всему миру, что упрощает сбор данных.
2. Машинное обучение без учителя
Алгоритмы обучения без учителя обучаются на неразмеченных данных. Такие алгоритмы просматривают новые данные, пытаясь установить значимые связи между входными и заранее определенными выходными данными. Они могут выявлять закономерности и классифицировать данные. Например, алгоритмы без учителя могут группировать новостные статьи с разных новостных веб-сайтов в общие категории, такие как спорт, криминал и т. д. Они могут использовать обработку естественного языка для понимания смысла и эмоций в статье. В розничной торговле обучение без учителя поможет найти закономерности в покупках клиентов и предоставить результаты анализа данных, такие как: покупатель, скорее всего, купит хлеб, если также купит масло.
Обучение без учителя полезно для распознавания образов, обнаружения аномалий и автоматического группирования данных по категориям. Поскольку обучающие данные не требуют маркировки, настройка проста. Эти алгоритмы также можно использовать для автоматической очистки и обработки данных для дальнейшего моделирования. Ограничение этого метода состоит в том, что он не может дать точных прогнозов. Кроме того, он не может самостоятельно выделять конкретные типы выходных данных.
3. Машинное обучение с частичным привлечением учителя
Как следует из названия, этот метод сочетает в себе обучение с учителем и без него. Этот метод основан на использовании небольшого количества размеченных данных и большого количества неразмеченных данных для обучения систем. Сначала размеченные данные используются для частичного обучения алгоритма машинного обучения. После этого частично обученный алгоритм сам размечает неразмеченные данные. Этот процесс называется псевдомаркировкой. Затем модель переобучается на результирующем наборе данных без явного программирования.
Преимущество этого метода в том, что вам не требуются большие объемы размеченных данных. Это удобно при работе с такими данными, как длинные документы, чтение и маркировка которых отнимает слишком много времени у человека.
4. Обучение с подкреплением
Обучение с подкреплением – это метод, в котором значения вознаграждения привязаны к различным шагам, которые должен пройти алгоритм. Таким образом, цель модели – накопить как можно больше призовых баллов и в конечном итоге достичь конечной цели. Большая часть практического применения обучения с подкреплением за последнее десятилетие была связана с видеоиграми. Передовые алгоритмы обучения с подкреплением добились впечатляющих результатов в классических и современных играх, часто значительно превосходя ручные аналоги.
Хотя этот метод лучше всего работает в неопределенных и сложных средах данных, он редко применяется в бизнес-контексте. Это неэффективно для четко определенных задач, и предвзятость разработчиков может повлиять на результаты. Поскольку специалист по работе с данными разрабатывает награды, они могут влиять на результаты.
Являются ли модели машинного обучения детерминированными?
Если выход системы предсказуем, то говорят, что она детерминирована. Большинство программных приложений предсказуемо реагируют на действия пользователя, поэтому можно сказать: что «если пользователь делает то-то, он получает то-то». Однако алгоритмы машинного обучения учатся на основе наблюдения и опыта. Поэтому они носят вероятностный характер. Утверждение теперь меняется на следующее: «если пользователь делает это, есть вероятность X %, что произойдет это».
В машинном обучении детерминизм – это стратегия, используемая при применении методов обучения, описанных выше. Любой из методов обучения (с учителем, без учителя и т. д.) можно сделать детерминированным в зависимости от желаемых бизнес-результатов. Вопрос исследования, поиск данных, структура и решения по хранению определяют, будет ли принята детерминированная или недетерминированная стратегия.
Детерминированный и вероятностный подходы
Детерминированный подход фокусируется на точности и объеме собранных данных, поэтому эффективность важнее неопределенности. С другой стороны, недетерминированный (или вероятностный) процесс предназначен для управления фактором случайности. Встроенные инструменты интегрированы в алгоритмы машинного обучения, чтобы помочь количественно определить, идентифицировать и измерить неопределенность во время обучения и наблюдения.
Что такое глубокое обучение?
Глубокое обучение – это метод машинного обучения, который моделируется мозгом человека. Алгоритмы глубокого обучения анализируют данные с логической структурой, аналогичной той, которую используют люди. Глубокое обучение использует интеллектуальные системы, называемые искусственными нейронными сетями, для обработки информации слоями. Данные проходят от входного слоя через несколько «глубоких» скрытых слоев нейронной сети, прежде чем попасть на выходной слой. Дополнительные скрытые слои поддерживают обучение, которое намного эффективнее, чем стандартные модели машинного обучения.
Что такое искусственная нейронная сеть?
Слои глубокого обучения представляют собой узлы искусственной нейронной сети (ИНС), которые работают как нейроны человеческого мозга. Узлы могут представлять собой комбинацию аппаратного и программного обеспечения. Каждый уровень в алгоритме глубокого обучения состоит из узлов ИНС. Каждый узел или искусственный нейрон соединяется с другим и имеет связанный с ним номер значения и пороговый номер. Узел отправляет номер своего значения в качестве входных данных узлу следующего слоя при активации. Он активируется, только если его выход превышает указанное пороговое значение. В противном случае никакие данные не передаются.
Что такое машинное зрение?
Компьютерное зрение – это реальное применение глубокого обучения. Точно так же, как искусственный интеллект позволяет компьютерам думать, компьютерное зрение позволяет им видеть, наблюдать и реагировать. Самоуправляемые автомобили используют компьютерное зрение, чтобы «читать» дорожные знаки. Камера автомобиля делает снимок знака. Это фото отправляется алгоритму глубокого обучения в машине. Первый скрытый слой обнаруживает края, следующий различает цвета, а третий слой идентифицирует детали алфавита на знаке. Алгоритм предсказывает, что на знаке написано СТОП, и автомобиль ответит срабатыванием тормозного механизма.
Машинное обучение и глубокое обучение – это одно и то же?
Глубокое обучение – это часть машинного обучения. Алгоритмы глубокого обучения можно рассматривать как непростую и математически сложную эволюцию алгоритмов машинного обучения.
Машинное обучение и искусственный интеллект – это одно и то же?
Короткий ответ: нет. Хотя термины «машинное обучение» и «искусственный интеллект» (ИИ) могут использоваться взаимозаменяемо, это не одно и то же. Искусственный интеллект – это общий термин для различных стратегий и методов, используемых для того, чтобы сделать машины более похожими на людей. ИИ включает в себя все, от умных помощников, таких как Alexa, до роботов-пылесосов и беспилотных автомобилей. Машинное обучение – одна из многих других ветвей искусственного интеллекта. Хотя машинное обучение – это ИИ, все действия ИИ нельзя назвать машинным обучением.
Машинное обучение и наука о данных – это одно и то же?
Нет, машинное обучение и наука о данных – это не одно и то же. Наука о данных – это область исследования, в которой используется научный подход для извлечения смысла и понимания из данных. Специалисты по работе с данными используют ряд инструментов для анализа данных, и машинное обучение является одним из таких инструментов. Специалисты по работе с данными понимают общую картину данных, таких как бизнес-модель, предметная область и сбор данных, в то время как машинное обучение — это вычислительный процесс, который работает только с необработанными данными.
Каковы преимущества и недостатки машинного обучения?
Мы предлагаем вашему вниманию возможности и ограничения машинного обучения.
Преимущества моделей машинного обучения:
- определение тенденций и закономерностей данных, которые может упустить человек;
- работа без вмешательства человека после настройки; например, машинное обучение в ПО для кибербезопасности может постоянно отслеживать и выявлять нарушения в сетевом трафике без участия администратора;
- результаты могут стать более точными с течением времени;
- обработка различных форматов данных в динамических, больших объемов и сложных сред данных.
Недостатки моделей машинного обучения:
- исходная подготовка является дорогостоящим и трудоемким процессом; трудоемкая реализация в отсутствии достаточного объема данных;
- ресурсоемкий процесс, требующий больших первоначальных инвестиций, если оборудование устанавливается собственными силами;
- без помощи специалиста может быть сложно правильно интерпретировать результаты и устранить неопределенность.
Как Amazon может содействовать машинному обучению?
AWS предоставляет машинное обучение в руки каждого разработчика, специалиста по данным и бизнес-пользователя. Сервисы Amazon Machine Learning предоставляют высокопроизводительную, экономически эффективную и масштабируемую инфраструктуру для удовлетворения потребностей бизнеса.
Работа только началась?
Овладейте машинным обучением с нашей помощью, используя учебные устройства: AWS DeepRacer, AWS DeepComposer и AWS DeepLens.
Архив данных уже существует?
Используйте маркировку данных Amazon SageMaker для встроенных рабочих процессов маркировки данных, поддерживающих видео, изображения и текст.
Системы машинного обучения уже имеются?
Используйте Amazon SageMaker Clarify для обнаружения смещений, а также Amazon SageMaker Debugger для мониторинга и оптимизации продуктивности.
Хотите внедрить глубокое обучение?
Используйте распределенное обучение Amazon SageMaker для автоматического обучения больших моделей глубокого обучения. Чтобы начать машинное обучение уже сегодня, зарегистрируйте бесплатный аккаунт!
Что такое машинное обучение и как оно работает

Единого определения для machine learning (машинного обучения) пока нет. Но большинство исследователей формулируют его примерно так: Машинное обучение — это наука о том, как заставить ИИ учиться и действовать как человек, а также сделать так, чтобы он сам постоянно улучшал свое обучение и способности на основе предоставленных нами данных о реальном мире.
Инженеры Google рассказывают, как устроено машинное обучение
Вот как определяют машинное обучение представители ведущих ИТ-компаний и исследовательских центров: Nvidia: «Это практика использования алгоритмов для анализа данных, изучения их и последующего определения или предсказания чего-либо». Университет Стэнфорда: «Это наука о том, как заставить компьютеры работать без явного программирования». McKinsey & Co: «Машинное обучение основано на алгоритмах, которые могут учиться на данных, не полагаясь на программирование на основе базовых правил». Вашингтонский университет: «Алгоритмы машинного обучения могут сами понять, как выполнять важные задачи, обобщая примеры, которые у них есть». Университет Карнеги Меллон: «Сфера машинного обучения пытается ответить на вопрос: «Как мы можем создавать компьютерные системы, которые автоматически улучшаются по мере накопления опыта и каковы фундаментальные законы, которые управляют всеми процессами обучения?»
История машинного обучения
- Первый компьютер с прототипом ИИ появился в 1946 году — в рамках ЭНИАК, сверхсекретного проекта армии США. Его можно было использовать для электронных вычислений и многих других задач;
- В 1950 году появился тест Алана Тьюринга для оценки интеллекта компьютера. С его помощью ученый предлагал определить, способен ли компьютер мыслить как человек;
- В 1958 году американский нейрофизиолог Фрэнк Розенблатт придумал Персептрон — первую искусственную нейронную сеть, а также первый нейрокомпьютер «Марк-1»;
- В 1959 году американский исследователь ИИ Марвин Минский создал SNARC — первую вычислительную машину на базе нейросети;
- В том же году его коллега Артур Самуэль изобрел первую программу по игре в шашки, которая обучалась самостоятельно. Он впервые ввел термин «машинное обучение», описав его как процесс, в результате которого машина показывает поведение, на которое не была изначально запрограммирована;
- В 1967 году был создан первый метрический алгоритм для классификации данных, который позволял ИИ использовать шаблоны для распознавания и обучения;
- В 1997 году программа Deep Blue впервые обыграла чемпиона мира по шахматам Гарри Каспарова;
- В 2006 году исследователь нейросетей Джеффри Хинтон ввел термин «глубокое обучение» (deep learning);
- В 2011 году была основана Google Brain — подразделение Google, которое занимается проектами в области ИИ;
- В 2012 году в рамках другого подразделения — Google X Lab — разработали нейросетевой алгоритм для распознавания котов на фото и видео. Тогда же Google запустила облачный сервис Google Prediction API для машинного обучения, который анализирует неструктурированные данные;
- В 2014 году Facebook (с 21 марта 2022 года соцсеть запрещена в России решением суда) разработала нейросеть DeepFace для распознавания лиц на фото и видео. Ее алгоритм работает с точностью 97%;
- В 2015 году Amazon запустила Amazon Machine Learning — платформу машинного обучения, несколько месяцев спустя аналогичная появилась и у Microsoft: Distributed Learning Machine Toolkit.
Как связаны машинное и глубокое обучение, ИИ и нейросети
Нейросети — один из видов машинного обучения.
Глубокое обучение — это один из видов архитектуры нейросетей.
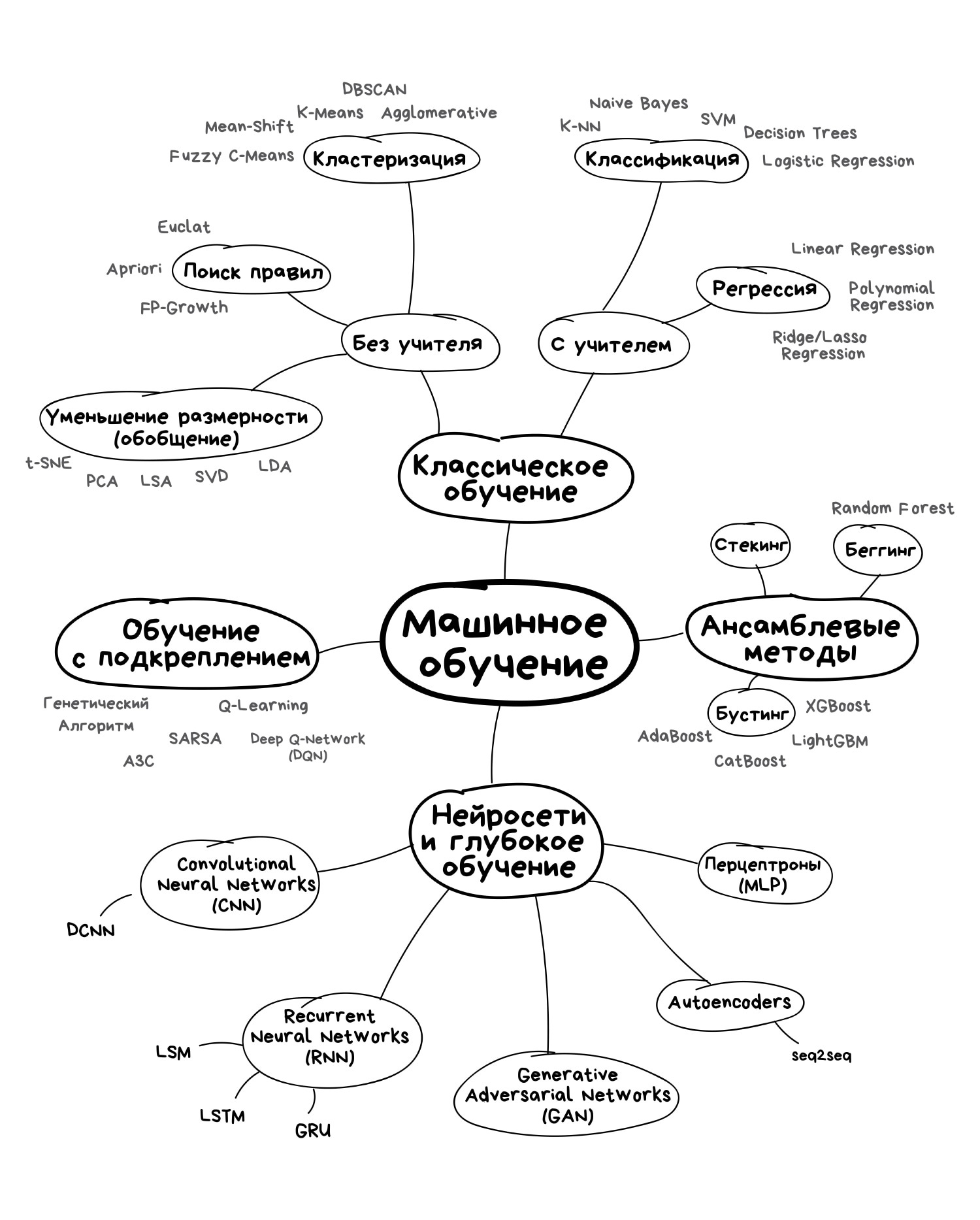
Так выглядят взаимосвязи машинного обучения с другими видами обучения в рамках технологий ИИ
Глубокое обучение также включает в себя исследование и разработку алгоритмов для машинного обучения. В частности — обучения правильному представлению данных на нескольких уровнях абстракции. Системы глубокого обучения за последние десять лет добились особенных успехов в таких областях как обнаружение и распознавание объектов, преобразование текста в речь, поиск информации.
Какие задачи решает машинное обучение?
С помощью машинного обучения ИИ может анализировать данные, запоминать информацию, строить прогнозы, воспроизводить готовые модели и выбирать наиболее подходящий вариант из предложенных.
Особенно полезны такие системы там, где необходимо выполнять огромные объемы вычислений: например, банковский скоринг (расчет кредитного рейтинга), аналитика в области маркетинговых и статистических исследований, бизнес-планирование, демографические исследования, инвестиции, поиск фейковых новостей и мошеннических сайтов.
В Леруа Мерлен используют Big Data и Machine Learning, чтобы находить остатки товара на складах.
В маркетинге и электронной коммерции машинное обучение помогает настроить сервисы и приложения так, чтобы они выдавали персональные рекомендации.
Стриминговый сервис Spotify с помощью машинного обучения составляет для каждого пользователя персональные подборки треков на основе того, какую музыку он слушает.
Сегодня ключевые исследования сфокусированы на разработке машинного обучения с эффективным использованием данных — то есть систем глубокого обучения, которые могут обучаться более эффективно, с той же производительностью, за меньшее время и с меньшими объемами данных. Такие системы востребованы в персонализированном здравоохранении, обучении роботов с подкреплением, анализе эмоций.
Китайский производитель «умных» пылесосов Ecovacs Robotics обучил свои пылесосы распознавать носки, провода и другие посторонние предметы на полу с помощью множества фотографий и машинного обучения.
«Умная» камера на базе микрокомпьютера Raspberry Pi 3B+ с помощью фреймворка TensorFlow Light научилась распознавать улыбку и делать снимок ровно в этот момент, а также — выполнять голосовые команды.
В сфере инвестиций алгоритмы на базе машинного обучения анализируют рынок, отслеживают новости и подбирают активы, которые выгоднее всего покупать именно сейчас. При этом с помощью предикативной аналитики система может предсказать, как будет меняться стоимость тех или иных акций за конкретный период и корректирует свои данные после каждого важного события в отрасли.
Согласно исследованию BarclayHedge, более 50% хедж-фондов используют ИИ и машинное обучение для принятия инвестиционных решений, а две трети — для генерации торговых идей и оптимизации портфелей.
Наконец, машинное обучение способствует настоящим прорывам в науке.
Нейросеть AlphaFold от DeepMind в 2020 году смогла расшифровать механизм сворачивания белка. Над этой задачей ученые-биологи бились больше 50 лет.
Процесс сворачивания белка, смоделированный при помощи ИИ
Как устроено машинное обучение
По словам Дмитрия Ветрова, процесс машинного обучения выглядит следующим образом.
Есть большое число однотипных задач, в которых известны условие и правильный ответ или один из возможных ответов. Например, машинный перевод, где условие — фраза на одном языке, а правильный ответ — ее перевод на другой язык.
Модель машинного обучения, например, глубинная нейронная сеть, работает по принципу «черного ящика», который принимает на вход условие задачи, а на выходе выдает произвольный ответ. Например, какой-либо текст на втором языке.
У «черного ящика» есть дополнительные параметры, которые влияют на то, как будет обрабатываться входной сигнал. Процесс обучения нейросети заключается в поиске таких значений параметров, при которых она будет выдавать ответ, максимально близкий к правильному. Когда мы настроим параметры нужным образом, нейросеть сможет правильно (или максимально близко к этому) решать и другие задачи того же типа — даже если никогда не знала ответов к ним.
- Данные — примеры решений и всё, что может помочь в процессе обучения: статистика, примеры текстов, расчеты, показатели, исторические события. Данные собирают годами и объединяют в огромные массивы — датасеты, которые есть у всех ИТ-корпораций. Примером сбора является капча, которая просит вас выбрать все фото с автомобилями и запоминает правильные ответы;
- Признаки — они же свойства или характеристики. Это то, на что должна обратить внимание машина в процессе обучения. Например, цена акций, изображение животного, частотность слов или пол человека. Чем меньше признаков и чем четче они обозначены и оформлены, тем проще обучаться. Однако для сложных задач современным моделям приходится учитывать десятки миллионов параметров, определяющих, как входы преобразуются в выходы;
- Алгоритмы — это способ решения задачи. Для одной и той же задачи их может быть множество и важно выбрать самый точный и эффективный.
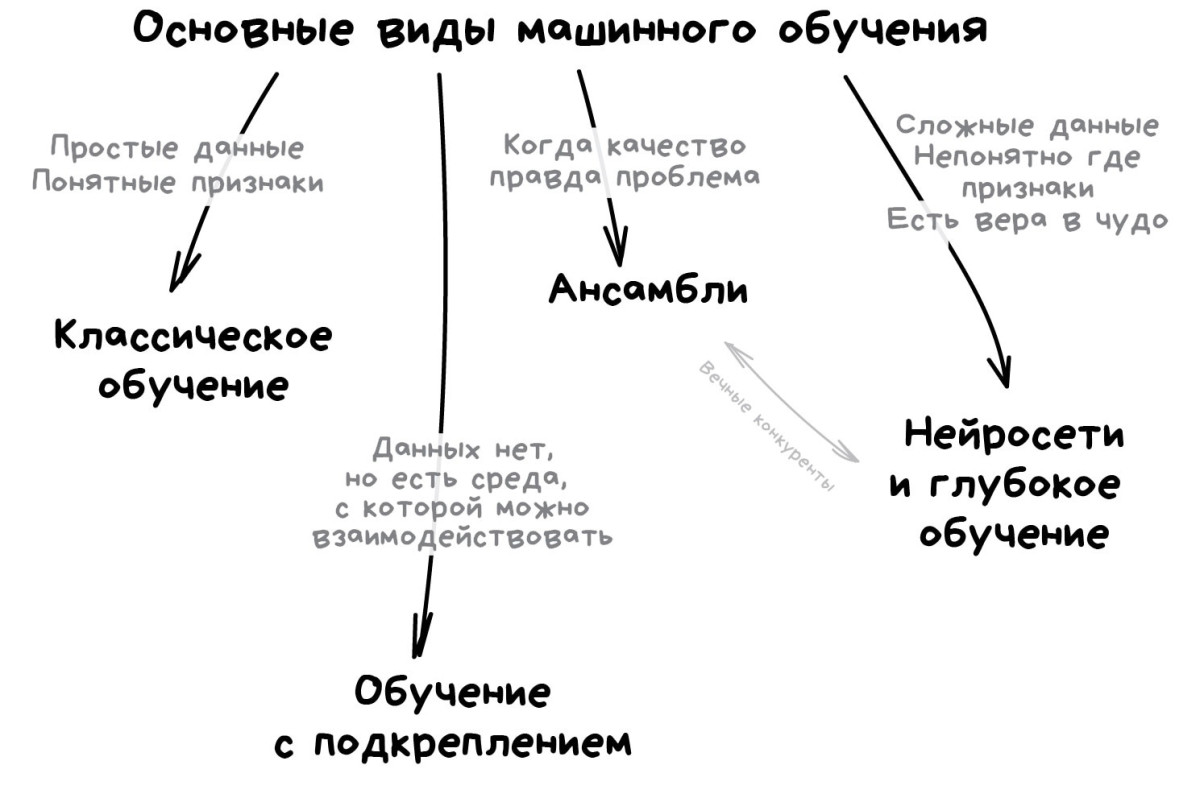
Основные виды машинного обучения
1. Классическое обучение
Это простейшие алгоритмы, которые являются прямыми наследниками вычислительных машин 1950-х годов. Они изначально решали формальные задачи — такие, как поиск закономерностей в расчетах и вычисление траектории объектов. Сегодня алгоритмы на базе классического обучения — самые распространенные. Именно они формируют блок рекомендаций на многих платформах.
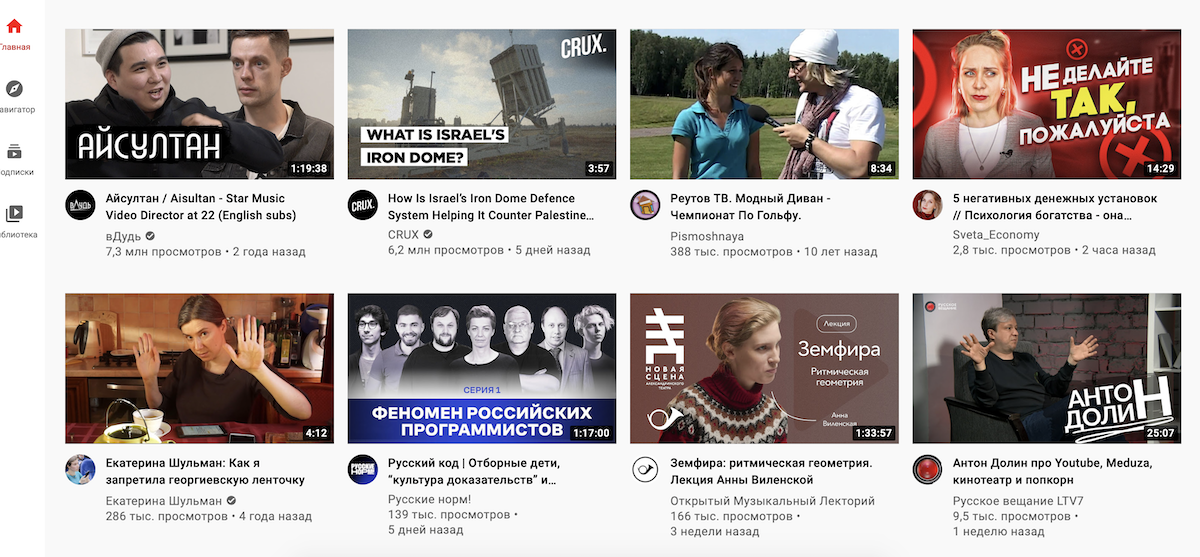
Так выглядит блок рекомендаций в YouTube
Но классическое обучение тоже бывает разным:
Обучение с учителем — когда у машины есть некий учитель, который знает, какой ответ правильный. Это значит, что исходные данные уже размечены (отсортированы) нужным образом, и машине остается лишь определить объект с нужным признаком или вычислить результат.
Такие модели используют в спам-фильтрах, распознавании языков и рукописного текста, выявлении мошеннических операций, расчете финансовых показателей, скоринге при выдаче кредита. В медицинской диагностике классификация помогает выявлять аномалии — то есть возможные признаки заболеваний на снимках пациентов.
Обучение без учителя — когда машина сама должна найти среди хаотичных данных верное решение и отсортировать объекты по неизвестным признакам. Например, определить, где на фото собака.
Эта модель возникла в 1990-х годах и на практике используется гораздо реже. Ее применяют для данных, которые просто невозможно разметить из-за их колоссального объема. Такие алгоритмы применяют для риск-менеджмента, сжатия изображений, объединения близких точек на карте, сегментации рынка, прогноза акций и распродаж в ретейле, мерчендайзинга. По такому принципу работает алгоритм iPhoto, который находит на фотографиях лица (не зная, чьи они) и объединяет их в альбомы.
2. Обучение с подкреплением
Это более сложный вид обучения, где ИИ нужно не просто анализировать данные, а действовать самостоятельно в реальной среде — будь то улица, дом или видеоигра. Задача робота — свести ошибки к минимуму, за что он получает возможность продолжать работу без препятствий и сбоев.
Нейросеть играет в Mario
Обучение с подкреплением инженеры используют для беспилотников, роботов-пылесосов, торговли на фондовом рынке, управления ресурсами компании. Именно так алгоритму AlphaGo удалось обыграть чемпиона по игре Го: просчитать все возможные комбинации, как в шахматах, здесь было невозможно.
Как создавался AlphaGo от DeepMind
3. Ансамбли
Это группы алгоритмов, которые используют сразу несколько методов машинного обучения и исправляют ошибки друг друга. Их получают тремя способами:
- Стекинг — когда разные алгоритмы обучают по отдельности, а потом передают их результаты на вход последнему, который и принимает решение;
- Беггинг — когда один алгоритм многократно обучают на случайных выборках, а потом усредняют ответы;
- Бустинг — когда алгоритмы обучают последовательно, при этом каждый обращает особое внимание на ошибки предыдущего.
Ансамбли работают в поисковых системах, компьютерном зрении, распознавании лиц и других объектов.
Как работает алгоритм «Яндекса» CatBoost
4. Нейросети и глубокое обучение
Самый сложный уровень обучения ИИ. Нейросети моделируют работу человеческого мозга, который состоит из нейронов, постоянно формирующих между собой новые связи. Очень условно можно определить их как сеть со множеством входов и одним выходом. Нейроны образуют слои, через которые последовательно проходит сигнал. Все это соединено нейронными связями — каналами, по которым передаются данные. У каждого канала свой «вес» — параметр, который влияет на данные, которые он передает.
ИИ собирает данные со всех входов, оценивая их вес по заданным параметрами, затем выполняет нужное действие и выдает результат. Сначала он получается случайным, но затем через множество циклов становится все более точным. Хорошо обученная нейросеть работает, как обычный алгоритм или точнее.
Настоящим прорывом в этой области стало глубокое обучение, которое обучает нейросети на нескольких уровнях абстракций.
Как устроена нейросеть
Здесь используют две главных архитектуры:
- Сверточные нейросети первыми научились распознавать неразмеченные изображения — самые сложные объекты для ИИ. Для этого они разбивают их на блоки, определяют в каждом доминирующие линии и сравнивают с другими изображениями нужного объекта;
- Рекуррентные нейросети отвечают за распознавание текста и речи. Они выявляют в них последовательности и связывают каждую единицу — букву или звук — с остальными.
Как работает глубокое обучение в беспилотниках
Нейросети с глубоким обучением требуют огромных массивов данных и технических ресурсов. Именно они лежат в основе машинного перевода, чат-ботов и голосовых помощников, создают музыку и дипфейки, обрабатывают фото и видео.
Как обучается нейросеть
Проблемы машинного обучения
- Для того чтобы эффективно обучать нейросети и любые сложные алгоритмы, нужны огромные массивы данных и технические ресурсы: серверы, специальные помещения для них, высокоскоростной интернет без сбоев, много электроэнергии. На получение нужных данных уходят годы работы и миллионы долларов. Такие затраты может позволить себе только крупная ИТ-корпорация. Открытых датасетов совсем не много, некоторые можно купить, но стоят они очень дорого;
- С ростом мощностей для сбора и обработки датасетов растут и вредные выбросы, которые производят крупнейшие датацентры;
- Данные нужно не только собрать, но и разметить — так, чтобы машина точно определила, где какой объект и какие у него признаки. Это касается числовых данных, текстов, изображений. Опять же, чтобы сделать это вручную, нужны миллионные вложения. Например, у «Яндекса» есть «Яндекс.Толока» — сервис, где неразмеченные данные вручную обрабатывают миллионы фрилансеров. Такое тоже может себе позволить далеко не каждый разработчик;
- Даже если данных много и они регулярно обновляются, в процессе обучения может выясниться, что алгоритм не работает. Проблема может быть и в данных, и в самом подходе: когда машина успешно решила задачу с одними данными, но не в состоянии масштабировать решение с новыми условиями;
- Несмотря на все прорывы в глубоком обучении нейросетей, ИИ пока что не может создавать что-то абсолютно новое, выходить за рамки предложенных условий и превзойти заложенные в него способности. Другими словами, он пока что не в состоянии превзойти человека.
Перспективы машинного обучения: не начнет ли ИИ думать за нас?
Вопрос о том, не сделает ли машинное обучение ИИ умнее человека, изначально не совсем корректный. Дело в том, что в природе нет универсальной иерархии в плане интеллекта. Мы по умолчанию считаем себя умнее остальных существ, но, к примеру, белка способна запоминать местонахождения тысячи тайников с запасами, что не под силу даже очень умному человеку. А у осьминогов каждое щупальце способно мыслить и действовать самостоятельно.
Так же и с ИИ: он уже превосходит нас во всем, что касается сложных вычислений, но по-прежнему не способен сам ставить себе новые задачи и решать их, подбирая нужные данные и условия. Это ограничение в последние годы пытаются преодолеть в рамках сильного ИИ, но пока безуспешно. Надежду на решение этой проблемы внушают квантовые компьютеры, которые выходят за пределы обычных вычислений.
Зато мы в ближайшем будущем сможем заметно расширить свои возможности с помощью ИИ, передавая ему рутинные и затратные операции, общаясь и управляя техникой при помощи нейроинтерфейсов.
Что еще почитать про машинное обучение
- Статья о машинном обучении Педро Домингоса, почетного профессора компьютерных наук и инженерии Вашингтонского университета (англ.)
- Видеолекции о машинном обучении от профессора канадского Университета МакГилла (англ.).
- Статья в AI Magazine о вызовах и возможностях машинного обучения от ведущих исследователей (англ.)
- Исследователи и разработчики Facebook отвечают на самые актуальные вопросы о машинном обучении (англ.)
- Статья о перспективах и особенностях репрезентативного обучения (англ.)
- Цикл статей в рамках проекта Machine Learning for Humans (англ.)
- Статья о пяти самых актуальных алгоритмов с кластеризацией (способ сортировки данных в рамках классического обучения) (англ.)
- Лекции «Яндекса» о том, как работают рекомендательные сервисы.
- Хронология развития машинного обучения (англ.)
- Как выглядят разновидности нейросетей и чем они отличаются
Машинное обучение: просто о сложном

За последние 15 лет машинное обучение (machine learning, ML) получило широкое распространение, но большинство людей не до конца не осознает его роль в повседневной жизни. Многие из нас ежедневно используют приложения, в основе которых лежат технологии искусственного интеллекта (ИИ) и машинного обучения. Эти технологии уже стали причиной революции во многих отраслях, например, способствовали появлению виртуальных помощников, таких, как Siri или семейства виртуальных ассистентов Салют (Сбер, Джой, Афина), позволили осуществлять прогнозирование трафика с помощью Google Maps. Рассказываем простыми словами, что такое machine learning, что оно представляет из себя сегодня и какие преимущества способно обеспечить компаниям из разных сфер деятельности.
Что такое машинное обучение?
Машинное обучение — это специализированный способ, позволяющий обучать компьютеры, не прибегая к программированию. Отчасти это похоже на процесс обучения младенца, который учится самостоятельно классифицировать объекты и события, определять взаимосвязи между ними.
ML открывает новые возможности для компьютеров в решении задач, ранее выполняемых человеком, и обучает компьютерную систему составлению точных прогнозов при вводе данных. Оно стимулирует рост потенциала искусственного интеллекта, являясь его незаменимым помощником, а в представлении многих даже синонимом.
Наконец, машинное обучение — одна из наиболее распространенных форм применения искусственного интеллекта современным бизнесом. Если компания еще не использует ML, то в ближайшее время наверняка оценит его потенциал, а ИИ станет основным двигателем IT-стратегии многих предприятий. Ведь искусственный интеллект уже сегодня играет огромную роль в трансформации развития ИТ-индустрии: клиенты больше внимания уделяют интеллектуальным приложениям, чтобы развивать свой бизнес с помощью ИИ. Он применим к любому рабочему процессу, реализованному в программном обеспечении, — не только в рамках традиционной деловой части предприятий, но также в исследованиях, производственных процессах и, во все большей степени, самих продуктах.
Примечание
На международной конференции по искусственному интеллекту и анализу данных Artificial Intelligence Journey (AI Journey) президент по глобальным продажам, маркетингу и операциям Microsoft Жан-Филипп Куртуа сообщил , что пандемия COVID-19 форсировала интерес к использованию машинного обучения: 80% компаний уже внедряют его в свою деятельность, а 56% планируют увеличить объем инвестиций в эту сферу.
Необычайный успех machine learning привел к тому, что исследователи и эксперты в области ИИ сегодня по умолчанию выбирают этот метод для решения задач.
Machine Learning: принципы и задачи
В основе машинного обучения лежат три одинаково важных компонента:
- Данные. Собираются всевозможными способами. Чем больше данных, тем эффективней машинное обучение и точнее будущий результат.
- Признаки. Определяют, на каких параметрах строится машинное обучение.
- Алгоритм. Выбор метода машинного обучения (при условии наличия хороших данных) будет влиять на точность, скорость работы и размер готовой модели.
Примечание
Доверие к результатам машинного обучения должно строиться на понимании: они хороши настолько, насколько хороши данные, на которых обучается алгоритм.
В основу существования и развития машинного обучения легли три основных принципа:
- Инновационность: возможности ML открывают новые перспективы развития и роста практически всех отраслей экономики.
- Специфичность: машинное обучение применяется для внедрения и разработки новых продуктов исключительно людьми, которые разбираются в IT-технологиях.
- Простота: продукты, реализуемые с использованием технологий машинного обучения, становятся понятны даже школьникам и людям преклонного возраста.
Задачи, которые способно решить машинное обучение, напрямую определяют выгоды для бизнеса и возможности решения социальных проблем государствами разных стран. К основным задачам относятся:
- Регрессия. Предоставляет прогноз на основе выборки объектов с различными признаками.По итогам анализа данных на выходе получается число или числовой вектор. Например, таким образом работает кредитный скоринг — оценка кредитоспособности потенциального заёмщика.
- Классификация. Выявляет категории объектов на основе имеющихся параметров. Продолжает традиции машинного зрения, поэтому часто можно встретить термин «распознавание образов»: например, идентификация разыскиваемых людей по фото или на основании словесного описания внешности.
- Кластеризация. Разделяет данные на схожие категории по объединяющему признаку. Например, космические объекты кластеризируют по удаленности, размерам, типам и другим признакам.
- Идентификация. Отделяет данные с заданными параметрами от остального массива данных. К примеру, участвует в постановке медицинского диагноза по набору симптомов.
- Прогнозирование. Работает с объемами данных за определенный период и предсказывает на основе анализа их значение через заданный период времени. Примером может служить прогноз погоды.
- Извлечение знаний. Исследует зависимости между рядом показателей одного и того же явления или события. Например, находит закономерности во взаимодействии биржевых показателей.
Как видим, спектр задач машинного обучения широк, что подтверждает его перспективность в использовании как коммерческими предприятиями, так и в социальных проектах.
Как это работает: типы машинного обучения
Для простоты восприятия типы машинного обучения принято разделять на три категории:
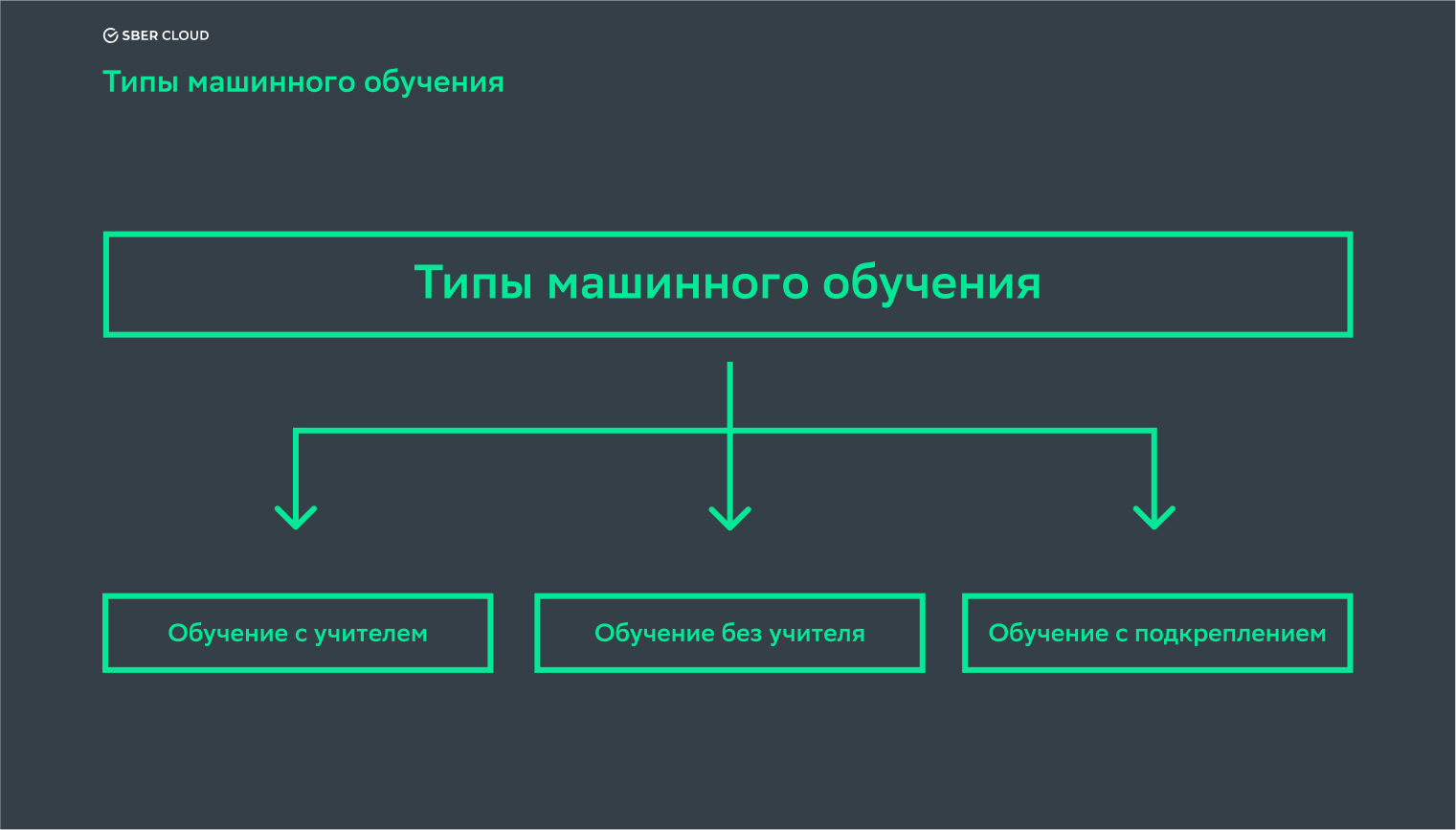
- обучение с учителем (supervised learning);
- обучение без учителя (unsupervised learning);
- обучение с подкреплением (reinforcement learning).
Обучение с учителем
Этот тип максимально похож на процесс познания окружающего мира ребенком, только в роли малыша выступает алгоритм. Данные, подготовленные для анализа, изначально содержат правильный ответ, поэтому цель алгоритма — не ответить, а понять, «Почему именно так?» путем выявления взаимосвязей. Результатом становится способность выстраивать корректные прогнозы и модели.
Обучение без учителя
Для данного типа обучения ключевым понятием является паттерн — обрабатывая значительные массивы данных, алгоритм должен сперва самостоятельно выявлять закономерности. На следующем этапе на основе выявленных закономерностей машина интерпретирует и систематизирует данные.
Обучение с подкреплением
Принципы обучения с подкреплением заимствованы из психологических экспериментов: машина пытается найти оптимальные действия, которые будет предпринимать, находясь в наборе различных сценариев. Эти действия могут иметь как краткосрочные, так и долгосрочные последствия, а от алгоритма требуется обнаружить эти связи.
Инструменты machine learning
Инструменты машинного обучения используют на следующих этапах:
- сбор и подготовка данных;
- построение модели;
- обучение и развертывание приложений.
Для выполнения каждого из этих этапов применяются специализированные платформы. Они различаются по языку программирования (Python, Cython, C, C++, CUDA, Java), операционным системам (Linux, Mac OS, Windows) и тому, какие задачи можно решить с их помощью.
Сегодня на рынке представлено несколько десятков программных инструментов:
- TensorFlow;
- Shogun;
- Keras.io;
- Rapid Miner;
- Google Cloud ML Engine;
- Amazon Machine Learning (AML);
- Accord.NET;
- Apache Mahout;
- Microsoft Azure ML;
- SberCloud ML Space
Практическое применение ML-технологий
Машинное обучение уже применяется во всех сферах деятельности человека. Еще в 2017 году под управлением Стэнфордского университета был запущен новый индекс AI100 для отслеживания динамики в сфере ИИ. Согласно данным, полученным университетом, количество стартапов с 2000 по 2018 год выросло в 14 раз. Рассмотрим, в каких областях нас ждут технологические прорывы благодаря ML.
Робототехника
В будущем роботы станут самообучаться ранее поставленным перед ними задачам. К примеру, смогут работать над добычей полезных ископаемых — нефти, газа и других. Они смогут, например, изучать морские глубины, тушить пожары. Программисты могут самостоятельно не писать массивные и сложные программы, опасаясь допустить ошибку в коде. ИИ повлияет и на повышение качества частной жизни человека: у нас уже есть беспилотные автомобили, роботы-пылесосы, трекеры сна, физической активности и здоровья и прочие продукты интернета поведения.
Маркетинг
Самый наглядный пример использования машинного обучения в маркетинге — поисковые системы Google и Яндекс, которые с его помощью контролируют релевантность рекламных объявлений.Социальные сети FaceBook, ВКонтакте, Instagram и другие применяют собственные аналитические машины для исследования интересов пользователей и совершенствования персонализации новостной ленты.Маркетинговые исследования, предваряющие разработку и релиз продуктов компании, станут проще с точки зрения реализации, а итоговые данные будут более точными. Выделение кластеров в группах со схожими параметрами превратит кастомизированные предложения в реальность — можно будет решать задачи не групп потребителей, а каждого в отдельности.
Безопасность
Современную сферу обеспечения безопасности невозможно представить без машинного обучения. Системы распознавания лиц в метро и использование камер, сканирующих лица и номера машин при движении по автодорогам, стали неотъемлемой частью человеческой жизни и незаменимыми помощниками для полиции в поиске преступников и потерявшихся людей.
Финансовый сектор и страхование
Более точные биржевые прогнозы и оценка капитализации брендов, решения о выдаче кредитных продуктов частным лицам и предприятиям, определение стоимости и целесообразности страховки и даже снижение очередей в офисах при параллельном сокращении издержек на персонал — только часть возможностей, которые станут доступны в этой сфере.
Общественное питание
На основе Big Data разрабатываются специальные предложения для гостей с учетом загрузки посадочных мест в ресторанах и кафе, функционируют сервисы по планированию закупок для поваров.
Примечание
Воронежская пивоварня Brewlok и разработчики из NewShift решили использовать возможности Big Data для разработки рецепта идеального пива. На протяжении месяца они собирали отзывы и выделяли критерии оценки вкуса, аромата и цвета. На основе полученных данных из почти двух с половиной тысяч отзывов аналитики сформулировали описание «идеального пива», которое легло в основу рецепта.
Медицина
В медицинских учреждениях машинное обучение позволяет быстро обрабатывать данные пациента, производить предварительную диагностику и подобрать индивидуальное лечение, опираясь на сведения о заболеваниях пациента из базы данных. ML также позволяет автоматически выделять группы риска при появлении новых штаммов вирусных заболеваний.
Добыча полезных ископаемых
Анализ почвы доказывает или опровергает наличие полезных ископаемых, помогает очертить площадь будущей разработки.
Примечание
Серьезным препятствием для повсеместного использования технологий машинного обучения был недостаток у значительного количества компаний финансовых ресурсов и инфраструктуры. Специалисты SberCloud разработал ML Space — платформу для ML-разработки полного цикла и совместной работы Data Science-команд над созданием и развертыванием моделей машинного обучения. Сервис предоставляет уникальную возможность эффективного внедрения машинного обучения в бизнес-процессы.
Резюме
Технологии машинного обучения уже стали частью повседневной жизни, при этом количество стартапов и продуктов на основе машинного обучения активно растет. Будучи причиной технологических революций в некоторых сферах экономики, ML способно быть драйвером в масштабах бизнеса и государств. Сегодня самое время задуматься об интеграции машинного обучения в бизнес-процессы, чтобы не утратить конкурентоспособность.
Технологии искусственного интеллекта и машинного обучения уже определяют экономический успех предприятий. По данным консалтинговой компании Gartner порядка 50% процессов в сфере обработки и анализа данных будут автоматизированы с помощью ИИ к 2025 году, что снизит острую нехватку высококвалифицированных специалистов. Компания SberCloud следует самым современным трендам. ИИ является неотъемлемой частью разработки наших продуктов и услуг. SberCloud располагает достаточными материальными ресурсами: это и самый мощный в России суперкомпьютер “Кристофари”, облачная инфраструктура и платформа ML Space. Платформа позволяет ускорить, оптимизировать и упростить процесс обучения моделей, препроцессинга данных и развертывания моделей на высокопроизводительной инфраструктуре с целью последующего обращения к этим моделям для распознавания или прогнозирования по новым данным. Сегодня ML Space — это единственная в мире облачная платформа, позволяющая обучать модели более чем на 1000 графических процессоров (GPU) Мария Рябенко Старший технический писатель направления AI Cloud
Источники
- Информационно-аналитический ресурс по машинному обучению
- Wikipedia.org
- Machine learning and learning theory research
Запросите бесплатную консультацию по вашему проекту