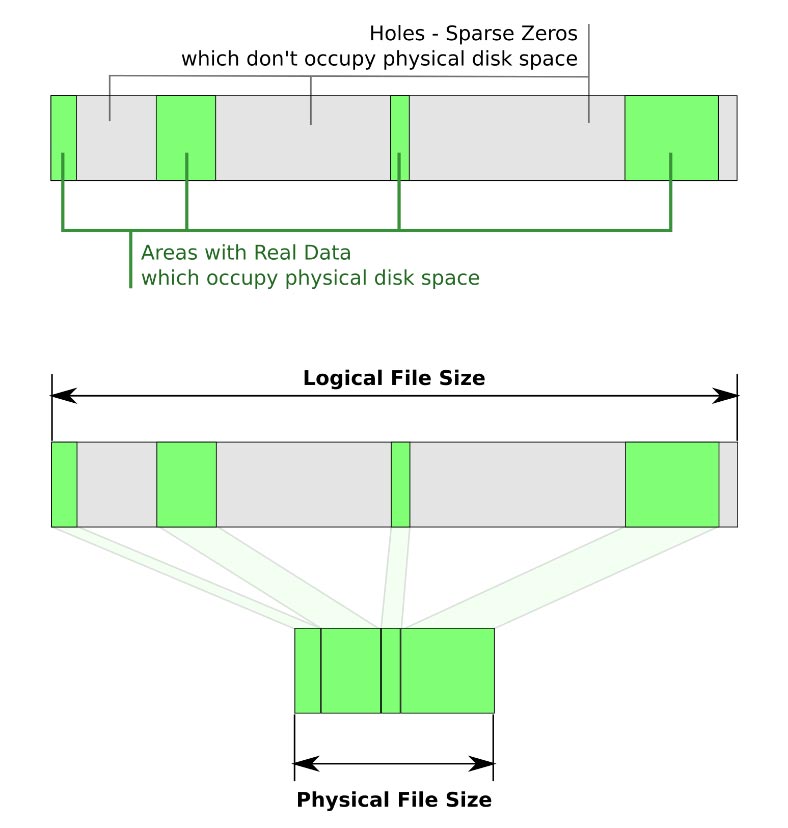
Sparse file
According to Wikipedia, in computer science, a sparse file is a type of computer file that attempts to use file system space more efficiently when blocks allocated to a file are mostly empty. This is achieved by writing brief information (metadata) representing the empty blocks to disk instead of the actual «empty» space which makes up the block, using less disk space. The full block size is written to disk as the actual size only when the block contains «real» (non-empty) data.
When reading sparse files, the file system transparently converts metadata representing empty blocks into «real» blocks filled with zero bytes at runtime. The application is unaware of this conversion.
Most modern file systems support sparse files, including most Unix variants and NTFS, but notably not Apple’s HFS+. Sparse files are commonly used for disk images (not to be confused with sparse images), database snapshots, log files and in scientific applications.
The advantage of sparse files is that storage is only allocated when actually needed: disk space is saved, and large files can be created even if there is insufficient free space on the file system.
Disadvantages are that sparse files may become fragmented; file system free space reports may be misleading; filling up file systems containing sparse files can have unexpected effects; and copying a sparse file with a program that does not explicitly support them may copy the entire file, including the empty blocks which are not on explicitly stored on the disk, which wastes the benefits of the sparse property of a file.
Creating sparse files
The truncate utility can create sparse files. This command creates a 512 MiB sparse file:
$ truncate -s 512M file.img
The dd utility can also be used, for example:
$ dd if=/dev/zero of=file.img bs=1 count=0 seek=512M
Sparse files have different apparent file sizes (the maximum size to which they may expand) and actual file sizes (how much space is allocated for data on disk). To check a file’s apparent size, just run:
$ du -h --apparent-size file.img
512M file.img
and, to check the actual size of a file on disk:
$ du -h file.img
0 file.img
As you can see, although the apparent size of the file is 512 MiB, its «actual» size is really zero—that’s because due to the nature and beauty of sparse files, it will «expand» arbitrarily to minimize the space required to store its contents.
Making existing files sparse
The fallocate utility can make existing files sparse on supported file systems:
$ fallocate -d copy.img $ du -h copy.img 0 copy.img
Making existing files non-sparse
The following command creates a non-sparse copy of a (sparse) file:
$ cp file.img copy.img --sparse=never $ du -h copy.img 512M copy.img
Creating a filesystem in a sparse file
This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.
Reason: Sparse files do not have to contain a file system, the purpose should be explained. (Discuss in Talk:Sparse file)
Now that we have created a sparse file, it is time to format it with a filesystem; for example ReiserFS:
$ mkfs.reiserfs -f -q file.img
We can now check its size to see how a filesystem has affected it:
$ du -h --apparent-size file.img
512M file.img
$ du -h file.img
33M file.img
As you may have expected, formatting it with a filesystem has increased its actual size, but left its apparent size the same. Now we can create a directory which we will use to mount our file:
# mount --mkdir -o loop file.img mountpoint
Tada! We now have both a file and a folder into which we may store almost 512 MiB worth of information!
Mounting a file at boot
To mount a sparse image automatically at boot, add an entry to your fstab:
/path/to/file.img /path/to/mountpoint reiserfs loop,defaults 0 0
Note: Be sure to include the loop option, otherwise it will not mount.
Detecting sparse files
Since sparse files occupy less blocks than the apparent file size would require, they can be detected by comparing the two sizes. This is not a bulletproof method if the filesystem uses compression, extended attributes take up the difference in space, file is internally fragmented, has indirect blocks, and similar. Still, the standard way to check is:
$ ls -ls sparse-file.bin
If a file size is greater than the allocated size in the first column a file is sparse. The same can be achieved with du by comparing:
$ du sparse-file.bin $ du --apparent-size sparse-file.bin
A step further is to print sparsiness value with find:
$ find sparse-file.bin -printf '%S\t%p\n'
A sparse file has a sparsiness value of less than one whereas normal files have exactly one or just slightly above. The above command can be easily extended to list sparse files in a desired path:
$ find path/ -type f -printf '%S\t%p\n' | gawk '$1 < 1.0 ' | cut -f '2-'
Copying a sparse file
Copying with cp
Normally, cp is good at detecting whether a file is sparse, so it suffices to run:
$ cp file.img new_file.img
Then new_file.img will be sparse. However, cp does have a --sparse=when option. This is especially useful if a sparse file has somehow become non sparse (i.e. the empty blocks have been written out to disk in full). Disk space can be recovered by:
$ cp --sparse=always new_file.img recovered_file.img
Archiving with tar
This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.
Reason: Informal writing, see Help:Style#Language register. (Discuss in Talk:Sparse file)
One day, you may decide to back up your well-loved sparse file, and choose the tar utility for that very purpose; however, you soon realize you have a problem:
$ du -h file.img
33M file.img
$ tar -cf file.tar file.img
$ du -h file.tar
513M file.tar
Apparently, even though the current size of the sparse file is only 33 MB, archiving it with tar created an archive of the ENTIRE SIZE OF THE FILE! Luckily for you, though, tar has a `--sparse' (`-S') flag, that when used in conjunction with the `--create' (`-c') operation, tests all files for sparseness while archiving. If tar finds a file to be sparse, it uses a sparse representation of the file in the archive. This is useful when archiving files, such as dbm files, likely to contain many nulls, and dramatically decreases the amount of space needed to store such an archive.
$ tar -Scf file.tar file.img
$ du -h file.tar
12K file.tar
Resizing a sparse file
This article or section needs language, wiki syntax or style improvements. See Help:Style for reference.
Reason: Dependence on #Creating a filesystem in a sparse file is not apparent, not every sparse file contains a file system. Also too informal writing, see Help:Style#Language register. (Discuss in Talk:Sparse file)
Before we resize a sparse file, let us populate it with a couple small files for testing purposes:
$ for f in ; do touch folder/file$; done
$ ls folder/ file1 file2 file3 file4 file5
Now, let us add some content to one of the files:
$ echo "This is a test to see if it works. " >> folder/file1
$ cat folder/file1 This is a test to see if it works.
Growing a file
Should you ever need to grow a file, you may do the following:
# umount folder # dd if=/dev/zero of=file.img bs=1 count=0 seek=1G 0+0 records in 0+0 records out 0 bytes (0 B) copied, 2.2978e-05 s, 0.0 kB/s
This will increase its size to 1 Gb, and leave its information intact. Next, we need to increase the size of its filesystem:
# resize_reiserfs file.img resize_reiserfs 3.6.21 (2009 www.namesys.com) ReiserFS report: blocksize 4096 block count 262144 (131072) free blocks 253925 (122857) bitmap block count 8 (4) Syncing..done resize_reiserfs: Resizing finished successfully.
# mount -o loop file.img folder
Checking its size gives us:
# du -h --apparent-size file.img 1.0G file.img # du -h file.img 33M file.img
. and to check for consistency:
# df -h folder Filesystem Size Used Avail Use% Mounted on /tmp/file.img 1.0G 33M 992M 4% /tmp/folder
# ls folder file1 file2 file3 file4 file5 # cat folder/file1 This is a test to see if it works.
Tools
- sparse-fio — dd-like program to work with files that are sparsely filled with non-zero data
- sparseutils — utilities to work with sparsely-populated files, provides mksparse.py and sparsemap.py , can be installed with pip
Sources
- wikipedia:Sparse_file
- https://web.archive.org/web/20121026035748/http://www.apl.jhu.edu/Misc/Unix-info/tar/tar_85.html
Retrieved from "https://wiki.archlinux.org/index.php?title=Sparse_file&oldid=752459"
Разреженные файлы
Файл, в котором большая часть данных равна нулям, содержит разреженный набор данных. Такие файлы обычно очень большие, например, файл, содержащий данные изображения для обработки, или матрица в высокоскоростной базе данных. Проблема с файлами, содержащими разреженные наборы данных, заключается в том, что большая часть файла не содержит полезных данных, и из-за этого они являются неэффективным использованием дискового пространства.
Сжатие файлов в файловой системе NTFS является частичным решением проблемы. Все данные в файле, которые не записаны явным образом, равны нулю. Сжатие файлов сжимает эти диапазоны нулей. Однако недостаток сжатия файлов заключается в том, что время доступа может увеличиться из-за сжатия и распаковки данных.
Поддержка разреженных файлов реализована в файловой системе NTFS в качестве еще одного способа повышения эффективности использования дискового пространства. Если функция разреженного файла включена, система не выделяет место на жестком диске для файла, за исключением регионов, где он содержит ненулевое значение. При попытке операции записи, когда большой объем данных в буфере равен нулям, нули не записываются в файл. Вместо этого файловая система создает внутренний список, содержащий расположения нулей в файле, и этот список обращается во время всех операций чтения. При выполнении операции чтения в областях файла, где были обнаружены нули, файловая система возвращает соответствующее количество нулей в буфере, выделенном для операции чтения. Таким образом, обслуживание разреженного файла прозрачно для всех процессов, обращаюющихся к нему, и более эффективно, чем сжатие для конкретного сценария.
Значение данных разреженного файла по умолчанию равно нулю; однако для него можно задать другие значения.
Дополнительные сведения о разреженных файлах см. в следующих разделах.
В этом разделе
| Раздел | Описание |
|---|---|
| Операции с разреженным файлом | Определите, поддерживает ли файловая система разреженные файлы, вызвав функцию GetVolumeInformation. |
| Получение размера разреженного файла | Получите выделенный размер или общий размер файла с помощью функции GetCompressedFileSize или GetFileSize . |
| Разреженные файлы и дисковые квоты | Разреженный файл влияет на квоты пользователей по номинальному размеру файла, а не фактическому выделенному объему дискового пространства. |
NTFS Sparse Files (NTFS5 only)
A sparse file has an attribute that causes the I/O subsystem to allocate only meaningful (nonzero) data. Nonzero data is allocated on disk, and non-meaningful data (large strings of data composed of zeros) is not. When a sparse file is read, allocated data is returned as it was stored; non-allocated data is returned, by default, as zeros.
NTFS deallocates sparse data streams and only maintains other data as allocated. When a program accesses a sparse file, the file system yields allocated data as actual data and deallocated data as zeros.
NTFS includes full sparse file support for both compressed and uncompressed files. NTFS handles read operations on sparse files by returning allocated data and sparse data. It is possible to read a sparse file as allocated data and a range of data without retrieving the entire data set, although NTFS returns the entire data set by default.
With the sparse file attribute set, the file system can deallocate data from anywhere in the file and, when an application calls, yield the zero data by range instead of storing and returning the actual data. File system application programming interfaces (APIs) allow for the file to be copied or backed as actual bits and sparse stream ranges. The net result is efficient file system storage and access. Next figure shows how data is stored with and without the sparse file attribute set.
Windows 2000 Data Storage
If you copy or move a sparse file to a FAT or a non-NTFS volume, the file is built to its originally specified size. If the required space is not available, the operation does not complete.
About
LSoft Technologies Inc. is a privately owned North American software company. Our goal is to create world’s leading data recovery, security and backup solutions by providing rock solid performance, innovation, and unparalleled customer service.
Разреженные файлы в Windows, Linux и MacOS, файловых систем NTFS, REFS, Ext3, Ext4, BTRFS и APFS.
В этой статье пойдет речь о разреженных файлах. Расскажем об их недостатках и достоинствах, какие файловые системы поддерживают такие файлы. А также, как создавать или преобразовать их из обычных.

- Разница между сжатием и разреженными файлами
- Преимущества и недостатки
- Создаем разреженный файл в Windows
- Как создать разреженный файл в Linux
- Как увеличить
- Разреженные файлы в ApFS
- Восстановление таких типов данных
- Заключение
- Вопросы и ответы
- Комментарии
Разреженные – это специальные файлы, которые с большей эффективностью используют файловую систему, они не позволяют ФС занимать свободное дисковое пространство носителя, когда разделы не заполнены. То есть, «пустое место» будет задействовано только при необходимости. Пустая информация в виде нулей, будет хранится в блоке метаданных ФС. Поэтому, разреженные файлы изначально занимают меньший объем носителя, чем их реальный объем.
Этот тип поддерживает большинство файловый систем: BTRFS, NILFS, ZFS, NTFS, ext2, ext3, ext4, XFS, JFS, ReiserFS, Reiser4, UFS, Rock Ridge, UDF, ReFS, APFS, F2FS.
Все эти ФС полностью поддерживают такой тип, но в тоже время не предоставляют прямой доступ к их функциям по средством своего стандартного интерфейса. Управлять их свойствами можно только через команды командной строки.
Разница между сжатием и разреженными файлами
Все файловые системы, которые я назвал выше, также поддерживают стандартную функцию сжатия. Оба этих инструмента дают преимущество в виде экономии места на диске, но достигают этой цели по-разному. Основным недостатком использования сжатия является то, что это может снизить производительность системы при выполнении операции чтения\ записи. Так как будут использоваться дополнительные ресурсы для распаковки или сжатия данных. Но некоторые программные продукты не поддерживают сжатие.
Перейти к просмотру

Преимущества и недостатки
Самым большим преимуществом разреженных файлов является то, что пользователь может создавать файлы большого размера, которые занимают очень мало места для хранения. Пространство для хранения выделяется автоматически по мере записи на него данных. Разреженные файлы большого объема создаются за относительно короткое время, поскольку файловой системе не требуется предварительно выделять дисковое пространство для записи нулей.
Преимущества ограничены лишь приложениями, которые их поддерживают. Если у программы нет возможности распознавать или использовать их, то она сохранит их в исходном – несжатом состоянии, что не даст никаких преимуществ. Также с ними нужно быть осторожными, поскольку разреженный файл размером всего несколько мегабайт может внезапно увеличиться до нескольких гигабайт, когда неподдерживаемые приложения скопируют его в место назначения.
Еще один из недостатков — это то, что нельзя скопировать или создать такой файл, если его номинальный размер превышает доступный объем свободного пространства (или ограничения размера квоты, налагаемые на учетные записи пользователей). Например, если исходный размер (со всеми нулевыми байтами) составляет 500 МБ, а для учетной записи пользователя, используемой для его создания, существует предел квоты в 400 МБ. Это приведет к ошибке даже если фактическое дисковое пространство, занимаемое им, составляет всего 50 МБ на диске.
Что касается накопителей, на которых хранятся такие данные, то они также подвержены фрагментации, поскольку файловая система будет записывать данные в разреженные файлы по мере необходимости. Со временем это может привести к снижению производительности. Кроме того, некоторые утилиты для управления дисками могут неточно отображать объем доступного свободного места. Когда файловая система почти заполнена, это может привести к неожиданным результатам. Например, могут возникать ошибки «переполнения диска», когда данные копируются поверх существующей части, которая была помечена как разреженная.
Создаем разреженный файл в Windows
Для этого в ОС Windows будем использовать командную строку. В поиске пишем cmd и запускаем ее от имени администратора.
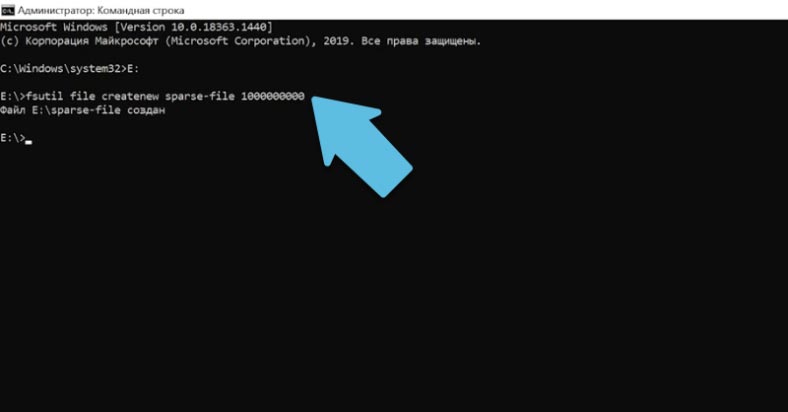
В Windows для управления такими данными используют программу fsutil (утилита файловой системы). При выполнении create, по умолчанию файл создается самый обычный. Переходим в папку где нужно его создать и вводим:
fsutil file createnew sparse-file 1000000000 Копировать
Где sparse-file – имя, а в конце указан его размер в байтах.
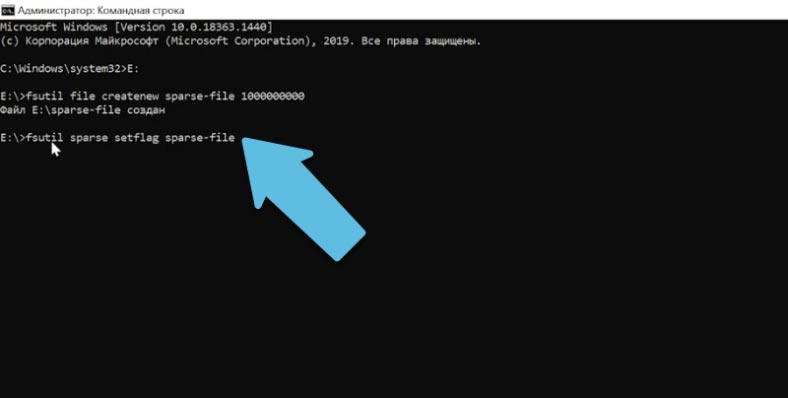
Чтобы присвоить файлу значение «разреженный» вводим:
fsutil sparse setflag sparse-file Копировать
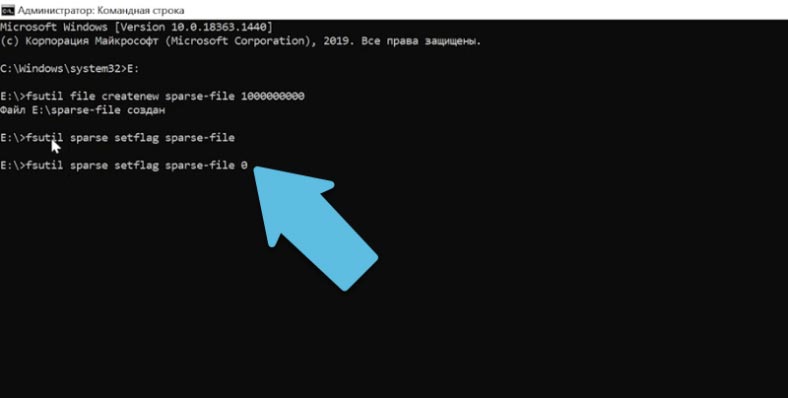
Для удаления этого флага выполняется следующая команда:
fsutil sparse setflag sparse-file 0 Копировать
И чтобы снова присвоить атрибут:
fsutil sparse setflag sparse-file Копировать
fsutil sparse queryflag sparse-file Копировать
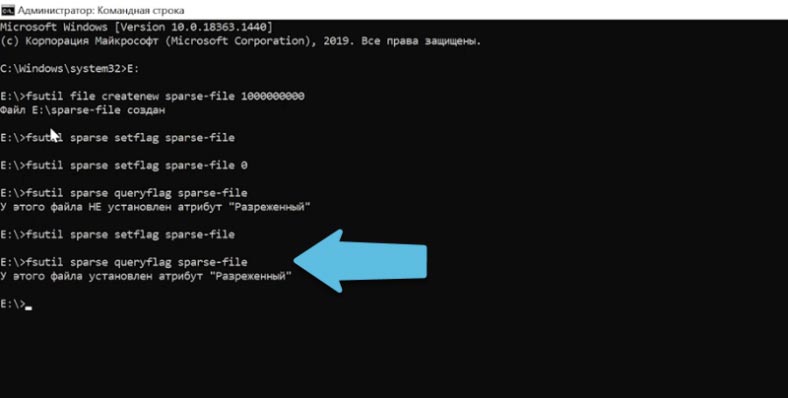
Сам по себе атрибут ещё не приводит к экономии дискового пространства. Для этого нужно разметить пустую область, которая будет освобождена внутри.
Для пометки пустой области введите:
fsutil sparse setrange sparse-file 0 1000000000 Копировать
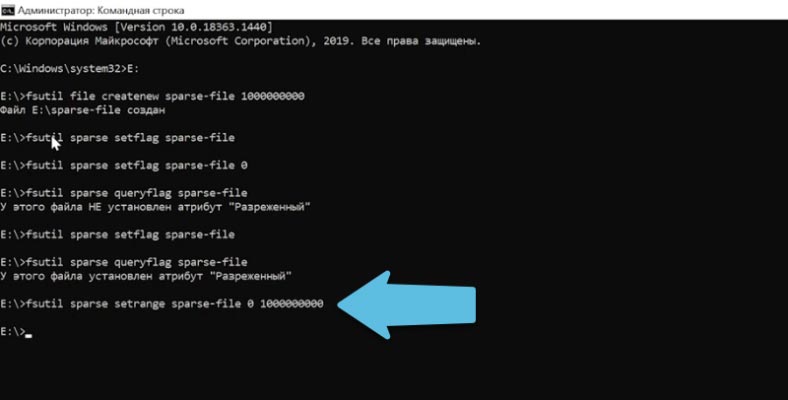
В конце указывается смещение и длина, они задаются в байтах. В моем случае от нуля до 1Гб.
Для установки полностью разреженного файла указываем полный объем. Если нужно можно расширить файл указав здесь большее значение.
Для того чтобы убедиться, что файлу присвоен данный атрибут выполним layout
fsutil file layout sparse-file Копировать
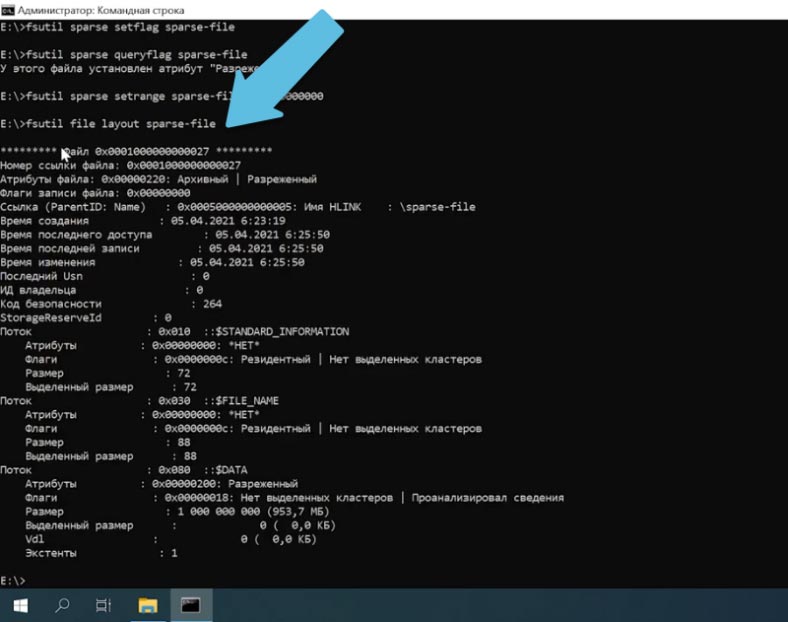
Такой Атрибут можно задать любому файлу. Просто выполнив эту команду с его именем и задать нужный вам размер.
В свойствах созданного ранее файла можно увидеть, что при размере в 1Гб. файл занимает на диске 0 байт.
Данный набор команд подходит для всех файловых систем Windows, которые поддерживают данный тип данных (NTFS, ReFS и т.д.).
Как создать разреженный файл в Linux
В Linux процесс создания таких типов данных немного проще, поскольку существует несколько команд для их создания. Этот набор подойдет для всех файловых систем Linux.
Здесь можно использовать команду dd, либо truncate.
Первая команда имеет следующий вид:
dd if=/dev/zero of=file-sparse bs=1 count=0 seek=2G Копировать
Где file-sparse – имя, и в конце указан его размер, можно задать в байтах, мегабайтах и т.д.
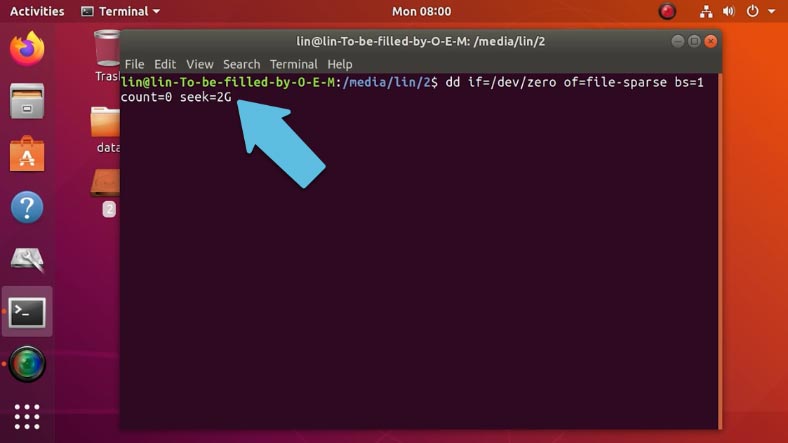
Вторая команда проще, она имеет такой вид:
truncate -s2G file-sparse Копировать
Где значение s – указывает размер, после которого идет имя.
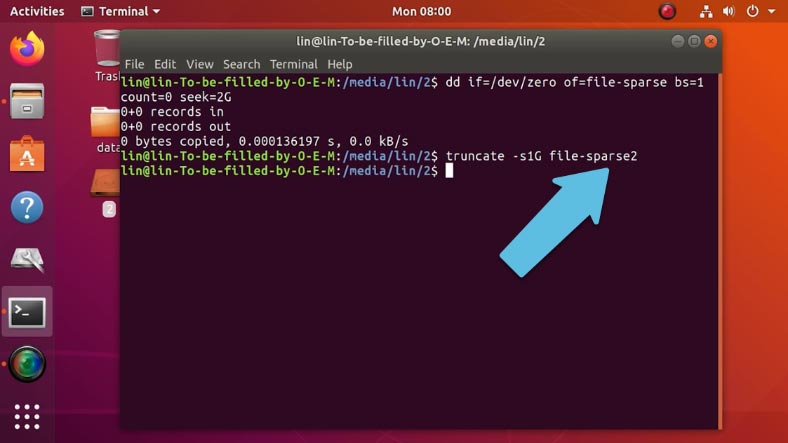
По сравнению с Windows, в Linux при создании такого файла одной из команд, он будет «разреженным» по умолчанию.
Для преобразования обычного в разреженный, есть отдельная команда:
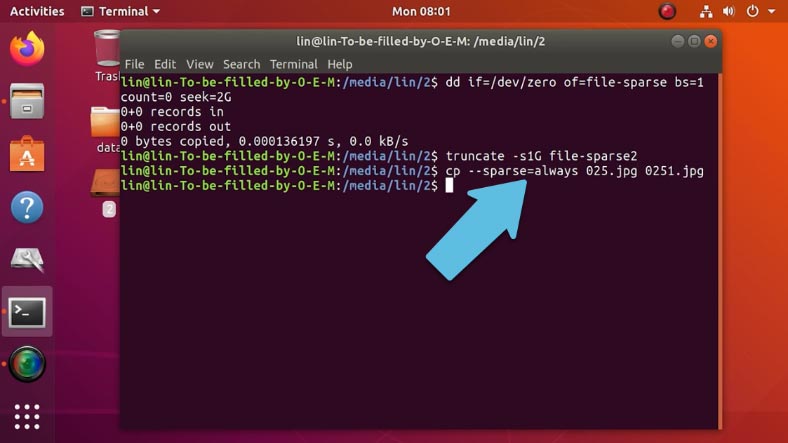
cp --sparse=always ./025.jpg ./0251.jpg Копировать
Где 025.jpg – первое имя обычного.
0251.jpg – и второе имя разреженного.
Как увеличить
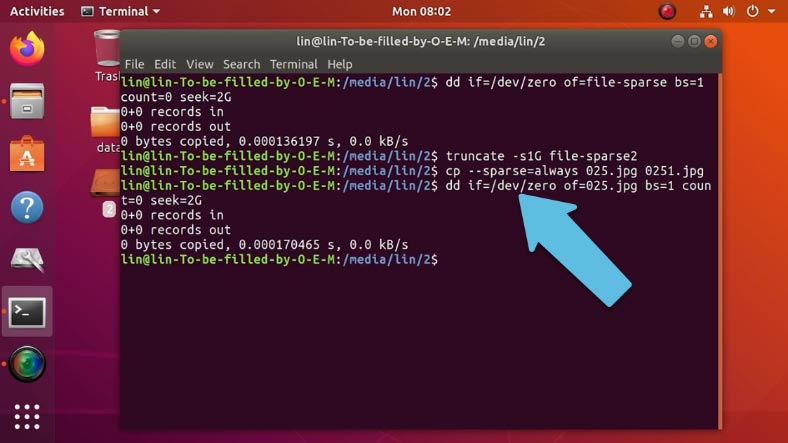
Если вам нужно увеличить уже существующий файл воспользуйтесь первой командой, здесь замените имя и укажите нужный размер.
dd if=/dev/zero of=025.jpg bs=1 count=0 seek=2G Копировать
Это увеличит его размер до 2 Гб.
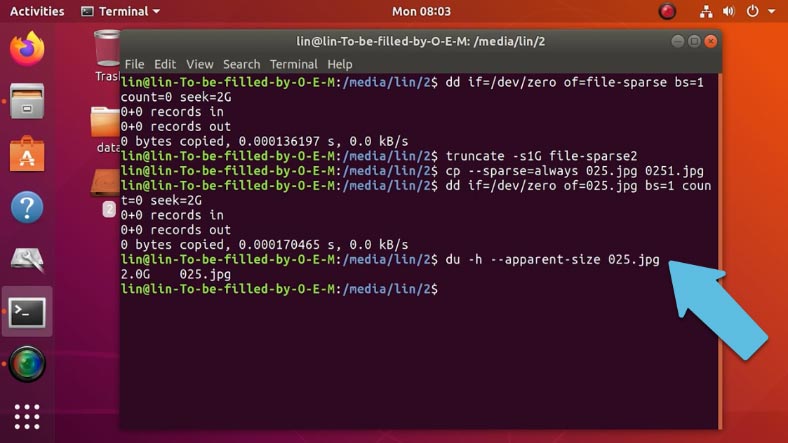
Для проверки размера выполним такую команду:
du -h --apparent-size 025.jpg Копировать
Разреженные файлы в ApFS
По сути, данный набор команд подходит и для файловой системы apple – ApFS, так как Linux и MacOS используют в своей основе архитектуру ядра Unix, они обе предоставляют доступ к Unix-командам и оболочке Bash.
Запустите терминал и выполните любую из команд, которую я использовал в Linux.
В MacOS Catalina работает только первая команда, и размер нужно указывать в байтах, иначе в результате команда выведет ошибку.
sudo dd if=/dev/zero of=sparse_APFS bs=1 count=0 seek=1000000000 Копировать
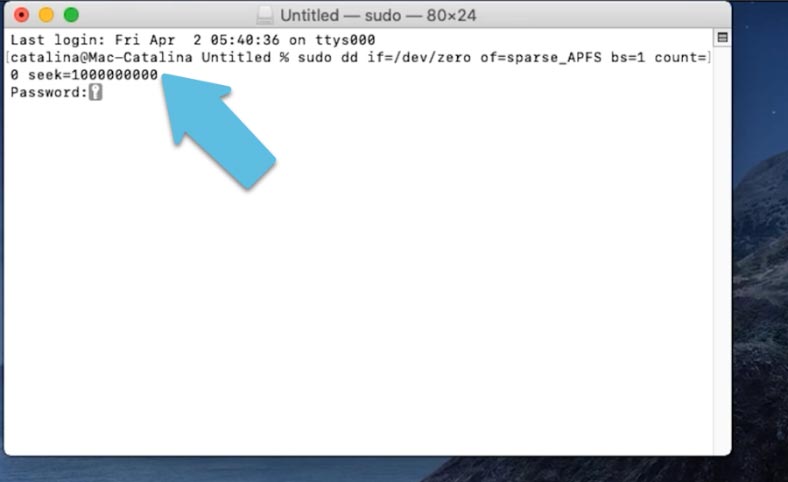
Файловая система ApFS при соблюдении определенных условий создает разреженные файлы по умолчанию, поэтому для увеличения любого файла можно использовать команду:
dd if=/dev/zero of=187.jpg bs=1 count=0 seek=500000000 Копировать
Зададим размер, к примеру, 500Мб, в MacOS размер нужно указывать в байтах.
В свойствах можно увидеть, что его размер увеличился до 500 Mb.
Восстановление таких типов данных
Если вы случайно удалили или отформатировали диск с важными данными, и они оказались разреженными? То, для их восстановления воспользуйтесь программой Hetman Partition или RAID Recovery. Наша программа поддерживает данный тип файлов во всех представленных в этом видео операционных и файловых системах. Скачайте установите и запустите программу, просканируйте носитель.
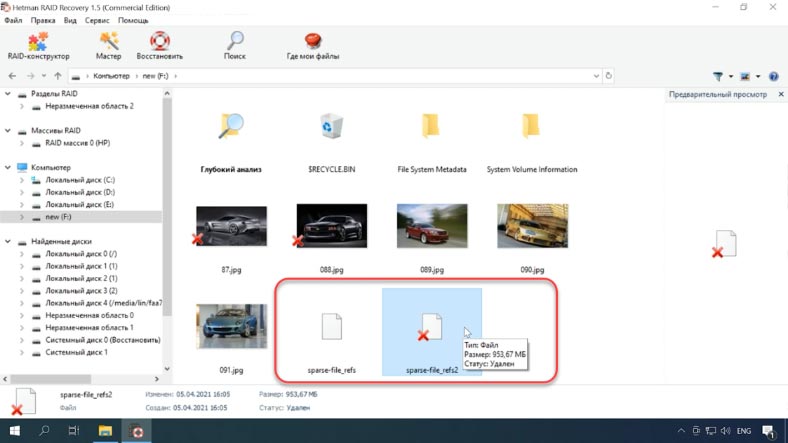
Как видите программа без труда находит существующие и удаленные разреженные файлы и отображает их содержимое. Открыв файл в HEX-редакторе можно убедиться, что он полностью заполнен нулями.
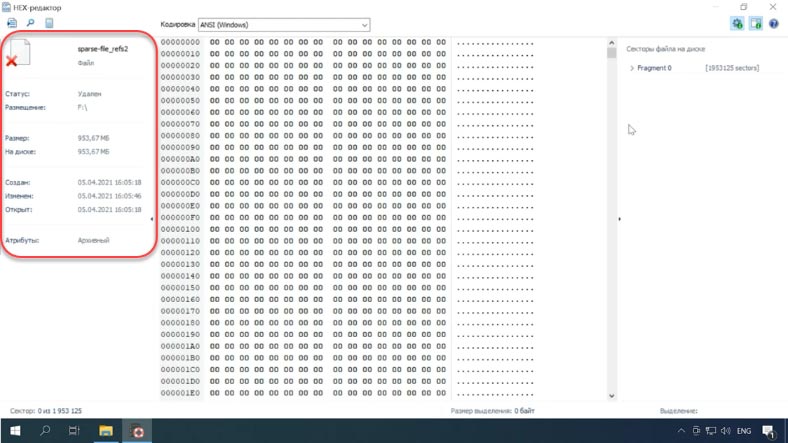
Программа нашла ранее удаленные данные на диске с файловой системой NTFS, REFS, BtrFS, Ext3, Ext4 и ApFS. Осталось лишь нажать кнопку Восстановить.
Восстановление данных с поврежденных RAID-массивов, недоступных для компьютера.
По завершению процесса все нужные данные будут лежать в указанной папке. Смотрим свойства, файлы восстановлены в полном объёме.
Заключение
Перед использованием этого функционала в любых ОС вам крайне важно узнать все их преимущества и недостатки. Знание этих особенностей гарантировано позволит вам избежать потенциальных проблем в будущем.

Автор: Dmytriy Zhura, Технический писатель
Дмитрий Жура – автор и один из IT-инженеров компании Hetman Software. Имеет почти 10 летний опыт работы в IT-сфере: администрирование и настройка серверов, установка операционных систем и различного программного обеспечения, настройка сети, информационная безопасность, внедрения и консультация по использованию специализированного ПО. Является экспертом в области восстановления данных, файловых систем, устройств хранения данных и RAID массивов.

Редактор: Andrey Mareev, Технический писатель
В далеком 2005 году, я получил диплом по специальности «Прикладная математика» в Восточноукраинском национальном университете. А уже в 2006 году, я создал свой первый проект по восстановлению данных. С 2012 года, начал работать в компании «Hetman Software», отвечая за раскрутку сайта, продвижение программного обеспечения компании, и как специалист по работе с клиентами.
- Обновлено:
- 3.11.2023 10:47
- Метки:
- APFS файловая система
- Ext3 файловая система
- Ext4 файловая система
- Файловая система NTFS