NVIDIA . Архитектура Turing.
В августе 2018 года NVIDIA представила новую графическую архитектуру Turing и первые три продукта, которые будут её использовать. NVIDIA вначале представила профессиональные ускорители Quadro для рабочих станций. Представители нового семейства Quadro RTX — 8000, 6000 и 5000 — это самые быстрые видеокарты NVIDIA для рабочих станций, и они должны были выйти на рынок в последнем квартале этого года.
Архитектура Turing представляет собой эволюцию Volta, которая взяла всё, что сделало чип GV100 столь быстрым, и развила эти новшества. Для пользователей, занимающихся профессиональной визуализацией (ProViz), главная новость заключалась в том, что карты поддерживают аппаратное ускорение трассировки лучей благодаря сочетанию новых ядер NVIDIA RT и тензорных ядер из Volta. Связку этих вычислительных блоков можно использовать для ускорения трассировки лучей, а затем задействовать дополнительные уловки постобработки, чтобы сократить объём работы, необходимой для создания фотореалистичного изображения.
Новые графические процессоры и основанные на них карты Quadro также были первыми продуктами NVIDIA, которые получили видеопамять стандарта GDDR6 (до 48 Гбайт, т. е. вдвое больше, чем в Quadro P6000) и одновременно значительно увеличили полосу пропускания. NVIDIA также включила поддержку собственной технологии межсетевого когерентного соединения NVLink, который позволит устанавливать карты Quadro RTX парами и обмениваться буферной памятью кадров. NVLink не так хорош, как локальная видеопамять, но с пропускной способностью в 100 Гбайт/с между двумя картами в несколько раз превосходит показатели интерфейса PCIe 3.0.
Новые решения NVIDIA очень сильно нацелены на отрасль визуальных эффектов (например, производство фильмов и телесериалов), так как последние являются одними из самых требовательных заказчиков с точки зрения производительности и обладают крупными финансами. Конечно, NVIDIA никогда не была чужда этому рынку, но с появлением аппаратного ускорения трассировки лучей её продукты становятся ещё более востребованными в области CG.
NVIDIA активно трудится, чтобы предоставить потенциальным клиентам и готовое ПО, умеющее задействовать преимущества её новых GPU и технологии RTX. Хотя речь шла только о первых шагах в этой области, компания уже тогда заручилась поддержкой таких влиятельных компаний, как Autodesk, Adobe, Chaos Group, Dassault Systèmes и, конечно же, Epic Games (среди прочих), чтобы поддержать технологию аппаратной трассировки лучей в том или ином виде.
В начале состоялся анонс трёх карт. Флагманские Quadro RTX 8000 и RTX 6000 почти не отличались друг от друга: обе обеспечивают одинаковую мощность и пропускную способность памяти благодаря комбинации 4608 ядер CUDA, 576 тензорных ядер и памяти GDDR6. Разница между ними заключалась в том, что RTX 8000 оснащается 48 Гбайт памяти (24 чипа GDDR6 14 Гбит/с, 384-бит шина), в то время как RTX 6000 наделена 24 Гбайт. Максимальная производительность в вычислениях с плавающей запятой была заявлена на уровне 16 терафлопс (видимо, 32 терафлопс для операций половинной точности) и 10 миллиардов лучей в секунду в режиме трассировки.
Вместе с этими монстрами NVIDIA предложила также более дешёвый ускоритель Quadro RTX 5000, наделённый 3702 ядрами CUDA, 384 тензорными ядрами и 16 Гбайт памяти GDDR6 (14 Гбит/с, 256-бит шина). Теоретическая производительность решения в вычислениях с плавающей запятой не сообщалась, но карта была способна обрабатывать до 6 миллиардов лучей в секунду в режиме трассировки.
NVIDIA сообщила, что на всех картах имеется 4 выхода DisplayPort 1.4 и разъём формата USB-C с поддержкой VirtualLink. Недавно введённый стандарт VirtualLink позволял по одному кабелю переносить всё видео, данные и питание, необходимые для шлемов виртуальной реальности и подключать гарнитуры напрямую к видеокарте, чтобы минимизировать задержки и избавиться от лишних шнуров. В то время не было совместимых с VirtualLink шлемов, но Oculus, Valve и Microsoft заявили о поддержке стандарта, так что это было лишь вопросом времени.
Энергопотребление ускорителей семейства Quadro RTX планировалось менее 250 Вт. Новые карты Quadro RTX вышли в последнем квартале этого года, а цены были весьма высокими: $2300 за RTX 5000, $6300 за RTX 6000 и, наконец, впечатляющие $10000 за флагманский ускоритель RTX 8000.
По словам производителей, архитектура Turing стала самым большим прорывом со времен изобретения GPU CUDA в 2006 году. Архитектура Turing оснащена специальными процессорами для трассировки лучей, которые называются RT-ядра. Они ускоряют расчеты движения света и звука в 3D-среде до 10 GigaRays в секунду. Как отмечает NVIDIA, Turing ускоряет трассировку лучей до 25 раз по сравнению с предыдущим поколением Pascal, а GPU-ноды справляются с финальным рендерингом при наложении эффектов в фильмах в 30 раз быстрее, чем ноды на базе GPU.
Архитектура Turing также располагает тензорными ядрами — процессорами, которые ускоряют обучение глубоких сетей и инференс, обеспечивая до 500 трлн тензорных операций в секунду. Turing впервые получила новые RT-ядра для ускорения трассировки лучей и новые тензорные ядра для инференса, что позволяет производить трассировку лучей в реальном времени.
Инференс – это та задача, для выполнения которой необходимы обученные нейронные сети. Так как новые данные поступают в систему в виде изображений, речи, поисковых запросов по изображениям, именно инференс позволяет находить ответы и давать рекомендации, что лежит в основе большинства сервисов искусственного интеллекта. Сервер, оснащенный одним Tesla GPU, обеспечивает в 27 раз более высокую производительность в задачах инференса по сравнению с сервером на основе CPU, что приводит к значительному снижению затрат на инфраструктуру дата-центра.
Ключевой особенностью новинок, как подсказывает название, является высокая производительность при трассировке лучей в реальном времени, обеспечиваемая за счёт специализированных RT-ядер. По оценкам самой компании, с данной задачей адаптеры на новой архитектуре справляются в 25 раз лучше, нежели их предшественники из семейства Pascal.
NVIDIA представила свои первые продукты на базе архитектуры Turing. Ими стали видеокарты NVIDIA Quadro RTX 8000, Quadro RTX 6000 и Quadro RTX 5000, предназначенные для дизайнеров и художников в разных областях промышленности.
Все три описанные выше профессиональные видеокарты имели двухслотовое исполнение и охлаждаются силами воздушного кулера с одним центробежным вентилятором. На торце карт помимо четырёх видеовыходов DisplayPort 1.4 также присутствует один USB Type-C, к которому можно будет подключать новые VR-гарнитуры, совместимые с VirtualLink. Видеокарты Quadro на базе Turing появились на рынке по цене 10 000, 6 300 и 2 300 долларов, соответственно.
Технология и архитектура NVIDIA Turing GeForce RTX
Архитектура Turing – это самый главный секрет компании NVIDIA, если они действительно работают над ней 15 лет. Эта архитектура несет в себе, возможно, самую значительную инновацию в области 3D-графики в режиме реального времени с момента появления (почти десять лет назад) программируемых шейдеров. Рейтрейсинг в режиме реального времени для 3D-графики действительно стал заветной целью, ибо он требует практически предельных вычислительных затрат. С новым семейством видеокарт GeForce RTX можно будет сделать вид, что рейтрейсинг уже в руках геймеров. Мы здесь говорим «сделать вид», поскольку в NVIDIA применили ряд хитроумных решений, в результате чего новые видеокарты позволяют получить в режиме реального времени 3D-изображения, очень похожие на те, которые получаются при рендеринге с рейтрейсингом, занимающим многие часы.
Примерно год назад мы впервые услышали кодовое наименование «Turing,» но не придали этому должного значения, потому что чип NVIDIA мог разрабатываться с корыстной целью настричь купонов на волне растущей популярности майнинга – и вот для этого они назвали архитектуру в честь математика, который спас миллионы жизней, расшифровав фашистский код «Enigma» и тем самым ускорив конец Второй мировой войны. Мы и не знали, что в NVIDIA присвоили новой архитектуре имя Алана Тьюринга (Alan Turing) не столько за его достижения в области криптографии, сколько за его всемирную известность как теоретика искусственного интеллекта (ИИ) и основателя теоретической информатики.

На протяжении пяти с лишним лет NVIDIA вкладывала в ИИ большие средства, разрабатывая первые модели глубокого обучения нейросетей, в которых основной упор был сделан на технологию CUDA и мощные графические процессоры NVIDIA. Первые попытки построения и обучения нейросетей показали, что эта задача требует очень больших временных затрат даже со стороны самых мощных GPU и, следовательно, необходимо применить компоненты, ускоряющие тензорные вычисления. Для этого в NVIDIA разработали первые компоненты с закрепленной функцией тензорных вычислений, которые назвали просто «Tensor Cores» – ядра Tensor. Это крупные специализированные компоненты, осуществляющие операции перемножения трехмерных матриц размером 3x3x3. Ядра Tensor были впервые применены в архитектуре «Volta», которая, как мы тогда думали, могла бы естественным образом прийти на смену архитектуре «Pascal». Однако в NVIDIA решили, что самое время представить свежеиспеченную технологию RTX.
В графической архитектуре Turing представлена третья, заключительная составляющая амбициозного проекта NVIDIA по разработке пользовательского аппаратного обеспечения, реализующего метод рейтрейсинга, – ядра RT. Ядра RT представляют собой специализированные компоненты, которые выполняют ту же функцию, что и ядра CUDA в NVIDIA Optix – предтече RTX. Вы вводите математическое представление луча, который пересекает сцену; при этом вычисляются координаты точки пересечения луча с любой треугольной областью в пределах сцены.
NVIDIA RTX – это универсальная гибкая модель рейтрейсинга для пользовательской графики, работающая в режиме реального времени. Она направлена на минимизацию набора инструментов, используемых в современном графическом 3D-программировании, и оптимизацию кривой обучения специалистов. В результате она должна оказать на реалистичность изображений столь же значительное влияние, как и антиалиазинг, программируемые шейдеры и тесселяция (все эти методы в свое время послужили отправными пунктами для стремительного роста вычислительной мощности графических процессоров). Технология RTX построена на основе ядер Tensor и архитектуры Turing, в которой ядра последнего поколения CUDA работают совместно с новым компонентом – ядром RT.
NVIDIA впервые представила технологию RTX в серии профессиональных видеокарт Quadro RTX, на конференции SIGGRAPH-2018 – не только потому, что это событие предшествует Gamescom, но и потому, что на нем новые технологии демонстрируются в первую очередь разработчикам контента. Серия GeForce RTX – это первое за десять лет семейство игровых видеокарт NVIDIA, у которых в наименовании отсутствует суффикс «GTX», и это просто говорит о том, насколько большое значение придается успеху технологии RTX.
Очень скоро, когда NVIDIA снимет свое эмбарго c обзоров характеристик этих новых видеокарт, мы предложим вашему вниманию обзор результатов производительности видеокарт Turing в ряде игр.
Архитектура Turing и особенности новых видеокарт GeForce RTX
Жизненный срок видеокарт семейства Pascal оказался довольно долгим. Старшие модели продержались на рынке более двух лет и еще будут присутствовать некоторое время в продаже. В течение этого периода мы увидели новые решения на архитектуре Volta, которые остались уделом специализированных ускорителей вычислений. Единственным игровым продуктом семейства Volta стал TITAN V, выпущенный небольшим тиражом при чрезвычайно высокой цене. Но теперь настал момент старта нового поколения, которое должно изменить все. Новые видеокарты на архитектуре Turing не просто привносят очередное повышение производительности, они несут в себе ряд технологических инноваций и являются первыми игровыми решениями, которые поддерживают трассировку лучей в реальном времени. Поэтому даже привычное название GeForce GTX было изменено на GeForce RTX. В данном обзоре мы поговорим об особенностях архитектуры Turing и технических параметрах новых GPU. Практическому знакомству с видеокартами, включая тестирование и сравнение со старыми моделями NVIDIA, будут посвящены следующие обзоры.

Видеокарты GeForce RTX
В семействе Turing можно выделить несколько ключевых изменений. Это абсолютно новая архитектура GPU, появление новых вычислительных блоков — тензорных и RT ядер, ускоренная обработка шейдеров.

На данный момент представлено три видеокарты — GeForce RTX 2080 Ti, GeForce RTX 2080 и GeForce RTX 2070. Все они базируются на разных GPU Turing. Топовая модель получила самый мощный процессор TU102, кристалл которого изображен ниже на слайде.

Вначале приведем блок-схему каждого нового GPU, опишем общие характеристики видеокарт, а потом детально рассмотрим архитектурные изменения. Все процессоры производятся по технологии 12-нм FinFET. Они сохраняют кластерную структуру, когда GPU состоит из нескольких GPC, и, меняя количество таких кластеров, масштабируется производительность каждого конкретного чипа.
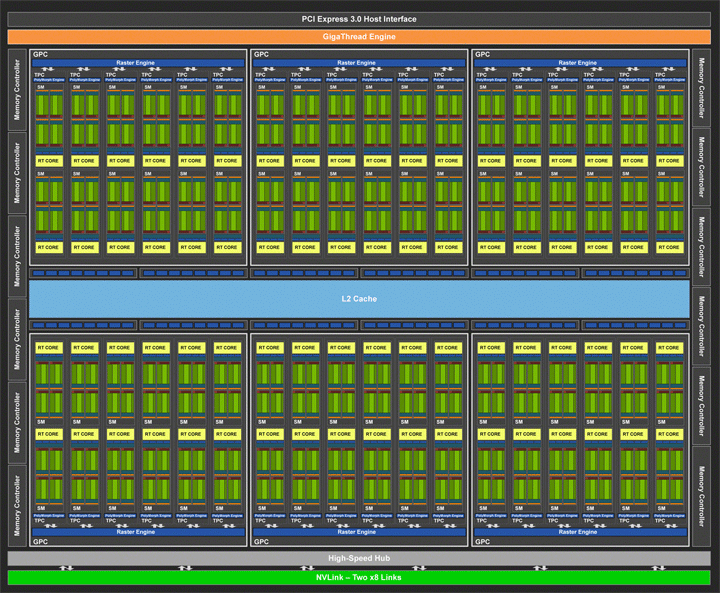
TU102 (GeForce RTX 2080 Ti)
Старший графический процессор TU102 состоит из 18,6 миллиардов транзисторов при площади кристалла 754 кв.мм. Если сравнить его с GP102 (GeForce GTX 1080 Ti), то площадь нового чипа и количество транзисторов выросло на 55–60%. У TU102 всего шесть кластеров GPC, каждый содержит по шесть текстурно-процессорных кластеров TPC, объединяющих мультипроцессорные блоки SM. Последние заметно реорганизованы и включают новые блоки, о чем подробнее будет сказано ниже. Каждый SM-блок насчитывает 64 основных вычислительных блока (CUDA-cores). При 72 SM всего получается 4608 потоковых процессоров. Однако GPU GeForce RTX 2080 Ti (как в свое время и у GeForce GTX 1080 Ti) немного урезан. У топовой видеокарты отключены два SM, в итоге общее количество потоковых процессоров равно 4352. Также у данного решения имеется 544 новых тензорных ядра и 68 RT-ядер, 272 текстурных блока и 88 блоков растеризации ROP.
Для сравнения можно напомнить, что GeForce GTX 1080 Ti на базе GP102 оперировал только 3584 ядрами CUDA при 224 текстурных блоках. Так что наращивание потенциала у нового TU102 весьма значительное. Шина памяти осталась 352-битной, но используются новые микросхемы памяти GDDR6 с эффективной частотой обмена данными, эквивалентной значению 14 ГГц. Объем памяти 11 ГБ на уровне старого флагмана, и это вполне достаточно для современных игр в высоких разрешениях.
Судя по блок-схеме у процессора TU102 всего 12 контроллеров памяти разрядностью 32 бита. Поэтому чип может работать с 384-битным интерфейсом. Возможно, мы увидим такую шину вместе с 4608 потоковыми процессорами в новых Titan. Кэш L2 у GeForce RTX 2080 Ti достигает 5632 КБ. Очевидно, что полный объем L2 равен 6 МБ, но он немного порезан вместе с шиной.
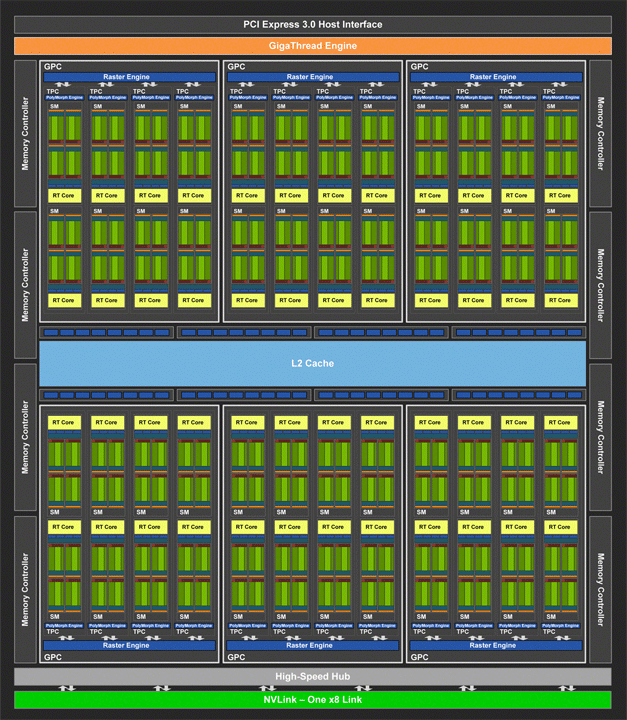
TU104 (GeForce RTX 2080)
Следующий в иерархии процессор TU104 имеет конфигурацию из шести кластеров GPC по четыре TPC. В прошлом поколении Pascal сохранялась идентичность внутренней структуры кластеров для решений среднего и топового уровня, лишь в бюджетных GPU уменьшалось количество TPC. Вероятно, такая конфигурация TU104 является оптимальной для сохранения некоего баланса производительности и гибкого управления ресурсами — число кластеров на уровне топового GPU, но они слабее. При этом задействовано 46 SM-блоков из 48, что дает 2944 активных вычислительных ядер CUDA, 368 тензорных ядер, 46 ядер RT и 184 текстурных блока. Объем кэш-памяти L2 равен 4 МБ, что вдвое выше объема L2 у GP102 (GeForce GTX 1080).
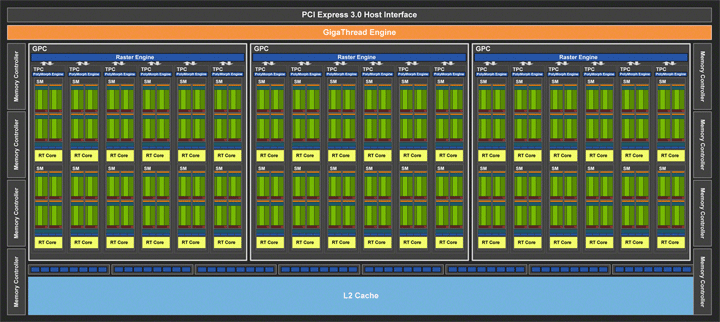
TU106 (GeForce RTX 2070)
Неожиданностью стала премьера третьего чипа для GeForce RTX 2070. По аналогии с прошлыми поколениями можно было ожидать простого урезания блоков на процессоре старшей видеокарты. Но основой GeForce RTX 2070 стал GPU TU106 с тремя стандартными кластерами по шесть TPC. Общее количество потоковых процессоров 2034, тензорных блоков 288, блоков RT 36, текстурных блоков 144. При прямом сравнении GeForce RTX 2070 с GeForce RTX 2080 получается разница 28% по вычислительным блокам. Кэш-память L2 осталась на уровне 4 МБ.
TU104 и TU106 обладают 256-битной шиной памяти (8 контроллеров разрядностью 32 бит). При этом видеокарты используют память GDDR6 с эффективной частотой 14 ГГц, что обеспечивает рост пропускной способности памяти относительно прошлого поколения.
Как видим, общая конфигурация вычислительных блоков даже у младшего GPU достаточно мощная, не говоря уже о топовом TU102. А ведь в них еще появились и новые функциональные блоки. Поэтому чипы Turing являются сложными и довольно крупными кристаллами. TU102 состоит из 18,6 млрд. транзисторов, TU104 из 13,6 млрд., а TU106 насчитывает 10,8 млрд. транзисторов. В итоге даже при переходе на 12-нм техпроцесс мы не видим роста рабочих частот. Если говорить, о GeForce RTX 2080 Ti, то тут вообще заявлено базовое значение в 1350 МГц при Boost Clock до 1635 МГц. Для младших GPU рабочие частоты выше, но они примерно на уровне моделей Pascal.
С частотами связан один интересный момент. Впервые NVIDIA вводит разные Boost-частоты при одинаковых базовых значениях. В официальных спецификациям мы видим более высокие значения Boost для моделей Founders Edition производства самой NVIDIA. При этом остальные карты тоже обозначены как Reference, что вводит в заблуждение, поскольку именно референсные версии мы привыкли ассоциировать с Founders Edition. У нас была возможность быстро сравнить видеокарту от NVIDIA с моделью другого производителя, и в реальности разница по частотам минимальная. Так что не стоит бояться разных характеристик. При наличии хорошего охлаждения производительность всех GeForce RTX одной серии будет схожей. Хуже остальных могут оказаться те редкие модели с кулером турбинного типа, которые анонсировали некоторые партнеры.
| Видеоадаптер | GeForce RTX 2080 Ti | GeForce RTX 2080 | GeForce RTX 2070 |
|---|---|---|---|
| Ядро | TU102 | TU104 | TU106 |
| Количество транзисторов, млн. шт | 18600 | 13600 | 10800 |
| Техпроцесс, нм | 12 | 12 | 12 |
| Площадь ядра, кв. мм | 754 | 545 | 445 |
| Количество потоковых процессоров CUDA | 4352 | 2944 | 2304 |
| Количество тензорных ядер | 544 | 368 | 288 |
| Количество ядер RT | 68 | 46 | 36 |
| Количество текстурных блоков | 272 | 184 | 144 |
| Количество блоков рендеринга | 88 | 64 | 64 |
| Частота ядра Base, МГц | 1350 | 1515 | 1410 |
| Частота ядра Boost, МГц (Reference) | 1545 | 1710 | 1620 |
| Частота ядра Boost, МГц (Founders Edition) | 1635 | 1800 | 1710 |
| Шина памяти, бит | 352 | 256 | 256 |
| Тип памяти | GDDR6 | GDDR6 | GDDR6 |
| Частота памяти, МГц | 14000 | 14000 | 14000 |
| Объём памяти, ГБ | 11 | 8 | 8 |
| Поддерживаемая версия DirectX | 12 | 12 | 12 |
| Интерфейс | PCI-E 3.0 | PCI-E 3.0 | PCI-E 3.0 |
| Мощность, Вт | 250/260 | 215/225 | 175/185 |
| Официальная стоимость | MSRP $999 Founders $1199 |
MSRP $699 Founders $799 |
MSRP $499 Founders $599 |
TDP новых видеокарт остался примерно на старом уровне. Так, для GeForce RTX 2080 Ti Founders Edition заявлено 260 Вт и 250 Вт для партнерских версий. Для GeForce RTX 2080 это 225 и 215 Вт, что выше TDP серии GeForce GTX 1080, но в целом приемлемо для топовых продуктов.
После общего обзора новых GPU поговорим непосредственно об инновациях архитектуры Turing.
Особенности архитектуры Turing
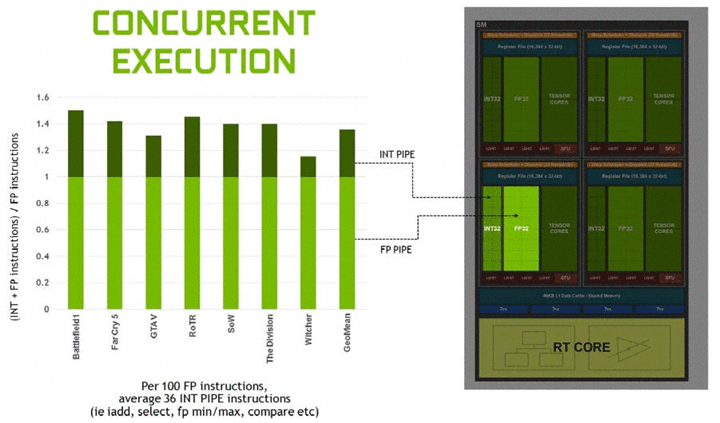
Важные изменения произошли на уровне мультипроцессорных блоков SM, которые имеют стандартную структуру во всех вариантах GPU Turing. Новая архитектура наследует возможности вычислительной архитектуры Volta и игровой архитектуры Pascal. Все вычислительные блоки внутри SM сгруппированы в четыре массива обработки данных со своей управляющей логикой (данные регистров, планировщик). В одном SM насчитывается 64 потоковых процессора. И эти вычислительные блоки теперь умеют одновременно выполнять целочисленные операции (INT32) и операции с плавающей запятой (FP32). Кстати, на схеме SM они обозначены, как разные функциональные блоки. Интересно, что у Pascal было по 128 ядер CUDA в SM, но расчеты формата INT и FP производились в последовательном порядке.
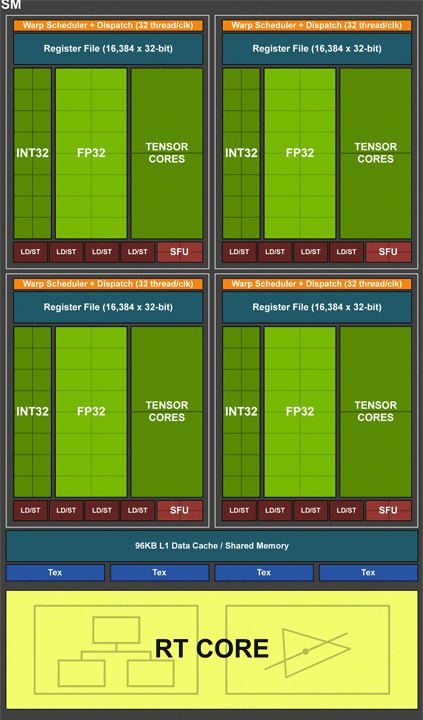
Согласно данным NVIDIA в современных приложениях при выполнении игровых шейдеров целочисленные вычисления занимают до 36%. И выполнение операций двух типов в один поток значительно ускорит общие вычисления. Тут заодно можно сказать о некоем дисбалансе, поскольку полное дублирование INT32 и FP32 не нужно. Но такая структура может быть актуальной для неигровых вычислений и задач.
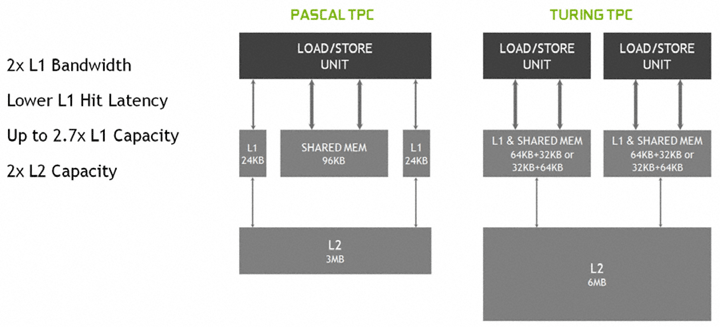
Обновленная унифицированная структура кэша L1 позволяет конвейеру TPC эффективнее работать с ним. При сохранении общего объема кэша L1 на уровне 96 КБ меньше латентность, а общая пропускная способность может вырасти до двух раз. Также во всех процессорах увеличен объем общего кэша L2. К примеру, в GPU TU102 это 6 МБ вместо 3 МБ у старого GP102.
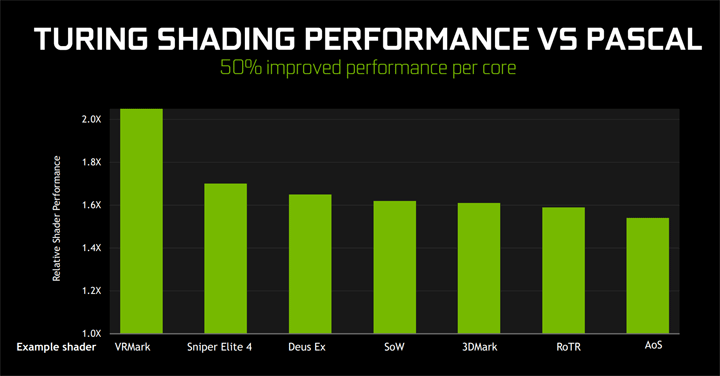
Появились и абсолютно новые блоки. Это восемь тензорных ядер для математических операций машинного обучения и один блок RT (Ray-tracing) для расчетов трассировки лучей. Но даже без учета новых блоков и новых возможностей рендеринга NVIDIA говорит о среднем росте шейдерной производительности около 50%, что звучит весьма внушительно. В виртуальной реальности VR этот прирост двукратный и даже выше. Это выглядит очень оптимистично, и походу статьи мы раскроем много нюансов, которые дают такой комплексный эффект.
В очередной раз улучшены алгоритмы сжатия данных в буфере кадра, что уменьшает количество обращений к внешней памяти. В сочетании с чипами GDDR6, которые работают при 14 Гбит/с, утверждается о росте эффективной пропускной способности до 50%. Отдельных пользователей насторожило, что GeForce RTX 2080 Ti сохранил объем в 11 ГБ, а GeForce RTX 2080/2070 получили по 8 ГБ памяти, ведь это на уровне существующих моделей Pascal. Однако такого объема сейчас хватает для высоких разрешений, а Turing в теории еще более эффективно работает с памятью.
Чипы Turing получили поддержку новых feature level из Direct 12. Улучшены асинхронные вычисления. Также новая архитектура имеет ряд улучшений для ускоренной обработки шейдеров.
Mesh Shading предлагает новый единый конвейер геометрии, заменяя вершинные, геометрические шейдеры и тесселяцию. Это более гибкий в управлении конвейер с новым типов шейдеров Task Shaders и Mesh Shaders, который позволяет одновременно работать с геометрией группы объектов, уменьшая общее количество draw calls.

Mesh Shading будет эффективен в сценах со множеством объектов и сложной геометрией, позволяя более гибко управлять LOD. На уровне DirectX 12 его можно реализовать через NVAPI. Также поддержку Mesh Shading добавят в OpenGL и Vulkan.

Перспективно выглядит технология Variable Rate Shading (VRS). Этот метод позволяет регулировать качество шейдинга в семплах 4×4 пикселя. Это дает возможности для гибкой оптимизации. Например, на периферии изображение может быть размыто эффектами Motion Blur и высокая точность проработки семплов тут не имеет значения. Это весьма актуально для гоночных игр, где дорога и окружение на периферии кадра часто смазываются.

Три алгоритма используют VRS:
- Content Adaptive Shading — уменьшает скорость шейдинга для зон со слабо изменяющимся цветом;
- Motion Adaptive Shading — вариативное качество для движущихся объектов;
- Foveated Rendering — снижение качества для областей вне зоны фокусировки.

Все это требует внедрения со стороны разработчиков. Однако VRS может реально улучшить производительность. Также это один из факторов, снижающих нагрузку на видеопамять.
Turing поддерживает новую модель Texture Space Shading (TSS). Значения шейдерных данных хранятся в памяти в специальном текстурном пространстве, откуда потом могут повторно вызываться. TSS позволяет использовать такие тексели для временного рендеринга и разных систем координат.
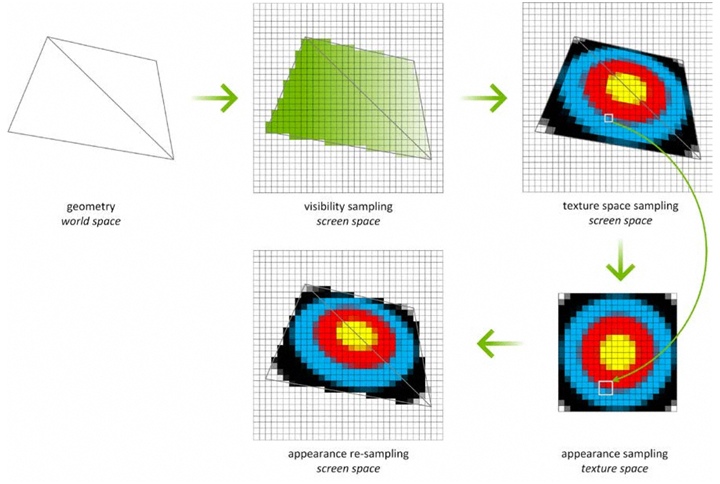
TSS является одним из элементов ускорения обработки VR. Каждый глаз видит похожее изображение. При визуализации кадра правого глаза используются данные из кадра левого глаза, а заново обработаны будут только те текстели, где нет подходящих образцов.

Тензорные ядра Turing являются улучшенными ядрами Volta. Они нужны для выполнения задач с применением искусственного интеллекта. Эти блоки поддерживают расчеты в режимах INT8, INT4 и FP16 при работе с массивами матричных данных для глубокого обучения в реальном времени. Каждое тензорное ядро выполняет до 64 операций с плавающей запятой, используя входные данные формата FP16. То есть один SM с восемью ядрами обрабатывает 512 операций FP16 за такт. Вычисления INT8 проходят на удвоенной скорости 1024 операций, а для INT4 выполняется 2048 операций за такт. И топовый GPU TU102 способен обеспечить пиковую тензорную производительность до 130,5 TFLOPS (Quadro RTX 6000).

Компания NVIDIA давно работает в области искусственного интеллекта. Однако до недавнего времени все технологии на базе обучаемых нейросетей казались уделом каких-то узкоспециализированных областей и больших дата-центров. С появлением Turing ситуация меняется, ведь мы получаем не только аппаратную платформу, но и новые программные возможности. Для интеграции возможностей искусственного интеллекта используется NVIDIA NGX (Neural Graphics Acceleration), позволяя задействовать возможности глубокого обучения для улучшения графики и визуального отображения.

На базе NGX уже реализована технология повышения разрешения изображения AI Super Rez, технология InPainting для восстановления фрагментов фотографий и некоторые другие интересные функции.

Но самым важным является сглаживание Deep Learning Super-Sampling (DLSS). Это развитие Temporal AntiAliasing (TAA) с использованием новых интеллектуальных возможностей Turing. Сейчас TAA является самым распространенным методом сглаживания, который дается с мизерными потерями производительности в несколько процентов. TAA использует данные прошлого кадра для семплов нового. При хорошем результате сглаживания краев этот метод дает определенное смазывание и дрожание картинки, особенно в динамике. DLSS использует специально обученную нейронную сеть для более быстрой и качественной выборки. Новый метод дает четкую картинку при еще меньших затратах производительности.


Сглаживание DLSS выглядит очень перспективно, причем оно легко интегрируется в игры, что упростит его популяризацию. Интересно, что на графиках NVIDIA показан весьма значительный рост fps при активации DLSS. Причина в том, что при DLSS возможны разные методы выборки, и в некоторых режимах речь, по сути, идет о реконструкции финального изображения из меньшего. То есть это действительно может ускорять рендеринг. Также надо понимать, что многие игры сейчас используют технологии адаптивного разрешения со сглаживанием через TAA. Не каждый пользователь в курсе таких тонких настроек. И если ему при автоматической настройке будет выставлен режим DLSS, то он получит заметное улучшение качества картинки при реальном росте быстродействия.
На данный момент известно об интеграции DLSS в движки Unreal Engine и Unity. А список игр, в которые добавят это сглаживание, постоянно растет.

Трассировка лучей
Также технологии нейронных сетей нужны для очистки изображения от шумов при рендеринге с использованием трассировки лучей. И тут мы подбираемся к главной особенности Turing — поддержке трассировки лучей в реальном времени. По сути, мы имеем первое поколение видеокарт, которое поддерживает новый метод рендеринга. Сейчас используется метод растеризации: объекты проецируются на плоскость экрана с последующей обработкой пикселей с учетом расстояния до плоскости проекции и наложения текстур. Поскольку индустрия развивалась много лет, то эффективность современных методов визуализации на актуальных GPU достаточно высокая. Трассировка лучей использует метод построения изображения, приближенный к реальному, имитируя прохождение лучей света в окружающей среде. При трассировке для каждого пикселя строится луч, определяющий его видимость. Далее строятся вторичные лучи от точки пересечения к источнику света для определения освещенности точки.
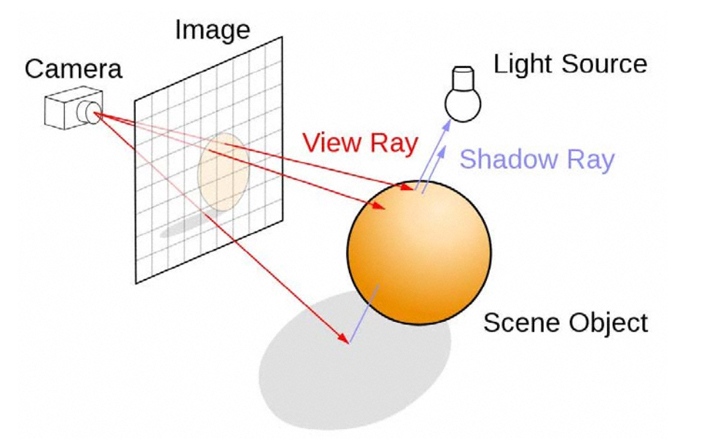
При трассировке можно корректно просчитывать не только освещенность каждой точки, но и взаимное влияние объектов друг на друга с учетом их материалов. При стандартных методах рендеринга мы видим качественную симуляцию, где правильное затенение или какие-то особенности освещения воссоздаются с использованием определенных упрощений, используются заранее подготовленные отражения, карты теней и разные методы симуляции глобального затенения. Трассировка лучей позволяет сделать все это более достоверным, лучше учитывая особенности окружающей среды и материалов объектов. И чем сложнее сцена, тем более очевидны будут преимущества трассировки.

К примеру, с трассировкой можно создавать корректные отражения с учетом всего окружения. При обычных методах лишние объекты вне зоны кадра просто отсекаются. Также лучше учитываются особенности преломленного и отраженного света, который определяется взаимным влияниеем объектов. Проще воссоздавать полупрозрачные объекты. Сейчас это неплохо симулируется, но не всегда картинка выглядит корректно во всех нюансах.
Трассировка позволяет воссоздавать реалистичные тени, учитывая направленность света и его рассеянность. Мы получим более точные контуры тени и реалистичное размытие по мере удаленности от источника освещения. Кстати, похожий эффект работает с технологией мягких теней NVIDIA HFTS.


Ну и ключевым моментом является воссоздание реалистичного объемного освещения и затенения. Многие преимущества рендеринга с использованием трассировки хорошо показаны в нижнем видеоролике.
Главным препятствием по внедрению трассировки были высокие требования к производительности системы, ведь еще недавно для этого требовались мощные графические фермы. С момента разработки этого алгоритма прошли десятки лет. Сейчас трассировка активно используется в киноиндустрии, а с выходом Turing начинается путь по внедрению данной технологии в игровую индустрию. Все понимают, что это первые шаги в данном направлении. Поэтому о полноценной трассировке пока речь не идет. NVIDIA внедряет гибридный метод рендеринга, который позволяет совмещать растеризацию с трассировкой для некоторых эффектов.

И среди новых игр, где уже заявлена поддержка трассировки, мы видим упоминание лишь некоторых эффектов. Так, в Shadow of the Tomb Raider будут реализованы реалистичные тени, в Battlefield V более качественные отражения, а в Metro Exodus реалистичное глобальное затенение.
Проект Atomic Heart обещает сразу несколько эффектов. Тут будет как реалистичное затенение, так и корректные отражения. Обратите внимание на рекурсию отражений в зеркальной поверхности в конце ролика — выглядит действительно круто.
И это лишь первая волна игр и первое поколение ускорителей GeForce RTX, которые могут обрабатывать трассировку в реальном времени.
Подробнее поговорим о технической реализации гибридного рендеринга. Процессоры Turing могут одновременно сочетать работу конвейера растеризации и трассировки. Растеризация быстрее для определения видимости объекта. Вторичные лучи при трассировке могут уже использоваться для создания качественных отражений, теней и прочих эффектов. Разработчики получат возможность регулировать степень покрытия отраженными лучами нужной поверхности. В целом же количество первичных и вторичных лучей зависит от сложности сцены и многих иных параметров.
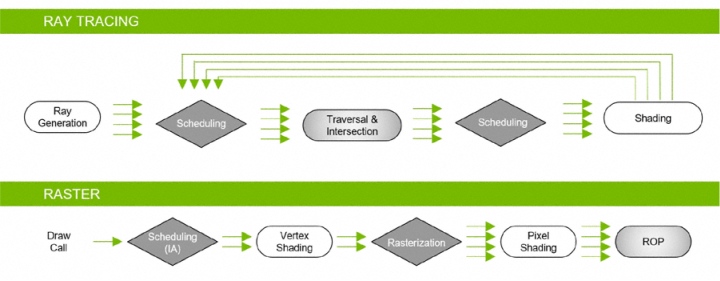
Сама трассировка не является некоей эксклюзивной особенностью NVIDIA. Компания Microsoft уже приняла расширение DirectX Raytracing (DXR) для DirectX 12. API определяет команды на выполнение, не ограничивая аппаратное устройство в методах их исполнения. Технология NVIDIA RTX предлагает сочетание программных алгоритмов и аппаратных возможностей для реализации трассировки. Естественно, что NVIDIA RTX работает в среде DirectX 12, но также NVIDIA работает над стандартизацией и внедрением технологии в Vulkan API. По слухам трассировку в среде Vulkan добавят в Final Fantasy XV: Windows Edition.
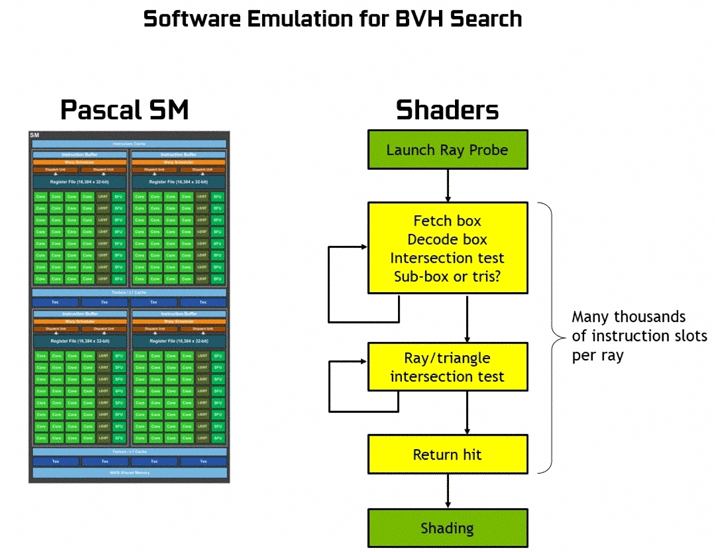
Одним из методов ускорения трассировки является применение алгоритма Bounding Volume Hierarchy (BVH). Он предполагает разбиение сцены на структуру иерархически связанных блоков, в которые входят разные геометрические примитивы. Каждый луч тестируется, проходя по этому дереву, пока не встретит на своем пути примитив. Создание иерархической структуры BVH избавляет от лишних тестов для луча.

Специальные RT-ядра берут на себя аппаратные расчеты по алгоритму BVH. Без этих блоков процессор вынужден выполнять тысячи лишних операций и расчетов.
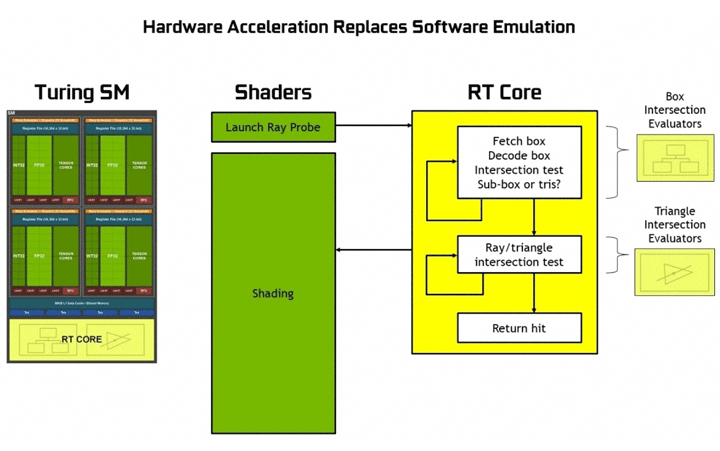
Pascal не имеет таких блоков и его производительность в трассировке значительно ниже. Для GeForce GTX 1080 Ti озвучивается цифра в 1,1 гигалучей в секунду (Giga Rays/s). GeForce RTX 2080 Ti с RT-блоками обрабатывает 10 гигалучей в секунду. Разница огромная.
При использовании трассировки лучей на изображении образуется шум, который убирается специальными фильтрами. У Turing используется аппаратное шумоподавление на основе интеллектуальных алгоритмов с использованием глубокого обучения, обеспечивая работой тензорные блоки.
С переходом к гибридному рендерингу получается разная нагрузка на определенные блоки GPU. Нижняя схема показывает примерное распределение нагрузки для вывода одного кадра. При использовании DLSS около 20% времени кадра нужно для тензорных вычислений, а 80% — для обычного рендеринга с использованием ядер CUDA. При этом трассировка требует примерно половину времени от обработки шейдеров FP32, т.е. ядра RT занимают 40% времени кадра. И еще 28% уходит на операции INT32.
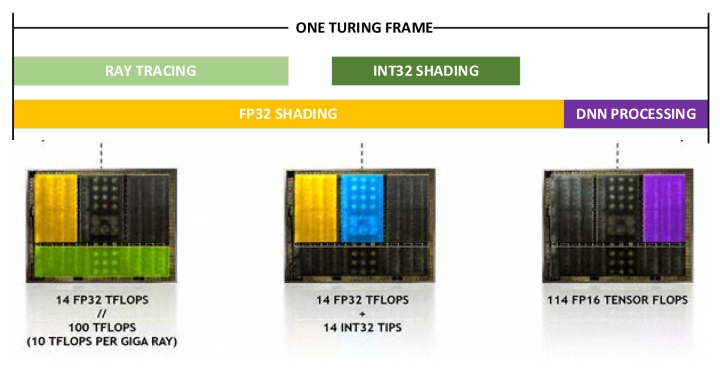
Из этого всего NVIDIA выводит новую метрику измерения комбинированной производительности в гибридном рендеринге:
RTX-OPS = TENSOR * 20% + FP32 * 80% + RTOPS * 40% + INT32 * 28% (Tera-OPS)
Для GeForce RTX 2080 Ti это 76–78 Tera-OPS, для GeForce RTX 2080 это 57–60 Tera-OPS, а для старого флагмана GeForce GTX 1080 Ti лишь 11,3 Tera-OPS.
Для наглядности приведем таблицу, в которой сведены вместе данные по скорости выполнения разных вычислений. Это пиковые показатели, с учетом небольшого различия в частотах Boost Clock.
| GeForce RTX 2080 Ti | GeForce RTX 2080 | GeForce RTX 2070 | GeForce GTX 1080 Ti | |
|---|---|---|---|---|
| RTX-OPS (Tera-OPS) | 76–78 | 57–60 | 42–45 | 11,3 |
| Rays Cast (Giga Rays/s) | 10 | 8 | 6 | 1,1 |
| FP32 TFLOPS | 13,4–14,2 | 10–10,6 | 7,5–7,9 | 16,3 |
| INT32 TIPS | 13,4–14,2 | 10–10,6 | 7,5–7,9 | н/д |
| FP16 TFLOPS | 26,9–28,5 | 20,1–21,2 | 14,9–15,8 | н/д |
| FP16 Tensor TFLOPS совместно с FP16 | 107,6–113,8 | 80,5–84,8 | 59,7–63 | н/д |
| FP16 Tensor TFLOPS совместно с FP32 | 53,8-56,9 | 40,3–42,4 | 29,9–31,5 | н/д |
| INT8 Tensor TOPS | 215,2–227,7 | 161,1–169,6 | 119,4–126 | н/д |
| INT4 Tensor TOPS | 430,3–455,4 | 322,2–339,1 | 238,9–252,1 | н/д |
Виртуальная реальность
Ускорители Turing станут самым быстрым решением для виртуальной реальности VR. Поддерживается технология Multi-View Rendering, которая является развитием Simultaneous Multi-Projection (Pascal). Это метод отрисовки изображения для разных проекций (вплоть до 32) с просчетом геометрии одновременно для нескольких проекций. Новый метод предусматривает возможность большего смещения точек обзора, позволяя работать в VR с большим углом обзора, вплоть до 200 градусов.

Из-за особенностей линз в очках виртуальной реальности на периферии качество изображения ниже, и тут можно снизить качество рендеринга. Для ускорения можно применить Foveated Rendering. Также важную роль в виртуальной среде играет правильное позиционирование звука. Качество объемного звука улучшит технология NVIDIA VRWorks Audio, которая использует метод трассировки для просчета пути звуковой волны. А поскольку теперь есть специальные блоки трассировки, то такие вычисления заметно ускорились.

Среди прочих достоинств новые видеокарты NVIDIA поддерживают VirtualLink USB Type-C для коммутации устройств VR через один интерфейс без лишних проводов.
Блок вывода изображения
Turing получил новый блок вывода изображения с интегрированной поддержкой HDR и более высоких разрешений. Появилась поддержка DisplayPort 1.4a с возможностью передавать картинку 8K при 60 Гц, плюс технология сжатия данных без потерь VESA Display Stream Compression (DSC) 1.2. Turing могут управлять двумя дисплеями 8K при частоте 60 Гц с HDR. Для сохранения оригинальных цветов рекомендуется подключать HDR-мониторы стандарта BT.2100. Всего же у видеокарт три порта DisplayPort. Еще есть один HDMI 2.0b с поддержкой HDCP 2.2.
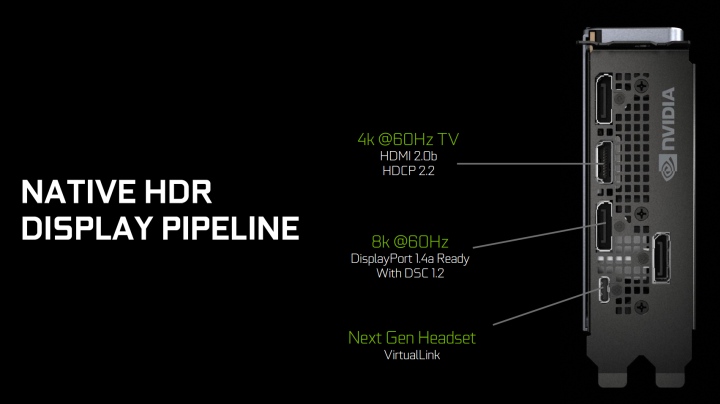
Упомянутый VirtualLink тоже позволяет подключать 8K-мониторы. Физически он выполнен в виде порта USB Type-C. Изначально интерфейс разработан для простого подключения гарнитур VR.
В процессорах Turing улучшен блок кодирования видео NVENC. Появилась поддержка кодирования H.265 8K при 30 кадрах. Заявлена некая экономия битрейта до 25% для HEVC и до 15% для H.264, что, вероятно, стоит понимать, как повышение качества кодирования относительно прошлого поколения видеокарт. При этом аппаратный кодер работает заметно быстрее программного x264, обеспечивая минимальную нагрузку на CPU при стриминге даже в 4K. Кроме качественного стриминга можно ожидать и новые возможности для обычного захвата видео. При наличии аппаратного 8K-кодировщика функция захвата в 8K должна появиться и в Shadowplay, хотя пока она не заявлена.
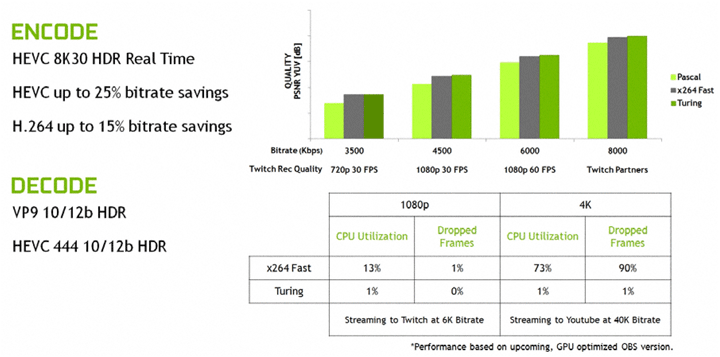
Обновлен и декодер видео для воспроизведения видеоконтента: поддерживается декодирование HEVC YUV444 10/12b HDR с частотой 30 кадров в секунду, H.264 8K и VP9 10/12b HDR.
Технология SLI
В поколении Pascal была улучшена пропускная способность в SLI-режиме благодаря использованию двух разъемов MIO с парой соответствующих мостиков. В новых процессорах Turing TU102 и TU104 используется интерфейс NVLink второго поколения для обмена данными между GPU. В TU102 реализовано две линии x8 второго поколения NVLink, а в TU104 одна линия x8. Двунаправленная пропускная способность одной такой линии составляет 50 Гбайт/с. Благодаря новому интерфейсу SLI поддерживаются новые высокие разрешения. Для GeForce GTX 2080 в SLI доступен режим 8K, 4K Surround 144 Гц или 5K при 75 Гц. GeForce GTX 2080 Ti поддерживает даже 8K Surround.
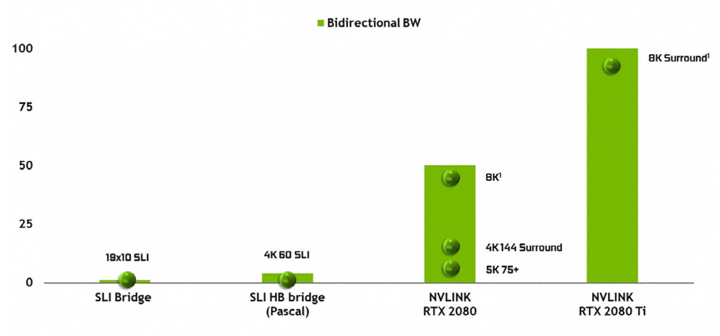
SLI позволяет объединять только две видеокарты. И сам этот режим доступен лишь на GeForce GTX 2080 Ti и GeForce GTX 2080. Стоимость нового мостика SLI на официальном сайте 79 долларов.
Новые возможности GeForce Experience
Появление новых аппаратных возможностей позволило расширить функциональность программного приложения GeForce Experience. В частности, владельцам новых видеокарт будет доступен Ansel RTX.

В новом Ansel можно создавать скриншоты с трассировкой лучей. Причем в режиме паузы качество трассировки будет выше, чем в игре в режиме реального времени.

Технология нейронных сетей позволит делать скриншоты повышенного разрешения с лучшим качеством и проработкой.

Плюс возможность обрабатывать снимки, накладывая разные изображения друг на друга, добавлять стикеры. Будут новые фильтры. Интеграцию Ansel получат многие новые игры, хотя не везде доступны абсолютно все функции. Среди громких релизов осени с Ansel подружатся Battlefield V, Hitman 2, некоторые функции будут в Metro: Exodus.
GPU Boost 4.0 и разгон
В видеоадаптерах NVIDIA давно применяется технология GPU Boost, которая регулирует и повышает частоты ядра. Это ускорение со множеством промежуточных значений, где ключевым является удержать видеокарту в определенных рамках мощности и температур. В очередной раз напомним, что NVIDIA указывает базовое (минимальное) значение частоты и среднее значение Boost Clock. При определенных условиях в игровой нагрузке частоты будут выше заявленного Boost. При хорошем охлаждении так зачастую и происходит. И это отличается от системы обозначений частот у видеокарт AMD, где вплоть до семейства Vega указывалось максимальное значение частоты ядра.
Алгоритм работы GPU Boost постоянно совершенствуется. В прошлом поколении был реализован GPU Boost 3.0, где впервые ппользователь получил возможность настроить кривую частот через через программные настройки специальных утилит. В новом GPU Boost 4.0 пользователю доступно еще больше возможностей для тонкой настройки, где можно контролировать вторую точку целевой температуры и определять время работы при достижении температурных лимитов.

Новые функции настройки Boost с гибким подбором параметров температурной кривой доступны в утилите EVGA Precision X1.
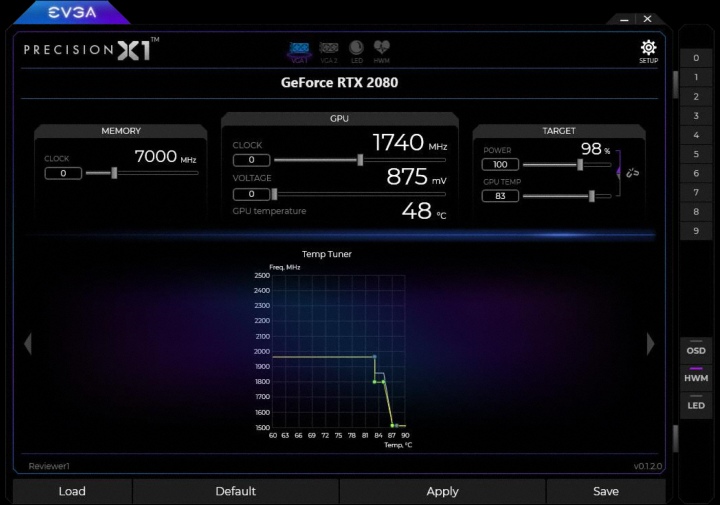
Также в Turing появилась функция автоматического подбора частот для разгона. NVIDIA Scanner запускает специальный тест для проверки на стабильность при постепенном повышении частот. Такое сканирование и тест занимают 20 минут, но довольно точно определяют потолок максимальных частот, избавляя пользователя от лишних тестов. Очень удобно, особенно, для тех, кто слабо разбирается в этой теме. Поддержка NVIDIA Scanner есть в новой версии MSI Afterburner и EVGA Precision X1.
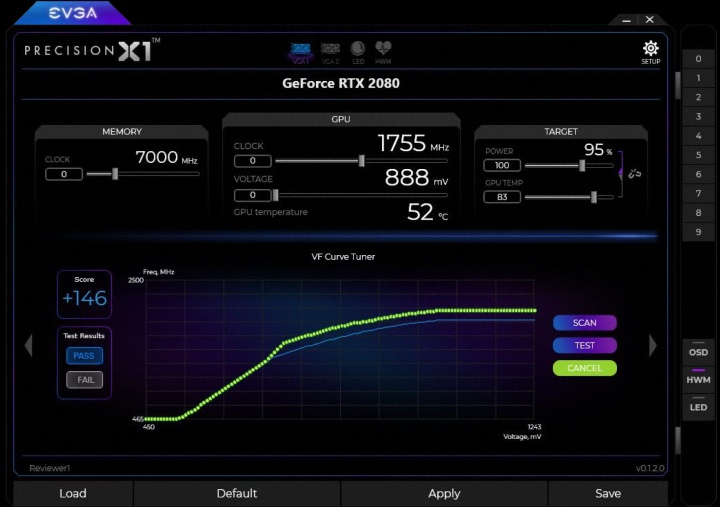
Если производитель дает некие возможности для ускорения видеокарт, то он уверен в качественной реализации питания и дополнительном потенциале охлаждения для таких манипуляций.
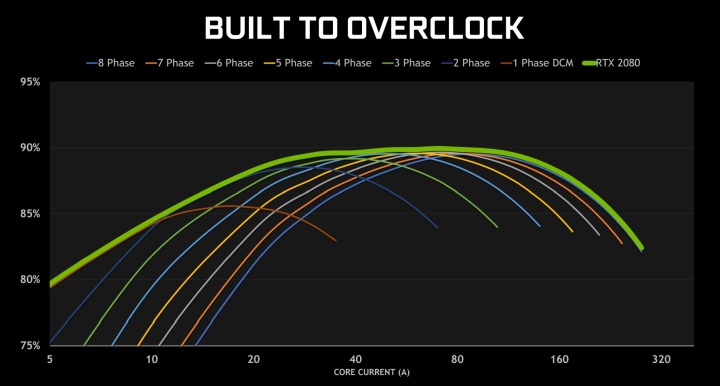
Не случайно установлены столь высокие цены на версии Founders Edition. Если в прошлом поколении это казалось переплатой исключительно за раннюю доступность на рынке и эксклюзивность, то теперь чувствуется серьезный основательный подход. Видеоадаптеры Turing получили новое охлаждение с большим радиатором, испарительной камерой и двумя вентиляторами. Даже по весу чувствуется, что это качественный продукт с мощным охлаждением.

Впервые референсные карты от NVIDIA не требуют компромиссов, а сразу обеспечивают отличные температурно-шумовые характеристики. Плюс изначально прошиты более высокие частоты Boost, и есть все возможности для реализации разгона без замены охлаждения.
Подробнее о конкретных экземплярах GeForce RTX мы поговорим в будущих обзорах.
Выводы
NVIDIA Turing — передовая графическая архитектура, которая расширяет возможности привычного рендеринга, добавляя трассировку лучей в реальном времени и возможность использовать нейронные сети для вспомогательных функций. Новые аппаратные возможности обеспечивают поддержку совершенно новых технологий и графических эффектов. Появление Turing стало знаковым событием, которое обозначает старт новой эры и постепенную интеграцию трассировки в игровую индустрию. Уже есть первые проекты, где будет поддержка эффектов на базе трассировки NVIDIA RTX. Еще больше игр получат поддержку нового сглаживания NVIDIA DLSS. Также в Turing есть много улучшений для ускорения традиционного рендеринга. Даже без учета трассировки вы изначально получаете самые быстрые игровые видеокарты с потенциалом для наращивания производительности после внедрения новых технологий.
Наряду со своей технологичностью новое поколение радует качественным подходом к проектированию конечных устройств. Референсные ускорители GeForce RTX перешли на новое охлаждение, есть функции для более простого разгона. Все сделано для того, чтобы удовлетворить запросы самого требовательного пользователя и оправдать высокую стоимость видеокарт.
О производительности GeForce RTX 2080 и GeForce RTX 2080 Ti в существующих играх мы поговорим в следующих обзорах, которые выйдут в ближайшие дни. Оставайтесь с нами и следите за новостями!
Ampere — новейшая игровая архитектура NVIDIA. Самое важное из вайт пейпера

С момента изобретения своего первого графического процессора в 1999 году NVIDIA находится в авангарде трехмерной графики и вычислений с ускорением на графическом процессоре. Каждая архитектура NVIDIA тщательно разработана для обеспечения революционного уровня производительности и эффективности.
A100, первый графический процессор с архитектурой NVIDIA Ampere, был выпущен в мае 2020 года. Он обеспечивает колоссальное ускорение для обучения ИИ, высокопроизводительных вычислений и анализа данных. В основе A100 лежит чип GA100 — чисто вычислительный и, в отличие от GA102, еще не игровой.
Графические процессоры GA10x основаны на архитектуре графических процессоров NVIDIA Turing. Turing — первая архитектура в мире, предлагающая высокопроизводительную трассировку лучей в реальном времени, графику с ИИ-ускорением и профессиональный рендеринг графики — все в одном устройстве.

В этой статье мы разберем основные изменения в архитектуре новых видеокарт NVIDIA по сравнению с предшественницей.
Рисунок 1. Архитектура Ampere GA10x
Основные характеристики GA102
GA102 изготовлен по собственной технологии NVIDIA на базе 8 нм — 8N NVIDIA Custom. Чип содержит 28,3 миллиарда транзисторов на кристалле размером 628,4 мм2. Как и во всех GeForce RTX, в основе GA102 лежит процессор, содержащий три различных типа вычислительных ресурсов:
- CUDA-ядра для программируемого шейдинга;
- RT-ядра, ускоряющие расчет пересечений геометрии сцены с ограничивающими объемами (BVH) во время трассировки лучей;
- Тензорные ядра, значительно ускоряющие вывод и обучение нейронной сети.
Описание архитектуры Ampere
Высокоуровневая архитектура GPC, TPC и SM
Как и предшественники, GA102 состоит из графических кластеров Graphics Processing Cluster (GPC), кластеров обработки текстур Texture Processing Cluster (TPC), потоковых мультипроцессоров (SM), блоков растеризации Raster Operator (ROP) и контроллеров памяти. Полный чип имеет семь блоков GPC, 42 TPC и 84 SM.
GPC — это доминирующий высокоуровневый блок, включающий все ключевые графические составляющие. Каждый GPC имеет выделенный движок Raster Engine, а теперь еще и по два раздела ROP из восьми блоков каждый, что является новшеством архитектуры Ampere. Кроме того, GPC содержит шесть TPC, в каждом из которых расположено по два мультипроцессора и по одному PolyMorph Engine.
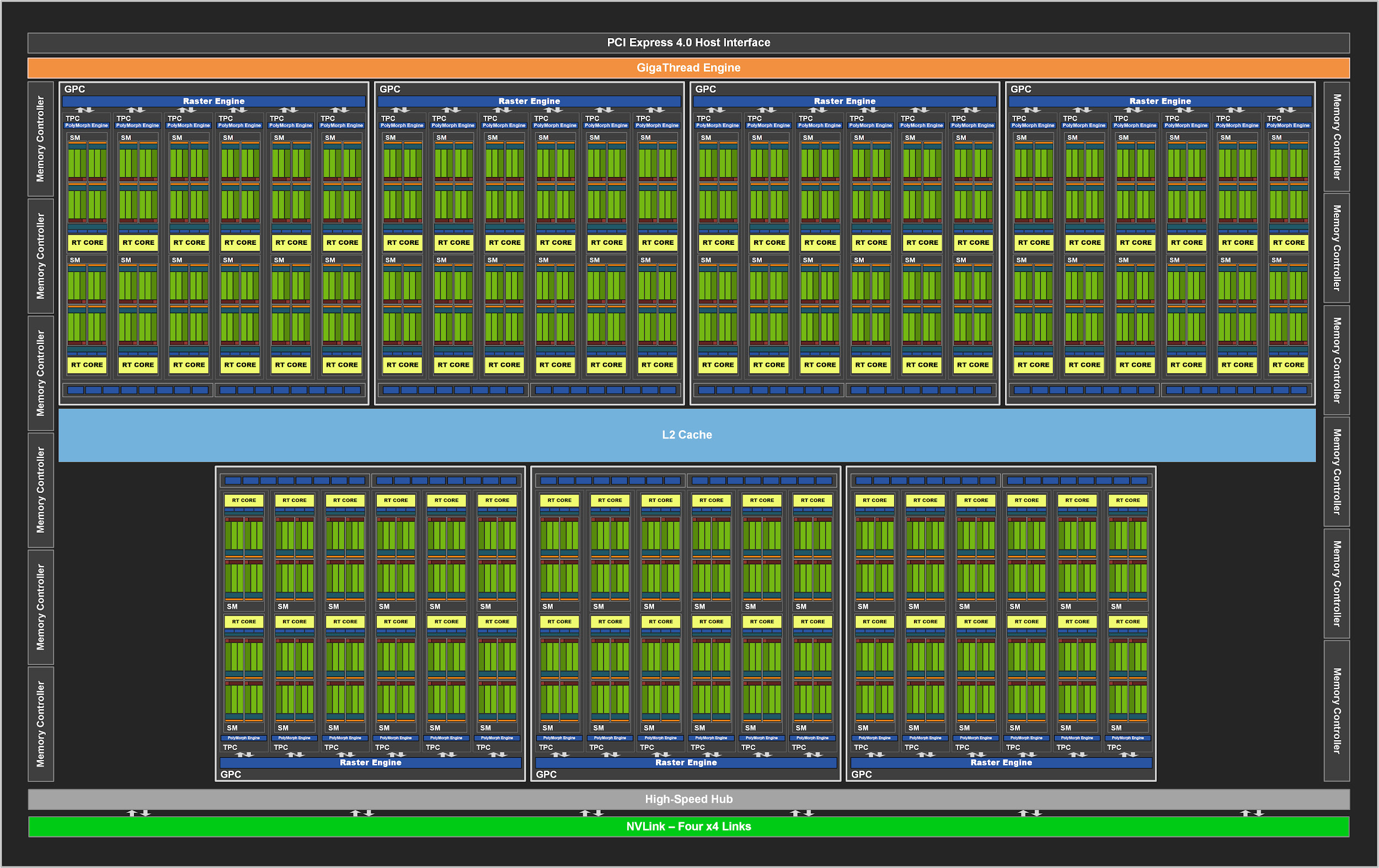
Рисунок 2. Полный GPU GA102 с 84 блоками SM
В свою очередь, каждый SM в GA10x содержит 128 CUDA-ядра, четыре тензорных ядра третьего поколения, регистровый файл 256 КБ, четыре текстурных блока, одно ядро трассировки лучей второго поколения и 128 КБ L1/общей памяти, которые могут быть настроены для различных мощностей в зависимости от потребностей вычислительных или графических задач.
Оптимизация блоков растеризации (ROP)
В предыдущих графических процессорах NVIDIA ROP были привязаны к контроллеру памяти и кэшу L2. Начиная с GA10x, они являются частью GPC, что повышает производительность растровых операций за счет увеличения общего числа ROP.
Итого, имея по семь кластеров GPC и 16 блоков ROP в каждом GPC, графический процессор GA102 состоит из 112 ROP вместо 96, например, в TU102. Все это оказывает положительное влияние на мультисэмпловое сглаживание, скорость заполнения пикселей и блендинг.
NVLink третьего поколения
Графические процессоры GA102 поддерживают интерфейс NVIDIA NVLink третьего поколения, включающий в себя четыре канала x4, каждый из которых обеспечивает пропускную способность 14,0625 ГБ/с между двумя графическими процессорами в любом направлении. Четыре канала вместе дают пропускную способность 56,25 ГБ/с в каждом направлении и в целом 112,5 ГБ/с между двумя графическими процессорами. Так, с помощью NVLink можно соединить два графических процессора RTX 3090.
PCIe четвертого поколения
Графические процессоры GA10x оснащены интерфейсом PCI Express 4.0, который обеспечивает вдвое большую пропускную способность по сравнению с PCIe 3.0, скорость передачи данных до 16 гигатрансферов в секунду, а благодаря слоту x16 PCIe 4.0 пиковая пропускная способность достигает 64 ГБ/с.
Архитектура мультипроцессоров GA10x
Архитектура мультипроцессоров Turing стала первой в NVIDIA, у которой имелись отдельные ядра для ускорения операций трассировки лучей. Затем в Volta появились первые тензорные ядра, а в Turing — усовершенствованные тензорные ядра второго поколения. Еще одним нововведением в Turing и Volta стала возможность одновременного выполнения операций FP32 и INT32. Мультипроцессор в GA10x поддерживает все вышеперечисленные возможности, а также имеет ряд собственных улучшений.
В отличие от TU102, состоящего из восьми тензорных ядер второго поколения, мультипроцессор GA10x имеет четыре тензорных ядра третьего поколения, причем каждое тензорное ядро GA10x в два раза мощнее, чем у Turing.
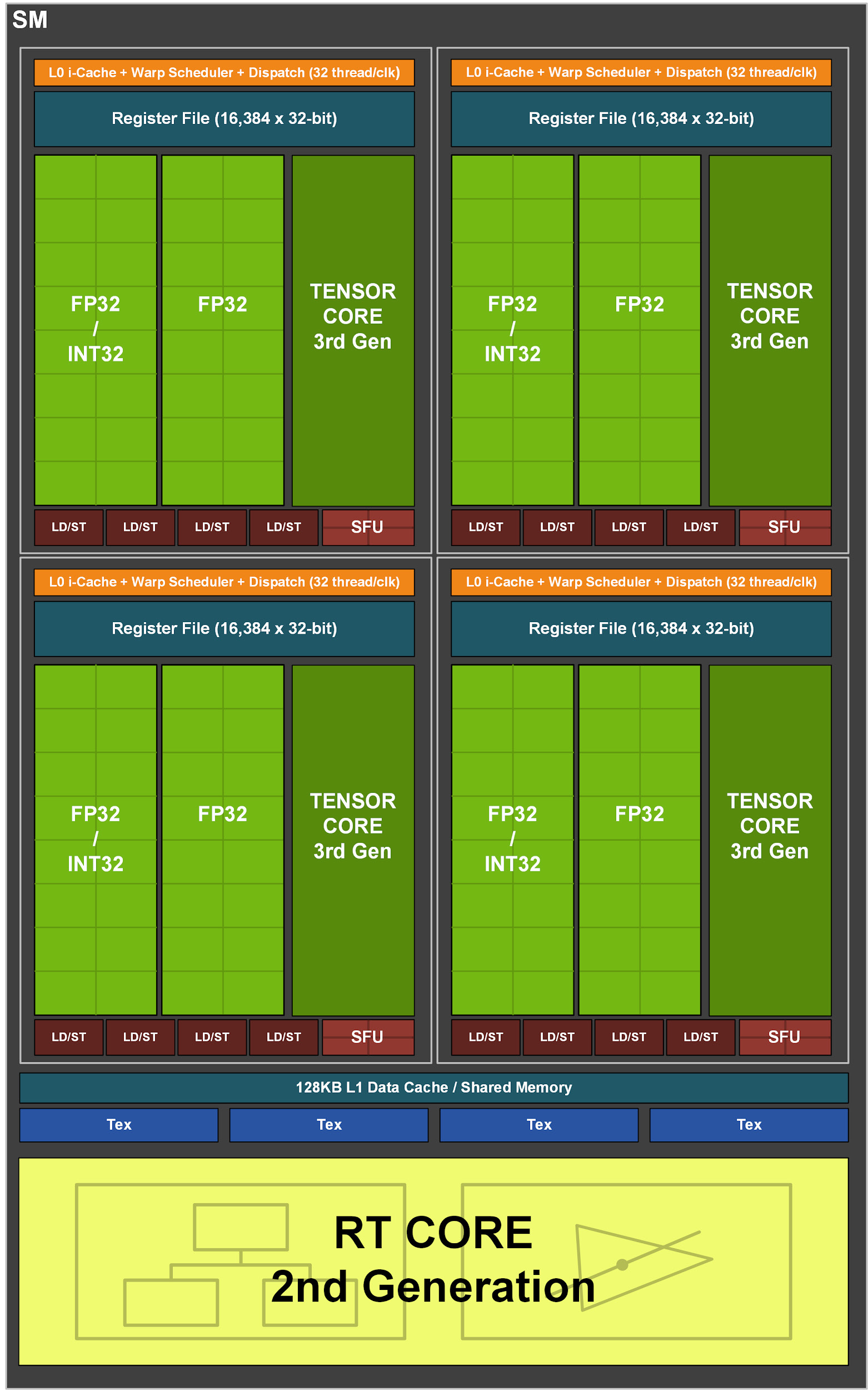
Рисунок 3. Потоковый мультипроцессор GA10x
Удвоенная скорость вычислений FP32
Большинство графических вычислений приходится на 32-битные операции с плавающей запятой (FP32). Потоковый мультипроцессор в архитектуре Ampere GA10x обеспечивает в два раза более быструю обработку операций FP32 в обоих каналах данных. В результате в разрезе FP32 GeForce RTX 3090 обеспечивает более 35 терафлопс, что более чем в 2 раза превышает возможности Turing.
GA10X может выполнять 128 FP32-операций или 64 операции FP32 и 64 INT32 за такт, что вдвое превышает скорость вычислений Turing.
Задачи современного гейминга имеют широкий спектр потребностей в обработке. Многие вычисления требуют связки операций FP32 (таких как FFMA, сложение с плавающей запятой (FADD) или умножение с плавающей запятой (FMUL)), а также выполнения множества более простых целочисленных вычислений.
Мультипроцессоры GA10x продолжают поддерживать двухскоростные операции FP16 (HFMA), которые поддерживались и в Turing. И, аналогично графическим процессорам TU102, TU104 и TU106, в GA10x стандартные операции FP16 тоже обрабатываются тензорными ядрами.
Разделяемая память и кэш данных L1
GA10x имеет унифицированную архитектуру для разделяемой памяти, кэша данных L1 и кэша текстур. Этот унифицированный дизайн можно изменить в зависимости от рабочей нагрузки и потребностей.
Чип GA102 содержит 10752 КБ кэша L1 (по сравнению с 6912 КБ в TU102). Помимо этого, GA10x также имеет удвоенную пропускную способность разделяемой памяти по сравнению с Turing (128 байт/такт против 64 байт/такт). Общая пропускная способность L1 для GeForce RTX 3080 составляет 219 ГБ/с против 116 ГБ/с у GeForce RTX 2080 Super.
Производительность на ватт
Все архитектура NVIDIA Ampere создана для повышения эффективности — от логики, памяти, питания и теплового режима до конструкции печатной платы, программного обеспечения и алгоритмов. При том же уровне производительности графические процессоры с архитектурой Ampere до 1,9 раз более энергоэффективны, чем аналогичные устройства Turing.
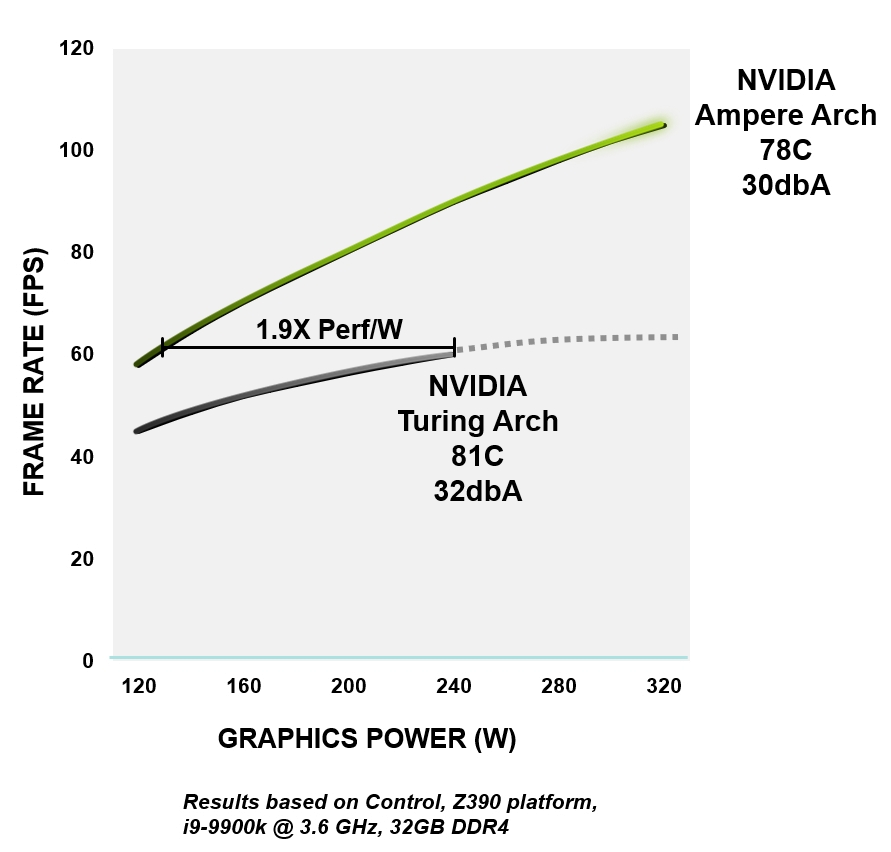
Рисунок 4. Эффективность энергопотребления RTX 3080 по сравнению с архитектурой GeForce RTX 2080 Super
RT-ядра второго поколения
Новые RT-ядра имеют ряд улучшений, которые в совокупности с обновленными системами кэширования эффективно удваивают производительность процессоров Ampere по сравнению с Turing в вопросах трассировки лучей. Кроме того, GA10x позволяет запускать одновременно с RT-вычислениями и другие процессы, тем самым значительно ускоряя многие задачи.
Трассировка лучей второго поколения в GA10x
GeForce RTX на основе архитектуры Turing стали первыми графическими процессорами, с которыми кинематографическая трассировка лучей стала реальностью в компьютерных играх. GA10x оснащены технологией трассировки лучей уже второго поколения. Как и у Turing, мультипроцессоры в GA10x имеют специализированные аппаратные блоки для проверки на пересечения лучей с BVH и треугольниками. При этом ядра мультипроцессоров Ampere имеют вдвое большую скорость тестирования пересечения лучей и треугольников по сравнению с Turing.
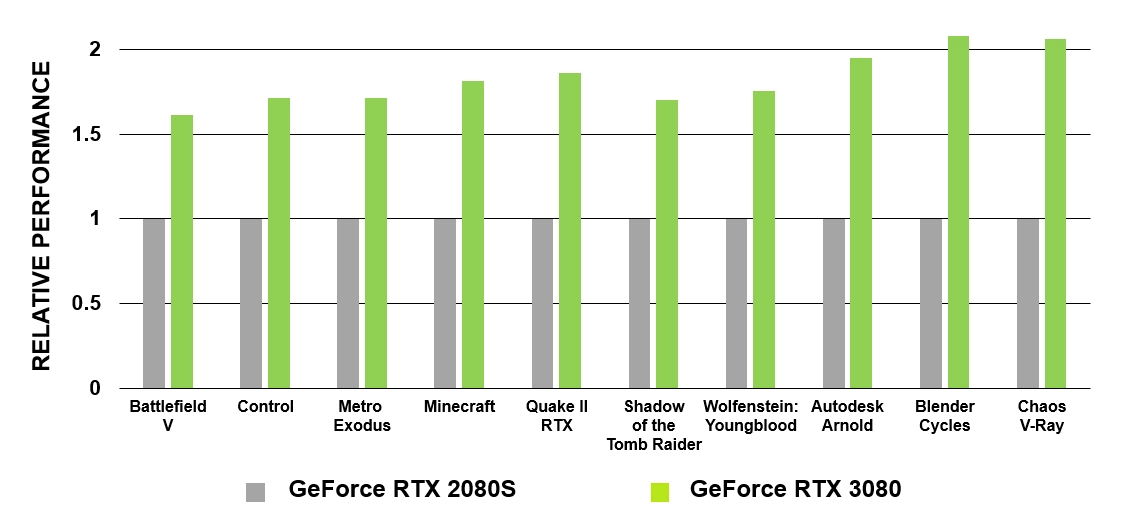
Рисунок 5. Сравнение производительности RT-ядер GeForce RTX 3080 и GeForce RTX 2080 Super
Мультипроцессор GA10x может выполнять операции одновременно и при этом не ограничивается только вычислениями и графикой, как это было в предыдущих поколениях графических процессоров. Так, например, в GA10x алгоритм шумоподавления может выполняться одновременно с трассировкой лучей.

Рисунок 6. Ядро RT второго поколения в графических процессорах GA10x
Обратите внимание, что рабочие нагрузки с интенсивным использованием RT-ядер не вызывают значительного повышения нагрузки на ядра мультипроцессора, тем самым позволяя использовать мультипроцессорную вычислительную мощность для других задач. Это большое преимущество перед другими конкурирующими архитектурами, которые не имеют выделенных RT -ядер, отчего вынуждены использовать свои стандартные блоки для выполнения как графических операций, так и трассировки лучей.
Процессоры RTX с архитектурой Ampere в действии
Трассировка лучей и работа шейдеров требуют больших вычислительных ресурсов. Но было бы намного дороже запускать все с помощью одних только CUDA-ядер, так что включение в работу тензорных и RT-ядер помогает значительно ускорить обработку. На рисунке 7 для примера показана игра Wolfenstein: Youngblood с включенной трассировкой лучей при различных сценариях работы.
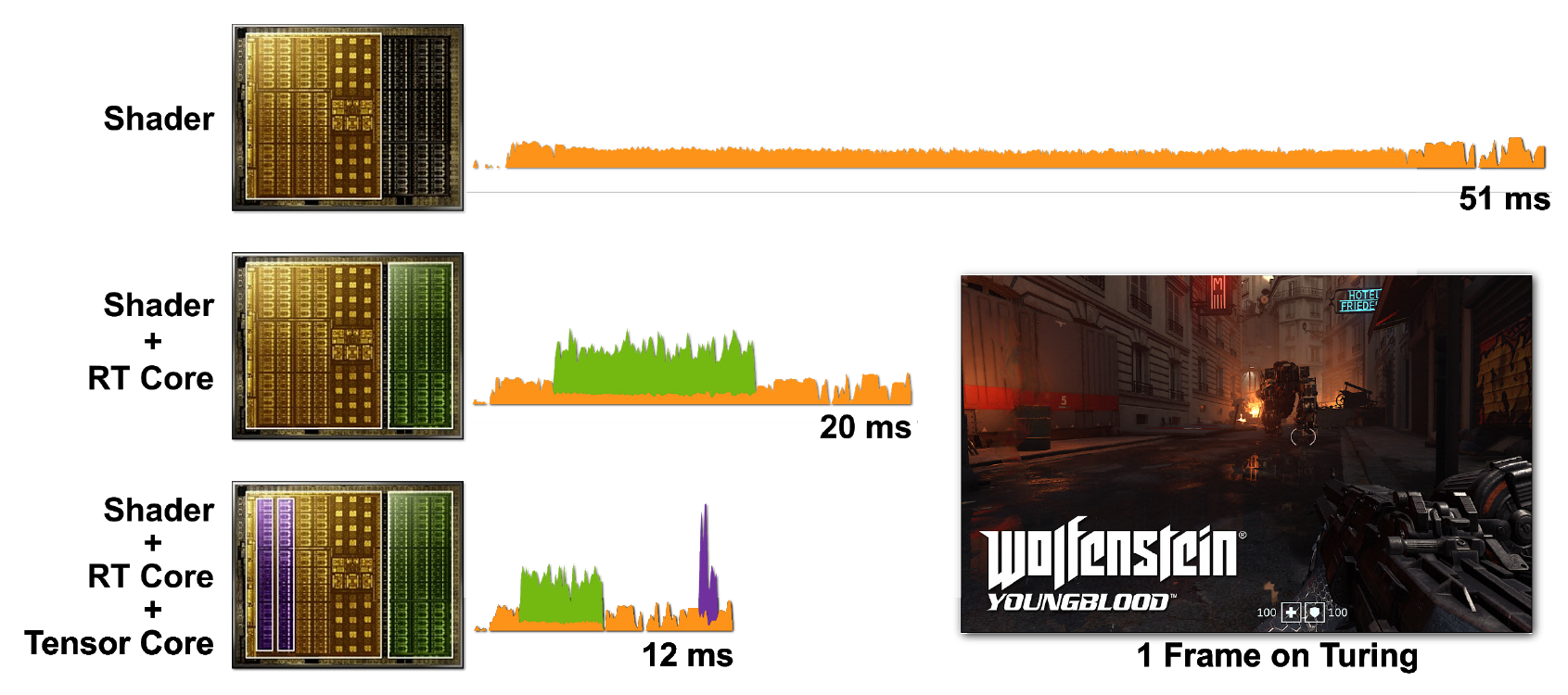
Рисунок 7. Рендеринг одного кадра Wolfenstein: Youngblood на RTX 2080 Super GPU с использованием а) шейдерных ядер (CUDA), б) шейдерных ядер и RT-ядер, в) шейдерных ядер, тензорных и RT-ядер. Обратите внимание на постепенно сокращающееся время кадра при добавлении мощностей различных процессорных ядер RTX.
В первом случае для запуска одного кадра требуется 51 мс (~ 20 fps). При включении в работу RT-ядер рендеринг кадра происходит намного быстрее — за 20 мс (50 fps). Использование же DLSS на тензорных ядрах сокращает время кадра до 12 мс (~ 83 fps).
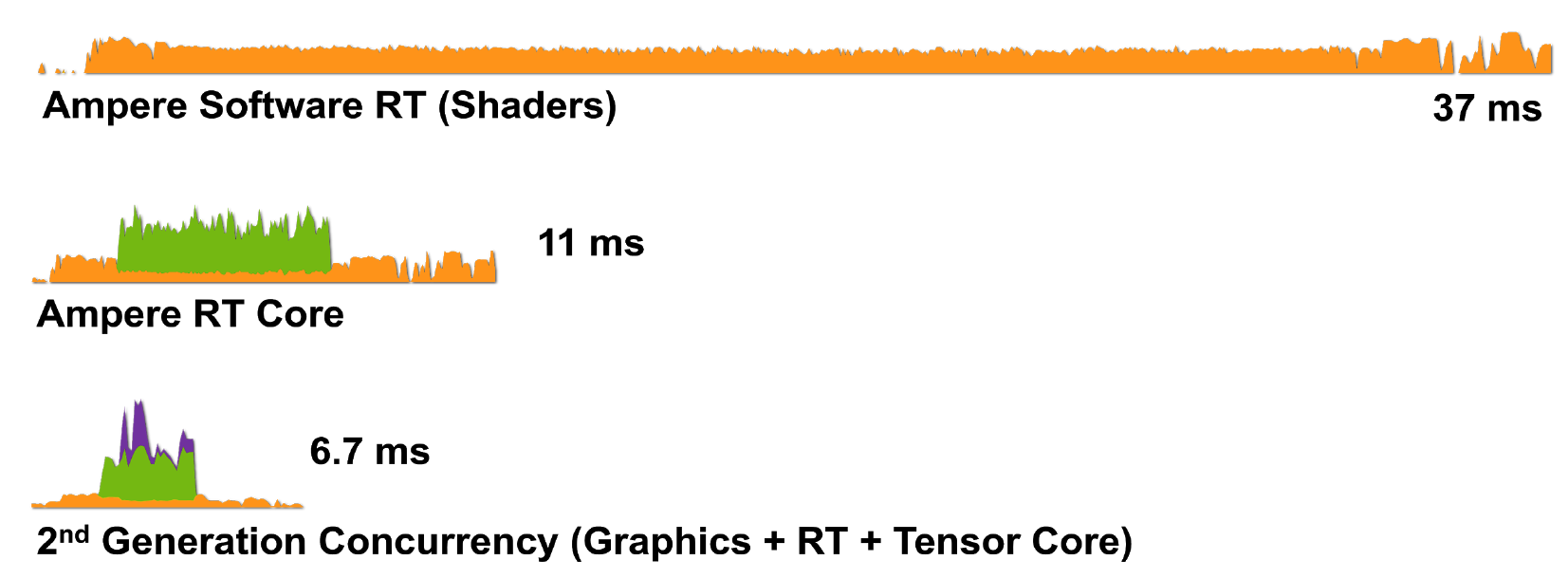
Рисунок 8. Рендеринг одного кадра Wolfenstein: Youngblood на RTX 3080 с использованием а) шейдерных ядер (CUDA), б) шейдерных ядер и RT-ядер, в) шейдерных ядер, тензорных и RT-ядер.
Итак, технология RTX с архитектурой Ampere еще эффективнее справляется с задачами рендеринга: в RTX 3080 рендеринг кадра происходит за 6,7 мс (150 fps), что является огромным улучшением по сравнению с RTX 2080.
Аппаратное ускорение трассировки лучей с использованием размытия движения
Размытие движения (motion blur) — часто используемый в компьютерной графике ход. Фотографическое изображение создается не мгновенно, а путем воздействия света на пленку в течение ограниченного периода времени. Объекты, движущиеся достаточно быстро по сравнению с продолжительностью выдержки камеры, будут отображаться на фотографии в виде полос или пятен. Чтобы графический процессор создавал реалистично выглядящее размытие движения в случае, когда объекты в сцене быстро перемещаются перед статической камерой, он должен уметь имитировать то, как камера и пленка работают с такими сценами. Размытие движения особенно важно в кинопроизводстве, поскольку фильмы воспроизводятся со скоростью 24 кадра в секунду, и сцена без размытия движения будет выглядеть резкой и прерывистой.
Графические процессоры Turing довольно хорошо справляются с ускорением размытия движения в целом. Однако в случае движущейся геометрии задача может оказаться более сложной, поскольку информация о BVH изменяется вместе с положением объектов в пространстве.
Как видно на рисунке 9, RT-ядро Turing производит аппаратный обход иерархии BVH, проверку пересечения лучей с BBox и треугольниками. GA10x умеет все то же самое, но вдобавок имеет новый блок Interpolate Triangle Position, ускоряющий размытие движения при трассировке лучей.
Оба RT-ядра Turing и GA10x реализуют архитектуру MIMD (Multiple Instruction Multiple Data — множественные команды, множественные данные), благодаря которой можно обрабатывать множество лучей одновременно.
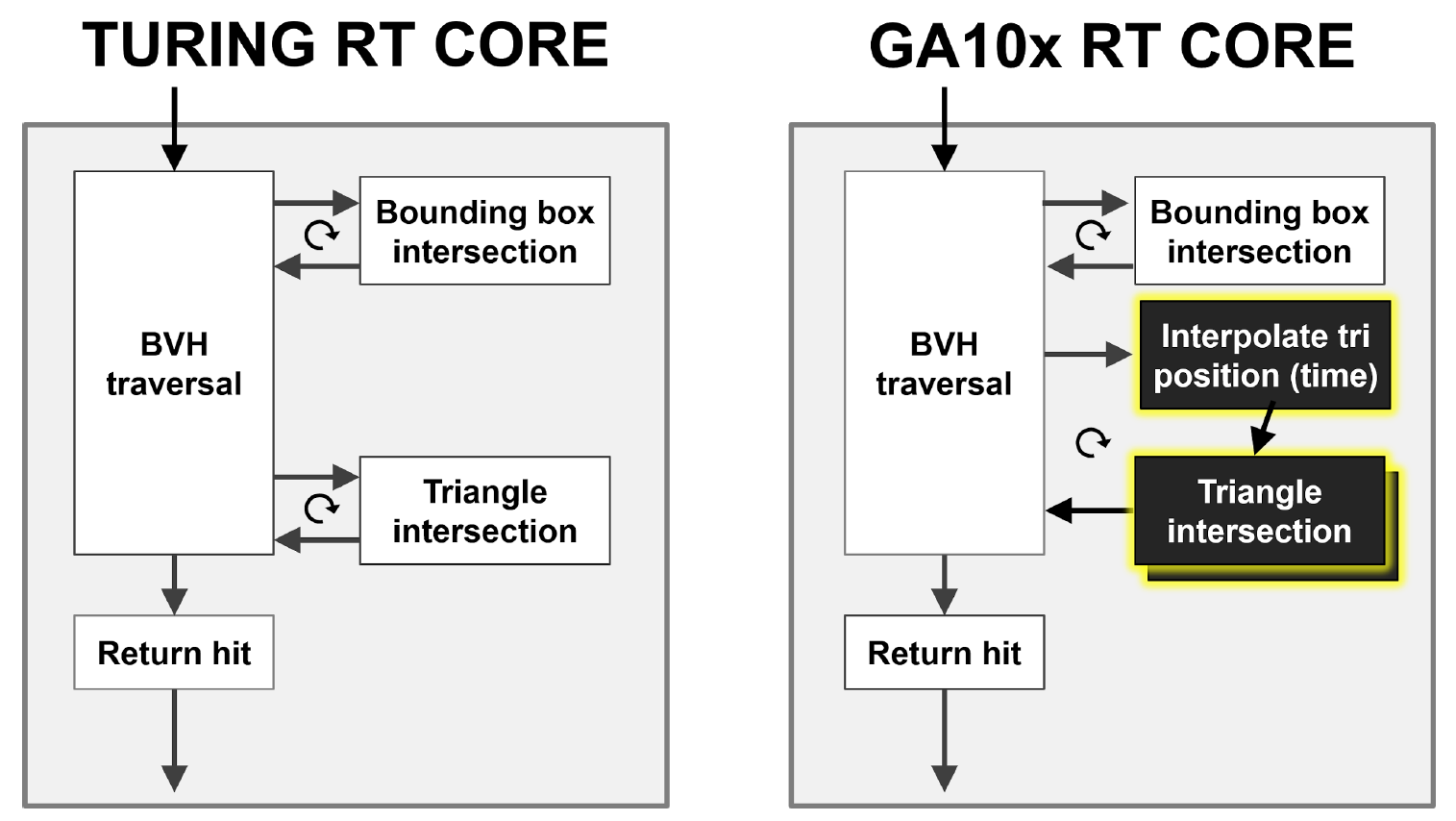
Рисунок 9. Сравнение аппаратного ускорения размытия движения в случае Turing и Ampere
Основная проблема с размытием движения заключается в том, что треугольники в сцене не фиксированы во времени. В базовой трассировке лучей выполняются статичные тесты на пересечение, и при попадании луча в треугольник производится возврат информации об этом попадании. Как показано на рисунке 10, при размытии движения ни у одного треугольника нет фиксированных координат. Каждому лучу присваивается временная метка, указывающая время его отслеживания, и уже из уравнения BVH определяется положение треугольника и пересечения с ним луча.
Если этот процесс не ускорить аппаратно, он может доставить действительно много проблем, в том числе за счет своей нелинейности.
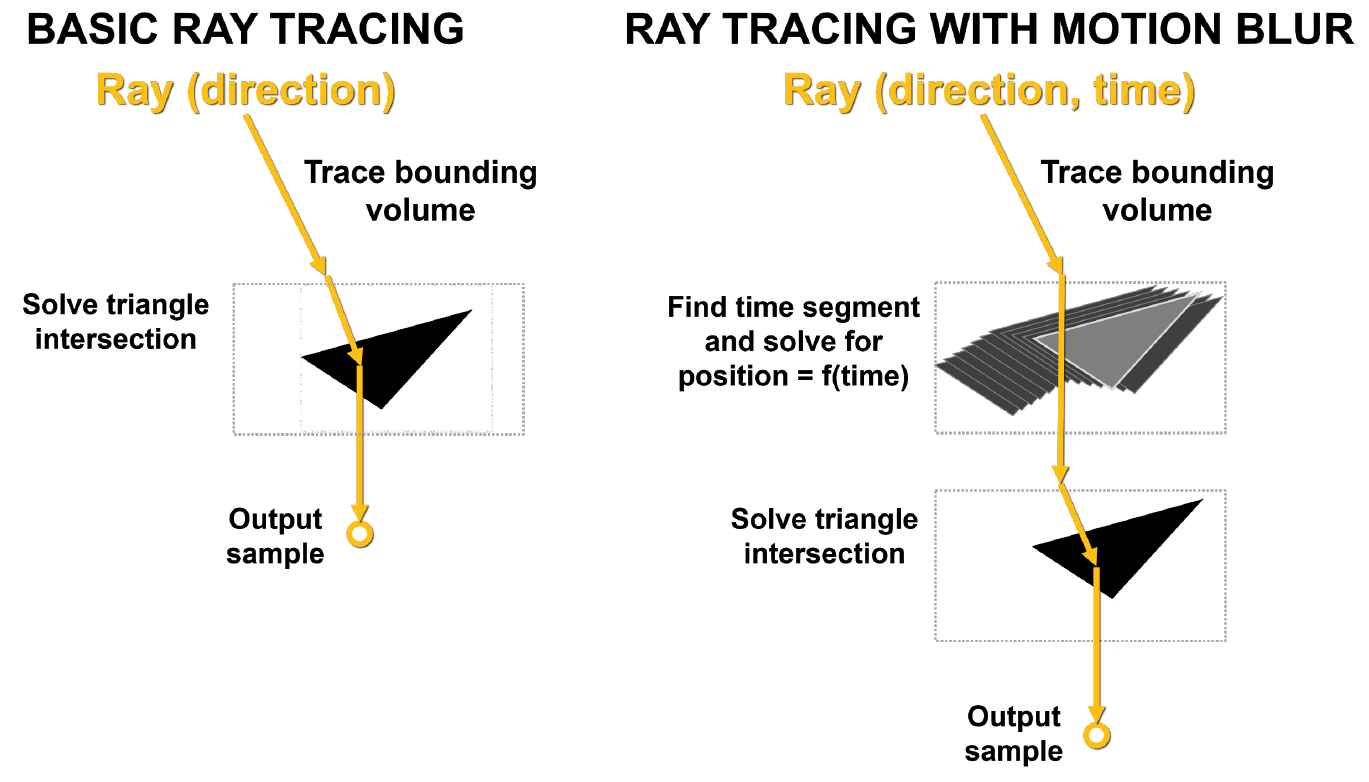
Рисунок. 10. Базовая трассировка лучей и трассировка лучей с размытием движения
В левой части рисунка 11 лучи, отправленные в статичную сцену, попадают в один и тот же треугольник одновременно. Белые точки показывают место попадания, этот результат и возвращается обратно. В случае размытия движения каждый луч существует в свой момент времени. Каждому лучу случайным образом назначается различная временная метка. Например, оранжевые лучи пытаются пересечь оранжевые треугольники в один момент времени, а затем зеленые и синие лучи производят те же самые действия. В конце сэмплы смешиваются, образовывая более математически правильный размытый результат.
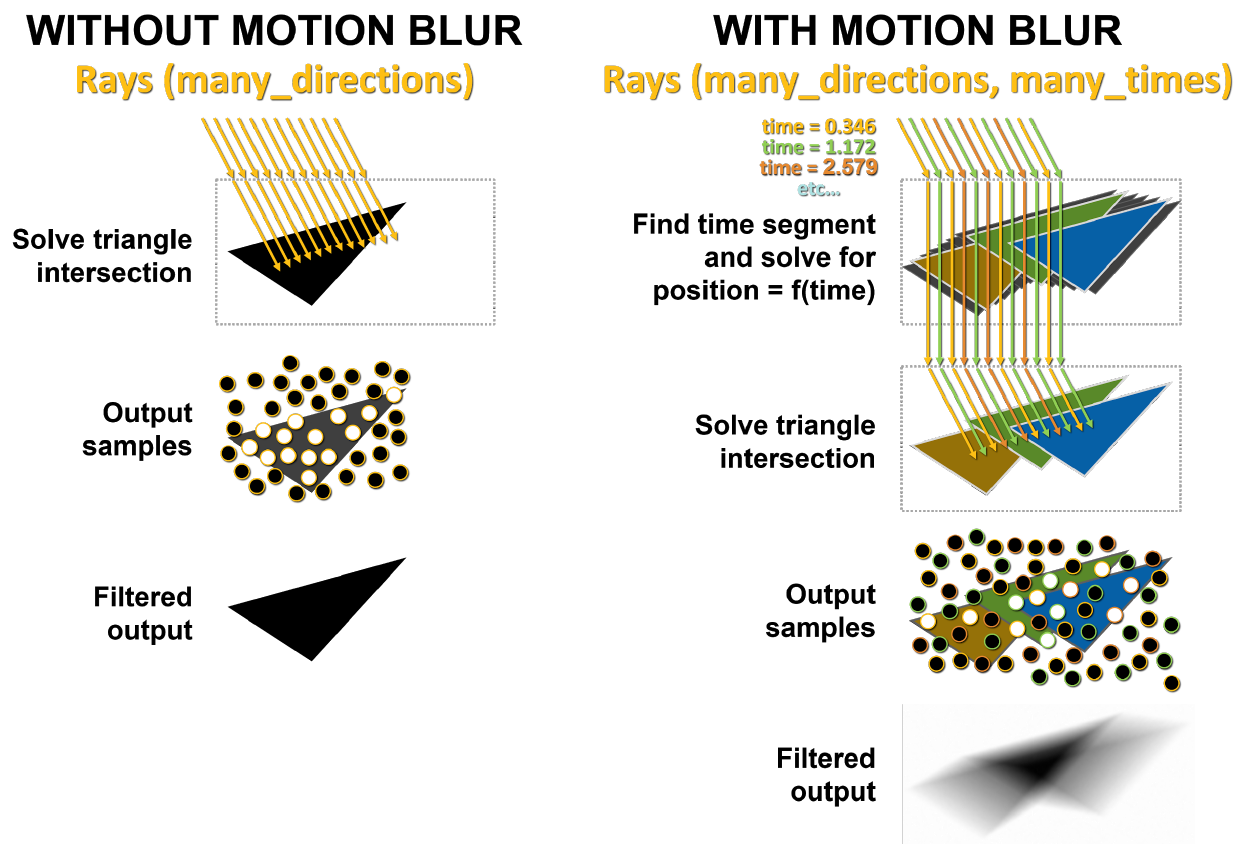
Рисунок 11. Рендеринг без размытия движения и с размытием в GA10x
Блок Interpolate Triangle Position интерполирует треугольники в BVH между уже существующими треугольниками на основе движения объекта, так что лучи будут пересекать их в ожидаемых местах в моменты, определяемые временными метками луча. Такой подход позволяет выполнять точный рендеринг размытия движения с трассировкой лучей до восьми раз быстрее по сравнению с Turing.
Размытие движения с аппаратным ускорением GA10x поддерживается Blender 2.90, Chaos V-Ray 5.0, Autodesk Arnold и Redshift Renderer 3.0.X с использованием NVIDIA OptiX 7.0 API.
Скорость рендеринга размытия движения до 5 раз выше в случае RTX 3080 по сравнению с RTX 2080 Super.
Тензорные ядра третьего поколения в графических процессорах GA10x
GA10x содержит в себе новые тензорные ядра NVIDIA третьего поколения, отличающиеся поддержкой новых типов данных, улучшенной производительностью, эффективностью и гибкостью программирования. Новая функция разреженности позволяет удвоить производительность тензорных ядер по сравнению с Turing предыдущего поколения. Быстрее происходит и выполнение функций ИИ, таких как NVIDIA DLSS для сверхразрешения ИИ (теперь и с поддержкой 8K), NVIDIA Broadcast для обработки голоса и видео и NVIDIA Canvas для рисования.
Тензорные ядра — это специализированные исполнительные блоки, разработанные для выполнения тензорных/матричных операций — основной вычислительной функции в глубоком обучении. Они необходимы для улучшения качества графики с помощью DLSS (Deep Learning Super Sampling), шумоподавления на основе ИИ, удаления фонового шума внутри игровых голосовых чатов с помощью RTX Voice и еще множества применений.
Внедрение тензорных ядер в игровые графические процессоры GeForce впервые позволило реализовать глубокое обучение в реальном времени в игровых приложениях. Конструкция тензорного ядра третьего поколения в графических процессорах GA10x дополнительно увеличивает чистую производительность и задействует новые режимы вычислительной точности, такие как TF32 и BFloat16. Это играет большую роль для основанных на ИИ приложений нейронных служб NVIDIA NGX, направленных на улучшение графики, рендеринга и другие функции.
Сравнение тензорных ядер Turing и Ampere
Тензорные ядра Ampere были реорганизованы в сравнении с Turing для повышения эффективности и снижения энергопотребления. Архитектура SM-ядер Ampere имеет меньшее количество тензорных ядер, но каждое из них оказывается более мощным.
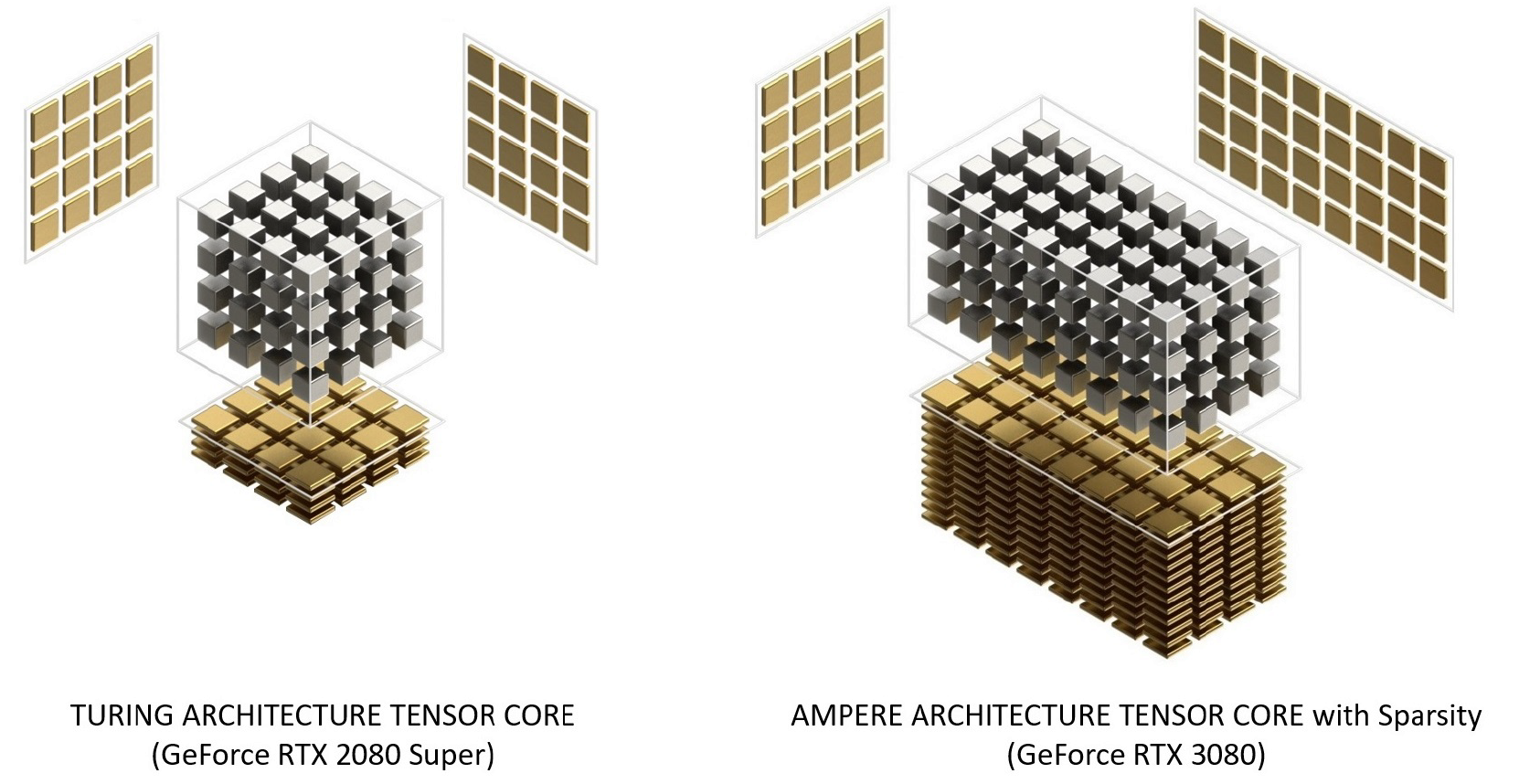
Рисунок 12. Тензорные ядра с архитектурой Turing и Ampere. GeForce RTX 3080 обеспечивает в 2,7 раза более высокую пиковую пропускную способность тензорного ядра в FP16-операциях по сравнению с GeForce RTX 2080 Super
Мелкозернистая структурированная разреженность
С графическим процессором A100 NVIDIA представила Fine-Grained Structured Sparsity — новый подход, способствующий удвоению вычислительной пропускной способности для глубоких нейронных сетей. Эта функция также поддерживается графическими процессорами GA10x и помогает ускорить некоторые операции вывода графики на основе ИИ.
Поскольку сети глубокого обучения могут адаптировать веса в процессе обучения на основе обратной связи, в целом структурные ограничения не влияют на точность обучаемых моделей.
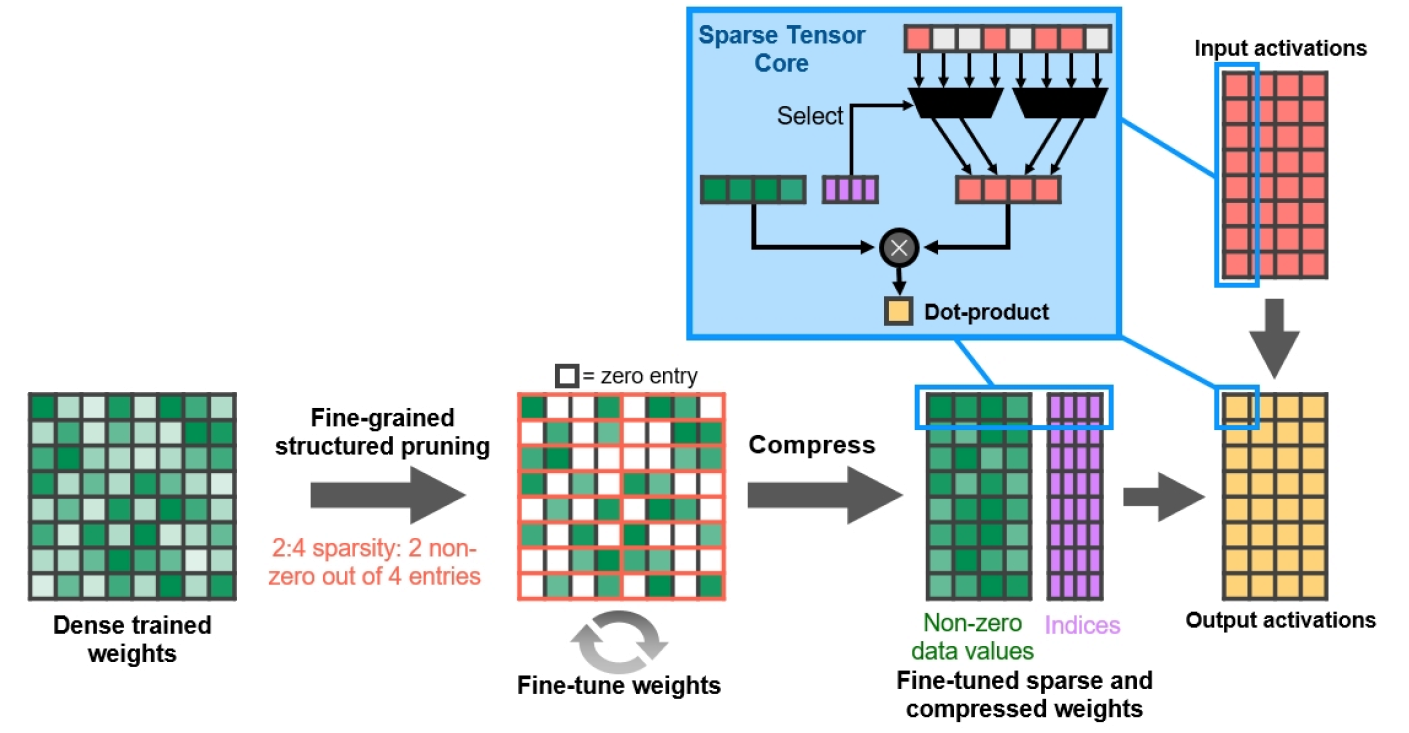
Рисунок 13. Мелкозернистая структурированная разреженность
NVIDIA разработала простой и универсальный алгоритм разреживания глубоких нейронных сетей с использованием структурированного шаблона разреженности 2:4. Сеть сначала обучается при помощи плотных весов, затем происходит мелкозернистая структурированная обрезка, после чего нулевые значения можно отбросить, а оставшаяся математика сжимается с целью повышения пропускной способности. Алгоритм не влияет на точность обученной сети для вывода, только ускоряет ее.
NVIDIA DLSS 8K
Рендеринг изображения с трассировкой лучей и высокой частотой кадров — чрезвычайно затратный с вычислительной точки зрения процесс. До появления NVIDIA Turing считалось, что его реализацию стоит ждать годы. Чтобы помочь с решением этой проблемы, NVIDIA создала суперсэмплинг при помощи глубокого обучения (DLSS).

Рисунок 14. Watch Dogs: Legion с DLSS с разрешением 1080p, 4К и 8К. Обратите внимание на более четкий текст и детализацию, обеспечиваемую DLSS в 8K
DLSS стал только лучше в случае NVIDIA Ampere за счет использования тензорных ядер третьего поколения и девятикратного коэффициента масштабирования сверхразрешения, который впервые делает возможными запуск игры с трассировкой лучей в разрешении 8K с 60 fps.
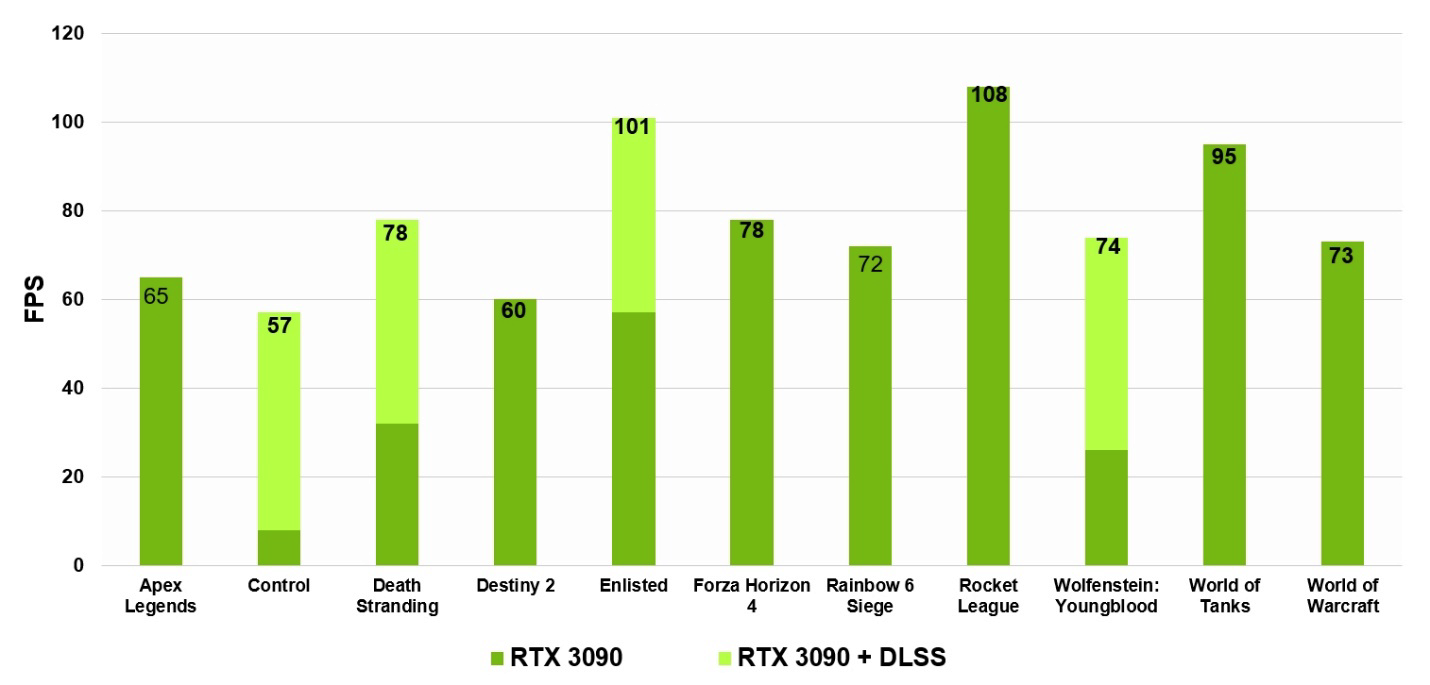
Рисунок 15. GeForce RTX 3090 может обеспечить частоту кадров 60 fps во многих играх с разрешением 8K с DLSS и без него. В перечисленных играх использовались высокие настройки графики и включена трассировка лучей, где это возможно. Протестировано на процессоре Core i9-10900K
Память GDDR6X
Современные компьютерные игры и творческие приложения требуют значительно большей пропускной способности памяти для обработки все более сложной геометрии сцены, более детальных текстур, трассировки лучей, операций вывода ИИ и, конечно же, затенения и суперсэмплинга.
GDDR6X — первая графическая память, пропускная способность которой превышает 900 ГБ/с. Чтобы этого достичь, была задействована инновационная технология передачи сигналов и четырехуровневая амплитудно-импульсная модуляция (PAM4), в совокупности полностью меняющие способ перемещения данных в памяти. При помощи алгоритма PAM4 GDDR6X передает большее количество данных с гораздо более высокой скоростью, перемещая по два бита данных за раз, что удваивает скорость передачи данных ввода/вывода по сравнению с предыдущей схемой PAM2/NRZ.
В настоящее время GDDR6X поддерживает скорость 19,5 Гбит/с для GeForce RTX 3090 и 19 Гбит/с для GeForce RTX 3080. Благодаря этому GeForce RTX 3080 обеспечивает в 1,5 раза большую производительность в операциях с памятью, чем предшественник — RTX 2080 Super.
На рисунке 16 показано сравнение структуры GDDR6 (слева) и GDDR6X (справа). GDDR6X передает те же данные на частоте вдвое меньшей, чем у GDDR6. Или, в качестве альтернативы, GDDR6X может удвоить эффективную полосу пропускания, сохранив той же частоту.

Рисунок 16. GDDR6X с использованием сигналов PAM4 показывает большую производительность и эффективность, чем GDDR6
Для решения проблем с отношением сигнал/шум (SNR), возникающих при передаче сигналов PAM4, была разработана новая схема кодирования MTA (максимальное предотвращение перехода). MTA предотвращает переход высокоскоростных сигналов с самого высокого уровня на самый низкий и наоборот.

Рисунок 17. Новое кодирование в GDDR6X
Поддерживая скорость передачи данных до 19,5 Гбит/с на чипах GA10x, GDDR6X обеспечивает пиковую пропускную способность памяти до 936 ГБ/с, что на 52% больше по сравнению с графическим процессором TU102, используемым в GeForce RTX 2080 Ti. GDDR6X имеет самый большой скачок пропускной способности за 10 лет после графических процессоров серии GeForce 200.
RTX IO
Современные игры содержат в себе огромные миры. С развитием таких технологий, как фотограмметрия, они все лучше имитируют реальность и, как следствие, содержатся в файлах с все большим объемом. Крупнейшие игровые проекты занимают более 200 ГБ, что в 3 раза больше, чем четыре года назад, и со временем их это число будет только расти.
Геймеры все чаще обращаются к твердотельным накопителям, чтобы сократить время загрузки игр: в то время, как жесткие диски ограничены пропускной способностью 50–100 МБ/с, новейшие твердотельные накопители M.2 PCIe Gen4 считывают данные на скорости до 7 ГБ/с.
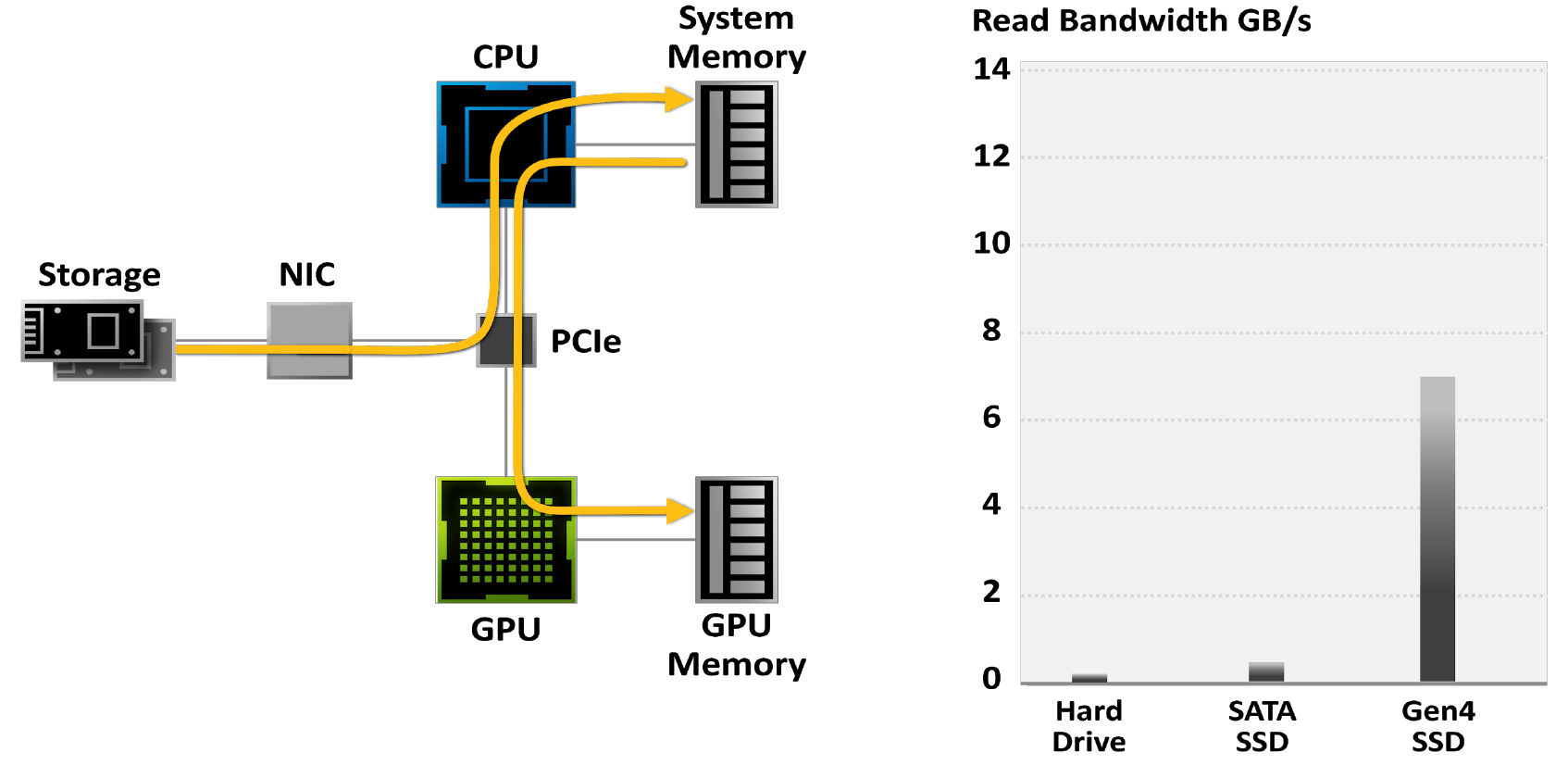
Рисунок 18. Игры, ограниченные традиционными системами ввода-вывода

Рисунок 19. При использовании традиционной модели хранения распаковка игры может занять все 24 ядра процессора. Современные игровые движки превзошли возможности традиционных API-хранилищ. Вот почему необходимо новое поколение архитектуры ввода-вывода. Здесь серые полосы обозначают скорость передачи данных, черно-синие блоки — необходимые на это ядра ЦП.
NVIDIA RTX IO — это набор технологий, обеспечивающих быструю загрузку и распаковку ресурсов на базе ГП и повышающих производительность ввода-вывода до 100 раз по сравнению с жесткими дисками и традиционными API-хранилищами.
NVIDIA RTX IO работает в связке Microsoft DirectStorage API — хранилищем следующего поколения, разработанным специально для современных игровых ПК с NVMe SSD. NVIDIA RTX IO обеспечивает декомпрессию без потерь, позволяя считывать данные через DirectStorage в сжатом виде и доставлять их на графический процессор. Это снимает нагрузку с ЦП, перемещая данные из хранилища в графический процессор в более эффективной сжатой форме и улучшая производительность ввода-вывода в два раза.

Рисунок 20. RTX IO обеспечивает в 100 раз большую пропускную способность и 20-кратное снижение загрузки ЦП. Серые и зеленые полосы обозначают скорость передачи данных, черно-синие блоки — необходимые для этого ядра ЦП.
Дисплей и видеодвижок
DisplayPort 1.4a с DSC 1.2a
Марш в сторону все более высоких разрешений с более высокой частотой обновления кадров продолжается, и графические процессоры на архитектуре NVIDIA Ampere стараются оставаться в числе передовых компаний, готовых обеспечить и то, и другое. Геймеры теперь могут играть на дисплеях с разрешением 4K (3820 x 2160) с частотой 120 Гц и в 8K (7680 x 4320) с частотой 60 Гц — с четырехкратным увеличением числа пикселей по сравнению с 4K.
Движок архитектуры Ampere разработан для поддержки многих новых технологий, включенных в самые быстрые на сегодняшний день интерфейсы отображения данных. Сюда входит и DisplayPort 1.4a, обеспечивающий разрешение 8K при 60 Гц с технологией сжатия без визуальных потерь VESA Display Stream Compression (DSC) 1.2a. К новым видеокартам с архитектурой Ampere можно подключить по два дисплеями с 8K и частотой 60 Гц — для этого понадобится всего лишь один кабель на дисплей.
HDMI 2.1 с DSC 1.2a
В архитектуре NVIDIA Ampere впервые для дискретных графических процессоров добавлена поддержка HDMI 2.1 — новейшего обновления спецификации HDMI. В HDMI максимальная пропускная способность увеличена до 48 Гбит/с, что также позволяет использовать динамические форматы HDR. Для поддержки 8K при 60 Гц с HDR необходимо сжатие DSC 1.2a или пиксельный формат 4:2:0.
NVDEC пятого поколения — декодирование видео с аппаратным ускорением
Графические процессоры NVIDIA содержат аппаратный декодер пятого поколения Hardware-Accelerated Video Decoding (NVDEC), обеспечивающий полностью аппаратное декодирование видео для множества популярных кодеков.

Рисунок 21. Форматы кодирования и декодирования видео, поддерживаемые графическими процессорами GA10x
Декодер NVIDIA пятого поколения в GA10x поддерживает декодирование с аппаратным ускорением следующих видеокодеков на платформах Windows и Linux: MPEG-2, VC-1, H.264 (AVCHD), H.265 (HEVC), VP8, VP9, и AV1.
NVIDIA — первый производитель графических процессоров, обеспечивающий аппаратную поддержку декодирования AV1.
Аппаратное декодирование AV1
Хотя AV1 очень эффективен при сжатии видео, его декодирование требует значительных вычислительных ресурсов. Современные программные декодеры вызывают высокую загрузку ЦП и затрудняют воспроизведение видео в сверхвысоком разрешении. В тестах NVIDIA процессор Intel i9 9900K в среднем воспроизводил на YouTube 28 кадров в секунду в 8K60 HDR, загрузка процессора при этом была выше 85%. Графические процессоры GA10x могут воспроизводить AV1, передавая декодирование на NVDEC, который способен воспроизводить до 8K60 HDR-контента с очень низкой загрузкой ЦП (~ 4% на том же ЦП, что и в предыдущем тесте).
NVENC седьмого поколения — кодирование видео с аппаратным ускорением
Кодирование видео может быть сложной вычислительной задачей, но, если выгрузить его в NVENC, графический движок и ЦП освободятся для других операций. Например, при потоковой передачи игр на Twitch.tv с использованием Open Broadcaster Software (OBS), выгрузка кодирования видео в NVENC позволит выделить графический движок графического процессора для рендеринга игры, а ЦП — для других задач пользователя.
- кодирование и потоковую передачу игр и приложений с высоким качеством и сверхнизкой задержкой без использования ЦП;
- кодирование с очень высоким качеством для архивирования, потоковой передачи OTT, веб-видео;
- кодирование со сверхнизким энергопотреблением на поток (Вт/поток).
Заключение
С каждой новой процессорной архитектурой NVIDIA стремится обеспечить революционную производительность для следующего поколения, одновременно вводя новые функции, улучшающие качество изображения. Turing был первым графическим процессором, который представил трассировку лучей с аппаратным ускорением — функцию, некогда считавшуюся святым Граалем компьютерной графики. Сегодня невероятно реалистичные и физически точные эффекты трассировки лучей добавляются во многие новые компьютерные игры класса AAA, а трассировка лучей с ускорением на ГП считается обязательной функцией для большинства компьютерных геймеров. Новые графические процессоры с архитектурой NVIDIA GA10x Ampere обеспечивают необходимые функции и производительность, чтобы наслаждаться этими новыми играми с трассировкой лучей и частотой кадров до 2 раз выше, чем можно достичь сейчас. Еще одна особенность Turing — усовершенствованная обработка ИИ с ускорением на ЦП, улучшающая шумоподавление, рендеринг и другие графические приложения, — тоже выходит на новый уровень благодаря архитектуре Ampere.
Напоследок — ссылка на полный документ.
- nvidia
- ampere
- geforce
- процессоры
- видеокарты
- архитектура процессоров
- высокая производительность
- Блог компании Pixonic
- Высокая производительность
- Компьютерное железо
- Видеокарты
- Процессоры