Количество совпадений в столбце Series
Вопрос — ‘d|c’ и ‘c|d’ это одно и то же вхождение или порядок имеет значение? ‘a|b’ и ‘b|a’ — это 2 вхождения ‘ab’ или 1 ‘ab’ и 1 ‘ba’?
21 дек 2020 в 13:42
Второй вопрос. вы говорите самые повторяющиеся ПАРЫ значений, и тут же указываете ТРОЙКУ значений abc. Считать и тройки? Или если юудут, то и 4-ки, 5-ки и т.д?
21 дек 2020 в 13:47
Зря вы тут упомянули Pandas/ думаю, он тут мало поможет ))
21 дек 2020 в 13:49
1 ответ 1
Сортировка: Сброс на вариант по умолчанию
Для столбца датафрейма:
df['x'].value_counts(sort=False).to_dict() df = pd.Series(['a|b', 'a', 'a', 'a|d', 'a|c|d', 'c|b|c', 'd|c', 'b|a']) df.value_counts(sort=False).to_dict() Второй вариант через groupby:
df.groupby(by=df).size() Out[20]: a 2 a|b 1 a|c|d 1 a|d 1 b|a 1 c|b|c 1 d|c 1 dtype: int64 Но можно получить тот же словарь:
df.groupby(by=df).size().to_dict() Отслеживать
ответ дан 20 дек 2020 в 7:54
Vasyl Kolomiets Vasyl Kolomiets
4,070 5 5 золотых знаков 26 26 серебряных знаков 49 49 бронзовых знаков
не совсем то. с первого раза нормально не объяснил. нужно узнать как какие значения в паре чаще всего встречаются друг с другом. чтобы применив к таким значениям столбца a|b, a|c|b, a|c|d, a|b|e получалось ab — раза, ас — два раза. обращу внимание, что в ячейке значения изначально разделены ‘|’
21 дек 2020 в 3:56
@Alexandr ну тут много решений будет. подправьте ваш основной вопрос — детализируйте. Думаю, тогда задача привлечет большее количество людей. А я сча подумаю над лобовым решением.
Pandas: как подсчитать вхождения определенного значения в столбце
Вы можете использовать следующий синтаксис для подсчета вхождений определенного значения в столбце кадра данных pandas:
df['column_name']. value_counts ()[ value ] Обратите внимание, что значение может быть как числом, так и символом.
В следующих примерах показано, как использовать этот синтаксис на практике.
Пример 1. Подсчет вхождений строки в столбце
В следующем коде показано, как подсчитать количество вхождений определенной строки в столбце кадра данных pandas:
import pandas as pd #create DataFrame df = pd.DataFrame() #count occurrences of the value 'B' in the 'team' column df['team']. value_counts ()['B'] 4 Из вывода мы видим, что строка «B» встречается 4 раза в столбце «команда».
Обратите внимание, что мы также можем использовать следующий синтаксис, чтобы узнать, как часто каждое уникальное значение встречается в столбце «команда»:
#count occurrences of every unique value in the 'team' column df['team']. value_counts () B 4 A 2 C 2 Name: team, dtype: int64 Пример 2. Подсчет вхождений числового значения в столбце
В следующем коде показано, как подсчитать количество вхождений числового значения в столбце кадра данных pandas:
import pandas as pd #create DataFrame df = pd.DataFrame() #count occurrences of the value 9 in the 'assists' column df['assists']. value_counts ()[ 9 ] 3 Из вывода мы видим, что значение 9 встречается 3 раза в столбце «ассисты».
Мы также можем использовать следующий синтаксис, чтобы узнать, как часто каждое уникальное значение встречается в столбце «помощь»:
#count occurrences of every unique value in the 'assists' column df['assists']. value_counts () 9 3 7 2 5 1 12 1 4 1 Name: assists, dtype: int64 Из вывода мы видим:
- Значение 9 встречается 3 раза.
- Значение 7 встречается 2 раза.
- Значение 5 встречается 1 раз.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
8 примеров использования value_counts из Pandas
Прежде чем начинать работать над проектом, связанным с данными, нужно посмотреть на набор данных. Разведочный анализ данных (EDA) — очень важный этап, ведь данные могут быть запутанными, и очень многое может пойти не по плану в процессе работы.
В библиотеке Pandas есть несколько функций для решения этой проблемы, и value_counts — одна из них. Она возвращает объект, содержащий уникальные значения из dataframe Pandas в отсортированном порядке. Однако многие забывают об этой возможности и используют параметры по умолчанию. В этом материале посмотрим, как получить максимум пользы от value_counts , изменив параметры по умолчанию.
Что такое функция value_counts()?
Функция value_counts() используется для получения Series , содержащего уникальные значения. Она вернет результат, отсортированный в порядке убывания, так что первый элемент в коллекции будет самым встречаемым. NA-значения не включены в результат.
Синтаксис
df[‘your_column’].value_counts() — вернет количество уникальных совпадений в определенной колонке.
Важно заметить, что value_counts работает только с series, но не dataframe. Поэтому нужно указать одни квадратные скобки df[‘your_column’] , а не пару df[[‘your_column’]] .
Параметры:
- normalize (bool, по умолчанию False) — если True , то возвращаемый объект будет содержать значения относительно частоты встречаемых значений.
- sort (bool, по умолчанию True) — сортировка по частоте.
- ascending (bool, по умолчанию False) — сортировка по возрастанию.
- bins (int) — вместе подсчета значений группирует их по отрезкам, но это работает только с числовыми данными.
- dropna (bool, по умолчанию True) — не включать количество NaN.
Загрузка данных для демонстрации
Рассмотрим, как использовать этот метод на реальных данных. Возьмем в качестве примера датасет из курса Coursera на Kaggle.
Для начала импортируем нужные библиотеки и сами данные. Это нужно в любом проекте. После этого проанализируем данные в notebook Jupyter.
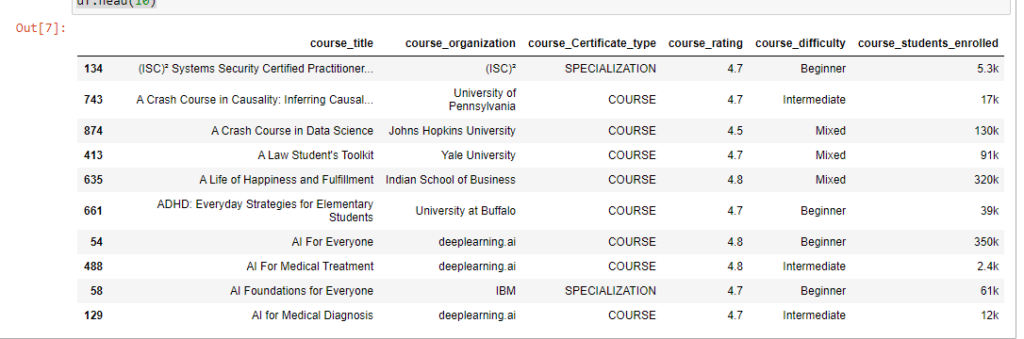
# импорт библиотеки import pandas as pd # Загрузка данных df = pd.read_csv('Downloads/coursea_data.csv', index_col=0) # проверка данных из csv df.head(10)
Проверьте, сколько записей в датасете и есть ли у нас пропуски.
df.info()Результат показывает, что в наборе 981 запись, и нет ни одного NA.
Int64Index: 891 entries, 134 to 163 Data columns (total 6 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 course_title 891 non-null object 1 course_organization 891 non-null object 2 course_Certificate_type 891 non-null object 3 course_rating 891 non-null float64 4 course_difficulty 891 non-null object 5 course_students_enrolled 891 non-null object dtypes: float64(1), object(5) memory usage: 48.7+ KB1. value_counts с параметрами по умолчанию
Теперь можно начинать использовать функцию value_counts . Начнем с базового применения функции.
Синтаксис: df['your_column'].value_counts() .
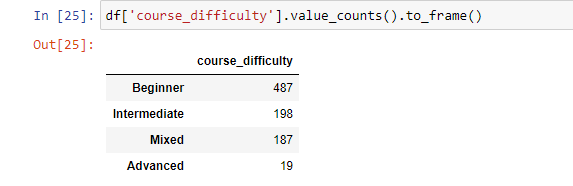
Получим количество каждого значения для колонки «course_difficulty».
Функция value_counts вернет количество совпадений всех уникальных значений по заданному индексу без пропусков. Это позволит увидеть, что больше всего курсов с уровнем сложности «Начинающий», после этого идут «Средний» и «Смешанный». А «Сложный» на последнем месте.
df['course_difficulty'].value_counts() --------------------------------------------------- Beginner 487 Intermediate 198 Mixed 187 Advanced 19 Name: course_difficulty, dtype: int64Теперь время поработать с параметрами.
2. Сортировка по возрастанию
По умолчанию value_counts() возвращает данные по убыванию. Изменит поведение можно, задав значение True для параметра ascending .
Синтаксис: df['your_column'].value_counts(ascending=True) .
df['course_difficulty'].value_counts(ascending=True) --------------------------------------------------- Advanced 19 Mixed 187 Intermediate 198 Beginner 487 Name: course_difficulty, dtype: int643. Сортировка в алфавитном порядке
В определенных случаях может существовать необходимость отсортировать записи в алфавитном порядке. Это делается с помощью добавления sort_index(ascending=True) после value_counts() .
По умолчанию функция сортирует «course_difficulty» по количеству совпадений, а с sort_index сортирует по индексу (имени колонки, для которой и используется функция):
df['course_difficulty'].value_counts().sort_index(ascending=True) --------------------------------------------------- Advanced 19 Beginner 487 Intermediate 198 Mixed 187 Name: course_difficulty, dtype: int64Если же требуется отобразить value_counts() в обратном алфавитном порядке, то нужно изменить направление сортировки: .sort_index(ascending=False) .
4. Сортировка по значению, а затем по алфавиту
Для этого примера используем другой датасет.
df_fruit = pd.DataFrame(< 'fruit': ['хурма']*5 + ['яблоки']*5 + ['бананы']*3 + ['персики']*3 + ['морковь']*3 + ['абрикосы'] + ['манго']*2 >)Так, нужно получить вывод, отсортированный в первую очередь по количеству совпадений значений, а потом уже и по алфавиту. Это можно сделать, объединив value_counts() c sort_index(ascending=False) и sort_values(ascending=False) .
df_fruit['fruit'].value_counts()\ .sort_index(ascending=False)\ .sort_values(ascending=False) ------------------------------------------------- хурма 5 яблоки 5 бананы 3 морковь 3 персики 3 манго 2 абрикосы 1 Name: fruit, dtype: int645. Относительная частота уникальных значений
Иногда нужно получить относительные значения, а не просто количество. С параметром normalize=True объект вернет относительную частоту уникальных значений. По умолчанию значение этого параметра равно False .
Синтаксис: df['your_column'].value_counts(normalize=True) .
df['course_difficulty'].value_counts(normalize=True) ------------------------------------------------- Beginner 0.546577 Intermediate 0.222222 Mixed 0.209877 Advanced 0.021324 Name: course_difficulty, dtype: float646. value_counts() для разбивки данных на дискретные интервалы
Еще один трюк, который часто игнорируют. value_counts() можно использовать для разбивки данных на дискретные интервалы с помощью параметра bin . Это работает только с числовыми данными. Принцип напоминает pd.cut . Посмотрим как это работает на примере колонки «course_rating». Сгруппируем значения колонки на 4 группы.
Синтаксис: df['your_column'].value_counts(bin=количество групп) .
df['course_rating'].value_counts(bins=4) ------------------------------------------------- (4.575, 5.0] 745 (4.15, 4.575] 139 (3.725, 4.15] 5 (3.297, 3.725] 2 Name: course_rating, dtype: int64Бинниг позволяет легко получить инсайты. Так, можно увидеть, что большая часть людей оценивает курс на 4.5. И лишь несколько курсов имеют оценку ниже 4.15.
7. value_counts() с пропусками
По умолчанию количество значений NaN не включается в результат. Но это поведение можно изменить, задав значение False для параметра dropna . Поскольку в наборе данных нет нулевых значений, в этом примере это ни на что не повлияет. Но сам параметр следует запомнить.
Синтаксис: df['your_column'].value_counts(dropna=False) .
8. value_counts() как dataframe
Как уже было отмечено, value_counts() возвращает Series, а не Dataframe. Если же нужно получить результаты в последнем виде, то для этого можно использовать функцию .to_frame() после .value_counts() .
Синтаксис: df['your_column'].value_counts().to_frame() .
Это будет выглядеть следующим образом:
Если нужно задать имя для колонки или переименовать существующую, то эту конвертацию можно реализовать другим путем.
value_counts = df['course_difficulty'].value_counts() # преобразование в df и присвоение новых имен колонкам df_value_counts = pd.DataFrame(value_counts) df_value_counts = df_value_counts.reset_index() df_value_counts.columns = ['unique_values', 'counts for course_difficulty'] df_value_countsGroupby и value_counts
Groupby — очень популярный метод в Pandas. С его помощью можно сгруппировать результат по одной колонке и посчитать значения в другой.
Синтаксис: df.groupby('your_column_1')['your_column_2'].value_counts() .
Так, с помощью groupby и value_counts можно посчитать количество типов сертификатов для каждого уровня сложности курсов.
df.groupby('course_difficulty')['course_Certificate_type'].value_counts() ------------------------------------------------- course_difficulty course_Certificate_type Advanced SPECIALIZATION 10 COURSE 9 Beginner COURSE 282 SPECIALIZATION 196 PROFESSIONAL CERTIFICATE 9 Intermediate COURSE 104 SPECIALIZATION 91 PROFESSIONAL CERTIFICATE 3 Mixed COURSE 187 Name: course_Certificate_type, dtype: int64Это мульти-индекс, позволяющий иметь несколько уровней индексов в dataframe. В этом случае сложность курса соответствует нулевому уровню индекса, а тип сертификата — первому.
Фильтрация значений по минимум и максимум
Работая с набором данных, может потребоваться вернуть количество ограниченных вхождений с помощью value_counts() .
Синтаксис: df['your_column'].value_counts().loc[lambda x : x > 1] .
Этот код отфильтрует все значения уникальных данных и покажет только те, где значение больше единицы.
Для примера ограничим рейтинг курса значением 4.
df.groupby('course_difficulty')['coudf['course_rating']\ .value_counts().loc[lambda x: x > 4] ------------------------------------------------- 4.8 256 4.7 251 4.6 168 4.5 80 4.9 68 4.4 34 4.3 15 4.2 10 Name: course_rating, dtype: int64value_counts() — удобный инструмент, позволяющий делать удобный анализ в одну строку.
Тест на знание функции value_counts
Дана колонка с днями недели, где 1 - понедельник, 7 - воскресенье. Как получить относительное количество только будних дней?
Как анализировать данные на Python с Pandas: первые шаги
Мария Жарова Эксперт по Python и математике для Data Science, ментор одного из проектов на курсе по Data Science.
Pandas — главная Python-библиотека для анализа данных. Она быстрая и мощная: в ней можно работать с таблицами, в которых миллионы строк. Вместе с Марией Жаровой, ментором проекта на курсе по Data Science, рассказываем про команды, которые позволят начать работать с реальными данными.
Среда разработки
Pandas работает как в IDE (средах разработки), так и в облачных блокнотах для программирования. Как установить библиотеку в конкретную IDE, читайте тут. Мы для примера будем работать в облачной среде Google Colab. Она удобна тем, что не нужно ничего устанавливать на компьютер: файлы можно загружать и работать с ними онлайн, к тому же есть совместный режим для работы с коллегами. Про Colab мы писали в этом обзоре. Пройдите тест и узнайте, какой вы аналитик данных и какие перспективы вас ждут. Ссылка в конце статьи.
Освойте профессию «Data Scientist» на курсе с МГУ
Data Scientist с нуля до PROОсвойте профессию Data Scientist с нуля до уровня PRO на углубленном курсе совместно с академиком РАН из МГУ. Изучите продвинутую математику с азов, получите реальный опыт на практических проектах и начните работать удаленно из любой точки мира.
25 месяцев
Data Scientist с нуля до PRO
Создавайте ML-модели и работайте с нейронными сетями
6 224 ₽/мес11 317 ₽/мес
Анализ данных в Pandas
Создание блокнота в Google Colab На сайте Google Colab сразу появляется экран с доступными блокнотами. Создадим новый блокнот:
Импортирование библиотеки Pandas недоступна в Python по умолчанию. Чтобы начать с ней работать, нужно ее импортировать с помощью этого кода:
import pandas as pd
pd — это распространенное сокращенное название библиотеки. Далее будем обращаться к ней именно так.





И прочитать с помощью такой команды:
Это можно сделать через словарь и через преобразование вложенных списков (фактически таблиц).

Если нужно посмотреть на другое количество строк, оно указывается в скобках, например df.head(12) . Последние строки фрейма выводятся методом .tail() .
Также чтобы просто полностью красиво отобразить датасет, используется функция display() . По умолчанию в Jupyter Notebook, если написать имя переменной на последней строке какой-либо ячейки (даже без ключевого слова display), ее содержимое будет отображено.

Характеристики датасета Чтобы получить первичное представление о статистических характеристиках нашего датасета, достаточно этой команды: df.describe()
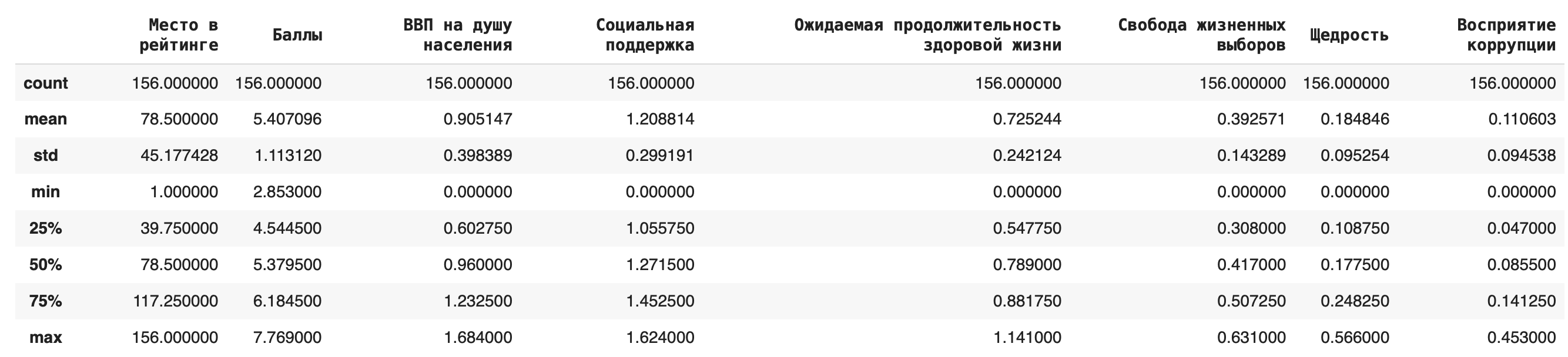

Обзор содержит среднее значение, стандартное отклонение, минимум и максимум, верхние значения первого и третьего квартиля и медиану по каждому столбцу.
Работа с отдельными столбцами или строками
Выделить несколько столбцов можно разными способами.
1. Сделать срез фрейма df[['Место в рейтинге', 'Ожидаемая продолжительность здоровой жизни']]

Срез можно сохранить в новой переменной: data_new = df[['Место в рейтинге', 'Ожидаемая продолжительность здоровой жизни']]
Теперь можно выполнить любое действие с этим сокращенным фреймом.
2. Использовать метод loc
Если столбцов очень много, можно использовать метод loc, который ищет значения по их названию: df.loc [:, 'Место в рейтинге':'Социальная поддержка']
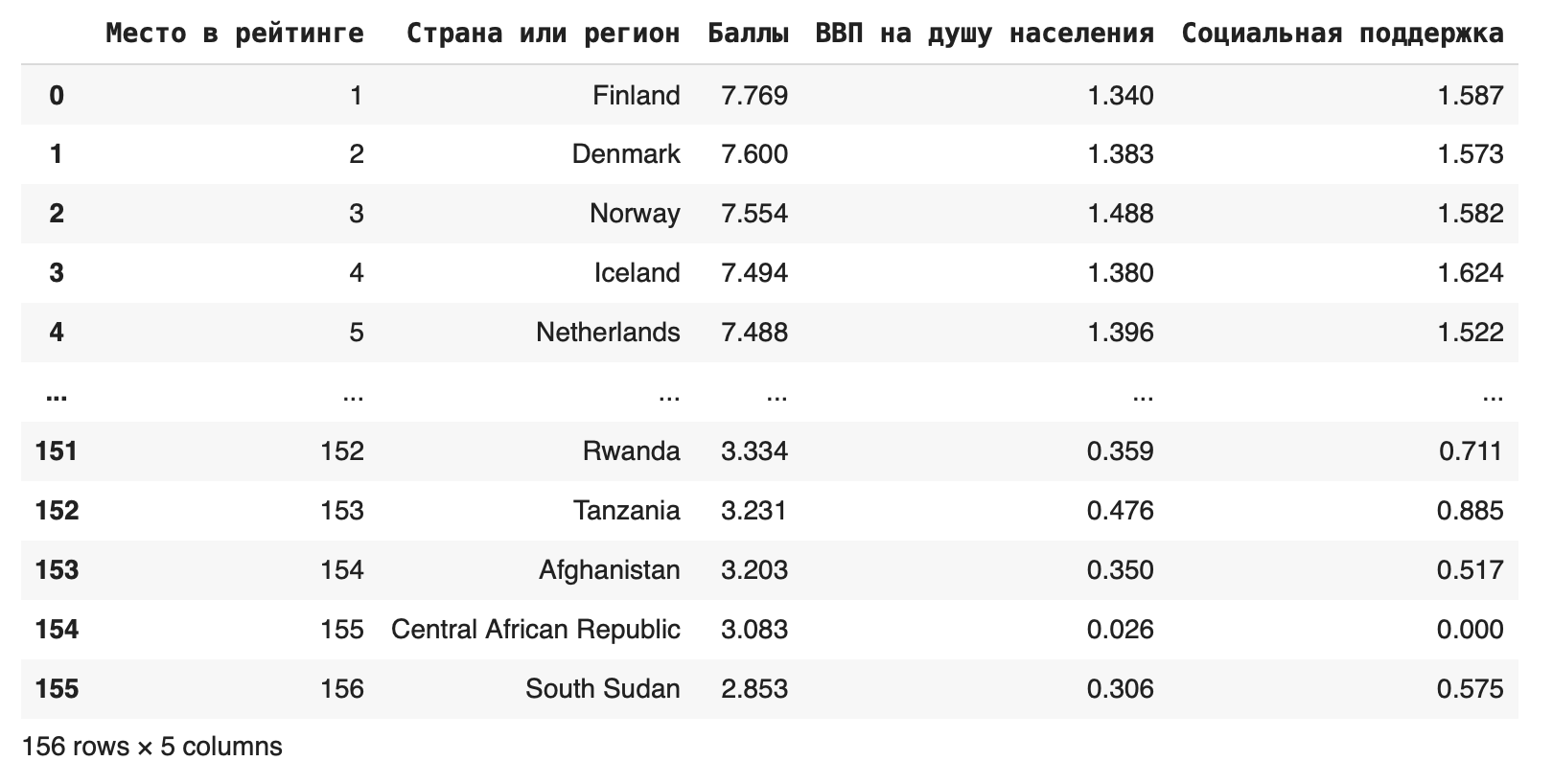
В этом случае мы оставили все столбцы от Места в рейтинге до Социальной поддержки.

Станьте дата-сайентистом на курсе с МГУ и решайте амбициозные задачи с помощью нейросетей
3. Использовать метод iloc
Если нужно вырезать одновременно строки и столбцы, можно сделать это с помощью метода iloc: df.iloc[0:100, 0:5]
Первый параметр показывает индексы строк, которые останутся, второй — индексы столбцов. Получаем такой фрейм:
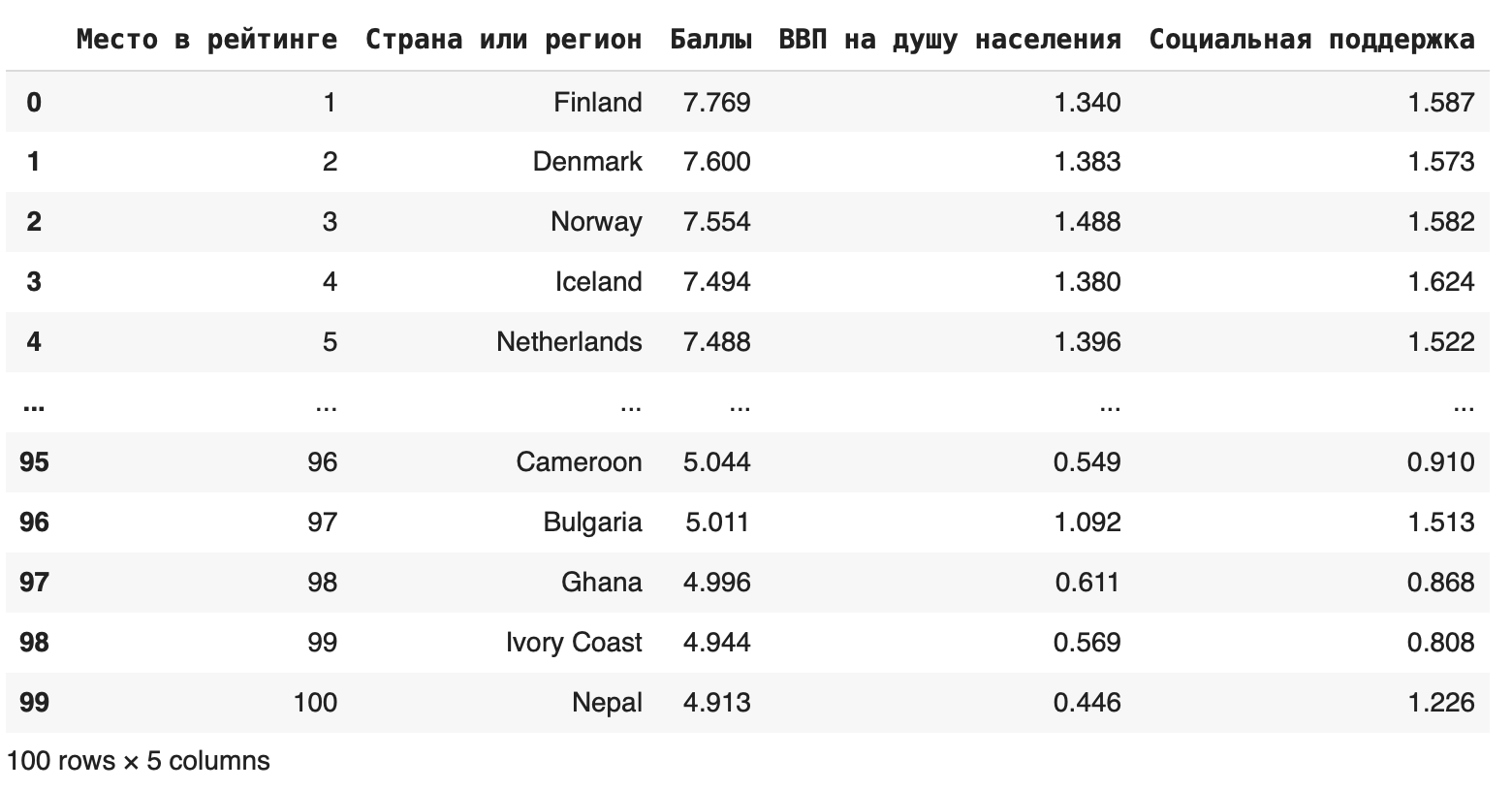
В методе iloc значения в правом конце исключаются, поэтому последняя строка, которую мы видим, — 99.
4. Использовать метод tolist()
Можно выделить какой-либо столбец в отдельный список при помощи метода tolist(). Это упростит задачу, если необходимо извлекать данные из столбцов: df['Баллы'].tolist()
Часто бывает нужно получить в виде списка названия столбцов датафрейма. Это тоже можно сделать с помощью метода tolist(): df.columns.tolist()

Добавление новых строк и столбцов
В исходный датасет можно добавлять новые столбцы, создавая новые «признаки», как говорят в машинном обучении. Например, создадим столбец «Сумма», в который просуммируем значения колонок «ВВП на душу населения» и «Социальная поддержка» (сделаем это в учебных целях, практически суммирование этих показателей не имеет смысла): df['Сумма'] = df['ВВП на душу населения'] + df['Социальная поддержка']

Можно добавлять и новые строки: для этого нужно составить словарь с ключами — названиями столбцов. Если вы не укажете значения в каких-то столбцах, они по умолчанию заполнятся пустыми значениями NaN. Добавим еще одну страну под названием Country: new_row = df = df.append(new_row, ignore_index=True)
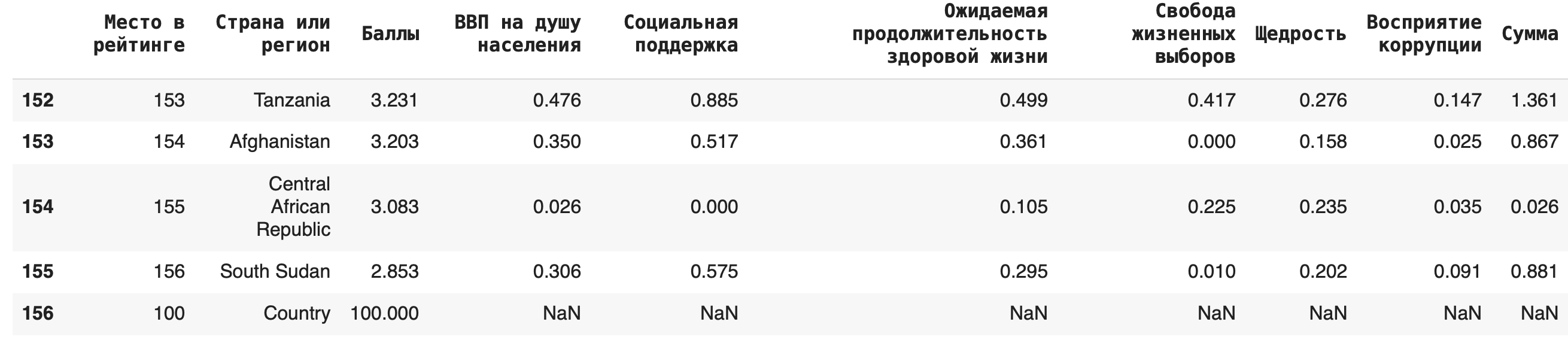
Важно: при добавлении новой строки методом .append() не забывайте указывать параметр ignore_index=True, иначе возникнет ошибка.
Иногда бывает полезно добавить строку с суммой, медианой или средним арифметическим) по столбцу. Сделать это можно с помощью агрегирующих (aggregate (англ.) — группировать, объединять) функций: sum(), mean(), median(). Для примера добавим в конце строку с суммами значений по каждому столбцу: df = df.append(df.sum(axis=0), ignore_index = True)
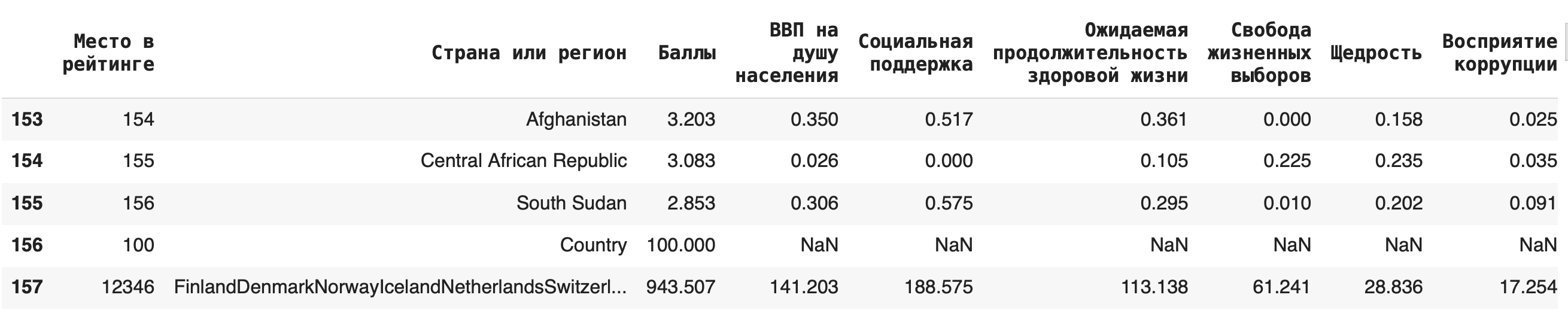
Удаление строк и столбцов
Удалить отдельные столбцы можно при помощи метода drop() — это целесообразно делать, если убрать нужно небольшое количество столбцов. df = df.drop(['Сумма'], axis = 1)
В других случаях лучше воспользоваться описанными выше срезами.
Обратите внимание, что этот метод требует дополнительного сохранения через присваивание датафрейма с примененным методом исходному. Также в параметрах обязательно нужно указать axis = 1, который показывает, что мы удаляем именно столбец, а не строку.
Соответственно, задав параметр axis = 0, можно удалить любую строку из датафрейма: для этого нужно написать ее номер в качестве первого аргумента в методе drop(). Удалим последнюю строчку (указываем ее индекс — это будет количество строк): df = df.drop(df.shape[0]-1, axis = 0)
Копирование датафрейма
Можно полностью скопировать исходный датафрейм в новую переменную. Это пригодится, если нужно преобразовать много данных и при этом работать не с отдельными столбцами, а со всеми данными: df_copied = df.copy()
Уникальные значения
Уникальные значения в какой-либо колонке датафрейма можно вывести при помощи метода .unique(): df['Страна или регион'].unique()
Чтобы дополнительно узнать их количество, можно воспользоваться функцией len(): len(df['Страна или регион'].unique())
Подсчет количества значений
Отличается от предыдущего метода тем, что дополнительно подсчитывает количество раз, которое то или иное уникальное значение встречается в колонке, пишется как .value_counts(): df['Страна или регион'].value_counts()

Группировка данных
Некоторым обобщением .value_counts() является метод .groupby() — он тоже группирует данные какого-либо столбца по одинаковым значениям. Отличие в том, что при помощи него можно не просто вывести количество уникальных элементов в одном столбце, но и найти для каждой группы сумму / среднее значение / медиану по любым другим столбцам.
Рассмотрим несколько примеров. Чтобы они были более наглядными, округлим все значения в столбце «Баллы» (тогда в нем появятся значения, по которым мы сможем сгруппировать данные): df['Баллы_new'] = round(df['Баллы'])
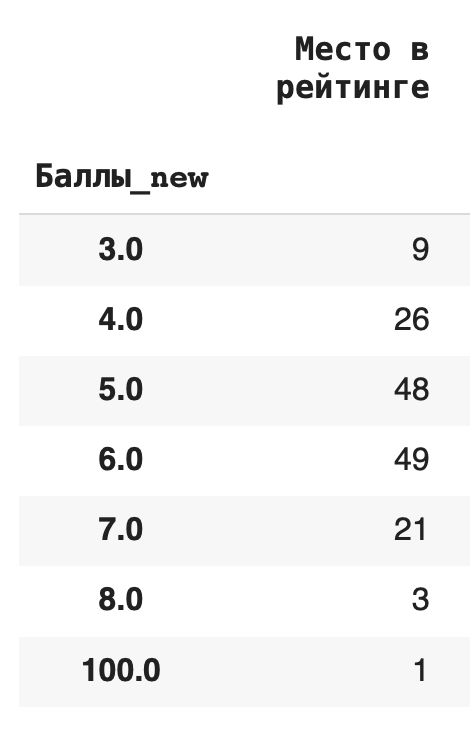
1) Сгруппируем данные по новому столбцу баллов и посчитаем, сколько уникальных значений для каждой группы содержится в остальных столбцах. Для этого в качестве агрегирующей функции используем .count(): df.groupby('Баллы_new').count()
Получается, что чаще всего страны получали 6 баллов (таких было 49):
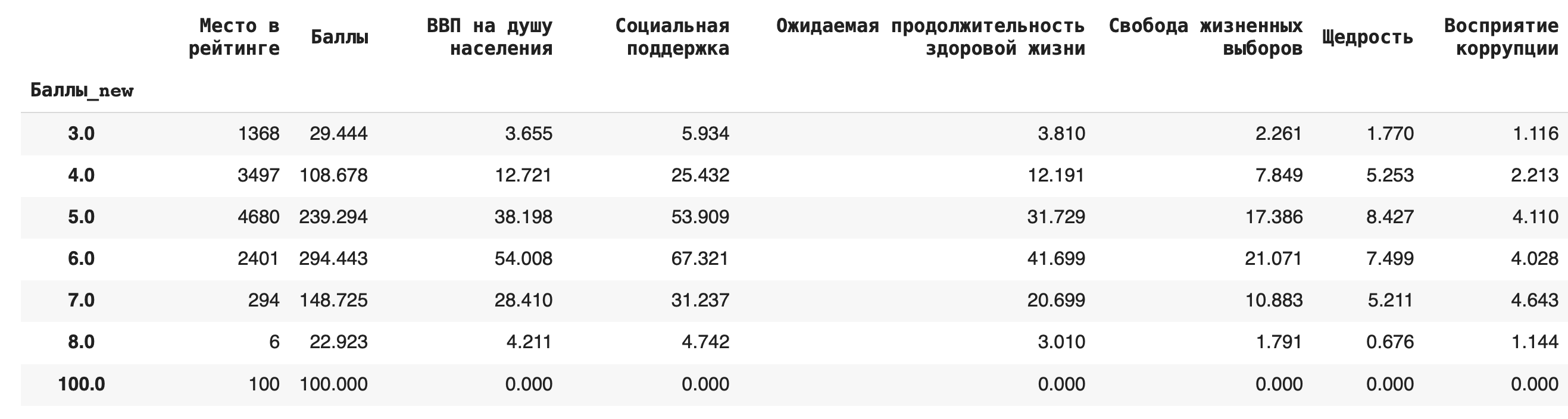
2) Получим более содержательный для анализа данных результат — посчитаем сумму значений в каждой группе. Для этого вместо .count() используем sum(): df.groupby('Баллы_new').sum()
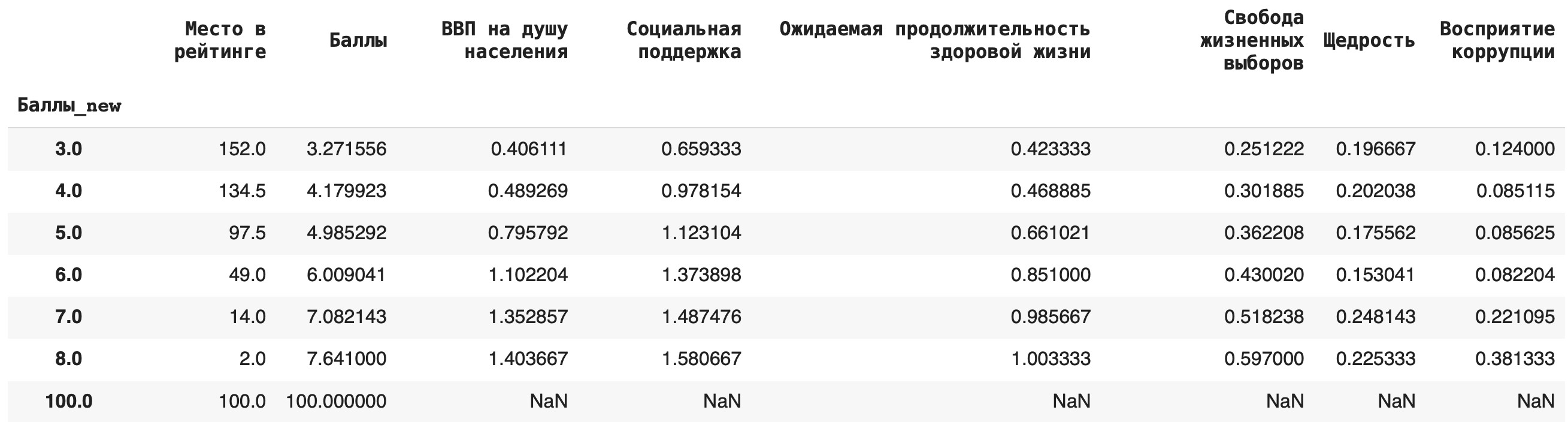
3) Теперь рассчитаем среднее значение по каждой группе, в качестве агрегирующей функции в этом случае возьмем mean(): df.groupby('Баллы_new').mean()
4) Рассчитаем медиану. Для этого пишем команду median(): df.groupby('Баллы_new').median()
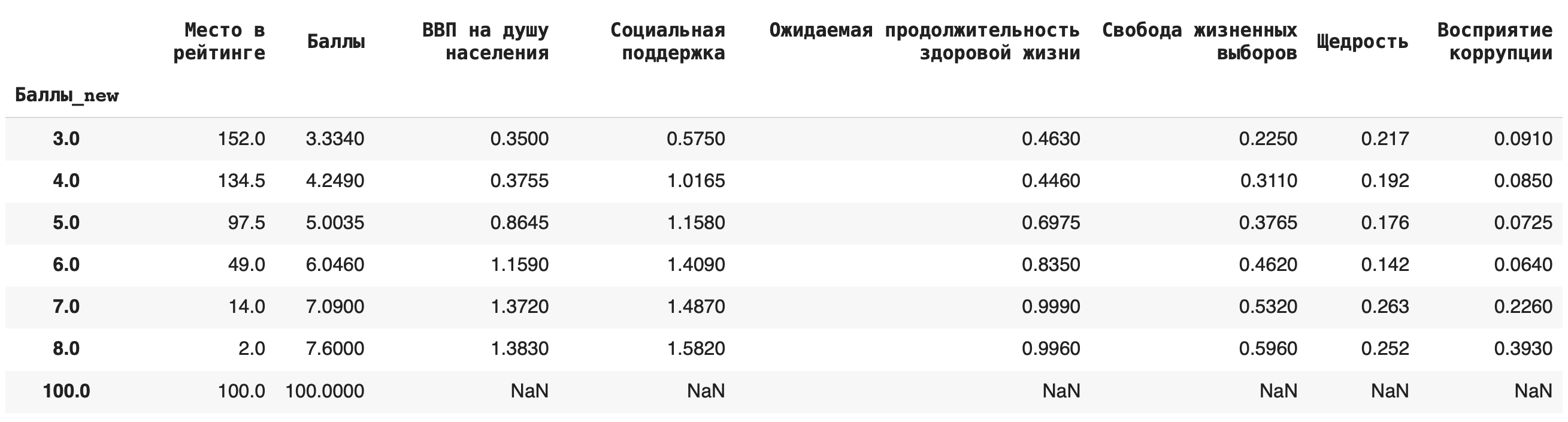
Это самые основные агрегирующие функции, которые пригодятся на начальном этапе работы с данными.
Вот пример синтаксиса, как можно сагрегировать значения по группам при помощи сразу нескольких функций:
df_agg = df.groupby('Баллы_new').agg(< 'Баллы_new': 'count', 'Баллы_new': 'sum', 'Баллы_new': 'mean', 'Баллы_new': 'median' >)
Сводные таблицы
Бывает, что нужно сделать группировку сразу по двум параметрам. Для этого в Pandas используются сводные таблицы или pivot_table(). Они составляются на основе датафреймов, но, в отличие от них, группировать данные можно не только по значениям столбцов, но и по строкам.
В ячейки такой таблицы помещаются сгруппированные как по «координате» столбца, так и по «координате» строки значения. Соответствующую агрегирующую функцию указываем отдельным параметром.
Разберемся на примере. Сгруппируем средние значения из столбца «Социальная поддержка» по баллам в рейтинге и значению ВВП на душу населения. В прошлом действии мы уже округлили значения баллов, теперь округлим и значения ВВП: df['ВВП_new'] = round(df['ВВП на душу населения'])
Теперь составим сводную таблицу: по горизонтали расположим сгруппированные значения из округленного столбца «ВВП» (ВВП_new), а по вертикали — округленные значения из столбца «Баллы» (Баллы_new). В ячейках таблицы будут средние значения из столбца «Социальная поддержка», сгруппированные сразу по этим двум столбцам: pd.pivot_table(df, index = ['Баллы_new'], columns = ['ВВП_new'], values = 'Социальная поддержка', aggfunc = 'mean')
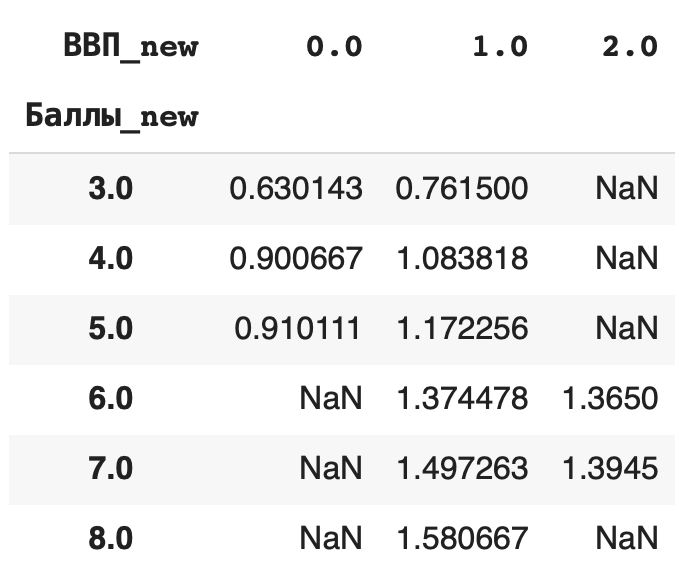
Сортировка данных
Строки датасета можно сортировать по значениям любого столбца при помощи функции sort_values(). По умолчанию метод делает сортировку по убыванию. Например, отсортируем по столбцу значений ВВП на душу населения: df.sort_values(by = 'ВВП на душу населения').head()
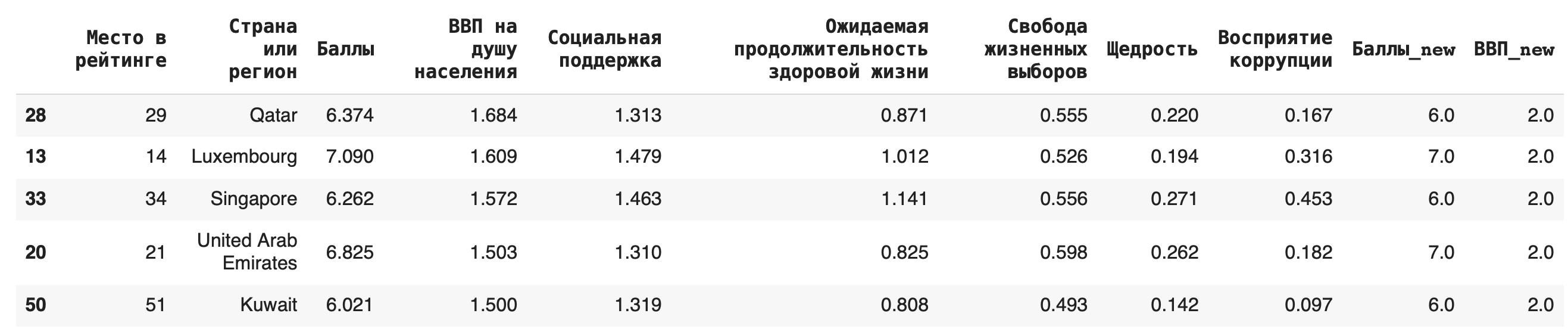
Видно, что самые высокие ВВП совсем не гарантируют высокое место в рейтинге.
Чтобы сделать сортировку по убыванию, можно воспользоваться параметром ascending (от англ. «по возрастанию») = False: df.sort_values(by = 'ВВП на душу населения', ascending=False)
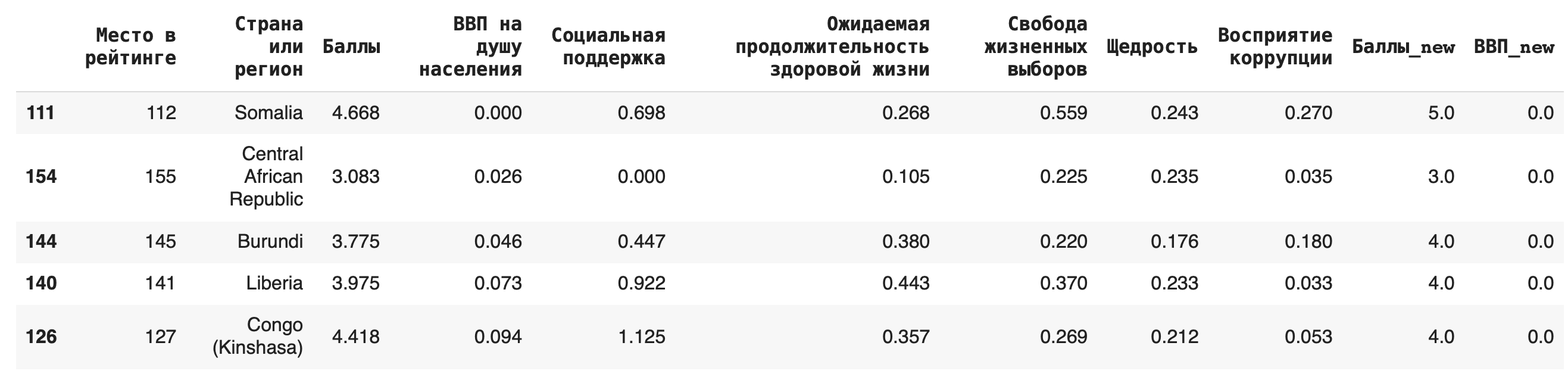
Фильтрация
Иногда бывает нужно получить строки, удовлетворяющие определенному условию; для этого используется «фильтрация» датафрейма. Условия могут быть самые разные, рассмотрим несколько примеров и их синтаксис:
1) Получение строки с конкретным значением какого-либо столбца (выведем строку из датасета для Норвегии): df[df['Страна или регион'] == 'Norway']

2) Получение строк, для которых значения в некотором столбце удовлетворяют неравенству. Выведем строки для стран, у которых «Ожидаемая продолжительность здоровой жизни» больше единицы:
df[df['Ожидаемая продолжительность здоровой жизни'] > 1]
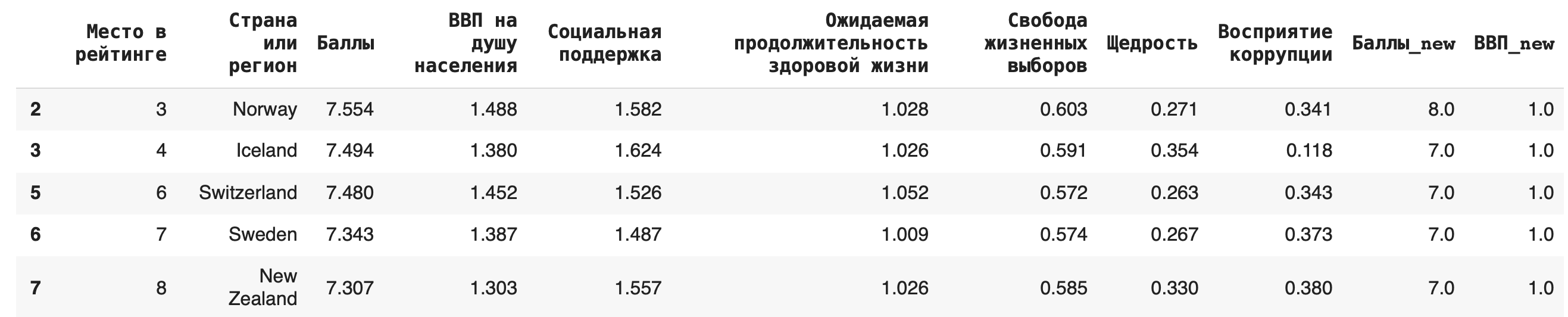
3) В условиях фильтрации можно использовать не только математические операции сравнения, но и методы работы со строками. Выведем строки датасета, названия стран которых начинаются с буквы F, — для этого воспользуемся методом .startswith():
df[df['Страна или регион'].str.startswith('F')]

4) Можно комбинировать несколько условий одновременно, используя логические операторы. Выведем строки, в которых значение ВВП больше 1 и уровень социальной поддержки больше 1,5: df[(df['ВВП на душу населения'] > 1) & (df['Социальная поддержка'] > 1.5)]

Таким образом, если внутри внешних квадратных скобок стоит истинное выражение, то строка датасета будет удовлетворять условию фильтрации. Поэтому в других ситуациях можно использовать в условии фильтрации любые функции/конструкции, возвращающие значения True или False.
Применение функций к столбцам
Зачастую встроенных функций и методов для датафреймов из библиотеки бывает недостаточно для выполнения той или иной задачи. Тогда мы можем написать свою собственную функцию, которая преобразовывала бы строку датасета как нам нужно, и затем использовать метод .apply() для применения этой функции ко всем строкам нужного столбца.
Рассмотрим пример: напишем функцию, которая преобразует все буквы в строке к нижнему регистру, и применим к столбцу стран и регионов: def my_lower(row): return row.lower() df['Страна или регион'].apply(lower)

Очистка данных
Это целый этап работы с данными при подготовке их к построению моделей и нейронных сетей. Рассмотрим основные приемы и функции.
1) Удаление дубликатов из датасета делается при помощи функции drop_duplucates(). По умолчанию удаляются только полностью идентичные строки во всем датасете, но можно указать в параметрах и отдельные столбцы. Например, после округления у нас появились дубликаты в столбцах «ВВП_new» и «Баллы_new», удалим их: df_copied = df.copy() df_copied.drop_duplicates(subset = ['ВВП_new', 'Баллы_new'])
Этот метод не требует дополнительного присваивания в исходную переменную, чтобы результат сохранился, — поэтому предварительно создадим копию нашего датасета, чтобы не форматировать исходный.
Строки-дубликаты удаляются полностью, таким образом, их количество уменьшается. Чтобы заменить их на пустые, можно использовать параметр inplace = True. df_copied.drop_duplicates(subset = ['ВВП_new', 'Баллы_new'], inplace = True)
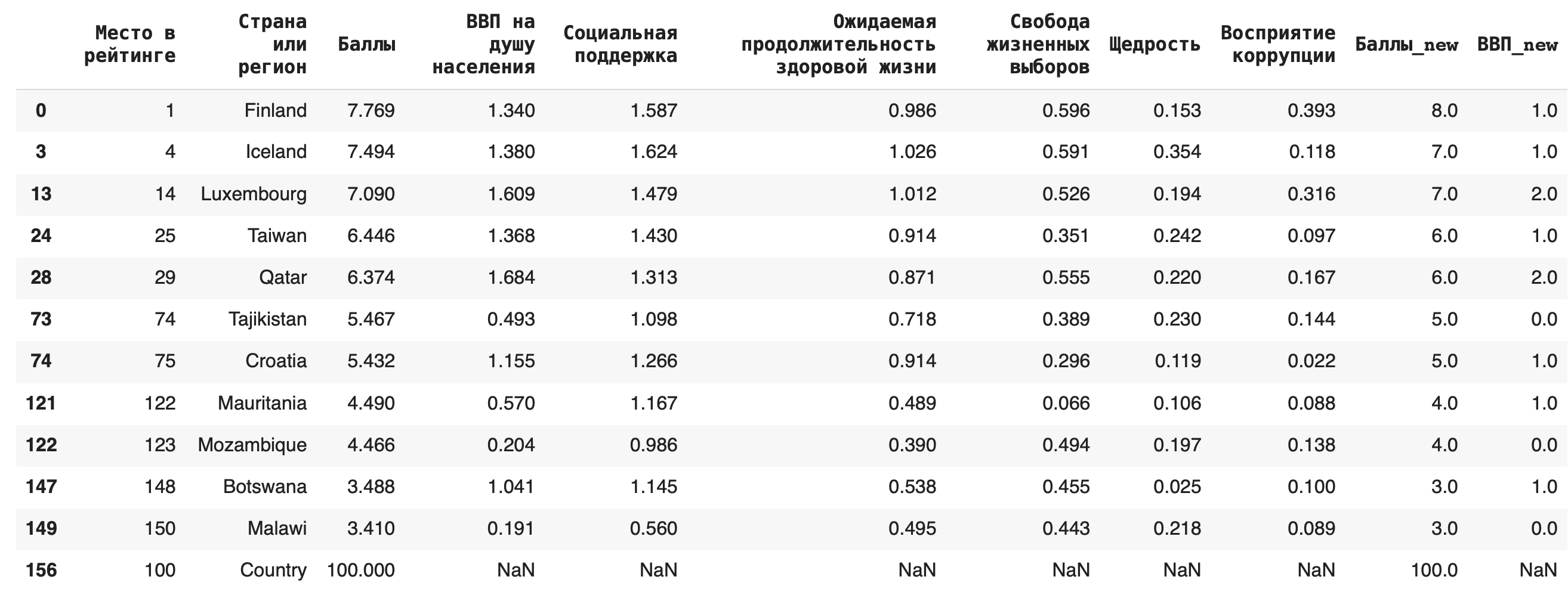
2) Для замены пропусков NaN на какое-либо значение используется функция fillna(). Например, заполним появившиеся после предыдущего пункта пропуски в последней строке нулями: df_copied.fillna(0)
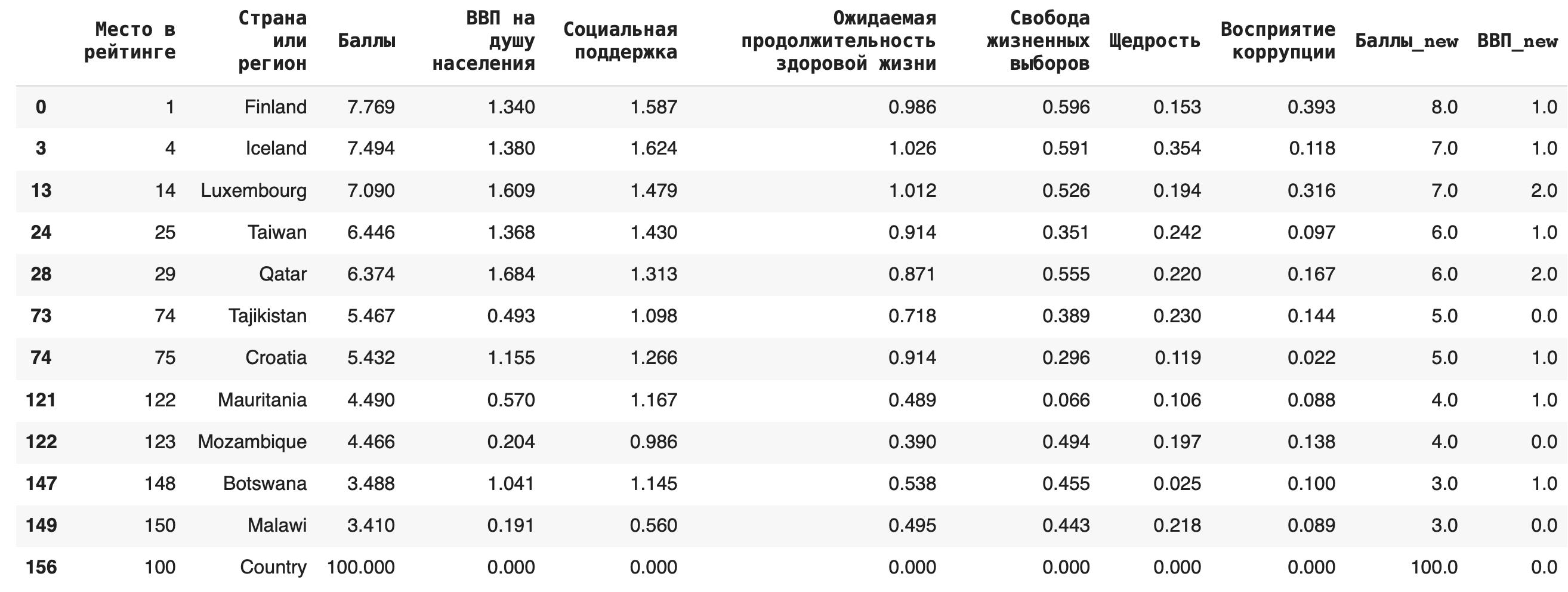
3) Пустые строки с NaN можно и вовсе удалить из датасета, для этого используется функция dropna() (можно также дополнительно указать параметр inplace = True): df_copied.dropna()
Построение графиков
В Pandas есть также инструменты для простой визуализации данных.
1) Обычный график по точкам.
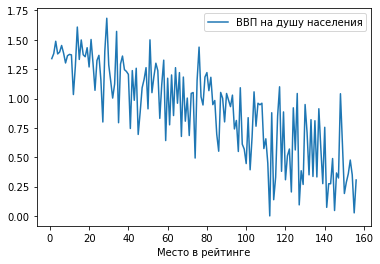
Построим зависимость ВВП на душу населения от места в рейтинге: df.plot(x = 'Место в рейтинге', y = 'ВВП на душу населения')
2) Гистограмма.
Отобразим ту же зависимость в виде столбчатой гистограммы: df.plot.hist(x = 'Место в рейтинге', y = 'ВВП на душу населения')
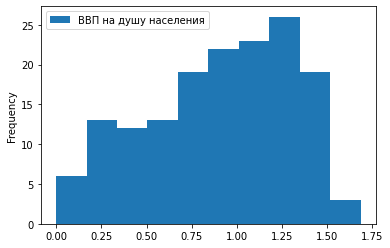
3) Точечный график.
df.plot.scatter(x = 'Место в рейтинге', y = 'ВВП на душу населения')
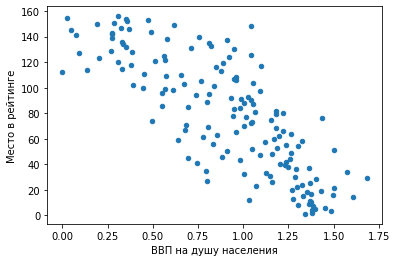
Мы видим предсказуемую тенденцию: чем выше ВВП на душу населения, тем ближе страна к первой строчке рейтинга.
Сохранение датафрейма на компьютер
Сохраним наш датафрейм на компьютер: df.to_csv('WHR_2019.csv')
Теперь с ним можно работать и в других программах.
Блокнот с кодом можно скачать здесь (формат .ipynb).