Что такое Apache Kafka: как устроен и работает брокер сообщений
Apache Kafka — распределенный брокер сообщений, работающий в стриминговом режиме. В статье мы расскажем про его устройство и преимущества, а также о том, где применяют это ПО.

Apache Kafka — распределенный брокер сообщений, работающий в стриминговом режиме. В статье мы расскажем про его устройство и преимущества, а также о том, где применяют «Кафку».
Что такое брокер сообщений
Главная задача брокера — обеспечение связи и обмена информацией между приложениями или отдельными модулями в режиме реального времени.
Брокер — система, преобразующая сообщение от источника данных (продюсера) в сообщение принимающей стороны (консьюмера). Брокер выступает проводником и состоит из серверов, объединенных в кластеры.
Apache Kafka — диспетчер сообщений, разработанный LinkedIn. В 2011 году был опубликован программный код. В 2012 году Kafka попал в инкубатор Apache, дальнейшая разработка ведется в рамках Apache Software Foundation. Открытое программное обеспечение с разрешительной лицензией написано на Java и Scala.
Изначально «Кафку» создавали как систему, оптимизированную под запись, и создатель Джей Крепс выбрал такое название в честь одного из своих любимых писателей.
Шаги передачи данных
Чтобы понять, как функционирует распределенная система Apache Kafka, необходимо проследить путь данных.
Событие или сообщение — данные, которые поступают из одного сервиса, хранятся на узлах Kafka и читаются другими сервисами. Сообщение состоит из:
- Key — опциональный ключ, нужен для распределения сообщений по кластеру.
- Value — массив байт, бизнес-данные.
- Timestamp — текущее системное время, устанавливается отправителем или кластером во время обработки.
- Headers — пользовательские атрибуты key-value, которые прикрепляют к сообщению.
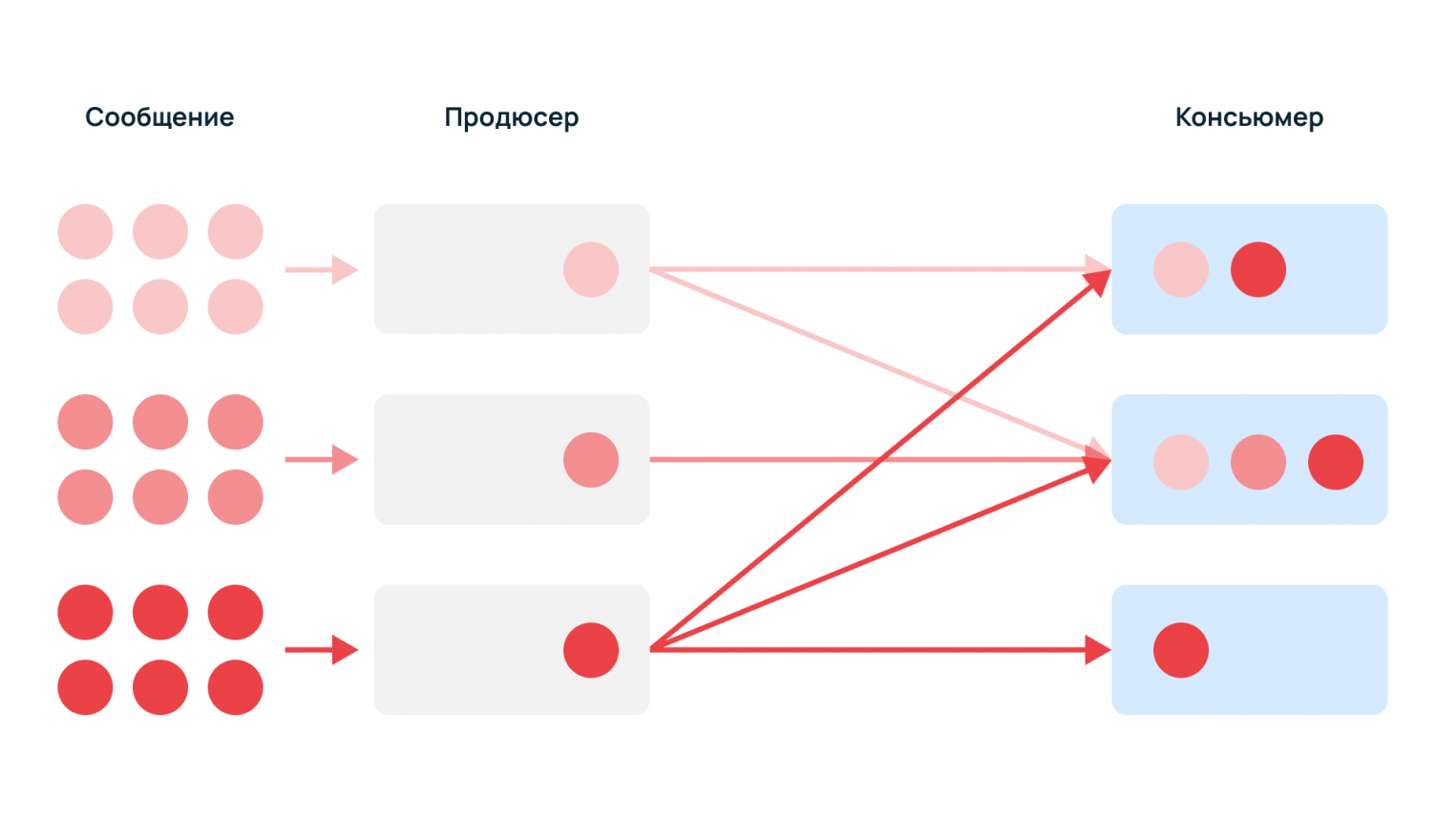
Продюсер — поставщик данных, который генерирует сообщения — например, служебные события, логи, метрики, события мониторинга.
Консьюмер — потребитель данных, который читает и использует события, пример — сервис сбора статистики.
Какие сложности решает распределенная система
Сообщения могут быть однотипными или разнородными, поскольку разным потребителям нужны разные данные. Один тип событий может быть нужен всем консьюмерам, а другие — только одному.
Без брокера продюсеры должны знать получателя и резервного консьюмера, если основной недоступен. К тому же, поставщикам данных придется самостоятельно регистрировать новых консьюмеров. С помощью брокера продюсеры просто отправляют информацию в единый узел.
Managed service для Apache Kafka
Сообщения хранятся на узлах-брокерах. Kafka — масштабируемый кластер со множеством взаимозаменяемых серверов, в которые добавляются новые брокеры, распределяющие задачи между собой.
ZooKeeper — инструмент-координатор, действует как общая служба конфигурации в системе. Работает как база для хранения метаданных о состоянии узлов кластера и расположении сообщений. ZooKeeper обеспечивает гибкую и надежную синхронизацию в распределенной системе, позволяя нескольким клиентам выполнять одновременно чтение и запись.
Kafka Controller — среди брокеров Zookeeper выбирает одного, который будет обеспечивать консистентность данных.
Topic — принцип деления потока данных, базовая и основная сущность Apache Kafka. В топик складывается стрим данных, единая очередь из входящих сообщений.
Partition — для ускорения чтения и записи топики делятся на партиции. Происходит параллелизация данных. Это конфигурируемый параметр, сообщения могут отправлять несколько продюсеров и принимать несколько консьюмеров.
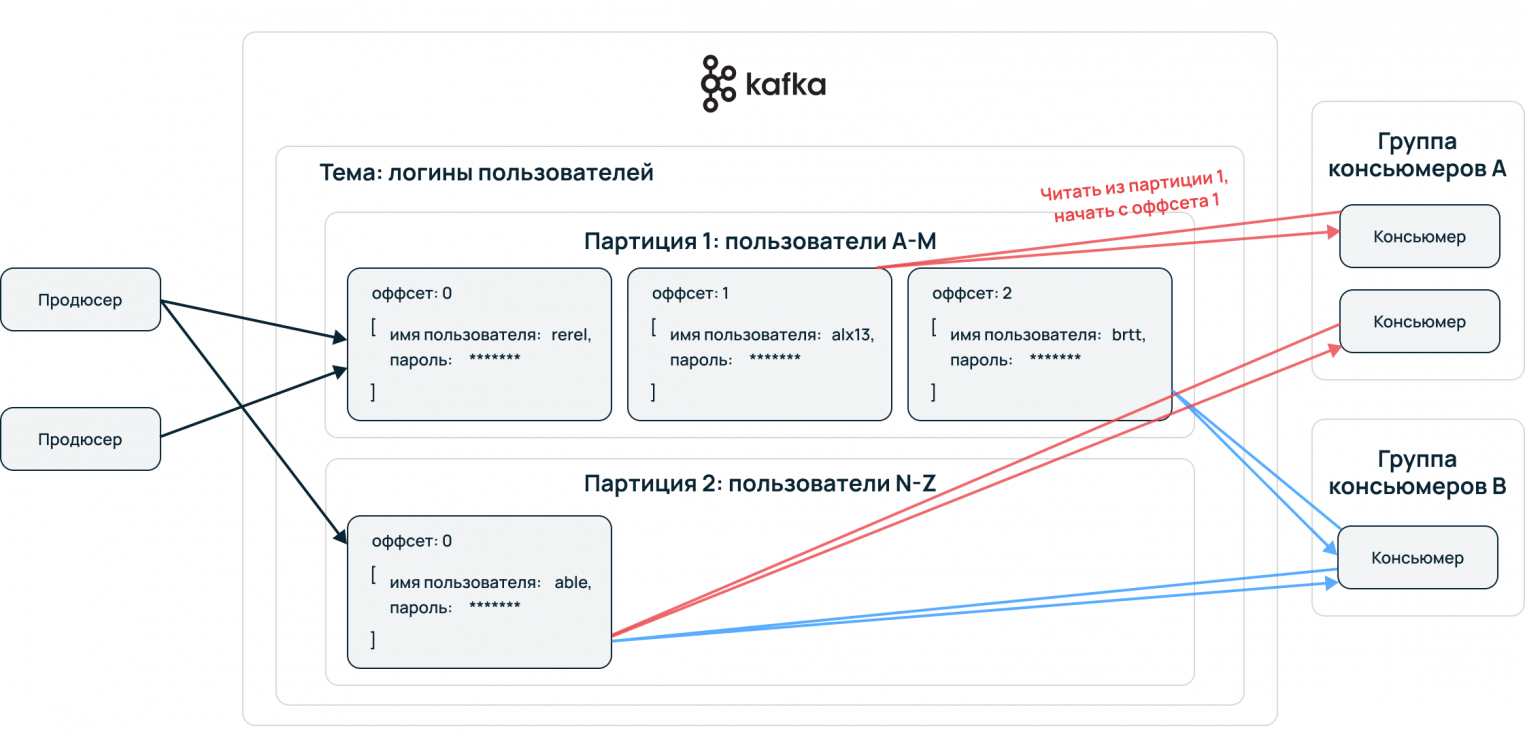
Упорядочение событий происходит на уровне партиций. Принимающая сторона потребляет данные в порядке расположения в партиции. Пример: все события одного пользователя сервисы принимают упорядоченно, обработка сохраняет последовательность пути пользователя. Выстраивается конвейер данных, алгоритмы машинного обучения могут извлекать из сырой информации необходимую для бизнеса информацию.
Преимущества Apache Kafka
Брокер распределяет информацию в широковещательном режиме. Применяющийся в Apache Kafka подход нужен для масштабирования и репликации данных.
Горизонтальное масштабирование
Множество объединенных серверов гарантируют высокую доступность данных — выход из строя одного из узлов не нарушает целостность. Кластер состоит из обычных машин, а не суперкомпьютеров, их можно менять и дополнять. Система автоматически перебалансируется.
Чтобы события не потерялись, существуют механизмы репликации. Данные записываются на несколько машин, если что-то случается с сервером, он переключается на резервный. Кластер в режиме реального времени определяет, где находятся данные, и продолжает их использовать.
Офсеты
Если консьюмер падает в процессе получения данных, то, когда он запустится вновь и ему нужно будет вернутся к чтению этого сообщения, он воспользуется офсетом и продолжит с нужного места.
Взаимодействие через API
Брокеры решают проблему интеграции разных технических стеков и протоколов. Интеграция происходит просто: продюсерам и консьюмерам необходимо знать только API брокера. Они не контактируют между собой, с помощью чего достигается высокая интегрируемость с другими системами.
Принцип first in — first out
Принцип FIFO действует на консьюмеров. Чтение происходит в том же порядке, в котором пришла информация.
Где применяется Apache Kafka
Отказоустойчивая система используется в бизнесе, где необходимо собирать, хранить и обрабатывать большие неструктурированные данные. Примеры — платформы, где требуется интеграция данных из большого количества источников, сервисы стриминговой аналитики, mission-critical applications.
Big Data
Первоначально LinkedIn разработали «Кафку» для своих целей: обмена данными между службами, репликации баз данных, потоковой передачи информации о деятельности и операционных показателях приложений.
Для IBM Apache Kafka работает как средство обмена сообщениями между микросервисами. В аналитических системах американской корпорации Apache Kafka обрабатывает потоковые и событийные данные.
Uber, Twitter, Netflix и AirBnb с помощью хорошо развитых пайплайнов обработки данных передают миллиарды сообщений в день. «Кафка» решает проблемы перемещения Big data из одного источника в другой.
Издание The New York Times использует Apache Kafka для хранения и распространения опубликованного контента среди различных приложений и систем, которые делают его доступным для читателей в режиме реального времени.
Internet of Things
IoT-платформы используют архитектуру с большим количеством конечных устройств: контроллеров, датчиков, сенсоров и smart-гаджетов. ПО интернета вещей с помощью алгоритмов ML составляет графики профилактического ремонта оборудования, анализируя данные, поступающие с устройств.
ML-системы работают с онлайн-потоками, когда приборы, приложения и пользователи постоянно посылают данные, а сервисы обрабатывают их в реальном времени. Apache Kafka выступает центральным звеном в этом процессе.
Отрасли
Kafka используют организации практически в любой отрасли: разработка ПО, финансовые услуги, здравоохранение, государственное управление, транспорт, телеком, геймдев.
Сегодня Kafka пользуются тысячи компаний, более 60% входят в список Fortune 100. На официальном сайте представлен полный список корпораций и учреждений, которые используют брокера Apache.
Конкуренты
Чаще всего Kafka сравнивают с RabbitMQ. Обе системы — брокеры сообщений. Главное отличие в модели доставки: Kafka добавляет сообщение в журнал, и консьюмер сам забирает информацию из топика; брокер RabbitMQ самостоятельно отправляет сообщения получателям — помещает событие в очередь и отслеживает его статус.
«Кролик» удаляет событие после доставки, «Кафка» хранит до запланированной очистки журнала. Таким образом, брокер Apache используется как источник истории изменений.
Разработчики RabbitMQ создали системы управления потоком сообщений: мониторинг получения, маршрутизация и шаблоны доставки. Подобное гибкое управление подойдет для высокоскоростного обмена сообщениями между несколькими сервисами. Минус такого подхода в снижении производительности при высокой нагрузке.
Главный вывод — для сбора и агрегации событий из большого количества источников, логов и метрик больше подойдет Apache Kafka.
Заключение
Благодаря высокой пропускной способности и согласованности данных Apache Kafka обрабатывает огромные массивы данных в реальном времени. Системы горизонтального масштабирования и офсеты гарантируют надежность. Kafka — удачное решение для проекта с очень большими нагрузками на обработку данных. Установить это ПО можно на серверы Ubuntu, Windows, CentOS и других популярных операционных систем.
Ваша Kafka, сэр!
В этот раз наш хакатон был посвящен темам, отдаленным от обыденной действительности, и состоял из эзотерики чуть более, чем наполовину. Мы выбрали в качестве подопытной технологии платформу Apache Kafka, главная причина этого выбора — хайп и детское любопытство. После пары шуток про овсянку мы принялись за дело. Первым делом нужно понять, что это и с чем его едят. Пожалуй, с этого и начнем.
Для начала отметим, что автор является абсолютным экспертом в этой области и его мнение является правдой в последней инстанции.
Apache Kafka — это так называемая “Distributed Streaming Platform” или по-русски распределенная система передачи сообщений, рассчитанная на высокую пропускную способность. Спроектирована и реализована эта платформа на не менее эзотерическом языке Scala. Главные достоинства Apache Kafka:
- Скорость: один узел кластера может обрабатывать сотни мегабайт записей в секунду.
- Масштабируемость: кластер можно прозрачно расширять без простоя, потоки данных партицированы.
- Надежность: сообщения в кластере реплицированы, каждый узел может содержать терабайты данных без потерь в производительности.
Определимся с терминологией:
- Producer — процесс/молодой человек/приложение, которое производит сообщения;
- Consumer — процесс, который читает эти сообщения;
- Topic — основная абстракция Apache Kafka. Это место, в котором хранятся все эти записи, каждый топик состоит из Partition.
- Partition — следующий уровень абстракции, который основан на разбиении каждого топика на 1, 2 и более частей. Каждое сообщение, находящееся в любом из partition, имеет так называемый offset.
- Offset, порядковый номер сообщения в partition. Тут полная аналогия с памятью, чем меньше offset , тем старше сообщение.
После того мы узнали все об Apache Kafka, кхе-кхе, мы решили приступить к делу и сразу столкнулись лицом к лицу с огромным мануалом по установке. Закатив глаза, мы погуглили и нашли магический docker-файл. В итоге 6 степов и овер 20 CLI команд для установки превратились в краткое и до боли знакомое:
Итак, теперь у нас появлиась работающая Apache Kafka, но нет самого главного — задачи. Мы решили, что самым логичным и правильным применением этой масштабируемой и распределенной платформы будет передача файлов ¯\_(ツ)_/¯.
Достав из ножен свеженький Node.js v7.6.0, мы принялись считывать/передавать/записывать. Создаем 3 файла producer.js, consumer.js, test.pdf. Начнем с producer.js. Главный ингредиент — это, конечно же, клиент для Apache Kafka. После того, как мы его установили с помощью богоугодного yarn, необходимо настроить подключение:
Чтобы убедится в том, что мы все сделали верно, мы добавили в наш код console.log(), который поведает нам о состоянии topic, к которому мы подключились:
Теперь разберемся с тем, как мы будем считывать файл. Чтобы привести все данные к единому формату, будем использовать формат base64:
Настало время смешать, но не взбалтывать, Apache Kafka. И
нашу файловую систему, и не забудьте приправить все это обработчиком
ошибок:
Охапка дров и Producer готов! Теперь определимся с Consumer’ом, который будет все это дело считывать и бережно записывать к вам на жесткий диск. Порядок действий тот же, что и с Producer’ом :
Перейдем к записи на диск:
И наконец-то мы можем запустить наш код и порадоваться тем безграничным возможностям, которые нам подарили ребята из Apache Foundation.
Спасибо за внимание! Следующий шабаш состоится 11.03.2017, на котором с нами поделятся опытом 2 лучших верстальщика города Минска.
Лайк! Репост! Подписка!
Описание работы Kafka
Kafka — это такой сетевой «лог-файл» в который можно писать сообщения и из которого их можно читать. Kafka часто используется как интеграционная шина, поэтому её можно сравшивать с RabbitMQ, и в первую очередь сравнить их нужно чтобы подчеркнуть различия.
RabbitMQ — это броккер сообщений. Он занимается передачей сообщений. В него можно послать сообщение, и оно, вероятно, будет доставлено адресату. После доставки сообщение удаляется из системы. Если при обработке сообщения возникла ошибка, сообщение может быть заново помещено в очередь.
В свою очередь кафка — это хранилище упорядоченных сообщений. У них нет адресата. Они не удаляются из системы если их кто-то прочитал. Подразумевается, что одно и то же сообщение может быть прочитано разными потребителями (consumer) с разными целями, и факт прочтения сообщения одним потребителем никак не влияет на других. Чтобы отслеживать какие сообщения уже были прочитаны потребителем, вводится понятие «смещение» (offset) — номер сообщения в последовательности.
Kafka хранит у себя текущее смещение для каждого известного потребителя, поэтому потребителю не нужно хранить его у себя, достаточно сделать запрос вида «дай следующее сообщение», а после «увеличь смещение на единицу».
Конкретное описание
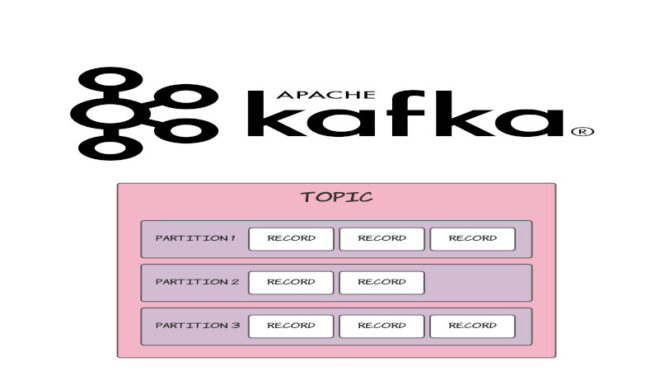
Сообщения пишутся в топик (topic). Топик — это последовательность сообщений. У топика нет схемы, в него могут писать и из него могут читать кто угодно и что угодно. Процесс, который пишет называется продюсер (producer). Процесс который читает — консюмер (consumer). Внутри топик состоит из партиций (partition). Партиция это уже реальный файл на диске. Если вы хотите распределить нагрузку по нескольким серверам, кафки, то вам нужно настроить топик так, чтобы у него было больше одной партиции.
Партиции ещё интересны тем, что они задают максимальное количество параллельных потоков конкурентного чтения. Не параллельного, а именно конкурентного. Вы можете иметь сколько угодно консюмеров читающих из одного топика. Все они получат каждое сообщение. Но если вам нужно сделать так чтобы сообщение было гарантировано прочитано только одним консюмером из определённой группы, вам нужно создать столько партиций сколько параллельных потоков вы хотите сделать.
Чтобы настроить несколько консюмеров на конкурентное чтение сообщений, нужно задать им одинаковый ID консюмер-группы (consumer group). Если у консюмера задана консюмер-группа, то кафка начинает сохранять смещения не для конкретного консюмера, а для группы. Таким образом, когда первый консюмер прочитает сообщение, он увеличит смещение, и второй консюмер иэ той же группы получит уже следующее сообщение, а не то же самое.
Настройка сервиса для работы с кафкой
Мы используем расширения php для работы с кафкой phprdkafka. Оно уже установлено в базовом docker образе и ничего дополнительно делать не нужно. Для удобства есть три пакета для ларавеля, которые скрывают низкоуровневые операции, предоставляя более простой интерфейс для чтения и записи сообщений в топики.
ensi/laravel-phprdkafka
Этот пакет добавляет в систему менеджер подключений к кафке, по аналогии с менеджером подключений к БД. Вы можете описать в config/kafka.php параметры подключения, отдельно для консюмеров, отдельно для продюсеров, можно задать несколько подключений с разными именами. И в дальнейшем можно получать уже сконфигурированные объекты RdKafka\Producer и RdKafka\KafkaConsumer просто вызывая соотвествующие методы у сервиса KafkaManager, получив его из сервис-контейнера или же обращаясь к нему через фасад Kafka . И консюмеры и продюсеры могут иметь немного разные настройки подключения, поэтому, чтобы не дублировать те настройки, которые у всех клиентов одинаковые, добавлена сущность «соединение» (connection). В соединении описываются такие настройки как: адрес кафки, параметры авторизации и т.д. В консюмере/продюсере мы указываем какое соединение будет использоваться и добавляем специфичные для текущего клиента параметры
# config/kafka.php return [ 'connections' => [ 'default' => [ 'settings' => [ 'metadata.broker.list' => env('KAFKA_BROKER_LIST'), 'security.protocol' => env('KAFKA_SECURITY_PROTOCOL', 'plaintext'), 'sasl.mechanisms' => env('KAFKA_SASL_MECHANISMS'), 'sasl.username' => env('KAFKA_SASL_USERNAME'), 'sasl.password' => env('KAFKA_SASL_PASSWORD'), 'log_level' => env('KAFKA_DEBUG', false) ? (string)LOG_DEBUG : (string)LOG_INFO, 'debug' => env('KAFKA_DEBUG', false) ? 'all' : null, ], 'topics' => [ 'foobars' => $contour . '.domain.fact.foobars.1' ] ] ], 'consumers' => [ 'default' => [ 'connection' => 'default', 'additional-settings' => [ 'group.id' => env('KAFKA_CONSUMER_GROUP_ID', env('APP_NAME')), 'enable.auto.commit' => true, 'auto.offset.reset' => 'beginning', ], ], ], 'producers' => [ 'default' => [ 'connection' => 'default', 'additional-settings' => [ 'compression.codec' => env('KAFKA_PRODUCER_COMPRESSION_CODEC', 'snappy'), ], ], ], ]; Настраивая подключение вы можете использовать любые параметры rdkafka. В пакете уже установлены некоторые параметры по умолчанию:
- group.id — идентификатор консюмер-группы. Он задаётся всегда, не важно планируете вы использовать один инстанс консюмера или несколько. Когда вам захочется отмасштабировать консюмеры, они уже будут в одной группе, останется только следить за тем чтобы хватало партиций.
- enable.auto.commit — автоматически обновляет смещение через некоторое время после получения сообщения
- auto.offset.reset — задаёт поведение в случае, когда для текущей консюмер-группы в кафке не сохранено смещение в каком-то топике. beginning означает что будут прочитаны все сообщения самого начала.
Помимо прочего, в соединении указывается список всех топиков, которые будут использоваться приложением.
'topics' => [ 'foobars' => $contour . '.domain.fact.foobars.1' ] В дальнейшем, в коде нужно будет ссылаться на кокретный топик используя ключ из этого списка, а не реальное название.
ensi/laravel-phprdkafka-consumer
Этот пакет добавляет в систему artisan команду kafka:consume topic и возможность настроить обработчик сообщения. Пример настройки:
# config/kafka-consumer.php return [ 'global_middleware' => [ TraceEventKafkaMiddleware::class ], 'stop_signals' => [SIGTERM, SIGINT], 'processors' => [ [ 'topic' => 'foobars', // ключ из kafka.connections..topics 'consumer' => 'default', 'type' => 'action', 'class' => \App\Domain\Kafka\Actions\Listen\ListenOfferAction::class, 'queue' => false, 'consume_timeout' => 5000, ], ] ]; Самое главное здесь — это то что вы указываете каким классом будут обрабатываться сообщения из конкретного топика, а так же какой консюмер будет использоваться для получения сообщений. Если вам для какого-то топика нужно задать другие настройки консюмера, то нужно создать другое подключение в config/kafka.php и сослаться на него.
Класс обработчик — это просто класс с методом execute(RdKafka\Message $message) , внутри которого вы описываете логику обработки сообщения.
class ListenOfferAction public function execute(Message $message) // . > > Кроме того вы можете задавать middleware, которые очень похожи на http middleware:
class TraceEventKafkaMiddleware public function handle(Message $message, Closure $next): mixed // . return $next($message); > > ensi/laravel-phprdkafka-producer
Этот пакет предоставляет обёртку над RdKafka\Producer , которая выполняет рутинные задачи.
$producer = new HighLevelProducer("my-topic", "my-producer"); $producer->sendOne($payload); Под капотом HighLevelProducer получает объект продюсера, настройки которого описаны в config/kafka.php , отправляет сообщение в топик, выполняет flush чтобы сообщение гарантировано ушло из буфера в кафку.
Настройка топиков
У топиков есть множество параметров, которые нужно задать при их создании, вот самые важные из них:
- количество партиций — влияет на максимальный размер консюмер-группы
- количество реплик — влияет на надёжность хранения данных
- количество данных в топике, которые нужно хранить, а лишние (самые старые) удалять
- время по истечении которого нужно удалять сообщения из топика
Эти параметры задаются не в консюмере или проюсере, а отдельно, при создании топика. Топик создаётся в ci/cd пайплайне при отгрузке сервиса, в котором используется этот топик, не важно является ли сервис источником данных или потребителем.
Пайплайн работает следующим образом:
- запускает команду php artisan kafka:find-not-created-topics , которая ищет в кафке топики, котрые перечислены в конфиге config/kafka.php
- если каких-то топиков нет, то формируется список отсутствующих топиков
- читается файл с настройками топиков из репозитория с конфигами развёртывания
- создаются топики
Вот пример файла настроек топиков:
topics: - name: prod.all.fct.my-topic.0 partitions: 2 replicas: 1 config: - name: retention.ms value: 60480000 # 7 days - name: retention.bytes value: 1073741824 # 1 Gb Если необходимый сервису топик не описан в таком файле, то пайплайн завершается с ошибкой.
Список топиков для локальной разработки
Тот же механизм описания топиков используется и для того чтобы создать все необходимые топики в локальной кафке. В воркспейсе есть аналогичный файл с топиками и скрипт, который их создаёт.
- Общее описание
- Конкретное описание
- Настройка сервиса для работы с кафкой
- Настройка топиков
Что такое Kafka-топики и какие базовые операции над ними выполняются
В прошлый раз мы говорили про использование и настройку пользовательских сериализаторов в брокере Кафка. Сегодня поговорим про основные операции над топиками в Кафка. Читайте далее про основные операции над Kafka-топиками, благодаря которым Кафка может эффективно обрабатывать Big Data и распределять ресурсы в параллельной среде.
Что такое топик в Кафка и какие операции над ним выполняются
Кафка-топик — это способ группировки и распределения потоков Big Data сообщений по категориям. Продюсеры (producers) публикуют сообщения определенной категории в топик, а потребители (consumer) подписываются на этот топик и читают из него сообщения в момент их поступления. Для каждого топика брокер Кафка ведет журнал сообщений, который разбивается на несколько разделов. В Кафка можно выполнять следующие 2 базовые с топиками [1]:
- создание нового топика — операция, отвечающая за создание топика, который включает в себя название, коэффициент репликации (характеризует количество реплик в кластере, отвечающих за копирование данных для повышения доступности и отказоустойчивости), а также количество разделов, которые отвечают за упорядочивание сообщений в зависимости от их поступления;
- удаление топика — отвечает за удаление неактуальных топиков с целью освобождения ресурсов.
Применение базовых операций с Кафка-топиком на практических примерах
За проведение операции с темами отвечает утилита kafka-topics.sh (в Windows kafka-topics.bat). Для того, чтобы создать новый топик, применяются 2 команды: create и topic . При этом команда topic является параметром команды create . Команда topic принимает в качестве параметра имя создаваемого топика. В качестве примера рассмотрим выполнение следующего кода в командной строке Linux [1]:
kafka-topics.sh --zookeeper zoo1.example.com:2181/kafka-cluster --create --topic my-topic --replication-factor 2 --partitions 8
В вышерассмотренном фрагменте кода помимо команд create и topic , также указаны 2 другие команды:
- replication-factor — команда, отвечающая за количество реплик в топике (коэффициент репликации);
- partitions — команда, задающая количество разделов для создаваемого топика.
Часто бывают случаи, когда необходимо увеличить количество разделов в уже существующем топике. За это отвечает команда утилиты kafka-topics.sh для изменения параметров топика alter , которая, как и create , используется совместно с командой topic [1]:
kafka-topics.sh --zookeeper zoo1.example.com:2181/kafka-cluster --alter --topic my-topic --partitions 16
Для того, чтобы удалить созданный топик, используется команда delete, которая также выполняется совместно с командой topic [1]:
kafka-topics.sh --zookeeper zoo1.example.com:2181/kafka-cluster --delete --topic my-topic
Таким образом, благодаря утилите kafka-topics.sh, брокер Кафка имеет возможность удобной работы с топиками Big Data без дополнительных затрат времени на разработку. Это делает Кафка универсальным и надежным средством для хранения и обмена большими потоками данных, что позволяет активно использовать этот брокер сообщений в задачах Data Science и разработке распределенных приложений.