PCI: жизнь продолжается
Андрей Борзенко Лихорадочная гонка в области наращивания производительности вычислительных систем не только не стихает, но, по-видимому, ускоряет темп. Однако если быстродействие процессоров за последнее десятилетие увеличилось более чем на порядок, то пропускная способность шин ввода-вывода — лишь в несколько раз. А ведь интегральная производительность вычислительной системы определяется самым медленным ее компонентом. Сегодня необходимость повышать быстродействие системы ввода-вывода диктуется не только возросшими возможностями процессора и памяти, но и появлением гигабитных сетевых технологий.

Микросхема моста IBM PCI-X Bridge
- поддержка “горячей” замены PCI-устройств — PCI Hot-Plug. Ввод этой функции позволяет добавлять (удалять) PCI-платы не выключая компьютера. Такая возможность особенно необходима для серверных платформ;
- система управления энергопотреблением для устройств на шине PCI, позволяющая управлять энергопотреблением как внешних PCI-плат, так и встроенных на системной плате устройств; механизм управления подстроен под стандарт ACPI, чем облегчается управление энергопотреблением PCI-устройств со стороны операционной системы;
- дополнение и переработка требований к конструктивной реализации PCI-плат.
PCI представляет собой шину с разделяемой архитектурой с распределением памяти — т. е. память совместно используется процессором (хостом) и устройствами. Разделяемый подход имеет очевидные недостатки, например, какое-либо одно периферийное устройство может монополизировать шину так, что другие устройства не будут иметь к ней доступа. Кроме того, шина с распределением памяти затрудняет выявление и изоляцию источника сбоя.
С повышением тактовой частоты процессоров до 1 ГГц при ширине шины процессор — память в 64 разряда, с одной стороны, и в связи с возрастанием пропускной способности локальной сети до 1 Гбит/с и появлением высокоскоростных периферийных устройств на базе Ultra3 SCSI и Fibre Channel — с другой, пропускной способности имеющихся на сегодня PCI оказывается недостаточно. Так, теоретический предел для 64-разрядной шины PCI на 66 МГц, наиболее производительной из возможных стандартных реализаций, составляет 533 Мб/с, к тому же наибольшее распространение имеют шины на 33 МГц, для которых максимум пропускной способности составляет 266 Мб/с.
Стандарт PCI-X
В 1998 г. три крупнейшие компьютерные компании — Compaq (www.compaq.com), Hewlett-Packard (www.hp.com) и IBM (www.ibm.com) разработали новую спецификацию расширения шины PCI под названием PCI-X. Эта спецификация опиралась на существовавшую технологию PCI, но за счет ряда усовершенствований протокола она позволила значительно увеличить производительность шины: при частоте 133 МГц и ширине 64 разряда ее максимальная пропускная способность составляет свыше 1 Гб/с (точнее, 1066 Мб/с). Осенью проект спецификации был представлен на рассмотрение в организацию PCI Special Interest Group (PCI SIG, www.pcisig.org). Надо отметить, что и до этого времени Compaq, Hewlett-Packard и ряд других производителей ПК-серверов уже выпускали продукцию с 64-разрядными разъемами PCI, рассчитанными на тактовую частоту 66 МГц, хотя в чипсетах Intel была обеспечена поддержка только 32-разрядных слотов и тактовой частоты 33 МГц.
Конечно, истинное преимущество PCI-X заключается в ее легкой масштабируемости по частоте. Используемый ею протокол типа “регистр — регистр” (register-to-register) предусматривает больше времени на стадию декодирования. А так как время, отводимое на эту операцию, уменьшалось при росте скорости обычной PCI, то создавать стабильно работающие на частоте 66 МГц устройства было затруднительно. Новая технология PCI-X обеспечивает стабильную работу устройствам на частотах 66, 100 и 133 МГц. А в будущем частота шины возрастет еще больше. Контроллер PCI-X, работающий на частоте 66 МГц, может присваивать адреса нескольким устройствам (до четырех), а дополнительный мост PCI-X-to-PCI-X позволит подключить большее их количество. Пропускная способность на 66 МГц достигает 533 Мб/с. В случае же работы всей периферии на 100 МГц возможное число устройств, подключаемых к PCI-X, сокращается до двух, зато пропускная способность 64-разрядной шины достигает 800 Мб/с. И наконец, допустимая ширина полосы пропускания PCI-X при подключении единственного устройства, работающего на частоте 133 МГц, достигает внушительных 1066 Мб/с. Подобным образом можно будет подсоединять наиболее требовательную к скорости периферийную аппаратуру (Fibre Channel, Gigabit Ethernet). Благодаря обеспечению обратной совместимости PCI-X будет использовать те же порты, что и классическая шина PCI (32- или 64-разрядные), причем можно использовать обычный PCI-слот (естественно, само устройство при этом будет работать как обычное). Спецификация PCI-X требует, чтобы адаптеры при установке в PCI-систему поддерживали любые ее режимы. И наоборот, если обычный PCI-адаптер устанавливается на шину PCI-X, то он и все остальные адаптеры данного шинного сегмента работают по протоколу PCI. Кроме того, PCI-X не будет требовать никаких изменений в BIOS в отношении шины PCI. Более того, возможно наличие в одной системе как шины PCI, так и PCI-X.
Кроме увеличения тактовой частоты, повышение производительности достигается с помощью таких усовершенствований, как межрегистровый протокол, атрибутивная фаза, поддержка разделенных транзакций, оптимизация состояний ожидания и оперирование блоками данных стандартного объема.
В случае традиционной шины PCI декодирование полученного сигнала на принимающей стороне происходит на протяжении того же цикла, что и отправка. Это налагает очень жесткие требования на время декодирования: в случае шины PCI с частотой 66 МГц оно составляет всего 3 нс. В соответствии же с новым межрегистровым протоколом декодирование производится за отдельный цикл. Такое решение, с одной стороны, упрощает реализацию шины с более высокой тактовой частотой, поскольку ослабляет ограничения на время декодирования, а с другой — лишь незначительно увеличивает общее число циклов для одной транзакции (если в случае PCI операция записи обычно выполняется за девять циклов, то с PCI-X она будет завершена за десять).
Атрибутивная фаза использует 36-разрядное поле атрибута, которое позволяет описать транзакции на шине более детально, чем в традиционном протоколе PCI. Фаза атрибута следует сразу за фазой адреса и содержит несколько бит, включающих информацию о транзакциях, например об их объеме и порядке, и об идентификаторе инициатора. Введение фазы атрибута позволяет более эффективно использовать ресурсы шины PCI-X, в частности смягчить требования к порядку транзакций. В традиционном протоколе PCI мосты host-to-PCI и PCI-to-PCI обрабатывают запросы по мере их поступления. Мосты должны выполнять транзакции в строгой последовательности, так как не могут идентифицировать устройство, от которого пришел запрос. Поле атрибута содержит специальный бит (relaxed ordering bit), причем если драйвер или управляющая программа устанавливают его значение равным единице, то транзакция может быть выполнена вне очереди. Таким образом, мост может перегруппировать транзакции и повысить пропускную способность системы ввода-вывода. Использование этого механизма особенно эффективно для аудио- и видеоприложений, чувствительных к временны/м задержкам.
Другим расширением протокола является счетчик байтов транзакции. В протоколе PCI мост по умолчанию считывает предопределенное количество строк (обычно одну или две) из кэш-памяти. Поскольку у моста нет возможности узнать, как много данных будет затребовано, то он всегда считывает обусловленное технологией количество строк. Совсем другая ситуация складывается с технологией PCI-X. Там мост точно знает, какое количество байтов необходимо выбрать, поскольку поле атрибута содержит их счетчик. Это позволяет применять более эффективные схемы управления буфером и повысить степень утилизации шины и других системных ресурсов. Еще одним дополнительным параметром, описывающим транзакцию, является ее порядковый номер — уникальный идентификатор инициатора транзакции (и сегмента шинной архитектуры, в котором располагается инициатор). Порядковый номер транзакции может быть использован для построения развитых алгоритмов управления буфером.
Традиционный протокол PCI ориентирован на задержанные транзакции. Его реализация предусматривает, что устройство, затребовавшее данные, должно постоянно опрашивать источник, чтобы определить момент завершения обработки запроса и готовности данных в регистре. Новый протокол устраняет фазу опроса, которая, по существу, приостанавливает работу шины. Суть механизма поддержки разделенных транзакций заключается в том, что устройство-инициатор посылает источнику данных только сигнал запроса, получая в ответ квитанцию. После этих операций связь между устройствами прекращается и регистр освобождается для обработки другой информации. Когда данные будут готовы, источник инициирует новую транзакцию и пошлет ее запросившему устройству.
PCI-устройства часто при выполнении транзакций добавляют дополнительные такты, так называемые состояния ожидания. Это делается для того, чтобы приостановить операции на шине, если данные еще не готовы. В ряде случаев такие вставки пустых тактов могут значительно снизить пропускную способность шины. Протокол PCI-X не предусматривает состояния ожидания, если не считать задержку при инициализации устройства-получателя. Когда устройство PCI-X по каким-то причинам не готово продолжить транзакцию, оно отключается от шины, предоставляя ее другим устройствам. Это повышает эффективность использования ресурсов компьютера.
При поддержке протокола PCI-X адаптеры и мосты могут прерывать транзакции только на естественной границе пакета 128 байт. Разбивка данных на более длинные пакеты позволяет оптимизировать по скорости операции как с кэш-памятью, так и с основной памятью и шиной процессора.
Летом 1999 г. консорциум PCISIG принял первую версию спецификации PCI-X. Несмотря на интересные технические параметры, корпорация Intel отнеслась к разработке новой шины весьма скептически: в ту пору она сама весьма активно занималась созданием собственной шины следующего поколения NGIO (Next Generation Input Output). Конечно, важнейшим вопросом для PCI-X является то, насколько широкое распространение она получит. Некоторые эксперты заявляют, что она просуществует два-три года, пока ее не сменит более быстрая спецификация системы ввода-вывода на базе коммутирующих структур InfiniBand. По сравнению с разделяемыми шинами, такими, как PCI, эта технология имеет два основных преимущества.
Во-первых, с увеличением скорости разделяемой шины ее протяженность и количество поддерживаемых ею устройств неизбежно уменьшается в целях обеспечения качества сигнала. Прямой же ввод-вывод, позволяя разносить устройства на большие расстояния, практически неограниченно расширяем с точки зрения числа устройств. Таким образом, он прекрасно подходит для корпоративных сетевых технологий, системных сетей и кластеров. Во-вторых, когда одно из устройств на разделяемой шине выходит из строя, это обычно сказывается на всех остальных. В случае коммутируемого прямого ввода-вывода отказавшее устройство может быть изолировано, так что оно не влияет на остальные.
Тем не менее председатель PCISIG Роджер Типли (Roger Tipley) имеет на этот счет свое мнение. В частности, он считает, что продолжателем дела PCI станет+ стандарт PCI 3.0, а его составной частью будут спецификации PCI-X и PCI Hot Plug. В ближайшее время InfiniBand мало повлияет на рынок PCI, поскольку, по мнению Типли, подобные серверы займут не более 3% рынка. К тому же пропускная способность адаптеров 1х и 4х InfiniBand пока не превышает возможностей PCI. По крайней мере до 2004 г. можно спать спокойно.
Мнение председателя не следует сбрасывать со счетов, ведь членами PCISIG стали уже более 940 ведущих компаний. Интересно, что по мере того, как PCI-X набирает обороты, ей начинают выделять роли, на которые она, по всей вероятности, вряд ли предназначалась с самого начала. Например, основываясь как на производительности, так и на простоте использования этой шины, эксперты PCISIG полагают, что она вполне может заменить собой AGP. Делались даже попытки убедить такие корпорации, как Sun и Apple, заменить в своих рабочих станциях AGP-порт на шину PCI-X. Напомним, что 64-разрядная PCI-X на 133 МГц имеет примерно одинаковую с AGP 4X пропускную способность. В качестве одного из основных аргументов указывалась возможность одновременной работы нескольких графических адаптеров на шине PCI-X в отличие от AGP. Впрочем, не лишне напомнить, что лицензия на AGP выдается бесплатно, чего не скажешь о PCI-X (цена $25).
С марта будущего года корпорация IBM начинает промышленный выпуск микросхем мостов PCI-X Bridge, что несомненно послужит мощным импульсом для внедрения PCI-X в создаваемые системы.
Опубликовано в журнале «PC Week» (269)47′ 2000
Помещена в музей с разрешения автора 14 июля 2014
Pci bridge что это
Настройка BIOS Setup Шина PCI CPU-to-PCI Bridge Retry
Использование опции CPU-to-PCI Bridge Retry позволяет системным устройствам инициировать повторную запись данных в шину PCI, если данные долго находятся в буфере отложенной записи.
Enabled (или On) – записывать повторно данные в шину PCI;
Disabled (или Off) – запретить повторную запись данных в шину PCI, если данные долго находятся в буфере отложенной записи.
Примечание 1. PCI (Peripheral Component Interconnect) – это компьютерная шина ввода/вывода, предназначена для подключения периферийных устройств к системной плате персонального компьютера.
PCI и PCI-X
Мосты PCI (PCI Bridge) — специальные аппаратные средства соединения шин PCI (и PCI-X) между собой и с другими шинами. Главный мост (Host Bridge) используется для подключения PCI к центру компьютера (системной памяти и процессору). «Почетной обязанностью» главного моста является генерация обращений к конфигурационному пространству под управлением центрального процессора, что позволяет хосту (центральному процессору) выполнять конфигурирование всей подсистемы шин PCI. В системе может быть и несколько главных мостов, что позволяет предоставить высокопроизводительную связь с центром большему числу устройств (число устройств на одной шине ограниченно). Из этих шин одна назначается условно главной (bus 0).
Равноранговые мосты PCI (PeertoPeer Bridge) используются для подключения дополнительных шин PCI. Эти мосты всегда вносят дополнительные накладные расходы на передачу данных, так что эффективная производительность при обмене устройства с центром снижается с каждым встающим на пути мостом.
Для подключения шин PCMCIA, CardBus, MCA, ISA/EISA, X-Bus и LPC используются специальные мосты, входящие в чипсеты системных плат или же являющиеся отдельными устройствами PCI (микросхемами). Эти мосты выполняют преобразование интерфейсов соединяемых ими шин, синхронизацию и буферизацию обменов данных.
Каждый мост программируется — ему указываются диапазоны адресов в пространствах памяти и ввода-вывода, отведенные устройствам его шин. Если адрес ЦУ текущей транзакции на одной шине (стороне) моста относится к шине противоположной стороны, мост транслирует транзакцию на соответствующую шину и обеспечивает согласование протоколов шин. Таким образом, совокупность мостов PCI выполняет маршрутизацию (routing) обращений по связанным шинам. Если в системе имеется несколько главных мостов, то сквозная маршрутизация между устройствами разных шин может оказаться невозможной: главные мосты друг с другом могут оказаться связанными лишь через магистральные пути контроллера памяти. Поддержка трансляции всех типов транзакций PCI через главные мосты в этом случае оказывается чересчур сложной, а потому спецификацией PCI строго и не требуется. Таким образом, все активные устройства всех шин PCI могут обращаться к системной памяти, но возможность равнорангового общения может оказаться в зависимости от принадлежности этих устройств той или иной шине PCI.
Применение мостов PCI предоставляет такие возможности, как:
- увеличение возможного числа подключенных устройств, преодолевая ограничения электрических спецификаций шины;
- разделение устройств PCI на сегменты — шины PCI — с различными характеристиками разрядности (32/64 бит), тактовой частоты (33/66/100/133 МГц), протокола (PCI, PC-X Mode 1, PCI-X Mode 2, PCI Express). На каждой шине все абоненты равняются на самого слабого участника; правильная расстановка устройств по шинам позволяет с максимальной эффективностью использовать возможности устройств и системной платы;
- организация сегментов с «горячим» подключением/отключением устройств;
- организация одновременного параллельного выполнения транзакций от инициаторов, расположенных на разных шинах.
Каждый мост PCI соединяет только две шины: первичную (primary bus), находящуюся ближе к вершине иерархии, с вторичной (secondary bus); интерфейсы моста, которыми он связан с этими шинами, называются соответственно первичным и вторичным. Допускается только чисто древовидная конфигурация, то есть две шины соединяются друг с другом лишь одним мостом и нет «петель» из мостов. Шины, подсоединяемые ко вторичному интерфейсу данного моста другими мостами, называются подчиненными (subordinated bus). Мосты PCI образуют иерархию шин PCI, на вершине которой находится главная шина с нулевым номером, подключенная к главному мосту. Если главных мостов несколько, то из их шин (равных друг другу по рангу) условно главной будет шина, которой назначен нулевой номер.
Мост должен выполнять ряд обязательных функций:
- обслуживать шину, подключенную к его вторичному интерфейсу:
- выполнять арбитраж — прием сигналов запроса REQx# от ведущих устройств шины и предоставление им права на управление шиной сигналами GNTx#
- парковать шину — подавать сигнал GNTx# какому-то устройству, когда управление шиной не требуется ни одному из задатчиков;
- генерировать конфигурационные циклы типа 0 с формированием индивидуальных сигналов IDSEL к адресуемому устройству PCI;
- «подтягивать» управляющие сигналы к высокому уровню;
- определять возможности подключенных устройств и выбирать удовлетворяющий их режим работы шины (частота, разрядность, протокол);
- формировать аппаратный сброс (RST#) по сбросу от первичного интерфейса и по команде, сообщая о выбранном режиме специальной сигнализацией.
- поддерживать карты ресурсов, находящихся по разные стороны моста;
- отвечать под видом целевого устройства на транзакции, инициированные мастером на одном интерфейсе и адресованные к ресурсу, находящемся со стороны другого интерфейса; транслировать эти транзакции на другой интерфейс, выступая в роли ведущего устройства (мастера), и передавать их результаты истинному инициатору.
Мосты, выполняющие данные функции, называются прозрачными (transparrent bridge); для работы с устройствами, находящимися за такими мостами, не требуется дополнительных драйверов моста. Именно такие мосты описаны в спецификации PCI Bridge 1.1, и для них, как устройств PCI, есть специальный класс (06). В данном случае подразумевается «плоская» модель адресации ресурсов (памяти и ввода-вывода): каждое устройство имеет свои адреса, уникальные (не пересекающиеся с другими) в пределах данной системы (компьютера).
Существуют и непрозрачные мосты (non-transparrent bridge), которые позволяют организовывать обособленные сегменты со своими локальными адресными пространствами. Непрозрачный мост выполняет трансляцию (преобразование) адресов для транзакций, у которых инициатор и целевое устройство находятся по разные стороны моста. Досягаемыми через такой мост могут быть и не все ресурсы (диапазоны адресов) противоположной стороны. Непрозрачные мосты используются, например, когда в компьютере выделяется подсистема «интеллигентного ввода-вывода» (I20) со своим процессором ввода-вывода и локальным адресным пространством.
Маршрутизация по иерархическому адресу
Задача маршрутизации — определение, где по отношению к мосту находится ресурс, адресованный каждой транзакции, — является первоочередной при обработке каждой транзакции, «увиденной» мостом на любом из своих интерфейсов. Эта задача решается двояко, поскольку в фазе адреса может передаваться как иерархический адрес PCI (шина -> устройство -> функция), так и «плоский» адрес памяти или порта ввода-вывода.
Маршрутизация по иерархическому адресу
Через номера шины и устройства адресуются транзакции конфигурационной записи и чтения, генерации специального цикла, а в PCI-X еще и завершение расщепленной транзакции, а также сообщения DIM. Для этих транзакций маршрутизация основана на системе нумерации шин. Номера назначаются шинам PCI при конфигурировании системы строго последовательно, номера мостов соответствуют номерам их вторичных шин. Так, главный мост имеет номер 0. Номера подчиненных шин моста начинаются с номера, следующего за номером его вторичной шины. Таким образом, для каждого моста необходимые ему знания топологии шин системы описываются списком номеров шин — тремя числовыми параметрами в его конфигурационном пространстве:
- Primary Bus Number — номер первичной шины;
- Secondary Bus Number — номер вторичной шины (это и номер моста);
- Subordinate Bus Number — максимальный номер подчиненной шины.
Все шины с номерами в диапазоне от Secondary Bus Number до Subordinate Bus Number включительно будут лежать со стороны вторичного интерфейса, все остальные — на стороне первичного.
Знание номеров шины позволяет мостам распространять обращения к конфигурационным регистрам устройств в сторону от хоста к подчиненным шинам и распространять специальные циклы во всех направлениях. Ответы на расщепленные транзакции (Split Complete) мост транслирует с одного интерфейса на другой, если они адресованы к шине противоположного интерфейса.
Конфигурационные циклы типа 0 и специальные циклы мостами не транслируются. Конфигурационные транзакции типа 1, обнаруженные на первичном интерфейсе, мост обрабатывает следующим образом:
- Преобразует их в конфигурационные циклы типа 0 или специальные циклы, если номер шины (на линиях AD[23:16]) соответствует номеру вторичной шины. При преобразовании в цикл типа 0 номер устройства с первичной шины, полученный в фазе адреса, декодируется в позиционный код на вторичной шине (см. главу 2), номер функции и регистра передается без изменений, биты AD[1:0] на вторичной шине обнуляются. В PCI-X кроме позиционного кода на вторичную шину передается и номер устройства. Преобразование в специальный цикл (изменение кода команды) производится, если в полях номера устройства и функции все биты единичные, а в поле номера регистра — нулевые.
- Пропускает их с первичного интерфейса на вторичный без изменения, если номер шины соответствует диапазону номеров подчиненных шин.
- Игнорирует, если номер шины лежит вне диапазона номеров шин стороны вторичного интерфейса.
Со стороны вторичного интерфейса мост передает на первичный только конфигурационные циклы типа 1, относящиеся к специальным циклам (в полях номера устройства и функции все биты единичные, а в поле номера регистра — нулевые). Если номер шины соответствует номеру первичной шины, мост преобразует эту транзакцию в специальный цикл.
Если конфигурационный цикл не воспринимается ни одним из устройств, мосты могут эту ситуацию отрабатывать двояко: фиксировать отсутствие устройства (сработает Master Abort) или же выполнять операции вхолостую. Однако в любом случае чтение конфигурационного регистра несуществующего устройства (функции) должно возвращать значение FFFFFFFFh (это будет безопасной информацией, поскольку даст недопустимое значение идентификатора устройства).
Маршрутизация по «плоскому» адресу
Для манипулирования с транзакциями обращения к памяти и портам ввода-вывода мосту нужны карты адресов, на которых отмечены области, принадлежащие устройствам вторичной и подчиненных шин. В системе с плоской уникальной адресацией этого достаточно. Для отмеченных областей мост должен отвечать в качестве целевого устройства на транзакции, «увиденные» им на первичном интерфейсе, и инициировать их в роли мастера на вторичном интерфейсе; остальные транзакции на первичном интерфейсе он игнорирует. Для адресов вне этих областей мост должен вести себя «зеркально»: отвечать в качестве целевого устройства на транзакции, «увиденные» им на вторичном интерфейсе, и инициировать их на первичном интерфейсе; остальные транзакции на вторичном интерфейсе он игнорирует. Каким образом мост транслирует транзакции, описано далее.
Каждый мост PCI-PCI имеет по одному описателю на каждый из трех типов ресурсов: ввода-вывода, «настоящей» памяти (допускающей предвыборку) и памяти, на которую отображены регистры ввода-вывода. В описателе указывается базовый адрес и размер области. Ресурсы одного типа для всех устройств, находящихся за мостом (на вторичной и всех подчиненных шинах), должны быть собраны в одну, по возможности компактную, область.
Область адресов вводавывода задается 8-битными регистрами I/O Base и I/O Limit с гранулярностью 4 Кбайт. Эти регистры своими старшими битами определяют только 4 старших бит 16-разрядного адреса начала и конца транслируемой области. Младшие 12 бит для I/O Base подразумеваются 000h, для I/O Limit — FFFh. Если на вторичной стороне моста нет портов ввода-вывода, то в I/O Limit записывается число меньшее, чем в I/O Base. Если мост не поддерживает карту адресов ввода-вывода, то оба регистра при чтении всегда возвращают нули; такой мост транзакции ввода-вывода с первичной на вторичную сторону не транслирует. Если мост поддерживает только 16-битную адресацию ввода-вывода, то при чтении в младших 4 бит обоих регистров всегда возвращает нули. При этом подразумевается, что старшие биты адресов AD[31:16] = 0, но они также подлежат декодированию. Если мост поддерживает 32-битную адресацию ввода-вывода, то при чтении в младших четырех битах обоих регистров возвращается 0001. При этом старшие 16 бит нижней и верхней границ находятся в регистрах I/O Base Upper 16 Bits и I/O Limit Upper 16 Bits.
Мост транслирует транзакции ввода-вывода указанной области с первичного интерфейса на вторичный только при установленном бите I/O Space Enable в регистре команд. Транзакции ввода-вывода со вторичного интерфейса на первичный транслируются только при установленном бите Bus Master Enable.
Вводвывод, отображенный на память, может использовать адреса в пределах первых 4 Гбайт (предел 32-битной адресации) с гранулярностью 1 Мбайт. Транслируемая область задается регистрами Memory Base (начальный адрес) и Memory Limit (конечный адрес), в которых задаются только старшие 12 бит адреса AD[31:20], младшие биты AD[19:0] подразумеваются равными 0 и FFFFFh соответственно. Кроме того, транслироваться может и область памяти VGA .
«Настоящая» память устройств PCI, допускающая предвыборку, может располагаться как в пределах 32-битной адресации (4 Гбайт), так и 64-битной, с гранулярностью 1 Мбайт. Транслируемая область задается регистрами Prefetchable Memory Base (начальный адрес) и Prefetchable Memory Limit (конечный адрес). Если в младших битах [3:0] этих регистров чтение возвращает 0001, то это признак поддержки 64-битной адресации. В этом случае старшая часть адресов находится в регистрах Prefetchable Base Upper 32 Bits и Prefetchable Limit Upper 32 Bits. Мост может и не иметь специальной поддержки предвыбираемой памяти, тогда вышеуказанные регистры будут при чтении возвращать нули.
Мост транслирует транзакции памяти указанных областей с первичного интерфейса на вторичный только при установленном бите Memory Space Enable в регистре команд. Транзакции памяти со вторичного интерфейса на первичный транcлируются только при установленном бите Bus Master Enable.
С мостами связаны понятия позитивного и субтрактивного декодирования адресов. Рядовые агенты PCI (устройства и мосты) отзываются только на обращения по адресам, принадлежащим областям, описанным в их конфигурационном пространстве (через базовые адреса и диапазоны памяти или ввода-вывода). Такой способ декодирования называется позитивным. Мост с позитивным декодированием (positive decoding) пропускает через себя только обращения, принадлежащие определенному списку адресов, заданному в его конфигурационных регистрах. Мост с субтрактивным декодированием (subtractive decoding) пропускает через себя обращения, не относящиеся к другим устройствам. Его области прозрачности формируются как бы вычитанием (откуда и название) из общего пространства областей, описанных в конфигурационных пространствах других устройств. Физически субтрактивное декодирование устройством (мостом) выполняется проще: устройство отслеживает на шине все транзакции интересующего его типа (обычно обращения к портам или памяти), и если не видит на них ответа (сигнала DEVSEL# в тактах 1–3 после FRAME#) ни от одного из обычных устройств, считает эту транзакцию «своей» и само вводит DEVSEL#. Возможность субтрактивного декодирования имеется только у мостов определенного типа, и она является дополнением к позитивному декодированию. Субтрактивное декодирование приходится применять для старых устройств (ISA, EISA), чьи адреса разбросаны по пространству так, что их не собрать в область позитивного декодирования приемлемого размера. Субтрактивное декодирование применяется для мостов, подключающих старые шины расширения (ISA, EISA). Позитивное и субтрактивное декодирование относится только к обращениям, направленным в пространства памяти и ввода-вывода. Конфигурационные обращения маршрутизируются с помощью номера шины, передаваемого в циклах типа 1 (см. главу 2): каждый мост «знает» номера всех шин, его окружающих. На поддержку субтрактивного декодирования может указывать только специфический код класса 060401h, обнаруженный в заголовке конфигурационных регистров данного моста.
Поддержка адресации ввода-вывода шины ISA
В адресации портов ввода-вывода есть особенности, связанные с «наследием», доставшимся от шины ISA. 10-битное декодирование адреса, применявшееся в шине ISA, приводит к тому, что каждый из адресов диапазона 0–3FFh (предел охвата 10-битным адресом) имеет еще по 63 псевдонима (aliase), по которым можно обращаться к тому же устройству ISA. Так, например, для адреса 0378h псевдонимами являются x778h, xB78h и xF78h (x — любая шестнадцатеричная цифра). Псевдонимы адресов ISA используются в разных целях, в частности, и в системе ISA PnP. Область адресов 0–FFh зарезервирована за системными (не пользовательскими) устройствами ISA, для которых псевдонимы не используют. Таким образом, в каждом килобайте адресного пространства ввода-вывода последние 768 байт (адреса 100–1FF) могут являться псевдонимами, а первые 256 байт (0–0FFh) — нет. В регистре управления мостом присутствует бит ISA Enable, установка которого приведет к вычеркиванию областей-псевдонимов из общей области адресов, описанной регистрами моста I/O Base и I/O Limit. Это вычеркивание действует только для первых 64 Кбайт адресного пространства (16-битного адреса). Мост не будет транслировать с первичного интерфейса на вторичный транзакции, принадлежащие этим вычеркнутым областям. И наоборот, с вторичного интерфейса транзакции, относящиеся к данным областям, будут транслироваться на первичный. Эта возможность нужна для совместного использования малого (64 Кбайт) пространства адресов устройствами PCI и ISA, примиряя «изрезанность» карты адресов ISA с возможностью задания лишь одной области адресов ввода-вывода для каждого моста. Данный бит имеет смысл устанавливать для мостов, за которыми нет устройств ISA. Эти мосты будут транслировать «вниз» все транзакции ввода-вывода, адресованные к первым 256 байтам каждого килобайта области адресов, описанной регистрами моста I/O Base и I/O Limit. Эти адреса конфигурационное ПО может выделять устройствам PCI, находящимся «ниже» данного моста (кроме адресов 0000h–00FFh, относящихся к устройствам системной платы).
Специальная поддержка VGA
В мостах может присутствовать специальная поддержка графического адаптера VGA, который может находиться на стороне вторичного интерфейса моста. Эта поддержка индицируется и разрешается битом VGA Enable конфигурационного регистра моста. При включенной поддержке мост осуществляет трансляцию обращений к памяти VGA в диапазоне адресов 0A0000h–0BFFFFh, а также регистрам ввода-вывода в диапазонах 3B0h–3BBh и 3C0h–3DFh и всех их 64 псевдонимов (линии адреса AD[15:10] не декодируются). Такой особый подход объясняется данью обеспечения совместимости с самым распространенным графическим адаптером и невозможностью описания всех необходимых областей в таблицах диапазонов адресов для позитивного декодирования. Кроме того, для поддержки VGA требуется особый подход к обращениям в регистры палитр, которые расположены по адресам 3C6h, 3C8h и 3C9h, и их псевдонимам (здесь опять же линии адреса AD[15:10] не декодируются).
Слежение за записью в палитры VGA (VGA Palette Snooping) является исключением из правила однозначной маршрутизации обращений к памяти и вводу-выводу. Графическая карта в компьютере с шиной PCI обычно устанавливается в эту шину или в порт AGP, что логически эквивалентно установке в шину PCI. На VGAкарте имеются регистры палитр (Palette Registers), традиционно приписанные к пространству ввода-вывода. Если графическая система содержит еще и карту смешения сигналов графического адаптера с сигналом «живого видео», перехватывая двоичную информацию о цвете текущего пиксела по шине VESA Feature Connector (снимаемую до регистра палитр), цветовая гамма будет определяться регистрами палитр, размещенными на этой дополнительной карте. Возникает ситуация, когда операция записи в регистр палитр должна отрабатываться одновременно и в графическом адаптере (на шине PCI или AGP), и в карте видеорасширения, которая может размещаться даже на другой шине (в том числе и ISA). В CMOS Setup может присутствовать параметр PCI VGA Palette Snoop, управляющий битом VGA Snoop Enable в конфигурационном регистре моста PCI-ISA. При его включении запись в порты ввода-вывода по адресу регистров палитр будет вызывать транзакцию не только на той шине, на которой установлен графический адаптер, но и на других шинах. Чтение же по этим адресам будет выполняться только с самого графического адаптера. Заметим, что если установлен бит VGA Enable, то через мост пойдут и транзакции чтения, поскольку адреса регистров палитр входят в диапазон общих адресов портов VGA. Реализация слежения может возлагаться и на графическую карту PCI. Для этого она во время записи в регистр палитр фиксирует данные, но сигналы квитирования DEVSEL# и TRDY# не вырабатывает, в результате мост распространяет этот неопознанный запрос на шину ISA.
Еще статьи.
- Транслирование транзакций и буферизация
- Отложенные транзакции
- Отправленные записи
- Особенности мостов PCI-X
Разработка драйвера PCI устройства под Linux

В данной статье я рассматриваю процесс написания простого драйвера PCI устройства под OC Linux. Будет кратко изучено устройство программной модели PCI, написание собственно драйвера, тестовой пользовательской программы и запуск всей этой системы.
В качестве подопытного выступит интерфейс датчиков перемещения ЛИР940/941. Это устройство, отечественного производства, обеспечивает подключение до 4 энкодеров с помощью последовательного протокола SSI поверх физического интерфейса RS-422.
На сегодняшний день шина PCI (и её более новый вариант — PCI Express) является стандартным интерфейсом для подключения широкого спектра дополнительного оборудования к современным компьютерам и в особом представлении эта шина не нуждается.
Не редко именно в виде PCI адаптера реализуются различные специализированные интерфейсы ввода-вывода для подключения не менее специализированного внешнего оборудования.
Так же до сих пор не редки ситуации когда производитель оборудования предоставляет драйвер лишь под OC Windows.
Плата ЛИР941 была приобретена организацией, в которой я работаю, для получения данных с высокоточных абсолютных датчиков перемещения. Когда встал вопрос о работе под Linux оказалось, что производитель не предоставляет ничего под эту ОС. В сети так же ничего не нашлось, что впрочем нормально для такого редкого и специализированного устройства.
На самой плате находится FPGA фирмы Altera, в которой реализуется вся логика взаимодействия, а также несколько (от 2 до 4) интерфейсов RS-422 с гальванической развязкой.
Обычно в такой ситуации разработчики идут по пути обратного инженеринга, пытаясь разобраться как работает Windows драйвер.
Морально готовясь к этому развлечению я решил для начала попробовать самый простой и прямой способ — написал запрос непосредственно производителю оборудования.
Я спросил не могут ли они предоставить какую-нибудь документацию или спецификацию на их устройство, дабы я мог разработать открытый драйвер под Linux. К моему удивлению производитель пошел на встречу, мне ответили очень быстро и прислали всю необходимую документацию!
Шина PCI
Прежде чем переходить к разработке собственно драйвера предлагаю рассмотреть как устроена программная модель PCI и как вообще происходит взаимодействие с устройством.
Небольшая заметка по поводу PCI и PCI Express.
Несмотря на то, что аппаратно это два разных интерфейса — оба они используют одну программную модель, так что с точки зрения разработчика особой разницы нет и драйвер будет работать одинаково.
Шина PCI позволяет подключать одновременно большое количество устройств и нередко состоит из нескольких физических шин, соединяющихся между собой посредством специальных «мостов» — PCI Bridge. Каждая шина имеет свой номер, устройствам на шине так же присваивается свой уникальный номер. Так же каждое устройство может быть многофункциональным, как бы разделенным на отдельные устройства, реализующие какие-то отдельные функции, каждой такой функции аналогично присваивается свой номер.
Таким образом системный «путь» к конкретному функционалу устройства выглядит так:
.
Что бы посмотреть какие устройства подключены к шине PCI в Linux достаточно выполнить команду lspci.
Вывод может оказаться неожиданно длинным, т. к. кроме устройств непосредственно физически подключенных через pci/pci express слоты (например видеоадаптера) есть множество системных устройств, распаянных (или же входящих в устройство микросхем чипсета) на материнской плате.
Первая колонка этого вывода, состоящая из чисел, как раз и представляет собой набор рассмотренных выше идентификаторов.
$ lspci 01:00.0 VGA compatible controller: NVIDIA Corporation GT215 [GeForce GT 240]Этот вывод означает, что видеоадаптер NVIDIA GT 240 находится на PCI шине 01, номер устройства — 00 и номер его единственной функции так же 0.
Следует еще добавить, что каждое PCI устройство имеет набор из двух уникальных идентификаторов — Vendor ID и Product ID, это позволяет драйверам однозначно идентифицировать устройства и правильно работать с ними.
Выдачей уникальных Vendor ID для производителей аппаратного обеспечения занимается специальный консорциум – PCI-SIG.
Что бы увидеть эти идентификаторы достаточно запустить lspci с ключами -nn:
$ lspci -nn 01:00.0 VGA compatible controller [0300]: NVIDIA Corporation GT215 [GeForce GT 240] [10de:0ca3] Где 10de — идентификатор производителя, NVIDIA Corporation, а 0ca3 — идентификатор конкретного оборудования.
Узнать кто есть кто можно с помощью специальных сайтов, например The PCI ID Repository
Чтение служебной информации и конфигурация PCI устройства осуществляется посредством набора конфигурационных регистров. Каждое устройство обязано предоставлять стандартный набор таких регистров, которые будут рассмотрены далее.
Регистры отображаются в оперативную память компьютера во время загрузки и ядро операционной системы связывает с устройством особую структуру данных — pci_dev, а так же предоставляет набор функций для чтения и записи.
Помимо конфигурационных регистров PCI устройства могут иметь до 6 каналов ввода-вывода данных. Каждый канал так же отображается в оперативную память по некоему адресу, назначаемому ядром ОС.
Операции чтения-записи этой области памяти, с определенными параметрами размера блока и смещения, приводят непосредственно к записи-чтению в устройство.
Получается, что для написания драйвера PCI необходимо знать какие конфигурационные регистры использует устройство, а так же по каким смещениям (и что именно) нужно записывать/читать. В моем случае производитель предоставил всю необходимую информацию.
Конфигурационное пространство PCI
Первые 64 байта являются стандартизированными и должны предоставляться всеми устройствами, независимо от того требуются они или нет.
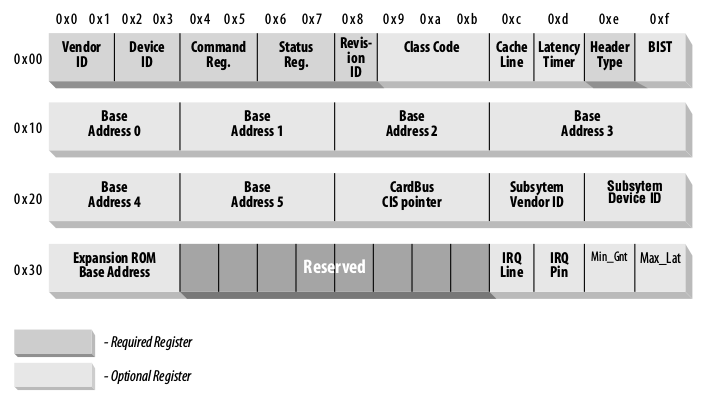
На картинке отмечены регистры являющиеся обязательными, они всегда должны содержать какие-либо осмысленные значения, остальные же могут содержать нули, если это не требуется в данном случае.
Порядок байт во всех регистрах PCI — little-endian, это следует учитывать, если разработка драйвера ведется для архитектуры с иным порядком.
Давайте посмотрим что из себя представляют некоторые регистры.
VendorID и ProductID — уже известные нам регистры, в которых хранятся идентификаторы производителя и оборудования. Каждый из регистров занимает 2 байта.
Command — этот регистр определяет некоторые возможности PCI устройства, например разрешает или запрещает доступ к памяти.
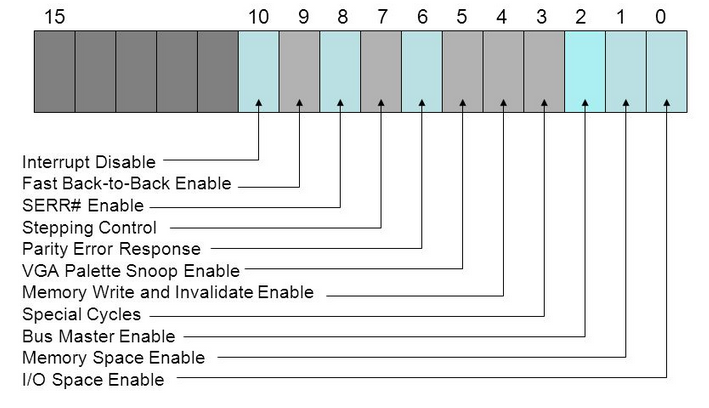
Инициализацией этих битов занимается операционная система.
Status — биты этого регистра хранят информацию о различных событиях PCI шины.
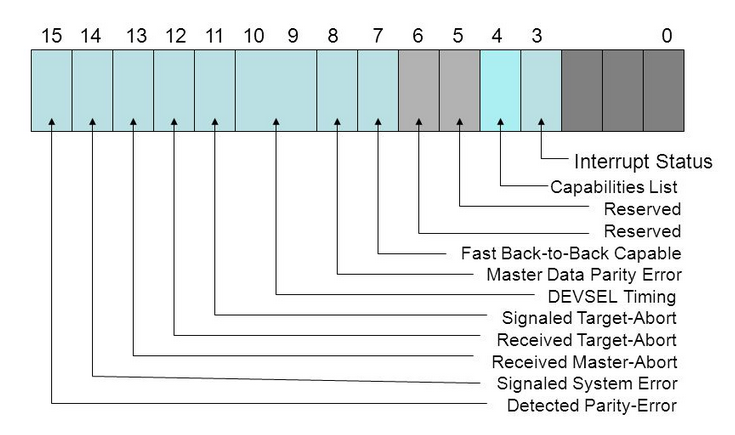
Эти значения выставляются оборудованием, в моём случае были сконфигурированы только биты 9, 10, определяющие время реакции платы.
Revision ID — число, ревизия конкретной платы. Полезно в тех случаях, когда есть несколько ревизий устройства и различия необходимо учитывать в коде драйвера.
Class Code — «волшебное» число, отображающее класс устройства, например: Network Controller, Display Controller и т. п. Список существующих кодов можно посмотреть тут.
Base Address Registers — эти регистры, в количестве 6 штук, служат для определения того как и сколько памяти выделется устройству для процедур ввода/вывода. Этот регистр используется pci подсистемой ядра и обычно не интересен разработчикам драйверов.
Теперь можно перейти к программирование и попробовать прочесть эти регистры и получить доступ к памяти ввода/вывода.
Разработка модуля ядра
Как наверное многие знают — точками входа и выхода в модуль ядра Linux являются специальные __init и __exit функции.
Определим эти функции и выполним процедуру регистрации нашего драйвера с помощью вызова специальной функции — pci_register_driver(struct pci_driver *drv), а так же процедуру выгрузки с помощью pci_unregister_driver(struct pci_driver *drv).
#include #include #include static int __init mypci_driver_init(void) < return pci_register_driver(&my_driver); >static void __exit mypci_driver_exit(void) < pci_unregister_driver(&my_driver); >module_init(mypci_driver_init); module_exit(mypci_driver_exit);Аргументом функций register и unregister является структура pci_driver, которую необходимо предварительно инициализировать, сделаем это в самом начале, объявив структуру статической.
static struct pci_driver my_driver = < .name = "my_pci_driver", .id_table = my_driver_id_table, .probe = my_driver_probe, .remove = my_driver_remove >;Поля структуры, которые мы инициализируем:
name — уникальное имя драйвера, которое будет использовано ядром в /sys/bus/pci/drivers
id_table — таблица пар Vendor ID и Product ID, с которым может работать драйвер.
probe — функция вызываемая ядром после загрузки драйвера, служит для инициализации оборудования
remove — функция вызываемая ядром при выгрузке драйвера, служит для освобождения каких-либо ранее занятых ресурсов
Так же в структуре pci_driver предусмотрены дополнительные функции, которые мы не будем использовать в данном примере:
suspend — эта функция вызывается при засыпании устройства
resume — эта функция вызывается при пробуждении устройства
Рассмотрим как определяется таблица пар Vendor ID и Product ID.
Это простая структура со списком идентификаторов.
static struct pci_device_id my_driver_id_table[] = < < PCI_DEVICE(0x0F0F, 0x0F0E) >, < PCI_DEVICE(0x0F0F, 0x0F0D) >, >; Где 0x0F0F — Vendor ID, а 0x0F0E и 0x0F0D — пара Product ID этого вендора.
Пар идентификаторов может быть как одна, так и несколько.
Обязательно завершать список с помощью пустого идентификатора
После объявления заполненной структуры необходимо передать её макросу
MODULE_DEVICE_TABLE(pci, my_driver_id_table);В функции my_driver_probe() мы можем делать, собственно, все что нам хочется.
static int my_driver_probe(struct pci_dev *pdev, const struct pci_device_id *ent)
Например можно попробовать прочитать конфигурационные регистры, описанные выше, с целью проверки корректности идентификаторов или выяснения ревизии платы.
В случае каких-либо проблем или несоответствий можно вернуть отрицательное значение кода ошибки и ядро прервет загрузку модуля. О чтении регистров конфигурации будет рассказано ниже.
Также обычно в этом месте выполняют инициализацию памяти ввода/вывода устройства для последующей работы с ней.
Полезным будет в этом месте определить некоторую «приватную» структуру драйвера в которой будут храниться данные, полезные во всех функциях драйвера. Например это может быть указатель на ту же память ввода/вывода устройства.
struct my_driver_priv
После инициализации приватной структуры необходимо выполнить её регистрацию
pci_set_drvdata(pdev, drv_priv);В функции my_driver_remove() удобно выполнять освобождение занятых ресурсов, например можно освободить память ввода/вывода.
Так же тут необходимо освобождать саму структуру struct pci_dev
static void my_driver_remove(struct pci_dev *pdev) < struct my_driver_priv *drv_priv = pci_get_drvdata(pdev); if (drv_priv) < kfree(drv_priv); >pci_disable_device(pdev); >Работа с регистрами конфигурации
Для выполнения процедур чтения/записи регистров в ядре Linux предусмотрены несколько функций. Все эти функции, связанные с PCI подсистемой, доступны в заголовочном файле
Чтение 8, 16 и 32 бит регистров соответственно:
int pci_read_config_byte(struct pci_dev *dev, int where, u8 *ptr); int pci_read_config_word(struct pci_dev *dev, int where, u16 *ptr); int pci_read_config_dword(struct pci_dev *dev, int where, u32 *ptr);Запись 8, 16 и 32 бит регистров соответственно:
int pci_write_config_byte (struct pci_dev *dev, int where, u8 val); int pci_write_config_word (struct pci_dev *dev, int where, u16 val); int pci_write_config_dword (struct pci_dev *dev, int where, u32 val);Первый аргумент всех этих функций — структура pci_dev, которая непосредственно связана с конкретным устройством PCI. Инициализация этой структуры будет рассмотрена далее.
Например мы хотим прочитать значения регистров Vendor ID, Product ID и Revision ID:
#include …. u16 vendor, device, revision; pci_read_config_word(pdev, PCI_VENDOR_ID, &vendor); pci_read_config_word(pdev, PCI_DEVICE_ID, &device); pci_read_config_word(pdev, PCI_REVISION_ID, &revision);Как видно — все предельно просто, подставляя необходимое значение аргумента whrere мы можем получить доступ к любому конфигурационному регистру конкретного pci_dev.
С чтением/записью памяти устройства все несколько сложнее.
Мы должны указать какой тип ресурса хотим получить, определиться с размером и смещением, выделить необходимый кусок памяти и отобразить этот кусок памяти на устройство.
После этого мы можем писать и читать данную память как нам угодно, взаимодействуя непосредственно с устройством.
#include int bar; unsigned long mmio_start, mmio_len; u8 __iomem *hwmem; struct pci_dev *pdev; . // определяем какой именно кусок памяти мы хотим получить, в данном случае этот ресурс ввода/вывода bar = pci_select_bars(pdev, IORESOURCE_MEM); // "включаем" память устройства pci_enable_device_mem(pdev); // запрашиваем необходимый регион памяти, с определенным ранее типом pci_request_region(pdev, bar, "My PCI driver"); // получаем адрес начала блока памяти устройства и общую длину этого блока mmio_start = pci_resource_start(pdev, 0); mmio_len = pci_resource_len(pdev, 0); // мапим выделенную память к аппаратуре hwmem = ioremap(mmio_start, mmio_len);
Дальше мы можем свободно работать с памятью, на которую указывает hwmem.
Правильнее всего использовать для этой цели специальные функции ядра.
Запись 8, 16 и 32 бит в память устройства:
void iowrite8(u8 b, void __iomem *addr) void iowrite16(u16 b, void __iomem *addr) void iowrite32(u16 b, void __iomem *addr)Чтение 8, 16 и 32 бит из памяти устройства:
unsigned int ioread8(void __iomem *addr) unsigned int ioread16(void __iomem *addr) unsigned int ioread32(void __iomem *addr)Полный код тестового модуля PCI драйвера
#include #include #include #define MY_DRIVER "my_pci_driver" static struct pci_device_id my_driver_id_table[] = < < PCI_DEVICE(0x0F0F, 0x0F0E) >, < PCI_DEVICE(0x0F0F, 0x0F0D) >, >; MODULE_DEVICE_TABLE(pci, my_driver_id_table); static int my_driver_probe(struct pci_dev *pdev, const struct pci_device_id *ent); static void my_driver_remove(struct pci_dev *pdev); static struct pci_driver my_driver = < .name = MY_DRIVER, .id_table = my_driver_id_table, .probe = my_driver_probe, .remove = my_driver_remove >; struct my_driver_priv < u8 __iomem *hwmem; >; static int __init mypci_driver_init(void) < return pci_register_driver(&my_driver); >static void __exit mypci_driver_exit(void) < pci_unregister_driver(&my_driver); >void release_device(struct pci_dev *pdev) < pci_release_region(pdev, pci_select_bars(pdev, IORESOURCE_MEM)); pci_disable_device(pdev); >static int my_driver_probe(struct pci_dev *pdev, const struct pci_device_id *ent) < int bar, err; u16 vendor, device; unsigned long mmio_start,mmio_len; struct my_driver_priv *drv_priv; pci_read_config_word(pdev, PCI_VENDOR_ID, &vendor); pci_read_config_word(pdev, PCI_DEVICE_ID, &device); printk(KERN_INFO "Device vid: 0x%X pid: 0x%X\n", vendor, device); bar = pci_select_bars(pdev, IORESOURCE_MEM); err = pci_enable_device_mem(pdev); if (err) < return err; >err = pci_request_region(pdev, bar, MY_DRIVER); if (err) < pci_disable_device(pdev); return err; >mmio_start = pci_resource_start(pdev, 0); mmio_len = pci_resource_len(pdev, 0); drv_priv = kzalloc(sizeof(struct my_driver_priv), GFP_KERNEL); if (!drv_priv) < release_device(pdev); return -ENOMEM; >drv_priv->hwmem = ioremap(mmio_start, mmio_len); if (!drv_priv->hwmem) < release_device(pdev); return -EIO; >pci_set_drvdata(pdev, drv_priv); return 0; > static void my_driver_remove(struct pci_dev *pdev) < struct my_driver_priv *drv_priv = pci_get_drvdata(pdev); if (drv_priv) < if (drv_priv->hwmem) < iounmap(drv_priv->hwmem); > kfree(drv_priv); > release_device(pdev); > MODULE_LICENSE("GPL"); MODULE_AUTHOR("Oleg Kutkov "); MODULE_DESCRIPTION("Test PCI driver"); MODULE_VERSION("0.1"); module_init(mypci_driver_init); module_exit(mypci_driver_exit);И Makefile для его сборки
BINARY := test_pci_module KERNEL := /lib/modules/$(shell uname -r)/build ARCH := x86 C_FLAGS := -Wall KMOD_DIR := $(shell pwd) TARGET_PATH := /lib/modules/$(shell uname -r)/kernel/drivers/char OBJECTS := test_pci.o ccflags-y += $(C_FLAGS) obj-m += $(BINARY).o $(BINARY)-y := $(OBJECTS) $(BINARY).ko: make -C $(KERNEL) M=$(KMOD_DIR) modules install: cp $(BINARY).ko $(TARGET_PATH) depmod -aУбедитесь, что у вас установлены заголовочные файлы ядра. Для Debian/Ubuntu установка необходимого пакета выполняется так:
sudo apt-get install linux-headers-$(uname -r)Компиляция модуля выполняется простой командой make, попробовать загрузить модуль можно командой
sudo insmod test_pci_module.koСкорее всего просто тихо ничего не произойдет, разве что у вас действительно окажется устройство с Vendor и Product ID из нашего примера.
Теперь я хотел бы вернуться к конкретному устройству, для которого разрабатывался драйвер.
Вот какую информацию про IO мне прислали разработчики платы ЛИР-941:
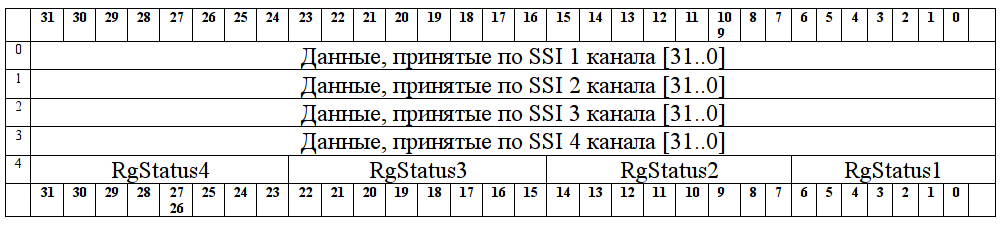
RgStatus:
b7 — Флаг паузы между транзакциями SSI (1 — пауза) (см. протокол SSI)
b6 — Флаг текущей трансакции (1- происходит передача данных) (см. протокол SSI)
b5 — Ext4 (Произошла защелка данных по сигналу Ext4)
b4 — Ext3 (Произошла защелка данных по сигналу Ext3)
b3 — Ext2 (Произошла защелка данных по сигналу Ext2)
b2 — Ext1 (Произошла защелка данных по сигналу Ext1)
b1 — Режим непрерывного опроса (По окончании передачи кода, аппаратно вырабатывается новый запрос)
b0 — По запросу от компьютера (Однократный запрос текущего положения)
Это значит, что если я хочу, например, прочитать данные от энкодера, подключенного к каналу 3 мне необходимо проверить седьмой бит блока RgStatus3, дождаться там еденички (пауза между транзакциями — значит уже ранее получили информацию от датчика и записали её в память платы, идет подготовка к следующему запросу) и прочитать число, хранящееся в третьем куске памяти длиной 32 бита.
Всё сводится к вычислению необходимо сдвига от начала куска памяти и чтения необходимого количества байт.
Из таблицы ясно, что данные каналов хранятся в виде 32 битных значений, а данные RgStatus — в виде значений длиной 8 бит.
Значит для чтения RgStatus3 необходимо сдвинуться 4 раза 32 бита и два раза по 8 бит и затем прочесть 8 бит из этой позиции.
А для чтения данных третьего канала необходимо сдвинуться 2 раза по 32 бита и прочесть значение длиной 32 бита.
Для выполнения всех этих операций можно написать удобные макросы:
#define CHANNEL_DATA_OFFSET(chnum) (sizeof(uint32_t) * chnum) #define CHANNEL_RG_ST_OFFSET(chnum) ((sizeof(uint32_t) * 4) + (sizeof(uint8_t) * chnum))Где chnum — номер требуемого канала, начиная с нуля.
Также не лишним в данном деле будет и такой простой макрос, определяющий «включен» ли бит на определенной позиции.
#define CHECK_BIT(var,pos) ((var) & (1 Получается такой код для чтения третьего канала данных:
#include … uint8_t chnum = 2; uint32_t enc_data; // hwmem — память устройства, которую мы получили ранее // r_addr указывает на точку в памяти, где находится RgStatus3 void* r_addr = hwmem + CHANNEL_RG_ST_OFFSET(chnum); // ждем паузы между транзакциями while(1) < // читаем 8 бит по указателю r_addr reg = ioread8(r_addr); // когда 7 бит «включен» - пауза между транзакциями, прерываем цикл if (!CHECK_BIT(reg, 7)) < break; >> // теперь прыгаем в точку, где лежат данные датчика r_addr = hwmem + CHANNEL_DATA_OFFSET(chnum); // читаем 32 битное значение enc_data = ioread32(r_addr);Все, мы получили от платы данные датчика, подключенного к третьему каналу и записали их в переменную enc_data.
Касательно записи в устройство производитель прислал уже другую табличку.
Видно, что на запись структура немного другая и придется писать новые макросы, с новыми смещениями.

DATA WIDTH — Определяет максимальное количество бит в одной трансакции SSI. (разрядность приемного регистра). Допустимые значения – от 1 до 32
CLOCK RATE – Порт, определяющий коэффициент деления системного Clk (33 МГц) для формирования Сlock SSI.
Kдел = (CLOCK RATE)*2+2
PAUSE RATE Порт, определяющий величину паузы после транзакции, в периодах Clk (30 нс)
CONTROL 1:
b7 — Режим SSI (0 – обычный режим, 1 – режим 16 разрядного абс. Датчика, с ожиданием стартового бита (устаревший вариант выдачи данных, нужен только для совместимости)).
b6 — Зарезервировано
b5 — Разрешение внешнего сигнала Ext4
b4 — Разрешение внешнего сигнала Ext3
b3 — Разрешение внешнего сигнала Ext2
b2 — Разрешение внешнего сигнала Ext1
b1 — Разрешение непрерывного опроса датчика
b0 — Выработать однократный опрос
Тут все аналогично — считаем сдвиг для необходимой области и записываем значение соответствующей функцией iowriteX
Взаимодействие пользовательского окружения с PCI драйвером
Существует несколько путей общения вышестоящего ПО с нашим драйвером. Одним из самых старых, простых и популярных способов является символьное устройство, character device.
Character device — это виртуальное устройство, которое может быть добавлено в каталог /dev, его можно будет открывать, что-то записывать, читать, выполнять вызовы ioctl для задания каких-либо параметров.
Хороший пример подобного устройства — драйвер последовательного порта с его /dev/ttySX
Регистрацию character device удобно вынести в отдельную функцию
int create_char_devs(struct my_driver_priv* drv);Указатель на нашу приватную структуру необходим для последующей инициализации файлового объекта, так что при каждом пользовательском вызове open/read/write/ioctl/close мы будем иметь доступ к нашей приватной структуре и сможем выполнять операции чтения/записи в PCI устройство.
Вызывать create_char_devs() удобно в функции my_driver_probe(), после всех инициализаций и проверок.
В моём случае эта функция называется именно create_char_devs(), во множественном числе. Дело в том, что драйвер создает несколько одноименных (но с разными цифровыми индексами в конце имени) character device, по одному на канал платы ЛИР941, это позволяет удобно, независимо и одноврменно работать сразу с несколькими подключенными датчиками.
Создать символьное устройство довольно просто.
Определяемся с количеством устройств, выделяем память и инициализируем каждое устройство настроенной структурой file_operations. Эта структура содержит ссылки на наши функции файловых операций, которые будут вызываться ядром при работе с файлом устройства в пространстве пользователя.
Внутри ядра все /dev устройства идентифицируются с помощью пары идентификаторов
Некоторые идентификаторы major являются зарезервированными и всегда назначаются определенным устройствам, остальные идентификаторы являются динамическими.
Значение major разделяют все устройства конкретного драйвера, отличаются они лишь идентификаторами minor.
При инициализации своего устройства можно задать значение major руками, ну лучше этого не делать, т. к. можно устроить конфликт. Самый лучший вариант — использовать макрос MAJOR().
Его применение будет показано в коде ниже.
В случае с minor значение обычно совпадает с порядковым номером устройства, при создании, начиная с нуля. Это позволяет узнать к какому именно устройству /dev/device-X обращаются из пространстрва ядра — достаточно посмотреть на minor доступный в обработчике файловых операций.
Идентификтаоры : отображаются утилитой ls с ключем -l
например если выполнить:
$ ls -l /dev/i2c-* crw------- 1 root root 89, 0 янв. 30 21:59 /dev/i2c-0 crw------- 1 root root 89, 1 янв. 30 21:59 /dev/i2c-1 crw------- 1 root root 89, 2 янв. 30 21:59 /dev/i2c-2 crw------- 1 root root 89, 3 янв. 30 21:59 /dev/i2c-3 crw------- 1 root root 89, 4 янв. 30 21:59 /dev/i2c-4Число 89 — это major идентификатор драйвера контроллера i2c шины, оно общее для всех каналов i2c, а 0,1,2,3,4 — minor идентификаторы.
Пример создания набора устройств.
#include #include #include #include #include #include // создаем 4 устройства #define MAX_DEV 4 // определение функций файловых операций static int mydev_open(struct inode *inode, struct file *file); static int mydev_release(struct inode *inode, struct file *file); static long mydev_ioctl(struct file *file, unsigned int cmd, unsigned long arg); static ssize_t mydev_read(struct file *file, char __user *buf, size_t count, loff_t *offset); static ssize_t mydev_write(struct file *file, const char __user *buf, size_t count, loff_t *offset); // настраиваем структуру file_operations static const struct file_operations mydev_fops = < .owner = THIS_MODULE, .open = mydev_open, .release = mydev_release, .unlocked_ioctl = mydev_ioctl, .read = mydev_read, .write = mydev_write >; // структура устройства, необходимая для инициализации struct my_device_data < struct device* mydev; struct cdev cdev; >; // в этой переменной хранится уникальный номер нашего символьного устройства // номер создается с помощью макроса ядра и используется в операциях инициализации // и уничтожения устройства, поэтому его необходимо объявлять глобально и статически static int dev_major = 0; // структура класса устройства, необходимая для появления устройства в /sys // это дает возможность взаимодействовать с udev static struct class *mydevclass = NULL; // каждое устройство инициализируется своим экземпляром структуры my_device_data, иначе возникнет путаница // поэтому необходимо создать массив таких структур, размер массива определяется количеством устройств static struct lir_device_data mydev_data[MAX_DEV]; int create_char_devs() < int err, i; dev_t dev; // выделяем память под необходимое количество устройств err = alloc_chrdev_region(&dev, 0, MAX_DEV, "mydev"); // создаем major идентификатор для нашей группы устройств dev_major = MAJOR(dev); // регистрируем sysfs класс под названием mydev mydevclass = class_create(THIS_MODULE, "mydev"); // в цикле создаем все устройства по порядку for (i = 0; i < MAX_DEV; i++) < //инициализируем новое устройство с заданием структуры file_operations cdev_init(&mydev_data[i].cdev, &mydev_fops); //указываем владельца устройства - текущий модуль ядра mydev_data[i].cdev.owner = THIS_MODULE; // добавляем в ядро новое символьное устройство cdev_add(&mydev_data[i].cdev, MKDEV(dev_major, i), 1); // и наконец создаем файл устройства /dev/mydev-// где вместо будет порядковый номер устройства mydev_data[i].mydev = device_create(mydevclass, NULL, MKDEV(dev_major, i), NULL, "mydev-%d", i); > return 0; >
Функция mydev_open() будет вызываться, если кто-то попробует открыть наше устройство в пространстве пользователя.
Очень удобно в этой функции инициализировать приватную структуру для открытого файла устройства. В ней можно сохранить значение minor для текущего открытого устройства
Также туда можно поместить указатель на какие-то более глобальные структуры, помогающие взаимодействовать с остальным драйвером, например, мы можем в этом месте сохранить указатель на my_driver_priv, с которым мы работали ранее. Указатель на эту структуру можно использовать в операциях ioctl/read/write для выполнения запросов к аппаратуре.
Мы можем определить такую структуру:
struct my_device_private < uint8_t chnum; struct my_driver_priv * drv; >;
static int mydev_open(struct inode *inode, struct file *file) < struct my_device_private* dev_priv; // получаем значение minor из текущего узла файловой системы unsigned int minor = iminor(inode); // выделяем память под структуру и инициализируем её поля dev_priv = kzalloc(sizeof(struct lir_device_private), GFP_KERNEL); // drv_access — глобальный указатель на структуру my_device_private, которая была // инициализирована ранее в коде, работающим с PCI dev_priv->drv = drv_access; dev_priv ->chnum = minor; // сохраняем указатель на структуру как приватные данные открытого файла // теперь эта структура будет доступна внутри всех операций, выполняемых над этим файлом file->private_data = dev_priv; // просто возвращаем 0, вызов open() завершается успешно return 0; >Операции чтения и записи являются довольно простыми, единственный «нюанс» — небезопаность (а то и невозможность) прямого доступа пользовательского приложения к памяти ядра и наоборот.
В связи с этим для получения данных, записиваемых с помощью функции write() необходимо использовать функцию ядра copy_from_user().
А при выполнении read() необходимо пользоваться copy_to_user().
Обе функции оснащены различными проверками и обеспечивают безопасное копирование данных между ядром и пользовательским пространством
static ssize_t mydev_read(struct file *file, char __user *buf, size_t count, loff_t *offset) < // получаем доступ к приватной структуре, сохраненной в функции open() struct my_device_private* drv = file->private_data; uint32_t result; // выполняем какой-то запрос к оборудованию с помощью нашей функции // get_data_from_hardware, передав ей данные драйвера result = get_data_from_hardware(drv->drv, drv->chnum); // копируем результат в пользовательское пространство if (copy_to_user(buf, &data, count)) < return -EFAULT; >// возвращаем количество отданных байт return count; > static ssize_t mydev_write(struct file *file, const char __user *buf, size_t count, loff_t *offset) < ssize_t count = 42; char data[count]; if (copy_from_user(data, buf, count) != 0) < return -EFAULT; >// в массив data, размером 42 байта получили какие-то данные от пользователя // и теперь можем безопасно с ним работать // возвращаем количество принятых байт return count; >Обработчик вызова ioctl() принимает в качестве аргументов собственно номер ioctl операции и какие-то переданные данные в качестве аргументов (если они необходимы).
Номера операций ioctl() определяются разработчиком драйвера. Это просто некие «волшебные» числа, скрывающиеся за читабельными define.
Об этих номерах должна знать пользовательская программа, поэтому удобно выносить их куда-то в виде отдельного заголовочного файла.
Пример обработчика ioctl
static long mydev_ioctl(struct file *file, unsigned int cmd, unsigned long arg) < struct my_device_private* drv = file->private_data; switch (cmd) < case MY_IOCTL_OP_1: do_hardware_op_1(drv->drv, drv->chnum); break; case MY_IOCTL_OP_2: do_hardware_op_2(drv->drv, drv->chnum); break; . default: return -EINVAL; >; return 0; >
Функция mydev_release() вызывается при закрыти файла-устройства.
В нашем случае достаточно лишь освободить память нашей приватной файловой структуры
static int mydev_release(struct inode *inode, struct file *file) < struct my_device_private* priv = file->private_data; kfree(priv); priv = NULL; return 0; >В функции уничтожения символьного устройства необходимо удалить все созданные устройства, уничтожить sysfs class и освободить память.
int destroy_char_devs(void) < int i; for (i = 0; i < MAX_DEV; i++) < device_destroy(mydevclass, MKDEV(dev_major, i)); >class_unregister(mydevclass); class_destroy(mydevclass); unregister_chrdev_region(MKDEV(dev_major, 0), MINORMASK); return 0; >Эту функцию следует вызывать в __exit методе модуля ядра, так что бы символьное устройство уничтожалось при выгрузке.
Вся остальная работа сводится к налаживанию взаимодействия между символьным устройством и фактической аппаратурой, а так же написанию различного вспомогательного кода.
Полный исходный код драйвера платы ЛИР941 можно посмотреть на Github.
А тут лежит простая тестовая утилита, работающая с этим драйвером.
Тестирование драйвера на настоящем железе 🙂
Спасибо за внимание!
Надеюсь этот материал будет полезен тем, кто решить написать свой драйвер для чего-нибудь.
- Системное программирование
- *nix
- Разработка под Linux